
Longwinded C# 1 syntax
Simplified delegate construction
Covariance and contravariance
Anonymous methods
Captured variables
The journey of delegates in C# and .NET is an interesting one, showing remarkable foresight (or really good luck) on the part of the designers. The conventions suggested for event handlers in .NET 1.0/1.1 didn’t make an awful lot of sense—until C# 2 showed up. Likewise, the effort put into delegates for C# 2 seems in some ways out of proportion to how widely used they are—until you see how pervasive they are in idiomatic C# 3 code. In other words, it’s as if the language and platform designers had a vision of at least the rough direction they would be taking, years before the destination itself became clear.
Of course, C# 3 is not a “final destination” in itself, and we may be seeing further advances for delegates in the future—but the differences between C# 1 and C# 3 in this area are startling. (The primary change in C# 3 supporting delegates is in lambda expressions, which we’ll meet in chapter 9.)
C# 2 is a sort of stepping stone in terms of delegates. Its new features pave the way for the even more dramatic changes of C# 3, keeping developers reasonably comfortable while still providing useful benefits. The extent to which this was a finely balanced act as opposed to intuition and a following wind is likely to stay unknown, but we can certainly reap the benefits.
Delegates play a more prominent part in .NET 2.0 than in earlier versions, although they’re not as common as they are in .NET 3.5. In chapter 3 we saw how they can be used to convert from a list of one type to a list of another type, and way back in chapter 1 we sorted a list of products using the Comparison delegate instead of the IComparer interface. Although the framework and C# keep a respectful distance from each other where possible, I believe that the language and platform drove each other here: the inclusion of more delegate-based API calls supported the improved syntax available in C# 2, and vice versa.
In this chapter we’ll see how C# 2 makes two small changes that make life easier when creating delegate instances from normal methods, and then we’ll look at the biggest change: anonymous methods, which allow you to specify a delegate instance’s action inline at the point of its creation. The largest section of the chapter is devoted to the most complicated part of anonymous methods, captured variables, which provide delegate instances with a richer environment to play in. We’ll cover the topic in significant detail due to its importance and complexity.
First, though, let’s remind ourselves of the pain points of C# 1’s delegate facilities.
The syntax for delegates in C# 1 doesn’t sound too bad—the language already has syntactic sugar around Delegate.Combine, Delegate.Remove, and the invocation of delegate instances. It makes sense to specify the delegate type when creating a delegate instance—it’s the same syntax used to create instances of other types, after all.
This is all true, but for some reason it also sucks. It’s hard to say exactly why the delegate creation expressions of C# 1 raise hackles, but they do—at least for me. When hooking up a bunch of event handlers, it just looks ugly to have to write “new EventHandler” (or whatever is required) all over the place, when the event itself has specified which delegate type it will use. Beauty is in the eye of the beholder, of course, and you could argue that there’s less call for guesswork when reading event handler wiring code in the C# 1 style, but the extra text just gets in the way and distracts from the important part of the code: which method you want to handle the event.
Life becomes a bit more black and white when you consider covariance and contravariance as applied to delegates. Suppose you’ve got an event handling method that saves the current document, or just logs that it’s been called, or any number of other actions that may well not need to know details of the event. The event itself shouldn’t mind that your method is capable of working with only the information provided by the EventHandler signature, even though it is declared to pass in mouse event details. Unfortunately, in C# 1 you have to have a different method for each different event handler signature.
Likewise it’s undeniably ugly to write methods that are so simple that their implementation is shorter than their signature, solely because delegates need to have code to execute and that code has to be in the form of a method. It adds an extra layer of indirection between the code creating the delegate instance and the code that should execute when the delegate instance is invoked. Often extra layers of indirection are welcome—and of course that option hasn’t been removed in C# 2—but at the same time it often makes the code harder to read, and pollutes the class with a bunch of methods that are only used for delegates.
Unsurprisingly, all of these are improved greatly in C# 2. The syntax can still occasionally be wordier than we might like (which is where lambda expressions come into play in C# 3), but the difference is significant. To illustrate the pain, we’ll start with some code in C# 1 and improve it in the next couple of sections. Listing 5.1 builds a (very) simple form with a button and subscribes to three of the button’s events.
Example 5.1. Subscribing to three of a button’s events
static void LogPlainEvent(object sender, EventArgs e)
{
Console.WriteLine ("LogPlain");
}
static void LogKeyEvent(object sender, KeyPressEventArgs e)
{
Console.WriteLine ("LogKey");
}
static void LogMouseEvent(object sender, MouseEventArgs e)
{
Console.WriteLine ("LogMouse");
}
...
Button button = new Button();
button.Text = "Click me";
button.Click += new EventHandler(LogPlainEvent);
button.KeyPress += new KeyPressEventHandler(LogKeyEvent);
button.MouseClick += new MouseEventHandler(LogMouseEvent);
Form form = new Form();
form.AutoSize=true;
form.Controls.Add(button);
Application.Run(form);The output lines in the three event handling methods are there to prove that the code is working: if you press the spacebar with the button highlighted, you’ll see that the Click and KeyPress events are both raised; pressing Enter just raises the Click event; clicking on the button raises the Click and MouseClick events. In the following sections we’ll improve this code using some of the C# 2 features.
Let’s start by asking the compiler to make a pretty obvious deduction—which delegate type we want to use when subscribing to an event.
