
Chapter 6. Simple Design

Design. The Holy Grail and ultimate objective of the software craft. We all seek to create a design so perfect that features can be added without effort and without fuss. A design so robust that, despite months and years of constant maintenance, the system remains facile and flexible. Design, in the end, is what it’s all about.
I have written a great deal about design. I have written books about design principles, design patterns, and architecture. And I am far from the only author to focus on this topic. The amount of literature on software design is enormous.
But that’s not what this chapter is about. You would be well advised to research the topic of design, read those authors, and understand the principles, the patterns, and the overall gestalt of software design and architecture.
But the key to it all, the aspect of design that imbues it with all the characteristics that we desire, is—in a word—simplicity. As Chet Hendrickson1 once said, “Uncle Bob wrote thousands of pages on clean code. Kent Beck wrote four lines.” It is those four lines we focus on here.
1 As cited by Martin Fowler in a tweet quoting Chet Hendrickson at AATC2017. I was in attendance when Chet said it, and I completely agreed with him.
It should be obvious, on the face of it, that the best design for a system is the simplest design that supports all the required features of that system while simultaneously affording the greatest flexibility for change. However, that leaves us to ponder the meaning of simplicity.2 Simple does not mean easy. Simple means untangled; and untangling things is hard.
2 In 2012, Rich Hickey gave a wonderful talk, Simple Made Easy. I encourage you to listen to it. https://www.youtube.com/watch?v=oytL881p-nQ.
What things get tangled in software systems? The most expensive and significant entanglements are those that convolve high-level policies with low-level details. You create terrible complexities when you conjoin SQL with HTML, or frameworks with core values, or the format of a report with the business rules that calculate the reported values. These entanglements are easy to write, but they make it hard to add new features, hard to fix bugs, and hard to improve and clean the design.
A simple design is a design in which high-level policies are ignorant of low-level details. Those high-level policies are sequestered and isolated from low-level details such that changes to the low-level details have no impact on the high-level policies.3
3 I write a great deal about this in Clean Architecture: A Craftsman’s Guide to Software Structure and Design (Addison-Wesley, 2018).
The primary means for creating this separation and isolation is abstraction. Abstraction is the amplification of the essential and the elimination of the irrelevant. High-level policies are essential, so they are amplified. Low-level details are irrelevant, so they are isolated and sequestered.
The physical means we employ for this abstraction is polymorphism. We arrange high-level policies to use polymorphic interfaces to manage the low-level details. Then we arrange the low-level details as implementations of those polymorphic interfaces. This practice keeps all source code dependencies pointing from low-level details to high-level policies and keeps high-level policies ignorant of the implementations of the low-level details. Low-level details can be changed without affecting the high-level policies (Figure 5.1).
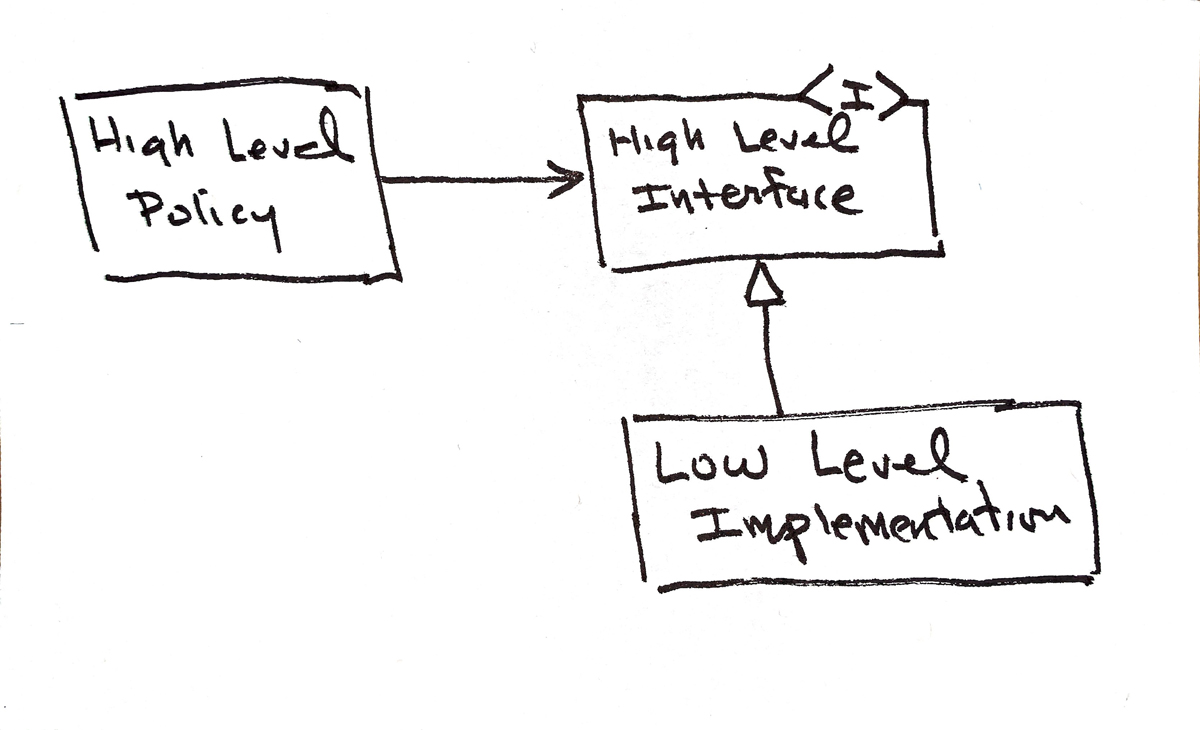
Figure 6.1 Polymorphism
If the best design of a system is the simplest design that supports the features, then we can say that such a design must have the fewest abstractions that manage to isolate high-level policy from low-level detail.
