
If there was a way for me to patent this concept, I would.
This could be the most important topic in this book and the cornerstone of a successful software build process. I see customers struggle with too many cross-project dependencies, source tree integration problems, constant build breaks, and developers and testers spending too much time on hotfixes instead of writing new code. The majority of the time, these things can be traced to the way people have their source trees configured. Some development groups incorrectly blame their build problems on their version control tool’s lack of branching functionality. By Microsoft’s own admission, Visual SourceSafe (VSS) is not a very powerful Source Code Control (SCC) tool. (As discussed in Chapter 18, “Future Build Tools from Microsoft,” Microsoft plans to change this with future releases of Visual Studio Team System [VSTS].) It’s true that some of the tools out there are weak, but it is usually the source tree structure that is broken, not the lack of features or knowledge of these features.
Keep in mind that an SCC tool is simply just a database with a front-end application that manages all the items in the database. In our particular case, the application manages sources. In this chapter, we discuss the concepts of organizing your code. Then it is a matter of figuring out how to use an SCC tool to make it happen.
Many books have been written on setting up source trees and different branching models of version control systems such as Rational ClearCase, Merant PVCS, and Microsoft’s own VSS. This chapter is about how to best set up your source trees and successfully track your code check-ins and your product, whether the application is a Web or a single platform application downloadable from the Internet or shipped out of the box. Also included in this chapter are the best practices that Microsoft has found in working with multiple development sites and using Virtual Build Labs (VBLs).
The VBL process was developed by Mark Lucovsky, a distinguished engineer at Microsoft who had a rich history at Digital Equipment Corporation (DEC) before coming to Microsoft in 1986 to work on NT (N10, or New Technology). The VBL model is an excellent one to use if you have multiple development sites or are trying to do parallel development on a product. This process is extremely good even if you have one central development location and one development team. However, if your product or company has a maximum of 10 or 12 developers and never plans to grow beyond that number, the VBL system might be overkill.
So, you ask, how does this topic on source tree configuration fit into a build book? Let’s start with some basic definitions. Then I’ll explain the connection.
Continuing the discussion from Chapter 1, “Defining a Build,” the following are additional build definitions that are good to standardize on. In keeping on the theme of “speaking the same language,” look over the terms and how they are defined here even if you are familiar with them. This will keep us in sync.
Source code—. Files written in high-level languages such as C# that need to be compiled (for example, foo.cs).
Source(s)—. All the files involved in building a product (for example, C, CPP, VB, DOC, HTM, H, and CS). This term is used mostly as a catch-all phrase that is specific not only to source code files but to all the files that are stored in version tracking systems.
Codeline—. A tree or branch of code that has a specific purpose, such as the mainline, release line, or hotfix line that grows collectively.
Mainline or trunk (“The Golden Tree”)—. The main codeline of the product that contains the entire source code, document files, and anything else necessary to build and release the complete product.
Snapshot—. A specific point in time in which the sources and build are captured and stored, usually on a release or build machine.
Milestone—. A measurement of work items that includes a specified number of deliverables for a given project scheduled for a specified amount of time that are delivered, reviewed, and fixed to meet a high quality bar. The purpose of a milestone is to understand what is done, what is left to do, and how that fits with the given schedule and resources. To do this, the team must complete a portion of the project and review it to understand where the project is in the schedule and to reconcile what is not done with the rest of the schedule. A milestone is the best way to know how much time a portion of the project will take.
Code freeze—. A period when the automatic updates and build processes are stopped to take the final check-ins at a milestone.
Public build—. A build using the sources from the mainline or trunk.
Private build (also referred to as a sandbox build)—. A build using a project component tree to build more specific pieces of the product. This is usually done prior to checking in the code to the mainline.
Branching—. A superset of files off the mainline taken at a certain time (snapshot) that contains new developments for hotfixes or new versions. Each branch continues to grow independently or dependently on the mainline.
Forking—. Cloning a source tree to allow controlled changes on one tree while allowing the other tree to grow at its own rate. The difference between forking and branching is that forking involves two trees, whereas branching involves just one. It is also important to note that forking or cloning makes a copy (snapshot) of the tree and does not share the history between the two trees, whereas branching does share the history.
