
Chapter 5
Scalability as an Architectural Concern
Learn from yesterday, live for today, hope for tomorrow. The important thing is not to stop questioning.
—Albert Einstein
Scalability has not been traditionally at the top of the list of quality attributes for an architecture. For example, Software Architecture in Practice1 lists availability, interoperability, modifiability, performance, security, testability, and usability as prime quality attributes (each of those has a dedicated chapter in that book) but mentions scalability under “Other Quality Attributes.” However, this view of scalability as relatively minor has changed during the last few years, perhaps because large Internet-based companies such as Google, Amazon, and Netflix have been focusing on scalability. Software architects and engineers realize that treating scalability as an afterthought may have serious consequences should an application workload suddenly exceed expectations. When this happens, they are forced to make decisions rapidly, often with insufficient data. It is much better to take scalability into serious consideration from the start. But what exactly do we mean by scalability in architecture terms, and what is its importance?
1. Len Bass, Paul Clements, and Rick Kazman, Software Architecture in Practice, 3rd ed. (Addison-Wesley, 2012).
Scalability can be defined as the property of a system to handle an increased (or decreased) workload by increasing (or decreasing) the cost of the system. The cost relationship may be flat, may have steps, may be linear, or may be exponential. In this definition, increased workload could include higher transaction volumes or a greater number of users. A system is usually defined as a combination of software and computing infrastructure and may include human resources required to operate the software and associated infrastructure.
Going back to the trade finance case study, the Trade Finance eXchange (TFX) team understands that creating a scalable TFX platform will be an important success factor. As explained in Chapter 1, “Why Software Architecture Is More Important than Ever,” the initial aim is to offer the letters of credit (L/C) platform that the team is developing to a single financial institution. In the longer term, the plan is to offer it as a white label2 solution for other financial institutions. The team’s challenge in creating a scalable platform is that they don’t really have good estimates of the associated increases (and rate of increase) in terms of transaction volumes, data size, and number of users. In addition, the team is struggling to create a scalable architecture when using the Continuous Architecture principles and toolbox. Principle 3, Delay design decisions until they are absolutely necessary, directs the team not to design for the unknown, and scalability estimates are unknown at this point. How the team can successfully overcome the challenge of not knowing their future state is described in this chapter.
2. A white label product is a product that can be branded by our customers.
This chapter examines scalability in the context of Continuous Architecture, discussing scalability as an architectural concern as well as how to architect for scalability. Using the TFX case study, it provides practical examples and actionable advice. It is important to note that, although we focus on the architectural aspects of scalability, a complete perspective for scalability requires us to look at business, social, and process considerations as well.3
3. For more details on this topic, see Martin L. Abbott and Michael J. Fisher, The Art of Scalability (Addison-Wesley 2015).
Scalability in the Architectural Context
To understand the importance of scalability, consider companies such as Google, Amazon, Facebook, and Netflix. They handle massive volumes of requests every second and are able to successfully manage extremely large datasets in a distributed environment. Even better, their sites have the ability to rapidly scale without disruption in response to increased usage due to expected events such as the holiday season or unexpected events such as health incidents (e.g., the COVID-19 pandemic) and natural disasters.
Testing for scalability is generally difficult for any system, as the resources needed may be available only in the production environment, and generating a synthetic workload may require significant resources and careful design. This is especially difficult for sites that need to handle both high and low traffic volumes without precise volume estimates. Yet companies such as Google, Amazon, Facebook, and Netflix excel at achieving scalability, and this is a critical factor behind their success. However, software architects and engineers need to remember that scalability tactics used at those companies do not necessarily apply to other companies that operate at a different scale.4 They need to be careful about too quickly reusing scalability tactics in their own environments without thoroughly understanding the implications of the tactics they are considering and documenting their requirements and assumptions explicitly as a series of architectural decisions (refer to Chapter 2, “Architecture in Practice: Essential Activities”).
4. Oz Nova, “You Are Not Google” (2017). https://blog.bradfieldcs.com/you-are-not-google-84912cf44afb
In Chapter 2, we recommended capturing quality attribute requirements in terms of stimulus, response, and measurement. However, the TFX stakeholders are struggling to provide scalability estimates for TFX because it is difficult to predict the future load of a system, as a lot depends on how successful it is.
Stakeholders may not always be a good source for scalability requirements, but those requirements can often be inferred from business goals. For example, in order to achieve a target revenue goal, a certain number of transactions would need to be conducted, assuming a particular conversion rate. Each of these estimated factors would have its own statistical distribution, which might tell you that you need 10 times more standby capacity than average to be able to handle loads at the 99th percentile.
Given the lack of business objectives for TFX, the team decides to focus their efforts on other, better-documented quality attribute requirements, such as those for performance (see Chapter 6, “Performance as an Architectural Concern”) and availability (see Chapter 7, “Resilience as an Architectural Concern”). Unfortunately, the team quickly notices that scalability impacts other quality attributes, as shown in Figure 5.1. They clearly can’t ignore scalability.
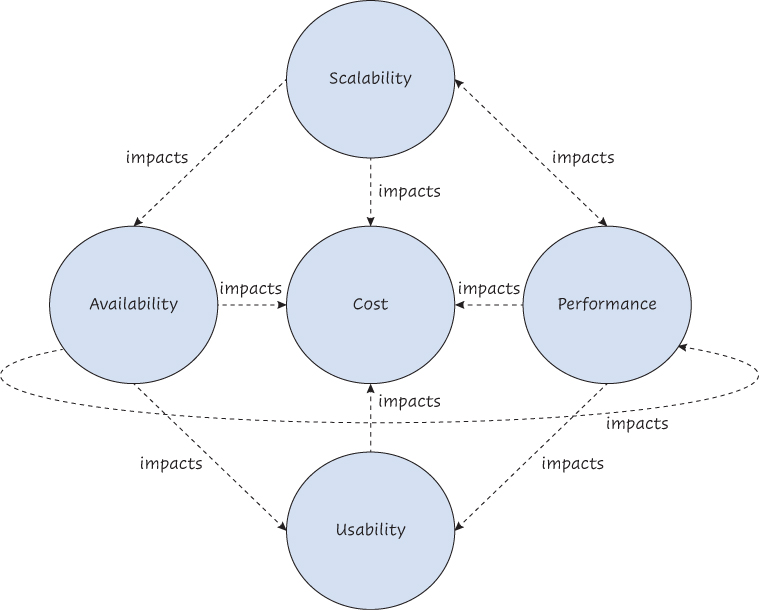
Figure 5.1 Scalability–performance–availability–usability cost relationships
The team also realizes that the four quality attributes, especially scalability, have an impact on cost. As we explained in chapter 3 of Continuous Architecture,5 cost effectiveness is not commonly included in the list of quality attribute requirements for a system, yet it is almost always a factor that must be considered. Architects of buildings and ships, as well as designers of everything from aircraft to microchips, routinely propose several options to their customers based on cost. All clients are cost sensitive, regardless of the engineering domain.
5. Murat Erder and Pierre Pureur, Continuous Architecture: Sustainable Architecture in an Agile and Cloud-Centric World (Morgan Kaufmann, 2015).
Developing an executable architecture quickly and then evolving it are essential for modern applications in order to rapidly deliver software systems that meet ever-changing business requirements. However, you do not want to paint yourself into a corner by underestimating the economic impact of scalability. Not planning for scalability up front and hoping that your platform will be able to survive a sudden load increase by relying on a relatively simple mechanism such as a load balancer6 and leveraging an ever-increasing amount of cloud-based infrastructure may turn out to be an expensive proposition. This strategy may not even work in the long run.
6. A load balancer is a network appliance that assigns incoming requests to a set of infrastructure resources in order to improve the overall processing.
Architectural decisions for scalability could have a significant impact on deployment costs and may require tradeoffs between scalability and other attributes, such as performance. For example, the TFX team may need to sacrifice some performance initially by implementing asynchronous interfaces between some services to ensure that TFX can cope with future loads. They may also increase the cost of TFX by including additional components such as a message bus to effectively implement interservice asynchronous interfaces. It is becoming clear that scalability is a key driver of the TFX architecture.
