
2Integrating natural language resources in mobile applications
Abstract: This paper discusses integrating natural language technology in mobile applications. It begins by discussing why natural language understanding is a valuable component of mobile applications. It then reviews some tasks that can be done with natural language understanding technology and gives an overview of some natural language systems that are currently available for integrating into applications. Because natural language understanding is a dynamic field, and the systems discussed may become out of date, the paper also discusses general criteria for selecting natural language technology for use in mobile applications. Despite the wide availability of natural language resources, the task of adding natural language understanding functionality to applications is made more difficult because most of the APIs to natural language systems are entirely proprietary. The paper emphasizes how standards can greatly simplify the task of integrating natural language resources into applications and concludes with an overview of two standards from the World Wide Web Consortium. Extensible Multimodal Annotation (EMMA) and the Multimodal Architecture and Interfaces (MMI) specification reduce the amount of effort required to integrate natural language understanding into other applications by providing a uniform interface between natural language understanding systems and other software.
2.1Natural language understanding and multimodal applications
2.1.1How natural language improves usability in multimodal applications
As smartphone and tablet applications increase in features and sophistication, it becomes more and more difficult to successfully navigate their user interfaces. Because of this rich functionality, typical graphical user interfaces must include multiple menus, buttons and gesture actions that users must navigate to find the features that they want to access. This means that users often have to explore many paths before they can reach their goal, frequently backtracking when they’ve gone down the wrong path. In addition, terminology both across and within applications is frequently inconsistent (clicking on “settings”, “options”, “preferences”, or “account” all can lead to similar functionality in different applications). This situation results from the fact that screen space is extremely limited on mobile devices, so that less functionality can be exposed at the level of a main screen. Instead features must be nested in submenus and sub-submenus. If the submenus and sub-submenus are organized into categories with clear semantics, users have a chance at finding what they need, but frequently the semantics is not clear. As even smaller devices (such as smart watches) become available, with even smaller screens, this problem worsens. In addition, current trends toward flat design contribute to the problem by hiding user interface options until a specific, non-intuitive, touch gesture is performed.
All of this means that learning a new application of even moderate complexity on a mobile device is often time-consuming and frustrating. Direct searching for functions, rather than traversing menus, of course, is another user interface option, and many applications support search in addition to menu interaction. However, open ended search with keyboard input is very painful on a mobile device. To avoid the problem of typing on tiny keyboards, current smartphones include very capable speech recognition, so simply entering keyword search terms has become much less difficult. However, voice input alone is not the answer, because simple keyword searches often lead to many unwanted results, burying the user’s real target in a long list of irrelevant suggestions. This leaves users in the position of trying different keywords over and over to try to find search terms that will get them the results they need, without ever knowing whether the application even has the capability they’re looking for. The problem is even more severe for users who are less familiar with mobile applications than the general population or for users who have cognitive disabilities.
This problem is not only evident with mobile devices. As the Internet of Things expands, it will become more and more difficult to use conventional graphical interfaces to interact with an environment that includes possibly hundreds of connected objects, each with its own capabilities.
More natural interfaces are needed – interfaces that support natural forms of interaction and which don’t require mastering a new user interface for each application. Spoken natural language can provide a uniform interface across applications by allowing users to state their requests directly, without navigating through nested menus or trying to guess the right keywords. Natural language also reduces the need for the user to learn special input idioms like application-specific swiping gestures.
Using spoken natural language is much simpler and more convenient than current touch-based approaches. With natural language, users speak their requests in a natural way. For example, in a shopping application, users could say things like “I’m looking for a short-sleeved cotton woman’s sweater” instead of navigating through a set of menus like “women’s → tops → sweaters →short-sleeved → cotton”. A user of a tourist information app could say things like “What’s the best bus to take from here to the Museum of Art?” instead of “transportation → local → bus → destinations → cultural → Museum of Art”. Similarly, a natural language tourist information app could also use translation services to answer questions like “how would I ask for directions to the Art Museum in French?” These kinds of use cases provide a strong argument for natural language as a routine mobile user interface.
2.1.2How multimodality improves the usability of natural language interfaces
Not only is there a strong case to be made that natural language improves the usability of multimodal applications, but there is also a powerful benefit of multimodality in improving the effectiveness of natural language interfaces. The graphical modality especially can complement natural language interaction in multiple ways. The simplest benefit is probably just a display of speech recognition or speech understanding results. If the system has made an error, it should be clear from the display of the results. The application could also display alternative results that the user could select from in case of a mistake. This is much faster and more efficient than error correction with a voice-only dialog. As another example, the graphical modality can guide the user toward context-appropriate utterances through the use of graphics that set the context of the expected user response. This can be as simple as displaying “breadcrumbs” on the screen to indicate the dialog path to the current topic of discussion. Speech can also be combined with digital ink and pointing gestures to support natural multimodal inputs such as “Tell me more about this one”, or “Do you have that in red?” Finally, system output displayed as text can speed the interaction by bypassing the need to speak lengthy system responses out loud.
