

This chapter is in three parts. The first part describes XML, what it’s for, and how you use it. It’s straightforward and can be described in a couple of sections in the chapter. The largest part of this chapter describes Java support for XML, covering how you access and update XML documents. The XML world defines two different algorithms for accessing XML documents (“everything at once” versus “piece by piece”), and Java supports them both. We put together a Java program that uses each of these algorithms. The third part of the chapter explains how to download and configure the Java library for XML so you can trying running the code for yourself.
You’ll probably be relieved to hear that the basics of XML can be learned in a few minutes, though it takes a while longer to master the “alphabet soup” of all the accompanying tools and standards. XML is a set of rules, guidelines, and conventions for describing structured data in a plain text editable file. The abbreviation XML stands for “eXtensible Mark-up Language.” It’s related to the HTML used to write web pages, and has a similar appearance of text with mark-up tags sprinkled through it. HTML mark-up tags are things like <br> (break to a new line), <table> (start a table), and <li> (make an entry in a list). In HTML the set of mark-up tags are fixed in advance, and the only purpose for most of them is to guide the way something looks on the screen. With XML, you define your own tags and attributes (and thus it is “extensible”) and you give them meaning, and that meaning goes way beyond minor points like the font size to use when printing something out.
Don’t make the mistake of thinking that XML is merely “HTML on steroids.” Although we approach it from HTML to make it easy to explain, XML does much more than HTML does. XML offers the following advantages:
it is an archival representation of data. Because its format is in plain text and carried around with the data, it can never be lost. That contrasts with binary representations of a file which all too easily become outmoded (e.g., do you have any old word processor files that you no longer have a way to read?). If this was all it did, it would be enough to justify its existence.
it provides a way to web-publish files that can be directly processed by computer, rather than merely human-readable text and pictures.
it is plain text, so it can be read by people without special tools.
it can easily be transformed into HTML, or PDF, or data structures internal to a program, or any other format yet to be dreamed up, so it is “future-proof.”
it’s portable, open, and a standard, which makes it a great fit with Java.
We will see these benefits as we go through this chapter. XML holds the promise of taking web-based systems to the next level by supporting data interchange everywhere. The web made everyone into a publisher of human-readable HTML files. XML lets everyone become a publisher or consumer of computer-readable data files.
Keep that concept in mind as we go through this example. We’ll start with HTML because it’s a good way to get into XML. Let’s say you have an online business selling CDs of popular music. You’ll probably have a catalog of your inventory online, so that customers know what’s in stock. Amazon.com works exactly like this. One possibility for storing your inventory is to put it in an HTML table. Each row will hold information on a particular CD title, and each column will be the details you keep about a CD—the title, artist, price, number in stock, and so on. The HTML for some of your online inventory might look like this:
<table> <tr> <th>title</th> <th>artist</th> <th>price</th> <th>stock</th> </tr> <tr> <td>The Tubes</td> <td>The Tubes</td> <td>22</td> <td>3</td> </tr> <tr> <td>Some Girls</td> <td>Rolling Stones</td> <td>25</td> <td>5</td> </tr> <tr> <td>Tubthumper</td> <td>Chumbawamba</td> <td>17</td> <td>6</td> </tr> </table>
We are using tags like <tr> to define table rows. When you display it in a web page, it looks like Figure 28-1.
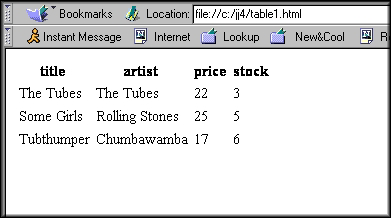
The HTML table is a reasonable format for displaying data, but it’s no help for all the other things you might want to do with your data, like search it, update it, or share it with others. Say we want to find all CDs by some particular artist. We can look for that string in the HTML file, but HTML doesn’t have any way to restrict the search to the “artist” column. When we find the string, we can’t easily tell if it’s in the title column or the artist column or somewhere else again. HTML tables aren’t very useful for holding data with a variable number of elements. Say imported CDs have additional fields relating to country, genre, non-discount status, and so on. With HTML, we have to add those fields to all CDs, or put imported CDs in a special table of their own, or find some other hack.
This is where XML comes in. The basic idea is that you represent your data in character form, and each field (or “element,” as it is properly called) has tags that say what it is. It looks that straightforward! Just as with HTML, XML tags consist of an opening angle bracket followed by a string and a closing angle bracket. The XML version of your online CD catalog might look like this:
<cd> <title>The Tubes</title> <artist>The Tubes</artist>
<price>22</price> <qty>3</qty> </cd>
<cd> <title>Some Girls</title> <artist>Rolling Stones</artist>
<price>25</price> <qty>5</qty> </cd>
<cd> <title>Tubthumper</title> <artist>Chumbawamba</artist>
<price>17</price> <qty>6</qty> </cd> It looks trivial, but the simple act of storing everything as character data and wrapping it with a pair of labels saying what it is opens up some powerful possibilities that we will get into shortly. XML is intended for some entirely different uses than displaying in a browser. In fact, most browsers ignore tags that they don’t recognize, so if you browse an XML file you’ll just get the embedded text without tags (unless the browser recognizes XML, as recent versions of Microsoft’s Internet Explorer do).
Should we also wrap HTML around the XML so it can be displayed in a browser? You could do that, but it is not the usual approach. XML is usually consumed by data-processing programs, not by a browser. The purpose of XML is to make it easy for enterprise programs to pass around data together with their structure. It’s much more common to keep the data as records in a database, extract and convert it into XML on demand, pass the XML around, then have a servlet or JSP program read the XML and transform it into HTML on the fly as it sends the data to a browser. The Java XSLT library does exactly that. Let us go on to make a few perhaps obvious remarks about the rules of XML.
XML follows the same kind of hierarchical data structuring rules that apply throughout most programming languages, and therefore XML can represent the same kind of data that we are used to dealing with in our programs. As we’ll see later in the chapter, you can always build a tree data structure out of a well-formed XML file and you can always write out a tree into an XML file. When you want to send XML data to someone, the XML file form is handy. When you want to process the data, the in-memory tree-form is handy. The purpose of the Java XML API is to provide classes that make it easy to go from one form to the other, and to grab data on the way.
Notice that all XML tags come in matched pairs of a begin tag and an end tag that surround the data they are describing, like this:
<someTagName> some data appears here </someTagName> The whole thing—start tag, data, and end tag—is called an element.
You can nest elements inside elements, and the end tag for a nested element must come before the end tag of the thing that contains it. Here is an example of some XML that is not valid:
<cd> <title>White Christmas </cd> </title>
It’s not valid because the title field (or “element” to use the proper term) is nested inside the cd element, but there is no end tag for it before we reach the cd end tag. This proper nesting requirement makes it really easy to check if a file has properly nested XML. You can just push start tags onto a stack as they come in. When you reach an end tag, it should match the tag on the top of the stack. If it does, pop the opening tag from the stack. If the tag doesn’t match, the file has badly-nested XML.
Just as some HTML tags can have several extra arguments or “attributes,” so can XML tags. The HTML <img> tag is an example of an HTML tag with several attributes. The <img> tag has attributes that specify the name of an image file, the kind of alignment on the page, and even the width and height in pixels of the image. It might look like this:
<img src="cover.jpg" height="150" width="100" align="right">
In HTML, we can leave off the quotes around attribute values unless the values contain spaces. In XML, attribute values are always placed in quotation marks, and you must not put commas in between attributes. We could equally describe our CD inventory using attributes like this:
<cd title="The Tubes" artist="The Tubes" price="22" qty="3"> </cd>
As frequently happens in programming, a software designer can express an idea in several different ways. Some experts recommend avoiding the use of attributes in XML where possible for technical reasons having to do with expressiveness.
