
Chapter 9. Docker at Scale
One of Docker’s major strengths is its ability to abstract away the underlying hardware and operating system so that your application is not constrained to any particular host or environment. It facilitates not just horizontally scaling a stateless application within your data center, but also across cloud providers without many of the traditional barriers to similar efforts. True to the shipping container metaphor, a container on one cloud looks like a container on another.
Many organizations will find cloud deployments of Docker very appealing because they can gain any of the immediate benefits of a scalable container-based platform without needing to completely build something in-house. But the barrier is low for creating your own clusters, and we’ll cover some options for doing that shortly.
It is easy to install Docker on almost any Linux-based cloud instance. However, Docker and almost every major public cloud provider is actively developing tooling for intelligently deploying and managing Docker containers across a cluster. At the time of this writing, many of these projects are usable, but still in the early stages.
If you have your own private cloud, you can leverage a tool like Docker Swarm to deploy containers easily across a large pool of Docker hosts, or use the community tool Centurion or Helios to quickly facilitate multi-host deployments. If you have already experimented with Docker at scale and are looking to build something more like what the cloud providers themselves offer, then you should consider Kubernetes or Mesos, which we addressed in the last chapter.
The major public cloud providers have all made efforts to support containers natively on their offering. Some of the biggest efforts to implement Docker containers on the public cloud include:
Even cloud providers running on non-Linux operating systems like SmartOS and Windows are actively finding ways to support the Docker ecosystem:
In this chapter, we’ll cover some options for running Docker at scale in your own data center, first with a pass through Docker Swarm and Centurion, and then take a dive into the Amazon EC2 Container Service (Amazon ECS). All of these examples will hopefully give you a view of how Docker can be succesfully leveraged to provide an incredibly flexible platform for your application workloads.
Docker Swarm
After first building the container runtime in the form of the Docker engine, the engineers at Docker turned to the problems of orchestrating a fleet of individual Docker hosts and effectively packing those hosts full of containers. The tool that evolved from this work is Docker Swarm. The idea behind Swarm is to present a single interface to the docker client tool, but have that interface be backed by a whole cluster rather than a single Docker daemon. Swarm doesn’t concern itself with application configuration or repeatable deployments; it is aimed at clustering computing resources for wrangling by the Docker tools. It has grown a lot since its first release and now contains several scheduler plugins with different strategies for assigning containers to hosts, and with basic service discovery built in. But, it remains only one building block of a more complex solution.
Swarm is implemented as a single Docker container that acts as both the central management hub for your Docker cluster and also as the agent that runs on each Docker host. By deploying it to all of your hosts, you merge them into a single, cohesive cluster than can be controlled with the Swarm and Docker tooling.
Note
It is actually possible to compile Swarm as a standalone binary that can be run directly on a host if you prefer not to use the containerized version. But, as with any containerized application, the container is simpler to deploy. Here we’ll cover the containerized deployment on a TLS-based Docker host utilizing port 2376.
Let’s get a Swarm cluster up and running. As with any Docker deployment, the very first thing we should do is download the Swarm container onto our Docker host by running a docker pull, as shown here:
$ docker pull swarm Using default tag: latest latest: Pulling from library/swarm 844fab328d6a: Pull complete d53941759232: Pull complete 3445c6fe19be: Pull complete a3ed95caeb02: Pull complete Digest: sha256:51a8eba9502f1f89eef83e10b9f457cfc67193efc3edf88b45b1e910dc48c906 Status: Downloaded newer image for swarm:latest
We now need to create our Docker cluster by running the Swarm container on our preferred Docker host.
$ docker run --rm swarm create e480f01dd24432adc551e72faa37bddd
This command returns a hash that represents a unique identifier for your newly created Docker cluster, and is typically referred to as the cluster ID.
Note
Docker Swarm needs to keep track of information about the cluster it will manage. When invoked, it needs to discover the hosts and their containers. The default method uses a token and a simple discovery API located on Docker Hub at discovery.hub.docker.com. But it also supports other discovery methods, including etcd and Consul.
We now want to deploy the Swarm manager to one of the Docker hosts in our cluster:
$ docker run -d -p 3376:3376 -t -v /var/lib/boot2docker:/certs:ro swarm manage -H 0.0.0.0:3376 --tlsverify --tlscacert=/certs/ca.pem --tlscert=/certs/server.pem --tlskey=/certs/server-key.pem token://e480f01dd24432adc551e72faa37bddd aba1c4d8e7eaad9bb5021fde3a32f355fad23b91bc45bf145b3f0f2d70f3002b
Note
You can expose the Swarm manager on any port. In this case, we are using 3376, since 2375 and/or 2376 are already in use on the Docker host by the Docker server.
If we rerun docker ps, we will now see the Swarm manager running on our Docker host:
$ docker ps ... IMAGE COMMAND ... PORTS ... ... swarm "/swarm manage -H 0.0" ... 2375/tcp, 0.0.0.0:3376->3376/tcp ...
