
Chapter 5. Data and XML
Almost everything we do in the software industry relates to data in some way. At some point, all software developers must deal with data, perhaps using a database, text file, spreadsheet, or some other method of data storage. There are many different methods and technologies for using, manipulating, and managing data, and newer methods are continually introduced to enhance existing ones. These methods range from function-based APIs to object-based frameworks and proprietary libraries.
Several years ago, it was common for a simple VB desktop application to access a private Microsoft Access database stored on the local hard disk, but this is no longer a typical scenario. Today’s applications take advantage of distributed-component technologies to exploit scalability and interoperability, thus widening the reach of the application to the enterprise. Although ActiveX Data Objects (ADO) served a typical VB application well a few years ago, it fails to meet the increasing demands for better scalability, performance, and interoperability across multiple platforms that web-based applications require.
Here’s where ADO.NET comes in. ADO.NET provides huge benefits that allow us to build even better enterprise applications. In this chapter, you will learn the benefits of ADO.NET, the ADO.NET architecture, the main classes in ADO.NET and how they work, and the integration of ADO.NET and XML.
ADO.NET Architecture
Microsoft ADO.NET’s object model encompasses two distinct groups of classes: content components and data-provider components.[1] The content components include the DataSet class and other supporting classes, such as DataTable, DataRow, DataColumn, and DataRelation. These classes contain the actual content of a data exchange. The data-provider components assist in data retrievals and updates. Developers can use the connection, command, and data reader objects to directly manipulate data. In more typical scenarios, developers use the DataAdapter class as the conduit to move data between the data store and the content components. The data can be actual rows from a database or any other form of data, such as an XML file or an Excel spreadsheet.
Figure 5-1 shows the high-level architecture of ADO.NET. ADO developers should have no problems understanding connection and command objects. We offer a brief overview then go into more detail in the rest of this chapter.
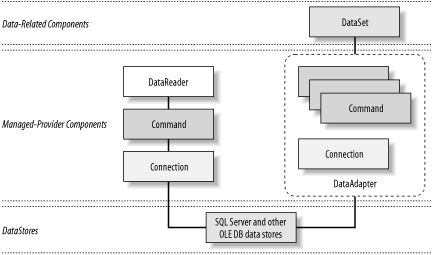
A data reader is a new object providing fast, forward-only, and read-only access to data. This structure is similar to an ADO Recordset, which has server-side, forward-only, and read-only cursor types.
The DataSet class is analogous to a lightweight cache of a subset of the database from the data store for disconnected operations. It also allows reading and writing of data and schema in XML, and it is tightly integrated with XmlDataDocument, as you will see later.
The DataAdapter class serves as a higher-level abstraction of the connection and command classes. It enables you to load content from a data store into a DataSet and reconcile DataSet changes back to the data store.
ADO.NET Benefits
ADO.NET brings with it a number of benefits, which fall into the following categories:
- Interoperability
The ability to communicate across heterogeneous environments.
- Scalability
The ability to serve a growing number of clients without degrading system performance.
- Productivity
The ability to quickly develop robust data access applications using ADO.NET’s rich and extensible component object model.
- Performance
An improvement over previous ADO versions due to the disconnected data model.
Interoperability
All communication involves data exchange, whether the communication between distributed components is through a request/response methodology or a message-based facility. Current distributed systems assume that the components involved in the communication are using the same protocol and data format. This assumption is too restrictive for a client base to expand across an enterprise or for multiple companies. Data-access layers should impose no such restrictions.
In current Microsoft Windows Distributed interNet Applications (DNA) Architecture, application components pass data back and forth as ADO disconnected recordsets. The data-providing components, as well as the data-consuming components, are required to use the Component Object Model (COM). The payload, the actual content we are passing around, is packaged in a data format called Network Data Representation (NDR). These NDR packages are streamed between components.
There are two issues with current Windows DNA systems. The first is the requirement that both ends of the communication pipe have the COM library. The second issue is that it is difficult to set up and manage these communications across firewalls. If your middle-tier components are COM/DCOM-based and you are using them within your intranet, you are in good shape. To put it another way: if all your components use Microsoft technology, you’re fine. With the advent of electronic commerce (e-commerce), however, enterprise applications must interoperate with more than just Microsoft-development shops. ADO must improve for cross-platform components to seamlessly share data, breaking away from the limitations of COM/DCOM.
ADO.NET addresses the common data-exchange limitation by using XML as its payload data format. Since XML is text-based and simple to parse, it’s a good choice for a common, platform-independent, and transportable data format. Furthermore, because XML is nothing more than structured text, employing XML as the data format on top of the HTTP network protocol minimizes firewall-related problems. With ADO and its XML format, the clients do not have to know COM to de-serialize the packaged data. All they need is an XML parser, which is readily available in many flavors on many different platforms. The data producers and consumers need only adhere to the XML schema to exchange data among themselves.
Scalability
In a client/server model, it is typical for a client to acquire and hold onto a connection to the server until all requests are fulfilled. While this solution works fine in small- to medium-scale applications, it is not scalable across a large enterprise. As soon as the number of clients reaches a certain threshold, the server becomes the bottleneck, as database connections eat up network and CPU resources. ADO.NET moves away from the client/server model by promoting the use of disconnected datasets. When a client requests some data, the data is retrieved, it’s transferred to the client, and—as soon as possible—the connection is torn down. Since the connection between the client and the data source is short-lived, this technique allows more clients to request information from the server, thus solving the problem of limited connections.
You might think that setting up and tearing down connections is not a good idea since the cost of establishing a connection is usually high. This is a concern only in the absence of connection pooling. ADO.NET automatically keeps connections to a data source in a pool, so when an application thinks it is tearing down a connection, it’s actually returning it to the resource pool. This allows connections to be reused, avoiding the cost of reconstructing new connections from scratch.
Working with data in this disconnected fashion is not new to ADO programmers. The disconnected recordset was introduced in early versions of ADO. However, in ADO, it is up to the developer to implement this feature, whereas in ADO.NET, data is disconnected by nature.
ADO.NET has enhanced its predecessor by growing out of the client/server model and into the distributed components model. By using disconnected datasets as the paradigm for data exchange, ADO.NET is much more scalable than its predecessors.
Productivity
ADO.NET’s rich data access classes allow developers to boost their productivity. Current ADO developers should have no problems getting up to speed with the object model, because ADO.NET is a natural evolution of ADO. The core functionality remains the same. We still have the connection object, representing the pipeline through which commands are executed.[2] With ADO.NET, the functionality is factored and distributed to each object in the model—much better than in previous versions of ADO. For example, the connection object is responsible only for connecting to and disconnecting from the data source. In ADO.NET, we can no longer execute a query directly through the connection object. Although some developers might miss this ability, it is a step in the right direction for cohesion of component development.
ADO.NET also boosts developers’ productivity through extensibility. Because ADO.NET framework classes are managed code, developers can inherit and extend these classes to their custom needs. If you prefer not to do this low-level legwork, you can use the Visual Studio. NET data-design environment to generate these classes for you.
Visual Studio .NET is a great Rapid Application Development (RAD) tool for developing applications with ADO.NET. You can have the Component Designer generate ADO.NET typed DataSets. These typed DataSets are extended types, modeled for your data. You don’t have to reference database fields by their names or indices but instead by their names as properties of typed objects. For example, instead of oRow(customerName), you can use oRow.customerName. The generated code is much more readable, when compared to previous Microsoft code generators. In addition, these generated classes are type-safe, thus reducing the chances for errors and allowing compilers and the CLR to verify type usage.
In short, ADO.NET improves developers’ productivity through its rich and extensible framework classes. These features are complemented by the rich toolsets for ADO.NET in Visual Studio .NET, which enable rapid application development.
Performance
Because ADO.NET is mainly about disconnected datasets, the system benefits from improved performance and scalability. The database server is no longer a bottleneck when the number of connection requests goes up. Data Providers in ADO.NET also enable implicit connection pooling, which reduces the time required to open a connection.
Previous marshaling of recordsets required type conversion to make sure that the data types were all COM-based. Since the disconnected dataset is in XML format, there is no need for this type conversion during transport, as opposed to dealing with data in Network Data Representation format.
With the ADO.NET architecture, the data providers can be optimized for better performance by talking directly to the database server. .NET Framework Data Provider for SQL Server is an example of this as we can see later in this chapter.
Content Components
Content components encapsulate data. In previous ADO versions, the Recordset object represented such a component. The data contained by the recordset component is in the form of a table, consisting of columns and rows. In ADO.NET, the data encapsulated by the DataSet component is in the form of a relational database, consisting of tables and relationships. This is a major improvement in data-access technology. In this section, we provide a high-level survey of the core classes that make up the content components, including DataSet, DataTable, DataColumn, DataRow, DataView, and DataRelation.[3]
DataSet
If you are familiar with ADO, you know that data is typically transferred between components in recordsets. The recordset contains data in a tabular form. Whether the recordset includes information from one or many tables in the database, the data is still returned in the form of rows and columns as if they were from a single table. ADO.NET allows for more than just a recordset to be shared between application components. This is one of the most important features of ADO.NET: we will be transferring a DataSet instead of a recordset.
