
LINQ to SQL
Building providers with
IQueryableLINQ to DataSet
LINQ to XML
Third party-LINQ
Future Microsoft LINQ technologies
In the previous chapter, we saw how LINQ to Objects works, with the C#3 compiler translating query expressions into normal C# code, which for LINQ to Objects just happens to call the extension methods present in the Enumerable class. Even without any other features, query expressions would have been useful for manipulating data in memory. It probably wouldn’t have been worth the extra complexity in the language, though. In reality, LINQ to Objects is just one aspect of the big picture.
In this chapter we’ll take a whirlwind tour of other LINQ providers and APIs. First we’ll look at LINQ to SQL, an Object Relational Mapping (ORM) solution from Microsoft that ships as part of .NET 3.5. After we’ve seen it working as if by magic, we’ll take a look at what’s happening behind the scenes, and how query expressions written in C# end up executing as SQL on the database.
LINQ to DataSet and LINQ to XML are both frameworks that tackle existing problems (manipulating datasets and XML respectively) but do so in a LINQ-friendly fashion. Both of them use LINQ to Objects for the underlying query support, but the APIs have been designed so that query expressions can be used to access data in a painless and consistent manner.
Having covered the LINQ APIs shipped with .NET 3.5, we’ll take a peek at some other providers. Microsoft developers aren’t the only ones writing LINQ providers, and I’ll show a few third-party examples, before revealing what Microsoft has in store for us with the ADO.NET Entity Framework and Parallel LINQ.
This chapter is not meant to provide you with a comprehensive knowledge of using LINQ by any means: it’s a truly massive topic, and I’m only going to scratch the surface of each provider here. The purpose of the chapter is to give you a broad idea of what LINQ is capable of, and how much easier it can make development. Hopefully there’ll be enough of a “wow” factor that you’ll want to study some or all of the providers further. To this end, there are great online resources, particularly blog posts from the various LINQ teams (see this book’s website for a list of links), but I also thoroughly recommend LINQ in Action (Manning 2008).
As well as understanding LINQ itself, by the end of this chapter you should see how the different pieces of the C# 3 feature set all fit together, and why they’re all present in the first place. Just as a reminder, you shouldn’t expect to see any new features of C# at this point—we’ve covered them all in the previous chapters—but they may well make more sense when you see how they help to provide unified querying over multiple data sources.
The change in pace, from the detail of the previous chapters to the sprint through features in this one, may be slightly alarming at first. Just relax and enjoy the ride, remembering that the big picture is the important thing here. There won’t be a test afterward, I promise. There’s a lot to cover, so let’s get cracking with the most impressive LINQ provider in .NET 3.5: LINQ to SQL.
I’m sure by now you’ve absorbed the message that LINQ to SQL converts query expressions into SQL, which is then executed on the database. There’s more to it than that, however—it’s a full ORM solution. In this section we’ll move our defect system into a SQL Server 2005 database, populate it with the sample defects, query it, and update it. We won’t look at the details of how the queries are converted into SQL until the next section, though: it’s easier to understand the mechanics once you’ve seen the end result. Let’s start off by getting our database and entities up and running.
To use LINQ to SQL, you need a database (obviously) and some classes representing the entities. The classes have metadata associated with them to tell LINQ to SQL how they map to database tables. This metadata can be built directly into the classes using attributes, or specified with an XML file. To keep things simple, we’re going to use attributes—and by using the designer built into Visual Studio 2008, we won’t even need to specify the attributes ourselves. First, though, we need a database. It’s possible to generate the database schema from the entities, but my personal preference is to work “database first.”
The mapping from the classes we had before to SQL Server 2005 database tables is straightforward. Each table has an autoincrementing integer ID column, with an appropriate name: ProjectID, DefectID, and so forth. The references between tables simply use the same name, so the Defect table has a ProjectID column, for instance, with a foreign key constraint. There are a few exceptions to this simple set of rules:
Useris a reserved word in T-SQL, so theUserclass is mapped to theDefectUsertable.The enumerations (status, severity, and user type) don’t have tables: their values are simply mapped to
tinyintcolumns in theDefectandDefectUsertables.The
Defecttable has two links to theDefectUsertable, one for the user who created the defect and one for the current assignee. These are represented with theCreatedByUserIdandAssignedToUserIdcolumns, respectively.
The database is available as part of the downloadable source code so that you can use it with SQL Server 2005 Express yourself. If you leave the files in the same directory structure that they come in, you won’t even need to change the connection string when you use the sample code.
Once our tables are created, creating the entity classes from Visual Studio 2008 is easy. Simply open Server Explorer (View, Server Explorer) and add a data source to the SkeetySoftDefects database (right-click on Data Connections and select Add Connection). You should be able to see four tables: Defect, DefectUser, Project, and NotificationSubscription.
In a C# project targeting .NET 3.5, you should then be able to add a new item of type “LINQ to SQL classes.” When choosing a name for the item, bear in mind that among the classes it will create for you, there will be one with the selected name followed by DataContext—this is going to be an important class, so choose the name carefully. Visual Studio 2008 doesn’t make it terribly easy to refactor this after you’ve created it, unfortunately. I chose DefectModel—so the data context class is called DefectModelDataContext.
The designer will open when you’ve created the new item. You can then drag the four tables from Server Explorer into the designer, and it will figure out all the associations. After that, you can rearrange the diagram, and adjust various properties of the entities. Here’s a list of what I changed:
I renamed the
DefectIDproperty toIDto match our previous model.I renamed
DefectUsertoUser(so although the table is still calledDefectUser, we’ll generate a class calledUser, just like before).I changed the type of the
Severity,Status, andUserTypeproperties to their enum equivalents (having copied those enumerations into the project).I renamed the parent and child properties used for the associations between
DefectandDefectUser—the designer guessed suitable names for the other associations, but had trouble here because there were two associations between the same pair of tables.
Figure 12.1 shows the designer diagram after all of these changes.
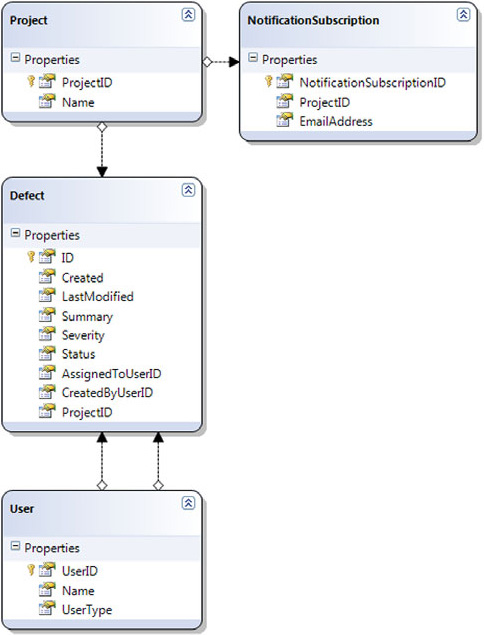
As you can see, the model in figure 12.1 is exactly the same as the code model shown in figure 11.3, except without the enumerations. The public interface is so similar that we can create instances of our entities with the same sample data code. If you look in the C# code generated by the designer (DefectModel.designer.cs), you’ll find five partial classes: one for each of the entities, and the DefectModelDataContext class I mentioned earlier. The fact that they’re partial classes is important when it comes to making the sample data creation code work seamlessly. I had created a constructor for User, which took the name and user type as parameters. By creating another file containing a partial User class, we can add that constructor to our model again, as shown in listing 12.1.
Example 12.1. Adding a constructor to the User entity class
public partial class User { public User (string name, UserType userType) : this() { Name = name; UserType = userType; } }
It’s important to call the parameterless constructor from our new one—the generated code initializes some members there. In the same way as we added a constructor, we can override ToString in all the entities, so that the results will be exactly as they were in chapter 11. The generated code contains many partial method declarations, so you can easily react to various events occurring on particular instances.
At this point, we can simply copy over the SampleData.cs file from chapter 11 and build the project. Now for the tricky bit—copying the sample data into the database from the in-memory version.
OK, I lied. Populating the database is ludicrously easy. Listing 12.2 shows just how simple it is.

I’m sure you’ll agree that’s not a lot of code—but all of it is new. Let’s take it one step at a time. First we create a new data context to work with ![]() . Data contexts are pretty multifunctional, taking responsibility for connection and transaction management, query translation, tracking changes in entities, and dealing with identity. For the purposes of this chapter, we can regard a data context as our point of contact with the database. We won’t be looking at the more advanced features here, but there’s one useful capability we’ll take advantage of: at
. Data contexts are pretty multifunctional, taking responsibility for connection and transaction management, query translation, tracking changes in entities, and dealing with identity. For the purposes of this chapter, we can regard a data context as our point of contact with the database. We won’t be looking at the more advanced features here, but there’s one useful capability we’ll take advantage of: at ![]() we tell the data context to write out all the SQL commands it executes to the console.
we tell the data context to write out all the SQL commands it executes to the console.
The four statements at ![]() add the sample entities to the context. The four properties of the context (
add the sample entities to the context. The four properties of the context (Users, Projects, Defects, and NotificationSubscriptions) are each of type Table<T> for the corresponding type T (User, Project, and so on). We access particular entities via these tables—in this case, we’re adding our sample data to the tables.
