
The vast majority of all computing today is distributed. Local computing, which forms the roots of computer science and is itself still evolving, has become the exception rather than the rule.
In the summer of 1969, the first manned moon landing connected all humanity through televised images from our nearest celestial neighbor. That spring, James Lovelock had first presented his “Gaia hypothesis,” which placed humanity (along with all terrestrial life) within a self-regulating, adaptive, interdependent biosphere we now call home. Autumn was witness to the beginning of the Internet, which now connects us ever more closely by computer surrogates. 1969 was a seminal year.
Computer science is both very young and very old. When I enrolled as a freshman at the University of Utah in the fall of 1969, there were few if any computer science departments in the entire world. But that is not to say that people were not studying computer science or that it was new at the time. In fact, we've been studying computer science since ancient Greece—if pattern matching, logic, and mathematics are considered part of the science of computing, as indeed they should be.
Some would argue that modern computer science began with Charles Babbage and the invention of his Analytical machine in the early 19th century, while others would insist on Alan Turing, with his theoretical Turing machine. Still others might honor the prodigy John Von Neumann. Regardless of its genesis, computer science has unleashed profound and undeniable changes on our shared planet over the past 35 years or so, affecting almost every aspect of our lives. There is nothing that software does not touch today—no art, science, discipline, economy, study, leisure activity, or human concern—that is not materially and essentially impacted by the growing science of computation and its implementations. And if you can manage to think of a human arena in which computer science doesn't yet play a role, be assured we will be there tomorrow.
Once it became clear that computers had great potential for many different applications, it was also apparent that interconnecting computers increased their potential. Despite Thomas Watson's oft-quoted misjudgment—“I think there is a world market for maybe five computers”[1]—there seems to be no end in sight for the novel purposes that computer science, coupled with boundless human ingenuity, can ultimately fulfill. Thanks almost entirely to computers that are hooked together and chattering away in networks, patterns of human interaction are changing more rapidly than at any time in human history. Indeed, the rate of this change is quickly accelerating.
Many terms might be used to describe this phase of our development: the Information Age, the Network Age, the Integral Age; the Decline of Western Civilization, the Death of Capitalism; the New Economy, the New New Economy. . . . Clearly, we are at a turning point in human history. Cultural changes as profound and as painful as those that marked the transition from the Dark Ages to the Enlightenment in the West some 500 years ago are now visited upon us, motivated and facilitated by computer science.
In fact, one word in particular lends itself to describing this epoch: paradox. What once appeared easily discernible through our sciences seems to have become profoundly counterintuitive. As we explore nature more deeply, as Einstein implored, with tools made sharper and eyes made keener by computer science, nature changes around us; the mindsets that gave rise to the very sciences that posit reality now are challenged by their own discoveries. For example, physics now teaches not only a fundamental uncertainty, not only a relativistic universe bound only to perspective and the speed of light, but a local universe that is merely a segment of a greater multiversal fruit, composed only of one-dimensional strings tightly enfolded and firmly packed, strings that give rise to a strange quantum reality which manifests as immediate, limited, relativistic, unlimited, and not really here at all upon deeper inspection.[2] This view seems so greatly at odds with what most of us have learned about the universe we inhabit that even accepting it is difficult, never mind comprehending it.
Becoming comfortable with the fundamentally paradoxical nature of our universe will be one of the greatest challenges we face in the early 21st century. And while computer science may drive the examination of paradox in other quarters, we practitioners of that science are not immune! Distributed computing is probably the clearest example of the many paradoxical challenges we face in computer science today.
So what is distributed computing anyway? How is it different from local computing? To understand what distributed computing is, we need to understand what it isn't, and that requires discussion of a few rudimentary concepts. Let's start simply and at the beginning so that complexity emerges.
