
Day 1. Getting Started
Welcome to Sams Teach Yourself C++ in 21 Days! Today, you will get started on your way to becoming a proficient C++ programmer.
Today, you will learn
• Why C++ is a standard in software development
• The steps to develop a C++ program
• How to enter, compile, and link your first working C++ program
A Brief History of C++
Computer languages have undergone dramatic evolution since the first electronic computers were built to assist in artillery trajectory calculations during World War II. Early on, programmers worked with the most primitive computer instructions: machine language. These instructions were represented by long strings of ones and zeros. Soon, assemblers were invented to map machine instructions to human-readable and -manageable mnemonics, such as ADD and MOV.
In time, higher-level languages evolved, such as BASIC and COBOL. These languages let people work with something approximating words and sentences (referred to as source code), such as Let I = 100. These instructions were then translated into machine language by interpreters and compilers.
An interpreter translates and executes a program as it reads it, turning the program instructions, or source code, directly into actions.
A compiler translates source code into an intermediary form. This step is called compiling, and it produces an object file. The compiler then invokes a linker, which combines the object file into an executable program.
Because interpreters read the source code as it is written and execute the code on the spot, interpreters can be easier for the programmer to work with. Today, most interpreted programs are referred to as scripts, and the interpreter itself is often called a “script engine.”
Some languages, such as Visual Basic 6, call the interpreter the runtime library. Other languages, such as the Visual Basic .NET and Java have another component, referred to as a “Virtual Machine” (VM) or a runtime. The VM or runtime is also an interpreter. However, it is not a source code interpreter that translates human-readable language into computer-dependent machine code. Rather, it interprets and executes a compiled computer-independent “virtual machine language” or intermediary language.
Compilers introduce the extra steps of compiling the source code (which is readable by humans) into object code (which is readable by machines). This extra step might seem inconvenient, but compiled programs run very fast because the time-consuming task of translating the source code into machine language has already been done once, at compile time. Because the translation is already done, it is not required when you execute the program.
Another advantage of compiled languages such as C++ is that you can distribute the executable program to people who don’t have the compiler. With an interpreted language, you must have the interpreter to run the program.
C++ is typically a compiled language, though there are some C++ interpreters. Like many compiled languages, C++ has a reputation for producing fast but powerful programs.
In fact, for many years, the principal goal of computer programmers was to write short pieces of code that would execute quickly. Programs needed to be small because memory was expensive, and needed to be fast because processing power was also expensive. As computers have become smaller, cheaper, and faster, and as the cost of memory has fallen, these priorities have changed. Today, the cost of a programmer’s time far outweighs the cost of most of the computers in use by businesses. Well-written, easy-to-maintain code is at a premium. Easy to maintain means that as requirements change for what the program needs to do, the program can be extended and enhanced without great expense.
Note
The word program is used in two ways: to describe individual instructions (or source code) created by the programmer, and to describe an entire piece of executable software. This distinction can cause enormous confusion, so this book tries to distinguish between the source code, on one hand, and the executable, on the other.
The Need for Solving Problems
The problems programmers are asked to solve today are totally different from the problems they were solving twenty years ago. In the 1980s, programs were created to manage and process large amounts of raw data. The people writing the code and the people using the program were computer professionals. Today, computers are in use by far more people, and most know very little about how computers and programs really work. Computers are tools used by people who are more interested in solving their business problems than struggling with the computer.
Ironically, as programs are made easier for this new audience to use, the programs themselves become far more sophisticated and complex. Gone are the days when users typed in cryptic commands at esoteric prompts, only to see a stream of raw data. Today’s programs use sophisticated “user-friendly interfaces” involving multiple windows, menus, dialog boxes, and the myriad of metaphors with which we’ve all become familiar.
With the development of the Web, computers entered a new era of market penetration; more people are using computers than ever before, and their expectations are very high. The ease at which people can use the Web has also increased the expectations. It is not uncommon for people to expect that programs take advantage of the Web and what it has to offer.
In the past few years, applications have expanded to different devices as well. No longer is a desktop PC the only serious target for applications. Rather, mobile phones, personal digital assistants (PDAs), Tablet PCs, and other devices are valid targets for modern applications.
In the few years since the first edition of this book, programmers have responded to the demands of users, and, thus, their programs have become larger and more complex. The need for programming techniques to help manage this complexity has become manifest.
As programming requirements change, both languages and the techniques used for writing programs evolve to help programmers manage complexity. Although the complete history is fascinating, this book only focuses briefly on the key part of this evolution: the transformation from procedural programming to object-oriented programming.
