
Chapter 13. Virtual Reality Enterprise Training Use Cases
This chapter is about virtual reality (VR) enterprise training, focusing on the usage of spherical video. In writing this chapter, my goal was to put down what would have been most useful to us, when we were getting started. I hope it can be useful to you.
Introduction: The Importance of Enterprise Training
Enterprise training will be the first major success story for VR because of how well VR’s strengths and limitations match to the enterprise training environment. Training is a bigger market than people think; in 2017, $121.7 billion was spent on gaming, but $362.2 billion was spent on training.10, 13
In 2018, STRIVR shipped 17,000 Oculus Go head-mounted displays (HMDs) to Walmart. That’s multiple HMDs in every single Walmart store in the United States, with more than a million Walmart employees having access to enterprise training in VR every day. That’s impact. Figure 13-1 depicts STRIVR’s makeshift warehouse, where everyone is pitching in to perform quality control on each headset.

Figure 13-1. 17,000 HMDs being prepared for shipping (© STRIVR 2018)
For VR to be successful, it needs to solve one specific problem at scale and do it better than any other technology. Enterprise training is an industry ready to be transformed. Enterprise training is that problem.
This chapter lays out use cases, challenges, and approaches to building content and scaling customers of VR training, with a focus on spherical video as a training medium.
Does VR Training Work?
The best way to learn something is to do it. For tasks like learning to fly an airplane or performing open heart surgery, this isn’t always safe or possible. People have invented various methods of conveying information about a task without actually putting scalpel to skin. Reading a manual about a task is one of the least immersive ways to learn, whereas being led through a task by an expert is one of the most immersive.
Being trained in VR can’t currently match having a human instructor walk you through a task one on one, but it can get close while being much cheaper and more scalable.
Figure 13-2 shows a scatter plot with one axis representing cost and scalability, and the other axis representing effectiveness. On one end, consider the training manual. You can send it anywhere, print it on demand, or read it on a screen, but it’s not a very effective teaching tool, especially when you consider teaching a physical task like tying a knot. A training manual is highly scalable, but not very effective.
On the other end of the spectrum is one-on-one expert mentorship, the most effective form of training. A human instructor knows everything about their subject and can walk you through it step by step, engaging you, guiding you, challenging you, and responding to your progress. However, this requires the valuable time of a highly paid expert. This form of training is highly effective but costly and difficult to scale.