To register a Docker host with our cluster, we need to run the Swarm container with the join argument. In the following command, we need to be sure and provide the address and port for our Docker host, and the token that we received when we first created the cluster:
$ docker run -d swarm join --addr=172.17.42.10:2376 token://e480f01dd24432adc551e72faa37bddd e96afd3b3f8e360ac63ec23827560bafcc44695a8cdd82aec8c44af2f2fe6910
Note
Remember that your Docker port in the command above may be different, depending on wether you are using TLS or not. Typically 2375 or 2376 is the correct value. Our example assumes that you are using TLS.
The swarm join command launches the Swarm agent on our Docker host and then returns the full hash to the agent container. If we now run docker ps against our Docker host we will see both the Swarm manager and the Swarm agent running. You can also see that the short hash for the agent matches the first 12 characters of the full hash that we received from the previous command:
$ docker ps CONTAINER ID IMAGE COMMAND ... PORTS ... e96afd3b3f8e swarm "/swarm join --addr=1" ... 2375/tcp ... aba1c4d8e7ea swarm "/swarm manage -H 0.0" ... 0.0.0.0:3376->3376/tcp, 2375/tcp
Note
At this point, we have a single host cluster. Under normal circumstances, we would want to add additional Docker hosts to the cluster, and you can do this very easily by starting a second Docker host using your preferred tool of choice, like docker-machine, vagrant, etc.
We can list all of the nodes in our cluster by running:
$ docker run --rm swarm list token://e480f01dd24432adc551e72faa37bddd 172.17.42.10:2376
The diagram in Figure 9-1 gives a good overview of the components that make up the Docker Swarm cluster.
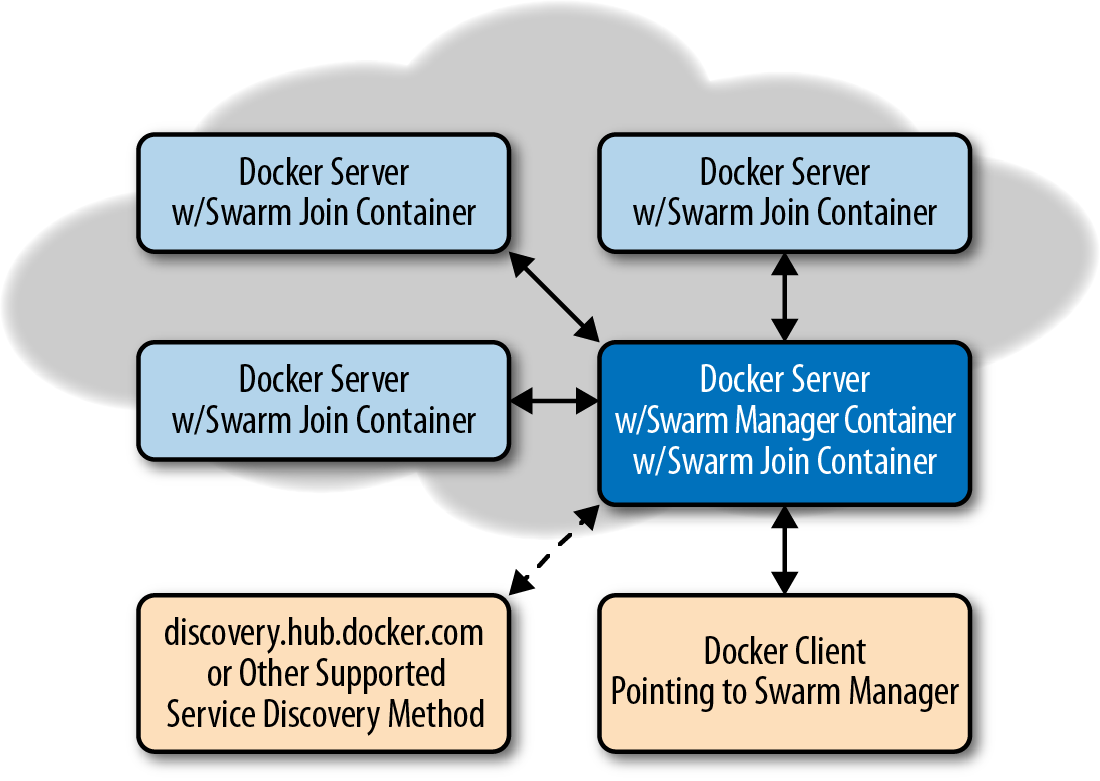
Figure 9-1. Swarm Manager controlling Docker cluster
At this point we can start using docker to interact with our Docker cluster, instead of with an individual host. By setting the DOCKER_HOST environment variable to the IP address and port that our Swarm manager is running on, we can now run normal Docker commands against our Swarm-based Docker cluster, as shown here:
Warning
If your local development environment and Docker Swarm evironment are not both using the same TLS settings, you might need to adjust the $DOCKER_TLS_VERIFY, $DOCKER_TLS, and $DOCKER_CERT_PATH environment variables when switching between them.