Comments have the same appearance as in HTML, and can be put in a file using this tag (everything between the two pairs of dashes is a comment):
<!-- comments -->
XML tags are case-sensitive. XML is generally much stricter about what constitutes a good document than is HTML. This strictness makes it easier for a program to read in an XML file and understand its structure. It doesn’t have to check for 50 different ways of doing something. An XML document that keeps all the rules about always having a matching closing tag, all tags being properly nested, and so on is called a “well-formed” document. There is a complete list of all the rules in the XML FAQ at www.ucc.ie/xml/.
There is another level of data validation in addition to a document being “well-formed.” You also want to be able to check that the document contains only elements that you expect, all the elements that you expect, and that they only appear where expected. For example, we know this is not a valid CD inventory entry:
<cd> <price>22</price> <qty>3</qty> </cd>
It’s not valid because it doesn’t have a title or artist field. Although we have 3 in stock, we can’t say what it is 3 of.
XML files therefore usually have a Document Type Definition or “DTD” that specifies how the elements can appear. The DTD expresses which tags can appear, in what order, and how they can be nested. The DTD can be part of the same file, or stored separately in another place. A well-formed document that also has a DTD and that conforms to its DTD is called valid.
The DTD is itself written using something close to XML tags, and there is a proposal underway to align the DTD language more closely to XML. You don’t need to be able to read or write a DTD to understand this chapter, but we’ll go over the basics anyway. There is a way to specify that some fields are optional and thus might not be present. In other words, it’s the usual type of “a foo is any number of bars followed by at least one frotz” grammar that we see throughout programming, with its own set of rules for how you express it. Here’s a DTD that specifies our CD inventory XML file.
<!ELEMENT inventory (cd)* >
<!ELEMENT cd (title, artist, price, qty)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT artist (#PCDATA)>
<!ELEMENT price (#PCDATA)>
<!ELEMENT qty (#PCDATA)> White space is not significant in an XML file, so we can indent elements to suggest to the human reader how they are nested. The first line says that the outermost tag, the top-level of our document, will be named “inventory,” and this is followed by zero or more “cd” elements (that’s what the asterisk indicates). Each cd element has four parts: title, artist, price, and qty, in that order. Definitions of those follow in the DTD. “#PCDATA” means that the element contains only “parsed character data,” and not tags or other XML information.
When you get down to the bottom level, every element is either “CDATA”—character data that is not examined by the parser—or “PCDATA”—parsed character data meaning the string of an element. The nesting rule automatically forces a certain simplicity on every XML document which takes on the structure known in computer science circles as a tree.
XML documents begin with a tag that says which version of XML they contain, like this:
<?xml version="1.0"?>
This line is known as the "declaration" and it may also contain additional information, in the form of more attributes, about the character set and so on. By convention, the next tag gives the name of the root element of the document. It also has the DTD nested within it, or it gives the filename if the DTD is in another file. Here’s what the tag looks like when it says “the DTD is in a file called “invfile.dtd”:
<!DOCTYPE inventory SYSTEM "inv-file.dtd" >
The version and DTD information is called the “prolog,” which comes at the start of an XML document. The marked-up data part of the XML file is called the “document instance.” It’s an instance of the data described by the DTD.
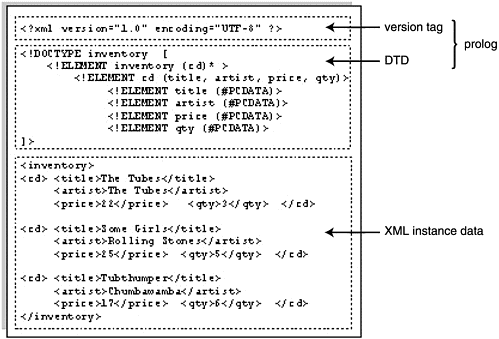
Figure 28-2 shows the different sections of an XML document and the names given to them. This example shows how the DTD looks when it is part of the XML file, rather than a separate file.
An important recent feature of XML is “namespaces.” A “namespace” is a computer science term for a place where a bunch of names (identifiers) can exist without interfering with any other bunches of names that you might have laying around. For instance, an individual Java method forms a namespace. You can give variables in a method any names you like, and they won’t collide with the names you have in any other method. A java package forms a namespace. When you refer to something by its full name, including the package name and class name, you unambiguously say what it is, and it cannot get mixed up with any other name that has identical parts. If we refer to “List” in our Java code, it may not be clear what we mean. If we write java.util.List or java.awt.List, we are saying which List we mean unambiguously by stating the namespace (the package) it belongs to. The reference cannot be confused with any other.
XML supports namespaces, so the markup tags that you define won’t collide with any similarly-named tags from someone else. When you give the name of a tag at the start of an element, you can also supply an attribute for that tag, saying which namespace it comes from. The attribute name is “xmlns” meaning “XML NameSpace,” and it looks like this:
<artist xmlns=”http://www.example.com/inventory" > Rolling Stones </artist>
This says that the artist element, and any elements contained within it, are the ones that belong to the namespace defined at www.example.com/inventory. You define a namespace within a DTD by adding a “xmlns=something” attribute to the element’s tag. By mentioning a namespace in the XML as in the example above, the CD inventory “artist” element will not be confused with any other element that uses the name “artist.” Namespaces are useful when you are building up big DTDs describing data from several domains. However, note that the Java XML parsers do not support namespaces in the current release.
Here’s a longer example of a DTD giving the XML format of Shakespearean plays! This shows the power of XML—you can use it to describe just about any structured data. This example is taken from the documentation accompanying Sun’s JAXP library. It was written by Jon Bosak, the chief architect of XML. You’ll notice a few more DTD conventions. A “?” means that element is optional. A “+” means there must be at least one of those things, and possibly more. You can group elements together inside parentheses.
DTD for Shakespeare’s Plays
<!-- DTD for Shakespeare J. Bosak 1994.03.01, 1997.01.02 --> <!-- Revised for case sensitivity 1997.09.10 --> <!-- Revised for XML 1.0 conformity 1998.01.27 (thanks to EveMaler) --> <!-- <!ENTITY amp "&#38;"> --> <!ELEMENT PLAY (TITLE, FM, PERSONAE, SCNDESCR, PLAYSUBT, INDUCT?,
The DTD says that a Shakespearean play consists of the title, followed by the FM (“Front Matter”—a publishing term), personae, a scene description, a play subtext, a possible induction, a possible prologue, at least one (and maybe many) act, then finally, an optional epilogue. I asked Jon Bosak why he didn’t use white space to better format this DTD. He explained that it’s hard to do for non-trivial DTDs, although people are doing it more now with schemas (data descriptions) that are truly based on XML.
One programmer recently wrote a DTD describing the format of strip cartoons and published it on the slashdot.com website. It’s a very flexible data description language! You don’t need to be able to read and write DTDs as part of your work, but it doesn’t hurt. There are automated tools called DTD editors that let you specify data relationships in a user-friendly way and automatically generate the corresponding DTD. There are a few additional DTD entries and conventions, but this summary provides a strong enough foundation of XML to present the Java features in the rest of the chapter.