At this point nothing has actually been sent “across the wire” to the database—it’s just in the context, in memory. All the associations in our model have been generated bi-directionally (a user entity knows all the defects currently assigned to it, as well as the defect knowing the user it’s assigned to, for example), which means that we could have just called InsertAllOnSubmit once, with any of the entity types, and everything else would have cascaded. However, I’ve explicitly added all the entities here for clarity. The data context makes sure that everything is inserted once, only once, and in an appropriate order to avoid constraint violations.
Statement ![]() is where the SQL is actually executed—it’s only here that we see any log entries in the console, too.
is where the SQL is actually executed—it’s only here that we see any log entries in the console, too. SubmitChanges is the equivalent of DataAdapter.Update from ADO.NET 1.0—it calls all the necessary INSERT, DELETE, and UPDATE commands on the actual database.
Running listing 12.2 multiple times will insert the data multiple times too. There are many ways of cleaning up the database before we start populating it. We could ask the data context to delete the database and re-create it, assuming we have enough security permissions: the metadata captured by the designer contains all the information required for simple cases like ours.
Alternatively, we can delete the existing data. This can either be done with a bulk delete statement, or by fetching all the existing entities and asking LINQ to SQL to delete them individually. Clearly deleting in bulk is more efficient, but LINQ to SQL doesn’t provide any mechanism to do this without resorting to a direct SQL command. The ExecuteCommand on DataContext makes this easy to accomplish without worrying about connection management, but it certainly sidesteps many of the benefits of using an ORM solution to start with. It’s nice to be able to execute arbitrary SQL where necessary, but you should only do so when there’s a compelling reason.
We won’t examine the code for any of these methods of wiping the database clean, but they’re all available as part of the source code you can download from the website.
So far, we’ve seen nothing that isn’t available in a normal ORM system. What makes LINQ to SQL different is the querying...
I’m sure you’ve guessed what’s coming, but hopefully that won’t make it any less impressive. We’re going to execute query expressions against our data source, watching LINQ to SQL convert the query into SQL on the fly. For the sake of familiarity, we’ll use some of the same queries we saw executing against our in-memory collections in chapter 11.
I’ll skip over the trivial examples from early in the chapter, starting instead with the query from listing 11.7 that checks for open defects assigned to Tim. Here’s the query part of listing 11.7, for the sake of comparison:
User tim = SampleData.Users.TesterTim;
var query = from defect in SampleData.AllDefects
where defect.Status != Status.Closed
where defect.AssignedTo == tim
select defect.Summary;The LINQ to SQL equivalent is shown in listing 12.3.

We can’t use SampleData.Users.TesterTim in the main query because that object doesn’t know the ID of Tim’s row in the DefectUser table. Instead, we use one query to load Tim’s user entity, and then a second query to find the open defects. The Single method call at the end of the query expression just returns a single result from a sequence, throwing an exception if there isn’t exactly one element. In a real-life situation, you may well have the entity as a product of other operations such as logging in—and if you don’t have the full entity, you may well have its ID, which can be used equally well within the main query.
Within the second query expression, the only difference between the in-memory query and the LINQ to SQL query is the data source—instead of using SampleData.Defects, we use context.Defects. The final results are the same (although the ordering isn’t guaranteed), but the work has been done on the database. The console output shows both of the queries executed on the database, along with the query parameter values:[1]
SELECT [t0].[UserID], [t0].[Name], [t0].[UserType] FROM [dbo].[DefectUser] AS [t0] WHERE [t0].[Name] = @p0 -- @p0: Input String (Size = 11; Prec = 0; Scale = 0) [Tim Trotter] SELECT [t0].[Summary] FROM [dbo].[Defect] AS [t0] WHERE ([t0].[AssignedToUserID] = @p0) AND ([t0].[Status] <> @p1) -- @p0: Input Int32 (Size = 0; Prec = 0; Scale = 0) [2] -- @p1: Input Int32 (Size = 0; Prec = 0; Scale = 0) [4]
Notice how the first query fetches all of the properties of the user because we’re populating a whole entity—but the second query only fetches the summary as that’s all we need. LINQ to SQL has also converted our two separate where clauses in the second query into a single filter on the database.
Note
An alternative to console logging: the debug visualizer—. For a more interactive view into LINQ to SQL queries, you can use the debug visualizer, which Scott Guthrie has made available. This shows the SQL corresponding to the query, and allows you to execute and even edit it manually within the debugger. It’s free, and includes source code: http://weblogs.asp.net/scottgu/archive/2007/07/31/linq-to-sql-debug-visualizer.aspx
LINQ to SQL is capable of translating a wide range of expressions. Let’s look at some more examples from chapter 11, just to see what SQL is generated.
Our next query shows what happens when we introduce a sort of “temporary variable” with a let clause. In chapter 11 we considered quite a bizarre situation, if you remember—pretending that calculating the length of a string took a long time. Again, the query expression is exactly the same as in listing 11.11, with the exception of the data source. Listing 12.4 shows the LINQ to SQL code.
Example 12.4. Using a let clause in LINQ to SQL
using (var context = new DefectModelDataContext())
{
context.Log = Console.Out;
var query = from user in context.Users
let length = user.Name.Length
orderby length
select new { Name = user.Name, Length = length };
foreach (var entry in query)
{
Console.WriteLine("{0}: {1}", entry.Length, entry.Name);
}
}The generated SQL is very close to the spirit of the sequences we saw in figure 11.5—the innermost sequence (the first one in the diagram) is the list of users; that’s transformed into a sequence of name/length pairs (as the nested select), and then the no-op projection is applied, with an ordering by length:
SELECT [t1].[Name], [t1].[value] FROM ( SELECT LEN([t0].[Name]) AS [value], [t0].[Name] FROM [dbo].[DefectUser] AS [t0] ) AS [t1] ORDER BY [t1].[value]
This is a good example of where the generated SQL is wordier than it needs to be. Although we couldn’t reference the elements of the final output sequence when performing an ordering on the query expression, you can in SQL. This simpler query would have worked fine:
SELECT LEN([t0].[Name]) AS [value], [t0].[Name] FROM [dbo].[DefectUser] AS [t0] ORDER BY [value]
Of course, what’s important is what the query optimizer does on the database—the execution plan displayed in SQL Server Management Studio Express is the same for both queries, so it doesn’t look like we’re losing out.
Next we’ll have a look at a couple of the joins we used in chapter 11.
We’ll try both inner joins and group joins, using the examples of joining notification subscriptions against projects. I suspect you’re used to the drill now—the pattern of the code is the same for each query, so from here on I’ll just show the query expression and the generated SQL unless something else is going on.
// Query expression (modified from listing 11.12)
from defect in context.Defects
join subscription in context.NotificationSubscriptions
on defect.Project equals subscription.Project
select new { defect.Summary, subscription.EmailAddress }
-- Generated SQL
SELECT [t0].[Summary], [t1].[EmailAddress]
FROM [dbo].[Defect] AS [t0]
INNER JOIN [dbo].[NotificationSubscription] AS [t1]
ON [t0].[ProjectID] = [t1].[ProjectID]Unsurprisingly, it uses an inner join in SQL. It would be easy to guess at the generated SQL in this case. How about a group join, though? Well, this is where things get slightly more hectic:
// Query expression (modified from listing 11.13)
from defect in context.Defects
join subscription in context.NotificationSubscriptions
on defect.Project equals subscription.Project
into groupedSubscriptions
select new { Defect = defect, Subscriptions = groupedSubscriptions }
-- Generated SQL
SELECT [t0].[DefectID] AS [ID], [t0].[Created],
[t0].[LastModified], [t0].[Summary], [t0].[Severity],
[t0].[Status], [t0].[AssignedToUserID],
[t0].[CreatedByUserID], [t0].[ProjectID],
[t1].[NotificationSubscriptionID],
[t1].[ProjectID] AS [ProjectID2], [t1].[EmailAddress],
(SELECT COUNT(*)
FROM [dbo].[NotificationSubscription] AS [t2]
WHERE [t0].[ProjectID] = [t2].[ProjectID]) AS [count]
FROM [dbo].[Defect] AS [t0]
LEFT OUTER JOIN [dbo].[NotificationSubscription] AS [t1]
ON [t0].[ProjectID] = [t1].[ProjectID]
ORDER BY [t0].[DefectID], [t1].[NotificationSubscriptionID]That’s a pretty major change in the amount of SQL generated! There are two important things to notice. First, it uses a left outer join instead of an inner join, so we would still see a defect even if it didn’t have anyone subscribing to its project. If you want a left outer join but without the grouping, the conventional way of expressing this is to use a group join and then an extra from clause using the DefaultIfEmpty extension method on the embedded sequence. It looks quite odd, but it works well. See the sample source code for this chapter on the book’s website for more details.
The second odd thing about the previous query is that it calculates the count for each group within the database. This is effectively a trick performed by LINQ to SQL to make sure that all the processing can be done on the server. A naive implementation would have to perform the grouping in memory, after fetching all the results. In some cases the provider could do tricks to avoid needing the count, simply spotting when the grouping ID changes, but there are issues with this approach for some queries. It’s possible that a later implementation of LINQ to SQL will be able to switch courses of action depending on the exact query.
You don’t need to explicitly write a join in the query expression to see one in the SQL, however. We’re able to express our query in an object-oriented way, even though it will be converted into SQL. Let’s see this in action.
