

Fundamental to all operating systems is the concept of a process. A process is a dynamic entity scheduled and controlled by the operating system. While somewhat abstract, a process consists of an executing (running) program, its current values, state information, and the resources used by the operating system to manage the process. In a UNIX-based operating system, such as Linux, at any given point in time, multiple processes appear to be executing concurrently. From the viewpoint of each of the processes involved, it appears they have access to and control of all system resources as if they were in their own standalone setting. Both viewpoints are an illusion. The majority of operating systems run on platforms that have a single processing unit capable of supporting many active processes. However, at any point in time, only one process is actually being worked upon. By rapidly changing the process it is currently executing, the operating system gives the appearance of concurrent process execution. The ability of the operating system to multiplex its resources among multiple processes in various stages of execution is called multiprogramming (or multitasking). Systems with multiple processing units, which by definition can support true concurrent processing, are called multiprocessing.
As noted, part of a process consists of the execution of a program. A program is an inactive, static entity consisting of a set of instructions and associated data.
If a program is invoked multiple times, it can generate multiple processes. We can consider a program to be in one of two basic formats:
source program—. A source program is a series of valid statements for a specific programming language (such as C or C++). The source program is stored in a plain ASCII text file. For purposes of our discussion we will consider a plain ASCII text file to be one that contains characters represented by the ASCII values in the range of 32–127. Such source files can be displayed to the screen or printed on a line printer. Under most conditions, the access permissions on the source file are set as nonexecutable. A sample C++ language source program is shown in Program 1.1.
executable program—. An executable program is a source program that, by way of a translating program such as a compiler, or an assembler, has been put into a special binary format that the operating system can execute (run). The executable program is not a plain ASCII text file and in most cases is not displayable on the terminal or printed by the user.
Example 1.1. A source program in C++.
File : p1.1.cxx
| /*
| Display Hello World 3 times
| */
| #include <iostream>
+ #include <unistd.h> // needed for write
| #include <cstring> // needed for strcpy
| #include <cstdlib> // needed for exit
| using namespace std;
| char *cptr = "Hello World
"; // static by placement
10 char buffer1[25];
| int main( ){
| void showit(char *); // function prototype
| int i = 0; // automatic variable
| strcpy(buffer1, "A demonstration
"); // library function
+ write(1, buffer1, strlen(buffer1)+1); // system call
| for ( ; i < 3; ++i)
| showit(cptr); // function call
| return 0;
| }
20 void showit( char *p ){
| char *buffer2;
| buffer2= new char[ strlen(p)+1 ];
| strcpy(buffer2, p); // copy the string
| cout << buffer2; // display string
+ delete [] buffer2; // release location
| }
Programs of any complexity make use of functions. A function is a collection of declarations and statements that carries out a specific action and/or returns a value. Functions are either defined by the user or have been previously defined and made available to the user. Previously defined functions that have related functionality or are commonly used (e.g., math or graphics routines) are stored in object code format in library (archive) files. Object code format is a special file format that is generated as an intermediate step when an executable program is produced. Like executable files, object code files are also not displayed to the screen or printed. Functions stored in library files are often called library functions or runtime library routines.
The standard location for library files in most UNIX systems is the directory /usr/lib. Ancillary library files may also be found in the /usr/local/lib directory. Two basic types of libraries are used in compilations—static libraries and shared object libraries. Static libraries are collections of object files that are used during the linking phase of a program. Referenced code is extracted from the library and incorporated in the executable image. Shared libraries contain relocatable objects that can be shared by more than one application. During compilation the object code from the library is not incorporated in the executable code only a reference to the object is made. When the executable that uses a shared object library is loaded into memory the appropriate shared object library is loaded and attached to the image. If the shared object library is already in memory this copy is referenced. As might be expected shared object libraries are more complex than static libraries. In Linux, by default, shared object libraries are used if present otherwise static libraries are used. Most, but not all, compiler installations include both types of libraries. In the examples below we will focus on the more ubiquitous static libraries.
By convention, the three-letter prefix for a library file is lib and the file extension for a static library is .a. The UNIX archive utility ar, which creates, modifies, and extracts members from an archive, can be used to examine library file contents.[1] For example, the command
linux$ ar t /usr/lib/libc.a | pr -4 -t
will pipe the table of contents (indicated by the t command-line option) of the standard C library file (libc.a) to the pr utility, which will display the output to the screen in a four-column format. The object code in this library is combined by default with all C programs when they are compiled. Therefore, in a C program when a reference is made to printf, the object code for the printf function is obtained from the /usr/lib/libc.a library file. Similarly, the command
linux$ ar t /usr/lib/libstdc++-3-libc6.2-2-2.10.0.a | pr -4 -t
will display the table of contents of the C++ library file used by the gcc compiler. Remember that the versions (and thus the names) of library files can change when the compiler is updated.
