
Chapter 5. Storage Management and Backups
Hacks 46–55: Introduction
One of the core responsibilities of any computer system is to provide enough storage space to enable users to get their work done. Storage requirements depend largely on the types of files your users work with, which may range in size from the 100–200 KB that many word processing documents use to the megabytes of disk space consumed by music and image files. Add the gigabytes of old email that most people have lying around, and you can see that today’s users require more disk space than ever before.
The obvious solution to increasing storage requirements is to add more disks and disk controllers. However, simply adding filesystems to your machine can result in an administrative nightmare of symbolic links that reflect the migration paths of certain directories as they move from disk to disk in search of lebensraum. This chapter opens with a hack that helps you address increasing storage requirements in a cool, calm, organized fashion by using logical volumes. This storage management technique makes it easy to add disk space to existing filesystems without having to move anything anywhere.
Once you’ve added new disk space in one fashion or another, backing up today’s large drives can pose a problem, so we’ve included hacks to help you back up and clone modern systems without needing a stack of mag tapes or tape cartridges that reaches to the moon. This chapter also includes a hack that explains how to combine RAID with logical volumes to increase system reliability in general. You can’t eliminate backups, but you can easily minimize the need for restores.
This chapter will also discuss how to help your users use disk space intelligently by sharing central collections of files whenever possible, preventing disk space bloat because all 500 of your users have their own copies of every file that their team has ever worked on. And because huge directories and filesystems often make it more difficult to find the specific file you’re looking for, we’ve added a hack about how to take advantage of Linux extended attributes to tag files with metadata that makes them easier to locate. This chapter ends with a hack that discusses Linux quotas, which provide an excellent mechanism to identify the biggest users of disk space on your systems and even enable you to set limits on per-user or per-group disk consumption. An ounce of protection is worth a pound of cure—or, in this case, a few hundred gigabytes, the cost of new disks, and the associated administrative overhead.
Create Flexible Storage with LVM
“User disk requirements expand to consume all available space” is a fundamental rule of system administration. Prepare for this in advance using Logical Volume Management (LVM).
When managing computer systems, a classic problem is the research project or business unit gone haywire, whose storage requirements far exceed their current allocation (and perhaps any amount of storage that’s currently available on the systems they’re using). Good examples of this sort of thing are simulation and image analysis projects, or my research into backing up my entire CD collection on disk. Logical volumes, which are filesystems that appear to be single physical volumes but are actually assembled from space that has been allocated on multiple physical partitions, are an elegant solution to this problem. The size of a logical volume can exceed the size of any of the physical storage devices on your system, but it cannot exceed the sum of all of their sizes.
Traditional solutions to storage management have their limitations. Imposing quotas [Hack #55] , can prevent users from hogging more than their fair share of disk resources, helping your users share their resources equitably. Similarly, paying scrupulous attention to detail in cleaning out old user accounts can maximize the amount of space available to the active users on your system. However, neither of these approaches solves the actual problem, which is the “fixed-size” aspect of disk storage. Logical volumes solve this problem in a truly elegant fashion by making it easy to add new disk storage to the volumes on which existing directories are located. Without logical volumes, you could still add new disk storage to the system by formatting new disks and partitions and mounting them at various locations in the existing filesystem, but your system would quickly become an unmanageable administrative nightmare of mount points and symbolic links pointing all over the place.
Linux has had two implementations of logical volumes, aptly known as LVM and LVM2. LVM2, which is backward compatible with logical volumes created with LVM, is the version that is provided by default with 2.6-based systems. This hack focuses on LVM2, although newer LVM technologies—such as the Enterprise Volume Management System (EVMS), which was originally developed by IBM and is now an active SourceForge project (http://sourceforge.net/projects/evms)—are actively under development.
Logical Volume Buzzwords
When using logical volumes, the pool of storage space from which specific volumes are created is known as a volume group. Volume groups are created by first formatting specific physical devices or partitions as
physical volumes, using the pvcreate command, and then creating the volume group on some number of physical volumes using the vgcreate command. When the volume group is created, it divides the physical volumes of which it is composed into
physical extents, which are the actual allocation units within a volume group. The size of each physical extent associated with a specific volume group can be set from 8 KB to 512 MB in powers of 2 when the volume group is created, with a default size of 4 MB.
Tip
Nowadays, all of the individual commands related to physical and logical volumes are implemented by one central binary called lvm. Most Linux distributions install symbolic links to this binary with the names of the traditional, individual commands for physical and logical volume management. The hacks in this chapter use the names of the specific commands, but you can also always execute them by prefacing them with the lvm command. For example, if your distribution doesn’t install the symlinks, you could execute the pvcreate command by executing lvm pvcreate.
When you create a volume group, a directory with the same name as that volume group is created in your system’s /dev directory, and a character-special device file called group is created in that directory. As you create logical volumes from that volume group, the block-special files associated with each of them are also created in this directory.
Once you’ve created a volume group, you can use the lvcreate command to create logical volumes from the accumulation of storage associated with that volume group. Physical extents from the volume group are allocated to logical volumes by mapping them through
logical extents, which have a one-to-one correspondence to specific physical extents but provide yet another level of abstraction between physical and logical storage space. Using logical extents reduces the impact of certain administrative operations, such as moving the physical extents on a specific physical volume to another physical volume if you suspect (or, even worse, know) that the disk on which a specific physical volume is located is going bad.
Once you have created a logical volume, you can create your favorite type of filesystem on it using the mkfs command, specifying the type of filesystem by using the -t type option. You can then modify your /etc/fstab file to mount the new logical volume wherever you want, and you’re in business. The rest of the hack shows you how to perform the actions I’ve just described.
Allocating Physical Volumes
You can use either existing partitions or complete disks as storage for logical volumes. As the first step in your LVM odyssey, you must use the pvcreate command to create physical volumes on those partitions or disks in order to identify them to the system as storage that you can assign to a volume group and subsequently use in a logical volume. There are several ways to allocate an entire disk for use with LVM2:
Make sure the disk does not contain a partition table and create a single physical volume on the disk.
Create a single partition on the disk and create a physical volume on that partition.
Create multiple partitions on your disk and create physical volumes on each.
Each of these has advantages and disadvantages, but I prefer the third as a general rule. The first two approaches don’t localize disk problems, meaning that sector failures on the disk can kick the entire physical volume out of your volume group and therefore quite possibly prevent recovery or repair. You can minimize the hassle inherent in this situation by combining RAID and LVM
[Hack #47]
, but you can minimize headaches and lost data in the first place (without using RAID) by manually partitioning the disk and allocating each of those smaller partitions as physical volumes. To do this, use the fdisk command to create reasonably sized, manageable partitions that are clearly identified as Linux LVM storage, and then use the pvcreate command to create physical volumes on each, as in the following example:
#fdisk /dev/hdbThe number of cylinders for this disk is set to 30401. There is nothing wrong with that, but this is larger than 1024, and could in certain setups cause problems with: 1) software that runs at boot time (e.g., old versions of LILO) 2) booting and partitioning software from other OSs (e.g., DOS FDISK, OS/2 FDISK) Command (m for help):pDisk /dev/hdb: 250.0 GB, 250059350016 bytes 255 heads, 63 sectors/track, 30401 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Device Boot Start End Blocks Id System Command (m for help):nCommand action e extended p primary partition (1-4)pPartition number (1-4):1First cylinder (1-30401, default 1): Using default value 1 Last cylinder or +size or +sizeM or +sizeK (1-30401, default 30401): Using default value 30401 Command (m for help):tSelected partition 1 Hex code (type L to list codes):8eChanged system type of partition 1 to 8e (Linux LVM) Command (m for help):pDisk /dev/hdb: 250.0 GB, 250059350016 bytes 255 heads, 63 sectors/track, 30401 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Device Boot Start End Blocks Id System /dev/hdb1 1 30401 244196001 8e Linux LVM Command (m for help):wThe partition table has been altered! Calling ioctl() to re-read partition table. Syncing disks. #
Tip
In some older versions of LVM, pvcreate will complain if it finds a partition table on a disk that you are allocating as a single physical volume. If this is the case with the version of LVM that you are using, you’ll need to allocate the entire disk as a physical volume. To do this, make sure you wipe any existing partition table (using dd if=/dev/zero of=/dev/
DISK
bs=512 count=1, where DISK is the base name of the disk, such as /dev/hda, /dev/sda, and so on—whatever is appropriate for your system).
With most modern versions of LVM2, this is not the case—disks can have existing partition tables and still be allocated in their entirety for use with LVM. Any partitions that you create on a disk for use as a physical volume should have their types set to Linux Logical Volume (0x8e) when you use fdisk (or any equivalent utility) to partition the disk. Always be kind to your fellow sysadmins. You won’t necessarily always work for the same company, and you should always follow the sysadmin’s golden rule: leave behind understandable systems, as you would have other sysadmins leave behind understandable systems for you.
In the preceding example and throughout this hack, I’m creating a single partition on a disk and using it as a physical volume. This is to keep the sample output from fdisk shorter than the rest of the book. In actual practice, as explained previously, I suggest creating smaller partitions of a more manageable size—40 GB or so—and using them as physical volumes. It doesn’t matter to LVM whether they’re primary or extended partitions on your disk drive. Using smaller partitions helps localize disk problems that you may encounter down the road.
After creating partitions you want to use as physical volumes, use the pvcreate command to allocate them for use as physical volumes, as in this example:
# pvcreate /dev/hdb1
Physical volume "/dev/hdb1" successfully createdYou can then confirm the status and size of your new physical volume by using the pvdisplay command:
# pvdisplay
--- NEW Physical volume --
PV Name /dev/hdb1
VG Name
PV Size 232.88 GB
Allocatable NO
PE Size (KByte) 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID hy8hck-B5lp-TLZf-hyD4-U9Mu-EFn8-wob9KmAssigning Physical Volumes to Volume Groups
Once you’ve created one or more physical volumes, you need to add them to a specific volume group so that they can be allocated for use in a logical volume. Adding a physical volume to a volume group is done with the vgcreate command, as in the following example:
# vgcreate data /dev/hdb1
Volume group "data" successfully createdIf you have multiple physical volumes to add to your volume group, simply specify them after the first physical volume. You can then confirm the status of your new volume group by using the vgdisplay command:
# vgdisplay data
--- Volume group ---
VG Name data
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 1
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 1
Act PV 1
VG Size 232.88 GB
PE Size 4.00 MB
Total PE 59618
Alloc PE / Size 0 / 0
Free PE / Size 59618 / 232.88 GB
VG UUID SeY0pJ-Q0Ej-AQbT-Fri0-tai6-5oED-7ujb1FCreating a Logical Volume from a Volume Group
As mentioned previously, creating a physical volume divides the allocated space in that volume into physical extents. Unlike traditional inode-based storage, filesystems that use logical volumes track free space by preallocated units of space known as extents. Extents are physically linear series of blocks that can be read one after the other, minimizing disk head movement.
When you create a logical volume, you must specify its size. If you’re only creating a single logical volume, you probably want to create it using all of the available space in the volume group where you create it.
The number of free extents is listed as the Free PE entry in the output of the pvdisplay command for each partition in the volume group (in this case, only the disk /dev/hdb1):
#pvdisplay /dev/hdb1--- Physical volume --- PV Name /dev/hdb1 VG Name data PV Size 232.88 GB / not usable 0 Allocatable yes PE Size (KByte) 4096 Total PE 59618 Free PE 59618 Allocated PE 0 PV UUID 90BP0t-OZeQ-2Zbl-DCmh-iEJu-p8Je-SLm1Gg #pvdisplay /dev/hdb1 | grep "Free PE"Free PE 59618
You could also infer this value by looking at the volume group itself, but the output there requires a little more thought:
# vgdisplay data
--- Volume group ---
VG Name data
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 2
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 1
Open LV 0
Max PV 0
Cur PV 1
Act PV 1
VG Size 232.88 GB
PE Size 4.00 MB
Total PE 59618
Alloc PE / Size 59618 / 232.88 GB
Free PE / Size 0 / 0
VG UUID SeY0pJ-Q0Ej-AQbT-Fri0-tai6-5oED-7ujb1FThis output shows that a total of 59,618 physical extents have been allocated to this volume group, but it also shows them all as being in use. They’re considered to be in use because they are allocated to the volume group—this doesn’t reflect whether they actually contain data, are mounted anywhere, and so on.
Your next step is to use the lvcreate command to create logical volumes within the volume group you just defined, using as much of the volume as you want to allocate to the new logical volume. To create a logical volume called music that uses all the space available in the data volume group, for example, you would execute the following command:
# lvcreate -l 59618 data -n music
Logical volume "music" createdYou can then use the lvdisplay command to get information about the logical volume you just created:
# lvdisplay
--- Logical volume ---
LV Name /dev/data/music
VG Name data
LV UUID yV06uh-BshS-IqiK-GeIi-A3vm-Tsjg-T0kCT7
LV Write Access read/write
LV Status available
# open 0
LV Size 232.88 GB
Current LE 59618
Segments 1
Allocation inherit
Read ahead sectors 0
Block device 253:0As you can see from this output, the actual access point for the new logical volume music is the directory /dev/data/music, which was created when the volume was created by the lvcreate command.