Virtual Build Labs (VBLs)—. A Virtual Build Lab is a build lab that is owned by a specific component or project team. The owner is responsible for propagating and integrating his code into the mainline or public build. Each VBL performs full builds and installable releases from the code in its source lines and the mainline. Although the term virtual is used in the name of the labs, don’t confuse it with Virtual PC or Virtual Machines because the labs are real physical rooms and computer boxes. It is not recommended that you use Virtual software for build machines except possibly for an occasional one-off or hotfix build. This concept is explained in Chapter 4, “The Build Lab and Personnel.” There is usually a hierarchy of VBLs so that code “rolls up” to the mainline or trunk. For example, let’s say that you have a mainline, Project A is a branch off of the mainline, and Developer 1 has a branch off the project branch. Developer 1 has several branches off his branch, with each branch representing a different component of the product. If he wants to integrate one of his branches into main, he should first merge his changes with all the levels above the branch to make sure he gets all the changes. Alternatively, he can just roll the changes into main, which sits higher in the hierarchy. This will become clearer in the next couple of pages.
Reverse integration (RI)—. The process of moving sources from one branch or tree to another that is higher in the VBL hierarchy.
Forward integration (FI)—. The process of moving sources from one branch or tree to another that is lower in the VBL hierarchy.
Buddy build—. A build performed on a machine other than the machine that the developer originally made changes on. This is done to validate the list of changed files so that there are no unintended consequences to the change in the mainline build.
To answer the question on how this topic relates to builds, I would like to borrow a quote.
In a paper read at the Eighth International Workshop on Software Configuration Management in Belgium in 1998, Laura Wingerd and Christopher Seiwald reported that “90% of the SCM ‘process’ is enforcing codeline promotion to compensate for the lack of a mainline.” This quote was taken from Software Configuration Management Patterns by Stephen P. Berczuk with Brad Appleton. The book offers an outstanding explanation of how to develop your branching model for your source trees. I agree that if you do not have a mainline to build your product from, you will encounter all kinds of delays in shipping your code that do not seem directly connected to source tree configuration, such as trouble deploying hotfixes (more on this in Chapter 16, “Hotfixes or Patch Management”).
By creating a mainline or golden source tree, you will have fewer build errors, because any potential breaks are caught before the reverse integration (RI) merge into the golden tree. Developers can work on different versions of a product simultaneously without affecting other components. These are the two biggest advantages to moving to a process like this among the other main points mentioned in the introduction.
The best way to show how a mainline owned by the build team works is by an example using VSS as the SCC tool. You can substitute any version control tool for this example. I chose VSS because it is from Microsoft, and it is free when you purchase Visual Studio Enterprise Edition.
Looking at Figure 2.1, you can see that the mainline or golden tree on the left is the shipping tree. This is the codeline that the build team owns, maintains, and administers. The goal of every development group—and in this example Dev Team 1—is to get its code into the golden tree so that it can ship the product and get paid.
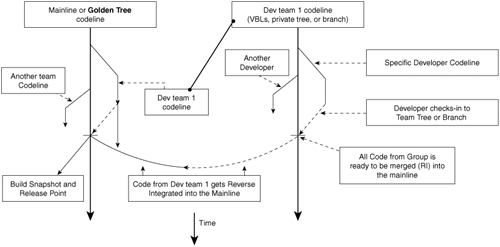
The codeline called Dev Team 1 is considered Virtual Build Lab 1, or a sandbox or private tree. With the limited functionality of VSS, this is a new instance of a source tree, not a branch off the mainline. With more powerful source code control tools, this can be just a branch off the mainline.
Each VBL should be able to take a snapshot of the sources in the mainline (forward integration), work in isolation, and then submit its changes in bulk back into the mainline. This allows each VBL to work independently from one another while picking up the latest, greatest stable code from the other VBLs. As stated in the definitions, all VBLs operate independently of one another and choose when to refresh the code in their tree or branch and when to reverse integrate (RI) their changes to the mainline, making their changes visible to the other VBLs. The VBL work can be happening one floor or 1,000 miles away from the Central Build Lab.