In C# 1, if you want to create a delegate instance you need to specify both the delegate type and the action. If you remember from chapter 2, we defined the action to be the method to call and (for instance methods) the target to call it on. So for example, in listing 5.1 when we needed to create a KeyPressEventHandler we used this expression:
new KeyPressEventHandler(LogKeyEvent)
As a stand-alone expression, it doesn’t look too bad. Even used in a simple event subscription it’s tolerable. It becomes a bit uglier when used as part of a longer expression. A common example of this is starting a new thread:
Thread t = new Thread (new ThreadStart(MyMethod));
What we want to do is start a new thread that will execute MyMethod as simply as possible. C# 2 allows you to do this by means of an implicit conversion from a method group to a compatible delegate type. A method group is simply the name of a method, optionally with a target—exactly the same kind of expression as we used in C# 1 to create delegate instances, in other words. (Indeed, the expression was called a method group back then—it’s just that the conversion wasn’t available.) If the method is generic, the method group may also specify type arguments. The new implicit conversion allows us to turn our event subscription into
button.KeyPress += LogKeyEvent;
Likewise the thread creation code becomes simply
Thread t = new Thread (MyMethod);
The readability differences between the original and the “streamlined” versions aren’t huge for a single line, but in the context of a significant amount of code, they can reduce the clutter considerably. To make it look less like magic, let’s take a brief look at what this conversion is doing.
First, let’s consider the expressions LogKeyEvent and MyMethod as they appear in the examples. The reason they’re classified as method groups is that more than one method may be available, due to overloading. The implicit conversions available will convert a method group to any delegate type with a compatible signature. So, if you had two method signatures as follows:
void MyMethod() void MyMethod(object sender, EventArgs e)
you could use MyMethod as the method group in an assignment to either a ThreadStart or an EventHandler as follows:
ThreadStart x = MyMethod; EventHandler y = MyMethod;
However, you couldn’t use it as the parameter to a method that itself was overloaded to take either a ThreadStart or an EventHandler—the compiler would complain that the conversion was ambiguous. Likewise, you unfortunately can’t use an implicit method group conversion to convert to the plain System.Delegate type since the compiler doesn’t know which specific delegate type to create an instance of. This is a bit of a pain, but you can still be slightly briefer than in C# 1 by making the conversion explicit. For example:
Delegate invalid = SomeMethod; Delegate valid = (ThreadStart)SomeMethod;
As with generics, the precise rules of conversion are slightly complicated, and the “just try it” rule works very well: if the compiler complains that it doesn’t have enough information, just tell it what conversion to use and all should be well. If it doesn’t complain, you should be fine. For the exact details, consult the language specification. Speaking of possible conversions, there may be more than you expect, as we’ll see in our next section.
We’ve already talked quite a lot about the concepts of covariance and contravariance in different contexts, usually bemoaning their absence, but delegate construction is the one area in which they are actually available in C#. If you want to refresh yourself about the meaning of the terms at a relatively detailed level, refer back to section 2.3.2—but the gist of the topic with respect to delegates is that if it would be valid (in a static typing sense) to call a method and use its return value everywhere that you could invoke an instance of a particular delegate type and use its return value, then that method can be used to create an instance of that delegate type. That’s all pretty wordy, but it’s a lot simpler with examples.
Let’s consider the event handlers we’ve got in our little Windows Forms application. The signatures[1] of the three delegate types involved are as follows:
void EventHandler (object sender, EventArgs e) void KeyPressEventHandler (object sender, KeyPressEventArgs e) void MouseEventHandler (object sender, MouseEventArgs e)
Now, consider that KeyPressEventArgs and MouseEventArgs both derive from EventArgs (as do a lot of other types—at the time of this writing, MSDN lists 386 types that derive directly from EventArgs). So, if you have a method that takes an EventArgs parameter, you could always call it with a KeyPressEventArgs argument instead. It therefore makes sense to be able to use a method with the same signature as EventHandler to create an instance of KeyPressEventHandler—and that’s exactly what C# 2 does. This is an example of contravariance of parameter types.
To see that in action, let’s think back to Listing 5.1 and suppose that we don’t need to know which event was firing—we just want to write out the fact that an event has happened. Using method group conversions and contravariance, our code becomes quite a lot simpler, as shown in listing 5.2.
We’ve managed to completely remove the two handler methods that dealt specifically with key and mouse events, using one event handling method ![]() for everything. Of course, this isn’t terribly useful if you want to do different things for different types of events, but sometimes all you need to know is that an event occurred and, potentially, the source of the event. The subscription to the
for everything. Of course, this isn’t terribly useful if you want to do different things for different types of events, but sometimes all you need to know is that an event occurred and, potentially, the source of the event. The subscription to the Click event ![]() only uses the implicit conversion we discussed in the previous section because it has a simple
only uses the implicit conversion we discussed in the previous section because it has a simple EventArgs parameter, but the other event subscriptions ![]() involve the conversion and contravariance due to their different parameter types.
involve the conversion and contravariance due to their different parameter types.
I mentioned earlier that the .NET 1.0/1.1 event handler convention didn’t make much sense when it was first introduced. This example shows exactly why the guidelines are more useful with C# 2. The convention dictates that event handlers should have a signature with two parameters, the first of which is of type object and is the origin of the event, and the second of which carries any extra information about the event in a type deriving from EventArgs. Before contravariance became available, this wasn’t useful—there was no benefit to making the informational parameter derive from EventArgs, and sometimes there wasn’t much use for the origin of the event. It was often more sensible just to pass the relevant information directly in the form of normal parameters, just like any other method. Now, however, you can use a method with the EventHandler signature as the action for any delegate type that honors the convention.
Demonstrating covariance of return types is a little harder as relatively few built-in delegates are declared with a nonvoid return type. There are some available, but it’s easier to declare our own delegate type that uses Stream as its return type. For simplicity we’ll make it parameterless:[2]
delegate Stream StreamFactory();
We can now use this with a method that is declared to return a specific type of stream, as shown in listing 5.3. We declare a method that always returns a MemoryStream with some random data,and then use that method as the action for a StreamFactory delegate instance.