Figure 13-2. Scalability versus effectiveness of training options (© STRIVR 2018)
The promise of VR is to build something as cheap to distribute as digital text, but as effective as one-on-one expert mentorship.
With that in mind, can VR training be that effective? No study has conclusively proven it, but there is more and more evidence pointing in that direction.
VR creates a physiological response closer to reality than any other medium. The classic example of this is “the plank,” in which a user wearing an HMD with room-scale tracking is placed into a 3D computer graphics environment where they’re suspended at a great height above a city. In reality, the user is standing on a beam of wood resting on the floor, but from the user’s perspective they’re teetering on the brink of death. Few users who try this experience can deny the visceral physical effect it has on you: your balance teeters, your legs buckle, and every step forward makes your heart race.
You learn best when you are doing something real, and VR feels real.
When training adult learners, creating an experience that feels real is a key to motivating them and helping them absorb new knowledge.6 VR brings learners closer to reality than any other training medium, with less risk and expense.
VR training is a particularly good fit for the needs of adult learners. In The Adult Learner, Malcolm S. Knowles posits that adults have different learning needs than children. When an adult learns, they are motivated by practical concerns. Why am I learning this? How can it be useful? In what real-life situation will I be able to apply this knowledge? Training in VR provides many benefits over non-experiential learning:
- Engagement
-
VR is an interaction-rich environment in which learners are constantly called upon to engage. Just putting on the headset and looking around means you’re already interacting. In the “Store Robbery Training” interaction scenario, for instance, the robbers first approach the learner from behind, and the learner must physically turn their head around to see what is happening. VR forces the user to be an active participant in the experience.
- Context
-
Good VR training puts the learner in a realistic environment in which the skills they are learning will be useful. In the “Flood House Training” scenario, the difference between Category 1 and Category 3 water is not academic; it’s the difference between tearing out and replacing all the flooring in a house versus simply drying it out.
- Motivation
-
The learner can see consequences of their actions. Applying the new skills effectively will demonstrate a good outcome, and failing to apply the learning will result in harm. For example, in the “Wire Down Training” scenario, failing to communicate the danger of a downed wire results in a pet dog being electrocuted.
At STRIVR, there have been opportunities to perform small studies on the efficacy of VR training. In the next section, we look at a use case in which the efficacy of a VR training method was tested against one-on-one expert mentorship.
Use Case: Flood House Training
A flood house is a real house that is intentionally flooded several times a year, so that insurance professionals can train. There are roughly 30 or so of these houses throughout the United States. An expert instructor works with a small class, and together they dry out the house and repair or replace what has been damaged. This is one of the most effective training methods because of how closely it matches reality.
Building a house, flooding it, and then repairing it is, unsurprisingly, expensive. The damage done to the house is real and costly. Plus, because there are only a few flood houses in each state, trainees must be flown to the location.
However, this outlay of expense is worth it, because of the huge amounts of money at play. For example, Hurricane Florence in 2018 caused insurance losses of three to five billion dollars. Not all insurance claims are made with honest intent, and fraud accounts for about 10% of claims. Having well-trained insurance professionals who can reduce that number is crucial to insurance companies. But what if they could get the same results with less expense?
STRIVR set out to create a VR version of a flood house training course, working closely with expert instructors. Camera crews recorded spherical video at the house from the perspective of a student being taught one on one, and then designers built a VR training module using those videos. In this case, the VR training module was made to comprehensively cover everything that would be taught during the class, regardless of whether every aspect of the training was a “good fit” for VR.
After the VR training module was built, STRIVR took a class of 60 students and ran half of them through the real flood house, and the other half through the VR training module. STRIVR’s data team then assessed the difference in effectiveness between the real flood house training and the VR experience.
In STRIVR’s VR training module, a narrator guides the trainee through an insurance claim scenario in which they must assess water damage done to Lisa’s house. The trainee is kept engaged by being asked to interact with locations in the video (Figure 13-3) or answer multiple-choice questions about what they’ve learned (Figure 13-4).

Figure 13-3. A marker question is used to keep the learner engaged and interacting during the lesson

Figure 13-4. A multiple-choice question about categories of water damage
STRIVR tested each group of trainees on their knowledge both before and after each training, to see how much they improved. They found that both groups improved by roughly the same amount in both the Water Mitigation training and the Framing training. This shows comparability; the experience in VR was roughly equivalent to being flown out to the actual flood house but at much less expense. Both groups improved, as illustrated in Figure 13-5, and there was no statistically significant difference between their results.
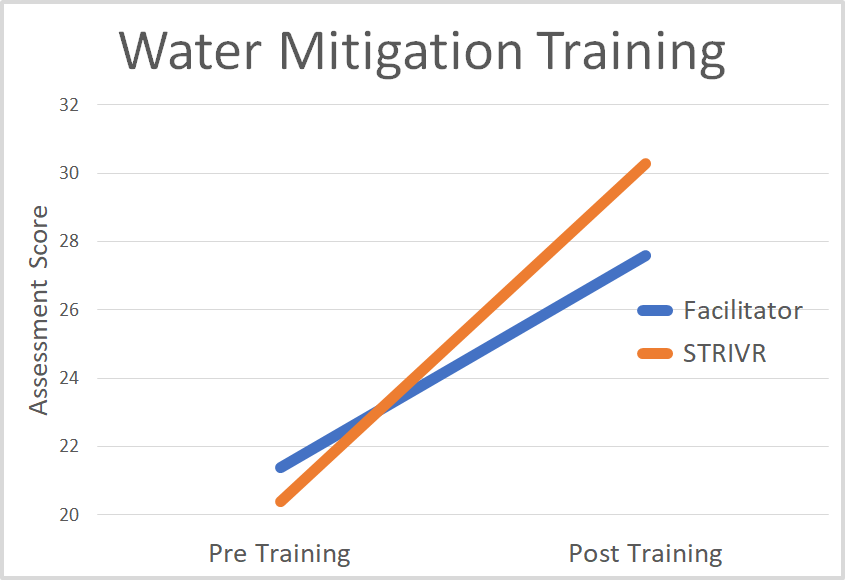
Figure 13-5. The VR training and the real-life flood house training yielded comparable improvements (© STRIVR 2018)
Data collection is also a benefit of VR training. STRIVR kept track of users’ movement data by logging their head and hand movements. One question in particular was very difficult for trainees, with more than half getting the wrong answer. The data analysis team saw that the group of trainees who answered incorrectly had more movement than the trainees who answered the question correctly. The data team speculated that this could mean trainees were fidgeting, scanning the environment, or not paying close attention. Because it was a small sample size, no hard conclusions could be drawn, but as tools improve, insights like these could be used to create more adaptive content.
STRIVR learned a couple important lessons from this use case:
- Content should be bite-sized
-
Content designers tend to overestimate the amount of time users want to spend in VR. It’s important to break up content so that users can take breaks. 20 minutes is a good benchmark for a training session, so an individual lesson should be well under this amount of time.
- Not all content is a “good fit” for VR
-
Because STRIVR wanted to include all of the content from the on-site training, it made the mistake of including content that was not a good fit for VR. For instance, in one section the trainees must use mathematical equations to calculate the amount of necessary air movers (see Figure 13-6). Under normal circumstances, trainees would have access to a calculator, but this was not provided in the VR scenario. This is a good example of the kind of learning that is better done in a classroom: it requires an outside tool, and doesn’t play to the strengths of the VR medium.

