
Tianhe-1A Supercomputer: System and Application
School of Computer Science, National University of Defense Technology
19.1.3 Applications and Workloads
19.4.3 System Administration and Schedulers
19.5.1 Hybrid Programming Model
19.5.2 Languages and Compilers
19.5.3 Domain-Specific Software Infrastructure
19.6 System and Application Statistics
19.6.4 Highlights of Main Applications
19.7 Discussion on Hybrid Computing
TianHe-1A(TH-1A) system [YLL+11] has been developed by the National University of Defense Technology (NUDT). It is the first petaflops system in China, and also in Asia. With the CPU and GPU hybrid architecture, the experiences of developing TH-1A have somehow impacted the succeeding HPC architecture and technology development.
One of the TH-1A systems, with peak performance of 4,700 TFlops, has been deployed at the national supercomputer center in Tianjin (NSCC-TJ) since November 2010, and another one, with peak performance 1,300 TFlops, has been deployed at the national supercomputer center in Changsha (NSCC-CS) since July 2011. Both systems are online providing High Performance Computing (HPC) services for users from different areas in China.
Breaking the barrier of petaflops has been a grand challenge in high-performance computing for the last decade. In order to provide competitive HPC resources to China researchers and industries, the National High-tech Research and Development Program (also known as the 863 Program), managed by the Ministry of Science and Technology (MOST), launched a major project on petaflops HPC systems and grid service environment during the 11th five-year plan period (2006-2010). The 863 Program sponsors the NUDT, in collaboration with Tianjin Binhai New Area, to develop the petaflops supercomputer in China. NUDT has undertaken HPC research activities for several decades, and developed a famous series of domestic YH/TH supercomputing systems in China.
The research and development of the Tianhe-1 system consisted of four stages: preliminary research, proof of concept, system implementation, and application exploitation. The development team in NUDT has been engaged in HPC studies for a long time, and has extensive experience in HPC technologies, including but not limited to chip design, high-speed interconnect communication technology, operating system, and heterogeneous parallel algorithms. The preliminary research started in 2005, and has been focused on investigating new HPC architecture based on stream processing technology. The first stream processor, named FT-64, was designed and tested in 2006. A proof-of-concept prototype was built during 2007 and 2008 to demonstrate the feasibility of our design [YYX+07]. We used general processors to construct a small-scale system with 1,024 compute nodes. System implementation began in 2008 and includes two phases. The first phase involved the implementation of the first petaflops hybrid system Tianhe-1 based on the prototype, and it was accomplished in September 2009. Tianhe-1 has 6,250 nodes connected by DDR InfiniBand. Each node has two Intel processors and one ATI GPGPU. The theoretical peak performance of Tianhe-1 is 1.206 petaflops and its Linpack test result reaches 0.5631 petaflops. The focus of the second phase is to enhance and upgrade the existing Tianhe-1 into TH-1A, and it was installed and deployed at the national supercomputer center in Tianjin in August 2010. TH-1A contains 7,168 compute nodes, and each node has two CPUs and one NVIDIA GPU. TH-1A adopts a proprietary interconnect network TH-net with a higher bandwidth than InfiniBand QDR. The theoretical peak performance of TH-1A is 4.7 petaflops, and its Linpack test result is 2.566 petaflops. It was ranked first on the TOP500 list [MSDS06] issued in November 2010. Subsequent to the completion of system installation and testing, TH-1A began to explore its scientific, industrial, and commercial applications, and is currently playing an important role in many domains.
19.1.3 Applications and Workloads
TH-1A supercomputer system began to run large-scale test applications and programs in November 2010, and then opened online to general users to provide high performance computing services. Now there are more than 300 users and groups from universities, institutes, and industries on TH-1A. The application areas span from petroleum exploration, bio-medical research, climate, new material, to Computational Fluid Dynamics (CFD), fusion, engineering, fundamental science (such as high energy physics, astronomy). In the past 18 months, more than 130,000 jobs have been launched on TH-1A. The utilization of the system is about 76%.

FIGURE 19.1: Profile of user number.
According to the entire design and deployment of economic construction of the Tianjin Binhai new area, five application platforms around the TH-1A supercomputer have been built, including petroleum exploring data processing platform, biological medicine development platform, 3D animation rendering and design platform, high-end equipment design and simulation platform, and geographic information service platform. In addition, the national science and technology innovation platform has been established lately aiming to support X research areas, mainly for national high-tech programs (such as 863, 973) and the application of national key areas. Those are colloquially referred to as the “five plus ×” scheme. Figure 19.1 and Figure 19.2 illustrate the profile of user numbers and resource usage.
We have also established the cloud computing center and industry zone for Binhai new area so that TH-1A supercomputer could provide computing service through the above five application platforms as well as the cloud computing center. There were many enterprise users on TH-1A all over the country by the end of 2011. Statistical data suggests that more than 100 million RMB have been saved from the cost of infrastructure upgrades or investment in hardware and software for these enterprises by using TH-1A in NSCC-TJ.
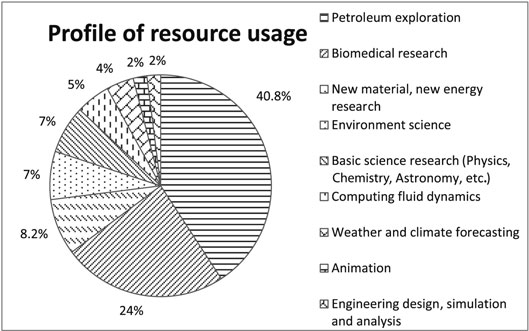
FIGURE 19.2: Profile of resource usage.
On the design of a high productivity petaflops system, we face many great challenges, including high computation performance, low latency and high bandwidth communication, high throughput and large capacity I/O operations, low power consumption, and easy use and maintenance. The balance among the performance of computation, communication, and storage is one of the key factors affecting the efficiency of large-scale parallel applications. Based on the advanced research on the stream processing architecture, high-speed interconnect and large-scale parallel I/O technology, TH-1A system adopts hybrid MPP architecture with CPUs and GPUs. It consists of five subsystems, namely, compute, service, interconnection network, I/O storage, and monitor/diagnose subsystem, as shown in Figure 19.3.
TH-1A system consists of 7,168 compute nodes and 16 commercial service nodes. Each compute node is configured with two Intel CPUs and one NVIDIA GPU. There are 186,368 cores, including 14,336 Intel Xeon X5670 CPUs (6 cores), and 7,168 NVIDIA M2050 GPUs (14 Stream Multi-processors/448 CUDA cores). The total memory of the system is 262 TB, and the disk capacity is 2 PB. There are 120 compute racks, 6 communication racks, and 14 I/O racks in the entire TH-1A system, as shown in Figure 19.4. The overall system occupies 700 m2. The power consumption at full load is 4.04 MW, the power efficiency is about 635.1 MFlops/W.
The interconnection network is a proprietary high-speed network, named TH-net, providing low latency and high bandwidth communication between all kinds of nodes in the TH-1A system. Two chips, including high-radix Network Routing Chips (NRC) and highspeed Network Interface Chips (NIC), as well as the high throughput switch, are designed by NUDT for constructing the TH-net. The interconnect topology is an optoelectronic hybrid fat-tree structure.