Propagating the changes into the mainline is a big deal and is treated as such. This is the point where the Central Build Team sees the VBL’s changes for the first time. Build breaks in the mainline are not acceptable and should never be tolerated. There should never be a reason for a break if the check-in policies for the mainline are followed. VBLs that are not able to produce reliable builds cannot propagate their changes into the mainline. Thus, their code does not make it into the product. This is good, tough logic, but it’s the Achilles’ heel of the VBL process. Although the threat of not shipping seems like it would be enough to keep the wheels rolling, it doesn’t always work. There are too many dependencies between groups to say “Sorry, you will not make it in the product.” That’s why there should be aggressive proactive management of the VBLs through the Central Build Team to make sure the VBLs follow a stricter process. That way, they do not delay other components of the project because their build system is not up to par with the mainline.
Table 2.1 is a summary of the differences between private and public builds.
Table 2.1. Private Versus Public Builds
Private (VBL Build) | Public (Mainline Build) |
|---|---|
Performed and managed by a VBL | Performed and managed by Central Build Team |
Testing is minimal before releasing build | Minimum suite of tests must be run and passed before releasing |
Can be done at any time | Usually done at a set time every day |
Released informally | Released at proper release servers; ready for general consumption |
Has its own rules and policies for check-in but should be dictated by the CBT | Strict, enforced procedure that must be followed for check-in |
Must go through WAR meeting to check in |
When setting up a VBL structure, it is a good idea to keep the information in Table 2.1 in mind. It outlines the most important differences between VBL builds and mainline builds. If you decide to adopt this type of tree structure, I suggest that you elaborate on the entries in the table. The details will be dictated by how your development and test team is organized.
Performing parallel development after the VBLs are set up should be rather painless, a huge benefit of the VBL process. Each developer can branch in his own VBL to work on multiple projects while sharing the code across other VBLs through the mainline. Because the structure of parallel development and hotfix codelines is similar, look at the examples in Chapter 16 to get a better idea about setting up the trees.
In some groups at Microsoft, we store only code or documents that need some kind of version control on them as they are being developed. Other groups use their SCC tool to store everything such as development tools, marketing work, and binaries. I am against the latter because I like to keep parts of the product separate. Despite what version control tool companies say, I do not think their tools are robust enough to track all binaries and other files that people like to store. Only code, documents, and anything else that needs to be built should be kept in an SCC tool. Third-party or external binaries, development tools such as compilers, and any other files that do not need to be built should be stored on a development server and kept up to date there. Release binaries belong on a release server. I discuss more about that in Chapter 3, “Daily, Not Nightly, Builds.”
Hatteras is an enterprise-class Software Configuration Management (SCM) product. The codename Hatteras comes from a lighthouse on the shores of North Carolina where the product is being developed. The final name of the product is Team Foundation, and it includes more than just the source control functionality. The Hatteras piece is referred to as Team Foundation Source Control (TFSC). The other pieces of the Team Foundation product are touched on in Chapter 18. I wanted to include this tool in this chapter as I just briefly talk about the upcoming VSTS tools in Chapter 18 but wanted to go into more details on TFSC. Another reason for me to include this section is that there are some important definitions that need to be added to our build dialect, such as all of the branching definitions.
This tool has been completely designed and developed from scratch; in other words, this is not a new generation of Microsoft’s infamous VSS. It provides standard source code version control functionality that scales across thousands of developers, such as Microsoft’s own development teams. As part of the Visual Studio (VS) 2005 release, Hatteras provides integration with the Visual Studio IDE and with other enterprise tools such as the Visual Studio work item (bug) tracking tool. Hatteras also provides a standalone GUI, a command-line interface, and a Web-based interface.
Let’s define some new terms as they relate to TFSC:
Repository—. The data store containing all files and folders in the TFSC database.
Mapping—. An association of a repository path with a local working folder on the client computer.
