
Generic types and methods
Generic collections in .NET 2.0
Limitations of generics
Comparisons with other languages
True[1] story: the other day my wife and I did our weekly grocery shopping. Just before we left, she asked me if I had the list. I confirmed that indeed I did have the list, and off we went. It was only when we got to the grocery store that our mistake made itself obvious. My wife had been asking about the shopping list whereas I’d actually brought the list of neat features in C# 2. When we asked an assistant whether we could buy any anonymous methods, we received a very strange look.
If only we could have expressed ourselves more clearly! If only she’d had some way of saying that she wanted me to bring the list of items we wanted to buy! If only we’d had generics...
For most people, generics will be the most important new feature of C# 2. They enhance performance, make your code more expressive, and move a lot of safety from execution time to compile time. Essentially they allow you to parameterize types and methods—just as normal method calls often have parameters to tell them what values to use, generic types and methods have type parameters to tell them what types to use. It all sounds very confusing to start with—and if you’re completely new to generics you can expect a certain amount of head scratching—but once you’ve got the basic idea, you’ll come to love them.
In this chapter we’ll be looking at how to use generic types and methods that others have provided (whether in the framework or as third-party libraries), and how to write your own. We’ll see the most important generic types within the framework, and take a look just under the surface to understand some of the performance implications of generics. To conclude the chapter, I’ll present some of the most frequently encountered limitations of generics, along with possible workarounds, and compare generics in C# with similar features in other languages.
First, though, we need to understand the problems that caused generics to be devised in the first place.
Have you ever counted how many casts you have in your C# 1 code? If you use any of the built-in collections, or if you’ve written your own types that are designed to work with many different types of data, you’ve probably got plenty of casts lurking in your source, quietly telling the compiler not to worry, that everything’s fine, just treat the expression over there as if it had this particular type. Using almost any API that has object as either a parameter type or a return type will probably involve casts at some point. Having a single-class hierarchy with object as the root makes things more straightforward, but the object type in itself is extremely dull, and in order to do anything genuinely useful with an object you almost always need to cast it.
Casts are bad, m’kay? Not bad in an “almost never do this” kind of way (like mutable structs and nonprivate fields) but bad in a “necessary evil” kind of way. They’re an indication that you ought to give the compiler more information somehow, and that the way you’re choosing is to get the compiler to trust you at compile time and generate a check to run at execution time, to keep you honest.
Now, if you need to tell the compiler the information somewhere, chances are that anyone reading your code is also going to need that same information. They can see it where you’re casting, of course, but that’s not terribly useful. The ideal place to keep such information is usually at the point of declaring a variable or method. This is even more important if you’re providing a type or method which other people will call without access to your code. Generics allow library providers to prevent their users from compiling code that calls the library with bad arguments. Previously we’ve had to rely on manually written documentation—which is often incomplete or inaccurate, and is rarely read anyway. Armed with the extra information, everyone can work more productively: the compiler is able to do more checking; the IDE is able to present IntelliSense options based on the extra information (for instance, offering the members of string as next steps when you access an element of a list of strings); callers of methods can be more certain of correctness in terms of arguments passed in and values returned; and anyone maintaining your code can better understand what was running through your head when you originally wrote it in the first place.
Note
Will generics reduce your bug count? Every description of generics I’ve read (including my own) emphasizes the importance of compile-time type checking over execution-time type checking. I’ll let you in on a secret: I can’t remember ever fixing a bug in released code that was directly due to the lack of type checking. In other words, the casts we’ve been putting in our C# 1 code have always worked in my experience. Those casts have been like warning signs, forcing us to think about the type safety explicitly rather than it flowing naturally in the code we write. Although generics may not radically reduce the number of type safety bugs you encounter, the greater readability afforded can reduce the number of bugs across the board. Code that is simple to understand is simple to get right.
All of this would be enough to make generics worthwhile—but there are performance improvements too. First, as the compiler is able to perform more checking, that leaves less needing to be checked at execution time. Second, the JIT is able to treat value types in a particularly clever way that manages to eliminate boxing and unboxing in many situations. In some cases, this can make a huge difference to performance in terms of both speed and memory consumption.
Many of the benefits of generics may strike you as being remarkably similar to the benefits of static languages over dynamic ones: better compile-time checking, more information expressed directly in the code, more IDE support, better performance. The reason for this is fairly simple: when you’re using a general API (for example, ArrayList) that can’t differentiate between the different types, you effectively are in a dynamic situation in terms of access to that API. The reverse isn’t generally true, by the way—there are plenty of benefits available from dynamic languages in many situations, but they rarely apply to the choice between generic/nongeneric APIs. When you can reasonably use generics, the decision to do so is usually a no-brainer.
So, those are the goodies awaiting us in C# 2—now it’s time to actually start using generics.
The topic of generics has a lot of dark corners if you want to know everything about it. The C# 2 language specification goes into a great deal of detail in order to make sure that the behavior is specified in pretty much every conceivable case. However, we don’t need to understand most of those corner cases in order to be productive. (The same is true in other areas, in fact. For example, you don’t need to know all the exact rules about definitely assigned variables—you just fix the code appropriately when the compiler complains.)
This section will cover most of what you’ll need in your day-to-day use of generics, both consuming generic APIs that other people have created and creating your own. If you get stuck while reading this chapter but want to keep making progress, I suggest you concentrate on what you need to know in order to use generic types and methods within the framework and other libraries; writing your own generic types and methods crops up a lot less often than using the framework ones.
We’ll start by looking at one of the collection classes from .NET 2.0—Dictionary<TKey,TValue>.
Using generic types can be very straightforward if you don’t happen to hit some of the limitations and start wondering what’s wrong. You don’t need to know any of the terminology to have a pretty good guess as to what the code will do when reading it, and with a bit of trial and error you can experiment your way to writing your own working code too. (One of the benefits of generics is that more checking is done at compile time, so you’re more likely to have working code by the time it all compiles—this makes the experimentation simpler.) Of course, the aim of this chapter is to give you the knowledge so that you won’t be using guesswork—you’ll know what’s going on at every stage.
For now, though, let’s look at some code that is straightforward even if the syntax is unfamiliar. Listing 3.1 uses a Dictionary<TKey,TValue> (roughly the generic equivalent of the Hashtable class you’ve almost certainly used with C# 1) to count the frequencies of words in a given piece of text.
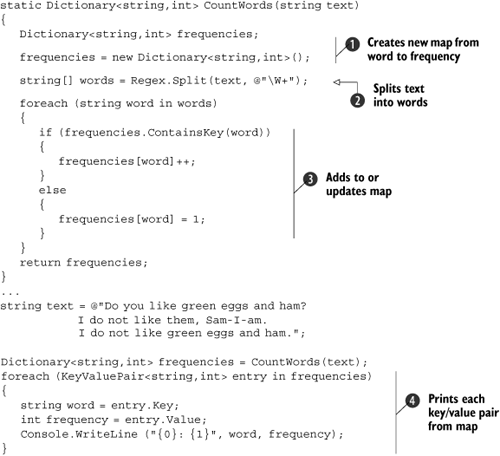
The CountWords method ![]() first creates an empty map from
first creates an empty map from string to int. This will effectively count how often each word is used within the given text. We then use a regular expression ![]() to split the text into words. It’s crude—we end up with two empty strings (one at each end of the text), and I haven’t worried about the fact that “do” and “Do” are counted separately. These issues are easily fixable, but I wanted to keep the code as simple as possible for this example. For each word, we check whether or not it’s already in the map. If it is, we increment the existing count; otherwise, we give the word an initial count of 1
to split the text into words. It’s crude—we end up with two empty strings (one at each end of the text), and I haven’t worried about the fact that “do” and “Do” are counted separately. These issues are easily fixable, but I wanted to keep the code as simple as possible for this example. For each word, we check whether or not it’s already in the map. If it is, we increment the existing count; otherwise, we give the word an initial count of 1 ![]() . Notice how the incrementing code doesn’t need to do a cast to
. Notice how the incrementing code doesn’t need to do a cast to int in order to perform the addition: the value we retrieve is known to be an int at compile time. The step incrementing the count is actually performing a get on the indexer for the map, then incrementing, then performing a set on the indexer. Some developers may find it easier to keep this explicit, using frequencies[word] = frequencies [word]+1; instead.
The final part of the listing is fairly familiar: enumerating through a Hashtable gives a similar (nongeneric) DictionaryEntry with Key and Value properties for each entry ![]() . However, in C# 1 we would have needed to cast both the word and the frequency as the key and value would have been returned as just
. However, in C# 1 we would have needed to cast both the word and the frequency as the key and value would have been returned as just object. That also means that the frequency would have been boxed. Admittedly we don’t really have to put the word and the frequency into variables—we could just have had a single call to Console.WriteLine and passed entry.Key and entry.Value as arguments. I’ve really just got the variables here to ram home the point that no casting is necessary.
There are some differences between Hashtable and Dictionary<TKey,TValue> beyond what you might expect. We’re not looking at them right now, but we’ll cover them when we look at all of the .NET 2.0 collections in section 3.4. For the moment, if you experiment beyond any of the code listed here (and please do—there’s nothing like actually coding to get the hang of a concept) and if it doesn’t do what you expect, just be aware that it might not be due to a lack of understanding of generics. Check the documentation before panicking!
Now that we’ve seen an example, let’s look at what it means to talk about Dictionary<TKey,TValue> in the first place. What are TKey and TValue, and why do they have angle brackets round them?
There are two forms of generics: generic types (including classes, interfaces, delegates, and structures—there are no generic enums) and generic methods. Both are essentially a way of expressing an API (whether it’s for a single generic method or a whole generic type) such that in some places where you’d expect to see a normal type, you see a type parameter instead.
A type parameter is a placeholder for a real type. Type parameters appear in angle brackets within a generic declaration, using commas to separate them. So in Dictionary <TKey,TValue> the type parameters are TKey and TValue. When you use a generic type or method, you specify the real types you want to use. These are called the type arguments—in listing 3.1, for example, the type arguments were string (for TKey) and int (for TValue).
Note
Jargon alert! There’s a lot of detailed terminology involved in generics. I’ve included it for reference—and because very occasionally it makes it easier to talk about topics in a precise manner. It could well be useful if you ever need to consult the language specification, but you’re unlikely to need to use this terminology in day-to-day life. Just grin and bear it for the moment.
The form where none of the type parameters have been provided with type arguments is called an unbound generic type. When type arguments are specified, the type is said to be a constructed type. Unbound generic types are effectively blueprints for constructed types, in a way similar to how types (generic or not) can be regarded as blueprints for objects. It’s a sort of extra layer of abstraction. Figure 3.1 shows this graphically.
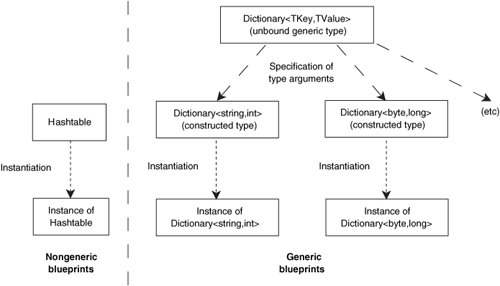
Figure 3.1. Unbound generic types act as blueprints for constructed types, which then act as blueprints for actual objects, just as nongeneric types do.
As a further complication, constructed types can be open or closed. An open type is one that involves a type parameter from elsewhere (the enclosing generic method or type), whereas for a closed type all the types involved are completely known about. All code actually executes in the context of a closed constructed type. The only time you see an unbound generic type appearing within C# code (other than as a declaration) is within the typeof operator, which we’ll meet in section 3.4.4.
The idea of a type parameter “receiving” information and a type argument “providing” the information—the dashed lines in figure 3.1—is exactly the same as with method parameters and arguments, although type arguments are always just names of types or type parameters.
You can think of a closed type as having the API of the open type, but with the type parameters being replaced with their corresponding type arguments.[2] Table 3.1 shows some method and property declarations from the open type Dictionary<TKey,TValue> and the equivalent member in closed type we built from it—Dictionary<string,int> .
