
Chapter 1
What is DAX?
DAX, which stands for Data Analysis eXpressions, is the programming language of Microsoft Power BI, Microsoft Analysis Services, and Microsoft Power Pivot for Excel. It was created in 2010, with the first release of PowerPivot for Microsoft Excel 2010. In 2010, PowerPivot was spelled without the space. The space was introduced in the Power Pivot name in 2013. Since then, DAX has gained popularity, both within the Excel community, which uses DAX to create Power Pivot data models in Excel, and within the Business Intelligence (BI) community, which uses DAX to build models with Power BI and Analysis Services. DAX is present in many different tools, all sharing the same internal engine named Tabular. For this reason, we often refer to Tabular models, including all these different tools in a single word.
DAX is a simple language. That said, DAX is different from most programming languages, so becoming acquainted with some of its new concepts might take some time. In our experience, having taught DAX to thousands of people, learning the basics of DAX is straightforward: you will be able to start using it in a matter of hours. When it comes to understanding advanced concepts such as evaluation contexts, iterations, and context transitions, everything will likely seem complex. Do not give up! Be patient. When your brain starts to digest these concepts, you will discover that DAX is, indeed, an easy language. It just takes some getting used to.
This first chapter begins with a recap of what a data model is in terms of tables and relationships. We recommend readers of all experience levels read this section to gain familiarity with the terms used throughout the book when referring to tables, models, and different kinds of relationships.
In the following sections, we offer advice to readers who have experience with programming languages such as Microsoft Excel, SQL, and MDX. Each section is focused on a certain language, for readers curious to briefly compare DAX to it. Focus on languages you know if a comparison is helpful to you; then read the final section, “DAX for Power BI users,” and move on to the next chapter where our journey into the DAX language truly begins.
Understanding the data model
DAX is specifically designed to compute business formulas over a data model. The readers might already know what a data model is. If not, we start with a description of data models and relationships to create a foundation on which to build their DAX knowledge.
A data model is a set of tables, linked by relationships.
We all know what a table is: a set of rows containing data, with each row divided into columns. Each column has a data type and contains a single piece of information. We usually refer to a row in a table as a record. Tables are a convenient way to organize data. A table is a data model in itself although in its simplest form. Thus, when we write names and numbers in an Excel workbook, we are creating a data model.
If a data model contains many tables, it is likely that they are linked through relationships. A relationship is a link between two tables. When two tables are tied with a relationship, we say that they are related. Graphically, a relationship is represented by a line connecting the two tables. Figure 1-1 shows an example of a data model.
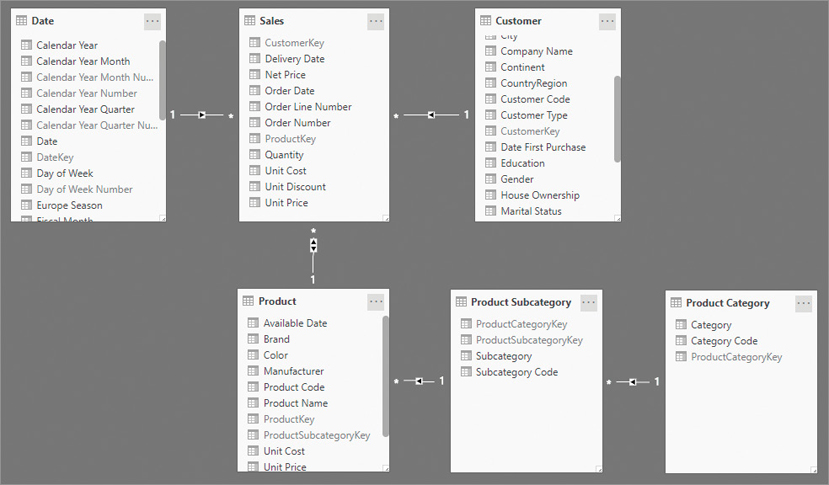
Following are a few important aspects of relationships:
Two tables in a relationship do not have the same role. They are called the one-side and the many-side of the relationship, represented respectively with a 1 and with a *. In Figure 1-1, focus on the relationship between Product and Product Subcategory. A single subcategory contains many products, whereas a single product has only one subcategory. Therefore, Product Subcategory is the one-side of the relationship, having one subcategory, while Product is the many-side having many products.