What Changed: The Assumption of Scalability
Scalability was not a major concern decades ago, when applications were mainly monolithic computer programs running on large Unix servers, and comparatively few transactions would be operating close to real time, with almost no direct customer access. Volumes and rate of change, as well as costs of building and operating those systems, could be predicted with reasonable accuracy. Business stakeholders’ expectations were lower than they are today, and the timeframe for software changes was measured in years and months rather than days, hours, and minutes. In addition, the businesses of the past were usually less scalable owing to physical constraints. For example, you could roughly estimate the daily transaction volume of a bank by the number of tellers the bank employed because all transactions were made through tellers. Today, unexpected transaction volumes can arrive at any time, as there is no human buffer between the systems and the customers.
As we described in Chapter 1, software systems evolved from monoliths to distributed software systems running on multiple distributed servers. The emergence and rapid acceptance of the Internet enabled the applications to be globally connected. The next evolution was the appearance and almost universal adoption of cloud computing, with its promise of providing a flexible, on-demand infrastructure at a predictable, usage-based optimal cost. Software architects and engineers quickly realized that even if monolithic software systems could be ported with minimal architecture changes to distributed environments and then to cloud infrastructures, they would run inefficiently, suffer scalability problems, and be expensive to operate. Monolithic architectures had to be refactored into service-oriented architectures and then into microservice-based architectures. Each architecture evolution required a system rewrite using new technologies, including new computer languages, middleware software, and data management software. As a result, software architects and engineers are now expected to learn new technologies almost constantly and to rapidly become proficient at using them.
The next evolution of software systems is the move toward intelligent connected systems. As described in Chapter 8, “Software Architecture and Emerging Technologies,” artificial intelligence (AI)–based technologies are fundamentally changing the capabilities of our software systems. In addition, modern applications now can directly interface with intelligent devices such as home sensors, wearables, industrial equipment, monitoring devices, and autonomous cars. For example, as described in Chapter 3, “Data Architecture,” one of the big bets for TFX is that it could alter the business model itself. Could the team replace the current reliance on delivery documentation with actual, accurate, and up-to-date shipping status of the goods? Sensors could be installed on containers used to ship the goods. These sensors would generate detailed data on the status of each shipment and the contents of the containers. This data could be integrated into and processed by TFX. We discuss this in more detail in the “Using Asynchronous Communications for Scalability” section.
Each evolution of software systems has increased their accessibility and therefore the load that they need to be able to handle. In a span of about 40 years, they evolved from software operating in batch mode, with few human beings able to access them and with narrow capabilities, into ubiquitous utilities that are indispensable to our daily lives. As a result, estimating transaction volumes, data volumes, and number of users has become extremely difficult. For example, according to the BigCommerce website, each month in 2018, more than 197 million people around the world used their devices to visit Amazon.com.7 Even if those numbers could be predicted a few years ago, how could anyone predict the traffic volumes caused by extraordinary events such as health incidents (e.g., COVID-19 pandemic) when Amazon.com suddenly became one of the few stores still selling everyday goods during country and state lockdowns?
7. Emily Dayton, “Amazon Statistics You Should Know: Opportunities to Make the Most of America’s Top Online Marketplace.” https://www.bigcommerce.com/blog/amazon-statistics
Forces Affecting Scalability
One way to look at scalability is to use a supply-and-demand model frame of reference. Demand-related forces cause increases in workload, such as increases in number of users, user sessions, transactions and events. Supply-related forces relate to the number and organization of resources that are needed to meet increases in demand, such as the way technical components (e.g., memory, persistence, events, messaging, data) are handled. Supply-related forces also relate to the effectiveness of processes associated with the management and operation of the technical component as well as the architecture of the software.
Architectural decisions determine how these forces interact. Scaling is optimized when there is a balance between these forces. When demand-related forces overwhelm supply-related forces, the system performs poorly or fails, which has a cost in terms of customer experience and potentially market value. When supply-related forces overwhelm demand, the organization has overbought and needlessly increased its costs, although using a commercial cloud may minimize this issue.
Types and Misunderstandings of Scalability
Calling a system scalable is a common oversimplification. Scalability is a multidimensional concept that needs to be qualified, as it may refer to application scalability, data scalability, or infrastructure scalability, to name a few of many possible types. Unless all of the components of a system are able to cope with the increased workload, the system cannot be considered scalable. Assessing the scalability of TFX involves discussing scenarios: Will TFX be able to cope with an unexpected transaction volume increase of 100 percent over the estimates? Even if TFX can’t scale, could it fail gracefully (many security exploits rely on hitting the system with unexpected load and then taking over when the application fails)?8 Will the platform be able to support a significant number of customers beyond the initial client without any major changes to the architecture? Will the team be able to rapidly add computing resources at a reasonable cost if necessary?
8. See Chapter 4, “Security as an Architectural Concern,” and Chapter 7, “Resilience as an Architectural Concern.”
Software architects and engineers often assess the ability of a system to respond to a workload increase in terms of vertical scalability and horizontal scalability.
Vertical scalability, or scaling up, involves handling volume increases by running an application on larger, more powerful infrastructure resources. This scalability strategy was commonly used when monolithic applications were running on large servers such as mainframes or big Unix servers such as the Sun E10K. Changes to the application software or the database may be required when workloads increase in order to utilize increased server capacity (e.g., to take advantage of an increase in server memory). Scalability is handled by the infrastructure, providing that a larger server is available, is affordable, and can be provisioned quickly enough to handle workload increases and that the application can take advantage of the infrastructure. This may be an expensive way to handle scaling, and it has limitations. However, vertical scaling is the only solution option for some problems such as scaling in-memory data structures (e.g., graphs). It can be cost effective if the workload does not change quickly. The challenge is matching processing, memory, storage, and input/output (I/O) capacity to avoid bottlenecks. It is not necessarily a bad strategy.
Horizontal scalability, or scaling out, refers to scaling an application by distributing it on multiple compute nodes. This technique is often used as an alternative to a vertical scalability approach, although it is also used to reduce latency and improve fault tolerance, among other goals. Several approaches may be used or even combined to achieve this. These classical approaches are still valid options, but containers and cloud-based databases provide new alternatives with additional flexibility:
The simplest option involves segregating incoming traffic by some sort of partitioning, perhaps a business transaction identifier hash; by a characteristic of the workload (e.g., the first character of the security identifier); or by user group. This is a similar approach to the one used for sharding databases.9 Using this option, a dedicated set of infrastructure resources, such as containers, handles a specific group of users. Because TFX will be deployed on a commercial cloud platform and is targeted to handle multiple banks using initially a multitenancy approach with full replication (see multitenancy considerations in the case study description in Appendix A), users could be segregated by bank (see Figure 5.2). Data would be distributed across separate tenant environments, as each bank would maintain its own set of TFX services and databases.
9. For more information about database sharding, see Wikipedia, “Shard (Database Architecture).” https://en.wikipedia.org/wiki/Shard_(database_architecture)
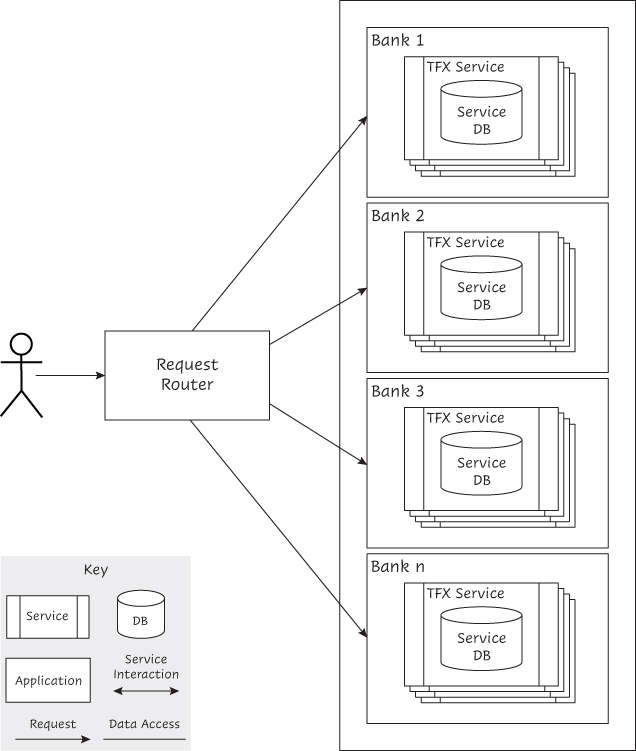
Figure 5.2 Distributing users for scalability
A second, more complex approach involves cloning the compute servers and replicating the databases. Incoming traffic is distributed across the servers by a load balancer. Still, there are data challenges associated with this approach. All the data updates are usually made to one of the databases (the master database) and then cascaded to all the others using a data replication mechanism. This process may cause update delays and temporary discrepancies between the databases (see the detailed discussion of the eventual consistency concept in Chapter 3). If the volume or frequency of database writes is high, it also causes the master database to become a bottleneck. For TFX, this option could be used for specific components, such as the Counterparty Manager (see Figure 5.3).

