
The preface of the book Essential XML by Don Box et al. (Addison-Wesley Professional 2000) states only half-jokingly: “The Extensible Markup Language (XML) has replaced Java, Design Patterns, and Object Technology as the software industry’s solution to world hunger.” Indeed, as you will see in this chapter, XML is a very useful technology for describing structured information. XML tools make it easy to process and transform that information. However, XML is not a silver bullet. You need domain-specific standards and code libraries to use it effectively. Moreover, far from making Java technology obsolete, XML works very well with Java. Since the late 1990s, IBM, Apache, and others have been instrumental in producing high-quality Java libraries for XML processing. Starting with Java SE 1.4, Sun has integrated the most important libraries into the Java platform.
This chapter introduces XML and covers the XML features of the Java library. As always, we point out along the way when the hype surrounding XML is justified and when you have to take it with a grain of salt and solve your problems the old-fashioned way, through good design and code.
In Chapter 10 of Volume I, you have seen the use of property files to describe the configuration of a program. A property file contains a set of name/value pairs, such as
fontname=Times Roman fontsize=12 windowsize=400 200 color=0 50 100
You can use the Properties class to read in such a file with a single method call. That’s a nice feature, but it doesn’t really go far enough. In many cases, the information that you want to describe has more structure than the property file format can comfortably handle. Consider the fontname/fontsize entries in the example. It would be more object oriented to have a single entry:
font=Times Roman 12
But then parsing the font description gets ugly—you have to figure out when the font name ends and when the font size starts.
Property files have a single flat hierarchy. You can often see programmers work around that limitation with key names such as
title.fontname=Helvetica title.fontsize=36 body.fontname=Times Roman body.fontsize=12
Another shortcoming of the property file format is caused by the requirement that keys be unique. To store a sequence of values, you need another workaround, such as
menu.item.1=Times Roman menu.item.2=Helvetica menu.item.3=Goudy Old Style
The XML format solves these problems because it can express hierarchical structures and thus is more flexible than the flat table structure of a property file.
An XML file for describing a program configuration might look like this:
<configuration>
<title>
<font>
<name>Helvetica</name>
<size>36</size>
</font>
</title>
<body>
<font>
<name>Times Roman</name>
<size>12</size>
</font>
</body>
<window>
<width>400</width>
<height>200</height>
</window>
<color>
<red>0</red>
<green>50</green>
<blue>100</blue>
</color>
<menu>
<item>Times Roman</item>
<item>Helvetica</item>
<item>Goudy Old Style</item>
</menu>
</configuration>The XML format allows you to express the structure hierarchy and repeated elements without contortions.
As you can see, the format of an XML file is straightforward. It looks similar to an HTML file. There is a good reason—both the XML and HTML formats are descendants of the venerable Standard Generalized Markup Language (SGML).
SGML has been around since the 1970s for describing the structure of complex documents. It has been used with success in some industries that require ongoing maintenance of massive documentation, in particular, the aircraft industry. However, SGML is quite complex, so it has never caught on in a big way. Much of that complexity arises because SGML has two conflicting goals. SGML wants to make sure that documents are formed according to the rules for their document type, but it also wants to make data entry easy by allowing shortcuts that reduce typing. XML was designed as a simplified version of SGML for use on the Internet. As is often true, simpler is better, and XML has enjoyed the immediate and enthusiastic reception that has eluded SGML for so long.
Note
You can find a very nice version of the XML standard, with annotations by Tim Bray, at http://www.xml.com/axml/axml.html.
Even though XML and HTML have common roots, there are important differences between the two.
Unlike HTML, XML is case sensitive. For example,
<H1>and<h1>are different XML tags.In HTML, you can omit end tags such as
</p>or</li>tags if it is clear from the context where a paragraph or list item ends. In XML, you can never omit an end tag.In XML, elements that have a single tag without a matching end tag must end in a
/, as in<img src="coffeecup.png"/>. That way, the parser knows not to look for a</img>tag.In XML, attribute values must be enclosed in quotation marks. In HTML, quotation marks are optional. For example,
<applet code="MyApplet.class" width=300 height=300>is legal HTML but not legal XML. In XML, you have to use quotation marks:width="300".In HTML, you can have attribute names without values, such as
<input type="radio" name="language" value="Java" checked>. In XML, all attributes must have values, such aschecked="true"or (ugh)checked="checked".
Note
The current recommendation for web documents by the World Wide Web Consortium (W3C) is the XHTML standard, which tightens up the HTML standard to be XML compliant. You can find a copy of the XHTML standard at http://www.w3.org/TR/xhtml1/. XHTML is backward-compatible with current browsers, but not all HTML authoring tools support it. As XHTML becomes more widespread, you can use the XML tools that are described in this chapter to analyze web documents.
An XML document should start with a header such as
<?xml version="1.0"?>
or
<?xml version="1.0" encoding="UTF-8"?>
Strictly speaking, a header is optional, but it is highly recommended.
Note
Because SGML was created for processing of real documents, XML files are called documents, even though many XML files describe data sets that one would not normally call documents.
The header can be followed by a document type definition (DTD), such as
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.2//EN" "http://java.sun.com/j2ee/dtds/web-app_2_2.dtd">
DTDs are an important mechanism to ensure the correctness of a document, but they are not required. We discuss them later in this chapter.
Finally, the body of the XML document contains the root element, which can contain other elements. For example,
<?xml version="1.0"?>
<!DOCTYPE configuration . . .>
<configuration>
<title>
<font>
<name>Helvetica</name>
<size>36</size>
</font>
</title>
. . .
</configuration>An element can contain child elements, text, or both. In the preceding example, the font element has two child elements, name and size. The name element contains the text "Helvetica".
Tip
It is best if you structure your XML documents such that an element contains either child elements or text. In other words, you should avoid situations such as
<font> Helvetica <size>36</size> </font>
This is called mixed contents in the XML specification. As you will see later in this chapter, you can simplify parsing if you avoid mixed contents.
XML elements can contain attributes, such as
<size unit="pt">36</size>
There is some disagreement among XML designers about when to use elements and when to use attributes. For example, it would seem easier to describe a font as
<font name="Helvetica" size="36"/>
than
<font> <name>Helvetica</name> <size>36</size> </font>
However, attributes are much less flexible. Suppose you want to add units to the size value. If you use attributes, then you must add the unit to the attribute value:
<font name="Helvetica" size="36 pt"/>
Ugh! Now you have to parse the string "36 pt", just the kind of hassle that XML was designed to avoid. Adding an attribute to the size element is much cleaner:
<font> <name>Helvetica</name> <size unit="pt">36</size> </font>
A commonly used rule of thumb is that attributes should be used only to modify the interpretation of a value, not to specify values. If you find yourself engaged in metaphysical discussions about whether a particular setting is a modification of the interpretation of a value or not, then just say “no” to attributes and use elements throughout. Many useful XML documents don’t use attributes at all.
Note
In HTML, the rule for attribute usage is simple: If it isn’t displayed on the web page, it’s an attribute. For example, consider the hyperlink
<a href="http://java.sun.com">Java Technology</a>
The string Java Technology is displayed on the web page, but the URL of the link is not a part of the displayed page. However, the rule isn’t all that helpful for most XML files because the data in an XML file aren’t normally meant to be viewed by humans.
Elements and text are the “bread and butter” of XML documents. Here are a few other markup instructions that you might encounter:
Character references have the form
&#decimalValue;or&#xhexValue;. For example, the character é can be denoted with either of the following:é Ù
Entity references have the form
&name;. The entity references< > & " '
have predefined meanings: the less than, greater than, ampersand, quotation mark, and apostrophe characters. You can define other entity references in a DTD.
CDATA sections are delimited by
<![CDATA[and]]>. They are a special form of character data. You can use them to include strings that contain characters such as< > &without having them interpreted as markup, for example,<![CDATA[< & > are my favorite delimiters]]>
CDATA sections cannot contain the string
]]>. Use this feature with caution! It is too often used as a back door for smuggling legacy data into XML documents.Processing instructions are instructions for applications that process XML documents. They are delimited by
<?and?>, for example,<?xml-stylesheet href="mystyle.css" type="text/css"?>
Every XML document starts with a processing instruction
<?xml version="1.0"?>
Comments are delimited by
<!--and-->, for example,<!-- This is a comment. -->
Comments should not contain the string
--. Comments should only be information for human readers. They should never contain hidden commands. Use processing instructions for commands.
To process an XML document, you need to parse it. A parser is a program that reads a file, confirms that the file has the correct format, breaks it up into the constituent elements, and lets a programmer access those elements. The Java library supplies two kinds of XML parsers:
Tree parsers such as the Document Object Model (DOM) parser that read an XML document into a tree structure.
Streaming parsers such as the Simple API for XML (SAX) parser that generate events as they read an XML document.
The DOM parser is easy to use for most purposes, and we explain it first. You would consider a streaming parser if you process very long documents whose tree structures would use up a lot of memory, or if you are just interested in a few elements and you don’t care about their context. For more information, see the section “Streaming Parsers” on page 138.
The DOM parser interface is standardized by the World Wide Web Consortium (W3C). The org.w3c.dom package contains the definitions of interface types such as Document and Element. Different suppliers, such as the Apache Organization and IBM, have written DOM parsers whose classes implement these interfaces. The Sun Java API for XML Processing (JAXP) library actually makes it possible to plug in any of these parsers. But Sun also includes its own DOM parser in the Java SDK. We use the Sun parser in this chapter.
To read an XML document, you need a DocumentBuilder object, which you get from a DocumentBuilderFactory, like this:
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder();
You can now read a document from a file:
File f = . . . Document doc = builder.parse(f);
Alternatively, you can use a URL:
URL u = . . . Document doc = builder.parse(u);
You can even specify an arbitrary input stream:
InputStream in = . . . Document doc = builder.parse(in);
Note
If you use an input stream as an input source, then the parser will not be able to locate other files that are referenced relative to the location of the document, such as a DTD in the same directory. You can install an “entity resolver” to overcome that problem.
The Document object is an in-memory representation of the tree structure of the XML document. It is composed of objects whose classes implement the Node interface and its various subinterfaces. Figure 2-1 shows the inheritance hierarchy of the subinterfaces.
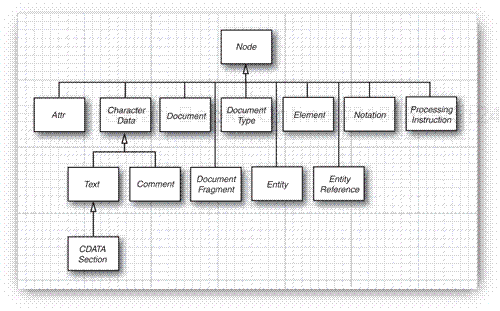
You start analyzing the contents of a document by calling the getDocumentElement method. It returns the root element.
Element root = doc.getDocumentElement();
For example, if you are processing a document
<?xml version="1.0"?> <font> . . . </font>
then calling getDocumentElement returns the font element.
The getTagName method returns the tag name of an element. In the preceding example, root.getTagName() returns the string "font".
To get the element’s children (which may be subelements, text, comments, or other nodes), use the getChildNodes method. That method returns a collection of type NodeList. That type was invented before the standard Java collections, and it has a different access protocol. The item method gets the item with a given index, and the getLength method gives the total count of the items. Therefore, you can enumerate all children like this:
NodeList children = root.getChildNodes();
for (int i = 0; i < children.getLength(); i++)
{
Node child = children.item(i);
. . .
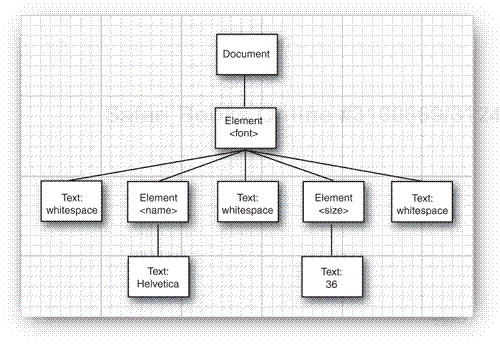
}Be careful when analyzing the children. Suppose, for example, that you are processing the document
<font> <name>Helvetica</name> <size>36</size> </font>
You would expect the font element to have two children, but the parser reports five:
The whitespace between
<font>and<name>The
nameelementThe whitespace between
</name>and<size>The
sizeelementThe whitespace between
</size>and</font>
Figure 2-2 shows the DOM tree.
If you expect only subelements, then you can ignore the whitespace:
for (int i = 0; i < children.getLength(); i++)
{
Node child = children.item(i);
if (child instanceof Element)
{
Element childElement = (Element) child;
. . .
}
}Now you look at only two elements, with tag names name and size.
As you see in the next section, you can do even better if your document has a DTD. Then the parser knows which elements don’t have text nodes as children, and it can suppress the whitespace for you.
When analyzing the name and size elements, you want to retrieve the text strings that they contain. Those text strings are themselves contained in child nodes of type Text. Because you know that these Text nodes are the only children, you can use the getFirstChild method without having to traverse another NodeList. Then use the getData method to retrieve the string stored in the Text node.
for (int i = 0; i < children.getLength(); i++)
{
Node child = children.item(i);
if (child instanceof Element)
{
Element childElement = (Element) child;
Text textNode = (Text) childElement.getFirstChild();
String text = textNode.getData().trim();
if (childElement.getTagName().equals("name"))
name = text;
else if (childElement.getTagName().equals("size"))
size = Integer.parseInt(text);
}
}Tip
It is a good idea to call trim on the return value of the getData method. If the author of an XML file puts the beginning and the ending tag on separate lines, such as
<size> 36 </size>
then the parser includes all line breaks and spaces in the text node data. Calling the trim method removes the whitespace surrounding the actual data.
You can also get the last child with the getLastChild method, and the next sibling of a node with getNextSibling. Therefore, another way of traversing a set of child nodes is
for (Node childNode = element.getFirstChild();
childNode != null;
childNode = childNode.getNextSibling())
{
. . .
}To enumerate the attributes of a node, call the getAttributes method. It returns a NamedNodeMap object that contains Node objects describing the attributes. You can traverse the nodes in a NamedNodeMap in the same way as a NodeList. Then call the getNodeName and getNodeValue methods to get the attribute names and values.
NamedNodeMap attributes = element.getAttributes();
for (int i = 0; i < attributes.getLength(); i++)
{
Node attribute = attributes.item(i);
String name = attribute.getNodeName();
String value = attribute.getNodeValue();
. . .
}Alternatively, if you know the name of an attribute, you can retrieve the corresponding value directly:
String unit = element.getAttribute("unit");You have now seen how to analyze a DOM tree. The program in Listing 2-1 puts these techniques to work. You can use the File -> Open menu option to read in an XML file. A DocumentBuilder object parses the XML file and produces a Document object. The program displays the Document object as a tree (see Figure 2-3).
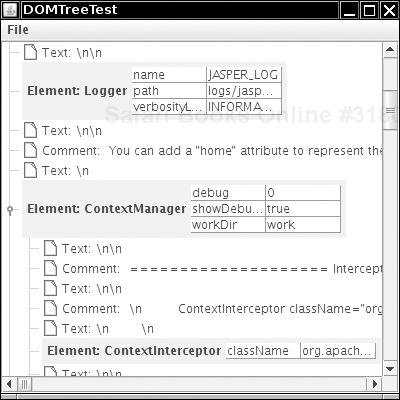
The tree display shows clearly how child elements are surrounded by text containing whitespace and comments. For greater clarity, the program displays newline and return characters as
and
. (Otherwise, they would show up as hollow boxes, the default symbol for a character that Swing cannot draw in a string.)