Additional information can be extracted from library files using the nm utility. For example, the command
linux$ nm -C /usr/lib/libstdc++-3-libc6.2-2-2.10.0.a | grep 'bool operator=='
will find all the C++ equality operators in the referenced library file. The -C command-line option for nm demangles the compiler-generated C++ function names and makes them a bit more readable.
The ar command can also be used to create a library. For example, say we have two functions. The first function, called ascii, is stored in a file called ascii.cxx. This function generates and returns an ASCII string when passed the starting and endpoint for the string. The second function, called change_case (stored in the file change_case.cxx), accepts a string and inverts the case of all alphabetic characters in the string. The listing for the two programs is shown in Figure 1.1.
Example 1.1. Source code for two functions to be stored in archive libmy_demo.a.
File : ascii.cxx
| char *
| ascii( int start, int finish ){
| char *b = new char(finish-start+1);
| for (int i=start; i <= finish; ++i)
+ b[i-start]=char( i );
| return b;
| }
____________________________________________________________________________________
File : change_case.cxx
| #include <ctype.h>
|
| char *
| change_case( char *s ){
+ char *t = &s[0];
| while ( *t ){
| if ( isalpha(*t) )
| *t += islower(*t) ? -32 : 32;
| ++t;
10 }
| return s;
| }
Each file is compiled into object code, the archive libmy_demo.a generated, and the object code added to the archive with the following command sequence:
linux$ g++ -c change_case.cxx linux$ g++ -c ascii.cxx linux$ ar cr libmy_demo.a ascii.o change_case.o
The prototypes for the functions in the my_demo library are placed in a corresponding header file called my_demo.h. Preprocessor directives are used in this file to prevent it from being inadvertently included more than once. A small C++ program, main.cxx, is created to exercise the functions. With the "" notation for the include statement in main.cxx, the compiler will look for the my_demo.h header file in the current directory. The contents of the my_demo.h header file and the main.cxx program are shown in Figure 1.2.
Example 1.2. Header file and test program for libmy_demo.a.
File : my_demo.h
| /*
| Prototypes for my_demo library functions
| */
| #ifndef MY_DEMO_H
+ #define MY_DEMO_H
|
| char * ascii( int, int );
| char * change_case( char * );
|
10 #endif
____________________________________________________________________________________
File : main.cxx
| #include <iostream>
| #include "my_demo.h"
| using namespace std;
| int
+ main( ) {
| int start, stop;
| char b[20]; // temp string buffer
|
| cout << "Enter start and stop value for string: ";
10 cin >> start >> stop;
| cout << "Created string : " << ascii(start, stop) << endl;
| cin.ignore(80,'
'),
| cout << "Enter a string : ";
| cin.getline(b,20);
+ cout << "Converted string: " << change_case( b ) << endl;
| return 0;
| }
The compilation shown below uses the -L command-line option to indicate that when the compiler searches for library files it should also include the current directory. The name of the library is passed using the -l command-line option. As source files are processed sequentially by the compiler, it is usually best to put linker options at the end of the command sequence to avoid the generation of any undefined reference errors.
linux$ g++ -o main main.cxx -L. -lmy_demo
A sample run of the main.cxx program is shown in Figure 1.3.
Example 1.3. Sample run testing the archived functions.
linux$ main <-- 1 Enter start and stop value for string: 56 68 Created string : 89:;<=>?@ABCD Enter a string : This is a TEST! Converted string: tHIS IS A test!
If your system supports the apropos command, you may issue the following command to obtain a single-line synopsis of the entire set of predefined library function calls described in the manual pages on your system:
linux$ apropos '(3'
As shown, this command will search a set of system database files containing a brief description of system commands returning those that contain the argument passed. In this case, the '(3' indicates all commands in Section 3 of the manual should be displayed. Section 3 (with its several subsections) contains the subroutine and library function manual pages. The single quotes are used in the command sequence so the shell will pass the parenthesis on to the apropos command. Without this, the shell would attempt to interpret the parenthesis, which would then produce a syntax error.
