
Progress doesn’t come from early risers—progress is made by lazy men trying to find easier ways to do things.
—Robert Heinlein, Time Enough For Love (1973)
Modern software development requires effective techniques. For an enterprise to incorporate the microservices paradigm, changes to development methodology are essential. It is necessary to reorganize development teams around modern development processes for successfully implementing any microservices architecture. This chapter introduces a few process techniques that redefine how software is built, tested, and delivered.
The 12 factors of applications (Wiggins A., 2012) cover some of the critical aspects of building microservices. However, there are more elements to building microservices—in the context of recommended software engineering practices. Any enterprise dealing with building software will have development and operation teams following some predefined processes. A conventional build process in any enterprise will enable the following capabilities: managing source code, building applications, testing and validating, prepare environments, deploy tested applications, and roll out to production.
- 1.Managing source code via a central code repository
- a.
Ensure appropriate tagging, branching, feature flags.
- b.
Ensure code is committed, merged, and reviewed after every check-in/merge.
- 2.Tools to automatically trigger the build process. The build process should
- a.
Statically check code for code smells, code metrics (complexity, maintainability indices), contract violations, and security vulnerabilities.
- b.
Run unit tests, validate correctness, and gather test statistics (such as failure rates, code-coverage, etc.).
- c.
Compile code into binary executable formats that can be “sealed in time.”
- d.
Move binaries into artifact repository, version/tag them.
- 3.Dynamically spin up a production-like test environment for testing environments and run integration tests.
- a.
Upon successful integration testing, mark the binary as a release candidate.
- b.
Tear down the test environment after running tests.
- 4.Prepare production deployment of the service’s release candidate.
- a.
Update feature flags to coordinate launches.
- b.
Carve out the required resources from the pool and allocate them against the new deployment.
- c.
Set up the environment for the new release by configuring resources to match service requirements.
- 5.Copy the binaries and launch the new service.
- a.
Based on release strategy–dark launch, canary test, pilot, or rolling deploy—set up traffic shaping and forwarding.
- b.
On successful testing—when new deployments are up and healthy—switch traffic.
- 6.Identify services that are retired as part of the new release.
- a.
Monitor for errors and faults until successful cut-over to new service.
- b.Shut down retired services and recover resources.
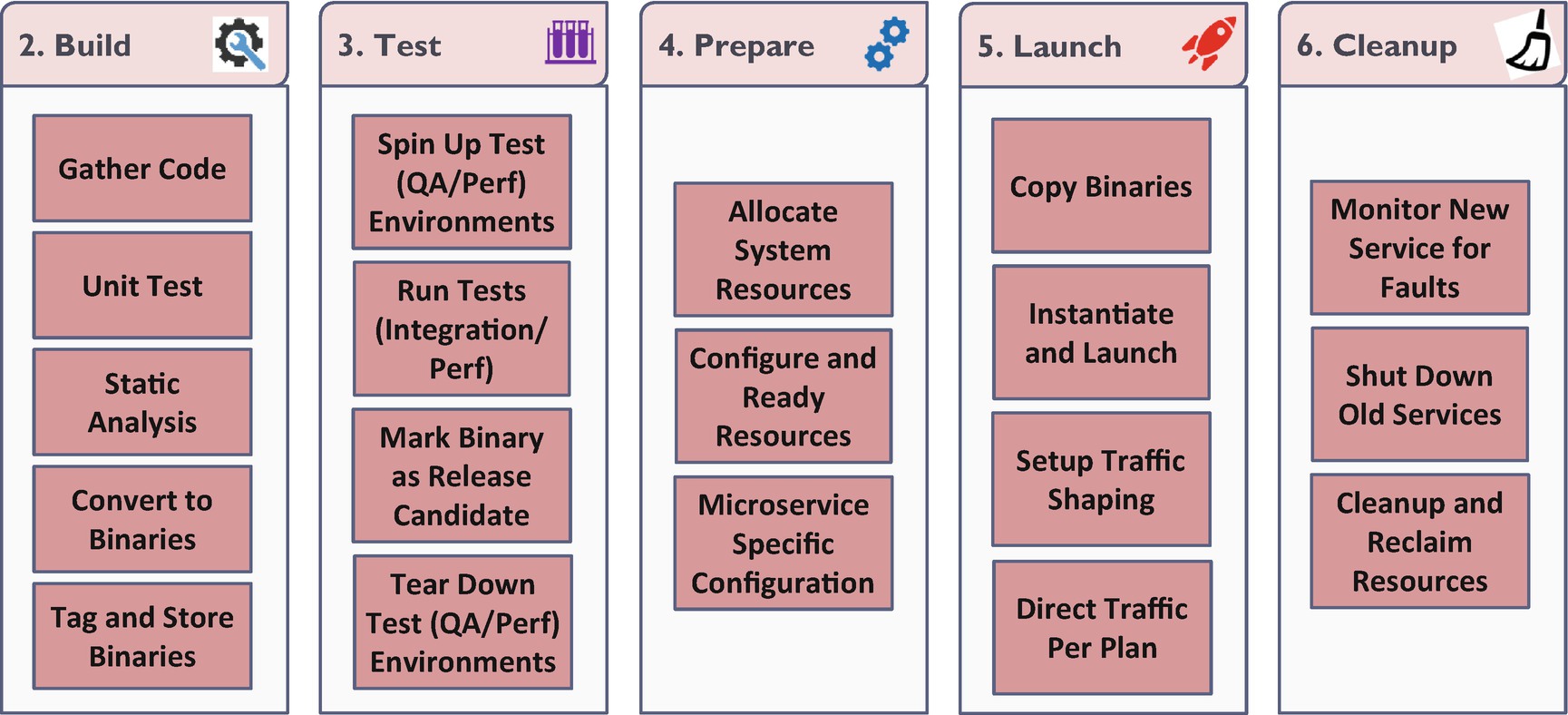 Figure 5-1
