
Chapter 2. Introducing Cassandra
An invention has to make sense in the world in which it is finished, not the world in which it is started.
Ray Kurzweil
In the previous chapter, we discussed the emergence of non-relational database technologies in order to meet the increasing demands of modern web scale applications. In this chapter, we’ll focus on Cassandra’s value proposition and key tenets to show how it rises to the challenge. You’ll also learn about Cassandra’s history and how you can get involved in the open source community that maintains Cassandra.
The Cassandra Elevator Pitch
Hollywood screenwriters and software entrepreneurs are often advised to have their “elevator pitch” ready. This is a summary of exactly what their product is all about—concise, clear, and brief enough to deliver in just a minute or two, in the lucky event that they find themselves sharing an elevator with an executive, agent, or investor who might consider funding their project. Cassandra has a compelling story, so let’s boil it down to an elevator pitch that you can present to your manager or colleagues should the occasion arise.
Cassandra in 50 Words or Less
“Apache Cassandra is an open source, distributed, decentralized, elastically scalable, highly available, fault-tolerant, tuneably consistent, row-oriented database. Cassandra bases its distribution design on Amazon’s Dynamo and its data model on Google’s Bigtable, with a query language similar to SQL. Created at Facebook, it now powers cloud-scale applications across many industries.” That’s exactly 50 words.
Of course, if you were to recite that to your boss in the elevator, you’d probably get a blank look in return. So let’s break down the key points in the following sections.
Distributed and Decentralized
Cassandra is distributed, which means that it is capable of running on multiple machines while appearing to users as a unified whole. In fact, there is little point in running a single Cassandra node. Although you can do it, and that’s acceptable for getting up to speed on how it works, you quickly realize that you’ll need multiple machines to really realize any benefit from running Cassandra. Much of its design and code base is specifically engineered toward not only making it work across many different machines, but also for optimizing performance across multiple data center racks, and even for a single Cassandra cluster running across geographically dispersed data centers. You can confidently write data to anywhere in the cluster and Cassandra will get it.
Once you start to scale many other data stores (MySQL, Bigtable), some nodes need to be set up as primary replicas in order to organize other nodes, which are set up as secondary replicas. Cassandra, however, is decentralized, meaning that every node is identical; no Cassandra node performs certain organizing operations distinct from any other node. Instead, Cassandra features a peer-to-peer architecture and uses a gossip protocol to maintain and keep in sync a list of nodes that are alive or dead. We’ll discuss this more in “Gossip and Failure Detection”.
The fact that Cassandra is decentralized means that there is no single point of failure. All of the nodes in a Cassandra cluster function exactly the same. This is sometimes referred to as “server symmetry.” Because they are all doing the same thing, by definition there can’t be a special host that is coordinating activities, as with the primary/secondary setup that you see in MySQL, Bigtable, and so many other databases.
In many distributed data solutions (such as RDBMS clusters), you set up multiple copies of data on different servers in a process called replication, which copies the data to multiple machines so that they can all serve simultaneous requests and improve performance. Typically this process is not decentralized, as in Cassandra, but is rather performed by defining a primary/secondary relationship. That is, all of the servers in this kind of cluster don’t function in the same way. You configure your cluster by designating one server as the primary (or primary replica) and others as secondary replicas. The primary replica acts as the authoritative source of the data, and operates in a unidirectional relationship with the secondary replicas, which must synchronize their copies. If the primary node fails, the whole database is in jeopardy. To work around the situation of the primary as a single point of failure, you often need to add complexity to the environment in the form of multiple primary nodes. Note that while we frequently understand primary/secondary replication in the RDBMS world, there are NoSQL databases such as MongoDB that follow the primary/secondary scheme as well. Even Mongo’s “replica set” mechanism is essentially a primary/secondary scheme in which the primary can be replaced by an automated leader election process.
Decentralization, therefore, has two key advantages: it’s simpler to use than primary/secondary, and it helps you avoid outages. It is simpler to operate and maintain a decentralized store than a primary/secondary store because all nodes are the same. That means that you don’t need any special knowledge to scale; setting up 50 nodes isn’t much different from setting up one. There’s next to no configuration required to support it. Because all of the replicas in Cassandra are identical, failures of a node won’t disrupt service.
In short, because Cassandra is distributed and decentralized, there is no single point of failure, which supports high availability.