Generally speaking, a computer is made of two elements: hardware and software. The hardware element is composed of stuff—plastic, copper, silicon doped with rare earth elements, perhaps a bit of rubber and some other material. Hardware, once designed and built, is usually fixed—a static collection of atoms that are subject only to the universal laws of entropy and the occasional user-induced trauma. To perform the everyday magic that computers give us, we need to add the software element. That's where programmers come in.
Software is, most simply, the set of instructions a computer needs in order to do something useful. An analogy might be a musical instrument, such as a clarinet. A clarinet is made of stuff, which is fixed. The musician who plays the clarinet provides the instructions the clarinet needs to make music: which holes and valves to open and close when, the amount, timing, and intensity of the air to be forced past the reed, the interruptions of the reed's vibrations caused by the tongue. Computer software is to the computer as the musician is to the clarinet. Computers, very much like clarinets, will follow precisely the instructions given them, regardless of the correctness or intent of the musician. If the musician is a good one, the clarinet makes music. If not, noise is the best we can expect. The same is true of computers and software.
Unlike musical instruments, computers store instructions, which become available when the computer is turned on; it's as if the clarinet could remember the exact sequence of events that made it play and was able to reproduce those events when properly motivated, resulting in the song or songs originally played by the musician but reproduced exactly as though it were played again live. Data is stored on computers by all sorts of methods: on hard disks and floppy disks, in nonvolatile RAM. . . . Indeed, this data is held in a computer's short-term memory as well, which is usually a thousand times faster to access than any long-term storage.
Computer programs—their instructions—are stored like any other kind of data. The browser on your computer is a program, a set of instructions. The image or icon that represents your browser is not a program; it's data that must be interpreted by a program (in this case, the operating system).
Programs, stored in so-called files, provide the data used as instructions for operating the computer. Other kinds of data are also stored in files but are apt to be more like a structured document; one program or another will likely know what to do with a data file, provided the file is not damaged or corrupted. An operating system (as a rule) is a program that manages the resources on the computer. All the devices, memory locations, program files, and data files are managed and enabled by the operating system. To extend our analogy, the operating system is the musician who ultimately controls the clarinet. But the musician must know what to play; sheet music is often involved. The sheet music is like a program running under the operating system (musician) on the hardware (clarinet) in question. So the operating system manages things, decides if and when another program should be loaded into fast memory for processing, how much time the program should take, how much disk space is available for the program to consume, and much more.
Most computers host many other programs in addition to an operating system. Each program functions and is governed by a set of rules, which the operating system (in conjunction with the hardware) provides, and a program must follow its instructions blindly, having no knowledge of whether it is operating with any degree of “correctness.”
The basic meaning of instructions is similar on most computer systems. There are differences in syntax between different languages—different languages offer different features and approaches to solving different kinds of problems—but in the end, there is a great deal of common ground from one system to the next and from one language to the next. Computers, like people who play the clarinet, share much in common, despite their apparent differences.
Despite these simple structures that govern computer systems, things get very complicated very quickly. To build a manageable framework within which to understand computers and computer programming, we must organize information in such a way as to provide both a human processing model upon which we can all agree, and one that computers can also use in common, once the model is properly programmed within that framework. Some very rudimentary but useful tools for organizing information are part and parcel of every beginning computer science class. Among them are things like problem analysis charts (flow charts), pseudocode, and the simple input-processing-output (IPO) model shown in Figure 1.1. For the programmer, the IPO model provides a simple but effective approach to organizing any local computing problem.
To understand that statement, let's first define local computing to be a program that runs on one and only one node. A node is a computer that provides a unified operating system interface. (This includes computers containing several CPUs that may run several different operating systems or several images of a single operating system, or the equivalent of an operating system on a I/O board.) A node, for the purposes of this book, however, is any system that offers a single unified interface to the programs that run on it.
Now, the IPO model helps organize information and describe the flow of data through this local computer system; this is the primary task in local computing. (It's useful at this juncture to note that both storage devices, such as hard disks, and human users are sources of input as well as targets for output.) The IPO process is directed by software but performed by hardware. If all we ever wanted or needed was one computer operating all by itself, alone in a world separate from all other systems, this model would suffice for organizing any programming need.