Figure 5-1Typical CI/CD pipeline for microservices architecture
Successful deployment of any software to production requires these six steps. The good news is that most modern software enterprises have these processes in some form or fashion. The first three steps (the first step, design and development, is considered a precursor) of the six listed define CI, continuous integration. The last three steps outline CD, continuous delivery. The usage of the word “continuous” is to show that they run frequently; ergo, these steps can be automated. It is important to note that continuous-deployment is a next-level paradigm, but with meager returns. In an enterprise that has the capability of continuous-deployment, steps two through six happen at every check-in. Contrast that with a continuous-delivery ready enterprise, where steps four through six happen when the engineering team decides to.
In a microservices architecture, we must automate all stages and run them without any manual intervention.
- 1.
The overhead of manual processes: Imagine the effort it would take to run commands for all six steps for every release of every microservice. And then there is documentation (Humble & Farley, 2010, p. 6).
- 2.
Delays due to coordination with the “responsible” team: Enterprises have a separate unit that manages infrastructure. If not automated, the development team must open tickets, set up meetings, and fill out forms: for every deployment. Also, this breeds animosity (Humble & Molesky, 2011).
- 3.
Manual errors in executing steps: To err is human, but to make grave mistakes is programming. Any human error that occurred in some stage of a pipeline becomes harder to debug—these errors are not reproducible or resolvable.
This need for automation requires traditional operations-engineers to develop code to automate their old job. The development team takes on more operations activities. This integration of project teams into a single group of engineers created “DevOps” (Humble & Molesky, 2011, p. 7). The intent is to enable the development team to handle operations of the application. Development teams are skilled in automating operations jobs—the same way most development teams have automated testing. Manual processes that are repeated, even as little as four or five times, are apropos for automation.
We have realized that automation makes microservices architecture development, testing, and deployment efficient. Such efficiency achieved by automation is even higher in a cloud environment, where the underlying infrastructure is invisible. The concept of “pets vs. livestock” compares traditional on-prem or dedicated infrastructure to cloud infrastructure. A “livestock” like cloud infrastructure mandates us to consider it as volatile, abstract, and transparent to all engineering teams. Automation is crucial in the cloud. We need to consider all manual processes as primary barriers to a successful deployment of microservices on the cloud.