Figure 13-6. Asking the learner to do calculations without context is not a “good fit” for VR
What Is VR Training Good for? R.I.D.E.
VR isn’t for every use case. STRIVR uses the acronym “RIDE” for determining the best places in which to use VR:
Rare
Impossible
Dangerous
Expensive
Here are some examples of situations fitting these criteria:
- Rare
-
Black Friday is rare, occurring only once each year, and yet it’s a critical financial moment for retailers. High turnover means that not enough employees carry over knowledge and experience from year to year.
- Impossible
-
Store robberies are impossible to predict, but failure to react appropriately in this situation can result in loss of life. It’s difficult to know how you’d react in this type of situation until you experience it yourself.
- Dangerous
-
A factory floor with improperly observed safety procedures is dangerous to stage, but it’s critical for employees to be able to recognize and correct errors quickly.
- Expensive
-
As we saw in the use case earlier in this chapter, insurance professionals are trained in “flood houses,” which use real houses and water to realistically portray flood conditions. Although this training is realistic, it is also expensive.
Right now, spatially oriented VR training is best for tasks that involve a human body interacting in an environment or with another human. Tasks that involve interfacing with a computer screen are particularly ill suited to VR, because these tasks could be more easily done through a common computer interface. Because of the nature of modern work and office jobs, this does eliminate a number of possible use cases.
What Makes Good VR Training?
Good VR training should be the following:
-
Spatial
-
Simple and accessible
-
Short
-
Goal-oriented
-
Scalable
Let’s take a closer look at each characteristic:
- Spatial
-
VR training should be spatial in order to take advantage of the 3D nature of VR, calling out locations above, behind, and below the user. This emphasizes the user’s embodiment and helps improve recall.
- Simple and accessible
-
A big advantage of VR is accessibility, and your control scheme needs to reflect that. Modern video games use complex and unintuitive control methods that rely on gamers’ experience and familiarity with the genre; you know this if you’ve ever watched someone unfamiliar with first-person shooter games attempt to move, shoot, and look around at the same time. Most VR hardware supports simple point-and-click hand controllers. Point-and-click is great because it’s conceptually similar to using a computer mouse or a laser pointer. Avoid making the user learn a variety of buttons and interfaces. You’re trying to teach real-life skills, and the more you bring forward the nature of the controllers, the less your experience will map comfortably to reality.
- Short
-
Sessions should be bite-sized. VR training sessions should be no longer than about 20 minutes. This helps to prevent headsets from becoming uncomfortable as well as making it easier for users to absorb content at their own pace. If your content is divided well, users will feel comfortable jumping in and doing a piece of training, knowing that they’ll soon be able to decide whether to continue or get back to another task in real life. Having a low barrier for entering and training means users will log in more often.
- Goal-oriented
-
Because session times must be short, and learners’ time is at a premium, VR is best used for learning tasks that have clear rules and procedures rather than for experimenting in a sandbox-like environment. (However, as technology improves and VR becomes more natural and comfortable, sandbox training might find more uses.)
- Scalable
-
VR’s advantage over other training mediums is that it is both high quality and scalable. Keep this in mind as you build your platform and content. It should either be easy to create new content or the content created should be highly reusable by a large number of users.
Spherical Video
A spherical video is a recording in which every direction of view is captured at once, allowing the viewer to physically turn their head to see different aspects of the video. The overall effect is as if the viewer were physically present at the location the video was shot, with the notable difference that the viewer cannot move or affect the environment in any way.
Spherical video is rarely thought of as a “first choice” for VR training content. When enterprise customers describe the kind of training experience they’d like to build, what comes to mind is a fully interactive, completely realistic 3D computer graphics environment.
But, for a training framework to be scalable and efficient, it needs to be quick and easy to build content. You need a tool. If you tried to build a system for creating 3D training content that could do anything a client might want (e.g., laparoscopic surgery, vehicle simulations, customer interactions), by the time you were done adding features, you’d probably be left with something that looks like a fully featured game engine.
