
12.2 Architectures for a Distributed System
Factors the designer of a DDBS must consider in choosing an architecture include data placement, the type of communications system, data models supported, and types of applications. Data placement alternatives differ in the amount of data replication they permit. Each alternative dictates a different type of system, using different update and query decomposition procedures. Various data models and accompanying manipulation languages are supported in distributed systems. In general, a designer should avoid models that use record-at-a-time retrieval and choose instead those that allow set-level operations because of the number of messages that are required for programmer-navigated retrieval. In considering the types of applications to be performed against the chosen database, the designer needs to estimate the size of the database, the number of transactions, the amount of data the transactions require, the complexity of transactions, the number of retrievals relative to the number of updates, and the number of transactions that refer to local data as opposed to remote data.
12.2.1 Distributed Processing Using a Centralized Database
In the architecture shown in FIGURE 12.1, the database itself is not distributed, but users access it over a computer network. Processing can be performed at multiple sites, using data from the central database site. The central site also does processing for its local applications and for some centralized applications. Local sites communicate only with the central site, not with one another, when they access data from the database for processing.
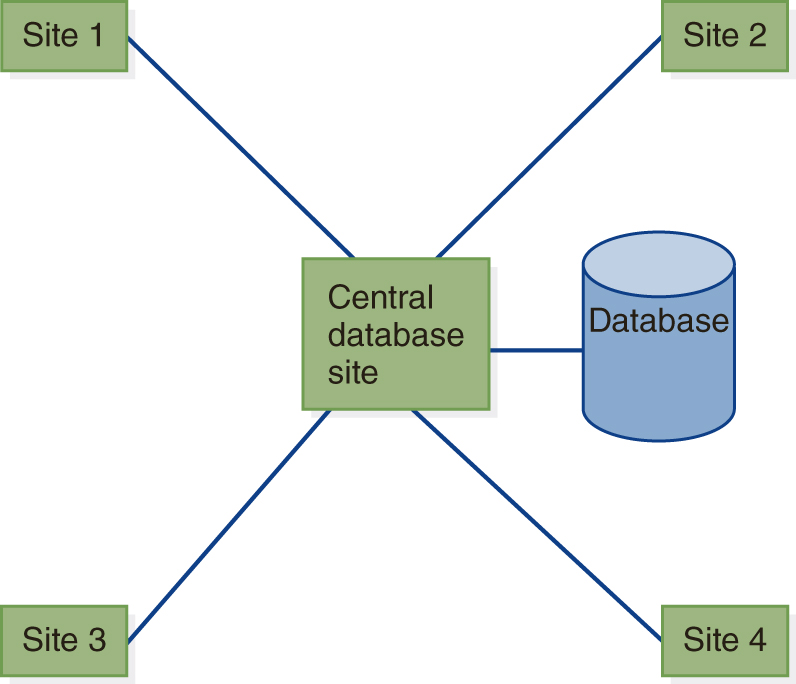
FIGURE 12.1 A Distributed Processing System
12.2.2 Client-Server Systems
In client-server systems, as shown in FIGURE 12.2, the data resides on a server, which may be either a transaction server or a data server. Users typically access the data through their own systems, which function as clients. The database functions are divided between client and server.