Elastic Scalability
Scalability is an architectural feature of a system that can continue serving a greater number of requests with little degradation in performance. Vertical scaling—simply adding more hardware capacity and memory to your existing machine—is the easiest way to achieve this. Horizontal scaling means adding more machines that have all or some of the data on them so that no one machine has to bear the entire burden of serving requests. But then the software itself must have an internal mechanism for keeping its data in sync with the other nodes in the cluster.
Elastic scalability refers to a special property of horizontal scalability. It means that your cluster can seamlessly scale up and scale back down. To do this, the cluster must be able to accept new nodes that can begin participating by getting a copy of some or all of the data and start serving new user requests without major disruption or reconfiguration of the entire cluster. You don’t have to restart your process. You don’t have to change your application queries. You don’t have to manually rebalance the data yourself. Just add another machine—Cassandra will find it and start sending it work.
Scaling down, of course, means removing some of the processing capacity from your cluster. You might do this for business reasons, such as adjusting to seasonal workloads in retail or travel applications. Or perhaps there will be technical reasons such as moving parts of your application to another platform. As much as we try to minimize these situations, they still happen. But when they do, you won’t need to upset the entire apple cart to scale back.
High Availability and Fault Tolerance
In general architecture terms, the availability of a system is measured according to its ability to fulfill requests. But computers can experience all manner of failure, from hardware component failure to network disruption to corruption. Any computer is susceptible to these kinds of failure. There are of course very sophisticated (and often prohibitively expensive) computers that can themselves mitigate many of these circumstances, as they include internal hardware redundancies and facilities to send notification of failure events and hot swap components. But anyone can accidentally break an Ethernet cable, and catastrophic events can beset a single data center. So for a system to be highly available, it must typically include multiple networked computers, and the software they’re running must then be capable of operating in a cluster and have some facility for recognizing node failures and failing over requests to another part of the system.
Cassandra is highly available. You can replace failed nodes in the cluster with no downtime, and you can replicate data to multiple data centers to offer improved local performance and prevent downtime if one data center experiences a catastrophe such as fire or flood.
Tuneable Consistency
Consistency is an overloaded term in the database world, but for our purposes we will use the definition that a read always returns the most recently written value. Consider the case of two customers attempting to put the same item into their shopping carts on an ecommerce site. If I place the last item in stock into my cart an instant after you do, you should get the item added to your cart, and I should be informed that the item is no longer available for purchase. This is guaranteed to happen when the state of a write is consistent among all nodes that have that data.
But as we’ll see later, scaling data stores means making certain trade-offs between data consistency, node availability, and partition tolerance. Cassandra is frequently called “eventually consistent,” which is a bit misleading. Out of the box, Cassandra trades some consistency in order to achieve total availability. But Cassandra is more accurately termed “tuneably consistent,” which means it allows you to easily decide the level of consistency you require, in balance with the level of availability.
Let’s take a moment to unpack this, as the term “eventual consistency” has caused some uproar in the industry. Some practitioners hesitate to use a system that is described as “eventually consistent.”
For detractors of eventual consistency, the broad argument goes something like this: eventual consistency is maybe OK for social web applications where data doesn’t really matter. After all, you’re just posting to Mom what little Billy ate for breakfast, and if it gets lost, it doesn’t really matter. But the data I have is actually really important, and it’s ridiculous to think that I could allow eventual consistency in my model.
Set aside the number of large-scale web applications (Amazon, Facebook, Google, Twitter) that use this model, and perhaps there’s something to this argument. Presumably such data is very important indeed to the companies running these applications, because that data is their primary product, and they are multibillion-dollar companies with billions of users to satisfy in a sharply competitive world. It may be possible to gain guaranteed, immediate, and perfect consistency throughout a highly trafficked system running in parallel on a variety of networks, but if you want clients to get their results sometime this year, it’s a very tricky proposition.
The detractors claim that databases like Cassandra have merely eventual consistency, and that all other distributed systems have strict consistency. As with so many things in the world, however, the reality is not so black and white, and the binary opposition between consistent and not-consistent is not truly reflected in practice. There are instead degrees of consistency, and in the real world they are very susceptible to external circumstance.