2.2Why natural language isn’t ubiquitous already
There are two major reasons why, despite these benefits, natural language isn’t already a ubiquitous user interface. The first is that spoken natural language understanding and speech recognition have not until recently been perceived as sufficiently reliable to support a wide variety of types of user interaction. However, this is rapidly changing, and the technologies are now mature enough to support many different types of applications. Unfortunately, while natural language understanding is becoming more common in mobile apps, this capability is not always available to developers because it is built in to the platform and lacks APIs. Some well-known systems that include natural language understanding components, such as Apple Siri, Google Now, Microsoft Cortana, or Amazon Echo, are essentially closed systems, without APIs, or with only limited APIs, that developers could leverage in their own applications. This is very limiting for the goal of natural language understanding as a ubiquitous interface, because it would be impossible for these individual vendors to ever integrate all the potential natural language applications to their current closed systems. Instead, for natural language to be truly ubiquitous developers will need to be able to independently create natural language UIs for any application.
A second, perhaps less obvious, reason that spoken natural language is not more common is that easy-to-use APIs and integration tools have not been available. This problem is being partially addressed as natural language technology is increasingly made available through the RESTful APIs (Fielding & Taylor 2000) that are becoming more and more common for accessing many different types of web services. While RESTful APIs do make integration easier, they don’t fully solve the problem because it is still necessary to code to specific natural language processing resource’s APIs. Standards such as Extensible Multimodal Interaction (EMMA) (Dahl 2010; Johnston et al. 2009a, Johnston 2016, Johnston et al. 2015) and the Multimodal Architecture (Barnett et al. 2012; Dahl 2013b), as discussed below, will also play a role in reducing development effort by providing more uniform APIs to natural language processing functionality.
However, despite the fact that standards are only beginning to be adopted, there nevertheless are an increasing number of web services and open source systems which are currently available for integration into applications. Full natural language understanding, as well as specific natural language tasks such as part of speech tagging, parsing, stemming, translation, and named entity recognition are only a few of the natural language processing technologies that are available. Because of this, developers who would like to use natural language processing in applications have many more resources available to them than they would have had only a few years ago.
2.3An overview of technologies related to natural language understanding
Before we discuss the details of different natural language processing resources, it is useful to situate natural language understanding in the context of some important related technologies. The relationship between natural language processing and these other technologies addresses the question of which other technologies would be needed to build a specific system. It also clarifies the architecture of products where natural language understanding is bundled with one or more related technology. In practice, natural language understanding is nearly always used in conjunction with one or more of these other related technologies.
Figure 2.1 illustrates the relationship between some of these technologies and natural language understanding (in the gray box). Natural language understanding analyzes text, which can originate from a variety of sources, including (1) existing documents (from the Internet or from databases) or (2) a user’s typed text or (3) recognized speech creating a representation in a structured format. Once natural language understanding has taken place, an interactive dialog manager can act directly on the user’s request and/or the results can be stored for later use, for example, to support applications such as search.
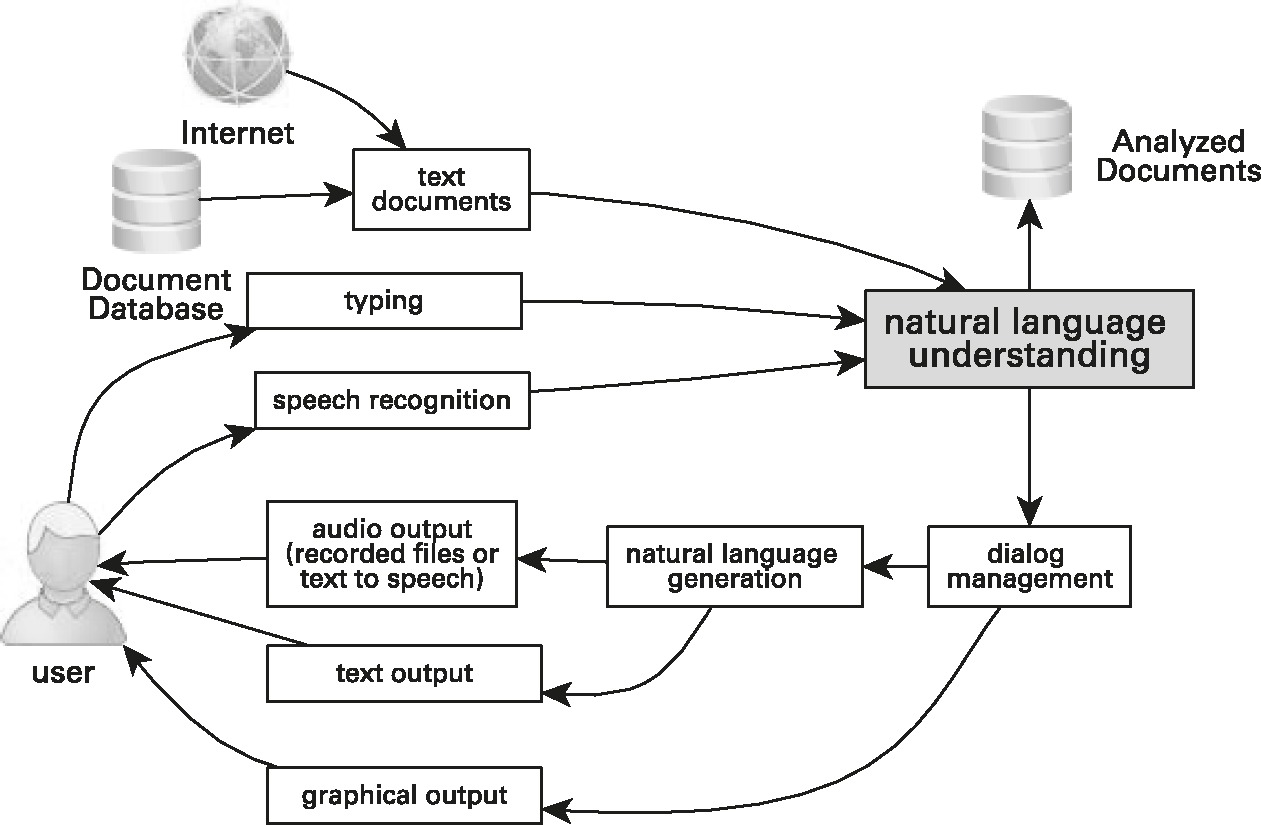
This paper will review some currently available natural language processing resources, describe how they can be used in mobile applications, and discuss how they can be used with W3C standards to provide the basis of a new generation of natural, easy to use, mobile user interfaces. The specific software resources detailed here are changing rapidly, so any discussion of current systems is likely to become out of date in the near future. In order to extend the value of this paper beyond the lifetime of the specific systems discussed here, we also discuss general categories of systems and how to select software for a specific application.