Clearly, however, that is not today's computing reality, despite programming models that appear to assume otherwise. And while many computers are still sold for which this model will suffice—things like calculators, for example, or your wrist watch (if it isn't a smart one!)—most computing devices produced today are a part of, or want to be part of, a network of other devices. The IPO model remains of some use, especially for those first learning to organize information for purposes of computer programming, but its simplifying assumptions are fundamentally flawed once a program leaves the local computing nest. Unintended but costly consequences easily arise from this fundamental misapplication.
An obvious example lies in the vast majority of computer viruses in the world today. Typically, when personal computers were first released, the IPO model guided their programming, on the assumption that each computer would stand alone. Our PCs are still vulnerable to the nuisance of viruses because of that flawed early assumption, which was necessary for useful programming to occur but not complete given the explosion of networked uses today for PCs and other intelligent devices. This is typical of many of the pitfalls that await in the land of distributed computing.
So how does distributed computing differ from local computing? Distributed computing comes in several forms, each of which requires a different set of considerations when it comes to constructing a reasonable programming model; that is, one for which its architects mindfully consider aspects not covered by the IPO model for software deployment on the system. Table 1.1 presents a simple taxonomy of distributed computing (DC) systems, which naturally includes networked distributed computing systems.
Table 1.1. Taxonomy of distributed computing systems
Family | Type | Typical Use |
|---|---|---|
Local (embedded, e.g., an automobile) | private DC | single user |
Local (single room to campuswide) | clustered DC | multi-multiuser |
Networked (private LAN) | private NDC | multi-multiuser |
Networked (private WAN) | private NDC | multiuser |
Networked (public LAN) | public NDC | multiuser |
Networked (Internet) | public NDC | embedded/single/multiuser |
Distributed systems can be embedded in a single device or can operate within a cluster of devices in which the nodes work together to appear as a single node, offering a unified view of system resources to the application. Such clustered systems are usually connected to a fixed, high-speed datacom line, rather than a public network, and can share space in a single room, a building, a campus, or even a community, depending on the use and quality of the connection among the nodes. By the same token, a collection of embedded processors tightly bound by a proprietary datacom protocol can just as easily represent a cluster. The distinction between DC and NDC is one of datacom, with NDC bound to standard networking protocols rather than to a private data connection.
Networked distributed computing adds another layer of complexity to the task of programming applications, especially those that run “in the wild” or outside a private local area network (LAN) or private wide area network (WAN), in environments such as the public Internet. In general terms, the simple model for understanding and organizing information and the flow of information in the NDC environment borrows from the IPO model but adds a layer of complexity, as shown in Figure 1.2.

In this simple NDC model, the output of one node becomes the input to another node. The communication, however, need not always be in one direction. Indeed, as the model indicates, information can and usually does flow bidirectionally. But the flow of information the type and reliability of the information and the directionality of the information may acquire any number of patterns, depending on the context of deployment. Information flow, and therefore programming constraints, will always depend on the context in which the nodes operate—which leads to an important and often unstated rule of engineering, software or otherwise.
Note the thick line between nodes labeled middleware in the simple NDC model. This insidious term is used in our times to indicate a vast array of confusing, competing, often contentious layers of software—things like protocols, filters, converters, and firewalls. Middleware is a central NDC concept, perhaps the most important of all. Information flow through the middleware is an aspect of NDC programming that does not apply for less connected generations of applications. Strictly speaking, middleware can be thought of as software that connects two or more otherwise separate applications or separate products, serving as the glue between the applications. It is sometimes called plumbing because it connects applications, passing data between them. Note that middleware is orthogonal to NDC, which is to say that middleware is often utilized on a solitary node, facilitating local application chatter. But the focus here is NDC and the inherent pitfalls when utilizing middleware therein.