$ export DOCKER_HOST="tcp://172.17.42.10:3376"((("docker", "info")))
$ docker info
Containers: 6
Images: 1
Role: primary
Strategy: spread
Filters: health, port, dependency, affinity, constraint
Nodes: 1
local: 192.168.99.100:2376
└ Status: Healthy
└ Containers: 6
└ Reserved CPUs: 0 / 1
└ Reserved Memory: 0 B / 1.021 GiB
└ Labels: executiondriver=native-0.2, kernelversion=4.1.17-boot2docker,
operatingsystem=Boot2Docker 1.10.1 (TCL 6.4.1); master : b03e158 -
Thu Feb 11 22:34:01 UTC 2016, provider=virtualbox, storagedriver=aufs
└ Error: (none)
└ UpdatedAt: 2016-02-15T19:39:05Z
Kernel Version: 4.1.17-boot2docker
Operating System: linux
CPUs: 1
Total Memory: 1.021 GiB
Name: e480f01dd244
The above output from docker info shows some basic details about all of the nodes in our cluster.
We can now run an nginx container in our new cluster, by using the following command:
$ docker run -d nginx 5519a2a379668ceab685a1d73d7692dd0a81ad92a7ef61f0cd54d2c4c95d3f6e
Running docker ps again will now show that we have a container running within the context of the cluster.
$ docker ps CONTAINER ID IMAGE COMMAND ... NAMES 5519a2a37966 nginx "nginx -g 'daemon off" ... local/furious_jennings
An interesting thing to note is that the container name (berserk_hodgkin) is now prefixed by the name of the node (local) that it is running on. If we look back at the output from docker info, we will see the node name listed there, like this:
local: 172.17.42.10:2376
If we now run docker ps -a, we will see an interesting behavior. In addition to containers that are not running, we will also see containers that are running outside the scope of the cluster (like the swarm containers, themselves) and therefore are “unknown” to the cluster, although still actually running on one of our hosts.
$ docker ps -a ... IMAGE COMMAND PORTS ... ... nginx "nginx -g 'daemon off" 80/tcp, 443/tcp ... ... swarm "/swarm manage -H 0.0" 2375/tcp, 192.168.99.100:3376->3376/tcp ... ... swarm "/swarm join --addr=1" 2375/tcp ... ...
Warning
Although Swarm does not list its own images in standard docker ps output, it will happily let you docker stop the Swarm management or agent containers, which will, in turn, break things. Don’t do that.
This covers the basics of using Docker Swarm and should help get you started building your own Docker cluster for deployment.
Centurion
Centurion, which we discussed in Chapter 8, is one of many tools that enables repeatable deployment of applications to a group of hosts. Unlike Swarm, which treats the cluster as a single machine, you tell Centurion about each host you want it to know about. Its focus is on guaranteeing repeatability of container creation and simplifying zero-down-time deployment. It assumes that a load balancer sits in front of your application instances. It is an easy first step in moving from traditional deployment to a Docker workflow.
Note
We could equally be covering Spotify’s Helios here, or Ansible’s Docker tooling, but we believe that Centurion is the simplest of these tools to get up and running. You are encouraged to see if there are tools that are a better fit for your deployment needs, but this section will hopefully give you a taste of what you might achieve as a first step.
Let’s look at deploying a simple application with Centurion. Here we’ll deploy the public nginx container as our web application. It won’t do much, but will serve up a welcome page that we can see in a browser. You could easily switch in your custom application. The only requirement is that it be deployed to a registry.
