
Chapter 2
Running data governance in four arenas

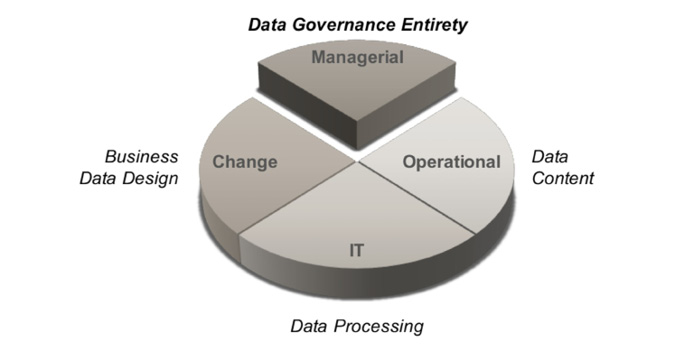
So, let us set the stage for data governance that runs on diplomacy. The stage is structured in four arenas:
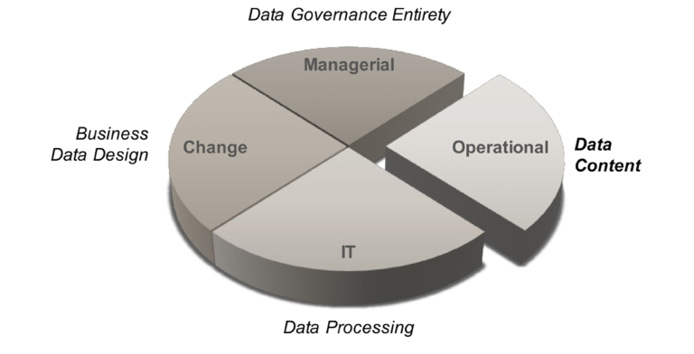
- The Data Governance Entirety arena is about how to perform data governance and architecture by setting the organizational prerequisites, roles and responsibilities, principles, strategies and plans. And, most important, to get things moving in a consistent way. It involves the CIO, the data governance lead, data strategists, lead data architect and possibly executive managers from various departments.
- In the Business Data Design arena, the business data is designed. It includes working toward a coherent business vocabulary and a consistent data structure throughout the organization. It also includes working to improve the business data design so that the organization can have the data it really needs. This involves the business representatives who take part in improving the data design assisted by business data architects. This is where the business’ metadata is formed, reviewed, decided and forwarded to be implemented in various IT solutions.
- The Data Content arena, where people or computers capture, use, amend, process and send the data. This could include any kind of co-worker, as everybody uses data in the daily business operations. From a data governance perspective this arena includes data workers that directly, or indirectly, take actions for data quality matters. Many requirements toward the data architecture and IT solutions are tracked in this arena.
- The IT arena, that is, the arena for data processing solutions. This where the IT capabilities are made and maintained. Many detailed decisions about data processing, storage and flow are settled here. Also, many inspirational innovations and insights can be elicited in this arena. Data architects in this arena work typically with designing solutions on a detailed level that are to be implemented into IT systems.
Each of the four arenas consists of different competence areas and perspectives. Different kinds of work are carried out in each arena as well.
Ideally, the work done in the arenas is well-integrated, preformed in parallel, and the competences and perspectives are mixed fruitfully whenever any data matter is resolved.
Any role can share or gain knowledge in any arena as important data matters occur in many aspects, perspectives and detail levels. One individual can perform activities in several arenas, but one individual person should not take full responsibility for more than two at a time as that person might create a bottleneck.
The arenas are illustrated as pies to emphasize that improving the company’s data is not an end-to-end process. Such processes suggest that there is a start and a finish, and, have defined points for handing over results. The concept of having data governance in arenas translates into ongoing knowledge sharing.
Constantly sharing knowledge and perspectives is a way to come to the best decisions about how to move organizational data requirements forward.
Regarding the four-arena image as a wheel, this wheel can rotate in any direction. There are however, different kinds of diplomacy jobs in the arenas since there are different goals and different kinds of roles in them.
Other data governance frameworks usually cover three of these four arenas. The missing piece in relation to this depiction of data governance, is the Business Data Design arena. The reason for this fourth arena is that the design of the business’ data is not an IT task. It is part of designing a business and thus it is a work for the business representatives. However, implementing this is an IT task. We should regard this arena as the data perspective in business innovation and business improvements, and not as a detail in IT work. From a diplomacy perspective, this is crucial.
The three lower arenas in the figure (data architecture, IT and data content), occur even if there is no formal data governance established. Data structures are nevertheless designed and computerized, while data content is nevertheless somewhat managed.
The description of the data governance arenas continues below, by going over what kind of work is carried out in each arena. In Chapter 3, the roles and responsibilities in each arena is described. But first, let us start with what the work is about and the purposes of the work in each arena.
Data diplomacy does not require a data governance organization. But it helps to have such an organization as it clarifies who to spend time with.
Sometimes, data governance is illustrated as a pyramid. But the pyramid shape can influence us to believe that this concerns the organizational structure when it is generally about competence and cooperation.
Meeting expectations for managing data
Everybody in an organization needs to meet expectations on how to manage data, as, again, everybody is a data worker, at least to some extent. The expectations include security, accuracy, and availability and other typical data governance objectives. The expectations vary with what kind of data it is, and also the context. The expectations are derived from mainly two kinds of sources: regulatory requirements and business requirements. Simplifying things, we can separate it into what the organization must do, and what it wants to do.
- Regulatory requirements are what you must comply with, such as laws, doctrines, and industry standards. Examples: Sarbanes-Oxley Act, GDPR, environmental legislations, and various reporting to authorities.
- Business expectations are what you need to fulfill or relate to, such as the market competition, employee attraction, innovativeness, agility, operational performance, contractual terms with partners and customers, and owner’s expectations.
These expectations are drivers for data governance. Any goals that are set for data governance are derived from these expectations.
Data governance does however not have goals of its own, such as “100% data quality”. Instead, data governance goals are always coherent or derived from the expectations related to how the organization manages its data.
An expectation may be “a customer’s claim on a product is to be resolved within one hour” which leaves no room for mistakes or unnecessary actions. The expectations on the data can then, for instance, include that the person who or the function that obtains the claim needs to capture all and only accurate data when a claim process is initiated.
To meet the organization’s expectations on data, data governance must include data architecture, which sometimes is, unfortunately, separated from data governance.
Working with data governance includes keeping track of both the metadata and the data.
The “data” is of course the business data, such as “23567” and “978-1-935504-63-4”. Metadata is “data that describes data” which in this case tells us that the first piece of data is a picking order number and the other is an ISBN number for a very good book. Data is means and results from daily business whereas metadata is a result from data design, traditionally carried out by data architects.
How data is designed heavily affects the ability to work efficiently with data; if data is designed poorly and implemented accordingly in the systems, the systems will obstruct daily work.
Metadata governance targets the data design including its definitions, structure, labeling, movements and some of the business rules. Data design is typically built into various IT solutions, into management systems, and tacit in people’s way of processing data.
To ensure proper data design, data architecting occurs in two data governance arenas; both in the Business Data Design arena, as a business design task, and in the Data Processing arena, as a solution data architecture task.
Governance of metadata and governance data require different kinds of skills, strategy, staffing and imply different kinds of outcomes. Hence, they need to form separate arenas. Metadata governance aims to meet expectations in
- proper data design, such as how data is defined, labeled and connected, and,
- how metadata is implemented in IT solutions,
whereas data (content) governance aims to meet expectations on business data correctness, security and availability. Below outlines a section describing each of the data governance arenas. The description includes each arena’s outcomes and how to work in each arena. Later, in the next chapter, this description is completed with the most important roles in each arena. There is also a separate section in Chapter 4 covering initiating data governance in a diplomatic way.