Table 3.1. Examples of how method signatures in generic types contain placeholders, which are replaced when the type arguments are specified
Method signature in generic type | Method signature after type parameter replacement |
|---|---|
public void Add
(TKey key, TValue value)
public TValue this [TKey key]
{ get; set; }
public bool ContainsValue
(TValue value)
public bool ContainsKey
(TKey key) | public void Add
(string key, int value)
public int this [string key]
{ get; set; }
public bool ContainsValue
(int value)
public bool ContainsKey
(string key) |
One important thing to note is that none of the methods in table 3.1 are actually generic methods. They’re just “normal” methods within a generic type, and they happen to use the type parameters declared as part of the type.
Now that you know what TKey and TValue mean, and what the angle brackets are there for, we can have a look at how Dictionary<TKey,TValue> might be implemented, in terms of the type and member declarations. Here’s part of it—although the actual method implementations are all missing, and there are more members in reality:
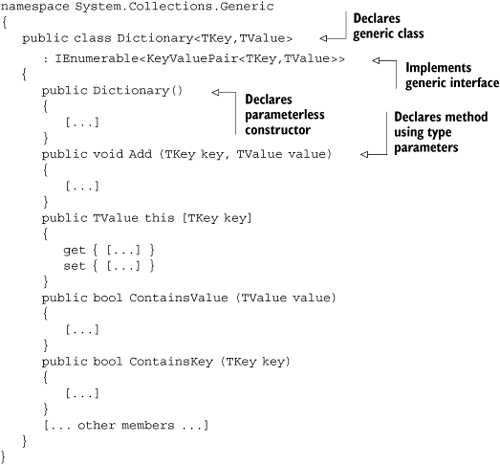
Notice how Dictionary<TKey,TValue> implements the generic interface IEnumerable <KeyValuePair<TKey,TValue>> (and many other interfaces in real life). Whatever type arguments you specify for the class are applied to the interface where the same type parameters are used—so in our example, Dictionary<string,int> implements IEnumerable<KeyValuePair<string,int>>. Now that’s actually sort of a “doubly generic” interface—it’s the IEnumerable<T> interface, with the structure KeyValuePair <string,int> as the type argument. It’s because it implements that interface that listing 3.1 was able to enumerate the keys and values in the way that it did. It’s also worth pointing out that the constructor doesn’t list the type parameters in angle brackets. The type parameters belong to the type rather than to the particular constructor, so that’s where they’re declared.
Generic types can effectively be overloaded on the number of type parameters—so you could define MyType, MyType<T>, MyType<T,U>, MyType<T,U,V>, and so forth, all within the same namespace. The names of the type parameters aren’t used when considering this—just how many there are of them. These types are unrelated except in name—there’s no default conversion from one to another, for instance. The same is true for generic methods: two methods can be exactly the same in signature other than the number of type parameters.
Note
Naming conventions for type parameters—. Although you could have a type with type parameters T, U, and V, it wouldn’t give much indication of what they actually meant, or how they should be used. Compare this with Dictionary <TKey,TValue>, where it’s obvious that TKey represents the type of the keys and TValue represents the type of the values. Where you have a single type parameter and it’s clear what it means, T is conventionally used (List<T> is a good example of this). Multiple type parameters should usually be named according to meaning, using the prefix T to indicate a type parameter. Every so often you may run into a type with multiple single-letter type parameters (SynchronizedKeyedCollection<K,T>, for example), but you should try to avoid creating the same situation yourself.
Now that we’ve got an idea of what generic types do, let’s look at generic methods.
We’ve mentioned generic methods a few times, but we haven’t actually met one yet. You may find the overall idea of generic methods more confusing than generic types—they’re somehow less natural for the brain—but it’s the same basic principle. We’re used to the parameters and return value of a method having firmly specified types—and we’ve seen how a generic type can use its type parameters in method declarations. Well, generic methods go one step further—even if you know exactly which constructed type you’re dealing with, an individual method can have type parameters too. Don’t worry if you’re still none the wiser—the concept is likely to “click” at some point after you’ve seen enough examples.
Dictionary<TKey,TValue> doesn’t have any generic methods, but its close neighbor List<T> does. As you can imagine, List<T> is just a list of items of whatever type is specified—so List<string> is just a list of strings, for instance. Remembering that T is the type parameter for the whole class, let’s dissect a generic method declaration. Figure 3.2 shows what the different parts of the declaration of the ConvertAll method mean.[3]
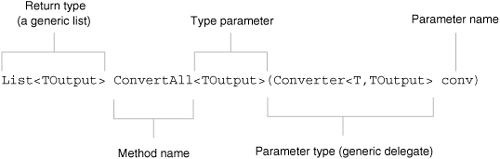
When you look at a generic declaration—whether it’s for a generic type or a generic method—it can be a bit daunting trying to work out what it means, particularly if you have to deal with generic types of generic types, as we did when we looked at the interface implemented by the dictionary. The key is not to panic—just take things calmly, and pick an example situation. Use a different type for each type parameter, and apply them all consistently.
In this case, let’s start off by replacing the type parameter of the type containing the method (the <T> part of List<T>). We’ve used List<string> as an example before, so let’s continue to do so and replace T with string everywhere:
List<TOutput> ConvertAll<TOutput>(Converter<string,TOutput> conv)That looks a bit better, but we’ve still got TOutput to deal with. We can tell that it’s a method’s type parameter (apologies for the confusing terminology) because it’s in angle brackets directly after the name of the method. So, let’s try to use another familiar type—Guid—as the type argument for TOutput. The method declaration becomes
List<Guid> ConvertAll<Guid>(Converter<string,Guid> conv)
To go through the bits of this from left to right:
The method returns a
List<Guid>.The method’s name is
ConvertAll.The method has a single type parameter, and the type argument we’re using is
Guid.The method takes a single parameter, which is a
Converter<string,Guid>and is calledconv.
Now we just need to know what Converter<string,Guid>
is and we’re all done. Not surprisingly, Converter<string,Guid> is a constructed generic delegate type(the unbound type is Converter<TInput,TOutput>), which is used to convert a string to a GUID.
So, we have a method that can operate on a list of strings, using a converter to produce a list of GUIDs. Now that we understand the method’s signature, it’s easier to understand the documentation, which confirms that this method does the obvious thing and converts each element in the original list into the target type, and adds it to a list, which is then returned. Thinking about the signature in concrete terms gives us a clearer mental model, and makes it simpler to think about what we might expect the method to do.
Just to prove I haven’t been leading you down the garden path, let’s take a look at this method in action. Listing 3.2 shows the conversion of a list of integers into a list of floating-point numbers, where each element of the second list is the square root of the corresponding element in the first list. After the conversion, we print out the results.
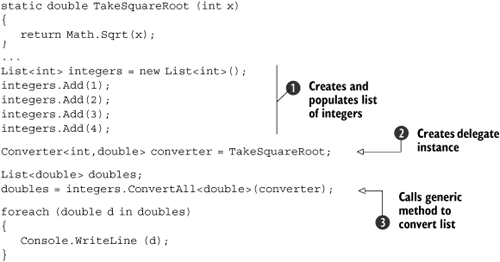
The creation and population of the list ![]() is straightforward enough—it’s just a strongly typed list of integers.
is straightforward enough—it’s just a strongly typed list of integers. ![]() uses a feature of delegates (method group conversions), which is new to C# 2 and which we’ll discuss in more detail in section 5.2. Although I don’t like using a feature before describing it fully, the line would just have been too long to fit on the page with the full version. It does what you expect it to, though. At
uses a feature of delegates (method group conversions), which is new to C# 2 and which we’ll discuss in more detail in section 5.2. Although I don’t like using a feature before describing it fully, the line would just have been too long to fit on the page with the full version. It does what you expect it to, though. At ![]() we call the generic method, specifying the type argument for the method in the same way as we’ve seen for generic types. We’ll see later (section 3.3.2) that you don’t always need to specify the type argument—often the compiler can work it out itself, making the code that bit more compact. We could have omitted it this time, but I wanted to show the full syntax. Writing out the list that has been returned is simple, and when you run the code you’ll see it print 1, 1.414..., 1.732..., and 2, as expected.
we call the generic method, specifying the type argument for the method in the same way as we’ve seen for generic types. We’ll see later (section 3.3.2) that you don’t always need to specify the type argument—often the compiler can work it out itself, making the code that bit more compact. We could have omitted it this time, but I wanted to show the full syntax. Writing out the list that has been returned is simple, and when you run the code you’ll see it print 1, 1.414..., 1.732..., and 2, as expected.
So, what’s the point of all of this? We could have just used a foreach loop to go through the integers and printed out the square root immediately, of course, but it’s not at all uncommon to want to convert a list of one type to a list of another by performing some logic on it. The code to do it manually is still simple, but it’s easier to read a version that just does it in a single method call. That’s often the way with generic methods—they often do things that previously you’d have happily done “longhand” but that are just simpler with a method call. Before generics, there could have been a similar operation to ConvertAll on ArrayList converting from object to object, but it would have been a lot less satisfactory. Anonymous methods (see section 5.4) also help here—if we hadn’t wanted to introduce an extra method, we could just have specified the conversion “inline.”
Note that just because a method is generic doesn’t mean it has to be part of a generic type. Listing 3.3 shows a generic method being declared and used within a perfectly normal class.
Example 3.3. Implementing a generic method in a nongeneric type
static List<T> MakeList<T> (T first, T second)
{
List<T> list = new List<T>();
list.Add (first);
list.Add (second);
return list;
}
...
List<string> list = MakeList<string> ("Line 1", "Line 2");
foreach (string x in list)
{
Console.WriteLine (x);
}The MakeList<T> generic method only needs one type parameter (T). All it does is build a list containing the two parameters. It’s worth noting that we can use T as a type argument when we create the List<T> in the method, however. Just as when we were looking at generic declarations, think of the implementation as (roughly speaking) replacing all of the places where it says T with string. When we call the method, we use the same syntax we’ve seen before. In case you were wondering, a generic method within a generic type doesn’t have to use the generic type’s type parameters—although most do.
All OK so far? You should now have the hang of “simple” generics. There’s a bit more complexity to come, I’m afraid, but if you’re happy with the fundamental idea of generics, you’ve jumped the biggest hurdle. Don’t worry if it’s still a bit hazy—particularly when it comes to the open/closed/unbound/constructed terminology—but now would be a good time to do some experimentation so you can see generics in action before we go any further.
The most important types to play with are List<T> and Dictionary<TKey,TValue>. A lot of the time you can get by just by instinct and experimentation, but if you want more details of these types, you can skip ahead to sections 3.5.1 and 3.5.2. Once you’re confident using these types, you should find that you rarely want to use ArrayList or Hashtable anymore.
One thing you may find when you experiment is that it’s hard to only go part of the way. Once you make one part of an API generic, you often find that you need to rework other code to either also be generic or to put in the casts required by the more strongly typed method calls you have now. An alternative can be to have a strongly typed implementation, using generic classes under the covers, but leaving a weakly typed API for the moment. As time goes on, you’ll become more confident about when it’s appropriate to use generics.
While the relatively simple uses of generics we’ve seen can get you a long way, there are some more features available that can help you further. We’ll start off by examining type constraints, which allow you more control over which type arguments can be specified. They are useful when creating your own generic types and methods, and you’ll need to understand them in order to know what options are available when using the framework, too.
We’ll then examine type inference—a handy compiler trick that means that when you’re using generic methods, you don’t always have to explicitly state the type parameters. You don’t have to use it, but it can make your code a lot easier to read when used appropriately. We’ll see in part 3 that the C# compiler is gradually being allowed to infer a lot more information from your code, while still keeping the language safe and statically typed.
The last part of this section deals with obtaining the default value of a type parameter and what comparisons are available when you’re writing generic code. We’ll wrap up with an example demonstrating most of the features we’ve covered, as well as being a useful class in itself.
Although this section delves a bit deeper into generics, there’s nothing really hard about it. There’s plenty to remember, but all the features serve a purpose, and you’ll be grateful for them when you need them. Let’s get started.
So far, all the type parameters we’ve seen can be applied to any type at all—they are unconstrained. We can have a List<int>, a Dictionary<object,FileMode>, anything. That’s fine when we’re dealing with collections that don’t have to interact with what they store—but not all uses of generics are like that. Often you want to call methods on instances of the type parameter, or create new instances, or make sure you only accept reference types (or only accept value types). In other words, you want to specify rules to say which type arguments are considered valid for your generic type or method. In C# 2, you do this with constraints.