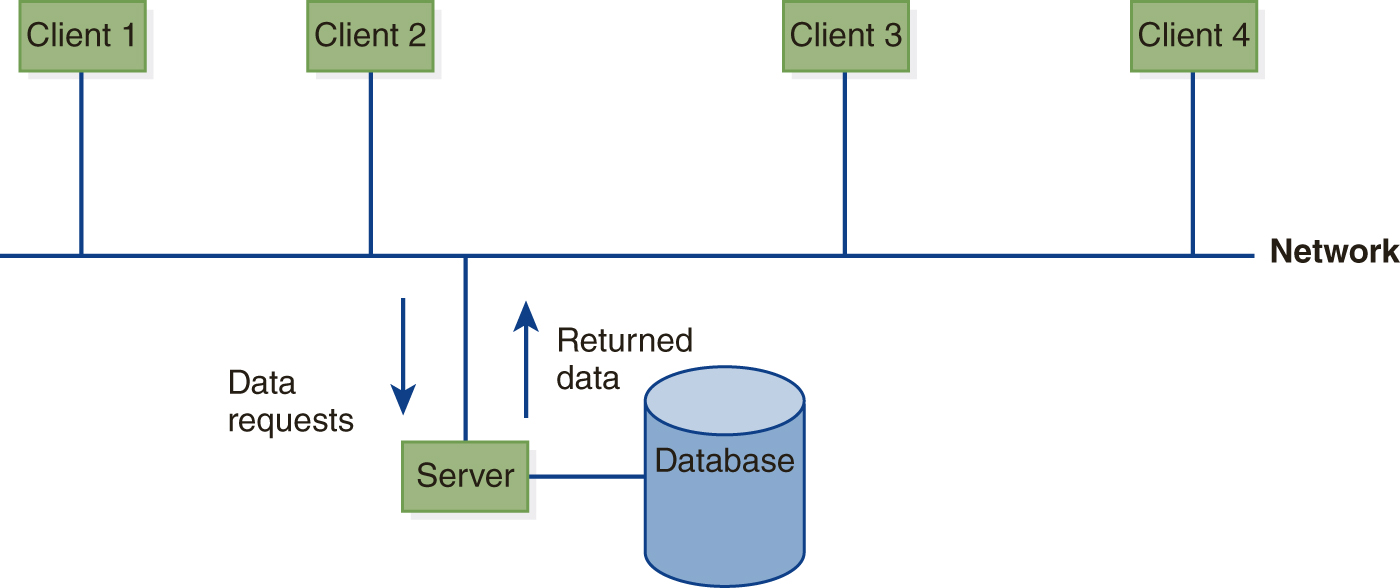
FIGURE 12.2 A Client-Server System
A transaction server is also known as a query server or SQL server because it is often used for relational systems. The client provides the user interface and runs the application logic, while the server manages the data and processes data requests. In a typical interactive transaction, the user interacts with the client system, using a graphical user interface provided either by the database system or by a third-party vendor. Besides handling the application logic, the client performs initial editing of data requests, checks the syntax of the request, and generates a database request, which is sent via the network to the server, using a remote procedure call (RPC). The server validates the request by checking the data dictionary, authorization, and integrity constraints; optimizes the query; applies concurrency controls and recovery techniques; retrieves the data; and sends it back to the client. The client presents the data to the user. Application programs also run on the client, passing data requests through an Application Programming Interface (API) such as Java Database Connectivity (JDBC) or Open Database Connectivity (ODBC) to the server in a similar fashion. Unlike the centralized database environment, the server does not do any application processing.
A data server or data storage system typically stores data in a nonrelational format, such as object-oriented (OO), XML, JavaScript Object Notation (JSON), semistructured, or unstructured. Clients acquire data items from the data server, process them on the client side, and send any modified data back to the server. To control concurrency over multiple clients, the server issues locks to the client for the data items it ships. Both data and locks can be cached by the client. Before reusing cached data, the client checks for cache consistency, sending a message to the server to ensure that the data has not been modified and to request a lock if necessary. For cached locks, if a second client requests a data item locked by a client, the server, which keeps track of cached locks, can call back a lock from the first client.
12.2.3 Parallel Databases
In a parallel database architecture, there are multiple processors that control multiple disk units containing the database. The database may be partitioned on the disks, or possibly replicated. If fault tolerance is a high priority, the system can be set up so that each component can serve as a backup for the other components of the same type, taking over the functions of any similar component that fails. Parallel database system architectures can be shared-memory, shared-disk, shared-nothing, or hierarchical, which is also called cluster.
In a shared-memory system, all processors have access to the same memory and to shared disks, as shown in FIGURE 12.3(A). The database resides on the disks, either replicated on them or partitioned across them. When a processor makes a data request, the data can be fetched from any of the disks to memory buffers that are shared by all processors. The database management system (DBMS) informs the processor what page in memory contains the requested data page.
In the shared-disk design, shown in FIGURE 12.3(B), each processor has exclusive access to its own memory, but all processors have access to the shared disk units. When a processor requests data, database pages are brought into that processor’s memory.
In shared-nothing systems, each processor has exclusive control of its own disk unit or units and its own memory, as shown in FIGURE 12.3(C), but processors can communicate with one another.
In hierarchical or cluster architecture, systems made up of nodes that are shared-memory are connected by an interconnection network, as seen in FIGURE 12.3(D). The systems share only communications with one another, making the overall intersystem architecture shared-nothing.