Figure 5.3 Distributing TFX component clones for scalability
A third, even more complex approach to horizontal scalability involves splitting the functionality of the application into services and distributing services and their associated data on separate infrastructure resource sets, such as containers (see Figure 5.4). This works well for TFX, as the design10 is based on a set of services organized around business domains, following the Domain-Driven Design11 approach, and it is deployed in cloud-based containers. Using this approach, data replication is minimal because TFX data is associated to services and organized around business domains.
10. See Appendix A for an outline of the TFX architectural design.
11. The Domain-Driven Design approach drives the design of a software system from an evolving model of key business concepts. For more information, see https://dddcommunity.org. Also see Vaughn Vernon, Implementing Domain-Driven Design (Addison-Wesley, 2013).

Figure 5.4 Distributing TFX services for scalability
The Effect of Cloud Computing
Commercial cloud platforms provide a number of important capabilities, such as the ability to pay for resources that are being used and to rapidly scale when required. This is especially true when containers are being used, because infrastructure resources such as virtual machines may take significant time to start. The result may be that the system experiences issues while processing workloads for several minutes if capacity is reduced and then must be rapidly increased again. This is often a cost tradeoff, and it is one of the reasons containers have become so popular. They are relatively inexpensive in terms of runtime resources and can be started relatively quickly.
Cloud computing offers the promise of allowing an application to handle unexpected workloads at an affordable cost without any noticeable disruption in service to the application’s customers, and as such, cloud computing is very important to scaling. However, designing for the cloud means more than packaging software into virtual machines or containers. For example, there are issues such as use of static IP addresses that require rework just to get the system working.
Although vertical scalability can be leveraged to some extent, horizontal scalability (called elastic scalability in cloud environments) is the preferred approach with cloud computing. Still, there are at least two concerns that need to be addressed with this approach. First, in a pay-per-use context, unused resources should be released as workloads decrease, but not too quickly or in response to brief, temporary reductions. As we saw earlier in this section, using containers is preferable to using virtual machines in order to achieve this goal. Second, instantiating and releasing resources should preferably be automated to keep the cost of scalability as low as possible. Horizontal scalability approaches can carry a hidden cost in terms of human resources required to operate all the resources required to handle the workload unless the operation of that infrastructure is fully automated.
Leveraging containers to deploy a suitably designed software system on cloud infrastructure has significant benefits over using virtual machines, including better performance, less memory usage, faster startup time, and lower cost. Design decisions such as packaging the TFX services and Web UI as containers, running in Kubernetes, ensure that TFX is designed to run natively on cloud infrastructures. In addition, the team has structured TFX as a set of independent runtime services, communicating only though well-defined interfaces. This design enables them to leverage horizontal scalability approaches.
Horizontal scalability approaches rely on using a load balancer of some sort (see Figures 5.2 and 5.3), for example, an API gateway and/or a service mesh,12 as in the TFX architecture. In a commercial cloud, the costs associated with the load balancer itself are driven by the number of new and active requests and the data volumes processed. For TFX, scalability costs could be managed by leveraging an elastic load balancer. This type of load balancer constantly adjusts the number of containers and data node instances according to workload. Using this tool, infrastructure costs are minimized when workloads are small, and additional resources (and associated costs) are automatically added to the infrastructure when workloads increase. In addition, the team plans to implement a governance process to review the configurations of each infrastructure element periodically to ensure that each element is optimally configured for the current workload.
12. A service mesh is a middleware layer that facilitates how services interact with each other.
An additional concern is that commercial cloud environments also may have scalability limits.13 Software architects and engineers need to be aware of those limitations and create strategies to deal with them, for example, by being able to rapidly port their applications to a different cloud provider if necessary. The tradeoff to such an approach is that you end up leveraging fewer of the cloud-native capabilities of the cloud provider of choice.
13. Manzoor Mohammed and Thomas Ballard, “3 Actions Now to Prepare for Post-crisis Cloud Capacity.” https://www.linkedin.com/smart-links/AQGGn0xF8B3t-A/bd2d4332-f7e6-4100-9da0-9234fdf64288
Architecting for Scalability: Architecture Tactics
How can a team leverage the Continuous Architecture approach to ensure that a software system is scalable? In this section, we discuss how the team plans to achieve overall scalability for TFX. We first focus on database scalability, because databases are often the hardest component to scale in a software system. Next, we review some scalability tactics, including data distribution, replication and partitioning, caching for scalability, and using asynchronous communications. We present additional application architecture considerations, including a discussion of stateless and stateful services as well as of microservices and serverless scalability. We conclude by discussing why monitoring is critical for scalability, and we outline some tactics for dealing with failure.
TFX Scalability Requirements
For TFX, the client has good volume statistics and projections for its L/C business for the current and next two years. The team can leverage those estimates to document scalability in terms of stimulus, response, and measurement. Here’s an example of the documentation that they are creating:
Scenario 1 Stimulus: The volume of issuances of import L/Cs increases by 10 percent every 6 months after TFX is implemented.
Scenario 1 Response: TFX is able to cope with this volume increase. Response time and availability measurements do not change significantly.
Scenario 1 Measurement: The cost of operating TFX in the cloud does not increase by more than 10 percent for each volume increase. Average response time does not increase by more than 5 percent overall. Availability does not decrease by more than 2 percent. Refactoring the TFX architecture is not required.
Scenario 2 Stimulus: The number of payment requests increases by 5 percent every 6 months after TFX is implemented, and the volume of issuances of export L/Cs remains roughly constant.
Scenario 2 Response: TFX is able to cope with this increase in payment requests. Response time and availability measurements do not change significantly.
Scenario 2 Measurement: The cost of operating TFX in the cloud does not increase by more than 5 percent for each volume increase. Average response time does not increase by more than 2 percent overall. Availability does not decrease by more than 3 percent. Refactoring the TFX architecture is not required.
Based on this documentation, the team feels that they have a good handle on the scalability requirements for TFX. Unfortunately, there is a significant risk associated with meeting these requirements. The plans to offer TFX to additional banks as a white label product are a major unknown at this time. Some of those banks may have larger L/C volumes than those they have predicted, and the TFX marketing plans have not been finalized yet. TFX volumes and data may triple or even quadruple over the next few years, and the ability of TFX to handle this workload may become critical. In addition, TFX operating costs would likely impact its success. Each bank’s portion of the fixed TFX costs may decrease as the number of banks using TFX increases, but a significant increase in variable costs due to a poor scalability design would more than offset this decrease. Should this situation happen, would banks quickly walk away from TFX? The team also wants to avoid a situation where scalability becomes a matter of urgency, or even survival, for TFX.
Given the uncertainty of marketing plans for TFX, the team decides to apply principle 3, Delay design decisions until they are absolutely necessary, and to architect the system for the known scalability requirements that they have already documented. Because the TFX architecture leverages principle 4, Architect for change—leverage the “power of small,” the team feels that enhancing TFX to handle additional banks if necessary would not be a major effort. For example, they are fairly confident that they could leverage one of the three horizontal scalability approaches (or a combination of those approaches) to achieve this. They feel that it is better to avoid overarchitecting TFX for scalability requirements that may never materialize. They are also considering leveraging a standard library to handle interservice interfaces in order to be able to quickly address potential bottlenecks should workloads significantly increase beyond expectations (see “Using Asynchronous Communications for Scalability” later in this chapter).