Remember, a major advantage of VR for training is scalability. It should be cheap and fast to create trainings for large numbers of people. The more labor intensive creating a training is, the less often you’ll be able to update it, and the less content you’ll be able to produce. Although video games have existed for decades, the current state of the art for enterprise training is still 2D video, because video is easy to create, maintain, update, and replace.
Spherical video is about as easy to shoot as conventional 2D video, while offering a number of benefits in regard to interactivity.
The Benefits of Spherical Video
Here are some of the benefits of using spherical video:
-
Scalable
-
Easy to generate content
-
Inexpensive
-
More interactive than 2D video
When building VR training, it’s necessary to re-create the training environment. With spherical video, this is simply a matter of filming that environment in situ. This guarantees that your filmed result is perfectly realistic and matches the real environment exactly.
When humans are a necessary part of the training, real instructors and employees can be helpful. These people will already have the right uniforms, know the procedures being taught, and have experience demonstrating them. (Caveat: as we discuss later, it is always worth hiring real actors when filming roles that require a portrayal of emotion or on-camera poise.)
With our current level of technology and computer graphics, right now there are no VR-capable graphics that can approach video’s level of realism.
The Challenges of Spherical Video
However, there are also challenges in using spherical video to create content.
Some situations are difficult to stage, even once for a camera. For these, we can use video editing to create the necessary effect, but this can create an unrealistic result.
Another challenge is that employees and instructors at the site might not be natural actors who perform well on film. If the training is for something like a store robbery, real actors might be necessary, creating additional expenditure. It’s critical to get the content right the first time because returning to the site to reshoot or digitally cleaning up the video are both expensive and time consuming.
But the biggest challenge of spherical video is interactivity within the experience.
Interactions with Spherical Video
When considering what can be accomplished with spherical video, one of the first places to look for inspiration is 2D video. What forms of interaction are possible with 2D video, and what advantages does spherical video bring in comparison?
- Reaction
-
As with any media, a portion of the user’s interactions take place within the user’s own head, as they watch and listen to the information being conveyed, and then process it. Even without asking for direct interaction, the user interacts with the media with their internal expectations, thoughts, and questions. In this way, 2D and spherical video share a requirement that the content be engaging, interesting, well produced, and relevant. When producing spherical video for training, a background in the techniques used to make 2D video entertaining is essential.
- Gaze
-
Gaze is a significantly richer form of interaction in spherical video than it is in 2D video. In a 2D video, the viewer is watching a bounded screen. The camera movement and shot transitions are deliberate choices by the editor to focus the viewer on certain places and times. But in spherical video, editing must be kept to a minimum to avoid disorienting the user. This means that a greater demand is placed on the viewer; the viewer is the camera, and they must take an active part in looking around and absorbing the information. In STRIVR’s “Store Robbery Training” experience, for example, the learner is first approached by the robbers from behind and must turn their head in order to see them. In this way, gaze can be a powerful interactive tool in spherical video.
- Multiple-choice questions
-
In contemporary elearning environments, video is often bookended with multiple-choice questions. In spherical video, multiple-choice questions can be presented from within the experience, rather than outside of it, adding context to the user’s decisions. For example, in Figure 13-7, one of the robbers points a gun at you and demands that you give him access to the safe. Seeing time freeze and hearing a heartbeat sound as you frantically try to decide what to do is a much more emotionally engaging experience in a spherical video than it would be on a computer screen. Spherical video also gives you the opportunity to use locations or objects in the video as “answers” to a question. In Figure 13-8, a football quarterback is prompted to select the location of his “runfit” after watching the first few seconds of a down.