Four kinds of constraints are available, and the general syntax is the same for all of them. Constraints come at the end of the declaration of a generic method or type, and are introduced by the contextual keyword where. They can be combined together in sensible ways, as we’ll see later. First, however, we’ll explore each kind of constraint in turn.
The first kind of constraint (which is expressed as T : class and must be the first constraint specified for that type parameter) simply ensures that the type argument used is a reference type. This can be any class, interface, array, or delegate—or another type parameter that is already known to be a reference type. For example, consider the following declaration:
struct RefSample<T> where T : class
Valid closed types include
RefSample<IDisposable>RefSample<string>RefSample<int[]>
Invalid closed types include
RefSample<Guid>RefSample<int>
I deliberately made RefSample a struct (and therefore a value type) to emphasize the difference between the constrained type parameter and the type itself. RefSample <string> is still a value type with value semantics everywhere—it just happens to use the string type wherever T is specified in its API.
When a type parameter is constrained this way, you can compare references (including null) with == and !=, but be aware that unless there are any other constraints, only references will be compared, even if the type in question overloads those operators (as string does, for example). With a derivation type constraint (described in a little while), you can end up with “compiler guaranteed” overloads of == and !=, in which case those overloads are used—but that’s a relatively rare situation.
This constraint (expressed as T : struct) ensures that the type argument used is a value type, including enums. It excludes nullable types (as described in chapter 4), however. Let’s look at an example declaration:
class ValSample<T> where T : struct
Valid closed types include
ValSample<int>ValSample<FileMode>
Invalid closed types include
ValSample<object>ValSample<StringBuilder>
This time ValSample is a reference type, despite T being constrained to be a value type. Note that System.Enum and System.ValueType are both reference types in themselves, so aren’t allowed as valid type arguments for ValSample. Like reference type constraints, when there are multiple constraints for a particular type parameter, a value type constraint must be the first one specified. When a type parameter is constrained to be a value type, comparisons using == and != are prohibited.
I rarely find myself using value or reference type constraints, although we’ll see in the next chapter that nullable types rely on value type constraints. The remaining two constraints are likely to prove more useful to you when writing your own generic types.
The third kind of constraint (which is expressed as T : new() and must be the last constraint for any particular type parameter) simply checks that the type argument used has a parameterless constructor, which can be used to create an instance. This applies to any value type; any nonstatic, nonabstract class without any explicitly declared constructors; and any nonabstract class with an explicit public parameterless constructor.
Note
C# vs. CLI standards—. There is a discrepancy between the C# and CLI standards when it comes to value types and constructors. The CLI specification states that value types can’t have parameterless constructors, but there’s a special instruction to create a value without specifying any parameters. The C# specification states that all value types have a default parameterless constructor, and it uses the same syntax to call both explicitly declared constructors and the parameterless one, relying on the compiler to do the right thing underneath. You can see this discrepancy at work when you use reflection to find the constructors of a value type—you won’t see a parameterless one.
Again, let’s look at a quick example, this time for a method. Just to show how it’s useful, I’ll give the implementation of the method too.
public T CreateInstance<T>() where T : new()
{
return new T();
}This method just returns a new instance of whatever type you specify, providing that it has a parameterless constructor. So CreateInstance<int>(); and CreateInstance<object>(); are OK, but CreateInstance<string>(); isn’t, because string doesn’t have a parameterless constructor.
There is no way of constraining type parameters to force other constructor signatures—for instance, you can’t specify that there has to be a constructor taking a single string parameter. It can be frustrating, but that’s unfortunately just the way it is.
Constructor type constraints can be useful when you need to use factory-like patterns, where one object will create another one as and when it needs to. Factories often need to produce objects that are compatible with a certain interface, of course—and that’s where our last type of constraint comes in.
The final (and most complicated) kind of constraint lets you specify another type that the type argument must derive from (in the case of a class) or implement (in the case of an interface).[4] For the purposes of constraints, types are deemed to derive from themselves. You can specify that one type argument must derive from another, too—this is called a type parameter constraint and makes it harder to understand the declaration, but can be handy every so often. Table 3.2 shows some examples of generic type declarations with derivation type constraints, along with valid and invalid examples of corresponding constructed types.
Table 3.2. Examples of derivation type constraints
| Constructed type examples |
|---|---|
class Sample<T>
where T :Stream | Valid: Sample<Stream> Sample<MemoryStream> Invalid: Sample<object> Sample<string> |
struct Sample<T>
where T : IDisposable | Valid: Sample<IDisposable> Sample<DataTable> Invalid: Sample<StringBuilder> |
class Sample<T>
where T : IComparable<T> | Valid: Sample<string> Invalid: Sample<FileInfo> |
class Sample<T,U>
where T : U | Valid: Sample<Stream,IDisposable> Sample<string,string> Invalid: Sample<string,IDisposable> |
The third constraint of T : IComparable<T> is just one example of using a generic type as the constraint. Other variations such as T : List<U> (where U is another type parameter) and T : IList<string> are also fine. You can specify multiple interfaces, but only one class. For instance, this is fine (if hard to satisfy):
class Sample<T> where T : Stream,
IEnumerable<string>,
IComparable<int>But this isn’t:
class Sample<T> where T : Stream,
ArrayList,
IComparable<int>No type can derive directly from more than one class anyway, so such a constraint would usually either be impossible (like this one) or part of it would be redundant (specifying that the type had to derive from both Stream and MemoryStream, for example). One more set of restrictions: the class you specify can’t be a struct, a sealed class (such as string), or any of the following “special” types:
System.ObjectSystem.EnumSystem.ValueTypeSystem.Delegate
Derivation type constraints are probably the most useful kind, as they mean you can use members of the specified type on instances of the type parameter. One particularly handy example of this is T : IComparable<T>, so that you know you can compare two instances of T meaningfully and directly. We’ll see an example of this (as well as discuss other forms of comparison) in section 3.3.3.
I’ve mentioned the possibility of having multiple constraints, and we’ve seen them in action for derivation constraints, but we haven’t seen the different kinds being combined together. Obviously no type can be both a reference type and a value type, so that combination is forbidden, and as every value type has a parameterless constructor, specifying the construction constraint when you’ve already got a value type constraint is also not allowed (but you can still use new T() within methods if T is constrained to be a value type). Different type parameters can have different constraints, and they’re each introduced with a separate where.
Let’s see some valid and invalid examples:
Valid:
class Sample<T> where T : class, Stream, new() class Sample<T> where T : struct, IDisposable class Sample<T,U> where T : class where U : struct, T class Sample<T,U> where T : Stream where U : IDisposable
Invalid:
class Sample<T> where T : class, struct class Sample<T> where T : Stream, class class Sample<T> where T : new(), Stream class Sample<T,U> where T : struct where U : class, T class Sample<T,U> where T : Stream, U : IDisposable
I included the last example on each list because it’s so easy to try the invalid one instead of the valid version, and the compiler error is not at all helpful. Just remember that each list of type parameter constraints needs its own introductory where. The third valid example is interesting—if U is a value type, how can it derive from T, which is a reference type? The answer is that T could be object or an interface that U implements. It’s a pretty nasty constraint, though.
Now that you’ve got all the knowledge you need to read generic type declarations, let’s look at the type argument inference that I mentioned earlier. In listing 3.2 we explicitly stated the type arguments to List.ConvertAll—but let’s now ask the compiler to work them out when it can, making it simpler to call generic methods.
Specifying type arguments when you’re calling a generic method can often seem pretty redundant. Usually it’s obvious what the type arguments should be, based on the method arguments themselves. To make life easier, the C# 2 compiler is allowed to be smart in tightly defined ways, so you can call the method without explicitly stating the type arguments.
Before we go any further, I should stress that this is only true for generic methods. It doesn’t apply to generic types. Now that we’ve got that cleared up, let’s look at the relevant lines from listing 3.3, and see how things can be simplified. Here are the lines declaring and invoking the method:
static List<T> MakeList<T> (T first, T second)
...
List<string> list = MakeList<string> ("Line 1", "Line 2");Now look at the arguments we’ve specified—they’re both strings. Each of the parameters in the method is declared to be of type T. Even if we hadn’t got the <string> part of the method invocation expression, it would be fairly obvious that we meant to call the method using string as the type argument for T. The compiler allows you to omit it, leaving this:
List<string> list = MakeList ("Line 1", "Line 2");That’s a bit neater, isn’t it? At least, it’s shorter. That doesn’t always mean it’s more readable, of course—in some cases it’ll make it harder for the reader to work out what type arguments you’re trying to use, even if the compiler can do it easily. I recommend that you judge each case on its merits.
Notice how the compiler definitely knows that we’re using string as the type parameter, because the assignment to list works too, and that still does specify the type argument (and has to). The assignment has no influence on the type parameter inference process, however. It just means that if the compiler works out what type arguments it thinks you want to use but gets it wrong, you’re still likely to get a compile-time error.
How could the compiler get it wrong? Well, suppose we actually wanted to use object as the type argument. Our method parameters are still valid, but the compiler thinks we actually meant to use string, as they’re both strings. Changing one of the parameters to explicitly be cast to object makes type inference fail, as one of the method arguments would suggest that T should be string, and the other suggests that T should be object. The compiler could look at this and say that setting T to object would satisfy everything but setting T to string wouldn’t, but the specification only gives a limited number of steps to follow. This area is already fairly complicated in C# 2, and C# 3 takes things even further. I won’t try to give all of the nuts and bolts of the C# 2 rules here, but the basic steps are as follows.
For each method argument (the bits in normal parentheses, not angle brackets), try to infer some of the type arguments of the generic method, using some fairly simple techniques.
Check that all the results from the first step are consistent—in other words, if one argument implied one type argument for a particular type parameter, and another implied a different type argument for the same type parameter, then inference fails for the method call.
Check that all the type parameters needed for the generic method have been inferred. You can’t let the compiler infer some while you specify others explicitly—it’s all or nothing.
To avoid learning all the rules (and I wouldn’t recommend it unless you’re particularly interested in the fine details), there’s one simple thing to do: try it to see what happens. If you think the compiler might be able to infer all the type arguments, try calling the method without specifying any. If it fails, stick the type arguments in explicitly. You lose nothing more than the time it takes to compile the code once, and you don’t have to have all the extra language-lawyer garbage in your head.
Although you’re likely to spend more time using generic types and methods than writing them yourself, there are a few things you should know for those occasions where you’re providing the implementation. Most of the time you can just pretend T (or whatever your type parameter is called) is just the name of a type and get on with writing code as if you weren’t using generics at all. There are a few extra things you should know, however.
When you know exactly what type you’re working with, you know its “default” value—the value an otherwise uninitialized field would have, for instance. When you don’t know what type you’re referring to, you can’t specify that default value directly. You can’t use null because it might not be a reference type. You can’t use 0 because it might not be a numeric type. While it’s fairly rare to need the default value, it can be useful on occasion. Dictionary<TKey,TValue> provides a good example—it has a TryGetValue method that works a bit like the TryParse methods on the numeric types: it uses an output parameter for the value you’re trying to fetch, and a Boolean return value to indicate whether or not it succeeded. This means that the method has to have some value of type TValue to populate the output parameter with. (Remember that output parameters must be assigned before the method returns normally.)
Note
The TryXXX pattern—. There are a few patterns in .NET that are easily identifiable by the names of the methods involved—BeginXXX and EndXXX suggest an asynchronous operation, for example. The TryXXX pattern is one that has had its use expanded between .NET 1.1 and 2.0. It’s designed for situations that might normally be considered to be errors (in that the method can’t perform its primary duty) but where failure could well occur without this indicating a serious issue, and shouldn’t be deemed exceptional. For instance, users can often fail to type in numbers correctly, so being able to try to parse some text without having to catch an exception and swallow it is very useful. Not only does it improve performance in the failure case, but more importantly, it saves exceptions for genuine error cases where something is wrong in the system (however widely you wish to interpret that). It’s a useful pattern to have up your sleeve as a library designer, when applied appropriately.
C# 2 provides the default value expression to cater for just this need. The specification doesn’t refer to it as an operator, but you can think of it as being similar to the typeof operator, just returning a different value. Listing 3.4 shows this in a generic method, and also gives an example of type inference and a derivation type constraint in action.
Example 3.4. Comparing a given value to the default in a generic way
static int CompareToDefault<T> (T value)
where T : IComparable<T>
{
return value.CompareTo(default(T));
}
...
