


Data Accelerator for AI and Analytics supporting data orchestration
Data Accelerator for AI and Analytics (DAAA) is a solution that addresses the needs of a data orchestrated environment.
It helps data scientists run their machine learning (ML) and deep learning (DL) (ML/DL) jobs without any knowledge about the underlaying storage infrastructure, and find and prefetch the data that is needed.
DAAA can accelerate output from artificial intelligence (AI) and analytics applications in an enterprise data pipeline. It can bring the correct data at the correct time closer to AI and analytics applications for faster model training, inference, or real-time analytics without having to create another persistent copy of the data from the data lake.
DAAA can abstract warm, cold, and cold archive storage systems for the data scientist, and provides them with a data catalog to find and access the correct data for their analytics.
2.1 Generic components
With DAAA, you can use different components for each layer, as described in 1.2, “Overview” on page 3.
To demonstrate DAAA, we provide a solution with a sample architecture. The following section explains the components in detail and provides suggestions for different components that might be used for each layer.
Figure 2-1 shows components that might be part of the DAAA solution.

Figure 2-1 Example of an enterprise data orchestrated environment
2.1.1 Data layer
The data layer might also be named the capacity tier or data lake. It addresses storage for which cost ($/TB); high durability, availability, reliability; and geo-distribution is key.
Figure 2-2 shows the capacity tier’s (lowest layer in the diagram) different data storage systems, such as network-attached storage (NAS) Filers, object storage, or an IBM Spectrum Scale storage system to which an IBM Archive system also might be attached.

Figure 2-2 Capacity tier: Different data storage systems
Typically, different storage systems are used for different purposes. Some act as an ingest layer for new incoming data and must provide decent performance to receive the data from instruments. Another example is the growing needs of the automotive industry, where cars provide more data, either video, picture, and sensor data, which is used as a base to create autonomous driving solutions. Some of this data is live data after the car is sold and used by customers.
Costs correlate with storage performance and size. As data gets colder, object storage and tape solutions become more wanted. Additionally, the data location might be different: on-premises, in the cloud, or hybrid.
A smart data cache function must handle the different attached storage systems and storage locations.
In our sample proof of concept (PoC), shown in Figure 2-2 on page 8, we used an autonomous driving data set and stored parts in a Network File System (NFS) server that acts as a warm storage tier, an IBM Cloud Object Storage on-premises storage system that acts a cold storage tier, and IBM Spectrum Archive Enterprise Edition, which acts as a cold archive storage tier.
2.1.2 High-performance storage with a smart data cache layer
This layer can be described as the high-performance smart storage tier. It addresses storage that is maximized for performance, where $/IOPps and $/GBps, low latency random I/O, and high sequential bandwidth are key.
This layer acts as a cache that can provide the data fast to the AI and analytic workloads. The ownership of the data stays within the capacity tier storage systems.
To ensure data integrity, updates that are done on either layer must be done with consistency. If data is updated in the capacity tier, the data in the cache also must receive the update automatically, and vice versa. For the typical use cases that are addressed with the DAAA solution, data read workloads are in the majority.
For the high-performance storage and cache acting layer in our PoC, we use an IBM ESS 3000 storage system that combines IBM Spectrum Scale file management software with NVMe flash storage for the ultimate in scale-out performance and simplicity.
IBM Spectrum Scale provides the Active File Management (AFM) function to cache data from cost-optimized capacity tiers and data lakes like NAS Filers, IBM Cloud Object Storage, or other IBM Spectrum Scale clusters. It acts as a cache that fetches only the required data either on demand or on a schedule from the capacity tiers. In addition to a read to cache function, AFM also provides a write to cache function and ensures that any written data (such as analytic results) is flushed to the capacity tier.
In most cases with proper networking, you gain administration and resource sizing advantages when you separate the compute cluster from the storage cluster. In our use case, we separate the compute cluster from the storage cluster. The data that is cached in the IBM ESS 3000 storage cluster is remote-mounted by the IBM Spectrum Scale cluster that is part of the compute cluster. With this configuration, we can separate the combination compute cluster and high-performance smart storage tier from the capacity tier, as shown in Figure 2-3.