Figure 13-7. Multiple-choice questions have added context in a VR environment where you can see the consequences of your choices

Figure 13-8. A football player must identify his “run fit” by selecting the correct location in the video
- Points of Interest
-
Spherical video has a powerful interaction tool that was rarely used with 2D videos: pointing and selecting locations within the video. This is possibly the best form of interaction with spherical video because it gives the learner an opportunity to interact directly with the medium. Points of Interest (PoIs) can be used informationally, to draw attention to key objects in the video, as in Figure 13-9.

Figure 13-9. Points of Interest can be used informationally to highlight key interest areas in the video
PoIs can also be used in the context of a “hidden object game,” in which the user is presented with only the video and asked to identify a class of item or mistake. Nothing is visible on the video other than the prompt, and the user must click in various places, searching for items or locations that match their target. This is great training because the learner is forced to look closely at their surroundings, consider them, and interact with them in a context similar to reality. This technique was used frequently in “Factory Floor Training,” in which the user is asked to identify trip hazards and other dangers in their environment. Pictured in Figure 13-10 is a scenario in which the user has found five PoIs and has about a minute left to identify the remaining 16.

- Choose your own adventure
-
Finally, there is a way to “cheat” and interact more directly with videos. The 1983 laserdisc arcade game Dragon’s Lair was one of the earliest examples. In this game, the player inputs simple commands in response to an animated cartoon. If they input the correct directional input at the correct time, the video continues. If they fail, the character is shown dying. Although video can’t interact directly with the user the way an interactive computer graphics experience can, it’s possible to film multiple videos portraying different results, which can show the trainee consequences of wrong actions they could take. In STRIVR’s “Wire Down Training” experience, for example, if the learner fails to inform a caller about the danger a downed wire can hold for pets, the learner will hear the caller’s dog being electrocuted.
-
To avoid a combinatorial explosion, it’s best to follow a “string of pearls” approach to designing branching content; only allow learners a limited amount of deviation from the scenario you’re teaching before guiding them back to the right path.
Use Case: Factory Floor Training
Factory floors are huge, loud, chaotic, and full of hidden dangers. In one study, safety errors in 10 factories cost a major food manufacturer five digits in the month of April 2015. Five digits. Not money, fingers.
A common thread for factory training is mistake identification. Given a spherical video of a factory floor, can employees identify safety violations around them?
The factory floor provides clear examples of the benefits of spherical video over 2D video. It’s easy to look at a PowerPoint slide with a picture of a loading vehicle on it, and understand that the loading vehicle is dangerous. But the loading vehicle that hits you isn’t the one you see coming. The vehicle that hits you is the one you didn’t see, the one that came from behind. Spherical video, like reality, comes at you from all angles.
To satisfy the client’s needs, STRIVR built a feature called scene hunt, in which trainees must identify hidden points of interest in the video. All around the scene are hidden “hitboxes,” which the trainee has a limited time to find, as shown in Figure 13-11.

Figure 13-11. In a “scene hunt,” the learner must find mistakes within a time limit and select an area containing a mistake, for the mistake to be revealed
If the user doesn’t find all the hotspots in time, they are notified of what they missed, as demonstrated in Figure 13-12.