Working with the entirety
Working with the entirety of data governance means managing the data governance work as such, covering all four arenas. The data governance work needs to be planned, coordinated, staffed, monitored, and improved, like any other kind of operation. A vital foundation of the Data Governance Entirety arena is to define the data governance mission, practices, results, outcomes and the impact it is intended to have on the organization.
Working with the data governance entirety also ensures that data improvement work is carried out in all arenas in a way that suits various parts of the enterprise, their environment and the prevailing culture.
For example, people in the Data Governance Entirety arena cannot “instruct” everybody else on how to do things. That would be very invasive and coercive. Instead, the entirety work is about defining core principles on which data governance is based and helping people in other roles work using these principles.
This arena is deliberately referred as “entirety” of a certain reason. An organization is not autonomous but is a part of a network of actors. These actors interact by sharing data. For example, what happens far ahead in a value chain, both good and bad, may depend on what we do, or do not do. To understand the impact of what an organization does in the context in which it operates, access to data created and used by others is required.
The scope of the data for an enterprise is wider than the organization.
Staffing
Another vital part of this arena is to find people who can take on responsibility of data governance work. Finding these individuals is a challenge in itself. Convincing their managers to let their employees spend time on data matters could be an even harder challenge.
Find is the keyword, rather than appoint. In many cases, organizations have made ungoverned improvements because individuals have recognized the need to act more responsibly toward data. Some act this way because it is part of their job description; others do so simply because it is the best thing to do for the organization, their co-workers, the clients or customers, or other stakeholders.
Finding such individuals can give the organized business data improvement effort a flying start since these people understand the work involved and are committed to it. Recognizing them and acknowledging their contributions also provides a positive example to other people who want to do the right thing but may have perceived obstacles to changing their behaviors. This is referred as the Non-Invasive Data Governance5 concept.
Proactivity
An important task in this managerial arena is to set the agenda for data improvement work on an overall level. This means looking for “gravity” in the organization by keeping track of what important changes and challenges the organization is facing and how they will affect the organization, especially with respect to business data. Such important changes can include product or services development, mergers and acquisitions. They can also be changes driven by technology or regulations.
Being aware of bold up and coming changes enable an organization to be proactive about data governance work. Organizations usually take on larger changes by starting projects. In order to be proactive, roadmaps for data improvements and data governance roll-out plans should be integrated or included in business projects portfolios and IT portfolio roadmaps. Such proactive planning work is vital to ensure attention to the data aspect when things are changing.
Decision-making
Data improvement work always includes many decisions. There are data design decisions, data content decisions, security decisions, and many more.
An important part of the data governance entirety work is to settle the data decision-making. Data matters are a part of everybody’s work so decision-making needs to occur within many existing forums and decision bodies. But a few new data governance decision bodies may also need to be formed, especially within the design arena.
Notice that within the Data Governance Entirety arena there are no decisions made regarding data – it is not a goal of data governance to centralizing the data decisions to this arena. As stated earlier, data governance should not be a separate thing. Instead, it is about keeping track of what decisions to make, in what contexts these are made and which decision maker or decision body makes them. And, it is about making sure that certain decisions are made, and not postponed or avoided.
Keeping the data governance lean and fruitful means that decisions about data need to be made close to where those decisions have the most important effects, which is usually also where the best knowledge is. As some of the testimonies in the introduction show, decisions regarding data require tactics and endurance.
The diplomatic way to set up data decision-making is to engage the decision-makers in steps and approach them once there are data matters that need decisions.
Then it will make sense to the organization and be easier for it to take an interest in data decision-making. An invasive and not very diplomatic data governance approach would be an organizational-wide big bang introduction of data governance with a detailed matrix for making any and all data governance decisions. Such an approach would be based on too many assumptions about what to decide and how data decisions really are made. It would simply not work. First there must be something to decide upon. Start there.
Growing
The Data Governance Entirety arena is also about making the data governance work grow in the organization. Data governance work is not static. It changes with the challenges that the organization is going through. It changes as new problem areas arise. It changes as people leave the company and new individuals come onboard. Formal data governance roles can even be reduced, or partly withdrawn, when things are completely adopted or no longer relevant.
Data improvement work needs to advance, mature and widen into new areas. Doing so, it constantly and repeatedly needs to be justified and motivated. The Data Governance Entirety arena consequently relies very much on communicating.
Data governance is knowledge-work. It produces knowledge, it takes knowledge to do it, and the daily data governance activities are very much about gaining, using and spreading knowledge.
Knowledge-work is enriching. It is however also done manually as it is hard, perhaps even impossible, to automate. It is also fragile; knowledge is tacit and personal. Consequently, working with the data governance entirety is fun, slow and fragile.
Data governance management system
Because governance work is largely about communicating knowledge, there is a need for a lean management system as a tool for those who are engaged in data governance activities. It can for instance describe the way of working, and have a set of templates, presentations and reusable material. It can also contain data design results or a direction where to find such resources. Using the diplomatic approach, the data governance management system is not the first thing to do. Rather, this is something you form as you go along. It will be useful when data governance is well established and matured.
Enterprise data model
A part of the entirety work is to be aware of what kind of data there is. An enterprise data model is a way of doing that. An enterprise data model depicts the data entirety at a very high level. It provides a tool for coordination and planning, rather than a basis for something to be built on. Thus, it does not need to be 100% accurate from the beginning. If it needs to be reorganized, just adapt it. Just don’t attempt to work out something perfect from start. There are not necessarily many people who completely depend on an enterprise data model in the start-up phase of data governance.
Quite an important aspect is that the enterprise data model reasonably follows the normalization principles, meaning that one type of data only occurs once in the model. That will simplify the data design planning and avoid the risk of overlaps and redundant work.
Ideally, the enterprise data model has the following purposes:
- Overview of data design responsibilities. This is about allocating accountability of the business design outcomes. The enterprise data model is an excellent map for showing where the organization has applied data governance, and where it has not.
- Reference for relating the systems to business data. The areas within the enterprise data model are suitable to oversee what kind of data the systems are managing. This is useful when talking system landscape roadmaps with other enterprise architects.
- Coordination of specialized individuals involved. Both business-oriented and IT-solution oriented data designers tend to specialize in areas that can be mapped to the enterprise data model.
- Reference for business data design models. The enterprise data model serves as a content framework for data design outcomes, such as various diagrams, and descriptions.
- Coordination of planned initiatives. By linking planned or proposed to areas in the enterprise data model, it is possible to plan for which data and which data models should be reused. It also gives a good picture of which modeling needs to be done, which in turn can guide which individual specialists need to attend through the intersection of project portfolio management and enterprise data architecture planning.
With such a wide range of applications, it is obvious that the enterprise data model should not be too detailed, nor technical. It needs to be graspable, e.g. somewhere between 20 to 40 data areas, and be expressed in a language that fits into the organization’s nomenclature.
There does not have to be a single, perfect enterprise data model in an organization but it is helpful to have at least one high-level depiction of enterprise data. There may be other models that are made for other purposes than data governance and thus can be cut in different ways. For example, people within business intelligence may have a similar model that slices the enterprise data slightly different. The database creators may have a different domain division and an enterprise-wide comprehensive model for their purposes and to organize their models.
By being diplomatic in the data governance entirety, you can and should acknowledge that there are these other maps for other purposes. You should be interested in them and establish relationships for collaboration, even though you have responsibility for a different perspective. But there should ideally be only one overall model for each purpose.
Working with data design – change

Working in the Business Data Design arena of data governance is about having business representatives taking over the business data design responsibility from the IT professionals. Or, more appropriate, taking back the responsibility as it was probably not delegated to IT in the first place.
The business data design comprises of two aspects of data:
- Data at rest, meaning the name, definition and structure of the business data, and
- Data in motion, meaning the data flow and how the data is processed (such as corrected, aggregated, calculated and transferred).
When designing data, you need to start with the first aspect.
