
This chapter is about reliability. It is again not a deep technical manual but instead encourages a mindset of frequently visualizing an uncertain future where you, your code, or your colleagues need to respond to changing conditions. That mindset is general, but we’ll move on from there to list some of the most important areas for concern in building any reliable system.
Think About the Future
What could break?
How can the system keep working if something breaks?
What could fail without our realizing it? How can we make sure we’ll be alerted?
What might we be asked to (or want to) change in the future? Will it be easy?
What would I want to know if something breaks?
What behavior would I want to be able to control or change if something goes wrong?
What could users do that we don’t intend?
What could be inconvenient, slow, or error-prone when we have customer problem?
What might trip up a future developer of the system?
What precondition or required invariant isn’t documented or tested?
This is at best an imperfect science of pattern matching and educated guesswork; you’ll get more accurate and more precise as your knowledge grows, and you don’t need to hold yourself to perfection. We all miss things and draw on the shared experience and wisdom of a team to achieve the best foresight. However, you can at least ask yourself the questions.
Design for Failure
System failures are inevitable—hard drives, RAM, switches, routers, and, above all, humans fail every single day. You already know to check your return values so you don’t crash when your code encounters errors; don’t stop doing that, but this principle says that you should look beyond the goal of “not crashing” to designs and implementations that (a) achieve unaltered or gently degraded user experiences even when things go wrong—online failure resilience—and (b) can be recovered when they experience disaster, support disaster recovery. The best reference I know of on these subjects is Site Reliability Engineering: How Google Runs Production Systems, and you should read it without delay, but I’m going to give you a little motivation here.
We’ll group failure resilience techniques into two big categories:
Redundancy: The very best case in the presence of failure is to deliver an unaltered user experience. This is an extremely rich and complex subject mostly beyond the scope of this book, but its essential technique is redundancy—having more than one of something so that if one fails (e.g., a human puts bad code on it), another keeps working. We can then help the user out with either a resilient distributed algorithm (like ZooKeeper might use) or a retry.
Graceful degradation : Sometimes an unaltered experience is impossible—maybe you’re writing mobile code, the request for user history failed, and we’ve already made the user wait as long as we can. Can we show an experience that’s less rich but still sane? Can we do things like show an unpersonalized view of the product, use a heuristic instead of machine learning prediction, or serve from a local durable cache that may be stale but will be sane? Can we generally “fail open,” doing something for the user despite failure? To make a decision, we need to reason deeply about which user experiences might be acceptable and which might not. If we’ve tried everything we can and there’s no way to deliver a sane user experience, we should do our best to show a helpful and attractive error message; at the very least, we should offer the user, “Sorry, we’re having a problem with our server, please try again in a few minutes”—don’t ever let me catch you showing the user “Error 0xCADE1F.”
Plan for Data Loss
Disaster recovery is the tooling for our worst nightmare: the loss of data or system state such that customer experiences may be down for days or indefinitely. Companies have failed for its lack; for motivation, I encourage you to try to visualize yourself and your beloved colleagues after an operator accidentally runs drop table users or cancels your GCP accounts or deletes your S3 buckets. The only route to safe harbor are the following:
Offline copies of your data, not just replicas: Data that can’t be irrevocably corrupted by a single bad SQL command or code deploy. These backups are only as trustworthy as the last time you tested restoring them, so test often.
System state restorable from source control: If your system setup requires extensive imperative human tweaking, then if your system is hit by a meteor, you’re in big, big trouble—it’s almost guaranteed to be a colossal effort to turn it up, and your company will be failing while you’re trying to restore it. Everything should be automatically restorable from git (or your source control of choice).
Build for Debugging (or Observability Is Everything)
Building observability into a system lets us ensure that (a) we can detect if it breaks and (b) when that happens, we have the tooling to figure out why.
We don’t need to stop there—many expert savvy engineers build simple, mostly static debugging UIs into their services, preparing for fast introspection of a single service instance under time pressure. I recently discovered that a colleague had built a simple little HTML UI into a long-running CLI tool, which is some next-level commitment to observability.
I personally feel that there’s almost no software pleasure greater than hitting a problem and knowing that you already added the perfect log.
Build for Operator Intervention
Improve scalability by reducing the maximum number of results we return.
Fall back to an older, unsophisticated behavior (e.g., a heuristic instead of machine learning).
Disable cache prefetching in case it for some reason runs amok and blows up the heap.
Build For Rollback
Most production problems are caused by human actions; therefore, our most potent remediation is usually to undo what humans did. That means that if at all possible, rollback should be fast and easy, and you should never, ever make a truly backward-incompatible change; it has ample “must-fix-forward” horror stories to set you on an honest path.
Ideally, code change rollouts should be quite easy to revert, with a blue-green deploy or easy way to reset the “running” version to a trusted build. New features, including backend, mobile, and web, are best deployed behind configuration control that allows them to be swiftly and orthogonally rolled back. Most importantly, database schema changes should be backward-compatible almost always (e.g., add a column, don’t delete); we should run on the new schema for weeks before the old data are deleted.
