
Chapter 3
High Availability and Scaling in Cloud Environments
This chapter covers the following official CompTIA Cloud+ exam objective:
 1.3 Explain the importance of high availability and scaling in cloud environments.
1.3 Explain the importance of high availability and scaling in cloud environments.
(For more information on the official CompTIA Cloud+ exam topics, see the Introduction.)
In this chapter you will learn about the components found with a cloud environment that are related to high availability and scalability. High availability is ensuring your cloud resources are highly available, accessible, and functioning properly at all times (or as close to all times as possible). Scalability is the capability to meet the increasing demand by scaling out (horizontal scaling) or scaling up (vertical scaling).
This chapter will include information on how hypervisors can affect high availability as well as how cloud providers use a technique called oversubscription that can impact high availability. You will also learn about regions and zones, which can be used to provide high availability.
You will also discover how networking components (switches, routers, load balancers, and firewalls) can impact high availability. Finally, you will learn about scalability, including auto-scaling, vertical scaling, horizontal scaling, and cloud bursting.
CramSaver
If you can correctly answer these questions before going through this section, save time by skimming the ExamAlerts in this section and then completing the CramQuiz at the end of the section.
1. Which type of hypervisor runs directly on the system hardware?
2. What type of hardware resources are oversubscribed by cloud providers?
3. What is the name for a collection of zones in a geographic location?
4. Which network component can affect high availability by blocking access to a resource?
Hypervisors
Some of the most common cloud-based resources will make use of virtual machines (VMs). A virtual machine is an operating system that shares hardware with other operating systems. Typically, this sharing would pose a problem because operating systems are designed to manage hardware devices directly and exclusively, which would lead to problems if two operating systems were to try to manage hardware devices concurrently.
This problem is solved with the introduction of the hypervisor. The hypervisor presents virtual hardware devices to the operating systems that are running as virtual machines. Each virtual machine is presented with a virtual CPU (vCPU), a virtual hard drive, a virtual network interface, and other virtual devices, depending on how the hypervisor is configured. So, what is managing the real (physical) hardware?
The answer depends on the type of the hypervisor. A Type 1 hypervisor runs directly on the system hardware, essentially acting as an operating system itself. This type of hypervisor directly manages the hardware and provides better performance than a Type 2 hypervisor.
A Type 2 hypervisor runs on a system that already has a host operating system. The Type 2 hypervisor works with the host operating system to manage the physical hardware, but it is ultimately the host operating system that has full control of the hardware. Because of the overhead that is created by the host operating system, Type 2 hypervisors are not commonly used in cloud computing solutions.
Affinity
While often associated with virtual machine technology, the term affinity can be applied to other cloud technologies. For virtual machines, think of affinity as a way of keeping virtual machines together, often on the same network or even the same hypervisor.
Most cloud environments are massive and include thousands of compute nodes (a fancy way of saying a computing device or a server). Many of these compute nodes will be physically close to one another, such as in the same data center or even the same rack. Others will be spread further apart in additional data centers or even in different buildings. This setup can present problems when two virtual machines need to communicate effectively.
For example, consider a virtual machine that hosts a web server that needs to read and write data to a database that is hosted on a separate virtual machine. While you could place the web server on a virtual machine that is hosted in the United Kingdom and place the database server on a virtual machine that is hosted in Japan, this arrangement really isn’t effective because the distance between the two (both physically and the number of routers between the two) will certainly result in latency issues when transporting the data. It would be better in this case to use an affinity rule that will result in keeping these two virtual machines close.
Depending on the cloud provider, there may be rules that keep the virtual machines in the same geographic area or even on the same compute node.
Anti-affinity
As you might expect, anti-affinity is the opposite of affinity. This term means “keep these things separate.” In terms of virtual machines, anti-affinity can mean “keep these virtual machines in different server rooms” or even “keep these virtual machines in different geographic regions.”
To understand the purpose of anti-affinity, consider a situation in which you have a virtual machine that hosts a database. This server is located on the East Coast of the United States and you want to have a backup server to ensure that you don’t lose any data in case of some sort of disaster in the data center where the database is located. In this case, it wouldn’t be a good decision to also place this backup database in the East Coast geographic region, so you would use an anti-affinity rule to have the backup database stored in a different location.