The actual generation and display of the data in listing 5.3 is only present to give the code something to do. (In particular, the way of generating random data is pretty awful!) The important points are the annotated lines. We declare that the delegate type has a return type of Stream ![]() , but the
, but the GenerateRandomData method ![]() has a return type of
has a return type of MemoryStream. The line creating the delegate instance ![]() performs the conversion we saw earlier and uses covariance of return types to allow
performs the conversion we saw earlier and uses covariance of return types to allow GenerateRandomData to be used for the action for StreamFactory. By the time we invoke the delegate instance ![]() , the compiler no longer knows that a
, the compiler no longer knows that a MemoryStream will be returned—if we changed the type of the stream variable to MemoryStream, we’d get a compilation error.
Covariance and contravariance can also be used to construct one delegate instance from another. For instance, consider these two lines of code (which assume an appropriate HandleEvent method):
EventHandler general = new EventHandler(HandleEvent); KeyPressEventHandler key = new KeyPressEventHandler(general);
The first line is valid in C# 1, but the second isn’t—in order to construct one delegate from another in C#1, the signatures of the two delegate types involved have to match. For instance, you could create a MethodInvoker from a ThreadStart—but you couldn’t do what we’re doing in the previous code. We’re using contravariance to create a new delegate instance from an existing one with a compatible delegate type signature, where compatibility is defined in a less restrictive manner in C#2 than in C#1.
This new flexibility in C# 2 causes one of the very few cases where existing valid C#1 code may produce different results when compiled under C# 2: if a derived class overloads a method declared in its base class, a delegate creation expression that previously only matched the base class method could now match the derived class method due to covariance or contravariance. In this case the derived class method will take priority in C#2. listing 5.4 gives an example of this.
Example 5.4. Demonstration of breaking change between C# 1 and C# 2
delegate void SampleDelegate(string x);
public void CandidateAction(string x)
{
Console.WriteLine("Snippet.CandidateAction");
}
public class Derived : Snippet
{
public void CandidateAction(object o)
{
Console.WriteLine("Derived.CandidateAction");
}
}
...
Derived x = new Derived();
SampleDelegate factory = new SampleDelegate(x.CandidateAction);
factory("test");Remember that Snippy[3] will be generating all of this code within a class called Snippet which the nested type derives from. Under C# 1, listing 5.4 would print Snippet.CandidateAction because the method taking an object parameter wasn’t compatible with SampleDelegate. Under C#2, however, it is compatible and is the method chosen due to being declared in a more derived type—so the result is that Derived. CandidateAction is printed. Fortunately, the C#2 compiler knows that this is a breaking change and issues an appropriate warning.
Enough doom and gloom about potential breakage, however. We’ve still got to see the most important new feature regarding delegates: anonymous methods. They’re a bit more complicated than the topics we’ve covered so far, but they’re also very powerful—and a large step toward C#3.
Have you ever been writing C# 1 and had to implement a delegate with a particular signature, even though you’ve already got a method that does what you want but doesn’t happen to have quite the right parameters? Have you ever had to implement a delegate that only needs to do one teeny, tiny thing, and yet you need a whole extra method? Have you ever been frustrated at having to navigate away from an important bit of code in order to see what the delegate you’re using does, only to find that the method used is only two lines long? This kind of thing happened to me quite regularly with C# 1. The covariance and contravariance features we’ve just talked about can sometimes help with the first problem, but often they don’t. Anonymous methods, which are also new in C#2, can pretty much always help with these issues.
Informally, anonymous methods allow you to specify the action for a delegate instance inline as part of the delegate instance creation expression. This means there’s no need to “pollute” the rest of your class with an extra method containing a small piece of code that is only useful in one place and doesn’t make sense elsewhere.
Anonymous methods also provide some far more powerful behavior in the form of closures, but we’ll come to them in section 5.5. For the moment, let’s stick with relatively simple stuff—as you may have noticed, a common theme in this book is that you can go a long way in C# 2 without dealing with the more complex aspects of the language. Not only is this good in terms of learning the new features gradually, but if you only use the more complicated areas when they provide a lot of benefit, your code will be easier to understand as well. First we’ll see examples of anonymous methods that take parameters but don’t return any values; then we’ll explore the syntax involved in providing return values and a shortcut available when we don’t need to use the parameters passed to us.
In chapter 3 we saw the Action<T> delegate type. As a reminder, its signature is very simple (aside from the fact that it’s generic):
public delegate void Action<T>(T obj)
In other words, an Action<T> does something with an instance of T. So an Action<string> could reverse the string and print it out, an Action<int> could print out the square root of the number passed to it, and an Action<IList <double>> could find the average of all the numbers given to it and print that out. By complete coincidence, these examples are all implemented using anonymous methods in listing 5.5.

listing 5.5 shows a few of the different features of anonymous methods. First, the syntax of anonymous methods: use the delegate keyword, followed by the parameters (if there are any), followed by the code for the action of the delegate instance, in a block. The string reversal code ![]() shows that the block can contain local variable declarations, and the “list averaging” code
shows that the block can contain local variable declarations, and the “list averaging” code ![]() demonstrates looping within the block. Basically, anything you can do in a normal method body, you can do in an anonymous method.[4] Likewise, the result of an anonymous method is a delegate instance that can be used like any other one
demonstrates looping within the block. Basically, anything you can do in a normal method body, you can do in an anonymous method.[4] Likewise, the result of an anonymous method is a delegate instance that can be used like any other one ![]() . Be warned that contravariance doesn’t apply to anonymous methods: you have to specify the parameter types that match the delegate type exactly.