Working folder—. A directory on the client computer containing a local copy of some subset of the files and folders in a repository.
Workspace—. A definition of an individual user’s copy of the files from the repository. The workspace contains a reference to the repository and a series of mappings that associate a repository path with a working folder on the user’s computer.
Change set—. A set of modifications to one or more files/folders that is atomically applied to the repository at check-in.
Shelve—. The operation of archiving all modifications in the current change set and replacing those files with original copies. The shelved files can be retrieved at a later time for development to be continued. This is my favorite feature.
Some of the features in TFSC are fairly standard among SCC tools:
Workspace creation
Workspace synchronization
File checkout
Overlapping checkout by multiple users of the same file
Atomic change-set check-in
File diffs
Automated merge
Code-line branching
File-set labeling
User management and security
What really sets TFSC apart from the competition is its powerful merging and branching features. I don’t try to explain the entire product here, but just touch on why I think these two features are so cool.
The merging functionality in TFSC is centered on the following typical development scenarios:
Scenario 1: The catch-up merge—. The user wants to merge all changes from a source branch that have not yet been migrated to the target branch. The source and target can be a subtree or an individual file/folder.
Scenario 2: The catch-up no-merge—. The user wants to discard nonmerged changes in the source branch from the set of candidate changes for future merges between the specified source and target.
Scenario 3: The cherry-pick merge—. The user wants to merge individual change sets from the source branch to the target branch. Changes introduced to those files prior to the specified change set should not be migrated.
The user can specify the change sets to merge with a change set number.
The user can specify individual file revisions to merge between the source and target.
Scenario 4: The cherry-pick no-merge—. The user wants to discard a single change set from the list of all possible changes to merge between the source and target so that this change set never appears in the list of candidates for a cherry pick merge.
Scenario 5: Merge history query—. The user wants to know whether the specified change set has been merged into the target branch. If it has, the user wants to know what change set the merge was committed in. The user also wants to know if part of the change set has been merged, but not all.
Scenario 6: Merge candidate query—. The user wants to obtain a list of change sets that have been committed to a source branch but have not yet been migrated to the target branch. From this list, the user selects change sets to migrate with a cherry pick merge.
TFSC merging is designed to provide users with an extremely powerful and flexible tool for managing the contents of branches. Merges can be made into a single file or into a tree of related files. Merges can also migrate the entire change history of the specified source files or an individual change set or revision that might contain a specific fix or feature that should be migrated without moving other changes from the source in the process. Merging the entire change history prior to a given point in time is known as a catch-up merge (Scenarios 1 and 2), whereas selecting individual change sets or revisions to merge is known as a cherry-pick merge (Scenarios 3 and 4). The merge command also allows users to query for merge history and merge candidates and perform the actual merge operation.
TFSC presents merge history and candidate merges as a list of change sets that have or can be migrated between a source and a target branch. Merges can be made to a subset of files in a change set, creating a situation in which a partial change set has been merged. In this case, TFSC represents the partial state of the merge and allows the user to finish merging the change set later.
Merges are pending changes in TFSC. The user can choose to perform several merge operations within a workspace without committing changes following each merge. All these merges can be staged in the user’s workspace and committed with a single check-in as a single change set. In addition, the pending merge operation can be combined with the checkout and rename commands to interject additional changes to the files that will be committed with the merge.
Hopefully you followed this summary and are still with me. Now let’s go into how branching works in TFSC.
Branching is the SCM operation of creating an independent line of development for one or more files. In a sense, branching a file results in two identical copies of the original file that can be modified as desired. Changes in the old line are not, by default, reflected in the new line and vice versa. Explicit operations can be performed to merge changes from one branch into another.
There are many different reasons for branching and many different techniques to accomplish it. In the most common scenarios, branching is reasonably simple, but branching can become complicated. A complex system with lots of branched files can be hard to visualize. I recommend mapping this with a visual product (such as Visio) so that the picture is clear.
Following are a handful of scenarios in which branching is interesting. Any SCM team should adopt these definitions.
