
Chapter 20. XML information modeling
This chapter addresses some of the general modeling and design questions that come up when designing XML documents, and to a lesser extent the schemas that describe them. For developers who are accustomed to defining data as entity-relationship models, relational tables, UML, and object-oriented models and classes, there is a learning curve associated with the hierarchical model of XML.
This chapter will help you up that curve. It first compares XML modeling and design to other disciplines, such as relational models and object-oriented models, and shows how XML Schema features can be used to describe these models. It then provides some general design principles for modeling web services, dealing with document-oriented narrative content, and working with a hierarchical information model.
20.1. Data modeling paradigms
If you are approaching the subject of XML Schema with some previous background in data design, you may be wondering how to represent in XML concepts from
• Relational models, such as entity-relationship data models or relational database design
• Object-oriented models, which may exist for example as UML class diagrams and/or object-oriented program code
You may continue to use these modeling paradigms along with your XML application. For example, you may be parsing XML and storing it in a relational database (this is sometimes known as “shredding”), in which case you still have a relational model for your data. You may be processing your XML documents with object-oriented code, so there still needs to be a correspondence between the XML and the object model.
Some schema designers choose to maintain these models, such as UML models, entity-relationship diagrams, and/or supplementary documentation, alongside the XML Schema. Others rely more heavily on the XML Schema to represent the entire model. This is convenient in that there is a one-to-one mapping to the actual XML documents that are in use. However, it does have some drawbacks in that XML Schema cannot express every constraint on the data and is somewhat technology-specific.
Some developers maintain a connection between the models using toolkits that generate program code or even databases. It is particularly common to use data binding toolkits to generate object-oriented classes from schemas. As appropriate, this chapter describes some of the considerations for designing XML documents to optimize the use of these toolkits.
20.2. Relational models
Designing an XML message structure is different in some ways from traditional entity-relationship modeling and relational database design, where the data model is a persistent-storage representation of the data. When creating an entity-relationship model, great care is (hopefully) taken to define what an entity is, as opposed to how it is used in any particular context. For example, when you model a “customer” entity, you decide on your definition of a customer, its unique identifier, and all of its attributes. You also normalize all the relationships between customers and other entities: For example, a customer can have one or more addresses, and can be associated with zero or more purchases.
An XML message, on the other hand, often represents a particular usage or view of the data, useful at a particular time in a certain operation. Instead of being the definitive source for all information about that entity, it contains only the subset that is useful for the operation in question. For a purchase order, you probably do not need to include all of the information that can be known about a customer; perhaps you just need an identifier, name, and shipping address. For a line item in the purchase order, you may need to know a product’s identifier, name, and price, but not its other attributes such as a long description or a list of features.
Relationships also differ in the two models. In an entity-relationship or relational model, there is no single starting point to the model; entities exist and can be accessed independently of each other. In an XML hierarchy, one element must be at the root of the structure, and there is an implied relationship between all of the elements within that hierarchy. Again, only the relationships that are relevant to the particular message are included, and their cardinality may differ in the message as compared to the relational data model. Representing relationships in XML is discussed later in this chapter.
In an ideal scenario, you will have a standardized canonical model that you will draw on for your XML message schemas. Just as in relational database design, in XML message design it makes sense to use the same element names, types, and relationships for the same data where possible. For example, if your corporate data model says that an Address entity has the properties line1, line2, city, state, and zip, it makes sense to use the same definitions and names (or the relevant subset of them) for the elements in your XML messages.
On the other hand, it is best to avoid tightly coupling your XML messages with any one relational database schema. You might use the same names and definitions if they are well-designed, but should not, for example, generate your XML schemas from relational databases or have your application automatically insert the contents of XML elements into relational columns of the same name. This would create too close a relationship between the XML message and the database, where the message schema would have to change if the database changes.
20.2.1. Entities and attributes
In a relational model, you will typically have entities, each with a set of attributes or properties. In a relational database, these would be implemented as tables and columns, with each instance represented as a row with multiple cells. In XML, this roughly translates into elements with complex content and elements with simple content. For the entity-relationship model shown in Figure 20–1, our first cut at representing that in XML (leaving aside the relationships for now) might be as shown in Example 20–1.

Figure 20–1. Entity-relationship diagram
Example 20–1. A simple representation of relational entities in XML
<model>
<order>
<number>1234</number>
<total>213.12</total>
</order>
<customer>
<number>12345</number>
<firstName>Priscilla</firstName>
<lastName>Walmsley</lastName>
</customer>
<address>
<type>Billing</type>
<line1>123 Main Street</line1>
<line2>Apartment 2B</line2>
<city>Traverse City</city>
<state>MI</state>
<zip>49684</zip>
</address>
<address>
<type>Shipping</type>
<line1>PO Box 9999999</line1>
<city>Traverse City</city>
<state>MI</state>
<zip>49686</zip>
</address>
<lineItem>
<giftWrap>bday</giftWrap>
<number>557</number>
<size>12</size>
<color>blue</color>
<quantity>1</quantity>
</lineItem>
<lineItem>
<number>443</number>
<size>L</size>
<color>tan</color>
<quantity>2</quantity>
</lineItem>
<product>
<number>557</number>
<name>Short-Sleeved Linen Blouse</name>
<availableSizes>2 4 6 8 10 12 14</availableSizes>
<availableColors>blue red</availableColors>
<desc>Our best-selling shirt!</desc>
</product>
<product>
<number>563</number>
<name>Ten-Gallon Hat</name>
<availableSizes>S M L</availableSizes>
</product>
<product>
<number>443</number>
<name>Deluxe Golf Umbrella</name>
<availableColors>tan black</availableColors>
<desc>Protect yourself from the rain!</desc>
</product>
</model>
This representation adheres strictly to a structure where every child of model is an entity, and every grandchild is an attribute. However, there can be any number of hierarchical levels of elements in XML, which allows additional flexibility to add structure that is sometimes useful. For example, it may be useful to combine firstName and lastName into a parent name structure. This is described further in Section 20.6.1 on p. 527.