And yet, this was precisely the opposite of the strategy we employed throughout the 1980s and 1990s. In those days, we were obsessed with future-proofing our code by putting the hooks in for the changes we anticipated in the future.
We took this path because software, in those days, was hard to change—even if the design was simple.
Why was software hard to change? Because build times were long and test times were longer.
In the 1980s, a small system might require an hour or more to build and many hours to test. Tests, of course, were manual and were therefore woefully inadequate. As a system grew larger and more complicated, the programmers became ever-more afraid of making changes. This led to a mentality of overdesign, which drove us to create systems that were far more complicated than necessary for the features they had.
We reversed course in the late 1990s with the advent of Extreme Programming and then Agile. By then, our machines had become so massively powerful that build times could be reduced to minutes or even seconds, and we found that we could afford to automate tests that could run very quickly.
Driven by this technological leap, the discipline of YAGNI and the four principles of simple design, described by Kent Beck, became practicable.
YAGNI
What if you aren’t gonna need it?
In 1999, I was teaching an Extreme Programming course with Martin Fowler, Kent Beck, Ron Jeffries, and a host of others. The topic turned to the dangers of overdesign and premature generalization. Someone wrote YAGNI on the white board and said: “You aren’t gonna need it.” Beck interrupted and said something to the effect maybe you are gonna need it, but you should ask yourself: “What if you aren’t?”
That was the original question that YAGNI asked. Every time you thought to yourself, I’m going to need this hook, you then asked yourself what would happen if you didn’t put the hook in. If the cost of leaving the hook out was tolerable, then you probably shouldn’t put it in. If the cost of carrying the hook in the design, year after year, would be high but the odds that you’d eventually need that hook were low, you probably shouldn’t put that hook in.
It is hard to imagine the furor this new perspective raised in the late 1990s. Designers everywhere had gotten very used to putting all the hooks in. In those days, putting the hooks in was considered conventional wisdom and a best practice.
So, when the YAGNI discipline of Extreme Programming surfaced, it was roundly criticized and panned as heresy and claptrap.
Nowadays, ironically, it is one of the most important disciplines of good software design. If you have a good suite of tests and you are skilled at the discipline of refactoring, then the cost of adding a new feature and updating the design to support that new feature will almost certainly be smaller than the cost of implementing and maintaining all the hooks you might need one day.
Hooks are problematic in any case. We seldom get them right. That’s because we are not particularly good at predicting what customers will actually do. Consequently, we tend to put in far more hooks than we need and base those hooks on assumptions that rarely pan out.
The bottom line is that that the effect that gigahertz clock rates and terabyte memories had on the process of software design and architecture took us all by surprise. We did not realize until the late 1990s that those advances would allow us to vastly simplify our designs.
It is one of the great ironies of our industry that the exponential increase of Moore’s law that drove us to build ever-more complex software systems also made it possible to simplify the designs of those systems.
YAGNI, it turns out, is the unintended consequence of the virtually limitless computer power now at our disposal. Because our build times have shrunk down into the seconds and because we can afford to write and execute comprehensive test suites that execute in seconds, we can afford to not put the hooks in and instead refactor the designs as the requirements change.
Does this mean that we never put the hooks in? Do we always design our systems only for the features we need today? Do we never think ahead and plan for the future?