. Be warned that contravariance doesn’t apply to anonymous methods: you have to specify the parameter types that match the delegate type exactly.
In terms of implementation, we are still creating a method for each delegate instance: the compiler will generate a method within the class and use that as the action it uses to create the delegate instance, just as if it were a normal method. The CLR neither knows nor cares that an anonymous method was used. You can see the extra methods within the compiled code using ildasm or Reflector. (Reflector knows how to interpret the IL to display anonymous methods in the method that uses them, but the extra methods are still visible.)
It’s worth pointing out at this stage that listing 5.5 is “exploded” compared with how you may well see anonymous methods in real code. You’ll often see them used as parameters to another method (rather than assigned to a variable of the delegate type) and with very few line breaks—compactness is part of the reason for using them, after all. For example, we mentioned in chapter 3 that List<T> has a ForEach method that takes an Action<T> as a parameter and performs that action on each element. Listing 5.6 shows an extreme example of this, applying the same “square rooting” action we used in listing 5.5, but in a compact form.
Example 5.6. Extreme example of code compactness. Warning: unreadable code ahead!
List<int> x = new List<int>();
x.Add(5);
x.Add(10);
x.Add(15);
x.Add(20);
x.Add(25);
x.ForEach(delegate(int n){Console.WriteLine(Math.Sqrt(n));});That’s pretty horrendous—especially when at first sight the last six characters appear to be ordered almost at random. There’s a happy medium, of course. I tend to break my usual “braces on a line on their own” rule for anonymous methods (as I do for trivial properties) but still allow a decent amount of whitespace. I’d usually write the last line of Listing 5.6 as something like
x.ForEach(delegate(int n)
{ Console.WriteLine(Math.Sqrt(n)); }
);The parentheses and braces are now less confusing, and the “what it does” part stands out appropriately. Of course, how you space out your code is entirely your own business, but I encourage you to actively think about where you want to strike the balance, and talk about it with your teammates to try to achieve some consistency. Consistency doesn’t always lead to the most readable code, however—sometimes keeping everything on one line is the most straightforward format.
You should also consider how much code it makes sense to include in anonymous methods. The first two examples in listing 5.5 are reasonable, but printMean is probably doing enough work to make it worth having as a separate method. Again, it’s a balancing act.
So far the only interaction we’ve had with the calling code is through parameters. What about return values?
The Action<T> delegate has a void return type, so we haven’t had to return anything from our anonymous methods. To demonstrate how we can do so when we need to, we’ll use the new Predicate<T> delegate type. We saw this briefly in chapter 3, but here’s its signature just as a reminder:
public delegate bool Predicate<T>(T obj)
listing 5.7 shows an anonymous method creating an instance of Predicate<T> to return whether the argument passed in is odd or even. Predicates are usually used in filtering and matching—you could use the code in Listing 5.7 to filter a list to one containing just the even elements, for instance.
Example 5.7. Returning a value from an anonymous method
Predicate<int> isEven = delegate(int x)
{ return x%2 == 0; };
Console.WriteLine(isEven(1));
Console.WriteLine(isEven(4));The new syntax is almost certainly what you’d have expected—we just return the appropriate value as if the anonymous method were a normal method. You may have expected to see a return type declared near the parameter type, but there’s no need. The compiler just checks that all the possible return values are compatible with the declared return type of the delegate type it’s trying to convert the anonymous method into.
Note
Just what are you returning from? When you return a value from an anonymous method it really is only returning from the anonymous method—it’s not returning from the method that is creating the delegate instance. It’s all too easy to look down some code, see the return keyword, and think that it’s an exit point from the current method.
Relatively few delegates in .NET 2.0 return values—in particular, few event handlers do, partly because when the event is raised only the return value from the last action to be called would be available. The Predicate<T> delegate type we’ve used so far isn’t used very widely in .NET 2.0, but it becomes important in .NET 3.5 where it’s a key part of LINQ. Another useful delegate type with a return value is Comparison<T>, which can be used when sorting items. This works very well with anonymous methods. Often you only need a particular sort order in one situation, so it makes sense to be able to specify that order inline, rather than exposing it as a method within the rest of the class. Listing 5.8 demonstrates this, printing out the files within the C: directory, ordering them first by name and then (separately) by size.
Example 5.8. Using anonymous methods to sort files simply
static void SortAndShowFiles(string title,
Comparison<FileInfo> sortOrder)
{
FileInfo[] files = new DirectoryInfo(@"C:").GetFiles();
Array.Sort(files, sortOrder);
Console.WriteLine (title);
foreach (FileInfo file in files)
{
Console.WriteLine (" {0} ({1} bytes)",
file.Name, file.Length);
}
}
...
SortAndShowFiles("Sorted by name:",
delegate(FileInfo first, FileInfo second)
{ return first.Name.CompareTo(second.Name); }
);
SortAndShowFiles("Sorted by length:",
delegate(FileInfo first, FileInfo second)
{ return first.Length.CompareTo(second.Length); }
);If we weren’t using anonymous methods, we’d have to have a separate method for each of these sort orders. Instead, listing 5.8 makes it clear what we’ll sort by in each case right where we call SortAndShowFiles. (Sometimes you’ll be calling Sort directly at the point where the anonymous method is called for. In this case we’re performing the same fetch/sort/display sequence twice, just with different sort orders, so I encapsulated that sequence in its own method.)
There’s one special syntactic shortcut that is sometimes available. If you don’t care about the parameters of a delegate, you don’t have to declare them at all. Let’s see how that works.