Figure 13-12. After the time expires, mistakes the learner didn’t find are revealed and must be interacted with
One of the great things about this kind of training is the ease in capturing footage and building the training. Factories usually have records of past accidents, knowledgeable veteran employees, and manuals that categorize potential errors. STRIVR found that it was easy to either identify real mistakes on the factory floor or to safely generate them with the help of instructors.
The Role of Narrative
You’re going to have a tough time getting learners to train if the training experience is boring. One of STRIVR’s major reasons for being is that the current state of the art for training…well, sucks. And a big reason for this is that it’s boring. Gamification has been a buzz word in the industry for years, but the focus has been on points, daily bonuses, and dopamine rushes. Why do people play games? Because they’re entertaining. They’re fun, they’re slick, they’re polished, and, usually, they give you a reason to care.
When you’re playing a game, you’re not just learning to fly a space fighter for kicks. You’re learning to fly a space fighter so you can defeat the evil emperor who killed your father. Especially for an adult learner, giving their learning a goal and a context goes a long way toward making it more immersive and engaging.8 Giving a task a goal adds an extra dimension to it and unlocks a little extra from the learner’s brain.
If you want to build VR training experiences that trainees will actually complete, you need to have narrative. You need task-oriented learning.
It can be difficult to embody the user in spherical video. The camera doesn’t have a physical presence, which can make the user feel like a ghost. Rather than letting the user focus on their lack of a body, you should film your video with characters who speak with the user, engage with them, and guide them. Humans are social animals, and our brains are keyed up for analyzing faces and reading social cues. Training the user by having them interact with a human instructor is a huge upgrade over using a disembodied voice. One-on-one expert mentorship is the ideal training scenario, and filming an instructor is the closest we can get to that in the context of spherical video.
This means that filming spherical video for training is a lot more like filming a movie than you might think. You need to have an interesting and engaging script, with characters and a story arc. If you want to make the best VR training you can, it also means that you need to hire actors.
Use Case: Store Robbery Training
A store robbery is a great example of a scenario that is nearly impossible to train on normally. Without any way to predict a robbery, the nearest training scenario would be a deeply involved workshop or roleplay.
In “Store Robbery Training,” STRIVR built a narrative-driven experience to test trainees on what they had learned about appropriate responses to a store robbery. Rather than build this VR training to teach all of the necessary skills, Store Robbery Training was built as an introduction and exit exam to supplement a class or online training.8 As a result, STRIVR’s instructional designers were able to focus more narrowly on things that work well in VR.
Store Robbery Training puts the learner in the position of a store manager opening up for a day of work with their coworker. While the learner is paying attention to the door, the robbers come up from behind, startling the learner’s coworker and forcing the learner to physically turn around to see what’s happening. The learner is then forced to cope with the situation and interact by answering multiple-choice questions, the theme of which is cooperating with and not antagonizing the robbers. The store has insurance and contingencies, and the role of the store manager is to prevent any harm in coming to their employees or anyone in the store. In this experience, if the learner chooses the wrong answer, a voice prompt will advise them on what the correct course of action is and why. Although STRIVR had used multiple-choice questions in many previous experiences, this was one of the first times they were utilized in such an immersive fashion. When the robber questions you, time slows down, the screen blurs and turns black and white, and a heartbeat sound gives a feeling of intensity. Figure 13-13 shows the stopped-time effect, which anchors the multiple-choice question in an immersive context.

Figure 13-13. When the robber questions you, time slows down, the surroundings blur, and a heartbeat sound adds a feeling of intensity
Store Robbery Training is a good example of a training experience that would not be possible without actors and a script. A robbery is a frightening and emotional experience; if the human characters don’t convey those emotions, the learner won’t be appropriately primed to react, and the experience will be comedic rather than scary.
The value of this training is its ability to prepare the learner mentally. The training forces the learner to visualize how to react and what to do. If the situation occurs in reality, the learner can fall back on a model of behavior that they’ve already rehearsed virtually.
While building this training, STRIVR’s designers noticed how strongly the learner’s gaze is drawn to human characters, and they began to utilize embodied human instructors for future trainings, rather than disembodied voices. Having actors interacting with the learner offered many advantages. The learners were more engaged, but also more embodied themselves. For a situation in which a participant in VR doesn’t have a visible body, having a human whose height you can relate to helps you feel more present in the scene. Another benefit was in gaze direction. Rather than put arrows or signs around the scene, it feels very natural for human characters to walk or point to direct the learner’s gaze.
One last thing to mention: when building an experience that has the potential to be traumatic or triggering, it’s crucial to let the learner know that they can abort at any time. For this training, we made sure that the learners were aware that they could pause, press the Oculus Home button, or physically remove the headset at any time if they felt uncomfortable.
The Future of XR Training: Beyond Spherical Video
In this chapter, the focus has been on VR, and especially spherical video, as a training medium. Spherical video hits a sweet spot because it’s easy to capture and provides a realistic result. However, we’ve also discussed that spherical video can be limited in its interactivity and fidelity.
What about other technologies? Where will XR training go in the future? In the rest of this chapter, we look at improvements and alternatives to spherical video.
Computer Graphics
The other major option for portraying a training environment is computer graphics (CG). CG gives great benefits in terms of interactivity. 3D models can move dynamically within an environment without needing to be filmed in an infinite variety of positions.
However, 3D graphics need to be modeled, animated, and lit. Building 3D assets and an interactive scenario is time consuming. It took Rockstar Studios more than three years to develop Red Dead Redemption 2; these kinds of timelines are typical for game companies. Because of these considerations, when building a CG training experience, it’s critical that the training be essential and evergreen.
Use Case: Soft Skills Training
This use case highlights a VR training framework that was built with CG. Soft Skills uses virtual humans to simulate difficult conversations, such as giving an employee a negative performance review. The trainee first chooses an avatar to represent themselves. They’re introduced to the scenario and then prompted with what to say. Figure 13-14 shows an example of a prompt. The virtual human reacts, and the conversation moves on. Despite the prescripted nature of the experience, most users believe that the virtual human is reacting to and adapting to what they’ve said.