FIGURE 12.3 Architectures for Parallel Databases
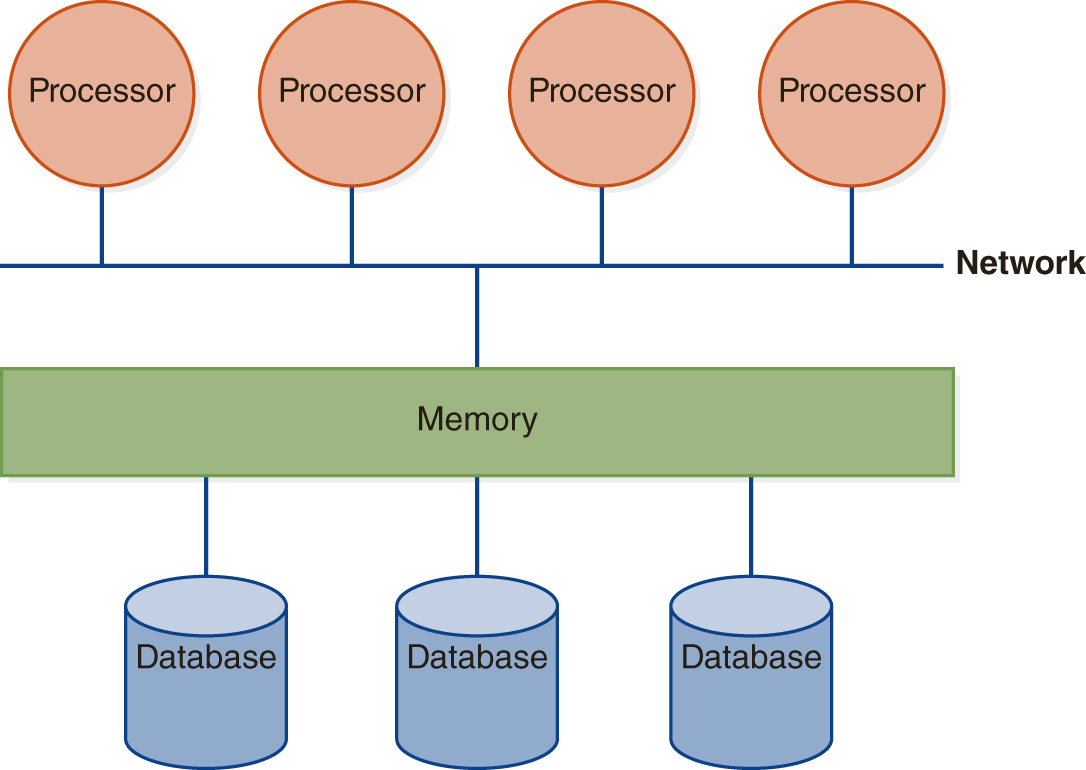
(A) Shared Memory
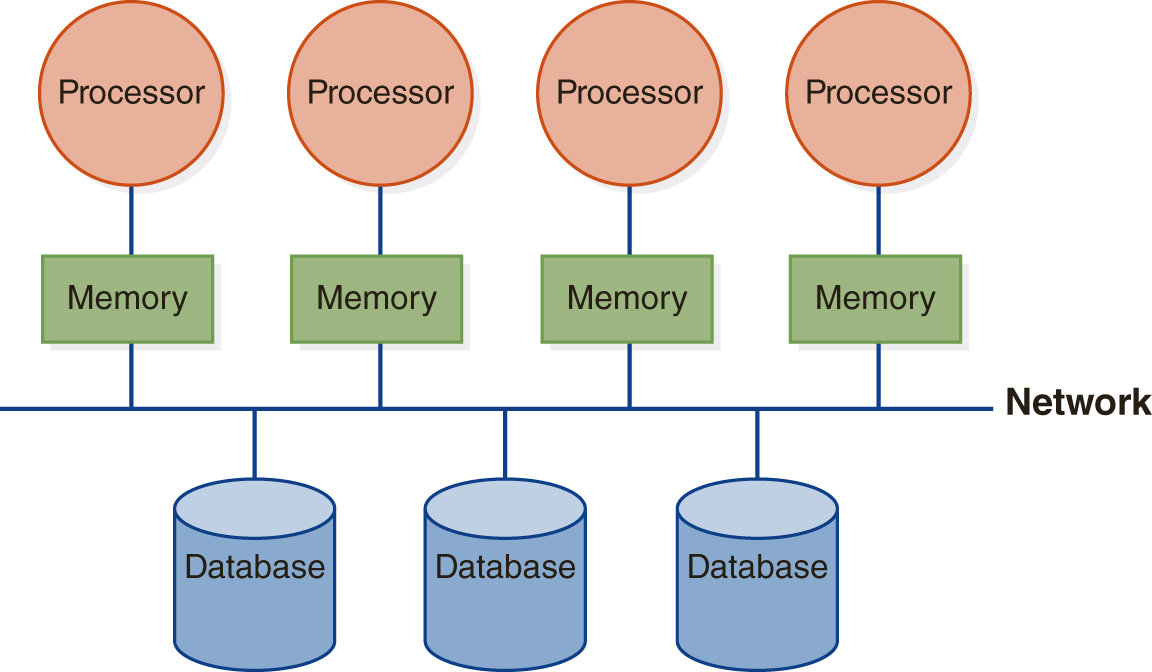
(B) Shared Disk
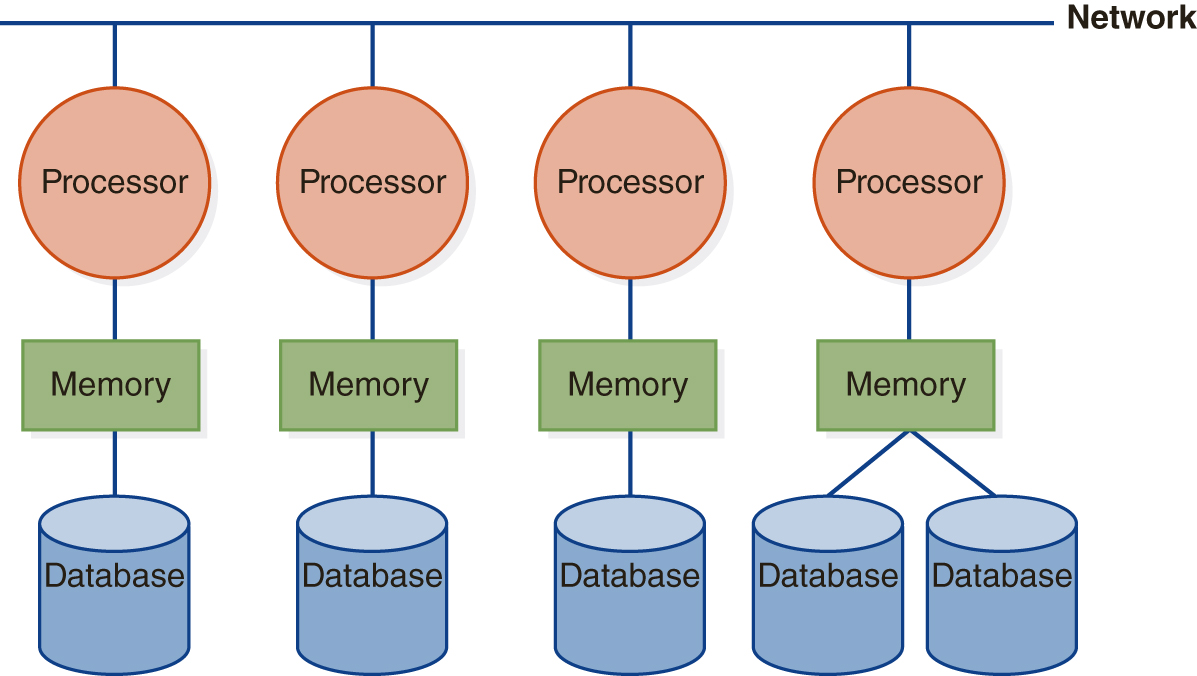
(C) Shared Nothing
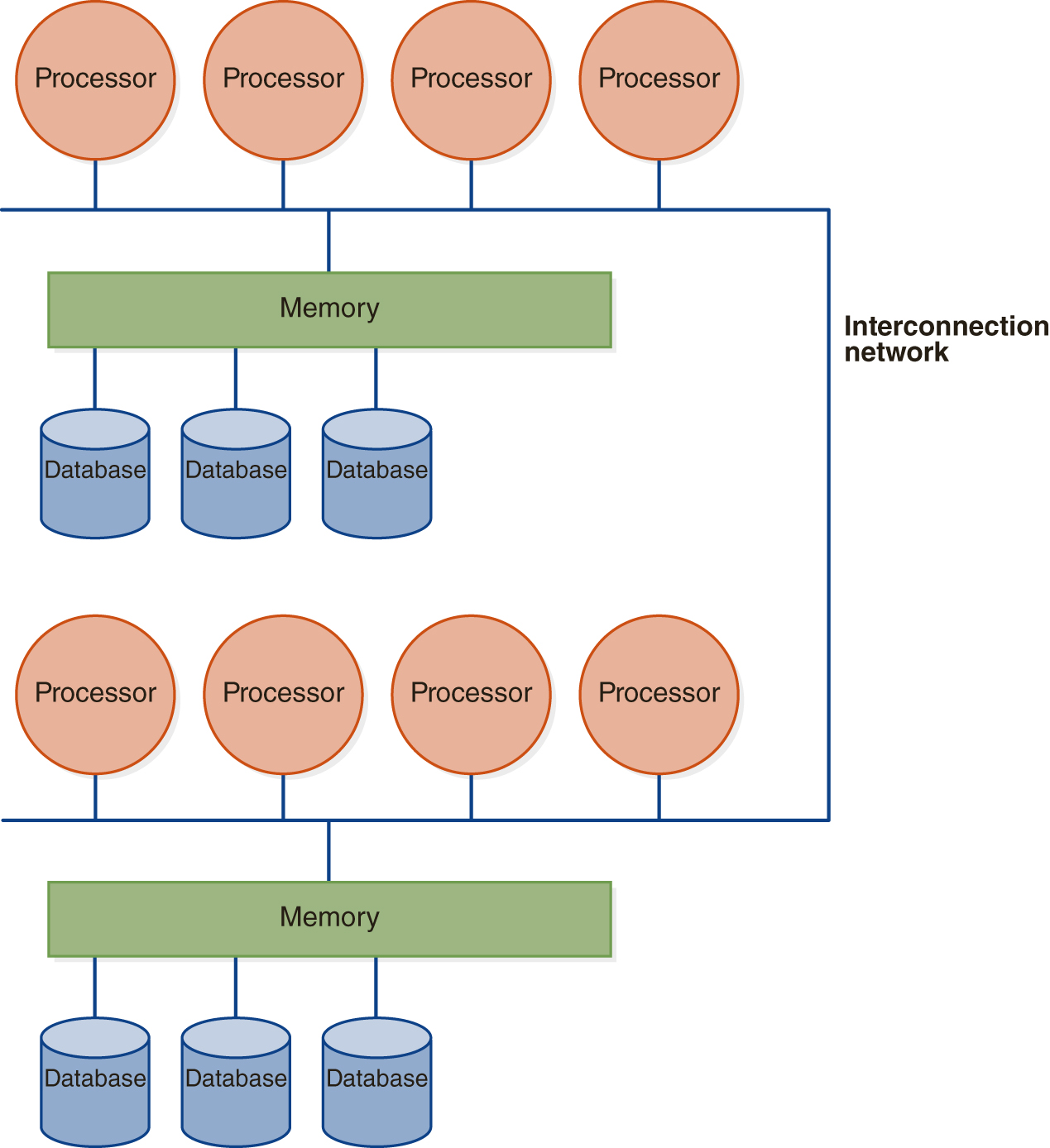
(D) Hierarchical
The purpose of parallel databases is to improve performance by executing operations in a parallel fashion on the various devices. Careful partitioning of data is essential so that parallel evaluation of queries is possible. Data partitioning can be done by range partitioning, which means placing records on designated disks according to a range of values for a certain attribute. Other methods are by hashing on some attribute or by placing new records on successive disks in round-robin fashion. The partitioning algorithm should be designed to minimize data skew, where too much data is concentrated at one or more sites. When a query is processed, because the required data may reside on different disks, the query is decomposed into subqueries that are then processed in parallel using the appropriate partition of the database. It is desirable to avoid transaction skew, where too much processing is performed at one or more sites.
Parallel databases using shared-nothing architecture provide linear speedup, which means that as the number of processors and disks increase, the speed of operations increases in a linear fashion. They also provide linear scale-up, which means that they are scalable, so that if more processors and disks are added, the performance level is sustained. This allows us to increase the amount of data stored and processed without sacrificing performance. These characteristics of shared nothing have made this the architecture of choice for web-based applications.