Before we can deploy, we have to satisfy the dependencies for the tool and get it installed. Centurion depends on having the Docker command-line tool present and requires that you have Ruby 1.9 or higher so you’ll want to make sure you have a system with these installed. Centurion can run on Linux or Mac OS X. Windows support is untested. Packages are available via yum or apt-get on all popular Linux distributions. Generally, any distribution with a kernel new enough to run Docker will ship with packages that meet this requirement. On recent Mac OS X versions, you will already have the right version of Ruby. If you are on an older release, you can install a recent Ruby with Homebrew. Most Linux distributions that are capable of running Docker also ship with a modern enough Ruby to run Centurion. You can check if you have Ruby installed and if you have a version new enough like this:
$ ruby -v ruby 2.2.1p85 (2015-02-26 revision 49769) [x86_64-darwin12.0]
Here, we have Ruby 2.2.1, which is plenty new enough. Once you have Ruby running, install Centurion with the Ruby package manager:
$ gem install centurion Fetching: logger-colors-1.0.0.gem (100%) Successfully installed logger-colors-1.0.0 Fetching: centurion-1.8.5.gem (100%) Successfully installed centurion-1.8.5 Parsing documentation for logger-colors-1.0.0 Installing ri documentation for logger-colors-1.0.0 Parsing documentation for centurion-1.8.5 Installing ri documentation for centurion-1.8.5 Done installing documentation for logger-colors, centurion after 0 seconds 2 gems installed
You can now invoke centurion from the command line to make sure it’s available:
$ centurion --help Options: -p, --project=<s> project (blog, forums...) -e, --environment=<s> environment (production, staging...) -a, --action=<s> action (deploy, list...) (default: list) -i, --image=<s> image (yourco/project...) -t, --tag=<s> tag (latest...) -h, --hosts=<s> hosts, comma separated -d, --docker-path=<s> path to docker executable (default: docker) -n, --no-pull Skip the pull_image step --registry-user=<s> user for registry auth --registry-password=<s> password for registry auth -o, --override-env=<s> override environment variables, comma separated -l, --help Show this message
There are a lot of options there, but right now we’re just making sure that it’s installed and working. If Centurion is not yet available and you get an error, we can add it to our path:
$ gempath=`gem environment | grep "INSTALLATION DIRECTORY" | awk '{print $4}'`
$ export PATH=$gempath/bin:$PATH
You should now be able to invoke centurion --help and see the output of the help.
To begin with, we’ll just make a directory in which we’ll store the Centurion configuration. If this were your own application, this might be the application’s directory, or it might be a directory in which you store all the deployment configs for all of your applications. We encourage that pattern for larger installations. Since we’re just going to deploy the public nginx container, let’s create a directory to house our configs. Then we’ll change into it and tell Centurion to scaffold a basic config for us with the centurionize tool:
$ mkdir nginx $ cd nginx $ centurionize -p nginx Creating /Users/someuser/apps/nginx/config/centurion Writing example config to /Users/someuser/apps/nginx/config/centurion/nginx.rake Writing new Gemfile to /Users/someuser/apps/nginx/Gemfile Adding Centurion to the Gemfile Remember to run `bundle install` before running Centurion Done!
We can ignore the Gemfile stuff for now and just open the config it generated for us. You might take a look at it to see what it put in place in order to get an idea of what Centurion can do. The scaffolded config contains examples of how to use many of the features of Centurion. We’ll just edit it down to the basics we care about:
namespace :environment do
desc 'Staging environment'
task :staging do
set_current_environment(:staging)
set :image, 'nginx'
env_vars MY_ENV_VAR: 'something important'
host_port 10234, container_port: 80
host 'docker1'
host 'docker2'
end
end
Centurion supports multiple environments in the same config. Here we’re just going to deploy to staging. We could add as many as we like. The default file also uses a pattern where common configurations between environments are put into a common section that is called by each of the environments. For demonstration purposes, we cut this config down to a bare minimum.
What we now have is a config that will let us deploy the nginx image from the public registry to two hosts, docker1 and docker2, while setting the environment variable MY_ENV_VAR to some text and mapping port 80 inside the container to the public port 10234. It supports any number of environment variables, hosts, ports, or volume mounts. The idea is to store a repeatable configuration for your application that can be stamped out onto as many Docker hosts as needed.
Centurion supports a rolling deployment model out of the box for web applications. It will cycle through a set of hosts, taking one container down at a time to keep the application up during deployment. It uses a defined health check endpoint on a container to enable rolling deployments. By default, this is “/” and that’s good enough for us with our simple welcome page application. Nearly all of this is configurable, but we’ll keep it simple.
We’re ready, so let’s deploy this to staging. We’ll tell Centurion to use the nginx project, the staging environment, and to do a web application zero-downtime deployment with rolling_deploy. Centurion will initiate a docker pull on the hosts in parallel, then on each host in turn it will create a new container, tear down the old one, and start up the new one. We’ll cut down the very verbose output to get a clearer idea of the process:
$ centurion -p nginx -e staging -a rolling_deploy
...
I, [2015... #51882] INFO -- : Fetching image nginx:latest IN PARALLEL
I, [2015... #51882] INFO -- : Using CLI to pull
I, [2015... #51882] INFO -- : Using CLI to pull
4f903438061c: Pulling fs layer
1265e16d0c28: Pulling fs layer
0cbe7e43ed7f: Pulling fs layer
...
** Invoke deploy:verify_image (first_time)
** Execute deploy:verify_image
I, [2015... #51882] INFO -- : ----- Connecting to Docker on docker1 -----
I, [2015... #51882] INFO -- : Image 224873bd found on docker1
...
I, [2015... #51882] INFO -- : ----- Connecting to Docker on docker2 -----
I, [2015... #51882] INFO -- : Image 224873bd found on docker2
...