2.4Natural language processing tasks
The goal of natural language processing is to create structured representations from unstructured natural language, the kind of language that we use to communicate with other people. Within this general characterization of natural language processing, there are many different types of structures that may be produced, depending on the goals of the application. Some systems produce several types of structures, often in a pipelined fashion where one task passes its result to the next task in the pipeline, each task adding new levels of structure.
There are many currently available natural language understanding systems, but there is no single system that can meet the natural language processing requirements for every application. Thus, it is important to carefully consider what needs to be accomplished in order to select the right system for any specific application. We begin by reviewing a few of the most common natural language processing tasks and their use cases.
Classification
One of the simplest natural language processing tasks is classification. This is a characterization of natural language inputs into categories, or intents. This is also called text classification. For some applications, this may be all that is needed for very useful results. Even if the users’ speech is very verbose, indirect and full of hesitations and false starts, classification can be very effective because the systems are developed or trained on just this kind of data. Table 2.1 shows some results from a classification system that classifies natural language utterances into different emotions (Dahl 2015).
One important application of classification is sentiment analysis, where sentiments expressed in text are represented. This is very useful, for example, in automatic processing of product reviews. Product reviews can be automatically classified as presenting positive, negative or neutral opinions about a product as well as the strength of the sentiment expressed. Similarly, classification has been used to classify tweets (Lee et al. 2011) into various categories of interest.
Tab. 2.1: Emotion classification from text.
| Input | Classification |
| I’m feeling unhappy right now | sad |
| This is gross | disgusted |
| I had a frightening experience | afraid |
| I’m in a cheerful mood today | happy |
Named entity recognition
Named entity recognition is a natural language processing task that attempts to find references to specific individuals or organizations in text. Asimple example of named entity recognition would be, given the sentence, “President Obama spoke to Congress about the Supreme Court”, identifying Obama as a person, and identifying Congress and the Supreme Court as organizations. This would be useful for topic spotting applications – for example, if a company wants to find out if their products are mentioned in blogs.
Interactive systems
Interactive systems are a large category of natural language applications that involve a back and forth dialog with a user; consequently, the specific natural language task in interactive systems is to structure the user’s input in such away that the system can act on it and provide a response to the user.
One type of interactive system is question answering. The goal of question answering is to answer questions about content, either generic knowledge such as Wolfram|Alpha (Claburn 2009), IBM Watson (Ferruci et al. 2010) or knowledge about specific documents (for example, product manuals) such as NLULite (NLULite 2015).
Another type of interactive system where natural language processing is used is spoken dialog systems. Spoken dialog systems are more general than question-answering systems, because they engage in many different types of dialogs, not just question answering (although they often do answer questions). Dialog systems include dialog managers (as shown in Fig. 2.1) that make decisions about what to say next in a conversation, taking into account the earlier parts of the conversation and previous interactions with the user. The more sophisticated a dialog manager is, the better it will be at adapting its behavior taking into account information about the context.
Currently, one important type of interactive dialog system is the personal assistant. Applications of this type include systems such as Siri, Google Now, Amazon Alexa, or Cortana. Personal assistants allow users to do tasks such as get information, manage their schedules, and interact with connected objects in the Internet of Things. As an example, natural language processing in a personal assistant application could convert something like “I need to add three heads of lettuce to my shopping list” to a structured format like the one shown in Fig. 2.2. A newer type of personal assistant is the Enterprise Assistant that represents a company and assists customers with tasks such as voice shopping or product support. Enterprise assistants are based on similar technologies as personal assistants. Examples of these enterprise assistants include Nuance Nina (Nuance Communications 2015) and Openstream Eva (Openstream 2015).
Traditional voice-only Interactive Voice Response (IVR) systems, as used in call centers, are also a type of interactive system. They typically help callers with self-service tasks such as checking on an order, reporting an electrical outage, checking bank balances. Interactions with IVRs tend to be relatively restricted and inflexible compared to personal assistant applications because they focus on a specific task.
Interactive applications in call centers also frequently use classification technology, discussed above, for call routing applications. The ideas behind these systems are based on the original work of Gorin, Riccardi and Wright (Gorin et al. 1997). Natural language call routing systems allow callers to express their concerns in ordinary language, with prompts like “In a few words, tell me what you’re calling about today.” The classification system then assigns the caller’s query to a specific category, which allows the call to be directed to an agent with knowledge of that category.