The monitor and diagnoses subsystem is constructed with control nodes, monitor network, and sensors on the node boards. Each node contains a Giga Ethernet interface for monitor and diagnoses subsystem connectivity, supporting a custom protocol for booting and IPMI protocol for controlling and monitoring of the system.

FIGURE 19.3: Structure of TH-1A system.

FIGURE 19.4: TH-1A system.
The I/O storage system of TH-1A adopts object storage architecture, supporting the custom Lustre filesystem [BZ02][LUS], with 6 I/O management nodes, 128 I/O storage nodes, and 2 PB storage capacity. There is another InfiniBand network for sharing the storage system with visualization clusters, and an ethernet network for connecting with external services such as the cloud computing environment.
In addition, the infrastructure design of the TH-1A system takes high power efficiency and low cost into consideration. TH-1A uses a high-density assembling technique, in which every eight mainboards can be plugged into a double-side backplane. There are 128 Xeon processors and 64 NVIDIA GPUs in each rack. The peak performance of one rack is about 42 TFlops. Unlike traditional air cooling system, TH-1A adopts a full obturation water cooling air-conditioning system, with two liquid cooling air-conditioners on each side of the rack, so that the cooling air may cycle in the rack to dissipate heat loads from chipsets. With these techniques, the power consumption of a compute rack is about 32 KW, thus the cost and complexity of TH-1A racks is acceptable.
The parallel software stack of TH-1A includes operating system, compiler system, parallel developing tools, virtualization, and visualization environment. The operating system of TH-1A is 64-bit Kylin Linux. It is designed and optimized for high-performance parallel computing, which supports power management and high-performance virtual zone. The Kylin Linux operating system is compatible with a broad range of third-party application software.
The compiler system supports C, C++, Fortran, and CUDA languages [CUD], as well as MPI and OpenMP parallel programming model. In order to develop applications on the hybrid system efficiently, TH-1A introduces a parallel heterogeneous programming framework to abstract the programming model on GPU and CPU.
The parallel application development environment provides a component-based network development platform for programming, compiling, debugging, and submitting jobs through the LAN or WAN. Users can also integrate different tools into this platform dynamically, such as Intel Vtune, TotalView, etc.
We have designed two kinds of ASICs, four types of nodes (compute node, service node, I/O management node, and I/O storage node), two sets of networks (communication network, monitor and diagnostic network), and fifteen kinds of Printed Circuit Boards (PCB) for the TH-1A system. There are more than 40,000 PCBs in the whole system.
Each compute node in TH-1A is configured with two Intel Xeon CPUs and one NVIDIA GPU. It has the 655.64 GFlops peak double precision computing performance (CPU has 140.64 GFlops and GPU has 515 GFlops) and 32 GB total memory.
The M2050 GPU integrates 3 GB GDDR5 memory, with a bit width of 384 bits and peak bandwidth of 148 GB/s. All the register files, caches, and specific memories support ECC, which improves the reliability of GPU computation.
The main task of the CPU in compute node is running the operation system, managing system resources, and executing general purpose computation. GPU mainly performs large-scale parallel computation. Facing the challenge of hybrid CPU and GPU architecture, we have to address some key issues, such as improving the efficiency of CPU and GPU cooperative computing, reducing energy consumption, and data communication overhead between CPU and GPU, to effectively accelerate many typical parallel algorithms and applications.
The main board structure of compute node is shown in Figure 19.5. The two processors in one compute node construct a SMP system using Intel Quick Path Interface (QPI). QPI is a platform architecture that provides high-speed (up to 25.6 GB/s), point-to-point connection between processors, and between processors and the I/O hub. Multiple processors can be connected directly to form a SMP node without a cache coherence chip. Furthermore, QPI interface supports adjusting link bandwidth dynamically and hot plugging. The IOH chip in compute node bridges the QPI interface and PCI-Express 2.0 interface, so that the NIC card can access the processor main memory effectively.
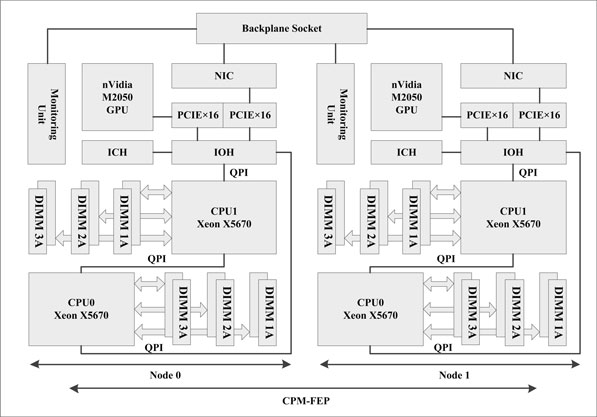
FIGURE 19.5: Architecture of compute node.
The physical package of the main board is constructed with two levels, the lower level and the upper level. The lower lever is the Compute Process Motherboard (CPM), and the upper level is the GPU board. The GPU is connected with the CPM via GPC, a PCI-E 2.0 bridging card. Each of the compute node main boards is constituted by two compute nodes (B0 and B1) with the same structure. Each compute node has its own CPU, memory, high-speed connection, IOH, and power supply. To be specific, there are 2 CPU sockets, 12 memory sockets, 1 GPU, and 1 NIC communication chip in each compute node.
In TH-1A high-speed communication network [XLW+11], the NRC is used for packet switching and routing, and the NIC is used for interfacing compute nodes and service nodes into the interconnect network.
1. NRC
Facing some requirements of the large-scale interconnect network in TH-1A, such as reducing the hops, lowering communication latency, and improving the reliability and flexibility, we use high radix routing techniques [SAKD06] to design the NRC. As shown in Figure 19.6, the NRC contains 16 switch ports. Internally, NRC uses a tile-based switching structure to simplify the design of a 16x16 crossbar. There are 16 tiles which are arranged in a 4x4 array, and each tile is a 4x4 subcrossbar. The transmission rate of each serial link in NRC is 10 Gbps, and each port integrates eight serial links, thus each port can provide 160 Gbps bidirectional bandwidth.
Besides using CRC on data packets, internal buffers in the NRC are ECC protected. The links of the NRC also support working at full-speed or half-speed mode, and can negotiate the bit-width statically or dynamically. With these supports, the NRC is able to isolate the failure links and improve the reliability and usability of the interconnect fabric.
2. NIC
Figure 19.7 shows the internal structure of the NIC. It integrates a 16-lane PCI-Express 2.0 interface, and connects with the NRC via 8 10 Gbps links. There is also an ECC protected 64bits@266Mhz memory controller interface to on-board memory whose function will be explained below.

FIGURE 19.6: Structure of NRC.

FIGURE 19.7: Structure of NIC.
The NIC utilizes user-level communication technique, and supports the overlap of computation and communication. Each NIC implements 32 virtual ports (VP). Each VP is a combination of a small set of memory-mapped registers and a set of related in-memory data structures, and the address range of registers in different VP are spaced out at least the length of the physical page. All of which can be mapped to user space, so that it can be accessed in user space concurrently and with protection.
To remove the overhead of data copy and achieve maximum bandwidth, the NIC support zero-copy of RDMA between process buffers. In TH-1A, RDMA access memory through Address Translation Table (ATT) [SH98], which is implemented in the onboard memory of a NIC card and managed by kernel module. Using ATT, we can construct a virtual address in the NIC so that non-contiguous physical pages can be merged into a contiguous virtual address range. NIC virtual address of buffer is used in the RDMA request. The NIC uses ATT to translate the virtual address into the PCI address of physical pages. An address aligning module is used in the NIC to byte-align the local and remote buffer of RDMA. Furthermore, several offload mechanisms have been developed to optimize collective communication, a set of important routines in MPI standard, which largely affects the performance of large-scale parallel applications.