Just occasionally, you want to implement a delegate that doesn’t depend on its parameter values. You may wish to write an event handler whose behavior was only appropriate for one event and didn’t depend on the event arguments: saving the user’s work, for instance. Indeed, the event handlers from our original example in Listing 5.1 fit this criterion perfectly. In this case, you can leave out the parameter list entirely, just using the delegate keyword and then the block of code to use as the action for the method. listing 5.9 is equivalent to listing 5.1 but uses this syntax.
Example 5.9. Subscribing to events with anonymous methods that ignore parameters
Button button = new Button();
button.Text = "Click me";
button.Click += delegate { Console.WriteLine("LogPlain"); };
button.KeyPress += delegate { Console.WriteLine("LogKey"); };
button.MouseClick += delegate { Console.WriteLine("LogMouse"); };
Form form = new Form();
form.AutoSize=true;
form.Controls.Add(button);
Application.Run(form);Normally we’d have had to write each subscription as something like this:
button.Click += delegate (object sender, EventArgs e) { ... };That wastes a lot of space for little reason—we don’t need the values of the parameters, so the compiler lets us get away with not specifying them at all. listing 5.9 also happens to be a perfect example of how consistency of formatting isn’t always a good thing—I played around with a few ways of laying out the code and decided this was the clearest form.
I’ve found this shortcut most useful when it comes to implementing my own events. I get sick of having to perform a nullity check before raising an event. One way of getting around this is to make sure that the event starts off with a handler, which is then never removed. As long as the handler doesn’t do anything, all you lose is a tiny bit of performance. Before C# 2, you had to explicitly create a method with the right signature, which usually wasn’t worth the benefit. Now, however, you can do this:
public event EventHandler Click = delegate {};From then on, you can just call Click without any tests to see whether there are any handlers subscribed to the event.
You should be aware of one trap about this “parameter wildcarding” feature—if the anonymous method could be converted to multiple delegate types (for example, to call different method overloads) then the compiler needs more help. To show you what I mean, let’s look at how we start threads. There are four thread constructors in .NET 2.0:
public Thread (ParameterizedThreadStart start) public Thread (ThreadStart start) public Thread (ParameterizedThreadStart start, int maxStackSize) public Thread (ThreadStart start, int maxStackSize)
The two delegate types involved are
public delegate void ThreadStart() public delegate void ParameterizedThreadStart(object obj)
Now, consider the following three attempts to create a new thread:
new Thread(delegate() { Console.WriteLine("t1"); } );
new Thread(delegate(object o) { Console.WriteLine("t2"); } );
new Thread(delegate { Console.WriteLine("t3"); } );The first and second lines contain parameter lists—the compiler knows that it can’t convert the anonymous method in the first line into a ParameterizedThreadStart, or convert the anonymous method in the second line into a ThreadStart. Those lines compile, because there’s only one applicable constructor overload in each case. The third line, however, is ambiguous—the anonymous method can be converted into either delegate type, so both of the constructor overloads taking just one parameter are applicable. In this situation, the compiler throws its hands up and issues an error. You can solve this either by specifying the parameter list explicitly or casting the anonymous method to the right delegate type.
Hopefully what you’ve seen of anonymous methods so far will have provoked some thought about your own code, and made you consider where you could use these techniques to good effect. Indeed, even if anonymous methods could only do what we’ve already seen, they’d still be very useful. However, there’s more to anonymous methods than just avoiding the inclusion of an extra method in your code. Anonymous methods are C# 2’s implementation of a feature known elsewhere as closures by way of captured variables. Our next section explains both of these terms and shows how anonymous methods can be extremely powerful—and confusing if you’re not careful.
I don’t like having to give warnings, but I think it makes sense to include one here: if this topic is new to you, then don’t start this section until you’re feeling reasonably awake and have a bit of time to spend on it. I don’t want to alarm you unnecessarily, and you should feel confident that there’s nothing so insanely complicated that you won’t be able to understand it with a little effort. It’s just that captured variables can be somewhat confusing to start with, partly because they overturn some of your existing knowledge and intuition.
Stick with it, though! The payback can be massive in terms of code simplicity and readability. This topic will also be crucial when we come to look at lambda expressions and LINQ in C#3, so it’s worth the investment. Let’s start off with a few definitions.
The concept of closures is a very old one, first implemented in Scheme, but it’s been gaining more prominence in recent years as more mainstream languages have taken it on board. The basic idea is that a function[5] is able to interact with an environment beyond the parameters provided to it. That’s all there is to it in abstract terms, but to understand how it applies to C#2, we need a couple more terms:
An outer variable is a local variable or parameter[6]. whose scope includes an anonymous method. The
thisreference also counts as an outer variable of any anonymous method where it can be used.A captured outer variable (usually shortened to just “captured variable”) is an outer variable that is used within an anonymous method. So to go back to closures, the function part is the anonymous method, and the environment it can interact with is the set of variables captured by it.
That’s all very dry and may be hard to imagine, but the main thrust is that an anonymous method can use local variables defined in the same method that declares it. This may not sound like a big deal, but in many situations it’s enormously handy—you can use contextual information that you have “on hand” rather than having to set up extra types just to store data you already know. We’ll see some useful concrete examples soon, I promise—but first it’s worth looking at some code to clarify these definitions. listing 5.10 provides an example with a number of local variables. It’s just a single method, so it can’t be run on its own. I’m not going to explain how it would work or what it would do yet, but just explain how the different variables are classified.