Classification extracts a fairly coarse meaning; a more fine-grained meaning can be obtained from entity extraction, or finding important key-value pairs in a user’s utterance, in addition to finding the overall intent of an utterance, as shown in Fig. 2.2. In Fig. 2.2, the overall classification of the user’s intent is “add item to shopping list”. There are three key-value pairs that have been extracted from the utterance – shopping_item: iceberg lettuce, measure: heads, and number: 3. Systems of this type are trained on examples of utterances expressing the intents and entities of interest to the application; other information in the utterance is ignored. Thus, the training process is extremely important. Poorly designed training data can easily result in a system that is unusable.

Natural language technology in spoken dialog systems is usually based on entity extraction with key-value pairs and may also include text classification for recognizing overall intents.
Linguistic analysis
Some natural language systems have the goal of analyzing language, independently of a specific application task. Lexical analysis, one type of linguistic analysis, means analyzing words; for example, stemming, or finding the roots of words, and lexical lookup, finding words in a dictionary. Tasks that analyze the grammatical structure of inputs include part of speech tagging, or assigning parts of speech to words in an input, and parsing, or analyzing the input’s syntactic structure. These tasks can be used standalone in applications such as grammar checking and correction, but they can also be used as intermediate tasks for applications that are aimed at finding the structured meaning of an utterance. As an example, Tab. 2.2 shows the part of speech tagging results for “I had a frightening but very interesting experience”.
Tab. 2.2: Part of speech tags (Penn Treebank tagset) for “I had a frightening but very interesting experience”.
| Word | Part of Speech Tag | Meaning of Tag |
| I | PRP | Personal pronoun |
| had | VBD | Past tense verb |
| a | DT | Article |
| frightening | JJ | Adjective |
| but | CC | Coordinating conjunction |
| very | RB | Adverb |
| interesting | JJ | Adjective |
| experience | NN | Common noun |
Syntactic analysis, as shown in Fig. 2.3, is a detailed analysis of the grammatical relationships in a sentence, showing how the words are related to each other syntactically. Syntactic information, for example, includes modification relationships, such as the fact that “frightening” and “interesting” describe or modify “experience”. This type of analysis could be useful on its own in grammar-checking applications, in foreign language learning, or it can be part of the process of creating the fuller meaning analysis shown in Fig. 2.2.
For more details about natural language processing technology and applications, Dahl (2013a) provides a high-level overview of natural language processing and Jurafsky and Martin (2008) provide an in-depth technical resource for speech and language technologies.

2.4.1Accessing natural language technology: Cloud or client?
Now that we have discussed the different types of tasks that can be accomplished with natural language understanding, we can turn to the question of how to access natural language processing from an application.
Web services
The most common style of API for online natural language processing systems is RESTful Web Services, with results provided in JSON or XML. This is an increasingly common format for Web Service results, and is applicable to many web-based APIs, not only those used for natural language. Clients for this kind of API can include native smartphone or tablet interfaces such as iOS, Android, or Windows, as well as more generic browser-based HTML5/JavaScript-based applications. In a RESTful approach, the client, for example a web browser, sends a request to a URL (the endpoint) with text or speech to be processed, along with possible application-specific parameters, usually using HTTP GET or POST, and receives a result with the results of the natural language processing. In most cases the details of the request and result formats are vendor-specific, but later on we will see examples of RESTful natural language APIs using the W3C EMMA (Johnston et al. 2009b) and Multimodal Architecture (Barnett et al. 2012) standard Life Cycle Events.
For commercial applications, the vendors of natural language web services will also usually support on-premise hosting, so that a commercial application does not have to be dependent on the vendor for mission-critical services.
Server-based software
Another alternative to accessing natural language systems is software hosted on an internal server. This will be necessary for commercial applications of most open source software, since open source projects don’t usually have the resources to maintain web services which get any significant traffic. As noted above, a hosted or on-premise solution is also appropriate for mission-critical systems. Of course, a RESTful interface can also be used internally within an enterprise for natural language processing services.
Natural language software on the user’s device
This is the only model for accessing interactive natural language processing which does not require the user to be online, and there are obvious advantages to this. Software on the device will work whether or not the cloud is accessible. At this time, there seem to be very few natural language systems that are available for installation locally on users’ devices (although there have been some interesting experiments – see (Kelly 2015) for example). However, it is theoretically possible for Java-based systems like Stanford Core NLP (Stanford Natural Language Processing Group 2014) or OpenNLP (OpenNLP 2015) to run on Android devices, keeping in mind that they would have significant storage and processing requirements. It would be interesting if future systems were to explore this approach.
2.4.2Existing natural language systems
This section summarizes some existing natural language systems, current as of this writing. We start with some general considerations.
Research and commercial systems
Open source research systems such as the Stanford CoreNLP tools (Stanford Natural Language Processing Group 2014), OpenNLP (OpenNLP 2015) and NLTK (Loper & Bird 2002) are especially suitable for learning about natural language processing. There is no support for production applications, although there are message boards that can offer community support. These research systems are also among the few natural language tools that can provide structural analyses like part of speech tagging or syntactic analysis. An advantage of open source systems is that it is also possible for developers to modify them; for example, to add a new language.
