
“I would advise students to pay more attention to the fundamental ideas rather than the latest technology. The technology will be out-of-date before they graduate. Fundamental ideas never get out of date.”
—David L. Parnas
In this chapter, I introduce the most important and fundamental principles of well-designed and well-crafted software. What makes these principles special is the fact that they are not tied to certain programming paradigms or programming languages. Some of them are not even specific to software development. For instance, the discussed KISS principle, an acronym for “keep it simple, stupid,” can be relevant to many areas of life. Generally speaking, it is not a bad idea to make everything as simple in life as possible—not only software development.
This means that you should not learn the following principles once and then forget them. I strongly recommend you internalize them. These principles are so important that they should ideally become second nature to every developer. Many of the more concrete principles I discuss later in this book have their roots in these basic principles.
What Is a Principle?
In this book you will find various principles for better C++ code and well-designed software. But what is a principle in general?
Many people have principles that guide them through their life. For example, if you’re against eating meat for several reasons, that would be a principle. If you want to protect your child, you give him principles along the way, guiding him to make the right decisions on their own, for example “Be careful and don’t talk to strangers!” With this principle in mind, the child can deduce the correct behavior in certain specific situations.
A principle is a kind of rule, belief, or idea that guides you. Principles are often directly coupled to values or a value system. For instance, we don’t need to be told that cannibalism is wrong because humans have an innate value regarding human life. And as a further example, the well-known “Manifesto for Agile Software Development” [Beck01] contains 12 principles that guide project teams in uncovering better ways to develop software.
Principles are not irrevocable laws. They are not carved in stone. Willful violations of principles are sometimes necessary in programming. If you have very good reasons to violate principles, do so, but do so very carefully! It should be an exception.
Some of the following basic principles are, at various points later in the book, revisited and deepened.
KISS
“Everything should be made as simple as possible, but not simpler.”
—Albert Einstein, theoretical physicist, 1879 - 1955
KISS is an acronym for “keep it simple, stupid” or “keep it simple and stupid” (okay, I know, there are other meanings for this acronym, but these two are the most common ones). In eXtreme Programming (XP), this principle is represented by a practice called “do the simplest thing that could possibly work” (DTSTTCPW). The KISS principle states that simplicity should be a major goal in software development, and that unnecessary complexity should be avoided.
I think that KISS is one of those principles that developers often forget when they are developing software. Software developers tend to write code in some elaborate way and make things more complicated than they should be. I know we are all excellently skilled and highly motivated developers, and we know everything about design and architecture patterns, frameworks, technologies, tools, and other cool and fancy stuff. Crafting cool software is not just our 9-to-5 job—it is our mission and we achieve fulfillment through our work.
But we have to keep in mind that any software system has an intrinsic complexity that is already challenging in itself. No doubt, complex problems often require complex code. The intrinsic complexity cannot be reduced. This kind of complexity is just there, due to the requirements to be fulfilled by the system. But it would be fatal to add unnecessary, homemade complexity to this intrinsic complexity. Therefore, it is advisable not to use every fancy feature of your language or cool design patterns just because you can. On the other hand, do not overplay simplicity. If 10 decisions are necessary in a switch-case statement and there is no better, alternative solution, that’s just how it is.
“Focusing on simplicity is probably one of the most difficult things for a programmer to do. And it is a life long learning experience.”
—Adrian Bolboaca (@adibolb), April 3, 2014, on Twitter
YAGNI
“Always implement things when you actually need them, never when you just foresee that you need them.”
—Ron Jeffries, You’re NOT gonna need it! [Jeffries98]
This principle is tightly coupled to the previously discussed KISS principle. YAGNI is an acronym for “you aren’t gonna need it!” or is sometimes translated to “you ain’t gonna need it!”. YAGNI is the declaration of war against speculative generalization and over-engineering. It states that you should not write code that is not necessary at the moment, but might be in the future.
Probably every developer knows these kinds of tempting impulses in their daily work: “Maybe we could use it later…”, or “We’re going to need…” No, we aren’t gonna need it! We should under all circumstances avoid producing anything today for an uncertain and speculative future. In most cases, this code is simply not needed. But if we have implemented that unnecessary thing, we’ve wasted our precious time and the code gets more complicated than it should be! And of course, we also violate the previously discussed KISS principle. Even worse, these code pieces could be buggy and could cause serious problems!