When you create a logical volume, the logical volume system also creates an appropriate entry in the directory /dev/mapper that maps the logical volume to the physical volume from which it was created, as in the following example:
# ls /dev/mapper
control data-musicNow that we’ve created the logical volume, let’s see how the output from pvdisplay changes to reflect this allocation:
# pvdisplay /dev/hdb1
--- Physical volume ---
PV Name /dev/hdb1
VG Name data
PV Size 232.88 GB / not usable 0
Allocatable yes (but full)
PE Size (KByte) 4096
Total PE 59618
Free PE 0
Allocated PE 59618
PV UUID 90BP0t-OZeQ-2Zbl-DCmh-iEJu-p8Je-SLm1GgThis output now shows that there are no free physical extents on the physical volume, because all of them have been allocated to the logical volume that we created from the volume group with which this physical volume is associated.
Now that we’ve created a logical volume, we have to put a filesystem on it in order to actually use it on our Linux box. You do this using the mkfs command that’s appropriate for the type of filesystem you want to create. I’m a big XFS fan, so I’d use the following command to create an XFS filesystem on the new logical volume and mount it at /mnt/music on my system:
#mkfs -t xfs /dev/data/musicmeta-data=/dev/data/music isize=256 agcount=16, agsize=3815552 blks = sectsz=512 data = bsize=4096 blocks=61048832, imaxpct=25 = sunit=0 swidth=0 blks, unwritten=1 naming =version 2 bsize=4096 log =internal log bsize=4096 blocks=29809, version=1 = sectsz=512 sunit=0 blks realtime =none extsz=65536 blocks=0, rtextents=0 # #mount -t xfs /dev/data/music /mnt/music
Doing a standard disk free listing on my system shows that the new volume is mounted and available:
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda1 10490040 3763676 6726364 36% /
tmpfs 511956 44 511912 1% /dev/shm
/dev/sda3 257012 43096 213916 17% /boot
/dev/sda8 160010472 127411776 32598696 80% /home
/dev/sda5 4200824 986308 3214516 24% /tmp
/dev/sda6 31462264 5795132 25667132 19% /usr
/dev/sda7 31454268 15228908 16225360 49% /usr/local
/dev/hda1 241263968 196779092 32229292 86% /opt2
/dev/mapper/data-music
244076092 272 244075820 1% /mnt/musicNote that mounting the logical volume /dev/data/music actually mounted the control device for that logical volume, which is /dev/mapper/data-music. This enables the logical volume system to better track allocations, especially in the case where a logical volume is composed of physical volumes that reside on physically distinct disks (which isn’t the case in this simple example, but almost certainly will be in a production environment).
To make sure that your new logical volume is automatically mounted each time you boot your system, add the following entry to your /etc/fstab file:
/dev/data/music /mnt/music xfs defaults,noatime 0 0
You’ll note that I specified the noatime option in the /etc/fstab mount options for my logical volume, which tells the filesystem not to update inodes each time the files or directories associated with them are accessed. This eliminates what I consider frivolous updates to the logical volume (I don’t really care when a file was accessed last) and therefore reduces some of the wear and tear on my drives.
That’s it—now that I have all this new space, it’s time for me to go back up some more of my music collection…but that’s outside the scope of this hack.
Suggestions
One general suggestion that I’ve found useful is to keep / and /boot on physical partitions, and use ext3 for those filesystems. The recovery tools for ext2/ext3 filesystems are time-tested and sysadmin-approved. If you can at least easily boot your system in single-user mode, you have a much better chance of recovering your logical volumes using established tools.
Also, always use multiple partitions on your systems. Resist the urge to simplify things by creating a single huge logical volume as / and putting everything in there. This makes complete system backups huge and provides a single point of failure. The time you save during installation will be spent tearing your hair out later if disk problems take your system to its knees. A recovery disk and a lost weekend are no substitutes for proper initial planning.
See Also
“Combine LVM and Software RAID” [Hack #47]
The EVMS Project: http://sourceforge.net/projects/evms
LVM HOWTO: http://www.tldp.org/HOWTO/LVM-HOWTO/
Combine LVM and Software RAID
Combining the flexibility of LVM with the redundancy of RAID is the right thing for critical file servers.
RAID (Redundant Array of Inexpensive Disks or Redundant Array of Independent Disks, depending on who you ask) is a hardware and/or software mechanism used to improve the performance and maintainability of large amounts of disk storage through some extremely clever mechanisms. As the name suggests, RAID makes a large number of smaller disks (referred to as a RAID array) appear to be one or more large disks as far as the operating system is concerned. RAID was also designed to provide both performance and protection against the failure of any single disk in your system, which it does by providing its own internal volume management interface.
RAID is provided by specialized disk controller hardware, by system-level software, or by some combination of both. The support for software RAID under Linux is known as the multiple device (md) interface. Hardware RAID has performance advantages over software RAID, but it can be a problem in enterprise environments because hardware RAID implementations are almost always specific to the hardware controller you are using. While most newer hardware RAID controllers from a given manufacturer are compatible with their previous offerings, there’s never any real guarantee of this, and product lines do occasionally change. I prefer to use the software RAID support provided by Linux, for a number of reasons:
It’s completely independent of the disk controllers you’re using.
It provides the same interface and customization mechanisms across all Linux distributions.
Performance is actually quite good.
It can be combined with Linux Logical Volume Management (LVM) to provide a powerful, flexible mechanism for storage expansion and management.
Hardware RAID arrays usually enable you to remove and replace failed drives without shutting down your system. This is known as hot swapping, because you can swap out drives while the system is running (i.e., “hot”). Hot swapping is supported by software RAID, but whether or not it’s possible depends on the drive hardware you’re using. If you’re using removable or external FireWire, SCSI, or USB drives with software RAID (though most USB drives are too slow for this purpose), you can remove and replace failed drives on these interfaces without shutting down your system.
Mirroring and Redundancy
To support the removal and replacement of drives without anyone but you noticing, RAID provides services such as mirroring, which is the ability to support multiple volumes that are exact, real-time copies of each other. If a mirrored drive (or a drive that is part of a mirrored volume) fails or is taken offline for any other reason, the RAID system automatically begins using the failed drive’s mirror, and no one notices its absence (except for the sysadmins who have to scurry for a replacement).
As protection against single-device failures, most RAID levels support the use of spare disks in addition to mirroring. Mirroring protects you when a single device in a RAID array fails, but at this point, you are immediately vulnerable to the failure of any other device that holds data for which no mirror is currently available. RAID’s use of spare disks is designed to immediately reduce this vulnerability. In the event of a device failure, the RAID subsystem immediately allocates one of the spare disks and begins creating a new mirror there for you. When using spare disks in conjunction with mirroring, you really only have a non-mirrored disk array for the amount of time it takes to clone the mirror to the spare disk. However, as explained in the next section, the automatic use of spare disks is supported only for specific RAID levels.
Tip
RAID is not a replacement for doing backups. RAID ensures that your systems can continue functioning and that users and applications can have uninterrupted access to mirrored data in the event of device failure. However, the simultaneous failure of multiple devices in a RAID array can still take your system down and make the data that was stored on those devices unavailable. If your primary storage fails, only systems of which you have done backups (from which data can therefore be restored onto your new disks) can be guaranteed to come back up.
Overview of RAID Levels
The different capabilities provided by hardware and software RAID are grouped into what are known as different RAID levels. The following list describes the most common of these (for information about other RAID levels or more detailed information about the ones listed here, grab a book on RAID and some stimulants to keep you awake):
- RAID-0
Often called stripe mode, volumes are created in parallel across all of the devices that are part of the RAID array, allocating storage from each in order to provide as many opportunities for parallel reads and writes as possible. This RAID level is strictly for performance and does not provide any redundancy in the event of a hardware failure.
- RAID-1
Usually known as mirroring, volumes are created on single devices and exact copies (mirrors) of those volumes are maintained in order to provide protection from the failure of a single disk through redundancy. For this reason, you cannot create a RAID-1 volume that is larger than the smallest device that makes up a part of the RAID array. However, as explained in this hack, you can combine Linux LVM with RAID-1 to overcome this limitation.
- RAID-4
RAID-4 is a fairly uncommon RAID level that requires three or more devices in the RAID array. One of the drives is used to store parity information that can be used to reconstruct the data on a failed drive in the array. Unfortunately, storing this parity information on a single drive exposes this drive as a potential single point of failure.
- RAID-5
One of the most popular RAID levels, RAID-5 requires three or more devices in the RAID array and enables you to support mirroring through parity information without restricting the parity information to a single device. Parity information is distributed across all of the devices in the RAID array, removing the bottleneck and potential single point of failure in RAID-4.
- RAID-10
A high-performance modern RAID option, RAID-10 provides mirrored stripes, which essentially gives you a RAID-1 array composed of two RAID-0 arrays. The use of striping offsets the potential performance degradation of mirroring and doesn’t require calculating or maintaining parity information anywhere.
In addition to these RAID levels, Linux software RAID also supports linear mode, which is the ability to concatenate two devices and treat them as a single large device. This is rarely used any more because it provides no redundancy and is functionally identical to the capabilities provided by LVM.
Combining Software RAID and LVM
Now we come to the conceptual meat of this hack. Native RAID devices cannot be partitioned. Therefore, unless you go to a hardware RAID solution, the software RAID modes that enable you to concatenate drives and create large volumes don’t provide the redundancy that RAID is intended to provide. Many of the hardware RAID solutions available on motherboards export RAID devices only as single volumes, due to the absence of onboard volume management software. RAID array vendors get around this by selling RAID arrays that have built-in software (which is often Linux-based) that supports partitioning using an internal LVM package. However, you can do this yourself by layering Linux LVM over the RAID disks in your systems—in other words, by using software RAID drives as physical volumes that you then allocate and export to your system as logical volumes. Voilà! Combining RAID and LVM gives you flexible volume management with the warm fuzzy feeling of redundancy provided by RAID levels such as 1, 5, and 10. It just doesn’t get much better than that.
Creating RAID Devices
RAID devices are created by first defining them in the file /etc/raidtab and then using the mkraid command to actually create the RAID devices specified in the configuration file.
For example, the following /etc/raidtab file defines a linear RAID array composed of the physical devices /dev/hda6 and /dev/hdb5:
raiddev /dev/md0
raid-level linear
nr-raid-disks 2
chunk-size 32
persistent-superblock 1
device /dev/hda6
raid-disk 0
device /dev/hdb5
raid-disk 1Executing the mkraid command to create the device /dev/md0 would produce output like the following:
# mkraid /dev/md0
handling MD device /dev/md0
analyzing super-block
disk 0: /dev/hda6, 10241406kB, raid superblock at 10241280kB
disk 1: /dev/hdb5, 12056751kB, raid superblock at 12056640kBIf you are recycling drives that you have previously used for some other purpose on your system, the mkraid command may complain about finding existing filesystems on the disks that you are allocating to your new RAID device. Double-check that you have specified the right disks in your /etc/raidtab file, and then use the mkraid command’s –f option to force it to use the drives, regardless.
At this point, you can create your favorite type of filesystem on the device /dev/md0 by using the mkfs command and specifying the type of filesystem by using the appropriate -t
type option. After creating your filesystem, you can then update the /etc/fstab file to mount the new volume wherever you want, and you’re in business.
A linear RAID array is RAID at its most primitive, and isn’t really useful now that Linux provides mature logical volume support. The /etc/raidtab configuration file for a RAID-1 (mirroring) RAID array that mirrors the single-partition disk /dev/hdb1 using the single partition /dev/hde1 would look something like the following:
raiddev /dev/md0 raid-level 1 nr-raid-disks 2 nr-spare-disks 0 chunk-size 4 persistent-superblock 1 device /dev/hdb1 raid-disk 0 device /dev/hde1 raid-disk 1
Other RAID levels are created by using the same configuration file but specifying other mandatory parameters, such as a third disk for RAID levels 4 and 5, and so on. See the references at the end of this hack for pointers to more detailed information about creating and using devices at other RAID levels.
Tip
An important thing to consider when creating mirrored RAID devices is the amount of load they will put on your system’s device controllers. When creating mirrored RAID devices, you should always try to put the drive and its mirror on separate controllers so that no single drive controller is overwhelmed by disk update commands.