Let’s take a simple example. Suppose we want to list each defect, showing its summary and the name of the project it’s part of. The query expression is just a matter of a projection:
// Query expression
from defect in context.Defects
select new { defect.Summary, ProjectName=defect.Project.Name }
-- Generated SQL
SELECT [t0].[Summary], [t1].[Name]
FROM [dbo].[Defect] AS [t0]
INNER JOIN [dbo].[Project] AS [t1]
ON [t1].[ProjectID] = [t0].[ProjectID]Notice how we’ve navigated from the defect to the project via a property—LINQ to SQL has converted that navigation into an inner join. It’s able to use an inner join here because the schema has a non-nullable constraint on the ProjectID column of the Defect table—every defect has a project. Not every defect has an assignee, however—the AssignedToUserID field is nullable, so if we use the assignee in a projection instead, a left outer join is generated:
// Query expression
from defect in context.Defects
select new { defect.Summary, Assignee=defect.AssignedTo.Name }
-- Generated SQL
SELECT [t0].[Summary], [t1].[Name]
FROM [dbo].[Defect] AS [t0]
LEFT OUTER JOIN [dbo].[DefectUser] AS [t1]
ON [t1].[UserID] = [t0].[AssignedToUserID]Of course, if you navigate via more properties, the joins get more and more complicated. I’m not going into the details here—the important thing is that LINQ to SQL has to do a lot of analysis of the query expression to work out what SQL is required.
Before we leave LINQ to SQL, I ought to show you one more feature. It’s part of what you’d expect from any decent ORM system, but leaving it out would just feel wrong. Let’s update some values in our database.
Although insertions are straightforward, updates can be handled in a variety of ways, depending on how concurrency is configured. If you’ve done any serious database work you’ll know that handling conflicts in updates from different users at the same time is quite hairy—and I’m not going to open that particular can of worms here. I’ll just show you how easy it is to persist a changed entity when there are no conflicts.
Let’s change the status of one of our defects, and its assignee, and that person’s name, all in one go. As it happens, I know that the defect with an ID of 1 (as created on a clean system) is a bug that was created by Tim, and is currently in an “accepted” state, assigned to Darren. We’ll imagine that Darren has now fixed the bug, and assigned it back to Tim. At the same time, Tim has decided he wants to be a bit more formal, so we’ll change his name to Timothy. Oh, and we should remember to update the “last modified” field of the defect too. (In a real system, we’d probably handle that with a trigger—in LINQ to SQL we could implement partial methods to set the last modified time when any of the other fields changed. For the sake of simplicity here, we’ll do it manually.)
Listing 12.5 accomplishes all of this and shows the result—loading it in a fresh DataContext to show that it has gone back to the database.

Listing 12.5 is easy enough to follow—we open up a context and fetch the first defect ![]() . After changing the defect and the entity representing Tim Trotter
. After changing the defect and the entity representing Tim Trotter ![]() , we ask LINQ to SQL to save the changes to the database
, we ask LINQ to SQL to save the changes to the database ![]() . Finally, we fetch the defect
. Finally, we fetch the defect ![]() again in a new context and write the details to the console. Just for a bit of variety, I’ve shown two different ways of fetching the defect—they’re absolutely equivalent, because the compiler translates the query expression form into the “method call” form anyway.
again in a new context and write the details to the console. Just for a bit of variety, I’ve shown two different ways of fetching the defect—they’re absolutely equivalent, because the compiler translates the query expression form into the “method call” form anyway.
That’s all the LINQ to SQL we’re going to see—hopefully it’s shown you enough of the capabilities to understand how it’s a normal ORM system, but one that has good support for query expressions and the LINQ standard query operators.
There are lots of ORMs out there, and many of them allow you to build up queries programmatically in a way that can look like LINQ to SQL—if you ignore compile-time checking. It’s the combination of lambda expressions, expression trees, extension methods, and query expressions that make LINQ special, giving these advantages:
We’ve been able to use familiar syntax to write the query (at least, familiar when you know LINQ to Objects!).
The compiler has been able to do a lot of validation for us.
Visual Studio 2008 is able to help us build the query with IntelliSense.
If we need a mixture of client-side and server-side processing, we can do both in a consistent manner.
We’re still using the database to do the hard work.
Of course, this comes at a cost. As with any ORM system, you want to keep an eye on what SQL queries are being executed for a particular query expression. That’s where the logging is invaluable—but don’t forget to turn it off for production! In particular, you will need to be careful of the infamous “N+1 selects” issue, where an initial query pulls back results from a single table, but using each result transparently executes another query to lazily load associated entities. Sometimes you’ll be able to find an elegant query expression that results in exactly the SQL you want to use; other times you’ll need to bend the query expression out of shape somewhat. Occasionally you’ll need to write the SQL manually or use a stored procedure instead—as is often the case with ORMs.
I find it interesting just to take query expressions that you already know work in LINQ to Objects and see what SQL is generated when you run them against a database. Sometimes you can predict how things will work, but sometimes there’s more going on than you might expect. There’s sample code on the book’s website for various queries, but query expressions are pretty easy to write, and I’d strongly encourage you to write your own for fun. The SkeetySoft defects model is quite a simple one to query, of course—but you’ve seen how Visual Studio 2008 makes it easy to generate entities, so give it a try with a schema from a real system. I can’t emphasize enough that this brief look at LINQ to SQL should not be taken as sufficient information to start building production code. It should be enough to let you experiment, but please read more detailed documentation before embarking on a real application!
I’ve deliberately not gone into how query expressions are converted into SQL in this section. I wanted you to get a feel for the capabilities of LINQ to SQL before starting to pick it apart.
In this section we’re going to find out the basics of how LINQ to SQL manages to convert our query expressions into SQL. This is the starting point for implementing your own LINQ provider, should you wish to. This is the most theoretical section in the chapter, but it’s useful to have some insight as to how LINQ is able to decide whether to use in-memory processing, a database, or some other query engine.
In all the query expressions we’ve seen in LINQ to SQL, the source has been a Table<T>. However, if you look at Table<T>, you’ll see it doesn’t have a Where method, or Select, or Join, or any of the other standard query operators. Instead, it uses the same trick that LINQ to Objects does—just as the source in LINQ to Objects always implements IEnumerable<T> (possibly after a call to Cast or OfType) and then uses the extension methods in Enumerable, so Table<T> implements IQueryable<T> and then uses the extension methods in Queryable. We’ll see how LINQ builds up an expression tree and then allows a provider to execute it at the appropriate time. Let’s start off by looking at what IQueryable<T> consists of.
If you look up IQueryable<T> in the documentation and see what members it contains directly (rather than inheriting), you may be disappointed. There aren’t any. Instead, it inherits from IEnumerable<T> and the nongeneric IQueryable.IQueryable in turn inherits from the nongeneric IEnumerable. So, IQueryable is where the new and exciting members are, right? Well, nearly. In fact, IQueryable just has three properties: QueryProvider, ElementType, and Expression. The QueryProvider property is of type IQueryProvider—yet another new interface to consider.
Lost? Perhaps figure 12.2 will help out—a class diagram of all the interfaces directly involved.
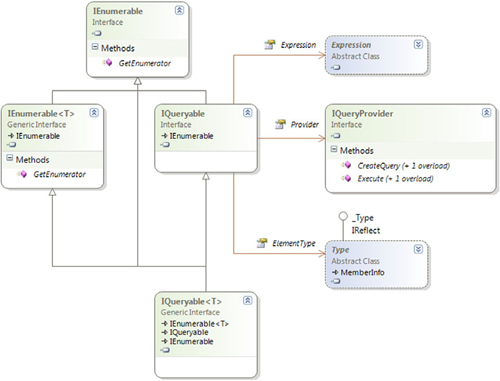
The easiest way of thinking of IQueryable is that it represents a query that, when executed, will yield a sequence of results. The details of the query in LINQ terms are held in an expression tree, as returned by the Expression property of the IQueryable. Executing a query is performed by beginning to iterate through an IQueryable (in other words, calling the GetEnumerator method) or by a call to the Execute method on an IQueryProvider, passing in an expression tree.
So, with at least some grasp of what IQueryable is for, what is IQueryProvider? Well, we can do more than execute a query—we can also build a bigger query from it, which is the purpose of the standard query operators in LINQ.[2] To build up a query, we need to use the CreateQuery method on the relevant IQueryProvider.[3]
Think of a data source as a simple query (SELECT * FROM SomeTable in SQL, for instance)—calling Where, Select, OrderBy, and similar methods results in a different query, based on the first one. Given any IQueryable query, you can create a new query by performing the following steps:
Ask the existing query for its query expression tree (using the
Expressionproperty).Build a new expression tree that contains the original expression and the extra functionality you want (a filter, projection, or ordering, for instance).
Ask the existing query for its query provider (using the
Providerproperty).Call
CreateQueryon the provider, passing in the new expression tree.
Of those steps, the only tricky one is creating the new expression tree. Fortunately, there’s a whole bunch of extension methods on the static Queryable class that do all that for us. Enough theory—let’s start implementing the interfaces so we can see all this in action.
Before you get too excited, we’re not going to build our own fully fledged query provider in this chapter. However, if you understand everything in this section, you’ll be in a much better position to build one if you ever need to—and possibly more importantly, you’ll understand what’s going on when you issue LINQ to SQL queries. Most of the hard work of query providers goes on at the point of execution, where they need to parse an expression tree and convert it into the appropriate form for the target platform. We’re concentrating on the work that happens before that—how LINQ prepares to execute a query.