Figure 13-14. The learner is guided through the broad strokes of what they should convey at each step (© STRIVR 2018)
The real impact of Soft Skills training happens after the conversation. The whole time you are following the prompts and speaking to the virtual employee, your voice and movements are being recorded. At the end of the experience, everything is played back with the roles reversed. In Figure 13-15, the learner is about to swap places with Morgan, the troubled employee. Sitting across from yourself and watching your words come out of another person’s mouth is a powerful experience. When I went through this training the first time, I said many things that I later realized came off as rude. For instance, early in the conversation, I said that the meeting was “no big deal.” Hearing it back on the other side of the table, I had a visceral reaction to how insincere that sounded.

Figure 13-15. After the conversation, the learner watches a playback of their own words from the perspective of their conversation partner (© STRIVR 2018)
Soft Skills is a good example of reusable application that can benefit from an investment in CG.
Soft Skills training is a reusable framework for an essential skill: communication. The majority of corporate jobs require communication skills, from assisting customers over the phone to managing teams of diverse employees. Because the same CG framework can be used for many different kinds of communications trainings, the investment of effort in building the 3D environments and avatars can have a chance to pay off over time.
CG in this context has many benefits over spherical video. For instance, one voice can be used with many different customized avatars to control for the appearance of the virtual human. Animations can be reused across avatars. The environment and avatar can be mixed and matched. Branching scenarios are easier to build with CG, as well, because the virtual humans can react dynamically to the user like video game characters can.
The Future: Photogrammetry
Photogrammetry is an attractive technology for capturing real-life environments, objects, or people and making them into 3D models. Thousands of photographs are taken of a subject from every angle, and then these images are combined into 3D models.
However, it’s difficult to build perfect 3D models from photogrammetry techniques alone. A lot of cleanup work has to be done to plug tiny gaps in the models and to fix other blemishes.9 At STRIVR, we used this technique to build a virtual grocery store wet wall, and our 3D artist Tyrone had to spend more time than we anticipated cleaning up both the captured environment and interactable elements. Figure 13-16 shows a particularly troublesome piece of broccoli.

Figure 13-16. Using photogrammetry to create models of real-life objects is still labor intensive (© STRIVR 2018)
Photogrammetry is a technology to consider, but keep in mind the challenges. This is a technology to keep an eye on as techniques improve.
The Future: Light Fields
Light fields are an exciting new technology that use a rotating ring of cameras to capture all the light entering a spherical area. This results in a captured area in which the viewer has full parallax. Whereas with mono spherical video, a viewer is confined to a single perspective, light fields allow the user to translate their head to see different angles of a scene,5 as demonstrated in Figure 13-17.