The data tier of the architecture could also be another scalability pitfall. Distributing application logic across multiple containers is easier than distributing data across multiple database nodes. Replicating data across multiple databases can especially be challenging (see “Data Distribution, Replication, and Partitioning” later in this chapter). Fortunately, as described in Appendix A, the TFX design is based on a set of services organized around business domains, following the Domain-Driven Design approach. This results in TFX data being associated to services and therefore organized around business domains. This design enables the data to be well partitioned across a series of loosely coupled databases and keeps replication needs to a minimum. The team feels that this approach should mitigate the risk of the data tier becoming a scalability bottleneck.
Identifying bottlenecks in TFX could be another challenge in solving scalability issues. It is expected that TFX users will occasionally experience response time degradation as workload increases. Based on the team’s recent experience with systems similar to TFX, services that perform poorly at higher workloads are a bigger issue than those that fail outright, as they create a backlog of unprocessed requests that can eventually bring TFX to a halt. They need an approach to identify service slowdowns and failures and to remedy them rapidly.
As the size of the workload grows, rare conditions become more common, as the system is more likely to experience performance and scalability edge cases as it approaches its limits. For example, hardcoding limits, such as hardcoding the maximum number of documents related to an L/C, can cause serious problems, creating scalability issues that manifest without warning. One such example, although a little dated, is what happened to U.S. airline Comair during the 2004 holiday season. The crew-scheduling system crashed, which, along with severe weather, caused large numbers of flight cancellations and necessitating crew rescheduling.14 The system had a limit of 32,000 crew-assignment inquiries a month, by design. We can only assume that the system designers and their business stakeholders felt that that limit was more than adequate when the system was first implemented 10 years earlier, and no one thought about adjusting it as the system was handling larger workloads.15
14. Julie Schmit, “Comair to Replace Old System That Failed,” USA Today (December 28, 2004). https://usatoday30.usatoday.com/money/biztravel/2004-12-28-comair-usat_x.htm
15. Stephanie Overby, “Comair’s Christmas Disaster: Bound to Fail,” CIO Magazine (May 1, 2005). https://www.cio.com/article/2438920/comair-s-christmas-disaster--bound-to-fail.html
Finally, we also need to consider the scalability of operational activities and processes because operations concerns are tied to actionable architecture concerns. Infrastructure configuration management could become an issue as infrastructure resources are added to cope with increased workloads. As the number of containers and database nodes grows significantly, monitoring and managing all these infrastructure resources becomes harder. For example, their software would need to be either upgraded fairly rapidly to avoid having multiple versions in production concurrently or architected to allow multiple versions operating side by side. Security patches would especially need to be quickly applied to all infrastructure elements. Those tasks need to be automated for a scalable system.
Database Scalability
As noted in the previous section, the TFX team has had some discussions about the ability of the TFX Contract Management database to cope with large workloads, especially if the TFX adoption rate would cause those workloads to exceed estimates. Theoretically, the design should enable the TFX platform to scale, because its data is well partitioned across a series of loosely coupled databases. In addition, data sharing and replication needs have been kept to a minimum. This approach should mitigate the risk of the data tier becoming a scalability bottleneck. However, the team decides to assess the upper scalability limit of the architecture by running an early scalability test.
The TFX team leverages principle 5, “Architect for build, test, deploy, and operate,” and decides to start testing for scalability as early in the development cycle as possible. The team designs and builds a simplified, bare-bones prototype of the TFX platform that implements only a few key transactions, such as issuing a simple L/C and paying it. Using this prototype, the team runs several stress tests16 using simulations of the expected TFX transaction mix. The workload used for these stress tests is based on volume projections for this year and the next 2 years, plus a 100 percent safety margin. Unfortunately, as the test workload increases, some of the databases associated with several TFX services, such as the Contract Manager and the Counterparty Manager, become bottlenecks and affect the performance of the overall platform. Services accessing and updating those components experience noticeable slowdowns, which have adverse repercussions on the performance and availability of the TFX platform.
16. See Chapter 6, “Performance as an Architectural Concern.”
The team verifies that database queries, especially those related to reporting, are a large part of the expected TFX workload and create scalability concerns. They take some initial steps, such as optimizing queries and reconfiguring the services for more capacity at increased cost, in order to facilitate vertical scaling. Those steps immediately help with the stress testing, but do not suffice as the test workloads are increased further. In addition, it proves to be hard to optimize the TFX database design for both the updates and queries that it needs to support. After some analysis, they conclude that attempting to support both workloads with a single database for each service could result in a compromised design that may not perform sufficiently well for either mode. This may also create performance and even availability issues as the TFX workload increases.
Given this challenge, one option the team can select is to use a separate database to process TFX queries related to reporting requirements (described as path C in Chapter 3). This database, called the analytics database (see Chapter 3 for more details on that database), ingests TFX transactional data and stores it in a format optimized to handle the TFX reporting requirements (see Figure 5.5). As the TFX transactional database is updated, the updates are replicated to the analytics database using the TFX database management system (DBMS) replication mechanism process. Another approach considered by the team would be to use an event bus17 to replicate the updates. However, after analyzing both options (see the architectural decision log, Table A.2, in Appendix A) and evaluating their tradeoffs, the team feels that using an event bus may increase latencies by milliseconds up to seconds at high volumes due to the data serialization, data transmission, data deserialization, and write processing. Using the TFX DBMS replication mechanism would reduce the propagation latency because, in most cases, it would be shipping database logs rather than processing events. This is very important for consistency and scalability.
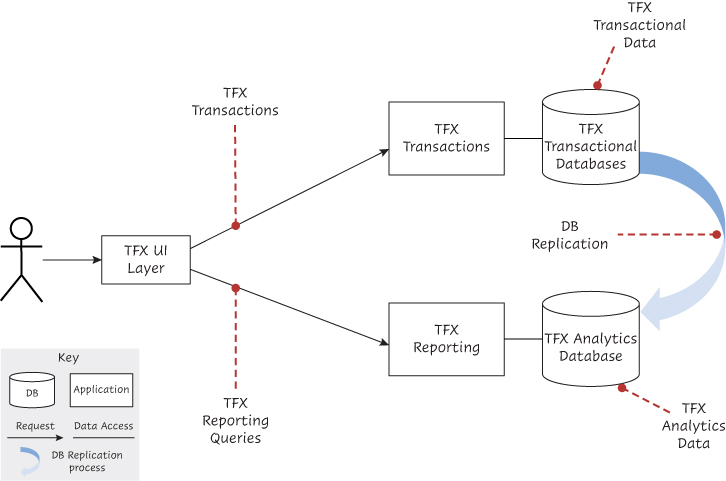
Figure 5.5 Scaling a TFX service for high workloads
17. An event bus is a type of middleware that implements a publish/subscribe pattern of communications between services. It receives events from a source and routes them to another service interested in consuming those events.
This new approach results in allowing TFX to handle higher workloads without issues, and additional stress tests are successful. However, the TFX data eventually may need to be distributed to cope with volumes beyond what the team expects for the current and next 2 years if the company is successful in getting other banks to adopt TFX. The team may be able to handle additional volumes by cloning the TFX analytics database and running each instance on a separate node without any major changes to the architecture.
Since the initial deployment of TFX will be a multitenancy installation with full replication (see multitenancy considerations in Appendix A), the team believes that the database tactics depicted in Figure 5.5 are sufficient to handle the expected workloads. However, as mentioned in the case study architectural description in Appendix A, a full replication approach becomes harder to administer as the number of banks using TFX increases. Each bank installation needs to be monitored and managed independently, and the software for each installation needs to be upgraded reasonably quickly to avoid having many versions in production simultaneously. The team may need to consider switching to other multitenancy approaches, such as data store replication or even full sharing, at some point in the future. This potentially means distributing, replicating, or partitioning TFX data.