In Chapter 6, you will learn the techniques that this program uses to display the tree and the attribute tables. The DOMTreeModel class implements the TreeModel interface. The getRoot method returns the root element of the document. The getChild method gets the node list of children and returns the item with the requested index. The tree cell renderer displays the following:
For elements, the element tag name and a table of all attributes.
For character data, the interface (Text, Comment, or CDATASection), followed by the data, with newline and return characters replaced by
For all other node types, the class name followed by the result of
toString.
Example 2-1. DOMTreeTest.java
1. import java.awt.*; 2. import java.awt.event.*; 3. import java.io.*; 4. import javax.swing.*; 5. import javax.swing.event.*; 6. import javax.swing.table.*; 7. import javax.swing.tree.*; 8. import javax.xml.parsers.*; 9. import org.w3c.dom.*; 10. 11. /** 12. * This program displays an XML document as a tree. 13. * @version 1.11 2007-06-24 14. * @author Cay Horstmann 15. */ 16. public class DOMTreeTest 17. { 18. public static void main(String[] args) 19. { 20. EventQueue.invokeLater(new Runnable() 21. { 22. public void run() 23. { 24. JFrame frame = new DOMTreeFrame(); 25. frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); 26. frame.setVisible(true); 27. } 28. }); 29. } 30. } 31. 32. /** 33. * This frame contains a tree that displays the contents of an XML document. 34. */ 35. class DOMTreeFrame extends JFrame 36. { 37. public DOMTreeFrame() 38. { 39. setTitle("DOMTreeTest"); 40. setSize(DEFAULT_WIDTH, DEFAULT_HEIGHT); 41. 42. JMenu fileMenu = new JMenu("File"); 43. JMenuItem openItem = new JMenuItem("Open"); 44. openItem.addActionListener(new ActionListener() 45. { 46. public void actionPerformed(ActionEvent event) 47. { 48. openFile(); 49. } 50. }); 51. fileMenu.add(openItem); 52. 53. JMenuItem exitItem = new JMenuItem("Exit"); 54. exitItem.addActionListener(new ActionListener() 55. { 56. public void actionPerformed(ActionEvent event) 57. { 58. System.exit(0); 59. } 60. }); 61. fileMenu.add(exitItem); 62. 63. JMenuBar menuBar = new JMenuBar(); 64. menuBar.add(fileMenu); 65. setJMenuBar(menuBar); 66. } 67. 68. /** 69. * Open a file and load the document. 70. */ 71. public void openFile() 72. { 73. JFileChooser chooser = new JFileChooser(); 74. chooser.setCurrentDirectory(new File(".")); 75. 76. chooser.setFileFilter(new javax.swing.filechooser.FileFilter() 77. { 78. public boolean accept(File f) 79. { 80. return f.isDirectory() || f.getName().toLowerCase().endsWith(".xml"); 81. } 82. 83. public String getDescription() 84. { 85. return "XML files"; 86. } 87. }); 88. int r = chooser.showOpenDialog(this); 89. if (r != JFileChooser.APPROVE_OPTION) return; 90. final File file = chooser.getSelectedFile(); 91. 92. new SwingWorker<Document, Void>() 93. { 94. protected Document doInBackground() throws Exception 95. { 96. if (builder == null) 97. { 98. DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 99. builder = factory.newDocumentBuilder(); 100. } 101. return builder.parse(file); 102. } 103. 104. protected void done() 105. { 106. try 107. { 108. Document doc = get(); 109. JTree tree = new JTree(new DOMTreeModel(doc)); 110. tree.setCellRenderer(new DOMTreeCellRenderer()); 111. 112. setContentPane(new JScrollPane(tree)); 113. validate(); 114. } 115. catch (Exception e) 116. { 117. JOptionPane.showMessageDialog(DOMTreeFrame.this, e); 118. } 119. } 120. }.execute(); 121. } 122. 123. private DocumentBuilder builder; 124. private static final int DEFAULT_WIDTH = 400; 125. private static final int DEFAULT_HEIGHT = 400; 126. } 127. 128. /** 129. * This tree model describes the tree structure of an XML document. 130. */ 131. class DOMTreeModel implements TreeModel 132. { 133. /** 134. * Constructs a document tree model. 135. * @param doc the document 136. */ 137. public DOMTreeModel(Document doc) 138. { 139. this.doc = doc; 140. } 141. 142. public Object getRoot() 143. { 144. return doc.getDocumentElement(); 145. } 146. 147. public int getChildCount(Object parent) 148. { 149. Node node = (Node) parent; 150. NodeList list = node.getChildNodes(); 151. return list.getLength(); 152. } 153. 154. public Object getChild(Object parent, int index) 155. { 156. Node node = (Node) parent; 157. NodeList list = node.getChildNodes(); 158. return list.item(index); 159. } 160. 161. public int getIndexOfChild(Object parent, Object child) 162. { 163. Node node = (Node) parent; 164. NodeList list = node.getChildNodes(); 165. for (int i = 0; i < list.getLength(); i++) 166. if (getChild(node, i) == child) return i; 167. return -1; 168. } 169. 170. public boolean isLeaf(Object node) 171. { 172. return getChildCount(node) == 0; 173. } 174. 175. public void valueForPathChanged(TreePath path, Object newValue) 176. { 177. } 178. 179. public void addTreeModelListener(TreeModelListener l) 180. { 181. } 182. 183. public void removeTreeModelListener(TreeModelListener l) 184. { 185. } 186. 187. private Document doc; 188. } 189. 190. /** 191. * This class renders an XML node. 192. */ 193. class DOMTreeCellRenderer extends DefaultTreeCellRenderer 194. { 195. public Component getTreeCellRendererComponent(JTree tree, Object value, boolean selected, 196. boolean expanded, boolean leaf, int row, boolean hasFocus) 197. { 198. Node node = (Node) value; 199. if (node instanceof Element) return elementPanel((Element) node); 200. 201. super.getTreeCellRendererComponent(tree, value, selected, expanded, leaf, row, hasFocus); 202. if (node instanceof CharacterData) setText(characterString((CharacterData) node)); 203. else setText(node.getClass() + ": " + node.toString()); 204. return this; 205. } 206. 207. public static JPanel elementPanel(Element e) 208. { 209. JPanel panel = new JPanel(); 210. panel.add(new JLabel("Element: " + e.getTagName())); 211. final NamedNodeMap map = e.getAttributes(); 212. panel.add(new JTable(new AbstractTableModel() 213. { 214. public int getRowCount() 215. { 216. return map.getLength(); 217. } 218. 219. public int getColumnCount() 220. { 221. return 2; 222. } 223. 224. public Object getValueAt(int r, int c) 225. { 226. return c == 0 ? map.item(r).getNodeName() : map.item(r).getNodeValue(); 227. } 228. })); 229. return panel; 230. } 231. 232. public static String characterString(CharacterData node) 233. { 234. StringBuilder builder = new StringBuilder(node.getData()); 235. for (int i = 0; i < builder.length(); i++) 236. { 237. if (builder.charAt(i) == ' ') 238. { 239. builder.replace(i, i + 1, "\r"); 240. i++; 241. } 242. else if (builder.charAt(i) == ' ') 243. { 244. builder.replace(i, i + 1, "\n"); 245. i++; 246. } 247. else if (builder.charAt(i) == ' ') 248. { 249. builder.replace(i, i + 1, "\t"); 250. i++; 251. } 252. } 253. if (node instanceof CDATASection) builder.insert(0, "CDATASection: "); 254. else if (node instanceof Text) builder.insert(0, "Text: "); 255. else if (node instanceof Comment) builder.insert(0, "Comment: "); 256. 257. return builder.toString(); 258. } 259. }
javax.xml.parsers.DocumentBuilder 1.4
Document parse(File f)Document parse(String url)Document parse(InputStream in)parses an XML document from the given file, URL, or input stream and returns the parsed document.
org.w3c.dom.Element 1.4
String getTagName()returns the name of the element.
String getAttribute(String name)returns the value of the attribute with the given name, or the empty string if there is no such attribute.
org.w3c.dom.Node 1.4
returns a node list that contains all children of this node.
Node getFirstChild()Node getLastChild()gets the first or last child node of this node, or
nullif this node has no children.Node getNextSibling()Node getPreviousSibling()gets the next or previous sibling of this node, or
nullif this node has no siblings.Node getParentNode()gets the parent of this node, or
nullif this node is the document node.NamedNodeMap getAttributes()returns a node map that contains
Attrnodes that describe all attributes of this node.String getNodeName()returns the name of this node. If the node is an
Attrnode, then the name is the attribute name.String getNodeValue()returns the value of this node. If the node is an
Attrnode, then the value is the attribute value.
In the preceding section, you saw how to traverse the tree structure of a DOM document. However, if you simply follow that approach, you’ll find that you will have quite a bit of tedious programming and error checking. Not only do you have to deal with whitespace between elements, but you also need to check whether the document contains the nodes that you expect. For example, suppose you are reading an element:
<font> <name>Helvetica</name> <size>36</size> </font>
You get the first child. Oops . . . it is a text node containing whitespace "
". You skip text nodes and find the first element node. Then you need to check that its tag name is "name". You need to check that it has one child node of type Text. You move on to the next nonwhitespace child and make the same check. What if the author of the document switched the order of the children or added another child element? It is tedious to code all the error checking, and reckless to skip the checks.
Fortunately, one of the major benefits of an XML parser is that it can automatically verify that a document has the correct structure. Then the parsing becomes much simpler. For example, if you know that the font fragment has passed validation, then you can simply get the two grandchildren, cast them as Text nodes, and get the text data, without any further checking.
To specify the document structure, you can supply a DTD or an XML Schema definition. A DTD or schema contains rules that explain how a document should be formed, by specifying the legal child elements and attributes for each element. For example, a DTD might contain a rule:
<!ELEMENT font (name,size)>
This rule expresses that a font element must always have two children, which are name and size elements. The XML Schema language expresses the same constraint as
<xsd:element name="font">
<xsd:sequence>
<xsd:element name="name" type="xsd:string"/>
<xsd:element name="size" type="xsd:int"/>
</xsd:sequence>
</xsd:element>XML Schema can express more sophisticated validation conditions (such as the fact that the size element must contain an integer) than can DTDs. Unlike the DTD syntax, the XML Schema syntax uses XML, which is a benefit if you need to process schema files.
The XML Schema language was designed to replace DTDs. However, as we write this chapter, DTDs are still very much alive. XML Schema is very complex and far from universally adopted. In fact, some XML users are so annoyed by the complexity of XML Schema that they use alternative validation languages. The most common choice is Relax NG (http://www.relaxng.org).
In the next section, we discuss DTDs in detail. We then briefly cover the basics of XML Schema support. Finally, we show you a complete application that demonstrates how validation simplifies XML programming.
There are several methods for supplying a DTD. You can include a DTD in an XML document like this:
<?xml version="1.0"?>
<!DOCTYPE configuration [
<!ELEMENT configuration . . .>
more rules
. . .
]>
<configuration>
. . .
</configuration>As you can see, the rules are included inside a DOCTYPE declaration, in a block delimited by [. . .]. The document type must match the name of the root element, such as configuration in our example.
Supplying a DTD inside an XML document is somewhat uncommon because DTDs can grow lengthy. It makes more sense to store the DTD externally. The SYSTEM declaration can be used for that purpose. You specify a URL that contains the DTD, for example:
<!DOCTYPE configuration SYSTEM "config.dtd">
or
<!DOCTYPE configuration SYSTEM "http://myserver.com/config.dtd">
Caution
If you use a relative URL for the DTD (such as "config.dtd"), then give the parser a File or URL object, not an InputStream. If you must parse from an input stream, supply an entity resolver—see the following note.
Finally, the mechanism for identifying “well known” DTDs has its origin in SGML. Here is an example:
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.2//EN" "http://java.sun.com/j2ee/dtds/web-app_2_2.dtd">
If an XML processor knows how to locate the DTD with the public identifier, then it need not go to the URL.
Note
If you use a DOM parser and would like to support a PUBLIC identifier, call the setEntityResolver method of the DocumentBuilder class to install an object of a class that implements the EntityResolver interface. That interface has a single method, resolveEntity. Here is the outline of a typical implementation:
class MyEntityResolver implements EntityResolver
{
public InputSource resolveEntity(String publicID,
String systemID)
{
if (publicID.equals(a known ID))
return new InputSource(DTD data);
else
return null; // use default behavior
}
}You can construct the input source from an InputStream, a Reader, or a string.
Now that you have seen how the parser locates the DTD, let us consider the various kinds of rules.
The ELEMENT rule specifies what children an element can have. You specify a regular expression, made up of the components shown in Table 2-1.
Table 2-1. Rules for Element Content
Rule | Meaning |
|---|---|
E | 0 or more occurrences of E |
E | 1 or more occurrences of E |
E | 0 or 1 occurrences of E |
E1 | One of E1, E2, . . . , En |
E1 | E1 followed by E2, . . . , En |
| Text |
| 0 or more occurrences of text and E1, E2, . . ., En in any order (mixed content) |
| Any children allowed |
| No children allowed |
Here are several simple but typical examples. The following rule states that a menu element contains 0 or more item elements:
<!ELEMENT menu (item)*>
This set of rules states that a font is described by a name followed by a size, each of which contain text:
<!ELEMENT font (name,size)> <!ELEMENT name (#PCDATA)> <!ELEMENT size (#PCDATA)>
The abbreviation PCDATA denotes parsed character data. The data are called “parsed” because the parser interprets the text string, looking for < characters that denote the start of a new tag, or & characters that denote the start of an entity.
An element specification can contain regular expressions that are nested and complex. For example, here is a rule that describes the makeup of a chapter in this book:
<!ELEMENT chapter (intro,(heading,(para|image|table|note)+)+)
Each chapter starts with an introduction, which is followed by one or more sections consisting of a heading and one or more paragraphs, images, tables, or notes.
However, in one common case you can’t define the rules to be as flexible as you might like. Whenever an element can contain text, then there are only two valid cases. Either the element contains nothing but text, such as
<!ELEMENT name (#PCDATA)>
or the element contains any combination of text and tags in any order, such as
<!ELEMENT para (#PCDATA|em|strong|code)*>
It is not legal to specify other types of rules that contain #PCDATA. For example, the following rule is illegal:
<!ELEMENT captionedImage (image,#PCDATA)>
You have to rewrite such a rule, either by introducing another caption element or by allowing any combination of image tags and text.
This restriction simplifies the job of the XML parser when parsing mixed content (a mixture of tags and text). Because you lose some control when allowing mixed content, it is best to design DTDs such that all elements contain either other elements or nothing but text.
Note
Actually, it isn’t quite true that you can specify arbitrary regular expressions of elements in a DTD rule. An XML parser may reject certain complex rule sets that lead to “nondeterministic” parsing. For example, a regular expression ((x,y)|(x,z)) is nondeterministic. When the parser sees x, it doesn’t know which of the two alternatives to take. This expression can be rewritten in a deterministic form, as (x,(y|z)). However, some expressions can’t be reformulated, such as ((x,y)*|x?). The Sun parser gives no warnings when presented with an ambiguous DTD. It simply picks the first matching alternative when parsing, which causes it to reject some correct inputs. Of course, the parser is well within its rights to do so because the XML standard allows a parser to assume that the DTD is unambiguous.
In practice, this isn’t an issue over which you should lose sleep, because most DTDs are so simple that you never run into ambiguity problems.
You also specify rules to describe the legal attributes of elements. The general syntax is
<!ATTLIST element attribute type default>Table 2-2 shows the legal attribute types, and Table 2-3 shows the syntax for the defaults.
