
Chapter 5. Integrating DSLs into your applications
- Structuring and managing DSL integration
- Reusing DSL scripts
- Performance considerations
- Separating the DSL from the application
We’ve covered a lot of ground, but only at the micro level so far. We’ve talked about how to build a DSL, how to ensure you have a good language, what the design parameters are, and so on. But we haven’t yet touched on the macro level: how to take a DSL and integrate it into an application. Chapter 4 covered this at the micro level (building the languages themselves), but in this chapter we’re going to discuss all that surrounds a DSL in an application. We’ll talk about when and where to integrate a DSL, how to handle errors, how to handle dependencies between scripts, and how to set up a DSL structure that will be easy to work with.
5.1. Exploring DSL integration
The first thing we’ll do is explore a DSL-integrated application to see what it looks like. That will give you an idea of the things you need to handle.
Figure 5.1 shows the DSLs integrated into our online shop example. We explored some of those DSLs in chapter 4 from the language-building perspective. Now we’ll explore them from the application-integration perspective. This will be somewhat easier, because you’ve already seen how to make the calls to the DSL scripts. But in chapter 4 we were focusing on the language, and the integration approaches we used were trivial.
Figure 5.1. The integrated DSLs in our online shop example

Let’s take the Message-Routing DSL as our first example. Listing 5.1 shows the integration of the Message-Routing DSL into the application. To refresh your memory, this method is part of the Router class, which dispatches incoming messages to the application services using the DSL scripts.
Listing 5.1. Router.Route() integrates the Message-Routing DSL into the application
public static string Route(IQuackFu msg)
{
RoutingBase[] routings =
dslFactory.CreateAll<RoutingBase>(
Settings.Default.RoutingScriptsDirectory
);
foreach (RoutingBase routing in routings)
{
routing.Initialize(msg);
routing.Route();
}
//removed for brevity's sake
return null;
}
The Route() method seems almost ridiculously simple, right? It just grabs all the items from the specified directory and executes them all. For simple scenarios, dumping everything into a single directory works; take a look at figure 5.2 to see what such a directory might look like.
Figure 5.2. A sample directory of Message-Routing DSL scripts

This looks good, right? But what happens if I don’t need to handle just five messages? What happens if I need to handle a hundred, or twelve thousand? I assume that, like me, you won’t want to hunt down one file in a huge directory. Also, if we have a large number of DSL scripts, and we scan all of them for every message that we route, we’re going to have a performance issue on our hands.
Note
Having a large number of scripts in a single directory will also have other effects. Rhino DSL batch compiles all scripts in a directory, and compiling takes time. This is a one-time cost, but it’s a real cost.
It’s clear that we need some sort of structure in place to select which DSL scripts we’re going to run. We already store the scripts in the filesystem, and filesystems long ago solved the problem of organizing large number of files using directories. So we could create a directory for all related scripts, and that would immediately give us a natural structure. But we’ll still need to scan all the scripts for a match, right?
Well, not if we’re smart about it. We can use the filesystem structure as a mirror of our messaging structure. Figure 5.3 shows a directory structure based on this idea. Now, when we get a message, we can check to see which broad category it’s relevant for, and then execute only the scripts that are in that directory.
Figure 5.3. A directory structure mirroring our messaging structure

In fact, we can take that one step further by saying that the filename should match the message name. This way, once we have the message, we know which script we should run to handle it. Using a naming convention like this is an important friction-free way to integrate a DSL into your applications. A naming convention like that is a special case of using the convention over configuration principle.
Convention over configuration is a design paradigm that states that we should only have to explicitly specify the unusual aspects of our application. Everything that is conventional should be implicitly understood by the application. You can read more about it here: http://en.wikipedia.org/wiki/Convention_over_configuration.
5.2. Naming conventions
One of the key reasons for using a DSL is to reduce the effort required to make changes to the application. The main focus when building a DSL is usually on the language and the resulting API, but it’s as critical to think about the environment in which the DSL will be used.
The Message-Routing DSL, for example, has a problem. It can’t handle large numbers of messages with the approach that we’ve taken. Just scanning through all the scripts would take too much time.
To solve this problem, we can use a naming convention. Let’s assume that we receive the message shown in table 5.1.
Table 5.1. A sample message
|
Key |
Value |
|---|---|
|
Type |
orders/new_order |
|
Version |
1.0 |
|
CustomerId |
15 |
|
TotalCost |
$10 |
What about encapsulation?
It seems like the directory structure for our DSL scripts is directly responsible for the type of messaging that we send, so isn’t this a violation of encapsulation?
Well, not really. What we have here is a hierarchical structure for our messages, which is mirrored in both the DSL scripts and the message types. This doesn’t break encapsulation; it simply lets us see the exact same thing from different perspectives.
Not a realistic message, I admit, but bear with me. Table 5.1 shows a structured message format with a field called Type, whose value is the name of the message-routing script to be run. This allows the Message-Routing DSL engine to go directly to the relevant script, without having to execute all the routing scripts.
Once we have read the message type, we can try to find a matching script by name, first for <type>_<version>.boo and then for <type>.boo. This means that we can match script versions to message versions for free as well, if we have different versions of particular message types that need different script versions.