I, [2015... #51882] INFO -- : ----- Connecting to Docker on docker1 -----
I, [2015... #51882] INFO -- : Stopping container(s):
[{"Command"=>"nginx -g 'daemon off;'", "Created"=>1424891086,
"Id"=>"6b77a8dfc18bd6822eb2f9115e0accfd261e99e220f96a6833525e7d6b7ef723",
"Image"=>"2485b0f89951", "Names"=>["/nginx-63018cc0f9d268"],
"Ports"=>[{"PrivatePort"=>443, "Type"=>"tcp"}, {"IP"=>"172.16.168.179",
"PrivatePort"=>80, "PublicPort"=>10234, "Type"=>"tcp"}],
"Status"=>"Up 5 weeks"}]
I, [2015... #51882] INFO -- : Stopping old container 6b77a8df
(/nginx-63018cc0f9d268)
I, [2015... #51882] INFO -- : Creating new container for 224873bd
I, [2015... #51882] INFO -- : Starting new container 8e84076e
I, [2015... #51882] INFO -- : Waiting for the port to come up
I, [2015... #51882] INFO -- : Found container up for 1 seconds
W, [2015... #51882] WARN -- : Failed to connect to http://docker1:10234/,
no socket open.
I, [2015... #51882] INFO -- : Waiting 5 seconds to test the / endpoint...
I, [2015... #51882] INFO -- : Found container up for 6 seconds
I, [2015... #51882] INFO -- : Container is up!
...
** Execute deploy:cleanup
I, [2015... #51882] INFO -- : ----- Connecting to Docker on docker1 -----
I, [2015... #51882] INFO -- : Public port 10234
I, [2015... #51882] INFO -- : Removing old container e64a2796 (/sad_kirch)
I, [2015... #51882] INFO -- : ----- Connecting to Docker on docker2 -----
I, [2015... #51882] INFO -- : Public port 10234
I, [2015... #51882] INFO -- : Removing old container dfc6a240 (/prickly_morse)
What we see happening here is pulling the requested image, verifying that it pulled properly, and then connecting to the hosts to stop the old container, create a new one, start it, and health-check it until it’s up. At the very end, it cleans up the old containers so they don’t hang around forever.
Now we have the container up and running on both docker1 and docker2. We can connect with a web browser by hitting http://docker2:10234 or the same URI on docker1. In real production, you’ll want a load balancer configured to sit in front of these hosts and point your clients to either of the instances. There is nothing dynamic to this setup, but it gets your application deployed with all the basic benefits of Docker for a minimal investment of time.
That’s all there is to it for a basic setup. Centurion supports a lot more than this, but you can start to get the sense of the kinds of things some of the community tooling can support.
This class of tooling is very easy to get started with and will get you to a production infrastructure quickly. But growing your Docker deployment to a vast scale will likely involve a distributed scheduler, or one of the cloud providers. In that vein, let’s look at Amazon’s new service.
Amazon EC2 Container Service
One of the most popular cloud providers is Amazon via their AWS offering. Support for running containers natively has existed in Elastic Beanstalk since mid-2014. But that service assigns only a single container to an Amazon instance, which means that it’s not ideal for short-lived or lightweight containers. EC2 itself is a great platform for hosting your own Docker environment, though, and because Docker is powerful, you don’t necessarily need much on top of your instances to make this a productive environment to work in. But Amazon has spent a lot of engineering time building a service that treats containers as first-class citizens: the EC2 Container Service.
This section assumes that you have access to an AWS account and some familiarity with the service. Amazon provides detailed documentation online that covers everything required to bootstrap an EC2 container install, including signing up for AWS, creating a user, creating a Virtual Private Cloud (VPC), etc.
The container service offering is an orchestration of several parts. You first define a cluster, then put one or more EC2 instances running Docker and Amazon’s special agent into the cluster, and then push containers into the cluster. The agent works with the ECS service to coordinate your cluster and schedule containers to hosts.
IAM Role Setup
In AWS, Identity and Access Management (IAM) roles are used to control what actions a user can take within your cloud environment. We need to make sure we can grant access to the right actions before moving on with the EC2 Container Service.
To work with the EC2 Container Service, you need a role that consists of a policy with the privileges:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ecs:CreateCluster",
"ecs:RegisterContainerInstance",
"ecs:DeregisterContainerInstance",
"ecs:DiscoverPollEndpoint",
"ecs:Submit*",
"ecs:Poll"
],
"Resource": [
"*"
]
}
]
}
Note
In this example, we are only giving out the specific ecs privileges that we need for normal interaction with the service. ecs:CreateCluster is optional if the cluster you will be registering the EC2 container agent with already exists.
AWS CLI Setup
Amazon supplies comand-line tools that make it easy to work with their API-driven infrastructure. You will need to install version 1.7 or higher of the AWS Command Line Interface (CLI) tools. Amazon has detailed documentation that covers installation of their tools, but the basic steps are as follows.