The DataSet can be viewed as an in-memory view of the database. It can contain multiple DataTable and DataRelation objects.[4] With previous versions of ADO, the closest you could get to this functionality was to exchange data with a chain of Recordset objects. When the client application receives this chained recordset, it can get to each of the recordsets through NextRecordset( ); however, there is no way to describe the relationship between each of the recordsets in the chain. With ADO.NET, developers can navigate and manipulate the collection of tables and their relationships.
As mentioned earlier, ADO.NET involves disconnected datasets because it is geared toward a distributed architecture. Since a DataSet is disconnected, it must provide a way to track changes to itself. The DataSet object provides a number of methods so that all data manipulation done to the DataSet can be easily reconciled with the actual database (or other data source) at a later time. They include: HasChanges( ), HasErrors, GetChanges( ), AcceptChanges( ), and RejectChanges( ). You can employ these methods to check for changes that have happened to the DataSet, obtain the modifications in the form of a changed DataSet, inspect the changes for errors, and then accept or reject the changes. If you want to communicate the changes to the data store back end (which is usually the case), you would ask the DataSet for an update.
The DataSet is intended to benefit enterprise web applications, which are disconnected by nature. You don’t know that the data at the back end has changed until you have updated records you were editing or performed any other tasks that required data reconciliation with the database.
As depicted in Figure 5-2, a DataSet contains two important collections. The first is the Tables (of type DataTableCollection), which holds a collection for all the tables belonging to a given DataSet. The second collection contains all the relationships between the tables, and it is appropriately named the Relations (of type DataRelationCollection).

Creating a DataSet: An example in C#
All the tables and relations inside the DataSet are exposed through its Tables and Relations properties, respectively. Normally, you obtain tables from some data sources such as SQL Server or other databases; however, we would like to show the nuts and bolts of the DataSet here first. The following block of C# code demonstrates how to create a DataSet dynamically that consists of two tables, Orders and OrderDetails, and a relationship between the two tables:
using System;
using System.Data;
// Class and method declarations omitted for brevity . . .
// Construct the DataSet object.
DataSet m_ds = new DataSet("DynamicDS");
// Add a new table named "Order" to m_ds's collection tables.
m_ds.Tables.Add ("Order");
// Add new columns to table "Order".
m_ds.Tables["Order"].Columns.Add("OrderID",
Type.GetType("System.Int32"));
m_ds.Tables["Order"].Columns.Add("CustomerFirstName",
Type.GetType("System.String"));
m_ds.Tables["Order"].Columns.Add("CustomerLastName",
Type.GetType("System.String"));
m_ds.Tables["Order"].Columns.Add("Date",
Type.GetType("System.DateTime"));
// Register the column "OrderID" as the primary key of table "Order".
DataColumn[] keys = new DataColumn[1];
keys[0] = m_ds.Tables["Order"].Columns["OrderID"];
m_ds.Tables["Order"].PrimaryKey = keys;
// Add a new table named "OrderDetail" to m_ds's collection of tables.
m_ds.Tables.Add ("OrderDetail");
// Add new columns to table "OrderDetail".
m_ds.Tables["OrderDetail"].Columns.Add("fk_OrderID",
Type.GetType("System.Int32"));
m_ds.Tables["OrderDetail"].Columns.Add("ProductCode",
Type.GetType("System.String"));
m_ds.Tables["OrderDetail"].Columns.Add("Quantity",
Type.GetType("System.Int32"));
m_ds.Tables["OrderDetail"].Columns.Add("Price",
Type.GetType("System.Currency"));
// Get the DataColumn objects from two DataTable objects in a DataSet.
DataColumn parentCol = m_ds.Tables["Order"].Columns["OrderID"];
DataColumn childCol = m_ds.Tables["OrderDetail"].Columns["fk_OrderID"];
// Create and add the relation to the DataSet.
m_ds.Relations.Add(new DataRelation("Order_OrderDetail",
parentCol,
childCol));
m_ds.Relations["Order_OrderDetail"].Nested = true;Let’s highlight some important points in this block
of code. After instantiating the DataSet object with the new
operator, we add some tables with the Add method of the Tables
object. We go through a similar process to add columns to each
Table’s Columns collection. Each of the added tables
or columns can later be referenced by name. In order to assign the
primary key for the Order table, we have to create the DataColumn
array to hold one or more fields representing a key or a composite
key. In this case, we have only a single key field,
OrderID. We set the
PrimaryKey property of the table to this array of key columns. For
the relationship between the two tables, we first create the
DataRelation called Order_OrderDetail with the two
linking columns from the two tables, and then we add this
DataRelation to the collection of relations of the DataSet. The last
statement indicates that we want to represent the relationship
between the Order and OrderDetail table as a nested structure. This
makes dealing with these entities easier in XML.
The following block of C# code shows how to insert data into each of the two tables:
DataRow newRow; newRow = m_ds.Tables["Order"].NewRow( ); newRow["OrderID"] = 101; newRow["CustomerFirstName"] = "John"; newRow["CustomerLastName"] = "Doe"; newRow["Date"] = new DateTime(2001, 5, 1);; m_ds.Tables["Order"].Rows.Add(newRow); newRow = m_ds.Tables["Order"].NewRow( ); newRow["OrderID"] = 102; newRow["CustomerFirstName"] = "Jane"; newRow["CustomerLastName"] = "Doe"; newRow["Date"] = new DateTime(2001, 4, 29); m_ds.Tables["Order"].Rows.Add(newRow); newRow = m_ds.Tables["OrderDetail"].NewRow( ); newRow["fk_OrderID"] = 101; newRow["ProductCode"] = "Item-100"; newRow["Quantity"] = 7; newRow["Price"] = "59.95"; m_ds.Tables["OrderDetail"].Rows.Add(newRow); newRow = m_ds.Tables["OrderDetail"].NewRow( ); newRow["fk_OrderID"] = 101; newRow["ProductCode"] = "Item-200"; newRow["Quantity"] = 1; newRow["Price"] = "9.25"; m_ds.Tables["OrderDetail"].Rows.Add(newRow); newRow = m_ds.Tables["OrderDetail"].NewRow( ); newRow["fk_OrderID"] = 102; newRow["ProductCode"] = "Item-200"; newRow["Quantity"] = 3; newRow["Price"] = "9.25"; m_ds.Tables["OrderDetail"].Rows.Add(newRow);
Tables and Relations are important properties of DataSet. Not only do they describe the structure of the in-memory database, but the DataTables inside the collection also hold the content of the DataSet.
XML and tables sets
Now that you have a DataSet filled with tables and relationships, let’s see how this DataSet helps in interoperability. XML is the answer. The DataSet has a number of methods that integrate DataSet tightly with XML, thus making it universally interoperable. These methods are WriteXml( ), WriteXmlSchema( ), ReadXml( ), and ReadXmlSchema( ).
WriteXmlSchema( ) dumps only the schema of the tables, including all tables and relationships between tables. WriteXml( ) can dump both the schema and table data as an XML encoded string. Both WriteXmlSchema( ) and WriteXml( ) accept a Stream, TextWriter, XmlWriter, or String representing a filename. WriteXml( ) accepts an XmlWriteMode as the second argument so you can optionally write the schema in addition to the data.
By default, WriteXml( ) writes only the data. To also write the schema, you will have to pass XmlWriteMode.WriteSchema as the second parameter to the call. You can also retrieve only the data portion of the XML by using the XmlWriteMode.IgnoreSchema property explicitly. Another mode that you can set is XmlWriteMode.DiffGram. In this DiffGram mode, the DataSet will be dumped out as both the original data and changed data. More on this topic when we get to the GetChanges( ) method of the DataSet.
The DataSet object also provides methods to reconstruct itself from an XML document. Use ReadXmlData( ) for reading XML data documents, and ReadXmlSchema( ) for reading XML schema documents.