The business data design should be a product of those who design the business; those who design how the organization needs to work to fulfill its expectations. Designing the business data must however be facilitated by a business data architect who has the skills needed to ensure that the result is useful, for both business and IT professionals. The result is not something that can be implemented directly; it is rather a result for communicating business data requirements as a base for designing IT solutions.
This is a controversial idea for many. Probably because data storage design and integration design are regarded as activities within systems design. According to the IT doctrine, business representatives, or users, are not expected to be concerned about such things. Since my ideas about data design challenge the accepted doctrine, I’ll take some time to explain the detail.
Stepping aside from data design yourself, as a data architect, and instead helping business representatives design their data, is an act of diplomacy.
Data modelers or, even worse, databases designers have traditionally carried out business data design. The latter will of course continue to do so, because the process involves a degree of technical work. But the starting point of what the business data should look like must include the direct perspective of business people. One of the reasons is that there is no quality assurance of the business data structure in having IT professionals ask questions to business representatives, turn their back to them and then producing a detailed system design on their own, solely based on what the IT persons were able to perceive. Such procedure entails basing a design on secondhand facts with opinions and assumptions added.
A great deal of the dissatisfaction with IT systems has to do with the fact that the business data does not really fit into the systems design; important data may be omitted, the system’s data structure is not coherent with the reality and may be put in indecorous places, data is labeled confusingly, or, the data design may be outdated.
Insufficient attention has been paid to understanding and getting consensus on how business data looks, how it behaves and what the purpose is of having this data. It even happens that data storage structures come out as a consequence of the system design, as if it were the systems that raise the requirements on data processing, instead of the people who create and use data on a daily basis. Business representatives should not get stuck with systems based on poor data design. Instead, they should take an active part in data design so that data meets business requirements and appropriate system design decisions can be made based on those business requirements and knowledge of the data.
Business data design is about improving the data we have, and, it is about designing the data we do not yet have. Therefore, this is an activity of designing the business.
The business data design is preferably carried out in the earlier phases of change initiatives, for example, as part of scoping and business requirement work. So, instead of asking questions about requirements and then going back to the IT department and drawing data models, the actual modeling work should be done in workshops with the business representatives as active parties.
Succeeding in this, depends on having a number of pieces in place:
- The participants must learn enough about modeling techniques to understand the model they are involved in designing.
- The modeling graphics must be very simple and comprehensible.
- The design outcome must be understandable even by those who did not participate in the design process, that is, understanding in what way the design result will affect the business.
- The model must reflect how the business representatives perceive the meaning of the data, rather than how the data appears in systems.
- The modeling workshop conductor must concentrate on being a facilitator of the data design process, not a data designer.
- The modeling activity needs to stop before it gets too detailed. Generally, business representatives are satisfied when they understand what the data means to them, how it is related to other data and how it is labeled.
Facilitating business data design with representatives from separate knowledge areas, and consequently separate perspectives, is indeed an act of diplomacy in itself. Such a design process unites various interests, perspectives and roles around a business data design the entire organization will benefit from. There is a section in Chapter 4 dealing with conducting such a business data modeling workshop.
A successful business data design
Let’s start by clarifying what can be considered as a successful design of business data. Purely pragmatic, the result is a substantially normalized data model that reflects the business data structure and vocabulary from a business operational perspective. As it is the question of design, this result shows how things should look, rather than reflecting it as it is.
A successful business data design leads to a result that the business representatives see as theirs.
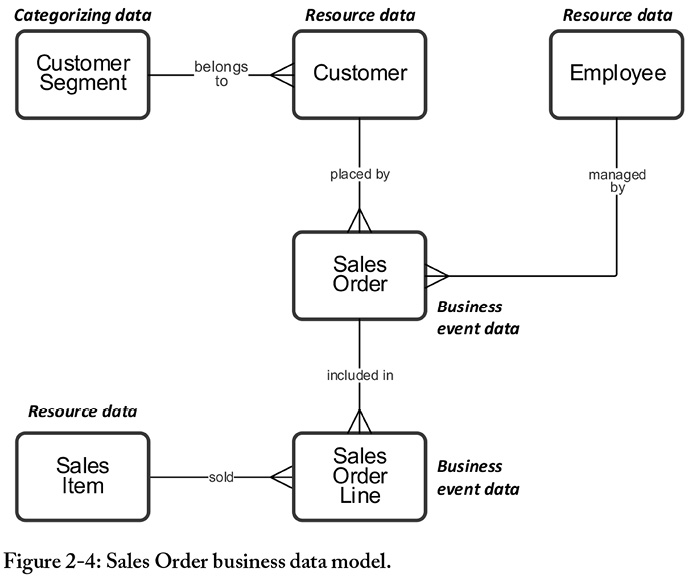
The model in Figure 2-2 is a simple example of a business data model that resulted from a workshop. It contains major entities (the boxes), how these entities are structured in terms of relationships (the lines between boxes), a few clarifying examples and maybe a few attributes that have turned up in the modeling process.
The crow’s foot symbol in the relationship line end represents a rule that describes the cardinality (one-to-one, one-to-many, etc.) between the concepts in the boxes. Note that when a one-to-many relationship line has a name, it reads from the many-side, called the crow’s foot side, of the relationship line.
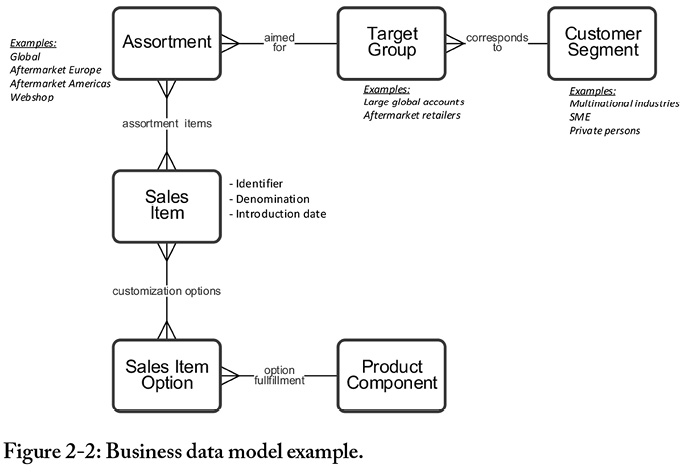
For instance, a Target Group corresponds to one Customer Segment, since there is no crow’s foot in the right line end. A Customer Segment may however correspond to more than one Target Group. (Don’t worry, I did not get this the first time, either.)
Simply determine if there should be a crow’s foot in a line end, or not. In business data modeling it is enough to determine whether two entities have a one-to-one, one-to-many, or many-to-many relationship.
Going further than this is to design systems for data storage and systems behaviors. Let’s save that for later.
There is surely a meticulous data modeler that sees limitations and unevenness in the model in Figure 2-2 and thinks “Shouldn’t there be a many-to-many between Target Group and Customer Segment?”, or, “Why don’t you generalize Target Group and Assortment making the concept last longer?” Thinking that way in this early stage might blow away the business’ engagement as it then will, again, shift the focus to data storage design, rather than keeping it on business design. A workshop modeling result must not be a perfect data architecture. It needs to have ample business design. The important thing is to decide what data means and how the data is connected.
- The focus should primarily be on the entities’ definitions, that is, what kind of data they represent. Express a few typical examples of the data to clarify the definition.
- Secondly, such a model should reflect how the entities are structurally related to each other, meaning what consists of what and what exists in the context of what in terms of “one-or-many”.
- Finally, there should be a working and acceptable business name for each entity. Strive to attain a name that will work in the entire organization, not just in one department. This avoids unnecessary misunderstandings caused by synonyms and homonyms.
