
9
Traceability in Problem-solving Processes
9.1. Introduction
Companies (and in general sociotechnical organizations) are facing problems every day. For the continuous improvement of products and processes, the major challenge facing companies is to solve problems and learn from them. The issue for companies is to address problems that arise at all levels in a streamlined and controlled way. This is why, for several years, they have systematized problem-solving by implementing processes dedicated to resolution. In the case of difficult problems, the resolution process may require a collaborative effort, involving actors dedicated to the different aspects of the resolution such as the management of the process, the expertise to identify the problem causes or the set-up and management of actions. The use of such processes is essential for the improvement of the company and needs expenditure; it is also important that the investigation is in-depth. Despite the investment required to solve these problems, it is very common that the information and knowledge generated during the resolution are stored using office tools (spreadsheets, for example) and no longer reused after the end of the process. However, the approaches used to solve a problem can often be validly used to solve other problems that may arise either later in the same place or at different sites of the company. Thus, we believe that significant value can be added by:
- – facilitating the capitalization of information and knowledge produced during the problem-solving process;
- – enabling the reuse of this information and knowledge to solve new problems.
That is why we have developed both a theoretical framework of representation of the information and knowledge (which we call for a particular problem, an experience), reuse mechanisms of these experiences and a software tool (ProWhy) to implement the capitalization upon and reuse of problem-solving experiences.
This chapter is organized into three parts. The first part details the structure of problem-solving processes and shows that these processes, although diverse, are quite similar from the produced information and knowledge point of view. The second part is devoted to the formal representation of the experiences and the presentation of reuse mechanisms exploiting the notion of similarity. The third part describes a software application, released under a free license, to facilitate problem-solving and reuse of capitalized items.
9.2. Problem-solving processes
Several standard problem-solving processes are commonly used in companies and we can cite in particular the following: the plan do check act (PDCA) process, the 8 disciplines (8D) process, the DMAICS (define measure analyze improve control standardize) process or, more recently, the 9 steps (9S) process.
All these processes have in common:
- – steps to describe the context of the problem;
- – steps to provide an analysis of the problem (especially root cause analysis);
- – and finally steps to propose and evaluate corrective and preventive actions.
These three elements are detailed in the following sections.
9.2.1. Problem context description
The description of the problem allows us to specify the key elements that will facilitate later analysis. The objective is to define the problem perimeter. For instance, the Five Whys method is used to encompass the following aspects of the problem: Who, What, Where, When, Why and sometimes How. The Is/Is Not method is also commonly used during this phase. Additional elements such as reports or pictures are also often provided to clarify the context.
9.2.2. Analysis
Analysis is a key phase of the problem-solving process during which the domain experts try to identify the causes of the problem. To achieve this goal, a progressive in-depth study is used. It consists of searching, at a first level, for the direct causes of the problem. This first identification of causes can be supported by tools such as Ishikawa diagrams (or fish bone diagrams) that classify the possible causes in several source domains such as people, methods, machines, materials, measurements and environment. The causes considered by experts are called hypotheses. Additional information and knowledge must be collected in order to validate or invalidate the hypotheses. These additional elements can come from validation actions (such as experimentation) or from the expertise of other actors. The progressive in-depth study then consists of launching, on the previously formulated hypotheses, a search for next-level causes (causes of the cause). The Five Whys method is based on this principle and recommends to limit investigation to five levels.
9.2.3. Proposal and evaluation of action plans
During the problem-solving process, actions are setup. These actions are of various natures and the following are usually distinguished:
- – containment actions, achieved in general before the analysis phase, allow us to put the problematic system in security;
- – validation actions, used during the analysis phase, allow us to validate or invalidate the hypotheses on the problem causes;
- – corrective actions that provide a solution to the current problem;
- – preventive actions that enable to avoid the problem reoccurrence.
The last two actions (corrective and preventive) may require monitoring to evaluate their efficiency. They prepare, in fine, the proposed solution to completely eradicate the problem.
Thus, the information and knowledge generated during the problem-solving process could be structured into the following three broad categories, regardless of the processes involved: context, analysis and solution (action plan). We assume in our work that the experience corresponds to a container incorporating the context (problem description and analysis), the analysis (expertise on finding the cause of the problem) and the solution (set of actions to resolve the problem). Thus, an experience Ei will be represented by a triplet Ei = ![]() Ci, Ai, Si
Ci, Ai, Si ![]() , where Ci, Ai and Si represent the context, analysis and solutions of the Ei experience. A base of experience is a set of experiments:
, where Ci, Ai and Si represent the context, analysis and solutions of the Ei experience. A base of experience is a set of experiments: ![]() . The ability to capitalize upon each experiment (context + analysis + solution) will then allow the reuse and therefore the feedback. In the next part of this chapter, we propose a mechanism to facilitate this feedback.
. The ability to capitalize upon each experiment (context + analysis + solution) will then allow the reuse and therefore the feedback. In the next part of this chapter, we propose a mechanism to facilitate this feedback.
9.3. Traceability and reuse
The academic papers published in the field of experience feedback can be organized into two broad categories. The first category of work focuses on the organizational aspect. The authors do not explain the information system or the underlying knowledge management system. Examples in this category are the model of experiential learning [KOL 84], the model of lessons learned [WEB 01] or the generic model of experience feedback systems [RAK 02]. In the second category, the focus is more on the knowledge representation and the related inference mechanisms necessary to instrument the feedback. Most of the work in this category is based on the use of inference mechanisms similar to those offered by case-based reasoning [KOL 93]. The proposals of Bergmann [BER 02] and Armaghan [ARM 08] are typical of this approach. We will use for our proposal some ideas commonly found in the area of case-based reasoning (e.g. similarity-based search). Finally, the PhD thesis submitted by Tea [TEA 09] tells the importance of integrating subjective data to enrich an information system for experience feedback. We also retain the idea of allowing the integration of the subjective opinion of the experts explicitly in the proposed system.
In this chapter, we will focus on the representation of the “context” part. The “context” will, when a new problem arises, allow us to identify interesting previous experiences (that is to say having a context similar to the problem being under resolution). We will propose a modeling context and a search mechanism of interesting previous experiences.
To simplify and systematize research on previous experience, we propose to represent the problem context with at least two descriptors. The first is the type of product or component that is subject to the problem. Depending on the available knowledge, this may correspond to a very global entity (e.g. a train) or a more specific entity (e.g. a power transformer). To formalize this aspect of the problem description, the use of a taxonomy (hierarchical “is a” type relationship between concepts, as illustrated in Figure 9.1) is particularly interesting. Indeed, it will allow us, in the description of the context, to associate a concept from the corresponding taxonomy (here that of the products/ components).