The following code creates an XML document from the previously created dataset:
// Dump the previously shown DataSet to
// the console (and to an XML file).
m_ds.WriteXml(Console.Out, XmlWriteMode.WriteSchema);
m_ds.WriteXml("DS_Orders.xml", XmlWriteMode.WriteSchema);
// Constructing a new DataSet object
DataSet ds2 = new DataSet("RestoredDS");
ds2.ReadXml("DS_Orders.xml");Let’s examine the resulting XML file and its representation of the dataset:
<?xml version="1.0" standalone="yes"?>
<DynamicDS>
<xs:schema id="DynamicDS"
xmlns=""
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:msdata="urn:schemas-microsoft-com:xml-msdata">
<xs:element name="DynamicDS" msdata:IsDataSet="true">
<xs:complexType>
<xs:choice maxOccurs="unbounded">
<xs:element name="Order">
<xs:complexType>
<xs:sequence>
<xs:element name="OrderID"
type="xs:int" />
<xs:element name="CustomerFirstName"
type="xs:string" minOccurs="0" />
<xs:element name="CustomerLastName"
type="xs:string" minOccurs="0" />
<xs:element name="Date"
type="xs:dateTime" minOccurs="0" />
<xs:element name="OrderDetail"
minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="fk_OrderID"
type="xs:int" minOccurs="0" />
<xs:element name="ProductCode"
type="xs:string" minOccurs="0" />
<xs:element name="Quantity"
type="xs:int" minOccurs="0" />
<xs:element name="Price"
msdata:DataType="System.Currency,
mscorlib, Version=n.n.nnnn.n,
Culture=neutral,
PublicKeyToken=nnnnnnnnnnnnnnnn"
type="xs:string" minOccurs="0" />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:choice>
</xs:complexType>
<xs:unique name="Constraint1"
msdata:PrimaryKey="true">
<xs:selector xpath=".//Order" />
<xs:field xpath="OrderID" />
</xs:unique>
<xs:keyref name="Order_OrderDetail"
refer="Constraint1"
msdata:IsNested="true">
<xs:selector xpath=".//OrderDetail" />
<xs:field xpath="fk_OrderID" />
</xs:keyref>
</xs:element>
</xs:schema>
< . . . Data Portion . . . >
</DynamicDS>The root element is named DynamicDS because that
is the name of the dataset we created earlier. The
xsd:schema tag contains all table and relationship
definitions in this DynamicDS dataset. Because we’ve
indicated that the relationship should be nested, the schema shows
the xsd:element OrderDetail nested within the
xsd:element Order. All columns are also
represented as xsd:elements.
After the table definitions, the document holds definitions for
various key types. The xsd:unique element is used
with msdata:PrimaryKey for keys, as shown in the
xsd:unique named Constraint1.
The
msdata:PrimaryKey
attribute makes this a primary key, which has the added effect of
enforcing uniqueness (every OrderID in the Order table must be
unique).
The xsd:keyref element is used for foreign keys,
as shown in the Order_OrderDetail key that refers
to the Constraint1 key. This links the OrderDetail
and Order tables where OrderDetail.fk_OrderID =
Order.OrderID.
Let’s now look at the data portion of the XML file:
<Order> <OrderID>101</OrderID> <CustomerFirstName>John</CustomerFirstName> <CustomerLastName>Doe</CustomerLastName> <Date>2001-05-01T00:00:00.0000000-04:00</Date> <OrderDetail> <fk_OrderID>101</fk_OrderID> <ProductCode>Item-100</ProductCode> <Quantity>7</Quantity> <Price>59.95</Price> </OrderDetail> <OrderDetail> <fk_OrderID>101</fk_OrderID> <ProductCode>Item-200</ProductCode> <Quantity>1</Quantity> <Price>9.25</Price> </OrderDetail> </Order> <Order> <OrderID>102</OrderID> <CustomerFirstName>Jane</CustomerFirstName> <CustomerLastName>Doe</CustomerLastName> <Date>2001-04-29T00:00:00.0000000-04:00</Date> <OrderDetail> <fk_OrderID>102</fk_OrderID> <ProductCode>Item-200</ProductCode> <Quantity>3</Quantity> <Price>9.25</Price> </OrderDetail> </Order>
This part of the XML document is fairly self-explanatory. For each row of data in the Order table, we end up with one record of type Order. This is the same for the OrderDetail table. The OrderDetail that relates to a particular Order is nested inside the Order element.
Because the dataset is inherently disconnected from its source, changes to the data inside the dataset have to be tracked by the dataset itself. This is done through the following methods: HasChanges( ), GetChanges( ), and Merge( ). The application can check the changes to the dataset and then ask the DataAdapter object to reconcile the changes with the data source through the DataAdapter Update( ) method.
The following block of code demonstrates how to the track and manage changes to a DataSet:
m_ds.AcceptChanges( );
/* Make a change to the data set. */
m_ds.Tables["OrderDetail"].Rows[0]["Quantity"] = 12;
if(m_ds.HasChanges( )){
/* Get a copy of the data set containing the changes. */
DataSet changeDS = m_ds.GetChanges( );
/* Dump the changed rows. */
changeDS.WriteXml("ChangedDS.xml" , XmlWriteMode.DiffGram);
/* Commit all changes. */
m_ds.AcceptChanges( );
}Because we create this DataSet dynamically, we want to tell the
DataSet to accept all changes made up to this point by first issuing
an AcceptChange( ) call. Knowing that the DataSet should start
tracking the changes again, we then change the quantity of one of the
OrderDetail rows. Next, we ask the dataset for all the changes and
dump it into a new dataset called changeDS. This
dataset results in the following XML dump when using DiffGram mode.
Notice that because OrderDetail is a child of Order, the change also
includes the parent row:
<?xml version="1.0" standalone="yes"?>
<diffgr:diffgram xmlns:msdata="urn:schemas-microsoft-com:xml-msdata"
xmlns:diffgr="urn:schemas-microsoft-com:xml-diffgram-v1">
<DynamicDS>
<Order diffgr:id="Order1" msdata:rowOrder="0">
<OrderID>101</OrderID>
<CustomerFirstName>John</CustomerFirstName>
<CustomerLastName>Doe</CustomerLastName>
<Date>2001-05-01T00:00:00.0000000-04:00</Date>
<OrderDetail diffgr:id="OrderDetail1"
msdata:rowOrder="0" diffgr:hasChanges="modified">
<fk_OrderID>101</fk_OrderID>
<ProductCode>Item-100</ProductCode>
<Quantity>12</Quantity>
<Price>59.95</Price>
</OrderDetail>
</Order>
</DynamicDS>
<diffgr:before>
<OrderDetail diffgr:id="OrderDetail1" msdata:rowOrder="0">
<fk_OrderID>101</fk_OrderID>
<ProductCode>Item-100</ProductCode>
<Quantity>7</Quantity>
<Price>59.95</Price>
</OrderDetail>
</diffgr:before>
</diffgr:diffgram>We would like to emphasize that the DataSet object is the most important construct in ADO.NET. Because DataSet does not tie to an underlying representation, such as SQL Server or Microsoft Access, it is extremely portable. Its data format is self-described in its schema, and its data is in pure XML. A DataSet is self-contained regardless of how it was created, whether by reading data from a SQL Server, from Microsoft Access, from an external XML file, or even by being dynamically generated as we have seen in an earlier example. This portable XML-based entity—without a doubt—should be the new standard for data exchange.
Enough said about DataSet. Let’s drill down from DataSet to DataTable.
DataTable
DataTable represents a table of data and, thus, contains a collection of DataColumns as a Columns property and a collection of DataRows as a Rows property. The Columns property provides the structure of the table, while the Rows property provides access to actual row data. Fields in the table are represented as DataColumn objects, and table records are represented as DataRow objects. Here is some sample code that dumps the name of each column as a row of headers, followed by each row of data:
/* Walk the DataTable and display all column headers
* along with all data rows.
*/
DataTable myTable = m_ds.Tables["OrderDetail"];
/* Display all column names. */
foreach(DataColumn c in myTable.Columns) {
Console.Write(c.ColumnName + " ");
}
Console.WriteLine(""); // Newline
/* Process each row. */
foreach(DataRow r in myTable.Rows) {
/* Display each column. */
foreach(DataColumn c in myTable.Columns) {
Console.Write(r[c] + " ");
}
Console.WriteLine(""); // Newline
}Here is the output of that code:
fk_OrderID ProductCode Quantity Price 101 Item-100 12 59.95 101 Item-200 1 9.25 102 Item-200 3 9.25
Typically, a DataTable has one or more fields serving as a primary key. This functionality is exposed as the PrimaryKey property. Because the primary key might contain more than one field, this property is an array of DataColumn objects. We revisit this excerpt of code here to put things in context. Note that in this example, the primary key consists of only one field; hence, the array of size one.
// Register the column "OrderID" as the primary key of table "Order". DataColumn[] keys = new DataColumn[1]; keys[0] = m_ds.Tables["Order"].Columns["OrderID"]; m_ds.Tables["Order"].PrimaryKey = keys;
Relations and constraints
Relations define how tables in a database relate to each other. The DataSet globally stores the collection of relations between tables in the Relations property; however, each of the tables participating in the relation also has to know about the relationship. ChildRelations and ParentRelations, two properties of the DataTable object, take care of this. ChildRelations enumerates all relations that this table participates in as a master table. ParentRelations, on the other hand, lists the relations in which this table acts as a slave table. We provide more information on the topic of relations when we explain the DataRelation object in an upcoming section of this chapter.