Special kinds of relationships are 1:1 and weak relationships. In 1:1 relationships, both tables are the one-side, whereas in weak relationships, both tables can be the many-side. These special kinds of relationships are uncommon; we discuss them in detail in Chapter 15, “Advanced relationships.”
The columns used to create the relationship, which usually have the same name in both tables, are called the keys of the relationship. On the one-side of the relationship, the column needs to have a unique value for each row, and it cannot contain blanks. On the many-side, the same value can be repeated in many different rows, and it often is. When a column has a unique value for each row, it is called a key for the table.
Relationships can form a chain. Each product has a subcategory, and each subcategory has a category. Thus, each product has a category. To retrieve the category of a product, one must traverse a chain of two relationships. Figure 1-1 includes an example of a chain made up of three relationships, starting with Sales and continuing on to Product Category.
In each relationship, one or two small arrows can determine the cross filter direction. Figure 1-1 shows two arrows in the relationship between Sales and Product, whereas all other relationships have a single arrow. The arrow indicates the direction of the automatic filtering of the relationship (cross filter). Because determining the correct direction of filters is one of the most important skills to learn, we discuss this topic in more detail in later chapters. We usually discourage the use of bidirectional filters, as described in Chapter 15. They are present in this model for educational purposes only.
Understanding the direction of a relationship
Each relationship can have a unidirectional or bidirectional cross filter. Filtering always happens from the one-side of the relationship to the many-side. If the cross filter is bidirectional—that is, if it has two arrows on it—the filtering also happens from the many-side to the one-side.
An example might help in understanding this behavior. If a report is based on the data model shown in Figure 1-1, with the years on the rows and Quantity and Count of Product Name in the values area, it produces the result shown in Figure 1-2.
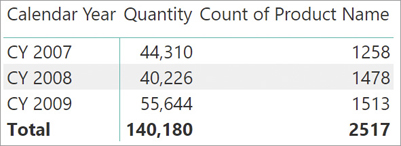
Calendar Year is a column that belongs to the Date table. Because Date is on the one-side of the relationship with Sales, the engine filters Sales based on the year. This is why the quantity shown is filtered by year.
With Products, the scenario is slightly different. The filtering happens because the relationship between the Sales and Product tables is bidirectional. When we put the count of product names in the report, we obtain the number of products sold in each year because the filter on the year propagates to Product through Sales. If the relationship between Sales and Product were unidirectional, the result would be different, as we explain in the following sections.
If we modify the report by putting Color on the rows and adding Count of Date in the values area, the result is different, as shown in Figure 1-3.
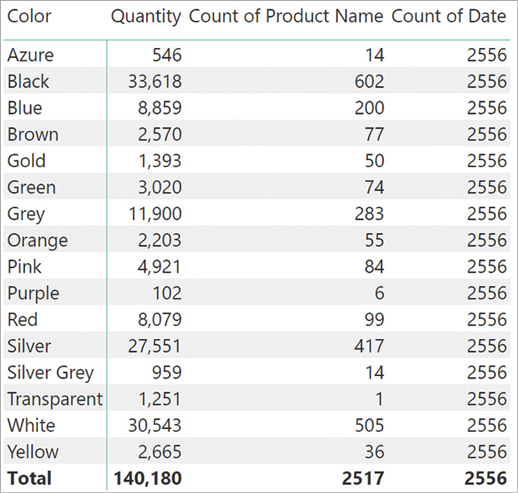
The filter on the rows is the Color column in the Product table. Because Product is on the one-side of the relationship with Sales, Quantity is filtered correctly. Count of Product Name is filtered because it is computing values from the table that is on the rows, that is Product. The unexpected number is Count of Date. Indeed, it always shows the same value for all the rows—that is, the total number of rows in the Date table.
The filter coming from the Color column does not propagate to Date because the relationship between Date and Sales is unidirectional. Thus, although Sales has an active filter on it, the filter cannot propagate to Date because the type of relationship prevents it.
If we change the relationship between Date and Sales to enable bidirectional cross-filtering, the result is as shown in Figure 1-4.