Figure 9.1. Taxonomy example
We will call Coi the concept “component” associated with the experience, Ei . Similarly, we will associate with each experience a concept that best describes the type of problem. This concept will be noted as Pbi . It will also be extracted from a taxonomy of problems. Thus, the context of an experiment will be described by two concepts from, respectively, a taxonomy of products and a taxonomy of issues. The context of the experience, Ei, is noted as Ci = ![]() Coi, Pbi
Coi, Pbi ![]() .
.
The description of the context may, when appropriate, involve additional descriptors (attribute − value), but this possibility will not be discussed in this chapter.
The proposed research mechanism is based on the assessment of the similarity between the context of a new problem to solve and the context of already solved problems. The context of the new problem is supposed to be described in the form, C′ = ![]() Co′, Pb′
Co′, Pb′ ![]() , where Co′ and Pb′ denote the concepts “Component” and “Problem” associated with the new problem. The goal is then to measure what is the level of similarity when compared to each context, Ci =
, where Co′ and Pb′ denote the concepts “Component” and “Problem” associated with the new problem. The goal is then to measure what is the level of similarity when compared to each context, Ci = ![]() Coi, Pbi
Coi, Pbi ![]() , of the experiences stored in the experience base.
, of the experiences stored in the experience base.
To evaluate this similarity, a measure of semantic similarity between concepts from the same taxonomy must be used. In the literature, several such similarity measures have been proposed. It is possible to distinguish the measures based on the taxonomic structure only and measures exploiting additional information, in general a corpus of texts, from the field in question, which allow refining the level of similarity of concepts. In our proposal, since an exploitable and sufficient text corpus is rarely accessible, we limit ourselves to measures based on the taxonomic structure. Several measures have been proposed for this purpose. One example is the measure proposed by Wu and Palmer [WU 94]:
where N1 and N2 represent, respectively, the number of links that separate the concepts Co′ and Coi of their first common ancestor, and N3 is the number of links between this first common ancestor and the root of the taxonomy (universal concept).
On the basis of the example of the taxonomy provided in Figure 9.2, Co′ = Co32 and Coi = Co311. The first common ancestor is Co3. Therefore, N1 = 1, N2 = 2 and N3 = 1, which leads to a similarity ![]()
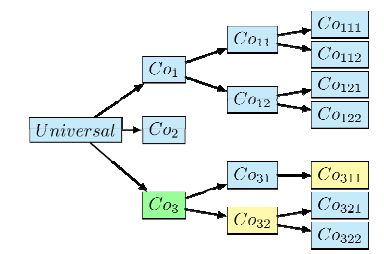
Figure 9.2. Concept similarity illustration
Other similarity measures based on taxonomies can be used, such as those proposed by Leacock and Chodorow [LEA 98], Choi and Kim [CHO 03] or Al-Mubaid and Nguyen [ALM 09]. More recently, in Batet et al. [BAT 11] an original measure is proposed in order to improve the preceding ones without requiring the use of an additional text corpus, which is difficult to obtain and process. According to the experimental results of the authors, the proposed measure obtains performances similar to measures based on a significant additional text corpus. This measure is based on the notion of a superconcept. A superconcept of a given concept C is a concept of which C is a descendant. For example, in the taxonomy shown in Figure 9.2, the superconcepts of Co32 are Co3 and Universal. For a concept C, T(C) = {SC /SC is a superconcept of C} U {C}.
The measure relies an aggregation of the total number of superconcepts required to characterize the two compared concepts and the number of common superconcepts ![]()
![]()
However, this measure is not normalized. In order to have a similarity in the interval [0,1], a normalization of the measure is added as follows:

where H is the height of the taxonomy.
For the example already used to illustrate the measure of Wu and Palmer, we obtain:
We propose to use the measures (simWP or simJKG) for each concept associated with the problem context (solved and to be solved). We call it sim, the used measure. The aggregation of the two obtained measures is achieved by using, for instance, a distance function of Minkovski:
where p is a parameter that enables us to tune the aggregation (for p = 1, we have an average of the elementary similarities and for p = +∞ an operator max).
Finally, with each context of the experiences in the experience base, we can associate a similarity measure with the context of the problem to be solved. These experiences can then be selected (or not) for reuse according to the level of contextual similarity. This search mechanism has been implemented in the software ProWhy presented in the following section.
9.4. ProWhy
ProWhy is the result of a successful academic/industry partnership. For 7 years, the LGP and the Axsens Bte Company have worked together to specify and develop a software tool for problem-solving support. ProWhy has been developed to structure, standardize, centralize and share each problem-solving experience. ProWhy is a free software, licensed under GNU Affero General Public License version 3.
The technological solution adopted is a web-based solution in which a web server is associated with a database to manage the information generated by users. ProWhy is developed in the language Ruby with Ruby on Rails as a web development framework. It can work with most web servers and databases (for instance we use an Apache production server connected to a MySql database).
This solution has a number of advantages. Because of the technology used, maintenance and updates are performed on the server and therefore does not require any setup or intervention on each of the user stations. Each new user must therefore be referenced in the application database and a login/password is enough to make it operational. Centralizing information in a relational database allows for any type of SQL query by the application itself, but also any other type of application can connect and manage SQL queries. Furthermore, centralization facilitates collaborative work and the traceability of the process.
ProWhy supports many problem-solving approaches widespread in the industry such as the PDCA, 8D and 9S. It also supports anomalies that are extremely lightweight treatment problems. Since each problem is likely to be over or underestimated at the beginning of the problem-solving, it is possible to change the selected process into another one to better satisfy the need (e.g. PDCA transformed into 8D).
Most of the implemented features are the result of discussions with industry practitioners. The use/adoption of the software is made easier because of various ergonomic choices. The use of JavaScript functions facilitates the type of action, for example by using drag and drop.
9.4.1. ProWhy: problem-solving process support
The different stages of the resolution process are represented by tabs to better structure the information. Each tab represents one step, suitable tools are proposed to complete this step. Transverse tools are also provided, such as the Action Plan or the pdf report that includes all the information about a problem under resolution (or already solved) and enables us to simply communicate this information with the problem-solving team. Figures 9.3–9.8 illustrate various functionalities of ProWhy.

Figure 9.3. Problem description

Figure 9.4. Team building
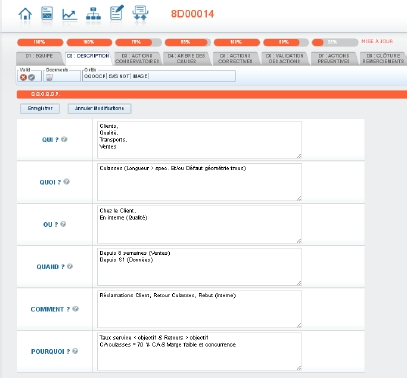
Figure 9.5. Detailed context description

Figure 9.6. Root cause analysis

Figure 9.7. Ishikawa diagram
Figure 9.8. ProWhy portal
A dedicated portal (see Figure 9.9), http://www.prowhy.org, presents the main features of the tool and provides access to a demo application as well as to the ProWhy project management platform (http://www.prowhy.org/redmine/projects/prowhy). This latter site provides the tools needed for the distribution and use of ProWhy:
- – a repository from which it is possible to download the source files and the documentation needed to install and use the application;
- – a discussion forum that provides a permanent connection with the development team;
- – a wiki that includes all documentation about the installation, configuration, administration and use of ProWhy.