12.2.4 Distributed Databases
In this architecture, the database is distributed, possibly with replication, among several relatively autonomous sites. The distribution is transparent to the user, who does not need to specify where the data is located (location transparency). A distributed system can be homogeneous or heterogeneous. In a homogeneous system, all nodes use the same hardware and software for the database system. In a heterogeneous system, nodes can have different hardware and/or software.
Because a homogeneous system is much easier to design and manage, a designer would normally choose such a system. Heterogeneous systems usually result when individual sites make their own hardware and software decisions, and communications are added later, which is the norm. The designer then has the task of tying together the disparate systems. In a heterogeneous system, translations are needed to allow the databases to communicate. Because location transparency is a major objective, the user at a particular site makes requests in the language of the DBMS at that site. The system then has the responsibility of locating the data, which might be at another site that has different hardware and software. The request might even require coordination of data stored at several sites, all using different facilities. If two sites have different hardware but the same DBMSs, the translation is not too difficult, consisting mainly of changing codes and word lengths. If they have the same hardware but different software, the translation is difficult, requiring that the data model and data structures of one system be expressed in terms of the models and structures of another. For example, if one database is relational and the other uses a semistructured model, objects must be presented in table form to users of the relational database. In addition, the query languages must be translated. The most challenging environment involves different hardware and software. This requires translation of data models, data structures, query languages, word lengths, and codes. This chapter primarily addresses the main components of a DDBS, outlining approaches for data placement and transparency, transaction processing, and query processing over distributed data.
12.2.5 Peer-to-Peer (P2P) Data Management Systems
A common characteristic of client server, parallel, and DDBSs is that, even though the data may be distributed, there are still central points of control for different system functionalities. For example, a relational distributed database may have a central component for distributed query processing, where an SQL query is divided into subqueries that must be executed at different sites. As we will describe in Section 12.7, an optimizer must make use of a global data dictionary to determine the location of different data items, to distribute the query for efficient and possibly parallel execution, and to combine the final results of the subqueries. In contrast, a peer-to-peer (P2P) data management system is a distributed system with a high level of decentralization. Decentralization refers to the distribution of control and autonomy within the operation of a system, with the objective of minimizing any central point of control so that peer sites can equally participate as clients and/or servers of data within the system.