Installation
Mac OS X
In Chapter 3, we discussed installing Homebrew. If you previously did this, you can install the AWS CLI using the following commands:
$ brew update $ brew install awscli
Windows
Amazon provides a standard MSI installer for Windows, which can be downloaded from Amazon S3 for your architecture:
Other
The Amazon CLI tools are written in Python. So on most platforms, you can install the tools with the Python pip package manager by running the following from a shell:
$ pip install awscli
Some platforms won’t have pip installed by default. In that case, you can use the easy_install package manager, like this:
$ easy_install awscli
Configuration
Quickly verify that your AWS CLI version is at least 1.7.0 with the following command:
$ aws --version aws-cli/1.10.1 Python/2.7.10 Darwin/15.3.0 botocore/1.3.23
To quickly configure the AWS CLI tool, ensure that you have access to your AWS Access Key ID and AWS Secret Access Key, and then run the following. You will be prompted for your authentication information and some preferred defaults:
$ aws configure AWS Access Key ID [None]: EXAMPLEEXAMPLEEXAMPLE AWS Secret Access Key [None]: ExaMPleKEy/7EXAMPL3/EXaMPLeEXAMPLEKEY Default region name [None]: us-east-1 Default output format [None]: json
You can quickly test that the CLI tools are working correctly by running the following command to list the IAM users in your account:
$ aws iam list-users
Assuming everything went according to plan and you chose JSON as your default output format, you should get something like the return shown here:
{
"Users": [
{
"UserName": "myuser",
"Path": "/",
"CreateDate": "2015-01-15T18:30:30Z",
"UserId": "EXAMPLE123EXAMPLEID",
"Arn": "arn:aws:iam::01234567890:user/myuser"
}
]
}
Container Instances
The first thing you need to do after installing the required tools is to create at least a single cluster that your Docker hosts will register with when they are brought online.
Note
The default cluster name is imaginatively named “default.” If you keep this name, you do not need to specify --cluster-name in many of the commands that follow.
The first thing we need to do is start a cluster in the container service. We’ll then push our containers into the cluster once it’s up and running. For these examples, we will start by creating a cluster called “testing”:
$ aws ecs create-cluster --cluster-name testing
{
"cluster": {
"clusterName": "testing",
"status": "ACTIVE",
"clusterArn": "arn:aws:ecs:us-east-1:0123456789:cluster/testing"
}
}
You will now need to create an instance via the Amazon console. You could use your own AMI with the ECS agent and Docker installed, but Amazon provides one that we’ll use here. This is almost always the way you’ll want to use it since most of your custom code will ship in Docker containers anyway, right? So we’ll deploy that AMI and configure it for use in the cluster. Consult Amazon’s detailed documentation for this step.
Note
If you are creating a new EC2 instance, be sure and note the IP address that it is assigned so that you can connect to it later.
As we mentioned, it is also possible to take an existing Docker host within your EC2 environment and make it compatible with the EC2 Container Service. To do this, you need to connect to the EC2 instance and ensure that you are running Docker version 1.3.3 or greater, and then deploy the Amazon ECS Container Agent to the local Docker host with the proper environment variable configured for your setup, as shown here:
$ sudo docker --version Docker version 1.4.1, build 5bc2ff8 $ sudo docker run --name ecs-agent -d -v /var/run/docker.sock:/var/run/docker.sock -v /var/log/ecs/:/log -p 127.0.0.1:51678:51678 -e ECS_LOGFILE=/log/ecs-agent.log -e ECS_LOGLEVEL=info -e ECS_CLUSTER=testing amazon/amazon-ecs-agent:latest
Once you have at least a single instance running and registered into your cluster, you can check it by running:
$ aws ecs list-container-instances --cluster testing
{
"containerInstanceArns": [
"arn:aws:ecs:us-east-1:01234567890:
container-instance/zse12345-12b3-45gf-6789-12ab34cd56ef78"
]
}
Warning
If the above output does not include a UID, then the ECS AMI or custom Docker host running the amazon-ecs-agent is not properly connected to the cluster. Carefully reread the preceding section and make sure that you did not skip any steps.
Taking the UID from the end of the previous command’s output, we can request even more details about the container instance with the command shown here:
$ aws ecs describe-container-instances --cluster testing
--container-instances zse12345-12b3-45gf-6789-12ab34cd56ef78
{
"failures": [],
"containerInstances": [
{
"status": "ACTIVE",
"registeredResources": [
{
"integerValue": 1024,
"longValue": 0,
"type": "INTEGER",
"name": "CPU",
"doubleValue": 0.0
},
{
"integerValue": 3768,
"longValue": 0,
"type": "INTEGER",
"name": "MEMORY",
"doubleValue": 0.0
},
{
"name": "PORTS",
"longValue": 0,
"doubleValue": 0.0,
"stringSetValue": [
"2376",
"22",
"51678",
"2375"
],
"type": "STRINGSET",
"integerValue": 0
}
],
"ec2InstanceId": "i-aa123456",
"agentConnected": true,
"containerInstanceArn": "arn:aws:ecs:us-east-1:
01234567890:container-instance/
zse12345-12b3-45gf-6789-12ab34cd56ef78",
"remainingResources": [
{
"integerValue": 1024,
"longValue": 0,
"type": "INTEGER",
"name": "CPU",
"doubleValue": 0.0
},
{
"integerValue": 3768,
"longValue": 0,
"type": "INTEGER",
"name": "MEMORY",
"doubleValue": 0.0
},
{
"name": "PORTS",
"longValue": 0,
"doubleValue": 0.0,
"stringSetValue": [
"2376",
"22",
"51678",
"2375"
],
"type": "STRINGSET",
"integerValue": 0
}
]
}
]
}
It is interesting to note that the output includes both the container instance’s registered resources, as well as its remaining resources. When you have multiple instances, this information helps the service determine where to deploy containers within the cluster.