No, that’s not what YAGNI means. There are times when putting a particular hook in is a good idea. Future-proofing the code is not dead, and it is always wise to think of the future.
It’s just that the trade-offs have changed so dramatically in the last few decades that it is now usually better to leave the majority of the hooks out. And that’s why we ask the question:
What if you aren’t gonna need it?
Covered by Tests
The first time I ran across Beck’s rules of simple design was in the first edition of Extreme Programming Explained.4 At that time, the four rules were as follows:
4 Kent Beck, Extreme Programming Explained (Addison-Wesley, 1999).
1. The system (code and tests) must communicate everything you want to communicate.
2. The system must contain no duplicate code.
3. The system should have the fewest possible classes.
4. The system should have the fewest possible methods.
By 2011, they had evolved to these:
1. Tests pass.
2. Reveal intent.
3. No duplication.
4. Small.
By 2014, Corey Haines had written a book5 about those four rules:
5 Corey Haines, Understanding the Four Rules of Simple Design (Leanpub, 2014).
In 2015, Martin Fowler wrote a blog6 about them in which he rephrased them:
6 Martin Fowler, “BeckDesignRules,” March 2, 2015, https://martinfowler.com/bliki/BeckDesignRules.html.
1. Passes the tests.
2. Reveals intention.
3. No duplication.
4. Fewest elements.
In this book I express the first rule as
1. Covered by tests.
Notice how the emphasis of that first rule has changed over the years. The first rule split in two and the last two rules merged into one. Notice also that, as the years went by, tests grew in importance from communication to coverage.
Coverage
The concept of tests coverage is an old one. The first mention I was able to find goes all the way back to 1963.7 The article begins with two paragraphs that I think you’ll find interesting, if not evocative.
7 Joan Miller and Clifford J Maloney, “Systematic Mistake Analysis of Digital Computer Programs,” Communications of the ACM 6, no. 2 (1963): 58–63.
Effective program checkout is imperative to any complex computer program. One or more test cases are always run for a program before it is considered ready for application to the actual problem. Each test case checks that portion of the program actually used in its computation. Too often, however, mistakes show up as late as several months (or even years) after a program has been put into operation. This is an indication that the portions of the program called upon only by rarely occurring input conditions have not been properly tested during the checkout stage.
In order to rely with confidence upon any particular program it is not sufficient to know that the program works most of the time or even that it has never made a mistake so far. The real question is whether it can be counted upon to fulfill its functional specifications successfully every single time. This means that, after a program has passed the checkout stage, there should be no possibility that an unusual combination of input data or conditions may bring to light an unexpected mistake in the program. Every portion of the program must be utilized during checkout in order that its correctness be confirmed.
Nineteen sixty-three was only seventeen years after the very first program ran on the very first electronic computer,8 and already we knew that the only way to effectively mitigate the threat of software errors is to test every single line of code.
8 Presuming that the first computer was the Automated Computing Engine and that the first program executed in 1946.
Code coverage tools have been around for decades. I don’t remember when I first encountered them. I think it was in the late 1980s or early 1990s. At the time, I was working on Sun Microsystems Sparc Stations, and Sun had a tool called tcov.
I don’t remember when I first heard the question, What’s your code coverage? It was probably in the very early 2000s. But thereafter the notion that code coverage was a number became pretty much universal.
Since then, it has become relatively commonplace for software teams to run a code coverage tool as part of their continuous build process and to publish the code coverage number for each build.
What is a good code coverage number? Eighty percent? Ninety percent? Many teams are more than happy to report such numbers. But six decades before the publication of this book, Miller and Maloney answered the question very differently: Their answer was 100 percent.
What other number could possibly make sense? If you are happy with 80 percent coverage, it means you don’t know if 20 percent of your code works. How could you possibly be happy with that? How could your customers be happy with that?
So, when I use the term covered in the first rule of simple design, I mean covered. I mean 100 percent line coverage and 100 percent branch coverage.
An Asymptotic Goal
You might complain that 100 percent is an unreachable goal. I might even agree with you. Achieving 100 percent line and branch coverage is no mean feat. It may, in fact, be impractical depending on the situation. But that does not mean that your coverage cannot be improved.
Think of the number 100 percent as an asymptotic goal. You may never reach it, but that’s no excuse for not trying to get closer and closer with every check-in.
I have personally participated in projects that grew to many tens of thousands of lines of code while constantly keeping the code coverage in the very high nineties.
Design?
But what does high code coverage have to do with simple design? Why is coverage the first rule?
Testable code is decoupled code.