Combining RAID and LVM
As mentioned earlier, RAID devices can’t be partitioned. This generally means that you have to use RAID devices in their entirety, as a single filesystem, or that you have to use many small disks and create a RAID configuration file that is Machiavellian in its complexity. A better alternative to both of these (and the point of this hack) is that you can combine the strengths of Linux software RAID and Linux LVM to get the best of both worlds: the safety and redundancy of RAID with the flexibility of LVM. It’s important to create logical volumes on top of RAID storage and not the reverse, though—even software RAID is best targeted directly at the underlying hardware, and trying to (for example) mirror logical devices would stress your system and slow performance as both the RAID and LVM levels competed to try to figure out what should be mirrored where.
Combining RAID and LVM is quite straightforward. Instead of creating a filesystem directly on top of /dev/md0, you define /dev/md0 as a physical volume that can be associated with a volume group [Hack #46] . You then create whatever logical volumes you need within that volume group, format them as described earlier in this hack, and mount and use them however you like on your system.
Tip
If you decide to use Linux software RAID and LVM and support for these is not compiled into your kernel, you must remember to update any initial RAM disks that you use to include the RAID and LVM kernel modules. I generally use a standard ext2/ext3 partition for /boot on my systems, which is where the kernel and initial RAM disks live. This avoids boot-strapping problems, such as when the system needs information from a logical volume or RAID device but has not yet loaded the kernel modules necessary to get that information.
To expand your storage after creating this sort of setup, you physically add additional new devices to your system, define the new RAID device in /etc/raidtab (as /dev/md1, etc.), and run the mkraid command followed by the name of the new device to have your system create and recognize it as a RAID volume. You then create a new physical volume on the resulting device, add that to your existing volume group, and then either create new logical volumes in that volume group or use the lvextend command to increase the size of your existing volumes. Here’s a sample sequence of commands to do all of this (using the mirrored /etc/raidtab from the previous section):
#mkraid /dev/md0#pvcreate /dev/md0#vgcreate data /dev/md0#vgdisplay data | grep "Total PE"Total PE 59618 #lvcreate -n music -l 59618 dataLogical volume "music" created #mkfs -t xfs /dev/data/musicmeta-data=/dev/mapper/data-music isize=256 agcount=16, agsize=3815552 blks = sectsz=512 data = bsize=4096 blocks=61048832, imaxpct=25 = sunit=0 swidth=0 blks, unwritten=1 naming =version 2 bsize=4096 log =internal log bsize=4096 blocks=29809, version=1 = sectsz=512 sunit=0 blks realtime =none extsz=65536 blocks=0, rtextents=0 #mount /dev/mapper/data-music /mnt/music
These commands create a mirrored RAID volume called /dev/md0 using the storage on /dev/hdb1 and /dev/hde1 (which live on different controllers), allocate the space on /dev/md0 as a physical volume, create a volume group called data using this physical volume, and then create a logical volume called music that uses all of the storage available in this volume group. The last two commands then create an XFS filesystem on the logical volume and mount that filesystem on /mnt/music so that it’s available for use. To make sure that your new logical volume is automatically mounted each time you boot your system, you’d then add the following entry to your /etc/fstab file:
/dev/data/music /mnt/music xfs defaults,noatime 0 0
Tip
Specifying the noatime option in the /etc./fstab mount options for my logical volume tells the filesystem not to update inodes each time the files or directories associated with them are accessed.
Until the Linux LVM system supports mirroring, combining software RAID and LVM will give you the reliability and redundancy of RAID with the flexibility and power of LVM. Combining software RAID and LVM on Linux is conceptually elegant and can help you create a more robust, flexible, and reliable system environment. Though RAID levels that support mirroring require multiple disks and thus “waste” some potential disk storage by devoting it to mirroring rather than actual, live storage, you’ll be glad that you used them if any of your disks ever fail.
See Also
Linux software RAID HOWTO: http://unthought.net/Software-RAID.HOWTO/Software-RAID.HOWTO.html
“Create Flexible Storage with LVM” [Hack #46]
Create a Copy-on-Write Snapshot of an LVM Volume
Logical volumes don’t just provide a great way to supply flexible storage— they can also provide a great way to preserve files that have changed recently, simplifying restores and reducing restore requests.
A snapshot is a copy of a logical volume that reflects the contents of that logical volume when the snapshot was created. With a copy-on-write snapshot, each time a file changes in the original volume, the contents of the original file (as of the time that the snapshot was made) are preserved in the snapshot volume. In other words, the complete contents of the original file are copied to the snapshot volume when you write changes to the file in the original volume. Implementing a copy-on-write volume to track changed files is like having a built-in backup mechanism, because it provides you with a point-in-time copy of the filesystem that is contained on your logical volume. This copy of your filesystem can then be used for retrieving files that have accidentally been deleted or modified. For system administrators, copy-on-write snapshots can be particularly useful in preserving the original copies of system configuration files (just in case you ever make a mistake). However, their real beauty is in preserving copies of volumes containing users’ home directories. I’ve found that taking a nightly snapshot of the logical volume that contains the users’ home directories and automatically mounting it enables most users to satisfy their own restore requests by simply retrieving the original copies of lost or incorrectly modified files from the snapshot. This makes them happier and also lightens my workload. Not a bad combination!
This hack explains how to create a snapshot of an existing volume and mount it, and provides some examples of how the snapshot preserves your original files when they are modified in the parent volume.
Kernel Support for Snapshots
Snapshots of logical volumes are created and maintained with the help of the dm_snapshot filesystem driver. This is built as a loadable kernel module on most modern Linux distributions. If you cannot find this module or snapshots simply do not work on your system, cd to your kernel source directory (typically /usr/src/linux) and check your kernel configuration file to make sure this module is either built in or available as a kernel module, as in the following example:
$cd /usr/src/linux$grep –i DM-SNAPSHOT .configCONFIG_SM_SNAPSHOT=m
In this case, the dm-snapshot driver is available as a loadable kernel module. If the value of the CONFIG_DM_SNAPSHOT configuration variable is n, this option is not available in your kernel. You will have to rebuild your kernel with this driver built in (a value of y) or as a loadable kernel module (a value of m) in order to take advantage of logical volume snapshots as discussed in this hack.
Creating a Snapshot
This section explains how to create a snapshot of an existing filesystem. The filesystem that you are taking a snapshot of must reside on a logical volume, as shown by the presence of the device mapper directory in the following example:
# df -Ph /test
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/testvg-testvol 485M 18M 442M 4% /testNext we’ll use the dd command to create a few sample files in the test volume for use in testing later in this hack:
#dd if=/dev/zero of=/test/5M bs=1048576 count=55+0 records in 5+0 records out #dd if=/dev/zero of=/test/10M bs=1048576 count=1010+0 records in 10+0 records out
To create a snapshot of the testvol volume, execute a command like the following:
# lvcreate -s -L 100M -n testsnap /dev/testvg/testvol
Logical volume "testsnap" createdIn this example, I allocated 100 MB for the snapshot. This means that we can make 100 MB in changes to the original volume before the snapshot is full. Snapshots eventually fill up because they are preserving old data, and there is no way to purge the files that it has preserved because it is a snapshot of another volume, not an original logical volume itself. Once a snapshot is 100% used, it becomes useless—you must remove it and create a new snapshot.
To confirm that the snapshot was created correctly, use the lvs command to display logical volume status information:
# lvs
LV VG Attr LSize Origin Snap% Move Copy%
testsnap testvg swi-a- 100.00M testvol 0.02
testvol testvg owi-ao 500.00MMounting a Snapshot
Having a snapshot of a logical volume is fairly useless unless you enable people to access it. To mount the sample testsnap snapshot, use a standard mount command such as the following:
#mount /dev/testvg/testsnap /testsnap#df -Ph /test*Filesystem Size Used Avail Use% Mounted on /dev/mapper/testvg-testvol 485M 18M 442M 4% /test /dev/mapper/testvg-testsnap 485M 18M 442M 4% /testsnap
Tip
Note that a snapshot volume always lives in the same volume group as the logical volume of which it is a copy.
Just to be sure, you can use the ls command to verify that both the snapshot and the original volume are available:
#ls -l /testtotal 15436 -rw-r--r--1 root root 10485760 Apr 21 23:48 10M -rw-r--r--1 root root 5242880 Apr 21 23:48 5M drwx------2 root root 12288 Apr 21 23:15 lost+found #ls -l /testsnap/total 15436 -rw-r--r--1 root root 10485760 Apr 21 23:48 10M -rw-r--r--1 root root 5242880 Apr 21 23:48 5M drwx------2 root root 12288 Apr 21 23:15 lost+found
Now, create a 50-MB file in the /test filesystem and examine what happens to the /testsnap filesystem and the snapshot usage (using our favorite lvs command):
#dd if=/dev/zero of=/test/50M bs=1048576 count=5050+0 records in 50+0 records out #df -Ph /test*Filesystem Size Used Avail Use% Mounted on /dev/mapper/testvg-testvol 485M 68M 392M 15% /test /dev/mapper/testvg-testsnap 485M 18M 442M 4% /testsnap #ls -l /testtotal 66838 -rw-r--r--1 root root 10485760 Apr 21 23:48 10M -rw-r--r--1 root root 52428800 Apr 22 00:09 50M -rw-r--r--1 root root 5242880 Apr 21 23:48 5M drwx------2 root root 12288 Apr 21 23:15 lost+found #ls -l /testsnap/total 15436 -rw-r--r--1 root root 10485760 Apr 21 23:48 10M -rw-r--r--1 root root 5242880 Apr 21 23:48 5M drwx------2 root root 12288 Apr 21 23:15 lost+found #lvsLV VG Attr LSize Origin Snap% Move Copy% testsnap testvg swi-ao 100.00M testvol 50.43 testvol testvg owi-ao 500.00M
Notice that the 50-MB file does not immediately show up in /testsnap, but some of the snapshot space has been used up (50.43%).
Next, simulate a user accidentally removing a file by removing /test/10M and examine the results:
#rm /test/10Mrm: remove regular file `/test/10M'? y #df -Ph /test*Filesystem Size Used Avail Use% Mounted on /dev/mapper/testvg-testvol 485M 58M 402M 13% /test /dev/mapper/testvg-testsnap 485M 18M 442M 4% /testsnap
Note that disk space utilization in your snapshot increased slightly:
# lvs
LV VG Attr LSize Origin Snap% Move Copy%
testsnap testvg swi-ao 100.00M testvol 50.44
testvol testvg owi-ao 500.00MTip
When using the lvs command after significant file operations, you may need to wait a few minutes for the data that lvs uses to be updated.
If you now need to recover the file 10M, you can get it back by simply copying it out of the snapshot (to somewhere safe). Say goodbye to most of your restore headaches!
Remember, once the snapshot is 100% full, its contents can no longer be relied upon, because no new files can be written to it and it is therefore no longer useful for tracking recent updates to its parent volume. You should monitor the size of your snapshots and recreate them as needed. I find that recreating them once a week and remounting them keeps them up to date and also usually prevents “snapshot overflow.”
See Also
Snapshot section of the LVM HWOTO: http://www.tldp.org/HOWTO/LVM-HOWTO/snapshots_backup.html
“Create Flexible Storage with LVM” [Hack #46]
“Combine LVM and Software RAID” [Hack #47]
—Lance Tost
Clone Systems Quickly and Easily
Once you’ve customized and fine-tuned a sample machine, you can quickly and easily deploy other systems based on its configuration by simply cloning it.
Now that Linux is in widespread use, many businesses that don’t want to roll their own Linux systems simply deploy out-of-the-box systems based on supported distributions from sources such as SUSE, Mandriva, Turbo Linux, and Red Hat. Businesses that need a wider array of system or application software than these distributions provide often spend significant effort adding this software to their server and desktop systems, fine-tuning system configuration files, setting up networking, disabling unnecessary services, and setting up their corporate distributed authentication mechanisms. All of this takes a fair amount of time to get “just right”—it also takes time to replicate on multiple systems and can be a pain to recreate if this becomes necessary. You do have backups, don’t you?
To speed up deploying multiple essentially identical systems, the classic Unix approach that I used to take in the “bad old days” was to purchase large numbers of disks that were the same size, use the Unix dd utility to clone system disks containing my tricked out systems to new disks, and then deploy the cloned disks in each new system of the specified type. This still works, but the downside of this approach is that the dd utility copies every block on a disk, regardless of whether it’s actually in use or not. This process can take hours, even for relatively small disks, and seems interminable when cloning today’s larger (200-GB and up) drives.