Another handy utility that searches the same database used by the apropos command is the whatis command. The command
linux$ whatis exit
would produce a single-line listing of all manual entries for exit. If the database for these commands is not present, the command /usr/ sbin/makewhatis, providing you have the proper access privileges, will generate it.
A more expansive overview of the library functions may be obtained by viewing the intro manual page entry for Section 3. On most systems the command
linux$ man 3 intro
will return the contents of the intro manual page. In this invocation the 3 is used to notify man of the appropriate section. For some versions of the man command, the option -s3 would be needed to indicate Section 3 of the manual. Additional manual page information addressing manual page organization and use can be found in Appendix A, “Using Linux Manual Pages.”
In addition to manual pages, most GNU/Linux systems come with a handy utility program called info. This utility displays documentation written in Info format as well as standard manual page documents. The information displayed is text-based and menu-driven. Info documents can support limited hypertext-like links that will bring the viewer to a related document when selected. When present, Info documentation is sometimes more complete than the related manual page. A few of the more interesting Info documents are listed in Table 1.1.
Table 1.1. Partial Listing of Info Documents.
Topic | Description |
|---|---|
| The GNU assembler. |
| GNU binary utilities (such as |
| GNU file manipulation utilities. |
| The |
| How to use the GNU symbolic debugger. |
| How to use the |
| System V style interprocess communication constructs: message queues, semaphores, and shared memory. |
| The C library (as implemented by GNU). A good place to start for an overview on topics such as signals, pipes, sockets, and threads. |
The info utility should be invoked on the command line and passed the item (a general topic or a specific command—system call, library function, etc.) to be looked up. If an Info document exists, it is displayed by the info utility. If no Info document exists but there is a manual page for the item, then it is displayed (at the top of the Info display will be the string *manpages* to notify you of the source of the information. If neither an Info document nor a manual page can be found, then info places the user in the info utility at the topmost level. When in the info utility, use the letter q to quit or a ? to have info list the commands it knows. Entering the letter h will direct info to display a primer on how to use the utility.
Some previously defined functions used by programs are actually system calls. While resembling library functions in format, system calls request the operating system to directly perform some work on behalf of the invoking process. The code that is executed by the operating system lies within the kernel (the central controlling program that is normally maintained permanently in memory). The system call acts as a high/mid-level language interface to this code. To protect the integrity of the kernel, the process executing the system call must temporarily switch from user mode (with user privileges and access permissions) to system mode (with system/root privileges and access permissions). This switch in context carries with it a certain amount of overhead and may, in some cases, make a system call less efficient than a library function that performs the same task. Keep in mind many library functions (especially those dealing with input and output) are fully buffered and thus allow the system some control as to when specific tasks are actually executed.
Section 2 of the manual contains the pages on system calls. Issuing an apropos command similar to the one previously discussed but using the value 2 in place of 3 will generate synopsis information on all the system calls defined in the manual pages. It is important to remember that some library functions have embedded system calls. For example, << and >>, the C++ insertion and extraction operators, make use of the underlying system calls read and write.
The relationship of library functions and system calls is shown in Figure 1.4. The arrows in the diagram indicate possible paths of communication, and the dark circles indicate a context switch. As shown, executable programs may make use of system calls directly to request the kernel to perform a specific function. On the other hand, the executable programs may invoke a library function, which in turn may perform system calls.
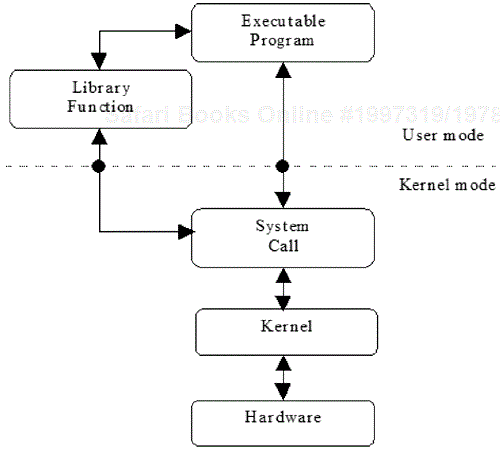
Code from library files, predefined or user-defined, is combined with object code from the source program at compile time on an as-needed basis. When programming in C/C++, additional library files containing the object code for system calls and library functions not contained in the standard library can be specified at compile time. This is done by using the -l compiler option, followed by the library name without the lib prefix and the .a extension. For example, the compilation command
linux$ gcc prgm.c -lm
indicates to the link-loader portion of the gcc compiler program that the math library object code found in libm.a should be combined with the object code created from the source program prgm.c. If a special library is needed that does not reside in the standard location, the compiler can be notified of this. The GNU compilers use the -L option, followed by the additional directory (or directories) to be searched. The processing of files passed on the command line to the compiler are done sequentially. Thus, linker options are usually placed at the end of the command sequence to avoid any undefined (unresolved) reference errors.