Here are two typical attribute specifications:
<!ATTLIST font style (plain|bold|italic|bold-italic) "plain"> <!ATTLIST size unit CDATA #IMPLIED>
The first specification describes the style attribute of a font element. There are four legal attribute values, and the default value is plain. The second specification expresses that the unit attribute of the size element can contain any character data sequence.
Note
We generally recommend the use of elements, not attributes, to describe data. Following that recommendation, the font style should be a separate element, such as <font><style>plain</style>...</font>. However, attributes have an undeniable advantage for enumerated types because the parser can verify that the values are legal. For example, if the font style is an attribute, the parser checks that it is one of the four allowed values, and it supplies a default if no value was given.
The handling of a CDATA attribute value is subtly different from the processing of #PCDATA that you have seen before, and quite unrelated to the <![CDATA[...]]> sections. The attribute value is first normalized; that is, the parser processes character and entity references (such as é or <) and replaces whitespace with spaces.
An NMTOKEN (or name token) is similar to CDATA, but most nonalphanumeric characters and internal whitespace are disallowed, and the parser removes leading and trailing whitespace. NMTOKENS is a whitespace-separated list of name tokens.
The ID construct is quite useful. An ID is a name token that must be unique in the document—the parser checks the uniqueness. You will see an application in the next sample program. An IDREF is a reference to an ID that exists in the same document—which the parser also checks. IDREFS is a whitespace-separated list of ID references.
An ENTITY attribute value refers to an “unparsed external entity.” That is a holdover from SGML that is rarely used in practice. The annotated XML specification at http://www.xml.com/axml/axml.html has an example.
A DTD can also define entities, or abbreviations that are replaced during parsing. You can find a good example for the use of entities in the user interface descriptions for the Mozilla/Netscape 6 browser. Those descriptions are formatted in XML and contain entity definitions such as
<!ENTITY back.label "Back">
Elsewhere, text can contain an entity reference, for example:
<menuitem label="&back.label;"/>
The parser replaces the entity reference with the replacement string. For internationalization of the application, only the string in the entity definition needs to be changed. Other uses of entities are more complex and less commonly used. Look at the XML specification for details.
This concludes the introduction to DTDs. Now that you have seen how to use DTDs, you can configure your parser to take advantage of them. First, tell the document builder factory to turn on validation.
factory.setValidating(true);
All builders produced by this factory validate their input against a DTD. The most useful benefit of validation is to ignore whitespace in element content. For example, consider the XML fragment
<font> <name>Helvetica</name> <size>36</size> </font>
A nonvalidating parser reports the whitespace between the font, name, and size elements because it has no way of knowing if the children of font are
(name,size) (#PCDATA,name,size)*
or perhaps
ANY
Once the DTD specifies that the children are (name,size), the parser knows that the whitespace between them is not text. Call
factory.setIgnoringElementContentWhitespace(true);
and the builder will stop reporting the whitespace in text nodes. That means you can now rely on the fact that a font node has two children. You no longer need to program a tedious loop:
for (int i = 0; i < children.getLength(); i++)
{
Node child = children.item(i);
if (child instanceof Element)
{
Element childElement = (Element) child;
if (childElement.getTagName().equals("name")) . . .
else if (childElement.getTagName().equals("size")) . . .
}
}Instead, you can simply access the first and second child:
Element nameElement = (Element) children.item(0); Element sizeElement = (Element) children.item(1);
That is why DTDs are so useful. You don’t overload your program with rule checking code—the parser has already done that work by the time you get the document.
Tip
Many programmers who start using XML are uncomfortable with validation and end up analyzing the DOM tree on the fly. If you need to convince colleagues of the benefit of using validated documents, show them the two coding alternatives—it should win them over.
When the parser reports an error, your application will want to do something about it—log it, show it to the user, or throw an exception to abandon the parsing. Therefore, you should install an error handler whenever you use validation. Supply an object that implements the ErrorHandler interface. That interface has three methods:
void warning(SAXParseException exception) void error(SAXParseException exception) void fatalError(SAXParseException exception)
You install the error handler with the setErrorHandler method of the DocumentBuilder class:
builder.setErrorHandler(handler);
javax.xml.parsers.DocumentBuilder 1.4
void setEntityResolver(EntityResolver resolver)sets the resolver to locate entities that are referenced in the XML documents to be parsed.
void setErrorHandler(ErrorHandler handler)sets the handler to report errors and warnings that occur during parsing.
org.xml.sax.EntityResolver 1.4
public InputSource resolveEntity(String publicID, String systemID)returns an input source that contains the data referenced by the given ID(s), or
nullto indicate that this resolver doesn’t know how to resolve the particular name. ThepublicIDparameter may benullif no public ID was supplied.
org.xml.sax.InputSource 1.4
InputSource(InputStream in)InputSource(Reader in)InputSource(String systemID)constructs an input source from a stream, reader, or system ID (usually a relative or absolute URL).
org.xml.sax.SAXParseException 1.4
int getLineNumber()int getColumnNumber()returns the line and column number of the end of the processed input that caused the exception.
javax.xml.parsers.DocumentBuilderFactory 1.4
boolean isValidating()void setValidating(boolean value)gets or sets the
validatingproperty of the factory. If set totrue, the parsers that this factory generates validate their input.boolean isIgnoringElementContentWhitespace()void setIgnoringElementContentWhitespace(boolean value)gets or sets the
ignoringElementContentWhitespaceproperty of the factory. If set totrue, the parsers that this factory generates ignore whitespace text between element nodes that don’t have mixed content (i.e., a mixture of elements and#PCDATA).
Because XML Schema is quite a bit more complex than the DTD syntax, we cover only the basics. For more information, we recommend the tutorial at http://www.w3.org/TR/xmlschema-0.
To reference a Schema file in a document, add attributes to the root element, for example:
<?xml version="1.0"?>
<configuration xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="config.xsd">
. . .
</configuration>This declaration states that the schema file config.xsd should be used to validate the document. If your document uses namespaces, the syntax is a bit more complex—see the XML Schema tutorial for details. (The prefix xsi is a namespace alias—see the section “Using Namespaces” on page 136 for more information.)
A schema defines a type for each element. The type can be a simple type—a string with formatting restrictions—or a complex type. Some simple types are built into XML Schema, including
xsd:string xsd:int xsd:boolean
Note
We use the prefix xsd: to denote the XML Schema Definition namespace. Some authors use the prefix xs: instead.
You can define your own simple types. For example, here is an enumerated type:
<xsd:simpleType name="StyleType">
<xsd:restriction base="xsd:string">
<xsd:enumeration value="PLAIN" />
<xsd:enumeration value="BOLD" />
<xsd:enumeration value="ITALIC" />
<xsd:enumeration value="BOLD_ITALIC" />
</xsd:restriction>
</xsd:simpleType>When you define an element, you specify its type:
<xsd:element name="name" type="xsd:string"/> <xsd:element name="size" type="xsd:int"/> <xsd:element name="style" type="StyleType"/>
The type constrains the element content. For example, the elements
<size>10</size> <style>PLAIN</style>
will validate correctly, but the elements
<size>default</size> <style>SLANTED</style>
will be rejected by the parser.
You can compose types into complex types, for example:
<xsd:complexType name="FontType">
<xsd:sequence>
<xsd:element ref="name"/>
<xsd:element ref="size"/>
<xsd:element ref="style"/>
</xsd:sequence>
</xsd:complexType>A FontType is a sequence of name, size, and style elements. In this type definition, we use the ref attribute and refer to definitions that are located elsewhere in the schema. You can also nest definitions, like this:
<xsd:complexType name="FontType">
<xsd:sequence>
<xsd:element name="name" type="xsd:string"/>
<xsd:element name="size" type="xsd:int"/>
<xsd:element name="style" type="StyleType">
<xsd:simpleType>
<xsd:restriction base="xsd:string">
<xsd:enumeration value="PLAIN" />
<xsd:enumeration value="BOLD" />
<xsd:enumeration value="ITALIC" />
<xsd:enumeration value="BOLD_ITALIC" />
</xsd:restriction>
</xsd:simpleType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>Note the anonymous type definition of the style element.
The xsd:sequence construct is the equivalent of the concatenation notation in DTDs. The xsd:choice construct is the equivalent of the | operator. For example,
<xsd:complexType name="contactinfo">
<xsd:choice>
<xsd:element ref="email"/>
<xsd:element ref="phone"/>
</xsd:choice>
</xsd:complexType>This is the equivalent of the DTD type email|phone.
To allow repeated elements, you use the minoccurs and maxoccurs attributes. For example, the equivalent of the DTD type item* is
<xsd:element name="item" type=". . ." minoccurs="0" maxoccurs="unbounded">
To specify attributes, add xsd:attribute elements to complexType definitions:
<xsd:element name="size">
<xsd:complexType>
. . .
<xsd:attribute name="unit" type="xsd:string" use="optional" default="cm"/>
</xsd:complexType>
</xsd:element>This is the equivalent of the DTD statement
<!ATTLIST size unit CDATA #IMPLIED "cm">
You enclose element and type definitions of your schema inside an xsd:schema element:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> . . . </xsd:schema>
Parsing an XML file with a schema is similar to parsing a file with a DTD, but with three differences:
You need to turn on support for namespaces, even if you don’t use them in your XML files.
factory.setNamespaceAware(true);
You need to prepare the factory for handling schemas, with the following magic incantation:
final String JAXP_SCHEMA_LANGUAGE = "http://java.sun.com/xml/jaxp/properties/schemaLanguage"; final String W3C_XML_SCHEMA = "http://www.w3.org/2001/XMLSchema"; factory.setAttribute(JAXP_SCHEMA_LANGUAGE, W3C_XML_SCHEMA);
The parser does not discard element content whitespace. This is a definite annoyance, and there is disagreement whether or not it is an actual bug. See the code in Listing 2-4 on page 122 for a workaround.
In this section, we work through a practical example that shows the use of XML in a realistic setting. Recall from Volume I, Chapter 9 that the GridBagLayout is the most useful layout manager for Swing components. However, it is feared not just for its complexity but also for the programming tedium. It would be much more convenient to put the layout instructions into a text file instead of producing large amounts of repetitive code. In this section, you see how to use XML to describe a grid bag layout and how to parse the layout files.
A grid bag is made up of rows and columns, very similar to an HTML table. Similar to an HTML table, we describe it as a sequence of rows, each of which contains cells:
<gridbag>
<row>
<cell>...</cell>
<cell>...</cell>
. . .
</row>
<row>
<cell>...</cell>
<cell>...</cell>
. . .
</row>
. . .
</gridbag>The gridbag.dtd specifies these rules:
<!ELEMENT gridbag (row)*> <!ELEMENT row (cell)*>
Some cells can span multiple rows and columns. In the grid bag layout, that is achieved by setting the gridwidth and gridheight constraints to values larger than 1. We use attributes of the same name:
<cell gridwidth="2" gridheight="2">
Similarly, we use attributes for the other grid bag constraints fill, anchor, gridx, gridy, weightx, weighty, ipadx, and ipady. (We don’t handle the insets constraint because its value is not a simple type, but it would be straightforward to support it.) For example,
<cell fill="HORIZONTAL" anchor="NORTH">
For most of these attributes, we provide the same defaults as the GridBagConstraints default constructor:
<!ATTLIST cell gridwidth CDATA "1"> <!ATTLIST cell gridheight CDATA "1"> <!ATTLIST cell fill (NONE|BOTH|HORIZONTAL|VERTICAL) "NONE"> <!ATTLIST cell anchor (CENTER|NORTH|NORTHEAST|EAST |SOUTHEAST|SOUTH|SOUTHWEST|WEST|NORTHWEST) "CENTER"> . . .
The gridx and gridy values get special treatment because it would be tedious and somewhat error prone to specify them by hand. Supplying them is optional:
<!ATTLIST cell gridx CDATA #IMPLIED> <!ATTLIST cell gridy CDATA #IMPLIED>
If they are not supplied, the program determines them according to the following heuristic: In column 0, the default gridx is 0. Otherwise, it is the preceding gridx plus the preceding gridwidth. The default gridy is always the same as the row number. Thus, you don’t have to specify gridx and gridy in the most common cases, in which a component spans multiple rows. However, if a component spans multiple columns, then you must specify gridx whenever you skip over that component.
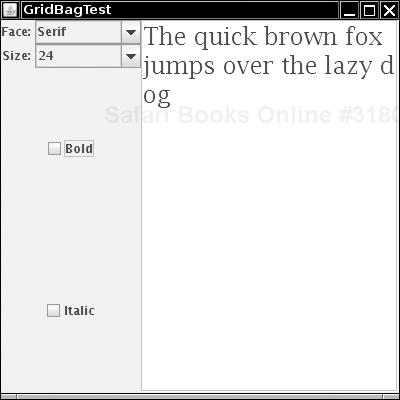
Note
Grid bag experts might wonder why we don’t use the RELATIVE and REMAINDER mechanism to let the grid bag layout automatically determine the gridx and gridy positions. We tried, but no amount of fussing would produce the layout of the font dialog example of Figure 2-4. Reading through the GridBagLayout source code, it is apparent that the algorithm just won’t do the heavy lifting that would be required to recover the absolute positions.
The program parses the attributes and sets the grid bag constraints. For example, to read the grid width, the program contains a single statement:
constraints.gridwidth = Integer.parseInt(e.getAttribute("gridwidth"));The program need not worry about a missing attribute because the parser automatically supplies the default value if no other value was specified in the document.
To test whether a gridx or gridy attribute was specified, we call the getAttribute method and check if it returns the empty string:
String value = e.getAttribute("gridy");
if (value.length() == 0) // use default
constraints.gridy = r;
else
constraints.gridx = Integer.parseInt(value);We found it convenient to allow arbitrary objects inside cells. That lets us specify noncomponent types such as borders. We only require that the objects belong to a class that follows the JavaBeans convention: to have a default constructor, and to have properties that are given by getter/setter pairs. (We discuss JavaBeans in more detail in Chapter 8.)
A bean is defined by a class name and zero or more properties:
<!ELEMENT bean (class, property*)> <!ELEMENT class (#PCDATA)>
A property contains a name and a value.
<!ELEMENT property (name, value)> <!ELEMENT name (#PCDATA)>
The value is an integer, boolean, string, or another bean:
<!ELEMENT value (int|string|boolean|bean)> <!ELEMENT int (#PCDATA)> <!ELEMENT string (#PCDATA)> <!ELEMENT boolean (#PCDATA)>
Here is a typical example, a JLabel whose text property is set to the string "Face: ".
<bean>
<class>javax.swing.JLabel</class>
<property>
<name>text</name>
<value><string>Face: </string></value>
</property>
</bean>It seems like a bother to surround a string with the <string> tag. Why not just use #PCDATA for strings and leave the tags for the other types? Because then we would need to use mixed content and weaken the rule for the value element to
<!ELEMENT value (#PCDATA|int|boolean|bean)*>
However, that rule would allow an arbitrary mixture of text and tags.
The program sets a property by using the BeanInfo class. BeanInfo enumerates the property descriptors of the bean. We search for the property with the matching name, and then call its setter method with the supplied value.
When our program reads in a user interface description, it has enough information to construct and arrange the user interface components. But, of course, the interface is not alive—no event listeners have been attached. To add event listeners, we have to locate the components. For that reason, we support an optional attribute of type ID for each bean:
<!ATTLIST bean id ID #IMPLIED>
For example, here is a combo box with an ID:
<bean id="face"> <class>javax.swing.JComboBox</class> </bean>
Recall that the parser checks that IDs are unique.