Let’s go through all the variables from the simplest to the most complicated:
normalLocalVariable isn’t an outer variable because there are no anonymous methods within its scope. It behaves exactly the way that local variables always have.
isn’t an outer variable because there are no anonymous methods within its scope. It behaves exactly the way that local variables always have.anonLocal isn’t an outer variable either, but it’s local to the anonymous method, not to
isn’t an outer variable either, but it’s local to the anonymous method, not to EnclosingMethod. It will only exist (in terms of being present in an executing stack frame) when the delegate instance is invoked.outerVariable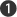 is an outer variable because the anonymous method is declared within its scope. However, the anonymous method doesn’t refer to it, so it’s not captured.
is an outer variable because the anonymous method is declared within its scope. However, the anonymous method doesn’t refer to it, so it’s not captured.capturedVariable is an outer variable because the anonymous method is declared within its scope, and it’s captured by virtue of being used at
is an outer variable because the anonymous method is declared within its scope, and it’s captured by virtue of being used at  .
.
Okay, so we now understand the terminology, but we’re not a lot closer to seeing what captured variables do. I suspect you could guess the output if we ran the method from listing 5.10, but there are some other cases that would probably surprise you. We’ll start off with a simple example and gradually build up to more complex ones.
When a variable is captured, it really is the variable that’s captured by the anonymous method, not its value at the time the delegate instance was created. We’ll see later that this has far-reaching consequences, but first we’ll make sure we understand what that means for a relatively straightforward situation. listing 5.11 has a captured variable and an anonymous method that both prints out and changes the variable. We’ll see that changes to the variable from outside the anonymous method are visible within the anonymous method, and vice versa. We’re using the ThreadStart delegate type for simplicity as we don’t need a return type or any parameters—no extra threads are actually created, though.
Example 5.11. Accessing a variable both inside and outside an anonymous method
string captured = "before x is created";
ThreadStart x = delegate
{
Console.WriteLine(captured);
captured = "changed by x";
};
captured = "directly before x is invoked";
x();
Console.WriteLine (captured);
captured = "before second invocation";
x();The output of listing 5.11 is as follows:
directly before x is invoked changed by x before second invocation
Let’s look at how this happens. First, we declare the variable captured and set its value with a perfectly normal string literal. So far, there’s nothing special about the variable. We then declare x and set its value using an anonymous method that captures captured. The delegate instance will always print out the current value of captured, and then set it to “changed by x”.
Just to make it absolutely clear that just creating the delegate instance didn’t read the variable and stash its value away somewhere, we now change the value of captured to “directly before x is invoked”. We then invoke x for the first time. It reads the value of captured and prints it out—our first line of output. It sets the value of captured to “changed by x” and returns. When the delegate instance returns, the “normal” method continues in the usual way. It prints out the current value of captured, giving us our second line of output.
The normal method then changes the value of captured yet again (this time to before second invocation) and invokes x for the second time. The current value of captured is printed out, giving our last line of output. The delegate instance changes captured to changed by x and returns, at which point the normal method has run out of code and we’re done.
That’s a lot of detail about how a pretty short piece of code works, but there’s really only one crucial idea in it: the captured variable is the same one that the rest of the method uses. For some people, that’s hard to grasp; for others it comes naturally. Don’t worry if it’s tricky to start with—it’ll get easier over time. Even if you’ve understood everything easily so far, you may be wondering why you’d want to do any of this. It’s about time we had an example that was actually useful.
To put it simply, captured variables get rid of the need for you to write extra classes just to store the information a delegate needs to act on, beyond what it’s passed as parameters. Before ParameterizedThreadStart existed, if you wanted to start a new (non-threadpool) thread and give it some information—the URL of a page to fetch, for instance—you had to create an extra type to hold the URL and put the action of the ThreadStart delegate instance in that type. It was all a very ugly way of achieving something that should have been simple.
As another example, suppose you had a list of people and wanted to write a method that would return a second list containing all the people who were under a given age. We know about a method on List<T> that returns another list of everything matching a predicate: the FindAll method. Before anonymous methods and captured variables were around, it wouldn’t have made much sense for List<T>.FindAll to exist, because of all the hoops you’d have to go through in order to create the right delegate to start with. It would have been simpler to do all the iteration and copying manually. With C# 2, however, we can do it all very, very easily:
List<Person> FindAllYoungerThan(List<Person> people, int limit)
{
return people.FindAll (delegate (Person person)
{ return person.Age < limit; }
);
}Here we’re capturing the limit parameter within the delegate instance—if we’d had anonymous methods but not captured variables, we could have performed a test against a hard-coded limit, but not one that was passed into the method as a parameter. I hope you’ll agree that this approach is very neat—it expresses exactly what we want to do with much less fuss about exactly how it should happen than you’d have seen in a C# 1 version. (It’s even neater in C#3, admittedly...[7]) It’s relatively rare that you come across a situation where you need to write to a captured variable, but again that can certainly have its uses.
Still with me? Good. So far, we’ve only used the delegate instance within the method that creates it. That doesn’t raise many questions about the lifetime of the captured variables—but what would happen if the delegate instance escaped into the big bad world? How would it cope after the method that created it had finished?
The simplest way of tackling this topic is to state a rule, give an example, and then think about what would happen if the rule weren’t in place. Here we go:
A captured variable lives for at least as long as any delegate instance referring to it.
Don’t worry if it doesn’t make a lot of sense yet—that’s what the example is for. Listing 5.12 shows a method that returns a delegate instance. That delegate instance is created using an anonymous method that captures an outer variable. So, what will happen when the delegate is invoked after the method has returned?
Example 5.12. Demonstration of a captured variable having its lifetime extended
static ThreadStart CreateDelegateInstance()
{
int counter = 5;
ThreadStart ret = delegate
{
Console.WriteLine(counter);
counter++;
};
ret();
return ret;
}
...
ThreadStart x = CreateDelegateInstance();
x();
x();The output of listing 5.12 consists of the numbers 5, 6, and 7 on separate lines. The first line of output comes from the invocation of the delegate instance within CreateDelegateInstance, so it makes sense that the value of i is available at that point. But what about after the method has returned? Normally we would consider counter to be on the stack, so when the stack frame for CreateDelegateInstance is destroyed we’d expect counter to effectively vanish... and yet subsequent invocations of the returned delegate instance seem to keep using it!