My advice is this: Trust in the power of refactoring and build things only when you know that they are actually necessary, not before.
DRY
“Copy and paste is a design error.”
—David L. Parnas
Although this principle is one of the most important, I’m quite sure that it is often violated, unintentionally or intentionally. DRY is an acronym for “don’t repeat yourself!” and states that we should avoid duplication, because duplication is evil. Sometimes this principle is also referred to as “once and only once” (OAOO).
The reason that duplication is very dangerous is obvious: when one piece is changed, its copies must be changed accordingly. And don’t have high hopes. It is a safe bet that change will occur. I think it’s unnecessary to mention that any copied piece will be forgotten sooner or later and we can say hello to bugs.
Okay, that’s it—nothing more to say? Wait, there is still something and we need to go deeper. In fact, I believe that the DRY principle is often misunderstood and also construed too pedantically by many developers! Thus, we should refresh our understanding of this principle.
It’s About Knowledge!
“Don’t Repeat Yourself (or DRY) is probably one of the most misunderstood parts of the book.”
—Dave Thomas, Orthogonality and the DRY Principle, 2003
In their brilliant book, The Pragmatic Programmer [Hunt99], Dave Thomas and Andy Hunt state that applying the DRY principle means that we have to ensure that “every piece of knowledge must have a single, unambiguous, authoritative representation within a system.” It is noticeable that Dave and Andy did not explicitly mention the code, but they talk about the knowledge.
First of all, a system’s knowledge is far broader than just its code. For instance, the DRY principle is also valid for business processes, requirements, database schemes, documentation, project plans, test plans, or the system’s configuration data. DRY affects everything! Perhaps you can imagine that strict compliance with this principle is not as easy as it might seem at first sight.
Building Abstractions Is Sometimes Hard
Moreover, an exaggerated application of the DRY principle at all costs in a code base can lead to some fiddly problems. The reason is that creating an adequate common abstraction from duplicated code pieces can quickly become a tricky task, sometimes deteriorating the readability and comprehensibility of the code.
The annoyance becomes really big if there are requirement changes or functional enhancements that affect only one locus of usage of a multiple used abstraction, as the following example demonstrates.
The Class for the Shopping Cart
The Class Used to Ship the Ordered Products
I’m pretty sure you would agree that these two classes are duplicated code and that they therefore violate the DRY principle. The only difference is the class name; all other lines of code are identical.
Before C++20, if developers wanted to eliminate elements from a container, such as a std::vector, they often applied the so-called Erase-Remove idiom on that container.
In this idiom, two steps were successively applied to the container. First, the algorithm std::remove was used to move those elements that did not match the removal criteria, to the front of the container. The name of this function is misleading, as no elements are actually removed by std::remove, but are shifted to the front of the container.
The Base Class ProductContainer, from which ShoppingCart and Shipment Is Derived
Alternative solutions would be to use C++ templates, or to use composition instead of inheritance, i.e., ShoppingCart and Shipment use ProductContainer for their implementation (see the section entitled “Favor Composition over Inheritance” in Chapter 6).
So, the code for the shopping cart and for the shipment of goods has been identical, and we have removed the duplication now … but wait! Maybe we should stop and ask ourselves the question: Why was the code identical?!
From the perspective of the business stakeholders, there may be very good reasons for making a very clear distinction between the two domain-specific concepts of a shopping basket and the product shipment. It is therefore highly recommended to ask the business people what they think of our idea to map the shopping basket and product shipping to the same piece of code. They might say, “ Well, yes, on first sight a nice idea, but remember that customers can order certain products by any number, but for safety reasons we have to make sure that we never ship more than a certain number of these products with the same delivery.”
By sharing the same code for two (or more) different domain concepts, we have coupled them very closely together. Often there are additional requirements to fulfill, which only affect one of both usages. In such a case, exceptions and special case handlings must be implemented for the several uses of the ProductContainer class. This can become a very tedious task, the readability of the code can suffer, and the initial advantage of the shared abstraction is quickly lost.
The conclusion is this: Reusing code is not basically a bad thing. But overzealous de-duplication of code creates the risk that we reuse code that only “accidentally” or “superficially” behaves the same, but that in fact has different meanings in the different places it is used. Mapping different domain concepts to the same piece of code is dangerous, because there are different reasons that this code needs to be changed.