A programmer can attach event handlers like this:
gridbag = new GridBagPane("fontdialog.xml");
setContentPane(gridbag);
JComboBox face = (JComboBox) gridbag.get("face");
face.addListener(listener);Note
In this example, we only use XML to describe the component layout and leave it to programmers to attach the event handlers in the Java code. You could go a step further and add the code to the XML description. The most promising approach is to use a scripting language such as JavaScript for the code. If you want to add that enhancement, check out the Rhino interpreter at http://www.mozilla.org/rhino.
The program in Listing 2-2 shows how to use the GridBagPane class to do all the boring work of setting up the grid bag layout. The layout is defined in Listing 2-3. Figure 2-4 shows the result. The program only initializes the combo boxes (which are too complex for the bean property-setting mechanism that the GridBagPane supports) and attaches event listeners. The GridBagPane class in Listing 2-4 parses the XML file, constructs the components, and lays them out. Listing 2-5 shows the DTD.
The program can also process a schema instead of a DTD if you launch it with
java GridBagTest fontdialog-schema.xml
Listing 2-6 contains the schema.
This example is a typical use of XML. The XML format is robust enough to express complex relationships. The XML parser adds value by taking over the routine job of validity checking and supplying defaults.
Example 2-2. GridBagTest.java
1. import java.awt.*; 2. import java.awt.event.*; 3. import javax.swing.*; 4. 5. /** 6. * This program shows how to use an XML file to describe a gridbag layout 7. * @version 1.01 2007-06-25 8. * @author Cay Horstmann 9. */ 10. public class GridBagTest 11. { 12. public static void main(final String[] args) 13. { 14. EventQueue.invokeLater(new Runnable() 15. { 16. public void run() 17. { 18. String filename = args.length == 0 ? "fontdialog.xml" : args[0]; 19. JFrame frame = new FontFrame(filename); 20. frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); 21. frame.setVisible(true); 22. } 23. }); 24. } 25. } 26. 27. /** 28. * This frame contains a font selection dialog that is described by an XML file. 29. * @param filename the file containing the user interface components for the dialog. 30. */ 31. class FontFrame extends JFrame 32. { 33. public FontFrame(String filename) 34. { 35. setSize(DEFAULT_WIDTH, DEFAULT_HEIGHT); 36. setTitle("GridBagTest"); 37. 38. gridbag = new GridBagPane(filename); 39. add(gridbag); 40. 41. face = (JComboBox) gridbag.get("face"); 42. size = (JComboBox) gridbag.get("size"); 43. bold = (JCheckBox) gridbag.get("bold"); 44. italic = (JCheckBox) gridbag.get("italic"); 45. 46. face.setModel(new DefaultComboBoxModel(new Object[] { "Serif", "SansSerif", 47. "Monospaced", "Dialog", "DialogInput" })); 48. 49. size.setModel(new DefaultComboBoxModel(new Object[] { "8", "10", "12", "15", "18", "24", 50. "36", "48" })); 51. 52. ActionListener listener = new ActionListener() 53. { 54. public void actionPerformed(ActionEvent event) 55. { 56. setSample(); 57. } 58. }; 59. 60. face.addActionListener(listener); 61. size.addActionListener(listener); 62. bold.addActionListener(listener); 63. italic.addActionListener(listener); 64. setSample(); 65. } 66. 67. /** 68. * This method sets the text sample to the selected font. 69. */ 70. public void setSample() 71. { 72. String fontFace = (String) face.getSelectedItem(); 73. int fontSize = Integer.parseInt((String) size.getSelectedItem()); 74. JTextArea sample = (JTextArea) gridbag.get("sample"); 75. int fontStyle = (bold.isSelected() ? Font.BOLD : 0) 76. + (italic.isSelected() ? Font.ITALIC : 0); 77. 78. sample.setFont(new Font(fontFace, fontStyle, fontSize)); 79. sample.repaint(); 80. } 81. 82. private GridBagPane gridbag; 83. private JComboBox face; 84. private JComboBox size; 85. private JCheckBox bold; 86. private JCheckBox italic; 87. private static final int DEFAULT_WIDTH = 400; 88. private static final int DEFAULT_HEIGHT = 400; 89. }
Example 2-3. fontdialog.xml
1. <?xml version="1.0"?> 2. <!DOCTYPE gridbag SYSTEM "gridbag.dtd"> 3. <gridbag> 4. <row> 5. <cell anchor="EAST"> 6. <bean> 7. <class>javax.swing.JLabel</class> 8. <property> 9. <name>text</name> 10. <value><string>Face: </string></value> 11. </property> 12. </bean> 13. </cell> 14. <cell fill="HORIZONTAL" weightx="100"> 15. <bean id="face"> 16. <class>javax.swing.JComboBox</class> 17. </bean> 18. </cell> 19. <cell gridheight="4" fill="BOTH" weightx="100" weighty="100"> 20. <bean id="sample"> 21. <class>javax.swing.JTextArea</class> 22. <property> 23. <name>text</name> 24. <value><string>The quick brown fox jumps over the lazy dog</string></value> 25. </property> 26. <property> 27. <name>editable</name> 28. <value><boolean>false</boolean></value> 29. </property> 30. <property> 31. <name>lineWrap</name> 32. <value><boolean>true</boolean></value> 33. </property> 34. <property> 35. <name>border</name> 36. <value> 37. <bean> 38. <class>javax.swing.border.EtchedBorder</class> 39. </bean> 40. </value> 41. </property> 42. </bean> 43. </cell> 44. </row> 45. <row> 46. <cell anchor="EAST"> 47. <bean> 48. <class>javax.swing.JLabel</class> 49. <property> 50. <name>text</name> 51. <value><string>Size: </string></value> 52. </property> 53. </bean> 54. </cell> 55. <cell fill="HORIZONTAL" weightx="100"> 56. <bean id="size"> 57. <class>javax.swing.JComboBox</class> 58. </bean> 59. </cell> 60. </row> 61. <row> 62. <cell gridwidth="2" weighty="100"> 63. <bean id="bold"> 64. <class>javax.swing.JCheckBox</class> 65. <property> 66. <name>text</name> 67. <value><string>Bold</string></value> 68. </property> 69. </bean> 70. </cell> 71. </row> 72. <row> 73. <cell gridwidth="2" weighty="100"> 74. <bean id="italic"> 75. <class>javax.swing.JCheckBox</class> 76. <property> 77. <name>text</name> 78. <value><string>Italic</string></value> 79. </property> 80. </bean> 81. </cell> 82. </row> 83. </gridbag>
Example 2-4. GridBagPane.java
1. import java.awt.*; 2. import java.beans.*; 3. import java.io.*; 4. import java.lang.reflect.*; 5. import javax.swing.*; 6. import javax.xml.parsers.*; 7. import org.w3c.dom.*; 8. 9. /** 10. * This panel uses an XML file to describe its components and their grid bag layout positions. 11. * @version 1.10 2004-09-04 12. * @author Cay Horstmann 13. */ 14. public class GridBagPane extends JPanel 15. { 16. /** 17. * Constructs a grid bag pane. 18. * @param filename the name of the XML file that describes the pane's components and their 19. * positions 20. */ 21. public GridBagPane(String filename) 22. { 23. setLayout(new GridBagLayout()); 24. constraints = new GridBagConstraints(); 25. 26. try 27. { 28. DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 29. factory.setValidating(true); 30. 31. if (filename.contains("-schema")) 32. { 33. factory.setNamespaceAware(true); 34. final String JAXP_SCHEMA_LANGUAGE = "http://java.sun.com/xml/jaxp/properties/ 35. schemaLanguage"; 36. final String W3C_XML_SCHEMA = "http://www.w3.org/2001/XMLSchema"; 37. factory.setAttribute(JAXP_SCHEMA_LANGUAGE, W3C_XML_SCHEMA); 38. } 39. 40. factory.setIgnoringElementContentWhitespace(true); 41. 42. DocumentBuilder builder = factory.newDocumentBuilder(); 43. Document doc = builder.parse(new File(filename)); 44. 45. if (filename.contains("-schema")) 46. { 47. int count = removeElementContentWhitespace(doc.getDocumentElement()); 48. System.out.println(count + " whitespace nodes removed."); 49. } 50. 51. parseGridbag(doc.getDocumentElement()); 52. } 53. catch (Exception e) 54. { 55. e.printStackTrace(); 56. } 57. } 58. 59. /** 60. * Removes all (heuristically determined) element content whitespace nodes 61. * @param e the root element 62. * @return the number of whitespace nodes that were removed. 63. */ 64. private int removeElementContentWhitespace(Element e) 65. { 66. NodeList children = e.getChildNodes(); 67. int count = 0; 68. boolean allTextChildrenAreWhiteSpace = true; 69. int elements = 0; 70. for (int i = 0; i < children.getLength() && allTextChildrenAreWhiteSpace; i++) 71. { 72. Node child = children.item(i); 73. if (child instanceof Text && ((Text) child).getData().trim().length() > 0) 74. allTextChildrenAreWhiteSpace = false; 75. else if (child instanceof Element) 76. { 77. elements++; 78. count += removeElementContentWhitespace((Element) child); 79. } 80. } 81. if (elements > 0 && allTextChildrenAreWhiteSpace) // heuristics for element content 82. { 83. for (int i = children.getLength() - 1; i >= 0; i--) 84. { 85. Node child = children.item(i); 86. if (child instanceof Text) 87. { 88. e.removeChild(child); 89. count++; 90. } 91. } 92. } 93. return count; 94. } 95. 96. /** 97. * Gets a component with a given name 98. * @param name a component name 99. * @return the component with the given name, or null if no component in this grid bag 100. * pane has the given name 101. */ 102. public Component get(String name) 103. { 104. Component[] components = getComponents(); 105. for (int i = 0; i < components.length; i++) 106. { 107. if (components[i].getName().equals(name)) return components[i]; 108. } 109. return null; 110. } 111. 112. /** 113. * Parses a gridbag element. 114. * @param e a gridbag element 115. */ 116. private void parseGridbag(Element e) 117. { 118. NodeList rows = e.getChildNodes(); 119. for (int i = 0; i < rows.getLength(); i++) 120. { 121. Element row = (Element) rows.item(i); 122. NodeList cells = row.getChildNodes(); 123. for (int j = 0; j < cells.getLength(); j++) 124. { 125. Element cell = (Element) cells.item(j); 126. parseCell(cell, i, j); 127. } 128. } 129. } 130. 131. /** 132. * Parses a cell element. 133. * @param e a cell element 134. * @param r the row of the cell 135. * @param c the column of the cell 136. */ 137. private void parseCell(Element e, int r, int c) 138. { 139. // get attributes 140. 141. String value = e.getAttribute("gridx"); 142. if (value.length() == 0) // use default 143. { 144. if (c == 0) constraints.gridx = 0; 145. else constraints.gridx += constraints.gridwidth; 146. } 147. else constraints.gridx = Integer.parseInt(value); 148. 149. value = e.getAttribute("gridy"); 150. if (value.length() == 0) // use default 151. constraints.gridy = r; 152. else constraints.gridy = Integer.parseInt(value); 153. 154. constraints.gridwidth = Integer.parseInt(e.getAttribute("gridwidth")); 155. constraints.gridheight = Integer.parseInt(e.getAttribute("gridheight")); 156. constraints.weightx = Integer.parseInt(e.getAttribute("weightx")); 157. constraints.weighty = Integer.parseInt(e.getAttribute("weighty")); 158. constraints.ipadx = Integer.parseInt(e.getAttribute("ipadx")); 159. constraints.ipady = Integer.parseInt(e.getAttribute("ipady")); 160. 161. // use reflection to get integer values of static fields 162. Class<GridBagConstraints> cl = GridBagConstraints.class; 163. 164. try 165. { 166. String name = e.getAttribute("fill"); 167. Field f = cl.getField(name); 168. constraints.fill = f.getInt(cl); 169. 170. name = e.getAttribute("anchor"); 171. f = cl.getField(name); 172. constraints.anchor = f.getInt(cl); 173. } 174. catch (Exception ex) // the reflection methods can throw various exceptions 175. { 176. ex.printStackTrace(); 177. } 178. 179. Component comp = (Component) parseBean((Element) e.getFirstChild()); 180. add(comp, constraints); 181. } 182. 183. /** 184. * Parses a bean element. 185. * @param e a bean element 186. */ 187. private Object parseBean(Element e) 188. { 189. try 190. { 191. NodeList children = e.getChildNodes(); 192. Element classElement = (Element) children.item(0); 193. String className = ((Text) classElement.getFirstChild()).getData(); 194. 195. Class<?> cl = Class.forName(className); 196. 197. Object obj = cl.newInstance(); 198. 199. if (obj instanceof Component) ((Component) obj).setName(e.getAttribute("id")); 200. 201. for (int i = 1; i < children.getLength(); i++) 202. { 203. Node propertyElement = children.item(i); 204. Element nameElement = (Element) propertyElement.getFirstChild(); 205. String propertyName = ((Text) nameElement.getFirstChild()).getData(); 206. 207. Element valueElement = (Element) propertyElement.getLastChild(); 208. Object value = parseValue(valueElement); 209. BeanInfo beanInfo = Introspector.getBeanInfo(cl); 210. PropertyDescriptor[] descriptors = beanInfo.getPropertyDescriptors(); 211. boolean done = false; 212. for (int j = 0; !done && j < descriptors.length; j++) 213. { 214. if (descriptors[j].getName().equals(propertyName)) 215. { 216. descriptors[j].getWriteMethod().invoke(obj, value); 217. done = true; 218. } 219. } 220. 221. } 222. return obj; 223. } 224. catch (Exception ex) // the reflection methods can throw various exceptions 225. { 226. ex.printStackTrace(); 227. return null; 228. } 229. } 230. 231. /** 232. * Parses a value element. 233. * @param e a value element 234. */ 235. private Object parseValue(Element e) 236. { 237. Element child = (Element) e.getFirstChild(); 238. if (child.getTagName().equals("bean")) return parseBean(child); 239. String text = ((Text) child.getFirstChild()).getData(); 240. if (child.getTagName().equals("int")) return new Integer(text); 241. else if (child.getTagName().equals("boolean")) return new Boolean(text); 242. else if (child.getTagName().equals("string")) return text; 243. else return null; 244. } 245. 246. private GridBagConstraints constraints; 247. }
Example 2-5. gridbag.dtd
1. <!ELEMENT gridbag (row)*> 2. <!ELEMENT row (cell)*> 3. <!ELEMENT cell (bean)> 4. <!ATTLIST cell gridx CDATA #IMPLIED> 5. <!ATTLIST cell gridy CDATA #IMPLIED> 6. <!ATTLIST cell gridwidth CDATA "1"> 7. <!ATTLIST cell gridheight CDATA "1"> 8. <!ATTLIST cell weightx CDATA "0"> 9. <!ATTLIST cell weighty CDATA "0"> 10. <!ATTLIST cell fill (NONE|BOTH|HORIZONTAL|VERTICAL) "NONE"> 11. <!ATTLIST cell anchor 12. (CENTER|NORTH|NORTHEAST|EAST|SOUTHEAST|SOUTH|SOUTHWEST|WEST|NORTHWEST) "CENTER"> 13. <!ATTLIST cell ipadx CDATA "0"> 14. <!ATTLIST cell ipady CDATA "0"> 15. 16. <!ELEMENT bean (class, property*)> 17. <!ATTLIST bean id ID #IMPLIED> 18. 19. <!ELEMENT class (#PCDATA)> 20. <!ELEMENT property (name, value)> 21. <!ELEMENT name (#PCDATA)> 22. <!ELEMENT value (int|string|boolean|bean)> 23. <!ELEMENT int (#PCDATA)> 24. <!ELEMENT string (#PCDATA)> 25. <!ELEMENT boolean (#PCDATA)>
Example 2-6. gridbag.xsd
1. <xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> 2. 3. <xsd:element name="gridbag" type="GridBagType"/> 4. 5. <xsd:element name="bean" type="BeanType"/> 6. 7. <xsd:complexType name="GridBagType"> 8. <xsd:sequence> 9. <xsd:element name="row" type="RowType" minOccurs="0" maxOccurs="unbounded"/> 10. </xsd:sequence> 11. </xsd:complexType> 12. 13. <xsd:complexType name="RowType"> 14. <xsd:sequence> 15. <xsd:element name="cell" type="CellType" minOccurs="0" maxOccurs="unbounded"/> 16. </xsd:sequence> 17. </xsd:complexType> 18. 19. <xsd:complexType name="CellType"> 20. <xsd:sequence> 21. <xsd:element ref="bean"/> 22. </xsd:sequence> 23. <xsd:attribute name="gridx" type="xsd:int" use="optional"/> 24. <xsd:attribute name="gridy" type="xsd:int" use="optional"/> 25. <xsd:attribute name="gridwidth" type="xsd:int" use="optional" default="1" /> 26. <xsd:attribute name="gridheight" type="xsd:int" use="optional" default="1" /> 27. <xsd:attribute name="weightx" type="xsd:int" use="optional" default="0" /> 28. <xsd:attribute name="weighty" type="xsd:int" use="optional" default="0" /> 29. <xsd:attribute name="fill" use="optional" default="NONE"> 30. <xsd:simpleType> 31. <xsd:restriction base="xsd:string"> 32. <xsd:enumeration value="NONE" /> 33. <xsd:enumeration value="BOTH" /> 34. <xsd:enumeration value="HORIZONTAL" /> 35. <xsd:enumeration value="VERTICAL" /> 36. </xsd:restriction> 37. </xsd:simpleType> 38. </xsd:attribute> 39. <xsd:attribute name="anchor" use="optional" default="CENTER"> 40. <xsd:simpleType> 41. <xsd:restriction base="xsd:string"> 42. <xsd:enumeration value="CENTER" /> 43. <xsd:enumeration value="NORTH" /> 44. <xsd:enumeration value="NORTHEAST" /> 45. <xsd:enumeration value="EAST" /> 46. <xsd:enumeration value="SOUTHEAST" /> 47. <xsd:enumeration value="SOUTH" /> 48. <xsd:enumeration value="SOUTHWEST" /> 49. <xsd:enumeration value="WEST" /> 50. <xsd:enumeration value="NORTHWEST" /> 51. </xsd:restriction> 52. </xsd:simpleType> 53. </xsd:attribute> 54. <xsd:attribute name="ipady" type="xsd:int" use="optional" default="0" /> 55. <xsd:attribute name="ipadx" type="xsd:int" use="optional" default="0" /> 56. </xsd:complexType> 57. 58. <xsd:complexType name="BeanType"> 59. <xsd:sequence> 60. <xsd:element name="class" type="xsd:string"/> 61. <xsd:element name="property" type="PropertyType" minOccurs="0" maxOccurs="unbounded"/> 62. </xsd:sequence> 63. <xsd:attribute name="id" type="xsd:ID" use="optional" /> 64. </xsd:complexType> 65. 66. <xsd:complexType name="PropertyType"> 67. <xsd:sequence> 68. <xsd:element name="name" type="xsd:string"/> 69. <xsd:element name="value" type="ValueType"/> 70. </xsd:sequence> 71. </xsd:complexType> 72. 73. <xsd:complexType name="ValueType"> 74. <xsd:choice> 75. <xsd:element ref="bean"/> 76. <xsd:element name="int" type="xsd:int"/> 77. <xsd:element name="string" type="xsd:string"/> 78. <xsd:element name="boolean" type="xsd:boolean"/> 79. </xsd:choice> 80. </xsd:complexType> 81. </xsd:schema>
If you want to locate a specific piece of information in an XML document, then it can be a bit of a hassle to navigate the nodes of the DOM tree. The XPath language makes it simple to access tree nodes. For example, suppose you have this XML document:
<configuration>
. . .