Procedural, Structured, and Object-Oriented Programming
Until recently, computer programs were thought of as a series of procedures that acted upon data. A procedure, also called a function or a method, is a set of specific instructions executed one after the other. The data was quite separate from the procedures, and the trick in programming was to keep track of which functions called which other functions, and what data was changed. To make sense of this potentially confusing situation, structured programming was created.
The principal idea behind structured programming is the idea of divide and conquer. A computer program can be thought of as consisting of a set of tasks. Any task that is too complex to be described simply is broken down into a set of smaller component tasks, until the tasks are sufficiently small and self-contained enough that they are each easily understood.
As an example, computing the average salary of every employee of a company is a rather complex task. You can, however, break it down into the following subtasks:
1. Count how many employees you have.
2. Find out what each employee earns.
3. Total all the salaries.
4. Divide the total by the number of employees you have.
Totaling the salaries can be broken down into the following steps:
1. Get each employee’s record.
2. Access the salary.
3. Add the salary to the running total.
4. Get the next employee’s record.
In turn, obtaining each employee’s record can be broken down into the following:
1. Open the file of employees.
2. Go to the correct record.
3. Read the data.
Structured programming remains an enormously successful approach for dealing with complex problems. By the late 1980s, however, some of the deficiencies of structured programming had become all too clear.
First, a natural desire is to think of data (employee records, for example) and what you can do with that data (sort, edit, and so on) as a single idea. Unfortunately, structured programs separate data structures from the functions that manipulate them, and there is no natural way to group data with its associated functions within structured programming. Structured programming is often called procedural programming because of its focus on procedures (rather than on “objects”).
Second, programmers often found themselves needing to reuse functions. But functions that worked with one type of data often could not be used with other types of data, limiting the benefits gained.
Object-Oriented Programming (OOP)
Object-oriented programming responds to these programming requirements, providing techniques for managing enormous complexity, achieving reuse of software components, and coupling data with the tasks that manipulate that data.
The essence of object-oriented programming is to model “objects” (that is, things or concepts) rather than “data.” The objects you model might be onscreen widgets, such as buttons and list boxes, or they might be real-world objects, such as customers, bicycles, airplanes, cats, and water.
Objects have characteristics, also called properties or attributes, such as age, fast, spacious, black, or wet. They also have capabilities, also called operations or functions, such as purchase, accelerate, fly, purr, or bubble. It is the job of object-oriented programming to represent these objects in the programming language.
C++ and Object-Oriented Programming
C++ fully supports object-oriented programming, including the three pillars of object-oriented development: encapsulation, inheritance, and polymorphism.
Encapsulation
When an engineer needs to add a resistor to the device she is creating, she doesn’t typically build a new one from scratch. She walks over to a bin of resistors, examines the colored bands that indicate the properties, and picks the one she needs. The resistor is a “black box” as far as the engineer is concerned—she doesn’t much care how it does its work, as long as it conforms to her specifications. She doesn’t need to look inside the box to use it in her design.
The property of being a self-contained unit is called encapsulation. With encapsulation, you can accomplish data hiding. Data hiding is the highly valued characteristic that an object can be used without the user knowing or caring how it works internally. Just as you can use a refrigerator without knowing how the compressor works, you can use a well-designed object without knowing about its internal workings. Changes can be made to those workings without affecting the operation of the program, as long as the specifications are met; just as the compressor in a refrigerator can be replaced with another one of similar design.
Similarly, when the engineer uses the resistor, she need not know anything about the internal state of the resistor. All the properties of the resistor are encapsulated in the resistor object; they are not spread out through the circuitry. It is not necessary to understand how the resistor works to use it effectively. Its workings are hidden inside the resistor’s casing.
C++ supports encapsulation through the creation of user-defined types, called classes. You’ll see how to create classes on Day 6, “Understanding Object-Oriented Programming.” After being created, a well-defined class acts as a fully encapsulated entity—it is used as a whole unit. The actual inner workings of the class can be hidden. Users of a well-defined class do not need to know how the class works; they just need to know how to use it.
Inheritance and Reuse
When the engineers at Acme Motors want to build a new car, they have two choices: They can start from scratch, or they can modify an existing model. Perhaps their Star model is nearly perfect, but they want to add a turbocharger and a six-speed transmission. The chief engineer prefers not to start from the ground up, but rather to say, “Let’s build another Star, but let’s add these additional capabilities. We’ll call the new model a Quasar.” A Quasar is a kind of Star, but a specialized one with new features. (According to NASA, quasars are extremely luminous bodies that emit an astonishing amount of energy.)