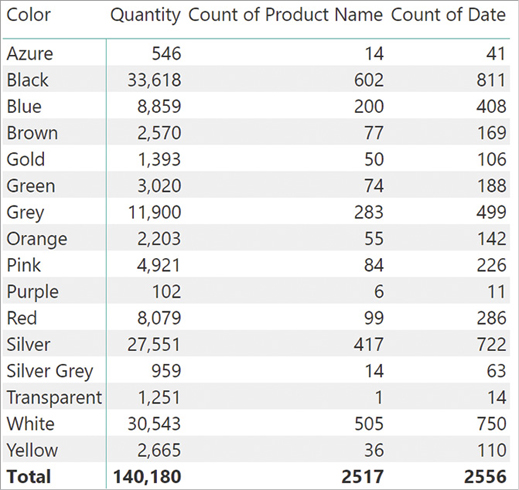
The numbers now reflect the number of days when at least one product of the given color was sold. At first sight, it might look as if all the relationships should be defined as bidirectional, so as to let the filter propagate in any direction and always return results that make sense. As you will learn later in this book, designing a data model this way is almost never appropriate. In fact, depending on the scenario you are working with, you will choose the correct propagation of relationships. If you follow our suggestions, you will avoid bidirectional filtering as much as you can.
DAX for Excel users
Chances are you already know the Excel formula language that DAX somewhat resembles. After all, the roots of DAX are in Power Pivot for Excel, and the development team tried to keep the two languages similar. This similarity makes the transition to this new language easier. However, there are some important differences.
Cells versus tables
Excel performs calculations over cells. A cell is referenced using its coordinates. Thus, we can write formulas as follows:
= (A1 * 1.25) - B2
In DAX, the concept of a cell and its coordinates does not exist. DAX works on tables and columns, not cells. As a consequence, DAX expressions refer to tables and columns, and this means writing code differently. The concepts of tables and columns are not new in Excel. In fact, if we define an Excel range as a table by using the Format as Table function, we can write formulas in Excel that reference tables and columns. In Figure 1-5, the SalesAmount column evaluates an expression that references columns in the same table instead of cells in the workbook.
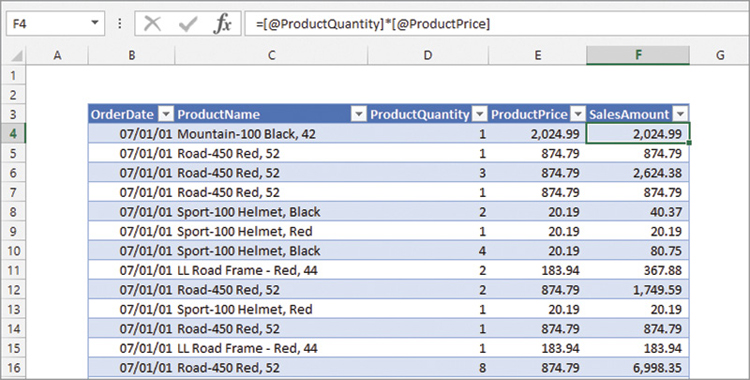
Using Excel, we refer to columns in a table using the [@ColumnName] format. ColumnName is the name of the column to use, and the @ symbol means “take the value for the current row.” Although the syntax is not intuitive, normally we do not write these expressions. They appear when we click a cell, and Excel takes care of inserting the right code for us.
You might think of Excel as having two different ways of performing calculations. We can use standard cell references, in which case the formula for F4 would be E4*D4, or we can use column references inside a table. Using column references offers the advantage that we can use the same expression in all the cells of a column and Excel will compute the formula with a different value for each row.
Unlike Excel, DAX works only on tables. All the formulas must reference columns inside tables. For example, in DAX we write the previous multiplication this way:
Sales[SalesAmount] = Sales[ProductPrice] * Sales[ProductQuantity]
As you can see, each column is prefixed with the name of its table. In Excel, we do not provide the table name because Excel formulas work inside a single table. However, DAX works on a data model containing many tables. As a consequence, we must specify the table name because two columns in different tables might have the same name.
Many functions in DAX work the same way as the equivalent Excel function. For example, the IF function reads the same way in DAX and in Excel:
Excel IF ( [@SalesAmount] > 10, 1, 0) DAX IF ( Sales[SalesAmount] > 10, 1, 0)
One important aspect where the syntax of Excel and DAX is different is in the way to reference the entire column. In fact, in [@ProductQuantity], the @ means “the value in the current row.” In DAX, there is no need to specify that a value must be from the current row, because this is the default behavior of the language. In Excel, we can reference the entire column—that is, all the rows in that column—by removing the @ symbol. You can see this in Figure 1-6.