Another difference is that with XML, any attribute or property can repeat. With a relational database design, you would either need to define a finite number of occurrences of an attribute or create a separate table with repeating rows. In this example, instead of line1 and line2, in XML it would be more natural to have a repeating line element. The order of elements is significant in XML, so the numeric designators are not required to indicate whether it is the first or second line of the address.
20.2.2. Relationships
An entity-relationship model allows entities to be independent of each other and have relationships to various other entities. Sometimes these relationships map naturally onto a hierarchical XML model, especially in the case of XML messages that represent a temporary view on the data. Sometimes it is more of a challenge to represent relationships in XML.
20.2.2.1. One-to-one and one-to-many relationships
Many relationships in XML are simply modeled as parent-child relationships, also known as containment relationships. For example, suppose each customer only has one address. In an entity-relationship model, there might be two separate entities: one for customer and one for address. This would be a good design if other entities (such as suppliers) also have addresses. In XML, this would be modeled as a parent-child relationship, where the customer element would contain a single address element.
A similar approach works if a customer can have more than one address. In an entity-relationship model, there would be a one-to-many relationship between the customer and the address. In XML, the customer element can simply contain more than one address element.
20.2.2.2. Many-to-many relationships
Many-to-many relationships are harder to represent directly in XML. In many cases, since an XML message represents a temporary view of the data, a one-to-many containment relationship is sufficient even if a many-to-many relationship exists in the real world. For example, a purchase order might represent orders for more than one product, and any one product can be ordered using many purchase orders, but for the purposes of the message you only need to follow the relationship in one direction: include all the products for the given purchase order.
Sometimes there is a many-to-many relationship that does need to be fully represented in one message. Suppose that instead of a single purchase order, our XML document represents a summary report that shows all the orders and the products that are ordered, over time. An order can be for multiple products, and a product can be part of multiple orders, and this many-to-many relationship needs to be represented in the XML. There are several ways to approach this, described in this section.
20.2.2.2.1. Approach #1: Use containment with repetition
In this approach, you choose one entity as the parent, for example order. Within each order, there is a repeating product child that contains all of the product information. This is shown in Example 20–2. This will result in some products being repeated, in their entirety, more than once in the message, as is the case for product number 557 in the example.
This is a perfectly acceptable solution for low volumes of information with low repetition. However, if there were a lot of other information in the message about each product, and a product could be repeated in dozens of orders, the message would quickly become unnecessarily large.
Example 20–2. Relationship with repetition
<report>
<order>
<number>1234</number>
<total>213.12</total>
<lineItem>
<giftWrap>bday</giftWrap>
<size>12</size>
<color>blue</color>
<quantity>1</quantity>
<product>
<number>557</number>
<name>Short-Sleeved Linen Blouse</name>
<availableColors>blue red</availableColors>
</product>
</lineItem>
<lineItem>
<size>L</size>
<color>tan</color>
<quantity>2</quantity>
<product>
<number>443</number>
<name>Deluxe Golf Umbrella</name>
<availableColors>tan black</availableColors>
</product>
</lineItem>
</order>
<order>
<number>5678</number>
<total>245.55</total>
<lineItem>
<giftWrap>bday</giftWrap>
<size>12</size>
<color>blue</color>
<quantity>1</quantity>
<product>
<number>557</number>
<name>Short-Sleeved Linen Blouse</name>
<availableColors>blue red</availableColors>
</product>
</lineItem>
<lineItem>
<size>L</size>
<quantity>1</quantity>
<product>
<number>563</number>
<name>Ten-Gallon Hat</name>
<availableSizes>S M L</availableSizes>
</product>
</lineItem>
</order>
</report>
20.2.2.2.2. Approach #2: Use containment with references
Another option is to keep the orders and products separate and use unique identifiers to specify the relationships. This approach is similar to foreign keys in a database. An order might contain several reference elements that refer to unique keys of the products. An example is shown in Example 20–3.
Here, as in the previous approach, the relationship from order to product is represented, but not the relationship back from product to order. However, the relationship from product to order can be gleaned from the XML using program code.
Example 20–3. Relationship via reference
<report>
<order>
<number>1234</number>
<total>213.12</total>
<lineItem>
<giftWrap>bday</giftWrap>
<size>12</size>
<color>blue</color>
<quantity>1</quantity>
<productRef ref="557"/>
</lineItem>
<lineItem>
<size>L</size>
<color>tan</color>
<quantity>2</quantity>
<productRef ref="443"/>
</lineItem>
</order>
<order>
<number>5678</number>
<total>245.55</total>
<lineItem>
<giftWrap>bday</giftWrap>
<size>12</size>
<color>blue</color>
<quantity>1</quantity>
<productRef ref="557"/>
</lineItem>
<lineItem>
<size>L</size>
<quantity>1</quantity>
<productRef ref="563"/>
</lineItem>
</order>
<product>
<number>443</number>
<name>Deluxe Golf Umbrella</name>
<availableColors>tan black</availableColors>
</product>
<product>
<number>557</number>
<name>Short-Sleeved Linen Blouse</name>
<availableColors>blue red</availableColors>
</product>
<product>
<number>563</number>
<name>Ten-Gallon Hat</name>
<availableSizes>S M L</availableSizes>
</product>
</report>
In your schema, you can use either ID- and IDREF-typed attributes or identity constraints to validate the relationship. Identity constraints, described fully in Chapter 17, use the key and keyref elements. This is shown in Example 20–4, where the key element defines the unique identifier of each product. Within it, selector identifies the element that needs to be unique (the product), and field specifies the element that contains the unique identifier (the number child).