Thanks to the thousands of clever people in the open source community, faster and more modern solutions to this classic problem are now readily available for Linux. The best known are Ghost for Linux (a.k.a. g4l, http://sourceforge.net/projects/g4l/), which takes its name from the commercial Ghost software package from Symantec (formerly Norton) for Windows systems, and partimage, the popular GNU Partition Image application (http://www.partimage.org). Both of these are open source software packages that are designed to create compressed images of partitions on your systems and make it easy for you to restore these partition images on different drives. The Ghost for Linux software is largely targeted for use on bootable system disks and provides built-in support for transferring the compressed filesystem or disk images that it creates to central servers using FTP. It is therefore extremely useful when you need to boot and back up a system that won’t boot on its own. This hack focuses on partimage because it is easier to build, deploy, and use as an application on a system that is currently running. Of course, you have to have enough local disk space to store the compressed filesystem images, but that’s easy enough to dig up nowadays. Like Ghost for Linux, you can’t use partimage to create an image of a filesystem that is currently mounted, because a mounted filesystem may change while the image is being created, which would be “a bad thing.”
Tip
The ability to create small, easily redeployed partition images is growing in popularity thanks to virtual machine software such as Xen, where each virtual machine requires its own root filesystem. Though many people use a loopback filesystem for this, those consume memory on both the host and client. partimage makes it easy to clone existing partitions that have been customized for use with Xen, which is something you can easily do while your system is running if you have already prepared a Xen root filesystem on its own partition.
partimage easily creates optimal, compressed images of almost any type of filesystem that you’d find on a Linux system (and even many that you would not). It supports ext2fs/ext3fs, FAT16/32, HFS, HPFS, JFS, NTFS, ReiserFS, UFS, and XFS partitions, though its support for both HFS (the older Mac OS filesystem) and NTFS (the Windows filesystem de jour) is still experimental.
Building partimage
partimage is easy enough to build, but it has a fair number of dependencies. To build partimage, you must build or already have installed the following libraries:
- liblzo
Used for fast compression. Available from http://www.oberhumer.com/opensource/lzo.
- libmcrypt
An encryption library required for newer versions of partimage. Available from http://mcrypt.hellug.gr/lib/index.html.
- libnewt
A text-oriented, semi-graphical interface. Available from http://www.partimage.org/deps/newt-0.50.tar.gz.
- libslang
An internationalization package used by newt. Available from http://www.s-lang.org.
- libssl
A Secure Sockets Layer library required for newer versions of partimage. Available from http://www.openssl.org. Must be built in shared mode after configuring it using the following
configurecommand:#
./configure --prefix=/usr -shared- libz
Used for gzip compression. Available from http://www.zlib.org.
- libbz2
Necessary for bzip2 compression. Available at http://sources.redhat.com/bzip2.
Once you’ve built and installed any missing libraries, you can configure and compile partimage using the standard commands for building most modern open source software:
# ./configure && make installThe fun begins once the build and installation is complete. The final product of the make command is two applications: partimage, which is the application that you run on a system to create an image of an existing partition; and partimaged, which is a daemon that you can run on a system in order to be able to save partition images to it over the network, much like the built-in FTP support provided by Ghost for Linux.
Tip
At the time that this book was written, the latest version of partimage was 0.6.4, which was not 64-bit clean and could not be compiled successfully on any of my 64-bit systems. If you need to run partimage on a 64-bit system and no newer version is available by the time that you read this (or if you’re just in a hurry), you can always download precompiled static binaries for your Linux system. Precompiled static binaries are available from the partimage download page listed at the end of this hack.
Cloning Partitions Using partimage
Using partimage to create a copy of an existing unmounted partition is easy. Because partimage needs raw access to partitions, you must execute the partimage command as root or via sudo. As shown in Figure 5-1, the initial partimage screen enables you to select the partition of which you want to create an image, the full pathname to which you want to save the partition image, and the operation that you want to perform (in this case, saving a partition into a file). To move to the next screen, press F5 or use the Tab key to select the Next button and press Enter.
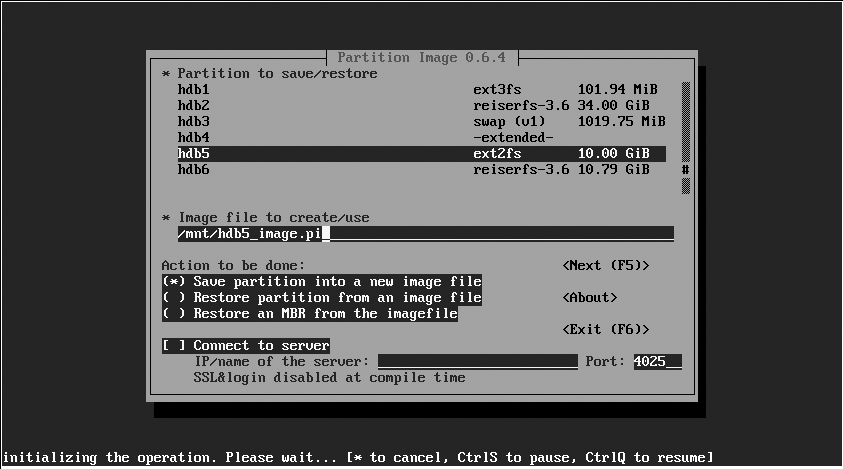
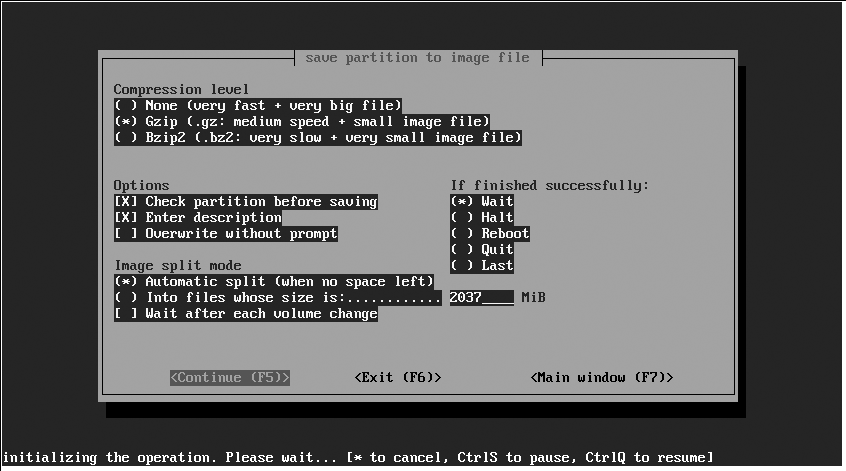
The second partimage backup screen, shown in Figure 5-2, enables you to specify the compression mechanism that you want to use in the image file. Here you can specify that you want to check the consistency of the partition that you are imaging before creating the partition image file, which is always a good idea since you don’t want to clone an inconsistent filesystem. You can also optionally specify that you want to add a descriptive comment to the file, which is often a good idea if you are going to be saving and working with a large number of partition image files. You can also specify what partimage should do after the image file has been created: wait for input, quit automatically, halt the machine, and so on. (The latter is probably only useful if you’ve booted from a rescue disk containing partimage in order to image one of the system partitions on your primary hard drive.) Press F5 to proceed to the next screen.
Tip
Note that the existing type of the partition in /dev/hdb6 is ReiserFS. The existing type of the target partition and the size of the partition that was backed up do not matter (as long as the target partition can hold the uncompressed contents of the partition image file). When restoring a partition image, the partition that is being populated with its contents is automatically created using the same type of filesystem as was used in the filesystem contained in the image file, but using all available space on the target partition.
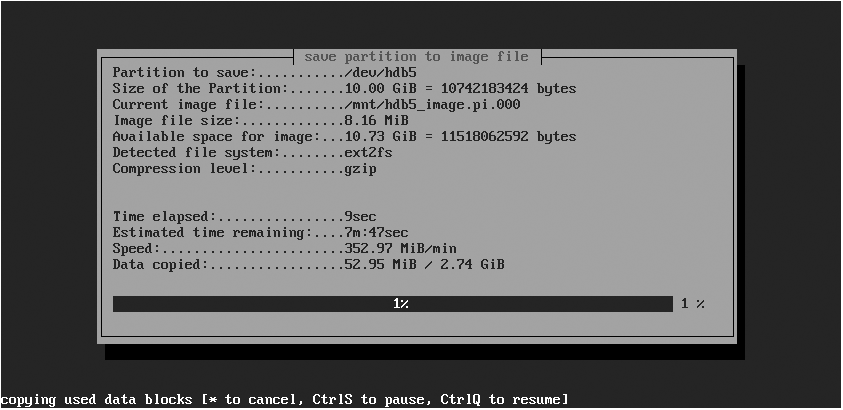
If you specified that you wanted to check the consistency of the filesystem before imaging it, partimage checks the filesystem and displays a summary screen that you can close after reviewing it by pressing Enter. partimage then proceeds to create an image file of the specified partition, as shown in Figure 5-3, displaying a summary screen when the image has been successfully created. If you specified Wait (i.e., wait for input—the default) as the action to perform after creating the image file, you will have to press Enter to close the summary screen and exit partimage.
Restoring Partitions Using partimage
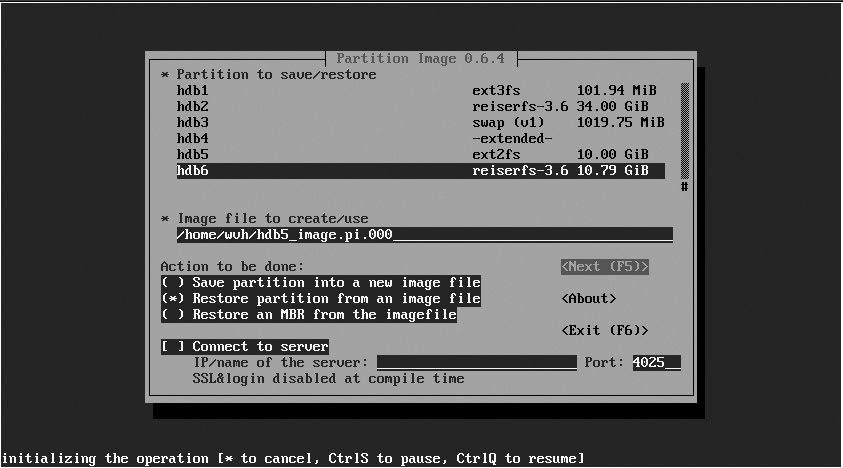
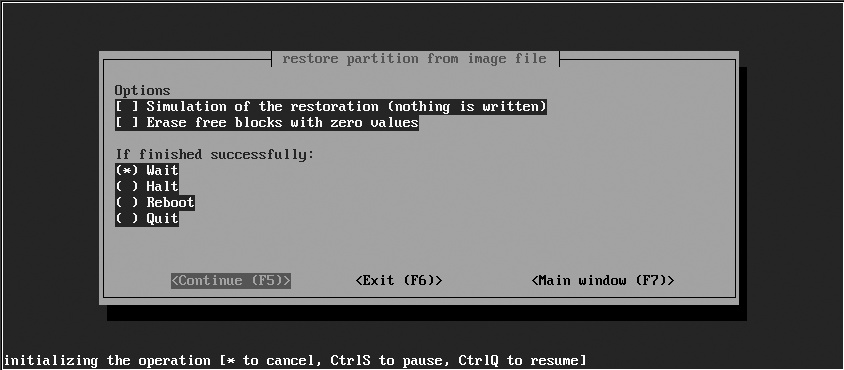
Using partimage to restore a partition image to an existing partition is even simpler than creating the image in the first place. The initial partimage restore screen, shown in Figure 5-4, is the same as that shown in Figure 5-1. It enables you to identify the partition to which you want to restore the partition image, the name of the image file that you want to restore from, and the action that you want to perform (in this case, restoring a partition from a file). To move to the next screen, press F5 or use the Tab key to select the Next button and press Enter.
The second partimage restore screen, shown in Figure 5-5, enables you to run a consistency check by performing a dry run of restoring from the image file and also enables you to zero out unused blocks on the target filesystem when it is created. As with the image-creation process, you can also specify what partimage should do after the image file has been restored: wait for input, quit automatically, halt or reboot the machine, and so on. Press F5 to proceed to the next screen.
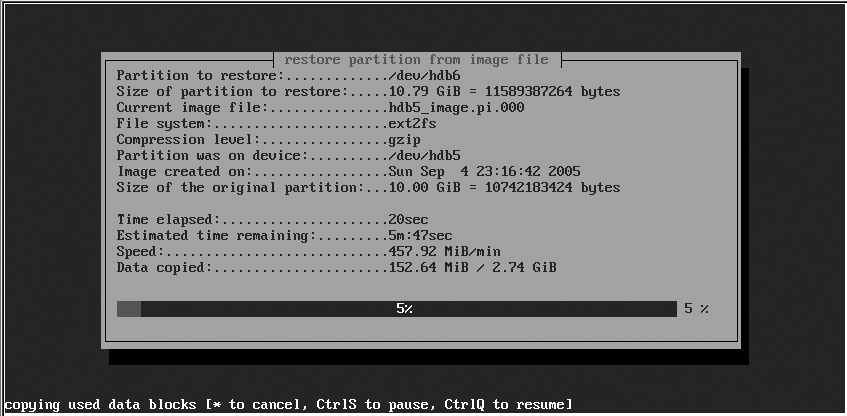
partimage then proceeds to restore the partition image file to the specified partition, as shown in Figure 5-6, displaying a summary screen by default when the image has been successfully restored. If you specified Wait (i.e., wait for input—the default) as the action to perform after creating the image file, you will have to press Enter to close the summary screen and exit partimage.
