
Chapter 6. Advanced Topics in Mesos
Although you now know the ropes of building applications on Mesos, you’ve probably got even more questions than when you started:
-
What is the internal architecture of Mesos?
-
How does Mesos handle failures?
-
How can I use Docker with Mesos?
In this chapter, we’ll learn more about all these things, so that you can build even more sophisticated, reliable systems.
Libprocess and the Actor Model
At a high level, Mesos is a hybrid strongly consistent/eventually consistent system, based on the message passing actor model, written in C++.
The actor model is a paradigm for programming concurrent and distributed systems. In the actor model, the developer implements processes or actors, which are single-threaded modules of code that process messages one at a time. While processing a message, an actor can send messages to other actors or create new actors. Actors can only send messages to those whose process identifiers (PIDs) they know. When an actor spawns another actor, it learns the PID of the newly created actor. In order to get more PIDs, actors must send the PIDs to one another in messages.
The actor model framework that Mesos uses is called libprocess, and it was written by Ben Hindman at the same time he wrote Mesos.1 Libprocess is a C++ API that provides actor model semantics and uses HTTP to communicate. Since everything speaks HTTP, it’s easy to interface with libprocess.
Libprocess messages are just protobufs over HTTP, and can benefit from the headers, content negotiation, and routing features therein. A libprocess process is identified by its PID, which is written as the hostname and the port of the actor.
Fun Fact
In order to support the asynchronous semantics that the actor model requires, libprocess uses a neat trick: it turns out that HTTP status code 202 means that the request has been accepted and is being asynchronously processed.
For most users of Mesos, you’ll need to understand nothing about libprocess and actors.
If, however, you are using advanced containerization techniques (like Docker bridged networking) or have multiple network interfaces, you may need to configure the LIBPROCESS_IP and LIBPROCESS_PORT environment variables for the Mesos masters and slaves.
These environment variables allow you to control which network interface the masters, slaves, and other libprocess actors bind to, so that their messages can successfully reach each other.
The Consistency Model
Let’s talk more about the consistency model of Mesos. Where does it lie on the CAP theorem?2 What guarantees do we get, as users and developers of Mesos? The answer to this question isn’t simple. For this section, we’re going to look at a Mesos cluster with three masters, the registry feature enabled, and the slave checkpointing and recovery features enabled. Really, any feature related to reliability and persistence will be assumed to be enabled, since they form the basis of Mesos’s robust consistency model.
Consider the block diagram of Mesos while a framework is running a task in Figure 6-1. There are four parts: the master, the slave, the framework’s scheduler, and the framework’s executor. There are three communication links: between the master and the scheduler, between the master and the slave, and between the slave and the executor. Let’s analyze the failure modes of each of these in turn.
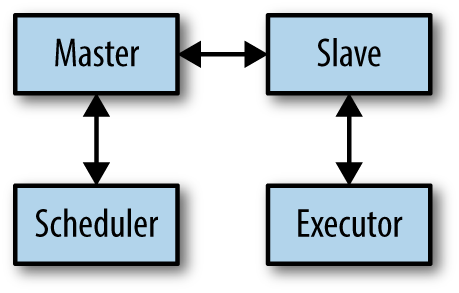
Figure 6-1. Message flows for a framework
How Is Slave Failure Handled?
First, let’s look at the lifecycle of the slave, and see how various failures are handled.
Initially, when a new slave starts up, it connects to Mesos and asks to register by sending a Register message to the master.
The master then stores the slave’s information in the registry, and once that operation has committed, it sends a Registered message to the slave, thus informing the slave that it’s successfully joined the Mesos cluster.
At this point, the master can begin to offer the slave’s resources to the connected schedulers.
Suppose now that the slave crashes.
In this case, the master will soon stop receiving the slave heartbeats, and after the configured timeout, the slave will be recognized as being “dead” and will be removed from the registry.
As a consequence, even if the slave was only temporarily partitioned from the network, as soon as it resumes heartbeating or attempts to reconnect to the master, the master will politely inform the slave to kill itself.3
At this point, let’s hope that you’re running your slave under a supervisor such as Supervisord, Monit, or SystemD.