There seems to be agreement from all sides that XML has a bright future. Microsoft chief executive Steve Ballmer said that he thinks use of XML will be a critically important trend in the industry. Why is this? What motivated XML’s design? XML was developed in the mid 1990s under the leadership of Sun Microsystems employee Jon Bosak. Jon was looking for ways to use the Internet for more than just information delivery and presentation. He wanted to create a framework that would allow information to be self-describing. That way applications could guarantee that they could access just about any data. That in turn would clear the path to intelligent data-sharing between different organizations. And that in turn would allow more and much better applications to be written and increase the demand for servers to run them on. Well, that last part isn’t a goal, but it’s certainly a great side-effect for anyone in the computer hardware industry.
Information access might not sound like a problem in these days of web publishing, but it used to be a significant barrier. The web is still not a good medium for arbitrary binary data or data that is not text, pictures, or audio. A few years ago, every hardware manufacturer had a different implementation of floating-point hardware, and the formats were incompatible between different computers. If you had a tape of floating-point data from an application run on a DEC minicomputer, you had to go through unreasonable effort to process it on another manufacturer’s mainframe. IBM promoted its EBCDIC (Extended Binary Coded Decimal Interchange Code) convention over the ASCII (American Standard Code for Information Interchange) codeset standardized in the rest of the Western world. People who wanted to see their printouts in Japanese resorted to a variety of non-standard approaches. By storing everything in character strings, XML avoids problems of incompatible byte order (big-endian/little-endian) that continue to plague people sharing data in binary formats. By stipulating Unicode or UTF encoding for the strings, XML opens up access to all the locales in the world, just as Java does.
XML makes your data independent of any vendor or implementation or application software. In the 1960s, IBM launched a transaction processing environment called CICS. CICS was an acronym for “Customer Information Control System.” When a site used CICS, after a while it usually became completely dependent on it, and had to buy large and continuing amounts of hardware and support from IBM in order to keep functioning. People used to joke that it was the customer that was being controlled, not the information. But it was no joke if you were in that position. Modern software applications cause the same kind of single-vendor lock-in today. XML goes a long way to freeing your data from this hidden burden. But note this key point: just because something is published in XML does not make it openly available. The DTD and semantic meaning of the tags must also be published before anyone can make sense of non-trivial documents.
So XML makes it possible for otherwise incompatible computer systems to share data in a way that all can read and write. XML markup can also be read by people because it is just ordinary text. So what new things can be done with XML? XML opens up the prospect of data comparisons and data sharing at every level on the web. If you want to buy a digital camera online today, you might spend a few hours visiting several retailer websites and jotting down your comparison shopping notes. With XML, you take a copy of the merchants’ product datasheets and run an automated comparison sorted in order of the product characteristics that matter most to you. Even more important, if you’re a business that needs to buy 1,000 digital cameras for resale, XML lets you put this business-to-business transaction up for bid in an automated way.
Two things have to happen for automated XML bids and comparisons to occur. First, suppliers have to use a common DTD for describing their wares online. Second, someone has to write the comparison software, probably as a browser plug-in. Neither of these is outlandish. Various industry groups have already started to cooperate on common data descriptions. The best known are RosettaNet for electronics, and Acord for insurance. The development community is also working on XML-based protocols to let software components and applications communicate using standard Internet HTTP. The leading contender here is SOAP—Simple Object Access Protocol—from IBM, HP, Microsoft, and others.
As one white paper pointed out, the applications that will drive the acceptance of XML are those that cannot be accomplished within the limitations of HTML. These applications can be classified in four broad categories:
Applications that require the Web client to work with two or more different databases (e.g., comparison shopping).
Applications that want to move a significant proportion of the processing load from the Web server to the Web client.
Applications that require the Web client to present different views of the same data to different users.
Applications in which intelligent Web agents attempt to tailor information discovery to the needs of individual users.
The alternative to XML for these applications is proprietary code embedded as “script elements” in HTML documents and delivered in conjunction with proprietary browser plug-ins or Java applets. XML gives content providers a data format that does not tie them to particular script languages, authoring tools, and delivery engines. XML supports a standardized, vendor-independent, level playing field upon which different authoring and delivery tools may freely compete.
Table 28-1 contains the latest version numbers relating to XML. This chapter describes the most up-to-date version of everything available at the time of this writing (Winter 2001).
Table 28-1. XML-Related Version Numbers
|
API |
Version |
Number Description |
|---|---|---|
|
JAXP |
ver 1.1 |
Java API for XML processing. Includes an XSLT framework based on TrAX (Transformation API for XML) plus updates to the parsing API to support DOM Level 2 and SAX version 2.0. The remainder of this chapter has more information on JAXP. |
|
XSLT |
ver 1 |
XSLT is a conversion language standardized by W3C that can be used to put XML data in some other form such as HTML, PDF, or a different XML format. For example, you can use XSLT to convert an XML document in a format used by one company to the format used by another company. See www.zvon.org for a tutorial on “eXtensible Stylesheet Language Transformations” (XSLT). |
|
SAXP |
ver 2.0 |
Simple API for XML Parsing. This is covered in the rest of this chapter. |
|
DOM |
level 2 |
Document Object Model, which is another API for XML parsing. This is covered in the rest of this chapter. |
|
JAXM |
ver 0.92 |
Java Architecture for XML Messaging. A new specification that describes a Java library for XML-based messaging protocols. Objects and arguments (messages) will be turned into XML and sent to other processes and processors as streams of characters. |
|
JAXB |
early access |
Java Architecture for XML Binding. A convenient new Java library for XML parsing under development by Sun and released in draft form as this text went to print. |
Table 28-2 contains a glossary of terms that you can review and refer back to as necessary.
As should be clear from the alphabet soup of different libraries and versions, XML is an emerging technology, and Java support for XML is evolving rapidly—on Internet time in fact.
Table 28-2. XML-Related Glossary
|
Name |
Example |
Description |
|---|---|---|
|
start tag |
<artist> |
Marks the beginning of an element. |
|
end tag |
</artist> |
Marks the end of an element. |
|
element |
<price>17</price> |
A unit of XML data, complete with its start and end tags. |
|
DTD |
see chapter text |
Document Type Definition, specifying which tags are valid, and what are the acceptable ways of nesting them in the document. |
|
entity |
< |
An entity is essentially a shorthand way of referring to something. Here, the four characters “<” form an entity representing a left chevron, which has special meaning if it appears literally. An entity is a distinct individual item that is included in an XML document by referencing its name. This item might be as small as an individual character, or a text string, or a complete other XML file, or it may be a reference to something defined earlier in this XML file. All entities have to be declared in the DTD before they can be used. |
|
attribute |
<foo someName=”someValue” ... |
The someName=”someValue” string pair holds additional information or detail about an element. |
|
JAXP |
see chapter text |
The Java API for XML processing. A package of classes that support a Java interface to XML. The package name is javax.xml, introduced in JDK 1.4 |
|
JAXB |
n/a |
The Java Architecture for XML Binding— a follow-up library to JAXP, which handles all the details of XML parsing and formatting. It can be more efficient than using a SAX (Simple API for XML) parser or an implementation of the DOM (Document Object Model) API. An early draft was released in July 2001. |
|
XML |
see chapter text |
eXtensible Mark-up Language. |
|
XSLT |
see chapter text |
eXtensible Stylesheet Language Transformations, a standard for transforming XML into text or other XML documents. An XSLT implementationis in JDK 1.4. |
|
URI |
Uniform Resource Identifier. The generic term for all types of names and addresses that refer to objects on the World Wide Web. A URL is one kind of URI. | |
|
URL |
Uniform Resource Locator. The address of a web site or web page. The first part of the address specifies the protocol to use (e.g., ftp, http). The second part of the address gives the IP address or domain name where the resource is located. |
This is a good point to review the packages that make up the Java XML library, their purpose, and their classes. The different package names reflect the different origins of the code. The Java interfaces came from Sun Microsystems, the DOM implementation came from the W3C, and the SAX parser implementation came from yet a third organization.