The DRY principle is only marginally about code. In fact, it’s about knowledge.
Information Hiding
Information hiding is a long-known and fundamental principle in software development. It was first documented in the seminal paper “On the Criteria to Be Used in Decomposing Systems Into Modules,” [Parnas72] written by David L. Parnas in 1972.
The principle states that one piece of code that calls another piece of code should not “know” the internals about that other piece of code. This makes it possible to change internal parts of the called piece of code without being forced to change the calling piece of code accordingly.
David L. Parnas describes information hiding as the basic principle for decomposing systems into modules. Parnas argued that system modularization should concern the hiding of difficult design decisions or design decisions that are likely to change. The fewer internals a software unit (e.g., a class or component) exposes to its environment, the lesser is the coupling between the implementation of the unit and its clients. As a result, changes in the internal implementation of a software unit will not be propagated to its environment.
Limitation of the consequences of changes in modules
Minimal influence on other modules if a bug fix is necessary
Significantly increasing the reusability of modules
Better testability of modules
Information hiding is often confused with encapsulation, but it’s not the same. I know that both terms have been used in many noted books synonymously, but I don’t agree. Information hiding is a design principle for aiding developers in finding good modules. The principle works at multiple levels of abstraction and unfolds its positive effect, especially in large systems.
Encapsulation is often a programming-language dependent technique for restricting access to the innards of a module. For instance, in C++ you can precede a list of class members with the private keyword to ensure that they cannot be accessed from outside the class. But just because we use these guards for access control, we are still far away from getting information hiding automatically. Encapsulation facilitates, but does not guarantee, information hiding.
A Class for Automatic Door Steering (Excerpt)
An Example of How AutomaticDoor Must Be Used to Query the Door’s Current State
With C++11 there has also been an innovation on enumerations types. For downward compatibility to earlier C++ standards, there is still the well-known enumeration with its keyword enum. Since C++11, there are also the enumeration classes.
It is strongly recommended to use enumeration classes instead of plain old enums for a modern C++ program, because it makes the code safer. And because enumeration classes are also classes, they can be forward declared.
What will happen if the internal implementation of AutomaticDoor must be changed and the enumeration class State is removed from the class? It is easy to see that this will have a significant impact on the client’s code. It will result in changes everywhere that member function AutomaticDoor::getState() is used.
