
As the computer world becomes more networked, network-aware applications are increasingly important. Linux provides the Berkeley socket API, which has become the standard networking API. We discuss the basics of using Berkeley sockets for both TCP/IP networking and simple interprocess communication (IPC) through Unix-domain sockets.
This chapter is not intended to be a complete guide to network programming. Network programming is a complicated topic, and we recommend dedicated network programming books for programmers who intend to do serious work with sockets [Stevens, 2004]. This chapter should be sufficient to allow you to write simple networked applications, however.
The Berkeley socket API was designed as a gateway to multiple protocols. Although this does necessitate extra complexity in the interface, it is much easier than inventing (or learning) a new interface for every new protocol you encounter. Linux uses the socket API for many protocols, including TCP/IP (both version 4 and version 6), AppleTalk, and IPX.
We discuss using sockets for two of the protocols available through Linux’s socket implementation. The most important protocol that Linux supports is TCP/IP,[1] which is the protocol that drives the Internet. We also cover Unix domain sockets, an IPC mechanism restricted to a single machine. Although they do not work across networks, Unix domain sockets are widely used for applications that run on a single computer.
Protocols normally come in groups, or protocol families. The popular TCP/IP protocol family includes the TCP and UDP protocols (among others). Making sense of the various protocols requires you to know a few networking terms.
Most users consider networking protocols to provide the equivalent of Unix pipes between machines. If a byte (or sequence of bytes) goes in one end of the connection, it is guaranteed to come out the other end. Not only is it guaranteed to come out the other end, but it also comes out right after the byte that was sent before it and immediately before the byte that was sent after it. Of course, all of these bytes should be received exactly as they were sent; no bytes should change. Also, no other process should be able to interject extra bytes into the conversation; it should be restricted to the original two parties.
A good visualization of this idea is the telephone. When you speak to your friends, you expect them to hear the same words you speak, and in the order you speak them.[2] Not only that, you do not expect your mother to pick up her phone (assuming she is not in the same house as you) and start chatting away happily to you and your friend.
Although this may seem pretty basic, it is not at all how underlying computer networks work. Networks tend to be chaotic and random. Imagine a first-grade class at recess, except they are not allowed to speak to each other and they have to stay at least five feet apart. Now, chances are those kids are going to find some way to communicate—perhaps even with paper airplanes!
Imagine that whenever students want to send letters to one another they simply write the letters on pieces of paper, fold them into airplanes, write the name of the intended recipient on the outside, and hurl them toward someone who is closer to the final recipient than the sender is. This intermediate looks at the airplane, sees who the intended target is, and sends it toward the next closest person. Eventually, the intended recipient will (well, may) get the airplane and unfold it to read the message.
Believe it or not, this is almost exactly how computer networks operate.[3] The intermediaries are called routers and the airplanes are called packets, but the rest is the same. Just as in the first-grade class, some of those airplanes (or packets) are going to get lost. If a message is too long to fit in a single packet, it must be split across multiple ones (each of which may be lost). All the students in between can read the packets if they like[4] and may simply throw the message away rather than try to deliver it. Also, anyone can interrupt your conversation by sending new packets into the middle of it.
Confronted with the reality of millions of paper airplanes, protocol designers endeavor to present a view of the network more on par with the telephone than the first-grade class. Various terms have evolved to describe networking protocols.
Connection-oriented protocols have two endpoints, like a telephone conversation. The connection must be established before any communication takes place, just as you answer the phone by saying “hello” rather than just talking immediately. Other users cannot (or should not be able to) intrude into the connection. Protocols that do not have these characteristics are known as connectionless.
Protocols provide sequencing if they ensure the data arrives in the same order it was sent.
Protocols provide error control if they automatically discard messages that have been corrupted and arrange to retransmit the data.
Streaming protocols recognize only byte boundaries. Sequences of bytes may be split up and are delivered to the recipient as the data arrives.
Packet-based protocols handle packets of data, preserving the packet boundaries and delivering complete packets to the receiver. Packet-based protocols normally enforce a maximum packet size.
Although each of these attributes is independent of the others, two major types of protocols are commonly used by applications. Datagram protocols are packet-oriented transports that provide neither sequencing nor error control; UDP, part of the TCP/IP protocol family, is a widely used datagram protocol. Stream protocols, such as the TCP portion of TCP/IP, are streaming protocols that provide both sequencing and error control.
Although datagram protocols, such as UDP, can be useful,[5] we focus on using stream protocols because they are easier to use for most applications. More information on protocol design and the differences between various protocols is available from many books [Stevens, 2004] [Stevens, 1994].
As every protocol has its own definition of a network address, the sockets API must abstract addresses. It uses a struct sockaddr as the basic form of an address; its contents are defined differently for each protocol family. Whenever a struct sockaddr is passed to a system call, the process also passes the size of the address that is being passed. The type socklen_t is defined as a numeric type large enough to hold the size of any socket address used by the system.
All struct sockaddr types conform to the following definition:
#include <sys/socket.h>
struct sockaddr {
unsigned short sa_family;
char sa_data[MAXSOCKADDRDATA];
}
The first two bytes (the size of a short) specifies the address family this address belongs to. A list of the common address families that Linux applications use is in Table 17.1, on page 413.
Table 17.1. Protocol and Address Families
Address | Protocol | Protocol Description |
|---|---|---|
|
| Unix domain |
|
| TCP/IP (version 4) |
|
| TCP/IP (version 6) |
|
| AX.25, used by amateur radio |
|
| Novell IPX |
|
| AppleTalk DDS |
|
| NetROM, used by amateur radio |
All of the examples in this section use two functions, copyData() and die().copyData() reads data from a file descriptor and writes it to another as long as data is left to be read. die() calls perror() and exits the program. We put both of these functions in the file sockutil.c to keep the example programs a bit cleaner. For reference, here is the implementation of these two functions:
1: /* sockutil.c */
2:
3: #include <stdio.h>
4: #include <stdlib.h>
5: #include <unistd.h>
6:
7: #include "sockutil.h"
8:
9: /* issue an error message via perror() and terminate the program */
10: void die(char * message) {
11: perror(message);
12: exit(1);
13: }
14:
15: /* Copies data from file descriptor 'from' to file descriptor
16: 'to' until nothing is left to be copied. Exits if an error
17: occurs. This assumes both from and to are set for blocking
18: reads and writes. */
19: void copyData(int from, int to) {
20: char buf[1024];
21: int amount;
22:
23: while ((amount = read(from, buf, sizeof(buf))) > 0) {
24: if (write(to, buf, amount) != amount) {
25: die("write");
26: return;
27: }
28: }
29: if (amount < 0)
30: die("read");
31: }
Like most other Linux resources, sockets are implemented through the file abstraction. They are created through the socket() system call, which returns a file descriptor. Once the socket has been properly initialized, that file descriptor may be used for read() and write() requests, like any other file descriptor. When a process is finished with a socket, it should be close() ed to free the resources associated with it.
This section presents the basic system calls for creating and initializing sockets for any protocol. It is a bit abstract due to this protocol independence, and does not contain any examples for the same reason. The next two sections of this chapter describe how to use sockets with two different protocols, Unix Domain and TCP/IP, and those sections include full examples of how to use most of the system calls introduced here.
New sockets are created by the socket() system call, which returns a file descriptor for the uninitialized socket. The socket is tied to a particular protocol when it is created, but it is not connected to anything. As it is not connected, it cannot yet be read from or written to.
#include <sys/socket.h> int socket(int domain, int type, int protocol);
Like open(), socket() returns a value less than 0 on error and a file descriptor, which is greater than or equal to 0, on success. The three parameters specify the protocol to use.
The first parameter specifies the protocol family that should be used and is usually one of the values specified in Table 17.1.
The next parameter, type, is SOCK_STREAM, SOCK_DGRAM, or SOCK_RAW.[6] SOCK_STREAM specifies a protocol from the specified family that provides a stream connection, whereas SOCK_DGRAM specifies a datagram protocol from the same family. SOCK_RAW provides the ability to send packets directly to a network device driver, which enables user space applications to provide networking protocols that are not understood by the kernel.
The final parameter specifies which protocol is to be used, subject to the constraints specified by the first two parameters. Usually this parameter is 0, letting the kernel use the default protocol of the specified type and family. For the PF_INET protocol family, Table 17.2 lists some of protocols allowed, with IPPROTO_TCP being the default stream protocol and IPPROTO_UDP the default datagram protocol.
Table 17.2. IP Protocols
Protocol | Description |
|---|---|
| Internet Control Message Protocol for IPv4 |
| Internet Control Message Protocol for IPv6 |
| IPIP tunnels |
| IPv6 headers |
| Raw IP packets |
| Transmission Control Protocol (TCP) |
| User Datagram Protocol (UDP) |
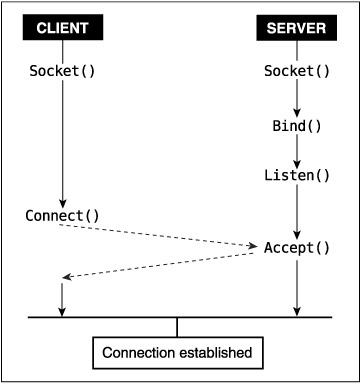
After you create a stream socket, it needs to be connected to something before it is of much use. Establishing socket connections is an inherently asymmetric task; each side of the connection does it differently. One side gets its socket ready to be connected to something and then waits for someone to connect to it. This is usually done by server applications that are started and continuously run, waiting for other processes to connect to them.
Client processes instead create a socket, tell the system which address they want to connect it to, and then try to establish the connection. Once the server (which has been waiting for a client) accepts the connection attempt, the connection is established between the two sockets. After this happens, the socket may be used for bidirectional communication.
Both server and client processes need to tell the system which address to use for the socket. Attaching an address to the local side of a socket is called binding the socket and is done through the bind() system call.
#include <sys/socket.h> int bind(int sock, struct sockaddr * my_addr, socklen_t addrlen);
The first parameter is the socket being bound, and the other parameters specify the address to use for the local endpoint.
After creating a socket, server processes bind() the socket to the address they are listening to. After the socket is bound to an address, the process tells the system it is willing to let other processes establish connections to that socket (at the specified address) by calling listen(). Once a socket is bound to an address, the kernel is able to handle processes’ attempts to connect to that address. However, the connection is not immediately established. The listen() ing process must first accept the connection attempt through the accept() system call. New connection attempts that have been made to addresses that have been listen() ed to are called pending connections until the connections has been accept() ed.
Normally, accept() blocks until a client process tries to connect to it. If the socket has been marked as nonblocking through fcntl(), accept() instead returns EAGAIN if no client process is available.[7] The select(), poll(), and epoll system calls may also be used to determine whether a connection to a socket is pending (those calls mark the socket as ready to be read from).[8]
Here are the prototypes of listen() and accept().
#include <sys/socket.h> int listen(int sock, int backlog); int accept(int sock, struct sockaddr * addr, socklen_t * addrlen);
Both of these functions expect the socket’s file descriptor as the first parameter. listen()’s other parameter, backlog, specifies how many connections may be pending on the socket before further connection attempts are refused. Network connections are not established until the server has accept() ed the connection; until the accept(), the incoming connection is considered pending. By providing a small queue of pending connections, the kernel relaxes the need for server processes to be constantly prepared to accept() connections. Applications have historically set the maximum backlog to five, although a larger value may sometimes be necessary. listen() returns zero on success and nonzero on failure.
The accept() call changes a pending connection to an established connection. The established connection is given a new file descriptor, which accept() returns. The new file descriptor inherits its attributes from the socket that was listen() ed to. One unusual feature of accept() is that it returns networking errors that are pending as errors from accept().[9] Servers should not abort when accept() returns an error if errno is one of ECONNABORTED, ENETDOWN, EPROTO, ENOPROTOOPT, EHOSTDOWN, ENONET, EHOSTUNREACH, EOPNOTSUPP, or ENETUNREACH. All of these should be ignored, with the server just calling accept() once more.