<database>
<username>dbuser</username>
<password>secret</password>
. . .
</database>
</configuration>You can get the database user name by evaluating the XPath expression
/configuration/database/username
That’s a lot simpler than the plain DOM approach:
Get the document node.
Enumerate its children.
Locate the
databaseelement.Get its first child, the
usernameelement.Get its first child, a
Textnode.Get its data.
An XPath can describe a set of nodes in an XML document. For example, the XPath
/gridbag/row
describes the set of all row elements that are children of the gridbag root element. You can select a particular element with the [] operator:
/gridbag/row[1]
is the first row. (The index values start at 1.)
Use the @ operator to get attribute values. The XPath expression
/gridbag/row[1]/cell[1]/@anchor
describes the anchor attribute of the first cell in the first row. The XPath expression
/gridbag/row/cell/@anchor
describes all anchor attribute nodes of cell elements within row elements that are children of the gridbag root node.
There are a number of useful XPath functions. For example,
count(/gridbag/row)
returns the number of row children of the gridbag root. There are many more elaborate XPath expressions—see the specification at http://www.w3c.org/TR/xpath or the nifty online tutorial at http://www.zvon.org/xxl/XPathTutorial/General/examples.html.
Java SE 5.0 added an API to evaluate XPath expressions. You first create an XPath object from an XPathFactory:
XPathFactory xpfactory = XPathFactory.newInstance(); path = xpfactory.newXPath();
You then call the evaluate method to evaluate XPath expressions:
String username = path.evaluate("/configuration/database/username", doc);You can use the same XPath object to evaluate multiple expressions.
This form of the evaluate method returns a string result. It is suitable for retrieving text, such as the text of the username node in the preceding example. If an XPath expression yields a node set, make a call such as the following:
NodeList nodes = (NodeList) path.evaluate("/gridbag/row", doc, XPathConstants.NODESET);If the result is a single node, use XPathConstants.NODE instead:
Node node = (Node) path.evaluate("/gridbag/row[1]", doc, XPathConstants.NODE);If the result is a number, use XPathConstants.NUMBER:
int count = ((Number) path.evaluate("count(/gridbag/row)", doc, XPathConstants.NUM-
BER)).intValue();You don’t have to start the search at the document root. You can start the search at any node or node list. For example, if you have a node from a previous evaluation, you can call
result = path.evaluate(expression, node);
The program in Listing 2-7 demonstrates the evaluation of XPath expressions. Load an XML file and type an expression. Select the expression type and click the Evaluate button. The result of the expression is displayed at the bottom of the frame (see Figure 2-5).
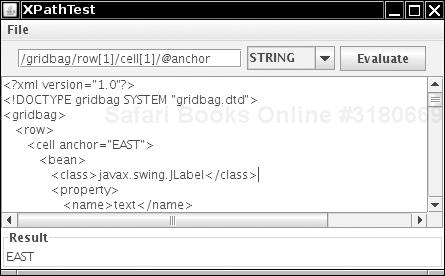
Example 2-7. XPathTest.java
1. import java.awt.*; 2. import java.awt.event.*; 3. import java.io.*; 4. import javax.swing.*; 5. import javax.swing.border.*; 6. import javax.xml.namespace.*; 7. import javax.xml.parsers.*; 8. import javax.xml.xpath.*; 9. import org.w3c.dom.*; 10. import org.xml.sax.*; 11. 12. /** 13. * This program evaluates XPath expressions 14. * @version 1.01 2007-06-25 15. * @author Cay Horstmann 16. */ 17. public class XPathTest 18. { 19. public static void main(String[] args) 20. { 21. EventQueue.invokeLater(new Runnable() 22. { 23. public void run() 24. { 25. JFrame frame = new XPathFrame(); 26. frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); 27. frame.setVisible(true); 28. } 29. }); 30. } 31. } 32. 33. /** 34. * This frame shows an XML document, a panel to type an XPath expression, and a text field 35. * to display the result. 36. */ 37. class XPathFrame extends JFrame 38. { 39. public XPathFrame() 40. { 41. setTitle("XPathTest"); 42. 43. JMenu fileMenu = new JMenu("File"); 44. JMenuItem openItem = new JMenuItem("Open"); 45. openItem.addActionListener(new ActionListener() 46. { 47. public void actionPerformed(ActionEvent event) 48. { 49. openFile(); 50. } 51. }); 52. fileMenu.add(openItem); 53. 54. JMenuItem exitItem = new JMenuItem("Exit"); 55. exitItem.addActionListener(new ActionListener() 56. { 57. public void actionPerformed(ActionEvent event) 58. { 59. System.exit(0); 60. } 61. }); 62. fileMenu.add(exitItem); 63. 64. JMenuBar menuBar = new JMenuBar(); 65. menuBar.add(fileMenu); 66. setJMenuBar(menuBar); 67. 68. ActionListener listener = new ActionListener() 69. { 70. public void actionPerformed(ActionEvent event) 71. { 72. evaluate(); 73. } 74. }; 75. expression = new JTextField(20); 76. expression.addActionListener(listener); 77. JButton evaluateButton = new JButton("Evaluate"); 78. evaluateButton.addActionListener(listener); 79. 80. typeCombo = new JComboBox(new Object[] { "STRING", "NODE", "NODESET", "NUMBER", 81. "BOOLEAN" }); 82. typeCombo.setSelectedItem("STRING"); 83. 84. JPanel panel = new JPanel(); 85. panel.add(expression); 86. panel.add(typeCombo); 87. panel.add(evaluateButton); 88. docText = new JTextArea(10, 40); 89. result = new JTextField(); 90. result.setBorder(new TitledBorder("Result")); 91. 92. add(panel, BorderLayout.NORTH); 93. add(new JScrollPane(docText), BorderLayout.CENTER); 94. add(result, BorderLayout.SOUTH); 95. 96. try 97. { 98. DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 99. builder = factory.newDocumentBuilder(); 100. } 101. catch (ParserConfigurationException e) 102. { 103. JOptionPane.showMessageDialog(this, e); 104. } 105. 106. XPathFactory xpfactory = XPathFactory.newInstance(); 107. path = xpfactory.newXPath(); 108. pack(); 109. } 110. 111. /** 112. * Open a file and load the document. 113. */ 114. public void openFile() 115. { 116. JFileChooser chooser = new JFileChooser(); 117. chooser.setCurrentDirectory(new File(".")); 118. 119. chooser.setFileFilter(new javax.swing.filechooser.FileFilter() 120. { 121. public boolean accept(File f) 122. { 123. return f.isDirectory() || f.getName().toLowerCase().endsWith(".xml"); 124. } 125. 126. public String getDescription() 127. { 128. return "XML files"; 129. } 130. }); 131. int r = chooser.showOpenDialog(this); 132. if (r != JFileChooser.APPROVE_OPTION) return; 133. File f = chooser.getSelectedFile(); 134. try 135. { 136. byte[] bytes = new byte[(int) f.length()]; 137. new FileInputStream(f).read(bytes); 138. docText.setText(new String(bytes)); 139. doc = builder.parse(f); 140. } 141. catch (IOException e) 142. { 143. JOptionPane.showMessageDialog(this, e); 144. } 145. catch (SAXException e) 146. { 147. JOptionPane.showMessageDialog(this, e); 148. } 149. } 150. 151. public void evaluate() 152. { 153. try 154. { 155. String typeName = (String) typeCombo.getSelectedItem(); 156. QName returnType = (QName) XPathConstants.class.getField(typeName).get(null); 157. Object evalResult = path.evaluate(expression.getText(), doc, returnType); 158. if (typeName.equals("NODESET")) 159. { 160. NodeList list = (NodeList) evalResult; 161. StringBuilder builder = new StringBuilder(); 162. builder.append("{"); 163. for (int i = 0; i < list.getLength(); i++) 164. { 165. if (i > 0) builder.append(", "); 166. builder.append("" + list.item(i)); 167. } 168. builder.append("}"); 169. result.setText("" + builder); 170. } 171. else result.setText("" + evalResult); 172. } 173. catch (XPathExpressionException e) 174. { 175. result.setText("" + e); 176. } 177. catch (Exception e) // reflection exception 178. { 179. e.printStackTrace(); 180. } 181. } 182. 183. private DocumentBuilder builder; 184. private Document doc; 185. private XPath path; 186. private JTextField expression; 187. private JTextField result; 188. private JTextArea docText; 189. private JComboBox typeCombo; 190. }
javax.xml.xpath.XPath 5.0
String evaluate(String expression, Object startingPoint)evaluates an expression, beginning with the given starting point. The starting point can be a node or node list. If the result is a node or node set, then the returned string consists of the data of all text node children.
Object evaluate(String expression, Object startingPoint, QName resultType)evaluates an expression, beginning with the given starting point. The starting point can be a node or node list. The
resultTypeis one of the constantsSTRING,NODE,NODESET,NUMBER, orBOOLEANin theXPathConstantsclass. The return value is aString,Node,NodeList,Number, orBoolean.
The Java language uses packages to avoid name clashes. Programmers can use the same name for different classes as long as they aren’t in the same package. XML has a similar namespace mechanism for element and attribute names.
A namespace is identified by a Uniform Resource Identifier (URI), such as
http://www.w3.org/2001/XMLSchema uuid:1c759aed-b748-475c-ab68-10679700c4f2 urn:com:books-r-us
The HTTP URL form is the most common. Note that the URL is just used as an identifier string, not as a locator for a document. For example, the namespace identifiers
http://www.horstmann.com/corejava http://www.horstmann.com/corejava/index.html
denote different namespaces, even though a web server would serve the same document for both URLs.
There need not be any document at a namespace URL—the XML parser doesn’t attempt to find anything at that location. However, as a help to programmers who encounter a possibly unfamiliar namespace, it is customary to place a document explaining the purpose of the namespace at the URL location. For example, if you point your browser to the namespace URL for the XML Schema namespace (http://www.w3.org/2001/XMLSchema), you will find a document describing the XML Schema standard.
Why use HTTP URLs for namespace identifiers? It is easy to ensure that they are unique. If you choose a real URL, then the host part’s uniqueness is guaranteed by the domain name system. Your organization can then arrange for the uniqueness of the remainder of the URL. This is the same rationale that underlies the use of reversed domain names in Java package names.
Of course, although you want long namespace identifiers for uniqueness, you don’t want to deal with long identifiers any more than you have to. In the Java programming language, you use the import mechanism to specify the long names of packages, and then use just the short class names. In XML, there is a similar mechanism, like this:
<element xmlns="namespaceURI"> children </element>
The element and its children are now part of the given namespace.
A child can provide its own namespace, for example:
<element xmlns="namespaceURI1"> <child xmlns="namespaceURI2"> grandchildren </child> more children </element>
Then the first child and the grandchildren are part of the second namespace.
That simple mechanism works well if you need only a single namespace or if the namespaces are naturally nested. Otherwise, you will want to use a second mechanism that has no analog in Java. You can have an alias for a namespace—a short identifier that you choose for a particular document. Here is a typical example:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <xsd:element name="gridbag" type="GridBagType"/> . . . </xsd:schema>
The attribute
xmlns:alias="namespaceURI"
defines a namespace and an alias. In our example, the alias is the string xsd. Thus, xsd:schema really means “schema in the namespace http://www.w3.org/2001/XMLSchema”.