When we need to handle a new type of message, we know immediately where to put the script that handles this message and how to name the script file. The reverse is also true. When we need the script that handles a given message type, we know where to look for it. This is the power of conventions, and I urge you to find a good convention when it comes to integrating your DSLs into applications.
Tip
When you come up with a convention, be sure to document it and how you got to it! A convention is only as good as it is conventional. If you have an uncommon convention, it is not only useless, it is actively harmful.
The naming convention and structure outlined here is important if you expect to have a large number of scripts, but it’s of much less importance if you only have a few. Examples of DSLs where you might have few scripts are application-configuration DSLs, build-script DSLs, code-generation DSLs, and so on. In those cases, the DSL is usually composed of a single script (maybe split into several files, but conceptually a single script) that is used in narrow parts of the application or application lifecycle.
In those cases, the structure of the script files isn’t relevant; you’re only ever going to have a single one of those scripts, so it doesn’t matter. The only interesting aspect of those DSLs from the application-integration perspective is how you execute them, and we more or less covered that already in chapter 4.
Let’s look at another example of conventions in the context of the Authorization DSL (which was discussed in chapter 4). Listing 5.2 shows an example script for that DSL to refresh your memory.
Listing 5.2. A simple Authorization DSL script
operation "/account/login"
if Principal.IsInRole("Administrators"):
Allow("Administrators can always log in")
return
if date.Now.Hour < 9 or date.Now.Hour > 17:
Deny("Cannot log in outside of business hours, 09:00 - 17:00")
return
In the first line of listing 5.2, the operation name has an interesting property. It’s already using a hierarchical structure, which is ideally suited for the type of convention-based structure we have been looking at.
Listing 5.3 shows how we can take advantage of the hierarchical nature of authorizable operations to handle the simple scenario where you have one script per operation and need to match them up.
Listing 5.3. Using operation names as conventions for the script names
private static AuthorizationResult ExecuteAuthorizationRules(
IPrincipal principal,
string operation,
object entity)
{
//assume that operations starts with '/'
string operationUnrooted = operation.Substring(1);
//create script path
string script = Path.Combine(
Settings.Default.AuthorizationScriptsDirectory,
operationUnrooted+".boo");
// try get the executable script
AuthorizationRule authorizationRule =
dslFactory.TryCreate<AuthorizationRule>(script, principal, entity);
if(authorizationRule == null)
{
return new AuthorizationResult(false,
"No rule allow this operation");
}
// perform authorization check
authorizationRule.CheckAuthorization();
return new AuthorizationResult(
authorizationRule.Allowed,
authorizationRule.Message
);
}
The code is even simpler than the version in chapter 4 (see listing 4.8 for comparison), and it’s obvious what is going on. But I did say that this was for the simplest scenario.
Consider a more complicated case where we have multiple rules for authorizing an operation. The /account/login operation, for instance, might be ruled by work hours, rank, remote worker privilege, and other factors. Right now, if we want to express all of this in the account/login.boo script, it’s fairly simple, but what happens when it grows? What happens if we want to split it up based on the different rules?
Again, we run into problems in scaling out the complexity. Never fear, though—there is a solution. Instead of putting all the logic for the operation inside account/login.boo, we’ll split it further, so the login operation will be handled by three different scripts:
- account/login/work-hours.boo
- account/login/remote-workers.boo
- account/login/administrators.boo
This allows us to separate the rules out into various well-named files, which reduces the number of balls we have to juggle whenever we need to edit an operation’s logic.
In this case, ExecuteAuthorizationRules() will look almost identical to listing 4.8, except that it will append the operation to the base directory name when it searches for all the relevant scripts.
Our problems aren’t all solved yet: what happens if we have dependencies and ordering requirements for the different scripts? Let’s say that administrators should always have access, even outside of work hours. If the work-hours rule is executed first, access will be denied.
We need some way to specify ordering, or at least dependencies.
5.3. Ordering the execution of scripts
Fairly often, we’ll need to execute scripts in some order. Security rules, where the first rule to allow or deny is the deciding one, are good examples. Many business rules follow the same pattern. This means we need to handle ordering in our DSL whenever we have to execute more than a single script for a certain action. (If we’re executing only a single script, we obviously don’t need to handle ordering.)
In general, there are several ways to enforce ordering in script execution:
- Providing no guaranteed ordering
- Ordering by naming
- Ordering with script priorities
- Ordering by external configuration
We’ll look at each of these in order.
5.3.1. Handling ordering without order
Handling ordering by forgoing order is a strategy that surprises many people. The main idea here is to set things up in such a way that explicit ordering of the scripts isn’t mandatory.
Let’s take the example of authorization rules; we can decide that it’s enough to have at least a single rule that says that we’re allowed to perform an operation. (This may not be a good idea from the point of view of an authorization system, but it will suffice to make my point.) With this system, we don’t care what the execution order is; we want to aggregate all the results and then check whether any authorization rule has allowed us in. This is probably the least-expensive approach (you don’t have to do anything), but it has serious implications.