The keyref element is used to establish the foreign key relationship from the productRef’s ref attribute to the product element’s number child. It uses a syntax similar to the key element, except that it also includes a refer attribute that indicates the key to which it refers.
Compared to the first approach, this type of structure can be harder to process, either in XPath or in program code generated by data binding tools. Although the relationship can be expressed and validated using a schema, defining it via the schema identity constraints will not have any particular representation or meaning in generated class definitions. For example, for a generated Order class, it will not generate a getProduct method that will go out and get a related Product object, whereas with the first approach you can simply use a getProduct method. However, this approach has the advantage of being a lot less verbose if there is a lot of product information and/or it is repeated many times.
Example 20–4. Using identity constraints to validate references
<xs:element name="report" type="ReportType">
<xs:key name="productKey">
<xs:selector xpath=".//product"/>
<xs:field xpath="number"/>
</xs:key>
<xs:keyref name="productKeyRef" refer="productKey">
<xs:selector xpath=".//productRef"/>
<xs:field xpath="@ref"/>
</xs:keyref>
</xs:element>
20.2.2.2.3. Approach #3: Use relationship elements
A third option is to use a separate relationship element (called, for example, orderProductRelationship) placed outside the contents of either the order or the product elements. This is shown in Example 20–5. This has the advantage of representing the relationship in both directions in a compact way. It also provides a container for information about that relationship, such as the quantity and color ordered in our example. The disadvantage is that this is even more difficult to process using generated classes. It compounds the issues with the previous method by requiring yet a third unrelated object (orderProductRelationship) that has to be retrieved.
Example 20–5. Using a separate relationship element
<report>
<order>
<number>1234</number>
<total>213.12</total>
</order>
<order>
<number>5678</number>
<total>245.55</total>
</order>
<product>
<number>443</number>
<name>Deluxe Golf Umbrella</name>
<availableColors>tan black</availableColors>
</product>
<product>
<number>557</number>
<name>Short-Sleeved Linen Blouse</name>
<availableColors>blue red</availableColors>
</product>
<product>
<number>563</number>
<name>Ten-Gallon Hat</name>
<availableSizes>S M L</availableSizes>
</product>
<orderProductRelationship>
<orderRef ref="1234"/>
<productRef ref="557"/>
<giftWrap>bday</giftWrap>
<size>12</size>
<color>blue</color>
<quantity>1</quantity>
</orderProductRelationship>
<orderProductRelationship>
<orderRef ref="1234"/>
<productRef ref="443"/>
<size>L</size>
<color>tan</color>
<quantity>2</quantity>
</orderProductRelationship>
<orderProductRelationship>
<orderRef ref="5678"/>
<productRef ref="557"/>
<giftWrap>bday</giftWrap>
<size>12</size>
<color>blue</color>
<quantity>1</quantity>
</orderProductRelationship>
<orderProductRelationship>
<orderRef ref="5678"/>
<productRef ref="563"/>
<size>L</size>
<quantity>1</quantity>
</orderProductRelationship>
</report>
20.3. Modeling object-oriented concepts
Object-oriented concepts fit nicely with XML Schema. Complex types in XML Schema are like classes, and element declarations are like instance variables that have those classes. Some of the considerations described in the previous section apply to object-oriented concepts as well. Objects are in some ways analogous to entities, and they can have associations (relationships) that can be represented using the three approaches described. Some additional object-oriented concepts are compared to XML in this section.
20.3.1. Inheritance
Object-oriented inheritance can be implemented using type derivation in XML Schema. For example, suppose we want to have separate elements for three different kinds of products: shirts, hats, and umbrellas. They have some information in common, such as product number, name, and description. The rest of their content is specific to their subclass: Shirts might have a choice of sizes and a fabric. A hat might also have a choice of sizes, with the values conforming to a different sizing scheme, as well as a different property like an SPF rating. This is depicted as an object model in Figure 20–2.
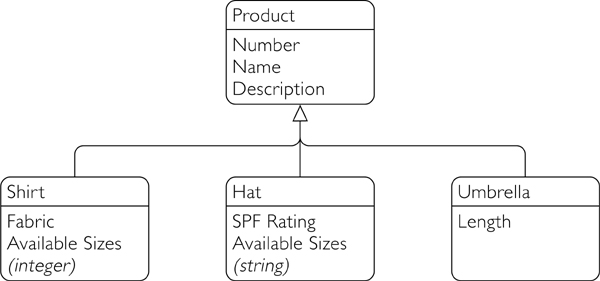
Figure 20–2. Class inheritance
In XML Schema, you can create a ProductType type, like the one shown in Example 20–6, that specifies the content common to all three types. The type can optionally be abstract, meaning that it cannot be used directly by an element declaration.