We’ve been working on a Version 1 release for a year now, and it is time to begin work on Version 2. We need to finish coding Version 1—fixing bugs, running tests, and so on—but many of the developers are finished with their Version 1 work (other than occasional interruption for bug fixes) and want to start designing and implementing features for Version 2. To enable this, we want to create a branch off the Version 1 tree for the Version 2 work. Over time, we want to migrate all the bug fixes we make in the process of releasing Version 1 into the Version 2 code base. Furthermore, we occasionally find a Version 1 bug that happens to be fixed already in Version 2. We want to migrate the fix from the Version 2 tree into the Version 1 tree.
Promotion modeling is equivalent to release branching, where each phase is a release. It is a development methodology in which source files go through stages. Source files might start in the development phase, be promoted to the test phase, and then go through integration testing, release candidate, and release. This phasing serves a couple of purposes. It allows parallel work in different phases, and it clearly identifies the status of all the sources. Separate branches are sometimes used for each phase of the development process.
A developer (or a group) needs to work on a new feature that will be destabilizing and take a long time to implement. In the meantime, the developer needs to be able to version his changes (check in intermediate progress, and so on). To accomplish this, he branches the code that he intends to work on and does all his work independently. Periodically, he can merge changes from the main branch to make sure that his changes don’t get too far out of sync with the work of other developers. When he is done, he can merge his changes back into the main branch.
Developer isolation also applies when semi-independent teams collaborate on a product. Each team wants to work with the latest version of its own source but wants to use an approved version of source from other teams. The teams can accomplish this in two ways. In the first way, the subscribing team “pulls” the snapshot that it wants into its configuration, and in the second way, the publishing team publishes the “approved” version for all the client teams to pick up automatically.
We label important points in time, such as every build that we produce. A partner team picks up and uses our published builds on a periodic basis, perhaps monthly. A couple of weeks after picking up a build, the team discovers a blocking bug. It needs a fix quickly but can’t afford the time to go through the approval process of picking up an entirely new build. The team needs the build it picked up before plus one fix. To do this, we create a branch of the source tree that contains all the appropriate file versions that are labeled with the selected build number. We can fix the bug in that branch directly and migrate the changes into the “main” branch, or we can migrate the existing fix (if it had been done) from the “main” branch into the new partner build branch.
We have a component that performs a function (for simplicity, let’s imagine it is a single file component). We discover that we need another component that does nearly the same thing but with some level of change. We don’t want to modify the code to perform both functions; rather, we want to use the code for the old component as the basis for creating the new component. We could just copy the code into another file and check it in, but among other things, the new copy loses all the history of what brought it to this point. The solution is to branch the file. That way, both files can be modified independently, both can preserve their history, and bug fixes can be migrated between them if necessary.
Partial branching is equivalent to component branching, where the “component” is the versioned product. In this case, we work on a product that has a series of releases. We shipped the Everett release and are working on the Whidbey release. As a general rule, all artifacts that make up each version should be branched for the release (source, tools, specs, and so on). However, some versioned files aren’t release specific. For example, we have an emergency contact list that has the home phone numbers for team members. When we update the list, we don’t want to be bothered with having to merge the changes into each of the product version branches, yet the developers who are enlisted in each version branch want to be able to sync the file to their enlistment.
When a file is branched, it is as if a new file is created. We need a way to identify that new file. Historically, this has been done by including the version number of the file as part of the name of the file. In such a mechanism, the version number consists of a branch number and a revision number. A branch number is formed by taking the version number of the file to be branched, appending an integer, and then adding a second integer as a revision number. For example, 1.2 becomes 1.2.1.1 (where 1.2.1 is the branch number and 1 is the revision number). See Chapter 16 for more details on branch labeling.
This is all well and good, but it quickly becomes unwieldy not only from the standpoint of dealing with individual files, but also from the standpoint of trying to pick version numbers apart to understand what they mean.
To address these issues, the notion of “configurations” was developed. A configuration is a collection of files and their version number. Configurations generally have a human-readable name, such as Acme 1.0. Having named configurations is great, but before long, even that will get to be a problem. You will need a way to organize them.