For example, it requires that the scripts have no side effects. You can’t perform any state changes in the script because we execute all of them. If the script will change the state of the application, we must know that it is valid to execute, and not just rely on discarding results that we don’t care about. For something like the Authorization DSL, this is not only acceptable but also highly desirable. On the other hand, doing this with the Message-Routing DSL is impossible.
For that matter, you could argue that this approach isn’t appropriate for authorization either, because authorization rules are generally naturally ordered. In most cases, we can’t avoid some sort of ordering, so let’s explore some of the other options.
5.3.2. Ordering by name
This is somewhat related to the naming-convention approach we used earlier. When you order scripts by name, you need to name your scripts in order. For example, in the Authorization DSL example, we’d have the following script names:
- account/login/01-administrators.boo
- account/login/02-work-hours.boo
- account/login/03-remote-workers.boo
This is a simple approach, and it works well in practice. In our code, we execute each script until we get a decisive answer. In fact, listing 4.8, unmodified, supports this exact model (Rhino DSL ensures that you get the script instances in ascending alphabetical order).
Although this works, it isn’t a favorite approach of mine. I don’t like this naming scheme because it’s a bit painful to change the order of scripts, particularly if you want to add a new first script, which necessitates renaming all the other scripts (unless you plan ahead and leave enough gaps in your numbering system).
This isn’t too onerous a task, but it is worth exploring other options, such as script priorities.
5.3.3. Prioritizing scripts
Script prioritization is a fancy name for a simple concept: giving each script a priority number and then executing each script according to its priority order. Figure 5.4 shows the main concept.
Figure 5.4. A base class for a DSL that supports script prioritization

In the DSL, we make use of a generated property (like the Authorization DSL’s Operation property) to set the priority in the script. Listing 5.4 shows an example of how it works.
Listing 5.4. A DSL script using prioritization
# specifying the priority of this script
priority 10
# the actual work done by this script
when order.TotalCost > 10_000:
add_discount_precentage 5
Now all you have to do is sort the scripts by their priority and execute the top-ranking script. Listing 5.5 shows the gist of it.
Using priorities encoded in the scripts does mean that we have to compile and execute a full directory to figure out the order in which we will execute the scripts. This isn’t as big a problem as it might sound at first, because we aren’t dealing with all the scripts, just the much smaller number of scripts for a particular operation.
Listing 5.5. Executing the highest priority script
MyDslBase [] dslInstances = Factory.CreateAll<MyDslBase>( pathToScripts );
Array.Sort(dslInstances, delegate (MyDslBase x, MyDslBase y)
{
// reverse order, topmost first
return y.Priority.Compare(x.Priority);
});
dslInstances[0].Execute();
This is trivial to implement, both from the DSL perspective and in terms of selecting the highest priority script to execute. Usually, you won’t simply execute the highest priority script; you’ll want to execute them all in order until you have a valid match.
In the case of the Authorization DSL, you’d execute all the scripts until you get an allow or deny answer from one of the scripts. A “doesn’t care” response will cause the application to try the next script in the queue.
Script prioritization does have some disadvantages:
- You have to go into the scripts to retrieve the priority order. This can be cumbersome if there are many scripts.
- You have no easy way of avoiding duplicate priorities, which happens when you assign the same priority to more than one script.
- Changing script priorities requires editing the scripts, which might cause problems if you want to reprioritize them at runtime. We had a similar issue when ordering using a naming convention.
- Responsibilities are mixed. The script is now responsible for both its own ordering and whatever action it’s supposed to perform.
For these reasons, you might consider using a completely different approach, such as handling the ordering externally.
5.3.4. Ordering using external configuration
External ordering of scripts is useful mainly when you want to control ordering (and execution) at runtime, probably programmatically, using some sort of user interface that allows an administrator to configure it.
We’ll talk more about this approach when we get to section 5.8, where we’ll consider how to manage and administer a DSL. For now, let’s focus on the implementation itself.
The simplest way to set up external configuration is to have a files.lst file in the scripts directory, which lists all the relevant scripts in the order they’re required. We can get this by overriding the GetMatchingUrlsIn(directory) method in our DSL engine. Listing 5.6 shows the code for doing just that.
Listing 5.6. Getting an ordered list of scripts from a file
public override Uri[] GetMatchingUrlsIn(string directory)
{
string fileListing = Path.Combine(directory, "files.lst");
string[] scriptsToRun = File.ReadAllLines(fileListing);
return Array.ConvertAll<string, Uri>(scriptsToRun,
delegate(string input)
{
return new Uri(Path.Combine(directory, input));
});
}
Other options include putting the information in an XML file or a database, but the overall approach is the same.
This is the most flexible solution, but it does come with its own problems. Adding a new script is now a two-step process: creating the script file and then adding it to whatever external configuration system you have chosen. My main concern in that situation is that handling the external configuration system will take a significant amount of time, not because it takes a long time to update, but because it’s another step in the process that can be forgotten or missed. You can avoid that by making the external configuration smart (by adding more conventions to it), but it’s still something to consider.
Now that we have ordering down pat, it’s time to consider reuse and dependencies between scripts.