Cost
Costs to get started with any natural language understanding are generally low. Open source systems like Stanford CoreNLP, OpenNLP and NLTK are free to use, although licensing terms may make some commercial applications difficult. Almost all commercial services have a low-volume free tier for development or research, but the licenses for production can become expensive at high volumes. It’s important to be aware of the full range of pricing if the application will be used commercially.
Development/training needed or ready to use?
Application-specific interactive dialog systems such as Wit.ai (wit.ai 2015), Microsoft LUIS (Microsoft 2015), or api.ai (api.ai 2015) require developers to create application-specific entities and intents that describe the objects that will be referred to in the application. This can be done manually or it can be done programmatically if a lot of data has to be entered. Wit.ai and api.ai both provide web interfaces and APIs that developers can use to supply training data programmatically for their application. Systems that perform linguistic analysis (like Stanford CoreNLP) will normally not require developers to train the system itself for specific applications because those systems are application independent; however, it is necessary to add an application component to these systems that maps the generic meanings to application-specific meanings. They also require training for new languages. If one of these systems has to be extended to a new language then it will be necessary to supply it with training data, usually through the use of an annotated corpus. Developing a new language is a very technical and time-consuming task that would be difficult for most developers.
Bundled with other technology
Some natural language technology is bundled with other technologies (common examples of bundled technology are information extraction from text or dialog management) and can’t be used independently of the other components. This is a benefit if the other technologies have value for the intended application, but if they are not needed in the application, then the bundling may make it impossible to use the natural language technology for other purposes.
2.4.3Natural language processing systems
Here we list a number of current systems. The following is by no means a complete list of available natural language understanding systems, but it represents a representative snapshot of the options available as of this writing. New and updated natural language processing systems become available frequently, so this list is not definitive.
api.ai
api.ai (api.ai 2015) is a natural language processing system that accepts text or speech input for use in interactive systems. It has an online developers’ interface, a REST interface and native SDKs for iOS, Android, Cordova, and HTML. Right now only English is supported, but major European and Asian languages are planned.
Watson
The IBM Watson Developer Cloud (IBM 2015) supports question answering based on a corpus of documents for use in interactive systems. It also has a structural analyzer, “Relationship Extraction” that finds semantic relationships between components of sentences. In addition, the IBM Watson suite has related services such as speech to text and object recognition. These services are currently in beta.
LingPipe
LingPipe (alias-i 2015) is a set of natural language processing tools from Alias-I with a Java API. The tasks it supports are sentence segmentation, part of speech tagging, named entity extraction, coreference resolution, and Chinese word segmentation. Except for Chinese word segmentation, only English is supported.
Linguasys
Linguasys (LinguaSys 2015) offers two APIs. The Carabao Linguistic Virtual Machine™ can extract named entities, perform sentiment analysis, and perform foreign language search. It includes a RESTful interface for interactive systems. Linguasys supports 23 languages.
LUIS (Microsoft Project Oxford)
LUIS (Microsoft 2015) is an application-specific RESTAPI for natural language processing. It returns JSON that includes the entities and intents found in the user’s utterance.
OpenEphyra
OpenEphyra (OpenEphyra 2015) is an open source, question answering system in Java developed at Carnegie-Mellon University.
OpenNLP
OpenNLP (OpenNLP 2015) is an open source Java system which supports a number of linguistic analysis tasks such as part of speech tagging and parsing. OpenNLP supports English and Spanish.
NLTK
NLTK (nltk.org 2015) is a set of open source natural language processing tools in Python that includes part of speech tagging and parsing. The license does not permit commercial use.
NLULite
NLULite (NLULite 2015) processes texts and then allows users to ask questions about those texts. NLULite has a client-server architecture. The server runs only on Linux x86_64 or Mac OS X. The Python client is open source but the server is proprietary. NLULite only supports English.
Pandorabots
Pandorabots (Pandorabots 2015) is a keyword based natural language processing system bundled with question answering and dialog management based on Artificial Intelligence Markup Language (AIML). A RESTful interface is available. Pandorabots is programmed using AIML (Wallace 2014).
Stanford CoreNLP
Stanford CoreNLP (Stanford Natural Language Processing Group 2014) is an extensive set of open source Java programs that support linguistic analysis as well as named entity recognition in English, Spanish, or Chinese.
Watson Developer Cloud (IBM)
The Watson Developer Cloud offers several services that perform natural language processing functions. Question and Answer is an application for question answering in the healthcare and travel domains. There is also a Natural Language Classifier for classifying texts into categories and related services such as machine translation and speech to text.
Wit.ai (Facebook)
Wit.ai (wit.ai 2015) provides natural language processing based on a RESTful web service. The developers’ interface allows developers to train a system (called an “instance”) with their own examples. The trained system can then be accessed via HTTP to process written or spoken inputs. The inputs are analyzed into intents, or overall classifications, and entities, which are specific key-value pairs within the intent. For example, for the analysis in Fig. 2.2, the overall intent might be “shopping list”, and the result would also include three entities; “measure”, “shopping_item” and “quantity”. Wit.ai also includes a wide range of generic, commonly used entities for concepts like numbers, money, times and dates. It is free to use since its acquisition by Facebook. Wit.ai currently supports English as well as nine European languages.