Note
Only child elements inherit the namespace of their parent. Attributes without an explicit alias prefix are never part of a namespace. Consider this contrived example:
<configuration xmlns="http://www.horstmann.com/corejava" xmlns:si="http://www.bipm.fr/enus/3_SI/si.html"> <size value="210" si:unit="mm"/> . . . </configuration>
In this example, the elements configuration and size are part of the namespace with URI http://www.horstmann.com/corejava. The attribute si:unit is part of the namespace with URI http://www.bipm.fr/enus/3_SI/si.html. However, the attribute value is not part of any namespace.
You can control how the parser deals with namespaces. By default, the Sun DOM parser is not “namespace aware.”
To turn on namespace handling, call the setNamespaceAware method of the DocumentBuilderFactory:
factory.setNamespaceAware(true);
Then all builders the factory produces support namespaces. Each node has three properties:
The qualified name, with an alias prefix, returned by
getNodeName,getTagName, and so on.The namespace URI, returned by the
getNamespaceURImethod.The local name, without an alias prefix or a namespace, returned by the
getLocalNamemethod.
Here is an example. Suppose the parser sees the following element:
<xsd:schema xmlns:xsl="http://www.w3.org/2001/XMLSchema">
It then reports the following:
Qualified name =
xsd:schemaNamespace URI = http://www.w3.org/2001/XMLSchema
Local name =
schema
The DOM parser reads an XML document in its entirety into a tree data structure. For most practical applications, DOM works fine. However, it can be inefficient if the document is large and if your processing algorithm is simple enough that you can analyze nodes on the fly, without having to see all of the tree structure. In these cases, you should use a streaming parser.
In the following sections, we discuss the streaming parsers supplied by the Java library: the venerable SAX parser and the more modern StAX parser that was added to Java SE 6. The SAX parser uses event callbacks, and the StAX parser provides an iterator through the parsing events. The latter is usually a bit more convenient.
The SAX parser reports events as it parses the components of the XML input, but it does not store the document in any way—it is up to the event handlers whether they want to build a data structure. In fact, the DOM parser is built on top of the SAX parser. It builds the DOM tree as it receives the parser events.
Whenever you use a SAX parser, you need a handler that defines the event actions for the various parse events. The ContentHandler interface defines several callback methods that the parser executes as it parses the document. Here are the most important ones:
startElementandendElementare called each time a start tag or end tag is encountered.charactersis called whenever character data are encountered.startDocumentandendDocumentare called once each, at the start and the end of the document.
For example, when parsing the fragment
<font> <name>Helvetica</name> <size units="pt">36</size> </font>
the parser makes the following callbacks:
Your handler needs to override these methods and have them carry out whatever action you want to carry out as you parse the file. The program at the end of this section prints all links <a href="..."> in an HTML file. It simply overrides the startElement method of the handler to check for links with name a and an attribute with name href. This is potentially useful for implementing a “web crawler,” a program that reaches more and more web pages by following links.
Note
Unfortunately, many HTML pages deviate so much from proper XML that the example program will not be able to parse them. As already mentioned, the W3C recommends that web designers use XHTML, an HTML dialect that can be displayed by current web browsers and that is also proper XML. Because the W3C “eats its own dog food,” their web pages are written in XHTML. You can use those pages to test the example program. For example, if you run
java SAXTest http://www.w3c.org/MarkUp
then you will see a list of the URLs of all links on that page.
The sample program is a good example for the use of SAX. We don’t care at all in which context the a elements occur, and there is no need to store a tree structure.
Here is how you get a SAX parser:
SAXParserFactory factory = SAXParserFactory.newInstance(); SAXParser parser = factory.newSAXParser();
You can now process a document:
parser.parse(source, handler);
Here, source can be a file, URL string, or input stream. The handler belongs to a subclass of DefaultHandler. The DefaultHandler class defines do-nothing methods for the four interfaces:
ContentHandler DTDHandler EntityResolver ErrorHandler
The example program defines a handler that overrides the startElement method of the ContentHandler interface to watch out for a elements with an href attribute:
DefaultHandler handler = new
DefaultHandler()
{
public void startElement(String namespaceURI, String lname, String qname, Attributes attrs)
throws SAXException
{
if (lname.equalsIgnoreCase("a") && attrs != null)
{
for (int i = 0; i < attrs.getLength(); i++)
{
String aname = attrs.getLocalName(i);
if (aname.equalsIgnoreCase("href"))
System.out.println(attrs.getValue(i));
}
}
}
};The startElement method has three parameters that describe the element name. The qname parameter reports the qualified name of the form alias:localname. If namespace processing is turned on, then the namespaceURI and lname parameters describe the namespace and local (unqualified) name.
As with the DOM parser, namespace processing is turned off by default. You activate namespace processing by calling the setNamespaceAware method of the factory class:
SAXParserFactory factory = SAXParserFactory.newInstance(); factory.setNamespaceAware(true); SAXParser saxParser = factory.newSAXParser();
Listing 2-8 contains the code for the web crawler program. Later in this chapter, you will see another interesting use of SAX. An easy way of turning a non-XML data source into XML is to report the SAX events that an XML parser would report. See the section “XSL Transformations” on page 157 for details.
Example 2-8. SAXTest.java
1. import java.io.*; 2. import java.net.*; 3. import javax.xml.parsers.*; 4. import org.xml.sax.*; 5. import org.xml.sax.helpers.*; 6. 7. /** 8. * This program demonstrates how to use a SAX parser. The program prints all hyperlinks links 9. * of an XHTML web page. <br> 10. * Usage: java SAXTest url 11. * @version 1.00 2001-09-29 12. * @author Cay Horstmann 13. */ 14. public class SAXTest 15. { 16. public static void main(String[] args) throws Exception 17. { 18. String url; 19. if (args.length == 0) 20. { 21. url = "http://www.w3c.org"; 22. System.out.println("Using " + url); 23. } 24. else url = args[0]; 25. 26. DefaultHandler handler = new DefaultHandler() 27. { 28. public void startElement(String namespaceURI, String lname, String qname, 29. Attributes attrs) 30. { 31. if (lname.equals("a") && attrs != null) 32. { 33. for (int i = 0; i < attrs.getLength(); i++) 34. { 35. String aname = attrs.getLocalName(i); 36. if (aname.equals("href")) System.out.println(attrs.getValue(i)); 37. } 38. } 39. } 40. }; 41. 42. SAXParserFactory factory = SAXParserFactory.newInstance(); 43. factory.setNamespaceAware(true); 44. SAXParser saxParser = factory.newSAXParser(); 45. InputStream in = new URL(url).openStream(); 46. saxParser.parse(in, handler); 47. } 48. }
javax.xml.parsers.SAXParserFactory 1.4
static SAXParserFactory newInstance()returns an instance of the
SAXParserFactoryclass.SAXParser newSAXParser()returns an instance of the
SAXParserclass.boolean isNamespaceAware()void setNamespaceAware(boolean value)gets or sets the
namespaceAwareproperty of the factory. If set totrue, the parsers that this factory generates are namespace aware.boolean isValidating()void setValidating(boolean value)gets or sets the
validatingproperty of the factory. If set totrue, the parsers that this factory generates validate their input.
org.xml.sax.ContentHandler 1.4
void startDocument()void endDocument()is called at the start or the end of the document.
void startElement(String uri, String lname, String qname, Attributes attr)void endElement(String uri, String lname, String qname)is called at the start or the end of an element.
Parameters:
uriThe URI of the namespace (if the parser is namespace aware)
lnameThe local name without alias prefix (if the parser is namespace aware)
qnameThe element name if the parser is not namespace aware, or the qualified name with alias prefix if the parser reports qualified names in addition to local names
void characters(char[] data, int start, int length)is called when the parser reports character data.
Parameters:
dataAn array of character data
startThe index of the first character in the data array that is a part of the reported characters
lengthThe length of the reported character string
org.xml.sax.Attributes 1.4
int getLength()returns the number of attributes stored in this attribute collection.
String getLocalName(int index)returns the local name (without alias prefix) of the attribute with the given index, or the empty string if the parser is not namespace aware.
String getURI(int index)returns the namespace URI of the attribute with the given index, or the empty string if the node is not part of a namespace or if the parser is not namespace aware.
String getQName(int index)returns the qualified name (with alias prefix) of the attribute with the given index, or the empty string if the qualified name is not reported by the parser.
String getValue(String qname)String getValue(String uri, String lname)returns the attribute value from a given index, qualified name, or namespace URI + local name. Returns
nullif the value doesn’t exist.
The StAX parser is a “pull parser.” Instead of installing an event handler, you simply iterate through the events, using this basic loop:
InputStream in = url.openStream();
XMLInputFactory factory = XMLInputFactory.newInstance();
XMLStreamReader parser = factory.createXMLStreamReader(in);
while (parser.hasNext())
{
int event = parser.next();
Call parser methods to obtain event details
}For example, when parsing the fragment
<font> <name>Helvetica</name> <size units="pt">36</size> </font>
the parser yields the following events:
START_ELEMENT, element name:fontCHARACTERS, content: white spaceSTART_ELEMENT, element name:nameCHARACTERS, content: HelveticaEND_ELEMENT, element name:nameCHARACTERS, content: white spaceSTART_ELEMENT, element name:sizeCHARACTERS, content: 36END_ELEMENT, element name:sizeCHARACTERS, content: white spaceEND_ELEMENT, element name:font
To analyze the attribute values, call the appropriate methods of the XMLStreamReader class. For example,
String units = parser.getAttributeValue(null, "units");
gets the units attribute of the current element.
By default, namespace processing is enabled. You can deactivate it by modifying the factory:
XMLInputFactory factory = XMLInputFactory.newInstance(); factory.setProperty(XMLInputFactory.IS_NAMESPACE_AWARE, false);
Listing 2-9 contains the code for the web crawler program, implemented with the StAX parser. As you can see, the code is simpler than the equivalent SAX code because you don’t have to worry about event handling.
Example 2-9. StAXTest.java
1. import java.io.*; 2. import java.net.*; 3. import javax.xml.stream.*; 4. 5. /** 6. * This program demonstrates how to use a StAX parser. The program prints all hyperlinks links 7. * of an XHTML web page. <br> 8. * Usage: java StAXTest url 9. * @author Cay Horstmann 10. * @version 1.0 2007-06-23 11. */ 12. public class StAXTest 13. { 14. public static void main(String[] args) throws Exception 15. { 16. String urlString; 17. if (args.length == 0) 18. { 19. urlString = "http://www.w3c.org"; 20. System.out.println("Using " + urlString); 21. } 22. else urlString = args[0]; 23. URL url = new URL(urlString); 24. InputStream in = url.openStream(); 25. XMLInputFactory factory = XMLInputFactory.newInstance(); 26. XMLStreamReader parser = factory.createXMLStreamReader(in); 27. while (parser.hasNext()) 28. { 29. int event = parser.next(); 30. if (event == XMLStreamConstants.START_ELEMENT) 31. { 32. if (parser.getLocalName().equals("a")) 33. { 34. String href = parser.getAttributeValue(null, "href"); 35. if (href != null) 36. System.out.println(href); 37. } 38. } 39. } 40. } 41. }
javax.xml.stream.XMLInputFactory 6
static XMLInputFactory newInstance()returns an instance of the
XMLInputFactoryclass.void setProperty(String name, Object value)sets a property for this factory, or throws an
IllegalArgumentExceptionif the property is not supported or cannot be set to the given value. The Java SE implementation supports the followingBooleanvalued properties:"javax.xml.stream.isValidating"When false (the default), the document is not validated. Not required by the specification.
"javax.xml.stream.isNamespaceAware"When true (the default), namespaces are processed. Not required by the specification.
"javax.xml.stream.isCoalescing"When false (the default), adjacent character data are not coalesced.
"javax.xml.stream.isReplacingEntityReferences"When true (the default), entity references are replaced and reported as character data.
"javax.xml.stream.isSupportingExternalEntities"When true (the default), external entities are resolved. The specification gives no default for this property.
"javax.xml.stream.supportDTD"When true (the default), DTDs are reported as events.
XMLStreamReader createXMLStreamReader(InputStream in)XMLStreamReader createXMLStreamReader(InputStream in, String characterEncoding)XMLStreamReader createXMLStreamReader(Reader in)XMLStreamReader createXMLStreamReader(Source in)creates a parser that reads from the given stream, reader, or JAXP source.
javax.xml.stream.XMLStreamReader 6
boolean hasNext()returns
trueif there is another parse event.int next()sets the parser state to the next parse event and returns one of the following constants:
START_ELEMENT,END_ELEMENT,CHARACTERS,START_DOCUMENT,END_DOCUMENT,CDATA,COMMENT,SPACE(ignorable whitespace),PROCESSING_INSTRUCTION,ENTITY_REFERENCE,DTD.boolean isStartElement()boolean isEndElement()boolean isCharacters()boolean isWhiteSpace()returns
trueif the current event is a start element, end element, character data, or whitespace.String getLocalName()gets the name of the element in a
START_ELEMENTorEND_ELEMENTevent.String getText()returns the characters of a
CHARACTERS,COMMENT, orCDATAevent, the replacement value for anENTITY_REFERENCE, or the internal subset of aDTD.int getAttributeCount()QName getAttributeName(int index)String getAttributeLocalName(int index)String getAttributeValue(int index)gets the attribute count and the names and values of the attributes, provided the current event is
START_ELEMENT.String getAttributeValue(String namespaceURI, String name)gets the value of the attribute with the given name, provided the current event is
START_ELEMENT. IfnamespaceURIisnull, the namespace is not checked.
You now know how to write Java programs that read XML. Let us now turn to the opposite process, producing XML output. Of course, you could write an XML file simply by making a sequence of print calls, printing the elements, attributes, and text content, but that would not be a good idea. The code is rather tedious, and you can easily make mistakes if you don’t pay attention to special symbols (such as " or <) in the attribute values and text content.
A better approach is to build up a DOM tree with the contents of the document and then write out the tree contents. To build a DOM tree, you start out with an empty document. You can get an empty document by calling the newDocument method of the DocumentBuilder class.
Document doc = builder.newDocument();
Use the createElement method of the Document class to construct the elements of your document.
Element rootElement = doc.createElement(rootName); Element childElement = doc.createElement(childName);
Use the createTextNode method to construct text nodes:
Text textNode = doc.createTextNode(textContents);
Add the root element to the document, and add the child nodes to their parents:
doc.appendChild(rootElement); rootElement.appendChild(childElement); childElement.appendChild(textNode);
As you build up the DOM tree, you may also need to set element attributes. Simply call the setAttribute method of the Element class:
rootElement.setAttribute(name, value);
Somewhat curiously, the DOM API currently has no support for writing a DOM tree to an output stream. To overcome this limitation, we use the Extensible Stylesheet Language Transformations (XSLT) API. For more information about XSLT, turn to the section “XSL Transformations” on page 157. Right now, consider the code that follows a “magic incantation” to produce XML output.
We apply the “do nothing” transformation to the document and capture its output. To include a DOCTYPE node in the output, you also need to set the SYSTEM and PUBLIC identifiers as output properties.
// construct the "do nothing" transformation
Transformer t = TransformerFactory.newInstance().newTransformer();
// set output properties to get a DOCTYPE node
t.setOutputProperty(OutputKeys.DOCTYPE_SYSTEM, systemIdentifier);
t.setOutputProperty(OutputKeys.DOCTYPE_PUBLIC, publicIdentifier);
// set indentation
t.setOutputProperty(OutputKeys.INDENT, "yes");
t.setOutputProperty(OutputKeys.METHOD, "xml");
t.setOutputProperty("{http://xml.apache.org/xslt}indent-amount", "2");
// apply the "do nothing" transformation and send the output to a file
t.transform(new DOMSource(doc), new StreamResult(new FileOutputStream(file)));Note
The resulting XML file contains no whitespace (that is, no line breaks or indentations). If you like whitespace, set the "OutputKeys.INDENT" property to the string "yes".