The addr and addrlen parameters point to data that the kernel fills in with the address of the remote (client) end of the connection. Initially, addrlen should point to an integer containing the size of the buffer addr points to. accept() returns a file descriptor, or less than zero if an error occurs, just like open().
Like servers, clients may bind() the local address to the socket immediately after creating it. Usually, the client does not care what the local address is and skips this step, allowing the kernel to assign it any convenient local address.
After the bind() step (which may be omitted), the client connect()s to a server.
#include <sys/socket.h> int connect(int sock, struct sockaddr * servaddr, socklen_t addrlen);
The process passes to connect() the socket that is being connected, followed by the address to which the socket should be connected.
Figure 17.1 shows the system calls usually used to establish socket connections, and the order in which they occur.
After a connection has been established, applications can find the addresses for both the local and remote end of a socket by using getpeername() and getsockname().
#include <sys/socket.h> int getpeername(int s, struct sockaddr * addr, socklen_t * addrlen); int getsockname(int s, struct sockaddr * addr, socklen_t * addrlen);
Both functions fill in the structures pointed to by their addr parameters with addresses for the connection used by socket s. The address for the remote side is returned by getpeername(), while getsockname() returns the address for the local part of the connection. For both functions, the integer pointed to by addrlen should be initialized to the amount of space pointed to by addr, and that integer is changed to the number of bytes in the address returned.
Unix domain sockets are the simplest protocol family available through the sockets API. They do not actually represent a network protocol; they can connect only to sockets on the same machine. Although this restricts their usefulness, they are used by many applications because they provide a flexible IPC mechanism. Their addresses are pathnames that are created in the file system when a socket is bound to the pathname. Socket files, which represent Unix domain addresses, can be stat() ed but cannot be opened through open(); the socket API must be used instead.
The Unix domain provides both datagram and stream interfaces. The datagram interface is rarely used and is not discussed here. The stream interface, which is discussed here, is similar to named pipes. Unix domain sockets are not identical to named pipes, however.
When multiple processes open a named pipe, any of the processes may read a message sent through the pipe by another process. Each named pipe is like a bulletin board. When a process posts a message to the board, any other process (with sufficient permission) may take the message from the board.
Unix domain sockets are connection-oriented; each connection to the socket results in a new communication channel. The server, which may be handling many simultaneous connections, has a different file descriptor for each. This property makes Unix domain sockets much better suited to many IPC tasks than are named pipes. This is the primary reason they are used by many standard Linux services, including the X Window System and the system logger.
Addresses for Unix domain sockets are pathnames in the file system. If the file does not already exist, it is created as a socket-type file when a socket is bound to the pathname through bind(). If a file (even a socket) exists with the pathname being bound, bind() fails and returns EADDRINUSE.bind() sets the permissions of newly created socket files to 0666, as modified by the current umask.
To connect() to an existing socket, the process must have read and write permissions for the socket file.[10]
Unix domain socket addresses are passed through a struct sockaddr_un structure.
#include <sys/socket.h>
#include <sys/un.h>
struct sockaddr_un {
unsigned short sun_family; /* AF_UNIX */
char sun_path[UNIX_PATH_MAX]; /* pathname */
};
In the Linux 2.6.7 kernel, UNIX_PATH_MAX is 108, but that may change in future versions of the Linux kernel.
The first member, sun_family, must contain AF_UNIX to indicate that the structure contains a Unix domain address. The sun_path holds the pathname to use for the connection. When the size of the address is passed to and from the socket-related system calls, the passed length should be the number of characters in the pathname plus the size of the sun_family member. The sun_path does not need to be '�' terminated, although it usually is.
Listening for a connection to be established on a Unix domain socket follows the procedure we described earlier: Create the socket, bind() an address to the socket, tell the system to listen() for connection attempts, and then accept() the connection.
Here is a simple server that repeatedly accepts connections on a Unix domain socket (the file sample-socket in the current directory) and reads all the data available from the socket, displaying it on standard output:
1: /* userver.c */
2:
3: /* Waits for a connection on the ./sample-socket Unix domain
4: socket. Once a connection has been established, copy data
5: from the socket to stdout until the other end closes the
6: connection, and then wait for another connection to the
7: socket. */
8:
9: #include <stdio.h>
10: #include <sys/socket.h>
11: #include <sys/un.h>
12: #include <unistd.h>
13:
14: #include "sockutil.h" /* some utility functions */
15:
16: int main(void) {
17: struct sockaddr_un address;
18: int sock, conn;
19: size_t addrLength;
20:
21: if ((sock = socket(PF_UNIX, SOCK_STREAM, 0)) < 0)
22: die("socket");
23:
24: /* Remove any preexisting socket (or other file) */
25: unlink("./sample-socket");
26:
27: address.sun_family = AF_UNIX; /* Unix domain socket */
28: strcpy(address.sun_path, "./sample-socket");
29:
30: /* The total length of the address includes the sun_family
31: element */
32: addrLength = sizeof(address.sun_family) +
33: strlen(address.sun_path);
34:
35: if (bind(sock, (struct sockaddr *) &address, addrLength))
36: die("bind");
37:
38: if (listen(sock, 5))
39: die("listen");
40:
41: while ((conn = accept(sock, (struct sockaddr *) &address,
42: &addrLength)) >= 0) {
43: printf("---- getting data
");
44: copyData(conn, 1);
45: printf("---- done
");
46: close(conn);
47: }
48:
49: if (conn < 0)
50: die("accept");
51:
52: close(sock);
53: return 0;
54: }
Although this program is small, it illustrates how to write a simple server process. This server is an iterative server because it handles one client at a time. Servers may also be written as concurrent servers, which handle multiple clients simultaneously.[11]
Notice the unlink() call before the socket is bound. Because bind() fails if the socket file already exists, this allows the program to be run more than once without requiring that the socket file be manually removed.
The server code typecasts the struct sockaddr_un pointer passed to both bind() and accept() to a (struct sockaddr *). All the various socket-related system calls are prototyped as taking a pointer to struct sockaddr; the typecast keeps the compiler from complaining about pointer type mismatches.
Connecting to a server through a Unix domain socket consists of creating a socket and connect() ing to the desired address. Once the socket is connected, it may be treated like any other file descriptor.
The following program connects to the same socket that the example server uses and copies its standard input to the server:
1: /* uclient.c */
2:
3: /* Connect to the ./sample-socket Unix domain socket, copy stdin
4: into the socket, and then exit. */
5:
6: #include <sys/socket.h>
7: #include <sys/un.h>
8: #include <unistd.h>
9:
10: #include "sockutil.h" /* some utility functions */
11:
12: int main(void) {
13: struct sockaddr_un address;
14: int sock;
15: size_t addrLength;
16:
17: if ((sock = socket(PF_UNIX, SOCK_STREAM, 0)) < 0)
18: die("socket");
19:
20: address.sun_family = AF_UNIX; /* Unix domain socket */
21: strcpy(address.sun_path, "./sample-socket");
22:
23: /* The total length of the address includes the sun_family
24: element */
25: addrLength = sizeof(address.sun_family) +
26: strlen(address.sun_path);
27:
28: if (connect(sock, (struct sockaddr *) &address, addrLength))
29: die("connect");
30:
31: copyData(0, sock);
32:
33: close(sock);
34:
35: return 0;
36: }
The client is not much different than the server. The only changes were replacing the bind(), listen(), accept() sequence with a single connect() call and copying a slightly different set of data.
The previous two example programs, one a server and the other a client, are designed to work together. Run the server from one terminal, then run the client from another terminal (but in the same directory). As you type lines into the client, they are sent through the socket to the server. When you exit the client, the server waits for another connection. You can transmit files through the socket by redirecting the input to the client program.
Because Unix domain sockets have some advantages over pipes (such as being full duplex), they are often used as an IPC mechanism. To facilitate this, the socketpair() system call was introduced.
#include <sys/socket.h> int socketpair(int domain, int type, int protocol, int sockfds[2]);
The first three parameters are the same as those passed to socket(). The final parameter, sockfds(), is filled in by socketpair() with two file descriptors, one for each end of the socket. A sample application of socketpair() is shown on page 425.
Unix domain sockets have a unique ability: File descriptors can be passed through them. No other IPC mechanism supports this facility. It allows a process to open a file and pass the file descriptor to another—possibly unrelated—process. All the access checks are done when the file is opened, so the receiving process gains the same access rights to the file as the original process.
File descriptors are passed as part of a more complicated message that is sent using the sendmsg() system call and received using recvmsg().
#include <sys/socket.h> int sendmsg(int fd, const struct msghdr * msg, unsigned int flags); int recvmsg(int fd, struct msghdr * msg, unsigned int flags);
The fd parameter is the file descriptor through which the message is transmitted; the second parameter is a pointer to a structure describing the message. The flags are not usually used and should be set to zero for most applications. More advanced network programming books discuss the available flags [Stevens, 2004].
A message is described by the following structure:
#include <sys/socket.h>
#include <sys/un.h>
struct msghdr {
void * msg_name; /* optional address */
unsigned int msg_namelen; /* size of msg_name */
struct iovec * msg_iov; /* scatter/gather array */
unsigned int msg_iovlen; /* number of elements in msg_iov */
void * msg_control; /* ancillary data */
unsigned int msg_controllen; /* ancillary data buffer len */
int msg_flags; /* flags on received message */
};
The first two members, msg_name and msg_namelen, are not used with stream protocols. Applications that send messages across stream sockets should set msg_name to NULL and msg_namelen to zero.
msg_iov and msg_iovlen describe a set of buffers that are sent or received. Scatter/gather reads and writes, as well as struct iovec, are discussed on pages 290-291. The final member of the structure, msg_flags, is not currently used and should be set to zero.
The two members we skipped over, msg_control and msg_controllen, provide the file descriptor passing ability. The msg_control member points to an array of control message headers; msg_controllen specifies how many bytes the array contains. Each control message consists of a struct cmsghdr followed by extra data.
#include <sys/socket.h>
struct cmsghdr {
unsigned int cmsg_len; /* length of control message */
int cmsg_level; /* SOL_SOCKET */
int cmsg_type; /* SCM_RIGHTS */
int cmsg_data[0]; /* file descriptor goes here */
};
The size of the control message, including the header, is stored in cmsg_len. The only type of control message currently defined is SCM_RIGHTS, which passes file descriptors.[12] For this message type, cmsg_level and cmsg_type must be set to SOL_SOCKET and SCM_RIGHTS, respectively. The final member, cmsg_data, is an array of size zero. This is a gcc extension that allows an application to copy data to the end of the structure (see the following program for an example of this).
Receiving a file descriptor is similar. Enough buffer space must be left for the control message, and a new file descriptor follows each struct cmsghdr that arrives.
To illustrate the use of these nested structures, we wrote an example program that is a fancy cat. It takes a file name as its sole argument, opens the specified file in a child process, and passes the resulting file descriptor to the parent through a Unix domain socket. The parent then copies the file to standard output. The file name is sent along with the file descriptor for illustrative purposes.