Wolfram|Alpha
Wolfram|Alpha (Claburn 2009) has an API which can be queried to get answers to a wide of types of questions in multiple subject areas, focusing on science, technology, geography and people. Wolfram Alpha also has tools for building custom natural language applications using their natural language technology. Wolfram|Alpha is only available for English.
Table 2.3 summarizes the above discussion.
Tab. 2.3: Summary of natural language systems.

2.4.4Selection Criteria
What should developers look for when selecting natural language processing technology for an application? Here are some technical criteria to consider.
- Does the software support the intended application?
- For commercial systems, the licensing has to be consistent with the intended use. Can the system be used commercially?
- How much application-specific development is required and is it necessary for the development to be done by natural language processing experts?
- Is the software accurate enough to support the intended application? No natural language understanding software will always be completely accurate for all inputs, so occasional errors are to be expected, but they must not be so frequent that the application is impossible.
- It is important to consider latency in interactive systems. When a user is actively interacting with systems, the latency between the user’s input and the system’s response must be minimized. For offline systems that process existing text, for example analysis of online product reviews, latency is much less of an issue.
- Are the required languages supported by the software and how well are they supported? Most NLU systems support English, and if other languages are supported, English is usually the language with the most complete implementation. If other languages are needed in an application, it is important to make sure that the implementations of the other languages are of high enough quality to support the application. If the required languages are not supported, how difficult and costly will it be to add them?
- Is the system actively maintained and is development continuing? This is particularly important for closed source systems because critical software errors may make it impossible to keep using the system if the system is not actively being maintained. However, it is important to be aware of this concern even for open source systems. Theoretically, anyone can repair problems with open source software, but it may not always be possible to find developers with the required expertise. A related issue is the stability of the vendor. If the software has been developed by only one or two key people, what happens if the key people become unavailable?
2.5Standards
As we can see from the discussion above, there is currently a rich variety of natural language processing software available for incorporation into mobile applications. The available software has many capabilities and covers many languages. However, it can still be difficult to make use of this software. Nearly every natural language web service or open source system has its own, vendor-specific, API. This means that developers who want to change the service they use, combine information from multiple services, or support several languages that use different services will have to learn a different API for every system. A standard interface to natural language understanding systems would make it much easier to support these use cases. This section discusses two standards developed by the World Wide Web Consortium; one for representing natural language results, and another, more general, standard for communication within multimodal systems, which will greatly improve the interoperability of natural language understanding technologies.
2.5.1EMMA
The details of existing APIs for natural language results are currently largely proprietary; however, they nearly always contain the same basic information – key-value pairs, confidences, alternative results and timestamps, for example. The proprietary APIs differ primarily only in formatting. Thus, there’s no reason to have multiple different formats for representing the same information, and this common information can be standardized. We discuss two standards here.
EMMA (Extensible Multimodal Annotation) (Johnston et al. 2009a, Johnston et al. 2015), a specification published by the World Wide Web Consortium, provides a standard way to represent user inputs and their associated metadata in any modality, including but not limited to speech, typing, handwriting, and touch/pointing. EMMA 1.0 documents include an extensive set of metadata about the user input, as well as an application-specific representation of the meaning of the input. The current official standard is EMMA 1.0, but a new version, EMMA 2.0, is under development. Some ideas which have been discussed for EMMA 2.0 include the ability to represent system outputs and the ability to return incremental results while the user input is still in progress. Figure 2.4 is an example of an EMMA document where the task is emotion identification from text.
While we will not go into the details of each annotation individually, it is worth pointing out several of the more important annotations, shown in bold in Fig. 2.4. The interpretation (“<emma:interpretation>”) is an EMMA element representing the application-specific meaning of the input, based on the original user input (“emma:tokens”). In this case the input was “I am happy yet just a little afraid at the same time”. There are actually two possible meanings – “happy” and “afraid”, since the utterance mentioned two emotions. These are ordered according to the confidence the emotion interpreter placed on each result, enclosed in an “emma:one-of” tag.

Fig. 2.4: EMMA representation for “I am happy yet just a little afraid at the same time”.
The information inside the <emma:interpretation> tag is application-specific and is not standardized. The decision not to standardize the application semantics was motivated by the desire to maximize flexibility in representing semantics, which is an active research area, and can vary greatly across applications. In the case of Fig. 2.4 the application-specific semantic information is represented in Emotion Markup Language (EmotionML) (Schröder et al. 2009), a W3C standard for representing emotion. Figure 2.4 is a fairly complete EMMA document, but many of the annotations are optional, and a complete EMMA document can be much smaller, if a simpler document meets the application’s requirements. In fact, in some use cases it is useful to create two EMMA documents for the same input; a simple one which can be sent to a mobile client with limited resources and used directly in an interactive dialog system, and a fuller document, including much more metadata about the utterance, which could be stored on a server as proposed in EMMA 2.0. The information in the fuller document could be used for detailed logging and analysis, which are very important for enterprise-quality deployments.
2.5.2MMI Architecture and Interfaces
The second standard we will discuss here is the Multimodal Architecture and Interfaces (MMI Architecture) standard (Barnett et al. 2012, Dahl 2013b, Barnett 2016). The W3C Multimodal Architecture and Interfaces standard provides a general communication protocol for controlling multimodal components, including natural language processing systems. This is useful for the task of integrating natural language into applications because it defines a specific, standard, API between the natural language processing components and the rest of the system. It also supports adding different, complementary, modalities, such as speech recognition or handwriting recognition. Since the API is standard, it doesn’t have to be changed if a new natural language processing technology is added to the system.