Data Distribution, Replication, and Partitioning
Using the TFX prototype developed for stress testing, let us follow the team in a scenario where they explore a few data architecture options to better understand their tradeoffs in terms of benefits versus costs, meaning effort to implement and to maintain.
The team first looks at implementing the approach of cloning the compute servers and sharing the databases described under “Types and Misunderstandings of Scalability” earlier in this chapter. They clone a few TFX services that may experience scalability issues, such as Counterparty Manager, and run each clone on a separate set of containers (see Figure 5.3). As depicted in Figure 5.3, all of the database updates are done on one of the instances (master database), and those updates are replicated to the other databases using the DBMS replication process. Stress testing shows that this approach yields some scalability benefits over their current architecture, but it does not solve the problem of managing multiple installations of the services that are cloned.
As an alternative option, they decide to look into partitioning the TFX data for specific services, such as the Counterparty Manager. This involves splitting the database rows using some criteria, for example, user group. In this case, it may make sense to partition the rows by bank. As their next step, they implement table partitioning for the Counterparty Manager and the ContractManager databases, using the TFX prototype. They then run a stress test using a scenario with workloads that they would expect five large banks and five small ones to generate. This test is successful, and they believe that they have a viable architectural approach to implement multitenancy without using full replication should the need arise. However, using table partitoning increases architectural complexity. Database design changes become more complicated when this capability is used. We should use database partitioning only when all other options for scaling the database have been exhausted.
For TFX, the team would probably opt for a managed cloud-based alternative should they need to implement data partitioning or even sharding. This approach would, of course, increase the cost of implementing the solution as well as its ongoing operating cost and possibly a large migration cost to a different database model. As we mentioned earlier in this chapter, architectural decisions for scalability have a significant impact on deployment costs. When selecting an architecture to increase the scalability of TFX, we need to make a tradeoff with other quality attributes, such as cost in this case.
As stated earlier and in Appendix A, because the initial TFX deployment will be a full replication installation, the team applies principle 3, Delay design decisions until they are absolutely necessary, and decides not to implement table partitioning at this time (see architectural decision log, Table A.2, in Appendix A). However, the team will need to reassess using table partitioning or even sharding when it becomes necessary to switch to other multitenancy approaches as the number of banks using TFX increases.
Caching for Scalability
In addition to highlighting some database issues, let us assume that the team’s earlier stress test uncovered some potential application related performance issues as well. As described under “Database Scalability,” the team stress tested the TFX platform prototype with simulations of the expected TFX transaction mix based on volume projections for this year and the next 2 years plus a 100 percent safety margin. Specifically, they observed that a few TFX transactions, such as L/C payment, using early versions of the Counterparty Manager, the Contract Manager, and the Fees and Commissions Manager services, were experiencing some unexpected slowdowns. What should they do about this? As Abbott and Fisher point out, “The absolute best way to handle large traffic volumes and user requests is to not have to handle it at all. . . . The key to achieving this is through the pervasive use of something called a cache.”18
Caching is a powerful technique for solving some performance and scalability issues. It can be thought of as a method of saving results of a query or calculation for later reuse. This technique has a few tradeoffs, including more complicated failure modes, as well as the need to implement a cache invalidation process to ensure that obsolete data is either updated or removed. There are many caching technologies and tools available, and covering all of them is beyond the scope of this book. Let us look at four common caching techniques and investigate how they may help with the TFX scalability challenge.
18. Abbott and Fisher, The Art of Scalability, 395.
Database object cache: This technique is used to fetch the results of a database query and store them in memory. For TFX, a database object cache could be implemented using a caching tool such as Redis or Memcached. In addition to providing read access to the data, caching utilities provide their clients with the ability to update data in cache. To isolate the TFX service from the database object caching tool, the team has the option of implementing a simple data access API. This API would first check the cache when data is requested and access the database (and update the cache accordingly) if the requested data isn’t already in cache. It also would ensure that the database is updated when data is updated in cache. The team runs several tests that show that the database object cache has a positive impact on scalability, as it eliminates the need for a process to access the TFX database and deserialize objects if they are already in cache. The TFX team could implement this technique for several TFX services. Because early scalability testing has shown that some TFX transactions, such as L/C payment, may experience some performance challenges, they consider implementing database object cache for the Counterparty Manager, the Contract Manager, and the Fees and Commissions Manager components.
Application object cache: This technique stores the results of a service, which uses heavy computational resources, in cache for later retrieval by a client process. This technique is useful because, by caching calculated results, it prevents application servers from having to recalculate the same data. However, the team does not yet have any use case that could benefit from this technique, so they decide to defer implementing application object cache for now.
Proxy cache: This technique is used to cache retrieved Web pages on a proxy server19 so that they can be quickly accessed next time they are requested, whether by the same user or by a different user. Implementing it involves some changes to the configuration of the proxy servers and does not require any changes to the TFX software system code. It may provide some valuable scalability benefits at a modest cost, but the team does not know yet of any specific issues that this technique would address, so they decide to defer its implementation following principle 3, Delay design decisions until they are absolutely necessary.
19. Proxy servers act as intermediaries for requests from enterprise clients that need to access servers external to the enterprise. For more details, see Wikipedia, “Proxy Server,” https://en.wikipedia.org/wiki/Proxy_server
Precompute cache: This technique stores the results of complex queries on a database node for later retrieval by a client process. For example, a complex calculation using a daily currency exchange rate could benefit from this technique. In addition, query results can be cached in the database object cache if necessary. Precompute cache is different from standard database caching provided by DBMS engines. Materialized views (see “Modern Database Performance Tactics” in Chapter 6), which are supported by all traditional SQL databases, are a type of precompute cache. Precomputing via database triggers is another example of precompute cache. The team does not know yet of any TFX use case that could benefit from this technique, so they decide to defer implementing it.
Two additional forms of caching may already be present in the TFX environment. The first one is a static (browser) cache, used when a browser requests a resource, such as a document. The Web server requests the resource from the TFX system and provides it to the browser. The browser uses its local copy for successive requests for the same resource rather than retrieving it from the Web server. The second one is a content delivery network (CDN)20 that could provide a cache for static JavaScript code and can be used for caching other static resources in case of a Web tier scalability problem. The benefits of a CDN are that it would cache static content close to the TFX customers regardless of their geographical location. However, because a CDN is designed for caching relatively static content, it is unclear whether its benefits would outweigh its costs for TFX.
20. AWS CloudFront is an example of a CDN.
Using Asynchronous Communications for Scalability
Initially, the TFX architecture assumes that most interservice interactions are synchronous, using the REST21 architecture style (see the architectural description of the case study in Appendix A for details). What do we mean by synchronous communications? If a service request is synchronous, it means that code execution will block (or wait) for the request to return a response before continuing. Asynchronous interservice interactions do not block (or wait) for the request to return from the service in order to continue.22 However, retrieving the results of the service execution involves extra design and implementation work. In a nutshell, synchronous interactions are simpler and less costly to design and implement than asynchronous ones, which is the rationale behind using them in the initial TFX architecture.
21. REST is a lightweight, HTTP-based architecture style used for designing and implementing Web services. For more details, see Wikipedia, “Representational State Transfer,” https://en.wikipedia.org/wiki/Representational_state_transfer.
22. For more details on this topic, see Abbott and Fisher, The Art of Scalability.
Unfortunately, the team just introduced a new scalability risk with this approach, and this risk needs to be addressed. Scalability is a key quality attribute for TFX, and we cannot ignore principle 2, Focus on quality attributes, not on functional requirements. Since synchronous interactions stop the execution of the requesting process until the software component being invoked completes its execution, they may create bottlenecks as the TFX workload increases. In a synchronous interaction model, there is only one request in flight at a time. In an asynchronous model, there may be more than one request in flight. An asynchronous approach improves scalability if the request-to-response time is long, but there is adequate request processing throughput (requests per second). It can’t help if there is inadequate request processing throughput, although it may help smooth over spikes in request volume. The team may need to switch from synchronous interactions to asynchronous ones for TFX components that are likely to experience resource contentions as workloads increase. Specifically, they suspect that the requests to the Payment Service may need to be switched to an asynchronous mode, as this service interfaces with a Payment Gateway that they do not control, as it is third-party software and may experience delays with high workloads (see Figure 5.6).