Despite the growth of NDC over the past twenty years or more, many of the pitfalls inherent in NDC programming have not been widely documented. While excellent university-level texts and a vast array of research have focused on principles and paradigms for distributed systems, little has been explicitly said regarding the essential differences between local and remote computing in the wild, even as demands for a post-client-server architecture mount in this Internet-fueled era.
In 1994, a paper innocuously entitled, “A Note on Distributed Computing” was published by four engineers from Sun Microsystems.[3] This oft-cited paper introduces several important observations for programmers creating NDC applications, including four key differences between local computing and remote (or distributed) computing. (While the paper focuses on object-oriented computing paradigms, these differences are just as applicable to other programming models.) The four key differences are as follows:
Latency
Memory access
Concurrency
Partial failure
At least two of these differences should be obvious: latency and memory access.
If Einstein is correct, the speed of light is a universal limit that we cannot ignore.[4] Although the speed of light as a constraint may not be of acute interest to a single node today,[5] it most certainly has an impact across an arbitrary network within which data transfer time, which is measured in milliseconds at best and which is a million times longer than the nanoseconds in which intranode latency is measured.
Memory maps will clearly differ from one node to the next, even if both nodes run identical operating systems on identical hardware. As such, memory access that is arbitrated through abstraction layers is both useful and utilized. Note that among other features, interface definition languages (IDLs) also function as intermediaries to memory; such approaches sometimes allow for a reasonable masking of fundamental memory differences between NDC nodes, depending on use and context.
The third and fourth key differences might not be so obvious but are nevertheless real.
Concurrency, strictly speaking, is the illusion a single node gives to multiple users: that their applications are running in a dedicated CPU environment. The terms multitasking, multiprocessing, multiprogramming, concurrency, and process scheduling all refer to techniques used by operating systems to share a single processor among several independent jobs.
Concurrency in a given node implies the existence of a system process that behaves like a “scheduler,” which suspends the currently running task after it has run for its time period (a “time slice”). The scheduler is also responsible for selecting the next task to run and (re)starting it.
A multiuser operating system generally provides some degree of protection of each task from others, to prevent tasks from interacting in unexpected and unplanned ways (such as accidentally modifying the contents of an unrelated process' memory area). When such an event occurs, it is generally classified as a bug. The processes in a multiuser or multitasking system can belong to one or many users, as opposed to parallel processing by which one user can run several tasks on several processors.
Multithreading is a kind of multitasking with low overheads and no protection of tasks from each other; all threads share the same memory. Multithreading applications are also part of the general topic of concurrency, as by implication are the concepts surrounding the sequence of execution of various threads.
The differences in a framework's ability to ensure predictable concurrency attributes in local and remote environments are a close cousin to the fourth key difference: the inevitability of a partial failure.
In a single node, either components in the system are working or they are not, and a central authority (i.e., an operating system) governs all resources. The multiple nodes of a distributed system provide potentially greater resources, but the lack of a central authority increases resource ambiguity. This problem, according to “A Note on Distributed Computing,” is as inevitable as it is unwise to ignore, as some approaches to distributed computing would seem to advise. In a single node, either a given transaction occurred, which can be known, or it did not, which can also be known; on a network, there is the added possibility that it might have occurred but a partial failure prevents us from finding out. For example, either the remote node expired before the transaction was complete, or it completed the transaction and then expired but couldn't confirm the transaction before it expired. This circumstance gives rise to an indeterminacy in the NDC model that is not present in the local model, due almost entirely to the lack of a central authority.
Because concurrency in NDC may involve the simultaneous execution of tasks or threads over multiple nodes or a sequencing of execution otherwise, it is also impacted by the lack of a central authority and is thus inherently different from assurances of concurrency, which are available on an isolated node.