Listing 2-10 on page 150 is a typical program that produces XML output. The program draws a modernist painting—a random set of colored rectangles (see Figure 2-6). To save a masterpiece, we use the Scalable Vector Graphics (SVG) format. SVG is an XML format to describe complex graphics in a device-independent fashion. You can find more information about SVG at http://www.w3c.org/Graphics/SVG. To view SVG files, download the Apache Batik viewer (Figure 2-7) from http://xmlgraphics.apache.org/batik.
We don’t go into details about SVG. If you are interested in SVG, we suggest you start with the tutorial on the Adobe site. For our purposes, we just need to know how to express a set of colored rectangles. Here is a sample:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 20000802//EN" "http://www.w3.org/TR/2000/CR-SVG-20000802/DTD/svg-20000802.dtd"> <svg width="300" height="150"> <rect x="231" y="61" width="9" height="12" fill="#6e4a13"/> <rect x="107" y="106" width="56" height="5" fill="#c406be"/> . . . </svg>
As you can see, each rectangle is described as a rect node. The position, width, height, and fill color are attributes. The fill color is an RGB value in hexadecimal.
Note
SVG uses attributes heavily. In fact, some attributes are quite complex. For example, here is a path element:
<path d="M 100 100 L 300 100 L 200 300 z">
The M denotes a “moveto” command, L is “lineto,” and z is “closepath” (!). Apparently, the designers of this data format didn’t have much confidence in using XML for structured data. In your own XML formats, you might want to use elements instead of complex attributes.
org.w3c.dom.Document 1.4
Element createElement(String name)returns an element with the given name.
Text createTextNode(String data)returns a text node with the given data.
org.w3c.dom.Node 1.4
Node appendChild(Node child)appends a node to the list of children of this node. Returns the appended node.
org.w3c.dom.Element 1.4
void setAttribute(String name, String value)sets the attribute with the given name to the given value.
void setAttributeNS(String uri, String qname, String value)sets the attribute with the given namespace URI and qualified name to the given value.
Parameters:
uriThe URI of the namespace, or
nullqnameThe qualified name. If it has an alias prefix, then
urimust not benullvalueThe attribute value
javax.xml.transform.TransformerFactory 1.4
static TransformerFactory newInstance()returns an instance of the
TransformerFactoryclass.Transformer newTransformer()returns an instance of the
Transformerclass that carries out an identity or “do nothing” transformation.
javax.xml.transform.Transformer 1.4
void setOutputProperty(String name, String value)sets an output property. See http://www.w3.org/TR/xslt#output for a listing of the standard output properties. The most useful ones are shown here:
doctype-publicThe public ID to be used in the
DOCTYPEdeclarationdoctype-systemThe system ID to be used in the
DOCTYPEdeclarationindent"yes"or"no"method"xml","html","text", or a custom stringvoid transform(Source from, Result to)transforms an XML document.
javax.xml.transform.dom.DOMSource 1.4
DOMSource(Node n)constructs a source from the given node. Usually,
nis a document node.
javax.xml.transform.stream.StreamResult 1.4
StreamResult(File f)StreamResult(OutputStream out)StreamResult(Writer out)StreamResult(String systemID)constructs a stream result from a file, stream, writer, or system ID (usually a relative or absolute URL).
In the preceding section, you saw how to produce an XML document by writing a DOM tree. If you have no other use for the DOM tree, that approach is not very efficient.
The StAX API lets you write an XML tree directly. Construct an XMLStreamWriter from an OutputStream, like this:
XMLOutputFactory factory = XMLOutputFactory.newInstance(); XMLStreamWriter writer = factory.createXMLStreamWriter(out);
To produce the XML header, call
writer.writeStartDocument()
Then call
writer.writeStartElement(name);
Add attributes by calling
writer.writeAttribute(name, value);
Now you can add child elements by calling writeStartElement again, or write characters with
writer.writeCharacters(text);
When you have written all child nodes, call
writer.writeEndElement();
This causes the current element to be closed.
To write an element without children (such as <img .../>), you use the call
writer.writeEmptyElement(name);
Finally, at the end of the document, call
writer.writeEndDocument();
This call closes any open elements.
As with the DOM/XSLT approach, you don’t have to worry about escaping characters in attribute values and character data. However, it is possible to produce malformed XML, such as a document with multiple root nodes. Also, the current version of StAX has no support for producing indented output.
The program in Listing 2-10 shows you both approaches for writing XML.
Example 2-10. XMLWriteTest.java
1. import java.awt.*; 2. import java.awt.geom.*; 3. import java.io.*; 4. import java.util.*; 5. import java.awt.event.*; 6. import javax.swing.*; 7. import javax.xml.parsers.*; 8. import javax.xml.stream.*; 9. import javax.xml.transform.*; 10. import javax.xml.transform.dom.*; 11. import javax.xml.transform.stream.*; 12. import org.w3c.dom.*; 13. 14. /** 15. * This program shows how to write an XML file. It saves a file describing a modern drawing 16. * in SVG format. 17. * @version 1.10 2004-09-04 18. * @author Cay Horstmann 19. */ 20. public class XMLWriteTest 21. { 22. public static void main(String[] args) 23. { 24. EventQueue.invokeLater(new Runnable() 25. { 26. public void run() 27. { 28. XMLWriteFrame frame = new XMLWriteFrame(); 29. frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); 30. frame.setVisible(true); 31. } 32. }); 33. } 34. } 35. 36. /** 37. * A frame with a component for showing a modern drawing. 38. */ 39. class XMLWriteFrame extends JFrame 40. { 41. public XMLWriteFrame() 42. { 43. setTitle("XMLWriteTest"); 44. setSize(DEFAULT_WIDTH, DEFAULT_HEIGHT); 45. 46. chooser = new JFileChooser(); 47. 48. // add component to frame 49. 50. comp = new RectangleComponent(); 51. add(comp); 52. 53. // set up menu bar 54. 55. JMenuBar menuBar = new JMenuBar(); 56. setJMenuBar(menuBar); 57. 58. JMenu menu = new JMenu("File"); 59. menuBar.add(menu); 60. 61. JMenuItem newItem = new JMenuItem("New"); 62. menu.add(newItem); 63. newItem.addActionListener(new ActionListener() 64. { 65. public void actionPerformed(ActionEvent event) 66. { 67. comp.newDrawing(); 68. } 69. }); 70. 71. JMenuItem saveItem = new JMenuItem("Save with DOM/XSLT"); 72. menu.add(saveItem); 73. saveItem.addActionListener(new ActionListener() 74. { 75. public void actionPerformed(ActionEvent event) 76. { 77. try 78. { 79. saveDocument(); 80. } 81. catch (Exception e) 82. { 83. JOptionPane.showMessageDialog(XMLWriteFrame.this, e.toString()); 84. } 85. } 86. }); 87. 88. JMenuItem saveStAXItem = new JMenuItem("Save with StAX"); 89. menu.add(saveStAXItem); 90. saveStAXItem.addActionListener(new ActionListener() 91. { 92. public void actionPerformed(ActionEvent event) 93. { 94. try 95. { 96. saveStAX(); 97. } 98. catch (Exception e) 99. { 100. JOptionPane.showMessageDialog(XMLWriteFrame.this, e.toString()); 101. } 102. } 103. }); 104. 105. JMenuItem exitItem = new JMenuItem("Exit"); 106. menu.add(exitItem); 107. exitItem.addActionListener(new ActionListener() 108. { 109. public void actionPerformed(ActionEvent event) 110. { 111. System.exit(0); 112. } 113. }); 114. } 115. 116. /** 117. * Saves the drawing in SVG format, using DOM/XSLT 118. */ 119. public void saveDocument() throws TransformerException, IOException 120. { 121. if (chooser.showSaveDialog(this) != JFileChooser.APPROVE_OPTION) return; 122. File f = chooser.getSelectedFile(); 123. Document doc = comp.buildDocument(); 124. Transformer t = TransformerFactory.newInstance().newTransformer(); 125. t.setOutputProperty(OutputKeys.DOCTYPE_SYSTEM, 126. "http://www.w3.org/TR/2000/CR-SVG-20000802/DTD/svg-20000802.dtd"); 127. t.setOutputProperty(OutputKeys.DOCTYPE_PUBLIC, "-//W3C//DTD SVG 20000802//EN"); 128. t.setOutputProperty(OutputKeys.INDENT, "yes"); 129. t.setOutputProperty(OutputKeys.METHOD, "xml"); 130. t.setOutputProperty("{http://xml.apache.org/xslt}indent-amount", "2"); 131. t.transform(new DOMSource(doc), new StreamResult(new FileOutputStream(f))); 132. } 133. 134. /** 135. * Saves the drawing in SVG format, using StAX 136. */ 137. public void saveStAX() throws FileNotFoundException, XMLStreamException 138. { 139. if (chooser.showSaveDialog(this) != JFileChooser.APPROVE_OPTION) return; 140. File f = chooser.getSelectedFile(); 141. XMLOutputFactory factory = XMLOutputFactory.newInstance(); 142. XMLStreamWriter writer = factory.createXMLStreamWriter(new FileOutputStream(f)); 143. comp.writeDocument(writer); 144. writer.close(); 145. } 146. 147. public static final int DEFAULT_WIDTH = 300; 148. public static final int DEFAULT_HEIGHT = 200; 149. 150. private RectangleComponent comp; 151. private JFileChooser chooser; 152. } 153. 154. /** 155. * A component that shows a set of colored rectangles 156. */ 157. class RectangleComponent extends JComponent 158. { 159. public RectangleComponent() 160. { 161. rects = new ArrayList<Rectangle2D>(); 162. colors = new ArrayList<Color>(); 163. generator = new Random(); 164. 165. DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 166. try 167. { 168. builder = factory.newDocumentBuilder(); 169. } 170. catch (ParserConfigurationException e) 171. { 172. e.printStackTrace(); 173. } 174. } 175. 176. /** 177. * Create a new random drawing. 178. */ 179. public void newDrawing() 180. { 181. int n = 10 + generator.nextInt(20); 182. rects.clear(); 183. colors.clear(); 184. for (int i = 1; i <= n; i++) 185. { 186. int x = generator.nextInt(getWidth()); 187. int y = generator.nextInt(getHeight()); 188. int width = generator.nextInt(getWidth() - x); 189. int height = generator.nextInt(getHeight() - y); 190. rects.add(new Rectangle(x, y, width, height)); 191. int r = generator.nextInt(256); 192. int g = generator.nextInt(256); 193. int b = generator.nextInt(256); 194. colors.add(new Color(r, g, b)); 195. } 196. repaint(); 197. } 198. 199. public void paintComponent(Graphics g) 200. { 201. if (rects.size() == 0) newDrawing(); 202. Graphics2D g2 = (Graphics2D) g; 203. // draw all rectangles 204. for (int i = 0; i < rects.size(); i++) 205. { 206. g2.setPaint(colors.get(i)); 207. g2.fill(rects.get(i)); 208. } 209. } 210. 211. /** 212. * Creates an SVG document of the current drawing. 213. * @return the DOM tree of the SVG document 214. */ 215. public Document buildDocument() 216. { 217. Document doc = builder.newDocument(); 218. Element svgElement = doc.createElement("svg"); 219. doc.appendChild(svgElement); 220. svgElement.setAttribute("width", "" + getWidth()); 221. svgElement.setAttribute("height", "" + getHeight()); 222. for (int i = 0; i < rects.size(); i++) 223. { 224. Color c = colors.get(i); 225. Rectangle2D r = rects.get(i); 226. Element rectElement = doc.createElement("rect"); 227. rectElement.setAttribute("x", "" + r.getX()); 228. rectElement.setAttribute("y", "" + r.getY()); 229. rectElement.setAttribute("width", "" + r.getWidth()); 230. rectElement.setAttribute("height", "" + r.getHeight()); 231. rectElement.setAttribute("fill", colorToString(c)); 232. svgElement.appendChild(rectElement); 233. } 234. return doc; 235. } 236. 237. /** 238. * Writers an SVG document of the current drawing. 239. * @param writer the document destination 240. */ 241. public void writeDocument(XMLStreamWriter writer) throws XMLStreamException 242. { 243. writer.writeStartDocument(); 244. writer.writeDTD("<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 20000802//EN" " 245. + ""http://www.w3.org/TR/2000/CR-SVG-20000802/DTD/svg-20000802.dtd">"); 246. writer.writeStartElement("svg"); 247. writer.writeAttribute("width", "" + getWidth()); 248. writer.writeAttribute("height", "" + getHeight()); 249. for (int i = 0; i < rects.size(); i++) 250. { 251. Color c = colors.get(i); 252. Rectangle2D r = rects.get(i); 253. writer.writeEmptyElement("rect"); 254. writer.writeAttribute("x", "" + r.getX()); 255. writer.writeAttribute("y", "" + r.getY()); 256. writer.writeAttribute("width", "" + r.getWidth()); 257. writer.writeAttribute("height", "" + r.getHeight()); 258. writer.writeAttribute("fill", colorToString(c)); 259. } 260. writer.writeEndDocument(); // closes svg element 261. } 262. 263. /** 264. * Converts a color to a hex value. 265. * @param c a color 266. * @return a string of the form #rrggbb 267. */ 268. private static String colorToString(Color c) 269. { 270. StringBuffer buffer = new StringBuffer(); 271. buffer.append(Integer.toHexString(c.getRGB() & 0xFFFFFF)); 272. while (buffer.length() < 6) 273. buffer.insert(0, '0'), 274. buffer.insert(0, '#'), 275. return buffer.toString(); 276. } 277. 278. private ArrayList<Rectangle2D> rects; 279. private ArrayList<Color> colors; 280. private Random generator; 281. private DocumentBuilder builder; 282. }
javax.xml.stream.XMLOutputFactory 6
static XMLOutputFactory newInstance()returns an instance of the
XMLOutputFactoryclass.XMLStreamWriter createXMLStreamWriter(OutputStream in)XMLStreamWriter createXMLStreamWriter(OutputStream in, String characterEncoding)XMLStreamWriter createXMLStreamWriter(Writer in)XMLStreamWriter createXMLStreamWriter(Result in)creates a writer that writes to the given stream, writer, or JAXP result.
javax.xml.stream.XMLStreamWriter 6
void writeStartDocument()void writeStartDocument(String xmlVersion)void writeStartDocument(String encoding, String xmlVersion)writes the XML processing instruction at the top of the document. Note that the
encodingparameter is only used to write the attribute. It does not set the character encoding of the output.void setPrefix(String prefix, String namespaceURI)sets the default namespace or the namespace associated with a prefix. The declaration is scoped to the current element, or, if no element has been written, to the document root.
void writeStartElement(String localName)void writeStartElement(String namespaceURI, String localName)writes a start tag, replacing the
namespaceURIwith the associated prefix.void writeEndElement()closes the current element.
void writeEndDocument()closes all open elements.
void writeEmptyElement(String localName)void writeEmptyElement(String namespaceURI, String localName)writes a self-closing tag, replacing the
namespaceURIwith the associated prefix.void writeAttribute(String localName, String value)void writeAttribute(String namespaceURI, String localName, String value)writes an attribute for the current element, replacing the
namespaceURIwith the associated prefix.void writeCharacters(String text)writes character data.
void writeCData(String text)writes a
CDATAblock.void writeDTD(String dtd)writes the
dtdstring, which is assumed to contain aDOCTYPEdeclaration.void writeComment(String comment)writes a comment.
void close()closes this writer.