Console.WriteLine(CompareToDefault("x"));
Console.WriteLine(CompareToDefault(10));
Console.WriteLine(CompareToDefault(0));
Console.WriteLine(CompareToDefault(-10));
Console.WriteLine(CompareToDefault(DateTime.MinValue));Listing 3.4 shows a generic method being used with three different types: string, int,and DateTime. The CompareToDefault method dictates that it can only be used with types implementing the IComparable<T> interface, which allows us to call CompareTo(T) on the value passed in. The other value we use for the comparison is the default value for the type. As string is a reference type, the default value is null—and the documentation for CompareTo states that for reference types, everything should be greater than null so the first result is 1. The next three lines show comparisons with the default value of int, demonstrating that the default value is 0. The output of the last line is 0, showing that DateTime.MinValue is the default value for DateTime.
Of course, the method in listing 3.4 will fail if you pass it null as the argument—the line calling CompareTo will throw NullReferenceException in the normal way. Don’t worry about it for the moment—there’s an alternative using IComparer<T>, as we’ll see soon.
Although listing 3.4 showed how a comparison is possible, we don’t always want to constrain our types to implement IComparable<T> or its sister interface, IEquatable<T>, which provides a strongly typed Equals(T) method to complement the Equals(object) method that all types have. Without the extra information these interfaces give us access to, there is little we can do in terms of comparisons, other than calling Equals(object), which will result in boxing the value we want to compare with when it’s a value type. (In fact, there are a couple of types to help us in some situations—we’ll come to them in a minute.)
When a type parameter is unconstrained (in other words, no constraints are applied to it), you can use == and != operators but only to compare a value of that type with null. You can’t compare two values of T with each other. In the case where the type argument provided for T is a value type (other than a nullable type), a comparison with null will always decide they are unequal (so the comparison can be removed by the JIT compiler). When the type argument is a reference type, the normal reference comparison will be used. When the type argument is a nullable type, the comparison will do the obvious thing, treating an instance without a value as null. (Don’t worry if this last bit doesn’t make sense yet—it will when you’ve read the next chapter. Some features are too intertwined to allow me to describe either of them completely without referring to the other, unfortunately.)
When a type parameter is constrained to be a value type, == and != can’t be used with it at all. When it’s constrained to be a reference type, the kind of comparison performed depends on exactly what the type parameter is constrained to be. If it’s just a reference type, simple reference comparisons are performed. If it’s further constrained to derive from a particular type that overloads the == and != operators, those overloads are used. Beware, however—extra overloads that happen to be made available by the type argument specified by the caller are not used. Listing 3.5 demonstrates this with a simple reference type constraint and a type argument of string.

Even though string overloads == (as demonstrated by ![]() printing
printing True), this overload is not used by the comparison at ![]() . Basically, when
. Basically, when AreReferencesEqual<T> is compiled the compiler doesn’t know what overloads will be available—it’s as if the parameters passed in were just of type object.
This is not just specific to operators—when the compiler encounters a generic type, it resolves all the method overloads when compiling the unbound generic type, rather than reconsidering each possible method call for more specific overloads at execution time. For instance, a statement of Console.WriteLine (default(T)); will always resolve to call Console.WriteLine(object value)—it doesn’t call Console.WriteLine (string value) when T happens to be string. This is similar to the normal situation of overloads being chosen at compile time rather than execution time, but readers familiar with templates in C++ may be surprised nonetheless.
Two classes that are extremely useful when it comes to comparing values are EqualityComparer<T> and Comparer<T>, both in the System.Collections.Generic namespace. They implement IEqualityComparer<T> (useful for comparing and hashing dictionary keys) and IComparer<T> (useful for sorting) respectively, and the Default property returns an implementation that generally does the right thing for the appropriate type. See the documentation for more details, but consider using these (and similar types such as StringComparer) when performing comparisons. We’ll use EqualityComparer<T> in our next example.
To finish off our section on implementing generics—and indeed “medium-level” generics—here’s a complete example. It implements a useful generic type—a Pair <TFirst,TSecond>, which just holds two values together, like a key/value pair, but with no expectations as to the relationship between the two values. As well as providing properties to access the values themselves, we’ll override Equals and GetHashCode to allow instances of our type to play nicely when used as keys in a dictionary. Listing 3.6 gives the complete code.
Example 3.6. Generic class representing a pair of values
using System;
using System.Collections.Generic;
public sealed class Pair<TFirst, TSecond>
: IEquatable<Pair<TFirst, TSecond>>
{
private readonly TFirst first;
private readonly TSecond second;
public Pair(TFirst first, TSecond second)
{
this.first = first;
this.second = second;
}
public TFirst First
{
get { return first; }
}
public TSecond Second
{
get { return second; }
}
public bool Equals(Pair<TFirst, TSecond> other)
{
if (other == null)
{
return false;
}
return EqualityComparer<TFirst>.Default
.Equals(this.First, other.First) &&
EqualityComparer<TSecond>.Default
.Equals(this.Second, other.Second);
}
public override bool Equals(object o)
{
return Equals(o as Pair<TFirst, TSecond>);
}
public override int GetHashCode()
{
return EqualityComparer<TFirst>.Default
.GetHashCode(first) * 37 +
EqualityComparer<TSecond>.Default
.GetHashCode(second);
}
}
Listing 3.6 is very straightforward. The constituent values are stored in appropriately typed member variables, and access is provided by simple read-only properties. We implement IEquatable<Pair<TFirst,TSecond>> to give a strongly typed API that will avoid unnecessary execution time checks. The equality and hash-code computations both use the default equality comparer for the two type parameters—these handle nulls for us automatically, which makes the code somewhat simpler.[5]
If we wanted to support sorting, we could implement IComparer <Pair <TFirst,TSecond>>, perhaps ordering by the first component and then the second. This kind of type is a good candidate for bearing in mind what functionality you might want, but not actually implementing until you need it.
We’ve finished looking at our “intermediate” features now. I realize it can all seem complicated at first sight, but don’t be put off: the benefits far outweigh the added complexity. Over time they become second nature. Now that you’ve got the Pair class as an example, it might be worth looking over your own code base to see whether there are some patterns that you keep reimplementing solely to use different types.
With any large topic there is always more to learn. The next section will take you through the most important advanced topics in generics. If you’re feeling a bit overwhelmed by now, you might want to skip to the relative comfort of section 3.5, where we explore the generic collections provided in the framework. It’s well worth understanding the topics in the next section eventually, but if everything so far has been new to you it wouldn’t hurt to skip it for the moment.
You may be expecting me to claim that in the rest of this chapter we’ll be covering every aspect of generics that we haven’t looked at so far. However, there are so many little nooks and crannies involving generics, that’s simply not possible—or at least, I certainly wouldn’t want to even read about all the details, let alone write about them. Fortunately the nice people at Microsoft and ECMA have written all the details in the freely available language specification,[6] so if you ever want to check some obscure situation that isn’t covered here, that should be your next port of call. Arguably if your code ends up in a corner case complicated enough that you need to consult the specification to work out what it should do, you should refactor it into a more obvious form anyway; you don’t want each maintenance engineer from now until eternity to have to read the specification.
My aim with this section is to cover everything you’re likely to want to know about generics. It talks more about the CLR and framework side of things than the particular syntax of the C# 2 language, although of course it’s all relevant when developing in C# 2. We’ll start by considering static members of generic types, including type initialization. From there, it’s a natural step to wonder just how all this is implemented under the covers—although we won’t be going so deep that you need a flashlight. We’ll have a look at what happens when you enumerate a generic collection using foreach in C# 2, and round off the section by seeing how reflection in the .NET Framework is affected by generics.
Just as instance fields belong to an instance, static fields belong to the type they’re declared in. That is, if you declare a static field x in class SomeClass, there’s exactly one SomeClass.x field, no matter how many instances of SomeClass you create, and no matter how many types derive from SomeClass.[7] That’s the familiar scenario from C# 1—so how does it map across to generics?
The answer is that each closed type has its own set of static fields. This is easiest to see with an example. Listing 3.7 creates a generic type including a static field. We set the field’s value for different closed types, and then print out the values to show that they are separate.
Example 3.7. Proof that different closed types have different static fields
class TypeWithField<T>
{
public static string field;
public static void PrintField()
{
Console.WriteLine(field+": "+typeof(T).Name);
}
}
...
TypeWithField<int>.field = "First";
TypeWithField<string>.field = "Second";
TypeWithField<DateTime>.field = "Third";
TypeWithField<int>.PrintField();
TypeWithField<string>.PrintField();
TypeWithField<DateTime>.PrintField();We set the value of each field to a different value, and print out each field along with the name of the type argument used for that closed type. Here’s the output from listing 3.7:
First: Int32 Second: String Third: DateTime
So the basic rule is “one static field per closed type.” The same applies for static initializers and static constructors. However, it’s possible to have one generic type nested within another, and types with multiple generic parameters. This sounds a lot more complicated, but it works as you probably think it should. Listing 3.8 shows this in action, this time using static constructors to show just how many types there are.
Example 3.8. Static constructors with nested generic types
public class Outer<T>
{
public class Inner<U,V>
{
static Inner()
{
Console.WriteLine("Outer<{0}>.Inner<{1},{2}>",
typeof(T).Name,
typeof(U).Name,
typeof(V).Name);
}
public static void DummyMethod()
{
}
}
}
...
Outer<int>.Inner<string,DateTime>.DummyMethod();
Outer<string>.Inner<int,int>.DummyMethod();
Outer<object>.Inner<string,object>.DummyMethod();
Outer<string>.Inner<string,object>.DummyMethod();
Outer<object>.Inner<object,string>.DummyMethod();
Outer<string>.Inner<int,int>.DummyMethod();Each different list of type arguments counts as a different closed type, so the output of listing 3.8 looks like this:
Outer<Int32>.Inner<String,DateTime> Outer<String>.Inner<Int32,Int32> Outer<Object>.Inner<String,Object> Outer<String>.Inner<String,Object> Outer<Object>.Inner<Object,String>
Just as with nongeneric types, the static constructor for any closed type is only executed once, which is why the last line of listing 3.8 doesn’t create a sixth line of output—the static constructor for Outer<string>.Inner<int,int> executed earlier, producing the second line of output. To clear up any doubts, if we had a nongeneric PlainInner class inside Outer, there would still have been one possible Outer<T>.PlainInner type per closed Outer type, so Outer<int>.PlainInner would be separate from Outer<long>.PlainInner, with a separate set of static fields as seen earlier.
Now that we’ve seen just what constitutes a different type, we should think about what the effects of that might be in terms of the amount of native code generated. And no, it’s not as bad as you might think...
Given that we have all of these different closed types, the JIT’s job is to convert the IL of the generic type into native code so it can actually be run. In some ways, we shouldn’t care exactly how it does that—beyond keeping a close eye on memory and CPU time, we wouldn’t see much difference if the JIT did the obvious thing and generated native code for each closed type separately, as if each one had nothing to do with any other type. However, the JIT authors are clever enough that it’s worth seeing just what they’ve done.
Let’s start with a simple situation first, with a single type parameter—we’ll use List<T> for the sake of convenience. The JIT creates different code for each value type argument—int, long, Guid, and the like—that we use. However, it shares the native code generated for all the closed types that use a reference type as the type argument, such as string, Stream, and StringBuilder. It can do this because all references are the same size (they are 4 bytes on a 32-bit CLR and 8 bytes on a 64-bit CLR, but within any one CLR all references are the same size). An array of references will always be the same size whatever the references happen to be. The space required on the stack for a reference will always be the same. It can use the same register optimizations whatever type is being used—the List<Reason> goes on.
Each of the types still has its own static fields as described in section 3.4.1, but the code that is executed is reused. Of course, the JIT still does all of this lazily—it won’t generate the code for List<int> before it needs to, and it will cache that code for all future uses of List<int>. In theory, it’s possible to share code for at least some value types. The JIT would have to be careful, not just due to size but also for garbage collection reasons—it has to be able to quickly identify areas of a struct value that are live references. However, value types that are the same size and have the same in-memory footprint as far as the GC is concerned could share code. At the time of this writing, that’s been of sufficiently low priority that it hasn’t been implemented and it may well stay that way.
