
Chapter 9. Numbering Lists
If you would like to add numbered lists to
a result tree, you can use the XSLT instruction element
number. The number element
allows you to do simple number formatting, generate alphabetical
lists, use Roman numerals, insert individual formatted numbers, and
number lists at various levels. (Before actually using
number, however, you’ll first
learn how to do numbering with the position( )
function.)
You can also format numbers with the XSLT function
format-number( ), used optionally with the
decimal-format instruction element. You can read
more about the number element in Section 7.7 of
the XSLT specification, and more about format-number(
) and decimal-format in Section 12.3 of
the same spec.
Numbering with the number element can be complex
and sometimes confusing with the possible combinations of all nine of
its optional attributes. I won’t touch on all
possible numbering schemes in XSLT in this chapter, as I
don’t think it would be reasonable to do so, even in
an advanced book. Rest assured, though, that by the time you finish
reading this chapter, you’ll understand most of what
you need to know to order numbered lists with XSLT.
Numbered Lists
As usual, to illustrate a concept, I’ll begin with a simple example. In the directory examples/ch09, you’ll find the document canada.xml , which contains a list of all the Canadian provinces, in alphabetical order, as shown in Example 9-1.
<?xml version="1.0" encoding="UTF-8"?> <provinces> <name>Alberta</name> <name>British Columbia</name> <name>Manitoba</name> <name>New Brunswick</name> <name>Newfoundland and Labrador</name> <name>Northwest Territories</name> <name>Nova Scotia</name> <name>Nunavut</name> <name>Ontario</name> <name>Prince Edward Island</name> <name>Quebec</name> <name>Saskatchewan</name> <name>Yukon</name> </provinces>
You can generate numbers manually from the XPath function
position( )
to number a list from
canada.xml. Example 9-2,
position.xsl
,
shows you one way to do this.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="provinces">
<xsl:apply-templates select="name"/>
</xsl:template>
<xsl:template match="name">
<xsl:value-of select="position( )"/>
<xsl:text>. </xsl:text>
<xsl:value-of select="."/>
<xsl:text> </xsl:text>
</xsl:template>
</xsl:stylesheet>In the first value-of element in the template rule
that matches name, the position(
) function returns an integer reflecting the current
position in the current node list. The current node list at this
point consists of all the name nodes in the source
tree. After giving you the position, the template inserts some text,
then the text node child of the current name, then
a linefeed. When you apply the stylesheet like this:
xalan canada.xml position.xsl
you will get the output shown in Example 9-3.
1. Alberta 2. British Columbia 3. Manitoba 4. New Brunswick 5. Newfoundland and Labrador 6. Northwest Territories 7. Nova Scotia 8. Nunavut 9. Ontario 10. Prince Edward Island 11. Quebec 12. Saskatchewan 13. Yukon
One pitfall of using position( ) is that if you
use apply-templates without a
select attribute, the whitespace text nodes are
numbered as well. position( ) is actually counting
nodes—that is, it is counting the nodes in processing order,
regardless of where they are in the tree. Don’t be
surprised if you get strange numbers in output as a result of
position( ) quietly counting whitespace nodes!
Tip
If you are producing HTML or XHTML output, remember that you can also
generate numbered lists using the ol and
li elements.
The number Element
You can get by just using position( ), but
XSLT’s number
instruction element is far more
powerful. Example 9-4, the stylesheet
number.xsl
,
is similar to Example 8-2,
sort.xsl in examples/ch08,
but with at least one obvious difference—the presence of the
number instruction element.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="provinces">
<xsl:apply-templates select="name"/>
</xsl:template>
<xsl:template match="name">
<xsl:number format=" 1. "/>
<xsl:value-of select="."/>
<xsl:text> </xsl:text>
</xsl:template>
</xsl:stylesheet>The template that matches name inserts a formatted
number into the result tree using number, followed
by the string value of each text node child of
name that it finds. This is followed by a line
break ( ). Without using
position( ), the number is derived from the
position of the node in the source tree, not the current node list.
When number is instantiated, it numbers all the
name elements in the source document.
The inserted number is formatted according to the contents of the
optional
format attribute.
The format attribute does the job that the first
text element in position.xsl
did. All of the attributes of number are optional,
by the way, but if you don’t use
format, you might find that your numbers
don’t look very good.
The content of format is a string that describes
how you want the number formatted in output. In the case of
number.xsl, format contains
first a space followed by the digit 1, followed by
a period (.), and ending with another space. The
digit 1 will be replaced by an incremented number
when the transformation takes place.
To see how this looks, transform canada.xml with number.xsl with:
xalan canada.xml number.xsl
and you will get the results shown in Example 9-5.
The count Attribute
Without the count
attribute, by default, only
the nodes of the same name and type as the current node are counted.
If the count attribute is present, however, the
nodes that match the pattern in count are counted.