Both the NRC and the NIC adopt the 90 nm CMOS fabrication and array flip-chip package. The substrate of the NRC chip contains 0.46 billion transistors and 2,577 pins, while the substrate of the NIC chip contains 0.15 billion transistors and 657 pins.
3. Topology
Based on NRC and NIC, we designed a high-speed, high-density, balanced, and scalable interconnection network. Figure 19.8 shows the topology which is a hierarchical fat-tree.
The first layer consists of 480 switching boards distributed in computing and service racks. Every 16 compute nodes connect a switching board through backplane, and communication on the switching board uses electrical transmission.
The second layer is composed of eleven 384-ports switches, which are fully connected using QSFP optical fibers. Each 384-port switch contains 12 leaf and 12 root switch boards which are connected by a high-density backplane board in an orthotropic way. All of the rack-mounted switching boards have an optical-fiber connection to the 384-ports switches. The throughput of one 384-port switch is 61.44 Tbps. The whole system aggregate bandwidth is 1146.88 Tbps, the bisection bandwidth is 307.2 Tbps.

FIGURE 19.8: TH-1A interconnection network.
4. Communication software
The basic message-passing infrastructure on the NIC is what we call the Galaxy Express (GLEX). Based on the NIC virtual port, GLEX encapsulates the communication interfaces of NIC, and provides both user space and kernel space programming interfaces which can fulfill the function and performance requirement from other software modules.
GLEX consists of a kernel module for managing NIC and providing kernel programming interfaces, a network driver module for supporting TCP/IP protocol, a user-level communication library for providing user space programming interfaces, and management tools for system administration and maintenance. GLEX is also used in the preboot execution environment to boot diskless computation nodes in order to lower the overhead of system booting and maintenance.
GLEX implements reduced communication protocol, and provides zero-copy RDMA transfer between user space data buffers. By utilizing virtual memory protection and memory mapping in CPU, GLEX permits several processes to communicate simultaneously and securely in user space and bypass the operating system kernel and data copy in communication operations. We also implemented GPU-Direct which permits zero-copy RDMA of CUDA pinned memory; this improves data transfer bandwidth for applications that utilize GPU.
The TH-1A storage system is a large-scale shared storage system equipped with different types of storage servers and disk arrays. All of the storage servers connect into TH-net, InfiniBand, and Gigabit Ethernet for sharing of its storage targets to both compute nodes inside and data processing facilities outside, constructing a shared object storage system based on a custom Lustre parallel filesystem. It provides parallel access with high aggregate bandwidth within the TH-1A system and centralized access to petascale data sets from other center-wide platforms to eliminate islands of data. The architecture of the TH-1A storage system is shown in Figure 19.9.

FIGURE 19.9: Architecture of TH-1A storage system.
The TH-1A storage system can provide storage in aggregate over 100 GB/s of I/O bandwidth and over 2 petabytes capacity from above 16,000 SATA drives. Performance benefits from the custom I/O protocol based on GLEX, which can fully exploit the performance of TH-net and the advantage of object-based architecture. The TH-1A storage system provides multiple filesystem volumes for data storage. The default setting is one user HOME directory called HOME-volume and another one for large simulation data sets called DATA-volume. The multiple volume management in TH-1A storage system, guided by hints from upper level software, can greatly reduce the interference from various applications I/O workload and metadata bottleneck. The DATA-volume consists of 110 embedded RAID enclosure storage servers. Each OSS server is equipped with two PCI-E connected RAID controllers attached with an 8-disk enclosure capable of above 600 MB/s raw device I/O bandwidth. For user HOME-volume, there are four OSS servers connected to a FC-shared two-controller RAID array with high capacity and high hardware reliability support. In this configuration, each storage server controls 4 LUNs and provides an aggregate raw write performance of up to 500 MB/s.
All of the volumes store their metadata into a two-controller FC array called metadata disk array, equipped with SSD and FC disks to improve metadata storage performance. Two pairs of the four MDS servers connect directly to a RAID array to provide shared metadata access for all kinds of filesystem clients. The TH-1A metadata storage system is designed to eliminate single point of failure. A pair of high-availability metadata servers are both connected to a pair of 12-disk dual-controller RAID enclosures to maximize availability.
TH-1A is designed for large-scale and high-accuracy numerical applications, such as numerical weather prediction, high-energy physics, and so on. The model of the application is complex and the scale of the resulting data is large (TB or even PB), which introduces a new requirement and great challenges for the high performance visualization environment of TH-1A. The storage system also connects the external visualization clusters through the InfiniBand network, to share the data produced by massive compute nodes in TH-1A, supporting the online and offline application visualization efficiently.
The storage system has a third network connection through Ethernet, which can let the center and wide-area network system access the data from the TH-1A storage system. The cloud computing environment around the TH-1A has been established.
TABLE 19.1: System software stack.
Operating system |
Kylin Linux |
Compiler |
Intel 10/11, Gcc 4.2, Cuda 3.0/4.0 |
MPI |
MPICH2 + custom GLEX |
Parallel filesystem |
Lustre + custom over THNET protocol |
Job batch and scheduler |
Slurm + custom modules |
System management |
THRMS |
Debugger |
GDB, STAT, STDump |
Performance tool |
PAPI, TAU, IDE |
Virtualization |
HPUC |
Visualization |
TH-DPVS |
TH-1A provides a conventional HPC system software stack (Table 19.1), including Kylin operating system, global parallel filesystem, resource management and scheduling system, administration, as well as the virtualization and visualization environments.
The operating system of TH-1A supercomputer is Kylin Linux. According to the architecture of TH-1A and user demands, the kernel of the Kylin Linux is optimized to support multi-core and multi-thread processors, heterogeneous computing synchronization, power management, system fault tolerance, and data security protection, which provides users an execution supporting environment with high efficiency, reliability, security, and usability.
Kylin Linux for the TH-1A supercomputer utilizes a coordinated heterogeneous architecture, running on each node. The basic service kernel contains the hardware abstraction layer, memory management module, task management module, interrupt management module, and the device management module. Above the basic service kernel, there is an extra support layer which provides the software and hardware coordinated power management, and the high performance user contains (HPUC). HPUC is used for quality of service, security, and environment customization.
The architecture of Kylin Linux in the TH-1A supercomputer can also be customized to fulfill the different requirements of the running environment. The operating system on service nodes provides each user an independent virtual environment based on the HPUC. The operating system on service nodes also implements the dynamic schedule of node access to balance the load between multiple service nodes. The compute nodes in the TH-1A system are diskless, thus the initial root filesystem is provided by a ram disk linked against the Kylin Linux kernel. The ram disk contains shells, simple utilities, shared libraries, network driver, custom Lustre client, etc. There is a quality of service module in the operating system on compute node, which avoids the excessive resource usage by malicious users or the faults in applications. We have designed and implemented the unified low power management techniques in the operating system of compute node, which can lower the power consumption through adjusting the running level of CPU and also control the state of GPU. This can reduce the maintenance cost when the system is deployed.