This level of detail is primarily of academic interest, but it does have a slight performance impact in terms of more code being JIT compiled. However, the performance benefits of generics can be huge, and again that comes down to having the opportunity to JIT to different code for different types. Consider a List<byte>, for instance. In .NET 1.1, adding individual bytes to an ArrayList would have meant boxing each one of them, and storing a reference to each boxed value. Using List<byte> has no such impact—List<T> has a member of type T[] to replace the object[] within ArrayList, and that array is of the appropriate type, taking the appropriate space. So List<byte> has a straight byte[] within it used to store the elements of the array. (In many ways this makes a List<byte> behave like a MemoryStream.)
Figure 3.3 shows an ArrayList and a List<byte>, each with the same six values. (The arrays themselves have more than six elements, to allow for growth. Both List<T> and ArrayList have a buffer, and they create a larger buffer when they need to.)
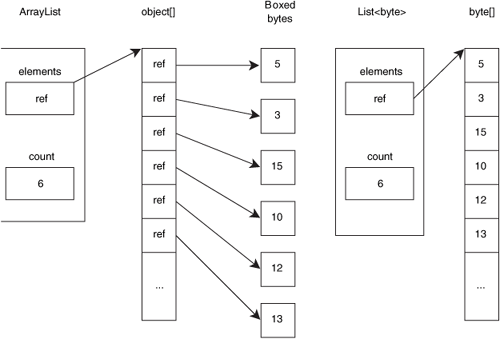
Figure 3.3. Visual demonstration of why List<T> takes up a lot less space than ArrayList when storing value types
The difference in efficiency here is incredible. Let’s look at the ArrayList first, considering a 32-bit CLR.[8] Each of the boxed bytes will take up 8 bytes of object overhead, plus 4 bytes (1 byte, rounded up to a word boundary) for the data itself. On top of that, you’ve got all the references themselves, each of which takes up 4 bytes. So for each byte of useful data, we’re paying at least 16 bytes—and then there’s the extra unused space for references in the buffer.
Compare this with the List<byte>. Each byte in the list takes up a single byte within the elements array. There’s still “wasted” space in the buffer, waiting to be used potentially by new items—but at least we’re only wasting a single byte per unused element there.
We don’t just gain space, but execution speed too. We don’t need the time taken to allocate the box, the type checking involved in unboxing the bytes in order to get at them, or the garbage collection of the boxes when they’re no longer referenced.
We don’t have to go down to the CLR level to find things happening transparently on our behalf, however. C# has always made life easier with syntactic shortcuts, and our next section looks at a familiar example but with a generic twist: iterating with foreach.
One of the most common operations you’ll want to perform on a collection (usually an array or a list) is to iterate through all its elements. The simplest way of doing that is usually to use the foreach statement. In C# 1 this relied on the collection either implementing the System.Collections.IEnumerable interface or having a similar GetEnumerator() method that returned a type with a suitable MoveNext() method and Current property. The Current property didn’t have to be of type object—and that was the whole point of having these extra rules, which look odd on first sight. Yes, even in C# 1 you could avoid boxing and unboxing during iteration if you had a custom-made enumeration type.
C# 2 makes this somewhat easier, as the rules for the foreach statement have been extended to also use the System.Collections.Generic.IEnumerable<T> interface along with its partner, IEnumerator<T>. These are simply the generic equivalents of the old enumeration interfaces, and they’re used in preference to the nongeneric versions. That means that if you iterate through a generic collection of value type elements—List<int>, for example—then no boxing is performed at all. If the old interface had been used instead, then although we wouldn’t have incurred the boxing cost while storing the elements of the list, we’d still have ended up boxing them when we retrieved them using foreach!
All of this is done for you under the covers—all you need to do is use the foreach statement in the normal way, using the type argument of the collection as the type of the iteration variable, and all will be well. That’s not the end of the story, however. In the relatively rare situation that you need to implement iteration over one of your own types, you’ll find that IEnumerable<T> extends the old IEnumerable interface, which means you’ve got to implement two different methods:
IEnumerator<T> GetEnumerator(); IEnumerator GetEnumerator();
Can you see the problem? The methods differ only in return type, and the rules of C# prevent you from writing two such methods normally. If you think back to section 2.2.2, we saw a similar situation—and we can use the same workaround. If you implement IEnumerable using explicit interface implementation, you can implement IEnumerable<T> with a “normal” method. Fortunately, because IEnumerator<T> extends IEnumerator, you can use the same return value for both methods, and implement the nongeneric method by just calling the generic version. Of course, now you need to implement IEnumerator<T> and you quickly run into similar problems, this time with the Current property.
Listing 3.9 gives a full example, implementing an enumerable class that always just enumerates to the integers 0 to 9.
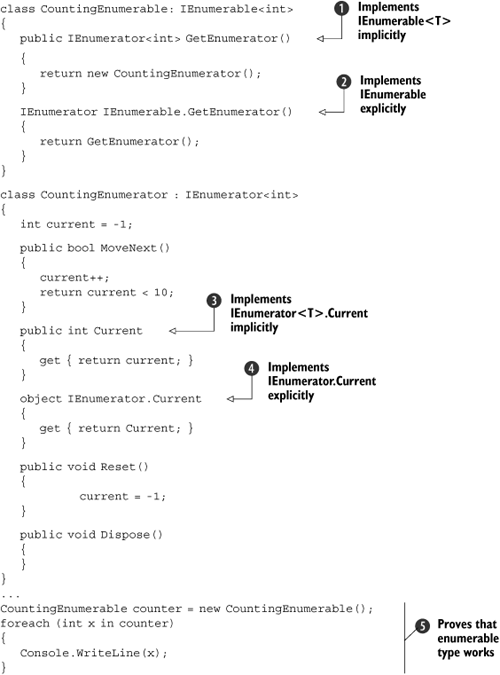
Clearly this isn’t useful in terms of the result, but it shows the little hoops you have to go through in order to implement generic enumeration appropriately—at least if you’re doing it all longhand. (And that’s without making an effort to throw exceptions if Current is accessed at an inappropriate time.) If you think that listing 3.9 looks like a lot of work just to print out the numbers 0 to 9, I can’t help but agree with you—and there’d be even more code if we wanted to iterate through anything useful. Fortunately we’ll see in chapter 6 that C# 2 takes a large amount of the work away from enumerators in many cases. I’ve shown the “full” version so you can appreciate the slight wrinkles that have been introduced by the design decision for IEnumerable<T> to extend IEnumerable.
We only need the trick of using explicit interface implementation twice—once for IEnumerable.GetEnumerator ![]() , and once at
, and once at IEnumerator.Current ![]() . Both of these call their generic equivalents (
. Both of these call their generic equivalents (![]() and
and ![]() respectively). Another addition to
respectively). Another addition to IEnumerator<T> is that it extends IDisposable, so you have to provide a Dispose method. The foreach statement in C# 1 already called Dispose on an enumerator if it implemented IDisposable, but in C# 2 there’s no execution time testing required—if the compiler finds that you’ve implemented IEnumerable<T>, it creates an unconditional call to Dispose at the end of the loop (in a finally block). Many enumerators won’t actually need to dispose of anything, but it’s nice to know that when it is required, the most common way of working through an enumerator (the foreach statement ![]() ) handles the calling side automatically.
) handles the calling side automatically.
We’ll now go from compile-time efficiency to execution-time flexibility: our final advanced topic is reflection. Even in .NET 1.0/1.1 reflection could be a little tricky, but generic types and methods introduce an extra level of complexity. The framework provides everything we need (with a bit of helpful syntax from C# 2 as a language), and although the additional considerations can be daunting, it’s not too bad if you take it one step at a time.
Reflection is used by different people for all sorts of things. You might use it for execution-time introspection of objects to perform a simple form of data binding. You might use it to inspect a directory full of assemblies to find implementations of a plug-in interface. You might write a file for an Inversion of Control[9] framework to load and dynamically configure your application’s components. As the uses of reflection are so diverse, I won’t focus on any particular one but give you more general guidance on performing common tasks. We’ll start by looking at the extensions to the typeof operator.
Reflection is all about examining objects and their types. As such, one of the most important things you need to be able to do is obtain a reference to the System. Type object, which allows access to all the information about a particular type. C# uses the typeof operator to obtain such a reference for types known at compile time, and this has been extended to encompass generic types.
There are two ways of using typeof with generic types—one retrieves the generic type definition (in other words, the unbound generic type) and one retrieves a particular constructed type. To obtain the generic type definition—that is, the type with none of the type arguments specified—you simply take the name of the type as it would have been declared and remove the type parameter names, keeping any commas. To retrieve constructed types, you specify the type arguments in the same way as you would to declare a variable of the generic type. Listing 3.10 gives an example of both uses. It uses a generic method so we can revisit how typeof can be used with a type parameter, which we previously saw in listing 3.7.

Most of listing 3.10 is as you might naturally expect, but it’s worth pointing out two things. First, look at the syntax for obtaining the generic type definition of Dictionary <TKey,TValue>. The comma in the angle brackets is required to effectively tell the compiler to look for the type with two type parameters: remember that there can be several generic types with the same name, as long as they vary by the number of type parameters they have. Similarly, you’d retrieve the generic type definition for MyClass<T,U,V,W> using typeof(MyClass<,,,>). The number of type parameters is specified in IL (and in full type names as far as the framework is concerned) by putting a back tick after the first part of the type name and then the number. The type parameters are then indicated in square brackets instead of the angle brackets we’re used to. For instance, the second line printed ends with List'1[T], showing that there is one type parameter, and the third line includes Dictionary'2[TKey,TValue].
Second, note that wherever the method’s type parameter is used, the actual value of the type argument is used at execution time. So the first line ![]() prints
prints List'1 <System.Int32> rather than List'1<X>, which you might have expected. In other words, a type that is open at compile time may be closed at execution time. This is very confusing. You should be aware of it in case you don’t get the results you expect, but otherwise don’t worry. To retrieve a truly open constructed type at execution time, you need to work a bit harder. See the MSDN documentation for Type.IsGenericType for a suitably convoluted example.
For reference, here’s the output of listing 3.10:
System.Int32 System.Collections.Generic.List'1[T] System.Collections.Generic.Dictionary'2[TKey,TValue] System.Collections.Generic.List'1[System.Int32] System.Collections.Generic.Dictionary'2[System.String,System.Int32] System.Collections.Generic.List'1[System.Int64] System.Collections.Generic.Dictionary'2[System.Int64,System.Guid]
Having retrieved an object representing a generic type, there are many “next steps” you can take. All the previously available ones (finding the members of the type, creating an instance, and so on) are still present—although some are not applicable for generic type definitions—and there are new ones as well that let you inquire about the generic nature of the type.
There are far too many new methods and properties to look at them all in detail, but there are two particularly important ones: GetGenericTypeDefinition and MakeGenericType. They are effectively opposites—the first acts on a constructed type, retrieving the generic type definition; the second acts on a generic type definition and returns a constructed type. Arguably it would have been clearer if this method had been called ConstructGenericType, MakeConstructedType, or some other name with construct or constructed in it, but we’re stuck with what we’ve got.
Just like normal types, there is only one Type object for any particular type—so calling MakeGenericType twice with the same types as parameters will return the same reference twice, and calling GetGenericTypeDefinition on two types constructed from the same generic type definition will likewise give the same result for both calls.
Another method—this time one which already existed in .NET 1.1—that is worth exploring is Type.GetType, and its related Assembly.GetType method, both of which provide a dynamic equivalent to typeof. You might expect to be able to feed each line of the output of listing 3.10 to the GetType method called on an appropriate assembly, but unfortunately life isn’t quite that straightforward. It’s fine for closed constructed types—the type arguments just go in square brackets. For generic type definitions, however, you need to remove the square brackets entirely—otherwise GetType thinks you mean an array type. Listing 3.11 shows all of these methods in action.
Example 3.11. Various ways of retrieving generic and constructed Type objects
string listTypeName = "System.Collections.Generic.List'1"; Type defByName = Type.GetType(listTypeName); Type closedByName = Type.GetType(listTypeName+"[System.String]"); Type closedByMethod = defByName.MakeGenericType(typeof(string)); Type closedByTypeof = typeof(List<string>); Console.WriteLine (closedByMethod==closedByName); Console.WriteLine (closedByName==closedByTypeof); Type defByTypeof = typeof(List<>); Type defByMethod = closedByName.GetGenericTypeDefinition(); Console.WriteLine (defByMethod==defByName); Console.WriteLine (defByName==defByTypeof);
The output of listing 3.11 is just True four times, validating that however you obtain a reference to a particular type object, there is only one such object involved.