Example 20–6. An abstract product type
<xs:complexType name="ProductType" abstract="true">
<xs:sequence>
<xs:element name="number" type="xs:integer"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="desc" type="xs:string"/>
</xs:sequence>
</xs:complexType>
You can then derive three new types from ProductType, one for each kind of product. An example of ShirtType is shown in Example 20–7.
Example 20–7. A derived shirt type
<xs:element name="shirt" type="ShirtType"/>
<xs:complexType name="ShirtType">
<xs:complexContent>
<xs:extension base="ProductType">
<xs:sequence>
<xs:element name="fabric" type="xs:string"/>
<xs:element name="availableSizes"
type="AvailableShirtSizesType"/>
</xs:sequence>
</xs:extension>
</xs:complexContent>
</xs:complexType>
<xs:simpleType name="AvailableShirtSizesType">
<xs:list>
<xs:simpleType>
<xs:restriction base="xs:integer">
<xs:minInclusive value="2"/>
<xs:maxInclusive value="18"/>
</xs:restriction>
</xs:simpleType>
</xs:list>
</xs:simpleType>
As you can see, ShirtType is defined as an extension of ProductType. This means that it inherits the entire content model of ProductType and adds two new elements, fabric and availableSizes, which must appear at the end. A valid instance of ShirtType is shown in Example 20–8.
Example 20–8. Instance of the derived shirt type
<shirt>
<number>557</number>
<name>Short-Sleeved Linen Blouse</name>
<desc>Our best-selling shirt!</desc>
<fabric>linen</fabric>
<availableSizes>2 4 6 8 10 12 14</availableSizes>
</shirt>
A different extension of ProductType could then be defined for the hat element, as shown in Example 20–9.
Example 20–9. A derived hat type
<xs:element name="hat" type="HatType"/>
<xs:complexType name="HatType">
<xs:complexContent>
<xs:extension base="ProductType">
<xs:sequence>
<xs:element name="spfRating" type="xs:integer"/>
<xs:element name="availableSizes"
type="AvailableHatSizesType"/>
</xs:sequence>
</xs:extension>
</xs:complexContent>
</xs:complexType>
<xs:simpleType name="AvailableHatSizesType">
<xs:list>
<xs:simpleType>
<xs:restriction base="xs:string"/>
</xs:simpleType>
</xs:list>
</xs:simpleType>
HatType also adds an availableSizes element, but its type is different from that in ShirtType. Using locally declared elements, as we do here, allows the same element name to have different types in different contexts.
Data binding tools will generally treat complex type extensions as class inheritance. They will generate a class named ShirtType that extends the class named ProductType. ShirtType will inherit all methods from ProductType and add new ones. This can be beneficial for the same reasons it is beneficial in object-oriented programming. Defining the common components once ensures that they are consistent and makes it easier to write and maintain the code that manipulates the common data. In addition, objects can be treated in the application code either generically as products, or specifically as shirts or hats, depending on the needs of the application.
XML Schema offers several other ways of representing class hierarchies.
• Complex types can be derived by restriction (rather than extension) from other complex types. The derived type must allow only a subset of what the base type allows. This is of limited usefulness unless you are attempting to define a subset of another schema.
• Type substitution allows the same element name to be used for derived types (by extension or restriction). For example, I could declare a product element whose type is ProductType, and then in the message itself use the xsi:type attribute to indicate a derived type—for example, <product xsi:type="ShirtType">. It is essentially casting an individual product element to a subtype, ShirtType, at runtime. While this can be an elegant way to achieve flexibility, it is not well supported in tools. For more interoperable schemas, it is best to define separate elements (shirt, hat, umbrella) for each type (ShirtType, HatType, UmbrellaType), as shown earlier in this section.
• Substitution groups describe hierarchies of elements rather than types. They allow you to specify that one or more elements are substitutable for another element. For example, I could put the shirt, hat, and umbrella elements in the substitution group of the product element. Then, anywhere product appears in a content model, any of the other three elements could appear instead. It is a more extensible alternative to choice groups. However, the support of substitution groups in data binding tools is also somewhat limited. Data-oriented messages are usually fairly predictable, so unless you need this kind of flexibility, you are better off creating a hierarchy of types and explicitly stating where elements of each type can appear.
20.3.2. Composition
There is an alternative way to represent the fact that shirts, hats, and umbrellas have properties in common. Through the use of named model groups, XML Schema allows you to identify shared content model fragments. This distinction could be seen as composition rather than generalization in object-oriented terminology. A shirt definition is composed of product properties, plus has its own properties.
Named model groups are described in detail in Chapter 15. Example 20–10 shows a named model group, ProductProperties, with a content model fragment describing all the generic product information.
Example 20–10. Product property group
<xs:group name="ProductProperties">
<xs:sequence>
<xs:element name="number" type="xs:integer"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="desc" type="xs:string"/>
</xs:sequence>
</xs:group>
Example 20–11 shows how ShirtType references the ProductProperties group. It also uses a group element, but this time with a ref attribute instead of a name attribute. The effect of referencing a group is as if you cut and pasted the content of the group into the place where it is referenced.
HatType could similarly reference the group to reuse the definition of the product properties. The instances of shirt and hat will look exactly the same as if we used type extension; there will be no ProductProperties element in the message content.
The advantage of this approach is its flexibility. When using named model groups, the shared portion can appear anywhere in the content model, not just at the beginning. This might be a consideration if the order matters, although you should avoid giving any significance to the order of elements. It’s also more flexible in that you can also include more than one group in a content model. With type derivation, there is only single inheritance.