A Better Designed Class for Automatic Door Steering
An Example of How Elegant Class AutomaticDoor Can Be Used After it Was Changed
Now it’s much easier to change the innards of AutomaticDoor. The client code does not depend on internal parts of the class anymore. You can remove the State enumeration and replace it with another kind of implementation without users of the class noticing this.
Strong Cohesion
A general piece of advice in software development is that any software entity (i.e., module, component, unit, class, function, etc.) should have a strong (or high) cohesion. In very general terms, cohesion is strong when the module does a well-defined job.
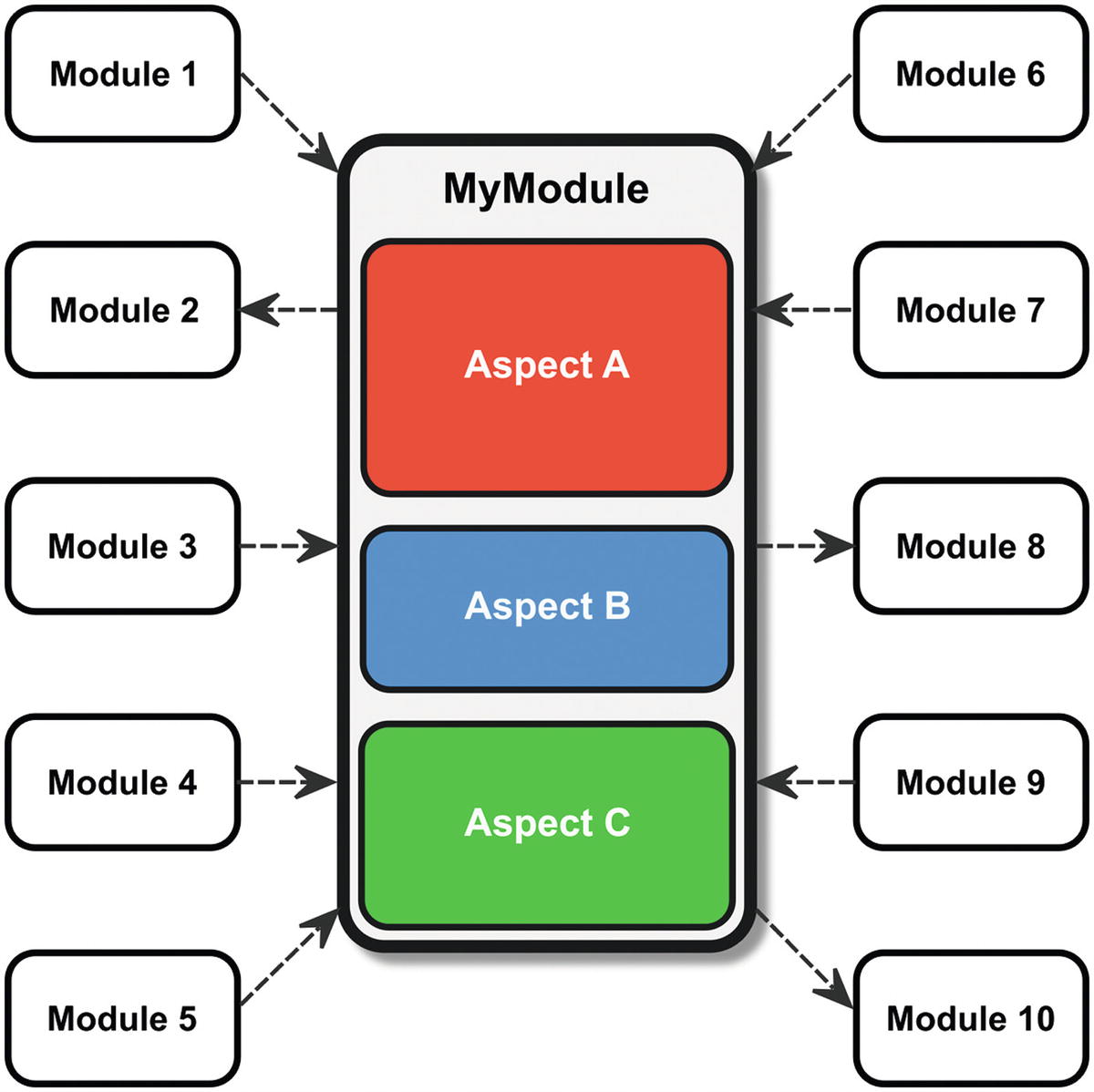
MyModule has too many responsibilities, and this leads to many dependencies from and to other modules
In this illustration of the modularization of an arbitrary system, three different aspects of the business domain are placed inside one single module. Aspects A, B, and C have nothing, or nearly nothing, in common, but all three are placed inside MyModule. Looking at the module’s code could reveal that the functions of A, B, and C are operating on different, and completely independent, pieces of data.
Now look at all the dashed arrows in that picture. Each of them is a dependency. The element at the tail of such an arrow requires the element at the head of the arrow for its implementation. In this case, any other module of the system that wants to use services offered by A, or B, or C will make itself dependent from the whole module MyModule. The major drawback of such a design is obvious: it will result in too many dependencies and the maintainability goes down the drain.

High cohesion: The previously mixed aspects A, B, and C have been separated into discrete modules
Now it is easy to see that each of these modules has far fewer dependencies than the old MyModule. It is clear that A, B, and C have nothing to do with each other directly. The only module that depends on all three modules A, B, and C is Module 1.

Aspect A is scattered over five modules
Even with this form of weak cohesion, many unfavorable dependencies arise. The distributed fragments of Aspect A must work closely together. That means that every module that implements a subset of Aspect A must interact at least with one other module containing another subset of Aspect A. This leads to a large number of dependencies crosswise through the design. At worst, it can lead to cyclic dependencies, like between Modules 1 and 3, or between Modules 6 and 7. This has, once again, a negative impact on the maintainability and extendibility. Furthermore, the testability is also very poor due to this design.
This kind of design will lead to something that is called shotgun surgery. A certain type of change regarding Aspect A leads to making lots of small changes to many modules. That’s really bad and should be avoided. We have to fix this by pulling all the parts of the code that are fragments of the same logical aspect together into a single cohesive module.