When the slave restarts, it’ll generate a new random slave ID for itself, at which point it’ll be able to successfully register as a new slave (see the following sidebar).
When a slave crashes, any tasks that were running on the slave originally are LOST, since the slave is dead.
How Is Master Failure Handled? (Or, the Registry)
Now, let’s look at what happens if the master crashes.
First and foremost, we know this isn’t a big deal, as Mesos is built to handle all sorts of distributed failures.
Plus, we’ve got those redundant backup masters around anyway, right?
After the current master crashes, a new leading master is elected.
Gradually the slaves will discover this information through the course of their regular communication with the masters.
Since the slaves are heartbeating periodically, they’ll see their heartbeats fail to connect or get rejected (depending on whether the old leader is down or merely restarted and now just a spare).
The slaves will query ZooKeeper again to learn of the new master.
At this point a slave will use a different RPC to connect to the new master, called Reregister, since the slave believes itself to already be registered but no longer connected.
When the new leader receives this RPC, it checks the registry to confirm that this slave is indeed live.
If it is, it accepts the slave’s registration; however, if the slave was not in the registry, then it will tell the slave to kill itself so that it can be revived with a new slave ID and rejoin the cluster as a new slave without any baggage.
You might wonder why we need the registry and the reregistration process. Let’s look at what happens if we remove reregistration and the registry. Reregistration’s an easy one: if a slave can’t reregister, then a master crash and subsequent failover will always force the slave to register as a new slave because (as discussed in the preceding sidebar) Mesos uses a fail-stop model. This means killing all the tasks on that slave. Needless to say, instantly killing all tasks across the entire cluster when the master needs to restart or fail over isn’t ideal, and defeats the purpose of using a highly available cluster operating system.
Now, let’s consider what happens if we remove the registry.
Suppose that a slave stops heartbeating due to a network partition, and the old leader decides that slave is dead, meaning all tasks on it are considered LOST.
Then, the masters fail over to a new leader, and at that time the slave, which was previously not sending heartbeats, miraculously manages to start sending heartbeats again.
Now, the new leader will receive the slave’s reregistration and accept it.
But wait!
The old leader thought that slave was dead, and sent the scheduler LOST messages about all of the tasks on that slave.
Now we’ve gotten into an unfortunate situation where tasks in the LOST state seem to magically resurrect; this is a bug because LOST is a terminal state for the tasks.
The registry allows us to ensure that tasks can never move out of the LOST state (or any terminal state) back into a nonterminal state: the old leader marks the slave dead in the registry so that the new leader will know to reject the reregistration.
One thing you might be thinking at this point is, “It sure seems like the masters will have to do a ton of bookkeeping to track what state every task on every slave is in, and store that in the registry.” And you’d be right, except that the masters don’t actually store any task information in the registry. Since the registry allows us to know which slaves are valid, Mesos allows those slaves to be the trusted, canonical sources of information about their tasks. So, when a master failover occurs, the new leader has no information about what tasks are running (and actually, the Mesos UI will reflect this, so don’t be worried if it takes a couple of minutes after a master failure to see all your tasks again). Over time, as the slaves reregister and report in, the master will rebuild its in-memory picture of the state of the cluster.
There’s one more consideration for the registry, however: strict and nonstrict mode. So far, I’ve only been describing the strict registry mode, since that’s the safe, always correct logic. Unfortunately, there’s an annoying limitation with the strict registry: you cannot add new slaves to the master until all slaves have either checked in or timed out (typically, there’s a 90-second grace period for slaves to reregister with a newly elected master). If, however, you use the nonstrict registry, then your frameworks must deal with a very challenging case during reconciliation. In the next section, we’ll learn about all the cases that can occur.
Reconciliation During Failover
At this point you’re probably satisfied with the idea that Mesos will keep its state nice and consistent.
Well, you shouldn’t be, because there’s still one problem as yet unexplored: how do the frameworks stay in sync with the Mesos cluster during transient failures?
For instance, what happens if a master marks a slave as dead and then crashes, thus missing its chance to inform the schedulers about all the tasks on that slave that have just reached the LOST state (because their slave died)?
After all, the leader’s state about the tasks is 100% derived from the slaves’ state, and the new leader has no idea what status updates have or haven’t already been sent.