1: /* passfd.c */
2:
3: /* We behave like a simple /bin/cat, which only handles one
4: argument (a file name). We create Unix domain sockets through
5: socketpair(), and then fork(). The child opens the file whose
6: name is passed on the command line, passes the file descriptor
7: and file name back to the parent, and then exits. The parent
8: waits for the file descriptor from the child, then copies data
9: from that file descriptor to stdout until no data is left. The
10: parent then exits. */
11:
12: #include <alloca.h>
13: #include <fcntl.h>
14: #include <stdio.h>
15: #include <string.h>
16: #include <sys/socket.h>
17: #include <sys/uio.h>
18: #include <sys/un.h>
19: #include <sys/wait.h>
20: #include <unistd.h>
21:
22: #include "sockutil.h" /* simple utility functions */
23:
24: /* The child process. This sends the file descriptor. */
25: int childProcess(char * filename, int sock) {
26: int fd;
27: struct iovec vector; /* some data to pass w/ the fd */
28: struct msghdr msg; /* the complete message */
29: struct cmsghdr * cmsg; /* the control message, which */
30: /* wil linclude the fd */
31:
32: /* Open the file whose descriptor will be passed. */
33: if ((fd = open(filename, O_RDONLY)) < 0) {
34: perror("open");
35: return 1;
36: }
37:
38: /* Send the file name down the socket, including the trailing
39: '�' */
40: vector.iov_base = filename;
41: vector.iov_len = strlen(filename) + 1;
42:
43: /* Put together the first part of the message. Include the
44: file name iovec */
45: msg.msg_name = NULL;
46: msg.msg_namelen = 0;
47: msg.msg_iov = &vector;
48: msg.msg_iovlen = 1;
49:
50: /* Now for the control message. We have to allocate room for
51: the file descriptor. */
52: cmsg = alloca(sizeof(struct cmsghdr) + sizeof(fd));
53: cmsg->cmsg_len = sizeof(struct cmsghdr) + sizeof(fd);
54: cmsg->cmsg_level = SOL_SOCKET;
55: cmsg->cmsg_type = SCM_RIGHTS;
56:
57: /* copy the file descriptor onto the end of the control
58: message */
59: memcpy(CMSG_DATA(cmsg), &fd, sizeof(fd));
60:
61: msg.msg_control = cmsg;
62: msg.msg_controllen = cmsg->cmsg_len;
63:
64: if (sendmsg(sock, &msg, 0) != vector.iov_len)
65: die("sendmsg");
66:
67: return 0;
68: }
69:
70: /* The parent process. This receives the file descriptor. */
71: int parentProcess(int sock) {
72: char buf[80]; /* space to read file name into */
73: struct iovec vector; /* file name from the child */
74: struct msghdr msg; /* full message */
75: struct cmsghdr * cmsg; /* control message with the fd */
76: int fd;
77:
78: /* set up the iovec for the file name */
79: vector.iov_base = buf;
80: vector.iov_len = 80;
81:
82: /* the message we're expecting to receive */
83:
84: msg.msg_name = NULL;
85: msg.msg_namelen = 0;
86: msg.msg_iov = &vector;
87: msg.msg_iovlen = 1;
88:
89: /* dynamically allocate so we can leave room for the file
90: descriptor */
91: cmsg = alloca(sizeof(struct cmsghdr) + sizeof(fd));
92: cmsg->cmsg_len = sizeof(struct cmsghdr) + sizeof(fd);
93: msg.msg_control = cmsg;
94: msg.msg_controllen = cmsg->cmsg_len;
95:
96: if (!recvmsg(sock, &msg, 0))
97: return 1;
98:
99: printf("got file descriptor for '%s'
",
100: (char *) vector.iov_base);
101:
102: /* grab the file descriptor from the control structure */
103: memcpy(&fd, CMSG_DATA(cmsg), sizeof(fd));
104:
105: copyData(fd, 1);
106:
107: return 0;
108: }
109:
110: int main(int argc, char ** argv) {
111: int socks[2];
112: int status;
113:
114: if (argc != 2) {
115: fprintf(stderr, "only a single argument is supported
");
116: return 1;
117: }
118:
119: /* Create the sockets. The first is for the parent and the
120: second is for the child (though we could reverse that
121: if we liked. */
122: if (socketpair(PF_UNIX, SOCK_STREAM, 0, socks))
123: die("socketpair");
124:
125: if (!fork()) {
126: /* child */
127: close(socks[0]);
128: return childProcess(argv[1], socks[1]);
129: }
130:
131: /* parent */
132: close(socks[1]);
133: parentProcess(socks[0]);
134:
135: /* reap the child */
136: wait(&status);
137:
138: if (WEXITSTATUS(status))
139: fprintf(stderr, "child failed
");
140:
141: return 0;
142: }
The primary use for sockets is to allow applications running on different machines to talk to one another. The TCP/IP protocol family [Stevens, 1994] is the protocol used on the Internet, the largest set of networked computers in the world. Linux provides a complete, robust TCP/IP implementation that allows it to act as both a TCP/IP server and client.
The most widely deployed version of TCP/IP is version 4 (IPv4). Version 6 of TCP/IP (IPv6) has become available for most operating systems and network infrastructure products, although IPv4 is still dominant. We concentrate here on writing applications for IPv4, but we touch on the differences for IPv6 applications, as well as for programs that need to support both.
TCP/IP networks are usually heterogenous; they include a wide variety of machines and architectures. One of the most common differences between architectures is how they store numbers.
Computer numbers are made up of a sequence of bytes. C integers are commonly 4 bytes (32 bits), for example. There are quite a few ways of storing those four bytes in memory. Big-endian architectures store the most significant byte at the lowest hardware address, and the other bytes follow in order from most significant to least significant. Little-endian machines store multibyte values in exactly the opposite order: The least significant byte is stored at the smallest memory address. Other machines store bytes in different orders yet.
Because multiple byte quantities are needed as part of the TCP/IP protocol, the protocol designers adopted a single standard for how multibyte values are sent across the network.[13] TCP/IP mandates that big-endian byte order be used for transmitting protocol information and suggests that it be used for application data, as well (although no attempt is made to enforce the format of an application’s data stream).[14] The ordering used for multibyte values sent across the network is known as the network byte order.
Four functions are available for converting between host byte order and network byte order:
#include <netinet/in.h> unsigned int htonl(unsigned int hostlong); unsigned short htons(unsigned short hostshort); unsigned int ntohl(unsigned int netlong); unsigned short ntohs(unsigned short netshort);
Although each of these functions is prototyped for unsigned quantities, they all work fine for signed quantities, as well.
The first two functions, htonl() and htons(), convert longs and shorts, respectively, from host order to network order. The final two, ntohl() and ntohs(), convert longs and shorts from network order to the host byte ordering.
Although we use the term long in the descriptions, that is a misnomer. htonl() and ntohl() both expect 32-bit quantities, not values that are C long s. We prototype both functions as manipulating int values, as all Linux platforms currently use 32-bit integers.
IPv4 connections are a 4-tuple of (local host, local port, remote host, remote port). Each part of the connection must be determined before a connection can be established. Local host and remote host are each IPv4 addresses. IPv4 addresses are 32-bit (4-byte) numbers unique across the entire connected network. Usually they are written as aaa. bbb. ccc. ddd, with each element in the address being the decimal representation of one of the bytes in the machine’s address. The left-most number in the address corresponds to the most significant byte in the address. This format for IPv4 addresses is known as dotted-decimal notation.
As most machines need to run multiple concurrent TCP/IP applications, an IP number does not provide a unique identification for a connection on a single machine. Port numbers are 16-bit numbers that uniquely identify one endpoint of a connection on a single host. The combination of an IPv4 address and a port number identifies a connection endpoint anywhere on a single TCP/IP network (the Internet is a single TCP/IP network). Two connection endpoints form a TCP connection, so two IP number/port number pairs uniquely identify a TCP/IP connection on a network.
Determining which port numbers to use for various protocols is done by a part of the Internet standards known as well-known port numbers, maintained by the Internet Assigned Numbers Authority (IANA).[15] Common Internet protocols, such as ftp, telnet, and http, are each assigned a port number. Most servers provide those services at the assigned numbers, making them easy to find. Some servers are run at alternate port numbers, usually to allow multiple services to be provided by a single machine.[16] As well-known port numbers do not change, Linux uses a simple mapping between protocol names (commonly called services) and port numbers through the /etc/services file.
Although the port numbers range from 0 to 65,535, Linux divides them into two classes. The reserved ports, numbering from 0 to 1,024, may be used only by processes running as root. This allows client programs to trust that a program running on a server is not a Trojan horse started by a user.[17]
IPv4 addresses are stored in struct sockaddr_in, which is defined as follows:
#include <sys/socket.h>
#include <netinet/in.h>
struct sockaddr_in {
short int sin_family; /* AF_INET */
unsigned short int sin_port; /* port number */
struct in_addr sin_addr; /* IP address */
}
The first member must be AF_INET, indicating that this is an IP address. The next member is the port number in network byte order. The final member is the IP number of the machine for this TCP address. The IP number, stored in sin_addr, should be treated as an opaque type and not accessed directly.
If either sin_port or sin_addr is filled with � bytes (normally, by memset()), that indicates a “do not care” condition. Server processes usually do not care what IP address is used for the local connection, for example, as they are willing to accept connections to any address the machine has. If an application wishes to listen for connections only on a single interface, however, it would specify the address. This address is sometimes called unspecified as it is not a complete specification of the connection’s address, which also needs an IP address.[18]
IPv6 uses the same (local host, local port, remote host, remote port) tuple as IPv4, and the port numbers are the same between both versions (16-bit values).
The local and remote host IPv6 addresses are 128-bit (16 bytes) numbers instead of the 32-bit numbers used for IPv4. Using such large addresses gives the protocol plenty of addresses for the future (it could easily give a unique address to every atom in the Milky Way). While this probably seems like overkill, network architectures tend to waste large numbers of addresses, and the designers of IPv6 felt that it was better to change to 128-bit addresses now than to worry about the need for a possible address change in the future.
IPv6’s equivalent of IPv4’s dotted-decimal notation is colon-separated notation. As the name suggests, colons are used to separate each pair of bytes in the address (instead of a period separating each individual byte). As the addresses are so long, IPv6 addresses are written in hexadecimal (instead of decimal) form to help keep the length of the addresses down. Here are some examples of what an IPv6 address looks like in colon-separated notation:[19]:
1080:0:0:0:8:800:200C:417A FF01:0:0:0:0:0:0:43 0:0:0:0:0:0:0:1
As these addresses are quite unwieldy and tend to contain quite a few zeros, a shorthand is available. Any zeros may be left out of the written address, and groups of more than two sequential colons may be written as exactly two colons. Applying these rules to the addresses above leaves us with
1080::8:800:200C:417A FF01::43 ::1
Taken to the extreme, the address 0:0:0:0:0:0:0:0 becomes just ::.[20]
A final method for writing IPv6 addresses is to write the last 32 bits in dotted-decimal notation, and the first 96 bits in colon-separated form. This lets us write the IPv6 loopback address, ::1, as either ::0.0.0.1 or 0:0:0:0:0:0:0.0.0.1.
IPv6 defines any address with 96 leading zeros (except for the loopback address and unspecified address) as a compatible IPv4 address, which allows network routers to easily route (tunnel) packets intended for IPv4 hosts through IPv6 networks. The colon shorthand makes it easy to write an IPv4 address as an IPv6 address by prepending the normal dotted-decimal address with ::; this type of address is called an “IPv4-compatible IPv6 address.” This addressing is used only by routers; normal programs cannot take advantage of it.
Programs running on IPv6 machines that need to address IPv4 machines can use mapped IPv4 addresses. They prepend the IPV4 address with 80 leading zeros and the 16-bit value 0xffff, which is written as ::ffff: followed by the machine’s dotted-decimal IPv4 address. This addressing lets most programs on an IPv6-only system communicate transparently with an IPv4-only node.
IPv6 addresses are stored in variables of type struct sockaddr_in6.
#include <sys/socket.h>
#include <netinet/in.h>
struct sockaddr_in6 {
short int sin6_family; /* AF_INET6 */
unsigned short int sin6_port; /* port number */
unsigned int sin6_flowinfo; /* IPv6 traffic flow info */
struct in6_addr sin6_addr; /* IP address */
unsigned int sin6_scope_id; /* set of scope interfaces */
}
This structure is quite similar to struct sockaddr_in, with the first member holding the address family (AF_INET6 in this case) and the next holding a 16-bit port number in network byte order. The fourth member holds the binary representation of an IPv6 address, performing the same function as the final member of struct sockaddr_in. The other two members of the structure, sin6_flowinfo and sin6_scope_id, are for advanced uses, and should be set to zero for most applications.
The standards restrict struct sockaddr_in to exactly three members, while struct sockaddr_in6 may have extra members. For that reason programs that manually fill in a struct sockaddr_in6 should zero out the data structure using memset().