For example, when applied to canada.xml, the
stylesheet
count.xsl
,
in Example 9-6, produces the same result as
number.xsl, though the nodes you want to count
are made explicit in the count attribute.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="provinces">
<xsl:apply-templates select="name"/>
</xsl:template>
<xsl:template match="name">
<xsl:number count="name" format=" 1. "/>
<xsl:value-of select="."/>
<xsl:text> </xsl:text>
</xsl:template>
</xsl:stylesheet>More on Formatting
The output from number.xsl and
count.xsl looks very similar to what you get
with position.xsl, but you can line things up a
bit better by adding a tab to the
format
attribute, as shown in Example 9-7, the stylesheet
tab.xsl.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="provinces">
<xsl:apply-templates select="name"/>
</xsl:template>
<xsl:template match="name">
<xsl:number format=" 01.	"/>
<xsl:value-of select="."/>
<xsl:text> </xsl:text>
</xsl:template>
</xsl:stylesheet>The value of the format attribute in
tab.xsl is a little different than what you saw
earlier. Instead of following the period with a space, there is a
decimal character reference (	) for a
horizontal tab. (You could also write this as a hexadecimal
reference, that is, 	.) As
you’ll see, the tab will help line up the output.
The digit 1 has also been replaced by
01. This indicates that you want to use at least
two places for your numbers instead of one. To see what I mean,
transform canada.xml with
tab.xsl with this command:
xalan canada.xml tab.xsl
Example 9-8 shows the result.
01. Alberta 02. British Columbia 03. Manitoba 04. New Brunswick 05. Newfoundland and Labrador 06. Northwest Territories 07. Nova Scotia 08. Nunavut 09. Ontario 10. Prince Edward Island 11. Quebec 12. Saskatchewan 13. Yukon
Because tab.xsl formats the number with two places, you will get a leading zero for the numbers 1-9. Notice also that, because of the addition of the tab, all the text lines up nicely.
Alphabetical Lists
Instead of decimal numbers, you can also
use alphabetical characters in lists generated by the
number element. To get this to work, just change
the digit in the format attribute value to a
single letter—a for lowercase and
A for uppercase. For example,
alpha.xsl, shown in Example 9-9, uses a lowercase a.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="provinces">
<xsl:apply-templates select="name"/>
</xsl:template>
<xsl:template match="name">
<xsl:number format=" a.  "/>
<xsl:value-of select="."/>
<xsl:text> </xsl:text>
</xsl:template>
</xsl:stylesheet>Preceding and following the lowercase letter a
are spaces defined by decimal character references
( ). You also could have used literal
characters (just plain spaces) or hexadecimal character references
(the hex reference for a space is  ). I
use character references here in format because I
think it’s easier to see where the whitespaces are
rather than the literal spaces, but you’re free to
choose which way you want to do it—it’s a
matter of personal style.
When you transform canada.xml against alpha.xsl with:
xalan canada.xml alpha.xsl
you get Example 9-10.
a. Alberta b. British Columbia c. Manitoba d. New Brunswick e. Newfoundland and Labrador f. Northwest Territories g. Nova Scotia h. Nunavut i. Ontario j. Prince Edward Island k. Quebec l. Saskatchewan m. Yukon
Using Uppercase
If you prefer uppercase characters in your list, use an uppercase
A in format instead of a
lowercase a, as shown in
upper-alpha.xsl, which is not shown here but is
in examples/ch09. When you transform
canada.xml with
upper-alpha.xsl, you will see this generate a
list ordered with uppercase letters rather than lowercase.
Longer Alphabetical Lists
What happens when an alphabetical list is longer than the English alphabet, that is, longer than 26 items? XSLT generates repeat characters, that is, lowercase, a, b, c...x, y, z is followed by aa, ab, ac, then followed by ba, bb, bc, then ca, cb, cc, and so on.
In Example 9-11, the document us.xml alphabetically lists all 50 states of the United States of America.
