
8
DYNAMIC BANDWIDTH ALLOCATION IN EPON AND GPON
8.1 INTRODUCTION
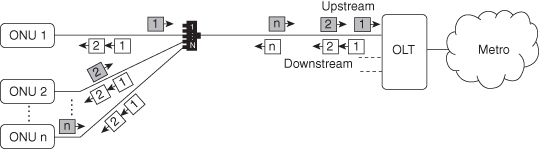
Dynamic bandwidth allocation (DBA) in passive optical networks (PON) presents a key issue for providing efficient and fair utilization of the PON upstream bandwidth while supporting the quality of service (QoS) requirements for different traffic classes. A PON consists of an optical line terminal (OLT) located at the provider central office and a number of optical network units (ONUs) or optical network terminals (ONTs) at the customer premises. In time-division multiplexing (TDM), PON downstream traffic is handled by broadcasts from the OLT to all connected ONUs, while in the upstream direction an arbitration mechanism is required so that only a single ONU is allowed to transmit data at a given point in time because of the shared upstream channel (see Figure 8.1). The start time and length of a transmission timeslot for each ONU are scheduled using a bandwidth allocation scheme. A merit of TDM-PON is the possibility to exploit the statistical multiplexing of network traffic in access networks by oversubscribing the shared optical distribution network in order to achieve high network utilization. A prerequisite for exploiting these multiplexing gains in the upstream is a well-designed and efficient DBA algorithm.
Figure 8.1. Schematic view of TDM-PON.
In this chapter we present an overview of DBA schemes for the two major standards for TDM-PON, namely, Ethernet PON (EPON) and gigabit-capable PON (GPON). The particular PON standard sets the framework for the design and operation of the DBA. As we will see, the challenges for designing DBA are quite different within the two standards. We illustrate the differences between EPON and GPON and how they are overcome. Furthermore, we consider the evolution toward next-generation TDM-PON with higher upstream bit rates and how this affects the design of the DBA.
8.2 STANDARDS
The EPON and GPON standards are said to embrace different philosophies, with EPON focusing on simplicity and looser hardware requirements, while GPON focuses on tighter hardware requirements and a fulfillment of telecom operator requirements. On a more detailed level, the two philosophies boil down to differences in guard times, overheads, and other forms of parameters influencing bandwidth allocation. The implementation of bandwidth allocation is outside the scope of both the EPON and GPON standards, although in GPON several aspects of the DBA are specified in the standard, introducing some constraints to the DBA implementation. These underlying design choices for the PON govern how DBA should be designed in order to cope with imposed traffic requirements and fairness policies while still maintaining efficient utilization of the PON’s shared upstream channel.
The design of the logical layer is crucial for the DBA implementation. One important parameter is burst overhead—that is, overhead related to the transmission of an optical burst from one ONU to the OLT. Burst overhead consists of the guard band between transmission of two bursts and, depending on implementation, either unused slot remainders (USR) or fragmentation overhead for treating allocation slot remainders which are too small to fit complete Ethernet frames (see Table 8.1). For systems with an overall large burst overhead, the DBA must provide a more coarse grained scheduling in order to maintain a large average burst size and minimize efficiency loss due to burst overhead. The EPON standard allows a relatively large burst overhead and consequently requires more coarse-grained scheduling.
TABLE 8.1. Protocol Differences in the EPON and GPON Upstream that Affect Bandwidth Allocation
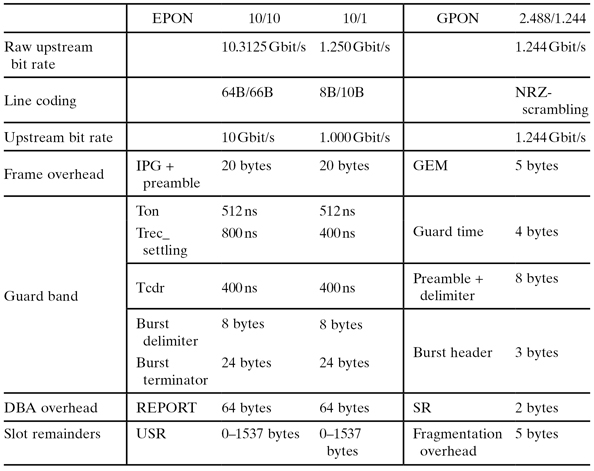
Another important part of the standard is the DBA communication messages. Both the EPON and GPON standards define (a) report messages used by the ONUs to communicate instantaneous buffer occupancy information to the OLT and (b) grant messages used by the OLT to communicate scheduling information back to the ONUs. This communication mechanism is vital for the operation of the DBA. The details of how these messages are defined will affect the design of the DBA in several ways. They govern the overhead associated with the ONU-OLT communication, which in turn affects the potential frequency of communication messages exchange. As shown in Table 8.1, EPON messages have a larger overhead associated with them compared to GPON messages. The definition of the DBA messages may also constrict at which points in time the DBA information exchange between the OLT and ONUs can occur. Regarding this issue, the EPON standard provides more flexibility in the design of the DBA algorithm than GPON. Within GPON, several status reporting modes are defined. For our comparison with EPON we consider what is most commonly used and referred to as status reporting mode 0. Our comparison of EPON and GPON is therefore based on a comparable type of communication between the OLT and ONUs.
8.2.1 EPON
EPON for 1 Gbit/s data transfer is defined in IEEE 802.3-2008 [1]. The standard defines raw downstream and upstream bit rates of 1.25 Gbit/s, which, by using 8B/10B line encoding, provides symmetric bit rate data transmission of 1 Gbit/s. There is an Ethernet frame overhead of 20 bytes—that is, 12 bytes interpacket gap (IPG) and 8 bytes preamble—which affects overall efficiency but is independent of DBA implementation. The DBA-dependent penalties are burst overhead and DBA communication overhead.
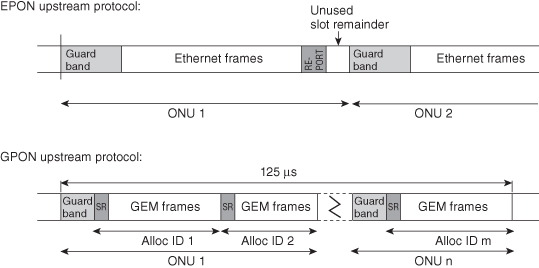
A large part of the burst overhead is guard band between two consecutive upstream bursts (Figure 8.2). For conventional 1G EPON, guard band consists of laser on–off time, receiver settling, and clock and data recovery (CDR). IEEE 802.3 presents maximum values for these overhead gaps. There is no fragmentation of Ethernet frames in EPON. As a result, there is typically burst overhead related to unused slot remainders (USR) that are too small to fit the consecutive Ethernet frame. The size of this USR overhead can be considerable but decreases with fewer ONUs, and higher bit rates as in 10G EPON, and it can even be eliminated by means of advanced DBA schemes.
Figure 8.2. Schematic diagram of EPON and GPON upstream transmission [6].
The Multipoint Control Protocol (MPCP) was designed in order to facilitate the discovery and registration of ONUs as well as medium access control in EPON. The MPCP consists of five messages, namely, REGISTER REQ, REGISTER, REGISTER ACK, GATE and REPORT. The first three messages are used for the discovery and registration of new ONUs, while the last two (REPORT and GATE) are used for bandwidth allocation and constitute the DBA overhead. GATE messages are sent by the OLT to grant nonoverlapping transmission windows to different ONUs in EPON. Usually, the information contained in GATE includes the start time and size of the granted transmission windows. REPORT messages are used to report the buffer occupancy of up to eight internal queues at an ONU to the OLT. Their exchange allows the time slots to be assigned according to the traffic demand of the individual ONUs and the available bandwidth. The MPCP allows for a very flexible communication mechanism between the OLT and ONUs. The drawback of MPCP is the rather large DBA overhead due to the large size of the REPORT and GATE messages, which are defined as the smallest size Ethernet frame (64 bytes).