Inflicted pains of any manual process are amplified tenfold on the cloud.
Continuous Integration
- 1.
A development environment that enables engineers to learn, develop, test, and prepare the application
- 2.
Test/QA (Quality Assurance) or integration environments for certification of applications in an environment that connects it with other applications
- 3.
Performance test environments that stress the application to its seams
- 4.
Production environment, which supports the real-world business
The life cycle of each of these environments will vary; the lifetimes and capacity change. A development environment should be the shortest-lived environment, which exists only for the duration of the development team’s test cycle. QA and performance will live longer based on the complexity and size of test runs. Performance environment might have higher capacity to run massive load tests.
Non-production Environments
When completely automated, build-processes trigger compilation, code verification, unit testing, and artifact creation at any configured event. Typically build pipelines have 1) triggers, 2) a sequence of stages, 3) configuration, and 4) coordinates for repositories. A variety of activities can trigger pipelines: code merge completion/scheduled time of the day/successful completion of another one. Once activated, build pipelines run a series of steps: pulling code from repository coordinates, static checking, unit testing, packaging into an artifact, and pushing to an artifact repository.
- 1.
It is true that based on the complexity of the system, the size of the pipeline varies. However, in the case of microservices architecture, individual applications tend to be similar. Variations are usually limited to the second step.
- 2.
Progress from monolithic to a microservices architecture will result in many smaller systems. When more systems exist, more pipelines are required to process them.
- 3.
Agile-meat-grinder techniques force engineers to work at a faster pace, resulting in increased count and execution frequency of pipelines. Though the quality and speed of software generally remain unaffected by such meat grinder techniques, the burden on infrastructure does increase.
Factors such as these underline the importance of automating the process of creating build pipelines itself, with an emphasis on templatizing and providing for their elasticity.
Multiple options to automate the creation of build pipelines exist. It is possible to create a single pipeline (the weak-hearted might choose one pipeline each for development, test, production environments), which, based on configuration and variables supplied, can build any project. This “common build pipeline” is the most straightforward technique to build applications. What makes practical implementation of a standard pipeline challenging is our initial goal of allowing microservices to be independent and polyglot. Commonality requires standardization, and polyglotism offers none. Techniques such as containerization do standardize many parts of CI and CD; however, some parts will need customization. (We will discuss containerization in the next chapter.) To achieve standardization, teams need to build the required skills and keep abreast of the tools and techniques.
Another option is “build pipelines as a service” offered by many providers. Many cloud platforms offer complete CI and CD processes as service. Leveraging these services still requires planning, configuration, and scripting of pipeline creation. Be advised that some enterprises might not choose these services for fear of vendor lock-in, wanting to build it in a vendor-neutral way.
Gaining the ability to automatically set up and configure build pipelines is worth the upfront effort involved.
Automated Testing
A novel undertaking in the microservices world is the automation of testing. Automated testing requires enterprises to shed legacy ideas. Process changes need to be in spirit and not enforcement. Concepts such as Test-Driven-Development need to be drilled into engineers and made second nature. Enterprises define a unit as the smallest piece of the compilation and proceed to rely on unit tests to measure correctness. However, unit tests do not certify accuracy (Buxton & Randell, 1969, p. 16). Enterprise build pipelines are often non-continuous, automating minimal steps of the overall process.
Enterprises now need to place importance on unit tests, and not whether the developers write them before or after writing the main code. Enterprises should realize that “unit” refers to the smallest atomic entity of any software system in a context. In the context of microservices architecture, a REST endpoint of a microservice is the real unit. This realization provides us an opportunity to advance and accelerate integration testing in the build process. We can approximate correctness at a higher level, much earlier in the pipeline. Small-sized microservices make integration testing more viable.