We’ll write our own implementations of IQueryable and IQueryProvider, and then try to run a few queries against them. The interesting part isn’t the results—we won’t be doing anything useful with the queries when we execute them—but the series of calls made up to the point of execution. We’ll write types FakeQueryProvider and FakeQuery. The implementation of each interface method writes out the current expression involved, using a simple logging method (not shown here). Let’s look first at FakeQuery, as shown in listing 12.6.

The property members of IQueryable are implemented in FakeQuery with automatic properties ![]() , which are set by the constructors. There are two constructors: a parameterless one that is used by our main program to create a plain “source” for the query, and one that is called by
, which are set by the constructors. There are two constructors: a parameterless one that is used by our main program to create a plain “source” for the query, and one that is called by FakeQueryProvider with the current query expression.
The use of Expression.Constant(this) as the initial source expression ![]() is just a way of showing that the query initially represents the original object. (Imagine an implementation representing a table, for example—until you apply any query operators, the query would just return the whole table.) When the constant expression is logged, it uses the overridden
is just a way of showing that the query initially represents the original object. (Imagine an implementation representing a table, for example—until you apply any query operators, the query would just return the whole table.) When the constant expression is logged, it uses the overridden ToString method, which is why we’ve given a short, constant description ![]() . This makes the final expression much cleaner than it would have been without the override. When we are asked to iterate over the results of the query, we always just return an empty sequence
. This makes the final expression much cleaner than it would have been without the override. When we are asked to iterate over the results of the query, we always just return an empty sequence ![]() to make life easy. Production implementations would parse the expression here, or (more likely) call
to make life easy. Production implementations would parse the expression here, or (more likely) call Execute on their query provider and just return the result.
As you can see, there’s not a lot going on in FakeQuery, and listing 12.7 shows that FakeQueryProvider is equally simple.
Example 12.7. An implementation of IQueryProvider that uses FakeQuery
class FakeQueryProvider : IQueryProvider
{
public IQueryable<T> CreateQuery<T>(Expression expression)
{
Logger.Log(this, expression);
return new FakeQuery<T>(this, expression);
}
public IQueryable CreateQuery(Expression expression)
{
Logger.Log(this, expression);
return new FakeQuery<object>(this, expression);
}
public T Execute<T>(Expression expression)
{
Logger.Log(this, expression);
return default(T);
}
public object Execute(Expression expression)
{
Logger.Log(this, expression);
return null;
}
}There’s even less to talk about in terms of the implementation of FakeQueryProvider than there was for FakeQuery. The CreateQuery methods do no real processing but act as factory methods for FakeQuery. The Execute method overloads just return empty results after logging the call. This is where a lot of analysis would normally be done, along with the actual call to the web service, database, or whatever the target platform is.
Even though we’ve done no real work, when we start to use FakeQuery as the source in a query expression interesting things start to happen. I’ve already let slip how we are able to write query expressions without explicitly writing methods to handle the standard query operators: it’s all about extension methods, this time the ones in the Queryable class.
Just as the Enumerable type contains extension methods on IEnumerable<T> to implement the LINQ standard query operators, the Queryable type contains extension methods on IQueryable<T>. There are two big differences between the implementations in Enumerable and those in Queryable.
First, the Enumerable methods all use delegates as their parameters—the Select method takes a Func<TSource,TResult>, for example. That’s fine for in-memory manipulation, but for LINQ providers that execute the query elsewhere, we need a format we can examine more closely—expression trees. For example, the corresponding overload of Select in Queryable takes a parameter of type Expression<Func<TSource,TResult>>. The compiler doesn’t mind at all—after query translation, it has a lambda expression that it needs to pass as a parameter to the method, and lambda expressions can be converted to either delegate instances or expression trees.
This is the reason that LINQ to SQL is able to work so seamlessly. The four key elements involved are all new features of C# 3: lambda expressions, the translation of query expressions into “normal” expressions that use lambda expressions, extension methods, and expression trees. Without all four, there would be problems. If query expressions were always translated into delegates, for instance, they couldn’t be used with a provider such as LINQ to SQL, which requires expression trees. Figure 12.3 shows the two paths taken by query expressions; they differ only in what interfaces their data source implements.
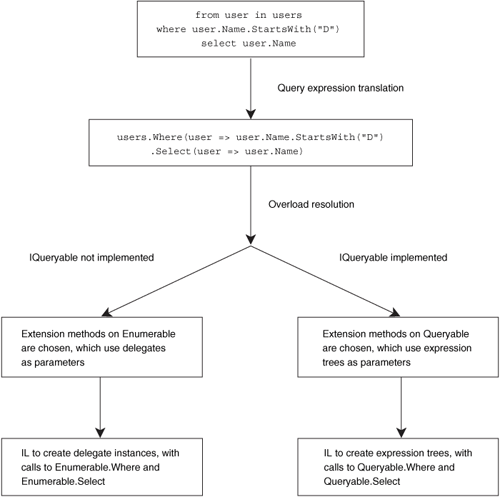
Figure 12.3. A query taking two paths, depending on whether the data source implements IQueryable or only IEnumerable
Notice how in figure 12.3 the early parts of the compilation process are independent of the data source. The same query expression is used, and it’s translated in exactly the same way. It’s only when the compiler looks at the translated query to find the appropriate Select and Where methods to use that the data source is truly important. At that point, the lambda expressions can be converted to either delegate instances or expression trees, potentially giving radically different implementations: typically in-memory for the left path, and SQL executing against a database in the right path.
The second big difference between Enumerable and Queryable is that the Enumerable extension methods do the actual work associated with the corresponding query operator. There is code in Enumerable.Where to execute the specified filter and only yield appropriate elements as the result sequence, for example. By contrast, the query operator “implementations” in Queryable do very little: they just create a new query based on the parameters or call Execute on the query provider, as described at the end of section 12.2.1. In other words, they are only used to build up queries and request that they be executed—they don’t contain the logic behind the operators. This means they’re suitable for any LINQ provider that uses expression trees.
With the Queryable extension methods available and making use of our IQueryable and IQueryProvider implementations, it’s finally time to see what happens when we use a query expression with our custom provider.
Listing 12.8 shows a simple query expression, which (supposedly) finds all the strings in our fake source beginning with “abc” and projects the results into a sequence of the lengths of the matching strings. We iterate through the results, but don’t do anything with them, as we know already that they’ll be empty. Of course, we have no source data, and we haven’t written any code to do any real filtering—we’re just logging which calls are made by LINQ in the course of creating the query expression and iterating through the results.
Example 12.8. A simple query expression using the fake query classes
var query = from x in new FakeQuery<string>()
where x.StartsWith("abc")
select x.Length;
foreach (int i in query) { }What would you expect the results of running listing 12.8 to be? In particular, what would you like to be logged last, at the point where we’d normally expect to do some real work with the expression tree? Here are the results of listing 12.8, reformatted slightly for clarity:
FakeQueryProvider.CreateQuery
Expression=FakeQuery.Where(x => x.StartsWith("abc"))
FakeQueryProvider.CreateQuery
Expression=FakeQuery.Where(x => x.StartsWith("abc"))
.Select(x => x.Length)
FakeQuery<Int32>.GetEnumerator
Expression=FakeQuery.Where(x => x.StartsWith("abc"))
.Select(x => x.Length)The two important things to note are that GetEnumerator is only called at the end, not on any intermediate queries, and that by the time GetEnumerator is called we have all the information present in the original query expression. We haven’t manually had to keep track of earlier parts of the expression in each step—a single expression tree captures all the information “so far” at any point in time.
Don’t be fooled by the concise output, by the way—the actual expression tree is quite deep and complicated, particularly due to the where clause including an extra method call. This expression tree is what LINQ to SQL would be examining to work out what query to execute. LINQ providers could build up their own queries (in whatever form they may need) as calls to CreateQuery are made, but usually looking at the final tree when GetEnumerator is called is simpler, as all the necessary information is available in one place.
The final call logged by listing 12.8 was to FakeQuery.GetEnumerator, and you may be wondering why we also need an Execute method on IQueryProvider. Well, not all query expressions generate sequences—if you use an aggregation operator such as Sum, Count, or Average, we’re no longer really creating a “source”—we’re evaluating a result immediately. That’s when Execute is called, as shown by listing 12.9 and its output.
Example 12.9. IQueryProvider.Execute
var query = from x in new FakeQuery<string>()
where x.StartsWith("abc")
select x.Length;
double mean = query.Average();
// Output
FakeQueryProvider.CreateQuery
Expression=FakeQuery.Where(x => x.StartsWith("abc"))
FakeQueryProvider.CreateQuery
Expression=FakeQuery.Where(x => x.StartsWith("abc"))
.Select(x => x.Length)
FakeQueryProvider.Execute
Expression=FakeQuery.Where(x => x.StartsWith("abc"))
.Select(x => x.Length)
.Average()The FakeQueryProvider can be quite useful when it comes to understanding what the C# compiler is doing behind the scenes with query expressions. It will show the transparent identifiers introduced within a query expression, along with the translated calls to SelectMany, GroupJoin, and the like.
We haven’t written any of the significant code that a real query provider would need in order to get useful work done, but hopefully our fake provider has given you insight into how LINQ providers are given the information from query expressions. It’s all built up by the Queryable extension methods, given an appropriate implementation of IQueryable and IQueryProvider.