In order to cater for the ever-increasing bandwidth requirements from end subscribers, the 10G EPON Task Force was formed, known as IEEE 802.3av [2], with an initiative to standardize requirements for the next-generation 10G EPON in 2006. The IEEE 802.3av draft focuses on a new physical layer standard while still keeping changes to the logical layer at a minimum, such as maintaining all the MPCP and operations, administration, and maintenance (OAM) specifications from the IEEE 802.3 standard. 10G EPON will consist of both a symmetric 10/10 Gbit/s and a nonsymmetric 10/1 Gbit/s solution (see Table 8.1). Considering the symmetric solution with 10 Gbit/s upstream, there will be a 64B/66B line coding using a raw bit rate of 10.3125 Gbit/s. The maximum value for receiver settling is increased and burst delimiters and terminators are introduced, effectively increasing the guard band overhead, while the DBA overhead and USRs are less significant because of the increased data rate.
8.2.2 GPON
The GPON standard is defined in the International Telecommunication Union–Telecommunication Standardization Sector (ITU-T) G.984.x series of Recommendations [3] sponsored by the full service access network (FSAN). The GPON standard is based on operator requirements and provides a management layer based on the GPON physical and logical layers. Upstream and downstream rates up to 2.48832 Gbit/s are specified in the standard, although upstream rates of 1.24416 Gbit/s are conventionally used in products. The GPON protocol strips off the IPG and preamble and introduces a 5-byte GEM (GPON Encapsulation Method) header to each Ethernet frame, improving link efficiency.
The requirements on the physical layer are tighter than those for EPON, providing significantly reduced guard band between bursts. The GPON protocol is based on the standard 125-µs periodicity used in the telecommunications industry. This periodicity provides certain efficiency advantages, because messages (control, buffer report, and grant messages) can efficiently be integrated into the header of each 125-µs frame, implying reduced DBA overhead. In order to efficiently pack Ethernet frames into the 125-µs frame, GEM encapsulation has been designed to support Ethernet frame fragmentation, which means that USRs are avoided at the cost of an extra GEM frame header and also at the expense of increased protocol complexity. Frame fragmentation allows the system to transport fragments of Ethernet frame in order to utilize bandwidth associated with slots that are too small for complete frames. The benefit of the increased protocol complexity of implementing frame fragmentation depends on the average burst size in bytes and is reduced as higher bit rates are introduced.
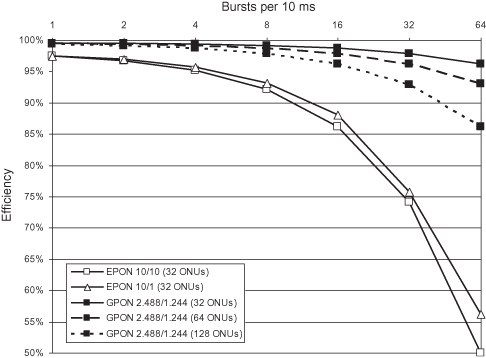
With the introduction of frame fragmentation and the reduced burst overhead compared to EPON, GPON efficiency is not as dependent on the DBA design as EPON. As illustrated in Figure 8.3, the average burst size is a crucial parameter for EPON DBA performance. The figure shows how the efficiency of the PON system depends on the burst rate (burst frequency) for an average ONU. For a given burst rate, split ratio is an additional parameter that further affects average burst size and thereby efficiency. The evaluation in Figure 8.3 was made based on a simple traffic model (30% 64-byte frames, 70% 1518-byte frames) and with worst-case parameters for EPON from Table 8.1. Note that efficiency is plotted after line-coding and FEC and does not include efficiency loss due to these operations. Increased burst rate and increased split ratio will significantly degrade EPON efficiency through increased overhead. Decreased burst rate will, on the other hand, increase delay by increasing the response time of the DBA. This tradeoff presents a key challenge for the design of an efficient EPON DBA algorithm. On the other hand, for GPON it is the set of constraints imposed by the DBA messaging protocol (Figure 8.2) that present the key challenge for the design of an efficient DBA algorithm.
Figure 8.3. PON efficiency dependence on burst rate, protocol (EPON, GPON), and number of ONUs.
In order to support more bandwidth demanding services, FSAN is currently working toward the next-generation 10G GPON (XG-PON, G.987.x) standard. The solution will most likely have a ∼10-Gbit/s downstream rate and 2.48832-Gbit/s upstream line rate.
8.3 TRAFFIC REQUIREMENTS
The implementation and performance of a DBA algorithm is related to the nature and the requirements of different types of network traffic. Traffic is mainly characterized by frame size distribution and burstiness. Several measurements of frame size distribution show that a large portion of network traffic consists of either minimum-sized Ethernet frames or maximum sized Ethernet frames. An older measurement is presented in [4]. The Hurst parameter (H), described in more detail in Sala and Gummalla [5], is a measurement of the degree of self-similarity or burstiness of traffic. Network traffic with H = 1 exhibits burstiness on all timescales.
Traffic requirements are given in terms of throughput, delay, jitter, and packet loss ratio, and they differ depending on service. Traffic requirements are typically given with respect to end-to-end requirements that need to be broken down to requirements on the access part of the network. We will now summarize the important aspects of network traffic that a PON must cater for.
- Voice: Voice traffic in access networks is carried through either legacy telephony or voice over IP (VoIP). EPON and GPON are designed for VoIP. The nature of VoIP traffic depends on codec and how voice is encapsulated in IP packets. Common speech codecs are G.711, G.723, and G.729. These convert speech to a bit stream of 2.15 to 64 kbit/s, depending on codec used. Instead of transmitting an 8-bit sample every 125 µs as in legacy telephony, several 8-bit samples are collected and packaged in an IP packet. The size of the IP packets is limited by coding latency. For G.711 and a 64-kbit/s stream, voice payloads are typically 160 bytes (20 ms of speech) or 240 bytes (30 ms of speech). Including packaging overhead, bit rates of 83 kbit/s and 76 kbit/s are required for the two schemes, respectively. Voice activity detection is used to eliminate packets of silence to be transmitted, reducing the average data rate by one-third. These variations can be modeled by the on–off model [7]. For acceptable service it is required that one-way end-to-end delay be less than 100 ms. VoIP is typically jitter sensitive although usually there is some buffer capacity for coping with a small amount of jitter. Some encoding schemes can handle single-packet losses maintaining acceptable voice quality. Voice is transported in accordance with the most stringent QoS requirements in Table 8.2.
- Video: The largest growth in network traffic during the coming years is expected to be because of video applications. However, for access networks this is primarily true for the downstream, although some amount of video traffic will still occupy the upstream. Video traffic is typically bursty and depends on the compression algorithm used in the codec. Common codecs are H.263, H.263+, V6, MPEG-2, and H.264/MPEG-4. Videos encoded without rate control show strong correlations over long time periods in contrast to videos encoded with rate control. It is the strong temporal correlations in video content that is exploited by the compression algorithms. In MPEG-2 every 15th frame is a larger I-frame. Between the I-frames a sequence of smaller P- and B-frames are transmitted. There have been measurements on frame size distribution and Hurst parameter for different video streams. Hurst parameters have been shown to be in the range of H = 0.7–0.8 [8]. Interactive video applications such as video conferencing impose high QoS requirements regarding jitter and delay. Video traffic within video on demand (VoD) applications is transmitted with some degree of QoS assurance, whereas a large amount of internet video content is transported as best effort Internet traffic.