The answer to this dilemma lies in the reconciliation feature.
Reconciliation is how a scheduler can check with the master to see whether the scheduler’s belief about the state of the cluster matches the master’s belief about the state of the cluster.
A scheduler is allowed to, at any time, ask the master to reconcileTasks—this is an RPC that allows the scheduler to provide a list of all the tasks and their statuses to the master, and the master to provide corrections for any tasks for which it knows a newer status.
Typically, reconciliation waits until the master is no longer waiting for slaves to check in (as would happen during a master failover); however, we’ll see now how the nonstrict mode of the registry complicates this.
Always Provide the Slave ID
Always provide the slave ID to the reconcileTasks RPC, even though it’s optional.
If you choose not to specify the slave ID, you may have to wait for up to two minutes for a response, since Mesos will wait until every registered slave has checked in or timed out.
Also, you may erroneously receive a TASK_LOST message for some tasks, and later see those tasks resurrect.
Rather than dealing with the excess latency and edge cases, just provide the slave ID for every reconciliation.
Task reconciliation can only provide details about a task when it’s in a nonterminal state.
Of course, the main reason to reconcile is to determine whether tasks are still running, or if they’ve moved to a terminal state.
Whenever a task is in a terminal state, reconciliation for that task can always claim that it is LOST, when in fact it may have reached some other terminal status.
It’s the framework developer’s responsibility to combine the information from reconciliation with other information, such as external services with which a successful task may have stored data, to determine what the true result of the completed task was.
Reconciling Completed Tasks
You should be careful to always ignore a TASK_LOST message from reconciliation when you’ve previously seen a different terminal status for that task.
As long as the task is not in a terminal state, reconciliation will result in the latest state for that task being sent (is either TASK_STAGING if the task hasn’t sent any status update yet, or whatever the latest status update was).
When the task is terminal, reconciliation is invalid.
When the task’s state is unknown to the master, however, the behavior is a bit trickier. There are a few situations to consider:
- Task is unknown, but its slave is known
-
In this case, the reconciliation mechanism will report that the task has been
LOST. This is logical because it means that the task has entered a terminal state. - Task is unknown, and the slave is in the registry but hasn’t reregistered
-
This situation happens after a master failure before the slave has had a chance to check in. Mesos will simply wait to send a response to the request for reconciliation until it’s heard from the slave, as it can’t know what has happened to the task since the previous master crashed.
- Task is unknown, and the slave is not in the registry
-
If you follow the advice about always providing the slave ID to
reconcileTasksand you are using the strict registry, you’ll never have to deal with this confusing case. When this happens, Mesos can’t know if it’s ever going to hear from the slave, since that very slave may exist but not yet have been included in the registry. As a result, Mesos will report that the task isLOST, but you may see other status updates for that task if the slave registers later on. This includes the chance that the task could appear to resurrect with aRUNNINGstatus, or complete with aFINISHEDorFAILEDstate! Using the strict option for the registry completely prevents this case from ever occurring, and as such it is strongly recommended to run in strict mode.
Containerizers
As you know, Mesos has first-class support for Docker.
But what does that mean?
I mean, Docker can basically be run by a docker run ... on the command line, so what else needs to be done?
Since Docker itself wants to manage the entire container, from the chroot, namespaces, and cgroups on through the entire userspace, it will conflict with the default Mesos containers.
Because of this, Mesos has added support for containerizers, a pluggable mechanism to allow Mesos’s containerization subsystem to be extensible: the original Mesos LXC/cgroups-based containers were ported to the containerizer API, Docker was added as the first new containerizer, and now there’s a well-documented protocol for adding new containerizers, such as KVM virtual machines.
Using Docker
In order to use the Docker containerizer, you must include it on the Mesos slave’s command line. For example, mesos-slave --containerizers=docker,mesos ... would allow Docker and plain Mesos containers on that slave.
You’ll probably also want to increase the executor registration timeout, so that Mesos doesn’t think that your container failed when it’s actually still downloading. Five minutes is a good conservative starting point for ensuring that your Docker images have enough time to download. Thus, you’ll end up with a slave command line like:
mesos-slave --containerizers=docker,mesos
--executor_registration_timeout=5mins ...