Oversubscription
If you have been a frequent airline traveler, you probably have gotten used to announcements like the following: “We are looking for passengers who are willing to take a later flight in exchange for a voucher for future travel.” This is the result of a practice in air travel called overbooking, in which the airline will book more passengers than there are seats because historically some of the passengers will cancel their flight at the last minute. This booking method tends to allow an airline to maximize the utilization of available seats, even if it does occasionally lead to some passengers having to be placed on other flights.
Cloud providers will use a similar technique. When a compute node is used to host multiple resources (virtual machines, databases, and so on), the cloud providers will allocate more hardware resources than would be physically possible to provide to maximize the revenue for that compute node. Cloud providers are essentially betting that clients won’t use all of the physical or virtual hardware resources that are provisioned for a cloud instance, so the provider will “overbook” the compute node’s resources. This process is called oversubscribing.
Just about any physical or virtual resource can be oversubscribed, but the most common three are the compute power (AKA, CPUs), the network, and the storage.
Compute
There are several components to the compute element of a cloud resource, including
 Physical CPUs
Physical CPUs- Number of processors
- The number of cores
- Threads (also known as hyperthreading)
- vCPUs (virtual CPUs)
You may choose these values when you create a virtual machine. For example, on AWS there is an option when creating a virtual machine where you can specify the number of CPUs, the number of threads, and the number of vCPUs, as demonstrated in Figure 3.1.

FIGURE 3.1 CPU Compute Options
Network
Cloud providers are aware that not all resources for their customers will be active at the same time. As a result, they will often oversubscribe network bandwidth.
For example, when you create a Relational Database Service (RDS) on AWS, you are required to choose the instance class, which includes the bandwidth for the database instance, as shown in Figure 3.2.
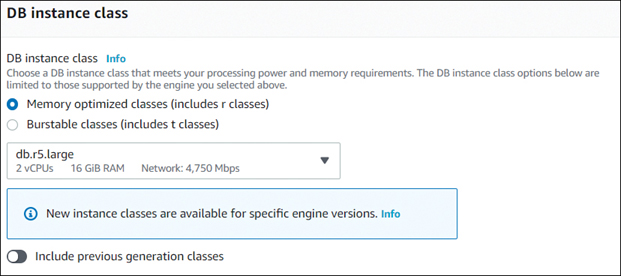
FIGURE 3.2 Database Class
Figure 3.2 indicates that the database instance will be allocated a maximum of 4,750 Mbps. If you added up all of the allocated bandwidth of all of the instances that are hosted on the physical system, you would likely discover that the total allocated bandwidth exceeds the actual bandwidth that is available for this system.
Storage
Storage is also often oversubscribed by cloud providers, but this one is a bit trickier. Often, two components of storage are allocated to a resource:
- The size of the storage: This is how much space the resource could use.
- IOPS (the input/output operations per second): This is how much data can be read from or written to the storage device.
As with CPU and network bandwidth, the cloud providers know that it is rare for all of the cloud customers to use 100 percent of the available shared storage space. Additionally, the odds are that not all of the customers who are sharing storage space will attempt to use the maximum IOPS. This means that the cloud provider can safely oversubscribe the storage allocation.
You may be wondering how cloud providers deal with situations in which oversubscription backfires. For example, it is almost inevitable that a vendor’s customers will at some point exceed the actual capacity of CPU processing, network bandwidth, or storage. How do cloud providers prevent that from happening?
The solution is monitoring. Cloud providers have applications that routinely monitor the utilization of these hardware components. When a specific threshold is reached, resources are moved to another system. This solution prevents unhappy customers and ensures that the cloud provider complies with the service-level agreement (SLA), a legal contract that stipulates that the cloud provider will provide a minimum level of service.
Regions and Zones
Keep in mind that the focus of this chapter is on high availability and scaling. There are multiple purposes of regions and zones, but the focus in this section will be on how regions and zones provide high availability features.
Cloud providers have data centers across different continents and geographic areas of the world. These are called regions. For example, Figure 3.3 shows a map that demonstrates the regions for Microsoft Azure.
FIGURE 3.3 Microsoft Azure Regions
Within each region, the cloud provider will create multiple sets of data centers. These sets are called zones (sometimes also called availability zones). Each zone is connected via a private high-speed network to the other zones in that region.
The purpose of regions is to ensure that all of the cloud customers can place their resources close to the customer’s user base. For example, if your organization’s user base is primarily in Japan and you wanted to create a virtual machine for these users to access, you would not want to place the virtual machine in the United Kingdom. If you did, access to this resource would be slow, and it is possible that network issues may make the resource unavailable at times. As a result, regions support the goal of making resources highly available.