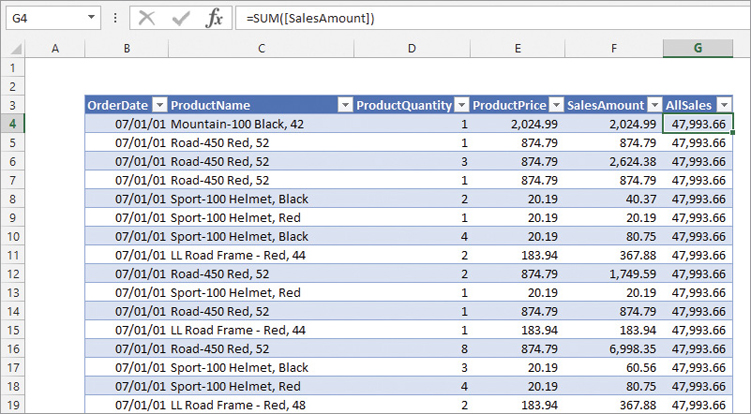
The value of the AllSales column is the same in all the rows because it is the grand total of the SalesAmount column. In other words, there is a syntactical difference between the value of a column in the current row and the value of the column as a whole.
DAX is different. In DAX, this is how you write the AllSales expression of Figure 1-6:
AllSales := SUM ( Sales[SalesAmount] )
There is no syntactical difference between retrieving the value of a column for a specific row and using the column as a whole. DAX understands that we want to sum all the values of the column because we use the column name inside an aggregator (in this case the SUM function), which requires a column name to be passed as a parameter. Thus, although Excel requires an explicit syntax to differentiate between the two types of data to retrieve, DAX does the disambiguation automatically. This distinction might be confusing—at least in the beginning.
Excel and DAX: Two functional languages
One aspect where the two languages are similar is that both Excel and DAX are functional languages. A functional language is made up of expressions that are basically function calls. In Excel and DAX, the concepts of statements, loops, and jumps do not exist although they are common to many programming languages. In DAX, everything is an expression. This aspect of the language is often a challenge for programmers coming from different languages, but it should be no surprise at all for Excel users.
Iterators in DAX
A concept that might be new to you is the concept of iterators. When working in Excel, you perform calculations one step at a time. The previous example showed that to compute the total of sales, we create one column containing the price multiplied by the quantity. Then as a second step, we sum it to compute the total sales. This number is then useful as a denominator to compute the percentage of sales of each product, for example.
Using DAX, you can perform the same operation in a single step by using iterators. An iterator does exactly what its name suggests: it iterates over a table and performs a calculation on each row of the table, aggregating the result to produce the single value requested.
Using the previous example, we can now compute the sum of all sales using the SUMX iterator:
AllSales :=
SUMX (
Sales,
Sales[ProductQuantity] * Sales[ProductPrice]
)This approach brings to light both an advantage and a disadvantage. The advantage is that we can perform many complex calculations in a single step without worrying about adding columns that would end up being useful only for specific formulas. The disadvantage is that programming with DAX is less visual than programming with Excel. Indeed, you do not see the column computing the price multiplied by the quantity; it exists only for the lifetime of the calculation.
As we will explain later, we can create a calculated column that computes the multiplication of price by quantity. Nevertheless, doing so is seldom a good practice because it uses memory and might slow down the calculations, unless you use DirectQuery and Aggregations, as we explain in Chapter 18, “Optimizing VertiPaq.”
DAX requires theory
Let us be clear: The fact that DAX requires one to study theory first is not a difference between programming languages. This is a difference in mindset. You are probably used to searching the web for complex formulas and solution patterns for the scenarios you are trying to solve. When you are using Excel, chances are you will find a formula that almost does what you need. You can copy the formula, customize it to fit your needs, and then use it without worrying too much about how it works.
This approach, which works in Excel, does not work with DAX, however. You need to study DAX theory and thoroughly understand how evaluation contexts work before you can write good DAX code. If you do not have a proper theoretical foundation, you will find that DAX either computes values like magic or it computes strange numbers that make no sense. The problem is not DAX but the fact that you do not yet understood exactly how DAX works.