5.4. Managing reuse and dependencies
Quite often, you’ll write a piece of code that you want to use in several places. This is true of DSLs too. There are several ways of reusing code when you’re using a DSL.
The first, and most obvious, method is to remember that you’re using Boo as the DSL language, and that Boo is a full-fledged CLR language. As such, it’s capable of calling your code without any hassle. That works if you want to express the reusable piece in your application code.
Often, though, you’ll want to take a piece of the DSL code and reuse that. Doing so allows you to take advantage of the benefits of using a DSL, after all. In this situation, reuse is more complex.
The first thing you need to recall is that although we have been calling the DSL files “scripts,” they don’t match the usual script terminology. They’re compiled to IL in an assembly that we can then load into an AppDomain and execute. The DSL itself does fancy footwork with the compiler, after all.
Because the DSL is compiled to assemblies, we can reference the compiled assembly and use that. Boo makes it easy, because it allows you to create an assembly reference from code, not using the compiler parameters.
Listing 5.7 shows a piece of reusable code that we want to share among several scripts.
Listing 5.7. A reusable piece of DSL code
import System.Security.Principal
class AuthorizationExtension:
# here we use an extension property to extend the IPrincipal interface
[Extension]
static IsManager[principal as IPrincipal] as bool:
get:
return principal.IsInRole("Managers")
We need to compile it to an assembly (by adding the SaveAssembly step to the pipeline, or by executing booc.exe) and save it to disk. This gives us the CommonAuthorizationMethods.dll assembly. Listing 5.8 shows how we can use that.
Listing 5.8. Using an import statement to create an assembly reference
# import the class and create assembly reference
import AuthorizationExtension from CommonAuthorizationMethods.dll
# use the extension property
if Principal.IsManager:
Allow("Managers can always log in")
return
if date.Now.Hour < 9 or date.Now.Hour > 17:
Deny("Cannot log in outside of business hours, 09:00 - 17:00")
This works well, but it forces you to deal with the compiled assembly of the DSL scripts. This is possible, but it’s awkward. It would be better to preserve the feeling that we’re working in an infrastructure-free environment. Having to deal with assembly references hurts this experience.
Luckily, there’s another way of dealing with this. Script references use the exact same mechanism that we have looked at so far (compiling the referenced script, adding a reference to the compiled assembly, and so on), but it’s transparent from our point of view. Listing 5.9 does exactly the same thing as listing 5.8, but it uses script references instead of assembly references.
Listing 5.9. Using an import statement to create a script reference
# create the script reference
import file from CommonAuthorizationMethods.boo
# import the class
import AuthorizationExtension
# use the extension property
if Principal.IsManager:
Allow("Managers can always log in")
return
if date.Now.Hour < 9 or date.Now.Hour > 17:
Deny("Cannot log in outside of business hours, 09:00 - 17:00")
As you can see, they’re practically identical. The only difference is that we use the import file from <filename> form to add a script reference, and we need a second import statement to import the class after we create the script reference. (We need to import the class so it will be recognized for looking up extension properties.)
Script references aren’t part of Boo
Script references are another extension to Boo; they aren’t part of the core language. You can enable support for script references by adding the following statement in the CustomizeCompiler() method in your DslEngine implementation:
pipeline.Insert(2, new AutoReferenceFilesCompilerStep());
It’s important to understand that script references aren’t #include statements. What happens is that the code is compiled on the fly, and the resulting assembly is referenced by the current script. (It’s actually a bit more involved than that, mostly to ensure that you only compile a script reference once, instead of multiple times.) This allows you to reuse DSL code between scripts, without causing issues with the usual include-based approach (such as increased code size and compilation time).
Speaking of which, it’s time to take another look at an issue that most developers see as even more important than reuse: performance.
5.5. Performance considerations when using a DSL
A lot of programmers will tell you that their number-one concern is performance. I personally give positions 0 through 7 to maintainability, but that doesn’t excuse bad performance, so let’s talk about it a bit.
Tip
There is also much to learn from the wisdom of the ages: “We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil” (Donald Knuth).
Let’s consider what effect using a DSL will have on the performance of an application. Here are some costs of integrating a DSL into an application:
5.5.1. Script compilation
Script compilation is the most easily noticeable issue. This is particularly true when you’re compiling large amounts of code or continuously reinterpreting the same code.
If you’re rolling your own DSL, you should be aware of this; make sure that you cache the results of compiling the DSL. Otherwise you’ll pay a high price every time you execute a script. Rhino DSL takes care of that for you already, so this isn’t something that you’ll generally need to worry about.
Tip
One of the major problems with caching is that you need to invalidate the cache when the underlying data changes. If you decide to roll your own caching infrastructure, make sure you take this into account. You don’t want to have to restart the application because you changed a script.
We’ll look at Rhino DSL’s caching and batching support in chapter 7.
5.5.2. Script execution
Script execution tends to be the least time-consuming operation when using a DSL. The DSL code is compiled to IL, and, as such, it enjoys all the benefits that the CLR has. This means that the DSL code is optimized by the JIT (just-in-time) compiler, runs at native speed, and in general has little runtime overhead.