package: javax.xml.parsers
purpose: is the Java interface to the XML standard for parsing
contains these classes/interfaces: DocumentBuilderFactory, DocumentBuilder, SAXParserFactory, SAXParser. These get instances of a Parser and undertake a parse on an XML file.
package: javax.xml.transform
purpose: is the Java interface to the XML standard for tree transformation
contains: classes to convert an XML tree into an HTML file or XML with a different DTD. Tree transformation is beyond the scope of this text, but you can read more about it by searching for “transform” at java.sun.com.
package: org.w3c.dom
purpose: has the classes that make up a DOM tree in memory
contains these classes/interfaces: Node plus its subtypes: Document, DocumentType, Element, Entity, Attr, Text, etc.
package: org.xml.sax
purpose: has the classes that can be used to navigate the data returned in a SAX parse
contains: two packages org.xml.sax.ext (extensions) and org.xml.sax.helpers plus these classes/interfaces: Attributes, ContentHandler, EntityResolver, DTDHandler, XMLReader. The helpers package contains the DefaultHandler class which is typically extended by one of your classes to handle a SAX parse, as explained below.
All the above packages are kept in a file called jaxp.jar. The JAXP distribution also includes two other jar files: crimson.jar and xalan.jar. Crimson.jar holds the DOM and SAX parser implementations. Xalan.jar contains the implementation of the xml transformation interface. Make sure that the right jar files are in your path for the features you are using.
Because of the seemingly unrelated package names, XML parsing may appear a little unorganized. Just remember it this way: You always need the java.xml.parsers package. And you need the package with “dom” in its name to do a DOM parse, or “sax” in its name to do a SAX parse. The SAX packages also have the error-handling classes for both kinds of parse.
XML documents are just text files, so you could read and write them using ordinary file I/O. But you’d miss the benefits of XML if you did that. Valid XML documents have a lot of structure to them, and we want to read them in a way that lets us check their validity, and also preserve the information about what fields they have and how they are laid out.
What we need is a program that reads a flat XML file and generates a tree data structure in memory containing all the information from the file. Ideally, this program should be general enough to build that structure for all possible valid XML files. Processing an XML file is called “parsing” it. Parsing is the computer science term (borrowed from compiler terminology) for reading something that has a fixed grammar, and checking that it corresponds to its grammar. The program is known as an “XML parser.” The parser provides a service to application programs. Application programs hand the parser a stream of XML from a document file or URL, the parser does its work and then hands back a tree of Java objects that represents or “models” the document.
An XML parser that works this way is said to be a “Document Object Model” or “DOM” parser. The key aspect is that once the DOM parser starts, it carries on until the end and then hands back a complete tree representing the XML file. The DOM parser is very general and doesn’t know anything about your customized XML tags. So how does it give you a tree that represents your XML? Well, the DOM API has some interfaces that allow any kind of data to be held in a tree. The parser has some classes that implement those interfaces, and it instantiates objects of those classes.
It’s all kept pretty flexible, and allows different parsers to be plugged in and out without affecting your application code. Similarly, you get information out of the tree by calling routines specified in the DOM API. The Node interface is the primary datatype for the Document Object Model. It represents a single node in the document tree, and provides methods for navigating to child Node. Most of the other interfaces, like Document, Element, Entity, and Attr, extend Node. In the next section we will review the code for a simple program that uses a DOM parser. DOM parsers can be and are written in any language, but we are only concerned with Java implementations here.
This section walks through a code example that instantiates and uses a DOM parser. If you want to try compiling this as you read the section, you’ll need to download and install JDK 1.4 first.
The DOM parser is just a utility that takes incoming XML data and creates a data structure for your application program (servlet, or whatever) to do the real work. See Figure 28-3 for the diagram form of this situation.
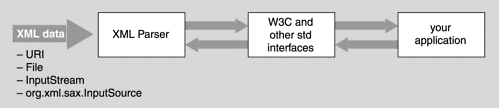
The code we show in this section is the code that is “your application” in Figure 28-3. The JAXP library has code for the other two boxes. The interface is a little more involved than simply having our class call the parser methods. This unexpected slight complication happens because the Java library implementors wanted to make absolutely sure that the installations never got locked into one particular XML parser. It’s always possible to swap the parser that comes with the library for another. To retain that flexibility, we instantiate the parser object in a funny way (the Factory design pattern), which we will explain later.
The program is going to read an XML file, get it parsed, and get back the output which is a tree of Java objects that mirror and represent the XML text file. Then the program will walk the tree, printing out what it finds. We hope it will be identical with what was read. In a real application, the code would do a lot more than merely echo the data; it would process it in some fashion, extracting, comparing, summarizing. However, adding a heavyweight application would complicate the example without any benefit. So our application simply echoes what it gets. The program we are presenting here is a simplified version of an example program called DOMEcho.java that comes with the JAXP library. The general skeleton of the code is this:
// import statements
public class DOMEcho {
main(String[] args) {
// get a Parser from the Factory
// Parse the file, and get back a Document
// do our application code
// walk the Document, printing out nodes
echo( myDoc );
}
echo( Node n ) {
// print the data in this node
for each child of this node,
echo(child);
}
} The first part of the program, the import statements, looks like this:
import javax.xml.parsers.*; import org.xml.sax.*; import org.xml.sax.helpers.*; import org.w3c.dom.*; import java.io.*;
That shows the JAXP and I/O packages our program will use. The next part of the program is the fancy footwork that we warned you about to obtain an instance of a parser—without mentioning the actual class name of the concrete parser we are going to use. This is known as the Factory design pattern, and the description is coming up soon. For now, take it for granted that steps 1 and 2 give us a DOM parser instance.
public class DOMEcho {
public static void main(String[] args) throws Exception {
// Step 1: create a DocumentBuilderFactory
DocumentBuilderFactory dbf =
DocumentBuilderFactory.newInstance();
// We can set various configuration choices on dbf now
// (to ignore comments, do validation, etc)
// Step 2: create a DocumentBuilder
DocumentBuilder db = null;
try {
db = dbf.newDocumentBuilder();
} catch (ParserConfigurationException pce) {
System.err.println(pce);
System.exit(1);
}
// Step 3: parse the input file
Document doc = null;
try {
doc = db.parse(new File(args[0]));
} catch (SAXException se) {
System.err.println(se.getMessage());
System.exit(1);
} catch (IOException ioe) {
System.err.println(ioe);
System.exit(1);
}
// Step 4: echo the document
echo( doc );
} That shows the key pieces of the main program. We will look at the code that echoes the document shortly, as it is an example of the data structure that the DOM parse hands back to your application. When you check the Javadoc html files for the JAXP library, you will see that the parse gives you back an object that fulfills the Document interface. Document in turn is a child of the more general Node interface.

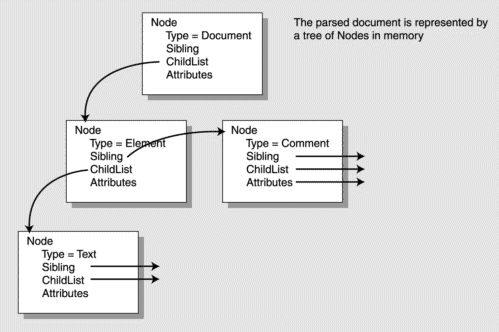
Your tree is a tree of Nodes. Each element, entity, PCData, Attribute, etc., in your XML file will have a corresponding Node that represents it in the data structure handed back by the DOM parse. Node is an interface promising a dozen or so common operations: get siblings, get children, get type, get name, and so on.