- Data: Data traffic primarily consists of file sharing and Web browsing. Web browsing possesses self-similar properties and is commonly modeled as a sum of on–off sources of Pareto-distribution with Hurst parameter 0.8. In access networks data traffic is usually managed in a best effort manner. Data are transported in accordance with the most relaxed QoS requirements in Table 8.2.
TABLE 8.2. QoS Parameters for Different Traffic Types for the Access Part of the Network [6]

Traffic requirements are crucial for the implementation of the DBA. There is often a tradeoff between supporting delay-sensitive traffic classes and providing overall high bandwidth utilization. This tradeoff will be discussed in Section 8.5 for the different DBA algorithms.
8.4 PERFORMANCE PARAMETERS
There are a number of performance parameters used for evaluating and comparing the operation of different DBA algorithms. These parameters represent important aspects of a DBA algorithm, and several are typically connected to traffic requirements.
8.4.1 Delay
An important performance parameter for any access technology is the delay imposed on data transported through the system. This delay is a combination of waiting time in a receiving buffer (at the ONU) and transmission time through the system. The delay of a certain traffic class typically depends on the priority it is given by the scheduling mechanism in the PON. The mechanisms responsible for delay differ between a congested traffic class and a noncongested traffic class. In a noncongested traffic class, delay is determined by the execution delay of the scheduling mechanism, the average cycle time of the scheduling algorithm, and the propagation delay through the PON. In a congested traffic class, delay is mainly decided by the magnitude of the congestion, which in turn depends on traffic characteristics such as burstiness and amount of traffic with the same or higher priority, buffer sizes, and PON efficiency.
It is primarily the noncongested traffic delay that is of interest when comparing delay of different algorithms. Traffic classes that are delay-sensitive are treated with higher priority by the scheduling algorithm and to a smaller extent overbooked. In a noncongested traffic class there is available bandwidth for all incoming traffic, and delay is determined by the delay of the scheduling algorithm.
Delay for a congested traffic class is of less interest because it refers to best-effort traffic with loose delay requirements. Here, delay can instead be seen as an inverse measure of PON efficiency as more efficient DBA algorithms are capable of more effectively utilizing the available bandwidth.
8.4.2 Jitter
Jitter is the standard deviation of delay. In analog to delay it is the jitter of noncongested traffic classes that are of importance. Some Internet applications are sensitive to jitter such as online multiplayer games and many video conferencing applications. It is determined by the operation of the DBA algorithm rather than traffic characteristics.
8.4.3 Efficiency
DBA algorithm efficiency is a critical performance metric. One way of defining efficiency is
![]()
For DBA efficiency (rather than PON efficiency), one would typically include Ethernet frame headers in the useful data rate and use the post line-code, post FEC bit rate denominator as in Figure 8.3. The efficiency metric is only meaningful for congested systems.
There are a number of sources of efficiency loss in a PON upstream that can be controlled by the DBA algorithm:
- PON Guard Band. The size of the guard band between two bursts is defined in the standard. The efficiency loss related to guard band depends on the defined size of the guard band and on the average burst size which is controlled by the DBA algorithm. Small bursts lead to increased guard band overhead.
- DBA Messages. Each PON standard defines the size of the DBA messages used for reporting buffer occupancy and granting bandwidth. The efficiency loss related to DBA messages depends on the size of these messages and on how often these messages are exchanged. The latter is controlled by the DBA algorithm.
- Unused Slot Remainders (USR). USR is an inherent problem for EPON systems which do not support Ethernet frame fragmentation. The contribution of USR to efficiency loss is determined by traffic profile and average burst size. There exist DBA algorithms for EPON that eliminate USR completely, but these typically introduce some additional DBA delay.
- Fragmentation Overhead. For systems that support Ethernet frame fragmentation, a small overhead is introduced due to fragmentation. Efficiency loss due to fragmentation depends on average burst size and average number of queues per ONU.
- DBA Waiting Time. For some nonoptimal DBA or computational expensive algorithms the PON system must wait for the DBA algorithm to complete its execution.
- Over-granting. Efficiency loss due to bandwidth over-granting typically occurs in DBA algorithms where bandwidth demand is estimated or predicted. This type of overhead may be reduced by using more conservative DBA algorithms.
8.4.5 Fairness
It is often required that the DBA algorithm should allocate bandwidth fairly among the queues. Fairness is a concept that becomes relevant first for congested traffic classes, where multiple queues compete for a limited amount of resources. We will now briefly examine the concept of fairness.
Fairness is related to some set of pre-decided principles for fair bandwidth allotment. For noncongested traffic classes, demand dictates the desired bandwidth distribution. For congested traffic classes, it is usually desired that a combination of demand and weights decide the bandwidth distribution. A bandwidth allocation algorithm may be designed to achieve the desired fair bandwidth distribution or an approximation of this fair distribution. Usually fairness is considered with respect to queues. Fairness with respect to queues on the same ONU (sibling fairness) is often regarded as important. Fairness with respect to queues on different ONUs (cousin-fairness) can be difficult to achieve within certain DBA schemes (hierarchical scheduling).
Fairness is also related to timescale. For example, an algorithm can be regarded as very unfair on a short timescale but fair on a longer timescale. Many times it is long-term fairness that is desired. Simple DBA algorithms are implemented to be fair on the timescale of the DBA cycle. Reducing the DBA cycle may therefore implicitly lead to a fairness on a shorter timescale at the expense of efficiency. For this reason it may be useful to extend the timescale for possible unfair allotment for the sake of overall efficiency. For bursty traffic, the tradeoff between fairness and efficiency becomes more accentuated.
8.5 DBA SCHEMES
The design of an efficient DBA scheme depends on the PON protocol (Section 8.2), the nature of network traffic (Section 8.3) in the system, and the service requirements (Section 8.4). As we have seen in previous sections, the GPON standard, with the 125-µs framing and standardized DBA output, imposes more stringent constraints to the implementation of the DBA. Flexibility is larger in EPON, which partly explains why there has been a significant amount of academic work on EPON DBA [9–23], whereas research on GPON DBA has been limited to a few number of system and chip vendors and research institutes [24–28]. Designing EPON DBA is in several aspects more challenging than designing GPON DBA. Large burst overhead and absence of Ethernet frame fragmentation in the EPON standard, delegates some of the complexity to the EPON DBA, which in GPON is handled by the GPON framework.
There are several ways of categorizing DBA algorithms. One important distinction relates to whether the DBA algorithm is interleaved with respect to ONU bursts (burst interleaved) or with respect to time intervals (time frame interleaved). Since the execution time of the DBA (including OLT-ONU communication) is non-negligible, it is necessary to interleave several DBA processes in order to avoid ONU idle time. In burst interleaved schemes the DBA is executed per ONU burst upon reception of an ONU report at the OLT (Figure 8.4a). In time frame interleaved schemes the DBA is executed at regular time intervals (Figure 8.4b). EPON DBA can be implemented either way but the most well-known implementations are burst interleaved. GPON DBA is restricted by the logical layer to a time-frame-interleaved implementation. The effect of this difference has profound implications and is discussed more in detail in Section 8.5.3.