This doesn’t mean that it isn’t possible to build slow DSL scripts. It means that the platform you choose to run on won’t be an issue, even if you want to use a DSL in a common code path, where performance is an important concern.
Another important advantage of building your DSL in Boo is that if performance problems result from script execution, you can pull out your favorite profiler and pinpoint the exact cause of the issue. It looks like basing the DSL on a language that’s compiled to IL has significant advantages.
DSL startup costs
One thing that might crop up is the startup cost of the DSL. Compilation does take time, even if the results of the compilation are cached after the first round.
For many applications, this isn’t an important consideration, but for others, the startup time can be a make-or-break decision regarding DSL usage.
For scenarios where startup time is critical, you can retain all the advantages that the DSL offers but also get the best startup speed by precompiling the DSL. (We’ll look at precompilation in chapter 12.) By using precompilation, you lose the flexibility of changing scripts on the fly, but you still have the richness of the language and you get a startup cost that’s near zero.
5.5.3. Script management
Script management is probably the main cause for performance issues when using a DSL. By script management I mean the code that decides which scripts to execute. For example, having to execute 500 scripts when we could execute 2 will cost us.
We spent some time exploring naming conventions and how to structure our DSL previously in this chapter. Then we talked about the advantages from the point of view of organization and manageability of the DSL.
Those aren’t the only benefits of good organization; there is also the issue of performance. Good organization often means that we can pinpoint exactly which script we need to run, instead of having to speculatively run many scripts.
5.5.4. Memory pressure
The last performance issue we need to consider is memory pressure. But these aren’t memory issues in the traditional C++ sense; our DSLs aren’t going to suffer from memory leaks, and garbage collection will still work the way you’re used to. By memory pressure, I mean assembly leakage. This is probably going to be a rare event, but as long as we’re talking about performance...
The DSL code that we use is compiled to IL, which resides in an assembly, which is loaded into an AppDomain. But an AppDomain can’t release assemblies, so once you load an assembly into an AppDomain, you can’t unload it without unloading the entire AppDomain. Because you probably want to have automatic refresh for scripts (so that when you change the script, it’s automatically compiled on the fly), you need to pay attention to that. Each compilation causes a new assembly to be loaded,[1] which can’t be unloaded.
1 Well, that’s not technically correct, but it’s close enough for now. We’ll get to the technicalities in chapter 7.
If you have many script changes, and you have a long-running application, all those assemblies being loaded can eventually cause memory issues. The usual solution is to segregate the DSL into a separate AppDomain and reload it after a certain number of recompilations have occurred.
This solves the problem, and it has other advantages besides reducing the number of in-memory assemblies. For example, it segregates the DSL from the rest of the application, which allows you to add security measures and protect yourself from rogue scripts. This segregation is our next topic.
5.6. Segregating the DSL from the application
Although having a DSL (or a set of DSLs) in place can make many things much easier, DSLs bring their own set of issues. You’re letting external entities add code to your application, and if you, or your team, are the ones adding those scripts, it’s all well and good. If it’s a separate team or business analysts who are doing so, you need to take precautions against unfortunate accidents and malicious attacks.
There are several vectors of attack that can be used when you have DSL code running in your application. These are the most common ones (but by no means the only ones):
- Malicious actions, such as deleting or corrupting data, installing malware, and the like
- Denial of service, hogging the CPU, leaking memory, or trying to kill the host application by triggering faults in the runtime or the OS
There are several options for limiting what a script can do, such as building your own security infrastructure to separate the DSL from the rest of the application, limiting the time that a script can run, or executing it under a lower security context.
5.6.1. Building your own security infrastructure
The first option is to dig into the compiler and try to build your own security infrastructure by disallowing all calls except a certain permitted set.
For myself, I am extremely nervous about doing such things. Rolling your own security is almost always a bad thing. You are going to miss something, and few solutions will be able to protect you from the code in listing 5.10.
Listing 5.10. A trivial malicious script
# Denial of service attack using a DSL
# this script never returns and takes 100% CPU
while true:
pass
You can try to detect that, but you’ll quickly get into the halting problem (proving that for all input, the program terminates in a finite amount of time), and Alan Turing[2] already proved in 1935 that it can’t be solved.
2 Alan Turing (1912–1954) was a British mathematician and computer scientist and is considered to be the father of modern computer science.
That said, we don’t have to roll our own security (nor should we). We can use the security infrastructure of the platform.
5.6.2. Segregating the DSL
The problem of segregating the DSL from the application is a subset of protecting a host application from add-ins. There is a lot of information available on that topic, and because we’re using IL all the way, everything that’s relevant to an add-in is also relevant to a DSL. It isn’t possible to cover all the options that the CLR offers to control add-ins. That’s a topic for whole book on its own, but we can touch on the high points.
The first thing to realize is that the unit of isolation on the CLR is the AppDomain, both in terms of loading and unloading the assembly, as we mentioned earlier, and in terms of permissions, safety, boundaries, and so on. In general, when the time comes to erect a security boundary, you’ll usually create a new AppDomain with the desired permission set and execute the suspected code there. Listing 5.11 shows how we can do that.