Luckily, the theory behind DAX is limited to a couple of important concepts, which we explain in Chapter 4, “Understanding evaluation contexts.” When you reach that chapter, be prepared for some intense learning. After you master that content, DAX will have no secrets for you, and learning DAX will mainly be a matter of gaining experience. Remember: knowing is half the battle. So do not try to go further until you are somewhat proficient with evaluation contexts.
DAX for SQL developers
If you are accustomed to the SQL language, you have already worked with many tables and created joins between columns to set relationships. From this point of view, you will likely feel at home in the DAX world. Indeed, computing in DAX is a matter of querying a set of tables joined by relationships and aggregating values.
Relationship handling
The first difference between SQL and DAX is in the way relationships work in the model. In SQL, we can set foreign keys between tables to declare relationships, but the engine never uses these foreign keys in queries unless we are explicit about them. For example, if we have a Customers table and a Sales table, where CustomerKey is a primary key in Customers and a foreign key in Sales, we can write the following query:
SELECT
Customers.CustomerName,
SUM ( Sales.SalesAmount ) AS SumOfSales
FROM
Sales
INNER JOIN Customers
ON Sales.CustomerKey = Customers.CustomerKey
GROUP BY
Customers.CustomerNameThough we declare the relationship in the model using foreign keys, we still need to be explicit and state the join condition in the query. Although this approach makes queries more verbose, it is useful because you can use different join conditions in different queries, giving you a lot of freedom in the way you express queries.
In DAX, relationships are part of the model, and they are all LEFT OUTER JOINs. When they are defined in the model, you no longer need to specify the join type in the query: DAX uses an automatic LEFT OUTER JOIN in the query whenever you use columns related to the primary table. Thus, in DAX you would write the previous SQL query as follows:
EVALUATE
SUMMARIZECOLUMNS (
Customers[CustomerName],
"SumOfSales", SUM ( Sales[SalesAmount] )
)Because DAX knows the existing relationship between Sales and Customers, it does the join automatically following the model. Finally, the SUMMARIZECOLUMNS function needs to perform a group by Customers[CustomerName], but we do not have a keyword for that: SUMMARIZECOLUMNS automatically groups data by selected columns.
DAX is a functional language
SQL is a declarative language. You define what you need by declaring the set of data you want to retrieve using SELECT statements, without worrying about how the engine actually retrieves the information.
DAX, on the other hand, is a functional language. In DAX, every expression is a function call. Function parameters can, in turn, be other function calls. The evaluation of parameters might lead to complex query plans that DAX executes to compute the result.
For example, if we want to retrieve only customers who live in Europe, we can write this query in SQL:
SELECT
Customers.CustomerName,
SUM ( Sales.SalesAmount ) AS SumOfSales
FROM
Sales
INNER JOIN Customers
ON Sales.CustomerKey = Customers.CustomerKey
WHERE
Customers.Continent = 'Europe'
GROUP BY
Customers.CustomerNameUsing DAX, we do not declare the WHERE condition in the query. Instead, we use a specific function (FILTER) to filter the result:
EVALUATE
SUMMARIZECOLUMNS (
Customers[CustomerName],
FILTER (
Customers,
Customers[Continent] = "Europe"
),
"SumOfSales", SUM ( Sales[SalesAmount] )
)You can see that FILTER is a function: it returns only the customers living in Europe, producing the expected result. The order in which we nest the functions and the kinds of functions we use have a strong impact on both the result and the performance of the engine. This happens in SQL too, although in SQL we trust the query optimizer to find the optimal query plan. In DAX, although the query optimizer does a great job, you, as programmer, bear more responsibility in writing good code.
DAX as a programming and querying language
In SQL, a clear distinction exists between the query language and the programming language—that is, the set of instructions used to create stored procedures, views, and other pieces of code in the database. Each SQL dialect has its own statements to let programmers enrich the data model with code. However, DAX virtually makes no distinction between querying and programming. A rich set of functions manipulates tables and can, in turn, return tables. The FILTER function in the previous query is a good example of this.
In that respect, it appears that DAX is simpler than SQL. When you learn it as a programming language—its original use—you will know everything needed to also use it as a query language.