Zones also support high availability. Each zone has its separate physical resources, such as power supplies, to ensure that problems in one zone won’t affect another. Additionally, because the zones are physically separated, some natural disasters that may affect one zone, like flooding or a fire, should not affect another zone. As a result, the cloud customer can better ensure high availability of its resources by providing a redundant instance in a different zone.
For example, suppose you had a virtual machine that hosts a critical web server. You can create a second virtual machine with a copy of that web server and host it in a different zone within a region. If the first virtual machine becomes unresponsive, web traffic could be redirected to the second virtual machine. You could also have the two web servers both handle the requests by implementing a load balancer (see the “Load Balancers” section later in this chapter).
Applications
A cloud application is software that is implemented in the cloud. For example, you may have a custom application that handles issuing payroll payments to all employees in your organization. The software that performs this task could be hosted in the cloud.
As you can imagine, some cloud applications are mission critical, making high availability of these applications an important feature. Additionally, the workload of these applications can increase over time, making it important to be able to use scaling to increase the performance of the applications. For example, the resources that were allocated to the payroll application may have been working as desired when your organization had 500 employees, but now that your company has grown to 6,000 employees, the application is no longer able to keep up. When you scale the application, it will have the capability to handle the increased workload.
Containers
A container is similar in some ways to a virtual machine; however, containers are not complete operating systems, but rather purpose-built compute components. They are much more “lightweight” in that they don’t use as many resources (vCPU, RAM, storage, and so on) as virtual machines. In terms of high availability and scaling, they may be better suited than virtual machines in some cases because of the following reasons:
- Because high availability often means having duplicate instances, there is an added cost to highly available systems. Full virtual machines require more physical resources, making them more expensive than containers.
- Scaling often requires creating another instance of a resource. This process can take time, especially when creating a large resource, like a virtual machine. Containers can be created much more quickly, making them more ideal for scaling.
Containers are not always the ideal solution, however. For example, you may want to deploy an application that really needs a large amount of dedicated hardware resources. This may require the use of a virtual machine.
Clusters
A cluster is a collection of instances that provide the same function. For example, you could implement multiple virtual machines, each of which hosts the same web server.
Clusters provide two primary features. They ensure that the resource is highly available because if one server is not responding, another server in the cluster can respond to requests. Additionally, as demand grows, additional instances can be added to the cluster, making the cluster more scalable.
High Availability of Network Functions
The components of the network play a major role in high availability. Consider the role of each of following components described next.
Switches
Switches are used to direct network traffic between devices that are attached on the same physical network. Typically, switches will associate an IP address with a MAC address (hardware address) to ensure that the network traffic is sent to the correct device. Switches operate at Open Systems Interconnection (OSI) layer 2. The switch will send network traffic only to the port that the destination device is connected to.
Modern switches can be configured to provide high availability. This is done by having the switch monitor the activity of the device that is attached to the network port. If the device stops responding, the switch can start sending the network traffic to an alternate port where another device is configured to handle the request.
Note that in a cloud environment, the cloud vendor is responsible for setting up this feature. The customer does not have access to any layer 2 functions in the cloud.
Routers
Routers are used to connect similar and dissimilar networks together. This is typically done by having a switch send network traffic that is destined for a device outside of the local network to a router. Routers operate at OSI layer 3.
The flaw to this system is when a router becomes unresponsive. This lack of response can halt all network traffic between networks. One way to prevent this problem is by implementing one or more backup routers, so if one router is no longer responsive, switches can send network traffic to another router. This solution results in high availability of network traffic. High availability can be achieved by various mechanisms, such as Virtual Router Redundancy Protocol (VRRP), Gateway Load Balancing Protocol (GLBP), and Hot Standby Router Protocol (HSRP).
Note that in a cloud environment, the cloud vendor is responsible for setting up this feature. Customers have access to layer 3 functions and can set up their own routing outside of the default routing set up by the cloud provider.
Load Balancers
Consider the situation previously mentioned in which you have multiple servers configured with web servers that serve up your company’s web pages. You might have this question: “How do the client web applications know which web server to contact?” The answer is a load balancer.
To understand how the load balancer performs its task, first look at Figure 3.4, which shows the steps that a web client would go through to access a web server. The web client first needs to know the IP address of the web server (private IPs are used in this example), which is determined by a DNS lookup. Then the web client sends the request to the web server using the appropriate IP address.