Figure 8.4. Burst interleaved and time frame interleaved DBA algorithms. (a) Burst interleaved scheme. (b) Time-frame interleaved scheme.
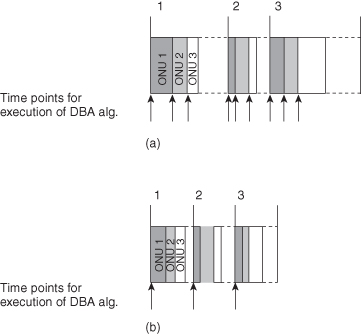
Another way of categorizing algorithms is whether the DBA is implemented with a fixed or a variable cycle length. Due to the absence of Ethernet frame fragmentation and flexibility of the protocol, EPON algorithms and burst interleaved schemes are more prone to have a variable DBA cycle. Due to the fixed protocol structure, GPON algorithms and time-frame-interleaved schemes are more prone to have a fixed DBA cycle. In general, a variable cycle length is advantageous with respect to bandwidth efficiency, whereas a fixed cycle simplifies QoS assurance.
DBA algorithms can also be categorized depending on if they are centralized or distributed. Figure 8.5 shows the taxonomy for general DBA schemes. We use this taxonomy as a framework for discussing DBA schemes.
Figure 8.5. Taxonomy for general DBA schemes.
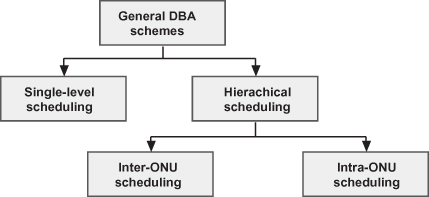
The remainder of this section is organized as follows. First we discuss the two main scheduling categories for DBA, namely, single-level (Section 8.5.1) and hierarchical (Section 8.5.2) scheduling. These schemes are discussed in the context of EPON, where the DBA communication protocol is more flexible. In Section 8.5.3, we discuss DBA within the GPON context. Finally, we illustrate DBA schemes for some alternative PON architectures.
8.5.1 Single-Level Scheduling
Single-level scheduling is used to denote centralized scheduling where a single scheduler at the OLT manages bandwidth allocation to the ONUs on a per queue basis. In EPON, single-level scheduling for ONUs with multiple internal queues is typically arranged by introducing an individual LLID (logical link ID) for each internal queue. The internal queue is then regarded as a virtual ONU. One of the most well-known single-level scheduling algorithms that can be implemented in EPON is the interleaved polling with adaptive cycle time (IPACT) algorithm [9]. In IPACT, the OLT polls and issues transmission grants to the ONUs cyclically in an interleaved fashion. The polling cycle is defined as the time between two consecutive report messages sent from the same ONU to the OLT. In IPACT the polling cycle is variable and adapts to the instantaneous bandwidth requirements of the ONUs.
The interleaved polling of ONUs entails that the OLT must inform the (i + 1)st ONU of grant information, including the start time and the size of the granted window, during or before the time that the ith ONU is transmitting Ethernet frames in the upstream. For efficient operation and high bandwidth utilization, the grants for the (i + 1)st ONU must be received before the data transmission of the ith ONU is completed and the transmission slots must be scheduled in such a way that the first bit from the (i + 1)st ONU arrives at the OLT right after the OLT receives the last bit from the ith ONU.
There are mainly three ways of allocating timeslot sizes to the ONUs in IPACT, namely, gated, limited, and limited with excess distribution. The most straightforward service discipline is the gated scheme, where the grants from the OLT are directly equal to the buffer occupancy reported by the ONUs. Here the polling cycle is here determined by the overall PON load. The scheme is efficient in terms of bandwidth utilization but inadequate in terms of fairness and QoS support. For example, it may lead to a situation where an ONU with heavy traffic load monopolizes the upstream channel so that frames from the other ONUs are delayed. To solve this problem, the limited service discipline was proposed [9] where a minimum guaranteed bandwidth is predefined for each ONU. The full bandwidth request by the ith ONU is granted if it is smaller than a predefined value ![]() . If the request is larger, then the ONU is granted bandwidth corresponding to
. If the request is larger, then the ONU is granted bandwidth corresponding to ![]() which sets an upper bound to the bandwidth allocated to the ith ONU in a given cycle. This scheme introduces some element of QoS control and fairness among the ONUs at the cost of reduced efficiency. A drawback with the limited service algorithm is that there can be a shrinking of the polling cycle due to burstiness of traffic arriving at the ONUs, degrading bandwidth utilization. The third service discipline, limited with excess distribution [10], was proposed to alleviate this shrinking of the polling cycle. In this discipline the ONUs are partitioned into two groups, namely, underloaded and overloaded. The underloaded ONUs are those with a bandwidth request below the guaranteed minimum. The unused capacity associated with these ONUs is shared in a weighted manner amongst the overloaded ONUs.
which sets an upper bound to the bandwidth allocated to the ith ONU in a given cycle. This scheme introduces some element of QoS control and fairness among the ONUs at the cost of reduced efficiency. A drawback with the limited service algorithm is that there can be a shrinking of the polling cycle due to burstiness of traffic arriving at the ONUs, degrading bandwidth utilization. The third service discipline, limited with excess distribution [10], was proposed to alleviate this shrinking of the polling cycle. In this discipline the ONUs are partitioned into two groups, namely, underloaded and overloaded. The underloaded ONUs are those with a bandwidth request below the guaranteed minimum. The unused capacity associated with these ONUs is shared in a weighted manner amongst the overloaded ONUs.
Additional variations of IPACT have been proposed with the aim of enhancing performance, in particular with respect to delay [11–13]. References 11 and 12 propose estimation-based schemes for effective upstream channel sharing among multiple ONUs. By estimating the amount of new packets arriving between two consecutive polling cycles and granting ONUs with excess bandwidth based on these estimations, proposed schemes can achieve reduced delays at light load compared to the limited service IPACT. Reference 13 proposes a heuristic where the OLT grants bandwidth to the ONUs in order of ONU buffer occupancy. In this way, packet delay can be reduced. In order to support differentiated services, some advanced algorithms are proposed for QoS diversification (e.g., in references 14 and 15). In Reference 14, a scheme is proposed where an ONU requests bandwidth for all of its queued traffic, and all traffic classes proportionally share the bandwidth based on their instantaneous demands and predefined threshold. Reference 15 shows that queuing delay using a strict priority algorithm results in an unexpectedly long delay for lower-priority traffic classes (light-load penalty), and they suggest the use of DBA with appropriate queue management to resolve the problem.
The main drawback of IPACT-based schemes is that the complexity of the algorithm increases dramatically with introduction of QoS support. IPACT is otherwise considered very efficient when it comes to best-effort traffic. For efficiency, the size of the polling cycle is a crucial parameter [16]. The polling cycle is determined by a combination of the total traffic load and the type of service discipline. For smaller polling cycles there may be severe efficiency penalties in terms of guard band, USRs, and ONU idle time due to non-optimal interleaving. In IPACT, efficiency increases with increased polling cycle time. However, increased polling cycle also leads to increased delay and jitter.