This is quite enough for the business representatives to produce and agree upon. Going further would be too detailed. Consequently, a business data design activity should, at least initially, leave out the following:
Omit business rules and special exceptions, an exhaustive list of attributes, detailed cardinalities, and data flows in business data modeling. That can be clarified later. Figuring out all that detail would be a waste of valuable workshop time.
This is where diplomacy comes in: the architect who helps the business by drawing a model of their data must reduce her/his own standards for a successful and completed data modeling result.
As a data modeling facilitator, you need to distinguish designing data for business purposes from designing data from system purposes. Designing how a system manages data is something completely different from understanding and expressing how business data fits together.
Introducing business data modeling as a separate activity in a project requires preparation as it may encounter resistance. Some people may question why it needs to be done at all, especially since such a model is not part of the project’s final delivery. So, it needs to be proven that making a business data model early in a development work saves time and that, correctly used, it contributes to better project outcomes. This is indeed true.
Designing business data as suggested above is an investment in saving IT projects´ resources. It increases the stability of the requirements, as names and definitions of data are resolved early in the process. It clarifies the scope for the coming systems and the need for integration and provides a reference point for all subsequent project work.
I conduct at least one business data modeling workshop each week (at least half day long) and have done so since the late 1990’s. Some weeks there may be even three to four workshops. These workshops have basically been with just business representatives and we model their data together. I have at least 20 colleagues who have the same experience. So, those who claim that this cannot be done are simply wrong. It is easier than playing the violin (believe me, I have tried that too). And those who suggest that these kinds of models are useless can call me, and my colleagues, or our clients and ask if anyone wants their money back. I am happy to supply contact information.
Someone might ask, “Is this not just ‘conceptual data modeling?’” Well, what it is called is not really that important; it is what the business data model reflects and the process of making it that is important. The reason for not using the words “conceptual data model” here is because that those words are already taken. And there are many conceptual data models out there that are not the result of a data design process produced by engaged business representatives. Conceptual models are not useful for data governance, as they are usually not normalized enough. There are conceptual models having “Sales statistics” and “emission reports” without resolving what kind of data such reports contain.
When IT specialists dive into a data design that business representatives have achieved, they need to embrace the efforts and be curious about the business requirements. This is a change for those data architects who have the tendency to review, criticize and even correct other people’s models. The diplomacy approach does not only apply to those data architects who conduct business data design workshops; it must include the entire community of data modelers and data architects within the organization.
If a business data model lacks in anything – ask. If the model is not sufficiently comprehensible – ask. If it is not clear how the model should be used – simply ask. But do not reject a commitment and time spent simply because a data model does not meet a data architect’s perception of quality. Data architects simply do not have a monopoly on data architecture, nor data model quality assessment.
Embrace the progress of having business representatives in the data design front seat, instead of searching for modeling errors in their results.
A business data model is not ready for implementation. There will always be things left to model. There is still plenty of modeling work to do before a system can be implemented. And, as mentioned, the business data modeling process needs to stop in time to avoid the risk of having the model overworked and turned into systems design. Obviously, a solution architect will need to do the systems design, as this involves applying technical knowledge that business people are not expected to have.
Data architects are important and are frequently requested and consequently easily become bottlenecks. Having business representatives taking data design responsibilities can ease the burden of solution data architect’s research work, given that the process of data architecture is somewhat amended. It implies a business data architect with skills in working with different people than data architects normally work with today.
Using a business data model
A business data model can be used in several ways to support the other data governance arenas.
Uses of the business data model in the Data Content arena:
- The business data model can be used as a starting point for addressing formal accountabilities and responsibilities for data capture and availability.
- The data that an entity represents, referred to as an entity instance, is captured (or will be) somewhere by someone or something. Before the data design goes too far in the implementation, it is best to check how data will be captured in practice, by whom and in which context. New business data design often lead to changes in the business’ processes.
- If we have designed and established a vocabulary and definitions, they should also be implemented in the organization, where needed. It also includes wordings in management systems, documents and spreadsheets and, by extension, terminology when people communicate.
- The data will be enriched during its lifetime. Data will be added, and relationships to other entities will be established. This will be done by people or by computers. Either way, these steps and events need to be known. The business data model can be a starting point for understanding enrichments and the model will evolve as these are documented within it.
Uses of the business data model in the IT processing arena:
- The business data model expresses business requirements. Having the definitions and the vocabulary in the model enhances communications concerning requirements. (See “Fact-based business requirements” in the Toolbox chapter.)
- The business data model is useful as an input for further requirement work, such as data security, data constraints, data flow and functional requirements.
- Validation of requirements – ensuring the right requirements are set. For instance, by producing test data examples from various business scenarios that might arise.
- Verification of fulfillment of requirements at a commercial off the shelf (COTS) or a built system.
Uses of the business data model in the Data Governance Entirety arena:
- Putting the business data model into a repository enables reuse of knowledge in future and parallel projects. This may require some model management, for instance making new material fit into existing material. Ideally, existing models should be taken into account during the data design process and not afterwards.
- In order to achieve stability and significance in the design result, the structures, definitions and vocabulary may benefit from going through a review and approval process. This would pave the way for the common direction of essential data, such as master data. This, of course, requires an established data governance process, which we will come to next.
Getting the proper representation
Data crosses all kinds of boundaries. The same data, or the same kind of data, can cross organizational boundaries, and geographical boundaries, and thus also system boundaries. There are also boundaries constituted by people’s professions; there are specialized vocabularies connected with job types. A field service engineer, an accountant, a purchaser, or a manufacturing optimizer have separate specialized terminologies, which are not always consistent.
The work on designing data cannot therefore be done in an isolated part of an organization. It must always be linked to a context and existing data in order to be meaningful in more places than it appears. This insight is a vital part of the job as an enterprise data architect. As stated earlier, data architecture is, after all, not only a design role, but also a coordinating role, and sometimes also a facilitating role. A single enterprise data architect cannot her/himself take responsibility for the accuracy of all kinds of data design in the organization.
The solution is to ensure that a broad set of perspectives influences the design of business data. That means getting input from a range of people when designing data. The sample model in Figure 2-3, which is similar to the one a few pages ago, depicts Sales Items. That is, it answers the question, “What do we have for sale?” This is data that naturally needs relationships to other data. It is for instance related to product development data to understand what lies under the magic that we sell. Also, we need to relate what we sell to finance reporting. Furthermore, it is also possibly related to ordering, order execution, logistics and invoicing. Sales Item is typically core and widely used business data.
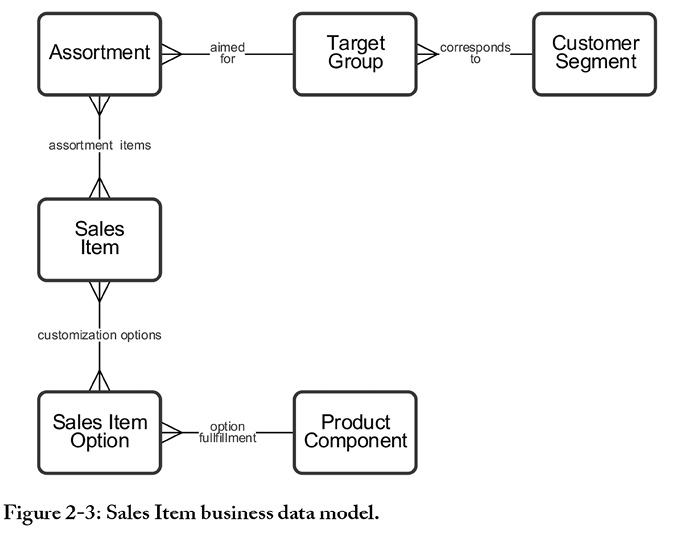
Thus, changing the definition, the attributes or the data range on Sales Item cannot be made in isolation. Ok, it sounds like we need to invite a lot of people to such data design activity.