Example 20–11. Shirt type that uses the product property group
<xs:complexType name="ShirtType">
<xs:sequence>
<xs:group ref="ProductProperties"/>
<xs:element name="fabric" type="xs:string"/>
<xs:element name="availableSizes"
type="AvailableShirtSizesType"/>
</xs:sequence>
</xs:complexType>
The disadvantage is that although the generic product components are shared in the schema, most data binding toolkits do not generate shared code or interfaces for these components. They will typically generate a ShirtType class that has all the generic product properties, and a separate HatType class that has separate definitions of the generic product properties. No separate ProductProperties class or interface will be generated; it will be as if the group did not exist.
Use of named model groups is most appropriate when the types represent different concepts that happen to have a few of the same child elements. However, if the types are really subclasses of a more generic class, it is better to use type derivation because the generated code will be more useful and representative of the real model.
Another option for composition is to define a child element to contain the shared information. We could use the same ProductType complex type we defined before. Instead of deriving ShirtType from it, we could give ShirtType a child element named productProperties that has the type ProductType. This is shown in Example 20–12.
Example 20–12. Using a child element for composition
<xs:complexType name="ProductType">
<xs:sequence>
<xs:element name="number" type="xs:integer"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="desc" type="xs:string"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="ShirtType">
<xs:sequence>
<xs:element name="productProperties" type="ProductType"/>
<xs:element name="fabric" type="xs:string"/>
<xs:element name="availableSizes"
type="AvailableShirtSizesType"/>
</xs:sequence>
</xs:complexType>
In this case, the message instance will have an extra level of structure with the productProperties element, as shown in Example 20–13.
Example 20–13. Instance of shirt type using child element
<shirt>
<productProperties>
<number>557</number>
<name>Short-Sleeved Linen Blouse</name>
<desc>Our best-selling shirt!</desc>
</productProperties>
<fabric>linen</fabric>
<availableSizes>2 4 6 8 10 12 14</availableSizes>
</shirt>
One advantage of this approach is that it clearly identifies the shared information and provides a hook to access it. This can make it easier for the consumer of the message, especially when using a tool like XSLT. Using toolkits, an advantage over using named model groups is that one class will be generated for productProperties, so the code to process and generate that part of the message can be shared for both shirts and hats.
The disadvantage of this approach is that it adds an additional layer, and therefore some additional complexity, to the messages. Compared to the type inheritance method, this can make the message more verbose and writing and maintaining the code that implements the service slightly more difficult.
20.4. Modeling web services
Modeling web services has a lot in common with the concepts already described in this chapter. Typically the information being passed in web service messages consists of entities and/or objects. Some people equate designing a web service with designing an object-oriented API. There are some similarities: There are interfaces (services) that have methods (operations) that encapsulate the underlying functionality. For very fine-grained utility services, this comparison holds true. For example, you might have some data services that are used to put a wrapper around certain low-level database transactions, such as inserting and updating customer information. These services might roughly resemble an object-oriented interface, with methods/operations like updateCustomerStatus and insertCustomerAddress.
However, as you design more coarse-grained composite services, especially those that will be used across organizational boundaries, the messages passed to and from the service are likely to be broader in scope than any data values you would normally pass in a call to a method. It is desirable, for reasons of performance, scalability, and reliability, for a service to not be too “chatty.” A chatty service is one to which multiple calls must be made, often synchronously, to get a useful result. Instead, all the information the service needs to give you in a result should be included in the same message. This means that information needed to accomplish several different actions may be included in the message itself.
For example, for a purchasing service, the message passed to the service might include security information such as logon parameters, the purchase order itself, the state of the purchase order, what action needs to be performed next with it, the format of the desired response or acknowledgement, and the location to send the response. Some of this information will appear in the header. As the message is passed from service to service, it might accumulate additional information, such as customer details and more detailed pricing and tax information, for each of the ordered items. Modeling all of this information as a single message to be passed to an operation may not be intuitive for the average object-oriented designer.
A complete discussion of designing service-oriented architectures and their contracts is outside the scope of this book, but it is useful to note several key points related to message design.
• As described above, the scope of a single message should be somewhat coarse-grained; it should provide all of the content needed for an entire operation. This means that the root element type should be broad enough to include a variety of information, not just a single entity.
• It is helpful to use specific root elements for individual operations. For example, if the operation is to submit a purchase order, it is helpful to have a root element name that specifically states this using a verb, for example submitPurchaseOrder rather than a generic message element or even a purchaseOrder element. If you are using WSDL, you specify the root element for the input and output of each operation in a service. Using more specific root element names improves validation and results in a more precise interface that makes it easier to develop code to process.
• Although individual operations may use different root elements, it is highly desirable for the contents of the various message types to have as much in common as possible. Reusing types at all levels is very important in a service-oriented environment to avoid thousands of point-to-point transformations between different representations of, for example, addresses or products. Some organizations develop canonical models in XML Schema whose use is mandatory in all newly developed services, as a way of formalizing proper reuse.
20.5. Considerations for narrative content
Narrative content—the kind you read in documents like books, articles, and web pages—is very different from what we have been discussing so far in this chapter. But that unpredictable human-written, human-readable stuff also occurs alongside data-oriented content in even (or especially) the best-managed documents.
This section first introduces a key distinguishing trait of narrative content, the relationship between semantics and style. It then discusses other considerations for modeling and schema design.