Figure 13-17. Light fields allow head translations to provide different perspectives
Full parallax greatly improves the viewer’s sense of presence, a key to creating higher-quality training experiences. If you haven’t had a chance to try it, do try Google’s “Welcome To Light Fields” demonstration. The result is striking.
As of 2018, there are still too many limitations on this technology to widely adopt it. The recorded area is about two feet in diameter, which is still small enough that the user’s head can easily exit the space. The rotation speed of the camera rig also means that only still images can be captured; appropriate for some training experiences focused on a static environment but less useful for anything involving actors or dynamic movement. However, light fields are a capture technology to watch.
The Future: AR Training
VR is a technology that, wherever you are, takes you someplace else and lets you experience it. AR is a technology that changes your perception of your existing world; it takes reality and then augments it.
VR is transportational; AR is transformational.
AR’s natural place is on-the-job assistance, but there are a couple key technologies that are not quite mature enough. For AR to provide useful on-the-job assistance, it must be able to do something that a human brain couldn’t, with enough accuracy to be safe and useful. We’re getting close. We have software that can translate text and replace it on the fly, and image recognition that can swap faces. But 99% accurate isn’t good enough for many use cases; we need to be 100% accurate. Hardware is also an issue. AR headsets need to be more comfortable and lightweight before people are interested in wearing them for eight hours each day.
Despite all that, there is potential for AR in dedicated location-based training. Take the flood house, and then imagine a training environment in which AR teaches you and trains you in a real environment. This would provide the benefit of exploring a real physical training space with the ability to give individualized feedback and assistance.
Similar technology is already in use. Museums and tourist destinations use audio tour devices that sense your location. Another great technology to look at is The VOID,12 which uses a mix of wearable VR, location tracking, and physical space to create an immersive entertainment experience.
The Future: Voice Recognition
Voice interfaces will be a huge addition to the training toolkit when we can cross that final accuracy threshold. A significant aspect of the training we do is interpersonal: training on customer service or interpersonal conflict resolution. Voice recognition could provide the perfect medium and control scheme as soon as it becomes integrated into an HMD’s toolkit, but first it needs to become reliable enough to work under all conditions, including a noisy retail backroom.
The Future: The Ideal Training Scenario
Imagine for a moment the future. A world with no limits, with AR contact lenses and strong AI. What would training look like?
Mary Poppins. Don’t laugh!
Mary Poppins comes out of the sky on a magic umbrella and transforms a mob of horrible children into model citizens. The children don’t even realize that they’re being trained, because the training is fun. Mary Poppins strikes a perfect balance between guiding, challenging, and nurturing her charges.
This is what it would take to have the perfect training experience. Strong AI that can understand who the learner is and train them based on their needs.
This kind of scenario is far out. In 2018, AR contact lenses and strong AI don’t exist. But considering an ideal world and thinking about where training could go in the future can be a great tool for figuring out how to get there, especially when considering what technologies to invest in and how to prepare.
References
-
Bailenson, Jeremy N., K. Patel, A. Nielsen, R. Bajcsy, S. Jung, and G. Kurillo. “The Effect of Interactivity on Learning Physical Actions in Virtual Reality.” Media Psychology, 2008. 11: 354–376. https://stanford.io/2C9Hdw5.
-
Belch, Derek, interview, 2018.
-
Bowie, Fraser G. “Experiencing Danger Safely is My Virtual Reality–Experience Matters.” Experience Matters, 2018. http://bit.ly/2XFrKwY.
-
Cordar, Andrew, Michael Borish, Adriana Foster, and Benjamin Lok. “Building Virtual Humans with Back Stories: Training Interpersonal Communication Skills in Medical Students.” Intelligent Virtual Agents (IVA) 8637 (2014): 144–153. http://bit.ly/2HdB4SU.
-
Debevec, Paul. “Experimenting With Light Fields.” Google, 2018. http://bit.ly/2VDENNK.
-
Knowles, Malcolm S., Elwood F. Holton III, and Richard A. Swanson. The Adult Learner. 5th ed. Houston, TX: Gulf Publishing Company, 1998.
-
Kraemer, Shannon, Sharon Hoosein, and Tyrone Schieszler, interview, 2018.
-
Schieszler, Tyrone, and Masaki Miyanohara, interview, 2018.
-
“Size of the Training Industry.” Training Industry, 2017. http://bit.ly/2TwPqV0.
-
Spinner, Amanda, Joe Willage, and Michael Casale. STRIVR internal presentation, 2018.
-
“Step Beyond Reality.” The VOID. https://www.thevoid.com/.
-
Wijman, Tom. “Mobile Revenues Account for More Than 50% of the Global Games Market as It Reaches $137.9 Billion in 2018.” Newzoo, 2018. http://bit.ly/2C3e9X6.