We’ve gone into a bit more detail in this section than we will for the rest of the chapter, as it’s involved the foundations that underpin the LINQ to SQL code we saw earlier. You’re unlikely to want to write your own query provider—it takes a lot of work to produce a really good one—but this section has been important in terms of conceptual understanding. The steps involved in taking a C# query expression and (at execution time) running some SQL on a database are quite profound and lie at the heart of the big features of C#3. Understanding why C# has gained these features will help keep you more in tune with the language.
In fact, LINQ to SQL is the only provider built into the framework that actually uses IQueryable—the other “providers” are just APIs that play nicely with LINQ to Objects. I don’t wish to diminish their importance—they’re still useful. However, it does mean that you can relax a bit now—the hardest part of the chapter is behind you. We’re still staying with database-related access for our next section, though, which looks at LINQ to DataSet.
Seeing all the neat stuff that LINQ to SQL can achieve is all very well, but most developers are likely to be improving an existing application rather than creating a new one from the ground up. Rather than ripping out the entire persistence layer and replacing it with LINQ to SQL, it would be nice to be able to gain some of the advantages of LINQ while using existing technology. Many ADO.NET applications use datasets, whether typed or untyped[4]—and LINQ to DataSet gives you access to a lot of the benefits of LINQ with little change to your current code.
The query expressions used within LINQ to DataSet are just LINQ to Objects queries—there’s no translation into a call to DataTable.Select, for example. Instead, data rows are filtered and ordered with normal delegate instances that operate on those rows.
Unsurprisingly, you’ll get a better experience using typed datasets, but a set of extension methods on DataTable and DataRow make it at least possible to work with untyped datasets too. In this section we’ll look at both kinds of datasets, starting with untyped ones.
Untyped datasets have two problems as far as LINQ is concerned. First, we don’t have access to the fields within the tables as typed properties; second, the tables themselves aren’t enumerable. To some extent both are merely a matter of convenience—we could use direct casts in all the queries, handle DBNull explicitly and so forth, as well as enumerate the rows in a table using dataTable.Rows.Cast<DataRow>. These workarounds are quite ugly, which is why the DataTableExtensions and DataRowExtensions classes exist.
Code using untyped datasets is never going to be pretty, but using LINQ is far nicer than filtering and sorting using DataTable.Select. No more escaping, worrying about date and time formatting, and similar nastiness.
Listing 12.10 gives a simple example. It just fills a single defect table and prints the summaries of all the defects that don’t have a status of “closed.”
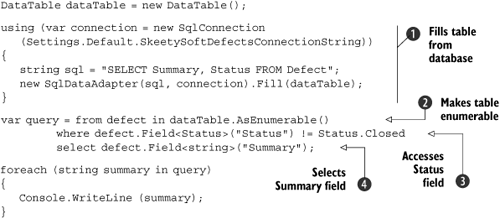
Coming so soon after the nice, clean world of LINQ to SQL, listing 12.10 makes me feel somewhat dirty. There’s hard-coded SQL, column names, and casts all over the place. However, we’ll see that things are better when we have a typed dataset—and this code does get the job done. If you’re using both LINQ to SQL and LINQ to DataSet, you can fill a DataTable using the DataTableExtensions.CopyToDataTable extension method, but I wanted to keep to just one new technology at a time for this example.
The first part ![]() is “old-fashioned” ADO.NET code to fill the data table. I haven’t used an actual dataset for this example because we’re only interested in a single table—putting it in a dataset would have made things slightly more complicated for no benefit. It’s only when we reach the query expression (
is “old-fashioned” ADO.NET code to fill the data table. I haven’t used an actual dataset for this example because we’re only interested in a single table—putting it in a dataset would have made things slightly more complicated for no benefit. It’s only when we reach the query expression (![]()
![]() and
and ![]() ) that LINQ starts coming in.
) that LINQ starts coming in.
The source of a query expression has to be enumerable in some form—and the DataTable type doesn’t even implement IEnumerable, let alone IEnumerable<T>. The DataTableExtensions class provides the AsEnumerable extension method (![]() ), which merely returns an
), which merely returns an IEnumerable<DataRow> that iterates over the rows in the table.
Accessing fields within a row is made slightly easier in LINQ to DataSet using the Field<T> extension method on DataRow. This not only removes the need to cast results, but it also deals with null values for you—it converts DBNull to a null reference for you, or the null value of a nullable type.
I won’t give any further examples of untyped datasets here, although there are a couple more queries in the book’s sample code. Hopefully you’ll find yourself in the situation where you can use a typed dataset instead.
Although typed datasets aren’t as rich as using LINQ to SQL directly, they provide much more static type information, which lets your code stay cleaner. There’s a bit of work to start with: we have to create a typed dataset for our defect-tracking system before we can begin using it.
The process for generating a typed dataset in Visual Studio 2008 is almost exactly the same as it is to generate LINQ to SQL entities. Again, you add a new item to the project (this time selecting DataSet in the list of options), and again you can drag and drop tables from the Server Explorer window onto the designer surface.
There aren’t quite as many options available in the property panes for typed datasets, but we can still rename the DefectUser table, the DefectID field, along with the associations. Likewise, we can still tell the Status, Summary, and UserType properties to use the enumeration types from the model. Figure 12.4 shows the designer after a bit of editing and rearranging.
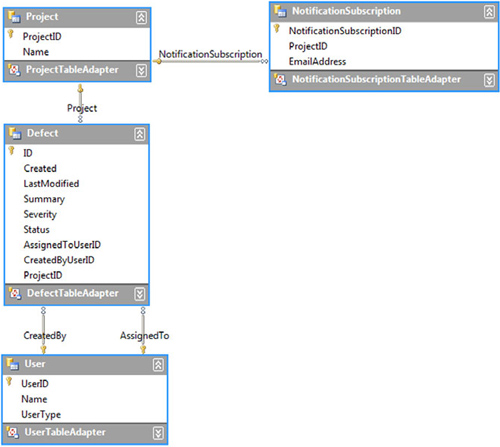
Each table in the dataset has its own types for the table, rows, notification event handlers, notification event arguments, and adapters. The adapters are placed into a separate namespace, based on the name of the dataset.
Once you’ve created the dataset, using it is easy.
As in previous versions of ADO.NET, typed datasets are populated using adapters. The adapters generated by the designer already use the connection string of the server originally used to create the dataset: this can be changed in the application settings. This means that in many cases, you can fill the tables with barely any code. Listing 12.11 achieves the same results as the query on the untyped dataset, but in a considerably cleaner fashion.
Example 12.11. Displaying the summaries of open defects from a typed dataset
DefectDataSet dataSet = new DefectDataSet();
new DefectTableAdapter().Fill(dataSet.Defect);
var query = from defect in dataSet.Defect
where defect.Status != Status.Closed
select defect.Summary;
foreach (string summary in query)
{
Console.WriteLine (summary);
}Creating and populating the dataset is now a breeze—and even though we use only one table, it’s as easy to do that using a complete dataset as it would have been if we’d only created a single data table. Of course, we’re pulling more data down this time because we haven’t specified a SQL projection, but you can access the “raw” adapter of a typed data adapter and modify the query yourself if you need to.
The query expression in listing 12.11 looks like it could have come straight from LINQ to SQL or LINQ to Objects, other than using dataSet instead of context or SampleData.AllDefects. The DefectDataSet.Defect property returns a DefectDataTable, which implements IEnumerable<DefectDataRow> already (via its base class, TypedTableBase<DefectDataRow>) so we don’t need any extension methods, and each row is strongly typed.
For me, one of the most compelling aspects of LINQ is this consistency between different data access mechanisms. Even if you only query a single data source, LINQ is useful—but being able to query multiple data sources with the same syntax is phenomenal. You still need to be aware of the consequences of querying against the different technologies, but the fundamental grammar of query expressions remains constant.
Using associations between different tables is also simple with typed datasets. In listing 12.12 we group the open defects according to their status, and display the defect ID, the name of the project, and the name of the user assigned to work on it.
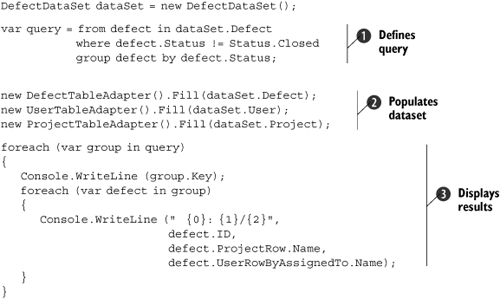
Unlike in LINQ to SQL (which can lazily load entities), we have to load all the data we’re interested in before we execute the query. Just for fun, this time I’ve populated the dataset ![]() after we’ve defined the query
after we’ve defined the query ![]() but before we’ve executed it
but before we’ve executed it ![]() . Apart from anything else, this proves that LINQ is still working in a deferred execution mode—it doesn’t try to look at the list of defects until we iterate through them.
. Apart from anything else, this proves that LINQ is still working in a deferred execution mode—it doesn’t try to look at the list of defects until we iterate through them.
When we display the results ![]() , the associations (
, the associations (ProjectRow, UserRowByAssignedTo) aren’t quite as neat as they are in LINQ to SQL, because the dataset designer doesn’t give us as much control over those names as the entity model designer does. It’s still a lot nicer than the equivalent code for untyped datasets, however.