When planning for a session that requires wide representation, there is a small trick: do a draft model to figure out what kind of related data must exist when a Sales Item, an Option and an Assortment is created. For example, there must be Product Components available, because otherwise there is nothing to make Options from. Okay, therefore, invite people who work where the Product Component originates from. If there is a hard and direct dependence downstream, such as sales order management, then it may be a reason to invite people even from there. This can be enough to carry out initial workshops and a first data design. After that, the result can be matched with representatives of other perspectives in shorter meetings.
Importantly, those who work where the data naturally appears must influence the design right from start.
The business data definition is applied where the data is originated.
This basic principle is very useful, understandable and unquestionable. It harmonizes well with the entire data diplomacy philosophy to get first-hand knowledge as a strategy for “doing things right from the beginning”. Always ask those who know, not just those who have opinions.
Getting a proper business data design is all about having the right people influencing the design.
Picture a situation where a sales rep becomes acquainted with a person at a marketing event. They talk about their purposes of being at the fair and discuss common interests. At some point, they exchange contact information and the sales rep makes a note of the meeting and a quick assessment of how this new relationship may evolve. If she or he thinks there are reasons to follow up the meeting for a possible future sale, the sales rep has unknowingly applied a couple of entity definitions. In that moment data for the entity “Sales Opportunity” and “Potential Customer Contact” is originated, and thus the definitions are applied at that moment. Just imagine having someone else other than the sales reps, such as an accountant, defining what “Sales Opportunity” is and relating data to it. Or a data architect.
Designing different kinds of data
All data cannot share the same data strategy, do not need the same attention, and do not require the same data governance ambitions. Consequently, depending on the kind of data, the investment in efforts and technology will differ. For instance, the following varied examples would require different kinds of activities:
- digitalize a frequent reoccurring manual process
- improve common master data
- improve business monitoring
- collect data from equipment remotely
- produce a report for management
- taking a note from a meeting.
These examples will all address different kinds of data, and, that will affect those who are active within data governance and their type of engagement.
As a diplomatic data design facilitator, you will benefit from understanding what kinds of data there are and how data governance should affect them. Having that understanding, you can explain what needs to be done and why to others. Giving people knowledge by teaching them new things is a way to gain trust and to have influence. The two following sections give guidance on how to recognize what kinds of data there are, and how these kinds can affect how you work with data governance.
This section deals with two ways of talking about different kinds of data:
- Data that has different kinds of lifecycles, such as long or short in a small or big volume.
- Data that is shared, and, data that should look alike, meaning, shared definitions.
Data lifetime
There are several ways to categorize data. Very often data is categorized by the data consumption, that is, categorized by who is using it, or, who is originating it. This is usually aligned with which system the data resides in, and, what department is managing the data. But this does not tell us very much about how the data behaves, that is, the lifetime of subject the data is reflecting.
Based on the lifetime, there are four distinguishable basic data6 types:
- Category data
- Resource data
- Business event data
- Detail operational transaction data.
This classification is vital to the planning of data governance and data design work since different types of data require different approaches. First, let’s define the data types by their lifetime.
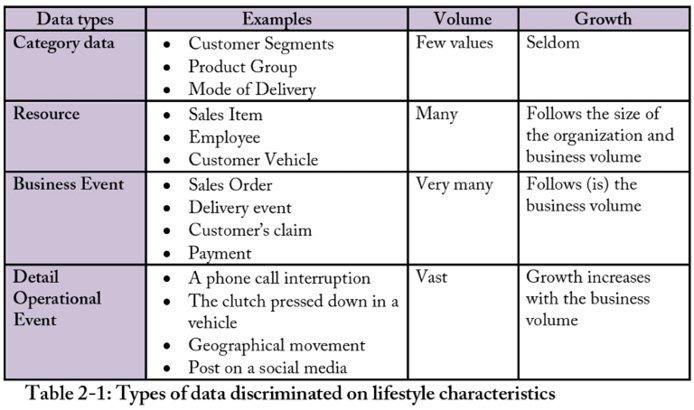
Let’s explain these four types of data from Table 2-1: 7
- Category data. Data used to classify and assign types to things. For example, customers classified by market categories or business sectors. Product categorization is another example.
- Resource data. Basic profiles of resources need conduct operational processes such as Sales Item, Customer, Supplier, Facility, Organization, and Account.
- Business event data. Data created while operational business processes are in progress. This type of data glues daily activities together into business processes. Examples include Customer Orders, Supplier Invoices, Cash Withdrawal, and Business Meetings.
- Detail operational data. These types of data are produced through social media systems, other Internet interactions (clickstream, etc.), and by sensors in machines, which can be parts of vessels and vehicles, industrial components, or personal devices.
The difference between these data types is the lifetime of the subject the data is representing. It is consequently, not how long the data is kept; a piece of data can be interesting and valid for a very long time for historical reasons. Rather, it is the lifetime of what the data reflects that is interesting. A business segment or a line of business (categories) may last for a century, a vehicle and an employment can last for decades (resource), a sales order may be processed in hours (event), and, a weather sensor can supply a temperature reading in a second.
Note that the definition of these lifetimes varies with the type of industry, or even with companies. For instance, the definition of resource data is not likely to be the same for a government, a bank and an online sales company.
The category data values seldom change. Within business intelligence these are often referred to as slowly changing dimensions. Categories always have something that is categorized, such as business segments to categorize customers and lots of other elements we wish to place in a segment. This data do not have a process creating them, in the way that most other kinds of data does; they are developed or fall into disuse as a business and its data grows. We, the humans, have a natural habit to simplify things through categorizing when things become complicated and overwhelming. Important category data can simply just occur.
Have a look at the business data model in Figure 2-4 below. The “Customer Segment” entity is a typical categorizing entity having maybe just four to five values. They may occur on external websites, in tons of spreadsheet files, in business warehouses, and in finance and ERP systems, among others.
There are a few important aspects when designing or improving category data:
- Data governance concerns the name and definition of each category value. The definition of a category includes the value range of the data being categorized.
- Reflect whether the category values are of company common interest – if so, they probably occur in lots of places already and may unfortunately take years to unify and cleanse.
The resource data is often referred as “master data”. Calling it “resource data” is simply because this kind of data reflects various resources. Resource data is traditionally the target for master data management and master data governance. Master data has however a wider definition than reflecting resources: “master data is the data we chose to manage in master data systems” which could be any kind of data.
There are a couple of important aspects when designing or improving resource data:
- Be sure to understand where the data is created originally. There is usually a process to establish this kind of data. Be aware that the human awareness about a resource is usually much earlier than it is put into systems. It tends often to take a quite long time in the process between something important has happened before the data is recorded. For instance, an employment can be offered and accepted at one point of time, and may be documented in a system days after, which is a quality loss.
- Business interests are often about the data definition, data structure, categorization and naming conventions. Just think of the perpetual discussions about the “customer” definition.
- Also, determine whether the data is of global/common or local interest (more about this in the next section).
The business event data is often referred to as “transactional data” among IT professionals. But “event data” is more encompassing. This kind of data reflects various business events and is not limited to transactions. Transactions refers to systems’ communications and is a much wider concept as any kinds of data may be transferred. As mentioned, this type of data is a business process carrier. A Sales Order for example, is typical business event data as it carries the execution of order management and keeps the sales order activities together forming a process. Business event data is typically the target for digitalization.
There are a few important aspects when designing or improving business event data:
- It always has at least one relationship to resource data. It connects the business process to data about the who, what and where of the process.
- Business event data always has important data about “when” things happen. A business event entity always has an important date attribute. Ideally there is data about “how” and “why”, too.
- Striving for standardized business data definitions does not necessarily imply standardized processes. The data structure needs to be designed so that it is neutral to how the process is performed. That way, process changes do not have to mean dramatic data changes.