High bandwidth I/O on TH-1A systems is provided by the object-based storage architecture powered by a deeply optimized Lustre filesystem. Lustre is an object-based parallel filesystem suitable for the I/O patterns typically seen in scientific applications and designed to provide large, high-bandwidth storage on large-scale supercomputers. Lustre is a Linux-based filesystem that uses the portals open networking API. TH-1A implements a native GLEX Lustre Network Device(GLND) designed to make Lustre run well with the TH-net GLEX communication system and Kylin OS, providing scalable high-throughput I/O on the TH-1A system.
The TH-1A system provides a consistent global name space that allows for identical pathnames to be used, regardless of which node on the system the application is running, whether Intel CPU compute nodes, FT CPU service nodes, or other service nodes. TH-1A has its custom design on its overall high-throughput storage solution. High data transfer throughput between clients and Luster OSSs is achieved by a carefully tuned RDMA transfer pipeline inside GLND. GLND can also set a balance between different RDMA policies, such as storage side push and client side pull, for better RDMA efficiency to achieve scalability for typical I/O communication patterns but with relatively lower consumed NIC resources. In the TH-1A storage system, each application can create files distributed or striped across OSTs within one filesystem volume. Any file that has a stripe count setting is broken into objects distributed on OSTs and a single client can gain high aggregated bandwidth above 2 GB/s.
The Metadata Server (MDS) is a central place that holds the file metadata for the entire filesystem. TH-1A has a carefully optimized MDS design. For the Lustre filesystem, metadata operation rate is restricted for its single metadata server design, which can result in a parallel I/O performance bottleneck at large scale. For this reason, all OSTs in TH-1A can be partitioned into multiple filesystem volumes served by multiple MDS to release the MDS load from the burden of a single server. The responsibility of the TH-1A upper level HPUC system is to help the users find their correct volume transparently or let them decide according to their special requirements. Latency also plays a key role in improving metadata operation efficiency. To reduce latency of each metadata operation, small or medium-sized metadata requests are encapsulated into one or multiple Mini-Packets for low latency transfer instead of using the handshake protocol seen in large data transfer modes with extra round trip overhead. SSD attached to MDS acting as MDT back-end filesystem external journal also plays an important role in metadata access optimization.
For I/O resilience, TH-1A is dependent on filesystem high availability (HA) support and hardware RAID support. Besides that, TH-1A has a central storage management system, which integrates both Lustre filesystem and storage hardware monitor facilities and can mask degraded storage target LUN from filesystem namespace to prevent further performance slowdown or data loss.
19.4.3 System Administration and Schedulers
The TH-1A system employs THRMS (Tianhe Resource Management System) for integrated system administration and unified jobs scheduling.
System administration of THRMS supports the system booting, interconnection network configuration, resource partition, node state monitoring, and temperature, voltage, and power monitoring. Medley methods including probe, registration, and health checking are used to ensure the accuracy of system state. There is a database to store information and variation of the whole system, which supports system diagnoses and data mining for maintenance.
The scheduler subsystem of THRMS is in charge of global resource allocation and task scheduling. It is customized based on SLURM for heterogeneous resource management and some adaptive scheduling mechanisms. A custom parallel job launcher is implemented to reduce the startup time of large-scale parallel jobs.
The scheduler subsystem provides common job scheduling policies including priority queuing, backfill, fair-share, and advance reservation. Topology-aware and power-aware node selection and allocation strategies are provided. Partitioned resource use and job QoS are also supported. A partition is equivalent to a job queue, which has availability state, access control, scheduling priority, and resource limits attached to it. Each job submitted to TH-1A has a QOS level associated with it. Different QOS levels differ in resource limits, job priority, and preemption relation.
Job logging and accounting is an important part of THRMS. Detailed information of jobs run on TH-1A is recorded in a database. Compute resource state changes are also logged in the database. The database stores account based resource limits and access control policies as well. Job accounting reports and system utilization analysis reports are generated from the log data.
THRMS supports event triggers which can be used for automatic administration. On hardware or software events like compute node state change, job state change, configuration modification, and daemon process failure, configured script programs will be executed automatically to perform predefined operations.
To improve the usability and security of the system, TH-1A utilizes virtualization techniques, i.e., the High Performance User Container (HPUC) technique which supports dynamic environment customization. Figure 19.10 shows the architecture of HPUC, which consists of three parts, virtual computing zone on the service nodes, high performance computing zone on the compute nodes, and task management system oriented virtual zone. Based on the high performance virtual zone technique, TH-1A can construct custom virtual running environments for various users, and enable data isolation between zones.
The virtual computing zone on the service nodes supports multiple users run in independent runtime environments on a single OS simultaneously. To reduce performance loss, the HPUC technology uses a lightweight security filesystem to reduce the overhead of constructing multiple running environments, and localize the file position to reduce the overhead of remote file access. The task management system oriented virtual zone is the linkage between the virtual computing zone on the service nodes and the high performance computing zone on the computing nodes, which couple the virtual zones on compute nodes and service nodes according to the configuration of the user runtime environment.
HPUC in the TH-1A system has two-levels to fulfill various user requirements, the common HPUC (CUC) and the specialized HPUC (SUC). The CUC environment is constructed during system initialization. It is the main working environment for most common users which provides basic tools for application programming, compiling, and debugging, as well as task submitting. The SUC environment is designed for users with special demands. When constructing an SUC, the system manager provides users a basic SUC template. Based on this template, users can construct their own running environment according to their own demands in this SUC.
A distribute and parallel visualization system (TH-DPVS) is developed to accelerate the large-scale data visualization. TH-DPVS is a tool for visualizing two- and three-dimensional data sets, aimed at scalability, platform independency, and distributed computation models.
TH-DPVS uses Client/Server mode to implement remote visualization, and applies a desktop deliver strategy. The client of TH-DPVS can be deployed on various OS platforms. The server processes of TH-DPVS are distributed on the visualization clusters. TH-DPVS introduces a hybrid method to partition the workloads, that is, it first performs data division to parallelize data streams, and then an image space based partition method is used to accomplish task parallelism. This hybrid method is implemented just like the strategy of the hybrid sort-last and sort-first rendering mode.
TH-DPVS exploits both a static and dynamic load balancing strategy. In the case of static load balancing, both space partition based and scalar sorting based data structures are used, such as quadtree, octree, kd-tree, interval tree, B-like tree, and so on. These data structures can guarantee that nearly the same number of data cells is distributed to all server processes. In the case of dynamic load balancing, a work-stealing strategy has been employed for TH-DPVS. Therefore, TH-DPVS can achieve high performance by both the static and dynamic methods.
The visualization modules in TH-DPVS include a geometric rendering module, a volume rendering module, a texture rendering module, and a feature extraction and interactive analysis module. The geometric rendering module provides traditional visualization technologies, such as color map, iso-contour line, streamlines, iso-surface, and so on. Besides the mainstream volume visualization methods, a direct visualization method is employed in the volume rendering module to visualize the unstructured cell-centered data more precisely. In the texture rendering module, an adaptive sparse texture rendering technology is proposed to overcome the occlusion problem in three-dimensional vector data visualization. Furthermore, two cool/warm illumination methods are proposed and implemented to enhance the direction representation of the vector field. TH-DPVS provides powerful tools for feature extraction and data analysis. Besides the traditional methods, a fuzzy-based feature definition language (FFDL) is also implemented in TH-DPVS, which can visualize the uncertainty of the scientific data.