While we are on the topic of tables and relationships, it is important to understand how to set up constraint enforcements. There are two types of constraints that we can set up and enforce, UniqueConstraint and ForeignKeyConstraint. UniqueConstraint enforces the uniqueness of a field value for a table. ForeignKeyConstraint enforces rules on table relationships. For ForeignKeyConstraint, we can set up UpdateRule and DeleteRule to dictate how the application should behave upon performing update or delete on a row of data in the parent table.
Table 5-1 shows the constraint settings and behavior of ForeignKeyConstraint rules.
|
Setting |
Behavior |
|
None |
Nothing. |
|
Dependent rows (identified by foreign key) are deleted/ updated when parent row is deleted/updated. | |
|
Foreign keys in dependent rows are set to the default value when parent row is deleted. | |
|
Foreign keys in dependent rows are set to null value when parent row is deleted. |
Constraints are activated only when the EnforceConstraint property of
the DataSet object is set to true.
The following block of code shows how we have altered the foreign key
constraint between the Order and
OrderDetail tables to allow cascading deletion:
m_ds.Relations["Order_OrderDetail"].ChildKeyConstraint.DeleteRule =
Rule.Cascade;
m_ds.WriteXml("DS_BeforeCascadeDelete.xml");
m_ds.Tables["Order"].Rows[0].Delete( );
m_ds.WriteXml("DS_AfterCascadeDelete.xml");As the result of running this code, the DataSet is left with only one order (order 102), which contains one line item.
DataView
The DataView object is similar to a view in conventional database programming. We can create different customized views of a DataTable, each with different sorting and filtering criteria. Through these different views, we can traverse, search, and edit individual records. This ADO.NET concept is the closest to the old ADO recordset. In ADO.NET, DataView serves another important role—data binding to Windows Forms and Web Forms. We show the usage of DataView when we discuss data binding on Windows Forms and Web Forms in Chapter 7 and Chapter 8.
DataRelation
A DataSet object as a collection of DataTable objects alone is not useful enough. A collection of DataTable objects returned by a server component provides little improvement upon the chained recordset in previous versions of ADO. In order for your client application to make the most of the returned tables, you also need to return the relations between these DataTables. This is where the DataRelation object comes into play.
With DataRelation, you can define relationships between the DataTable objects. Client components can inspect an individual table or navigate the hierarchy of tables through these relationships. For example, you can find a particular row in a parent table and then traverse all dependent rows in a child table.
The DataRelation contains the parent table name, the child table name, the parent table column (primary key), and the child table column (foreign key).
Because it has multiple DataTables and DataRelations within the DataSet, ADO.NET allows for a much more flexible environment where consumers of the data can choose to use the data in whichever way they wish.
One example might be the need to display all information about a particular parent table and all of its dependent rows in a child table. You have ten rows in the parent table. Each of the rows in the parent table has ten dependent rows in the child table. Let’s consider two approaches to getting this data to the data consumer. First, we will just use a join in the query string:
Select
Order.CustomerFirstName, Order.CustomerLastName, Order.OrderDate,
OrderDetail.ProductCode, OrderDetail.Quantity, OrderDetail.Price
from
Order, OrderDetail
where Order.OrderID = OrderDetail.fk_OrderIDThe result set contains 100 rows, in which each group of ten rows contains duplicate information about the parent row.
A second approach is to retrieve the list of rows from the parent table first, which would be ten rows:
Select Order.OrderID, Order.CustomerFirstName, Order.CustomerLastName, Order.OrderDate from Order
Then for each of the ten rows in the parent table, you would retrieve the dependent rows from the child table:
Select
OrderDetail.ProductCode, OrderDetail.Quantity, OrderDetail.Price
from
OrderDetail where fk_OrderID = thisOrderID
This second approach is less of a resource hog since there is no redundant data; however, you end up making 11 round-trips (one time for the parent table, and 10 times for each parent of the child table).
It’s better to get the parent table, the child table, and the relation between them using one round-trip, without all the redundant data. This is one of the biggest benefits that DataSet brings. The following block of code demonstrates the power of having tables and relationships:
/*
* Given an order id, display a single order.
*/
public static void DisplaySingleOrder(DataSet m_ds, int iOrderID) {
Decimal runningTotal = 0;
Decimal lineTotal = 0;
Decimal dPrice = 0;
int iQty = 0;
DataTable oTable = m_ds.Tables["Order"];
// Find an order from the Order table.
DataRow oRow = oTable.Rows.Find(iOrderID);
/* Navigate to the OrderDetail table
* through the Order_Details relationship.
*/
DataRow[] arrRows = oRow.GetChildRows("Order_OrderDetail");
/* Display the order information. */
Console.WriteLine ("Order: {0}", iOrderID);
Console.WriteLine ("Name: {0} {1}",
oRow["CustomerFirstName"].ToString( ),
oRow["CustomerLastName"].ToString( ));
Console.WriteLine ("Date: {0}", oRow["Date"].ToString( ));
Console.WriteLine("---------------------------");
/*
* Display and calculate line total for each item.
*/
for(int i = 0; i < arrRows.Length; i++) {
foreach(DataColumn myColumn in m_ds.Tables["OrderDetail"].Columns)
{
Console.Write(arrRows[i][myColumn] + " ");
}
iQty = System.Int32.Parse(arrRows[i]["Quantity"].ToString( ));
dPrice = System.Decimal.Parse(arrRows[i]["Price"].ToString( ));
lineTotal = iQty * dPrice;
Console.WriteLine("{0}", lineTotal);
/* Keep a running total. */
runningTotal += lineTotal;
}
/* Display the total of the order. */
Console.WriteLine("Total: {0}", runningTotal);
}DisplaySingleOrder finds a single row in the Order table with a given
order ID. Once this row is found, we ask the row for an array of
dependent rows from the OrderDetail table according to the
Order_OrderDetail relationship. With the returned
array of DataRows, we then proceed to display all fields in the row.
We also calculate the lineTotal value based on the
quantity ordered and the price of the item, as well as keeping a
runningTotal for the whole order. The following
shows the output from the DisplaySingleOrder function:
Order: 101 Name: John Doe Date: 5/1/2001 12:00:00 AM --------------------------- 101 Item-100 12 59.95 719.4 101 Item-200 1 9.25 9.25 Total: 728.65
.NET Framework Data Providers
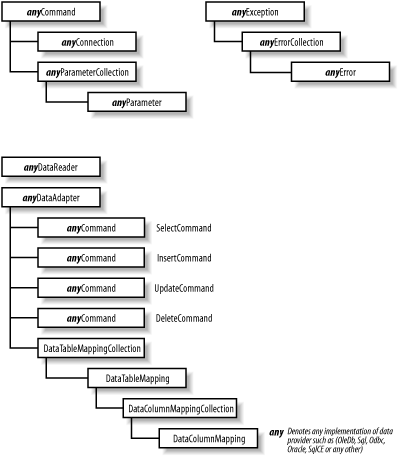
.NET Framework Data Provider (a.k.a. Managed Provider) is a term used for a group of .NET components that implement a fixed set of functionality put forth by the ADO.NET architecture. This enforces a common interface for accessing data. In order to build our own data provider, we must provide our own implementation of System.Data.Common.DbDataAdapter objects and implement interfaces such as IDbCommand, IDbConnection, and IDataReader. We are not building our own data provider here;[5] however, we do dive into each of these classes and interfaces in this section.
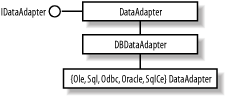
Most of the time, developers don’t have to know how to implement data providers, even though this might increase their productivity with regard to ADO.NET. Understanding how to use the stock data providers alone is sufficient to develop your enterprise application. Microsoft provides the following data providers in its current release of ADO.NET: OLE DB and SQL (Version 1 of .NET Framework) and ODBC, Oracle, SQL CE. The OLE DB data provider comes with OleDbConnection, OleDbCommand, OleDbParameter, and OleDbDataReader. The SQL Server data provider comes with a similar set of objects, whose names start with SqlClient instead of OleDb, and so on, as illustrated in Figure 5-3. The implementation of this core function set for data providers is packaged in the System.Data namespace. The assemblies are: System.Data.{Odbc, OleDb, OracleClient SqlClient, SqlServerCe}.

All of the included data providers implement a set of interfaces that access the appropriate data store. The OLE DB provider relies on OLE DB as an access layer to a broad variety of data sources, including Microsoft SQL Server. For performance reasons, the SQL data provider uses a proprietary protocol to communicate directly with SQL Server. In Version 1.1 of the .NET framework, ODBC, Oracle, and SQL CE data providers are added to provide better performance for these data store. Regardless of how the data is obtained, the resulting dataset remains the same. This clean separation of data providers and the XML-based dataset helps ADO.NET achieve portable data.