Tasks
Now that our container cluster is up and running, we need to start putting it to work. To do this, we need to create at least one task definition. The Amazon EC2 Container Service defines the phrase “task definition” as a list of containers grouped together.
To create your first task definition, open up your favorite editor, copy in the following JSON, and then save it as starwars-task.json in your home directory, as shown here:
[
{
"name": "starwars",
"image": "rohan/ascii-telnet-server:latest",
"essential": true,
"cpu": 50,
"memory": 128,
"portMappings": [
{
"containerPort": 23,
"hostPort": 2323
}
],
"environment": [
{
"name": "FAVORITE_CHARACTER",
"value": "Boba Fett"
},
{
"name": "FAVORITE_EPISODE",
"value": "V"
}
],
"entryPoint": [
"/usr/bin/python",
"/root/ascii-telnet-server.py"
],
"command": [
"-f",
"/root/sw1.txt"
]
}
]
In this task definition, we are saying that we want to create a task called starwars that will be based on the Docker image rohan/ascii-telnet-server:latest. This Docker image launches a Python-based telnet server that serves the Ascii Art version of the movie Star Wars to anyone who connects.
In addition to typical variables included in a Dockerfile or via the docker run command, we define some constraints on memory and CPU usage for the container, in addition to telling Amazon whether this container is essential to the task. The essential flag is useful when you have multiple containers defined in a task, and not all of them are required for the task to be successful. If essential is true and the container fails to start, then all the containers defined in the task will be killed and the task will be marked as failed.
To upload this task definition to Amazon, we run a command similar to that shown here:
$ aws ecs register-task-definition --family starwars-telnet
--container-definitions file://$HOME/starwars-task.json
{
"taskDefinition": {
"taskDefinitionArn": "arn:aws:ecs:us-east-1:
01234567890:task-definition/starwars-telnet:1",
"containerDefinitions": [
{
"environment": [
{
"name": "FAVORITE_EPISODE",
"value": "V"
},
{
"name": "FAVORITE_CHARACTER",
"value": "Boba Fett"
}
],
"name": "starwars",
"image": "rohan/ascii-telnet-server:latest",
"cpu": 50,
"portMappings": [
{
"containerPort": 23,
"hostPort": 2323
}
],
"entryPoint": [
"/usr/bin/python",
"/root/ascii-telnet-server.py"
],
"memory": 128,
"command": [
"-f",
"/root/sw1.txt"
],
"essential": true
}
],
"family": "starwars-telnet",
"revision": 1
}
}
We can then list all of our task definitions by running the following:
$ aws ecs list-task-definitions
{
"taskDefinitionArns": [
"arn:aws:ecs:us-east-1:01234567890:task-definition/starwars-telnet:1"
]
}
Now we are ready to run our first task in our cluster. This is easily achieved with the command here:
$ aws ecs run-task --cluster testing --task-definition starwars-telnet:1
--count 1
{
"failures": [],
"tasks": [
{
"taskArn": "arn:aws:ecs:us-east-1:
01234567890:task/b64b1d23-bad2-872e-b007-88fd6ExaMPle",
"overrides": {
"containerOverrides": [
{
"name": "starwars"
}
]
},
"lastStatus": "PENDING",
"containerInstanceArn": "arn:aws:ecs:us-east-1:
01234567890:container-instance/
zse12345-12b3-45gf-6789-12ab34cd56ef78",
"desiredStatus": "RUNNING",
"taskDefinitionArn": "arn:aws:ecs:us-east-1:
01234567890:task-definition/starwars-telnet:1",
"containers": [
{
"containerArn": "arn:aws:ecs:us-east-1:
01234567890:container/
zse12345-12b3-45gf-6789-12abExamPLE",
"taskArn": "arn:aws:ecs:us-east-1:
01234567890:task/b64b1d23-bad2-872e-b007-88fd6ExaMPle",
"lastStatus": "PENDING",
"name": "starwars"
}
]
}
]
}
The count argument allows us to define how many copies of this task we want deployed into our cluster. For this job, one is enough.