Listing 5.11. Creating a sandboxed AppDomain
// Create local intranet permissions
// This is what I would generally use for DSL
Evidence intranetEvidence = new Evidence(
new object[] { new Zone(SecurityZone.Intranet) },
new object[] { });
// Create the relevant permission set
PermissionSet intranetPermissions =
SecurityManager.ResolvePolicy(intranetEvidence);
AppDomainSetup setup = new AppDomainSetup();
setup.ApplicationBase = AppDomain.CurrentDomain.BaseDirectory;
// create a sandboxed domain
AppDomain sandboxedDomain = AppDomain.CreateDomain(
"DSL Domain", intranetEvidence, setup,
intranetPermissions);
// Create an instance of a class that we can use to execute
// our DSL in the remote domain
DslExecuter unwrap = (DslExecuter)
sandboxedDomain.CreateInstanceAndUnwrap(
typeof(DslExecuter).Assembly.FullName,
typeof(DslExecuter).FullName);
The DslExecuter is something that you’ll have to write yourself; its code will depend on what you want done in the sandboxed domain. Using a separated AppDomain with lower security settings, you’re mostly protected from whatever malicious acts the scripts can perform. You can enhance that by applying code access security policies, but those tend to be fairly complex, and I have rarely found them useful. Since you’re running the scripts in a separate AppDomain, they can’t corrupt application state. This is almost the perfect solution.
It’s almost perfect because there are two additional vectors of attack against which the CLR doesn’t give us the tools to protect ourselves. Unhandled thread exceptions and stack overflows are both exceptions that the runtime considers critical, and they’ll cause the termination of the process they occurred on. And there are also denial of service attacks like the example in listing 5.10.
It’s important to note that those critical exceptions will kill the process, not just the responsible AppDomain. There are no easy solutions for this problem, and the two options I have found aren’t ideal. The first involves writing unmanaged code to host the CLR, so you can control how it will behave under those scenarios. The second is spinning off another process and handling the possibility of it crashing by spinning it up again.
Neither option makes me happy, but that’s the way it is. Most of the time, I believe that running DSL code in a separate AppDomain is an acceptable risk and carry on without the additional complexity each option involves.
5.6.3. Considerations for securing a DSL in your application
As a result, when it comes time to protect my applications from rogue scripts, I focus on two main subjects:
- Protecting the application by limiting what the script can do (using a separate AppDomain with limited permissions)
- Protecting the application by limiting how long a script can run (executing scripts with a timeout, and when the time limit is reached, killing the thread executing the DSL code and reporting a failure)
Most of the time, I don’t bother with all of that. It all depends on the type of application that you write, the people who are developing the scripts, what level they’re at, and how trustworthy they are.
Table 5.2 outlines the options you have for segregating the DSL, and the implications of each option.
Table 5.2. Summary of segregation options
|
Segregation approach |
Implications |
Suitable for |
|---|---|---|
|
No segregation—run DSL code in the same AppDomain |
Fastest performance DSL code runs under the same privileges as application code Frequent changes in DSL scripts may necessitate application restart |
This is ideal when the DSL code has the same level of trust as the application code itself. But if you expect to have frequent changes to the DSL scripts, you may want to consider the next level to prevent assembly leakage. |
|
High segregation—run DSL code in a different AppDomain |
High level of separation from the application Permissions can be tuned down, so the DSL can do little Can reload the AppDomain after a certain number of recompilations Slower performance (cross-AppDomain communication is slower than just calling a method on an object in the current AppDomain) |
This is appropriate when the DSL code isn’t as trusted as the application code and you want to ensure separation between the two. It’s also important when you suspect that you’ll have many changes in the scripts and you want to be able to perform an AppDomain restart when needed. Malicious scripts can take down the application if they really try. |
|
Complete segregation—run DSL code in a separate process |
High cost for communication between processes High level of separation from the application Permissions can be tuned down as needed Supports AppDomain reloading DSLs can’t take application down |
This is suitable when you do not trust the DSL or when you want to ensure even greater separation of application and DSL. It requires you to take care of recovering the process if it dies. |
In general, I would recommend that you go with the first approach (no segregation) unless you have solid reasons to do otherwise. In nearly all scenarios, this is the easiest and simplest way to go, and it will handle most requirements well.
Handling isolation with System.AddIns
System.AddIns is a namespace in .NET that offers support for those scenarios when you want to run untrusted plug-in code in your application. I haven’t had time to investigate it in detail, but it supports isolation on the AppDomain and process levels, and it takes care of much of the grunt work.
If isolation is important for your application, I suggest taking a look at System.AddIns before rolling an isolation layer independently.
Even the main reason for moving to the other approaches (AppDomain reload, and the subsequent assembly unload that frees the loaded assemblies) isn’t a real issue in most systems. Most script changes happen during development, when the application is rarely operating continuously for significant enough amounts of time to cause problems.
In practice, I have found the problem of DSL segregation to be a minor concern. The handling of script errors is a far bigger concern.
5.7. Handling DSL errors
In general, errors in DSLs are divided into two broad categories: compilation errors (which might include problems with the syntax or with transformation code), and runtime errors when executing scripts. We’ll look at the second one first, since it’s the more familiar.