20.5.1. Semantics vs. style
It is desirable in designing a narrative XML vocabulary to focus on the semantics, or meaning, of the content, as opposed to its appearance. For example, a phrase might be italicized because it is a foreign phrase or a citation. It is helpful to have separate elements (for example, foreign and citation) to reflect the semantics, instead of a single element indicating the italicization (i). Presentation-only features, such as colors and fonts, are best left to a stylesheet, not embedded in an XML document itself.
20.5.1.1. Benefits of excluding styling
The separation of pure semantic content from presentation style allows you to
• Style content separately for different output devices such as smartphones, e-book readers, and alternative web browsers
• Implement interactive behavior associated with certain kinds of text—for example, hyperlinks for intra- or inter-document references or pop-up directions for addresses
• Generate derivative presentations of the content, such as tables of contents, indexes, and summary views
• Provide more focused searching based on names of elements in the content
• Ensure more consistent formatting across an entire body of content
• Improve verification of the content—for example, determine whether intra-document references in a legal document are valid
20.5.1.2. Rendition elements: “block” and “inline”
Formatting an XML document occurs conceptually in two steps:
1. Rendition, which produces an abstract layout of the document, not yet particularized for a specific output device. It contains such elements as “page,” “frame,” “block,” and “inline.”
2. Presentation, which applies precise styling to produce a layout that is coded for the specific output device.
The mapping from elements in the document to rendition elements occurs in the stylesheet, along with the presentation styling. Usually, an element with characters at the top level of its content is rendered as either a “block” or an “inline” element. When presented, the content of a block element occupies its own vertical space in a page or frame, and the content of its inline elements occurs within that space. Examples of block elements are p in HTML and block in XSL-FO.
Elements rendered inline are generally used for identifying text within a paragraph for distinctive formatting and/or special processing (such as getting its content from a database). In HTML, b (bold) and a (anchor) are examples of inline elements. Substitution groups are often used to represent inline elements, since they can appear interchangeably in many different content models.
20.5.2. Considerations for schema design
20.5.2.1. Flexibility
XML models for narrative content tend to be much more flexible than data-oriented models. While you can mandate that every product has a product number and name, you are unlikely to mandate that every paragraph must contain a URL and an emphasized phrase in bold. The order of the actual elements is important in a narrative model (it is important that Chapter 1 appears before Chapter 2) but the order of the kinds of elements is generally less important. You would not require, for example, that all tables must appear after all paragraphs in a section.
20.5.2.2. Reusing existing vocabularies
If you are writing schemas to model general narrative content, it is highly desirable to reuse existing vocabularies, such as XHTML, XSLFO, DocBook, and NLM XML. Be sure to choose appropriate elements for the degree of semantic specificity of your schema. XHTML and XSL-FO, for example, include rendition elements.
Reusing parts of these vocabularies will save you time and ensure that your vocabulary is consistent with industry-accepted norms. You can either extend these standards using their formally defined methods, or pick and choose a subset of them that is useful to you.
20.5.2.3. Attributes are for metadata
Another characteristic of narrative XML models is that all of the “real” content of an element, such as visible content of a web page or a printed page, is contained in the element’s syntactic content (i.e., between its start and end tags). Attributes are reserved for metadata about that content, for example the content’s last revision date or its source.
20.5.2.4. Humans write the documents
Another consideration for designing narrative content models is that the corresponding XML document instances are far more likely to be hand-created by human users. Although they will be most likely using an editor to help them navigate the model, you should take their needs into consideration when designing the schemas:
• Pay special attention to consistency and clarity in the model.
• Do not offer multiple different ways to represent the same thing.
• Although flexibility is sometimes desirable, too many choices can be overwhelming. Instead of allowing an article, for example, to have too many child element choices, introduce an intermediate level comprising front, body, and back elements: front would allow elements such as title, author, etc.; the body, elements like section, list, figure, table, etc.; and the back, elements like index and appendix.
• Create separate authoring documentation that does not make use of XML Schema terminology.
20.6. Considerations for a hierarchical model
XML modeling has more flexibility than other modeling paradigms in that you can have an unlimited number of levels of a hierarchy, and there are a variety of ways of organizing that hierarchy. This section describes some special considerations that allow you to take advantage of the flexibility of XML.
20.6.1. Intermediate elements
In XML, you can introduce intermediate elements anywhere in a model to make the document easier to process and understand. Using them as containers to group related elements together can be beneficial in promoting reuse, organizing the messages and generated code more logically, simplifying mapping to existing systems, and allowing more expressive content models.
Going back to our order example, you could define it using a fairly flat structure, depicted in Example 20–14. There are lineItem elements to group each line item together, but otherwise all of the data elements are at the same level of the purchase order. One possible schema to describe this document is shown in Example 20–15.
Example 20–14. A flat order example
<order>
<number>12345</number>
<date>2012-10-31</date>
<customerNumber>12345</customerNumber>
<customerName>Priscilla Walmsley</customerName>
<billToAddressLine>123 Main Street</billToAddressLine>
<billToCity>Traverse City</billToCity>
<billToState>MI</billToState>
<billToZip>49684</billToZip>
<shipToAddressLine>5100 Garfield Road</shipToAddressLine>
<shipToCity>Hillsborough</shipToCity>
<shipToState>NJ</shipToState>
<shipToZip>08876</shipToZip>
<!--...-->
<lineItem>
<number>557</number>
<!--...-->
</lineItem>
<lineItem>
<number>443</number>
<!--...-->
</lineItem>
</order>
The order element shown in Example 20–14 contains all the required data, but its design has several weaknesses. The first is that it does not take advantage of reuse opportunities. The structure of the bill-to and ship-to addresses is the same, but it is defined twice in the design. The schema describing this document has to declare each city element twice, each state element twice, and so on. Since the element names are different, any code that handles address information (for example, to populate it or display it) also has to be written twice, once for each set of element names.