Subqueries and conditions in DAX and SQL
One of the most powerful features of SQL as a query language is the option of using subqueries. DAX features similar concepts. In the case of DAX subqueries, however, they stem from the functional nature of the language.
For example, to retrieve customers and total sales specifically for the customers who bought more than US$100 worth, we can write this query in SQL:
SELECT
CustomerName,
SumOfSales
FROM (
SELECT
Customers.CustomerName,
SUM ( Sales.SalesAmount ) AS SumOfSales
FROM
Sales
INNER JOIN Customers
ON Sales.CustomerKey = Customers.CustomerKey
GROUP BY
Customers.CustomerName
) AS SubQuery
WHERE
SubQuery.SumOfSales > 100We can obtain the same result in DAX by nesting function calls:
EVALUATE
FILTER (
SUMMARIZECOLUMNS (
Customers[CustomerName],
"SumOfSales", SUM ( Sales[SalesAmount] )
),
[SumOfSales] > 100
)In this code, the subquery that retrieves CustomerName and SumOfSales is later fed into a FILTER function that retains only the rows where SumOfSales is greater than 100. Right now, this code might seem unreadable to you. However, as soon as you start learning DAX, you will discover that using subqueries is much easier than in SQL, and it flows naturally because DAX is a functional language.
DAX for MDX developers
Many Business Intelligence professionals start learning DAX because it is the new language of Tabular. In the past, they used the MDX language to build and query Analysis Services Multidimensional models. If you are among them, be prepared to learn a completely new language: DAX and MDX do not share much in common. Worse, some concepts in DAX will remind you of similar existing concepts in MDX though they are different.
In our experience, we have found that learning DAX after learning MDX is the most challenging option. To learn DAX, you need to free your mind from MDX. Try to forget everything you know about multidimensional spaces and be prepared to learn this new language with a clear mind.
Multidimensional versus Tabular
MDX works in the multidimensional space defined by a model. The shape of the multidimensional space is based on the architecture of dimensions and hierarchies defined in the model, and this, in turn, defines the set of coordinates of the multidimensional space. Intersections of sets of members in different dimensions define points in the multidimensional space. You may have taken some time to realize that the [All] member of any attribute hierarchy is indeed a point in the multidimensional space.
DAX works in a much simpler way. There are no dimensions, no members, and no points in the multidimensional space. In other words, there is no multidimensional space at all. There are hierarchies, which we can define in the model, but they are different from hierarchies in MDX. The DAX space is built on top of tables, columns, and relationships. Each table in a Tabular model is neither a measure group nor a dimension: it is just a table, and to compute values, you scan it, filter it, or sum values inside it. Everything is based on the two simple concepts of tables and relationships.
You will soon discover that from the modeling point of view, Tabular offers fewer options than Multidimensional does. In this case, having fewer options does not mean being less powerful because you can use DAX as a programming language to enrich the model. The real modeling power of Tabular is the tremendous speed of DAX. In fact, you probably try to avoid overusing MDX in your model because optimizing MDX speed is often a challenge. DAX, on the other hand, is amazingly fast. Thus, most of the complexity of the calculations is not in the model but in the DAX formulas instead.
DAX as a programming and querying language
DAX and MDX are both programming languages and query languages. In MDX, the difference is made clear by the presence of the MDX script. You use MDX in the MDX script, along with several special statements that can be used in the script only, such as SCOPE statements. You use MDX in queries when you write SELECT statements that retrieve data. In DAX, this is somewhat different. You use DAX as a programming language to define calculated columns, calculated tables, and measures. The concept of calculated columns and calculated tables is new to DAX and does not exist in MDX; measures are similar to calculated members in MDX. You can also use DAX as a query language—for example, to retrieve data from a Tabular model using Reporting Services. Nevertheless, DAX functions do not have a specific role and can be used in both queries and calculation expressions. Moreover, you can also query a Tabular model using MDX. Thus, the querying part of MDX works with Tabular models, whereas DAX is the only option when it comes to programming a Tabular model.