It is possible to augment build-pipelines to guarantee correctness earlier in the process. Build pipelines can do Contract Testing for higher accuracy, and to ensure client compatibility. Build pipelines can run API tests, thus validating all REST endpoints of microservice as part of Step 3. They can also run integration tests, simulating the complete system.
- 1.
Test data: dynamic vs. static vs. combination
- 2.
Dependencies on other microservices: mocking vs. static vs. injection
- 3.
Dependencies on infrastructure: messaging layer, cache, database, etc.
Performance Testing
- 1.
The behavior of systems under various types of load
- 2.
The resource requirement of systems against varying traffic
- 3.
Sustainability of handling load over time
Factors and Reasons for Capturing Metrics
Factors | Reasons |
|---|---|
Response times of microservice, for various load factors per instance. | It helps identify the breaking points of the application and ways to circumvent failures in any incorrigible parts. |
Resource usage percentages at extreme loads. | Usage benchmarks help establish the apt size of the computational unit. Knowing the suitable size enables deciding multiples needed to handle expected traffic patterns. |
Throughput attained by a single, or multiple computational units of a specific size. | It helps identify load factors—the points at which replication becomes necessary to handle the increased load. Contrarily, it helps identify scaling down instances to reduce running costs. |
Errors and response lag plotted against various load volumes. | Identifying the breaking point of infrastructure helps size the infrastructure to support expected traffic. Entire infrastructure—microservices and its supporting resources, such as communication channels, databases, messaging middleware, etc.—are tested under various volumes. |
Errors and response lag plotted against surges in traffic. | Exposing services to a sudden surge in traffic helps identify the capabilities of handling irregular variations in traffic. It is vital to capture metrics of failures and slow responses. Such metrics help redesign systems to match expected behavior under spikes. |
Errors and response lag plotted against sustained peak traffic. | Subjecting services to some heavy traffic for a sustained amount of time exhibits the capability of handling traffic for a sustained duration of load. |
Ephemerality and Equivalence of Environments
- 1.
All environments, starting from dev to production, must consistently get carved out of the same outline. Minimizing differences reduces surprises and increases testability.
- 2.
Cloud costs are directly related to usage. Maintaining environments for the duration of necessity reduces cloud costs.
- 3.
Development teams become habitually accustomed to deploying break-fixes or reconfiguring production environments as a quick way to continue business functionality. Ensuring automation to roll out any changes to production avoids similar problems in the future.
The final advantage is a hard requirement, and it brings us to the concept of equivalence of environments. All environments are equivalent—they are created with strictly the same script, set up precisely alike, and every aspect of every environment exactly matches each other. Equivalence of environments avoids surprises from the underlying infrastructure, which is vital in running microservices architecture. The key takeaway here is how all these aspects strongly emphasize the importance of automation. Achieving a complete run of finding fault, fixing in development environments, testing in QA, stress testing in the performance environment, and pushing to production should be a single, connected, automated pipeline. This automation is the topic of our next section on continuous delivery.
Equivalence ➤ Development = QA = Stress = Production
Continuous Delivery
Achieving continuous delivery is a more demanding goal compared to continuous integration. The ability to create a production-ready application from its source code at the proverbial “push of a button”—while automatically running through build, test, and certification—requires process rigor. This section focuses on automated techniques to push newer version of applications to production with little or no downtime and business disruption.
Infrastructure as Code
Essential characteristics of microservices—scalability, elasticity, and upgradability—increase instances of instance management. Typical scenarios include 1) creating new instances handle more load, 2) destroying inactive ones when load decreases, 3) setting up new sets to roll-out new versions, 4) and destroying and reclaiming old instance sets. The creation and destruction of instances require changes to infrastructure—networking, monitoring, load balancing, supporting services, and inter-service connectivity.
The dynamic and transient nature of the cloud requires us to employ automation to gain control and achieve efficiency. Every step needed to bring up a microservice and to make it functional needs to be automated. Every step required to shut a microservice down and tear down its resources needs to be scripted. It is not only needed for efficiency but also to keep the cost of running microservices down by reclaiming unused resources.