Example 20–15. A flat order schema
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="order" type="OrderType"/>
<xs:complexType name="OrderType">
<xs:sequence>
<xs:element name="number" type="xs:integer"/>
<xs:element name="date" type="xs:date"/>
<xs:element name="customerNumber" type="xs:integer"/>
<xs:element name="customerName" type="xs:string"/>
<xs:element name="billToAddressLine" type="xs:string"
maxOccurs="unbounded"/>
<xs:element name="billToCity" type="xs:string"/>
<xs:element name="billToState" type="xs:string"/>
<xs:element name="billToZip" type="xs:string"/>
<xs:element name="shipToAddressLine" type="xs:string"
maxOccurs="unbounded"/>
<xs:element name="shipToCity" type="xs:string"/>
<xs:element name="shipToState" type="xs:string"/>
<xs:element name="shipToZip" type="xs:string"/>
<xs:element name="lineItem" type="LineItemType"
maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="LineItemType">
<xs:sequence>
<xs:element name="number" type="xs:integer"/>
<!--...-->
</xs:sequence>
</xs:complexType>
</xs:schema>
A better design is shown in Example 20–16, where two intermediate elements, billToAddress and shipToAddress, have been added to represent the bill-to and ship-to addresses. The two have identical children, which means that they can share the same complex type. It is named AddressType and is shown in Example 20–17 with the revised OrderType, whose elements reference it. AddressType is not only used twice in the revised schema for this message, but may also be reused in other schemas in other contexts.
Example 20–16. More structured address information
<order>
<!--...-->
<billToAddress>
<addressLine>123 Main St.</addressLine>
<city>Traverse City</city>
<state>MI</state>
<zip>49684</zip>
</billToAddress>
<shipToAddress>
<addressLine>5100 Garfield Road</addressLine>
<city>Hillsborough</city>
<state>NJ</state>
<zip>08876</zip>
</shipToAddress>
<!--...-->
</order>
Example 20–17. AddressType and revised OrderType definitions
<xs:complexType name="OrderType">
<xs:sequence>
<xs:element name="number" type="xs:integer"/>
<xs:element name="date" type="xs:date"/>
<xs:element name="customerNumber" type="xs:integer"/>
<xs:element name="customerName" type="xs:string"/>
<xs:element name="billToAddress" type="AddressType"/>
<xs:element name="shipToAddress" type="AddressType"/>
<xs:element name="lineItem" type="LineItemType"
maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="AddressType">
<xs:sequence>
<xs:element name="addressLine" type="xs:string"/>
<xs:element name="city" type="xs:string"/>
<xs:element name="state" type="xs:string"/>
<xs:element name="zip" type="xs:string"/>
</xs:sequence>
</xs:complexType>
In addition to reuse, another benefit of the more detailed structure is that a code generation tool will generate a separate class to represent the address information. This tends to be more logical to the developer, and can make it easier to integrate existing systems if, for example, the party information is part of a different application or database than the purchase order information. This further promotes reuse, since the class written to handle address information can be reused as well as the complex type.
Intermediate elements can also allow more robust content models. In this case, if the ship-to address can be optional (for example, when it is the same as the bill-to address), you can make the entire shipToAddress element optional. You can then specify that if the shipToAddress does appear, it must have certain required children such as addressLine and zip. In the flat structure, the only option would be to make all of the shipToXxx elements optional, which would be a much less expressive content model. It would allow illogical or incomplete documents—for example, one containing a shipToAddressLine but not a shipToCity.
Finally, the use of intermediate elements can address extensibility and address versioning problems. If you later decide that there can be more than one ship-to address (for example, in the case of multishipment orders), you can simply increase the maxOccurs attribute on the shipToAddress element declaration without introducing a backward-incompatible change.
Example 20–17 shows an appropriate structure for the purchase order document. However, it is possible to have too many intermediate elements. Excessive levels of nesting in an XML message can make it difficult to understand and overly lengthy. It can also make the schema and program code more difficult to maintain.
20.6.2. Wrapper lists
A slightly different kind of intermediate element is a container element that is used to group lists of like elements together. In the flat order example shown in Example 20–14, all of the lineItem elements appear at the top level of the order. It is common practice to place repeating elements into a container element whose name is usually the plural of the name of the element being repeated. In our case, we would wrap our lineItem elements into a lineItems element, as shown in Example 20–18.
This has some of the same benefits described in the previous section, namely extensibility and more expressive content models. It is more extensible because, if you later decide to keep some other information about the list, or change the contents of the list, you do not need to make a backward-incompatible change to the outer complex type (OrderType). In version 1.0, it will also allow a more expressive content model if you choose to use all groups instead of sequence groups in the outer content model, because it will get around the problem of all groups not allowing repeating elements. Finally, documents with container elements can be easier to process using technologies like XSLT.