Hierarchies
Using MDX, you rely on hierarchies to perform most of the calculations. If you wanted to compute the sales in the previous year, you would have to retrieve the PrevMember of the CurrentMember on the Year hierarchy and use it to override the MDX filter. For example, you can write the formula this way to define a previous year calculation in MDX:
CREATE MEMBER CURRENTCUBE.[Measures].[SamePeriodPreviousYearSales] AS
(
[Measures].[Sales Amount],
ParallelPeriod (
[Date].[Calendar].[Calendar Year],
1,
[Date].[Calendar].CurrentMember
)
);The measure uses the ParallelPeriod function, which returns the cousin of the CurrentMember on the Calendar hierarchy. Thus, it is based on the hierarchies defined in the model. We would write the same calculation in DAX using filter contexts and standard time-intelligence functions:
SamePeriodPreviousYearSales :=
CALCULATE (
SUM ( Sales[Sales Amount] ),
SAMEPERIODLASTYEAR ( 'Date'[Date] )
)We can write the same calculation in many other ways using FILTER and other DAX functions, but the idea remains the same: instead of using hierarchies, we filter tables. This difference is huge, and you will probably miss hierarchy calculations until you get used to DAX.
Another important difference is that in MDX you refer to [Measures].[Sales Amount], and the aggregation function that you need to use is already defined in the model. In DAX, there is no predefined aggregation. In fact, as you might have noticed, the expression to compute is SUM(Sales[Sales Amount]). The predefined aggregation is no longer in the model. We need to define it whenever we want to use it. We can always create a measure that computes the sum of sales, but this would be beyond the scope of this section and is explained later in the book.
One more important difference between DAX and MDX is that MDX makes heavy use of the SCOPE statement to implement business logic (again, using hierarchies), whereas DAX needs a completely different approach. Indeed, hierarchy handling is missing in the language altogether.
For example, if we want to clear a measure at the Year level, in MDX we would write this statement:
SCOPE ( [Measures].[SamePeriodPreviousYearSales], [Date].[Month].[All] ) THIS = NULL; END SCOPE;
DAX does not have something like a SCOPE statement. To obtain the same result, we need to check for the presence of filters in the filter context, and the scenario is much more complex:
SamePeriodPreviousYearSales :=
IF (
ISINSCOPE ( 'Date'[Month] ),
CALCULATE (
SUM ( Sales[Sales Amount] ),
SAMEPERIODLASTYEAR ( 'Date'[Date] )
),
BLANK ()
)Intuitively, this formula returns a value only if the user is browsing the calendar hierarchy at the month level or below. Otherwise, it returns a BLANK. You will later learn what this formula computes in detail. It is much more error-prone than the equivalent MDX code. To be honest, hierarchy handling is one of the features that is really missing in DAX.
Leaf-level calculations
Finally, when using MDX, you probably got used to avoiding leaf-level calculations. Performing leaf-level computation in MDX turns out to be so slow that you should always prefer to precompute values and leverage aggregations to return results. In DAX, leaf-level calculations work incredibly fast and aggregations serve a different purpose, being useful only for large datasets. This requires a shift in your mind when it is time to build the data models. In most cases, a data model that fits perfectly in SSAS Multidimensional is not the right fit for Tabular and vice versa.
DAX for Power BI users
If you skipped the previous sections and directly came here, welcome! DAX is the native language of Power BI, and if you do not have experience in Excel, SQL, or MDX, Power BI will be the first place where you learn DAX. If you do not have previous experience in building models with other tools, you will learn that Power BI is a powerful analytical and modeling tool, with DAX as the perfect companion.
You might have started using Power BI a while ago and now you want to get to the next level. If this is the case, be prepared for a wonderful journey with DAX.
Here is our advice to you: do not expect to be able to write complex DAX code in a matter of a few days. DAX requires your time and dedication, and mastering it requires some practice. Based on our experience, you will be excited at first when you are rewarded with a few simple calculations. The excitement fades away as soon as you start learning about evaluation contexts and CALCULATE, the most complex topics of the language. At that point, everything looks complex. Do not give up; most DAX developers had to move past that level. When you are there, you are so close to reaching a full understanding that it would be a real pity to stop. Read and practice again and again because a lightbulb will go off much sooner that you would expect. You will be able to finish the book quickly, reaching DAX guru status.
Evaluation contexts are at the core of the language. Mastering them takes time. We do not know anyone who was able to learn all about DAX in a couple of days. Besides, as with any complex topic, you will learn to appreciate a lot of the details over time. When you think you have learned everything, give the book a second read. You will discover many details that looked less important at first sight but, with a more trained mindset, really make a difference.
Enjoy the rest of this book!