Be aware that library functions often require the inclusion of additional header files in the source program. The header files contain such information as the requisite function prototypes, macro definitions, and defined constants. Without the inclusion of the proper header files, the program will not compile correctly. Conversely, the program will not compile correctly if you include the proper header file(s) and forget to link in the associated library containing the object code! Such omissions are often the source of cryptic compiler error messages. For example, attempting to compile a C program with gcc that uses a math function (such as pow) without linking in the math library generates the message
linux$ gcc m.c /tmp/ccjKMi3A.o: In function 'main': /tmp/ccjKMi3A.o(.text+0x15): undefined reference to 'pow' collect2: ld returned 1 exit status
The synopsis section of the manual page (see Appendix A) lists the names of header file(s) if they are required. When multiple inclusion files are indicated, the order in which they are listed in the source program should match the order specified in the manual pages. The order of the inclusion is important, as occasionally the inclusion of a specific header file will depend upon the inclusion of the previously referenced header file. This dependency relationship is most commonly seen as the need for inclusion of the <sys/types.h> header file prior to the inclusion of other system header files. The notation <sys/types.h> indicates that the header file types.h can be found in the usual place (most often /usr/include on a UNIX-based system) in the subdirectory sys.
In most cases,[2] if a system call or library function is unsuccessful, it returns a value of −1 and assigns a value to an external (global) variable called errno to indicate what the actual error is. The defined constants for all error codes can be found in the header file <sys/errno.h> (or in <asm/errno.h> on some systems). By convention, the defined constants are in uppercase and start with the letter E. It is a good habit to have the invoking program examine the return value from a system call or library function to determine if it was successful. If the invocation fails, the program should take an appropriate action. A common action is to display a short error message and exit (terminate) the program. The library function perror can be used to produce an error message.
For each system call and library function discussed in detail in the text, a summary table is given. The summary table is a condensed version of manual page information. The format of a typical summary table (in this case the one for perror) is shown in Figure 1.5.
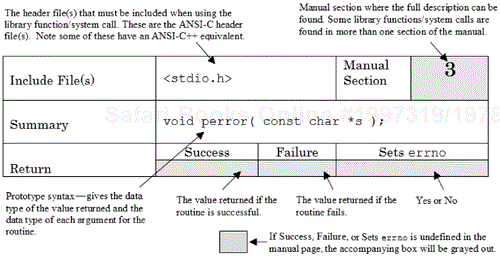
The summary table for perror indicates the header file <stdio.h> must be included if we are to use perror. Notice that the header file <sys/errno.h>, which was mentioned previously, is not referenced in the summary table. The <sys/errno.h> file is included only if the defined constants for specific error codes are to be referenced. The perror library function takes a single argument, which is a pointer to a character string constant (i.e., const char *). In addition, the perror library function does not return a value (as indicated by the data type void) and will not modify errno if it itself fails.
A program example using systems calls that provides some error checking by perror and errno is shown in Program 1.2.
Example 1.2. Using errno and perror.
File : p1.2.cxx
| /*
| Checking errno and using perror
| */
| #include <iostream>
+ #include <cstdio> // needed for perror
| #include <cstdlib> // needed for exit
| #include <unistd.h> // needed for read and write
| using namespace std;
| extern int errno;
10 int
| main(int argc, char *argv[ ]) {
| int n_char = 0, // # of chars read
| buffer[10]; // temporary buffer
|
+ // Initially n_char is set to 0 and errno is 0 by default
|
| cout << "n_char = " << n_char << " errno = " << errno << endl;
|
| // Display a prompt to stdout
20
| n_char = write(1, "Enter a word: ", 15);
|
| // Use the read system call to obtain 10 characters from stdin
|
+ n_char = read(0, buffer, 10);
| cout << "n_char = " << n_char << " errno = " << errno << endl;
|
| if (n_char == -1) { // If the read has failed
| perror(argv[0]);
30 exit(1);
| }
|
| n_char = write(1, buffer, n_char); // Display the characters read
| return 0;
+ }
Notice that to use the errno variable it must first be declared as an external (extern) integer at the top of the program. If this program is run, the initial output indicates that both n_char and errno contain the value 0. Figure 1.6 shows the output if the user enters the word testing when prompted.