<?xml version="1.0"?> <us> <state>Alabama</state> <state>Alaska</state> <state>Arizona</state> <state>Arkansas</state> <state>California</state> <state>Colorado</state> <state>Connecticut</state> <state>Delaware</state> <state>Florida</state> <state>Georgia</state> <state>Hawaii</state> <state>Idaho</state> <state>Illinois</state> <state>Indiana</state> <state>Iowa</state> <state>Kansas</state> <state>Kentucky</state> <state>Louisiana</state> <state>Maine</state> <state>Maryland</state> <state>Massachusetts</state> <state>Minnesota</state> <state>Michigan</state> <state>Mississippi</state> <state>Missouri</state> <state>Montana</state> <state>Nebraska</state> <state>Nevada</state> <state>New Hampshire</state> <state>New Jersey</state> <state>New Mexico</state> <state>New York</state> <state>North Carolina</state> <state>North Dakota</state> <state>Oklahoma</state> <state>Oregon</state> <state>Ohio</state> <state>Pennsylvania</state> <state>Rhode Island</state> <state>South Carolina</state> <state>South Dakota</state> <state>Tennessee</state> <state>Texas</state> <state>Utah</state> <state>Vermont</state> <state>Virginia</state> <state>Washington</state> <state>West Virginia</state> <state>Wisconsin</state> <state>Wyoming</state> </us>
The stylesheet us.xsl uses
number to list the states in
us.xml using lowercase letters:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="us">
<xsl:apply-templates select="state"/>
</xsl:template>
<xsl:template match="state">
<xsl:number format=" a.	"/>
<xsl:value-of select="."/>
<xsl:text> </xsl:text>
</xsl:template>
</xsl:stylesheet>The format attribute in this stylesheet uses two
longer hexadecimal character references, one for space
( ) and another for tab
(	). The number 32 in decimal is
equivalent to 20 in hexadecimal; the numbers 0 through 9 are
represented identically in decimal and hexadecimal. You can drop the
leading zeros if you want, and write the references as
  and 	.
Apply the stylesheet us.xsl to the document us.xml with:
xalan us.xml us.xsl
and you will see the following results in Example 9-12.
a. Alabama b. Alaska c. Arizona d. Arkansas e. California f. Colorado g. Connecticut h. Delaware i. Florida j. Georgia k. Hawaii l. Idaho m. Illinois n. Indiana o. Iowa p. Kansas q. Kentucky r. Louisiana s. Maine t. Maryland u. Massachusetts v. Minnesota w. Michigan x. Mississippi y. Missouri z. Montana aa. Nebraska ab. Nevada ac. New Hampshire ad. New Jersey ae. New Mexico af. New York ag. North Carolina ah. North Dakota ai. Oklahoma aj. Oregon ak. Ohio al. Pennsylvania am. Rhode Island an. South Carolina ao. South Dakota ap. Tennessee aq. Texas ar. Utah as. Vermont at. Virginia au. Washington av. West Virginia aw. Wisconsin ax. Wyoming
Roman Numerals
XSLT also supports numbering
with Roman numerals in either upper- or lowercase—with
I, II,
III, IV, or
i, ii,
iii, iv, and so forth. To
get Roman numerals in your output, just supply an upper- or lowercase
letter I or i in the
format attribute.
The roman.xsl stylesheet, shown in Example 9-13, formats its output with lowercase Roman numerals.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="us">
<xsl:apply-templates select="state"/>
</xsl:template>
<xsl:template match="state">
<xsl:number format="i	"/>
<xsl:value-of select="."/>
<xsl:text> </xsl:text>
</xsl:template>
</xsl:stylesheet>In this example, the lowercase letter i
isn’t preceded by any character, and it is followed
by a single tab (	). Apply this stylesheet
to us.xml with:
xalan us.xml roman.xsl
and you get the results shown in Example 9-14.
i Alabama ii Alaska iii Arizona iv Arkansas v California vi Colorado vii Connecticut viii Delaware ix Florida x Georgia xi Hawaii xii Idaho xiii Illinois xiv Indiana xv Iowa xvi Kansas xvii Kentucky xviii Louisiana xix Maine xx Maryland xxi Massachusetts xxii Minnesota xxiii Michigan xxiv Mississippi xxv Missouri xxvi Montana xxvii Nebraska xxviii Nevada xxix New Hampshire xxx New Jersey xxxi New Mexico xxxii New York xxxiii North Carolina xxxiv North Dakota xxxv Oklahoma xxxvi Oregon xxxvii Ohio xxxviii Pennsylvania xxxix Rhode Island xl South Carolina xli South Dakota xlii Tennessee xliii Texas xliv Utah xlv Vermont xlvi Virginia xlvii Washington xlviii West Virginia xlix Wisconsin l Wyoming
Uppercase Roman Numerals
For uppercase Roman numerals, do the same thing as you do with
alphabetical lists. The stylesheet
upper-roman.xsl replaces the lowercase
i with an uppercase I,
followed by a decimal character reference for a tab
(	). (This stylesheet is not shown here but
is in examples/ch09.) If you transform
us.xml with
upper-roman.xsl, it will give you uppercase
Roman numerals rather than lowercase.
Inserting an Individual Formatted Value
The value attribute of the
number
elements can be an individual value that you can format and then
insert into the output. As a single value, it will also be a fixed
value that isn’t based on the position of the
current node in the source document.
However, the value attribute can contain an
expression whose result is a number that is not fixed. If, for
example, the expression in value consists only of
the position( ) function, numbering will be
sequential and not fixed. See the stylesheet
value.xsl in examples/ch09
for an example of this (not shown here). You can apply this
stylesheet to canada.xml if you want to try it.
This stylesheet also sorts the content of
canada.xml in reverse, or descending, order.