Each Node has a list of child Nodes that are the elements contained within it. There is also a field that points to a collection of attributes, if the node has attributes. When you examine the class org.w3c.dom.Node using Javadoc, you will see that it has10 or 20 fields and methods allowing you to get and set data associated with the Node, as shown in Table 28-3.
Table 28-3. Methods of org.w3c.dom.Node
|
Method |
Purpose |
|---|---|
|
|
Returns a NodeList that contains all children of this node. |
|
|
Returns a boolean signifying if the node has children or not. |
|
|
Returns the node immediately following this node, i.e., its next sibling. |
|
|
Returns an int code representing the type of the node, e.g., attribute, cdata section, comment, document, element, entity, etc. |
|
|
Returns a String representing the name of the node. For an element, this is its tag name. |
|
|
Returns a String that means different things depending on what type of Node this is. An Element that just has PCData will have a child Node of type “text” and the node value that is the element's PCData. |
|
|
Returns the parent of this node. |
You invoke these Node methods on the document value returned from the parse, as shown in the following example. Here is the remainder of the code. It does a depth-first traversal of a DOM tree and prints out what it finds. Once again, real application programs will do much more than just echo the data. We have omitted any processing of the XML data for simplicity here. All we do is echo the XML to prove that we have a tree that accurately reflects it.
/**
* Recursive routine to print out DOM tree nodes
*/
private void echo(Node n) {
int type = n.getNodeType();
switch (type) {
case Node.DOCUMENT_NODE:
out.print("DOC:");
break;
case Node.DOCUMENT_TYPE_NODE:
out.print("DOC_TYPE:");
break;
case Node.ELEMENT_NODE:
out.print("ELEM:");
break;
case Node.TEXT_NODE:
out.print("TEXT:");
break;
default:
out.print("OTHER NODE: " + type);
break;
}
out.print(" nodeName="" + n.getNodeName() + """);
String val = n.getNodeValue();
if (val != null) {
if ( !(val.trim().equals(""))) {
out.print(" nodeValue ""
+ n.getNodeValue() + """);
}
}
out.println();
// Print children if any
for (Node child = n.getFirstChild(); child != null;
child = child.getNextSibling()) {
echo(child);
}
}
} Note that the code above switches on the NodeType int field to deal with different types of Node. A better, more object-oriented way to do this is to use the instanceof operator:
private void echo(Node n) {
if (n instanceof Document)
out.print("DOC:");
else if (n instanceof DocumentType)
out.print("DOC_TYPE:");
else if (n instanceof Element)
out.print("ELEM:"); The Node interface is further specialized by child interfaces that extend it. The interfaces that extend the Node interface are Attr, CDATASection, CharacterData, Comment, Document, DocumentFragment, DocumentType, Element, Entity, EntityReference, Notation, ProcessingInstruction, and Text. These subinterfaces can do all the things that a Node can do, and have additional operations peculiar to their type that allow the getting and setting of data specific to that subtype.
As an example, the org.w3c.dom.CharacterData subinterface of Node adds a few methods to allow the inserting, deleting, and replacing of Strings. Table 28-4 lists the key methods of CharacterData. You should review Node and all its child interfaces using Javadoc when you start to use XML parsers.
Table 28-4. Methods of org.w3c.dom.CharacterDat
|
Method |
Purpose |
|---|---|
|
|
Returns the CharacterData of this Node. |
|
|
Appends this string onto the end of the existing character data. |
|
|
Inserts this string at the specified offset in the character data. |
|
|
Replaces 'count' characters starting at the specified offset with the string s. |
|
|
Replaces the entire CharacterData of this node with this string. |
You will invoke these methods on any Node to modify its character data.
The Document subinterface of Node is particularly useful, having a number of methods that allow you to retrieve information about the document as a whole, e.g.,get all the elements with a specified tagname. Some of the most important methods of Document are outlined in Table 28-5.
Table 28-5. Methods of org.w3c.dom.Document
|
Method |
Purpose |
|---|---|
|
|
Returns a NodeList of all the Elements with a given tag name in the order in which they are encountered in a preorder traversal of the Document tree. |
|
|
Creates an Element of the type specified. |
|
|
Returns the DTD for this document. The type of the return value is DocumentType. |
You will invoke these methods on the document value returned from the parse.
Once you have parsed an XML file, it is really easy to query it, extract from it, update it, and so on. The XML is for storing data, moving data around, sharing data with applications that haven’t yet been thought of, and sharing data with others outside your own organization (e.g., an industry group or an auction site). The purpose of the parser is to rapidly convert a flat XML file into the equivalent tree data structure that your code can easily access and process.
DOM level 1 was recommended as a standard by the World Wide Web consortium, W3C, in October 1998. In the years since then, a weakness in the DOM approach has become evident. It works fine for small and medium-sized amounts of data, up to, say, hundreds of megabytes. But DOM parsing doesn’t work well for very large amounts of data, in the range of many gigabytes, which cannot necessarily fit in memory at once. In addition, it can waste a lot of time to process an entire document when you know that all you need is one small element a little way into the file.
To resolve these problems, a second algorithm for XML parsing was invented. It became known as the “Simple API for XML” or “SAX,” and it’s distinguishing characteristic is that it passes back XML elements to the calling program as it finds them. In other words, a SAX parser starts reading an XML stream, and whenever it notices a tag that starts an element, it tells the calling program. It does the same thing for closing tags too. The way a SAX parser communicates with the invoking program is via callbacks, just like event handlers for GUI programs.
The application program registers itself with the SAX parser, saying in effect “when you see one of these tags start, call this routine of mine.” It is up to the application program what it does with the information. It may need to build a data structure, or add up values, or process all elements with one particular value, or whatever. For example, to search for all CDs by The Jam, you would look for all the artist elements where the PCDATA is “The Jam.”
SAX parsing is very efficient with machine resources, but it also has a couple of drawbacks. The programmer has to write more code to interface to a SAX parser than to a DOM parser. Also, the programmer has to manually keep track of where he is in the parse in case the application needs this information (and that’s a pretty big disadvantage). Finally, you can’t “back up” to an earlier part of the document, or rearrange it, anymore than you can back up a serial data stream. You get the data as it flies by, and that’s it.
The error handling for JAXP SAX and DOM applications are identical in that they share the same exceptions. The specifications require that validation errors are ignored by default. If you want to throw an exception in the event of a validation error, then you need to write a brief class that implements the org.xml.sax.ErrorHandler interface, and register it with your parser by calling the setErrorHandler() method of either javax.xml.parsers.DocumentBuilder or org.xml.sax.XMLReader. Error handling is the reason why DOM programs import classes from the org.xml.sax and org.xml.sax.helpers packages.
JAXP includes both SAX and DOM parsers. So which should you use in a given program? You will want to choose the parser with an eye on the following characteristics:
SAX parsers are generally faster and use less resources, so they are a good choice for servlets and other transaction oriented requirements
SAX parsers require more programming effort to set them up and interact with them
SAX parsers are well suited to XML that contains structured data (e.g., serialized objects)
DOM parsers are simpler to use
DOM parsers require more memory and processor work
DOM parsers are well suited to XML that contains actual documents (e.g., Office or Excel documents in XML form)
If it’s still not clear, use a DOM parser, as it needs less coding on your part.