5.7.1. Handling runtime errors
As you can imagine, because a DSL compiles to IL, any runtime error will be an exception. This means that you already know how to handle it. You just use a try ... catch block when you execute the DSL code, and handle the error according to your exception policies. That’s it, almost.
There is one issue to deal with. Because the whole purpose of the DSL is to give you a better way to express yourself, the DSL code and what is executing aren’t necessarily the same. In fact, they’re often radically different.
Take a look at listing 5.12, which shows a Message-Routing DSL script that will cause a runtime exception.
Listing 5.12. A Message-Routing DSL script that will cause a runtime exception
HandleWith NewOrderHandler:
zero = 0
print 1/zero # will cause error
When you execute this script, you’ll get the exception in listing 5.13.
Listing 5.13. The exception message from executing listing 5.12
System.DivideByZeroException: Attempted to divide by zero.
at RouteNewOrder.Route$closure$1()
in SourceScriptsRoutingRouteNewOrder.boo:line 7
at CompilerGenerated.$adaptor$___callable0$MessageTransformer$0.Invoke()
at RoutingBase.HandleWith(Type handlerType,
MessageTransformer transformer)
in SourceBDSLiBMessageRoutingDSLRoutingBase.cs:line 55
at RouteNewOrder.Route()
in SourceScriptsRoutingRouteNewOrder.boo:line 5
at Router.Route(IQuackFu msg)
in SourceBDSLiBMessageRoutingRouter.cs:line 32
at JSONEndPoint.ProcessRequest(HttpContext context)
in SourceBDSLiB.EndPointsJSON.EndPoint.ashx.cs:line 29
In this case, it’s pretty clear what’s going on. We have a divide by zero error. But where did it happen? In RouteNewOrder.Route$closure$1(), of all places. How did we get that?
This is a good example of the type of changes between DSL and IL that can confuse you when you try to figure out exactly where the error is. In this case, because of the structure of the Message-Routing DSL, the code inside the handle statement is a closure (or block or anonymous delegate), which explains why it has this strange name.
When you want to analyze exactly where this error happened, the method name isn’t much help—you won’t be able to make the connection between the method name and the code in the DSL unless you’re well versed in the internals of the Boo compiler. I know that I certainly can’t.
But while we don’t know which statement in the DSL caused the error, we do have the line-number location in the file that caused the error (and this is why we’ll look at lexical info in detail in chapter 6). This location information allows us to go to the file and see exactly where the error occurred. This is incredibly useful when you need to deal with errors.
Now that I have the error, what do I do with it?
This section discusses how to get the error and how to catch the exception. But what should you do with the error once you get it?
You can start from the assumption that you’ll have errors in your scripts and runtime errors when you execute them. As such, error handling should be a key consideration when designing your DSLs.
One approach is to let the error bubble up, and let the application code handle this. Another is to consider a DSL script that failed compilation to be invalid and ignore the error, whereas an error in executing the script would be passed to higher levels.
There is no one-size-fits-all solution here. You need to tailor the error-handling strategy to the purpose of the DSL.
That’s about all you need to do to deal with runtime errors. And with the one caveat of finding the exact error location, we handle DSL errors in the same way we handle application code errors.
Now we can talk about compilation errors and how to handle them.
5.7.2. Handling compilation errors
Compilation errors are divided into three broad categories: syntax errors, invalid code, and errors thrown by extensions to the compiler.
Syntax errors are caused by mistakes like forgetting to put a colon at the end of an if statement. They will usually cause an error of the “unexpected token” variety.
Invalid code is when you use correct syntax but the code is wrong. Calling int.LaunchRocket() is valid syntax, but int doesn’t have a LaunchRocket() method (at least not the last time I checked), so it will generate an error similar to this one: “ERROR: ‘LaunchRocket’ is not a member of ‘int’.”
There isn’t much that can be done for those first two categories of errors, although Boo is smart enough in many cases to suggest alternatives for misspelled identifiers. For example, trying to call int.Prase() will generate the following error: “ERROR: ‘Prase’ is not a member of ‘int’. Did you mean ‘Parse’?”
The third category of compilation error is errors that are thrown from your extensions to the compiler. This code is run as part of the compilation process, and errors in this code will be reported as compilation errors. These errors (unless they’re intentional) are plain old bugs, and should be treated as such. The compiler will show the exception information from your extensions, which will allow you to pinpoint the issue and create a fix for it. You could also execute the compiler while in the debugger and debug your compiler extensions.
5.7.3. Error-handling strategies
Now that we’ve covered error management in DSLs specifically, I want to recommend a few best practices for handling those errors.
First, you should log all errors (compilation and runtime errors) to someplace where you can analyze them later. This is particularly true after you go to production. This log should be accessible to the developers.
Tip
I was once denied read privileges to the production application logs, which meant that I had to guess what the problem was. Make sure that you log the errors to an operation database that is explicitly defined as accessible to developers, rather than the production database, where regulatory concerns may prevent developer access.