The detail operational data does not have a generic name within IT, but this type of data usually adds up to what is called “big data” due to its massive growth in data volumes. This data is often produced by various devices, or, by large amounts of people who leave traces in social media, web visits, pods or blogs. There is an important aspect when designing or improving detail operational data. Business representatives should be able to influence how data in technical devices is architected. The data design in sensors, engines, portable devices are usually architected by the engineers constructing the technology. Without a business perspective, important contextual data can easily be missed which reduces the potential value of the data.
Figure 2-5 is an overview of the four data types.
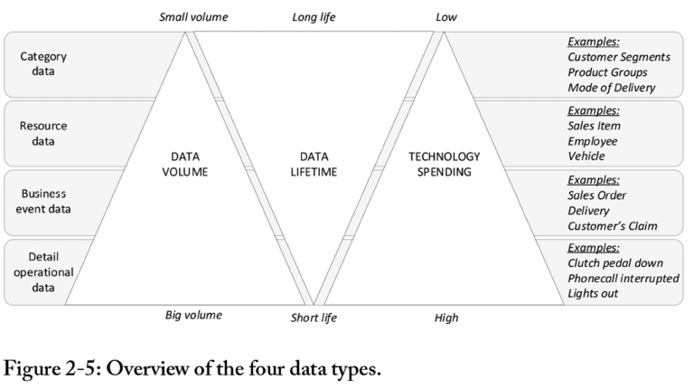
For each data type, the triangles reflect high and low data volumes, the long and short lifetime the data is reflecting, and the spending in technology. Most spending is put into digitalizing the business event data and detail operational data; we automate frequent processes and we control, monitor and log by introducing Internet of things (IoT) technology rapidly.
Applying modern technology to collecting valuable data we never had is indeed fascinating. But we cannot forget the category data and resource data, since ultimately, the business event and detailed operational data represents things that happen to resources of different categories.
Since we spend a lot on technology for fast and big data, manual work remains for managing small and slow data. Data governance is therefore very relevant in digitalization for enabling big data to become knowledge.
Common data and shared data definitions
“Sharing data” usually means two things: using the same data definition, and, using the same data content. These are two completely different things. In this section, we work out this and present a model for dealing, and perhaps negotiating with it. The model can be used for several purposes, such as:
- To determine what data should be shared or commonly defined.
- Settling differences in interest between central and local parties.
- Settling difference between data architects and business representatives.
- Consequently, setting the right limits for data sharing.
- A starting point for setting strategies for different kinds of data.
- Explaining and motivating such strategies.
Data sharing means that you are using exactly the same data. Data definition sharing means that you are using the same definition but not necessarily sharing the data.
Let us start with sharing data definitions. Using the same data definition means common terminology, data structure and thus the possibility of using a common system. For instance, two subsidiaries can share the same CRM system as they have a similar conception of “customer”, but do not need to share the data about activities regarding their customers.
Sharing definitions implies having a common vocabulary.
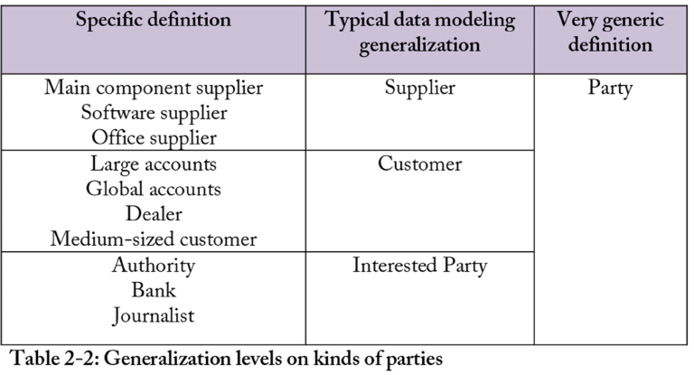
Architecting data includes defining the business meaning of the data. A part of the definition consideration is to determine whether the definition should be wide and generic, or, be specific. The designation assigned to the data, also known as the ‘label’ or ‘data entity name’, is usually the way to determine the definition.
In Table 2-2, there are a few examples regarding various parties a manufacturing company is interacting with.
A generic definition will include more data than the specific as it will include a wider range of data. Also, a very generic data definition will include more people and types of professions. Accordingly, a more specific definition will give meaning to fewer persons which is not very useful.
Nobody says, “Today I am going to have a meeting with a Party”. I will probably meet with a customer, a dealer, a supplier or a bank.
“Party”, the most generic example, requires subcategories. The data may need to be organized at several levels. Moreover, there are consequences with having too many generic definitions, and, also having too many specific ones:
- The more generic a data definition becomes, the fewer people will be satisfied with the definition and the labeling of the data.
- The more specific a data definition becomes, the less reusable it is and the more difficult it is to compare across data sets.
The advantage of generalizing is to cover more data in an IT-solution and thereby reduce costs. Data architects are therefore willing to generalize and handle specific definitions as categories and subcategories. But the reality is often more complex than that. To generalize means to simplify. Not only do IT systems need to be cheap, they also need to be able to provide support in complex contexts. It is therefore often a struggle between the architects’ willingness to simplify and the challenges of the business with complexity.
Let us move on to sharing data. Some data is common, other data is not. Data concerning sales items, the organization’s structure, customer segments and the profit centers are typically shared data. These kinds of shared data are also usually centrally created and managed in larger companies.
The opposite, the unshared data, is data that could very well be accessible but not of immediate interest to perform the daily operations. For instance, a meeting with a client implies data about who is meeting who and where, and, includes a calendar booking. Who uses this data except for the people attending the meeting?
Combining specific or generic data definitions, with high or low data share, we get four fields of data management situations. There is no good or bad here, just different challenges. This model is intended to be conferred when setting targets and strategies for how to cope with various data management challenges.

It is inspired by Jeanne W. Ross’s operating model8 covering process integration and process standardization. Like in Ross’ model, this model does not have a “magic quadrant”, indicating that one quadrant is better than the others. It is simply four directions that are described to simplify quite complex conditions.
Data centralization is about striving for high degree of data sharing, meaning, that as many kinds of data as possible should be accessible, usable and meaningful for as many as possible. We strive for common definitions and common data. The resource data of common interests (explained in the previous section) typically occurs here.
Data disparation is the natural behavior for ungoverned data9. Without guidelines, we do whatever solves our problems, as we are not aware of what happens simultaneously with other clients or at other plants. Data is locally defined, captured and stored. For example, a local unit uses centralized data for sales items and financial terms but captures disparate data for everything that is unique in that unit’s environment. What happens in local businesses can however be of central interest but because the data is not defined generically and is not shared, it is very hard to compare it to and relate it to other data. Disparation is not only caused by geographical distances, it is commonly caused by organizational units or professions.
Data design standardization is about using standardized definitions without sharing data. In this situation, the definition of the data is standardized regardless of what process it is used or captured in, or wherever the work is performed. The standardization of how the data looks enables central monitoring and reuse of supporting IT-system, even if two local offices or two parallel processes do not share their data. This is very useful when having replicated local units, such as retailers and local service units.
Data unification is about everybody using the same terminology and data definitions and sharing the data. Data may be captured centrally or locally. Processes are enabled to be fully integrated. This usually works well for some of the financial data, like the general ledger. It can also include global customer contracts, legal data and common regulations. The ambition to put everything in this corner is often the enterprise data architect’s dream. It is also very rare to have it like that, unless you are very small organization.
A classical direction for data strategy is to keep a combination of data centralization and data standardization. Typically, this means having selected category and resource data centralized and mastered, and business event data locally captured and for local eyes only. This model can be used for forming data strategies, such as deciding what kind of data should be managed according to what quadrant. Such discussion could include sharing data and definitions in central, global and local management, data crossing organizational borders or professions, or, any combinations of these.

Working with this model can bridge differences between business and IT, and between local and central management.
Working with data content – operational
The Data Content arena concerns the data as such, and not the metadata or data models. In this arena it is about managing the business data as a part of the daily work, or rather, managing data is usually the daily work.