It is vital to consider the entire infrastructure as code (IaC): load balancers, container orchestration, databases and datastores, messaging, and anything else the microservice uses. IaC allows standardization of infrastructure and equivalence of production and non-production environments. It is also cost-effective, as ecosystems are built for use, kept running till needed, and destroyed when no longer required.
Delivery Techniques
In the era of monoliths, there were many delivery techniques; however, all were variations of big-bang release with a rollback plan. A sample outline of the technique was as follows: 1) identify a “downtime” with business, when the users of the system were least affected; 2) line up maximum number of deliverables that can be forced to production in that window; 3) create a rollout and rollback plan and execute it.
We entered a window of opportunity set aside for release, and we spent nerve wracking hours firefighting in war rooms. Oftentimes, we emerged at the other end of the downtime window bloody faced, but with a brand-new version of software running, champagne, and bouquets. On a few occasions, we rolled back to where we began, restoring business to old versions, all the efforts futile. Sometimes the gods of software would punish us by landing in purgatory hell, where we exhaust our downtime timer but still have the system in shambles. Gallantry and heroism would ensue, finally fixing the system and restoring original operations. Fortunately, these gallants would be showered with corporate medals.
With the modernization of software engineering and agile methods, we discovered new ways to deliver software. One popular technique was blue-green deployment, where a new environment (green) runs the next version of the application that has breaking changes. The old version (blue) continues to take traffic. At some point, we start rerouting requests from blue to green, until all traffic points to green. Once the green environment is successfully in place, the old version is retired. Variations to this technique exists, where traffic gets mirrored to both blue and green, and at some specific point, green becomes the master. Blue continues to take requests for ease of rollback. Once the green environment is certified stable, blue environment is retired. This was considered a breakthrough idea, and shower of praises ensued. However, this was only marginally better from our earlier approach. In blue-green technique, we had all the same problems as the original, the only thing we solved was the percentage of users affected. If our application ran on two servers, we affected half the user population by redirecting them to new servers. Failure there often resulted in requiring heroics again, in reverting the affected half.
Unfortunately, continuous delivery eliminates such heroics and cancels all gallantry awards. Microservices architecture, along with continuous software engineering, demonstrates that such heroics are unnecessary and completely avoidable. Microservices architecture fosters, enables, and encourages rapid change and deployment of systems. With the right traffic control tools, engineers pilot new features in production! An excellent and popular way to test new features in production is via a dark launch, wherein the new feature is running in a listen-only mode and is not affecting the outcome. A dark-launch enables test-and-learn, where we test the newer version of application without disrupting the customers. Another popular approach is roll out the new feature to a small segment of users as canary deployment. The canary population is selected either based on some characteristics, of user traffic, or simply based on a random percentage of traffic. Canary deployments are targeted to a very small percentage of user base (often a selected subset) as a precursor to a complete roll-out. Techniques such as dark launches and canary deployments offer a minimally invasive method of pushing changes to production. There are many tools on the cloud that enable us to do dark launches and canary deployments using techniques such as traffic mirroring, traffic shaping, etc. We will look at these techniques in detail further ahead in the book.
DevSecOps
Akin to the Infrastructure-as-Code concept embraced by the engineering community, the idea of Security-as-Code has parallelly emerged. It was common for security to be an afterthought, possibly bolted on at the end of the development life cycle. Unfortunately, security processes in enterprises have been limited to filing some archaic security forms in “good faith.” Information gathered for security improvements was restricted to data points discovered in past audits. An automated enterprise might collate scans and reports at the end of the development life cycle, and before deployment. Regrettably, such data only surface vulnerabilities when present, and never guarantees an absence of weaknesses. DevSecOps is a concept that attempts to address precisely this: security embedded into the engineering team that develops and manages operations. DevSecOps teams automate security controls, use security metrics to harden code, and own security of their system (Myrbakken & Colomo-Palacios, 2017).
Code safety checked at compile time: Using techniques such as data-flow analysis and taint analysis begins security checks early in the life cycle. These techniques trace data as it flows through the system, from every source to every sink, against potential vulnerabilities.