The secret is to challenge the assumption that counter is on the stack in the first place. It isn’t. The compiler has actually created an extra class to hold the variable. The CreateDelegateInstance method has a reference to an instance of that class so it can use counter, and the delegate has a reference to the same instance—which lives on the heap in the normal way. That instance isn’t eligible for garbage collection until the delegate is ready to be collected. Some aspects of anonymous methods are very compiler specific (in other words different compilers could achieve the same semantics in different ways), but it’s hard to see how the specified behavior could be achieved without using an extra class to hold the captured variable. Note that if you only capture this, no extra types are required—the compiler just creates an instance method to act as the delegate’s action.
OK, so local variables aren’t always local anymore. You may well be wondering what I could possibly throw at you next—let’s see now, how about multiple delegates capturing different instances of the same variable? It sounds crazy, so it’s just the kind of thing you should be expecting by now.
On a good day, captured variables act exactly the way I expect them to at a glance. On a bad day, I’m still surprised when I’m not taking a great deal of care. When there are problems, it’s almost always due to forgetting just how many “instances” of local variables I’m actually creating. A local variable is said to be instantiated each time execution enters the scope where it’s declared. Here’s a simple example comparing two very similar bits of code:
int single;
for (int i=0; i < 10; i++)
{
single = 5;
Console.WriteLine(single+i);
} | for (int i=0; i < 10; i++)
{
int multiple = 5;
Console.WriteLine(multiple+i);
} |
In the good old days, it was reasonable to say that pieces of code like this were semantically identical. Indeed, they’d usually compile to the same IL. They still will, if there aren’t any anonymous methods involved. All the space for local variables is allocated on the stack at the start of the method, so there’s no cost to “redeclaring” the variable for each iteration of the loop. However, in our new terminology the single variable will be instantiated only once, but the multiple variable will be instantiated ten times—it’s as if there are ten local variables, all called multiple, which are created one after another.
I’m sure you can see where I’m going—when a variable is captured, it’s the relevant “instance” of the variable that is captured. If we captured multiple inside the loop, the variable captured in the first iteration would be different from the variable captured the second time round, and so on. Listing 5.13 shows exactly this effect.

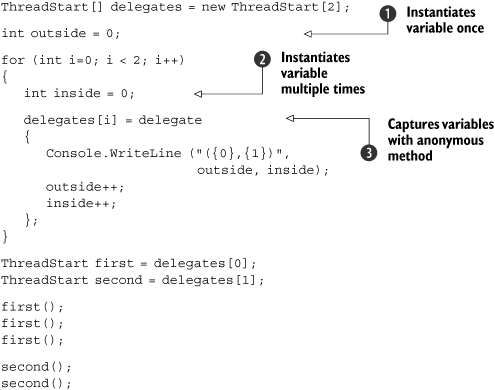
Listing 5.13 creates five different delegate instances ![]() —one for each time we go around the loop. Invoking the delegate will print out the value of
—one for each time we go around the loop. Invoking the delegate will print out the value of counter and then increment it. Now, because counter is declared inside the loop, it is instantiated for each iteration ![]() , and so each delegate captures a different variable. So, when we go through and invoke each delegate
, and so each delegate captures a different variable. So, when we go through and invoke each delegate ![]() , we see the different values initially assigned to
, we see the different values initially assigned to counter: 0, 10, 20, 30, 40. Just to hammer the point home, when we then go back to the first delegate instance and execute it three more times ![]() , it keeps going from where that instance’s
, it keeps going from where that instance’s counter variable had left off: 1, 2, 3. Finally we execute the second delegate instance ![]() , and that keeps going from where that instance’s
, and that keeps going from where that instance’s counter variable had left off: 11.
So, each of the delegate instances has captured a different variable in this case. Before we leave this example, I should point out what would have happened if we’d captured index—the variable declared by the for loop—instead of counter. In this case, all the delegates would have shared the same variable. The output would have been the numbers 5 to 14; 5 first because the last assignment to index before the loop terminates would have set it to 5, and then incrementing the same variable regardless of which delegate was involved. We’d see the same behavior with a foreach loop: the variable declared by the initial part of the loop is only instantiated once. It’s easy to get this wrong! If you want to capture the value of a loop variable for that particular iteration of the loop, introduce another variable within the loop, copy the loop variable’s value into it, and capture that new variable—effectively what we’ve done in listing 5.13 with the counter variable.
For our final example, let’s look at something really nasty—sharing some captured variables but not others.
Let me just say before I show you this next example that it’s not code I’d recommend. In fact, the whole point of presenting it is to show how if you try to use captured variables in too complicated a fashion, things can get tricky really fast. Listing 5.14 creates two delegate instances that each capture “the same” two variables. However, the story gets more convoluted when we look at what’s actually captured.
How long would it take you to predict the output from listing 5.14 (even with the annotations)? Frankly it would take me a little while—longer than I like to spend understanding code. Just as an exercise, though, let’s look at what happens.
First let’s consider the outside variable ![]() . The scope it’s declared in is only entered once, so it’s a straightforward case—there’s only ever one of it, effectively. The
. The scope it’s declared in is only entered once, so it’s a straightforward case—there’s only ever one of it, effectively. The inside variable ![]() is a different matter—each loop iteration instantiates a new one. That means that when we create the delegate instance
is a different matter—each loop iteration instantiates a new one. That means that when we create the delegate instance ![]() the
the outside variable is shared between the two delegate instances, but each of them has its own inside variable.