This section walks through a code example of a SAX parser. Because we have already covered much of the background, it will seem shorter than the DOM example. Don’t be fooled. The general skeleton of the code is this:
// import statements
public class MySAXEcho extends DefaultSAXHandler {
main(String[] args) {
// get a Parser
// register my callbacks, and parse the file
}
// my routines that get called back
public void startDocument() { ...}
public void startElement( ...
public void characters ( ...
public void endElement(
...
} The first part of the program, the import statements, looks like this:
import java.io.*; import org.xml.sax.*; import org.xml.sax.helpers.DefaultHandler; import javax.xml.parsers.SAXParserFactory; import javax.xml.parsers.ParserConfigurationException; import javax.xml.parsers.SAXParser;
That shows the JAXP and I/O packages our program will use. The next part of the program is the fancy footwork to obtain an instance of a parser without mentioning the actual class name of the concrete parser we are going to use. As a reminder, it will be explained before the end of the chapter. For now, take it for granted that we end up with a SAX parser instance.
The next part of the program is critical. It shows how we register our routines for the callbacks. Rather than register each individual routine, the way we do with basic event handling in Swing, we make our class extend the class org.xml.sax.helpers.DefaultHandler. That class has 20 or so methods and is the default base class for SAX2 event handlers. When we extend that class, we can provide new implementations for any of the methods. Where we provide a new implementation, our version will be called when the corresponding SAX event occurs.
For those familiar with Swing, this is exactly the way the various Adapter classes, e.g., MouseAdapter, work.
public class MySAXEcho extends org.xml.sax.helpers.DefaultHandler {
public static void main(String argv[]) {
// Get a SAX Factory
SAXParserFactory factory = SAXParserFactory.newInstance();
// Use an instance of ourselves as the SAX event handler
DefaultHandler me = new MySAXEcho();
try {
SAXParser sp = factory.newSAXParser();
// Parse the input
sp.parse( new File(argv[0]), me);
} catch (Throwable t) {
t.printStackTrace();
}
}
static private PrintStream o = System.out; The two lines in bold show where we create an instance of our class and then pass it as an argument to the parse routine, along with the XML file. At that point, our routines will start to be invoked by the SAX parser. The routines we have provided in this case are shown here:
//===========================================================
// SAX DocumentHandler methods
//===========================================================
public void startDocument()
throws SAXException
{
o.println("In startDocument");
}
public void startElement(String namespaceURI,
String sName, // simple name (localName)
String qName, // qualified name
Attributes attrs)
throws SAXException
{
o.print( "got elem <"+sName);
if (attrs != null) {
for (int i = 0; i < attrs.getLength(); i++) {
o.println(attrs.getLocalName(i)+"=""+attrs.getValue(i)+""");
}
}
o.println("");
}
public void characters (char buf[], int offset, int len)
throws SAXException {
String s = new String(buf, offset, len);
o.print(s);
}
public void endElement(String namespaceURI,
String sName, // simple name
String qName // qualified name
)
throws SAXException
{
o.println("</"+sName+"");
}
} And that’s our complete SAX parser. In this case, we have provided the routines to get callbacks for the start of the document and each element, for the character data inside each element, and for the end of each element. A review of the DefaultHandler class will show all the possibilities. The code is on the CD that comes with this book. You should compile and test run the program.
A sample data file of a CD, complete with DTD, looks like this:
<?xml version="1.0"?>
<!DOCTYPE inventory [
<!ELEMENT inventory (cd)* >
<!ELEMENT cd (title, ar tist, price, qty)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT ar tist (#PCDATA)>
<!ELEMENT price (#PCDATA)>
<!ELEMENT qty (#PCDATA)>
]>
<inventory>
<cd> <title>Some Girls</title> <artist>Rolling Stones</artist>
<price>25</price> <qty>5</qty> </cd>
</inventory> This data file can be found on the CD. Compile and execute in the usual way:
javac SAXEcho.java java SAXEcho cd.xml
You will see output from the echo part of the code like this:
In startDocument Some Girls</> got elt < > Rolling Stones</> got elt < > 25</>
One of the exercises at the end of the chapter is to update the program to provide more readable output about the elements it finds.
You can safely skip this section on first reading, as it simply describes how and why you use a design pattern with the JAXP library.
If you implement an XML parser in the most straightforward way, code that uses the parser will need implementation-specific knowledge of the parser (such as its classname). That’s very undesirable. The whole XML initiative is intended to free your data from single platform lock-ins, so having your code tied to a particular parser undermines the objective. The Java API for XML Processing (JAXP) takes special steps to insulate the API from the specifics of any individual parser.
This makes the parser “pluggable,” meaning you can replace the parsers that come with the library with any other compliant SAX or DOM parser. This is achieved by making sure that you never get a reference to the implementation class directly; you only ever work using an object of the interface type in the JAXP library. It’s known as the “Factory” design pattern.
Factories have a simple function: churn out objects. Obviously, a factory is not needed to make an object. A simple call to a constructor will do it for you. However, the use of factories allows the library-writer to define an interface for creating an object, but let the Factory decide which exact class to instantiate. The Factory method allows your application classes use a general interface or abstract class, rather than a specific implementation. The interface or abstract class defines the methods that do the work. The implementation fulfills that interface, and is used by the application, but never directly seen by the application.
Figure 28-6 shows an abstract class called “Worker.” Worker has exactly two methods: a() and b(). An interface can equally be used, but let’s stick with an abstract class for the example. You also have some concrete classes that extend the abstract class (WorkByJane, WorkByPete, etc.). These are the different implementations that are available to you. They might differ in anything: one is fast but uses a lot of memory, another is slow but uses encryption to secure the data, a third might be able to reach remote resources.
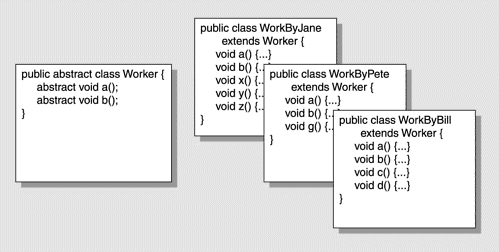
The idea behind the factory pattern is that you don’t want your application code to know about these implementation classes. You don’t want it to be able to invoke the extra methods in the implementation, for example. You want a way to declare and use an instance of one of the implementation classes but have it be typed as the abstract worker class. You further want to do that with your application code seeing as little as possible of the implementation and ideally none. Figure 28-7 shows the Factory pattern that achieves this:

The factory has a method (usually static, though it doesn’t have to be) that will return something that is the type of our abstract class, Worker. Here we have called this routine getWorker. It will actually send back a subtype of Worker, but as you know, if Dog is a subtype of Mammal, wherever a parameter or assignment calls for a Mammal you can give it a Dog. This is not true the other way around, of course, as you cannot supply a general class when a more specific one is called for. The Factory method getWorker will look at the parameters it was sent and decide which kind of Worker implementation is the best one to use: a fast one, a secure one, a small memory one, or whatever. Then it will instantiate one of these subclasses, and return it. Notice that the return type is that of our abstract class, not one of the concrete subtypes.
Our code that calls into the Factory will resemble Figure 28-8.

It gets back a Worker, and the only thing that can be done with a worker is to call a() or b(). There is no opportunity to call any of Pete or Jane’s extra methods, shown in Figure 28-7.