Summary
Creating partition image files of customized, optimized, and fine-tuned desktop and server partitions provides a quick and easy way of cloning those systems to new hardware. You can always clone partitions containing applications, such as /opt,/var,/usr, and /usr/local. (Your actual partition scheme is, of course, up to you.) If your new systems have the same devices as the system on which the image file was created, you can even easily copy preconfigured system partitions such as /boot and / itself. Either way, applications such as partimage can save you lots of time in configuring additional hardware by enabling you to reuse your existing customizations as many times as you want to.
See Also
“Make Disk-to-Disk Backups for Large Drives” [Hack #50]
Ghost for Linux home page: http://sourceforge.net/projects/g4l/
Ghost for Linux download page: ftp://fedoragcc.dyndns.org
partimage home page: http://www.partimage.org
partimage download page: http://www.partimage.org/download.en.html
System Rescue CD home page: http://www.sysresccd.org
Make Disk-to-Disk Backups for Large Drives
Today’s hard drives are large enough that you could spend the rest of your life backing them up to tape. Putting drive trays in your servers and using removable drives as a backup destination provides a modern solution.
Some of us are old, and therefore remember when magnetic tape was the de facto backup medium for any computer system. Disk drives were small, and tapes were comparatively large. Nowadays, the reverse is generally true— disk drives are huge, and few tapes can hold more than a fraction of a drive’s capacity. But these facts shouldn’t be used as an excuse to skip doing backups! Backups are still necessary, and they may be more critical today than ever, given that the failure of a single drive can easily cause you to lose multiple partitions and hundreds of gigabytes of data.
Luckily, dynamic device buses such as USB and FireWire ( a.k.a. IEEE 1094) and adaptors for inexpensive ATA drives to these connection technologies provide inexpensive ways of making any media removable without disassembling your system. Large, removable, rewritable media can truly simplify life for you (and your operators, if you’re lucky enough to have some). A clever combination of removable media and a good backup strategy will make it easy for you to adapt disk drives to your systems to create large, fast, removable media devices that can solve your backup woes and also get you home in time for dinner (today’s dinner, even). If you’re fortunate enough to work somewhere that can buy the latest, partial terabyte backup tape technology, I’m proud to know you. This hack is for the rest of us.
Convenient Removable Media Technologies for Backups
Depending on the type of interfaces available on your servers, an easy way to roll your own removable media is to purchase external drive cases that provide USB or FireWire interfaces, but in which you can insert today’s largest IDE or SATA disk drives. Because both USB and FireWire support dynamic device detection, you can simply attach a new external drive to your server and power it up, and the system will assign it a device identifier. If you don’t know every possible device on your system, you can always check the tail of your system’s logfile, /var/log/messages, to determine the name of the device associated with the drive you’ve just attached. Depending on how your system is configured, you may also need to insert modules such as uhci_hcd, ehci_hcd, and usb_storage in order to get your system to recognize new USB storage devices, or ohci1394 for FireWire devices.
Tip
This presumes that the default USB and FireWire controller modules (usbcore and sbp2, respectively) are already being loaded by your kernel (as well as the SCSI emulation module, scsi_mod, if you need it), and that what you really need is support for recognizing hot-plug storage devices.
Empty external drive cases with USB and/or FireWire interfaces start at around $35 on eBay or from your local computer vendor, but can run much higher if you decide you want a case that holds multiple drives. I was a Boy Scout eons ago and have been a sysadmin for a long time, and I like to “be prepared.” I therefore further hedge my external drive options by putting drive trays in the external cases, so that I can quickly and easily swap drives in and out of the external cases without having to look for a screwdriver in a time of crisis.
Figure 5-7 shows a sample drive tray. Drive trays come with a small rack that you mount in a standard drive bay and a drive tray into which you insert your hard drive. This combination makes it easy to swap hard drives in and out of the external drive case without opening it. I also put drive racks in the standard drive bays in my servers so that I can quickly add or replace drives as needed.
Tip
If you decide to use USB as the underpinnings of a removable media approach to backups, make sure that the USB ports on your servers support USB 2.0. USB 1.x is convenient and fine for printing, connecting a keyboard or mouse, and so on, when speed is really not a factor. However, it’s painfully slow when transferring large amounts of data, which is the best-case scenario for new backups and the worst-case scenario for all others.

Choosing the Right Backup Command
Once you have a mechanism for attaching removable storage devices to your system and have a few large drives ready, it’s important to think through the mechanism that you’ll use for backups. Most traditional Unix backups are done using specialized backup and restore commands called dump and restore, but these commands take advantage of built-in knowledge about filesystem internals and therefore aren’t portable across all of the different filesystems available for Linux. (A version of these commands for ext2/ext3 filesystems is available at http://dump.sourceforge.net.) Another shortcoming of the traditional dump/restore commands for Unix/Linux is that they reflect their origins in the days of mag tapes by creating output data in their own formats in single output files (or, traditionally, a stream written to tape). This is also true of more generic archiving commands that are also often used for backups, such as tar, cpio, and pax.
Tip
If you’re using logical volumes, “Create a Copy-on-Write Snapshot of an LVM Volume” [Hack #48] explained how to create a copy-on-write snapshot of a volume that automatically picks up a copy of any file that’s modified on its parent volume. That’s fine for providing a mechanism that enables people to recover copies of files that they’ve just deleted, which satisfies the majority of restore requests. However, copy-on-write volumes don’t satisfy the most basic tenet of backups—thou shalt not store backups on-site. (There are exceptions, such as if you’re using a sophisticated distributed filesystem such as AFS or OpenAFS, but that’s a special case that we’ll ignore here.) The removable storage approach satisfies the off-site backup rule as long as you actually take the backup drives elsewhere.
So I can use the same backup scripts and commands regardless of the type of Linux filesystem that I’m backing up, I prefer to use file-and directory-level commands such as cp rather than filesystem-level commands. This is easy to do when doing disk-to-disk backups, because the backup medium is actually a disk that contains a filesystem that I mount before starting the backup. After mounting the drive, I use a script that invokes cp to keep the backup drive synchronized with the contents of the filesystem that I’m backing up, using a cp command such as the following:
# cp –dpRux /home /mnt/home-backupAs you can see from this example, the script creates mount points for the backup filesystems that indicate their purpose, which makes it easier for other sysadmins to know why a specific drive is mounted on any given system. I use names that append the string –backup to the name of the filesystem that I’m backing up—therefore, /mnt/home-backup is used as a mount point for the backup filesystem for the filesystem mounted as /home. You’re welcome to choose your own naming convention, but this seems intuitive to me. The cp options that I use have the following implications:
|
|
Don’t dereference symbolic links (i.e., copy them as symbolic links rather than copying what they point to). |
|
|
Preserve modes and ownership of the original files in the copies. |
|
|
Recursively copy the specified directory. |
|
|
Copy files only when the original file is newer than an existing copy, or if no copy exists. |
|
|
Display information about each file that is copied. |
|
|
Don’t follow mount points to other filesystems. |
The Code
The actual script that I use to do these sorts of backups is the following (feel free to use or modify it if you’d like):
#!/bin/bash
#
# wvh's simple backup script using cp
#
if [ $# != 2 ] ; then
echo " Usage: cp_backup partition backup-device"
echo " Example: cp_backup /home /dev/sda1"
exit
fi
VERBOSE="no"
STDOPTS="-dpRux"
LOGFILE="/var/log/backup/simple.log"
TARGETBASE=`echo $1 | sed -e 's;^/;;' -e 's;/;-;g'`
FULLTARGET="/mnt/"$TARGETBASE"-backup"
DATE=`date`
export BACKUPTASK="$1 to $2"
trap cleanup 1 2 3 6
cleanup()
{
echo " Uh-oh, caught signal: tidying up…" | tee -a $LOGFILE
DATE=`date`
umount $FULLTARGET
echo "Aborted simple backups of $BACKUPTASK $DATE" | tee -a $LOGFILE
exit 1
}
if [ ! -d /var/log/backup ] ; then
mkdir -p /var/log/backup
fi
echo "Starting simple backups of $BACKUPTASK at $DATE" | tee -a $LOGFILE
if [ ! -d $FULLTARGET ] ; then
echo " Creating mountpoint $FULLTARGET" | tee -a $LOGFILE
mkdir -p $FULLTARGET
fi
MOUNTED=`df | grep $FULLTARGET`
if [ "x$MOUNTED" != "x" ] ; then
echo " Something is already mounted at $FULLTARGET - exiting" | tee -a
$LOGFILE
exit
fi
mount $2 $FULLTARGET
if [ x$? != "x0" ] ; then
echo " Mount of backup volume $2 failed - exiting" | tee -a $LOGFILE
exit
fi
#
# This block keeps copies of important system files on all backup volumes
# in a special directory called .123_admin. They're small, it's only slow
# once, and I'm paranoid.
#
if [ ! -d $FULLTARGET"/.123_admin" ] ; then
mkdir -p $FULLTARGET"/.123_admin/conf"
fi
echo " Backing up system files to $FULLTARGET/.123_admin" | tee -a $LOGFILE
cd /etc
cp -u passwd group shadow $FULLTARGET"/.123_admin"
if [ -d sysconfig ] ; then
cp -uR sysconfig $FULLTARGET"/.123_admin"
fi
find . -name "*.conf" -print | while read file ; do
cp -u $file $FULLTARGET"/.123_admin/conf"
done
#
# Now we actually do the cp backups
#
DATE=`date`
echo " Starting actual backup of $BACKUPTASK at $DATE" | tee -a $LOGFILE
cd $1
if [ x$VERBOSE != "xno" ] ; then
cp $STDOPTS"v" . $FULLTARGET
else
cp $STDOPTS . $FULLTARGET
fi
umount $FULLTARGET
DATE=`date`
echo "Completed simple backups of $BACKUPTASK at $DATE" | tee -a $LOGFILEYou’ll note that I don’t log each file that’s being backed up, though that would be easy to do if running the script in verbose mode by using the tee command to clone the cp command’s output to the logfile. The traditional Unix/Linux dump and restore commands use the file /etc/dumpdates to figure out which full and incremental backups to use in order to restore a specific file or filesystem, but this isn’t necessary in this case because we’re copying the updated files from the specified partition to a full backup of that partition, not just doing an incremental backup in traditional Unix/Linux terms.
Running the Code
If you’re following along at home, you can use this script by entering it in your favorite text editor, saving it to a file called cp_backup in /usr/local/bin, making it executable (chmod 755 /usr/local/bin/cp_backup), and then executing it (after making sure that you’ve mounted a spare disk as a backup target, and that the spare disk is the same size as or larger than the filesystem that you want to back up). For example, to back up the partition mounted as /mnt/music on my system (which contains 100% legally purchased music in digital form) to a 250-GB disk containing the single partition /dev/sda1, I would use the following command:
# /usr/local/bin/cp_backup /mnt/music /dev/sda1You can even automate these sorts of backups by adding an entry that executes them to root’s crontab file. As the root user or via sudo, execute the crontab –e command and append a line like the following to the end of the file:
0 2 * * * $/usr/local/bin/cp_backup /mnt/music /dev/sda1
This will run the cp_backup script to back up /mnt/music to /dev/sda1 every night at 2 A.M.
Choosing What to Back Up
The previous sections explained why disk-to-disk backups are the smartest choice for low-cost backups of today’s huge disk drives, and advocated file-and directory-level commands as an easy backup mechanism that is independent of the actual format of the filesystem that houses the data you’re backing up. Keeping a large number of spare drives around can be costly, though, so I try to minimize the number of filesystems that I back up. The traditional Unix/Linux dump command does this through entries in the /etc/fstab file that identify whether the filesystem should be backed up or not—if the entry in the next-to-last column in /etc/fstab is non-zero, the filesystem will be backed up. My general rule is to only back up filesystems that contain user data. Standard Linux filesystems such as / and /usr can easily be recreated from the distribution media or from partition images
[Hack #49]
. Since the backup script I use keeps copies of system configuration files, I’m not that worried about preserving system configuration information.