Figure 5-3 shows the base classes and the all implementations of data provider. Because all data providers, adhere to a fixed, common set of interfaces (IDbCommand, IDbConnection, IDataParameterCollection, IDataReader, and IDataAdapter), you can easily adapt your application to switch data providers as the need arises.
Connection
All Connection classes implement System.Data.IDbConnection and, thus, inherit properties such as the connection string and the state of the connection. They implement the core set of methods specified by IDbConnection, including Open and Close.
Unlike the ADO Connection object, transaction support for the ADO.NET connection object has been moved to a Transaction object (such as OleDbTransaction and SqlTransaction). The reason for this is that we cannot assume that all data providers implement transaction the same way, so it’s better for the Connection object not to have transaction-related functionalities. To create a new transaction, execute the BeginTransaction( ) method of the Connection object. This returns an IDbTransaction implementation that supports transaction-oriented functionality such as Commit and Rollback. The SqlTransaction is currently the only provider that also supports saving checkpoints so that we can rollback to a specific checkpoint instead of rolling back the whole transaction. Again, if you examine the list of methods that any Connection class (such as OleDbConnection and SqlConnection) supports, you will find that the functionality is very much the same as the old ADO Connection object’s. However, none of the Connection classes allows SQL statements or provider-specific text statements to be executed directly any more. In other words, Execute( ) is no longer supported by the Connection object. This is a better way for distributing functionality between classes. All execution is done through the Command object, which is discussed in the next section along with how to initiate a connection.
The Command and Data Reader Objects
Fortunately for ADO developers, ADO.NET’s Command objects behave like ADO’s Command object; however, the Command objects are the only way we can make execution requests to insert, update, and delete data in ADO.NET. This makes it easier to learn the object model. Developers are not faced with as many ways of doing the same things, as in the case (with ADO) of whether to execute the query through a Connection, Command, or even a Recordset object.
Command execution
All commands are associated with a connection object through the Command’s Connection property. Think of the connection object as the pipeline between the data-reading component and the database back end. In order to execute a command, the active connection has to be opened. The command object also accepts parameters to execute a stored procedure at the back end. The top left of Figure 5-5 shows the relationships between command, connection, and parameters objects.
There are two types of execution. The first type is a query command, which returns an IDataReader implementation. It is implemented by the ExecuteReader( ) method. The second type of command typically performs an update, insert, or deletion of rows in a database table. This type of execution is implemented by the ExecuteNonQuery( ) method.
One of the main differences between ADO.NET’s Command objects and ADO’s Command object is the return data. In ADO, the result of executing a query command is a recordset, which contains the return data in tabular form.[6] In ADO.NET, however, recordsets are no longer supported. The result of executing a query command is now a data reader object (see the following section). This data reader object can be an OleDbDataReader for OLE DB, SqlDataReader for SQL Server (as of v.1 of .NET Framework), or any class implementing the IDataReader for custom reading needs. Once you’ve obtained a valid data reader object, you can perform a Read operation on it to get to your data.
Employing the command, connection, and data reader objects is a low-level, direct way to work with the data provider. As you will find out a little later, the data adapter encapsulates all this low-level plumbing as a more direct way to get the data from the data source to your disconnected dataset.
The data reader object
The data reader is a brand new concept to ADO developers, but it is straightforward. A data reader is similar to a stream object in object-oriented programming (OOP). If you need to access records in a forward-only, sequential order, use a data reader because it is very efficient. Since this is a server-side cursor, the connection to the server is open throughout the reading of data. Because of this continually open connection, we recommend that you exercise this option with care and not have the data reader linger around longer than it should. Otherwise, it might affect the scalability of your application.
The following code demonstrates basic use of OleDbConnection, OleDbCommand, and OleDbDataReader. Though we’re using the OLE DB data provider here, the connection string is identical to the one we used earlier for ADO:[7]
using System;
using System.Data;
using System.Data.OleDb;
public class pubsdemo {
public static void Main( ) {
/* An OLE DB connection string. */
String sConn =
"provider=sqloledb;server=(local);database=pubs; Integrated Security=SSPI";
/* An SQL statement. */
String sSQL = "select au_fname, au_lname, phone from authors";
/* Create and open a new connection. */
OleDbConnection oConn = new OleDbConnection(sConn);
oConn.Open( );
/* Create a new command and execute the SQL statement. */
OleDbCommand oCmd = new OleDbCommand(sSQL, oConn);
OleDbDataReader oReader = oCmd.ExecuteReader( );
/* Find the index of the columns we're interested in. */
int idxFirstName = oReader.GetOrdinal("au_fname");
int idxLastName = oReader.GetOrdinal("au_lname");
int idxPhone = oReader.GetOrdinal("phone");
/* Retrieve and display each column using their column index. */
while(oReader.Read( )) {
Console.WriteLine("{0} {1} {2}",
oReader.GetValue(idxFirstName),
oReader.GetValue(idxLastName),
oReader.GetValue(idxPhone));
}
}
}The code opens a connection to the local SQL Server (using integrated security)[8] and issues a query for first name, last name, and phone number from the authors table in the pubs database.
If you don’t have the pubs database installed on
your system, you can load and run
instpubs.sql
in Query Analyzer
(instpubs.sql can be found under the
MSSQLInstall directory on your machine). For
those that install the VS.NET Quickstart examples, change the server
parameter of the connection string to
server=(local)\NetSDK because the Quickstart
examples installation lays down the NetSDK SQL Server instance that
also include the infamous Pubs database. The following example uses
SqlClient to get the same information. This time, instead of
obtaining the indices for the columns and getting the values based on
the indices, this example indexes the column directly using the
column names:
using System;
using System.Data;
using System.Data.SqlClient;
public class pubsdemo {
public static void Main( ) {
/* A SQL Server connection string. */
String sConn = "server=(local);database=pubs;Integrated Security=SSPI";
/* An SQL statement. */
String sSQL = "select au_fname, au_lname, phone from authors";
/* Create and open a new connection. */
SqlConnection oConn = new SqlConnection(sConn);
oConn.Open( );
/* Create a new command and execute the SQL statement. */
SqlCommand oCmd = new SqlCommand(sSQL, oConn);
SqlDataReader oReader = oCmd.ExecuteReader( );
/* Retrieve and display each column using the column names. */
while(oReader.Read( )) {
Console.WriteLine("{0} {1} {2}",
oReader["au_fname"],
oReader["au_lname"],
oReader["phone"]);
}
}
}We leave the example code utilizing other data providers to the readers as an exercise.
The DataAdapter Object
Along with the introduction of data reader, ADO.NET also brings the DataAdapter object, which acts as the bridge between the data source and the disconnected DataSet. It contains a connection and a number of commands for retrieving the data from the data store into one DataTable in the DataSet and updating the data in the data store with the changes currently cached in the DataSet. Although each DataAdapter maps only one DataTable in the DataSet, you can have multiple adapters to fill the DataSet object with multiple DataTables. The class hierarchy of DataAdapter is shown in Figure 5-4. All Data Adapters are derived from DbDataAdapter, which in turn is derived from the DataAdapter abstract class. This DataAdapter abstract class implements the IDataAdapter interface, which specifies that it supports Fill and Update. IDataAdapter is specified in the System.Data namespace, as is the DataSet itself.
The data adapter can fill a DataSet with rows and update the data source when you make changes to the dataset. For example, you can use OleDbAdapter to move data from an OLE DB provider into a DataSet using the OleDbDataAdapter.Fill( ) method. Then you can modify the DataSet and commit the changes you made to the underlying database using the OleDbDataAdapter.Update( ) method. These adapters act as the middleman bridging the data between the database back end and the disconnected DataSet.
For data retrieval, a data adapter uses the SQL
SELECT command (exposed as the SelectCommand
property). This
SELECT command is
used in the implementation of the IDataAdapter
interface’s Fill method. For updating data, a data
adapter uses the SQL UPDATE,
INSERT, and
DELETE commands (exposed
as the UpdateCommand, InsertCommand, and DeleteCommand properties).
Along with the Fill and Update methods from DbDataAdapter class, All data adapters also inherit the TableMappings property, a collection of TableMapping objects that enable the mapping of actual database column names to user-friendly column names. This further isolates the DataSet from the source where the actual data comes from. Even table names and column names can be mapped to more readable names, making it easier to use the DataSet. The application developer can be more productive at what he does best, which is to implement business logic and not to decipher cryptic database column names. Figure 5-5 shows the relationship between data provider components.
Out of the four commands in the IDbDataAdapter object, only the
SELECT command is required. The rest of the
commands are optional since they can be generated automatically by
the system. However, the auto-generation of these commands only works
when certain conditions are met. For example, if your data adapter
fills the data set from some database view that includes more than
one table, you will have to explicitly define all four commands.
Another example is when your adapter does not return key fields from
the table, the system won’t be able to generate the
insert, update, or delete command. A typical usage of the data
adapter involves the following steps:
Create a data-adapter object.
Set up the query string for the internal SelectCommand object.