You cannot instantiate a Worker object, because it’s an abstract class. But by using the Factory pattern, you now hold a concrete object that is of type Worker. Describing how this works with XML parsers will bring some clarity to the Factory pattern.
When using an interface, you don’t want to access the underlying implementation classes. If you break this rule, you might as well not be using an interface at all; you have locked yourself into one implementation. In the case of a DOM parser, you want to do everything through the interface, and not directly use the actual DOM parser that implements the interface. The interface is:
package org.w3c.dom;
public interface Document ... { ... And the concrete class that implements the DOM parser currently looks something like this:
public class PetesPrettyGoodParser implements org.w3c.dom.Document { ... But we don’t want our code to be tied to any one implementation. That means you don't want your code to say:
class MyXMLApp { ...
Document myDoc = new PetesPrettyGoodParser(); // Avoid this!
... = myDoc.petesSpecialMethod(); // Avoid this! If you did that, you are building knowledge of Pete’s Parser into your code and you can accidentally start calling additional methods of Pete’s, which violates the intended API. Instead, we want a way to instantiate and access something that is a “PetesPrettyGoodParser,” but without actually naming it. We want to create it and use it totally using interface methods. This is where the Factory Design Pattern comes in. The library code will have a ParserFactory class. The ParserFactory will have a static field or method that will give you a reference to the thing you are trying to keep out of your code. This field or method will typically be called something like “getInstance” or “newInstance.” (If the library writer gave it a name of newInstance, don’t confuse it with the method of the same name that has a similar purpose in class java.lang.Class.) The Factory method will look like this:
package javax.xml.parsers;
class DocumentBuilderFactory { ...
static DocumentBuilderFactory newInstance() {
... In summary, a classic “Factory” design pattern looks like this:
You have an interface or abstract class, Worker.
You have some implementations of that, WorkerBill, WorkerJane, WorkerFred.
You have a Factory that has a method, often static, often called “getSomething” or newSomething.” It returns something of type “Worker.” That method chooses which of the implementors to use. It does a new WorkerBill (say) and returns it as the supertype.
The application code now has a concrete class, but typed as the abstract superclass or interface. It cannot use more methods than are in the interface. Voila.
The Document building code is not guaranteed to be well-behaved in threads. You may very well have many XML files to parse, and you may want to use a thread for each. An implementation of the DocumentBuilderFactory class is not guaranteed to be thread-safe. To avoid problems, the application can get a new instance of the DocumentBuilderFactory per thread, and they can be configured differently in terms of how much validation they do, whether they ignore comments and so on.
Here’s how we use the Factory instance to get back a Parser which has the type of the abstract class javax.xml.parsers.DocumentBuilder:
... myDb = myDbf.newDocumentBuilder();
Now that we have a DocumentBuilder (which is actually a Pete’sPrettyGoodParser, or equivalent), we can use it in a type-safe, future-proof way to parse an XML file and build the corresponding document, like this:
org.w3c.dom.Document doc = myDb.parse( new File("myData.xml")); We did not simply move the dependency from your code into the runtime library. The JAXP runtime library has put the hooks in place to make it possible to switch parser implementations. The full details are the in the Specification document which you will download. However, to summarize, the runtime looks for a property file that contains the class name of any different parser you want to use. If the property is not found, it uses the default. So it all works as desired. Everything is hands-off. You’re manipulating the tree by remote control, which admittedly makes this harder to follow.
The JAXP package is a java extension that is downloaded separately from JDK 1.3. However, JDK 1.4 beta includes support for W3C DOM 1.0 API and the SAX parser 1.0 API. If time permits, JDK 1.4 FCS may instead have support for the W3C DOM 2.0 API and SAX parser 2.0 API. Sun intends to release JDK 1.4 some time in the first quarter of 2002. If the version 2.0 software is ready by the beta release of JDK 1.4, it will probably be in the final release of JDK 1.4. If you are using JDK 1.4 or later, you do not need to do this download step, as the software is already part of the release.
To get started with, go to the XML part of Sun’s Java website at java.sun.com/xml
Click on the “downloads” link. If the website has been redesigned and this link has moved, simply search the website for the XML download. You should download two things:
The Java API for XML Processing (JAXP) 1.1 Reference Implementation. There is a “click through” license agreement on this, and then you can download the 1.6MB file called jaxp-1_1.zip. This zip file contains three jar files that comprise the implementation, and a couple of hundred HTML files that provide the documentation in Javadoc form. No source code is currently available at the time of this writing.
The Java API for XML Processing Specification. This is a PDF file about 1 MB in size. It’s a 130-page document that provides an overview of the Java interface to XML. It also contains configuration information and some programming examples that will help you further explore the Java/XML relationship.
Create a top level directory on your disk called, say, “xml” and move the downloaded file “jaxp-1_1.zip” into that disk directory. Unpack the file in your xml directory. You could instead unpack the file under your JDK directory, and move the javadoc html into the same directory with all the Javadoc for the JDK, but that makes it hard to see what is new with JAXP. To unpack, you can use WinZip or the Java “jar” utility with these commands:
cd c:xml jar -xf jaxp-1_1.zip
That will create a directory tree in your “xml” directory containing the JAXP software and documentation. You should also move the specification PDF file into the xml directory. If you don’t already have it on your system, you’ll need to download the Acrobat PDF reader (it’s free) from www.adobe.com. It’s available as a stand-alone application and as a browser plug-in. Either is fine.
Now take a look at the jar files in your xml directory. There will be three of these, as outlined in Table 28-6.
Table 28-6. Jar Files in the jaxp-1_1.zip Download
|
Name of File |
Contents |
|---|---|
|
jaxp.jar |
This file contains the JAXP-specific APIs. |
|
crimson.jar |
This file contains the interfaces and classes that make up the SAX and DOM APIs, as well as the reference implementation for the parser. To use a different parser, substitute it for this file. For example, you could put xerces.jar in place to use the parser from apache.org. |
|
xalan.jar |
This file contains the implementation classes for the XSLT transform package, used when you want to convert XML into HTML or an XML file with a different DTD. Using this is not difficult, but it is beyond the scope of this chapter. |
Make these libraries visible to your java compiler and runtime. There are at least three ways to do that on a Windows system:
Add the full pathname of each library to the $CLASSPATH variable in the autoexec.bat or other start-up file.
Move the files to the
jrelibextsubdirectory of your Java installation. Jar files in here are automatically regarded as part of the standard runtime library.Use the “-classpath” option to the compiler and JVM, and give the pathname to each of these three jar files. This is best done by writing a command batch file.
Note: these commands are for Windows. Make the obvious adjustments for Unix, Linux, Mac, etc. Be careful to get this right. You may already have a CLASSPATH variable, in which case you want to add to it, not replace it. If you used a batch file, execute it to make sure the variables are set. You can see what environment variables are set by typing “set” at the command line.
The next step is to try running one of the example XML programs that accompany the release. Go to your XML directory with this command:
cd c:xmljaxp-1.1examplesDOMEcho
Then compile and run the sample DOMEcho application that comes with the release. This is a longer, fuller version of the DOMEcho presented here.
javac DOMEcho.java java DOMEcho build.xml
You will see that the program prints out the nodes that it has read in. Note that if you don’t provide a DTD for the sample data, you will have a non-validating parse by definition. The “build.xml” is an XML file that comes with the release. It is actually a file that is used to configure a part of the Tomcat servlet container that we saw in an earlier chapter. The output in part looks like this:
ELEM: nodeName="project"
ATTR: nodeName="name" nodeValue="DOMEcho"
ATTR: nodeName="default" nodeValue="main"
ATTR: nodeName="basedir" nodeValue="."