FIGURE 3.4 Single Web Server
When a load balancer is used, the DNS server is configured to report the IP address of the load balancer. The load balancer then redirects the incoming client request to one of the web servers that the load balancer has been configured to utilize. This method is demonstrated in Figure 3.5.

FIGURE 3.5 Multiple Web Servers with Load Balancing
In cloud computing, there are many different types of load balancing. Which methods are available really depend on the cloud provider. The most common methods are:
- Round robin: The load balancer sends the requests in a preset order equally between the servers.
- Weighted: Each server is given a weight, typically based on how capable the server is to respond. For example, a server that has more vCPUs, RAM, and bandwidth would be granted a higher weight. The load balancer sends more requests to the servers that have higher weight values.
- Geographic-based: The load balancer sends the client request to a server that is located closest to the client geographically.
Firewalls
A firewall can have an impact on high availability because the purpose of a firewall is to just allow or block traffic to a network. If a resource in a network is not available, the reason may be that a firewall rule has blocked access to that resource or the firewall is unavailable due to a failure (fail close configuration).
Avoid Single Points of Failure
To ensure high availability, you need to avoid any single points of failure. Avoiding them can be tricky because many components can impact the availability of a resource. For instance, while having just a single resource is an obvious single point of failure, having only a single network path to access the resource is another single point of failure.
To avoid single points of failure, you should map out how the resource is accessed and map the components required for the resource to work. Here’s another example: you may have multiple web servers and multiple network paths to access the servers, but the servers rely on a database, and currently you have only a single instance of that database. If that database becomes unresponsive, this single point of failure could make the web server resource fail as well.
Scalability
In cloud computing, scalability is the capability of a resource to adapt to growing demands. This is a critical feature and often one of the compelling reasons to migrate on-premises systems to the cloud.
There are different methods used for scaling, including auto-scaling, horizontal scaling, vertical scaling, and cloud bursting.
Auto-scaling
Auto-scaling occurs when the scaling process happens automatically. For example, you could have a system in place in which, if the current resource reaches a specific threshold such as a specific number of client connections, a second resource is automatically started to handle additional requests.
Note
The terms scalability and elasticity are often used interchangeably, but although they are related, they do not really mean the same thing. Scaling is all about providing additional capability to handle additional demands, but it does not address when the demand diminishes.
For example, consider a scenario in which you spin up a new web server whenever existing web servers handle more than 50 client connections. Suppose in this scenario you now have five web servers, then at some point later, the client connections die down. This means you do not need five web servers any longer.
Elasticity can handle this situation. A cloud solution that provides elasticity means that those extra web servers would be deactivated when no longer needed. Think of elasticity as meaning not only the capability to scale up to meet demand but also the capability to scale down when the demand is no longer present.
Horizontal Scaling
When additional web servers are spun up to handle increased demand, this scenario is called horizontal scaling. With horizontal scaling, more resources are provided on the fly to meet demand. This approach is less intrusive.
Vertical Scaling
In vertical scaling, additional resources are not allocated, but rather the existing resource is beefed up to handle the demand. In cloud computing, this typically means that the resource is provided additional hardware, such as more vCPUs, RAM, or storage capacity. This can be an intrusive process because the instance may need to be shut down for changing the resource configuration.
Cloud Bursting
Consider the following scenario: your organization has already heavily invested in your own private cloud structure. This means you are using on-premises resources to provide cloud-based features. However, there is some concern in your organization that during peak times the resource available in your private cloud will not be able to handle the demand.
For example, each year your organization hosts an online conference, and the utilization of your web servers and video hosting software skyrockets. You want to be able to meet this demand without having to spend a lot of money on hardware resources that won’t be used during the rest of the year. The solution: leverage cloud bursting.
With cloud bursting you configure your scaling (typically using auto-scaling) to make use of the resources of a cloud provider. You are essentially augmenting the capability of your private cloud to scale by using the resources of a public cloud. You can redirect the additional demand to cloud-based resources instead of on-premises by leveraging routing of traffic and load balancers.
What Next?
If you want more practice on this chapter’s exam objectives before you move on, remember that you can access all of the CramQuiz questions on the companion website. You can also create a custom exam by objectives with the practice exam software. Note any objectives you struggle with and go to that objective’s material in this chapter.