Don’t Order Dependencies; Wait
The best engineer I ever worked with taught me this principle in a random offhand comment; I’ve never been more reminded that the very best engineers don’t just hack but generalize, finding the reusable principle they can share with everyone. He said, roughly: when building a system with a complex dependency graph, especially a distributed system, it’s tempting to enforce an explicit startup ordering and fail hard if dependencies aren’t available when we start. Unfortunately, this is hard to maintain (you’ll always forget to specify one edge in the graph) and also brittle—if your dependency stutters, crashes, or is restarted, you may fail hard. Better it is to have each component calmly wait for its dependencies, retrying with some backoff; then you never need to maintain an explicit graph, and your system will tend to heal when the unexpected happens.
Plan for Overload
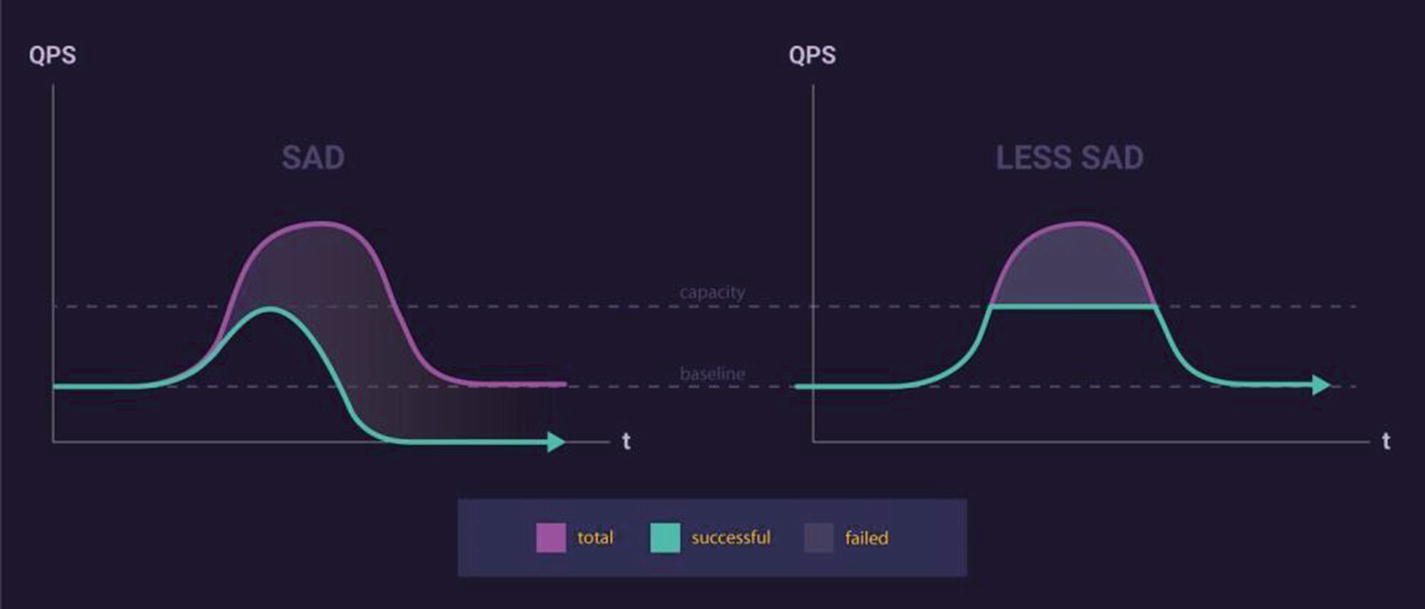
Leveling off under overload vs. failing
The most common reason for that prolonged downtime is excessive queueing. Most systems queue requests for processing with some pool of resources (e.g., threads or database connections). If request volume exceeds maximum throughput, those queues can become more and more full, sometimes to the point that a request will already be worthless (i.e., user has given up) when it reaches the head of the queue. In pathological cases, a system may spend many minutes, or even hours, draining queues of useless work after request volume returns to normal. I’ve worked on maybe ten serious outages caused by this kind of excessive queuing.
Bound your queue sizes; consider LIFO rather than FIFO!
Use a circuit-breaking library any time you use a service client.
Use an inbound loadshedder if you can! A CPU-based load-shedding trigger can be easy to configure.
Ensure you have some way to rate-limit inbound traffic, whether at load balancers/forwarding plane or at the service level.
Data Layer Isolation (In Which Database Migrations Are Our Biggest Problem)
In Real Life™, it often feels like most engineering effort is spent migrating from one system to another—either from one database to another or one microservice to another. That means that one of the most painful common obstacles is data access code sprinkled together with business logic, like a SQL query embedded in your controller or data model; SQL queries, often being literally just string literals, are particularly hard to find and analyze when doing migrations. You’ll do your future self a favor by reviewing the MVCS pattern; keep data access code like microservice requests and SQL queries in its own layer with as tight an interface as possible, hopefully enabling you to swap out databases and downstream services with less painful hunting, pecking, and refactoring.