If you want to insert the single number
1,000,000 into a result tree, you could do so
with the value attribute on
number. Given the little document
thanks.xml:
<thank>Thanks a </thanks>
you could insert a single number into it with thanks.xsl , as shown in Example 9-15.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="thanks">
<xsl:value-of select="."/>
<xsl:number value="1000000" grouping-size="3" grouping-separator=","/>
<xsl:text>!</xsl:text>
</xsl:template>
</xsl:stylesheet>The value attribute holds the desired number,
1000000. The
grouping-size
attribute indicates
that you want to group the number at the thousands place. The
grouping-separator
attribute specifies
a separator character (a comma [,]) that will
occur at the thousands place. In order to work, the two grouping
attributes must be used together.
Process thanks.xml with thanks.xsl for this result:
Thanks a 1,000,000!
Without the two grouping attributes used on number
in thanks.xsl, the commas
wouldn’t appear in this output.
If you live in a locale that uses a period or dot (.) instead of a comma (,) as a group separator, you will prefer to use the stylesheet in Example 9-16, dot.xsl .
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="thanks">
<xsl:value-of select="."/>
<xsl:number value="1000000" grouping-size="3" grouping-separator="."/>
<xsl:text>!</xsl:text>
</xsl:template>
</xsl:stylesheet>The only difference between thanks.xsl and
dot.xsl is the value of the
grouping-separator attribute. When used against
thanks.xml, this stylesheet generates:
Thanks a 1.000.000!
The grouping attributes grouping-size and
grouping-separator also work with numbers
generated in the ordinary way by the number
element, not just with a number supplied by the
value attribute, as shown in
dot.xsl. For example, if you have a document
that has several thousand nodes that you want to count, the following
instance of the number element with no
value attribute would place a comma at the
thousands place:
<xsl:number format=" " grouping-size="3" grouping-separator=","/>
If you want to see this in action, generate the numbers 1 through
2,000 by applying generator.xsl to
generator.xml, which contains 2,000
num nodes (not shown here but available in
examples/ch09). These files—a trivial
pair—exist among the examples only to demonstrate how the
grouping attributes work with ordinary numbering. As you might have
guessed, listing 2,000 nodes is impractical to print in a book!
Numbering Levels
An
XSLT processor analyzes a source tree before any processing takes
place. This makes it reasonably easy for the processor to determine
how many nodes lie along a given axis, and makes it possible to
produce different numbering levels when transforming a document. You
can control this with number’s
level attribute.
The level attribute lets you set the level at
which numbering takes place with one of three values:
single, multiple, and
any. So far, you have only seen numbering
single level, which is the default. Here is a
brief explanation of the three numbering levels, assuming that you
don’t use the from attribute and
that the count attribute matches the current node:
By default, the value of
levelissingle, meaning that numbering takes place only with regard to sibling nodes on one level. More precisely, nodes on thesingle(one) level are counted along the preceding-sibling axis, and include all the preceding sibling nodes that matchcountor the current node.If the value of
levelismultiple, this means that all nodes on the ancestor-or-self axis, that matchcountor the current node, are counted.If the
levelattribute has a value ofany, all nodes on the preceding or ancestor axes before the current node, that matchcountor the current node, are counted as they appear in document order.
That’s the technical explanation. The different numbering levels will be clearer to you after you get a chance to go through a couple of examples.
Counting on Multiple Levels
To start out, take a look at Example 9-17, outline.xml , which lists some information about money in the United States.
<?xml version="1.0"?> <outline> <section title="US coin denominations"> <item>cent</item> <item>nickel</item> <item>dime</item> <item>quarter</item> <item>half dollar</item> <item>dollar</item> </section> <section title="Persons on US coins"> <item>Abraham Lincoln (cent)</item> <item>Thomas Jefferson (nickel)</item> <item>Franklin Roosevelt (dime)</item> <item>George Washington (quarter)</item> <item>John Kennedy (half dollar)</item> <item>Sacagawea (dollar)</item> </section> <section title="US currency in bills"> <item>$1 dollar bill</item> <item>$2 dollar bill</item> <item>$5 dollar bill</item> <item>$10 dollar bill</item> <item>$20 dollar bill</item> <item>$50 dollar bill</item> <item>$100 dollar bill</item> </section> <section title="Persons on US bills"> <item>George Washington ($1)</item> <item>Thomas Jefferson ($2)</item> <item>Abraham Lincoln ($5)</item> <item>Alexander Hamilton $10</item> <item>Andrew Jackson ($20)</item> <item>Ulysses Grant ($50)</item> <item>Benjamin Franklin ($100)</item> </section> </outline>
There are two levels to count in outline.xml,
namely, section and item nodes.
The following stylesheet,
outline.xsl
,
counts on both levels because it uses multiple as
the value of the level attribute on
number.