Peter Deutsch, now retired from Sun Microsystems, is often credited for having articulated the Eight Fallacies of Distributed Computing, which are related to the paper previously cited. According to James Gosling, Deutsch originally articulated only four or five of the fallacies. The rest were added (by Deutsch or others) to the list over time. Regardless of the origin of the fallacies, Deutsch is credited with listing them, all of which are obvious and insightful. And all are likely to be ignored, not only by novice NDC programmers but sometimes by major frameworks that attempt to solve myriad middleware problems in order to allow NDC developers to ignore the differences between local and distributed computing.
Deutsch wrote:
Essentially everyone, when they first build a distributed application, makes the following eight assumptions. All prove to be false in the long run and all cause big trouble and painful learning experiences.[6]
The eight fallacies are
The network is reliable
Latency is zero
Bandwidth is infinite
The network is secure
Topology doesn't change
There is one administrator
Transport cost is zero
The network is homogeneous
Any reasonable examination of NDC must clearly acknowledge the fallaciousness of these assumptions.
If we juxtapose the key differences cited in A Note on Distributed Computing with the Deutsch Fallacies, it is clear that the lack of a central authority is responsible for many of the dissimilarities between local and distributed computing, as shown in Table 1.2.
Table 1.2. Fallacies and key differences: Primary causes
Key Differences | Deutsch's Fallacies | Primary cause |
|---|---|---|
Partial failure, concurrency | The network is reliable | Implicit in network design/implementation |
Latency | Latency is zero | Speed of light constraint |
Concurrency | Bandwidth is infinite | Implicit in network design/implementation |
The network is secure | Lack of central authority | |
Partial failure, concurrency | Topology doesn't change | Lack of central authority |
Single administrator | Lack of central authority | |
Concurrency | Transport cost is zero | Implicit in datacom design/implementation |
Memory access | Network homogeneity | Implicit in network design/implementation |
It is generally deemed impossible to engineer around the fundamental NDC constraint of the absence of a central authority. So, to cope with the differences listed above—the speed of light limit, the inevitability of partial failure, and the tenuous-at-best assurance of concurrency—NDC must ignore the semantic assurances proffered by models that try to mask the differences. Instead, NDC must somehow learn to adapt to the inherent differences, either by exposing them to software developers or by masking them and hoping for the best. A Note on Distributed Computing makes this very point.
In addition to an examination of the differences between local and remote computing—the context in which applications must operate—it is also useful to review the context in which programmers actually develop code. The metatrends that drive the computer industry have had and may continue to have a strong influence on design decisions, available tools, and economic constraints, all of which form an ecological framework in which programmers compete in order to make a living. The metatrends that have driven software development recently differ markedly from trends of previous development periods. Moore's law, for example, has been a well-documented trend that has impacted software development for at least two decades. The acceleration of that trend in recent years, however, when coupled with other, exponentially expressed, trends has given rise to a rapidly changing fitness landscape, or fitscape,[7] in which programs (and programmers) must continually compete anew.
The three exponentially expressed metatrends are:
Moore's law: The density of transistors doubles every 18–24 months.
Gilder's law: Global communications bandwidth doubles every 6 months.
Metcalfe's law: The potential value of a network is the number of nodes squared.
These three “Nth Laws”[8] can be viewed as metatrends because they shaped the current fitscape in which software must compete. As shapers of the fitscape, these laws are manifest in specific terms but are not directly measurable otherwise.
For example, Moore's law ensures that processor speeds will increase over time, in addition to providing more compute capability per average processor. It also ensures that memory (both silicon and disk) will increase in capacity just as rapidly; it also says that relative costs for computing resources will fall just as rapidly over time.