A general problem with single-level schemes concerns the scheduling of a large number of queues. Scheduling a large number of queues requires plenty of control messages between the OLT and ONUs. For example, an EPON system with 32 ONUs, 128 subscribers per ONU, and three queues (for service differentiation) per subscriber will be required to handle a total of 12,288 queues. This adds a considerable amount of GATE and REPORT messages, and hence the important performance metrics (bandwidth utilization, delay, jitter, etc.) may be significantly degraded. Thus, single-level schedulers are not scalable with respect to the number of queues. This scalability problem can be resolved by hierarchical scheduling.
8.5.2 Hierarchical Scheduling
Hierarchical scheduling is a type of distributed scheduling where the scheduler is divided into an intra-ONU and an inter-ONU scheduler. The intra-ONU scheduler manages bandwidth allocation to queues within each ONU, while the inter-ONU scheduler takes care of bandwidth allocation to the ONUs. The concept of hierarchical scheduling is shown in Figure 8.6. The inter-ONU scheduler treats each ONU as one aggregated queue and does not need information on the internal bandwidth requirements of the queues. The control messages exchanged between the OLT and ONUs only contain grant and report information related to the aggregated bandwidth requirements of the ONU (i.e., a large allocated timeslot that can be internally shared among the queues within an ONU). Compared to single-level scheduling, the complexity of both the intra-ONU and inter-ONU scheduler is relatively low due to the smaller number of queues that needs to be handled at each level. The reduced number of queues handled at the OLT also reduces the amount of control messages compared to single-level scheduling. There is furthermore a potential performance gain in using hierarchical scheduling as the intra-ONU and inter-ONU algorithms are run in parallel. Hence, the main advantage of hierarchical scheduling is scaling for a large number of queues. The nature of how the scalability problem will develop for next-generation TDM-PON depends on to what extent the increased bandwidth in next-generation TDM-PON is used for increased bandwidth per subscriber and to what extent it is used for aggregating more subscribers in the PON system.
Figure 8.6. Framework for the hierarchical scheduling algorithm.
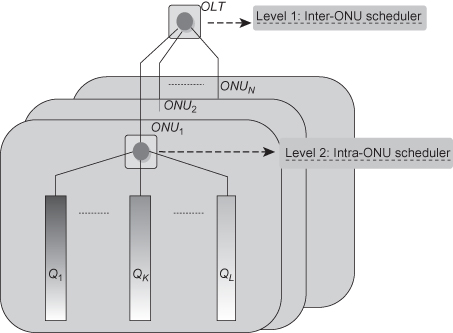
The most challenging problem in hierarchical scheduling is supporting global QoS characteristics (such as global fairness, global priority, etc.) of resource distribution among queues of different ONUs. Hierarchical scheduling algorithms in references 17–21 allow fairness and/or priority only among queues within the same ONU. Failure to provide global fairness and priority may imply poor distribution of the available bandwidth among subscribers of different ONUs. The fact that concepts such as fairness and priority only have local meaning within each ONU has the consequence that high-priority traffic at one ONU may not receive sufficient bandwidth due to lower priority traffic at another ONU. The following sections describe recent work in references 17–23 related to the intra-ONU and inter-ONU scheduling.
8.5.2.1 Intra-ONU Scheduling.
The intra-ONU scheduler manages bandwidth allocation to queues within an ONU. We assume that an ONU is equipped with L queues serving L priority traffic classes (denoted Q1, Q2, … , QL in Figure 8.6) with Q1 being the highest priority and QL being the lowest. When a packet is received from a user, the ONU classifies it according to type and places it in the corresponding queue. In traditional strict priority scheduling, when a grant arrives, the ONU serves a higher-priority queue before taking care of a lower-priority queue. The priority requirement entails that traffic with higher service requirements, such as voice, receive higher priority and better service than traffic with lower service requirements such as best-effort Internet traffic.
It has been found in reference 17 that the strict priority scheduling algorithm for intra-ONU scheduling results in an unexpected phenomenon where the average delay for some (lower-priority) traffic classes increases when the traffic load decreases. In fact, under light load, ONUs with the first come first serve (FCFS) queue discipline perform better than ONUs with strict priority scheduling. This phenomenon is referred to as the light-load penalty. To alleviate this penalty, two optimization schemes with different tradeoffs for intra-ONU scheduling were proposed in reference 17. The first one is a two-stage queuing scheme that totally eliminates the light-load penalty at the expense of increased packet delay for all types of traffic. The second scheme attempts to predict high-priority packet arrivals. This scheme eliminates the light-load penalty for most of the packets. Some low-priority packets are delayed excessively, but the number of such packets is small and does not affect the average packet delay. The drawback of this second scheme is the increased complexity due to the estimation of the traffic-arrival process.
Another consequence of strict priority scheduling is that non-greedy queues of lower priority are mistreated as the system is overloaded. The urgency fair queuing (UFQ) [18] scheme for intra-ONU scheduling is proposed in order to achieve a better balance in bandwidth assignment among different traffic classes within the same ONU. In the UFQ scheme, packets are scheduled based on urgency regarding delay requirements; that is, packets with higher priority which are not so urgent for transmission can give way to the ones with lower priority. Other schemes have been proposed where bandwidth is assigned to each traffic class within an ONU based on its load-based weight. One of these, the modified start-time fair queuing (MSFQ) algorithm, tracks aggregate ONU service via a global virtual time. Variables are also maintained for tracking local per-queue start and finish time which are related to the global virtual time and the weight of different traffic classes. The packet in the queue with minimal start time is selected to be transmitted first. In this way, load-based fairness can be achieved. The MSFQ algorithm can provide fairness for differentiated services even when the network is overloaded. Simulations of MSFQ [19] show that when a traffic class of priority i is greedy (i.e., it requires more bandwidth than guaranteed), the other traffic classes with higher priority have stable delay while the classes of low-volume traffic with the lower priority maintain throughput performance, but with slightly increased average delay. Conversely, the strict priority scheduler yields unacceptably high delay and throughput degradation for the classes of traffic with lower priority than i.
The MSFQ algorithm does not adequately fulfill the priority requirement when the load distribution of different traffic classes is changed. To solve this problem, the modified token bucket (MTB) [20] algorithm for the intra-ONU scheduling was proposed. The MTB algorithm assigns bandwidth in two stages. In the first stage, bandwidth is allocated to each queue according to the size of a token that is related to a load-based weight. This first stage limits greedy traffic classes from monopolizing all bandwidths. In the second stage, the remaining bandwidth is allocated according to the strict priority policy. MTB provides a method of obtaining a compromise between complying with strict priority and preventing single queues from monopolizing all bandwidths, which holds also when the load distribution of different traffic classes is changed. The computational complexity of the proposed MTB algorithm is O(k) where k is the total number of packets that can be sent in one grant window. This can be compared to the strict priority and the MSFQ algorithms which have a complexity of O(k) and O(k log L), respectively.
Each ONU may contain multiple queues for multiple subscribers and multiple services. In reference 21 a hierarchical intra-ONU scheduling scheme was designed in order to handle scalability issues at the ONU with respect to a large number of queues. As shown in Figure 8.7, there may be several queues for each priority class for different users. There are two levels of scheduling: One is the interclass scheduling (to serve L classes of traffic with differentiated priorities) and the second one is the intraclass scheduling (to allocate fairly the bandwidth among M users within the same class). The proposed hierarchical intra-ONU scheduler realizes fine granularity scheduling to support QoS for traffic of each individual user by combining the MTB algorithm [20] and the MSFQ algorithm [19], where MTB is used for interclass scheduling and MSFQ is used for intraclass scheduling.
Figure 8.7. Framework of the hierarchical intra-ONU scheduling algorithm in reference 21.