Applications often need to convert IP addresses between a human readable notation (either dotted-decimal or colon-separated) and struct in_addr’s binary representation. inet_ntop() takes a binary IP address and returns a pointer to a string containing the dotted-decimal or colon-separated form.
#include <arpa/inet.h>
const char * inet_ntop(int family, const void * address, char * dest,
int size);
The family is the address family of the address being passed as the second parameter; only AF_INET and AF_INET6 are supported. The next parameter points to a struct in_addr or a struct in6_addr6 as specified by the first parameter. The dest is a character array in which the human-readable address is stored, and is an array of size elements. If the address was successfully formatted, inet_ntop() returns dest; otherwise, it returns NULL. There are only two reasons inet_ntop() can fail: If the destination buffer is not large enough to hold the formatted address errno is set to ENOSPC, or if the family is invalid, errno contains EAFNOSUPPORT.
INET_ADDRSTRLEN is a constant that defines the largest size dest needs to be to hold any IPv4 address while INET6_ADDRSTRLEN defines the maximum array size for an IPv6 address.
The netlookup.c sample program gives an example of using inet_ntop(); the full program starts on page 445.
120: if (addr->ai_family == PF_INET) {
121: struct sockaddr_in * inetaddr = (void *) addr->ai_addr;
122: char nameBuf[INET_ADDRSTRLEN];
123:
124: if (serviceName)
125: printf(" port %d", ntohs(inetaddr->sin_port));
126:
127: if (hostName)
128: printf(" host %s",
129: inet_ntop(AF_INET, &inetaddr->sin_addr,
130: nameBuf, sizeof(nameBuf)));
131: } else if (addr->ai_family == PF_INET6) {
132: struct sockaddr_in6 * inetaddr =
133: (void *) addr->ai_addr;
134: char nameBuf[INET6_ADDRSTRLEN];
135:
136: if (serviceName)
137: printf(" port %d", ntohs(inetaddr->sin6_port));
138:
139: if (hostName)
140: printf(" host %s",
141: inet_ntop(AF_INET6, &inetaddr->sin6_addr,
142: nameBuf, sizeof(nameBuf)));
143: }
To perform the inverse, converting a string containing a dotted-decimal or colon-separated address into a binary IP address, use inet_pton().
#include <arpa/inet.h> int inet_pton(int family, const char * address, void * dest);
The family specifies the type of address being converted, either AF_INET or AF_INET6, and address points to a string containing the character representation of the address. If AF_INET is used, the dotted-decimal string is converted to a binary address stored in the struct in_addr dest points to. For AF_INET6, the colon-separated string is converted and stored in the struct in6_addr dest points to. Unlike most library functions, inet_pton() returns 1 if the conversion was successful, 0 if dest did not contain a valid address, and -1 if the family was not AF_INET or AF_INET6.
The example program reverselookup, which starts on page 451, uses inet_pton() to convert IPv4 and IPv6 addresses given by the user into struct sockaddr structures. Here is the code region that performs the conversions of the IP address pointed to by hostAddress. At the end of this code, the struct sockaddr * addr points to a structure containing the converted address.
79: if (!hostAddress) {
80: addr4.sin_family = AF_INET;
81: addr4.sin_port = portNum;
82: } else if (!strchr(hostAddress, ':')) {
83: /* If a colon appears in the hostAddress, assume IPv6.
84: Otherwise, it must be IPv4 */
85:
86: if (inet_pton(AF_INET, hostAddress,
87: &addr4.sin_addr) <= 0) {
88: fprintf(stderr, "error converting IPv4 address %s
",
89: hostAddress);
90: return 1;
91: }
92:
93: addr4.sin_family = AF_INET;
94: addr4.sin_port = portNum;
95: } else {
96:
97: memset(&addr6, 0, sizeof(addr6));
98:
99: if (inet_pton(AF_INET6, hostAddress,
100: &addr6.sin6_addr) <= 0) {
101: fprintf(stderr, "error converting IPv6 address %s
",
102: hostAddress);
103: return 1;
104: }
105:
106: addr6.sin6_family = AF_INET6;
107: addr6.sin6_port = portNum;
108: addr = (struct sockaddr *) &addr6;
109: addrLen = sizeof(addr6);
110: }
Although long strings of numbers are a perfectly reasonable identification method for computers to use for recognizing each other, people tend to get dismayed at the idea of dealing with large numbers of digits. To allow humans to use alphabetic names for computers instead of numeric ones, the TCP/IP protocol suite includes a distributed database for converting between hostnames and IP addresses. This database is called the Domain Name System (DNS) and is covered in depth by many books [Stevens, 1994] [Albitz, 1996].
DNS provides many features, but the only one we are interested in here is its ability to convert between IP addresses and hostnames. Although it may seem like this should be a one-to-one mapping, it is actually a many-to-many mapping: Every IP address corresponds to zero or more hostnames and every hostname corresponds to zero or more IP addresses.
Although using a many-to-many mapping between hostnames and IP addresses may seem strange, many Internet sites use a single machine for their ftp site and their Web site. They would like www.some.org and ftp.some.org to refer to a single machine, and they have no need for two IP addresses for the machine, so both hostnames resolve to a single IP address. Every IP address has one primary, or canonical hostname, which is used when an IP address needs to be converted to a single hostname during a reverse name lookup.
The most popular reason for mapping a single hostname to multiple IP addresses is load balancing. Name servers (programs that provide the service of converting hostnames to IP addresses) are often configured to return different addresses at different times for the same name, allowing multiple physical machines to provide a single service.
The arrival of IPv6 provides another reason for a single hostname to have multiple addresses; many machines now have both IPv4 and IPv6 addresses.
The getaddrinfo()[21] library function provides programs easy access to DNS’s hostname resolution.
#include <sys/types.h>
#include <socket.h>
#include <netdb.h>
int getaddrinfo(const char * hostname, const char * servicename,
const struct addrinfo * hints, struct addrinfo ** res);
This function is conceptually quite simple, but it is very powerful, so the details are a bit tricky. The idea is for it to take a hostname, a service name, or both, turn it into a list of IP addresses, and use the hints to filter out some of those addresses that the application is not interested in. The final list is returned as a linked list in res.
The hostname that is being looked up is in the first parameter, and may be NULL if only a service lookup is being done. The hostname may be a name (such as www.ladweb.net) or an IP address in either dotted-decimal or colon-separated form, which getaddrinfo() converts to a binary address.
The second parameter, servicename, specifies the name of the service whose well-known port is needed. If it is NULL, no service lookup is done.
struct addrinfo is used for both the hints that are used to filter the full list of addresses and for returning the final list of addresses to the application.
#include <netdb.h>
struct addrinfo {
int ai_flags;
int ai_family;
int ai_socktype;
int ai_protocol;
socklen_t ai_addrlen;
struct sockaddr_t * ai_addr;
char * ai_canonname;
struct addrinfo * next;
}
When struct addrinfo is used for the hints parameter, only the first four members are used; the rest should be set to zero or NULL. If ai_family is set, getaddrinfo() returns addresses only for the protocol family (such as PF_INET) it specifies. Similarly, if ai_socktype is set, only addresses for that type of socket are returned.
The ai_protocol member allows the results to be limited to a particular protocol. It should never be used unless ai_family is set as well, as the numeric value of a protocol (such as IPPROTO_TCP) is not unique across all protocols; it is well defined only for PF_INET and PF_INET6.
The final member that is used for the hints is ai_flags, which is one or more of the following values logically OR’ed together:
| By default, |
| On return, the |
| The |
| When |
[22] The loopback address is a special address that lets programs talk through TCP/IP to applications on the same machine only. | |
The final parameter to getaddrinfo(), res, should be the address of a pointer to a struct addrinfo. On successful completion, the variable pointed to by res is set to point to the first entry in a singly linked list of addresses that match the query. The ai_next member of the struct addrinfo points to the next member in the linked list, and the last node in the list has ai_next set to NULL. When the application is finished with the linked list that is returned, freeaddrinfo() frees the memory used by the list.
#include <sys/types.h> #include <socket.h> #include <netdb.h> void freeaddrinfo(struct addrinfo * res);
The sole parameter to freeaddrinfo is a pointer to the first node in the list.
Each node in the returned list is of type struct addrinfo, and specifies a single address that matches the query. Each address includes not only the IPv4 or IPv6 address, but also specifies the type of connection (datagram, for example) and the protocol (such as udp). If the query matches multiple types of connections for a single IP address, that address is included in multiple nodes.
Each node contains the following information:
ai_familyis the protocol family (PF_INETorPF_INET6) the address belongs to.ai_socktypeis the type of connection for the address and is normallySOCK_STREAM, SOCK_DGRAM, orSOCK_RAW.ai_protocolis the protocol for the address (normallyIPPROTO_TCPorIPPROTO_UDP).If
AI_CANONNAMEwas specified in thehintsparameter,ai_canonnamecontains the canonical name for the address.ai_addrpoints to astruct sockaddrfor the appropriate protocol. Ifai_familyisPF_INET, thenai_addrpoints to astruct sockaddr_in, for example. Theai_addrlenmember contains the length of the structureai_addrpoints to.If a
servicenamewas provided, the port number in each address is set to the well-known port for that service; otherwise, the port number for each address is zero.If no
hostnamewas provided, the port numbers are set for each address but the IP address is set to either the loopback address or the unspecified address, as specified above in the description of theAI_PASSIVEflag.
While all of this seems very complicated, there are only two different ways getaddrinfo() is normally used. Most client programs want to turn a hostname supplied by the user and a service name known by the program into a fully specified address to which the client can connect. Accomplishing this is pretty straightforward; here is a program that takes a hostname as its first argument and a service name as its second and performs the lookups:
1: /* clientlookup.c */
2:
3: #include <netdb.h>
4: #include <stdio.h>
5: #include <string.h>
6:
7: int main(int argc, const char ** argv) {
8: struct addrinfo hints, * addr;
9: const char * host = argv[1], * service = argv[2];
10: int rc;
11:
12: if (argc != 3) {
13: fprintf(stderr, "exactly two arguments are needed
");
14: return 1;
15: }
16:
17: memset(&hints, 0, sizeof(hints));
18:
19: hints.ai_socktype = SOCK_STREAM;
20: hints.ai_flags = AI_ADDRCONFIG;
21: if ((rc = getaddrinfo(host, service, &hints, &addr)))
22: fprintf(stderr, "lookup failed
");
23: else
24: freeaddrinfo(addr);
25:
26: return 0;
27: }
The interesting part of this program is lines 17-24. After clearing the hints structure, the application asks for SOCK_STREAM addresses that use a protocol configured on the local system (by setting the AI_ADDRCONFIG flag). It then calls getaddrinfo() with the hostname, service name, and hints, and displays a message if the lookup failed. On success, the first node in the linked list pointed to by addr is an appropriate address for the program to use to contact the specified service and host; whether that connection is best made using IPv4 or IPv6 is transparent to the program.
Server applications are a little bit simpler; they normally want to accept connection on a particular port, but on all addresses. Setting the AI_PASSIVE flags tells getaddrinfo() to return the address that tells the kernel to allow connections to any address it knows about when NULL is passed as the first parameter. As in the client example, AI_ADDRCONFIG is used to ensure that the returned address is for a protocol the machine supports.
1: /* serverlookup.c */
2:
3: #include <netdb.h>
4: #include <stdio.h>
5: #include <string.h>
6:
7: int main(int argc, const char ** argv) {
8: struct addrinfo hints, * addr;
9: const char * service = argv[1];
10: int rc;
11:
12: if (argc != 3) {
13: fprintf(stderr, "exactly one argument is needed
");
14: return 1;
15: }
16:
17: memset(&hints, 0, sizeof(hints));
18:
19: hints.ai_socktype = SOCK_STREAM;
20: hints.ai_flags = AI_ADDRCONFIG | AI_PASSIVE;
21: if ((rc = getaddrinfo(NULL, service, &hints, &addr)))
22: fprintf(stderr, "lookup failed
");
23: else
24: freeaddrinfo(addr);
25:
26: return 0;
27: }
After getaddrinfo() returns successfully, the first node in the linked list can be used by the server for setting up its socket.