Figure 9.9. ProWhy portal
Associated with the ProWhy software, a community site has been launched (http://www.problem-solving-community.org/). This site aims to federate and facilitate the cooperation of people involved in industrial problem-solving. Unlike the previous two sites, it is more dedicated to problem-solving methodologies.
9.4.2. ProWhy: reuse of past experiences
One of the objectives of the ProWhy application is to allow experience feedback through search and reuse of past experiences. This search can be performed in two ways:
- – standard search by keywords: a form is available to the users, allowing them to search by keywords in past experiences (search in texts of problem descriptions, causes and actions mainly). The search can also be performed according to the dates, team members, advancement states, etc.;
- – search by similarity context: two taxonomies (Figure 9.10) are proposed to characterize the problem. The first is formed by a set of components related to a specific industrial field; the second taxonomy lists all types of problems. A similarity search engine (Figure 9.11) can find similar past experiences by using these taxonomies.
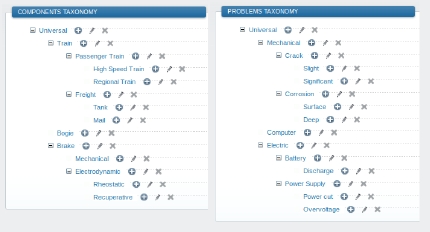
Figure 9.10. Taxonomies

Figure 9.11. Conceptual similarity search
9.5. Conclusions
Problem-solving is a daily activity in sociotechnical organizations. In companies, an effort is required to manage problem-solving in a structured and rational way. However, the capitalization of each problem-solving experience and the related lesson learned is often limited and traceability is impossible.
In this chapter, we propose an approach to structure the information and knowledge produced during problem-solving processes and to store it in an experience base. In order to facilitate the reuse, taxonomies, tagging and conceptual similarity measures offer a simple and relevant approach.
The problem-solving process support has been implemented in a software called ProWhy, which is distributed under free license (AGPL-3.0), and experimental features including conceptual similarity based reuse of past experiences are currently being developed.
9.6. Bibliography
[ALM 09] AL-MUBAID H., NGUYEN H. A., Measuring semantic similarity between biomedical concepts within multiple ontologies”, Transactions on Systems, Man, and Cybernetics– Part C, vol. 39, pp. 389–398, 2009.
[ARM 08] ARMAGHAN N., LIEBER J., RENAUD J., “Towards a conversational case-based reasoning system to assist the operator of an after sales service”, Third European Conference on Management of Technology (EuroMOT), CERAM Business School, Nice, Sophia Antipolis, France, 17–19 September 2008.
[BAT 11] BATET M., SÁNCHEZ D., VALLS A., “An ontology-based measure to compute semantic similarity in biomedicine”, Journal of Biomedical Informatics, vol. 44, no. 1, pp. 118–125, 2011.
[BER 02] BERGMANN R., Experience Management: Foundations, Development Methodology, and Internet-based Applications, Springer-Verlag Berlin, Heidelberg, vol. 2432, 2002.
[CHO 03] CHOI I., KIM M., “Topic distillation using hierarchy concept tree”, SIGIR, pp. 371–372, 2003.
[JAB 11] JABROUNI H., KAMSU-FOGUEM B., GENESTE L. et al. “Continuous improvement through knowledge-guided analysis in experience feedback”, Engineering Applications of Artificial Intelligence, vol. 24, no. 8, pp. 1419–1431, 2011.
[KOL 84] KOLB D. A., Experiential Learning: Experience as the Source of Learning and Development, Prentice Hall, Englewood Cliffs, NJ, 1984.
[KOL 93] KOLODNER J., Case-Based Reasoning, Morgan Kaufmann San Francisco, CA, 1993.
[LEA 98] LEACOCK C., CHODOROW M., “Combining local context and word-net similarity for word sense identification”, in FELLBAUM C. (ed), WordNet: An Electronic Lexical Database, MIT Press, Cambridge, MA, pp. 265–283, 1998.
[RAK 02] RAKOTO H., CLERMONT P., GENESTE, L., “Elaboration and exploitation of lessons learned”, IFIP 17th World Computer Congress, Montréal, Québec, Canada, 25–30 August 2002.
[WEB 01] WEBER R., AHA D. W., FERNANDEZ B. I., “Elaboration and exploitation of lessons learned”, IFIP 17th World Computer Congress, Montréal, Québec, Canada, August 25–30 2002.
[WU 94] WU Z., PALMER M. “Verb semantics and lexical selection”, 32nd Annual Meeting of the Association for Computational Linguistics, New Mexico State University, Las Cruces, New Mexico, pp. 133–138, 1994.
[TEA 09] TEA C., Retour d’expérience et données subjectives: quel système d’information pour la gestion des risques?, Doctoral thesis, Paristech-ENSAM, 2009.
Chapter written by Elisabeth KUNTZ, Eric REUBREZ, Laurent GENESTE, Juan Camilo ROMERO, Valentina LLAMAS and Aymeric DE VALROGER.