FIGURE 19.10: Architecture of HPUC.
TH-DPVS can also integrate many existing visualization toolkits (e.g., VTK, VisIt, ParaView), making it able to deal with various file formats.
The programming system of TH-1A supports a hybrid programming model, provides serial programming languages such as C/C++, Fortran77/90/95, Java, and the parallel programming languages such as OpenMP, MPI, and OpenMP/MPI. TH-1A can use CUDA or OpenCL for GPU programming, and supports a hybrid programming model to fit the hardware architecture. TH-1A also provides various programming tools, including debugging, performance, etc.
19.5.1 Hybrid Programming Model
To fully exploit the computing ability of a petascale heterogeneous CPU/GPU super-computing system, we employ a hybrid programming model consisting of MPI, OpenMP, and CUDA, which efficiently explore the task parallel, thread parallel, and data parallel of the parallel application as Figure 19.11 shows.
For the heterogeneous CPU/GPU supercomputer system, we map one MPI process on each compute element, which is the hardware model of the basic computing unit of TH-1A. These compute elements connect each other with TH-net. There are two CPUs as the host and one GPU as the accelerator in a compute element. The host controls the communication with others and the compute-intensive tasks are performed by the host and the accelerator cooperatively.
To parallelize the computation-intensive tasks, we use an OpenMP programming model on the host and configure 12 threads spawned at runtime when the progress enters into the parallel region. OpenMP dynamic scheduling is in charge of dynamic task assignment on CPU and GPU in one compute node. Each thread is bound with one core of the CPU. One of the 12 threads controls the GPU to finish the major part of the computing workload, and the other 11 threads consume the remaining fractions. Synchronization is performed at the end of all the OpenMP threads.
With powerful arithmetic engines, GPU devices can run thousands of lightweight threads in parallel. Powerful data parallel capability makes them well suited to computations. In order to facilitate scientists to program the scientific applications for better performance from the NVIDIA GPU, NVIDIA builds an easily used GPU programming model called CUDA. In the CUDA model, the SIMD engine is regarded as the streaming multi-processor (SM), among which the basic unit of execution flow is the warp, a collection of 32 threads. These 32 threads execute the same instruction with different data. In one SM, multiple warps are allowed to be concurrently executed in the way of groups called blocks.
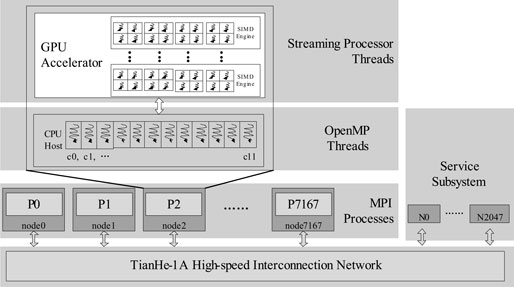
FIGURE 19.11: Hybrid programming model for the TH-1A system.
19.5.2 Languages and Compilers
The compiler on TH-1A supports multiple programming languages, from C, C++, Fortran77/90/95, and Java languages, to OpenMP API3.0 and global MPI library based on TH-net. TH-1A also uses CUDA toolkit and libraries for GPU programming and optimizations.
The TH-1A MPI, which we’ve named MPICH2-GLEX, is an optimized port of the Argonne National Laboratory’s MPI-2 implementation: MPICH2. Currently, we’ve implemented software code that uses GLEX in the nemesis channel layer of MPICH2 [BGG+09]. It provides high performance communication within and between compute nodes. It also contains optimized MPI-IO interfaces.
In MPICH2-GLEX, we’ve implemented the short message eager protocol with two kinds of channel: shared RDMA channel and exclusive RDMA channel, to optimize the performance and memory usage. For the implementation of long message rendezvous protocol, we use zero-copy RDMA data transfer. There are also some optimized collective interfaces, such as MPI_Barrier and MPI_Bcast, which utilize the offloaded collective mechanisms the NIC provided.
19.5.3 Domain-Specific Software Infrastructure
The exponential growth of computer power in the last 10 years is now creating a great challenge for parallel programming toward achieving realistic performance in the field of scientific computing. To help the traditional program with a large amount of numerical simulations, TH-1A adopts an efficient heterogeneous programming infrastructure, J Adaptive Structured Meshes applications Infrastructure (JASMIN) [MZC+10][IAP].
JASMIN is developed by the Institute of Applied Physics and Computational Mathematics (IAPCM), with higher levels of abstraction and parallelism extraction of applications.
The programming challenges mainly arise from two types of increasing complexity. The first lies in the computer architecture. More and more cores are integrated into each CPU, and more and more CPUs are clustered into each computing node, and hundreds or thousands of nodes are interconnected. Parallel algorithms should have sufficient parallelism to utilize so many cores. The design of such data structures and parallel algorithms is too professional for the application users. The second complexity is in the application system. Large-scale simulations are mainly used to study the characteristics of the complex systems. With increasing computer capabilities, the complexity of the application systems should also increase simultaneously.
JASMIN is a new program design method based on the adaptive structured meshes applications. A large amount of common data structure, algorithm, and libraries are integrated into the software infrastructure. Using these data structures and programming interfaces, the user can easily develop parallel programs for complex computers. JASMIN simplifies and accelerates the development of parallel programs on the heterogeneous CPU/GPU supercomputer systems like TH-1A.
To assist users in developing correct and efficient parallel applications, a range of programming tools are offered on TH-1A, including a set of debuggers, performance analysis tools, and an easy-to-use IDE, which can help users to explore the available computing power and parallelism.
1. Debugger and performance analysis tools
Several serial and parallel debuggers are offered on TH-1A, including GDB, STAT, and STDump (Stack Trace Dump) to help users to quickly locate, identify, and fix application bugs. After complex parallel applications have been running for a long time, it would be highly preferred to locate the context of the potential problems when applications are terminated exceptionally. STDump is a lightweight tool we developed to serve this purpose. It dumps stack traces of a parallel application in case of exceptional termination caused by asynchronous signals, such as SIGSEGV, SIGFPE. STDump installs a signal callback into the target application, which dumps the call stacks in case of invalid address access or floating point exception. STDump works using the LD_PRELOAD mechanism and does not require any change to the application source code. STDump stores the dumped stack trace into a human readable log file. By providing a separate log file for each individual task/thread, STDump provides support for large-scale MPI/OpenMP parallel applications.
The commonly used performance tool on TH-1A is TAU. The OS kernel of TH-1A compute nodes is also enhanced to provide the necessary support for obtaining PMU statistics. An application’s performance data can be visually analyzed via TAU’s ParaProf GUI tool. The installed version of TAU on TH-1A has been updated to support the performance analysis of CUDA applications. Various performance analysis tools can run on TH-1A, including gprof, Vtune, Oprofile, PAPI, Open SpeedShop, Perfsuite, SCALASCA, etc., to help users identify the performance bottlenecks and hot spot code regions of applications.
Apart from the aforementioned tools, TH-1A also provides some correctness tools, such as Valgrind and Marmot, to make user applications faster, safer, and correct.