Eventual consistency is one of several consistency models available to architects. Let’s take a look at these models so we can understand the trade-offs:
- Strict consistency
-
This is sometimes called sequential consistency, and is the most stringent level of consistency. It requires that any read will always return the most recently written value. That sounds perfect, and it’s exactly what I’m looking for. I’ll take it! However, upon closer examination, what do we find? What precisely is meant by “most recently written”? Most recently to whom? In one single-processor machine, this is no problem to observe, as the sequence of operations is known to the one clock. But in a system executing across a variety of geographically dispersed data centers, it becomes much more slippery. Achieving this implies some sort of global clock that is capable of timestamping all operations, regardless of the location of the data or the user requesting it or how many (possibly disparate) services are required to determine the response.
- Causal consistency
-
This is a slightly weaker form of strict consistency. It does away with the fantasy of the single global clock that can magically synchronize all operations without creating an unbearable bottleneck. Instead of relying on timestamps, causal consistency takes a more semantic approach, attempting to determine the cause of events to create some consistency in their order. It means that writes that are potentially related must be read in sequence. If two different, unrelated operations suddenly write to the same field at the same time, then those writes are inferred not to be causally related. But if one write occurs after another, we might infer that they are causally related. Causal consistency dictates that causal writes must be read in sequence.
- Weak (eventual) consistency
-
Eventual consistency means on the surface that all updates will propagate throughout all of the replicas in a distributed system, but that this may take some time. Eventually, all replicas will be consistent.
Eventual consistency becomes suddenly very attractive when you consider what is required to achieve stronger forms of consistency.
When considering consistency, availability, and partition tolerance, we can achieve only two of these goals in a given distributed system, a trade-off known as the CAP theorem (we explore this theorem in more depth in “Brewer’s CAP Theorem”). At the center of the problem is data update replication. To achieve a strict consistency, all update operations will be performed synchronously, meaning that they must block, locking all replicas until the operation is complete, and forcing competing clients to wait. A side effect of such a design is that during a failure, some of the data will be entirely unavailable. As Amazon CTO Werner Vogels puts it, “rather than dealing with the uncertainty of the correctness of an answer, the data is made unavailable until it is absolutely certain that it is correct.”1
We could alternatively take an optimistic approach to replication, propagating updates to all replicas in the background in order to avoid blowing up on the client. The difficulty this approach presents is that now we are forced into the situation of detecting and resolving conflicts. A design approach must decide whether to resolve these conflicts at one of two possible times: during reads or during writes. That is, a distributed database designer must choose to make the system either always readable or always writable.
Dynamo and Cassandra choose to be always writable, opting to defer the complexity of reconciliation to read operations, and realize tremendous performance gains. The alternative is to reject updates amidst network and server failures.
In Cassandra, consistency is not an all-or-nothing proposition. A more accurate term is “tuneable consistency” because the client can control the number of replicas to block on for all updates. This is done by setting the consistency level against the replication factor.
The replication factor lets you decide how much you want to pay in performance to gain more consistency. You set the replication factor to the number of nodes in the cluster you want the updates to propagate to (remember that an update means any add, update, or delete operation).
The consistency level is a setting that clients must specify on every operation and that allows you to decide how many replicas in the cluster must acknowledge a write operation or respond to a read operation in order to be considered successful. That’s the part where Cassandra has pushed the decision for determining consistency out to the client.
So if you like, you could set the consistency level to a number equal to the replication factor, and gain stronger consistency at the cost of synchronous blocking operations that wait for all nodes to be updated and declare success before returning. This is not often done in practice with Cassandra, however, for reasons that should be clear (it defeats the availability goal, would impact performance, and generally goes against the grain of why you’d want to use Cassandra in the first place). So if the client sets the consistency level to a value less than the replication factor, the update is considered successful even if some nodes are down.
Brewer’s CAP Theorem
In order to understand Cassandra’s design and its label as an “eventually consistent” database, we need to understand the CAP theorem. The CAP theorem is sometimes called Brewer’s theorem after its author, Eric Brewer.
While working at the University of California at Berkeley, Eric Brewer posited his CAP theorem in 2000 at the ACM Symposium on the Principles of Distributed Computing. The theorem states that within a large-scale distributed data system, there are three requirements that have a relationship of sliding dependency:
- Consistency
-
All database clients will read the same value for the same query, even given concurrent updates.
- Availability
-
All database clients will always be able to read and write data.