Example 1.6. Initial run of Program 1.2 with no errors.
linux$ p1.2 n_char = 0 errno = 0 Enter a word: testing n_char = 8 errno = 0 testing
In this case the read system call did not fail and has instead, as defined in the manual page, returned the number of characters read from standard input (the keyboard). Note, as we have used read in the program, not cin, the newline will be one of the characters that is read and counted. As there was no error, the value in errno was not modified and remained at 0. Figure 1.7 shows the output if we run the program again and input more than 10 characters when prompted (in hopes of generating an error).
Example 1.7. Second run of Program 1.2 with additional keyboard input.
$ p1.2 n_char = 0 errno = 0 Enter a word: testing further n_char = 10 errno = 0 testing fu$rther rther: Command not found.
This time the program reads exactly 10 characters and displays them. The remaining characters are left in the input buffer and end up being processed by the operating system after the program finishes execution. This produces the output of the strange line testing fu$rther followed by the line rther: Command not found. The characters testing fu are displayed by the program. The Command not found message is generated by the operating system when it attempts to execute the leftover input rther as a command. In this case, providing more input values than needed (i.e., extra characters) does not cause the read system call to fail, and as a result errno is not changed.
However, if we change the file number for the read system call to 3 (a file number that has not been opened versus 0 [standard input] which is automatically opened for us by the operating system when the program runs), the read system call will fail. When run, the program output will be as shown in Figure 1.8.
Example 1.8. Third run of Program 1.2 with an induced error.
linux$ p1.2 n_char = 0 errno = 0 Enter a word: n_char = -1 errno = 9 p1.2: Bad file descriptor
As expected, this time the return value from the read system call is −1. The external variable errno now contains the value 9 that is equivalent to the symbolic constant EBADF defined in the <sys/errno.h> file.[3] If we call perror with a NULL argument, “”, the message “Bad file descriptor” will be displayed (the error message the system associates with error code 9). As noted, perror does take one argument: a character pointer. If passed a character pointer to a valid string, perror will display the referenced string followed by a colon (:) and then append its predefined error message. Programmers often use the argument to perror to qualify the error message (e.g., to pass the name of the executing program, as was done in the prior example) or in the case of file manipulation, pass the name of the current file. Unfortunately, perror issues a new line following the error message it produces, thus preventing the user from appending additional information to the perror display line. There are two ways around this oversight.
Associated with perror are two additional external variables. These variables are extern const char *sys_errlist[ ] and extern int sys_nerr. The external variable sys_nerr contains a value that is one greater than the largest error message number value, while sys_errlist is a pointer to an external character array of error messages. In place of calling perror to return the specific error, we may (if we have provided the proper declarations) use the value in errno to index the sys_errlist[ ] array to obtain the error message directly.
Another approach to error message generation is to use the library function strerror (see Table 1.2).
Table 1.2. Summary of the strerror Library Function.
Include File(s) |
| Manual Section | 3 | |
Summary |
| |||
Return | Success | Failure | Sets | |
Reference to error message | ||||
The strerror function maps the integer errnum argument (which is usually the errno value) to an error message and returns a reference to the message. The error message generated by strerror should be the same as the message generated by perror. If needed, additional text can be appended to the string returned by strerror.
Furthermore, Linux provides a command-line utility program called perror that returns the error message associated with a specific error code. A sample call of this utility follows:
linux$ perror 9 Error code 9: Bad file descriptor
Note that the system never clears the errno variable (even after a successful system call). It will always contain the value assigned by the system for the last failed call. Appendix B, “Linux Error Messages,” contains additional information on error messages.
In a Linux environment, source files that have been compiled into an executable form to be run by the system are put into a special format called ELF (Executable and Linking Format). Files in ELF format contain a header entry (for specifying hardware/program characteristics), program text, data, relocation information, and symbol table and string table information. Files in ELF format are marked as executable by the operating system and may be run by entering their name on the command line. Older versions of UNIX stored executable files in a.out format (Assembler OUtpuT Format). While this format is little used today, its name is still tied to the compilation sequence. When C/C++ program files are compiled, the compiler, by default, places the executable file in a file called a.out.