As you can see, Microsoft has made LINQ work nicely with databases and associated technologies. That’s not the only form of data access we can use, though—in a world where XML is so frequently used for storing and exchanging data, LINQ makes processing documents that much simpler.
Whereas LINQ to DataSet is really just some extensions to the existing dataset capabilities (along with a new base class for typed data tables), LINQ to XML is a completely new XML API. If your immediate reaction to hearing about yet another XML API is to ask whether or not we need one, you’re not alone. However, LINQ to XML simplifies document manipulation considerably, and is designed to play well with LINQ to Objects. It doesn’t have much extra querying functionality in itself, and it doesn’t perform any query translations in the way that LINQ to SQL does, but the integration with LINQ via iterators makes it a pleasure to work with.
It’s not just about querying, though—one of the major benefits of LINQ to XML over the existing APIs is its “developer friendliness” when it comes to creating and transforming and XML documents too. We’ll see that in a moment, when we create an XML document containing all our sample data, ready for querying. Of course, this won’t be a comprehensive guide to LINQ to XML, but the deeper topics that we won’t cover here (such as XML namespace handling) have been well thought out to make development easier.
Let’s start by looking at two of the most important classes of LINQ to XML.
The bulk of LINQ to XML consists of a set of classes in the System.Xml.Linq namespace, most of which are prefixed with X: XName, XDocument, XComment, and so forth. Even though lots of classes are available, for our purposes we only need to know about XElement and XAttribute, which obviously represent XML elements and attributes, respectively.
We’ll also be using XName indirectly, which is used for names of elements and attributes, and can contain namespace information. The reason we only need to use it indirectly is that there’s an implicit conversion from string to XName, so every time we create an element or attribute by passing the name as a string, it’s converting it into an XName. I mention this only so that you won’t get confused about what’s being called if you look at the available methods and constructors in MSDN.
One of the great things about LINQ to XML is how easy it is to construct elements and attributes. In DOM, to create a simple document with a nested element you’d have to go through lots of hoops:
Adding attributes was relatively painful, too. None of this would be naturally nested in the code to give an at-a-glance indication of the final markup. LINQ to XML makes life easier in the following ways:
You don’t need an
XDocumentunless you want one—you can create elements and attributes separately.You can specify the contents of an element (or document) in the constructor.
These don’t immediately sound important, but seeing the API in action makes things clearer. Listing 12.13 creates and prints out an XML element with attributes and a nested element containing some text.
Example 12.13. Creating a simple piece of XML
var root = new XElement("root",
new XAttribute ("attr", "value"),
new XElement("child",
"text")
);
Console.WriteLine (root);Choosing how you format LINQ to XML creation code is a personal decision, in terms of where to use whitespace and how much to use, where to place parentheses, and so forth. However, the important point to note from listing 12.13 is how it’s quite clear that the element “root” contains two nodes: an attribute and a child element. The child element then has a text node (“text”). In other words, the structure of the result is apparent from the structure of the code. The output from listing 12.13 is the XML we’d hope for:
<root attr="value"> <child>text</child> </root>
The equivalent code in DOM would have been much nastier. If we’d wanted to include an XML declaration (<xml version="1.0" encoding="utf-8">, for instance), it would have been easy to do so with XDocument—but I’m trying to keep things as simple as possible for this brief tour. Likewise, you can modify XElements after creating them in a DOM-like manner, but we don’t need to go down that particular path here.
The constructor for XElement accepts any number of objects using a params parameter, but importantly it will also then recurse into any enumerable arguments that are passed to it. This is absolutely crucial when using LINQ queries within XML creation expressions. Speaking of which, let’s start building some XML with our familiar defect data.
We’ve currently got our sample data available in three different forms—in memory as objects, in the database, and in a typed dataset. Of course, the typed dataset can write XML directly, but let’s convert our original in-memory version for simplicity. To start with, we’ll just generate a list of the users. Listing 12.14 creates a list of user elements within a users element, and then writes it out; the output is shown beneath the listing.
Example 12.14. Creating an element from the sample users
var users = new XElement("users",
from user in SampleData.AllUsers
select new XElement("user",
new XAttribute("name", user.Name),
new XAttribute("type", user.UserType))
);
Console.WriteLine (users);
// Output
<users>
<user name="Tim Trotter" type="Tester" />
<user name="Tara Tutu" type="Tester" />
<user name="Deborah Denton" type="Developer" />
<user name="Darren Dahlia" type="Developer" />
<user name="Mary Malcop" type="Manager" />
<user name="Colin Carton" type="Customer" />
</users>I hope you’ll agree that listing 12.14 is simple, once you’ve got your head around the idea that the contents of the top-level element depend on the result of the embedded query expression. It’s possible to make it even simpler, however. I’ve written a small extension method on object that generates an IEnumerable<XAttribute> based on the properties of the object it’s called on, which are discovered with reflection. This is ideal for anonymous types—listing 12.15 creates the same output, but without the explicit XAttribute constructor calls. With only two attributes, there isn’t much difference in the code, but for more complicated elements it’s a real boon.
Example 12.15. Using object properties to generate XAttributes with reflection
var users = new XElement("users",
from user in SampleData.AllUsers
select new XElement("user",
new { name=user.Name, type=user.UserType }
.AsXAttributes()
)
);
Console.WriteLine (users);For the rest of the chapter I’ll use the “vanilla” LINQ to XML calls, but it’s worth being aware of the possibilities available with a bit of reusable code. (The source for the extension method is available as part of the code for the book.)
You can nest query expressions and do all kinds of other clever things with them. Listing 12.16 generates an element containing the project information: the notification subscriptions for a project are embedded within the project element by using a nested query. The results are shown beneath the listing.
Example 12.16. Generating projects with nested subscription elements
var projects = new XElement("projects",
from project in SampleData.AllProjects
select new XElement("project",
new XAttribute("name", project.Name),
new XAttribute("id", project.ProjectID),
from subscription in SampleData.AllSubscriptions
where subscription.Project == project
select new XElement("subscription",
new XAttribute("email", subscription.EmailAddress)
)
)
);
Console.WriteLine (projects);
// Output
<projects>
<project name="Skeety Media Player" id="1">
<subscription email="[email protected]" />
<subscription email="[email protected]" />
</project>
<project name="Skeety Talk" id="2">
<subscription email="[email protected]" />
</project>
<project name="Skeety Office" id="3">
<subscription email="[email protected]" />
</project>
</projects>The two queries are highlighted in bold. There are alternative ways of generating the same output, of course—you could use a single query that groups the subscriptions by project, for instance. The code in listing 12.16 was just the first way I thought of tackling the problem—and in cases where the performance isn’t terribly important it doesn’t matter that we’ll be running the nested query multiple times. In production code you’d want to consider possible performance issues more carefully, of course!
I won’t show you all the code to generate all the elements—even with LINQ to XML, it’s quite tedious just because there are so many attributes to set. I’ve placed it all in a single XmlSampleData.GetElement() method that returns a root XElement. We’ll use this method as the starting point for the examples in our final avenue of investigation: querying.
You may well be expecting me to reveal that XElement implements IEnumerable and that LINQ queries come for free. Well, it’s not quite that simple, because there are so many different things that an XElement could iterate through. XElement contains a number of axis methods that are used as query sources. If you’re familiar with XPath, the idea of an axis will no doubt be familiar to you. Here are the axis methods used directly for querying, each of which returns an appropriate IEnumerable<T>:
AncestorsAncestorsAndSelfAnnotationsAttributesDescendantsDescendantsAndSelfDescendantNodesDescendantNodesAndSelfElementsElementsAfterSelfElementsBeforeSelf
All of these are fairly self-explanatory (and the MSDN documentation provides more details). There are useful overloads to retrieve only nodes with an appropriate name: calling Descendants("user") on an XElement will return all user elements underneath the element you call it on, for instance. A number of extension methods also make these axes available to whole sequences of nodes: the result is a concatenated sequence as if the method has been called on each node in turn.
As well as these calls returning sequences, there are some methods that return a single result—Attribute and Element are the most important, returning the named attribute and the first descendant element with the specified name, respectively.
One aspect of XAttribute that is particularly relevant to querying is the set of the explicit conversions from an XAttribute to any number of other types, such as int, string, and DateTime. These are important for both filtering and projecting results.
Enough talk! Let’s see some code. We’ll start off simply, just displaying the users within our XML structure, as shown in listing 12.17.
Example 12.17. Displaying the users within an XML structure
XElement root = XmlSampleData.GetElement();
var query = from user in root.Element("users").Elements()
select new { Name=(string)user.Attribute("name"),
UserType=(string)user.Attribute("type") };
foreach (var user in query)
{
Console.WriteLine ("{0}: {1}", user.Name, user.UserType);
}After creating the data at the start, we navigate down to the users element, and ask it for its direct child elements. This two-step fetch could be shortened to just root.Descendants("user"), but it’s good to see the more rigid navigation so you can use it where necessary. It’s also more robust in the face of changes to the document structure, such as another (unrelated) user element being added elsewhere in the document.
The rest of the query expression is merely a projection of an XElement into an anonymous type. I’ll admit that we’re cheating slightly with the user type: we’ve kept it as a string instead of calling Enum.Parse to convert it into a proper UserType value. The latter approach works perfectly well—but it’s quite longwinded when you only need the string form, and the code becomes hard to format sensibly within the strict limits of the printed page.