- Partition tolerance
-
The database can be split into multiple machines; it can continue functioning in the face of network segmentation breaks.
Brewer’s theorem is that in any given system, you can strongly support only two of the three. This is analogous to the saying you may have heard in software development: “You can have it good, you can have it fast, you can have it cheap: pick two.”
We have to choose between them because of this sliding mutual dependency. The more consistency you demand from your system, for example, the less partition-tolerant you’re likely to be able to make it, unless you make some concessions around availability.
The CAP theorem was formally proved to be true by Seth Gilbert and Nancy Lynch of MIT in 2002. In distributed systems, however, it is very likely that you will have network partitioning, and that at some point, machines will fail and cause others to become unreachable. Networking issues such as packet loss or high latency are nearly inevitable and have the potential to cause temporary partitions. This leads us to the conclusion that a distributed system must do its best to continue operating in the face of network partitions (to be partition tolerant), leaving us with only two real options to compromise on: availability and consistency.
Figure 2-1 illustrates visually that there is no overlapping segment where all three are obtainable.
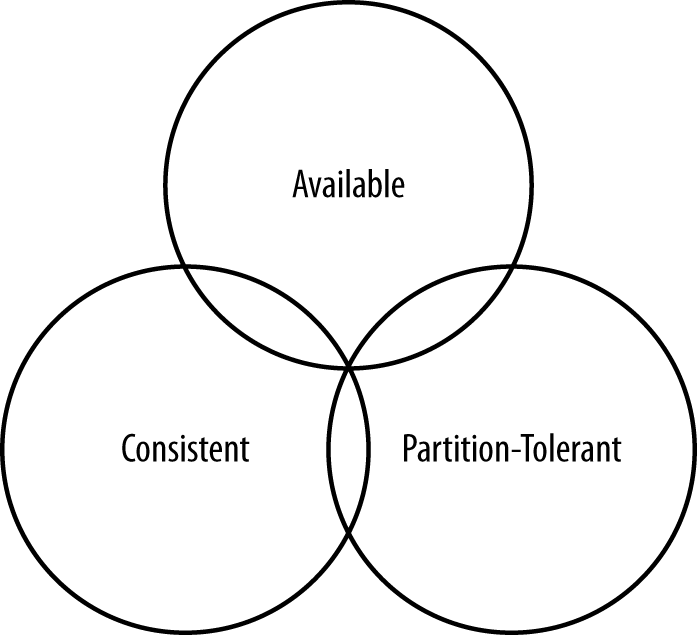
Figure 2-1. CAP theorem indicates that you can realize only two of these properties at once
It might prove useful at this point to see a graphical depiction of where each of the non-relational data stores we’ll look at falls within the CAP spectrum. The graphic in Figure 2-2 was inspired by a slide in a 2009 talk given by Dwight Merriman, CEO and founder of MongoDB, to the MySQL User Group in New York City. However, we have modified the placement of some systems based on research.

Figure 2-2. Where different databases appear on the CAP continuum
Figure 2-2 shows the general focus of some of the different databases we discuss in this chapter. Note that placement of the databases in this chart could change based on configuration. As Stu Hood points out, a distributed MySQL database can count as a consistent system only if you’re using Google’s synchronous replication patches; otherwise, it can only be available and partition tolerant (AP).
It’s interesting to note that the design of the system around CAP placement is independent of the orientation of the data storage mechanism; for example, the CP edge is populated by graph databases and document-oriented databases alike.
In this depiction, relational databases are on the line between consistency and availability, which means that they can fail in the event of a network failure (including a cable breaking). This is typically achieved by defining a single primary replica, which could itself go down, or an array of servers that simply don’t have sufficient mechanisms built in to continue functioning in the case of network partitions.
Graph databases such as Neo4J and the set of databases derived at least in part from the design of Google’s Bigtable database (such as MongoDB, HBase, Hypertable, and Redis) all are focused slightly less on availability and more on ensuring consistency and partition tolerance.