C++ supports inheritance. With inheritance, you can declare a new type that is an extension of an existing type. This new subclass is said to derive from the existing type and is sometimes called a derived type. If the Quasar is derived from the Star and, thus, inherits all of the Star’s qualities, then the engineers can add to them or modify them as needed. Inheritance and its application in C++ are discussed on Day 12, “Implementing Inheritance,” and Day 16, “Advanced Class Relationships.”
Polymorphism
A new Quasar might respond differently than a Star does when you press down on the accelerator. The Quasar might engage fuel injection and a turbocharger, whereas the Star simply lets gasoline into its carburetor. A user, however, does not have to know about these differences. He can just “floor it,” and the right thing happens, depending on which car he’s driving.
C++ supports the idea that different objects do “the right thing” through what is called function polymorphism and class polymorphism. Poly means many, and morph means form. Polymorphism refers to the same name taking many forms, and it is discussed on Day 10, “Working with Advanced Functions,” and Day 14, “Polymorphism.”
How C++ Evolved
As object-oriented analysis, design, and programming began to catch on, Bjarne Stroustrup took the most popular language for commercial software development, C, and extended it to provide the features needed to facilitate object-oriented programming.
Although it is true that C++ is a superset of C and that virtually any legal C program is a legal C++ program, the leap from C to C++ is very significant. C++ benefited from its relationship to C for many years because C programmers could ease into their use of C++. To really get the full benefit of C++, however, many programmers found they had to unlearn much of what they knew and learn a new way of conceptualizing and solving programming problems.
Should I Learn C First?
The question inevitably arises: “Because C++ is a superset of C, should you learn C first?” Stroustrup and most other C++ programmers agree that not only is it unnecessary to learn C first, it might be advantageous not to do so.
C programming is based on structured programming concepts; C++ is based on object-oriented programming. If you learn C first, you’ll have to “unlearn” the bad habits fostered by C.
This book does not assume you have any prior programming experience. If you are a C programmer, however, the first few days of this book will largely be review. Starting on Day 6, you will begin the real work of object-oriented software development.
C++, Java, and C#
C++ is one of the predominant languages for the development of commercial software. In recent years, Java has challenged that dominance; however, many of the programmers who left C++ for Java have recently begun to return. In any case, the two languages are so similar that to learn one is to learn 90 percent of the other.
C# is a newer language developed by Microsoft for the .NET platform. C# uses essentially the same syntax as C++, and although the languages are different in a few important ways, learning C++ provides a majority of what you need to know about C#. Should you later decide to learn C#, the work you do on C++ will be an excellent investment.
Microsoft’s Managed Extensions to C++
With .NET, Microsoft introduced Managed Extensions to C++ (“Managed C++”). This is an extension of the C++ language to allow it to use Microsoft’s new platform and libraries. More importantly, Managed C++ allows a C++ programmer to take advantage of the advanced features of the .NET environment. Should you decide to develop specifically for the .NET platform, you will need to extend your knowledge of standard C++ to include these extensions to the language.
The ANSI Standard
The Accredited Standards Committee, operating under the procedures of the American National Standards Institute (ANSI), has created an international standard for C++.
The C++ Standard is also referred to as the ISO (International Organization for Standardization) Standard, the NCITS (National Committee for Information Technology Standards) Standard, the X3 (the old name for NCITS) Standard, and the ANSI/ISO Standard. This book continues to refer to ANSI standard code because that is the more commonly used term.
Note
ANSI is usually pronounced “antsy” with a silent “t.”
The ANSI standard is an attempt to ensure that C++ is portable—ensuring, for example, that ANSI-standard-compliant code you write for Microsoft’s compiler will compile without errors using a compiler from any other vendor. Further, because the code in this book is ANSI compliant, it should compile without errors on a Macintosh, a Windows box, or an Alpha.
For most students of C++, the ANSI standard is invisible. The most recent version of the standard is ISO/IEC 14882-2003. The previous version, ISO/IEC 14882-1998, was stable and all the major manufacturers support it. All of the code in this edition of this book has been compared to the standard to ensure that it is compliant.
Keep in mind that not all compilers are fully compliant with the standard. In addition, some areas of the standard have been left open to the compiler vendor, which cannot be trusted to compile or operate in the same fashion when compiled with various brands of compilers.
Note
Because the Managed Extensions to C++ only apply to the .NET platform and are not ANSI standard, they are not covered in this book.