An interesting way to address this organization problem is to make configurations part of the actual source code hierarchy. This method of organization is natural because it is how people do it without version control. It avoids the problem of having to teach most people the concept of configuration, and it provides a great deal of flexibility in how you combine configurations. For example, two versions of an Acme product (where Version 2.0 is branched from Version 1.0) might look something like this:
Branching granularity has different approaches. In the traditional approach, branching is done on a file-by-file basis. Each file can be branched independently at different times, from different versions, and so on. Configurations help prevent this from becoming chaotic. They provide an umbrella to help people understand the purpose of the various branches. File-by-file branching is flexible, but you must take care to ensure that it doesn’t get out of hand. In addition, file-by-file branching can be hard to visualize.
Another technique is always to do branching globally. Whenever a branch is created, all files in the system are branched. (There are ways to do this efficiently, so it’s not as bad as it sounds.) The upside of this global branching is that it is easy to understand and visualize. The downsides include the fact that it forces a new namespace (the branches namespace) and is less flexible. For example, I can’t have a single configuration that includes two copies of the same file from different configurations, as in the previous component branching scenario.
Shelving and offline work are such excellent features that they alone justifies moving from whatever SCC tool you currently use to TFSC.
A contributor, working on a new feature, checks out a series of files from the repository.
A critical bug is found that needs immediate attention by this contributor.
The contributor chooses to shelve his current change set for the feature he was working on. All of his currently checked-out files are archived on the server, where they can be retrieved later. The files are replaced by the unmodified copies of the same version he originally synced from the server. The files do not appear to be checked out in the contributor’s workspace.
The contributor makes changes to address the bug as needed. The modified files are checked in as a new change set.
The contributor now unshelves his previous change set from the server. The modified files that he previously archived to the server are placed in his workspace. The files once again appear to be checked out in his workspace.
The contributor, wanting to merge any modifications to these files that were made during the bug fix, syncs his workspace with the server. The updates are automatically merged into the checked-out files in the local workspace.
The contributor continues work on the new feature and checks in all modifications as a single changeset when the feature is complete.
A contributor syncs his workspace and takes his laptop home for the evening.
At home, he continues working and chooses to check out a file.
An unmodified copy of the checked-out file is placed in the contributor’s cache on his local computer.
The contributor continues to work and check out additional files. Unmodified copies of all these files are placed in the cache.
When the feature is complete, the user attempts to check in the change set. Because the user is offline, the check-in option is not available.
Wanting to begin work on the next feature, the user shelves his modifications for retrieval and check-in when he is able to go back online.
I have designed VBLs with customers using several different SCC tools. Some worked better than others, but what I really like about TFSC is that it is designed from the ground up to work most efficiently with the way that developers and projects interact. It’s not necessary to customize the tool with hacks or tricks to get it to do what you want. All the features are there.
I hope that after reading this chapter, you have an idea of what a VBL is and can grasp the concept of having a mainline to build and store your product sources. This is such a large topic that I could easily write a book on it. I covered only the basics here. What you should take away from this chapter are some clear definitions of terms that are used on a daily basis in any development team. You should also have a better understanding of why a mainline is necessary and how to set one up using a VBL model. Finally, I offered some recommendations and a preview of Microsoft’s enterprise-class TFSC tool that will be out in the fall of 2005.
Create the mainline (public) and virtual build labs (private) codelines.
Make sure the mainline is pristine and always buildable and consumable. Create shippable bits on a daily basis. Use consistent, reliable builds.
Build private branches in parallel with the main build at a frequency set by the CBT.
Use consistent reverse and forward integration criteria across teams.
Be aware that dev check-ins are normally made only into a private branch or tree, not the mainline.
Know that check-ins into a private branch are only reverse integrated (RId) into main when stringent, division-wide criteria are met.
Use atomic check-ins (RI) from private into main. Atomic means all or nothing. You can back out changes if needed.
Make project teams accountable for their check-ins, and empower them to control their build process with help from the CBT.
Configure the public/private source so that multisite or parallel development works.
Optimize the source tree or branch structure so that you have only one branch per component of your product.