The next example is a much more useful program. It provides a command line interface to most of the capabilities of getaddrinfo(). It allows the user to specify the hostname or service name to look up (or both), the type of socket (stream or datagram), the address family, and the protocol (TCP or UDP). The user can also ask that it display the canonical name, and that it display only addresses for protocols for which the machine is configured (via the AI_ADDRCONFIG flag). Here is how the program can be used to find the addresses to use for a telnet connection to the local machine (this machine has been configured for both IPv4 and IPv6):
$./netlookup --host localhost --service telnet IPv6 stream tcp port 23 host: :1 IPv6 dgram udp port 23 host: :1 IPv4 stream tcp port 23 host 127.0.0.1 IPv4 dgram udp port 23 host 127.0.0.1
As there is no protocol for telnet over a datagram connection defined (although a well-known port for such a service has been reserved), it is probably a good idea to restrict the search to stream protocols.
[ewt@patton code]$./netlookup --host localhost --service telnet --stream IPv6 stream tcp port 23 host: :1 IPv4 stream tcp port 23 host 127.0.0.1
After unconfiguring the local machine for IPv6, the same command looks like this:
[ewt@patton code]$./netlookup --host localhost --service telnet --stream IPv4 stream tcp port 23 host 127.0.0.1
Here is what a lookup looks like for an Internet host that has both IPv4 and IPv6 configurations:
$./netlookup --host www.6bone.net --stream IPv6 stream tcp host 3ffe:b00:c18:1::10 IPv4 stream tcp host 206.123.31.124
For a complete list of the command-line options netlookup.c supports, run it without any parameters.
1: /* netlookup.c */
2:
3: #include <netdb.h>
4: #include <arpa/inet.h>
5: #include <netinet/in.h>
6: #include <stdio.h>
7: #include <string.h>
8: #include <stdlib.h>
9:
10: /* Called when errors occur during command line processing;
11: this displays a brief usage message and exits */
12: void usage(void) {
13: fprintf(stderr, "usage: netlookup [--stream] [--dgram] "
14: "[--ipv4] [--ipv6] [--name] [--udp]
");
15: fprintf(stderr, " [--tcp] [--cfg] "
16: "[--service <service>] [--host <hostname>]
");
17: exit(1);
18: }
19:
20: int main(int argc, const char ** argv) {
21: struct addrinfo * addr, * result;
22: const char ** ptr;
23: int rc;
24: struct addrinfo hints;
25: const char * serviceName = NULL;
26: const char * hostName = NULL;
27:
28: /* clear the hints structure */
29: memset(&hints, 0, sizeof(hints));
30:
31: /* parse the command line arguments, skipping over argv[0]
32:
33: The hints structure, serviceName, and hostName will be
34: filled in based on which arguments are present. */
35: ptr = argv + 1;
36: while (*ptr && *ptr[0] == '-') {
37: if (!strcmp(*ptr, "--ipv4"))
38: hints.ai_family = PF_INET;
39: else if (!strcmp(*ptr, "--ipv6"))
40: hints.ai_family = PF_INET6;
41: else if (!strcmp(*ptr, "--stream"))
42: hints.ai_socktype = SOCK_STREAM;
43: else if (!strcmp(*ptr, "--dgram"))
44: hints.ai_socktype = SOCK_DGRAM;
45: else if (!strcmp(*ptr, "--name"))
46: hints.ai_flags |= AI_CANONNAME;
47: else if (!strcmp(*ptr, "--cfg"))
48: hints.ai_flags |= AI_ADDRCONFIG;
49: else if (!strcmp(*ptr, "--tcp")) {
50: hints.ai_protocol = IPPROTO_TCP;
51: } else if (!strcmp(*ptr, "--udp")) {
52: hints.ai_protocol = IPPROTO_UDP;
53: } else if (!strcmp(*ptr, "--host")) {
54: ptr++;
55: if (!*ptr) usage();
56: hostName = *ptr;
57: } else if (!strcmp(*ptr, "--service")) {
58: ptr++;
59: if (!*ptr) usage();
60: serviceName = *ptr;
61: } else
62: usage();
63:
64: ptr++;
65: }
66:
67: /* we need a hostName, serviceName, or both */
68: if (!hostName && !serviceName)
69: usage();
70:
71: if ((rc = getaddrinfo(hostName, serviceName, &hints,
72: &result))) {
73: fprintf(stderr, "service lookup failed: %s
",
74: gai_strerror(rc));
75: return 1;
76: }
77:
78: /* walk through the linked list, displaying all results */
79: addr = result;
80: while (addr) {
81: switch (addr->ai_family) {
82: case PF_INET: printf("IPv4");
83: break;
84: case PF_INET6: printf("IPv6");
85: break;
86: default: printf("(%d)", addr->ai_family);
87: break;
88: }
89:
90: switch (addr->ai_socktype) {
91: case SOCK_STREAM: printf(" stream");
92: break;
93: case SOCK_DGRAM: printf(" dgram");
94: break;
95: case SOCK_RAW: printf(" raw ");
96: break;
97: default: printf(" (%d)",
98: addr->ai_socktype);
99: break;
100: }
101:
102: if (addr->ai_family == PF_INET ||
103: addr->ai_family == PF_INET6)
104: switch (addr->ai_protocol) {
105: case IPPROTO_TCP: printf(" tcp");
106: break;
107: case IPPROTO_UDP: printf(" udp");
108: break;
109: case IPPROTO_RAW: printf(" raw");
110: break;
111: default: printf(" (%d)",
112: addr->ai_protocol);
113: break;
114: }
115: else
116: printf(" ");
117:
118: /* display information for both IPv4 and IPv6 addresses */
119:
120: if (addr->ai_family == PF_INET) {
121: struct sockaddr_in * inetaddr = (void *) addr->ai_addr;
122: char nameBuf[INET_ADDRSTRLEN];
123:
124: if (serviceName)
125: printf(" port %d", ntohs(inetaddr->sin_port));
126:
127: if (hostName)
128: printf(" host %s",
129: inet_ntop(AF_INET, &inetaddr->sin_addr,
130: nameBuf, sizeof(nameBuf)));
131: } else if (addr->ai_family == PF_INET6) {
132: struct sockaddr_in6 * inetaddr =
133: (void *) addr->ai_addr;
134: char nameBuf[INET6_ADDRSTRLEN];
135:
136: if (serviceName)
137: printf(" port %d", ntohs(inetaddr->sin6_port));
138:
139: if (hostName)
140: printf(" host %s",
141: inet_ntop(AF_INET6, &inetaddr->sin6_addr,
142: nameBuf, sizeof(nameBuf)));
143: }
144:
145: if (addr->ai_canonname)
146: printf(" name %s", addr->ai_canonname);
147:
148: printf("
");
149:
150: addr = addr->ai_next;
151: }
152:
153: /* free the results of getaddrinfo() */
154: freeaddrinfo(result);
155:
156: return 0;
157: }
Unlike most library functions, getaddrinfo() returns an integer that is zero on success, and describes the error on failure; errno is not normally used by these functions. Table 17.3 summarizes the various error codes that these functions can return.
Table 17.3. Address and Name Lookup Errors
Error | Description |
|---|---|
| The name could not be found, but trying again later might succeed. |
| The flags passed to the function were invalid. |
| The lookup process had a permanent error occur. |
| The address family was not recognized. |
| A memory allocation request failed. |
| The name or address cannot be converted. |
| An buffer passed was too small. |
| The service does not exist for the socket type. |
| An invalid socket type was given. |
| A system error occured, and the error is in |
These error codes can be converted to a string describing the failure through gai_strerror().
#include <netdb.h> const char * gai_strerror(int error);
The error should be the nonzero return value from getaddrinfo(). If the error is EAI_SYSTEM, the program should instead use strerror(errno) to get a good description.
Fortunately, turning IP addresses and port numbers into host and service names is simpler than going the other way.
#include <sys/socket.h>
#include <netdb.h>
int getnameinfo(struct sockaddr * addr, socklen_t addrlen,
char * hostname, size_t hostlen,
char * servicename, size_t servicelen,
int flags);
The addr parameter points to either a struct sockaddr_in or struct sockaddr_in6 structure, and addrlen contains the size of the structure addr points to. The IP address and port number specified by addr are converted to a hostname, which is stored at the location pointed to by hostname and a service name, which is stored in servicename. Either one may be NULL, causing getnameinfo() to not perform any name lookup for that parameter.
The hostlen and servicelen parameters specify how many bytes are available in the buffers pointed to by hostname and servicename respectively. If the either name does not fit in the space available, the buffers are filled up and an error (EAI_OVERFLOW) is returned.
The final argument, flags, changes how getnameinfo() performs name lookups. It should be zero or more of the following values logically OR’ed together:
| The UDP service name for the specified port is looked up instead of the TCP service name.[23] |
| If the IP address to hostname lookup fails and this flag is specified, |
| Hostnames are normally returned as full qualified domain names; this means that the complete hostname is returned rather than a local abbreviation. If this flag is set, your host is |
| Rather than performing a hostname lookup, |
| The port number is placed in |
[23] The two are almost always identical, but there are a few ports that are defined only for UDP ports (the SNMP trap protocol is one) and a few cases where the same port number is used for different TCP and UDP services (port 512 is used for the TCP exec service and the UDP biff service, for example). | |
The return codes for getnameinfo() are the same as for gethostinfo(); zero is returned on success and an error code is returned on failure. A full list of the possible errors is in Table 17.3, and gai_strerror() can be used to convert those errors into descriptive strings.
Here is an example of how to use getnameinfo() to perform some reverse name lookups for both IPv4 and IPv6 addresses:
$ ./reverselookup --host ::1
hostname: localhost
$ ./reverselookup --host 127.0.0.1
hostname: localhost
$ ./reverselookup --host 3ffe:b00:c18:1::10
hostname: www.6bone.net
$ ./reverselookup --host 206.123.31.124 --service 80
hostname: www.6bone.net
service name: http
1: /* reverselookup.c */
2:
3: #include <netdb.h>
4: #include <arpa/inet.h>
5: #include <netinet/in.h>
6: #include <stdio.h>
7: #include <string.h>
8: #include <stdlib.h>
9:
10: /* Called when errors occur during command line processing; this
11: displays a brief usage message and exits */
12: void usage(void) {
13: fprintf(stderr, "usage: reverselookup [--numerichost] "
14: "[--numericserv] [--namereqd] [--udp]
");
15: fprintf(stderr, " [--nofqdn] "
16: "[--service <service>] [--host <hostname>]
");
17: exit(1);
18: }
19:
20: int main(int argc, const char ** argv) {
21: int flags;
22: const char * hostAddress = NULL;
23: const char * serviceAddress = NULL;
24: struct sockaddr_in addr4;
25: struct sockaddr_in6 addr6;
26: struct sockaddr * addr = (struct sockaddr *) &addr4;
27: int addrLen = sizeof(addr4);
28: int rc;
29: int portNum = 0;
30: const char ** ptr;
31: char hostName[1024];
32: char serviceName[256];
33:
34: /* clear the flags */
35: flags = 0;
36:
37: /* parse the command line arguments, skipping over argv[0] */
38: ptr = argv + 1;
39: while (*ptr && *ptr[0] == '-') {
40: if (!strcmp(*ptr, "--numerichost")) {
41: flags |= NI_NUMERICHOST;
42: } else if (!strcmp(*ptr, "--numericserv")) {
43: flags |= NI_NUMERICSERV;
44: } else if (!strcmp(*ptr, "--namereqd")) {
45: flags |= NI_NAMEREQD;
46: } else if (!strcmp(*ptr, "--nofqdn")) {
47: flags |= NI_NOFQDN;
48: } else if (!strcmp(*ptr, "--udp")) {
49: flags |= NI_DGRAM;
50: } else if (!strcmp(*ptr, "--host")) {
51: ptr++;
52: if (!*ptr) usage();
53: hostAddress = *ptr;
54: } else if (!strcmp(*ptr, "--service")) {
55: ptr++;
56: if (!*ptr) usage();
57: serviceAddress = *ptr;
58: } else
59: usage();
60:
61: ptr++;
62: }
63:
64: /* we need a hostAddress, serviceAddress, or both */
65: if (!hostAddress && !serviceAddress)
66: usage();
67:
68: if (serviceAddress) {
69: char * end;
70:
71: portNum = htons(strtol(serviceAddress, &end, 0));
72: if (*end) {
73: fprintf(stderr, "failed to convert %s to a number
",
74: serviceAddress);
75: return 1;
76: }
77: }
78:
79: if (!hostAddress) {
80: addr4.sin_family = AF_INET;
81: addr4.sin_port = portNum;
82: } else if (!strchr(hostAddress, ':')) {
83: /* If a colon appears in the hostAddress, assume IPv6.