In UNIX, when an executable program is read into system memory by the kernel and executed, it becomes a process. We can consider system memory to be divided into two distinct regions or spaces. First is user space, which is where user processes run. The system manages individual user processes within this space and prevents them from interfering with one another. Processes in user space, termed user processes, are said to be in user mode. Second is a region called kernel space, which is where the kernel executes and provides its services. As noted previously, user processes can only access kernel space through system calls. When the user process runs a portion of the kernel code via a system call, the process is known temporarily as a kernel process and is said to be in kernel mode. While in kernel mode, the process will have special (root) privileges and access to key system data structures. This change in mode, from user to kernel, is called a context switch.
In UNIX environments, kernels are reentrant, and thus several processes can be in kernel mode at the same time. If the system has a single processor, then only one process will be making progress at any given time while the others are blocked. The operating system uses a bit, stored in the program status word (PSW), to keep track of the current mode of the process.
Each process runs in its own private address space. When residing in system memory, the user process, like Gaul, is divided into three segments or regions: text, data, and stack.
text segment—. The text segment (sometimes called the instruction segment) contains the executable program code and constant data. The text segment is marked by the operating system as read-only and cannot be modified by the process. Multiple processes can share the same text segment. Processes share the text segment if a second copy of the program is to be executed concurrently. In this setting the system references the previously loaded text segment rather than reloading a duplicate. If needed, shared text, which is the default when using the C/C++ compiler, can be turned off by using the
-Noption on the compile line. In Program 1.1, the executable code for the functionsmainandshowitwould be found in the text segment.data segment—. The data segment, which is contiguous (in a virtual sense) with the text segment, can be subdivided into initialized data (e.g., in C/C++, variables that are declared as
staticor are static by virtue of their placement) and uninitialized data.[4] In Program 1.1, the pointer variablecptrwould be found in the initialized area and the variablebuffer1in the uninitialized area. During its execution lifetime, a process may request additional data segment space. In Program 1.1 the call to the library routinenewin theshowitfunction is a request for additional data segment space. Library memory allocation routines (e.g.,new,malloc,calloc, etc.) in turn make use of the system callsbrkandsbrkto extend the size of the data segment. The newly allocated space is added to the end of the current uninitialized data area. This area of available memory is sometimes called the heap. In Figure 1.9 this region of memory is labeled as unmapped.stack segment—. The stack segment is used by the process for the storage of automatic identifiers, register variables, and function call information. The identifier
iin the functionmain,buffer2in the functionshowit, and stack frame information stored when theshowitfunction is called within theforloop would be found in the stack segment. As needed, the stack segment grows toward the uninitialized data segment. The area beyond the stack contains the command-line arguments and environment variables for the process. The actual physical location of the stack is system-dependent.
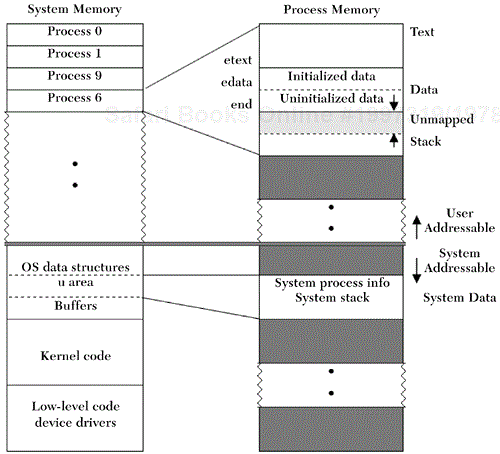
In addition to the text, data, and stack segments, the operating system also maintains for each process a region called the u area (user area). The u area contains information specific to the process (e.g., open files, current directory, signal actions, accounting information) and a system stack segment for process use. If the process makes a system call (e.g., the system call to write in the function main in Program 1.1), the stack frame information for the system call is stored in the system stack segment. Again, this information is kept by the operating system in an area that the process does not normally have access to. Thus, if this information is needed, the process must use special system calls to access it. Like the process itself, the contents of the u area for the process are paged in and out by the operating system.
The conceptual relationship of system and process memory is illustrated in Figure 1.9.
The system keeps track of the virtual addresses[5] associated with each user process segment. This address information is available to the process and can be obtained by referencing the external variables etext, edata, and end. The addresses (not the contents) of these three variables correspond respectively to the first valid address above the text, initialized data, and uninitialized data segments. Program 1.3 shows how this information can be obtained and displayed.