Finally, the databases derived from Amazon’s Dynamo design include Cassandra, Project Voldemort, CouchDB, and Riak. These are more focused on availability and partition tolerance. However, this does not mean that they dismiss consistency as unimportant, any more than Bigtable dismisses availability. According to the Bigtable paper, the average percentage of server hours that “some data” was unavailable is 0.0047% (section 4), so this is relative, as we’re talking about very robust systems already. If you think of each of these letters (C, A, P) as knobs you can tune to arrive at the system you want, Dynamo derivatives are intended for employment in the many use cases where “eventual consistency” is tolerable and where “eventual” is a matter of milliseconds, read repairs mean that reads will return consistent values, and you can achieve strong consistency if you want to.
So what does it mean in practical terms to support only two of the three facets of CAP?
- CA
-
To primarily support consistency and availability means that you’re likely using two-phase commit for distributed transactions. It means that the system will block when a network partition occurs, so it may be that your system is limited to a single data center cluster in an attempt to mitigate this. If your application needs only this level of scale, this is easy to manage and allows you to rely on familiar, simple structures.
- CP
-
To primarily support consistency and partition tolerance, you may try to advance your architecture by setting up data shards in order to scale. Your data will be consistent, but you still run the risk of some data becoming unavailable if nodes fail.
- AP
-
To primarily support availability and partition tolerance, your system may return inaccurate data, but the system will always be available, even in the face of network partitioning. DNS is perhaps the most popular example of a system that is massively scalable, highly available, and partition tolerant.
Note that this depiction is intended to offer an overview that helps draw distinctions between the broader contours in these systems; it is not strictly precise. For example, it’s not entirely clear where Google’s Bigtable should be placed on such a continuum. The Google paper describes Bigtable as “highly available,” but later goes on to say that if Chubby (the Bigtable persistent lock service) “becomes unavailable for an extended period of time [caused by Chubby outages or network issues], Bigtable becomes unavailable” (section 4). On the matter of data reads, the paper says that “we do not consider the possibility of multiple copies of the same data, possibly in alternate forms due to views or indices.” Finally, the paper indicates that “centralized control and Byzantine fault tolerance are not Bigtable goals” (section 10). Given such variable information, you can see that determining where a database falls on this sliding scale is not an exact science.
Row-Oriented
Cassandra’s data model can be described as a partitioned row store, in which data is stored in sparse multidimensional hashtables. “Sparse” means that for any given row you can have one or more columns, but each row doesn’t need to have all the same columns as other rows like it (as in a relational model). “Partitioned” means that each row has a unique key which makes its data accessible, and the keys are used to distribute the rows across multiple data stores. Somewhat confusingly, this type of data model is also frequently referred to as a wide column store, for example by the DB Engines website.
Row-Oriented Versus Column-Oriented
Cassandra has frequently been referred to as a column-oriented or columnar database, but this is not technically correct. The mistake is based on confusion between similar sounding terms. A column-oriented database is one in which the data is stored by columns, as opposed to relational databases, which store data in rows (hence the term row-oriented). Column-oriented databases such as Apache HBase or Apache Kudu are designed for analytic use cases.
In the relational storage model, all of the columns for a table are defined beforehand and space is allocated for each column whether it is populated or not. In contrast, Cassandra stores data in a multidimensional, sorted hash table. As data is stored in each column, it is stored as a separate entry in the hash table. Column values are stored according to a consistent sort order, omitting columns that are not populated, which enables more efficient storage and query processing. We’ll examine Cassandra’s data model in more detail in Chapter 4.
High Performance
Cassandra was designed specifically from the ground up to take full advantage of multiprocessor/multi-core machines, and to run across many dozens of these machines housed in multiple data centers. It scales consistently and seamlessly to hundreds of terabytes. Cassandra has been shown to perform exceptionally well under heavy load. It consistently can show very fast throughput for writes per second on basic commodity computers, whether physical hardware or virtual machines. As you add more servers, you can maintain all of Cassandra’s desirable properties without sacrificing performance.
Where Did Cassandra Come From?
The Cassandra data store is an open source Apache project. Cassandra originated at Facebook in 2007 to solve its inbox search problem—the company had to deal with large volumes of data in a way that was difficult to scale with traditional methods. Specifically, the team had requirements to handle huge volumes of data in the form of message copies, reverse indices of messages, and many random reads and many simultaneous random writes.