Summary and Tips
This hack provides an overview of doing modern backups and a script that I use to do them on most of the systems I deploy. To use this approach, the target devices that you’re backing up to have to have at least as much space as the filesystem that you’re backing up, and you’ll have to preen or wipe the daily backup devices every so often (generally after a full backup) in order to minimize the number of copies of files and directories that have been deleted from the live filesystem but still exist on the backup drives. If your systems use logical volumes that span multiple disks, you’ll have to use equivalent, multi-disk backup devices, but they can often be simpler, cheaper devices than those that house your live data. For example, if you’re backing up filesystems that live on a RAID array, you don’t have to have a RAID backup device—you can get away with sets of drives that are large enough to hold the data itself, not its mirrors or checksum disks.
Free Up Disk Space Now
Moving large files to another partition isn’t always an option, especially if running services are holding them open. Here are a few tips for truncating large files in emergency situations.
Server consolidation takes planning, and it usually means adjusting the way you set up your OS installations. Running multiple services on a single OS image means not only increased network traffic to the same hardware, but increased disk usage for logfiles.
What’s more is that administrators’ thirst for more data about the services they run has resulted in a tendency for logging to be more verbose these days than it was in the past, partially because the tools for analyzing the data are getting better.
However, someday you’ll inevitably be faced with a situation where you’re receiving pages from some form of service monitoring agent telling you that your web server has stopped responding to requests. When you log in, you immediately type df –h to see if what you suspect is true, and it is—your verbose logging has just bitten you by filling up the partition, leaving your web server unable to write to its logfiles, and it has subsequently stopped serving pages and become useless. What to do?
There are several commands you can use to deal with this. If the service is completely dead, you could actually move the file to another partition, or simply run rm -f
logfile if you know that the data is not particularly useful. If the service is still running, however, and needs its logfile to be available in order to do anything useful, truncation may be the way to go. Some admins have a watchdog script that polls for large files created by noncritical services and truncates them before they get out of control, without having to restart the service. A command that might appear in a script to do this (which can also be issued at a command line) is:
$cat /dev/null >filename
Obviously, you should run this command as root if the file you are truncating requires elevated privileges. Why use /dev/null? You could also use the following command:
$cat >filename
This is certainly a little shorter, but the downfall here is that it doesn’t exit by itself—you need to terminate it manually. On the command line, that means typing Ctrl-C to exit.
While these commands definitely work, I’d like to show you what I believe to be the shortest file truncation command known to bash. It goes a little something like this:
$ > filenameThe above command has no dependency on anything except for the redirection operator >. Essentially, you are redirecting what’s on the left of the operator (which is to say, nothing) into the file in question. What makes this perfectly elegant is that it exits all by itself and leaves behind a file of zero bytes in length. What more could an admin ask for?
Technically, understanding what has happened above involves knowing how redirection in the shell works. In the bash shell, if the redirection operator is pointing to the right (i.e., >), what is being directed is the standard output of whatever is on the left. Since we’ve specified no command on the lefthand side, the standard output is nothing, and our redirection operator happily overwrites our large file, replacing the contents with…nothing.
Share Files Using Linux Groups
Traditional Unix/Linux groups have always made it easy to share files among users.
Though this is more of a basic system capability than a hack, creating files that other users can both read and write can be done in various ways. The easiest way to do this is to make all files and directories readable and writable by all users, which is the security equivalent of putting a sign on your computer reading, “Please screw this up.” No sysadmin in his right mind would do this, and most would also want to protect their users against accidentally setting themselves up for a catastrophe by doing so.
This hack provides an overview of how to use Linux protections to create directories that can be protected at the group level, but in which all members of that group will be able to read and write files. This doesn’t involve any special scripts or software packages, but provides a simple refresher that will help you help your users get their work done as efficiently as possible— and with as few phone calls or pages to you as possible.
Linux Protections 101
Basic Linux protection modes, inherited from Unix, provide the ability to protect files and directories at three basic levels:
Owner-specific permissions that control what the person who owns a file can do
Group-specific permissions that control what other members of the group that owns a file or directory can do
One more set of permissions that control what anyone else on the system can do
These permissions are reflected in the leftmost entry in the long listing of any file or directory, as in the following example:
$ ls -al /home/top-secret
total 8
drwxrwx---2 ts top-secret 80 2005-07-04 16:02 .
drwxr-xr-x 8 root root 184 2005-07-04 15:57 ..
-rw-r--r--1 wvh top-secret 5386 2005-07-04 16:02 wmd_overview.sxwThis listing shows three sets of Unix permissions: those for the directory in which the command was executed (.), those for that directory’s parent directory (..), and those for a file in that directory (wmd_overview.sxw). The permissions for the directory show that it is owned by the user ts and the group top-secret, and that the directory can only be read, written to, or searched by the user ts or anyone in the top-secret group. The permissions entry for the wmd_overview.sxw file say that the file can be read or written to by its owner (wvh) and by any member of the top-secret group. In practice, this seems pretty straightforward—anyone in the top-secret group who needs to modify the wmd_overview.sxw file can just open it, make their changes, and save the file. Because only the user ts user and people in the top-secret group have access to the directory in the first place, it seems like a natural place for members of the group to create files that they can share with other group members.
Setting the umask to Create Sharable Files
The ownership and permissions on files that a user creates are controlled by three things: the user’s user ID when creating the file, the group to which she belongs, and her default protection file settings, known as her umask. The umask is a numeric value that is subtracted from the permissions used when creating or saving files or directories.
In the previous example, assume that the users wvh and juser are both members of the top-secret group. The user juser creates a file called juser_comments.txt in the /home/top-secret directory, but its protections are set to -rw-r--r--.
This means that no other user in the top-secret group can modify this file unless juser changes the permissions so that the file is also writable by group members, which can be done with either of the following commands:
$chmod 660 juser_comments.txt$chmod g+w,o-r juser_comments.txt
You find out a user’s default umask setting by issuing the umask command, which is a built-in command in most Linux shells. By default, most users’ umasks are set to 0022 so that newly created files are writable only by their owners, as in the example in the previous paragraph.
Setting the user’s umask to 0002 may seem like an easy way to ensure that files are created with permissions that enable other group members to modify them. This turns off the world-writable bit for the file, but leaves the group-writable bit set. However, there are two problems with this approach:
It affects every file that the user creates, including files that are typically kept private, such as the user’s mailbox.
It applies only to the group to which the user belonged at the time the file was created.
If you want to use a group-writable umask setting everywhere, the first of these issues is usually solved by turning off the executable and read permissions for group members and standard users on your home directory. (In Unix/Linux permissions, the executable bit on a directory determines whether the directory is searchable.) This means that while the files being created there are writable by group members, group members can’t view the directory or locate the files in the first place.
If you don’t want to globally set your umask to create files that are group-writable, another common approach is to define an alias for file creation (in your shell’s startup file, such as ~/.bashrc) that automatically sets file permissions appropriately, as in the following example:
alias newfile=`(umask 0002 ; touch $1)`
This command forks a sub-shell, sets the umask within that shell, and then creates the file and exits the sub-shell. You can do the same sort of thing without forking a sub-shell by manually changing the file permissions within an alias:
alias newfile=`touch $1; chmod 660 $1`
Any of these solutions works fine if the group that you want to be able to share files with is the group that you initially belong to when you log in, known as your login group.
Linux enables users to belong to multiple groups at the same time, in order to let people work on multiple projects that are protected at the group level. For the purposes of creating files, Linux users function as members of a single group at any given time, and they can change the group that is in effect via the newgrp command. However, as explained in the next section, you can also set Linux directory protections to control the group that owns files created in a particular directory.
Using Directory Permissions to Set Group Membership
Directory permissions in Linux have a different impact on the group ownership of files created in a directory than they do in other Unix-like operating systems. On BSD-based systems, for example, files created in a directory are always created with the group ownership of the group that owns the directory. On Linux systems, files created in a directory retain the group membership of the user that was in effect at the time the file was created.
However, you can easily force group membership under Linux by taking advantage of a special permission mode, known as the s-bit. Unix systems have traditionally used this bit to enable users to run applications that require specific user or group privileges, but when set on a directory, the s-bit causes any files created in that directory to be created with the group membership of the directory itself. The s-bit on a directory is set using the command chmod g+s
filename. If the s-bit is set on a specific directory, the x in the group permissions for that directory is replaced with an s.
The following is an example of group ownership after the s-bit has been set on the same /home/top-secret directory (note the s in the executable bit of the group settings):
#chmod g+s /home/top-secret#ls -altotal 8 drwxrws---2 ts top-secret 80 2005-07-04 16:02 . drwxr-xr-x 8 root root 184 2005-07-04 15:57 .. -rw-r--r--1 wvh top-secret 5386 2005-07-04 16:02 wmd_overview.sxw
At this point, creating any file in this directory gives it the same group ownership as the directory, as in the following example:
$touch testfile.txt$ls -altotal 8 drwxrws--- 2 ts top-secret 112 2005-07-04 16:06 . drwxr-xr-x 8 root root 184 2005-07-04 15:57 .. -rw-r--r-- 1 wvh top-secret 0 2005-07-04 16:06 testfile.txt -rw-rw-r-- 1 wvh top-secret 5386 2005-07-04 16:02 wmd_overview.sxw
Because of the umask settings discussed earlier, this file was created with a mode that made it both user- and group-writable, which is exactly what you want.
As you can see, Unix groups provide a useful and flexible mechanism for enabling users to share access to selected files and directories. They work in the same way on every modern Unix system, and thus provide a portable and standard protection mechanism.
See Also
“Refine Permissions with ACLs” [Hack #53]
Refine Permissions with ACLs
Access control lists bring granular permissions control to your files and directories.
Standard Unix/Linux file permissions are fine if you have a relatively small number of users with limited requirements for sharing and working on the same files. (“Share Files Using Linux Groups” [Hack #52] explained the classic approaches to enabling multiple users to work on the same files.) However, using groups to control shared access requires the intervention of a system administrator and can result in incredibly huge and complex /etc/group files. This makes it difficult to set the group memberships for any new accounts correctly and requires frequent sysadmin intervention as users leave or move between projects. ACLs, which are supported in most modern Linux distributions, eliminate this hassle by providing a fine-grained set of permissions that users can impose on their own directories, going far beyond the permissions and protections provided by standard Linux groups.
Simply put, an ACL is a list of Linux users and/or groups and the access rights that they have to a specific file or directory. ACLs enable you to define totally granular permissions such as “only the users wvh and alex can write this file, but the user juser can at least read it” without requiring that you create any special-purpose Linux groups.
ACLs as implemented on Linux systems today are defined by the draft Portable Operating System Interface (POSIX) standard 1003.1e, draft 17, from the Institute of Electrical and Electronics Engineers (IEEE). This is not an official standard, but it is publicly available and has become the foundation for ACL implementations for modern operating systems such as Linux. (See the end of this hack for pointers to this document on the Web.)
Installing and Activating ACL Support
To use ACLs to enhance the granularity of permissions on your system, you must have several things in place:
Your kernel must be compiled with both enhanced attribute and ACL support for the type(s) of filesystem(s) that you are using.
Your filesystem(s) must be mounted with extended attribute and ACL support enabled [Hack #54] .
You must install the user-space ACL utilities (chacl, getfacl, and setfacl) in order to examine and set ACLs.
Kernel ACL support.
Most modern Linux distributions provide support for ACLs in the default kernels that they deliver. If you have access to the configuration file used to build your kernel, you can use the grep utility to check to make sure that the POSIX_ACL configuration variable associated with the types of filesystems that you are using is set to y, as in the following example:
$ grep POSIX_ACL /boot/config-2.6.8-24.16-default
EXT2_FS_POSIX_ACL=y
EXT3_FS_POSIX_ACL=y
REISERFS_FS_POSIX_ACL=y
JFS_POSIX_ACL=y
XFS_POSIX_ACL=yIf the POSIX_ACL value associated with any of the types of filesystems you are using is set to n, you will have to enable it, save the updated kernel configuration, and recompile your kernel in order to use ACLs. To enable the appropriate POSIX_ACL value, you will also have to enable extended attributes for that filesystem. Extended attributes must be separately enabled for each type of filesystem you are using (with the exception of the XFS journaling filesystem, which inherently supports them). The kernel configuration options that enable them are located on the File Systems pane in your favorite kernel configuration editor (make xconfig, make menuconfig, and so on). See “Make Files Easier to Find with Extended Attributes”
[Hack #54]
for more information about enabling and using extended attributes.
fstab ACL support.