Example 20–18. A repeating container element lineItems
<order>
<!--...-->
<lineItems>
<lineItem>
<number>557</number>
<!--...-->
</lineItem>
<lineItem>
<number>443</number>
<!--...-->
</lineItem>
</lineItems>
</order>
20.6.3. Level of granularity
Another factor to consider is how far down to take the hierarchy. Many data items have composite values, and it is sometimes unclear to what extent they should be broken down into separate elements. For example, suppose a product ID consists of two letters that represent its department, followed by a four-digit number. Should all six characters be modeled as one element, or should it be broken down into two subelements?
It depends on how that data item is to be used. The value should be split up if:
• The components are available separately, or can be separated by a known parsing algorithm. For example, if an address is always stored as a whole text block by an application that gathers this information, it may not be feasible to split it apart to put it in the XML document.
• The components will be processed separately, for example for display or for use in arithmetic operations.
• The objects will be sorted by one or more of the components separately.
• The components have different data types.
• The components should be validated separately.
• The components need to establish a higher level of constraint granularity.
It is easier to concatenate two data values back together than it is to parse them apart, especially if the logic for splitting them is complex.
On the other hand, if the value is always used as a whole by message consumers, it can be kept together. It comes down to the functional nature of the application. For example, a service that simply provides product information for display might offer the product ID as one value, while an order application that needs to treat departments separately may split it up.
20.6.4. Generic vs. specific elements
Another decision to make when modeling XML is how specific to make your element names. Using more generic element names allows for flexibility, but can limit validation specificity. One case where this comes into play is when you have several data items that represent a particular class of things, but each is a specialization. It is a design decision whether to use element names that represent the overall class or the specialized subclasses. Using the product example, each product has a number of features associated with it. Each feature has a name and a value. One way to represent this is by declaring a different specific element for each feature. To indicate whether a product is monogrammable, you might have a monogrammable element of type boolean. Example 20–19 shows some product features marked up with specific elements.
Example 20–19. Specific element names
<product>
<!--...-->
<availableColors>blue red</availableColors>
<availableSizes>S M L</availableSizes>
<monogrammable>true</monogrammable>
<weight units="g">113</weight>
</product>
The downside of using these specific element names is that they are not very flexible. Every time a new feature comes along, which can be relatively often, a number of changes have to be made. The schema must be modified to add the new element declaration for the feature. Applications that use those documents, including any generated code, must also be changed to handle the new features.
On the other hand, you could use a more generic feature element that contains the value of the feature, and put the name of the feature in a name attribute, as shown in Example 20–20.
A product schema that uses a generic feature element is shown in Example 20–21. Certain fundamental features such as number and name still have specific elements, because they are common to all products and are important to validate. Both the value and the name of the feature are defined as strings.
Example 20–20. Generic element names
<product>
<!--...-->
<feature name="availableColors">blue red</feature>
<feature name="availableSizes">S M L</feature>
<feature name="monogrammable">true</feature>
<feature name="weight">113</feature>
</product>
Example 20–21. ProductType with generic feature capability
<xs:complexType name="ProductType">
<xs:sequence>
<xs:element name="number" type="xs:integer"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="desc" type="xs:string"/>
<xs:element name="feature" maxOccurs="unbounded"
type="FeatureType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="FeatureType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="name" type="xs:string"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
This is far more flexible, in that new features do not require changes to the schema or the basic structure of the service classes. The only modification that needs to be made is that the code that creates feature elements must add one for the new feature.
There is a downside to using generic elements, however. One is that you cannot specify data types for the values. There is no way in XML Schema to say “if a feature element’s name attribute is weight, make the content integer, and if it’s monogrammable, make it boolean.” In version 1.0, this means that you cannot take advantage of XML Schema type validation to ensure that the values in the message conform to, for example, an enumerated list or range of values. This is not an issue when using specific elements because you simply create separate weight and monogrammable elements with different types.
Another downside to generic elements is that you have no control over their order or whether they are required or repeating. Using XML Schema 1.0, you cannot specify that there must be a feature element whose name is weight. You also cannot specify that there can only be one feature element whose name is monogrammable. For any feature name, there can be zero, one, or more values for it, and they can appear in any order. You could enforce this as part of the application, but then it would not be written into the service contract. Again, this is not a problem when you use specific elements for each feature because you can use minOccurs and maxOccurs on individual element declarations to control this.
Here are some considerations on whether to use generic versus specific elements.
• If there is little change (for example, if new features are rarely added), there is not much benefit to using generic elements.
• If the features are treated similarly (for example, if the consumer of the message is simply going to turn them into a “features” table on a web page for human consumption), it is easier to process them as generic elements.
• If the features are often treated differently, it can be easier to process them as specific elements. For example, if code is generated from the schema and the application needs to know the product’s weight to determine shipping cost, it is more convenient to simply call a method like product.getWeight() than retrieve all the features through product.getFeatures() and loop through them until (possibly) finding one called weight.
• If the content is likely to be significantly different for each specialization (or example, if some features can have differing multipart or complex values), it is best to use specific elements so that you can adequately describe their structure in the schema.
• If it is important to validate the contents, or the order or appearance of the data items, it is best to use specific elements, because these constraints cannot be expressed in XML Schema 1.0 for generic elements.1
The decision whether to use generic versus specific elements can be made at any level, not just for low-level name-value pairs like features. One level higher, a decision must be made whether to use a generic product element versus separate shirt and hat elements. This can be taken all the way up to the root element of the document, where you could have a generic root element such as message with an attribute saying what type of message it is, or choose to use a specific root element for every kind of message. The same considerations described in this section apply, regardless of the level in the hierarchy.