The team was led by Jeff Hammerbacher, with Avinash Lakshman, Karthik Ranganathan, and Facebook engineer on the Search Team Prashant Malik as key engineers. The code was released as an open source Google Code project in July 2008. During its tenure as a Google Code project in 2008, the code was updatable only by Facebook engineers, and little community was built around it as a result. So in March 2009, it was moved to an Apache Incubator project, and on February 17, 2010, it was voted into a top-level project. On the Apache Cassandra Wiki, you can find a list of the committers, many of whom have been with the project since 2010/2011. The committers represent companies including Twitter, LinkedIn, Apple, as well as independent developers.
The Paper that Introduced Cassandra to the World
“A Decentralized Structured Storage System” by Facebook’s Lakshman and Malik was a central paper on Cassandra. An updated commentary on this paper was provided by Jonathan Ellis corresponding to the 2.0 release, noting changes to the technology since the transition to Apache.
As commercial interest in Cassandra grew, the need for production support became apparent. Jonathan Ellis, the first Apache Project Chair for Cassandra, and his colleague Matt Pfeil formed a services company called DataStax (originally known as Riptano) in April of 2010. DataStax provided leadership and support for the Cassandra project, employing several Cassandra committers, as well as free products including Cassandra drivers for various languages and tools for development and administration of Cassandra. Paid product offerings include enterprise versions of the Cassandra server and tools, integrations with other data technologies, and product support.
During the period from 2010-2016, the Apache Project matured Cassandra over a series of releases from 0.6 to 3.0. While the original API provided by Cassandra was based on Apache Thrift, the introduction of the Cassandra Query Language in the 0.8 release marked a major shift toward improved usability and devloper productivity due to its similarity with the SQL known by many from their previous RDBMS experience. With the completion of a new storage engine in the 3.0 release, the Cassandra codebase is fully aligned from top to bottom around the CQL data model.
After the 3.0 release in 2016, Nate McCall took on the role of Apache Project Chair for Cassandra. This period has been marked by continued growth in the community, with enterprises including Apple, Facebook / Instagram, Netflix, and Uber providing increased contributions to the project, as well as significant contributions from consultancies such as The Last Pickle and Pythian toward both the core database and supporting tooling. These efforts have culminated in the release of Cassandra 4.0 in late 2019.
A well-known axiom in the software industry is that it takes 5-10 years for a new database engine to reach a true battle-hardened level of maturity, and it has become clear that Cassandra has reached this milestone. As Patrick McFadin, VP of Developer Relations at DataStax is fond of saying, “Everyone seems to have a bit of Cassandra running somewhere in their infrastructure.”
Is Cassandra a Good Fit for My Project?
We have now unpacked the elevator pitch and have an understanding of Cassandra’s advantages. Despite Cassandra’s sophisticated design and smart features, it is not the right tool for every job. So in this section, let’s take a quick look at what kind of projects Cassandra is a good fit for.
Large Deployments
You probably don’t drive a semitruck to pick up your dry cleaning; semis aren’t well suited for that sort of task. Lots of careful engineering has gone into Cassandra’s high availability, tuneable consistency, peer-to-peer protocol, and seamless scaling, which are its main selling points. None of these qualities is even meaningful in a single-node deployment, let alone allowed to realize its full potential.
There are, however, a wide variety of situations where a single-node relational database is all we may need. So do some measuring. Consider your expected traffic, throughput needs, and SLAs. There are no hard-and-fast rules here, but if you expect that you can reliably serve traffic with an acceptable level of performance with just a few relational databases, it might be a better choice to do so, simply because RDBMSs are easier to run on a single machine and are more familiar.
If you think you’ll need at least several nodes to support your efforts, however, Cassandra might be a good fit. If your application is expected to require dozens of nodes, Cassandra might be a great fit.
Lots of Writes, Statistics, and Analysis
Consider your application from the perspective of the ratio of reads to writes. Cassandra is optimized for excellent throughput on writes.
Many of the early production deployments of Cassandra involved storing user activity updates, social network usage, recommendations/reviews, and application statistics. These are strong use cases for Cassandra because they involve lots of writing with less predictable read operations, and because updates can occur unevenly with sudden spikes. In fact, the ability to handle application workloads that require high performance at significant write volumes with many concurrent client threads is one of the primary features of Cassandra.
According to the project wiki, Cassandra has been used to create a variety of applications, including a windowed time-series store, an inverted index for document searching, and a distributed job priority queue.