This stylesheet also introduces the for-each
instruction element. As stated earlier, the
for-each element works like a template within a
template, and it is instantiated each time the node in the required
select attribute is matched.
Example 9-18 shows outline.xsl.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="text"/> <xsl:template match="outline"> <xsl:for-each select="section|//item"> <xsl:number level="multiple" count="section | item" format="i. a. "/> <xsl:value-of select="@title | text( )"/> <xsl:text> </xsl:text> </xsl:for-each> <xsl:text> see http://www.usmint.gov and http://www.bep.treas.gov </xsl:text> </xsl:template> </xsl:stylesheet>
The select
attribute of
for-each can contain an expression. In
outline.xsl, the select attribute
instructs the processor to iterate through the
section elements and
(signified by |) all item
elements in outline.xml. The two slashes
(//
) preceding
item in the select attribute
refer to all item elements that are descendants of
the root node—in other words, all
item elements in the entire
source document.
The
number element
specifies a multilevel count for section and
item elements by using the value of
multiple for level, meaning
that all ancestors will be counted. number also
formats the numbers with lowercase Roman numerals on one level and
with lowercase letters on another. After the appropriate number is
inserted, a value-of grabs
title attributes and text nodes. When
for-each is done iterating through the nodes, the
template adds a couple of URLs on to the end of the result to show
where the information came from.
The result of applying outline.xsl to outline.xml with:
xalan outline.xml outline.xsl
is shown in Example 9-19.
i. US coin denominations i. a. cent i. b. nickel i. c. dime i. d. quarter i. e. half dollar i. f. dollar ii. Persons on US coins ii. a. Abraham Lincoln (cent) ii. b. Thomas Jefferson (nickel) ii. c. Franklin Roosevelt (dime) ii. d. George Washington (quarter) ii. e. John Kennedy (half dollar) ii. f. Sacagawea (dollar) iii. US currency in bills iii. a. $1 dollar bill iii. b. $2 dollar bill iii. c. $5 dollar bill iii. d. $10 dollar bill iii. e. $20 dollar bill iii. f. $50 dollar bill iii. g. $100 dollar bill iv. Persons on US bills iv. a. George Washington ($1) iv. b. Thomas Jefferson ($2) iv. c. Abraham Lincoln ($5) iv. d. Alexander Hamilton $10 iv. e. Andrew Jackson ($20) iv. f. Ulysses Grant ($50) iv. g. Benjamin Franklin ($100) see http://www.usmint.gov and http://www.bep.treas.gov
As a result of using level="multiple“, the
section nodes are counted at one level with Roman
numerals, and the item nodes are counted at
another level, alphabetically.
Now I’ll clean up the Roman numerals that repeat in
the previous example. I want to see the Roman numerals only on the
section nodes, and the alphabetical numbering only
on the item nodes. The way to make this happen is
to number each node-set differently, in separate templates that
don’t use level="multiple“, which
is what is done in Example 9-20,
better.xsl
.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="text"/> <xsl:template match="outline"> <xsl:apply-templates select="section"/> <xsl:text> </xsl:text> <xsl:text>see http://www.usmint.gov and http://www.bep.treas.gov</xsl:text> <xsl:text> </xsl:text> </xsl:template> <xsl:template match="section"> <xsl:number format="I. "/> <xsl:value-of select="@title"/> <xsl:text> </xsl:text> <xsl:apply-templates select="item"/> </xsl:template> <xsl:template match="item"> <xsl:number format=" a. "/> <xsl:value-of select="text( )"/> <xsl:text> </xsl:text> </xsl:template> </xsl:stylesheet>
The template that matches the outline node applies
templates to section nodes, and the template that
matches section nodes applies templates to
item nodes, in that order. The template that
matches section nodes numbers the
section nodes on the single
level (the default) using one format, and the template that matches
item nodes numbers item nodes
also on the single level using a different format. I think the result
is more attractive than the previous, multilevel example. When
applied to outline.xml, using:
xalan outline.xml better.xsl
better.xsl creates the output shown in Example 9-21.
I. US coin denominations a. cent b. nickel c. dime d. quarter e. half dollar f. dollar II. Persons on US coins a. Abraham Lincoln (cent) b. Thomas Jefferson (nickel) c. Franklin Roosevelt (dime) d. George Washington (quarter) e. John Kennedy (half dollar) f. Sacagawea (dollar) III. US currency in bills a. $1 dollar bill b. $2 dollar bill c. $5 dollar bill d. $10 dollar bill e. $20 dollar bill f. $50 dollar bill g. $100 dollar bill IV. Persons on US bills a. George Washington ($1) b. Thomas Jefferson ($2) c. Abraham Lincoln ($5) d. Alexander Hamilton $10 e. Andrew Jackson ($20) f. Ulysses Grant ($50) g. Benjamin Franklin ($100) see http://www.usmint.gov and http://www.bep.treas.gov
That looks better. If you increased the depth of the outline by
adding child elements to item elements, you could
add another template to better.xsl that numbers
the new level of nodes and is invoked from the template that
processes nodes just above this new level.