Listing 12.17 isn’t doing anything particularly impressive, of course. In particular, it would be easy to achieve a similar effect with a single XPath expression. Joins, however, are harder to express in XPath. They work, but they’re somewhat messy. With LINQ to XML, we can use our familiar query expression syntax. Listing 12.18 demonstrates this, showing each open defect’s ID with its assignee and project.
Example 12.18. Two joins and a filter within a LINQ to XML query
XElement root = XmlSampleData.GetElement();
var query = from defect in root.Descendants("defect")
join user in root.Descendants("user")
on (int?)defect.Attribute("assigned-to") equals
(int)user.Attribute("id")
join project in root.Descendants("project")
on (int)defect.Attribute("project") equals
(int)project.Attribute("id")
where (string)defect.Attribute("status") != "Closed"
select new { ID=(int)defect.Attribute("id"),
Project=(string)project.Attribute("name"),
Assignee=(string)user.Attribute("name") };
foreach (var defect in query)
{
Console.WriteLine ("{0}: {1}/{2}",
defect.ID,
defect.Project,
defect.Assignee);
}I’m not going to pretend that listing 12.18 is particularly pleasant. It has lots of string literals (which could easily be turned into constants) and it’s generally pretty wordy. On the other hand, it’s doing quite a lot of work, including coping with the possibility of a defect not being assigned to a user (the int? conversion in the join of defect to assignee). Consider how horrible the corresponding XPath expression would have to be, or how much manual code you’d have to write to perform the same query in direct code. The other standard query operators are available, too: once you’ve got a query source, LINQ to XML itself takes a back seat and lets LINQ to Objects do most of the work. We’ll stop there, however—you may have seen enough query expressions to make you dizzy by now, and if you want to experiment further it’s easy enough to do so.
Like the other topics in this chapter, we’ve barely scratched the surface of the LINQ to XML API. I haven’t touched the integration with the previous technologies such as DOM and XPath, nor have I given details of the other node types—not even XDocument!
Even if I were to go through all of the features, that wouldn’t come close to explaining all the possible uses of it. Practically everywhere you currently deal with XML, I expect LINQ to XML will make your life easier. To reiterate a cliché, the only limit is your imagination.
Just as an example, remember how we created our XML from LINQ queries? Well, there’s nothing to stop the sources involved in those queries being LINQ to XML in the first place: lo and behold, a new (and powerful) way of transforming one form of XML to another is born.
Even though we’ve been so brief, I hope that I’ve opened the door for you—given you an inkling of the kind of XML processing that can be achieved relatively simply using LINQ to XML. You’ll need to learn a lot more before you master the API, but my aim was to whet your appetite and show you how LINQ query expressions have a consistency between providers that easily surpasses previous query techniques and technologies.
We’ve now seen all of the LINQ providers that are built into the .NET 3.5 Framework. That’s not the same thing as saying that you’ve seen all the LINQ providers you’ll ever use, however.
Even before .NET 3.5 was finally released, developers outside Microsoft were hard at work writing their own providers, and Microsoft isn’t resting on its laurels either. We’ll round this chapter off with a quick look at what else is available now, and some of what’s still to come. In this section we’re moving even faster than before, covering providers in even less depth. We don’t need to know much about them, but their variety is important to demonstrate LINQ’s flexibility.
From the start, LINQ was designed to be general purpose. It would be hard to deny its SQL-like feel, but at the same time LINQ to Objects proves that you don’t need to be working with a database in order to benefit from it.
A number of third-party providers have started popping up, and although at the time of this writing most are “proof of concept” more than production code—ways of exploring LINQ as much as anything else—they give a good indication of the wide range of potential uses for LINQ. We’ll only look at three examples, but providers for other data sources (SharePoint and Flickr, for example) are emerging, and the list will only get longer. Let’s start off with a slightly closer look at the example we first saw in chapter 1.
One of the flagship e-commerce sites, Amazon has always tried to drive technology forward, and it has a number of web services available for applications to talk to. Some cost money—but fortunately searching for a list of books is free. Simply visit http://aws.amazon.com, sign up to the scheme, and you’ll receive an access ID by email. You’ll need this if you want to run the example for yourself.
As part of Manning’s LINQ in Action book, Fabrice Marguerie implemented a LINQ provider to make requests to the Amazon web service.[5] Listing 12.19 shows an example of using the provider to query Amazon’s list of books with “LINQ” in the title.

I’ve taken Fabrice’s provider and tweaked it slightly so that we can pass our own Amazon Access ID into the provider’s constructor ![]() . The source is part of the Visual Studio 2008 solution containing the examples for this chapter.
. The source is part of the Visual Studio 2008 solution containing the examples for this chapter.
You may be slightly surprised to see two query expressions in listing 12.19. As a proof of concept, the LINQ to Amazon provider only allows a limited number of operations, not including ordering. We use the web query ![]() as the source for an in-memory LINQ to Objects query expression
as the source for an in-memory LINQ to Objects query expression ![]() . The web service call still only takes place when we start executing the query
. The web service call still only takes place when we start executing the query ![]() , due to the deferred execution approach taken by LINQ.
, due to the deferred execution approach taken by LINQ.
The output at the time of this writing is included here. By the time you read this, I expect the list may be considerably longer.
1998: A linq between nonwovens and wovens. (...) 2007: Introducing Microsoft LINQ 2007: LINQ for VB 2005 2007: LINQ for Visual C# 2005 2007: Pro LINQ: Language Integrated Query in C# 2008 2008: Beginning ASP.NET 3.5 Data Access with LINQ , C# (...) 2008: Beginning ASP.NET 3.5 Data Access with LINQ, VB (...) 2008: LINQ in Action 2008: Professional LINQ
Even though LINQ to Amazon is primitive, it demonstrates an important point: LINQ is capable of more than just database and in-memory queries. Our next provider proves that even when it’s talking to databases, there’s more to LINQ than just LINQ to SQL.
NHibernate is an open source ORM framework for .NET, based on the Hibernate project for Java. It supports textual queries in its own query language (HQL) and also a more programmatic way of building up queries—the Criteria API.
Prolific blogger and NHibernate contributor Ayende[6] has initiated a LINQ to NHibernate provider that converts LINQ queries not into SQL but into NHibernate Criteria queries, taking advantage of the SQL translation code in the rest of the project. Aside from anything else, this means that the feature of RDBMS independence comes for free. The same LINQ queries can be run against SQL Server, Oracle, or Postgres, for example: any system that NHibernate knows about, with SQL tailored for that particular implementation.
Before writing this book, I hadn’t used NHibernate (although I am reasonably experienced with its cousin in the Java world), and it’s a testament to the project that within about an hour I was up and running with the SkeetySoft defect database, using nothing but the online tutorial. Listing 12.20 shows the same query we used against LINQ to SQL in listing 12.3 to list all of Tim’s open defects.
Example 12.20. LINQ to NHibernate query to list defects assigned to Tim Trotter
ISessionFactory sessionFactory =
new Configuration().Configure().BuildSessionFactory();
using (ISession session = sessionFactory.OpenSession())
{
using (ITransaction tx = session.BeginTransaction())
{
User tim = (from user in session.Linq<User>()
where user.Name == "Tim Trotter"
select user).Single();
var query = from defect in session.Linq<Defect>()
where defect.Status != Status.Closed
where defect.AssignedTo == tim
select defect.Summary;
foreach (var summary in query)
{
Console.WriteLine(summary);
}
tx.Commit();
}
}As you can see, once the session and transaction have been set up, the code is similar to that used in LINQ to SQL. The generated SQL is different, although it executes the same sort of queries. In other cases, identical query expressions can generate different SQL, mostly due to decisions regarding the lazy or eager loading of entities. This is an example of a leaky abstraction[7]—where in theory the abstraction layer of LINQ might be considered to isolate the developer from the implementation performing the actual query, but in practice the implementation details leak through. Don’t fall for the abstraction: it takes nothing away from the value of LINQ, but you do need to be aware of what you’re coding against, and keep an eye on what queries are being executed for you.
So, we’ve seen LINQ working against both web services and multiple databases. There’s another piece of infrastructure that is commonly queried, though: an enterprise directory.
Almost all companies running their IT infrastructure on Windows use Active Directory to manage users, computers, settings, and more. Active Directory is a directory server that implements LDAP as one query protocol, but other LDAP servers are available, including the free OpenLDAP platform.[8]
Bart De Smet[9] (who now works for Microsoft) implemented a prototype LINQ to Active Directory provider as a tutorial on how LINQ providers work—but it has also proved to be a valuable reminder of how broadly LINQ is targeted. Despite the name, it is capable of querying non-Microsoft servers. He has also repeated the feat with a LINQ to SharePoint provider, which we won’t cover here, but which is a more complete provider implementation.
If you’re not familiar with directories, you can think of them as a sort of cross between file system directory trees and databases. They form hierarchies rather than tables, but each node in the tree is an entity with properties and an associated schema. (For those of you who are familiar with directories, please forgive this gross oversimplification.)
Installing and populating a directory is a bit of an effort, so for the sample code I’ve connected to a public server. If you happen to have access to an internal server, you’ll probably find the results more meaningful if you connect to that.
Listing 12.21 connects to an LDAP server and lists all the users whose first name begins with K. The Person type is described elsewhere in the sample source code, complete with attributes to describe to LINQ to Active Directory how the properties within the object map to attributes within the directory.