FIGURE 12.4 provides a high-level view of a P2P data management system. In a P2P system, a peer can generally enter and leave the system at any time, with full control over the data that it stores. A peer site can connect to any other peer site, discover data at other sites, and request access to peer site data.
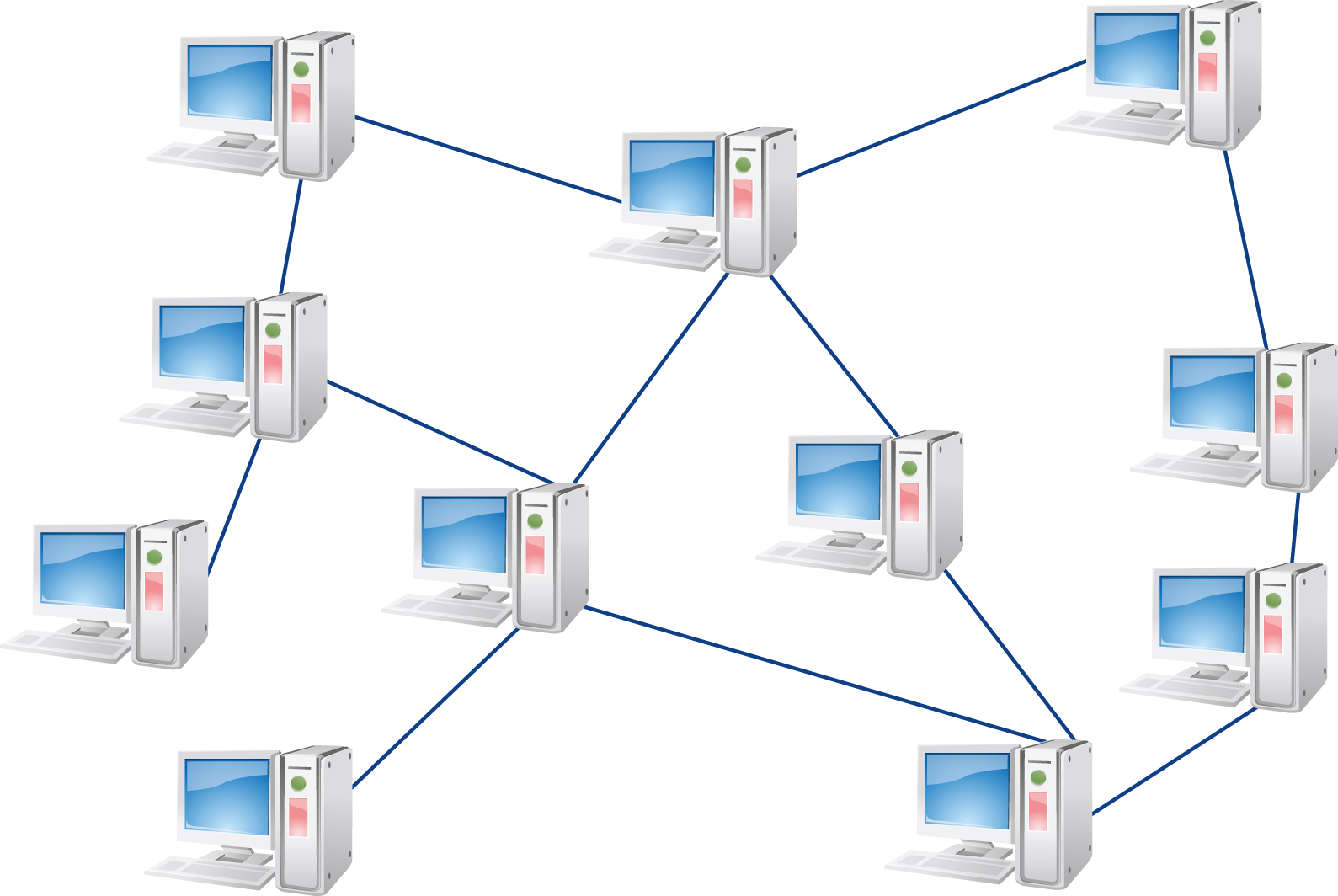
FIGURE 12.4 P2P Data Management System
P2P systems can either be unstructured or structured networks, having either centralized or distributed indexes for locating data. Because of the heterogeneous nature of the data, unstructured networks have primarily been file sharing systems that support a single type of application. Napster and Kazaa are examples of initial P2P systems that were primarily used for sharing MP3 music files and eventually shut down over copyright infringement issues. Gnutella and BitTorrent are still in operation for use in sharing audio and video files, although copyright infringement in the use of these systems is still a concern.
A data request in an unstructured P2P system often involves flooding the network with requests to all peers to locate the data. Structured networks attempt to improve scalability by using distributed hash tables for more control over the placement of data and routing of data requests at the cost of decreasing the autonomy of peers in the network. Tapestry, Pastry, Chord, and CAN (Content Addressable Network) are examples of structured file sharing P2P systems.
A special concern in a P2P system is fault tolerance. To address fault tolerance, data is sometimes replicated at multiple sites in case of the failure of a peer. Security is also a concern because it is important to have trusted servers that are not acting in a malicious way within the network. The most recent form of P2P data management that addresses fault tolerance and security in a fully decentralized system is known as blockchain technology, which will be addressed in more detail in Section 12.8.
12.2.6 Cloud Database Systems
Recent years have seen a shift from organizations purchasing hardware and software for on-premises usage to using cloud computing resources. Cloud databases reside on platforms such as Amazon Web Services, Microsoft Azure, or the Google Cloud Platform. Databases can be created using a variety of DBMSs, from traditional relational to NoSQL systems, on cloud platforms. The provider maintains both the hardware and software, which offers several advantages: ease of scalability, security, and economies of scale. Payment for cloud databases can be configured based on different factors such as the type of system, the size of the data, and/or the workload. Gartner analysts predict that cloud databases will comprise 50% of the global database market (approximately $55M USD in 2020) in the near future. Cloud databases are also called Database-as-a-Service (DBaaS).
Data as a service (DaaS) is related to cloud databases because it does not require a user to manage a database system. Data is available through APIs. DaaS allows data owners to configure and provide data to other organizations; one example is external data that is used to augment proprietary data to enhance analytical applications.