There are certain other principles—for instance, the single responsibility principle (SRP) of object-oriented design (see Chapter 6)—that foster high cohesion. High cohesion often correlates with loose coupling and vice versa.
Loose Coupling
A Switch That Powers a Lamp On and Off

A class diagram of Switch and Lamp
What’s the problem with this design?
The problem is that the Switch contains a direct reference to the concrete class Lamp. In other word, the switch knows that there is a lamp.
Maybe you would argue, “Well, but that’s the purpose of the switch. It has to power on and off lamps.” That’s true if that is the one and only thing the switch should do. If that’s the case, this design might be adequate. But go to a DIY store and look at the switches that you can buy there. Do they know that lamps exist?
And what do you think about the testability of this design? Can the switch be tested independently as it is required for unit testing? No, this is not possible. And what will we do when the switch has to power on not only a lamp, but also a fan or an electric roller blind?
In this example, the switch and the lamp are tightly coupled.
In software development, a loose coupling (also known as low or weak coupling) between modules is best. That means that you should build a system in which each of its modules has, or makes use of, little or no knowledge of the definitions of other separate modules.
The key to achieve loose coupling in object-oriented software designs is to use interfaces. An interface declares publicly accessible behavioral features of a class without committing to a particular implementation of that class. An interface is like a contract. Classes that implement an interface are committed to fulfill the contract, that is, these classes must provide implementations for the method signatures of the interface.
The Switchable Interface
The Modified Switch Class, Whereby Lamp Is Gone
The Lamp Class Implements the Switchable Interface
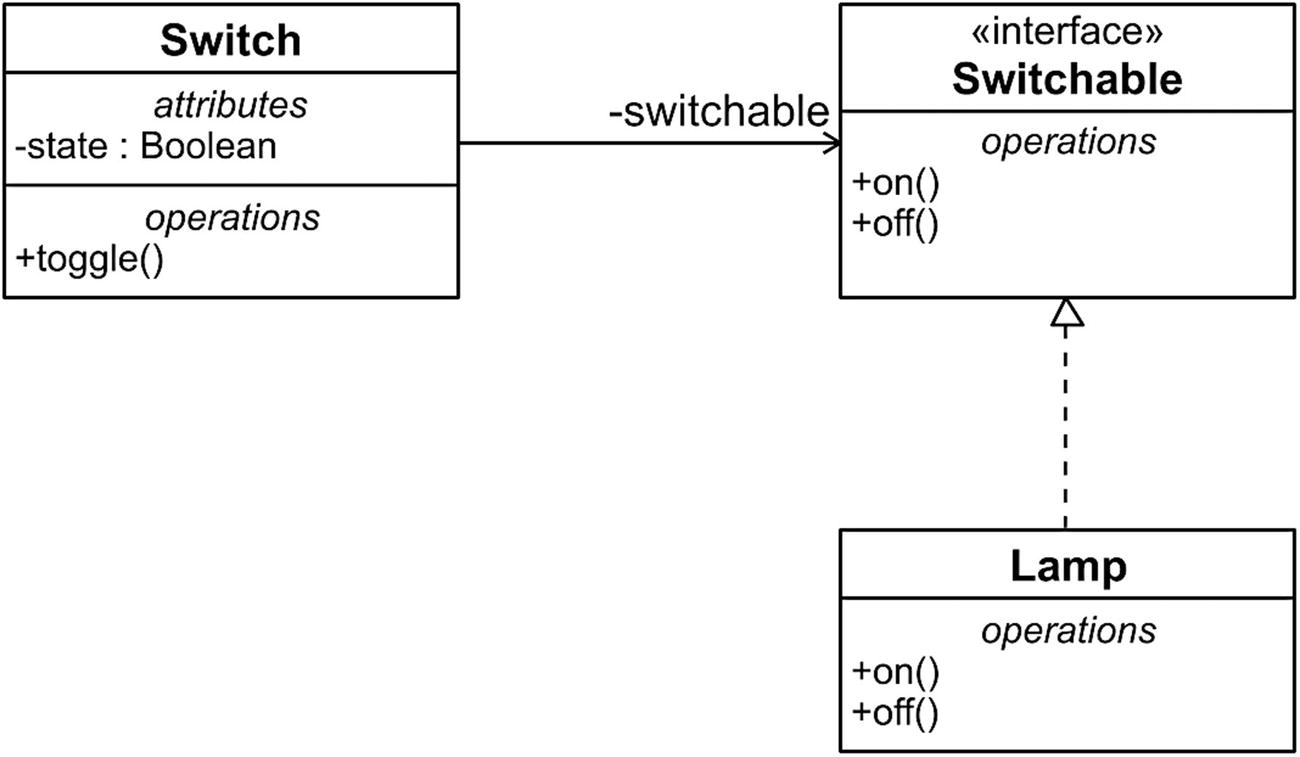
Loosely coupled Switch and Lamp via an interface
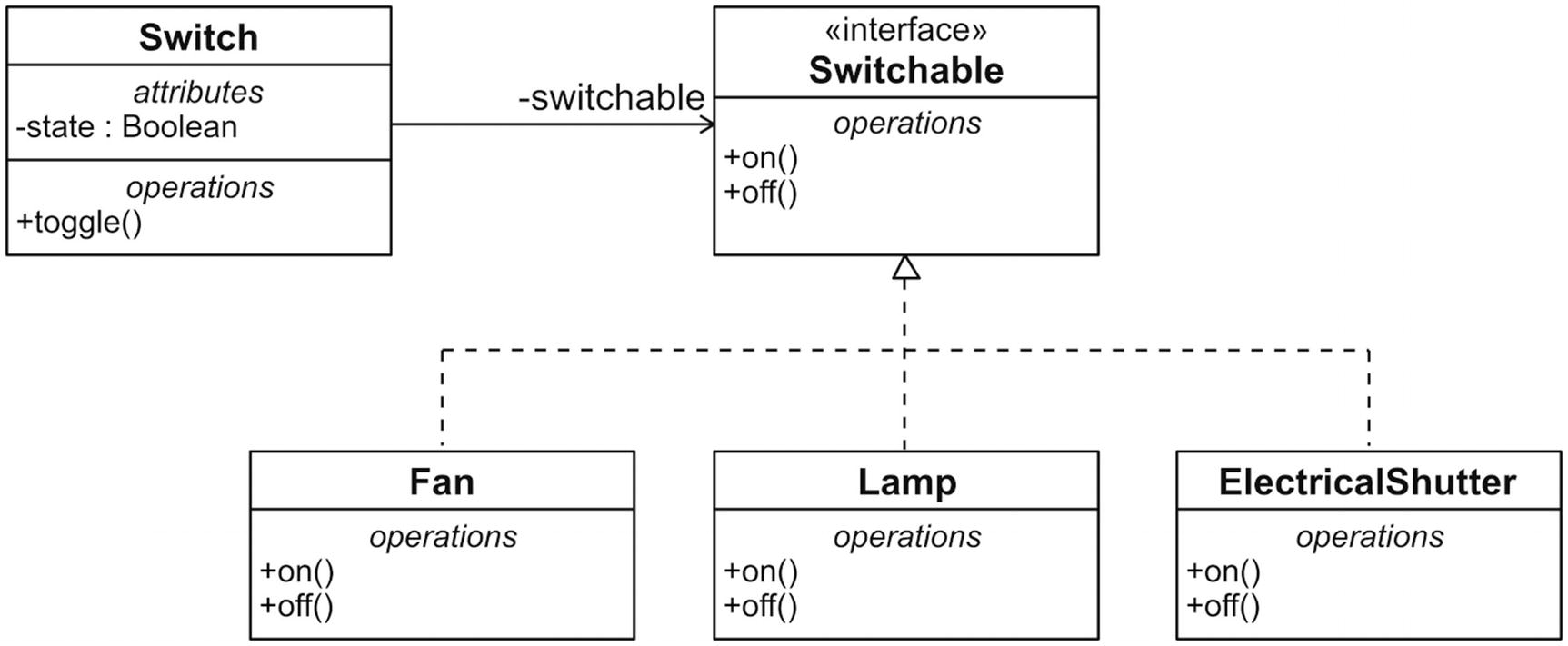
Via an interface, a Switch can control different classes for electrical devices
Attention to loose coupling can provide a high degree of autonomy for individual modules of a system. The principle can be effective at different levels: both at the smallest modules, as well as on the system’s architecture level for large components. High cohesion fosters loose coupling, because a module with a clearly defined responsibility usually depends on fewer collaborators.