Example 12.21. LINQ to Active Directory sample, querying users by first name
string url = "LDAP://ldap.andrew.cmu.edu/dc=cmu,dc=edu";
DirectoryEntry root = new DirectoryEntry(url);
root.AuthenticationType = AuthenticationTypes.None;
var users = new DirectorySource<Person>(root, SearchScope.Subtree);
users.Log = Console.Out;
var query = from user in users
where user.FirstName.StartsWith("K")
select user;
foreach (Person person in query)
{
Console.WriteLine (person.DisplayName);
foreach (string title in person.Titles)
{
Console.WriteLine(" {0}", title);
}
}Are you getting a sense of déjà vu yet? Listing 12.21 shows yet another query expression, which just happens to target LDAP. If you didn’t have the first part, which sets the scene, you wouldn’t know that LDAP was involved at all. As we’ve already noted, you should be aware of the data source particularly with regard to the limitations of any one provider—but I’m sure you understood the query expression despite not knowing LDAP. The plain text version is (&(objectClass=person)(givenName=K*)), which isn’t horrific but isn’t nearly as familiar as the query expression should be by now.
The third-party examples we’ve seen are all “early adoption” code, largely written for the sake of investigating what’s possible rather than creating production code. I predict that 2008 and 2009 will see a number of more feature-complete and high-quality providers emerging. At least two of these are likely to come from Microsoft.
LINQ providers can work in very different ways. As we’ve already seen, LINQ to XML and LINQ to DataSet are just APIs that offer easy integration with LINQ to Objects, whereas LINQ to SQL is a more fully fledged provider, offering translation of queries to SQL. There are more providers being developed by Microsoft at the time of this writing, however—another ORM system, and an intriguing project to provide “no cost” parallelism where appropriate.
While LINQ to SQL is far from a toy, it doesn’t have all the features that many developers expect from a modern ORM solution. For example, fetching strategies can be set on a per-context basis, but they can’t be set for individual queries. Likewise, the entity inheritance strategies of LINQ to SQL are somewhat limited. Also, LINQ to SQL only supports SQL Server, which will obviously rule out its use for many projects that have already chosen a different RDBMS.
The “ADO.NET Entity Framework” forms the basis of Microsoft’s “Data Access Strategy” and will ship with SQL Server 2008. The entity framework is a much more powerful solution than LINQ to SQL, including its own text-based query language (Entity SQL, also known as eSQL) and allowing a flexible mapping between the conceptual model (which is what the business layer of your code will use) and the logical model (which is what the database sees). An Object Services aspect of the entity framework deals with object identity and update management, and an Entity Client layer is responsible for all queries. The LINQ part of the entity framework is known as LINQ to Entities.
As with so many aspects of software development, flexibility comes with the burden of complexity—the two models and the mapping between them require their own XML files, for example. Microsoft will release an update to Visual Studio 2008 when the entity framework is released, with designers to help lighten the load of the various mapping tasks. The framework itself is still more complicated than LINQ to SQL, however, and will take longer to master.
Rather than provide yet another ORM query against the SkeetySoft defect database—and one that would look nearly identical to those we’ve already seen—I’ve just included some examples in the downloadable source code.[10]
All of the LINQ providers we’ve seen so far have acted on a particular data source, and performed the appropriate transformations. Our next topic is slightly different—but it’s one I’m particularly excited about.
Ten years ago, the idea of even fairly low-to-middling laptops having dual-processor cores would have seemed ridiculous. Today, that’s taken for granted—and if the chip manufacturers’ plans are anything to go by, that’s only the start. Of course, it’s only useful to have more than one processor core if you’ve got tasks you can run in parallel.
Parallel LINQ, or PLINQ for short, is a project with one “simple” goal: to execute LINQ to Objects queries in parallel, realizing the benefits of multithreading with as few headaches as possible. At the time of this writing, PLINQ is targeted to be released as part of Parallel Extensions, the next generation of .NET concurrency support. The sample I describe is based on the December 2007 Community Technology Preview (CTP).
Using PLINQ is simple, if (and only if) you have to perform the same task on each element in a sequence, and those tasks are independent. If you need the result of one calculation step in order to find the next, PLINQ is not for you—but many CPU-intensive tasks can in fact be done in parallel. To tell the compiler to use PLINQ, you just need to call AsParallel (an extension method on IEnumerable<T>) on your data source, and let PLINQ handle the threading. As with IQueryable, the magic is just normal compiler method resolution: AsParallel returns an IParallelEnumerable, and the ParallelEnumerable class provides static methods to handle the standard query operators.
Listing 12.22 demonstrates PLINQ in an entirely artificial way, putting threads to sleep for random periods instead of actually hitting the processor hard.
Example 12.22. Executing a LINQ query on multiple threads with Parallel LINQ
static int ObtainLengthSlowly(string name)
{
Thread.Sleep(StaticRandom.Next(10000));
return name.Length;
}
...
string[] names = {"Jon", "Holly", "Tom", "Robin", "William"};
var query = from name in names.AsParallel(3)
select ObtainLengthSlowly(name);
foreach (int length in query)
{
Console.WriteLine(length);
}Listing 12.22 will print out the length of each name. We’re using a random[11] sleep to simulate doing some real work within the call to ObtainLengthSlowly. Without the AsParallel call, we would only use a single thread, but AsParallel and the resulting calls to the ParallelEnumerable extension methods means that the work is split into up to three threads.[12]
One caveat about this: unless you specify that you want the results in the same order as the strings in the original sequence, PLINQ will assume you don’t mind getting results as soon as they’re available, even if results from earlier elements haven’t been returned yet. You can prevent this by passing QueryOptions.PreserveOrdering as a parameter to AsParallel.
There are other subtleties to using PLINQ, such as handling the possibility of multiple exceptions occurring instead of the whole process stopping on the first problematic element—consult the documentation for further details when Parallel Extensions is fully released. More examples of PLINQ are included in the downloadable source code.
As you can see, PLINQ isn’t a “data source”—it’s a kind of meta-provider, altering how a query is executed. Many developers will never need it—but I’m sure that those who do will be eternally grateful for the coordination it performs for them behind the scenes.
These won’t be the only new providers Microsoft comes up with—we should expect new APIs to be built with LINQ in mind, and that should include your own code as well. I confidently expect to see some weird and wonderful uses of LINQ in the future.
Phew! This chapter has been the exact opposite of most of the rest of the book. Instead of focusing on a single topic in great detail, we’ve covered a vast array of LINQ providers, but at a shallow level.
I wouldn’t expect you to feel particularly familiar with any one of the specific technologies we’ve looked at here, but I hope you’ve got a deeper understanding of why LINQ is important. It’s not about XML, or in-memory queries, or even SQL queries—it’s about consistency of expression, and giving the C# compiler the opportunity to validate your queries to at least some extent, regardless of their final execution platform.
You should now appreciate why expression trees are so important that they are among the few framework elements that the C# compiler has direct intimate knowledge of (along with strings, IDisposable, IEnumerable<T>, and Nullable<T>, for example). They are passports for behavior, allowing it to cross the border of the local machine, expressing logic in whatever foreign tongue is catered for by a LINQ provider.
It’s not just expression trees—we’ve also relied on the query expression translation employed by the compiler, and the way that lambda expressions can be converted to both delegates and expression trees. Extension methods are also important, as without them each provider would have to give implementations of all the relevant methods. If you look back at all the new features of C#, you’ll find few that don’t contribute significantly to LINQ in some way or other. That is part of the reason for this chapter’s existence: to show the connections between all the features.
I shouldn’t wax lyrical for too long, though—as well as the upsides of LINQ, we’ve seen a few “gotchas.” LINQ will not always allow us to express everything we need in a query, nor does it hide all the details of the underlying data source. The impedance mismatches that have caused developers so much trouble in the past are still with us: we can reduce their impact with ORM systems and the like, but without a proper understanding of the query being executed on your behalf, you are likely to run into significant issues. In particular, don’t think of LINQ as a way of removing your need to understand SQL—just think of it as a way of hiding the SQL when you’re not interested in the details.
Despite the limitations, LINQ is undoubtedly going to play a major part in future .NET development. In the final chapter, I will look at some of the ways development is likely to change in the next few years, and the part I believe C#3 will play in that evolution.
[1] Additional log output is generated showing some details of the data context, which I’ve cut to avoid distracting from the SQL.
[2] Well, the ones that keep deferring execution, such as Where and Join. We’ll see what happens with the aggregations such as Count in a little while.
[3] Both Execute and CreateQuery have generic and nongeneric overloads. The nongeneric versions make it easier to create queries dynamically in code. Compile-time query expressions use the generic version.
[4] An untyped dataset is one that has no static information about the contents of its tables. Typed datasets, usually generated in the Visual Studio designer, know the tables which can be present in the dataset, and the columns within the rows in those tables.
[5] See http://linqinaction.net for more information and updates.
[10] I will update these when the entity framework is released, if necessary.
[11] The StaticRandom class used for this is merely a thread-safe wrapper of static methods around a normal Random class. It’s part of my miscellaneous utility library.
[12] I’ve explicitly specified the number of threads in this example to force parallelism even on a single-core system. If the number of threads isn’t specified, the system acts as it sees fit, depending on the number of cores available and how much other work they have.