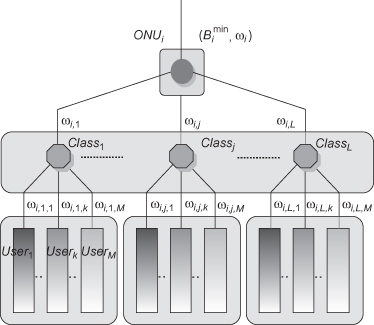
8.5.2.2 Inter-ONU Scheduling.
The inter-ONU scheduler allocates bandwidth to the ONUs. It treats each ONU as one aggregated queue and does not need information on the internal queues of each ONU [17–22]. Using EPON as an example, the GATE and REPORT messages would grant and request aggregated bandwidth per ONU rather than to individual queues.
Most single-level scheduling algorithms can also be applied to inter-ONU scheduling. For instance, the limited and limited with excess distribution schemes are widely employed in inter-ONU scheduling to allocate aggregated bandwidth to each ONU. In reference 17, IPACT with the limited service discipline algorithm described in references 9 and 10 is used for inter-ONU scheduling. This service discipline has the same problems with shrinking of polling cycle as the single-level version. The limited with excess distribution service discipline from reference 10 adopted in references 19 and 20 can alleviate this shrinking of the polling cycle. However, by utilizing this weighted inter-ONU scheduling, an overloaded ONU may get more bandwidth than requested, and thus some bandwidth may be wasted on over-granting. With this in mind, a novel inter-ONU scheduler based on recursive calculation is proposed in reference 21 to guarantee that no ONU gets more bandwidth than requested. For an ONU where assigned bandwidth is less than the requested, the bandwidth actually used may be less than the assigned, if packet fragmentation is not supported such as in EPON. This causes an increase in USRs and a decrease in bandwidth utilization. In reference 21 a novel GATE/REPORT approach for EPON to eliminate unused timeslot reminders is introduced in order to further improve the bandwidth utilization.
There has also been work on adjusting hierarchical scheduling to support global QoS characteristics. The fair queuing with service envelopes (FQSE) [22] algorithm was developed in order to realize global fair scheduling in hierarchical scheduling. Simulations of the FQSE algorithm show that excess bandwidth due to idle queues can be redistributed among multiple queues in proportion to their assigned weights regardless of whether the queues are located on the same or different ONUs. Reference 23 proposes a hierarchical scheduling algorithm with a novel inter-ONU scheduling approach to support global traffic priority among multiple service providers and end users. Using EPON as an example, an ONU needs to issue REPORT messages informing the OLT of the aggregated queue sizes of all the priority traffic classes destined to different service providers. After collecting all the REPORT messages, the inter-ONU scheduler at OLT calculates the corresponding granted bandwidth based on the weight and priority of the aggregated queues representing different priority traffic classes from various ONUs.
8.5.3 Schemes for GPON
Research on GPON DBA is limited to a few number of research institutes and vendors [24–28], and there is limited public domain information available on the topic. Resource scheduling in GPON differs significantly from EPON. In GPON the scheduling of bandwidth is inherently connected to the 125-µs periodicity of the GTC superframes and effective DBA algorithms must be tailored for GPON. The connection between the DBA and the frame structure is due to the way DBA messages, status reports (SRs), and upstream bandwidth maps (BW maps) are integrated into the GTC (GPON transmission convergence) frames. Figure 8.8 illustrates an example of the DBA process in GPON. Upstream bandwidth maps, each specifying the bandwidth allocation for a specific upstream GTC frame, are generated at the OLT and broadcasted every 125 µs (not shown in Figure 8.8) to the ONUs integrated in the GTC downstream headers. Upon request, each Alloc ID (logical queue) prepends a 2-byte SR message to the upstream data transmission specifying its current buffer occupancy. Status request could be collected during a single GTC frame as in Figure 8.8 or during several GTC frames. Once status reports from all Alloc IDs have been received, bandwidth allocation can be calculated. The resulting bandwidth allocation may be scheduled over a series of upstream bandwidth maps.
Figure 8.8. Schematic overview of GPON DBA.
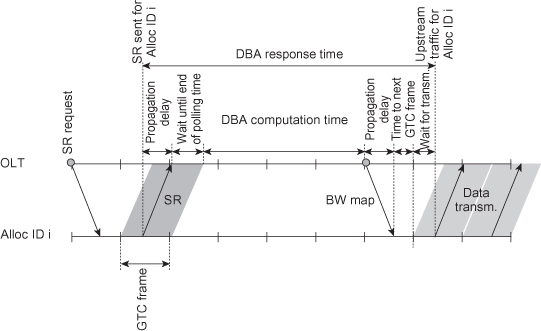
As a consequence of the GPON framework, GPON DBA is most naturally interleaved with respect to GTC frames rather than ONU bursts as in IPACT. Because of the way complete bandwidth maps are broadcasted to the ONUs, it is nontrivial to implement an IPACT-type algorithm in GPON. The GPON DBA must produce a complete prescription for bandwidth allocation at the end of each DBA cycle. This prescription is then used as input toward generating a sequence of bandwidth maps for transmission to the ONUs. The GPON procedure stands in contrast to EPON where GATE messages are transmitted flexibly to individual ONUs at any point in time. The two ways of interleaving DBA processes provide different DBA challenges. Interleaving bandwidth allocation with respect to different ONUs is more challenging with respect to fairness and QoS provisioning, because these concepts typically have an inter-ONU nature. Interleaving bandwidth allocation with respect to time frames is more challenging with respect to accurately predicting bandwidth demand, because bandwidth demand depends on bandwidth allocation in subsequent time frames. Because of the framing structure used in GPON, the DBA typically uses a fixed cycle.
GTC frame interleaving is illustrated in Figure 8.9. Figure 8.9a shows a schematic view of the single DBA process described in Figure 8.8. This process updates the bandwidth allocation to the ONUs through the upstream bandwidth map embedded in the header of each downstream GTC frame. We refer to the DBA delay as the delay from the GTC frame of the issuing of a status report at the ONU to the GTC frame of the transmission of data according to the updated bandwidth map (Figure 8.9a). With DBA process we refer to the DBA mechanism executed during the DBA delay as well as the data transmission period during which the updated bandwidth allocation is used (Figure 8.9a). In order to continuously update the bandwidth allocation, we execute multiple DBA processes (Figure 8.9b). The frequency defines the DBA cycle. In Figure 8.9b we set the DBA cycle equal to the DBA delay. As a result, the DBA process is here twice as long as the DBA delay with the first half of the DBA process used for updating the bandwidth allocation and the second half for transmitting data according to the updated allocation. Note that in this example the DBA processes are interleaved in the sense that there are always two DBA processes active at a given time. While one process is in a data transmission phase, the other process is in the phase of updating the bandwidth allocation map. With this example structure of the GPON DBA, we find that the average DBA response time is given by the sum of the DBA cycle and the DBA delay as shown in Figure 8.10. This response time is valid for noncongested traffic classes.
Figure 8.9. GPON DBA process interleaving with status reports (SR) and bandwidth grants (G). (a) Single DBA process. (b) Multiple DBA processes (DBA cycle = DBA delay).
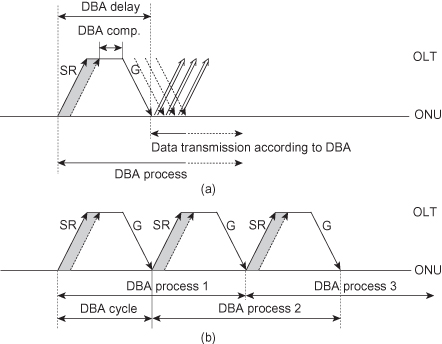
Figure 8.10. GPON DBA response time.