Note
The task-definition value is a name followed by a number (starwars-telnet:1). The number is the revision. If you edit your task and reregister it with the aws ecs register-task-definition command, you will get a new revision, which means that you will want to reference that new revision in your aws ecs run-task. If you don’t change that number, you will continue to launch containers using the older JSON. This versioning makes it very easy to roll back changes and test new revisions without impacting all future instances.
In the output from the previous command, it is very likely that the lastStatus key displayed a value of PENDING.
You can now describe that task to ensure that it has transitioned into a RUNNING state by locating the task Arn from the previous output and then executing the code shown here:
$ aws ecs describe-tasks --cluster testing
--task b64b1d23-bad2-872e-b007-88fd6ExaMPle
{
"failures": [],
"tasks": [
{
"taskArn": "arn:aws:ecs:us-east-1:
01234567890:task/b64b1d23-bad2-872e-b007-88fd6ExaMPle",
"overrides": {
"containerOverrides": [
{
"name": "starwars"
}
]
},
"lastStatus": "RUNNING",
"containerInstanceArn": "arn:aws:ecs:us-east-1:
017663287629:container-instance/
zse12345-12b3-45gf-6789-12ab34cd56ef78",
"desiredStatus": "RUNNING",
"taskDefinitionArn": "arn:aws:ecs:us-east-1:
01234567890:task-definition/starwars-telnet:1",
"containers": [
{
"containerArn": "arn:aws:ecs:us-east-1:
01234567890:container/
zse12345-12b3-45gf-6789-12abExamPLE",
"taskArn": "arn:aws:ecs:us-east-1:
01234567890:task/b64b1d23-bad2-872e-b007-88fd6ExaMPle",
"lastStatus": "RUNNING",
"name": "starwars",
"networkBindings": [
{
"bindIP": "0.0.0.0",
"containerPort": 23,
"hostPort": 2323
}
]
}
]
}
]
}
After verifying that the lastStatus key is set to RUNNING, we should be able to test our container.
Testing the Task
You will need either netcat or a telnet client installed on your system to connect to the container.
Installing NetCat/Telnet
Mac OS X
Mac OS X ships with a copy of netcat in /usr/bin/nc, but you can also install it via Homebrew:
$ brew install netcat
In this case, you will find the binary is called netcat rather than nc.
Debian-based system
$ sudo apt-get install netcat
RedHat-based systems
$ sudo yum install nc
Windows
Windows comes with a supported telnet client, but it is typically not installed by default. You can launch an administrative command prompt and type a single command to install the telnet client.
-
Click
Startand under search, typeCMD. -
Right-click
CMDand clickRun as administrator. -
If prompted, enter your Administrator password.
-
In the command prompt that launches, type the following command to enable the telnet client:
$ pkgmgr /iu:"TelnetClient"
Connecting to the container
We can now test the containerized task using either netcat or telnet. Launch a command prompt and then run the following commands. Be sure to replace the IP address with the address assigned to your EC2 instance.
When you connect to the container, you should see an ASCII version of the Star Wars movie playing on your console.
netcat
$ clear $ nc 192.168.0.1 2323
To exit, simply press Ctrl-C.
telnet
$ clear $ telnet 192.168.0.1 2323
To exit, press Ctrl-], and in the telnet prompt, type quit, then press Enter.
Stopping the Task
We can list all the tasks running in our cluster using the following command:
$ aws ecs list-tasks --cluster testing
{
"taskArns": [
"arn:aws:ecs:us-east-1:
01234567890:task/b64b1d23-bad2-872e-b007-88fd6ExaMPle"
]
}
We can further describe the task by reusing the aws ecs describe-tasks command:
$ aws ecs describe-tasks --cluster testing --task b64b1d23-bad2-872e-b007-88fd6ExaMPle ...
Finally, we can stop the task by running:
$ aws ecs stop-task --cluster testing
--task b64b1d23-bad2-872e-b007-88fd6ExaMPle
{
...
"lastStatus": "RUNNING",
...
"desiredStatus": "STOPPED",
...
}
If we describe the task again, we should now see that the lastStatus key is set to STOPPED:
$ aws ecs describe-tasks --cluster staging_cluster
--task b64b1d23-bad2-872e-b007-88fd6ExaMPle
{
...
"lastStatus": "STOPPED",
...
"desiredStatus": "STOPPED",
...
}
And finally, listing all the tasks in our cluster should return an empty set.
$ aws ecs list-tasks --cluster testing
{
"taskArns": []
}
At this point, we can start creating more complicated tasks that tie multiple containers together and rely on the EC2 Container Service tooling to deploy the tasks to the most idle hosts in our cluster.
Wrap-Up
After reading this chapter, you should have a good idea of the type of tools you can use to create a truly dynamic Docker cluster for your applications to live in. With Docker’s highly portable container format and its ability to abstract away so much of the underlying Linux system, it is easy to move your applications fluidly between your data center and as many cloud providers as you want.