As I mentioned earlier, there are many new methods and properties on Type, such as GetGenericArguments, IsGenericTypeDefinition, and IsGenericType. The documentation for IsGenericType is probably the best starting point for further exploration.
Generic methods have a similar (though smaller) set of additional properties and methods. Listing 3.12 gives a brief demonstration of this, calling a generic method by reflection.
Example 3.12. Retrieving and invoking a generic method with reflection
public static void PrintTypeParameter<T>()
{
Console.WriteLine (typeof(T));
}
...
Type type = typeof(Snippet);
MethodInfo definition = type.GetMethod("PrintTypeParameter");
MethodInfo constructed;
constructed = definition.MakeGenericMethod(typeof(string));
constructed.Invoke(null, null);First we retrieve the generic method definition, and then we make a constructed generic method using MakeGenericMethod. As with types, we could go the other way if we wanted to—but unlike Type.GetType, there is no way of specifying a constructed method in the GetMethod call. The framework also has a problem if there are methods that are overloaded purely by number of type parameters—there are no methods in Type that allow you to specify the number of type parameters, so instead you’d have to call Type.GetMethods and find the right one by looking through all the methods.
After retrieving the constructed method, we invoke it. The arguments in this example are both null as we’re invoking a static method that doesn’t take any “normal” parameters. The output is System.String, as we’d expect.
Note that the methods retrieved from generic type definitions cannot be invoked directly—instead, you must get the method from a constructed type. This applies to both generic methods and nongeneric methods.
Again, more methods and properties are available on MethodInfo, and IsGeneric-Method is a good starting point in MSDN. Hopefully the information in this section will have been enough to get you going, though—and to point out some of the added complexities you might not have otherwise anticipated when first starting to access generic types and methods with reflection.
That’s all we’re going to cover in the way of advanced features. Just to reiterate, this is not meant to have been an absolutely complete guide by any means—but most developers are unlikely to need to know the more obscure areas. I hope for your sake that you fall into this camp, as specifications tend to get harder to read the deeper you go into them. Remember that unless you’re working alone and just for yourself, you’re unlikely to be the only one to work on your code. If you need features that are more complex than the ones demonstrated here, you almost certainly shouldn’t assume that anyone reading your code will understand it without help. On the other hand, if you find that your coworkers don’t know about some of the topics we’ve covered so far, please feel free to direct them to the nearest bookshop...
The next section is much more down to earth than our investigations into reflection and the bowels of the JIT. It covers the most common use of generics: the standard collection classes.
Although this book is primarily about C# as a language, it would be foolish to ignore the fact that C# is almost always used within the .NET Framework, and that in order to use the language effectively you’ll need to have a certain amount of knowledge of the libraries too. I won’t be going into the details of ADO.NET, ASP.NET, and the like, but you’re bound to use collections in almost any .NET program of any size. This section will cover the core collections found in the System.Collections.Generic namespace. We’ll start in familiar territory with List<T>.
We’ve already seen List<T> several times. Broadly speaking, it’s the generic equivalent of the nongeneric ArrayList type, which has been a part of .NET from the word go. There are some new features, and a few operations in ArrayList didn’t make it to List<T>. Most of the features that have been removed from List<T> have also been removed from other collections, so we’ll cover them here and then just refer to them later on when talking about the other collections. Many of the new features in List<T> (beyond “being generic”) aren’t available in the other generic collections. The combination of these factors leads to our discussion of List<T> being the longest in this section—but then it’s probably the most widely used collection in real-life code, too. When you think of using a list of data items in your code, List<T> is the default choice.
I won’t bore you with the most common operations (adding, removing, fetching, and replacing items) but will merely point out that List<T> makes itself available in a large number of situations using old APIs by implementing IList as well as IList<T>. Enough of looking backward, though—let’s see what’s new.
The new methods available within List<T> are all powered by generics—in particular, generic delegates. This is part of a general trend toward using delegates more heavily in the framework, which has been made simpler by the improvements in delegate syntax available in C# 2. (There would have been little point in adding lots of delegate-specific features into the framework with the syntax being as clunky as it was in C# 1.) We can now do the following:
Convert each element of the list to a different type, resulting in a new list (
ConvertAll).Check whether any of the elements in the list match a given predicate (
Exists).Check whether all of the elements in the list match a given predicate (
TrueForAll).Find the first, last, or all elements in the list matching a predicate (
FindXXX).Remove all elements in the list matching a given predicate (
RemoveAll).Perform a given action on each element on the list (
ForEach).[10]
We’ve already seen the ConvertAll method in listing 3.2, but there are two more delegate types that are very important for this extra functionality: Predicate<T> and Action<T>, which have the following signatures:
public delegate bool Predicate<T> (T obj) public delegate void Action<T> (T obj)
A predicate is a way of testing whether a value matches a criterion. For instance, you could have a predicate that tested for strings having a length greater than 5, or one that tested whether an integer was even. An action does exactly what you might expect it to—performs an action with the specified value. You might print the value to the console, add it to another collection—whatever you want.
For simple examples, most of the methods listed here are easily achieved with a foreach loop. However, using a delegate allows the behavior to come from somewhere other than the immediate code in the foreach loop. With the improvements to delegates in C# 2, it can also be a bit simpler than the loop.
Listing 3.13 shows the last two methods—ForEach and RemoveAll—in action. We take a list of the integers from 2 to 100, remove multiples of 2, then multiples of 3, and so forth up to 10, finally listing the numbers. You may well recognize this as a slight variation on the “Sieve of Eratosthenes” method of finding prime numbers. I’ve used the streamlined method of creating delegates to make the example more realistic. Even though we haven’t covered the syntax yet (you can peep ahead to chapter 5 if you want to get the details), it should be fairly obvious what’s going on here.

Listing 3.13 starts off by just creating a list of all the integers between 2 and 100 inclusive ![]() —nothing spectacular here, although once again I should point out that there’s no boxing involved. The delegate used in step
—nothing spectacular here, although once again I should point out that there’s no boxing involved. The delegate used in step ![]() is a
is a Predicate <int>, and the one used in ![]() is an
is an Action<int>. One point to note is how simple the use of RemoveAll is. Because you can’t change the contents of a collection while iterating over it, the typical ways of removing multiple elements from a list have previously been as follows:
Iterate using the index in ascending order, decrementing the index variable whenever you remove an element.
Iterate using the index in descending order to avoid excessive copying.
Create a new list of the elements to remove, and then iterate through the new list, removing each element in turn from the old list.
None of these is particularly satisfactory—the predicate approach is much neater, giving emphasis to what you want to achieve rather than how exactly it should happen. It’s a good idea to experiment with predicates a bit to get comfortable with them, particularly if you’re likely to be using C# 3 in a production setting any time in the near future—this more functional style of coding is going to be increasingly important over time.
Next we’ll have a brief look at the methods that are present in ArrayList but not List<T>, and consider why that might be the case.
A few methods in ArrayList have been shifted around a little—the static ReadOnly method is replaced by the AsReadOnly instance method, and TrimToSize is nearly replaced by TrimExcess (the difference is that TrimExcess won’t do anything if the size and capacity are nearly the same anyway). There are a few genuinely “missing” pieces of functionality, however. These are listed, along with the suggested workaround, in table 3.3.
Table 3.3. Methods from ArrayList with no direct equivalent in List<T>
| Way of achieving similar effect |
|---|---|
| None provided |
|
|
| None |
|
|
|
|
|
|
The Synchronized method was a bad idea in ArrayList to start with, in my view. Making individual calls to a collection doesn’t make the collection thread-safe, because so many operations (the most common is iterating over the collection) involve multiple calls. To make those operations thread-safe, the collection needs to be locked for the duration of the operation. (It requires cooperation from other code using the same collection, of course.) In short, the Synchronized method gave the appearance of safety without the reality. It’s better not to give the wrong impression in the first place—developers just have to be careful when working with collections accessed in multiple threads. SynchronizedCollection<T> performs broadly the same role as a synchronized ArrayList. I would argue that it’s still not a good idea to use this, for the reasons outlined in this paragraph—the safety provided is largely illusory. Ironically, this would be a great collection to support a ForEach method, where it could automatically hold the lock for the duration of the iteration over the collection—but there’s no such method.
That completes our coverage of List<T>. The next collection under the microscope is Dictionary<TKey,TValue>, which we’ve already seen so much of.
There is less to say about Dictionary<TKey,TValue> (just called Dictionary<,> for the rest of this section, for simplicity) than there was about List<T>, although it’s another heavily used type. As stated earlier, it’s the generic replacement for Hashtable and the related classes, such as StringDictionary. There aren’t many features present in Dictionary<,> that aren’t in Hashtable, although this is partly because the ability to specify a comparison in the form of an IEqualityComparer was added to Hashtable in .NET 2.0. This allows for things like case-insensitive comparisons of strings without using a separate type of dictionary. IEqualityComparer and its generic equivalent, IEqualityComparer<T>, have both Equals and GetHashCode. Prior to .NET 2.0 these were split into IComparer (which had to give an ordering, not just test for equality) and IHashCodeProvider. This separation was awkward, hence the move to IEqualityComparer<T> for 2.0. Dictionary<,> exposes its IEqualityComparer<T> in the public Comparer property.
The most important difference between Dictionary and Hashtable (beyond the normal benefits of generics) is their behavior when asked to fetch the value associated with a key that they don’t know about. When presented with a key that isn’t in the map, the indexer of Hashtable will just return null. By contrast, Dictionary<,> will throw a KeyNotFoundException. Both of them support the ContainsKey method to tell beforehand whether a given key is present. Dictionary<,> also provides TryGetValue, which retrieves the value if a suitable entry is present, storing it in the output parameter and returning true. If the key is not present, TryGetValue will set the output parameter to the default value of TValue and return false. This avoids having to search for the key twice, while still allowing the caller to distinguish between the situation where a key isn’t present at all, and the one where it’s present but its associated value is the default value of TValue. Making the indexer throw an exception is of more debatable merit, but it does make it very clear when a lookup has failed instead of masking the failure by returning a potentially valid value.
Just as with List<T>, there is no way of obtaining a synchronized Dictionary<,>, nor does it implement ICloneable. The dictionary equivalent of SynchronizedCollection<T> is SynchronizedKeyedCollection<K,T> (which in fact derives from SynchronizedCollection<T>).
With the lack of additional functionality, another example of Dictionary<,> would be relatively pointless. Let’s move on to two types that are closely related to each other: Queue<T> and Stack<T>.
The generic queue and stack classes are essentially the same as their nongeneric counterparts. The same features are “missing” from the generic versions as with the other collections—lack of cloning, and no way of creating a synchronized version. As before, the two types are closely related—both act as lists that don’t allow random access, instead only allowing elements to be removed in a certain order. Queues act in a first in, first out (FIFO) fashion, while stacks have last in, first out (LIFO) semantics. Both have Peek methods that return the next element that would be removed but without actually removing it. This behavior is demonstrated in listing 3.14.
Example 3.14. Demonstration of Queue<T> and Stack<T>
Queue<int> queue = new Queue<int>();
Stack<int> stack = new Stack<int>();
for (int i=0; i < 10; i++)
{
queue.Enqueue(i);
stack.Push(i);
}
for (int i=0; i < 10; i++)
{
Console.WriteLine ("Stack:{0} Queue:{1}",
stack.Pop(), queue.Dequeue());
}The output of listing 3.14 is as follows:
Stack:9 Queue:0 Stack:8 Queue:1 Stack:7 Queue:2 Stack:6 Queue:3 Stack:5 Queue:4 Stack:4 Queue:5 Stack:3 Queue:6 Stack:2 Queue:7 Stack:1 Queue:8 Stack:0 Queue:9
You can enumerate Stack<T> and Queue<T> in the same way as with a list, but in my experience this is used relatively rarely. Most of the uses I’ve seen have involved a thread-safe wrapper being put around either class, enabling a producer/consumer pattern for multithreading. This is not particularly hard to write, and third-party implementations are available, but having these classes directly available in the framework would be more welcome.
Next we’ll look at the generic versions of SortedList, which are similar enough to be twins.