2. Integrated development environment(IDE)
TH-1A provides a parallel application integrated development environment (IDE) based on the Eclipse parallel tools platform (PTP). This IDE fully supports application editing, compiling, linking, launching, debugging, and performance analysis in a unified, standard GUI interface. By enriching PTP’s support for TH-1A resource management system, a graphical job submission and monitoring environment is provided within this IDE. Through the GUI interface, the job submission process is greatly simplified. TH-1A IDE can remarkably improve the efficiency of parallel application development and greatly simplify the end-user interaction with TH-1A.
19.6 System and Application Statistics
TH-1A has been deployed in NSCC-Tianjin, in Tianjin Binhai new area district since November 2010.
NSCC-TJ occupies 8,500 square meters of floor space. There are two large computer rooms with total area of 3,600 square meters; one room hosts the TH-1A supercomputer and the other the cloud computing and system extension. NSCC-TJ is provided with one power station and one cooling station. The capacity of power equipment and cooling equipment is 13,600 KW and 9,600 KW, respectively, sufficient to meet the needs of NSCC-TJ.
TH-1A occupies 700 square meters of floor space, and its computer room has approximately 1,200 square meters and is equipped with a safety monitoring system consisting of smoke detectors and temperature sensors. Peak power consumption under a full CPU/GPU load is 4.04 MW. Short-term emergency power is served by an uninterruptible power supply (UPS). The computer room offers an environment of constant temperature and humidity. The temperature is 20 degrees centigrade and the humidity ranges from about 30% to 40%. The cooling system is equipped with a fully water-cooled air conditioning system. The monitoring facilities provide 24-hour monitoring services for the cooling system, power system, air-conditioner, and computer room environment.
TH-1A has been providing HPC services for more the 300 users for the past 18 months. The scientific opportunities include energy assurance, earth science, material science, fundamental science, biology and medicine, engineering design, etc. Based on TH-1A, a creative scientific research platform is constructed through the collaboration between universities and institutes; a novel technology developing platform is also constructed through the collaboration between industry enterprises. These efforts aim to improve and boost the development of HPC applications in China.
The characteristics of some main applications are categorized as follows:
1. Energy assurance
To address the key scientific issues related to energy, such as fusion, combustion, nuclear fuel cycle, renewables (wind, solar, hydro), energy efficiency, storage and transmission, the research has been done on simulation of electronic pulse complex cavity coupling, eradiation dynamic particles transportation, neutron dynamic transportation, laser solid reaction, and unstructured MC computation. The main scalar algorithms include 2D convective diffused equations, low latency parallel SN scan, 3D particles simulation of overlap of the computation and communication, Fokker-Planck parallel algorithm, non-stationary MC simulation, etc.
These kinds of applications on TH-1A can scale from thousands to ten thousands CPU cores, with performance from teraflops to petaflops, supporting the simulation from 2-dimensional, partial 3-dimensional, to fully 3-dimensional.
2. Climate
To address the key scientific issues related to weather and environment, the climate research has been conducted to establish the efficient numerical forecast business systems for medium-term numerical weather forecaster, high-resolution borderline weather forecaster, and global ocean marine environment forecaster. The main algorithms include multi-measurements multi-patterns scalar parallel algorithm, tangential concomitant mode, spherical syntonic pedigree transformation based 3D data transpose, 3D complex Helmholtz equations, 4D alternated assimilation frame, divisional parallel algorithm of directed assimilation, etc.
These applications usually scale to thousands of cores; the largest one scales to 20,000 CPU cores. The applications’ running time can last a few days or even one week, with computation intensive, data intensive, and collective communication. These applications have used about 7% of the CPU time resource of TH-1A, supporting research and business services for global and area climate changing model, including ocean, atmosphere, terrene, zoology, and multiple model coupling.
3. Petroleum exploration
To address the petroleum exploration integrative process, the seismic exploration method is widely used in hydrocarbon energy development to improve the exploration efficiency. The fine simulations of multimillion dimension gridding have been done to improve the precision and resolution of petroleum seismic data processing. The main algorithms focus on the collection equips, array disposal methods, and fine description of style layers, for example, the 3D prestack depth migration.
These kinds of applications usually scale thousands of nodes; the largest one scales to all 7,168 nodes, 86,016 cores in the system. The applications’ running time can last tens of hours to a few days. The applications are custom Geoeast, iCluster software, and some other software with hybrid parallel model including data parallelism and task parallelism, with high requirements for the capability and performance of memory and I/O accessing. By now, these kinds of applications have used about 40% of the CPU time resource of TH-1A, supporting the actual businesses.
4. Biomedical research
The research work in the biomedical field has been focused on high-resolution analysis of population genomics, AIDS and senile dementia research, new immunity drug design, and Molecular Dynamics methods to elucidate the relationship of structure and function of biological macro molecules. This kind of research can provide a theoretical reference for further study under conclusions and methods used in the design, and help us to design and synthesize new drugs, and expand the breadth and depth of life science research.
Applications cover from life science, new medicine development, gene sorting, protein folding, to molecule juncture. These kinds of applications scale from hundreds to ten thousands of cores, implementing the virtual filtration of 100 thousands of chemical combinations per day. The software includes open source software, such as Gromacs, NAMD, and some custom MD and gene sorting software. The running time usually lasts a few days or weeks. These applications have used about 24% CPU time resource of TH-1A, supporting either research work or businesses.
5. Materials
Materials science, especially the area of nanoscience and nanotechnology, is an interdisciplinary field applying the properties of matter to various areas of science and engineering. The research has been focused on addressing the key issues related to nanoscience, material life cycles, response, failure, and manufacturing. The algorithms used in these types of applications are mainly molecular dynamics, with intensive computation and frequently collective communication. The data scales to gigabytes or terabytes.
These types of applications usually scale to hundreds and thousands of cores. The largest one, the trans-scale simulation of the silicon deposition process, based on self-developed scalable bond-order potential (BOP) code, scales to all 7,168 nodes, using more than 180,000 hybrid CPU and GPU cores, with the performance reaching 1.87 Pflops in single precision (SP). The application softwares include Vasp, NAMD, Gromacs, and some custom software. These applications have used about 8.2% of the CPU time resource of TH-1A, supporting a wide range of research work.
6. Engineering
The main focus of the research on engineering is to address the design, deploy, and operate safe and economical structures, machines, processes, and systems with reduced concept-to-deployment time. Vehicle design uses more than tens of millions grid, high-precision simulation on structure modeling and collision testing to improve the performance and safety of vehicles. Aviation and space applications support low mach number flow for aviation and hypersonic flow for space. Civil engineering and structure simulation support the design, aseismatic and safety analysis of large-scale dams, subway tunnels, and flyover bridges.
These types of applications scale tens to thousands of cores. Structure design scales tens to hundreds of cores, and fluent design and simulation scales hundreds to ten thousands of cores. The largest parallelism algorithm now uses 12,375 cores, with more than 300 million grids simulation for aircrafts, with about 70% parallel efficiency. These kinds of applications are computation intensive, various communication intensive, and I/O intensive among different areas. Pre- and post-processing need nodes with large memory capacity, and use differential finite elements methods as the main algorithms. The applications include custom software and commercial software (such as Ansys, Ls-dyna, CFX, Fluent, etc.). Those applications are both for research and business use.
7. Animation
The Chinese government strongly supports the culture creative industry to drive the boom of Chinese culture. Supercomputer is a good mainstream choice in massive animation manufacturing. Large-scale heterogeneous supercomputers such as TH-1A could improve the capability of the Chinese animation and image industry.