Gilder's law promised fat pipes approaching light speed as opto-electrical switching devices inevitably gave rise to pure optical devices, even as wireless technologies vied for mobile and last-mile connections to the fiber-optic backbone, which too was increasing in capacity. That is, of course, until the implosion of the telecom sector, beginning in the spring of 2000, with names like Global Crossing and WorldCom, once grand leaders of this burgeoning space, running afoul of both corporate prudence and financial viability. But despite economic shakeouts in telecommunications, which inevitably impacts investment capital, Gilder's law is likely to resume in full force in relatively short order. Why? The assets of a bankrupt firm are often sold at huge discounts. Thus, buyers of such assets are in a much better position to profitably capitalize them, enabling more cost-competitive products in the end. Ultimately, progress is a function of demand. As long as increased bandwidth correlates to increased productivity, some form of Gilder's law will remain a factor that software developers must consider.
At the same time, Metcalfe's law ensures that as technology adoption increases linearly, the potential value, or opportunity, represented by that adoption increases exponentially. Figure 1.3 illustrates the combination of these metatrends.
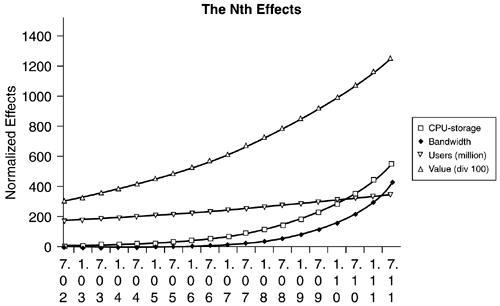
If these trends continue as they have in the past, then over the next nine years, the potential value of the network will increase dramatically even if there is only a modest growth (10 percent per annum) in the number of users over the same period. By the same token, aggregate bandwidth (normalized to 1 in 7/2002 in Figure 1.3) should easily keep pace with CPU-storage increases (normalized to 10 in 7/2002) and should surpass the ability of the average CPU-storage unit to assimilate fat pipes (in the aggregate) before the end of the decade.
This does not necessarily suggest that the “world wide wait” will be over; in fact, the timely availability of data-on-demand will likely be just as much a function of application design and the NDC frameworks those applications utilize as of aggregate bandwidth potential. Nor are these metatrends inevitable. Indeed, the collapse of significant telecom players may yet cool Gilder's enthusiasm. But in the spirit of optimism, significant growth, based on productivity-enhancing demand not only for more bandwidth but more of Moore and Metcalfe as well, is assumed.
More bandwidth, faster CPUs, and lots of storage won't make up for bad NDC design, however. The need to pay close attention to the fundamental differences between local and remote computing will be even more magnified in light of these Nth Laws if consumer expectations and experiences continue to shape the fitscape of technology adoption in the coming decade.
Two other trends that affect and shape the overall NDC fitscape bear mention as well. Probably an echo of the three Nth laws, these trends are more measurable:
Decomposition and the drive to components: At some critical juncture, computing must be distributed even further. This is true at the macro and micro levels, driven by shrinking physical components, network growth, and other economic factors.
Sedimentation and consolidation: Things that were once differentiators are now expected, fundamental pieces of a technology. An operating system, for example, may now embed applications, such as a browser.
Another derivative of the software fitscape deserves mention here—not a “law” as the three cited above, but rather more of a side effect of software itself. Since software is merely data, which is independent of substrate—bits can easily be transferred from one medium to another, from one communication modality to another, at relatively low cost—it can be said that the distribution of a unit of data is effectively free, given required storage and pervasive datacom capabilities.
In other words, once I have a PC with sufficient storage capability and an Internet connection of reasonable speed, theoretically any information on the network can be mine to download or share for free. From an NDC perspective, all software products (spreadsheets, word processors, database engines and the data that fills them), along with anything else that can be digitally represented (movies, music, news, weather, sports, telephony, books, and even education) can all be effectively free.
Inspired by a wall of currencies I studied while doing my laundry in Amsterdam in the summer of 1998, I started to speak of “the Zero Dollar Bill,” shown in Figure 1.4. I have continued to promote this metaphor despite the implosion of the dotcom bubble because the concept is still germane to software development and deployment, which in turn is still germane to our economies.