The naming of SortedList has always bothered me. It feels more like a map or dictionary than a list. You can access the elements by index as you can for other lists (although not with an indexer)—but you can also access the value of each element (which is a key/value pair) by key. The important part of SortedList is that when you enumerate it, the entries come out sorted by key. Indeed, a common way of using SortedList is to access it as a map when writing to it, but then enumerate the entries in order.
There are two generic classes that map to the same sort of behavior: SortedList<TKey,TValue> and SortedDictionary<TKey,TValue>. (From here on I’ll just call them SortedList<,> and SortedDictionary<,> to save space.) They’re very similar indeed—it’s mostly the performance that differs. SortedList<,> uses less memory, but SortedDictionary<,> is faster in the general case when it comes to adding entries. However, if you add them in the sort order of the keys to start with, SortedList<,> will be faster.
Note
A difference of limited benefit—. SortedList<,> allows you to find the index of a particular key or value using IndexOfKey and IndexOfValue, and to remove an entry by index with RemoveAt. To retrieve an entry by index, however, you have to use the Keys or Values properties, which implement IList<TKey> and IList<TValue>, respectively. The nongeneric version supports more direct access, and a private method exists in the generic version, but it’s not much use while it’s private. SortedDictionary<,> doesn’t support any of these operations.
If you want to see either of these classes in action, use listing 3.1 as a good starting point. Just changing Dictionary to SortedDictionary or SortedList will ensure that the words are printed in alphabetical order, for example.
Our final collection class is genuinely new, rather than a generic version of an existing nongeneric type. It’s that staple of computer science courses everywhere: the linked list.
I suspect you know what a linked list is. Instead of keeping an array that is quick to access but slow to insert into, a linked list stores its data by building up a chain of nodes, each of which is linked to the next one. Doubly linked lists (like LinkedList<T>) store a link to the previous node as well as the next one, so you can easily iterate backward as well as forward.
Linked lists make it easy to insert another node into the chain—as long as you already have a handle on the node representing the insertion position. All the list needs to do is create a new node, and make the appropriate links between that node and the ones that will be before and after it. Lists storing all their data in a plain array (as List<T> does) need to move all the entries that will come after the new one, which can be very expensive—and if the array runs out of spare capacity, the whole lot must be copied. Enumerating a linked list from start to end is also cheap—but random access (fetching the fifth element, then the thousandth, then the second) is slower than using an array-backed list. Indeed, LinkedList<T> doesn’t even provide a random access method or indexer. Despite its name, it doesn’t implement IList<T>. Linked lists are usually more expensive in terms of memory than their array-backed cousins due to the extra link node required for each value. However, they don’t have the “wasted” space of the spare array capacity of List<T>.
The linked list implementation in .NET 2.0 is a relatively plain one—it doesn’t support chaining two lists together to form a larger one, or splitting an existing one into two, for example. However, it can still be useful if you want fast insertions at both the start and end of the list (or in between if you keep a reference to the appropriate node), and only need to read the values from start to end, or vice versa.
Our final main section of the chapter looks at some of the limitations of generics in C# and considers similar features in other languages.
There is no doubt that generics contribute a great deal to C# in terms of expressiveness, type safety, and performance. The feature has been carefully designed to cope with most of the tasks that C++ programmers typically used templates for, but without some of the accompanying disadvantages. However, this is not to say limitations don’t exist. There are some problems that C++ templates solve with ease but that C# generics can’t help with. Similarly, while generics in Java are generally less powerful than in C#, there are some concepts that can be expressed in Java but that don’t have a C# equivalent. This section will take you through some of the most commonly encountered weaknesses, as well as briefly compare the C#/.NET implementation of generics with C++ templates and Java generics.
It’s important to stress that pointing out these snags does not imply that they should have been avoided in the first place. In particular, I’m in no way saying that I could have done a better job! The language and platform designers have had to balance power with complexity (and the small matter of achieving both design and implementation within a reasonable timescale). It’s possible that future improvements will either remove some of these issues or lessen their impact. Most likely, you won’t encounter problems, and if you do, you’ll be able to work around them with the guidance given here.
We’ll start with the answer to a question that almost everyone raises sooner or later: why can’t I convert a List<string> to List<object>?
In section 2.3.2, we looked at the covariance of arrays—the fact that an array of a reference type can be viewed as an array of its base type, or an array of any of the interfaces it implements. Generics don’t support this—they are invariant. This is for the sake of type safety, as we’ll see, but it can be annoying.
Let’s suppose we have two classes, Animal and Cat, where Cat derives from Animal. In the code that follows, the array code (on the left) is valid C# 2; the generic code (on the right) isn’t:
|
|
|
|
|
|
The compiler has no problem with the second line in either case, but the first line on the right causes the error:
error CS0029: Cannot implicitly convert type
'System.Collections.Generic.List<Cat>' to
'System.Collections.Generic.List<Animal>'This was a deliberate choice on the part of the framework and language designers. The obvious question to ask is why this is prohibited—and the answer lies on the second line. There is nothing about the second line that should raise any suspicion. After all, List<Animal> effectively has a method with the signature void Add(Animal value)—you should be able to put a Turtle into any list of animals, for instance. However, the actual object referred to by animals is a Cat[] (in the code on the left) or a List<Cat> (on the right), both of which require that only references to instances of Cat are stored in them. Although the array version will compile, it will fail at execution time. This was deemed by the designers of generics to be worse than failing at compile time, which is reasonable—the whole point of static typing is to find out about errors before the code ever gets run.
Note
So why are arrays covariant? Having answered the question about why generics are invariant, the next obvious step is to question why arrays are covariant. According to the Common Language Infrastructure Annotated Standard (Addison-Wesley Professional, 2003), for the first edition the designers wished to reach as broad an audience as possible, which included being able to run code compiled from Java source. In other words, .NET has covariant arrays because Java has covariant arrays—despite this being a known “wart” in Java.
So, that’s why things are the way they are—but why should you care, and how can you get around the restriction?
Suppose you are implementing a platform-agnostic storage system,[11] which could run across WebDAV, NFS, Samba, NTFS, ReiserFS, files in a database, you name it. You may have the idea of storage locations, which may contain sublocations (think of directories containing files and more directories, for instance). You could have an interface like this:
public interface IStorageLocation
{
Stream OpenForRead();
...
IEnumerable<IStorageLocation> GetSublocations();
}That all seems reasonable and easy to implement. The problem comes when your implementation (FabulousStorageLocation for instance) stores its list of sublocations for any particular location as List<FabulousStorageLocation>. You might expect to be able to either return the list reference directly, or possibly call AsReadOnly to avoid clients tampering with your list, and return the result—but that would be an implementation of IEnumerable<FabulousStorageLocation> instead of an IEnumerable<IStorageLocation>.
Here are some options:
Make your list a
List<IStorageLocation>instead. This is likely to mean you need to cast every time you fetch an entry in order to get at your implementation-specific behavior. You might as well not be using generics in the first place.Implement
GetSublocationsusing the funky new iteration features of C# 2, as described in chapter 6. That happens to work in this example, because the interface usesIEnumerable<IStorageLocation>. It wouldn’t work if we had to return anIList<IStorageLocation>instead. It also requires each implementation to have the same kind of code. It’s only a few lines, but it’s still inelegant.Create a new copy of the list, this time as
List<IStorageLocation>. In some cases (particularly if the interface did require you to return anIList <IStorageLocation>), this would be a good thing to do anyway—it keeps the list returned separate from the internal list. You could even useList.ConvertAllto do it in a single line. It involves copying everything in the list, though, which may be an unnecessary expense if you trust your callers to use the returned list reference appropriately.Make the interface generic, with the type parameter representing the actual type of storage sublocation being represented. For instance,
FabulousStorageLocationmight implementIStorageLocation<FabulousStorageLocation>. It looks a little odd, but this recursive-looking use of generics can be quite useful at times.[12]Create a generic helper method (preferably in a common class library) that converts
IEnumerator<TSource>toIEnumerator<TDest>, whereTSourcederives fromTDest.
When you run into covariance issues, you may need to consider all of these options and anything else you can think of. It depends heavily on the exact nature of the situation. Unfortunately, covariance isn’t the only problem we have to consider. There’s also the matter of contravariance, which is like covariance in reverse.
Contravariance feels slightly less intuitive than covariance, but it does make sense. Where covariance is about declaring that we will return a more specific object from a method than the interface requires us to, contravariance is about being willing to accept a more general parameter.
For instance, suppose we had an IShape interface[13] that contained the Area property. It’s easy to write an implementation of IComparer<IShape> that sorts by area. We’d then like to be able to write the following code:
IComparer<IShape> areaComparer = new AreaComparer(); List<Circle> circles = new List<Circle>(); circles.Add(new Circle(20)); circles.Add(new Circle(10)); circles.Sort(areaComparer); |
That won’t work, though, because the Sort method on List<Circle> effectively takes an IComparer<Circle>. The fact that our AreaComparer can compare any shape rather than just circles doesn’t impress the compiler at all. It considers IComparer <Circle> and IComparer<IShape> to be completely different types. Maddening, isn’t it? It would be nice if the Sort method had this signature instead:
void Sort<S>(IComparer<S> comparer) where T : S |
Unfortunately, not only is that not the signature of Sort, but it can’t be—the constraint is invalid, because it’s a constraint on T instead of S. We want a derivation type constraint but in the other direction, constraining the S to be somewhere up the inheritance tree of T instead of down.
Given that this isn’t possible, what can we do? There are fewer options this time than before. First, you could create a generic class with the following declaration:
ComparisonHelper<TBase,TDerived> : IComparer<TDerived>
where TDerived : TBaseYou’d then create a constructor that takes (and stores) an IComparer<TBase> as a parameter. The implementation of IComparer<TDerived> would just return the result of calling the Compare method of the IComparer<TBase>. You could then sort the List<Circle> by creating a new ComparisonHelper<IShape,Circle> that uses the area comparison.
The second option is to make the area comparison class generic, with a derivation constraint, so it can compare any two values of the same type, as long as that type implements IShape. Of course, you can only do this when you’re able to change the comparison class—but it’s a nice solution when it’s available.
Notice that the various options for both covariance and contravariance use more generics and constraints to express the interface in a more general manner, or to provide generic “helper” methods. I know that adding a constraint makes it sound less general, but the generality is added by first making the type or method generic. When you run into a problem like this, adding a level of genericity somewhere with an appropriate constraint should be the first option to consider. Generic methods (rather than generic types) are often helpful here, as type inference can make the lack of variance invisible to the naked eye. This is particularly true in C# 3, which has stronger type inference capabilities than C# 2.
Note
Is this really the best we can do?—. As we’ll see later, Java supports covariance and contravariance within its generics—so why can’t C#? Well, a lot of it boils down to the implementation—the fact that the Java runtime doesn’t get involved with generics; it’s basically a compile-time feature. However, the CLR does support limited generic covariance and contravariance, just on interfaces and delegates. C# doesn’t expose this feature (neither does VB.NET), and none of the framework libraries use it. The C# compiler consumes covariant and contravariant interfaces as if they were invariant. Adding variance is under consideration for C# 4, although no firm commitments have been made. Eric Lippert has written a whole series of blog posts about the general problem, and what might happen in future versions of C#: http://blogs.msdn.com/ericlippert/archive/tags/Covariance+and+Contravariance/default.aspx.
This limitation is a very common cause of questions on C# discussion groups. The remaining issues are either relatively academic or affect only a moderate subset of the development community. The next one mostly affects those who do a lot of calculations (usually scientific or financial) in their work.
C# is not without its downside when it comes to heavily mathematical code. The need to explicitly use the Math class for every operation beyond the simplest arithmetic and the lack of C-style typedefs to allow the data representation used throughout a program to be easily changed have always been raised by the scientific community as barriers to C#’s adoption. Generics weren’t likely to fully solve either of those issues, but there’s a common problem that stops generics from helping as much as they could have. Consider this (illegal) generic method:
public T FindMean<T>(IEnumerable<T> data)
{
T sum = default(T);
int count = 0;
foreach (T datum in data)
{
sum += datum;
count++;
}
return sum/count;
} |
Obviously that could never work for all types of data—what could it mean to add one Exception to another, for instance? Clearly a constraint of some kind is called for... something that is able to express what we need to be able to do: add two instances of T together, and divide a T by an integer. If that were available, even if it were limited to built-in types, we could write generic algorithms that wouldn’t care whether they were working on an int, a long, a double, a decimal, and so forth. Limiting it to the built-in types would have been disappointing but better than nothing. The ideal solution would have to also allow user-defined types to act in a numeric capacity—so you could define a Complex type to handle complex numbers, for instance. That complex number could then store each of its components in a generic way as well, so you could have a Complex<float>, a Complex<double>, and so on.[14]
Two related solutions present themselves. One would be simply to allow constraints on operators, so you could write a set of constraints such as
where T : T operator+ (T,T), T operator/ (T, int)
This would require that T have the operations we need in the earlier code. The other solution would be to define a few operators and perhaps conversions that must be supported in order for a type to meet the extra constraint—we could make it the “numeric constraint” written where T : numeric.