After the loop has ended, we call the first delegate instance we created three times. Because it’s incrementing both of its captured variables each time, and we started off with them both as 0, we see (0,0), then (1,1), then (2,2). The difference between the two variables in terms of scope becomes apparent when we execute the second delegate instance. It has a different inside variable, so that still has its initial value of 0, but the outside variable is the one we’ve already incremented three times. The output from calling the second delegate twice is therefore (3,0), then (4,1).
Note
How does this happen internally? Just for the sake of interest, let’s think about how this is implemented—at least with Microsoft’s C# 2 compiler. What happens is that one extra class is generated to hold the outer variable, and another one is generated to hold an inner variable and a reference to the first extra class. Essentially, each scope that contains a captured variable gets its own type, with a reference to the next scope out that contains a captured variable. In our case, there were two instances of the type holding inner, and they both refer to the same instance of the type holding outer. Other implementations may vary, but this is the most obvious way of doing things.
Even after you understand this code fully, it’s still quite a good template for experimenting with other elements of captured variables. As we noted earlier, certain elements of variable capture are implementation specific, and it’s often useful to refer to the specification to see what’s guaranteed—but it’s also important to be able to just play with code to see what happens.
It’s possible that there are situations where code like listing 5.14 would be the simplest and clearest way of expressing the desired behavior—but I’d have to see it to believe it, and I’d certainly want comments in the code to explain what would happen. So, when is it appropriate to use captured variables, and what do you need to look out for?
Hopefully this section has convinced you to be very careful with captured variables. They make good logical sense (and any change to make them simpler would probably either make them less useful or less logical), but they make it quite easy to produce horribly complicated code.
Don’t let that discourage you from using them sensibly, though—they can save you masses of tedious code, and when they’re used appropriately they can be the most readable way of getting the job done. But what counts as “sensible”?
The following is a list of suggestions for using captured variables:
If code that doesn’t use captured variables is just as simple as code that does, don’t use them.
Before capturing a variable declared by a
fororforeachstatement, consider whether your delegate is going to live beyond the loop iteration, and whether you want it to see the subsequent values of that variable. If not, create another variable inside the loop that just copies the value you do want.If you create multiple delegate instances (whether in a loop or explicitly) that capture variables, put thought into whether you want them to capture the same variable.
If you capture a variable that doesn’t actually change (either in the anonymous method or the enclosing method body), then you don’t need to worry as much.
If the delegate instances you create never “escape” from the method—in other words, they’re never stored anywhere else, or returned, or used for starting threads—life is a lot simpler.
Consider the extended lifetime of any captured variables in terms of garbage collection. This is normally not an issue, but if you capture an object that is expensive in terms of memory, it may be significant.
The first point is the golden rule. Simplicity is a good thing—so any time the use of a captured variable makes your code simpler (after you’ve factored in the additional inherent complexity of forcing your code’s maintainers to understand what the captured variable does), use it. You need to include that extra complexity in your considerations, that’s all—don’t just go for minimal line count.
We’ve covered a lot of ground in this section, and I’m aware that it can be hard to take in. I’ve listed the most important things to remember next, so that if you need to come back to this section another time you can jog your memory without having to read through the whole thing again:
The variable is captured—not its value at the point of delegate instance creation.
Captured variables have lifetimes extended to at least that of the capturing delegate.
Multiple delegates can capture the same variable...
...but within loops, the same variable declaration can effectively refer to different variable “instances.”
for/foreachloop declarations create variables that live for the duration of the loop—they’re not instantiated on each iteration.Captured variables aren’t really local variables—extra types are created where necessary.
Be careful! Simple is almost always better than clever.
We’ll see more variables being captured when we look at C# 3 and its lambda expressions, but for now you may be relieved to hear that we’ve finished our rundown of the new C#2 delegate features.
C# 2 has radically changed the ways in which delegates can be created, and in doing so it’s opened up the framework to a more functional style of programming. There are more methods in .NET 2.0 that take delegates as parameters than there were in .NET 1.0/1.1, and this trend continues in .NET 3.5. The List<T> type is the best example of this, and is a good test-bed for checking your skills at using anonymous methods and captured variables. Programming in this way requires a slightly different mind-set—you must be able to take a step back and consider what the ultimate aim is, and whether it’s best expressed in the traditional C# manner, or whether a functional approach makes things clearer.
All the changes to delegate handling are useful, but they do add complexity to the language, particularly when it comes to captured variables. Closures are always tricky in terms of quite how the available environment is shared, and C# is no different in this respect. The reason they’ve lasted so long as an idea, however, is that they can make code simpler to understand and more immediate. The balancing act between complexity and simplicity is always a difficult one, and it’s worth not being too ambitious to start with. As anonymous methods and captured variables become more common, we should all expect to get better at working with them and understanding what they’ll do. They’re certainly not going away, and indeed LINQ encourages their use even further.
Anonymous methods aren’t the only change in C#2 that involves the compiler creating extra types behind the scenes, doing devious things with variables that appear to be local. We’ll see a lot more of this in our next chapter, where the compiler effectively builds a whole state machine for us in order to make it easier for the developer to implement iterators.
[1] I’ve removed the public delegate part for reasons of space.
[2] Return type covariance and parameter type contravariance can be used at the same time, although you’re unlikely to come across situations where it would be useful.
[3] In case you skipped the first chapter, Snippy is a tool I’ve used to create short but complete code samples. See section 1.4.2 for more details.
[4] One slight oddity is that if you’re writing an anonymous method in a value type, you can’t reference this from within it. There’s no such restriction within a reference type.
[5] This is general computer science terminology, not C# terminology.
[6] Excluding ref and out parameters
[7] In case you’re wondering: return people.Where(person => person.Age < limit);