Set up the connection string for the SelectCommand’s Connection object.
Set up the InsertCommand, UpdateCommand, or DeleteCommand query strings and connections (Recommended).
Call Fill( ) to fill the given dataset with the results from the query string.
Make changes and call the adapter’s Update( ) method with the changed DataSet (Optional).
The following block of code demonstrates these steps:
static DataSet GenerateDS( ) {
/* Create the DataSet object. */
DataSet ds = new DataSet("DBDataSet");
String sConn =
"provider=SQLOLEDB;server=(local);database=pubs; Integrated Security=SSPI ";
/* Create the DataSet adapters. */
OleDbDataAdapter dsAdapter1 =
new OleDbDataAdapter("select * from authors", sConn);
OleDbDataAdapter dsAdapter2 =
new OleDbDataAdapter("select * from titles", sConn);
OleDbDataAdapter dsAdapter3 =
new OleDbDataAdapter("select * from titleauthor", sConn);
/* Fill the data set with three tables. */
dsAdapter1.Fill(ds, "authors");
dsAdapter2.Fill(ds, "titles");
dsAdapter3.Fill(ds, "titleauthor");
// Add the two relations between the three tables. */
ds.Relations.Add("authors2titleauthor",
ds.Tables["authors"].Columns["au_id"],
ds.Tables["titleauthor"].Columns["au_id"]);
ds.Relations.Add("titles2titleauthor",
ds.Tables["titles"].Columns["title_id"],
ds.Tables["titleauthor"].Columns["title_id"]);
// Return the DataSet.
return ds;
}This is a demonstration of constructing a dataset with three tables from the sample pubs database. The DataSet also contains two relationships that tie the three tables together. Let’s take a look at the dataset in XML by trying out the next couple lines of code:
DataSet ds = GenerateDS( );
ds.WriteXml("DBDataSet.xml", XmlWriteMode.WriteSchema);The content of DBDataSet.xml (with some omission for brevity) is shown next:
<?xml version="1.0" standalone="yes"?>
<DBDataSet>
<xsd:schema id="DBDataSet" targetNamespace="" xmlns=""
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:msdata="urn:schemas-microsoft-com:xml-msdata">
<xsd:element name="DBDataSet" msdata:IsDataSet="true">
<xsd:complexType>
<xsd:choice maxOccurs="unbounded">
<xsd:element name="authors">
<xsd:complexType>
<xsd:sequence>
<!-- columns simplified for brevity -->
<xsd:element name="au_id" type="xsd:string" />
<xsd:element name="au_lname" type="xsd:string" />
<xsd:element name="au_fname" type="xsd:string" />
<xsd:element name="phone" type="xsd:string" />
<xsd:element name="address" type="xsd:string" />
<xsd:element name="city" type="xsd:string" />
<xsd:element name="state" type="xsd:string" />
<xsd:element name="zip" type="xsd:string" />
<xsd:element name="contract" type="xsd:boolean" />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<!-- titles and titleauthor omitted for brevity -->
</xsd:choice>
</xsd:complexType>
<xsd:unique name="Constraint1">
<xsd:selector xpath=".//authors" />
<xsd:field xpath="au_id" />
</xsd:unique>
<xsd:unique name="titles_Constraint1"
msdata:ConstraintName="Constraint1">
<xsd:selector xpath=".//titles" />
<xsd:field xpath="title_id" />
</xsd:unique>
<xsd:keyref name="titles2titleauthor"
refer="titles_Constraint1">
<xsd:selector xpath=".//titleauthor" />
<xsd:field xpath="title_id" />
</xsd:keyref>
<xsd:keyref name="authors2titleauthor"
refer="Constraint1">
<xsd:selector xpath=".//titleauthor" />
<xsd:field xpath="au_id" />
</xsd:keyref>
</xsd:element>
</xsd:schema>
<!-- Most rows removed for brevity -->
<authors>
<au_id>899-46-2035</au_id>
<au_lname>Ringer</au_lname>
<au_fname>Anne</au_fname>
<phone>801 826-0752</phone>
<address>67 Seventh Av.</address>
<city>Salt Lake City</city>
<state>UT</state>
<zip>84152</zip>
<contract>true</contract>
</authors>
<titles>
<title_id>PS2091</title_id>
<title>Is Anger the Enemy?</title>
<type>psychology </type>
<pub_id>0736</pub_id>
<price>10.95</price>
<advance>2275</advance>
<royalty>12</royalty>
<ytd_sales>2045</ytd_sales>
<notes>Carefully researched study of the effects of strong
emotions on the body. Metabolic charts included.</notes>
<pubdate>1991-06-15T00:00:00.0000</pubdate>
</titles>
<title_id>MC3021</title_id>
<title>The Gourmet Microwave</title>
<type>mod_cook</type>
<pub_id>0877</pub_id>
<price>2.99</price>
<advance>15000</advance>
<royalty>24</royalty>
<ytd_sales>22246</ytd_sales>
<notes>Traditional French gourmet recipes adapted for modern
microwave cooking.</notes>
<pubdate>1991-06-18T00:00:00.0000</pubdate>
</titles>
<titleauthor>
<au_id>899-46-2035</au_id>
<title_id>MC3021</title_id>
<au_ord>2</au_ord>
<royaltyper>25</royaltyper>
</titleauthor>
<titleauthor>
<au_id>899-46-2035</au_id>
<title_id>PS2091</title_id>
<au_ord>2</au_ord>
<royaltyper>50</royaltyper>
</titleauthor>
</DBDataSet>The tables are represented as <xsd:element
name="table
name"> . . .
</xsd:element> tag pairs that contain column
definitions. In addition to one xsd:element for
each table, we have one xsd:unique for each key
and one xsd:keyref for each relationship. The
xsd:unique specifies the key of the parent table
in a relationship. The tag xsd:keyref is used for
child tables in a relationship. This xsd:keyref
serves as the foreign key and refers to the key in the parent table.
For brevity, we’ve stripped down the data portion of
the XML to contain just one author, Anne
Ringer, and two books she authored.
We can have many different DataAdapters populating the DataSet. Each of these DataAdapters can be going against a completely different data source or data server. In other words, you can construct a DataSet object filled with data that is distributed across multiple servers. In the previous example, we have three different DataAdapters; however, all of them are going to the same server.
XML in the .NET Framework
XML has rapidly gained popularity. Enterprise applications are using XML as the main data format for data exchanges.
ADO.NET breaks away from the COM-based recordset and employs XML as its transport data format. Because XML is platform independent, ADO.NET extends the reach to include anyone who is able to encode/decode XML. This is a big advantage over ADO because a COM-based recordset is not platform independent.
XML Parsers
Even though XML is text-based and readable by humans, you still should have some way of programmatically reading, inspecting, and changing XML. This is the job of XML parsers. There are two kinds of XML parsers: tree-based and stream-based. Depending on your needs, these two types of parsers should complement each other and serve you well.
Tree-based XML parsers read the XML file (or stream) in its entirety to construct a tree of XML nodes. Think of these XML nodes as your XML tag:
<car> <vin>VI00000383148374</vin> <make>Acura</make> <model>Integra</model> <year>1995</year> </car>
When parsed into a tree, this information would have one root node:
car; under car, there are four nodes:
vin, make,
model, and year. As you might
have suspected, if the XML stream is very large in nature, then a
tree-based XML parser might not be a good idea. The tree would be too
large and consume a lot of memory.
A Stream-based XML parser reads the XML stream as it goes. SAX (Simple API for XML) is a specification for this kind of parsing. The parser raises events as it reads the data, notifying the application of the tag or text the parser just read. It does not attempt to create the complete tree of all XML nodes as does the tree-based parser. Therefore, memory consumption is minimal. This kind of XML parser is ideal for going through large XML files to look for small pieces of data. The .NET framework introduces another stream-based XML parser: the XmlReader. While SAX pushes events at the application as it reads the data, the XmlReader allows the application to pull data from the stream.
Microsoft implements both types of parsers in its XML parser. Because XML is so powerful, Microsoft, among other industry leaders, incorporates XML usage in almost all the things they do. That includes, but is not limited to, the following areas:
XML+HTTP in SOAP
XML+SQL in SQL2000
XML+DataSet in ADO.NET
XML in web services and Web Services Discovery (DISCO) (see Chapter 6)
In this chapter, we will discuss XML+Dataset in ADO.NET, and XML in web services will be examined in the next chapter. Because XML is used everywhere in the .NET architecture, we also provide a high-level survey of the XML classes.
XML Classes
To understand the tree-based Microsoft XML parser, which supports the Document Object Model (DOM Level 2 Core standard), there are only a handful of objects you should know:
XmlNode and its derivatives
XmlNodeList, as collection XmlNode
XmlNamedNodeMap, as a collection of XmlAttribute
We will walk through a simple XML example to see how XML nodes are mapped into these objects in the XML DOM.