These kinds of applications are task parallel and data parallel; the largest parallelism now needs 2,000 nodes; running time is from hours to days. The characteristics of these types of applications are computation intensive and I/O intensive, which perform frequently file read and write, with little collective communication. The main algorithm is ray-track. The applications include custom software (with sound scalability) and commercial software (such as 3DMAX, Maya, etc., with weak scalability). These applications are mainly for business use.
Linpack is a widely recognized benchmark for system-level performance of high performance computing systems. We used High Performance Linpack (HPL), and developed the Level 3 Basic Linear Algebra Subprograms library for the TH-1A system (THBLAS3) [WYD+11] and optimized for GPU accelerated heterogeneous architecture.
For the Linpack benchmark we focused on the DGEMM and DTRSM which are the main time-consuming functions. To accelerate the DGEMM and the DTRSM, all the computing capacities including the host and the accelerator were used. The load balance and data exchange are the key issues to achieve high performance. We developed some novel methods and used some other well-known optimizations to solve or release these problems.
1. Two-level adaptive task mapping
We measured the performance of GPUs and CPUs in GFLOPS and used it to guide the split of the next workload. The optimal split by the GPU can be obtained by this formula:
PGPU and PCPU are the results of the workloads (the amount of floating-point operations) divided by the execution time of the GPU and the CPU, respectively. The performance of the GPU varies with the workload. So we store the Gsplit in a database called databaseg which is indexed by the workload.
The second level is the mapping of the computations of CPU part to each CPU core, which is different with the GPU and the CPU split. The split fractions are stored in the database named databasec and are indexed by the core number i, instead of the workload. Suppose that the total number of CPU cores executing the DGEMM is n, the split fraction of the ith CPU core is:
where PCPU[i] is the performance of the ith CPU core.
When DGEMM and DTRSM are invoked in the Linpack, the whole workload is calculated first. The split ratio across the CPU and GPU can be obtained from databaseg indexed by the workload. The split ratio of the CPU cores can be got from databasec indexed by the core number. After all the DGEMM parts are finished, the split ratios in databaseg and databasec are tuned according to the above equations, and then are stored into the databases. The overhead of the whole procedure is almost negligible compared with the execution time of the DGEMM or DTRSM.
2. Software pipelining
On the CPU/GPU heterogeneous platform, the communication bandwidth between the CPU and GPU is much lower than the bandwidth of the device memory. We propose a neat software pipelining method that can overlap the kernel execution and the data transferring between the CPU and GPU.
In the Linpack, a large matrix-matrix multiplication can be split into a series of tasks that form a task queue. For example, the matrix multiplication A × B = C can be split to and four tasks are formed T0 : C1 = A1 × B1, T1 : C2 = A1 × B2, T2 : C3 = A2 × B1, and T3 : C4 = A2 × B2. To optimize the data-transfer time, we implemented the software pipelining among the tasks. Since the same matrix between tasks can be reused, the order of the four tasks is like T0,T1,T3,T2 by using the “bounce corner turn” method. When T1 is executed, matrix A1 does not need to be transferred, so neither does B2 for T3 and A2 for T2. In all, the entire matrix A and matrix B1 are skipped. In each task, the input phase is responsible for transferring the matrix from the CPU to the GPU. Then the execution phase finishes the matrix multiplication. At last, in the output phase the result of the multiplication is transferred to the CPU.
TABLE 19.2: Linpack evaluations.
Matrix size (N) |
3600000 |
Panel broadcast |
2ringM |
Block size (N B) |
512 |
Look-ahead depth |
1 |
Process mapping |
Row-major |
Swap |
Mix (threshold=768) |
process grid (P × Q) |
64 × 112 |
Matrix form |
L1:no-trans, U:no-trans |
Panel factorization |
Left-looking |
Equilibration |
no |
NBMIN, NDIV |
2,2 |
Alignment |
8 double precision words |
3. Traditional optimizations combination
Apart from the optimizations methods mentioned above related to the hybrid nature of the TH-1A system, we employed a combination method consisting of some traditional and important optimizations for homogeneous systems. These optimizations are processes and threads affinity, streaming load/store, memory management strategy tuning, look-ahead technology, and large block size, etc.
4. Linpack evaluations
The configurations of the full compute nodes are shown in Table 19.2. HPL provides many tuning parameters, such as broadcast topology and block size, which have to be carefully tuned in order to achieve the best performance. For the TH-1A system, N, NB, P, Q, and look-ahead depth significantly impact the HPL performance whereas the others play relatively minor roles. With the coefficient matrix size N = 360,000 on P × Q = 64 × 112 = 7,168 processes, the final result was 2,566 TFLOPS. The progress of Linpack executing on the TH-1A system is shown in Figure 19.12.
19.6.4 Highlights of Main Applications
To accelerate the development and deployment of parallel applications on the heterogeneous CPU/GPU supercomputer system TH-1A, we introduced the domain-specific parallel programming frameworks, for example, JASMIN.
In the field of scientific computing, a mesh is the base representation of a set of non-overlapping zones partitioning the computational domain. On a mesh, a discrete system results from the discretization of differential equations and may be solved by parallel algorithms. Many types of mesh have been used, but the structured mesh and the unstructured mesh are the most important. JASMIN is aiming to improve on the traditional program for numerical simulations of laser fusion in inertial confinement fusion (ICF), and also could support various applications in the field of global climate modeling, CFD, material simulations, etc.

FIGURE 19.12: Linpack result on TH-1A.
JASMIN promotes a new paradigm of parallel programming, which integrates the common algorithms and technologies to hide the parallel programming, support the visualization of computing results and tolerance computing, and so on. JASMIN enables domain-specific experts to develop the high-efficient parallel applications without learning many details of the parallel programming paradigms, which greatly reduces the developing difficulty of parallel programs and improves the developing efficiency of the large-scale parallel applications. Now JASMIN has released version 2.0 and has achieved its original objectives. A large amount of parallel programs have been reconstructed or developed on thousands of CPU/GPU nodes.
Aiming at the problems of large-scale heterogeneous parallel programming, such as program segmentation, data distribution, processes synchronization, load balancing, and performance optimization, JASMIN uses three layers: top layer for interfaces, middle layer for numerical algorithms, and supporting layer for SAMR meshes, shown in Figure 19.13.
The supporting layer for SAMR meshes contains three sublayers: toolbox layer, data structure layer, and mesh adaptivity layer. Toolbox provides the basic tools for object-oriented program design; the data structure layer provides the packages of managing patch data structure to divide the user program area into many data patches. Because of these packages, the details of parallel computation and the communication between nodes can be hidden from users. Users only need to emphasize the inner-patch calculations. The mesh adaptability layer implements the data copy among the data pieces of memory variables and completes data communications between processors. The middle layer for numerical algorithms supplies the common solvers for computing methods and numerical algorithms by the geometry method, which also provides the convenient numerical computing toolbox. The top layer for interfaces provides developing interfaces for user applications. These interfaces help the user to make full use of the infrastructure. They also guide the user to parallelize the calculation kernel by creating a nested threading model to control the cores of CPUs and GPUs on each node.
JASMIN provides the users a suite of C++ interface through encapsulating the above three layers to develop the parallel applications. Domain-specific experts mainly focus on the physics model computing methods without being concerned about parallel implementation. Task partition, data distribution, and communication are all automatically implemented by JASMIN.