Example 1.3. Displaying segment address information.
File : p1.3.cxx
| /*
| Displaying process segment addresses
| */
| #include <iostream>
+ extern int etext, edata, end;
| using namespace std;
| int
| main( ){
| cout << "Adr etext: " << hex << int(&etext) << " ";
10 cout << "Adr edata: " << hex << int(&edata) << " ";
| cout << "Adr end: " << hex << int(&end ) << "
";
| return 0;
| }
If we add a few lines of code to our original Program 1.1, we can verify the virtual address location of key identifiers in our program. Program 1.4 incorporates an inline function, SHW_ADR( ), to display the address of an identifier.
Example 1.4. Confirming Program 1.1 address locations.
File : p1.4.cxx
| /*
| Program 1.1 modified to display identifier addresses
| */
| #include <iostream>
+ #include <unistd.h> // needed for write
| #include <cstring> // needed for strcpy
| #include <cstdlib> // needed for exit
| using namespace std;
| char *cptr = "Hello World
"; // static by placement
10 char buffer1[25];
|
| inline void SHW_ADR(char *ID, int address){
| cout << "The id " << ID << " is at : "
| << hex << address << endl;
+ }
| extern int etext, edata, end;
|
| int main( ){
| void showit(char *); // function prototype
20 int i = 0; // automatic variable
| // display addresses
| cout << "Adr etext: " << hex << int(&etext) << " ";
| cout << "Adr edata: " << hex << int(&edata) << " ";
| cout << "Adr end: " << hex << int(&end ) << "
";
+ SHW_ADR("main", int(main)); // function addresses
| SHW_ADR("showit", int(showit));
| SHW_ADR("cptr", int(&cptr)); // static
| SHW_ADR("buffer1", int(&buffer1));
| SHW_ADR("i", int(&i)); // automatic
30
| strcpy(buffer1, "A demonstration
"); // library function
| write(1, buffer1, strlen(buffer1)+1); // system call
| showit(cptr); // function call
| return 0;
+ }
| void showit( char *p ){
| char *buffer2;
| SHW_ADR("buffer2", int(&buffer2)); // display address
|
40 if ((buffer2= new char[ strlen(p)+1 ]) != NULL){
| strcpy(buffer2, p); // copy the string
| cout << buffer2; // display string
| delete [] buffer2; // release location
| } else {
+ cerr << "Allocation error.
";
| exit(1);
| }
| }
A run of this program produces output (Figure 1.10) that verifies our assertions concerning the range of addresses for identifiers of different storage types. Note the actual addresses displayed by the program are system-dependent. Note that the command-line nm utility program can also be used verify the addresses displayed by Program 1.4.
Example 1.10. Output of Program 1.4.
Adr etext: 8048bca Adr edata: 8049e18 Adr end: 8049ea8 The id main is at : 8048890 The id showit is at : 8048a44 The id cptr is at : 8049c74 The id buffer1 is at : 8049e8c The id i is at : bffffc54 A demonstration The id buffer2 is at : bffffc34 Hello World
The output of Program 1.4 is presented pictorially in Figure 1.11.
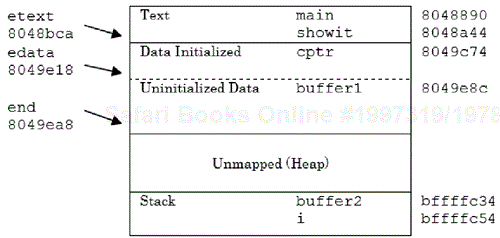
For those with a further interest in this topic, many versions of Linux have an objdump utility that provides additional information for a specified object file.
It is apparent that there must be some mechanism by which the system can create a new process. With the exception of some special initial processes generated by the kernel during bootstrapping (e.g., init), all processes in a Linux environment are created by a fork system call, shown in Table 1.3. The initiating process is termed the parent, and the newly generated process, the child.
Table 1.3. Summary of the fork System Call.
Include File(s) |
<sys/types.h> <unistd.h> | Manual Section | 2 | |
Summary[*] |
| |||
Return | Success | Failure | Sets | |
0 in child, child process ID in the parent | −1 | Yes | ||
[*] The include file | ||||
The fork system call does not take an argument. If the fork system call fails, it returns a −1 and sets the value in errno to indicate one of the error conditions shown in Table 1.4.