Geographical Distribution
Cassandra has out-of-the-box support for geographical distribution of data. You can easily configure Cassandra to replicate data across multiple data centers. If you have a globally deployed application that could see a performance benefit from putting the data near the user, Cassandra could be a great fit.
Hybrid- and Multi-Cloud Deployment
Another benefit of Cassandra’s flexible deployment means that not only can you deploy it across multiple data centers, these data centers can be from multiple different providers. This makes Cassandra a great choice for a variety of different topologies. In a hybrid-cloud architecture, you might use Cassandra to replicate data from a traditional on-premises data center to data centers within your favorite publc cloud provider as part of a digital transformation effort.
Further down the road, you might adopt a multi-cloud architecture and leverage Cassandra to replicate data between clouds in order to make that data accessible to best-of-breed managed services offered by the top providers, such as a machine learning service. Or perhaps you need your data accessible in multiple clouds in order to ensure the highest possible availability for a mission-critical application. After all, even the big public clouds have been known to have occasional region-wide outages. The good news is that the challenging part of a multi-cloud Cassandra deployment is more likely to be the network configuration, not the database.
Getting Involved
The strength and relevance of any technology depend on the investment of individuals in a vibrant community environment. Thankfully, the Cassandra community is active and healthy, offering a number of ways for you to participate. The awesome-cassandra list maintained by Rahul Singh is a great resource that provides a comprehensive list of Cassandra resources; we’ll highlight a few items here:
- Forums
-
Cassandra is a popular topic on forums including Stack Overflow and Quora. DataStax maintains a community site at community.datastax.com which features areas for both the open-source project as well as DataStax products.
- Mailing lists
-
The Apache project hosts several mailing lists to which you can subscribe to learn about various topics of interest:
-
[email protected] provides a general discussion list for users and is frequently used by new users or those needing assistance.
-
[email protected] is used by developers to discuss changes, prioritize work, and approve releases.
-
[email protected] is used for discussion specific to development of Cassandra clients for various programming languages.
-
[email protected] tracks Cassandra code commits. This is a fairly high volume list and is primarily of interest to committers.
-
Releases are typically announced to both the developer and user mailing lists.
- Chat
-
Many of the Cassandra developers and community members hang out in the
cassandraandcassandra-devchannels on the Apache Software Foundation’s Slack. This informal environment is a great place to get your questions answered or offer up some answers of your own. You can get an invitation to join the Slack org at s.apache.org/slack-invite. - Blogs
-
The Apache Cassandra Blog provides deep-dive technical articles on Cassandra implementation details and features under development. Other blogs that reference Cassandra frequently include the DataStax Developer Blog, the Instaclustr Blog and the Last Pickle Blog.
- Issues and Improvements
-
If you encounter issues using Cassandra and feel you have discovered a defect, you should feel free to submit an issue to the Cassandra JIRA. In fact, users who identify defects on the [email protected] list are frequently encouraged to create JIRA issues.
In November 2019, the Cassandra community formally approved a Cassandra Enhancement Proposal (CEP) process to promote effective collaboration between project contributors toward development of new features and significant changes.
- Meetups
-
A meetup group is a local community of people who meet face to face to discuss topics of common interest. These groups provide an excellent opportunity to network, learn, or share your knowledge by offering a presentation of your own. There are Cassandra meetups on every continent, so you stand a good chance of being able to find one in your area.
- Conferences
-
Cassandra is a popular topic at the ApacheCon conferences hosted by the Apache Software Foundation as well as the Strata Data Conferences hosted by O’Reilly. The Cassandra Project Management Committee (PMC) periodically hosts Next Generation Cassandra Conferences (NGCC) where Cassandra committers and other contributors share research and proposals for nenhancements and new features. After hosting a Cassandra Summit from 2012-2016, DataStax resumed hosting conferences in 2019 with Accelerate, a conference focused on Cassandra and DataStax technologies.
- Training
-
DataStax offers training and certification on Apache Cassandra and DataStax Enterprise at DataStax Academy.
A Marketable Skill
There continues to be increased demand for Cassandra developers and administrators. A 2015 Dice.com salary survey placed Cassandra as the second most highly compensated software skill set. (More recent surveys are available but require login.)
Summary
In this chapter, we’ve taken an introductory look at Cassandra’s defining characteristics, history, and major features. We have learned about the Cassandra user community and how companies are using Cassandra. Now we’re ready to start getting some hands-on experience.