More Depth
Now, let’s look at a document that has a little more depth, where you can see a varied hierarchy in the elements. Example 9-22, the document data.xml , contains some contact information for several standards organizations headquartered in the United States.
<?xml version="1.0" encoding="US-ASCII"?> <data locale="us"> <record> <name> <full>Internet Assigned Numbers Authority</full> <brief>IANA</brief> </name> <address> <street>4676 Admiralty Way, Suite 330</street> <city>Marina del Rey</city> <state>CA</state> <code>90292</code> <nation>USA</nation> </address> <tel> <phone>+1 310 823 9358</phone> <fax>+1 310 823 8649</fax> <email>[email protected]</email> </tel> </record> <record> <name> <full>Internet Society</full> <brief>ISOC</brief> </name> <address> <street>1775 Wiehle Ave., Suite 102</street> <city>Reston</city> <state>VA</state> <code>20190</code> <nation>USA</nation> </address> <tel> <phone>+1 703 326 9880</phone> <fax>+1 703 326 9881</fax> <email>[email protected]</email> </tel> </record> <record> <name> <full>Organization for the Advancement of Structured Information Standards</full> <brief>OASIS</brief> </name> <address> <street>630 Boston Rd.</street> <city>Billerica</city> <state>MA</state> <code>01821</code> <nation>USA</nation> </address> <tel> <phone>+1 978 667 5115</phone> <fax>+1 978 667 5114</fax> <email>[email protected]</email> </tel> </record> </data>
The stylesheet shown in Example 9-23,
data.xsl
,
counts all elements on the multiple level from
the data element.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:strip-space elements="*"/>
<xsl:template match="/">
<xsl:apply-templates select="data//*"/>
</xsl:template>
<xsl:template match="data//*">
<xsl:number level="multiple" count="*" from="data" format="1.1.1 "/>
<xsl:value-of select="name( )"/>
<xsl:text>: </xsl:text>
<xsl:text>	</xsl:text>
<xsl:value-of select="text( )"/>
<xsl:text> </xsl:text>
</xsl:template>
</xsl:stylesheet>I’ll discuss the from attribute
in a moment. data.xsl prints each
element’s name with its immediate text node
children, with each name preceded by a formatted section number and
interspersed with a colon and whitespace. The result of processing
data.xml with data.xsl
with:
xalan data.xml data.xsl
is shown in Example 9-24.
1 record: 1.1 name: 1.1.1 full: Internet Assigned Numbers Authority 1.1.2 brief: IANA 1.2 address: 1.2.1 street: 4676 Admiralty Way, Suite 330 1.2.2 city: Marina del Rey 1.2.3 state: CA 1.2.4 code: 90292 1.2.5 nation: USA 1.3 tel: 1.3.1 phone: +1 310 823 9358 1.3.2 fax: +1 310 823 8649 1.3.3 email: [email protected] 2 record: 2.1 name: 2.1.1 full: Internet Society 2.1.2 brief: ISOC 2.2 address: 2.2.1 street: 1775 Wiehle Ave., Suite 102 2.2.2 city: Reston 2.2.3 state: VA 2.2.4 code: 20190 2.2.5 nation: USA 2.3 tel: 2.3.1 phone: +1 703 326 9880 2.3.2 fax: +1 703 326 9881 2.3.3 email: [email protected] 3 record: 3.1 name: 3.1.1 full: Organization for the Advancement of Structured Information Standards 3.1.2 brief: OASIS 3.2 address: 3.2.1 street: 630 Boston Rd. 3.2.2 city: Billerica 3.2.3 state: MA 3.2.4 code: 01821 3.2.5 nation: USA 3.3 tel: 3.3.1 phone: +1 978 667 5115 3.3.2 fax: +1 978 667 5114 3.3.3 email: [email protected]
The numbering in Example 9-24 shows the structure of the elements and the hierarchical relationship of these elements to each other. It also shows how markup can be structured into numbered sections that technical or legal documents sometimes require.
Counting on Any Level
I’ll now show you the
difference between counting with multiple levels compared to counting
on any level. The stylesheet
any.xsl
is a little different than outline.xsl: the
value of level is any instead
of multiple, and the value of
format is also changed (i.
a. becomes 1.). When you
process outline.xml with
any.xsl:
xalan outline.xml any.xsl
you get the result shown in Example 9-25.