84: Otherwise, it must be IPv4 */
85:
86: if (inet_pton(AF_INET, hostAddress,
87: &addr4.sin_addr) <= 0) {
88: fprintf(stderr, "error converting IPv4 address %s
",
89: hostAddress);
90: return 1;
91: }
92:
93: addr4.sin_family = AF_INET;
94: addr4.sin_port = portNum;
95: } else {
96:
97: memset(&addr6, 0, sizeof(addr6));
98:
99: if (inet_pton(AF_INET6, hostAddress,
100: &addr6.sin6_addr) <= 0) {
101: fprintf(stderr, "error converting IPv6 address %s
",
102: hostAddress);
103: return 1;
104: }
105:
106: addr6.sin6_family = AF_INET6;
107: addr6.sin6_port = portNum;
108: addr = (struct sockaddr *) &addr6;
109: addrLen = sizeof(addr6);
110: }
111:
112: if (!serviceAddress) {
113: rc = getnameinfo(addr, addrLen, hostName, sizeof(hostName),
114: NULL, 0, flags);
115: } else if (!hostAddress) {
116: rc = getnameinfo(addr, addrLen, NULL, 0,
117: serviceName, sizeof(serviceName), flags);
118: } else {
119: rc = getnameinfo(addr, addrLen, hostName, sizeof(hostName),
120: serviceName, sizeof(serviceName), flags);
121: }
122:
123: if (rc) {
124: fprintf(stderr, "reverse lookup failed: %s
",
125: gai_strerror(rc));
126: return 1;
127: }
128:
129: if (hostAddress)
130: printf("hostname: %s
", hostName);
131: if (serviceAddress)
132: printf("service name: %s
", serviceName);
133:
134: return 0;
135: }
Listening for TCP connections is nearly identical to listening for Unix domain connections. The only differences are the protocol and address families. Here is a version of the example Unix domain server that works over TCP sockets instead:
1: /* tserver.c */
2:
3: /* Waits for a connection on port 4321. Once a connection has been
4: established, copy data from the socket to stdout until the other
5: end closes the connection, and then wait for another connection
6: to the socket. */
7:
8: #include <arpa/inet.h>
9: #include <netdb.h>
10: #include <netinet/in.h>
11: #include <stdio.h>
12: #include <string.h>
13: #include <sys/socket.h>
14: #include <unistd.h>
15:
16: #include "sockutil.h" /* some utility functions */
17:
18: int main(void) {
19: int sock, conn, i, rc;
20: struct sockaddr address;
21: size_t addrLength = sizeof(address);
22: struct addrinfo hints, * addr;
23:
24: memset(&hints, 0, sizeof(hints));
25:
26: hints.ai_socktype = SOCK_STREAM;
27: hints.ai_flags = AI_PASSIVE | AI_ADDRCONFIG;
28: if ((rc = getaddrinfo(NULL, "4321", &hints, &addr))) {
29: fprintf(stderr, "hostname lookup failed: %s
",
30: gai_strerror(rc));
31: return 1;
32: }
33:
34: if ((sock = socket(addr->ai_family, addr->ai_socktype,
35: addr->ai_protocol)) < 0)
36: die("socket");
37:
38: /* Let the kernel reuse the socket address. This lets us run
39: twice in a row, without waiting for the (ip, port) tuple
40: to time out. */
41: i = 1;
42: setsockopt(sock, SOL_SOCKET, SO_REUSEADDR, &i, sizeof(i));
43:
44: if (bind(sock, addr->ai_addr, addr->ai_addrlen))
45: die("bind");
46:
47: freeaddrinfo(addr);
48:
49: if (listen(sock, 5))
50: die("listen");
51:
52: while ((conn = accept(sock, (struct sockaddr *) &address,
53: &addrLength)) >= 0) {
54: printf("---- getting data
");
55: copyData(conn, 1);
56: printf("---- done
");
57: close(conn);
58: }
59:
60: if (conn < 0)
61: die("accept");
62:
63: close(sock);
64: return 0;
65: }
Notice that the IP address bound to the socket specifies a port number, 4321, but not an IP address. This leaves the kernel free to use whatever local IP address it likes.
The other thing that needs some explaining is this code sequence on lines 41-42:
41: i = 1; 42: setsockopt(sock, SOL_SOCKET, SO_REUSEADDR, &i, sizeof(i));
Linux’s TCP implementation, like that of most Unix systems, restricts how soon a (local host, local port)can be reused.[24] This code sets an option on the socket that bypasses this restriction and allows the server to be run twice in a short period of time. This is similar to the reason the Unix domain socket example server removed any preexisting socket file before calling bind().
The setsockopt() allows you to set many socket- and protocol-specific options:
#include <sys/socket.h>
int setsockopt(int sock, int level, int option,
const void * valptr, int vallength);
The first argument is the socket whose option is being set. The second argument, level, specifies what type of option is being set. In our server, we used SOL_SOCKET, which specifies that a generic socket option is being set. The option parameter specifies the option to be changed. A pointer to the new value of the option is passed through valptr and the size of the value pointed to by valptr is passed as vallength. For our server, we use a pointer to a non-zero integer, which turns on the SO_REUSEADDR option.
TCP clients are similar to Unix domain clients. Usually, a socket is created and immediately connect() ed to the server. The only differences are in how the address passed to connect() is set. Rather than use a file name, most TCP clients look up the hostname to connect to through getaddrinfo(), which provides the information for connect().
Here is a simple TCP client that talks to the server presented in the previous section. It takes a single argument, which is the name or IP number (in dotted-decimal notation) of the host the server is running on. It otherwise behaves like the sample Unix domain socket client presented on page 422.
1: /* tclient.c */
2:
3: /* Connect to the server whose hostname or IP is given as an
4: argument, at port 4321. Once connected, copy everything on
5: stdin to the socket, then exit. */
6:
7: #include <arpa/inet.h>
8: #include <netdb.h>
9: #include <netinet/in.h>
10: #include <stdio.h>
11: #include <stdlib.h>
12: #include <string.h>
13: #include <sys/socket.h>
14: #include <unistd.h>
15:
16: #include "sockutil.h" /* some utility functions */
17:
18: int main(int argc, const char ** argv) {
19: struct addrinfo hints, * addr;
20: struct sockaddr_in * addrInfo;
21: int rc;
22: int sock;
23:
24: if (argc != 2) {
25: fprintf(stderr, "only a single argument is supported
");
26: return 1;
27: }
28:
29: memset(&hints, 0, sizeof(hints));
30:
31: hints.ai_socktype = SOCK_STREAM;
32: hints.ai_flags = AI_ADDRCONFIG;
33: if ((rc = getaddrinfo(argv[1], NULL, &hints, &addr))) {
34: fprintf(stderr, "hostname lookup failed: %s
",
35: gai_strerror(rc));
36: return 1;
37: }
38:
39: /* this lets us access the sin_family and sin_port (which are
40: in the same place as sin6_family and sin6_port */
41: addrInfo = (struct sockaddr_in *) addr->ai_addr;
42:
43: if ((sock = socket(addrInfo->sin_family, addr->ai_socktype,
44: addr->ai_protocol)) < 0)
45: die("socket");
46:
47: addrInfo->sin_port = htons(4321);
48:
49: if (connect(sock, (struct sockaddr *) addrInfo,
50: addr->ai_addrlen))
51: die("connect");
52:
53: freeaddrinfo(addr);
54:
55: copyData(0, sock);
56:
57: close(sock);
58:
59: return 0;
60: }
While most network applications benefit from the streaming TCP protocol, some prefer to use UDP. Here are some reasons that the connectionless datagram model provided by UDP might be useful:
Connectionless protocols handle machine restarts more gracefully as there are no connections that need to be reestablished. This can be very attractive for network file systems (like NFS, which is UDP based), since it allows the file server to be restarted without the clients having to be aware of it.
Protocols that are very simple may run much faster over a datagram protocol. The Domain Name System (DNS) uses UDP for just this reason (although it optionally supports TCP as well). When a TCP connection is being established, the client machine needs to send a message to the server to establish the connection, get an acknowledgment back from the server saying the connection is available, and then tell the server when the client side has been established.[25] Once this occurs, the client can send its hostname query to the server, which responds. All of this took five messages, ignoring the error checking and sequencing for the actual query and response. By using UDP, hostname queries are sent as the first packet to the server, which then responds with one more UDP packet, reducing the total packet count to five. If the client does not get a response, it simply resends the query.
When computers are first initialized, they often need to establish an IP address and then download the first part of the operating system over the network.[26] Using UDP for these operations makes the protocol stack that is embedded on such machines much simpler than it would be if a full TCP implementation were required.
Like any other socket, UDP sockets are created through socket(), but the second argument should be SOCK_DGRAM, and the final argument is either IPPROTO_UDP or just zero (as UDP is the default IP datagram protocol).
Once the socket is created, it needs to have a local port number assigned to it. This occurs when a program does one of three things:
A port number is explicitly set by calling
bind(). Servers that need to receive datagrams on a well-known port number need to do this, and the system call is exactly the same as for TCP servers.A datagram is sent through the socket. The kernel assigns a UDP port number to that socket the first time data is sent through it. Most client programs use this technique, as they do not care what port number is used.
A remote address is set for the socket by
connect()(which is optional for UDP sockets).
There are also two different ways of assigning the remote port number. Recall that TCP sockets have the remote address assigned by connect(), which can also be used for UDP sockets.[27] While TCP’s connect() causes packets to be exchanged to initialize the connection (making connect() a slow system call), calling connect() for UDP sockets simply assigns a remote IP address and port number for outgoing datagrams, and is a fast system call. Another difference is applications can connect() a TCP socket only once; UDP sockets can have their destination address changed by calling connect() again.[28]
One advantage of using connected UDP sockets is that only the machine and port that are specified as the remote address for the socket can send datagrams to that socket. Any IP address and port can send datagrams to an unconnected UDP socket, which is required in some cases (this is how new clients initially contact servers), but forces programs to keep track of where datagrams are being sent from.
Four system calls are normally used for sending and receiving UDP packets,[29] send(), sendto(), recv(), and recvfrom().[30]
#include <sys/types.h>
#include <sys/sockets.h>
int send(int s, const void * data, size_t len, int flags);
int sendto(int s, const void * data, size_t len, int flags,
const struct sockaddr * to, socklen_t toLen);
int recv(int s, void * data, size_t maxlen, int flags);
int recvfrom(int s, void * data, size_t maxlen, int flags,
struct sockaddr * from, socklen_t * fromLen);
For our purposes, the flags for all of these are always zero. There are many values it can take, and [Stevens, 2004] discusses them in detail.
The first of the system calls, send(), can be used only for sockets whose destination IP address and port have been specified by calling connect(). It sends the first len bytes pointed to by data to the other end of the socket s. The data is sent as a single datagram. If len is too long to the data to be passed in a single datagram, EMSGSIZE is returned in errno.
The next system call, sendto() works like send() but allows the destination IP address and port number to be specified for sockets that have not been connected. The last two parameters are a pointer to the socket address and the length of the socket address. Using this function does not set a destination address for the socket; it remains unconnected and future sendto() calls can send datagrams to different destinations. If the to argument is NULL, sendto() behaves exactly like send().