XmlNode and its derivatives
XmlNode is a base class that represents a single node in the XML document. In the object model, almost everything derives from XmlNode (directly or indirectly). This includes: XmlAttribute, XmlDocument, XmlElement, and XmlText, among other XML node types.
The following XML excerpt demonstrates mapping of XML tags to the node types in the DOM tree:
<books> <book category="How To"> <title>How to drive in DC metropolitan</title> <author>Jack Daniel</author> <price>19.95</price> </book> <book category="Fiction"> <title>Bring down the fence</title> <author>Jack Smith</author> <price>9.95</price> </book> </books>
After parsing this XML stream, you end up with the tree depicted in
Figure 5-6. It contains one root node, which is
just a derivative of XmlNode. This root node is of type XmlDocument.
Under this books root node, you have two children,
also derivatives of XmlNode. This time, they are of type XmlElement.
Under each book element node, there are four
children. The first child is category. This
category node is of type XmlAttribute, a
derivative of XmlNode. The next three children are of type
XmlElement: title, author, and
price. Each of these elements has one child of
type XmlText.

As a base class, XmlNode supports a number of methods that aid in the constructing of the XML document tree. These methods include AppendChild( ), PrependChild( ), InsertBefore( ), InsertAfter( ), and Clone( ).
XmlNode also supports a group of properties that aid in navigation within the XML document tree. These properties include FirstChild, NextSibling, PreviousSibling, LastChild, ChildNodes, and ParentNode. You can use the ChildNodes property to navigate down from the root of the tree. For traversing backward, use the ParentNode property from any node on the tree.
XmlNodeList
Just as an XmlNode represents a single XML element,
XmlNodeList represents a collection of
zero or more XmlNodes. The ChildNodes property of the XmlNode is of
type XmlNodeList. Looking at the root node books,
we see that its ChildNodes property would be a collection of two
XmlNodes. XmlNodeList supports enumeration, so we can iterate over
the collection to get to each of the XmlNode objects. We can also
index into the collection through a zero-based index.
Each of the book XmlElement objects would have a ChildNodes
collection that iterates over title,
author, and price XmlElements.
XmlNamedNodeMap
Similar to XmlNodeList, XmlNamedNodeMap is also a
collection object. XmlNamedNodeMap is a collection of XmlAttribute
objects that enable both enumeration and indexing of attributes by
name. Each XmlNode has a property named Attributes. In the case of
the book elements, these collections contain only one attribute,
which is category.
XmlDocument
In addition to all methods and properties supported by XmlNode, this derivative of XmlNode adds or restricts methods and properties. Here, we inspect only XmlDocument as an example of a derivative of XmlNode.
XmlDocument extends XmlNode and adds a number of helper functions. These helper functions are used to create other types of XmlNodes, such as XmlAttribute, XmlComment, XmlElement, and XmlText. In addition to allowing for the creation of other XML node types, XmlDocument also provides the mechanism to load and save XML contents.
The following code demonstrates how an XmlDocument is programmatically generated with DOM:
using System;
using System.Xml;
public class XmlDemo {
public static void Main( ) {
// Code that demonstrates how to create XmlDocument programmatically
XmlDocument xmlDom = new XmlDocument( );
xmlDom.AppendChild(xmlDom.CreateElement("", "books", ""));
XmlElement xmlRoot = xmlDom.DocumentElement;
XmlElement xmlBook;
XmlElement xmlTitle, xmlAuthor, xmlPrice;
XmlText xmlText;
xmlBook= xmlDom.CreateElement("", "book", "");
xmlBook.SetAttribute("category", "", "How To");
xmlTitle = xmlDom.CreateElement("", "title", "");
xmlText = xmlDom.CreateTextNode("How to drive in DC metropolitan");
xmlTitle.AppendChild(xmlText);
xmlBook.AppendChild(xmlTitle);
xmlAuthor = xmlDom.CreateElement("", "author", "");
xmlText = xmlDom.CreateTextNode("Jack Daniel");
xmlAuthor.AppendChild(xmlText);
xmlBook.AppendChild(xmlAuthor);
xmlPrice = xmlDom.CreateElement("", "price", "");
xmlText = xmlDom.CreateTextNode("19.95");
xmlPrice.AppendChild(xmlText);
xmlBook.AppendChild(xmlPrice);
xmlRoot.AppendChild(xmlBook);
xmlBook= xmlDom.CreateElement("", "book", "");
xmlBook.SetAttribute("category", "", "Fiction");
xmlTitle = xmlDom.CreateElement("", "title", "");
xmlText = xmlDom.CreateTextNode("Bring down the fence");
xmlTitle.AppendChild(xmlText);
xmlBook.AppendChild(xmlTitle);
xmlAuthor = xmlDom.CreateElement("", "author", "");
xmlText = xmlDom.CreateTextNode("Jack Smith");
xmlAuthor.AppendChild(xmlText);
xmlBook.AppendChild(xmlAuthor);
xmlPrice = xmlDom.CreateElement("", "price", "");
xmlText = xmlDom.CreateTextNode("9.95");
xmlPrice.AppendChild(xmlText);
xmlBook.AppendChild(xmlPrice);
xmlRoot.AppendChild(xmlBook);
Console.WriteLine(xmlDom.InnerXml);
}
}The XmlDocument also supports LoadXml and Load methods, which build the whole XML tree from the input parameter. LoadXml takes a string in XML format, whereas Load can take a stream, a filename or a URL, a TextReader, or an XmlReader. The following example continues where the previous one left off. The XML tree is saved to a file named books.xml. Then this file is loaded back into a different XML tree. This new tree outputs the same XML stream as the previous one:
. . .
xmlDom.Save("books.xml");
XmlDocument xmlDom2 = new XmlDocument( );
xmlDom2.Load("books.xml");
Console.WriteLine(xmlDom2.InnerXml);XmlReader
The XmlReader object is a fast, noncached, forward-only way of accessing streamed XML data. There are two derivatives of XmlReader: XmlTextReader and XmlNodeReader. Both of these readers read XML one tag at a time. The only difference between the two is the input to each reader. As the name implies, XmlTextReader reads a stream of pure XML text. XmlNodeReader reads a stream of nodes from an XmlDocument. The stream can start at the beginning of the XML file for the whole XmlDocument or only at a specific node of the XmlDocument for partial reading.
Consider the following XML excerpt for order processing. If this file
is large, it is not reasonable to load it into an
XmlDocument and perform parsing on it. Instead, we
should read only nodes or attributes we are interesting in and ignore
the rest. We can use XmlReader derived classes to do so:
<Orders> <Order id="ABC001" . . . > <Item code="101" qty="3" price="299.00" . . . >17in Monitor</Item> <Item code="102" qty="1" price="15.99" . . . >Keyboard</Item> <Item code="103" qty="2" price="395.95" . . . >CPU</Item> </Order> <Order id="ABC002" . . . > <Item code="101b" qty="1" price="499.00" . . . >21in Monitor</Item> <Item code="102" qty="1" price="15.99" . . . >Keyboard</Item> </Order> < . . . > </Orders>
The following block of code traverses and processes each order from
the large Orders.xml input file:
using System;
using System.IO;
using System.Xml;
class TestXMLReader
{
static void Main(string[] args)
{
TestXMLReader tstObj = new TestXMLReader( );
StreamReader myStream = new StreamReader("Orders.xml");
XmlTextReader xmlTxtRdr = new XmlTextReader(myStream);
while(xmlTxtRdr.Read( ))
{
if(xmlTxtRdr.NodeType == XmlNodeType.Element
&& xmlTxtRdr.Name == "Order")
{
tstObj.ProcessOrder(xmlTxtRdr);
}
}
}
public void ProcessOrder(XmlTextReader reader)
{
Console.WriteLine("Start processing order: " +
reader.GetAttribute("id"));
while(!(reader.NodeType == XmlNodeType.EndElement
&& reader.Name == "Order")
&& reader.Read( ))
{
// Process Content of Order
if(reader.NodeType == XmlNodeType.Element
&& reader.Name == "Item")
{
Console.WriteLine("itemcode:" + reader.GetAttribute("code") +
". Qty: " + reader.GetAttribute("qty"));
}
}
}
}Let’s take a closer look at what is going on. Once
we have established the XmlTextReader object with the stream of data
from the string, all we have to do is loop through and perform a
Read( )
operation until there is nothing else to read. While we are reading,
we start to process the order only when we come across a node of type
XmlElement and a node named Order. Inside the
ProcessOrder function, we read and process all items inside an order
until we encounter the end tag of Order. In this
case, we return from the function and go back to looking for the next
Order tag to process the next order.
XmlNodeReader is similar to XmlTextReader because they both allow processing of XML sequentially. However, XmlNodeReader reads XML nodes from a complete or fragment of an XML tree. This means XmlNodeReader is not helpful when processing large XML files.