Unit and integration tests that verify security: Unit tests and integration tests targeted at exploiting vulnerabilities ensure regressive testing against security-related errors.
Red teams/drills are needed (Myrbakken & Colomo-Palacios, 2017): Red team drills are exercises with specific predefined goals that simulate how potential threats might attempt to exploit vulnerabilities. Automating the setup, creating a library of attack tools, and constantly updating these tools allow continuous security checks even after deployment.
Binaries are verified against known list threats and exploits: There are many tools to statically check binaries engaged in the build process against known errors.
The attack surface is analyzed and reduced: It is essential to continually analyze the attack surface of the application, in terms of API endpoints, external services, and classified/sensitive data (and involved code).
The system is subjected to random conditions. The abstract nature of software makes it impossible to predict all possible scenarios it will face. Randomness leading to failures in systems is so common, that it might be necessary to simulate random failures. Chaos engineering1, fuzz testing2, exploratory testing3 are all invaluable techniques to ensure resiliency, especially in a cloud environment.
We touched upon a small subset of aspects regarding microservices security. The engineering teams need to be aware of a large body of security principles and techniques when building microservices. The chapter Securing Microservices on Cloud addresses the various security aspects of cloud-based microservices explicitly.
Changes to Energence
Energence now has the overall view of process changes it needs to bring in for a successful microservices architecture. Few enterprise-wide changes are needed to the enterprise structure, general software development process, and the IT setup. The software development groups could get segregated into departments that align with the overall enterprise hierarchy. Four departments within software development organizations partner with the four verticals of Energence—Planning, Manufacturing, Distribution, and Portal.
Changes to promote a continuous software engineering process across all departments, if not already present, are the next important steps. Individual departments should invest in automating the entire process of managing environments. They should set up their team structure to enable the process, which means changing the skill set of teams. Development teams should have knowledge and skill to build software, test it, certify it, stress test it, script environments to run it, and follow the continuous software engineering process from development to production. It is important to note that these continuous processes apply to the life cycle of every individual microservice.
The IT operations, a completely independent department that maintains all infrastructure requirements, should get matrixed into individual teams. Other enterprises might have business architecture teams and QA departments, which should integrate into development teams. It is valuable to retain the departments, and only comingle engineers into team structures. Maintaining departments restricts technology proliferation, enables standardization of tools and processes, and cross-pollinates ideas and techniques between development teams.
Energence has now prepared itself for a journey to the cloud—it has broken down its monoliths, identified issues in microservices architecture, found ways to overcome those challenges, and has enabled a continuous software engineering process. The next step is cloudification—the process taking this architecture, software process, and technical solutions to the cloud.
Summary
The underlying theme of process changes is automation, and the golden rule is any process that is manually executed more than thrice is a candidate for automation. Engineers responsible for infrastructure and QA should change their mindsets from being eager-on-the-job-to-fix-failures-immediately to being lazy-to-not-change-anything-except-correcting-an-automated-process. Every request to change a process should result in a code that implements the steps. This process of continuous software engineering, with emphasis on frequent and automated building and delivery of software, is paramount for microservices architecture. Building such processes should keep in mind standardization, reusability, and elasticity. These factors become essential with larger codebases, increased release frequency, and polyglotism. The cloud brings about an additional set of problems, due to its temporal nature and its inherent opacity of infrastructure. The importance of continuous software engineering increases when enterprises adopt modern development paradigms. For these enterprises, it is mandatory to implement DevOps and DevSecOps models.
Points to Ponder
- 1.
Is it possible to automate every process of operations and support? Are there any exceptions?
- 2.
How do we balance automation effort with release urgency?
- 3.
What are the differences between performance testing monoliths vs. performance testing microservices?
- 4.
How can we automate the many concepts of security into code?
Further Related Reading
Continuous Delivery by Jez Humble and David Farley (Humble & Farley, 2010).
The DevOps Handbook by Gene Kim et al. (Kim, Humble, Debois, & Willis, 2016).