In order to achieve high line and branch coverage of each individual part of the code, each of those parts must be made accessible to the test code. That means those parts must be so well decoupled from the rest of the code that they can be isolated and invoked from an individual test. Therefore, those tests not only are tests of behavior but also are tests of decoupling. The act of writing isolated tests is an act of design, because the code being tested must be designed to be tested.
In Chapter 4, “Testing Design,” we talked about how the test code and the production code evolve in different directions in order to keep the tests from coupling too strongly to the production code. This prevents the problem of fragile tests. But the problem of fragile tests is no different from the problem of fragile modules, and the cure for both is the same. If the design of your system keeps your tests from being fragile, it will also keep the other elements of your system from being fragile.
But There’s More
Tests don’t just drive you to create decoupled and robust designs. They also allow you to improve those designs with time. As we have discussed many times before in these pages, a trusted suite of tests vastly reduces the fear of change. If you have such a suite, and if that suite executes quickly, then you can improve the design of the code every time you find a better approach. When the requirements change in a way that the current design does not easily accommodate, the tests will allow you to fearlessly shift the design to better match those new requirements.
And this is why this rule is the first and most important rule of simple design. Without a suite of tests that covers the system, the other three rules become impractical, because those rules are best applied after the fact. Those other three rules are rules that involve refactoring. And refactoring is virtually impossible without a good, comprehensive suite of tests.
Maximize Expression
In the early decades of programming, the code we wrote could not reveal intent. Indeed, the very name “code” suggests that intent is obscured. Back in those days, code looked like what is shown in Figure 6.2.

Figure 6.2 An example of an early program
Notice the ubiquitous comments. These were absolutely necessary because the code itself revealed nothing at all about the intent of the program.
However, we no longer work in the 1970s. The languages that we use are immensely expressive. With the proper discipline, we can produce code that reads like “well written-prose [that] never obscures the designer’s intent.”9
9 Martin, Clean Code, p. 8 (personal correspondence with Grady Booch).
As an example of such code, consider this little bit of Java from the video store example in Chapter 4:
public class RentalCalculator {
private List<Rental> rentals = new ArrayList<>();
public void addRental(String title, int days) {
rentals.add(new Rental(title, days));
}
public int getRentalFee() {
int fee = 0;
for (Rental rental : rentals)
fee += rental.getFee();
return fee;
}
public int getRenterPoints() {
int points = 0;
for (Rental rental : rentals)
points += rental.getPoints();
return points;
}
}If you were not a programmer on this project, you might not understand everything that is going on in this code. However, after even the most cursory glance, the basic intent of the designer is easy to identify. The names of the variables, functions, and types are deeply descriptive. The structure of the algorithm is easy to see. This code is expressive. This code is simple.
The Underlying Abstraction
Lest you think that expressivity is solely a matter of nice names for functions and variables, I should point out that there is another concern: the separation of levels and the exposition of the underlying abstraction.
A software system is expressive if each line of code, each function, and each module lives in a well-defined partition that clearly depicts the level of the code and its place in the overall abstraction.
You may have found that last sentence difficult to parse, so let me be a bit clearer by being much more longwinded.
Imagine an application that has a complex set of requirements. The example I like to use is a payroll system.
• Hourly employees are paid every Friday on the basis of the timecards they have submitted. They are paid time and a half for every hour they work after forty hours in a week.
• Commissioned employees are paid on the first and third Friday of every month. They are paid a base salary plus a commission on the sales receipts they have submitted.
• Salaried employees are paid on the last day of the month. They are paid a fixed monthly salary.
It should not be hard for you to imagine a set of functions with a complex switch statement or if/else chain that captures these requirements. However, such a set of functions is likely to obscure the underlying abstraction. What is that underlying abstraction?
public List<Paycheck> run(Database db) {
Calendar now = SystemTime.getCurrentDate();
List<Paycheck> paychecks = new ArrayList<>();
for (Employee e : db.getAllEmployees()) {
if (e.isPayDay(now))
paychecks.add(e.calculatePay());
}
return paychecks;
}Notice that there is no mention of any of the hideous details that dominate the requirements. The underlying truth of this application is that we need to pay all employees on their payday. Separating the high-level policy from the low-level detail is the most fundamental part of making a design simple and expressive.
Tests: The Other Half of the Problem
Look back at Beck’s original first rule:
1. The system (code and tests) must communicate everything you want to communicate.
There is a reason he phrased it that way, and in some ways, it is unfortunate that the phrasing was changed.