Preparing to Program
C++, perhaps more than other languages, demands that the programmer design the program before writing it. Trivial problems, such as the ones discussed in the first few days of this book, don’t require much design. Complex problems, however, such as the ones professional programmers are challenged with every day, do require design, and the more thorough the design, the more likely it is that the program will solve the problems it is designed to solve, on time and on budget. A good design also makes for a program that is relatively bug-free and easy to maintain. It has been estimated that fully 90 percent of the cost of software is the combined cost of debugging and maintenance. To the extent that good design can reduce those costs, it can have a significant impact on the bottom-line cost of the project.
The first question you need to ask when preparing to design any program is, “What is the problem I’m trying to solve?” Every program should have a clear, well-articulated goal, and you’ll find that even the simplest programs in this book do so.
The second question every good programmer asks is, “Can this be accomplished without resorting to writing custom software?” Reusing an old program, using pen and paper, or buying software off the shelf is often a better solution to a problem than writing something new. The programmer who can offer these alternatives will never suffer from lack of work; finding less-expensive solutions to today’s problems always generates new opportunities later.
Assuming you understand the problem and it requires writing a new program, you are ready to begin your design.
The process of fully understanding the problem (analysis) and creating a plan for a solution (design) is the necessary foundation for writing a world-class commercial application.
Your Development Environment
This book makes the assumption that your compiler has a mode in which you can write directly to a “console” (for instance, an MS-DOS/Command prompt or a shell window), without worrying about a graphical environment, such as the ones in Windows or on the Macintosh. Look for an option such as console or easy window or check your compiler’s documentation.
Your compiler might be part of an Integrated Development Environment (IDE) or might have its own built-in source code text editor, or you might be using a commercial text editor or word processor that can produce text files. The important thing is that whatever you write your program in, it must save simple, plain-text files, with no word processing commands embedded in the text. Examples of safe editors include Windows Notepad, the DOS Edit command, Brief, Epsilon, Emacs, and vi. Many commercial word processors, such as WordPerfect, Word, and dozens of others, also offer a method for saving simple text files.
The files you create with your editor are called source files, and for C++ they typically are named with the extension .cpp, .cp, or .c. This book names all the source code files with the .cpp extension, but check your compiler for what it needs.
Note
Most C++ compilers don’t care what extension you give your source code, but if you don’t specify otherwise, many use .cpp by default. Be careful, however; some compilers treat .c files as C code and .cpp files as C++ code. Again, please check your compiler’s documentation. In any event, it is easier for other programmers who need to understand your programs if you consistently use .cpp for C++ source code files.

The Process of Creating the Program
The first step in creating a new program is to write the appropriate commands (statements) into a source file. Although the source code in your file is somewhat cryptic, and anyone who doesn’t know C++ will struggle to understand what it is for, it is still in what we call human-readable form. Your source code file is not a program and it can’t be executed, or run, as an executable program file can.
Creating an Object File with the Compiler
To turn your source code into a program, you use a compiler. How you invoke your compiler and how you tell it where to find your source code varies from compiler to compiler; check your documentation.
After your source code is compiled, an object file is produced. This file is often named with the extension .obj or .o. This is still not an executable program, however. To turn this into an executable program, you must run your linker.
Creating an Executable File with the Linker
C++ programs are typically created by linking one or more object files (.obj or .o files) with one or more libraries. A library is a collection of linkable files that were supplied with your compiler, that you purchased separately, or that you created and compiled. All C++ compilers come with a library of useful functions and classes that you can include in your program. You’ll learn more about functions and classes in great detail in the next few days.
The steps to create an executable file are
1. Create a source code file with a .cpp extension.
2. Compile the source code into an object file with the .obj or .o extension.
3. Link your object file with any needed libraries to produce an executable program.
The Development Cycle
If every program worked the first time you tried it, this would be the complete development cycle: Write the program, compile the source code, link the program, and run it. Unfortunately, almost every program, no matter how trivial, can and will have errors. Some errors cause the compile to fail, some cause the link to fail, and some show up only when you run the program (these are often called “bugs”).
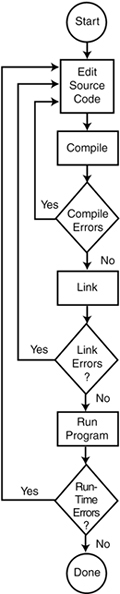
Whatever type of error you find, you must fix it, and that involves editing your source code, recompiling and relinking, and then rerunning the program. This cycle is represented in Figure 1.1, which diagrams the steps in the development cycle.