Data content management is sometimes confused with data quality management. Data quality management is an extensive topic with lots of theoretical models and approaches, all aiming for the same goal: reaching high data quality according to data quality measurement specifications.
In this diplomatic approach to data management, the “data quality” topic is rationalized and simplified:
Your job includes data. Simply do your work as it should be done and the data you create will be of high quality. Improve it, if needed.
There are those who suggest that data quality rates are the ultimate measurement of the success of data governance. That cannot be true. The only thing that such measurement indicates is the success of data quality efforts.
Data quality is not a measure of its own right. It is a performance indicator that needs context. Data quality rate can however be used to estimate operational efficiency.
Data supplied to other parties and data stored and made available for use are however expected to be correct, complete and consistent. Not only for regulatory reasons but also for safety, contractual and efficiency reasons. That means that there should be quality checks in data flows or workflows. But it does not imply that all data needs to always be 100% correct and complete everywhere.
The diplomatic approach brings a few messages in the everyday data content management context:
- Nobody is called a data manager. Very few claims to work with data content. A construction engineer and a salesman do not see themselves as data content managers. Yet, almost everyone is a data manager working with data content.
- Regard data capture, data improvement and data availability as a natural part of work being done. Thus, integrate the data quality perspectives whenever doing work improvements instead of having separate data quality activities.
- Reduce risks for data quality shortcomings and improve the workflow efficiency by enhancing the “I” in “IT-requirements”.
- Cooperate with entity managers and data architects when defining data requirements for IT systems. They have much to contribute.
- Organize the data improvement work by applying a few useful principles instead of focusing on separate data management roles.
Data content real-life cases
Here are a few real-life cases describing how to do data quality work pragmatically:
- Ove oversees product documentation at the product development department in a global industry. His team is managing product data that is provided for sales, logistics and manufacturing product data. “We know we have some data quality shortcomings in our product construction structure database. Some items are outdated, and some bill of materials are inconsistent. But as long as nobody suffers from this, we won’t spend time correcting it.”
- A key account manager in the same company as Ove keeps track of and logs his sales activities in a CRM system where he also constantly updates the predicted value of the sales opportunities. He is aware that the accuracy of his forecast figures is questionable. And, there are some performed sales activities that are not recorded in the CRM log. So, that kind of data, which he is the obvious originator for, is neither always correct nor complete. However, each piece of data in the customer contracts is 100% accurate, simply because the expectations on that data quality is much higher.
- Eva works at an IT services desk in a bank’s back-office function. One of her tasks is to manage user accounts. They have many older systems that do not work with modern user catalog services for single sign-in so some user administration needs to be managed manually. Since it is a bank, user authorization is indeed important, both for enabling employees to carry out services and to prevent misconduct by the bank’s employees. As things are supposed to work, every time there is a change in an employee’s job function, the user authorization needs to be immediately amended. Especially when someone leaves the company, the access to the systems must be revoked directly. The problem is that Eva is not always informed when people quit or when their responsibilities are reduced. Many attempts were made to fix this, mostly by trying to straighten up the procedures when an employee leaves, such as introducing checklists of what to do. Automating this was not feasible as the criteria for reducing accesses could not be defined in a deterministic way. The pragmatic way to solve it was having Eva take charge of quality checks periodically. Every six months, each department manager checked the job function of their staff against a list of employees’ accesses to various systems. Eva provided the list and updated the access based on the result from the checks. So, the pragmatic way was to accept a portion of low data quality for six months. This was easier than trying to induce people to report every change in the workforce as they occurred.
Data content management principles
As shown in the various examples above, it is not possible to form a generic process for keeping data accurate. How this process is applied in each case depends on what kind of data it involves and what degree of accuracy is expected, desired or required. This is where data governance can easily become a bureaucracy.
To avoid that, principles can be used instead of attempting to form heavy data quality procedures. These principles can, in turn, be used to form procedures for a management system, job introduction or form IT-requirements to support systems. There are, of course, cases where rigid data controls and checks are required. But getting things right and efficient can be accomplished using principles.
Principles are based on values. Business rules are based on principles. Stating principles can thus be a way to simplify things.
Data content management principles include:
- Trusting people
- Always the right data from me
- Capture data close at the spot-of-origination
- Opportunity is power.
Trusting people is a part of the diplomatic approach. In data content management you assume that employees want to and strive to do their work well. Doing things well includes doings things well for more than yourself. It is also important to do things well for people who are depending on what you are doing.
“Always the right data from me” is a pragmatic principle based on the assumption that nobody wishes to create issues for others. Everyone takes the responsibility of always delivering correct and consistent data to downstream activities. A giant furniture company resounded this principle throughout its organization and consequently gained a notably improved performance.
The principle of “capture data close at the spot-of-origination” definitely applies to data content management. Everything else than data at the source is secondhand knowledge and thereby a quality risk. Close to the natural source of data means:
- where the data is naturally created first, as a result, or a log, of an activity in a process. Examples include a customer asking for a quotation, and the quote provided.
- where it is discovered for the first time, such as measured. Examples include a measured volume of fuel in a storage, or the weight of a newly developed product.
- where it is determined, as in a result from a decision. Examples include the acceptance of a vendor’s offer, the setting of a maximum load weight, and the determination of the sale price of an item.
- where it is processed, not just aggregated (manually or automatically), but with judgments added to it. Examples include forecasted sales figures and a production plan.
This means that, with all the best intention, the person entering data into a system should preferably be a part of the occasion, or the event, when the knowledge arises and consequently can be captured as data. Putting it on a piece of paper and handing that paper to another person is begging for quality risks.
Following the spot-of-origination principle for capturing data derives from another principle: assigning accountability for data.
The accountable for data content is a manager of those co-workers who are responsible for capturing data at its point of origin.
Another principle is “opportunity is power”. Anyone who discovers something bad should be able to fix it immediately. If it cannot be done, then at least the responsible person is notified. Everyone contributes to making everything better and does not neglect something important. The habit of neglecting issues and errors is fatal to the overall performance.
Again, having a diplomatic data governance approach is not narrowed to avoiding errors. The starting point for securing data is therefore not a rigorous control system where someone checks what others have done. Rather, it is about providing employees and data suppliers with high quality standards, with the support they need and trusting people. Quality systems are usually designed to find errors. The diplomatic approach proposes that it should be easy to do things right in the first place.
Data quality is not equivalent to the absence of errors. Achieving high data quality is meeting expectations. Therefore, achieving expected data quality should be about how we do the right thing. Not about avoiding doing wrong.
Working with data processing – IT

A great deal of demands on IT solutions crop up in the Business Data Design arena and the Data Content arena. These become requirements that are expected to become reality in the Data Processing arena. This arena is where blueprints, such as data models, become constructions. This is where the detailed requirements are defined and implemented into systems, which will have an impact on daily work for the rest of the organization.
If the other arenas are working properly, the chances of doing things correctly right from the start within IT increase tremendously.
If the other arenas manage to come up with consistent and coherent results that can bring value to the organization, it should be just a walk in the park for IT to implement these. Now, why is that so?
“How hard can it be?”
As mentioned earlier, a great deal of the dissatisfaction with IT systems has to do with business data not fitting well into the systems design. One explanation is that insufficient attention has been paid to understanding what business data looks like and how it behaves. A major goal of the diplomacy approach is to fill that gap.
It is, however, quite understandable why IT professionals do not take time enough to analyze what business data looks like. Just consider what characterizes “good” system development. By “good” we usually include accurate functions, technical robustness and high tolerance of user misuse, which of course are all important. But it makes the programming profession devoted to write codes that is able to cope with any possible exceptions. This is where the largest workload lies.
Thus, some system requirements are about what a system should do, but even more about what it should not do. The business representatives usually have their greatest interest in what a system should do and how that would improve things, while system builders spend most of their time on what a system should not do.