The GTC framing implies that DBA messages are handled compactly, resulting in small DBA overhead. Combined with the tight requirements on the physical layer overhead and Ethernet frame fragmentation, GPON provides high efficiency also for very small upstream ONU bursts. In principle, bursts from all ONUs could be collected every 125 µs without significant overhead, although typically the DBA is executed less frequently. Another consequence of the small overheads in GPON there is that is no scalability problem with respect to number of queues per PON.
Because of the structure provided by the GPON framework, the bandwidth allocation task in GPON DBA algorithm can be subdivided into three tasks: (1) prediction of bandwidth demand, (2) bandwidth assignment, and (3) scheduling. This makes it possible to isolate tasks related to different performance metrics. In IPACT these three tasks are integrated and interdependent, making it more difficult to understand the effect of small changes in the DBA algorithm on different performance metrics.
8.5.3.1 Predicting Bandwidth Demand.
Due to the type of interleaving used in GPON DBA, predicting bandwidth demand for an Alloc ID presents a greater challenge in GPON than in EPON. In practice, the status report information from an Alloc ID may be outdated once the resulting bandwidth allocation will be used for upstream transmission. Since the point in time when the status report was issued, data have both entered and exited the Alloc ID buffer. Poor estimation of bandwidth demand leads to problems with over-granting, which in turn leads to serious problems at high load as capacity is used in a suboptimal manner. High-priority traffic is typically unaffected by over-granting, whereas low-priority traffic experiences reduced bandwidth. The minimum guaranteed T-CONT content scheme (MGTC) [25] was designed to eliminate the problem of over-granting. MGTC provides a more conservative estimation of bandwidth demand. The minimum guaranteed Alloc ID content is extracted by subtracting an estimate of the total outgoing traffic from the Alloc ID since the status report was issued and assuming there is no incoming traffic to the Alloc ID. The method eliminates the over-granting problem at the expense of slightly higher DBA response time. This leads to slightly increased delay for high-priority traffic, but with substantially increased efficiency as a result.
8.5.3.2 Bandwidth Assignment.
The bandwidth assignment task consists in partitioning available bandwidth to Alloc IDs based on predicted bandwidth demand and on requirements such as priority and fairness. Several descriptions of possible GPON bandwidth assignment algorithms are available [26, 27]. Bandwidth assignment is relatively straightforward in GPON as bandwidth demand for all Alloc IDs from one polling period is used to produce a global bandwidth assignment. GPON frame fragmentation also simplifies bandwidth assignment because the DBA algorithm does not need to consider USRs. For EPON DBA at high load, in order to avoid a large frame from completely blocking a queue, a minimum slot size might be required which introduces extra complexity to the EPON DBA.
8.5.3.3 Scheduling.
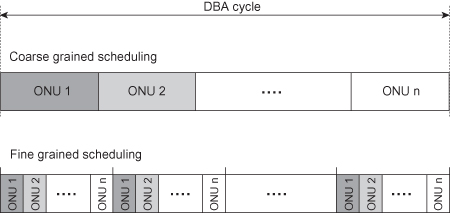
The scheduling task refers to the problem of scheduling assigned bandwidth over a sequence of GTC frames through a series of upstream bandwidth maps. A partial solution to the scheduling problem is described in reference 28. There are many ways of implementing the scheduling. In general, the scheduling can be made more or less granular (Figure 8.11). A more fine-grained scheduling leads to lower delay and jitter at the expense of more burst overhead and reduced efficiency. Ultimately, the scheduling depends on traffic requirements; and as these differ for different traffic classes, one could schedule different traffic classes in different ways.
Figure 8.11. Fine-grained and coarse-grained scheduling.
8.5.4 DBA for Alternative PON Architectures
All the DBA schemes discussed above are for the standard PON architecture, where downstream traffic is broadcasted while in the upstream direction the ONUs cannot detect signals from the other ONUs. In the following subsections we consider DBA for two alternative architectures (i.e., broadcast PON and two-stage PON).
8.5.4.1 Broadcast PON.
The broadcast PON architecture proposed in references 29 and 30 supports reflection of the upstream signal back to each ONU, as illustrated in Figure 8.12a. This architecture can employ decentralized DBA schemes, in which the OLT is excluded from the implementation of the resource scheduling. In reference 30, the full-utilization local-loop request contention multiple access (FULL-RCMA) scheme is proposed for dynamically allocating bandwidth to ONUs in a broadcast PON. In FULL-RCMA, one of the ONUs is designated as master and generates a token list. According to the order determined by the master, all the ONUs pick up the token to access the medium for their data transmission. Performance analysis [30] shows that FULL-RCMA can outperform IPACT with the limited service discipline in terms of upstream bandwidth utilization. In the DBA scheme proposed in reference 31 the ONUs independently compute the transmission schedule of all ONUs. This scheme can also integrate inter- and intra-ONU scheduling at the ONU in order to provide better QoS support. Compared to standard PON, ONUs that support broadcast PON would be more expensive, since they must (1) contain more expensive hardware to support the implementation of the medium access control, (2) have an extra receiver for the reflected upstream signal, and (3) need higher-power lasers to compensate for the loss caused by splitting upstream signals which are reflected back to other the ONUs.
Figure 8.12. Two representative alternative architecture: (a) Broadcast PON [29, 30]. (b) Two-stage PON [31].
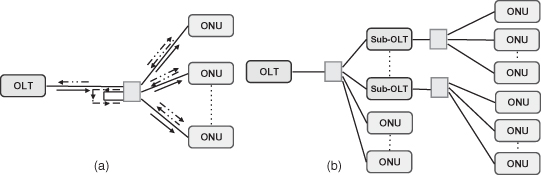
8.5.4.2 Two-Stage PON.
A two-stage architecture [31] allows more end-users to share the bandwidth in a single PON and enables longer access reach (beyond the usual 20 km; e.g., defined in references 1–3). As illustrated in Figure 8.4b, in the first stage of this architecture there are several ONUs and sub-OLTs, which can regenerate the optical signals in the upstream and downstream as well as aggregate the traffic to/from their child ONUs in the second stage. Reference 31 proposes a DBA scheme that can take advantage of some of the predictability of the aggregated traffic at the sub-OLTs. Compared with the traffic from a single ONU, the aggregated traffic from several child ONUs of the sub-OLT tends to be less bursty and more predictable if traffic is not fully self-similar.
8.5 CONCLUSIONS
Dynamic bandwidth allocation presents a key issue for providing efficient utilization of the upstream bandwidth in TDM-PON. As we have shown, the design of an efficient DBA scheme depends on the PON standard, the nature of network traffic in the system, and the service requirements of different traffic classes. The requirements on the DBA algorithm are to provide efficient and fair utilization of the upstream bandwidth while still satisfying the minimum service requirements for the different traffic classes. We have described how differences in the GPON and EPON standards result in a series of distinct challenges for the design of the DBA. We have furthermore shown how these differences result in different design choices and have discussed some of these choices. With the evolution of TDM-PON toward higher bit rates, there will be a shift in the parameters governing the design of the DBA. As a result, DBA solutions will have to be tailored for future generations of TDM-PON, depending on parameters in the standard, the nature of network traffic, and new service requirements.