FIGURE 19.13: Software architecture of JASMIN.
Tens of large-scale application programs have been reconstructed or developed on JASMIN. These programs are suitable for different numerical simulations arising from multi-material hydrodynamics, radiation hydrodynamics, neutron transport, hydrodynamics instability, laser plasma interactions, materials science, climate forecasting, and so on.
The following five complex application programs based on JASMIN could easily scale to tens of thousands of cores on TH-1A. These programs are developed for high performance computation arising from inertial confinement fusion and material science as well as high-power microwave. Their complexities are characterized by multi-physics coupling, extreme physical condition simulation, complex three-dimensional spatial configuration, etc.
In our tests [GCZ+11], the problem size for each program is fixed and various numbers of cores (5,250, 10,500, 21,000, 42,000, 84,000) are used. The number of cores is the product of the process number and the thread number per process. In the case of 84,000 cores, 12 threads are used on each process; in the other cases, 6 threads are launched on each process. One new feature of JASMIN 2.0 is the encapsulation of the MPI/OpenMP mixed programming while the users are free to direct it. The parallel efficiency is compared to the case of 5,250 cores. In the following, we present these five application programs and their test performance in more detail.
1) LARED-P is a three-dimensional program for the simulation of laser plasma intersections using the method of Particle-In-Cell (PIC). Electrons and ions are distributed in the cells of a uniform rectangular mesh. The Maxwell electromagnetic equations coupled with particle movement equations are solved. Particles intersect with the electromagnetic fields. For this simulation, efficient load balancing strategies are essential for successful executions. LARED-P achieves a parallel efficiency of 73% for a typical test using 76 billion particles and 768 million cells on 84,000 processors.
2) LAP3D is a three-dimensional program for the simulation of filament instabilities for laser plasma intersections in the space scale of hydrodynamics. A uniform rectangular structured mesh is used. Euler hydrodynamics equations coupled with the laser broadcasting equations are solved. LAP3D achieves a parallel efficiency of 63% for the test using 300 million cells on 42,000 cores.
3) LARED-S is a three-dimensional program for the simulation of radiation hydrodynamics instabilities occurring in the process of radiation-driven compression explosion. While the radiation effects are enforced, the implicit discrete stencils should be used. So, the performance of the sparse linear system solver is pivotal in large-scale simulations. For a typical test of Richtmyer-Meshkov hydrodynamics instability, LARED-S has a parallel efficiency of 47% for a single patch level using 300 million cells on 84,000 processors.
4) MD3D is a three-dimensional program for the short range molecular dynamics simulations of fusion material. A typical simulation using 512 million molecules achieves a parallel efficiency of 47% on 84,000 cores.
5) FDTD3D is a three-dimensional program for the time-domain simulation of the coupling and scattering of electromagnetic waves in the PC chassis. This program needs to handle the complex three-dimensional spatial configuration for the PC chassis. So it results in a very large amount of data, which challenges the bandwidth. FDTD3D has a parallel efficiency of 21% for a typical test using 1.7 billion cells on 42,000 cores.
These tests can be summarized as in Table 19.3. It can be shown that, based on the programming framework JASMIN, the scalability and performance of application programs could be extended and developed further.
TABLE 19.3: Results of selected applications based on JASMIN.
Program |
Application domain |
#Cores |
Parallel efficiency |
LARED-P |
Inertial confinement fusion |
84,000 |
73% |
LAP3D |
Inertial confinement fusion |
42,000 |
63% |
LARED-S |
Inertial confinement fusion |
84,000 |
47% |
MD3D |
Material science |
84,000 |
47% |
FDTD3D |
High-power microwave |
42,000 |
21% |
19.7 Discussion on Hybrid Computing
TH-1A aids in the exploration of the petaflops scale CPU-GPU hybrid computing. It demonstrates that this architecture is proper for large-scale scientific applications apart from graphic processing. GPU as the computing accelerator brings a series of problems, such as performance, efficiency, reliability, programming, etc. Nowadays, in designing the hardware, we need to make a choice for GPU which has memory ECC protected and can provide higher peak performance of double precision float computing based on benchmarks, decide the proper proration of CPU and GPU in a node, and consider the PCI-Express channel performance and cooling capacity for the main board design. In designing the software programming environment, we need to reduce the complexity of multi-level hybrid parallel programming for users and provide abundant optimization mechanics for improving the performance of the CPU-GPU hybrid applications. We have provided a parallel programming framework to support usable hybrid parallel application development, which is also capable of adapting to various types of system optimization and fault tolerance mechanics in the future.
The advances in hardware and software push the heterogeneous architecture to becoming an important way toward extreme large-scale computing systems, which looks like a pretty feasible choice to achieve success at present. The experiences from the exploration of hybrid computing in TH-1A show many achievements, but also show some problems which need to be continually improved in the design of future systems and applications The following are some points for future consideration:
(1) The hybrid structure of CPU-GPU can reduce the power consumption and the total cost of the HPC system, compared with the pure CPU homogeneous system. We believe that the heterogeneous architecture is one of the promising approaches to break the power wall and finally achieve the next-generation extreme large-scale supercomputer.
(2) The architecture of GPU still needs to be improved to target more complex problems in HPC fields. So far GPU has illustrated overwhelming advantages on some structured problems. However, the current architectures of GPUs are not suited for some irregular problems, in which the global memory is accessed discontinuously and different threads execute different control flow divergences. To solve these problems, more coalesced data access patterns on the global memory should be supported, and the bank conflict removal of the shared memory is expected to be more efficient. In addition, the bandwidth of data moving between CPUs and GPUs, GPUs and GPUs, still needs to be improved through some new mechanisms.
(3) Continuous efforts should be devoted to the programming languages and developing tools on the GPU platform. Most of the real-world applications running on the GPUs are tuned manually now to achieve high performance by empirical search. The automated optimizing compilers are desired to help programmers prune the searching space. More accurate performance models and profile tools are required to help people understand and find the bottleneck of the GPU programs easily.
(4) On the CPU-GPU hybrid systems, the algorithms of the applications need to be redesigned and reconstructed carefully to maximize performance. We have to fundamentally rethink the algorithms of the applications from parallel paradigms, data structure, data access pattern, to load balancing, which could fully exploit the large data parallel metric of GPU-class processors. Creative designs of algorithms may take quite a long time with efforts by scientists from various application areas.
(5) The domain-specific programming framework is becoming an accelerator to boost the developments of large-scale heterogeneous applications. With the help of the programming frameworks, on the one hand, the application developers could focus on the algorithm depiction, utilize the efficient stencils and libraries, supporting code reuse and aiming to improve productivity. On the other hand, the system software developers could focus on the organization of communication operations, data distribution, task allocation, load balance, and even fault tolerant mechanics fitted to different system structures, to optimize the performance and reliability of the applications.
The authors want to thank Zeyao Mo and Xiaolin Cao from the Institute of Applied Physics and Computational Mathematics for their contributions to the JASMIN framework. The authors also thank Wei Zhang, Feng Wang, Hongjia Cao, Enqiang Zhou, Chun Huang, and Kai Lu from NUDT for their contributions to this chapter. This work is supported in part by the National High Technology Research and Development 863 Program of China under grant 2009AA01A128 and 2012AA01A301, and the National Natural Science Foundation of China under grant 61120106005.