Furthermore, the goal for IT professionals is to supply suitable IT solutions. The motivation for business people taking part in data design and data content management is to have better support for the business data in order to meet expectations in the organization.
The first step to diplomacy is to understand, and then acknowledge, that we have separate motivations.
Typically, neither side sympathizes with, or tries to understand, the other perspective. Business representatives often regard IT work as slow; “I know what I need. It is not that complicated. How hard can it be?”
IT professionals, on their hand, often refer to people that work in the operations as “users” who act inconsistently and do not always know what is best for them. “We constantly get conflicting requirements from different departments. And then the requirements change. Just figure out what you want. How hard can it be?” This is of course an exaggerated and prejudiced description. But still not unusual.
When there are separate motivations, there will be differences. Where there are differences, there will be conflicts. Hence, diplomacy is needed.
There is consequently a need for data diplomats to act as intermediates between business and IT.
Both sides are, however, often united in the pressure of reducing costs. Unfortunately, that fuels further problems. When there are cost reductions in the daily operations, there are usually reductions in manpower, which calls for more automated work and investments in efficiency. Meanwhile, if there are reductions in IT spending, there are not enough resources to automate and invest in efficiency.
Improvements in operations are however not only achieved through new systems. There is much to be gained by consistently having the right data and thus reducing unnecessary work. The Data Content arena overcomes that.
Getting the most out of IT investments is basically about the same thing; making sure to do the right thing from the start. The Business Data Design arena addresses that.
The Data Processing arena also considers how those who buy, build and integrate IT solutions can cooperate with business data designers and business data content workers.
Benefits for IT processes
The demands on how systems need to be improved become more clear, pragmatic and distinct when you have well-organized data content work. Without this, situations can be cloudy. IT professionals work on detailed levels and need to understand exactly what is wrong with the system if they are to address issues. The conversation may otherwise be very undiplomatic:
“The system contains bad data.”
“So what? Just stop putting bad data into it.”
A person actively responsible for data content and knowledgeable about business and technical processes can often get insight into the kinds of improvements that will reduce errors. Such a person may express demands in a more diplomatic way:
“We can reduce manual data entry checks in system A if the system would do a consistency control against system B. Also, if the system could make sure that the field NNN is not left empty, we would reduce hundreds of unnecessary phone calls each week.”
These are suggestions and not complaints. They center around the data, and, there is a small business case motivating the suggestions. And, these suggestions do not blame anyone for buying or building a bad system. They merely observe how to make the system better.
A diplomatic example
A recent case shows how dissatisfaction with IT gave way to thinking in new directions resulting in a win-win situation. It took place at a utility company whose infrastructure grows by close to 10% annually. The company tried to keep its network documentation up to date. It had a brand-new IT-system for network documentation and a small group of full-time employees to keep the documentation up to date. They were provided with data by the field installers who sent in notes and drawings of what they had built. But the documentaries complained that the system was hard to use, especially given the large volume of information they had to document. There were very many hearty complaints about the system as the stress of having a constantly increasing backlog grew.
An expert who analyzed the situation, saw that the reason for the system being perceived to be sluggish was because the documentation required was actually quite extensive. The solution was however as elegant as simple. Instead of letting the documentaries do all the documentation, they let the installers do it in the field. This simplified the process and enabled data capture at the point of origin. The field people were already at the source of the data, so the quality of the documentation also improved. The system came to fruition as this was how it was built. The documentaries went on to support the field workers with their work. The problem was that they have acquired a new system but had remained with a process optimized for paperwork. In this case, there was dissatisfaction with IT but a process improvement created two winners.
Introducing data diplomacy in the IT arena
In the IT arena it is indeed important for data governance representatives to have a service-minded attitude. Data governance representatives can easily be regarded as authorities and fault-finders instead of guides and knowledgeable resources.
Bridging the business data architecture with IT solutions, data architecture implies that bridging normally goes two ways. That bridge can hence be used in both directions. There is a lot to learn from experienced solution architects. There is a lot to gain from having well-organized data management work as an input to, or a part of, IT work. Following the principle that “data governance is not a separate thing”, the IT side also needs to be prepared for such an engagement. Below are some diplomacy features that make life easier to fulfill the data governance intentions.
When everything is working well, this is how it is done.
- We include data perspectives when planning IT. That means that every IT project or IT activity is well aware of what kind of data it is about to take on. This can be made possible by having each project portfolio using the enterprise data model to show what data is targeted, improved and used. Data is a part of a project’s scope.
- An IT project hosts Business Data Design arena activities. Business data modeling is done as a part of understanding and clarifying business requirements.
- IT professionals can distinguish between business design data models and IT-solution data models. Both kinds of models are most likely produced in the same project.
- IT professionals embrace business design data models.
- Data migration toward new business data design is a part of IT projects’ deliverables.
- Data content responsibilities for new data business design is also a part of IT projects’ deliverables.
- The IT solutions are mapped to the business data models verifying the outcomes from the projects.
- Data models are stored to be reused in other projects and in IT maintenance. All changes in reused models are updated. If a model is governed, the changes are also approved.
In addition, many insights from business data management are useful for IT on almost any level, such as:
- overall enterprise architecture matters such as determining what data each system should manage,
- integration considerations including what and how data should be transferred and consistency checks between systems,
- authorization and security, like who should do or see what,
- detail requirements such as automating data checks for reducing data errors.
Many frustrated data modelers have spent a huge amount of time with business representatives to come up with an excellent model. But, since they have not spent time with the IT teams who will implement the model and did not prepare them for how to use the model, the implementors skip it and re-do the whole thing from their perspective.
Given these conditions, a diplomat can face many challenges in the IT arena. For instance, it is common to have a solution architect on an IT project. That person is focused on the project’s results. Enterprise architects keep the entirety in mind; the entire organization’s data including the data in value chains and end-to-end processes. Sometimes, these two perspectives are on the same track, but sometimes they only meet occasionally at the same spot. So sometimes they are enemies. For the same reasons, a solution data architect can come into conflict with an enterprise data architect on how data design should be implemented.
There are a couple of typical reasons for this. First, it is a symptom of having disparity in requirements from business representatives. If this occurs, they could be fighting someone else’s war. The working methods in the business design arena try to impede this.
Another reason is that data architecture concerns often appear too late in the project. When data design is done by architects, and not modeled with the business representatives, at least one of the two architects has got things wrong. Maybe both.
Making agile methods diplomatic
When agile methods came about, retrospective architecture meetings also came about aimed to ensure architectural compliances and to keep control of the ongoing projects. Such meetings are often an inheritance from project gates, which are quite popular project management tools. The project’s results are controlled, checked against agreed standards and sometimes questioned in such architect’s check-up meetings. Every check that does not pass will result in a change request in order to meet the architect’s standards. Those kinds of meetings tend to be reactive, formal and sometimes picky.
The whole purpose of these gates and reviews is to keep the system landscape consistent and coordinated. The only way of achieving that is by closing the knowledge gaps. It does not have to be undertaken in a reactive way.
As an act of diplomacy, these could instead be prospective meetings. This means introducing all the relevant business data models to the projects in the early phases and indicating where to find everything they should be aware of. That means that requirement analysts, project lead architects and the solution data architects can have the correct knowledge from the start by reading and digesting things that have already been settled. Closing the knowledge gaps like that save a large amount of time.
Additionally, there is a possibility of reducing heavy change request processes. Digging into models and enhancing them leads to more insights, which in turn can be reasons to change existing systems.
A change request process concerning an existing system can include many roles commenting, granting or preventing changes. Having all four arenas represented can provide a shortcut; simply include the people who are concerned from the other arenas and discuss the matter as soon as a potential change is encountered. This could resolve the matter easier and quicker. If a change is required, the change request will be much better prepared.