Table 1.4. fork Error Messages.[6]
# | Constant |
| Explanation |
|---|---|---|---|
11 | EAGAIN | Resource temporarily unavailable | The operating system was unable to allocate sufficient memory to copy the parent's page table information and allocate a task structure for the child. |
12 | ENOMEM | Cannot allocate memory | Insufficient swap space available to generate another process. |
[6] If the library function/system call sets | |||
Otherwise, when successful, fork returns the process ID (a unique integer value) of the child process to the parent process, and it returns a 0 to the child process. By checking the return value from fork, a process can easily determine if it is a parent or child process. A parent process may generate multiple child processes, but each child process has only one parent. Figure 1.12 shows a typical parent/child process relationship.
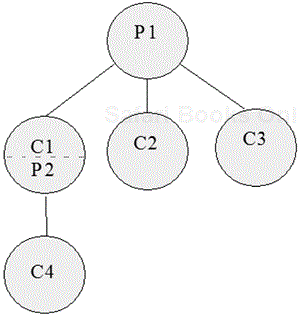
As shown, process P1 gives rise to three child processes: C1, C2, and C3. Child process C1 in turn generates another child process (C4). As soon as a child process generates a child process of its own, it becomes a parent process.
When a fork system call is made, the operating system generates a copy of the parent process, which becomes the child process. The operating system passes to the child process most of the parent's system information (e.g., open file descriptors, environment information). However, some information is unique to the child process:
The child has its own process ID (PID).
The child will have a different parent process ID (PPID) than its parent.
System-imposed process limits (amount of CPU time the process is allotted) are reset.
All record locks on files are reset.
The action to be taken when receiving signals is different.
A program that uses the fork system call is shown in Program 1.5.
Example 1.5. Generating a child process.
File : p1.5.cxx
| /*
| First example of a fork system call (no error check)
| */
| #include <iostream>
+ #include <sys/types.h>
| #include <unistd.h>
| using namespace std;
| int
| main( ) {
10 cout << "Hello
";
| fork( );
| cout << "bye
";
| return 0;
| }
The output of the program is listed in Figure 1.13.
Notice that the statement cout << "bye
"; only occurs once in the program at line 12, but the run of the program produces the word “bye” twice—once by the parent process and once by the child process. Once the fork system call at line 11 is executed there are two processes each of which executes the remaining program statements. A more detailed description of the fork system call and its uses can be found in Chapter 3, “Using Processes.”
Processes are instances of executable programs that are run and managed by the operating system. Programs make use of predefined functions to implement their tasks. Some of these predefined functions are actually system calls. System calls request the kernel to directly perform a task for the process. Other predefined functions are library functions. Library functions, which may indirectly contain system calls, also perform tasks for the process, but in a less intrusive manner. The object code for system calls and library functions is stored in object code format in library files. The object code for system calls and library functions is included, on an as-needed basis, when a program is compiled.
When a system call or library function fails, the external variable errno can be examined to determine the reason for failure. The library functions perror or strerror can be used to generate a descriptive error message.
Executing programs are placed in system memory. The executable code and constant data for the program are placed in a region known as the text segment. The initialized and uninitialized program data is placed in the data segment. The program stack segment is used to handle automatic program variables and function call data. In addition, the system will keep process-specific information and system call data in the user area (u area) of memory.
Processes are generated by the fork system call. A newly generated process inherits the majority of its state information from its parent.
a.out format
apropos command
ar command
child process
context switch
data segment
ELF format
errno variable
executable program
fork system call
function
heap
info command
kernel
kernel mode
kernel process
kernel space
library file
library function
man command
multiprocessing
multiprogramming
multitasking
nm command
object code
parent process
perror library function
process
program
runtime library routine
source program
stack segment
strerror library function
sys_errlist variable
sys_nerr variable
system call
system mode
text segment
u area
user mode
user process
user space
whatis command
[1] The archive utility is one of the many exceptions to the rule that all command-line options for system utilities begin with a hyphen (-).
[2] This type of hedging is necessary, since system calls/library functions that return an integer value usually return a −1 on failure, while those that return a pointer return a NULL pointer. However, as these routines are written by a disjointed set of programmers with differing ideas on what should be done, a return value that does not meet this rule of thumb is occasionally encountered.
[3] Again, in some Linux environments you may find that this constant is actually defined in the errno.h include file located in the directory /usr/include/asm directory.
[4] Some authors use the term BSS segment for the unitialized data segment.
[5] Logical addresses—calculated and used without concern as to their actual physical location.