Once you are running a kernel with support for POSIX ACLs, you will also need to make sure that the filesystems in which you want to use ACLs are mounted with ACL support enabled. Check your /etc/fstab file to verify this. Filesystems mounted with ACL support will have the acl keyword in the mount options portions of their entries in the file. In the following example, the reiserfs filesystem on /dev/sda6 is mounted with ACL support, while the ext3 filesystem on /dev/hda1 is not:
/dev/sda6 /usr reiserfs noatime,acl,user_xattr 1 2 /dev/hda1 /opt2 ext3 defaults 0 0
If your kernel supports ACLs, you can edit this file to enable ACL support when you initially mount a filesystem by adding the acl keyword to the mount options for that filesystem, as in the following example:
/dev/hda1 /opt2 ext3 defaults,acl 0 0
After updating this file, you can enable ACL support in currently mounted filesystems without rebooting by executing a command like the following, which would remount the example ext3 filesystem /dev/hda1, activating ACL support:
# mount -o remount,acl /dev/hda1User-space ACL support.
The last step in using ACLs on your system is to make sure that the user-space applications that enable you to display and set ACLs are present. If your system uses a package management system, you can query that system’s database to see if the acl package and its associated library, libacl, are installed. The following is an example query on a system that uses RPM:
# rpm -qa | grep acl
acl-2.2.25-2
libacl-2.2.25-2You can also look for the utilities themselves, using the which command:
#which getfacl/usr/bin/getfacl #which setfacl/usr/bin/setfacl #which chacl/usr/bin/chacl
If the acl package is not installed and the binaries are not present on your system, you can find the source code or binary packages for your system by following links from http://acl.bestbits.at. You’ll need to install these packages before continuing.
Overview of Linux ACLs and Utilities
Linux supports two basic types of ACLs:
ACLs used to control access to specific files and directories
Per-directory ACLs (known as mask ACLs), which define the default ACLs that will be assigned to any files created within that directory
Conversationally and in print, ACLs are represented in a standard format consisting of three colon-separated fields:
The first field of an ACL entry is the entry type, which can be one of the following: user (
u), group (g), other (o), or mask (m).The second field of an ACL entry is a username, numeric UID, group name, or numeric GID, depending on the value of the first field. If this field is empty, the ACL refers to the user or group that owns the file or directory. mask and other ACLs must have an empty second field.
The third field lists the access permissions for the ACL. These are represented in two forms:
A standard Unix-like permissions string or “rwx” (read, write, and execute permissions, where execute permissions on directories indicate the ability to search those directories). Each letter may be replaced by a dash (-), indicating that no access of that type is permitted. These three permissions must appear in this order.
A relative symbolic form that is preceded by a plus sign (+) or a caret symbol (^), much like the symbolic permissions that are designed for use with the
chmodcommand by people who are octally challenged. In this ACL representation, the + or ^ symbols are followed by singler, w, orxpermission characters, indicating that these permissions should be added to the current set for a file or directory (+) or removed from the current set (^) for a given file or directory.
When listed or stored in files, different ACL entries are separated by white space or new lines. Everything after a # character to the end of a line is considered a comment and is ignored.
The Linux acl package provides the following three utilities for ACL creation, modification, and examination:
- chacl
Lets you change, examine, or remove user, group, mask,or other ACLs on files or directories
- getfacl
Lets you examine file ACLs for files and directories
- setfacl
Lets you set file and directory ACLs
Displaying Current ACLs
As an example of using ACLs, let’s use a directory with the following contents and permissions:
$ ls -al
total 49
drwxr-xr-x 2 wvh users 80 2005-07-04 13:59 .
drwxr-xr-x 106 wvh users 5288 2005-07-04 14:47 ..
-rw-r-----1 wvh users 44032 2005-07-04 13:58 resume.xmlThe default ACL for this directory is the following:
$ getfacl .
# file: .
# owner: wvh
# group: users
user::rwx
group::r-x
other::r-xThe default ACL for the file resume.xml is the following:
$ getfacl resume.xml
# file: resume.xml
# owner: wvh
# group: users
user::rw-
group::r--
other::---The default ACL for a file in a directory for which a default ACL has not been set reflects the default Unix permissions associated with the user that created the file. The default Unix permissions for a file are based on the setting of the umask environment variable
[Hack #52]
.
Setting ACLs
There are three common ways to change the ACL of a file or directory:
By setting it explicitly using the
setfaclcommand, which overwrites any existing ACL settingsBy using the
setfaclcommand with the-m(modify) option to modify an existing ACLBy using the
chaclcommand to modify an existing ACL
For the examples in this hack, I’ll use the chacl command to change ACLs, since this doesn’t overwrite the existing ACL. It also provides a bit more information about how ACLs really work than the shorthand version of the setfacl command.
For example, to add the user alex as someone who can read the file resume.xml, I would use a chacl (change ACL) command like the following:
$ chacl u::rw-,g::r--,o::---,u:alex:r--,m::rw- resume.xmlNo, that isn’t static from a bad modem or Internet connection (though it probably is a command in the old TECO editor)—that’s the way ACLs look in real life. As mentioned previously, ACLs consist of three colon-separated fields that represent the permissions of the user (the owner of the file), group (the group ownership of the file), and others. When changing an ACL with the chacl command, you need to first specify the ACL of the file and then append the changes that you want to make to that ACL. The u::rw-,g::r--,o::--- portion of the ACL in this example is the existing ACL of the file; the u:alex:r--,m::rw- portion specifies the new user that I want to add to the ACL for that file and the effective rights mask to be used when adding that user. The effective rights mask is the union of all of the existing user, group, and other permissions for a file or directory. You must specify a mask when adding a random user to the ACL for a file.
Using the getfacl command to retrieve the ACL for my resume shows that the user alex has indeed been added to the list of people who have access to the file:
$ getfacl resume.xml
# file: resume.xml
# owner: wvh
# group: wvh
user::rwx
group::r--
other::---
user:alex:r--
mask::rw-Tip
Though the content is the same, the format of the output of the getfacl command depends on the version of the ACL suite that is being used on your Linux system.
Using the ls -al command shows that the visible, standard Unix file and directory permissions haven’t changed:
$ ls -al
total 49
drwxr-xr-x 2 wvh users 80 2005-07-04 13:59 .
drwxr-xr-x 106 wvh users 5288 2005-07-04 14:47 ..
-rw-r-----1 wvh users 44032 2005-07-04 13:58 resume.xmlYou can verify that the user alex now has access to the file by asking him to attempt to read the file. (If you know his password, you can check this yourself by su’ing to that user or by connecting to your machine over the network, logging in as alex, and examining the file using a text editor or a command such as more or cat.)
Even more interesting and useful than just giving specific individuals read access to files is the ability to give specific users the ability to write to specific files. For example, to add the user alex as someone who can both read and write to the file resume.xml, I would use a chacl command like the following:
$ chacl u::rw-,g::r--,o::---,u:alex:rw-,m::rw- resume.xmlUsing the getfacl command shows that the user alex now has both read and write access to the file:
$ getfacl resume.xml
# file: resume.xml
# owner: wvh
# group: users
user::rw-
group::rw-
other::---
user:alex:rw-
mask::rw-As before, you can verify that the user alex now has both read and write access to the file by asking him to attempt to read and write to the file. (If you know the test user’s password, you can check this yourself by connecting to your machine over the network, logging in as that user, and editing and saving the file using a text editor.)
I’m a big fan of ACLs, primarily because they give knowledgeable users total control over who can access their files and directories. ACLs remove one of the main administrative complaints about Unix systems: the need for root access to set up granular permissions. As a fringe benefit, they also silence one more argument for using systems such as Windows 2000/2003/XP.
See Also
“Share Files Using Linux Groups” [Hack #52]
“Make Files Easier to Find with Extended Attributes” [Hack #54]
POSIX.1e draft specification: http://wt.xpilot.org/publications/posix.1e
POSIX ACLs on Linux: http://www.suse.de/~agruen/acl/linux-acls/online
Make Files Easier to Find with Extended Attributes
Define file- and directory-specific metadata to make it easier to find critical data.
Most projects and users organize their files by taking advantage of the inherently hierarchical nature of the Linux filesystem. Conceptually related items are given meaningful names and stored in hierarchical directories with equally memorable or evocative names. But unfortunately, file and directory names and structures that were memorable at the time of creation are not always equally memorable a month or two later, when you’re desperately looking for a specific file.
Extended attributes are name/value pairs that you can associate with any file or directory in a Linux filesystem. These are a special type of metadata, which is the term for data about data, such as modification and access times, user and group ownership, protections, and so on. Extended attributes can be associated with any object in a Linux filesystem that has an inode. The names of extended attributes can be up to 256 bytes long, are usually standard ASCII text, and (like standard Linux strings) are terminated by the first NULL byte. The value of an attribute can be up to 64 KB of arbitrary data in any format.
Extended attributes are often used for system purposes, by tagging files with metadata about who can access them, and under what circumstances. This hack discusses how extended attributes can be extremely useful for any user or system administrator who wants to tag important files and directories with information that makes them easier to find, work with, track modifications to, and so on.
Getting and Installing Extended Attribute Support
Extended attributes are currently supported by all major Linux filesystems for desktop and server use, including ext2, ext3, reiserfs, JFS, and XFS. They are not currently supported in NFS filesystems, even if they are being set and used in the actual filesystem being exported via NFS—the code that transfers file data and metadata across the network does not currently understand extended attributes.
Like the ACLs [Hack #53] , using extended attributes also requires that your kernel supports them, that the filesystems in which you want to use them are mounted with extended attribute support, and that the user-space utilities for displaying and setting the values of different extended attributes (attr, getfattr, and setfattr) are compiled and installed on your system.
Tip
The JFS and XFS filesystems automatically support extended attributes in the 2.6 Linux kernel. If you are using an earlier version of the kernel, see http://acl.bestbits.at for links to any patches needed to add extended attribute support to the kernel you are using.
Configuring your kernel for extended attributes.
Most modern Linux distributions provide support for extended attributes in the default kernels that they deliver. If you have access to the configuration file used to build your kernel, you can use the grep utility to check that the FS_XATTR configuration variable associated with your ext2, ext3,or reiserfs filesystem is set to y, as in the following example:
$ grep FS_XATTR /boot/config-2.6.8-24.16-default
CONFIG_EXT2_FS_XATTR=y
CONFIG_EXT3_FS_XATTR=y
CONFIG_REISERFS_FS_XATTR=yIf the FS_XATTR value associated with the type of filesystem you are using is set to n, you will have to enable that configuration variable, save the updated kernel configuration, and recompile your kernel in order to use extended attributes. Extended attributes must be separately enabled for each type of filesystem you are using (with the exception of the XFS journaling filesystem, which inherently supports them). The kernel configuration options that enable them are located on the File Systems pane in your favorite kernel configuration editor (make xconfig, make menuconfig, and so on).
Configuring fstab for extended attributes.
Once you are running a kernel with support for extended attributes, you will need to make sure that the filesystems in which you want to use extended attributes are mounted with extended attribute support enabled. Check your /etc/fstab file to verify this. Filesystems mounted with extended attribute support will have the user_ xattr keyword in the mount options portions of their entries in the file. In the following example, the reiserfs filesystem on /dev/sda6 is mounted with extended attribute support, while the ext3 filesystem on /dev/hda1 is not:
/dev/sda6 /usr reiserfs noatime,user_xattr 1 2 /dev/hda1 /opt2 ext3 defaults 0 0
If your kernel supports extended attributes, you can edit this file to enable extended attribute support when you initially mount a filesystem by adding the user_xattr keyword to that filesystem’s mount options, as in the following example:
/dev/hda1 /opt2 ext3 defaults,user_xattr 0 0
After updating this file, you can enable extended attribute support in currently mounted filesystems without rebooting by executing a command like the following, which would enable extended attribute support in the example ext3 filesystem /dev/hda1:
# mount -o remount,user_xattr /dev/hda1Installing user-space applications for extended attributes.
The last step in using extended attributes on your system is to make sure that the user-space applications that enable you to display and set attributes are present. The Linux attr package provides the following three utilities for extended creation, modification, and examination:
- attr
Lets you set, get, or remove an extended attribute on any filesystem object(s) represented by an inode (files, directories, symbolic links, and so on)
- getfattr
Lets you examine extended attributes for any filesystem object(s)
- setfacl
Lets you set extended attributes for any filesystem object(s)
If your system uses a package management system, you can query that system’s database to see if the attr package and its associated library, libattr, are installed. The following is an example query on a system that uses RPM:
# rpm -qa | grep attr
libattr-2.4.16-2
attr-2.4.16-2You can also look for the utilities themselves, using the which command:
#which attr/usr/bin/attr #which getfattr/usr/bin/getfattr #which setfattr/usr/bin/setfattr
If the attr package is not installed and the binaries are not present on your system, you can find the source code or binary packages for your system by following links from http://acl.bestbits.at. You must install this package before continuing with the rest of this hack.
Displaying Extended Attributes and Their Values
Both the attr and getfattr commands enable you to display the name and value of a specific extended attribute on a given file or files. To look for the value of the extended attribute backup for the file hack_attrs.txt, I could use either of the following commands:
$attr -g backup hack_attrs.txtAttribute "backup" had a 3 byte value for hack_attrs.txt: yes $getfattr -n user.backup hack_attrs.txt# file: hack_attrs.txt user.backup="yes"
As you’d expect, querying the attributes of a file that does not have any returns nothing.