The recv() and recvfrom() system calls are analogous to send() and sendto(), but they receive datagrams instead of sending them. Both write a single datagram to data, up to *maxlen bytes, and discard any part of the datagram that does not fit in the buffer. The remote address that sent the datagram is stored in the from parameter of recvmsg() as long as it is no more than fromLen bytes long.
This simple tftp server illustrates how to send and receive UDP datagrams for both connected and unconnected sockets. The tftp protocol is a very simple file transfer protocol that is built on UDP.[31] It is often used by a computer’s firmware to download an initial boot image during a network boot. The server we implement has a number of limitations that make it ill-suited for any real work:
Only a single client can talk to the server at a time (although this is easy to fix).
Files can only be sent by the server; it cannot receive them.
There are no provisions for restricting what files the server sends to an anonymous remote user.
Very little error checking is done, making it quite likely that there are exploitable security problems in the code.
A tftp client starts a tftp session by sending a “read request packet,” which contains a file name it would like to receive and a mode. The two primary modes are netascii, which performs some simple translations of the file, and octet, which sends the file exactly as it appears on the disk. This server supports only octet mode, as it is simpler.
Upon receiving the read request, the tftp server sends the file 512 bytes at a time. Each datagram contains the block number (starting from 1), and the client knows that the file has been properly received when it receives a data block containing less than 512 bytes. After each datagram, the client sends a datagram containing the block number, which acknowledges that the block has been received. Once the server sees this acknowledgment, it sends the next block of data.
The basic format of a datagram is defined by lines 17-46. Some constants are defined that specify the type of datagram being sent, along with an error code that is sent if the requested file does not exist (all other errors are handled quite unceremoniously by the server, which simply exits). The struct tftpPacket outlines what a datagram looks like, with an opcode followed by data that depends on the datagram type. The union nested inside of the structure then defines the rest of the datagram format for error, data, and acknowledgment packets.
The first part of main(), in lines 156-169, creates the UDP socket and sets up the local port number (which is either the well-known service for tftp or the port specified as the program’s sole command-line argument) by calling bind(). Unlike our TCP server example, there is no need to call either listen() or accept() as UDP is connectionless.
Once the socket has been created, the server waits for a datagram to be sent to by calling recvfrom(). The handleRequest() function is invoked on line 181, which transmits the file requested and then returns. After this call, the server once more calls recvfrom() to wait for another client to make a request. The comment right above the call to handleRequest() notes that it is quite easy to switch this server from an iterative server to a concurrent one by letting each call to handleRequest() run as its own process.
While the main part of the program used an unconnected UDP socket (which allowed any client to connect to it), handleSocket() uses a connected UDP socket to transfer the file.[32] After parsing out the file name that needs to be sent and making sure the transfer mode is correct, line 93 creates a socket of the same family, type, and protocol that the server was contacted on. It then uses connect() to set the remote end of the socket to the address that requested the file, and begins sending the file. After sending each block, the server waits for an acknowledgment packet before continuing. After the last one is received, it closes the socket and goes back to the main loop.
This server should normally be run with a port number as its only argument. To test it, the normal tftp client program can be used, with the first argument being the hostname to connect to (localhost is probably a good choice) and the second being the port number the server is running on. Once the client is running, the bin command should be issued to it so that it requests files in octet mode rather than the default netascii. Once this has been done, a get command will be able to transfer any file from the server to the client.
1: /* tftpserver.c */
2:
3: /* This is a partial implementation of tftp. It doesn't ever time
4: out or resend packets, and it doesn't handle unexpected events
5: very well. */
6:
7: #include <netdb.h>
8: #include <stdio.h>
9: #include <stdlib.h>
10: #include <string.h>
11: #include <sys/socket.h>
12: #include <unistd.h>
13: #include <fcntl.h>
14:
15: #include "sockutil.h" /* some utility functions */
16:
17: #define RRQ 1 /* read request */
18: #define DATA 3 /* data block */
19: #define ACK 4 /* acknowledgement */
20: #define ERROR 5 /* error occured */
21:
22: /* tftp error codes */
23: #define FILE_NOT_FOUND 1
24:
25: struct tftpPacket {
26: short opcode;
27:
28: union {
29: char bytes[514]; /* largest packet we can handle has 2
30: bytes for block number and 512
31: for data */
32: struct {
33: short code;
34: char message[200];
35: } error;
36:
37: struct {
38: short block;
39: char bytes[512];
40: } data;
41:
42: struct {
43: short block;
44: } ack;
45: } u;
46: };
47:
48: void sendError(int s, int errorCode) {
49: struct tftpPacket err;
50: int size;
51:
52: err.opcode = htons(ERROR);
53:
54: err.u.error.code = htons(errorCode); /* file not found */
55: switch (errorCode) {
56: case FILE_NOT_FOUND:
57: strcpy(err.u.error.message, "file not found");
58: break;
59: }
60:
61: /* 2 byte opcode, 2 byte error code, the message and a '�' */
62: size = 2 + 2 + strlen(err.u.error.message) + 1;
63: if (send(s, &err, size, 0) != size)
64: die("error send");
65: }
66:
67: void handleRequest(struct addrinfo tftpAddr,
68: struct sockaddr remote, int remoteLen,
69: struct tftpPacket request) {
70: char * fileName;
71: char * mode;
72: int fd;
73: int s;
74: int size;
75: int sizeRead;
76: struct tftpPacket data, response;
77: int blockNum = 0;
78:
79: request.opcode = ntohs(request.opcode);
80: if (request.opcode != RRQ) die("bad opcode");
81:
82: fileName = request.u.bytes;
83: mode = fileName + strlen(fileName) + 1;
84:
85: /* we only support bin mode */
86: if (strcmp(mode, "octet")) {
87: fprintf(stderr, "bad mode %s
", mode);
88: exit(1);
89: }
90:
91: /* we want to send using a socket of the same family and type
92: we started with, */
93: if ((s = socket(tftpAddr.ai_family, tftpAddr.ai_socktype,
94: tftpAddr.ai_protocol)) < 0)
95: die("send socket");
96:
97: /* set the remote end of the socket to the address which
98: initiated this connection */
99: if (connect(s, &remote, remoteLen))
100: die("connect");
101:
102: if ((fd = open(fileName, O_RDONLY)) < 0) {
103: sendError(s, FILE_NOT_FOUND);
104: close(s);
105: return ;
106: }
107:
108: data.opcode = htons(DATA);
109: while ((size = read(fd, data.u.data.bytes, 512)) > 0) {
110: data.u.data.block = htons(++blockNum);
111:
112: /* size is 2 byte opcode, 2 byte block number, data */
113: size += 4;
114: if (send(s, &data, size, 0) != size)
115: die("data send");
116:
117: sizeRead = recv(s, &response, sizeof(response), 0);
118: if (sizeRead < 0) die("recv ack");
119:
120: response.opcode = ntohs(response.opcode);
121: if (response.opcode != ACK) {
122: fprintf(stderr, "unexpected opcode in response
");
123: exit(1);
124: }
125:
126: response.u.ack.block = ntohs(response.u.ack.block);
127: if (response.u.ack.block != blockNum) {
128: fprintf(stderr, "received ack of wrong block
");
129: exit(1);
130: }
131:
132: /* if the block we just sent had less than 512 data
133: bytes, we're done */
134: if (size < 516) break;
135: }
136:
137: close(s);
138: }
139:
140: int main(int argc, char ** argv) {
141: struct addrinfo hints, * addr;
142: char * portAddress = "tftp";
143: int s;
144: int rc;
145: int bytes, fromLen;
146: struct sockaddr from;
147: struct tftpPacket packet;
148:
149: if (argc > 2) {
150: fprintf(stderr, "usage: tftpserver [port]
");
151: exit(1);
152: }
153:
154: if (argv[1]) portAddress = argv[1];
155:
156: memset(&hints, 0, sizeof(hints));
157:
158: hints.ai_socktype = SOCK_DGRAM;
159: hints.ai_flags = AI_ADDRCONFIG | AI_PASSIVE;
160: if ((rc = getaddrinfo(NULL, portAddress, &hints, &addr)))
161: fprintf(stderr, "lookup of port %s failed
",
162: portAddress);
163:
164: if ((s = socket(addr->ai_family, addr->ai_socktype,
165: addr->ai_protocol)) < 0)
166: die("socket");
167:
168: if (bind(s, addr->ai_addr, addr->ai_addrlen))
169: die("bind");
170:
171: /* The main loop waits for a tftp request, handles the
172: request, and then waits for another one. */
173: while (1) {
174: bytes = recvfrom(s, &packet, sizeof(packet), 0, &from,
175: &fromLen);
176: if (bytes < 0) die("recvfrom");
177:
178: /* if we forked before calling handleRequest() and had
179: the child exit after the function returned, this server
180: would work perfectly well as a concurrent tftp server */
181: handleRequest(*addr, from, fromLen, packet);
182: }
183: }
A number of errno values occur only with sockets. Here is a list of socket-specific errors and a short description of each:
EADDRINUSE
A requested address is already in use and cannot be reassigned.
EADDRNOTAVAIL
An unavailable address was requested.
EAFNOSUPPORT
An unsupported address family was specified.
ECONNABORTED
The connection was aborted by software.
ECONNREFUSED
ECONNRESET
The connection was reset by the remote end. This usually indicates that the remote machine was restarted.
EDESTADDRREQ
An attempt was made to send data over a socket without providing the destination address. This can occur only for datagram sockets.
EHOSTDOWN
The remote host is not on the network.
EHOSTUNREAD
The remote host cannot be reached.
EISCONN
A connection is already established for the socket.
EMSGSIZE
The data being sent through a socket is too large to be sent as a single, atomic message.
ENETDOWN
The network connection is down.
ENETRESET
The network was reset, causing the connection to be dropped.
ENETUNREACH
The specified network cannot be reached.
ENOBUFS
Not enough buffer space is available to handle the request.
ENOPROTOOPT
An attempt to set an invalid option was made.
ENOTCONN
A connection must be established before the operation can succeed.
ENOTSOCK
A socket-specific operation was attempted on a file descriptor that references a file other than a socket.
EPFNOSUPPORT
An unsupported protocol family was specified.
EPROTONOSUPPORT
A request was made for an unsupported protocol.
EPROTOTYPE
An inappropriate protocol type was specified for the socket.
ESOCKTNOSUPPORT
An attempt was made to create an unsupported socket type.
ETIMEDOUT
The connection timed out.
There are a number of library functions related to TCP/IP networking that should not be used in new applications. They are widely used in existing IPv4-only programs, however, so they are covered here to aid in understanding and updating this older code.
The inet_ntop() and inet_pton() functions are relatively new and were introduced to allow a single set of functions to handle both IPv4 and IPv6 addresses. Before they were around, programs used inet_addr(), inet_aton(), and inet_ntoa(), all of which are IPv4 specific.
Recall that struct sockaddr_in is defined as
struct sockaddr_in {
short int sin_family; /* AF_INET */
unsigned short int sin_port; /* port number */
struct in_addr sin_addr; /* IP address */
}
The sin_addr member is a struct in_addr, which these legacy functions use as a parameter.[33] This structure is meant to be opaque; application programs should never manipulate a struct in_addr except through library functions.The old function for converting an IPv4 address to its dotted-decimal form is inet_ntoa().
#include <netinet/in.h> #include <arpa/inet.h> char * inet_ntoa(struct in_addr address);
The address passed is converted to a string in dotted-decimal form, and a pointer to that string is returned. The string is stored in a static buffer in the C library and will be destroyed on the next call to inet_ntoa().[34]
There are two functions that provide the inverse, converting a dotted-decimal string to a binary IP address. The older of the two, inet_addr() function has two problems, both caused by its returning a long. Not returning a struct in_addr, which is what the rest of the standard functions expect, forced programmers into ugly casts. In addition, if a long was 32 bits, programs could not differentiate between a return of -1 (indicating an error, such as a malformed address) and the binary representation of 255.255.255.255.