Using Docker with your application is very simple—once you’ve enabled support for Docker, you just need to set the container field (of type ContainerInfo) in the TaskInfo or ExecutorInfo.
Warning
Confusingly, the message CommandInfo.ContainerInfo is not the correct message—you want to set the top-level ContainerInfo in mesos.proto that has Docker-related fields.
To use Docker, set the type of the ContainerInfo to DOCKER, and set the docker field to an instance of the ContainerInfo.Docker message, which should have the image property set to your Docker image’s name (e.g., myusername/webapp).
At this point, you can configure many Docker parameters, such as whether to use HOST or BRIDGE networking, what port mappings to use, or additional Docker command-line options.
If you’d like the Docker container to use the docker run ... specified in the Dockerfile, then you should set the CommandInfo of the TaskInfo to have shell = false.
If you set shell = true, then you’ll disable the run built into the Dockerfile, and instead the specified command will be run via sh -c "<command>".
When you launch a Docker containerized task, the slave first fetches (and unpacks) all the specified URIs into the sandbox, and it pulls the Docker image locally.
Next, the slave launches the Docker image by running docker.
The docker command’s HOME environment variable is set to the sandbox, so that you can configure Docker via fetched URIs (as discussed in the following note).
The sandbox will be available inside the Docker image, and its path will be stored in the MESOS_SANDBOX environment variable as usual.
Finally, Docker’s stdout and stderr will be redirected to files named stdout and stderr in the Mesos sandbox.
Advanced Docker Configuration
One thing you should be aware of is that the Docker containerizer always attempts to pull the Docker image down from the registry.
This means that you cannot use a local-only installed Docker image—you must have deployed it somewhere.
If you’d like to use a private registry, you can provide a .dockercfg file.
This file should be specified by a URI, so that the Mesos slave can use its automatic URL-fetching facilities to copy the .dockercfg into the HOME for the Docker process to use.
The same API works for Docker-based executors too, except that then your executor code can actually run inside the Docker container.
To achieve this, do the exact same thing as described here, but in the ExecutorInfo message instead of the TaskInfo message.
The New Offer API
We’ve chosen to run Mesos because it allows us to flexibly allocate our workloads across our clusters, so that we can use our infrastructure more efficiently. Sometimes, however, we want to make longer-term allocation decisions with Mesos. For example, we may want to reserve certain machines to guarantee capacity for an application even when it’s not running tasks. Of course, slave reservations exist (as discussed in “Static and Dynamic Slave Reservations”), but this new API allows us to make reservations programmatically, without shutting down a slave. We’ll need a way to manage these dynamically created reservations on the cluster, which is where the new API comes in.
The launchTasks API that we first saw used in Example 4-5 has a drawback for some frameworks: once a task exits, whether normally or due to failure, its resources become available for other frameworks to claim.
In this section, we’ll take a look at the new offer API, which allows frameworks to dynamically reserve and release resources beyond the lifetimes of their tasks, as well as some of the additional features this API enables.
Framework Dynamic Reservations API
Dynamic reservations are a new feature that enables slave reservations to be made on the fly by frameworks that need to retain their resources through restarts (like databases and systems with strict SLAs).
Rather than using the launchTasks API, we’ll use the acceptOffers API.
Example 6-1 illustrates two equivalent launchTasks and acceptOffers invocations.
Example 6-1. Comparing launchTasks and acceptOffers
driver.launchTasks(Collections.singletonList(offer.getId()),Collections.singletonList(taskInfo));// VersusLaunchlaunch=Offer.Operation.Launch.newBuilder().addTaskInfos(taskInfo).build();OperationlaunchOp=Offer.Operation.newBuilder().setType(Offer.Operation.Type.LAUNCH).setLaunch(launch).build();driver.acceptOffers(Collections.singletonList(offer.getId()),Collections.singletonList(launchOp),Filters.newBuilder().build());
First, we construct the actual command that we want to do with the offer—launching these tasks.
Then, we construct the operation that we’ll send to Mesos—all the different commands represented by the
Offer.Operationunion. Note thatOperationis a protobuf tagged union (see “Understanding mesos.proto”).