Figure 2-3 Hybrid cloud example: On-premises and cloud combinations
The compute cluster and high-performance smart storage tier may be on-premises or in the cloud, and the capacity tier is on-premises or in the cloud. All combinations are supported by the AFM function, so you can have use cases in which on-premises compute resources are exhausted in the short term and expanded into the cloud while the capacity tier stays on-premises.
Active File Management details
IBM Spectrum Scale AFM enables sharing of data across clusters, even if the networks are unreliable or have high latency. Figure 2-4 on page 11 shows how AFM acts as the smart data cache.

Figure 2-4 IBM Spectrum Scale Active File Management acting as a smart data cache
With AFM, you can create associations to NFS data sources, Amazon Simple Storage Service (Amazon S3) Object data sources, or further IBM Spectrum Scale clusters. With AFM, a single namespace view across sites around the world can be implemented, which makes the global namespace truly global.
AFM uses the terms home site and cache site. In DAAA, the Home site is the capacity tier, and the Cache site is the high-performance smart storage tier.
AFM constantly maintains an active relationship between the cache and home sites. Changes are managed by the IBM Spectrum Scale file set, which results in a modular and scalable architecture that can support billions of files and petabytes of data. Synchronization of the cache site works for both read (main DAAA use case) and writes.
AFM can prefetch data so that it is available when the analytic job starts. AFM caches data on the application request to ensure that any analytic job that is running in the compute cluster does not fail, for example, when a single file not available yet.
Prefetching data and caching an application request keeps data on both sites synchronized, which makes AFM the heart of the solution.
For more information about, IBM Spectrum Scale AFM, see IBM Knowledge Center.
2.1.3 Compute cluster layer
This layer represents any kind of compute clusters running traditional or new generation applications, such as a Kubernetes or a Red Hat OpenShift cluster, as shown in Figure 2-5.

Figure 2-5 Example of different compute clusters with IBM Spectrum Scale and GPU-accelerated worker nodes
IBM Spectrum Scale nodes or clients that are part of the compute cluster remote mount the data that is stored in the connected IBM ESS storage cluster.
Traditional non-containerized applications can directly access the data in the IBM Spectrum Scale file system through the IBM Spectrum Scale client, but containerized applications running on container orchestration platforms such as Kubernetes or Red Hat OpenShift also require the IBM Spectrum Scale Container Storage Interface (CSI) driver to access data in IBM Spectrum Scale through persistent volumes (PVs).
For more information about IBM Spectrum Scale CSI, see IBM Knowledge Center.
In our PoC, we used a Red Hat OpenShift V4.5.9 compute cluster with the IBM Spectrum Scale CSI Driver V2.0. We also used IBM Spectrum Load Sharing Facility (IBM LSF) as a workload manager that provided a customizable GUI window and acted as the data scientists interface to provide requests for the data that was needed.
2.1.4 Data catalog layer
This layer represents the key to the data. The data catalog layer holds the metadata of the data that is stored in the capacity tier, so you can easily search for the data that is needed.
Together with IBM Spectrum Scale AFM, the data catalog layer provides the correct data at the correct time for fast storage for analytic workloads.
DAAA is designed to allow integration with metadata management software such as
IBM Spectrum Discover or other solutions like Starfish or pixit search to automate the selection of the correct data sets.
IBM Spectrum Discover or other solutions like Starfish or pixit search to automate the selection of the correct data sets.
A data catalog must be able to catalog billions of files that are stored in different storage architectures. Search queries should be answered in a short time and must provide details about which storage system owns the data and where it is located.
Metadata in the best case should be pushed into the catalog, not pulled. If data scans are run, they must be lightweight but still fast enough to represent the details that are found in the data lake.
Other functions like finding duplicate data help to reduce the needed storage capacity.
2.1.5 Interfaces between the layers
The following sections provide more information about the interfaces that are used between the different layers.
Data to data catalog and high-performance storage
Data is scanned by the metadata search engine. If available, storage systems can also send data updates as an event to the metadata search engine, which reduces search load on the storage systems and provides real-time updates.
In our PoC, we used IBM Spectrum Discover as our metadata search engine, which can manage several connections to different storage systems. It can scan these systems by using policies and schedules. Scans are done by connecting to the storage system and reading the metadata that comes with the data. It is also possible to load metadata files that provide more details to the data. Furthermore, it provides functions to publish data about updated events into a Kafka queue to which IBM Spectrum Discover listens.
IBM Spectrum Scale AFM connects the data with the high-performance layer through the storage system by using interface protocols like NFS, Amazon S3, or Network Shared Disk (NSD) (IBM Spectrum Scale). AFM can sync the data in both directions (upwards and downwards) automatically. Data can be cached either on request or on-demand.
High-performance storage to data catalog and compute
In our PoC, we did not connect the metadata search engine to the high-performance storage because it was sufficient to show the concept without this connection. In a production environment, this connection helps to validate which data is already cached. Then, those details can be considered when you build the AFM prefetch or evict lists.
In our PoC, we connect an IBM Spectrum Scale Client cluster through a remote mount to the high-performance storage. IBM Spectrum Scale manages this connection. Depending on your environment and use case, the compute workloads might directly connect to the fast cache storage or if the workloads are in a separate compute cluster.
2.2 Proof of concept environment
Figure 2-6 shows the environment that we use for this PoC.