#include <netinet/in.h> #include <arpa/inet.h> unsigned long int inet_addr(const char * ddaddress);
The function takes the passed string, which should contain a dotted-decimal IP address, and converts it to a binary IP address.
To remedy the shortcomings of inet_addr(), inet_aton() was introduced.
#include <netinet/in.h> #include <arpa/inet.h> int inet_aton(const char * ddaddress, struct in_addr * address);
This function expects a string containing a dotted-decimal IP address and fills in the struct in_addr pointed to by address with the binary representation of the address. Unlike most library functions, inet_aton() returns zero if an error occurred and non-zero if the conversion was successful.
The getaddrinfo() getnameinfo() functions, which make it easy to write a program that supports both IPv4 and IPv6, were added to do just that. The original hostname functions could not be easily extended for IPv6, and their interfaces require applications to know quite a bit about the version-specific structures that store IP addresses; the new interfaces are abstract and so support IPv4 and IPv6 equally.
Rather than returning a linked list like getaddrinfo() does, the older host-name functions use struct hostent, which can contain all the hostnames and addresses for a single host.
#include <netdb.h>
struct hostent {
char * h_name; /* canonical hostname */
char ** h_aliases; /* aliases (NULL terminated) */
int h_addrtype; /* host address type */
int h_length; /* length of address */
char ** h_addr_list; /* list of addresses (NULL term) */
};
The h_name is the canonical name for the host. The h_aliases array contains any aliases for the host. The final entry in h_aliases is a NULL pointer, signaling the end of the array.
h_addrtype tells the type of address the host has. For the purposes of this chapter, it is always AF_INET. Applications that were written to support IPv6 will see other address types.[35] The next member, h_length, specifies the length of the binary addresses for this host. For AF_INET addresses, it is equal to sizeof(struct in_addr). The final member, h_addr_list, is an array of pointers to the addresses for this host, with the final pointer being NULL to signify the end of the list. When h_addrtype is AF_INET, each pointer in this list points to a struct in_addr.
Two library functions convert between IP numbers and hostnames. The first, gethostbyname(), returns a struct hostent for a hostname; the other, gethostbyaddr(), returns information on a machine with a particular IP address.
#include <netdb.h> struct hostent * gethostbyname(const char * name); struct hostent * gethostbyaddr(const char * addr, int len, int type);
Both functions return a pointer to a struct hostent. The structure may be overwritten by the next call to either function, so the program should save any values it will need later. gethostbyname() takes a single parameter, a string containing a hostname. gethostbyaddr() takes three parameters, which together specify an address. The first, addr, should point to a struct in_addr. The next, len, specifies how long the information pointed to by addr is. The final parameter, type, specifies the type of address that should be converted to a hostname—AF_INET for IPv4 addresses.
When errors occur during hostname lookup, an error code is set in h_errno. The herror() function call prints a description of the error, behaving almost identically to the standard perror() function.
The only error code that most programs test for is NETDB_INTERNAL, which indicates a failed system call. When this error is returned, errno contains the error that led to the failure.
Here is a sample program that makes use of inet_aton(), inet_ntoa(), gethostbyname(), and gethostbyaddr(). It takes a single argument that may be either a hostname or an IP address in dotted-decimal notation. It looks up the host and prints all the hostnames and IP addresses associated with it.
Any argument that is a valid dotted-decimal address is assumed to be an IP number, not a hostname.
1: /* lookup.c */
2:
3: /* Given either a hostname or IP address on the command line, print
4: the canonical hostname for that host and all of the IP numbers
5: and hostnames associated with it. */
6:
7: #include <netdb.h> /* for gethostby* */
8: #include <sys/socket.h>
9: #include <netinet/in.h> /* for address structures */
10: #include <arpa/inet.h> /* for inet_ntoa() */
11: #include <stdio.h>
12:
13: int main(int argc, const char ** argv) {
14: struct hostent * answer;
15: struct in_addr address, ** addrptr;
16: char ** next;
17:
18: if (argc != 2) {
19: fprintf(stderr, "only a single argument is supported
");
20: return 1;
21: }
22:
23: /* If the argument looks like an IP, assume it was one and
24: perform a reverse name lookup */
25: if (inet_aton(argv[1], &address))
26: answer = gethostbyaddr((char *) &address, sizeof(address),
27: AF_INET);
28: else
29: answer = gethostbyname(argv[1]);
30:
31: /* the hostname lookup failed :-( */
32: if (!answer) {
33: herror("error looking up host");
34: return 1;
35: }
36:
37: printf("Canonical hostname: %s
", answer->h_name);
38:
39: /* if there are any aliases, print them all out */
40: if (answer->h_aliases[0]) {
41: printf("Aliases:");
42: for (next = answer->h_aliases; *next; next++)
43: printf(" %s", *next);
44: printf("
");
45: }
46:
47: /* display all of the IP addresses for this machine */
48: printf("Addresses:");
49: for (addrptr = (struct in_addr **) answer->h_addr_list;
50: *addrptr; addrptr++)
51: printf(" %s", inet_ntoa(**addrptr));
52: printf("
");
53:
54: return 0;
55: }
Here is what this program looks like when it is run:
$. /lookup ftp.netscape.com Canonical hostname: ftp25.netscape.com Aliases: ftp.netscape.com anonftp10.netscape.com Addresses: 207.200.74.21
While getaddrinfo() and getnameinfo() make it easy for application to convert service names to port numbers at the same time hostname resolution is performed, the older functions for service name lookups are completely independent of hostname lookups. Service names are accessed through the getservbyname() function.
#include <netdb.h>
struct servent * getservbyname(const char * name,
const char * protocol);
The first parameter, name, is the service name about which the application needs information. The protocol parameter specifies the protocol to use. The services database contains information on other protocols (especially UDP); specifying the protocol allows the function to ignore information on other protocols. The protocol is usually the string "tcp", although other protocol names, such as "udp", may be used.
getservbyname() returns a pointer to a structure that contains information on the queried service. The information may be overwritten by the next call to getservbyname(), so any important information should be saved by the application. Here is the information returned by getservbyname():
#include <netdb.h>
struct servent {
char * s_name; /* service name */
char ** s_aliases; /* service aliases */
int s_port; /* port number */
char * s_proto; /* protocol to use */
}
Each service may have multiple names associated with it but only one port number. s_name lists the canonical name of the service, s_port contains the well-known port number for the service (in network byte order), and s_proto is the protocol for the service (such as "tcp"). The s_aliases member is an array of pointers to aliases for the service, with a NULL pointer marking the end of the list.
If the function fails, it returns NULL and sets h_errno.
Here is an example program that looks up a TCP service specified on the command line and displays the service’s canonical name, port number, and all of its aliases:
1: /* services.c */
2:
3: #include <netdb.h>
4: #include <netinet/in.h>
5: #include <stdio.h>
6:
7: /* display the TCP port number and any aliases for the service
8: which is named on the command line */
9:
10: /* services.c - finds the port number for a service */
11: int main(int argc, const char ** argv) {
12: struct servent * service;
13: char ** ptr;
14:
15: if (argc != 2) {
16: fprintf(stderr, "only a single argument is supported
");
17: return 1;
18: }
19:
20: /* look up the service in /etc/services, give an error if
21: we fail */
22: service = getservbyname(argv[1], "tcp");
23: if (!service) {
24: herror("getservbyname failed");
25: return 1;
26: }
27:
28: printf("service: %s
", service->s_name);
29: printf("tcp port: %d
", ntohs(service->s_port));
30:
31: /* display any aliases this service has */
32: if (*service->s_aliases) {
33: printf("aliases:");
34: for (ptr = service->s_aliases; *ptr; ptr++)
35: printf(" %s", *ptr);
36: printf("
");
37: }
38:
39: return 0;
40: }
Here is an example of running the program; notice it can look up services by either their canonical name or an alias:
$ ./services http service: http tcp port: 80 $ ./services source service: chargen tcp port: 19 aliases: ttytst source
[1] The 2.6.x kernels covered by this book support both version 4 and version 6 (commonly referred to as IPv6 of the TCP/IP suite).
[2] Well, this depends on the character of the friends and how late they were out the night before the conversation.
[3] This is how packet-switched networks work, anyway. An alternative design, circuit-switched networks, acts more like telephone connections. They are not widely used in computer networking, however.
[4] This is why cryptography has gained so much importance since the advent of the Internet.
[5] Many higher-level protocols, such as BOOTP and NFS, are built on top of UDP.
[6] A couple of other values are available, but they are not usually used by application code.
[7] The connect() system call can also be nonblocking, which allows clients to open multiple TCP connections much more quickly (it lets the program continue to run while TCP’s three-way handshake is performed). Details on how to do this can be found in [Stevens, 2004].
[8] The various forms of select() mark a socket as ready for reading when an accept() would not block even if the socket is not marked as nonblocking. For maximum portability, select() should be used only for accepting connections with nonblocking sockets, although under Linux it is not actually necessary. [Stevens, 2004] talks about the reasons for this in detail.
[9] BSD variants do not have this behavior; on those systems the errors go unreported.
[10] For both bind() and connect(), the process must have execute permission for the directories traversed during the pathname lookup, just as with opening normal files.
[11] While it may seem like most real-world server programs would need to be concurrent, many of them are actually written as iterative servers. Many Web servers, for example, handle only a single connection at a time per process. To allow more clients to connect, the server is run as many individual processes. This makes the Web server much simpler to write, and if a bug causes one of those processes to terminate it affects only a single client connection.
[12] This is sometimes called passing access rights.
[13] Although it may seem like this is an obvious thing to do, some protocols allow the sender to use any byte order and depend on the recipient to convert the information to the proper (native) order. This gives a performance boost when like machines communicate, at the expense of algorithmic complexity.
[14] All Intel and Intel-compatible processors store data as little-endian, so getting the conversions right is important for programs to ever work properly.
[15] See http://www.iana.org for information on the IANA.
[16] Or, increasingly, to hide them from broadband ISPs who do not want their low-dollar customers running servers at home.
[17] It may still be a Trojan horse started by the superuser, however.
[18] The value for IPv4 unspecified addresses is contained in the constant INADDR_ANY, which is a 32-bit numeric value.
[19] These examples were borrowed from RFC 1884, which defines the IPv6 addressing architecture
[20] This is the unspecified address for IPv6.
[21] If you have done much socket programming in the past (or are comparing this book to its first edition) you’ll notice that the functions used for hostname resolution have changed dramatically. These changes allow programs to be written completely independently of the protocol they use. The changes were made to make it easy to write programs that work on both IPv4 and IPv6 machines, but they should extend to other protocols as well, although getaddrinfo() works only on IPv4 and IPv6 at this time.
[24] For TCP ports, the combination may not be used within a two-minute period.
[25] This is known as TCP’s three-way handshake, which is actually more complicated than described here.
[26] This process is called network booting.
[27] UDP sockets that have permanant destinations assigned by connect() are sometimes called connected UDP sockets.
[28] It is also possible to use connect() to make a connected socket an unconnected one, but doing so is not well standardized. See [Stevens, 2004] for information on how to do this if it is needed.
[29] These functions can be used to send data across any socket, and occasionally there are reasons to use them for TCP connections.
[30] The sendmsg() and recvmsg() system calls can also be used, but there is rarely a reason to do so.
[31] Full descriptions of tftp can be found in both [Stevens, 2004] and [Stevens, 1994].
[32] The tftp protocol specification requires servers to send data to a client on a port number other than the port the server is waiting for new requests on. It also makes it easier to write a concurrent server as each server socket is intended for exactly one client.
[33] Using this structure directly made it impossible to extend these functions for IPv6 without changing their interface.
[34] Functions using static memory to store results make it difficult to build threaded applications, as locks need to be added by the application code to protect those static buffers.
[35] There probably are not any IPv6 programs that use struct hostaddr, but it is possible for them to do so. The functions we discuss here return only IPv4 information by default and we do not talk about using these functions with IPv6.