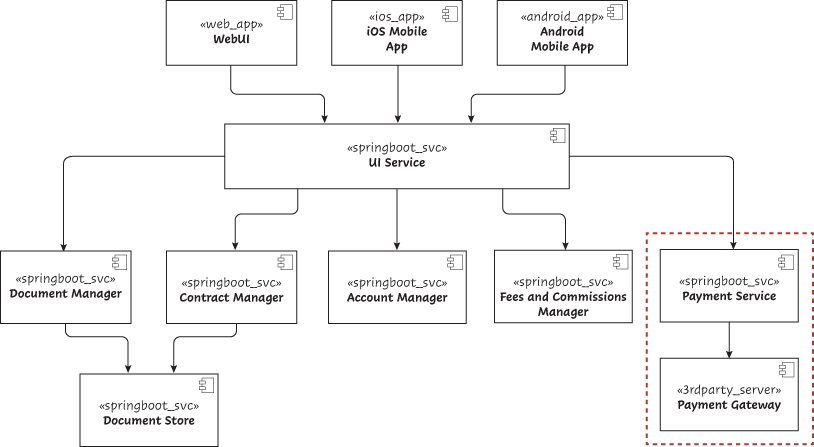
Figure 5.6 TFX component diagram
To avoid a major rework of the TFX application, should this switch become necessary, the team decides to use a standard library for all interservice interactions. Initially, this library implements synchronous interactions using the REST architectural style. However, it can be switched to an asynchronous mode for selected interservice communications should the need arise. To mitigate concurrency issues that may be introduced by this switch, the library will use a message bus23 for asynchronous requests. In addition, the library implements a standard interface monitoring approach in order to make sure that interservice communication bottlenecks are quickly identified (see Figure 5.7). An important characteristic of the TFX asynchronous service integration architecture is that, unlike an enterprise service bus (ESB) that is usually used to implement a service-oriented architecture (SOA), the message bus used in TFX has only one function, which is to deliver messages from publishing services such as the Payment Service to subscribing services such as the Payment Gateway. Any message processing logic is implemented in the services that use the message bus, following what is sometimes called a smart endpoints and dumb pipes24 design pattern. This approach decreases the dependency of services on the message bus and enables the use of a simpler communication bus between services.
23. For example, AWS EventBridge.
24. Martin Fowler, “Microservices.” https://martinfowler.com/articles/microservices.html#SmartEndpointsAndDumbPipes
Another example of where asynchronous communications can be applied was initially introduced in Chapter 3. Here is a brief summary of that example: the TFX team decides to prototype a solution based on using sensors affixed to shipping containers in order to better track the shipment of goods. They partner with a company that deals with the complexity of physically installing and tracking sensors for each shipment. These sensors generate data that need to be integrated with TFX. The scalability requirements of the TFX component responsible for this integration are unknown at this point. However, given the amount of data that is likely to be generated by the sensors, the TFX team decides to use an asynchronous communication architecture for this integration (see Figure 5.7). In addition, this approach would enable the TFX platform to integrate with several other sensor providers should the organization decide to partner with them as well.

Figure 5.7 TFX asynchronous service integration architecture
Additional Application Architecture Considerations
Presenting an exhaustive list of application architecture and software engineering considerations to develop scalable software is beyond the scope of this book. Some of the materials mentioned under “Further Reading” provide additional information on this topic. However, the following are a few additional guidelines for ensuring scalability.
Stateless and Stateful Services
Software engineers may engage in animated discussions about whether a service is stateless or stateful, especially during architecture and design reviews. During those discussions, stateless services are usually considered good for scalability, whereas stateful services are not. But what do we mean by stateless and stateful? Simply put, a stateful service is a service that needs additional data (usually the data from a previous request) besides the data provided with the current request in order to successfully execute that request. That additional data is referred to as the state of the service. User session data, including user information and permissions, is an example of state. There are three places where state can be maintained: in the client (e.g., cookies), in the service instance, or outside the instance. Only the second one is stateful. A stateless service does not need any additional data beyond what is provided with the request,25 usually referred to as the request payload. So why do stateful services create scalability challenges?
25. For example, HTTP is considered stateless because it doesn’t need any data from the previous request to successfully execute the next one.
Stateful services need to store their state in the memory of the server they are running on. This isn’t a major issue if vertical scalability is used to handle higher workloads, as the stateful service would execute successive requests on the same server, although memory usage on that server may become a concern as workloads increase. As we saw earlier in this chapter, horizontal scalability is the preferred way of scaling for a cloud-based application such as TFX. Using this approach, a service instance may be assigned to a different server to process a new request, as determined by the load balancer. This would cause a stateful service instance processing the request not to be able to access the state and therefore not to be able to execute correctly. One possible remedy would be to ensure that requests to stateful services retain the same service instance between requests regardless of the server load. This could be acceptable if an application includes a few seldom-used stateful services, but it would create issues otherwise as workloads increase. Another potential remedy would be to use a variant of the first approach for implementing horizontal scalability, covered earlier in this chapter. The TFX team’s approach would be to assign a user to a resource instance for the duration of a session based on some criteria, such as the user identification, thereby ensuring that all stateful services invoked during that session execute on the same resource instance. Unfortunately, this could lead to overutilization of some resource instances and underutilization of others, because traffic assignment to resource instances would not be based on their load.
It would clearly be better to design and implement stateless services for TFX rather than stateful ones. However, the team faces two challenges with mandating that all TFX services be stateless. The first one is that their software engineers are used to working with stateful services due to their training, design knowledge, experience, and the tools that they are using. Familiarity with stateful service design makes creating those services easier and simpler than creating stateless ones, and engineers need time to adapt their practices accordingly.
The second challenge deals with accessing user session data from a stateless service. This requires some planning, but it’s an easier challenge to solve than the first one. After conducting a design session, the team decides to keep the size of the user session data object to a minimum and to cache26 it (see “Caching for Scalability” earlier in this chapter). A small user session data item can be quickly transmitted between servers in order to facilitate distributed access, and caching that data ensures that stateless processes can quickly access it using a reference key included in each request payload.
26. Using a caching tool such as Redis or Memcached.
Using this pattern, the team should be able to make the vast majority of TFX services stateless. Stateful exceptions should be reviewed and approved by the team.
Microservices and Serverless Scalability
In Chapter 2 of the original Continuous Architecture book, we wrote the following about using microservices in order to implement principle 4, Architect for change—leverage the “power of small”:
Using this approach, many services are designed as small, simple units of code with as few responsibilities as possible (a single responsibility would be optimal), but leveraged together can become extremely powerful. The “Microservice” approach can be thought of as an evolution of Service Oriented Architectures (SOAs). . . . Using this design philosophy, the system needs to be architected so that each of its capabilities must be consumable independently and on demand. The concept behind this design approach is that applications should be built from components that do a few things well, are easily understandable—and are easily replaceable should requirements change. Those components should be easy to understand, and small enough to be thrown away and replaced if necessary. . . . Microservices can be leveraged for designing those parts of the system that are most likely to change—and therefore making the entire application more resilient to change. Microservices are a critical tool in the Continuous Architecture toolbox, as they enable loose coupling of services as well as replaceability—and therefore quick and reliable delivery of new functionality.27
27. Erder and Pureur, Continuous Architecture, 31.
We believe that what we wrote is still applicable to microservices today, especially the part on thinking of this approach as a refinement of the SOA approach to create loosely coupled components with as few responsibilities as possible. The challenge with the SOA approach may have been that it was hierarchical and defined in a rigid manner with a protocol (WSDL)28 that was inflexible. Microservices evolved from this approach and use simpler integration constructs such as RESTful APIs. The term microservice may be misleading, as it implies that those components should be very small. Among the microservices characteristics, size has turned out to be much less important than loose coupling, stateless design, and doing a few things well. Leveraging a Domain-Driven Design approach, including applying the bounded context pattern to determine the service boundaries, is a good way to organize microservices.