No matter how expressive you make the production code, it cannot communicate the context in which it is used. That’s the job of the tests.
Every test you write, especially if those tests are isolated and decoupled, is a demonstration of how the production code is intended to be used. Well-written tests are example use cases for the parts of the code that they test.
Thus, taken together, the code and the tests are an expression of what each element of the system does and how each element of the system should be used.
What does this have to do with design? Everything, of course. Because the primary goal we wish to achieve with our designs is to make it easy for other programmers to understand, improve, and upgrade our systems. And there is no better way to achieve that goal than to make the system express what it does and how it is intended to be used.
Minimize Duplication
In the early days of software, we had no source code editors at all. We wrote our code, using #2 pencils, on preprinted coding forms. The best editing tool we had was an eraser. We had no practical means to copy and paste.
Because of that, we did not duplicate code. It was easier for us to create a single instance of a code snippet and put it into a subroutine.
But then came the source code editors, and with those editors came copy/paste operations. Suddenly it was much easier to copy a snippet of code and paste it into a new location and then fiddle with it until it worked.
Thus, as the years went by, more and more systems exhibited massive amounts of duplication in the code.
Duplication is usually problematic. Two or more similar stretches of code will often need to be modified together. Finding those similar stretches is hard. Properly modifying them is even harder because they exist in different contexts. Thus, duplication leads to fragility.
In general, it is best to reduce similar stretches of code into a single instance by abstracting the code into a new function and providing it with appropriate arguments that communicate any differences in context.
Sometimes that strategy is not workable. For example, sometimes the duplication is in code that traverses a complex data structure. Many different parts of the system may wish to traverse that structure and will use the same looping and traversal code only to then operate on the data structure in the body of that code.
As the structure of the data changes over time, programmers will have to find all the duplications of the traversal code and properly update them. The more the traversal code is duplicated, the higher the risk of fragility.
The duplications of the traversal code can be eliminated by encapsulating it in once place and using lambdas, Command objects, the Strategy pattern or even the Template Method pattern10 to pass the necessary operations into the traversal.
10 Erich Gamma, Richard Helm, Ralph Johnson, and John M Vlissides, Design Patterns: Elements of Reusable Object-Oriented Software (Addison-Wesley, 1995).
Accidental Duplication
Not all duplication should be eliminated. There are instances in which two stretches of code may be very similar, even identical, but will change for very different reasons.11 I call this accidental duplication. Accidental duplicates should not be eliminated. The duplication should be allowed to persist. As the requirements change, the duplicates will evolve separately and the accidental duplication will dissolve.
11 See the single responsibility principle. Robert C. Martin, Agile Software Development: Principles, Patterns, and Practices (Pearson, 2003).
It should be clear that managing duplication is nontrivial. Identifying which duplications are real and which are accidental, and then encapsulating and isolating the real duplications, requires a significant amount of thought and care.
Determining the real duplications from the accidental duplications depends strongly on how well the code expresses its intent. Accidental duplications have divergent intent. Real duplications have convergent intent.
Encapsulating and isolating the real duplications, using abstraction, lambdas, and design patterns, involves a substantial amount of refactoring. And refactoring requires a good solid test suite.
Therefore, eliminating duplication is third in the priority list of the rules of simple design. First come the tests and the expression.
Minimize Size
A simple design is composed of simple elements. Simple elements are small. The last rule of simple design states that for each function you write, after you’ve gotten all the tests to pass, and after you have made the code as expressive as possible, and after you have minimized duplication, then you should work to decrease the size of the code within each function without violating the other three principles.
How do you do that? Mostly by extracting more functions. As we discussed in Chapter 5, “Refactoring,” you extract functions until you cannot extract any more.
This practice leaves you with nice small functions that have nice long names that help to make the functions very small and very expressive.
Simple Design
Many years back, Kent Beck and I were having a discussion on the principles of design. He said something that has always stuck with me. He said that if you followed these four things as diligently as possible, all other design principles would be satisfied—the principles of design can be reduced to coverage, expression, singularization, and reduction.
I don’t know if this is true or not. I don’t know if a perfectly covered, expressed, singularized, and reduced program necessarily conforms to the open-closed principle or the single responsibility principle. What I am very sure of, however, is that knowing and studying the principles of good design and good architecture (e.g., the SOLID principles) makes it much easier to create well-partitioned and simple designs.
This is not a book about those principles. I have written about them many times before,12 as have others. I encourage you to read those works and study those principles as part of maturing in your craft.
12 See Martin, Clean Code; Clean Architecture; and Agile Software Development: Principles, Patterns, and Practices.