REFERENCES
1. IEEE Standard for Information technology-Specific requirements—Part 3 [Online], IEEE Standard 802.3, 2008. Available at http://standards.ieee.org/getieee802/802.3.html.
2. IEEE 802.3av task force home page [Online]. Available at :http://www.ieee802.org/3/av.
3. Gigabit-Capable Passive Optical Networks (GPON), ITU-T G.984.x series of recommendations [Online]. Available at http://www.itu.int/rec/T-REC-G/e.
4. D. Sala and A. Gummalla, PON Functional Requirements: Services and Performance, Ethernet in the First Mile Study Group 2001 [online]. Available at http://grouper.ieee.org/groups/802/3/efm/public/jul01/presentations/sala_1_0701.pdf.
5. M. S. Taqqu, W. Willinger, and R. Sherman, Proof of a fundamental result in self-similar traffic modeling, ACM/SIGCOMM Computer Commun. Rev., Vol. 27, pp. 5–23, 1997.
6. A. Cauvin, A. Tofanelli, J. Lorentzen, J. Brannan, A. Templin, T. Park, and K. Saito, Common technical specification of the G-PON system among major worldwide access carriers, IEEE Commun. Mag., Vol. 44, pp. 34–40, October 2006.
7. P. Seeling, M. Reisslein, and B. Kulapala, Network performance evaluation using frame size and quality traces of single layer and two layer video: A tutorial, IEEE Commun. Surv. Tutorials, Vol. 6, pp. 58–78, 2004.
8. S. H. Hong, R.-H. Park, and C. B. Lee, Hurst parameter estimation of long-range dependent VBR MPEG video traffic in ATM networks, J. Visual Commun. Image Representation, Vol. 12, pp. 44–65, June 2001.
9. G. Kramer, B. Mukherjee, and G. Pesavento, IPACT: A dynamic protocol for an Ethernet PON (EPON), IEEE Commun. Mag., Vol. 40, pp. 74–80, February 2002.
10. C. M. Assi, Y. Ye, S. Dixit, and M. A. Ali, Dynamic bandwidth allocation for quality-of-service over Ethernet PONs, IEEE J. Selected Areas in Commun., Vol. 21, pp. 1467–1477, November 2003.
11. H. Byun, J. Nho, and J. Lim, Dynamic bandwidth allocation algorithm in Ethernet passive optical networks, Electron. Lett., Vol. 39, pp. 1001–1002, June 2003.
12. Y. Zhu and M. Ma, IPACT with grant estimation (IPACT-GE) scheme for Ethernet passive optical networks, IEEE/OSA J. Lightwave Technol., Vol. 26, pp. 2055–2063, July 2008.
13. S. Bhatia and R. Bartos, IPACT with smallest available report first: A new DBA algorithm for EPON, in Proceedings of the IEEE International Conference on Communications (ICC’07), Glasgow, UK, June 2007.
14. J. Xie, S. Jiang, and Y. Jiang, A dynamic bandwidth allocation scheme for differentiated services in EPONs, IEEE Commun. Mag., Vol. 42, pp. S32–S39, August 2004.
15. Y. Luo and N. Ansari, Bandwidth allocation for multiservice access on EPONs, IEEE Commun. Mag., Vol. 43, pp. S16–S21, February 2005.
16. B. Skubic, J. Chen, J. Ahmed, L. Wosinska, and B. Mukherjee, A comparison of dynamic bandwidth allocation for EPON, GPON, and next-generation TDM PON, IEEE Commun. Mag., Vol. 47, pp. S40–S48, March 2009.
17. G. Kramer, B. Mukherjee, S. Dixit, Y. Ye, and R. Hirth, On supporting differentiated classes of service in EPON-based access network, OSA J. Optical Networking, pp. 280–298, August 2002.
18. Y. Zhu and M. Ma, Supporting differentiated services with fairness by an urgent queuing scheduling scheme in EPONs, Photonic Network Commun., Vol. 12, pp. 99–110, July 2006.
19. N. Ghani, A. Shami, C. Assi, and M. Y. A. Raja, Intra-ONU bandwidth scheduling in ethernet passive optical networks, IEEE Commun. Lett., Vol. 8, pp. 683–685, August 2004.
20. J. Chen, B. Chen, and S. He, A novel algorithm for Intra-ONU bandwidth allocation in Ethernet passive optical networks, IEEE Commun. Lett., Vol. 9, pp. 850–852, September 2005.
21. B. Chen, J. Chen, and S. He, Efficient and fine scheduling algorithm for bandwidth allocation in Ethernet passive optical networks, IEEE J. Selected Topics Quantum Electron., Vol. 12, pp. 653–660, July–August 2006.
22. G. Kramer, A. Banerjee, N. Singhal, B. Mukherjee, S. Dixit, and Y. Ye, Fair queueing with service envelopes (FQSE): A cousin-fair hierarchical scheduler for subscriber access networks, IEEE J. Selected Areas Commun., Vol. 22, No. 8, pp. 1497–1513, October 2004.
23. J. Chen, B. Chen, and L. Wosinska, A novel joint scheduling algorithm for multiple services in 10G EPON, in Proceedings of Asia-Pacific Optical Communications Conference (APOC’08), Vol. 7137, pp. 71370L–71370L-6, October 2008.
24. H. Yoo, B.-Y. Yoon, K.-H. Doo, K.-O. Kim, M.-S. Lee, B.-T. Kim, and M.-S. Han, Dynamic bandwidth allocation device for an optical network and method thereof, WO 2008/039014 A1, September 28, 2007.
25. B. Skubic, B. Chen, J. Chen, J. Ahmed, and L. Wosinska, Improved scheme for estimating T-CONT bandwidth demand in status reporting DBA for NG-PON, Asia Communications and Photonics Conference and Exhibition (ACP ’09), Vol. 2009, Supplement, pp. 1–6, November 2–6, 2009.
26. Y.-G. Kim, B.-H. Kim, T.-S. Park, J.-W. Park, J.-Y. Park, J.-K. Kim, D.-K. Kim, S.-H. Kim, J.-Y. Lee, J.-H. Kim, and H.-J. Yeon, GPON system and method for bandwidth allocation in GPON system, US 2007/0133989 A1, November 3, 2006.
27. Y.-G. Kim, B.-H. Kim, T.-S. Park, J.-W. Park, J.-Y. Park, J.-K. Kim, D.-K. Kim, S.-H. Kim, J.-Y. Lee, J.-H. Kim, and H.-J. Yeon, GPON system and method for bandwidth allocation in GPON system, US 2007/0133988 A1, November 3, 2006.
28. E. Elmoalem, Y. Angel, and D. A. Vishai, Method and grant scheduler for cyclically allocating time slots to optical network units, US 2006/0233197 A1, April 18, 2005.
29. C. Foh, L. Andrew, E. Wong, and M. Zukerman, FULL-RCMA: A high utilization EPON, IEEE J. Selected Areas Commun., Vol. 22, pp. 1514–1524, October 2004.
30. S. R. Sherif, A. Hadjiantonis, G. Ellinas, C. Assi, and M. A. Ali, A novel decentralized Ethernet-based PON access architecture for provisioning differentiated QoS, IEEE/OSA J. Lightwave Technol., Vol. 22, pp. 2483–2497, November 2004.
31. A. Shami, X. Bai, N. Ghani, C. M. Assi, and H. T. Mouftah, QoS control schemes for two-stage Ethernet passive optical access networks, IEEE J. Selected Areas Commun., Vol. 23, pp. 1467–1478, August 2005.