1. US coin denominations 2. cent 3. nickel 4. dime 5. quarter 6. half dollar 7. dollar 8. Persons on US coins 9. Abraham Lincoln (cent) 10. Thomas Jefferson (nickel) 11. Franklin Roosevelt (dime) 12. George Washington (quarter) 13. John Kennedy (half dollar) 14. Sacagawea (dollar) 15. US currency in bills 16. $1 dollar bill 17. $2 dollar bill 18. $5 dollar bill 19. $10 dollar bill 20. $20 dollar bill 21. $50 dollar bill 22. $100 dollar bill 23. Persons on US bills 24. George Washington ($1) 25. Thomas Jefferson ($2) 26. Abraham Lincoln ($5) 27. Alexander Hamilton $10 28. Andrew Jackson ($20) 29. Ulysses Grant ($50) 30. Benjamin Franklin ($100) see http://www.usmint.gov and http://www.bep.treas.gov
Using the any level produces a sequential
numbering of all nodes—no matter what level they are on. This
could be useful, for example, when numbering diagrams in a
document.
The from Attribute
The from
attribute was shown earlier in
data.xsl. This attribute tells the XSLT
processor the node where you want the counting to start
from. Example 9-26, the
stylesheet from.xsl, uses the
from attribute.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="outline">
<xsl:for-each select="section|//item">
<xsl:number from="section" level="multiple" count="section | item" format=" a "/>
<xsl:value-of select="@title | text( )"/>
<xsl:text> </xsl:text>
</xsl:for-each>
<xsl:text> see http://www.usmint.gov and http://www.bep.treas.gov </xsl:text>
</xsl:template>
</xsl:stylesheet>When you count using from="section“, the processor
counts the nodes after the
section nodes in the source tree, that is, all the
item nodes. The result of this is that
item nodes are counted, but the
section nodes are not, as Example 9-27 shows.
US coin denominations a cent b nickel c dime d quarter e half dollar f dollar Persons on US coins a Abraham Lincoln (cent) b Thomas Jefferson (nickel) c Franklin Roosevelt (dime) d George Washington (quarter) e John Kennedy (half dollar) f Sacagawea (dollar) US currency in bills a $1 dollar bill b $2 dollar bill c $5 dollar bill d $10 dollar bill e $20 dollar bill f $50 dollar bill g $100 dollar bill Persons on US bills a George Washington ($1) b Thomas Jefferson ($2) c Abraham Lincoln ($5) d Alexander Hamilton $10 e Andrew Jackson ($20) f Ulysses Grant ($50) g Benjamin Franklin ($100) see http://www.usmint.gov and http://www.bep.treas.gov
Notice that no number precedes the section text (U.S. coin denominations and so forth). Now that you’ve seen several examples of multilevel numbering, I hope you can find at least one of them that meets your needs.
The lang and letter-value Attributes
I’ll mention a pair
of attributes from number that I
haven’t yet discussed, but without concrete
examples. These attributes have to do with the different way
numbering is handled in different human languages. Speakers of
English and other European languages are accustomed to numbering with
so-called Arabic numerals, that is, with the ten digits 0-9. Some
languages, such as Hebrew and Greek, use letters from their alphabets
as numbers.
The lang attribute, like
xml:lang, takes a language token as a value, such
as en, fr,
de, or es. This language
token is supposed to signal to the XSLT processor what language is in
use with regard to numbering. Another attribute,
letter-value, takes the values
alphabetic or traditional.
These values are there to help distinguish between language-specific
numbering systems that assign numerical values to alphabetical
sequences or assign numerical values to letters in a traditional way.
Unless you are familiar with a given language, such as Hebrew or
Greek, some of these numbering schemes can be elusive.
Tip
The specification is somewhat loose in regard to this aspect of
numbering, probably because the variations and ambiguities of
numbering could make implementing number an
overwhelming task. If you need to use traditional numbering, check
the documentation provided with your XSLT processor of choice to find
out how the processor handles these cases.
More Help with Formatted Numbers
The format attribute of the
number element isn’t the only
place to turn for help with formatting numbers in XSLT. You can also
use the format-number( )
function coupled optionally with the
decimal-format
element. The top-level
decimal-format element has 10 attributes that
define number characteristics, such as the decimal separator and
percent sign used when formatting a number. Table 9-1 lists these 10 attributes with their default
values.
Tip
The default values of decimal-format are assumed
if the element is not present; if decimal-format
is present, the default values are assumed if a given attribute is
not used.
|
Attribute |
Default |
Description |
Example |
|
|
. |
Symbol that acts as a decimal point |
|
|
|
|
Symbol that represents any digit in number patterns |
|
|
|
, |
Symbol that separates groups of digits |
|
|
|
|
Symbol that represents infinity |
|
|
|
|
Symbol that represents a minus sign |
|
|
|
Name for a decimal format |
| |
|
|
|
Symbol for Not a Number |
? |
|
|
|
Symbol for separating pattern definitions |
|
|
|
|
Symbol for percent sign |
|
|
|
|
Symbol for per mille sign |
|
The number characteristics defined by
decimal-format are used with the
format-number( ) function. The
decimal-format element has no effect unless used
with the format-number( ) function.