XmlWriter
The XmlWriter object is a fast, noncached way of writing streamed XML data. It also supports namespaces. The only derivative of XmlWriter is XmlTextWriter.
XmlWriter supports namespaces by providing a number of overloaded functions that take a namespace to associate with the element. If this namespace is already defined and there is an existing prefix, XmlWriter automatically writes the element name with the defined prefix. Almost all element-writing methods are overloaded to support namespaces.
The following code shows how to use an XmlTextWriter object to write a valid XML file:
XmlTextWriter writer =
new XmlTextWriter("test.xml", new System.Text.ASCIIEncoding( ));
writer.Formatting = Formatting.Indented;
writer.Indentation = 4;
writer.WriteStartDocument( );
writer.WriteComment("Comment");
writer.WriteStartElement("ElementName", "myns");
writer.WriteStartAttribute("prefix", "attrName", "myns");
writer.WriteEndAttribute( );
writer.WriteElementString("ElementName", "myns", "value");
writer.WriteEndElement( );
writer.WriteEndDocument( );
writer.Flush( );
writer.Close( );This produces the following XML document in test.xml:
<?xml version="1.0" encoding="us-ascii"?>
<!--Comment-->
<ElementName prefix:attrName="" xmlns:prefix="myns" xmlns="myns">
<prefix:ElementName>value</prefix:ElementName>
</ElementName>XslTransform
XslTransform converts XML from one format to another. It is typically used in data-conversion programs or to convert XML to HTML for the purpose of presenting XML data in a browser. The following code demonstrates how such a conversion takes place:
using System;
using System.Xml; // XmlTextWriter
using System.Xml.Xsl; // XslTransform
using System.Xml.XPath; // XPathDocument
using System.IO; // StreamReader
public class XSLDemo {
public static void Main( ) {
XslTransform xslt = new XslTransform( );
xslt.Load("XSLTemplate.xsl");
XPathDocument xDoc = new XPathDocument("Books.xml");
XmlTextWriter writer = new XmlTextWriter("Books.html", null);
xslt.Transform(xDoc, null, writer, new XmlUrlResolver( ));
writer.Close( );
StreamReader stream = new StreamReader("Books.html");
Console.Write(stream.ReadToEnd( ));
}
}The code basically transforms the XML in the Books.xml file, which we’ve seen earlier, into HTML to be displayed in a browser. Even though you can replace the XPathDocument with XmlDocument in the previous code, XPathDocument is the preferred class in this case because it is optimized for XSLT processing.[9]
Figure 5-7 and Figure 5-8 show the source XML and the output HTML when viewed in a browser.
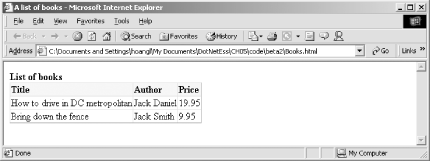
The template XSL file that was used to transform the XML is:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match = "/" >
<html>
<head><title>A list of books</title></head>
<style>
.hdr { background-color=#ffeedd; font-weight=bold; }
</style>
<body>
<B>List of books</B>
<table style="border-collapse:collapse" border="1">
<tr>
<td class="hdr">Title</td>
<td class="hdr">Author</td>
<td class="hdr">Price</td>
</tr>
<xsl:for-each select="//books/book">
<tr>
<td><xsl:value-of select="title"/></td>
<td><xsl:value-of select="author"/></td>
<td><xsl:value-of select="price"/></td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>XmlDataDocument
One of the most important points in ADO.NET is the tight integration of DataSet with XML. DataSet can easily be streamed into XML and vice versa, making it easy to exchange data with any other components in the enterprise system. The schema of the DataSet can be loaded and saved as XML Schema Definition (XSD), as described earlier.
XmlDataDocument can be associated with DataSet. The following code excerpt illustrates how such an association takes place:
using System;
using System.Data;
using System.Data.OleDb;
using System.Xml;
class TestXMLDataDocument
{
static void Main(string[] args)
{
TestXMLDataDocument tstObj = new TestXMLDataDocument( );
// Construct the XmlDataDocument with the DataSet.
XmlDataDocument doc = tstObj.GenerateXmlDataDocument( );
XmlNodeReader myXMLReader = new XmlNodeReader(doc);
while (myXMLReader.Read( ))
{
if(myXMLReader.NodeType == XmlNodeType.Element
&& myXMLReader.Name == "Orders")
{
tstObj.ProcessOrder(myXMLReader);
}
}
}
public void ProcessOrder(XmlNodeReader reader)
{
Console.Write("Start processing order: ");
while(!(reader.NodeType == XmlNodeType.EndElement
&& reader.Name == "Orders")
&& reader.Read( ))
{
if(reader.NodeType == XmlNodeType.Element
&& reader.Name == "OrderID")
{
reader.Read( );
Console.WriteLine(reader.Value);
}
if(reader.NodeType == XmlNodeType.Element
&& reader.Name == "OrderDetails")
{
ProcessLine(reader);
}
}
}
public void ProcessLine(XmlNodeReader reader)
{
while(!(reader.NodeType == XmlNodeType.EndElement
&& reader.Name == "OrderDetails")
&& reader.Read( ))
{
if(reader.NodeType == XmlNodeType.Element && reader.Name == "ProductID")
{
reader.Read( );
Console.Write(". ItemCode: " + reader.Value);
}
if(reader.NodeType == XmlNodeType.Element && reader.Name == "Quantity")
{
reader.Read( );
Console.WriteLine(". Quantity: " + reader.Value);
}
}
}
public XmlDataDocument GenerateXmlDataDocument( )
{
/* Create the DataSet object. */
DataSet ds = new DataSet("DBDataSet");
String sConn =
"provider=SQLOLEDB;server=(local);database=NorthWind;Integrated Security=SSPI";
/* Create the DataSet adapters. */
OleDbDataAdapter dsAdapter1 =
new OleDbDataAdapter("select * from Orders", sConn);
OleDbDataAdapter dsAdapter2 =
new OleDbDataAdapter("select * from [Order Details]", sConn);
/* Fill the data set with three tables. */
dsAdapter1.Fill(ds, "Orders");
dsAdapter2.Fill(ds, "OrderDetails");
DataColumn[] keys = new DataColumn[1];
keys[0] = ds.Tables["Orders"].Columns["OrderID"];
ds.Tables["Orders"].PrimaryKey = keys;
// Add the two relations between the three tables. */
ds.Relations.Add("Orders_OrderDetails",
ds.Tables["Orders"].Columns["OrderID"],
ds.Tables["OrderDetails"].Columns["OrderID"]);
ds.Relations["Orders_OrderDetails"].Nested = true;
//ds.WriteXml("NorthWindOrders.xml");
return new XmlDataDocument(ds);
}
}The previous section describing DataSet has already shown you that once we have a DataSet, we can persist the data inside the DataSet into an XML string or file. This time, we demonstrated how to convert the DataSet into an XmlDataDocument that we can manipulate in memory.
Summary
This chapter describes the core of ADO.NET. Having focused on the disconnected dataset, ADO.NET enables us not only to build high-performance, scalable solutions for e-commerce, but also allows the applications to reach other platforms through the use of XML. This chapter serves as a high-level survey into the classes that make up ADO.NET and serves to familiarize you with the System.Xml library.[10] In the next chapter, we delve into building software as services. We will make use of ADO.NET as the data-access and exchange mechanism in our software services.
[1] In previous releases of this book, we referred to the Data-Provider components as managed-provider components.
[2] Along with the familiar connection and command objects, ADO.NET introduces a number of new objects, such as DataSet and DataAdapter. All of these objects are discussed earlier in this chapter.
[3] The complete list of all classes can be found in the Microsoft .NET SDK.
[4] Furthermore, the DataSet can be persisted into disconnected XML datafiles so that your application can continue to work offline. More information on this topic will be presented in later sections.
[5] There is a reference implementation of a .NET Framework Data Provider included in the .NET Framework documentation for any other type of data. In the near future, we are sure that the list of .NET Framework Data Providers will grow to cover even more different data sources.
[6] Disconnected record set.
[7] In
addition, you can create a Command object from the
current connection by using this instead: oCmd =
oConn.CreateCommand( );.
[8] Please be aware that database connection pooling relies on the uniqueness of the connection strings. When using the integrated security model of SQL Server, if you make the data access code run under the security context of each of the logged-in users, database connection pooling will suffer. You must create a small set of Windows accounts to overcome this problem; we don’t discuss security in great depth in this book, due to its compact size.
[9] XPathDocument loads data faster than XmlDocument because it does not maintain node identity and it does not perform rule checking. One catch to this advantage is that the content is read-only.
[10] For additional information on ADO.NET, see O’Reilly’s ADO.NET in a Nutshell, by Bill Hamilton and Matthew MacDonald, and ADO.NET Cookbook, by Bill Hamilton.