28. Web Service Definition Language. For more details, see https://www.w3.org/TR/wsdl.html.
Microservices communicate with each other using a lightweight protocol such as HTTP for synchronous communications or a simple message or event bus that follows the smart endpoints and dumb pipes pattern for asynchronous ones (refer to “Using Asynchronous Communications for Scalability”). A microservices-based architecture can fairly easily be scaled using any of the three techniques described in our discussion of horizontal scalability earlier in this chapter.
What about serverless computing, which has emerged since we wrote the original Continuous Architecture and is also known as Function as a Service (FaaS)? FaaS can be thought of as a cloud-based model in which the cloud provider manages the computing environment that runs customer-written functions as well as manages the allocation of resources. Serverless functions (called lambdas [λ] on Amazon’s AWS cloud) are attractive because of their ability to autoscale, both up and down, and their pay-per-use pricing model. Using serverless computing, a software engineer can ignore infrastructure concerns such as provisioning resources, maintaining the software, and operating software applications. Instead, software engineers can focus on developing application software. Serverless functions can be mixed with more traditional components, such as microservices, or the entire software system can even be composed of serverless functions.
Of course, serverless functions do not exist in isolation. Their use depends on using a number of components provided by the cloud vendor, collectively referred to as the serverless architecture. A full description of a serverless architecture is beyond the scope of this book;29 however, it is important to point out that those architectures usually increase the dependency of the application on the cloud vendor because of the number of vendor-specific components that they use. Applications that leverage a serverless architecture provided by a cloud vendor are usually not easily ported to another cloud.
29. For more information, see Martin Fowler, “Serverless Architectures.” https://martinfowler.com/articles/serverless.html
From an architectural perspective, serverless functions should have as few responsibilities as possible (one is ideal) and should be loosely coupled as well as stateless. So, what is the benefit of microservices beyond the fact that software engineers do not need to provision servers for serverless functions? It has to do with the way micro-services interface with each other compared to serverless functions. Microservices mostly communicate using a request/reply model, although they can be designed to communicate asynchronously using a message bus or an event bus. Serverless functions are event based, although they can also be invoked using a request/reply model through an API gateway. A common mode of operation is to be triggered by a database event, such as a database update, or by an event published on an event bus. Figure 5.8 illustrates various ways of invoking serverless functions. It depicts the following scenarios:

Figure 5.8 Combining microservices and serverless functions
Function Lambda 1 is invoked when a database update is made by Microservice 1.
Function Lambda 2 is invoked when Microservice 2 publishes an application to an event bus.
Finally, both Lambda 1 and Lambda 2 can also be directly invoked via an API gateway.
The team has the option to use a few serverless functions as part of the TFX system, mainly to provide notifications. For example, a serverless function could notify both the importer and the exporter that an L/C has been issued and that documents have been presented for payment.
Serverless functions such as lambdas are scalable for some workloads, but other workloads can be challenging. They tend to be dependent on other services, so the team needs to make sure they don’t accidentally cause a scalability problem by calling a service that doesn’t scale as well as lambdas do. In addition, the serverless event-driven model may create design challenges for architects who are not used to this model. If not careful, utilizing serverless functions can create a modern spaghetti architecture with complex and unmanageable dependencies between functions. On the other hand, a serverless architecture can react more rapidly to unexpected workload spikes, as there are no delays in provisioning additional infrastructure. Table 5.1 summarizes the differences and tradeoffs between microservices and serverless architecture styles.
Table 5.1 Comparison of Microservices and Serverless Architecture Styles
Element |
Microservices |
Serverless |
|---|---|---|
Architecture style |
Primarily service based architecture (can also support event based) |
Primarily event-based architecture (can also support service based). Serverless functions can also act as scheduled jobs. |
Components |
Services |
Functions |
Technology maturity |
Mature technology with tools and processes |
Less mature and evolving rapidly. Tightly coupled to the provider, and the technology is changing in ways that affect performance and other qualities. You need to be ready to keep up with someone else’s roadmap. |
Scalability |
Medium to high—depends on architecture and implementation |
Great scalability for some workloads, but others can be challenging. Limited by the provider, as are the processor and memory profiles of the execution environment. Also can be limited by the scalability of other architecture components. Unpredictable cold-start latency can be an issue for some workloads. |
Openness |
Open technology |
Not open. Need to buy into the providers’ infrastructure not only for the serverless function execution but for all the other cloud services that you need for security, request routing, monitoring, persistence, etc. |
Programming language support |
Supports most modern languages |
Fewer languages supported |
Granularity |
High to low |
Higher than microservices |
State management |
Both stateful and stateless modes are available |
Stateless by design, but the instance life cycle is not under your control, and there is no option for sticky sessions. |
Deployment time |
Architecture and implementation dependent |
Serverless is faster if you don’t have a microservices infrastructure already in place. |
Cost model |
Depends on implementation |
Pay-as-you-go |
Operational costs |
Implementation dependent |
Could be lower than for microservices |
Overall tradeoff |
You design and operate your microservices infrastructure and develop and deploy services that are compatible with that infrastructure. However, microservices can get bound to the hosting cloud infrastructure as well. |
You delegate all the architecture and operations decisions to the provider, and you buy into its entire platform, since serverless functions need a lot of surrounding services to work. If you fit the provider’s target use case, things will be smooth and easy. If you don’t fit the use case (or more significantly, if you evolve so that you no longer fit the use case), then it becomes hard, and there is no easy migration path from serverless to something else. |
Achieving Scalability for TFX
The TFX team is planning to achieve scalability based on current requirements by applying a number of architecture tactics, which are discussed earlier in this chapter. In addition, monitoring the system for scalability and dealing with failure are two key aspects of achieving scalability.
We briefly recapitulate some of the tactics they plan to use for this purpose (see Table 5.2). Those tactics are discussed in detail in this chapter. The team believes that this approach will enable the TFX system to scale adequately and meet both current requirements and future expansion plans.
Table 5.2 Sample TFX Scalability Tactics
Tactic |
TFX Implementation |
|---|---|
Database scalability tactics |
Focus on database scalability because databases are often the hardest component to scale in a software system. Use data distribution and replication when necessary. Delay using complex approaches such as data partitioning and sharding until there are no other options. |
Caching |
Leverage caching approaches and tools, including database object caching and proxy caching. |
Stateless services |
Use stateless services and microservices when possible. Stateful services should be used when no other option exists. |
Microservices and serverless |
Serverless functions should be used for scalability when it makes sense to do so. |
Monitoring TFX scalability |
Design and implement a monitoring architecture, which is critical for scalability. |
Dealing with failure |
Use specific tactics for dealing with failure, such as circuit breakers, governors, timeouts, and bulkheads. |
Measuring TFX Scalability
Monitoring is a fundamental aspect of the TFX system that is needed to ensure that it is scalable. Monitoring is discussed in detail in the “Operational Visibility” section of Chapter 7, so we include only a brief summary in this section.
As we saw earlier in this chapter, it is hard to predict exactly how large a transaction volume TFX will have to handle. In addition, determining a realistic transaction mix for that workload may be an even bigger challenge. As a result, it is hard to load and stress test a complex software system like TFX in a realistic manner. This does not mean that load and stress testing, described in Chapter 6, are not useful or should not be used, especially if an effort has been made to document scalability requirements as accurately as possible based on business estimates. However, testing should not be the only way to ensure that TFX will be able to handle high workloads.
Figure 5.9 on page 153 provides a high-level overview of the TFX scalability monitoring architecture.