The MMI Architecture is organized around an Interaction Manager (IM), which coordinates the information received from user inputs to Modality Components (MCs). MCs are capable of processing information from one or more modalities, such as speech recognition, handwriting recognition, touchscreen, typing, object recognition or other forms of user input. Figure 2.5 shows an example of an MMI Architecture-based system with an IM coordinating an interaction that includes six modalities.

The MCs are black boxes with respect to each other and to the IM; all communication between IMs and MCs takes place through a set of Life-Cycle events. The Life-Cycle events are very generic and are widely applicable across applications. They include events for starting, canceling, pausing and resuming processing, as well as events for returning the results of processing and other data. EMMA-formatted data is used in the Data field of Life-Cycle events that represent user inputs. Figure 2.6 is an example of a “DoneNotification” Life-Cycle event, whose purpose is to return the results of processing (Dahl 2015). In this case, the result (not shown in detail) is an EMMA document, the result of natural language processing on a user input. In addition to the EMMA-formatted result, the DoneNotification event also includes metadata that identifies the context that the message is related to (“mmi:Context”), whether or not the processing was successful (“mmi:Status”) and the source and target of the message (“mmi:Source” and “mmi:Target”). More information about the MMI Architecture can be found in the standard itself (Barnett et al. 2012), or a summary of the standard (Dahl 2013b, Barnett 2016).

The availability of standards formats such as EMMA and the MMI Architecture will make it much more convenient to use natural language processing technology in many types of applications by greatly enhancing interoperability across different natural language understanding systems.
2.6Future directions
While natural language processing technology has greatly advanced in the last few years, there is still a lot of work to be done. The application-specific natural language processing systems discussed in this chapter are very good at handling simple commands and recognizing basic intents that involve only a few entities. Specifically, they are very capable at extracting simple meanings from utterances specific to their domains.
The application-independent systems, on the other hand, are good at analyzing syntax and some generic semantics, such as recognizing named entities. However, two important capabilities are missing. First of all, application-independent systems attempt to extract very little application-independent meaning. Consequently, a specific application that is based on an application-independent system is required to build its own meaning analysis system. Depending on the system, this can be accomplished either by providing examples of utterances and their meanings, or by providing rules, depending on whether the system is statistical or rule based. This leads to an application development bottleneck, even for systems that only need to understand simple commands. Work on semantic role labeling (Gildea & Jurafsky 2000) may help close the gap between application-independent systems and real-world applications, but there is still a gap between semantic-role labeled data and application concepts that must be bridged by the developer.
The second problem is that semantically complex utterances are very difficult for today’s application-specific systems to handle. Semantically complex utterances include, for example, those with a negative meaning, utterances with multiple commands, or utterances with time references. For example, utterances including negatives might include something like “Please record every Phillies game unless they’re playing the Nationals”, said to a DVR. Even an apparently simple utterance with multiple commands like “Put 2 bottles of orange juice and 1 bag of baby carrots on my shopping list” would be very hard to handle because simpler systems are not very good at associating the correct numbers with the items mentioned. Although currently users are more familiar with interacting with systems with simpler language, I believe these types of capabilities will be increase in importance as users become accustomed to interacting with technology by voice.
2.7Summary
This chapter has discussed a wide variety of types of natural language processing resources that are available for developers who wish to incorporate natural language processing into mobile applications. We also discussed specific systems and selection criteria for finding the right natural language processing technology for particular applications. Finally, we presented a brief overview of two relevant standards, EMMA and the MMI Architecture, that show significant promise for accelerating the integration of language understanding into mobile applications.
Abbreviations
| EMMA | Extensible Multimodal Interaction |
| REST | Representational State Transfer |
| API | Application Programmer’s Interface |
| MMI | Multimodal Architecture and Interfaces |
| W3C | World Wide Web Consortium |
| IVR | Interactive Voice Response |
| JSON | Javascript Object Notation |
| XML | Extensible Markup Language |
| URL | Uniform Resource Locator |
| HTTP | Hypertext Transfer Protocol |
| NLP | Natural Language Processing |
| IM | Interaction Manager |
| MC | Modality Component |
References
Alias-I 2015, LingPipe [Online]. Available: http://alias-i.com/lingpipe/ [17 March 2015].
Api.ai 2015, api.ai [Online]. Available: http://api.ai/ [17 March 2015].
Barnett, J, Bodell, M, Dahl, DA, Kliche, I, Larson, J, Porter, B, Raggett, D, Raman, TV, Rodriguez, BH, Selvaraj, M, Tumuluri, R, Wahbe, A, Wiechno, P & Yudkowsky, M 2012, Multimodal Architecture and Interfaces [Online], World Wide Web Consortium. Available: http://www.w3.org/TR/mmi-arch/ [20 November 2012].
Barnett, J 2016, Introduction to the Multimodal Architecture, in Multimodal Interaction with W3C Standards: Towards Natural User Interfaces to Everything, ed, D Dahl, New York, Springer, to appear.
Claburn, T 2009, Stephen Wolfram’s Answer To Google [Online]. Available: http://www.informationweek.com/news/internet/search/215801388?pgno=1 [9 November 2012].
Dahl, DA 2010, Extensible Multimodal Annotation (EMMA) for Intelligent Virtual Agents, 10th Annual Conference on Intelligent Virtual Agents. Philadelphia, PA, USA.