TEXT: nodeName="#text" nodeValue=[WS]
COMM: nodeName="#comment" nodeValue=" The distribution top directory "
TEXT: nodeName="#text" nodeValue=[WS]
ELEM: nodeName="property"
ATTR: nodeName="name" nodeValue="top"
ATTR: nodeName="value" nodeValue="../.."
TEXT: nodeName="#text" nodeValue=[WS]
COMM: nodeName="#comment" nodeValue=" Common classpath "
TEXT: nodeName="#text" nodeValue=[WS]
ELEM: nodeName="path" As Sun’s JAXP specification points out, XML and Java form a marriage made in heaven. XML provides a cross platform way to describe data, and Java provides a cross-platform way to process data.
There is a centralized portal for people developing with XML languages at www.xml.org. The website was formed in 1999 by OASIS, the non-profit Organization for the Advancement of Structured Information Systems, to provide public access to XML information and XML Schemas. You can find everything there from tutorials to case studies.
The website www.w3schools.com/dtd/default.asp has a good DTD Tutorial under the title “Welcome to DTD School.” It also has links to many other tutorials of interest to XML developers.
If you’re interested in getting more information on XML and the Java XML API, be aware there are a few items we haven’t covered. First, there is an additional XML mark-up tag, known as a “processing instruction.” This is a piece of XML inherited from SGML, but not really a good fit. (SGML is the mother of all mark-up languages, too large and too complicated to ever get much use in the real world. XML and HTML are simplifications of SGML.) A processing instruction is used to link style sheets (regular HTML CSS style sheets) into documents. Second, the topics of both elements and attributes are deeper than we have room for here. We have not covered the third library in JAXP: the transformation library in javax.xml.transform.
There is an independently-developed open source library called JDOM. This is a Java API that does the same job as W3C’s DOM. It was created as a more object-oriented and easier to use alternative to DOM, and there is a good possibility it will be adopted into JAXP (or even replace it). It has been adopted as Java Specification Request number 102, if you want to check on its progress. Please see the JDOM website at www.jdom.org for the most up-to-date information.
IBM offers a series of free tutorials on their website. There are tutorials covering parsers, DOM, SAX, and the transformation library. Go to www.ibm.com/developerworks and click or search on XML. You have to register at the site, but it is free and quick.
Describe the Factory design pattern and state its use.
Write a DTD that describes a CD inventory file. Each CD is either domestic or imported. These details are stored for all CDs: artist, title, price, quantity in stock. Imported CDs also have these fields: “country of origin,” genre, non-discount status, language, and lead time for reorder. Write some XML instance data describing your five favorite CDs (include a couple of imported CDs, too).
Validate your XML file from the previous question by running it against the DOMEcho program that comes with the Java XML library. In the output you get, explain what the text nodes with a value of “[WS]” are. Hint: Try varying the number of spaces and blank lines in your instance data, and seeing how that changes the output.
Rewrite the DTD describing Shakespearean plays making better use of names, comments, and indenting.
It is possible to implement a DOM parser using a SAX parser, and vice versa, although not particularly efficiently. Write a couple of paragraphs of explanation suggesting how both of these cases might be done.
Write a servlet that reads an XML file of a CD inventory and sends HTML to the browser, putting the data into a table.
Improve the output of the SAXEcho program to make it more presentable and understandable.
Write an application that uses a DOM parser to get CD information and outputs the total number of all kinds of CDs that you have in stock, and the total number by each artist. Remember that some artists may have several titles in print at once.
The 5K Contest first ran in the year 2000. It’s a new annual challenge for web developers and HTML gurus to create the most interesting web page in less than 5120 bytes. That’s right, all HTML, scripts, image, style sheets, and any other associated files must collectively total less than 5 kilobytes in size and be entirely self-contained (no server-side processing).
The 5k competition was originally conceived in the fall of 1999 after an argument about the acceptable file size of a template for a project at work. The creator says, “It took a long time to actually get it organized because, back in those days, we all worked hard at our soul-destroying dot.com jobs and didn’t have time for fun personal projects.”
The 5K size limit is pretty much the only rule, and some of the entries are a bit too Zen for a meat-and-potatoes guy like me, but everyone seems to be having a good time. There is the usual crop of games written in Javascript. You’ve got your Space Invaders, your Maze solvers, your Game of Life. It’s the International Obfuscated C Code Competition (see my text “Expert C Programming”), updated for the new medium and the new millennium. 3D Tetris, post modernism, poetry, art, angst—it’s all there, with clever use of javascript, style sheets, and DHTML. You can even enter an applet if you want.
One nice entry in 2001 is the Timepiece (shown in Figure 28-9). This is an animated clock showing seconds, minutes, hours, date, day-of-week, month, phase of moon, and year. You can choose the time zone.
Timepiece is incredibly busy to look at, but somehow the complexity adds to its appeal. All umpteen axes grind past each other as seconds tick away, a fusion of traffic, tectonics, and time. (Sorry, that Zen poetry style is catching. In less than 5K of Javascript code.) You can see all the 5K winners at www.the5k.org/.
One of the unexpected winners this year was, amazingly and appropriately, an XML entry. Think about it: XML is a “storing” thing, not a “doing” thing! So how can it compete with flashy graphic entries like the 3D Tetris or the Virtual Reality Dolphin? It competed with imagination. People are always looking for something fresh, something original, something that hasn’t been done to death before.
Winner Kevin Conboy described his entry as “a subtle comment on the pervasive nature of the Internet.” He tried to imagine doing a “view source” on his life to see what an actual day would look like. Here is an extract from Kevin’s essay entry—an XML diary. Kevin starts by getting up, washing, and dressing.
<!DOCTYPE KCML PUBLIC "-//KVC//DTD KCML 1.0 EXPERIMENTAL//EN"
"http://www.alternate.org/TR/REC-html40/loose.dtd"><br>
<day length='24' start='730' end='1046' name='kevinconboy'>
<wake>
<home temp='70' ac='true' tv='true' computer='false'>
<shower length='12' soap='ivory' shave='true'> </shower>
<style shirt='bananaRepublic' shorts='#000000'
shoes='bananaRepublic('sandals'),'
hat='false' boxers='true'> </style>
<kiss wife='true' son='true'></kiss>
<elevator down='true' up='false' occupied='true' conversation='no'>
</elevator>
</home> Kevin lunches at a Mexican restaurant with three friends, and spends the afternoon working on graphics production for a client.
<lunch type='external' length='1' transport='walk' location='wahoos'>
<meal type='mexican'
companions='('vijayPatel','jeffVoreis','triciaChaya')'
src='chickenQuesadillas' beverage='mountainDew' refill='true'></meal>
</lunch>
<afternoon>
<task type='graphicsProduction' client='pearlIzumi'></task> Finally, he drives home, has an evening meal, bathes his son, and soothes him to bed before watching a little TV and turning in himself.
<son activity='bath' cry='false'>
<bath length='15' clean='true' curSanity='('prevSanity+20'),'> </bath>
<toSleep length='15' cry='true' blanket='false' pacifier='true'
bottle='false' curSanity='('prevSanity+30'),'> </toSleep>
</son>
<television>
<program src='HBO' type='dennisMiller' entertain='true'>
</television>
</wake>
</day> That very human sentiment of soothing his family strikes a chord. You (the reader) and I are both now near the end of the day, at the last sentence in the body of this book, and maybe we both feel the same way too: curSanity++; good night, dear programmer, sleep tight, and don’t let the Tera byte.