World economics, in fact, is fundamentally disrupted by Zero Dollar Bill–derived software. As computer science continues to influence literally all aspects of human activities, accelerating rates of change across the board because of the Nth-Law cycles enabled by software, the disruptive influence of the Zero Dollar Bill has profound impact.
Indeed, software piracy alone is a huge issue. Microsoft's Windows XP operating system raison d'être is arguably one of a serious attempt at software piracy prevention. Will it stop illegal distribution? Probably not. Especially in light of the growth of Linux, which is effectively free, the idea of paying nonzero currencies for something like an operating system is beginning to seem more suspect than it might have been just a decade ago. Software piracy may therefore actually increase, despite Microsoft's attempts to preserve its historically successful business model.
Witness, too, the disruptive influence of Napster and other peer-to-peer technologies that encourage Internet users to enjoin groups designed with the expressed purpose of trading digital versions of material that is supposed to be licensed and controlled by entities other than the users themselves. The Zero Dollar Bill—a metaphor for the potential of software economics—will continue to challenge the basic assumptions of in tellectual property, copyrights and licenses, and all the related institutions we remember from 20th century.
Indeed, all the assumptions and institutions that brought us here are fundamentally challenged by the work we do in computer science. The Zero Dollar Bill is a reminder of the disruptive nature of our work, a symbol of imminent egalitarian wealth as well as inevitable economic restructuring. Great change does not happen without pain.
I now discuss an algorithmic model of the real economic web, the one outside in the bustling world of the shopping mall, of mergers and acquisitions. While powerful, however, no algorithmic model is complete, for neither the biosphere nor the econosphere is finitely prestatable. Indeed, the effort to design and construct an algorithmic model of the real economic web will simultaneously help us see the weakness of any finite description. It all hangs on object-oriented programming . . . | ||
| --Stuart Kauffman | ||
Kauffman's Investigations is about a biologist who has been studying the emerging science of complexity from the confines of the Sante Fe Institute in New Mexico (by definition and charter cross-disciplinary). Kauffman offers a refreshing view of phenomena and our processes for understanding them, one we must consider if the promise of computer science is to be realized. As Einstein taught us, “The significant problems we face cannot be solved at the same level of thinking we were at when we created them.” We sorely need new insights if we are to emerge from our current epoch enlightened if not fully intact.
Science has an honored tradition. Indeed, were it not for the discipline of science, we likely would have never loosened the shackles of pre-Enlightenment thinking. In 1600, Renaissance writer and monk Giordano Bruno was burned at the stake for advocating the unthinkable idea that other worlds orbited other suns in our universe. The mindset that punished Bruno then might still be in vogue today were it not for science, firmly rooted in mathematics and the discipline of the scientific method, which is summarized below and illustrated in Figure 1.5.
State the question.
Form a hypothesis.
Do experiments.
Interpret data and draw conclusions.
Revise theory (go back to step 2).

Leveraged from Aristotle, borrowed from Socrates, the scientific method is grounded in a Newtonian world view that is (a) linear, (b) finitely prestatable (as in formation of a hypothesis), (c) observable, and (d) mathematically bound. The linear attribute is key to understanding science for the past 500 years. Indeed, before the maturation of computer science and the great solution-in-search-of-a-problem it has given us, science had no other choice.
As Kauffman and many others from traditionally reductionist quarters have begun to realize, all living systems, including our brains, reflect nonlinear dynamics. The strategy of classical science, which has been to separate the elements of such systems in order to study the parts in isolated, controlled environments, was necessary before we dreamed of useful computer systems because of the mathematics involved. Such environments require the rounding-off of small differences to allow scientists the opportunity to examine the nature of causality in a simplified manner; either reduced to solvable linear equations or, when that was impossible, to a statistical analysis of averages.