Be Careful with Optimizations
“Premature optimization is the root of all evil (or at least most of it) in programming.”
—Donald E. Knuth, American computer scientist [Knuth74]
I’ve seen developers starting time-wasting optimizations just with vague ideas of overhead, but not really knowing where the performance is lost. They often fiddled with individual instructions or tried to optimize small, local loops, to squeeze out even the last drop of performance. Just as a footnote, one of these programmers I’m talking about was me.
The success of these activities is generally marginal. The expected performance advantages usually do not arise. In the end it’s just a waste of precious time. On the contrary, often the understandability and maintainability of the allegedly optimized code suffers drastically. Particularly bad is that sometimes it even happens that bugs are subtly slipped into the code during such optimization measures. My advice is this: As long as there are no explicit performance requirements to satisfy, keep your hands off optimizations.
The comprehensibility and maintainability of our code should be our first goal. And as I explain in the section “But the Call Time Overhead!” in Chapter 4, compilers are nowadays very good at optimizing code. Whenever you feel a desire to optimize something, think about YAGNI.
You should spring into action only when explicit performance requirements (requested by a stakeholder) are not satisfied. First carefully analyze where the performance gets lost. Don’t make any optimizations on the basis of a gut feeling. For instance, you can use a profiler to find out where the bottlenecks are. After using such a tool, developers are often surprised to find that the performance gets lost at a completely different location than where they assumed it to be.
A profiler is a tool for dynamic program analysis. It measures, among other metrics, the frequency and duration of function calls. The gathered profiling information can be used to aid program optimization.
Principle of Least Astonishment (PLA)
The principle of least astonishment (POLA/PLA), also known as the principle of least surprise (POLS), is well known in user interface design and ergonomics. The principle states that the user should not be surprised by unexpected responses of the user interface. The user should not be puzzled by appearing or disappearing controls, confusing error messages, unusual reactions on established keystroke sequences or other unexpected behavior. For example, Ctrl+C is the de facto standard for the Copy command on Windows operating systems, and not to exit a program.
This principle can also be well transferred to API design in software development. Calling a function should not surprise the caller with unexpected behavior or mysterious side effects. A function should do exactly what its function name implies (see the section entitled “Function Naming” in Chapter 4). For instance, calling a getter on an instance of a class should not modify the internal state of that object.
The Boy Scout Rule
This principle is about you and your behavior. It reads as follows: Always leave the campground cleaner than you found it.
Boy scouts are very principled. One of their principles states that they should clean up a mess or pollution in the environment immediately, once they’ve found such issues. As responsible software craftspeople, we should apply this principle to our daily work. Whenever we find something in a piece of code that needs to be improved, or that’s a bad code smell, we should do one of two things. We should fix it immediately if it is a simple change (e.g., renaming a bad named variable). Or we should create a ticket in the issue tracker if it would result in a major refactoring, for example, in the case of a design or architecture problem. It does not matter who the original author of this piece of code was.
Renaming a poorly named class, variable, function, or method (see the sections “Good Names” and “Function Naming” in Chapter 4).
Cutting the innards of a large function into smaller pieces (see the section entitled “Let Them Be Small” in Chapter 4).
Deleting a comment by making the commented piece of code self-explanatory (see the section entitled “Avoid Comments” in Chapter 4).
Cleaning up a complex and puzzling if-else compound.
Removing a small bit of duplicated code (see the section about the DRY principle in this chapter).
Since most of these improvements are code refactorings, a solid safety net consisting of good unit tests, as described in Chapter 2, is essential. Without unit tests in place, you cannot be sure that you won’t break something.
Besides good unit test coverage, we still need a special culture on our team: collective code ownership.
Collective Code Ownership
This principle was first formulated in the context of the eXtreme Programming (XP) movement and addresses the corporate culture as well as the team culture. Collective code ownership means that we should work as a community. Every team member, at any time, is allowed to make a change or extension to any piece of code. There should be no attitude like “this is Sheila’s code, and that’s Fred’s module. I don’t touch them!” It should be considered valueable that other people can easily take over the code we wrote. A set of well-crafted unit tests (see Chapter 2) supports this, as it allows safe refactorings and thus takes away the fear of change. Nobody on a real team should be afraid, or have to obtain permission, to clean up code or add new features to it. With a culture of collective code ownership, the Boy Scout rule explained in the previous section works fine.