Here, we’re only doing one operation on the offer. We could choose to specify a list of several operations, perhaps combining reserving resources, creating persistent volumes, and launching tasks into a single message.

acceptOffersrequires you to pass aFiltersprotobuf; feel free to just use the default, which does no filtering.
Besides using acceptOffers to launch a task, a framework can also reserve that task’s resources as a dynamic reservation.
When that task terminates, its resources are held in a reservation that’s valid only for this framework’s role.
This means that you can launch your production workload, and in spite of it not having preconfigured static reservations, machine reboots and transient failures will not permanently disrupt its capacity (for services that must maintain a strict SLA) or functionality (for services that need to retain their data, like databases).
Let’s enhance our Java snippet to also reserve those resources.
We’ll add another Offer.Operation to the list of operations we are performing on those offers, as seen in Example 6-2.
Example 6-2. Reserving resources and launching a task in a single acceptOffers
Offer.Operation.Launchlaunch=Offer.Operation.Launch.newBuilder().addTaskInfos(taskInfo).build();Offer.OperationlaunchOp=Offer.Operation.newBuilder().setType(Offer.Operation.Type.LAUNCH).setLaunch(launch).build();Offer.Operation.Reservereserve=Offer.Operation.Reserve.newBuilder().addAllResources(taskInfo.getResourcesList()).build();Offer.OperationreserveOp=Offer.Operation.newBuilder().setType(Offer.Operation.Type.RESERVE).setReserve(reserve).build();driver.acceptOffers(Collections.singletonList(offer.getId()),Arrays.asList(reserveOp,launchOp),Filters.newBuilder().build());
As before, we construct the launch operation.
We also need to construct the reserve operation; here, we’re simply copying all the resources from the launched task so that the reservation for the task will persist beyond the task’s lifetime.
We can pass multiple operations into an
acceptOffers. This is equivalent to waiting for the reservation to be acknowledged and reoffered by the master, but it saves a round-trip across the network.
Now that we know how to reserve resources and launch tasks on them, a logical question pops up: how do we determine whether an offered resource is from an existing dynamic reservation?
Resources can have an additional field, reservation, that we can check to see if those resources been reserved, and by whom, as shown in Example 6-3.
Example 6-3. Querying resources for the reservation status
if(resource.hasReservation()){resource.getReservation().getPrincipal();}
This call will return
trueif the resource is reserved.If the resource was reserved, we can get the name of the principal that reserved it. The principal is often the same as the framework’s
user.
Handling Reservations in Offers
When using dynamic reservations, you may need to revise the code used to count how many resources are in an offer.
Take another look at Example 4-10.
Notice that we actually used += every time we encountered a CPU or memory resource.
This ensures that we’ll be able to use both reserved and unreserved resources for launching our tasks.
Once a slave dies, the reservation will be automatically freed.
If your framework is tracking all the outstanding reservations, you can use the slaveLost callback to determine when a reservation on an old slave no longer exists.
If you no longer need a reservation, you can free it by using the unreserve operation in acceptOffers, as demonstrated in Example 6-4.
Example 6-4. Unreserving resources
List<Resource>resources=newArrayList<>();for(Resourcer:offer.getResourcesList()){if(r.hasReservation()){resources.add(r);}}Offer.Operation.Unreserveunreserve=Offer.Operation.Unreserve.newBuilder().addAllResources(resources).build();Offer.OperationunreserveOp=Offer.Operation.newBuilder().setType(Offer.Operation.Type.UNRESERVE).setUnreserve(unreserve).build();driver.acceptOffers(Collections.singletonList(offer.getId()),Collections.singletonList(unreserveOp),Filters.newBuilder().build());
We find all the previously reserved resources.
Here, we unreserve all of the resources that were previously reserved.
Reservations Are Forever
If you don’t unreserve resources when you’re finished, Mesos will continue to hold those resources aside forever, until you unreserve them. Dynamic reservations will leave beta once their administrative HTTP API is put into place. The HTTP API will allow the Mesos cluster’s human operators to unreserve resources on a framework’s behalf.
The dynamic reservations API is a powerful tool for building even more robust applications on Mesos.
An HTTP API is available on the master as another way to manage dynamic reservations (see “Dynamic reservations”).
This API makes it easy to alter reservations across the Mesos cluster on the fly.