Dahl, DA 2013a, Natural language processing: Past, present and future, in Mobile Speech and Advanced Natural Language Solutions, eds, A Neustein & J Markowitz, Springer.
Dahl, DA 2013b, ‘The W3C multimodal architecture and interfaces standard’ Journal on Multimodal User Interfaces, pp. 1–12.
Ferruci, DA, Brown, EW, Fan, J, Gondek, AK, Lally, A, Murdock, JW & Nyberg, E 2010, ‘Building Watson: An overview of the DeepQA Project’, AI Magazine, vol. 31, no. 3, pp. 59–79.
Fielding, RT & Taylor, RN 2000, Principled design of the modern Web architecture, Proceedings of the 22nd International Conference on Software Engineering. Limerick, Ireland, ACM, pp. 263–272.
Gildea, D & Jurafsky, D 2000, Automatic labeling of semantic roles, Proceedings of the 38th Annual Conference of the Association for Computational Linguistics (ACL-00), Hong Kong, ACL, pp.512–520.
Gorin, AL, Riccardi, G & Wright, JH 1997, ‘How may I help you’, Speech Communication, vol. 23, pp. 113–127.
IBM 2015, IBM Watson Developer Cloud [Online]. Available: http://www.ibm.com/smarterplanet/us/en/ibmwatson/developercloud/ [17 March 2015].
Johnston, M, Dahl, DA, Denny, T & Kharidi, N 2015, EMMA: Extensible MultiModal Annotation markup language Version 2.0 [Online]. World Wide Web Consortium. Available: http://www.w3.org/TR/emma20/ [16 December 2015].
Johnston, M, Baggia, P, Burnett, D, Carter, J, Dahl, DA, Mccobb, G & Raggett, D 2009a, EMMA: Extensible MultiModal Annotation markup language [Online], W3C. Available: http://www.w3.org/TR/emma/ [9 November 2012].
Johnston, M 2016, EMMA, in Multimodal Interaction with W3C Standards: Towards Natural User Interfaces to Everything, ed, D Dahl, New York, Springer, to appear. .
Johnston, M, Dahl, DA, Kliche, I, Baggia, P, Burnett, DC, Burkhardt, F & Ashimura, K 2009b, Use Cases for Possible Future EMMA Features [Online], World Wide Web Consortium. Available: http://www.w3.org/TR/emma-usecases/.
Jurafsky, D & Martin, J 2008, Speech and language processing: An introduction to natural language processing, Prentice-Hall, Upper Saddle River, NJ, USA.
Kelly, S 2015, nlp_compromise [Online]. Available: https://github.com/spencermountain/nlp_compromise [18 March 2015].
Lee, K, Palsetia, D, Narayanan, R, Patwary, MMA, Agrawal, A & Choudhary, A 2011, Twitter Trending Topic Classification, Proceedings of the 2011 IEEE 11th International Conference on Data Mining Workshops, IEEE Computer Society.
LinguaSys 2015, LinguaSys [Online]. Available: https://www.linguasys.com/ [17 March 2015].
Loper, E & Bird, S 2002, ‘Nltk: The Natural Language Toolkit’, ACL Workshop on Effective Tools and Methodologies for Teaching Natural Language Processing and Computational Linguistics, 40th Annual Meeting of the Association for Computational Linguistics, July 11–12, 2002, Philadelphia, PA, USA.
Microsoft 2015, Language Understanding Intelligent Service (LUIS) [Online], Micosoft. Available: http://www.projectoxford.ai/luis [5 June 2015].
NLTK.org 2015, Natural Language Toolkit [Online]. Available: http://www.nltk.org/[17 March 2015].
NLULite 2015, NLULite [Online]. Available: http://nlulite.com/ [13 March 2015].
Nuance Communications 2015, Nina – The intelligent virtual assistant [Online], Nuance Communications. Available: http://www.nuance.com/for-business/customer-service-solutions/nina/index.htm [16 March 2015].
OpenEphyra 2015, OpenEphyra [Online], Carnegie-Mellon University. Available: https://mu.lti.cs.cmu.edu/trac/Ephyra/wiki/OpenEphyra [18 March 2015].
OpenNLP 2015, Apache OpenNLP [Online], The Apache Software Foundation. Available: http://opennlp.apache.org/ [17 March 2015].
Openstream I 2015, Eva, Face of the Digital Workplace [Online], Openstream. Available: http://www.openstream.com/eva.htm [16 March 2015].
Pandorabots 2015, Pandorabots [Online], Available: http://www.pandorabots.com/[17 March 2015].
Schröder, M, Baggia, P, Burkhardt , F, Pelachaud, C, Peter, C & Zovato, E 2009, Emotion Markup Language (EmotionML) 1.0 [Online], World Wide Web Consortium. Available: http://www.w3.org/TR/emotionml/.
Stanford Natural Language Processing Group 2014, Stanford CoreNLP [Online], Palo Alto, CA: Stanford University. Available: http://nlp.stanford.edu/software/corenlp.shtml.
Wallace, RS 2014, AIML 2.0 Working Draft [Online]. Available: http://alicebot.blogspot.com/2013/01/aiml-20-draft-specification-released.html [3 February 2015].
Wit.ai 2015, wit.ai [Online]. Available: https://wit.ai/ [17 March 2015].