Figure 2-6 The environment that we use for this proof of concept
The solution that is described in this paper uses the following major components for the installation:
•Red Hat OpenShift V4.5.9 with access to Red Hat subscriptions and other external resources on the internet (for example, GitHub and container images registries)
•IBM Spectrum Scale Cluster V5.1.0 with IBM Spectrum Scale GUI and REST
•IBM ESS 3000 running IBM Spectrum Scale V5.1.0
•IBM Spectrum LSF V10.1.0 with IBM Spectrum LSF Application Center V10.2
• IBM Spectrum Discover V2.0.2 with extra functions added in Version 2.0.4, specifically the ImportTags embedded application
•NFSv3 server
•IBM Cloud Object Storage V3.14.7.56
•IBM Spectrum Scale V5.0.4.3 with IBM Spectrum Archive Enterprise Edition V1.3.0.7 connected to it
•Standard 100 Gbps Ethernet high-speed data network
•Standard 1 Gbps (or higher) Ethernet admin network for all components
Figure 2-7 on page 15 shows the software release levels that are used for Red Hat OpenShift and IBM Spectrum Scale, and the role of each node.

Figure 2-7 Red Hat OpenShift and IBM Spectrum Scale node roles and software releases
The following sections describe the clusters that were created for this PoC.
2.2.1 Red Hat OpenShift V4.5.9 cluster
Red Hat OpenShift is an open source container orchestration platform that is based on the Kubernetes container orchestrator. It is designed for enterprise app development and deployment. As an operating system, we deployed Red Hat Enterprise Linux CoreOS (RHCOS), and Red Hat Enterprise Linux (RHEL). For more information about RHCOS, see Appendix A, “Code samples” on page 71. RHCOS is the only supported operating system for Red Hat OpenShift Container Platform (Red Hat OCP) master node hosts. RHCOS and RHEL are both supported operating systems for Red Hat OCP on x86-based worker nodes. Because IBM Spectrum Scale is supported only on RHEL, we used RHEL V7.8 for these systems.
The compute cluster consists of the following items:
•Three master nodes running RHCOS on Lenovo SR650 servers
•Two worker nodes running RHCOS in a virtual machine (VM) on a Lenovo SR650 server (You must have a healthy Red Hat OCP cluster with a minimum of three master and two worker nodes running as a base before adding the GPU-accelerated workers.)
•Two GPU-accelerated worker nodes with NVIDIA GPU adapters
2.2.2 IBM Spectrum Scale V5.1.0 storage cluster
IBM Spectrum Scale is a high-performance and highly available clustered file system with associated management software that is available on various platforms. IBM Spectrum Scale can scale in several dimensions, including performance (bandwidth and input/output per second (IOPS)), capacity, and number of nodes or instances that can mount the file system.
The IBM Spectrum Scale storage cluster in our PoC consists of the following items:
•IBM Spectrum Scale clients running on every worker node, which are based on Red Hat V7.8
•IBM Spectrum Scale client running in a VM (providing GUI and REST interfaces, and quorum and management functions) that is based on Red Hat V7.8
•A remote-mounted IBM Spectrum Scale file system that is called ess3000_4M on an
IBM ESS 3000 storage system that is configured with a 4 MiB blocksize (a good fit for the average image size of 3 - 4 MiB of the Audi Autonomous Driving Dataset (A2D2))
IBM ESS 3000 storage system that is configured with a 4 MiB blocksize (a good fit for the average image size of 3 - 4 MiB of the Audi Autonomous Driving Dataset (A2D2))
2.2.3 IBM ESS storage cluster
IBM ESS 3000 combines IBM Spectrum Scale file management software with NVMe flash storage for the ultimate scale-out performance and unmatched simplicity, and delivers