The XSL Transformations (XSLT) mechanism allows you to specify rules for transforming XML documents into other formats, such as plain text, XHTML, or any other XML format. XSLT is commonly used to translate from one machine-readable XML format to another, or to translate XML into a presentation format for human consumption.
You need to provide an XSLT style sheet that describes the conversion of XML documents into some other format. An XSLT processor reads an XML document and the style sheet, and it produces the desired output (see Figure 2-8).
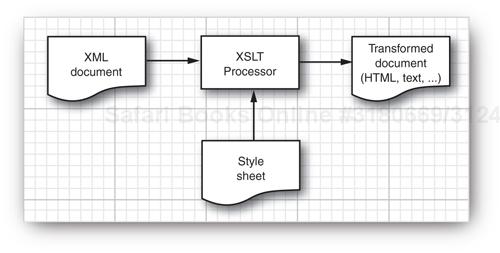
Here is a typical example. We want to transform XML files with employee records into HTML documents. Consider this input file:
<staff>
<employee>
<name>Carl Cracker</name>
<salary>75000</salary>
<hiredate year="1987" month="12" day="15"/>
</employee>
<employee>
<name>Harry Hacker</name>
<salary>50000</salary>
<hiredate year="1989" month="10" day="1"/>
</employee>
<employee>
<name>Tony Tester</name>
<salary>40000</salary>
<hiredate year="1990" month="3" day="15"/>
</employee>
</staff>The desired output is an HTML table:
<table border="1"> <tr> <td>Carl Cracker</td><td>$75000.0</td><td>1987-12-15</td> </tr> <tr> <td>Harry Hacker</td><td>$50000.0</td><td>1989-10-1</td> </tr> <tr> <td>Tony Tester</td><td>$40000.0</td><td>1990-3-15</td> </tr> </table>
The XSLT specification is quite complex, and entire books have been written on the subject. We can’t possibly discuss all the features of XSLT, so we just work through a representative example. You can find more information in the book Essential XML by Don Box et al. (Addison-Wesley Professional 2000). The XSLT specification is available at http://www.w3.org/TR/xslt.
A style sheet with transformation templates has this form:
<?xml version="1.0" encoding="ISO-8859-1"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:output method="html"/> template1 template2 . . . </xsl:stylesheet>
In our example, the xsl:output element specifies the method as HTML. Other valid method settings are xml and text.
Here is a typical template:
<xsl:template match="/staff/employee"> <tr><xsl:apply-templates/></tr> </xsl:template>
The value of the match attribute is an XPath expression. The template states: Whenever you see a node in the XPath set /staff/employee, do the following:
Emit the string
<tr>.Keep applying templates as you process its children.
Emit the string
</tr>after you are done with all children.
In other words, this template generates the HTML table row markers around every employee record.
The XSLT processor starts processing by examining the root element. Whenever a node matches one of the templates, it applies the template. (If multiple templates match, the best matching one is used—see the specification at http://www.w3.org/TR/xslt for the gory details.) If no template matches, the processor carries out a default action. For text nodes, the default is to include the contents in the output. For elements, the default action is to create no output but to keep processing the children.
Here is a template for transforming name nodes in an employee file:
<xsl:template match="/staff/employee/name"> <td><xsl:apply-templates/></td> </xsl:template>
As you can see, the template produces the <td>...</td> delimiters, and it asks the processor to recursively visit the children of the name element. There is just one child, the text node. When the processor visits that node, it emits the text contents (provided, of course, that there is no other matching template).
You have to work a little harder if you want to copy attribute values into the output. Here is an example:
<xsl:template match="/staff/employee/hiredate"> <td><xsl:value-of select="@year"/>-<xsl:value-of select="@month"/>-<xsl:value-of select="@day"/></td> </xsl:template>
When processing a hiredate node, this template emits
The string
<td>The value of the
yearattributeA hyphen
The value of the
monthattributeA hyphen
The value of the
dayattributeA hyphen
The string
</td>
The xsl:value-of statement computes the string value of a node set. The node set is specified by the XPath value of the select attribute. In this case, the path is relative to the currently processed node. The node set is converted to a string by concatenation of the string values of all nodes. The string value of an attribute node is its value. The string value of a text node is its contents. The string value of an element node is the concatenation of the string values of its child nodes (but not its attributes).
Listing 2-11 contains the style sheet for turning an XML file with employee records into an HTML table.
Listing 2-12 shows a different set of transformations. The input is the same XML file, and the output is plain text in the familiar property file format:
employee.1.name=Carl Cracker employee.1.salary=75000.0 employee.1.hiredate=1987-12-15 employee.2.name=Harry Hacker employee.2.salary=50000.0 employee.2.hiredate=1989-10-1 employee.3.name=Tony Tester employee.3.salary=40000.0 employee.3.hiredate=1990-3-15
That example uses the position() function, which yields the position of the current node as seen from its parent. We get an entirely different output simply by switching the style sheet. Thus, you can safely use XML to describe your data, even if some applications need the data in another format. Just use XSLT to generate the alternative format.
It is extremely simple to generate XSL transformations in the Java platform. Set up a transformer factory for each style sheet. Then get a transformer object, and tell it to transform a source to a result.
File styleSheet = new File(filename); StreamSource styleSource = new StreamSource(styleSheet); Transformer t = TransformerFactory.newInstance().newTransformer(styleSource); t.transform(source, result);
The parameters of the transform method are objects of classes that implement the Source and Result interfaces. There are three implementations of the Source interface:
DOMSource SAXSource StreamSource
You can construct a StreamSource from a file, stream, reader, or URL, and a DOMSource from the node of a DOM tree. For example, in the preceding section, we invoked the identity transformation as
t.transform(new DOMSource(doc), result);
In our example program, we do something slightly more interesting. Rather than starting out with an existing XML file, we produce a SAX XML reader that gives the illusion of parsing an XML file by emitting appropriate SAX events. Actually, our XML reader reads a flat file, as described in Chapter 1. The input file looks like this:
Carl Cracker|75000.0|1987|12|15 Harry Hacker|50000.0|1989|10|1 Tony Tester|40000.0|1990|3|15
Our XML reader generates SAX events as it processes the input. Here is a part of the parse method of the EmployeeReader class that implements the XMLReader interface.
AttributesImpl attributes = new AttributesImpl();
handler.startDocument();
handler.startElement("", "staff", "staff", attributes);
while ((line = in.readLine()) != null)
{
handler.startElement("", "employee", "employee", attributes);
StringTokenizer t = new StringTokenizer(line, "|");
handler.startElement("", "name", "name", attributes);
String s = t.nextToken();
handler.characters(s.toCharArray(), 0, s.length());
handler.endElement("", "name", "name");
. . .
handler.endElement("", "employee", "employee");
}
handler.endElement("", rootElement, rootElement);
handler.endDocument();The SAXSource for the transformer is constructed from the XML reader:
t.transform(new SAXSource(new EmployeeReader(), new InputSource(new FileInputStream(filename))), result);
This is an ingenious trick to convert non-XML legacy data into XML. Of course, most XSLT applications will already have XML input data, and you can simply invoke the transform method on a StreamSource, like this:
t.transform(new StreamSource(file), result);
The transformation result is an object of a class that implements the Result interface. The Java library supplies three classes:
DOMResult SAXResult StreamResult
To store the result in a DOM tree, use a DocumentBuilder to generate a new document node and wrap it into a DOMResult:
Document doc = builder.newDocument(); t.transform(source, new DOMResult(doc));
To save the output in a file, use a StreamResult:
t.transform(source, new StreamResult(file));
Listing 2-13 contains the complete source code.
Example 2-11. makehtml.xsl
1. <?xml version="1.0" encoding="ISO-8859-1"?> 2. 3. <xsl:stylesheet 4. xmlns:xsl="http://www.w3.org/1999/XSL/Transform" 5. version="1.0"> 6. 7. <xsl:output method="html"/> 8. 9. <xsl:template match="/staff"> 10. <table border="1"><xsl:apply-templates/></table> 11. </xsl:template> 12. 13. <xsl:template match="/staff/employee"> 14. <tr><xsl:apply-templates/></tr> 15. </xsl:template> 16. 17. <xsl:template match="/staff/employee/name"> 18. <td><xsl:apply-templates/></td> 19. </xsl:template> 20. 21. <xsl:template match="/staff/employee/salary"> 22. <td>$<xsl:apply-templates/></td> 23. </xsl:template> 24. 25. <xsl:template match="/staff/employee/hiredate"> 26. <td><xsl:value-of select="@year"/>-<xsl:value-of 27. select="@month"/>-<xsl:value-of select="@day"/></td> 28. </xsl:template> 29. 30. </xsl:stylesheet>
Example 2-12. makeprop.xsl
1. <?xml version="1.0"?> 2. 3. <xsl:stylesheet 4. xmlns:xsl="http://www.w3.org/1999/XSL/Transform" 5. version="1.0"> 6. 7. <xsl:output method="text"/> 8. <xsl:template match="/staff/employee"> 9. employee.<xsl:value-of select="position()"/>.name=<xsl:value-of select="name/text()"/> 10. employee.<xsl:value-of select="position()"/>.salary=<xsl:value-of select="salary/text()"/> 11. employee.<xsl:value-of select="position()"/>.hiredate=<xsl:value-of select="hiredate/@year"/> 12. -<xsl:value-of select="hiredate/@month"/>-<xsl:value-of select="hiredate/@day"/> 13. </xsl:template> 14. 15. </xsl:stylesheet>
Example 2-13. TransformTest.java
1. import java.io.*; 2. import java.util.*; 3. import javax.xml.transform.*; 4. import javax.xml.transform.sax.*; 5. import javax.xml.transform.stream.*; 6. import org.xml.sax.*; 7. import org.xml.sax.helpers.*; 8. 9. /** 10. * This program demonstrates XSL transformations. It applies a transformation to a set 11. * of employee records. The records are stored in the file employee.dat and turned into XML 12. * format. Specify the stylesheet on the command line, e.g. java TransformTest makeprop.xsl 13. * @version 1.01 2007-06-25 14. * @author Cay Horstmann 15. */ 16. public class TransformTest 17. { 18. public static void main(String[] args) throws Exception 19. { 20. String filename; 21. if (args.length > 0) filename = args[0]; 22. else filename = "makehtml.xsl"; 23. File styleSheet = new File(filename); 24. StreamSource styleSource = new StreamSource(styleSheet); 25. 26. Transformer t = TransformerFactory.newInstance().newTransformer(styleSource); 27. t.setOutputProperty(OutputKeys.INDENT, "yes"); 28. t.setOutputProperty(OutputKeys.METHOD, "xml"); 29. t.setOutputProperty("{http://xml.apache.org/xslt}indent-amount", "2"); 30. 31. t.transform(new SAXSource(new EmployeeReader(), new InputSource(new FileInputStream( 32. "employee.dat"))), new StreamResult(System.out)); 33. } 34. } 35. /** 36. * This class reads the flat file employee.dat and reports SAX parser events to act as if 37. * it was parsing an XML file. 38. */ 39. class EmployeeReader implements XMLReader 40. { 41. public void parse(InputSource source) throws IOException, SAXException 42. { 43. InputStream stream = source.getByteStream(); 44. BufferedReader in = new BufferedReader(new InputStreamReader(stream)); 45. String rootElement = "staff"; 46. AttributesImpl atts = new AttributesImpl(); 47. 48. if (handler == null) throw new SAXException("No content handler"); 49. 50. handler.startDocument(); 51. handler.startElement("", rootElement, rootElement, atts); 52. String line; 53. while ((line = in.readLine()) != null) 54. { 55. handler.startElement("", "employee", "employee", atts); 56. StringTokenizer t = new StringTokenizer(line, "|"); 57. 58. handler.startElement("", "name", "name", atts); 59. String s = t.nextToken(); 60. handler.characters(s.toCharArray(), 0, s.length()); 61. handler.endElement("", "name", "name"); 62. 63. handler.startElement("", "salary", "salary", atts); 64. s = t.nextToken(); 65. handler.characters(s.toCharArray(), 0, s.length()); 66. handler.endElement("", "salary", "salary"); 67. 68. atts.addAttribute("", "year", "year", "CDATA", t.nextToken()); 69. atts.addAttribute("", "month", "month", "CDATA", t.nextToken()); 70. atts.addAttribute("", "day", "day", "CDATA", t.nextToken()); 71. handler.startElement("", "hiredate", "hiredate", atts); 72. handler.endElement("", "hiredate", "hiredate"); 73. atts.clear(); 74. 75. handler.endElement("", "employee", "employee"); 76. } 77. 78. handler.endElement("", rootElement, rootElement); 79. handler.endDocument(); 80. } 81. 82. public void setContentHandler(ContentHandler newValue) 83. { 84. handler = newValue; 85. } 86. 87. public ContentHandler getContentHandler() 88. { 89. return handler; 90. } 91. 92. // the following methods are just do-nothing implementations 93. public void parse(String systemId) throws IOException, SAXException 94. { 95. } 96. 97. public void setErrorHandler(ErrorHandler handler) 98. { 99. } 100. 101. public ErrorHandler getErrorHandler() 102. { 103. return null; 104. } 105. 106. public void setDTDHandler(DTDHandler handler) 107. { 108. } 109. 110. public DTDHandler getDTDHandler() 111. { 112. return null; 113. } 114. 115. public void setEntityResolver(EntityResolver resolver) 116. { 117. } 118. 119. public EntityResolver getEntityResolver() 120. { 121. return null; 122. } 123. 124. public void setProperty(String name, Object value) 125. { 126. } 127. 128. public Object getProperty(String name) 129. { 130. return null; 131. } 132. 133. public void setFeature(String name, boolean value) 134. { 135. } 136. 137. public boolean getFeature(String name) 138. { 139. return false; 140. } 141. 142. private ContentHandler handler; 143. }
javax.xml.transform.stream.StreamSource 1.4
StreamSource(File f)StreamSource(InputStream in)StreamSource(Reader in)StreamSource(String systemID)constructs a stream source from a file, stream, reader, or system ID (usually a relative or absolute URL).
javax.xml.transform.sax.SAXSource 1.4
SAXSource(XMLReader reader, InputSource source)constructs a SAX source that obtains data from the given input source and uses the given reader to parse the input.
org.xml.sax.XMLReader 1.4
void setContentHandler(ContentHandler handler)sets the handler that is notified of parse events as the input is parsed.
void parse(InputSource source)parses the input from the given input source and sends parse events to the content handler.
javax.xml.transform.dom.DOMResult 1.4
DOMResult(Node n)constructs a source from the given node. Usually,
nis a new document node.
org.xml.sax.helpers.AttributesImpl 1.4
void addAttribute(String uri, String lname, String qname, String type, String value)adds an attribute to this attribute collection.
Parameters:
uriThe URI of the namespace
lnameThe local name without alias prefix
qnameThe qualified name with alias prefix
typeThe type, one of
"CDATA","ID","IDREF","IDREFS","NMTOKEN","NMTOKENS","ENTITY","ENTITIES", or"NOTATION"valueThe attribute value
void clear()removes all attributes from this attribute collection.
This example concludes our discussion of XML support in the Java library. You should now have a good perspective on the major strengths of XML, in particular, for automated parsing and validation and as a powerful transformation mechanism. Of course, all this technology is only going to work for you if you design your XML formats well. You need to make sure that the formats are rich enough to express all your business needs, that they are stable over time, and that your business partners are willing to accept your XML documents. Those issues can be far more challenging than dealing with parsers, DTDs, or transformations.
In the next chapter, we discuss network programming on the Java platform, starting with the basics of network sockets and moving on to higher level protocols for e-mail and the World Wide Web.