Example 9-28, the document format.xml, provides a list of eight positive integers that will be formatted in this example.
<?xml version="1.0"?> <?xml-stylesheet href="format.xsl" type="text/xsl"?> <format> <number>100</number> <number>1000</number> <number>10000</number> <number>100000</number> <number>1000000</number> <number>10000000</number> <number>100000000</number> <number>1000000000</number> </format>
The XML stylesheet PI references the format.xsl stylesheet shown in Example 9-29.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="html"/> <xsl:decimal-format name="de" decimal-separator="," grouping-separator="."/> <xsl:decimal-format name="fr" decimal-separator="," grouping-separator=" "/> <xsl:decimal-format name="ru" decimal-separator="," grouping-separator=" "/> <xsl:decimal-format name="uk" decimal-separator="." grouping-separator=","/> <xsl:decimal-format name="us" decimal-separator="." grouping-separator=","/> <xsl:template match="convert"> <html> <head> <title>Number Formatter</title> <style type="text/css"> table {margin-left:auto;margin-right:auto} td {text-align:right;padding: 5px 5px 5px 5px} h3 {text-align:center} </style> </head> <body> <h3>Number Formatter</h3> <table rules="all"> <thead> <tr> <th>Deutschland</th> <th>France</th> <th>Россия</th> <!— Russia —> <th>United Kingdom</th> <th>United States</th> </tr> </thead> <tbody> <xsl:apply-templates select="number"/> </tbody> </table> </body> </html> </xsl:template> <xsl:template match="number"> <tr> <td><xsl:value-of select="format-number(.,'.###,00€','de')"/></td> <td><xsl:value-of select="format-number(.,' ###,00€','fr')"/></td> <td><xsl:value-of select="format-number(.,' ###,00p.','ru')"/></td> <td><xsl:value-of select="format-number(.,'£,###.00','uk')"/></td> <td><xsl:value-of select="format-number(.,'$,###.00','us')"/></td> </tr> </xsl:template> </xsl:stylesheet>
Each of the five instances of the decimal-format
element at the top of the stylesheet define a number format, each
with its own name. These formats define currency patterns for Germany
(Deutschland), France,
Р
о
с
с
и
я
(Russia), the United Kingdom, and the United States. The currency patterns identify the decimal and grouping separators that are formally used when describing currency in those countries.
The stylesheet creates some HTML and CSS for the result tree. The
headings (th) include the name
Russia spelled in Cyrillic
Р
о
с
с
и
я
using character references. As the table rows are formed with the second template, each number element in format.xml is processed with each of the five named number formats by calling the format-number( ) function. I’ll pick apart the first function call so you can better understand what’s going on with all five:
format-number(.,'.###,00€','de')
The format-number( ) function can take three
arguments (as this call does), but only two arguments are required.
The first argument in this call is a period (.).
This is a synonym for the current node (current( )
and self::node( ) also work here). The current
node is a node from the node list containing all the
number nodes in the source tree.
The second argument is a number pattern for formatting the number, as follows:
The period (.) represents a grouping separator.
The three hashes, or pound signs (
###), each represent digits. (You could change this to some other symbol with thedigitattribute indecimal-format; the default is#.)The comma (,) after the
###represents a decimal point or separator.The character reference (
€) is for the Euro currency symbol €.This pattern can produce a formatted number such as
1.000,00€.
The third and final argument for format-number( )
references a named number format (as in de) that
is defined by a decimal-format element.
The result of formatting format.xml with format.xsl is shown in Figure 9-1 in Mozilla Firebird. One reason I did this example in HTML is so that I could show the Cyrillic characters and currency symbols. They don’t show well in a command prompt window!
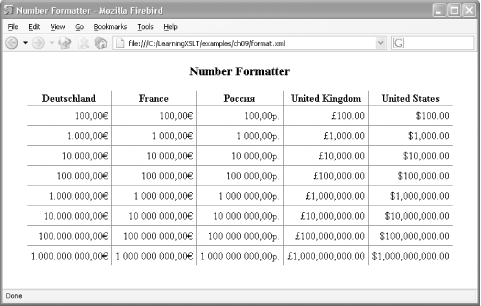
I researched the currency formats using IBM’s open source International Components for Unicode (ICU) project. ICU provides libraries of services that use the latest versions of Unicode, including international number formats (see http://oss.software.ibm.com/icu/). For information on these currency patterns discussed here, check out the ICU LocaleExplorer at http://oss.software.ibm.com/cgi-bin/icu/lx/en/utf-8/.
Summary
In this chapter, you learned how to create numbered lists for a
result tree. You learned how to format numbers, create alphabetical
and Roman numeral lists, insert single, formatted numbers into the
result, and number lists at different levels. You also learned how to
format numbers with the format-number( ) function
coupled with the decimal-format element.
You can put numbering behind you for now—it’s time to learn more about templates.