Tip
Note that these two commands require slightly different attribute syntax, which is confusing at best. User-defined extended attributes in the ext2, ext3, JFS, and reiserfs filesystems are always prepended with the string “user”. The attr command is an older command for retrieving extended attributes and is primarily intended for use with extended attributes in the XFS journaling filesystem; therefore, it follows slightly different (older) syntax conventions. As a general rule, you should always use the getfattr command to accurately query extended attributes across different filesystems.
It is sometimes useful to query all of the extended attributes on a specific file, which you can do with the getfattr command’s -d option:
$ getfattr -d hack_attrs.txt
# file: hack_attrs.txt
user.backup="yes"
user.status="In progress"If you are only interested in seeing the value of an extended attribute without any additional explanation, you can use the getfattr command’s --only-values option, as in the following example:
$ getfattr -n user.backup --only-values hack_attrs.txt
yes$Note that the output of this command does not have a newline appended, so any scripts from which you invoke this command must take into account the fact that its output will appear to include the bash prompt of the user who executed the script (here, a $).
Setting Extended Attributes
System capabilities such as SELinux make internal use of extended attributes. These attributes are not viewable or settable by normal users. However, normal users can take advantage of extended attributes to provide convenient meta-information about the files that they are working on, simplifying searching and eliminating the “now what was I working on?” problem.
Setting extended attribute values can be done with either the attr or setfattr commands. The following are examples of setting the user.status attribute to the value "In progress" using each of these commands:
$attr -s status -V "In Progress" hack_attrs.txtAttribute "status" set to a 11 byte value for hack_attrs.txt: In Progress $setfattr -n status -v "In progress" hack_attrs.txtsetfattr: hack_attrs.txt: Operation not supported $setfattr -n user.status -v "In progress" hack_attrs.txt
As you’ll note from the second of these examples, the setfattr command explicitly requires that you identify the attribute you are setting as being a user-defined extended attribute. Attempting to set an attribute in any other attribute namespace, or to create a namespace, results in the “Operation not supported” error shown in this example. The third example command shows the correct syntax for setting a user-defined extended attribute with setfattr.
Removing Extended Attributes
The ability to set user-defined extended attributes isn’t completely useful for associating user-defined metadata unless you can also remove existing attributes. You can do this with both the attr and setfattr commands, though the setfattr command is recommended because its syntax is consistent with the values returned by the getfattr command. For example, you can remove the user.status attribute from the file hack_attrs.txt using either of the following commands:
$attr -r status hack_attrs.txt$setfattr -x user.status hack_attrs.txt
Searching Using Extended Attributes
Extended attributes are inherently interesting, but the proof of their value is in using them cleverly. On my systems, I use a shell script called find_by_attr to query extended attributes and display a list of files that contain a specific extended attribute. The script is the following:
#!/bin/bash
#
# Simple script to find files by attribute and value
# - Bill von Hagen (wvh)
#
if [ $# -lt 3 ] ; then
echo "Usage: find_by_attr attribute value files…"
exit -1
fi
attr=$1
val=$2
shift 2
#
# Set IFS to TAB to allow files with space in their names
#
IFS=' '
for file in $* ; do
result=`getfattr -d "$file" | grep $attr |
sed -e "s;user.$attr=;;" -e "s;$attr=;;" -e 's;";;g'`
if [ x$result = x$val ] ; then
echo $file
fi
doneUsing the getfattr command’s -d option to dump all file/directory attributes and then searching the output for the attribute specified as the first argument with a value of the second argument may seem like overkill, but I did this to eliminate error messages from files on which the specified attribute has not been set.
You can invoke this script either from the command line, by specifying explicit filenames, or as the target of a find command, as in the following example:
$ find . -exec find_by_attr backup yes {} ; 2>/tmp/find_by_attr.$$.errNote that you’ll want to redirect standard error to a temporary file (as shown here) or to /dev/null in order to eliminate any noise from filenames that can’t be resolved, such as bad symlinks and the like.
I use this script in combination with the user.backup extended attribute that I used in the previous command examples to identify critical files that I back up daily. This makes it easy for me to use the script as input to a backup command to save an archive of the files that I am actively working on.
Extended attributes are powerful tools that are immediately useful to users and system administrators. They serve as the foundation for Linux desktop search tools such as the GNOME project’s Beagle tool, and they provide an infinitely flexible way of passing information to other programs, identifying specific files to multiple users, and accomplishing many other tasks. Once you become familiar with using extended attributes, you’ll find yourself using them in more and varied ways. As SUSE says, “Have a lot of fun!”
Prevent Disk Hogs with Quotas
Wasting disk space can cost you resources and bloat backup times and storage requirements. Setting up disk quotas provides a quick solution.
Every network has one of those users who’s the quintessential digital packrat, storing files and emails for years and years, regardless of their content or relative unimportance. With the growing popularity of digital media files that can range from 3 MB to 3 GB in size, these users can fill a disk to capacity in very little time. To prevent these types of users from crashing your server, consider implementing disk quotas to keep them in line.
Setting Up Disk Quotas
There are a few steps to setting up quotas, but it’s a relatively simple process. After setting up quotas, you’ll either have to reboot your system or manually unmount and remount any partitions to which you’ve added quotas. Adding and configuring disk quotas is best done while the system is in single-user mode or otherwise down for maintenance.
Let’s first explore the basic concepts of disk quotas, which are soft and hard limits. The soft limit is the maximum number of disk blocks or inodes that the user can use. Once this number is exceeded, the user is warned and allowed to continue for a specified grace period. Once that grace period expires, the user may no longer allocate any additional blocks or inodes (depending on how you have the quota configured).
Hard limits are indeed hard. A hard limit may never be exceeded, and once it’s reached the user will automatically be barred from using further disk space.
Installing the Quota Software
Your system may or may not already have the software for implementing and managing disk quotas installed. It is usually located in /sbin or /usr/sbin, depending on your Linux distribution. To check, su to root and use the which command to determine if the quotacheck package is installed, as in the following example:
# which quotacheck
/sbin/quotacheckIf you get a response from the which command (as shown above), you have the quota software installed and can proceed to the next step. If you don’t already have it, the latest version can be found at http://www.sourceforge.net/projects/linuxquota. The software installs with the typical commands:
# ./configure, make, make installAlternatively, if you’re using a package- or RPM-based distribution, you can install the quota software via your package manager. For instance, with Ubuntu or Debian you can simply issue the following command:
$ sudo apt-get install quotaThis will install and configure the software for you. SUSE users can use YaST to accomplish the same thing. These days, many distributions come with quota enabled by default, though, so most likely you won’t have to worry about it.
Entering Single-User Mode
To configure your partitions to work with quotas, you’ll need to bring the system into single-user mode. If this is not possible for you, at the very least you’ll want to make sure that no one is logged in when you start this process, and that the system will remain in a quiet state [Hack #3] . To bring the system down to single-user mode, physically log into the console and issue the following command:
# init 1This will bring the system into single-user mode, thereby disabling all network services (such as ssh and ftp).
Editing /etc/fstab
Navigate to the /etc directory. Fire up vi (or your favorite text editor) and edit the file /etc/fstab. The contents of an /etc/fstab file from a typical one-disk system might look something like the following:
LABEL=/ / ext3 defaults 1 1 LABEL=/boot /boot ext3 defaults 1 2 none /dev/pts devpts gid=5,mode=620 0 0 none /dev/shm tmpfs defaults 0 0 LABEL=/data /data ext3 defaults 1 3 none /proc proc defaults 0 0 none /sys sysfs defaults 0 0 LABEL=SWAP-hda2 swap swap defaults 0 0
The only change that you need to make to this file is to add the usrquota option next to the partitions on which you wish to enable disk quotas. Once you’ve done that, you’re done editing the fstab file—simply save it and exit your text editor to commit your changes to the file.
Next, you’ll need to remount your filesystems so that your changes to the filesystem mount options will take effect. If, for example, you want to remount the /data partition, you can do this by simply issuing the following command:
# mount –o remount /dataOnce the partition is remounted, you’re ready to revert back into your original runlevel. To do so, issue the command init 5 or init 3, depending on what your original runlevel was.
Initializing the Quota Configuration Files
You’ll then need to create two files in the root of each partition to which you’ve just added quotas. These two files are named aquota.user for userbased disk quotas and aquota.group for group-based quotas. You can create both of these files using the touch command. Make sure you change the access permissions with the command chmod 600. This will help prevent your disk quotas from being circumvented.
Once you’ve created these files, you’ll need to import your user and group data into the quota files that you just created in each filesystem. This might take a long time if you had to do it by hand, but thankfully there’s an automated utility to do it for you:
# quotacheck –vguamThe options tell the quotacheck command to be verbose (v), to check group (g) and user (u) quotas on all (a) filesystems on which quotas have been enabled, and not to try to mount (m) the filesystem as read-only in order to do the check.
The first time you use the quotacheck command, it might return an error telling you that it can’t save the quota settings. This is normal and can safely be ignored.
Configuring Your Quotas
Now that you’ve created and initialized the files, you may now edit the quota information. This can be accomplished with the edquota command. This command offers several options that are of interest to us. The three most prominent are –u, –g, and –t. Using any of these options launches your default text editor to edit the relevant configuration files. The –u flag allows you to edit the quotas on a per-user basis, while the –g flag acts on a per-group basis (the –t option will be explained in just a bit). Both of these configuration files are largely the same, so we’ll just look at the user file here:
$ sudo edquota -u jdouble
Disk quotas for user jdouble (uid 1001):
Filesystem blocks soft hard inodes soft hard
/dev/hda1 100000 200000 250000 127 0 0As you can see, there are two main ways in which you may limit users: via the total number of blocks they can utilize, or via the total number of inodes (i.e., the total number of files the user may have on the partition). I tend to use blocks when allocating disk space, but you may of course do as you see fit. While assigning quotas, keep in mind that 1,000 blocks equals 1 MB. In the example above, you can see that the user jdouble is currently using 100 MB of space and has a soft limit of 200MB and a hard limit of 250MB. The listing under inodes tells us that jdouble has 127 files on the filesystem /dev/hda1. You might also note that as the hard and soft limits after the inodes listing are set to zero, there is no quota for the total number of files the user can have.
The edquota –t command allows you to configure grace periods for your users. Grace periods are periods of time during which users are allowed to temporarily violate their disk quotas while they receive warnings regarding their disk utilization. Once the grace period has ended, the user may no longer violate her quota, and the soft-limit quota is enforced. You’ll see something like this when you run this command:
# edquota -t
Grace period before enforcing soft limits for users:
Time units may be: days, hours, minutes, or seconds
Filesystem Block grace period Inode grace period
/dev/hda1 3days 99daysBe sure to set something reasonable here so that your users have at least a few minutes to free up some space if they accidentally overrun their quotas.
Even with quotas enabled, you’ll probably be interested to know which of your users are utilizing the most disk space. Thankfully, there’s a built-in feature to handle that as well. The repquota command, which takes a directory or filesystem as an argument, will give you a brief report of your users’ total disk utilization, as well as their configured hard and soft limits.
# repquota /
*** Report for user quotas on device /dev/hda1
Block grace time: 3days; Inode grace time: 99days
Block limits File limits
User used soft hard grace used soft hard grace
----------------------------------------------------------------
root -- 20932272 0 0 73865 0 0
daemon -- 44 0 0 4 0 0
man -- 396 0 0 21 0 0
news -- 4 0 0 1 0 0
postfix -- 88 0 0 45 0 0
jdouble -- 100000 200000 250000 127 0 0
klog -- 8 0 0 3 0 0
kida -- 2800 0 0 181 0 0
cupsys -- 72 0 0 11 0 0
fetchmail-- 4 0 0 1 0 0
hal -- 8 0 0 2 0 0Through this report, you can see the disk utilization of every user on the system, including our test case jdouble. Any user with the default 0 under the hard or soft column is not subject to disk quotas.
By using the report feature within a cron job, you can be updated on disk utilization as often as you’d like. I have this information emailed to me every weekday morning so that I can keep track of my users and hunt down those pesky disk hogs. To do this, I added the following entry to root’s crontab file using the crontab –e command as root:
0 5 * * * repquota -a
This tells the cron processes to check all filesystems on which quotas are enabled at 5 A.M. every day and to mail the output of the repquota command to root. Configuring disk quotas can be a lifesaver if you run a heavily used, multi-user server and can be made even more powerful if you take advantage of the group features of disk quotas. The Linux quota system’s group mechanism provides a way of creating different levels of users, from those that may only need 10MB of space all the way up to those who want (and actually need) gigabytes of space.
See Also
man edquotaman repquotaman quotaman quotacheckman quotactl
—Brian Warshawsky