It also makes it easy to unreserve resources a framework may have left behind after it was shut down for the last time.
Dynamic resources are just the start of the acceptOffers API; we’ll now look at the persistent volumes API.
Persistent Volumes for Databases
Until recently, Mesos could only run services that didn’t need to store data to disk. That’s because there was no way to reserve the chunk of disk necessary. As of Mesos 0.23, reserving disks is now possible.
Remember from Chapter 1, you can think of Mesos as a deployment system. Wouldn’t it be great if our MySQL databases automatically backed themselves up and created new read replicas as needed? Or if we could have simple, self-service REST APIs to create new Riak and Cassandra clusters? There’s been work ongoing since 2014 to build database frameworks for Mesos. The issue with those frameworks is that every host has to have special data partitions created and managed outside of Mesos. With persistent volumes, projects like Apache Cotton (for MySQL) and the Cassandra and Riak Mesos frameworks will be able to independently bootstrap and maintain themselves.
In Mesos’s design, disk space is ephemeral and isolated for every task. This is usually a good thing, unless you want to store data persistently. To solve this, Mesos introduced a new subtype of disk resources, called a volume. A volume is simply a chunk of disk that is allocated for a task and mounted at a specified location. The API for doing this is essentially the same as the Marathon API for mounting host volumes, see “Mounting host volumes”. You can even create a volume that isn’t persistent, which will be useful in the future when multiple independent disks can be exposed to Mesos. Now, we’ll look at how to create and use persistent volumes.
There are two acceptOffers Operations that are used to create and destroy persistent volumes.
Unsurprisingly, they’re called Create and Destroy.
Persistent volumes can only be created on disk resources that have been reserved.
Typically, you’ll reserve the resources, create the volumes, and launch the tasks in a single acceptOffers, as shown in Example 6-2.
A persistent volume resource is the same as a regular disk resource (see “Resources”), but it has the field disk configured with the appropriate DiskInfo.
The DiskInfo names the persistent volume so that it can be mounted by name via the nested string subfield persistence.id.
The Volume of the DiskInfo should have the mode RW (as of Mesos 0.24, only RW is supported).
The container_path field of the Volume will specify where the container will be mounted in the task’s sandbox.
The persistent volume API is so new that no production frameworks have been written using it yet.
It has limitations, such as that the volumes must always be mounted RW, and there’s no way to expose multiple disks or have any disk or I/O isolation.
The API will remain backward-compatible even as new features and functionality are added, though;
because of this, projects such as Apache Cotton are already integrating persistent volumes into their codebases.
Summary
Mesos offers sophisticated, well-thought-out APIs for many different use cases. First, we discussed the internal architecture of Mesos at a high level, to help us understand why things are built the way they are. We then dove into a thorough analysis of how Mesos maintains internal and external consistency. By understanding the consistency model, we can build far more robust and failure-tolerant frameworks.
Next, we learned about the reconciliation process that is used to synchronize frameworks with the Mesos master. By understanding the mechanisms of the reconciliation process, it’s possible to understand how to eventually guarantee consistency across a Mesos cluster, what types of inconsistencies can occur, and how to interpret those inconsistencies.
Then, we moved on to Mesos’s integration with Docker, a popular application containerization and deployment format. By integrating containerization into frameworks, we can leverage broader ecosystems, such as all Dockerized applications.
Finally, we looked at dynamic reservations and persistent volumes, features enabled by the new acceptOffers API.
Dynamic reservations allow us to far more easily guarantee capacity for critical workloads.
Persistent volumes allow us to build database frameworks for Mesos that can persist their data in spite of unanticipated failures and faults throughout the system.
At this point, we’ve covered a variety of topics and techniques that are useful in building applications on Mesos today. In the next chapter, we’re going to look at what’s coming for Mesos tomorrow.
1 It appeared as a component of the Lithe project.
2 The CAP theorem is a theoretical result about the possible and impossible behaviors of distributed systems. You can read about it in “Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services,” by Seth Gilbert and Nancy Lynch.
3 Note that if the slave reconnects within its configured timeout, the slave and all its tasks will continue as normal. This behavior is what zero-downtime live upgrades of Mesos rely on.