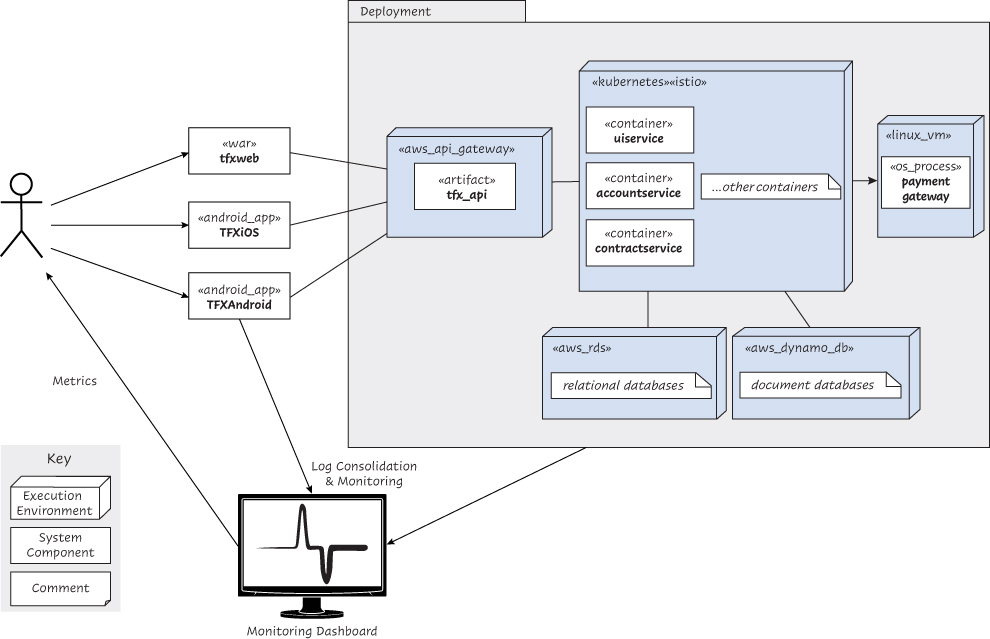
Figure 5.9 TFX scalability monitoring architecture overview
Effective logging, metrics, and the associated automation are critical TFX components of the monitoring architecture. They enable the team to make data-driven scalability decisions when required and to cope with unexpected spikes in the TFX workload. The team needs to know precisely which TFX components start experiencing performance issues at higher workloads and to be able to take remedial action before the performance of the whole TFX system becomes unacceptable. The effort and cost of designing and implementing an effective monitoring architecture is part of the overall cost of making TFX scalable.
Dealing with Scalability Failure
Why do we need to deal with failure caused by scalability issues? System component failures are inevitable, and the TFX system must be architected to be resilient. Large Internet-based companies such as Google and Netflix have published information on how they deal with that challenge.30 But why is the TFX monitoring architecture not sufficient for addressing this issue? Unfortunately, even the best monitoring framework does not prevent failure, although it would send alerts when a component fails and starts a chain reaction that could bring down the whole platform. Leveraging principle 5, Architect for build, test, deploy, and operate, the team applies additional tactics to deal with failure. Those tactics are described in detail in the “Dealing with Incidents” section of Chapter 7, so we include only a brief overview in this section. Examples of these tactics include implementing circuit breakers, throttling, load shedding, autoscaling, and bulkheads as well as ensuring that system components fail fast, if necessary, and performing regular health checks on system components (see Figure 5.10 on page 154).
30. Please see, for example, “What Is Site Reliability Engineering (SRE)?” https://sre.google, and Yury Izrailevsky and Ariel Tseitlin, “The Netflix Simian Army” [blog post]. https://netflixtechblog.com/the-netflix-simian-army-16e57fbab116

Figure 5.10 Overview of tactics for dealing with scalability failure
It is important to point out that all the TFX components that deal with failure are integrated into the TFX monitoring architecture. They are an essential source of information for the monitoring dashboard and for the automation components of that architecture.
Summary
This chapter discussed scalability in the context of Continuous Architecture. Scalability has not been traditionally at the top of the list of quality attributes list for an architecture. However, this has changed during the last few years, perhaps because large Internet-based companies such as Google, Amazon, and Netflix have been focusing on scalability. Software architects and engineers realize that treating scalability as an afterthought may have serious consequences should an application workload suddenly exceed expectations. When this happens, architects and software engineers are forced to make decisions rapidly, often with insufficient data.
Dealing with other high-priority quality attribute requirements, such as security, performance, and availability, is usually hard enough. Unfortunately, unforeseen workload spikes sometimes propel scalability to the top of the priority list in order to keep the system operational. Like any other quality attribute, scalability is achieved by making tradeoffs and compromises, and scalability requirements need to be documented as accurately as possible. In this chapter, we covered the following topics:
Scalability as an architectural concern. We reviewed what has changed over the last few years. We discussed the assumption of scalability, the forces affecting scalability, the types of scalability (including horizontal scalability and vertical scalability), some misunderstandings of scalability, and the effect of cloud computing on scalability.
Architecting for scalability. Using the TFX case study, we presented some common scalability pitfalls. We first focused on database scalability because databases are often the hardest component to scale in a software system. We reviewed additional scalability tactics, including data distribution, replication and partitioning, caching for scalability, and using asynchronous communications for scalability. We presented additional application architecture considerations, including a discussion of stateless and stateful services as well as of microservices and serverless scalability. We finally discussed why monitoring is critical for scalability and gave a brief overview of some tactics for dealing with failure.
Scalability is distinct from performance. Scalability is the property of a system to handle an increased (or decreased) workload by increasing (or decreasing) the cost of the system. Performance is “about time and the software system’s ability to meet its timing requirements.”31 In addition, a complete perspective for scalability requires us to look at business, social, and process considerations as well as its architectural and technical aspects.
31. Bass, Clements, and Kazman, Software Architecture in Practice, 131.
A number of proven architectural tactics can be used to ensure that modern systems are scalable, and we presented some of the key ones in this chapter. However, it is also important to remember that performance, scalability, resilience, usability. and cost are tightly related and that scalability cannot be optimized independently of the other quality attributes. Scenarios are an excellent way to document scalability requirements, and they help the team create software systems that meet their objectives.
It is important to remember that for cloud-based systems, scalability (like performance) isn’t the problem of the cloud provider. Software systems need to be architected to be scalable, and porting a system with scalability issues to a commercial cloud will probably not solve those issues.
Finally, to provide acceptable scalability, the architecture of a modern software system needs to include mechanisms to monitor its scalability and deal with failure as quickly as possible. This enables software practitioners to better understand the scalability profile of each component and to quickly identify the source of potential scalability issues.
Chapter 6 discusses performance in the Continuous Architecture context.
Further Reading
This section includes a list of books and websites that we have found helpful to further our knowledge in the scalability space.
Martin L. Abbott and Michael T. Fisher’s The Art of Scalability: Scalable Web Architecture, Processes, and Organizations for the Modern Enterprise (Addison-Wesley, 2015) is a classic textbook that extensively covers most aspects of scalability, including organizations and people, processes, architecting for scalability, emerging technologies and challenges, as well as measuring availability, capacity, load, and performance.
John Allspaw and Jesse Robbins’s Web Operations: Keeping the Data on Time (O’Reilly Media, 2010) has a lot of good information, based on practical experience, on how to operate web sites and deal with a number of challenges, including scalability, from an operational viewpoint.
In Designing Data-Intensive Applications: The Big Ideas behind Reliable, Scalable, and Maintainable Systems (O’Reilly Media, 2017), Martin Kleppmann discusses scalability, reliability, and performance for data-oriented applications. It is a classic text of its type.
Michael T. Nygard’s Release It!: Design and Deploy Production-Ready Software (Pragmatic Bookshelf, 2018) is primarily about resilience but contains a lot of information that is relevant to scalability as well.
Betsy Beyer, Chris Jones, Jennifer Petoff, and Niall Richard Murphy’s Site Reliability Engineering: How Google Runs Production Systems (O’Reilly Media, 2016) is a useful book on recognizing, handling, and resolving production incidents, including scalability issues.
Ana Oprea, Betsy Beyer, Paul Blankinship, Heather Adkins, Piotr Lewandowski, and Adam Stubblefield’s Building Secure and Reliable Systems (O’Reilly Media, 2020) is a newer book from a Google team. This book focuses on system design and delivery for creating secure, reliable, and scalable systems.
High Scalability (http://highscalability.com) is a great resource for information on scalability of websites. This site directs you to many tutorials, books, papers, and presentations and is a great place to start. All of the advice is practical and is based on the experiences of large Internet companies.