One problem with both of these options is that they can’t be expressed as normal interfaces, because operator overloading is performed with static members, which can’t implement interfaces. It would require a certain amount of shoehorning, in other words.
Various smart people (including Eric Gunnerson and Anders Hejlsberg, who ought to be able to think of C# tricks if anyone can) have thought about this, and with a bit of extra code, some solutions have been found. They’re slightly clumsy, but they work. Unfortunately, due to current JIT optimization limitations, you have to pick between pleasant syntax (x=y+z) that reads nicely but performs poorly, and a method-based syntax (x=y.Add(z)) that performs without significant overhead but looks like a dog’s dinner when you’ve got anything even moderately complicated going on.
The details are beyond the scope of this book, but are very clearly presented at http://www.lambda-computing.com/publications/articles/generics2/ in an article on the matter.
The two limitations we’ve looked at so far have been quite practical—they’ve been issues you may well run into during actual development. However, if you’re generally curious like I am, you may also be asking yourself about other limitations that don’t necessarily slow down development but are intellectual curiosities. In particular, just why are generics limited to types and methods?
We’ve seen generic types (classes, structs, delegates, and interfaces) and we’ve seen generic methods. There are plenty of other members that could be parameterized. However, there are no generic properties, indexers, operators, constructors, finalizers, or events. First let’s be clear about what we mean here: clearly an indexer can have a return type that is a type parameter—List<T> is an obvious example. KeyValuePair<TKey,TValue> provides similar examples for properties. What you can’t have is an indexer or property (or any of the other members in that list) with extra type parameters. Leaving the possible syntax of declaration aside for the minute, let’s look at how these members might have to be called:
SomeClass<string> instance = new SomeClass<string><Guid>("x");
int x = instance.SomeProperty<int>;
byte y = instance.SomeIndexer<byte>["key"];
instance.Click<byte> += ByteHandler;
instance = instance +<int> instance; |
I hope you’ll agree that all of those look somewhat silly. Finalizers can’t even be called explicitly from C# code, which is why there isn’t a line for them. The fact that we can’t do any of these isn’t going to cause significant problems anywhere, as far as I can see—it’s just worth being aware of it as an academic limitation.
The one exception to this is possibly the constructor. However, a static generic method in the class is a good workaround for this, and the syntax with two lists of type arguments is horrific.
These are by no means the only limitations of C# generics, but I believe they’re the ones that you’re most likely to run up against, either in your daily work, in community conversations, or when idly considering the feature as a whole. In our next two sections we’ll see how some aspects of these aren’t issues in the two languages whose features are most commonly compared with C#’s generics: C++ (with templates) and Java (with generics as of Java 5). We’ll tackle C++ first.
C++ templates are a bit like macros taken to an extreme level. They’re incredibly powerful, but have costs associated with them both in terms of code bloat and ease of understanding.
When a template is used in C++, the code is compiled for that particular set of template arguments, as if the template arguments were in the source code. This means that there’s not as much need for constraints, as the compiler will check whether you’re allowed to do everything you want to with the type anyway while it’s compiling the code for this particular set of template arguments. The C++ standards committee has recognized that constraints are still useful, though, and they will be present in C++0x (the next version of C++) under the name of concepts.
The C++ compiler is smart enough to compile the code only once for any given set of template arguments, but it isn’t able to share code in the way that the CLR does with reference types. That lack of sharing does have its benefits, though—it allows type-specific optimizations, such as inlining method calls for some type parameters but not others, from the same template. It also means that overload resolution can be performed separately for each set of type parameters, rather than just once based solely on the limited knowledge the C# compiler has due to any constraints present.
Don’t forget that with “normal” C++ there’s only one compilation involved, rather than the “compile to IL” then “JIT compile to native code” model of .NET. A program using a standard template in ten different ways will include the code ten times in a C++ program. A similar program in C# using a generic type from the framework in ten different ways won’t include the code for the generic type at all—it will refer to it, and the JIT will compile as many different versions as required (as described in section 3.4.2) at execution time.
One significant feature that C++ templates have over C# generics is that the template arguments don’t have to be type names. Variable names, function names, and constant expressions can be used as well. A common example of this is a buffer type that has the size of the buffer as one of the template arguments—so a buffer<int,20> will always be a buffer of 20 integers, and a buffer<double,35> will always be a buffer of 35 doubles. This ability is crucial to template metaprogramming[15]—an advanced C++ technique the very idea of which scares me, but that can be very powerful in the hands of experts.
C++ templates are more flexible in other ways, too. They don’t suffer from the problem described in 3.6.2, and there are a few other restrictions that don’t exist in C++: you can derive a class from one of its type parameters, and you can specialize a template for a particular set of type arguments. The latter ability allows the template author to write general code to be used when there’s no more knowledge available but specific (often highly optimized) code for particular types.
The same variance issues of .NET generics exist in C++ templates as well—an example given by Bjarne Stroustrup[16] is that there are no implicit conversions between Vector<shape*> and Vector<circle*> with similar reasoning—in this case, it might allow you to put a square peg in a round hole.
For further details of C++ templates, I recommend Stroustrup’s The C++ Programming Language(Addison-Wesley, 1991). It’s not always the easiest book to follow, but the templates chapter is fairly clear (once you get your mind around C++ terminology and syntax). For more comparisons with .NET generics, look at the blog post by the Visual C++ team on this topic: http://blogs.msdn.com/branbray/archive/2003/11/19/51023.aspx.
The other obvious language to compare with C# in terms of generics is Java, which introduced the feature into the mainstream language for the 1.5 release,[17] several years after other projects had compilers for their Java-like languages.
Where C++ includes more of the template in the generated code than C# does, Java includes less. In fact, the Java runtime doesn’t know about generics at all. The Java bytecode (roughly equivalent terminology to IL) for a generic type includes some extra metadata to say that it’s generic, but after compilation the calling code doesn’t have much to indicate that generics were involved at all—and certainly an instance of a generic type only knows about the nongeneric side of itself. For example, an instance of HashSet<T> doesn’t know whether it was created as a HashSet<String> or a HashSet<Object>. The compiler effectively just adds casts where necessary and performs more sanity checking. Here’s an example—first the generic Java code:
ArrayList<String> strings = new ArrayList<String>();
strings.add("hello");
String entry = strings.get(0);
strings.add(new Object());and now the equivalent nongeneric code:
ArrayList strings = new ArrayList();
strings.add("hello");
String entry = (String) strings.get(0);
strings.add(new Object());They would generate the same Java bytecode, except for the last line—which is valid in the nongeneric case but caught by the compiler as an error in the generic version. You can use a generic type as a “raw” type, which is equivalent to using java.lang.Object for each of the type arguments. This rewriting—and loss of information—is called type erasure. Java doesn’t have user-defined value types, but you can’t even use the built-in ones as type arguments. Instead, you have to use the boxed version—ArrayList<Integer> for a list of integers, for example.
You may be forgiven for thinking this is all a bit disappointing compared with generics in C#, but there are some nice features of Java generics too:
The runtime doesn’t know anything about generics, so you can use code compiled using generics on an older version, as long as you don’t use any classes or methods that aren’t present on the old version. Versioning in .NET is much stricter in general—you have to compile using the oldest environment you want to run on. That’s safer, but less flexible.
You don’t need to learn a new set of classes to use Java generics—where a non-generic developer would use
ArrayList, a generic developer just usesArrayList<T>. Existing classes can reasonably easily be “upgraded” to generic versions.The previous feature has been utilized quite effectively with the reflection system—
java.lang.Class(the equivalent ofSystem.Type) is generic, which allows compile-time type safety to be extended to cover many situations involving reflection. In some other situations it’s a pain, however.Java has support for covariance and contravariance using wildcards. For instance,
ArrayList<? extends Base>can be read as “this is anArrayListof some type that derives fromBase, but we don’t know which exact type.”
My personal opinion is that .NET generics are superior in almost every respect, although every time I run into a covariance/contravariance issue I suddenly wish I had wildcards. Java with generics is still much better than Java without generics, but there are no performance benefits and the safety only applies at compile time. If you’re interested in the details, they’re in the Java language specification, or you could read Gilad Bracha’s excellent guide to them at http://java.sun.com/j2se/1.5/pdf/generics-tutorial.pdf.
Phew! It’s a good thing generics are simpler to use in reality than they are in description. Although they can get complicated, they’re widely regarded as the most important addition to C# 2 and are incredibly useful. The worst thing about writing code using generics is that if you ever have to go back to C# 1, you’ll miss them terribly.
In this chapter I haven’t tried to cover absolutely every detail of what is and isn’t allowed when using generics—that’s the job of the language specification, and it makes for very dry reading. Instead, I’ve aimed for a practical approach, providing the information you’ll need in everyday use, with a smattering of theory for the sake of academic interest.
We’ve seen three main benefits to generics: compile-time type safety, performance, and code expressiveness. Being able to get the IDE and compiler to validate your code early is certainly a good thing, but it’s arguable that more is to be gained from tools providing intelligent options based on the types involved than the actual “safety” aspect.
Performance is improved most radically when it comes to value types, which no longer need to be boxed and unboxed when they’re used in strongly typed generic APIs, particularly the generic collection types provided in .NET 2.0. Performance with reference types is usually improved but only slightly.
Your code is able to express its intention more clearly using generics—instead of a comment or a long variable name required to describe exactly what types are involved, the details of the type itself can do the work. Comments and variable names can often become inaccurate over time, as they can be left alone when code is changed—but the type information is “correct” by definition.
Generics aren’t capable of doing everything we might sometimes like them to do, and we’ve studied some of their limitations in the chapter, but if you truly embrace C# 2 and the generic types within the .NET 2.0 Framework, you’ll come across good uses for them incredibly frequently in your code.
This topic will come up time and time again in future chapters, as other new features build on this key one. Indeed, the subject of our next chapter would be very different without generics—we’re going to look at nullable types, as implemented by Nullable<T>.
[1] By which I mean “convenient for the purposes of introducing the chapter”—not, you know, accurate as such.
[2] It doesn’t always work exactly that way—there are corner cases that break when you apply that simple rule—but it’s an easy way of thinking about generics that works in the vast majority of situations.
[3] I’ve renamed the parameter from converter to conv so that it fits on one line, but everything else is as documented.
[4] Strictly speaking, an implicit reference conversion is OK too. This allows for a constraint such as where T : IList<Shape> to be satisfied by Circle[]. Even though Circle[] doesn’t actually implement IList <Shape>, there is an implicit reference conversion available.
[5] The formula used for calculating the hash code based on the two “part” results comes from reading Effective Java (Prentice Hall PTR, 2001) by Joshua Bloch. It certainly doesn’t guarantee a good distribution of hash codes, but in my opinion it’s better than using a bitwise exclusive OR. See Effective Java for more details, and indeed for many other useful tips.
[7] Well, one per application domain. For the purposes of this section, we’ll assume we’re only dealing with one application domain. The concepts for different application domains work the same with generics as with non-generic types.
[8] When running on a 64-bit CLR, the overheads are bigger.
[10] Not to be confused with the foreach statement, which does a similar thing but requires the actual code in place, rather than being a method with an Action<T> parameter.
[11] Yes, another one.
[12] For instance, you might have a type parameter T with a constraint that any instance can be compared to another instance of T for equality—in other words, something like MyClass<T> where T : IEquatable<T>.
[13] You didn’t really expect to get through the whole book without seeing a shape-related example, did you?
[14] More mathematically minded readers might want to consider what a Complex<Complex<double>> would mean. You’re on your own there, I’m afraid.
[16] The inventor of C++.
[17] Or 5.0, depending on which numbering system you use. Don’t get me started.