Second, refer to management of faulty DSL scripts (ones that cannot be compiled). If a script fails to compile, you should make a note of that and ignore it until the next time it has been changed (in which case you can try compiling it again).
Attempting to execute a script that compiles successfully but fails every time it is executed is a waste of CPU cycles, so allowing a script a certain number of consecutive failures and then suspending its execution would also be a good idea. Keep in mind, though, that suspending a script that contains critical business logic is probably not a good idea. At that point, you would want the entire application to come to a screeching halt until someone can fix it.
Circuit breakers
When you suspend a script that keeps failing, you’re using the Circuit Breaker pattern.[3] It’s used to minimize the effects of failure in one part of a system on the rest of the system.
3 Circuit Breaker is the name of a pattern in Release It! Design and Deploy Production-Ready Software by Michael T. Nygard. I highly recommend this book. It’s available from http://www.pragprog.com/titles/mnee.
You’ll probably want to set a time limit for the script’s suspension, after which it’s valid for execution again (or after it has been changed, presumably fixing the error). Also, make sure you take into account that the input might have caused the error; if a script fails on invalid input, it isn’t the script’s fault.
Note that this technique is not always appropriate. For example, if the authentication module is throwing errors, it’s probably a bad idea to disable authentication and allow full access for everyone. But it’s often a good way to stop propagating failures.
I can’t stress how important it is that administrators should be notified when scripts are turned off. For example, they should see when account/login.boo has been disabled because it keeps throwing errors (perhaps because the LDAP directory was taken down). Something like this certainly requires administrator intervention.
This brings us to the last topic for this chapter—administrating our DSL integration.
5.8. Administrating DSL integration
When I talk about administrating an application’s DSL integration, I’m really talking about several related tasks.
Usually, you’ll administer DSLs using the administration section of your application, although sometimes you will use a custom application for administering the DSLs in an application. We’ll discuss building such tools in chapter 10.
Administrating the DSL and the DSL scripts consists of several tasks:
- Reviewing logging and auditing information— Logging is particularly important when it’s related to errors, but other information is also important. You can use this information to track the usage of certain scripts, check the timing of scripts, review the success of particular operations, and so on.
- Reviewing information about suspended and ignored scripts— This information will let you know which scripts have failed to run, so you can fix them. Ignored scripts are those with compiler errors, whereas suspended scripts are those that tripped the circuit breaker and have been disabled for a time.
- Configuring the order of scripts— We looked at the ordering of scripts in section 5.3. In your application administration UI you can configure the mechanism that you use to set the script execution order, which gives you more flexibility at deployment time.
- Configuring which scripts should run for certain actions— You can treat scripts as part of the rules in the system, and work with them dynamically. This approach, of dynamic rule composition,
is useful when you have rapidly changing environments. With DSLs, making changes is easy, and providing a user interface to
decide which scripts to run in response to what actions makes change management easy (we’ll talk about DSL change management
in chapter 12). Figure 5.5 shows a sample user interface that could be used to administer such rules.
Figure 5.5. An administration screen for specifying which rules to execute on an operation
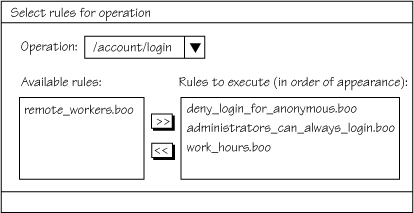
- Updating scripts— You can also use the administration section of the application to update scripts, but this should be considered carefully, because production code changes are not something you want to make too easy. Change management and source control are two things that you definitely want in place for DSLs, and we’ll discuss them in chapter 12.
The list just enumerates common tasks that come up in most DSL implementations. I generally implement each of those on an as-needed basis, and there are others (audit information, for example) that you might want to implement as well. The DSL administration should be considered as part of the DSL design, and chapter 12 talks extensively about that topic.
5.9. Summary
We’ve covered quite a bit of ground in this chapter. We talked about the macro concerns of using a DSL in your application and how the DSL solution can scale easily as the complexity of the application grows.
We looked at using naming and ordering conventions to allow our DSLs to find the appropriate scripts to run and the order in which to run them with as little work as possible. Reducing the work required to find the right set of scripts to handle a certain action is important, both in terms of the amount of work that the DSL has to do and our own mental processes when we try to add a new script or find out how particular scripts work.
We also explored the reuse, performance, and segregation aspects of using a DSL. In all three cases, we saw that compiling the scripts to IL gives us the advantages of native CLR code, which means that we can take advantage of all the CLR services, from easily reusing scripts, to profiling a DSL, to using the built-in sandboxing features of the runtime.
We also looked at error handling. Again, because our DSLs are based on Boo, which compiles to IL, we can use all our familiar tools and concepts.
Looking at the big picture, you should now be starting to see how you can plug a DSL implementation into an application to make the implementation of policies more convenient, readable, and dynamic.
Throughout this chapter, we continued building the DSL, looking at how to deal with the compiler and use Rhino DSL. We touched briefly on cache invalidation, script references, and some other goodies, but we haven’t looked at those topics in detail. It’s now time to discover exactly what the compiler can do for us. That’s the topic of the next chapter.