It wasn't until the availability of computers that science could imagine kicking the habit of translating nonlinear equations into linear approximations. Once we began to perceive the universe through our silicon-adapted eyes, the presence of a more complex dynamic, which had previously been hidden, began to appear. The emerging science of complexity recognizes first and foremost the sensitive dependency on initial conditions that is the essence of complex systems. This awakening is still just beginning, its genesis coming sometime after the appearance of the first personal computer in the mid-1980s.[9]
Today we find ourselves confronted with a universe in which nonlinear interdependence is more the rule than the exception, and we are beginning to acknowledge that it is from a nonlinear standard that our models must proceed.
Kauffman makes several important points which prudent NDC designers and programmers will be cognizant of, given the increasingly complex context of software development which now capture our collective imaginations:
There is a fitscape that comprises the ecosphere in which the game is played. Whether it be a biosphere, an economy, a football league, or the fitscape of NDC development, complex, adaptive environments manifest fitscapes which will share abstract attributes with other fitscapes.
Autonomous agents pursue competitive activities within their respective fitscapes to survive or “make a living.”
Autonomous agents persistently explore the “adjacent possible,” giving rise to novelty (innovation).
It is impossible to finitely prestate the adjacent possible. Whether it be the set of all possible protein molecules, life forms, economic models, legal systems, or computer programs, the derivatives and combinations of possibilities exceed our ability to express a finite set (which Step 2 in our scientific method requires).
The rate of innovation cannot exceed the ability of the fitscape to adequately test the novelty without risking systemic collapse.
Of course, there is more, which is beyond the scope of this effort. But it is my view that if we are to move forward in NDC development in a manner that best suits the needs of all of humanity in these most interesting times, an appreciation of the concepts that Stuart Kauffman has articulated will be most useful. Indeed, Turing taught us with the Halting Problem that at least one class of prestatable conditions is indeed impossible for computer science. As direct heirs to Gödel's realizations (which overturned our assumptions about mathematics in the 20th century as dramatically as Einstein did our pre-20th-century assumptions regarding time), computer science is best positioned not only to lead the way to a richer, more complete understanding of our universe, but to help humanity comfortably embrace the paradoxes it will discover along the way.
| 1. | At the time of this writing, www.google.com found 6,440 references to the famous 1943 quotation by Thomas Watson, the IBM chairman. The reference for the purpose of this footnote will be to an FCC archived page. Given the U.S. government's penchant for long maintenance of archived materials, it is likely that this URL (http://www.fcc.gov/Speeches/Ness/spsn705.txt) will not fade any time soon. Clearly, what Watson forgot to add at the end of his famous sentence was “per person.” |
| 2. | Brian Greene, The Elegant Universe (New York: Norton 1999). |
| 3. | Samuel C. Kendall, Jim Waldo, Ann Wollrath, and Geoff Wyant, http://research.sun.com/techrep/1994/abstract_29.html |
| 4. | Quantum entanglement may one day provide a means to ignore even this limit, although such an accomplishment would require not only engineering feats of unknown magnitude but a rather impressive modification of currently understood fundamental laws of the universe. |
| 5. | As clock speeds for processors increase, the speed of light may one day have an impact on local computing models as well, once memory access across a board or a bus takes orders of magnitude longer than on-chip cache. |
| 6. | The only known “original” reference is on James Gosling's Web site (java.sun.com/people/jag/Fallacies.html). I have taken the liberty of replicating Deutsch's fallacies on my own Web site (www.maxgoff.com/Fallacies.html) as well. |
| 7. | Stuart Kauffman discusses the concept of a “fitness landscape” in Investigations (New York: Oxford University Press, 2000). The term “fitscape” is meant to convey the abstract essence of a Darwinian fitness landscape, as described by Kauffman, complete with all the attributes cited herein. |
| 8. | Note that only Metcalfe's Law is firmly rooted in mathematics; Moore's and Gilder's laws are really observations of historical trends, the result of “virtuous cycles” which may or may not continue for any predictable period. |
| 9. | James Gleick, Chaos: Making a New Science (New York: Viking, 1987). |