40 GBps of data throughput per 2U system.
40 GBps of data throughput per 2U system.
The storage cluster consists of the following items:
•An IBM ESS 3000 storage system that has two canisters, each running IBM Spectrum Scale V5.1.0 on Red Hat V8.1. For more information about IBM Spectrum Scale V5.1 support on IBM ESS 3000, see the note at 4.3.1, “IBM ESS 3000 and IBM Spectrum Scale” on page 31.
•A2D2 downloaded and extracted into NFS, cloud object, and archive storage systems.
•A Lenovo SR650 server running IBM Spectrum Scale V5.1.0 on Red Hat V8.1 (providing GUI and REST, and quorum and management functions).
2.2.4 Capacity tier storage
For the capacity storage systems, we use the following items for this PoC:
•An NFS server that provides a single NFS share.
•An on-premises IBM Cloud Object Storage system with a single bucket.
•An IBM Spectrum Scale cluster with IBM Spectrum Archive Enterprise Edition connected to it.
For more information about IBM Spectrum Scale, IBM ESS 3000, IBM Spectrum LSF,
IBM Spectrum Discover, IBM Spectrum Archive Enterprise Edition, IBM Cloud Object Storage, see “Related publications” on page 73.
IBM Spectrum Discover, IBM Spectrum Archive Enterprise Edition, IBM Cloud Object Storage, see “Related publications” on page 73.
2.2.5 IBM Spectrum Discover V2.0.2+ metadata catalog
For the metadata catalog, we use IBM Spectrum Discover. Connections to all configured capacity tier storage systems are created. For IBM Cloud Object Storage and IBM Spectrum Scale, we also configure the notification service that allows the storage systems to push events about metadata changes into the metadata catalog automatically.
In this solution, a pre-release version of IBM Spectrum Discover V2.0.4 is used. This upcoming release adds the ability to ingest pre-curated tags or labels for a data set.
2.2.6 IBM Spectrum LSF Workload Manager
For the workload manager to create jobs, we use IBM Spectrum LSF and the Application Center. They provide a customizable GUI and act as the data scientist's interface to make requests for the data that is needed.
2.2.7 Description of the Audi Autonomous Driving Dataset
Audi published the A2D2, which can be used to support academic institutions and commercial startups working on autonomous driving research (for more information, see A2D2). The data set consists of recorded images and labels like bounding boxes, semantic segmentation, instance segmentation, and data that is extracted from the automotive bus. The sensor suite consists of six cameras and five LIDAR units, which provide 360-degree coverage. The recorded data is time synchronized and mutually registered. There are 41,277 frames with semantic segmentation and point cloud labels. Out of those frames, there are 12,497 frames that have 3D bounding box annotations for objects within the field of view of the front camera.
The semantic segmentation data set features 38 categories. Each pixel in an image has a label describing the type of object it represents, for example, pedestrian, car, or vegetation.
Figure 2-8 shows an example of a real picture compared to the segmentation picture.
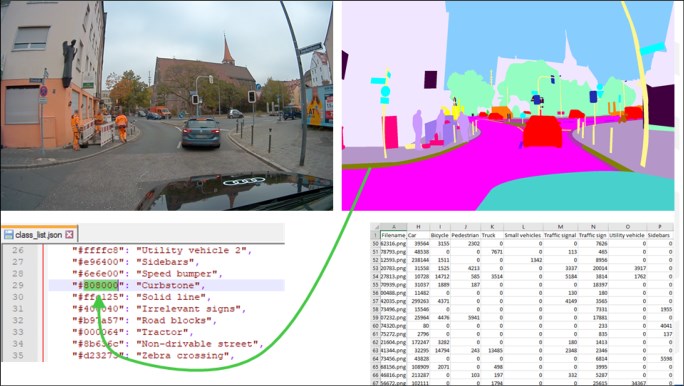
Figure 2-8 Real picture compared to the segmentation picture showing the color to label match
The data set was loaded into the different capacity tiers as follows:
•/camera_lidar_semantic/201811… and 201812… directories into the NFS storage
•/camera_lidar_semantic/201809… and 201810… directories into IBM Cloud Object Storage storage
•/camera_lidar_semantic/201808… directories into IBM Spectrum Scale / Archive storage
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.