Figure 1.1. The steps in the development of a C++ program.
HELLO.cpp—Your First C++ Program
Traditional programming books begin by writing the words “Hello World” to the screen, or a variation on that statement. This time-honored tradition is carried on here.
Type the source code shown in Listing 1.1 directly into your editor, exactly as shown (excluding the line numbering). After you are certain you have entered it correctly, save the file, compile it, link it, and run it. If everything was done correctly, it prints the words Hello World to your screen. Don’t worry too much about how it works; this is really just to get you comfortable with the development cycle. Every aspect of this program is covered over the next couple of days.
Caution
The following listing contains line numbers on the left. These numbers are for reference within the book. They should not be typed into your editor. For example, on line 1 of Listing 1.1, you should enter:
#include <iostream>
Listing 1.1. HELLO.cpp, the Hello World Program
1: #include <iostream>
2:
3: int main()
4: {
5: std::cout << "Hello World!
";
6: return 0;
7: }
Be certain you enter this exactly as shown. Pay careful attention to the punctuation. The << on line 5 is the redirection symbol, produced on most keyboards by holding the Shift key and pressing the comma key twice. Between the letters std and cout on line 5 are two colons (:). Lines 5 and 6 each end with semicolon (;).
Also check to ensure you are following your compiler directions properly. Most compilers link automatically, but check your documentation to see whether you need to provide a special option or execute a command to cause the link to occur.
If you receive errors, look over your code carefully and determine how it is different from the preceding listing. If you see an error on line 1, such as cannot find file iostream, you might need to check your compiler documentation for directions on setting up your include path or environment variables.
If you receive an error that there is no prototype for main, add the line int main(); just before line 3 (this is one of those pesky compiler variations). In that case, you need to add this line before the beginning of the main function in every program in this book. Most compilers don’t require this, but a few do. If yours does, your finished program needs to look like this:

Note
It is difficult to read a program to yourself if you don’t know how to pronounce the special characters and keywords. You read the first line “Pound include (some say hash-include, others say sharp-include) eye-oh-stream.” You read the fifth line “ess-tee-dee-see-out Hello World.”
On a Windows system, try running HELLO.exe (or whatever the name of an executable is on your operating system; for instance, on a Unix system, you run HELLO, because executable programs do not have extensions in Unix). The program should write
Hello World!
directly to your screen. If so, congratulations! You’ve just entered, compiled, and run your first C++ program. It might not look like much, but almost every professional C++ programmer started out with this exact program.
Some programmers using IDEs (such as Visual Studio or Borland C++ Builder) will find that running the program flashes up a window that promptly disappears with no chance to see what result the program produces. If this happens, add these lines to your source code just prior to the “return” statement:
char response;
std::cin >> response;
These lines cause the program to pause until you type a character (you might also need to press the Enter key). They ensure you have a chance to see the results of your test run. If you need to do this for hello.cpp, you will probably need to do it for most of the programs in this book.
1: #include <iostream.h>
2:
3: int main()
4: {
5: cout << "Hello World!
";
6: return 0;
7: }
Getting Started with Your Compiler
This book is not compiler specific. This means that the programs in this book should work with any ANSI-compliant C++ compiler on any platform (Windows, Macintosh, Unix, Linux, and so on).
That said, the vast majority of programmers are working in the Windows environment, and the vast majority of professional programmers use the Microsoft compilers. The details of compiling and linking with every possible compiler is too much to show here; however, we can show you how to get started with Microsoft Visual C++ 6, and that ought to be similar enough to whatever compiler you are using to be a good head start.
Compilers differ, however, so be certain to check your documentation.
Building the Hello World Project
To create and test the Hello World program, follow these steps:
1. Start the compiler.
2. Choose File, New from the menus.
3. Choose Win32 Console Application and enter a project name, such as hello, and click OK.
4. Choose An Empty Project from the menu of choices and click Finish. A dialog box is displayed with new project information.
5. Click OK. You are taken back to the main editor window.
6. Choose File, New from the menus.
7. Choose C++ Source File and give it a name, such as hello. You enter this name into the File Name text box.
8. Click OK. You are taken back to the main editor window.
9. Enter the code as indicated previously.
10. Choose Build, Build hello.exe from the menus.
11. Check that you have no build errors. You can find this information near the bottom of the editor.
12. Run the program by pressing Ctrl+F5 or by selecting Build, Execute hello from the menus.
13. Press the spacebar to end the program.
char response;
std::cin >> response;
Compile Errors
Compile-time errors can occur for any number of reasons. Usually, they are a result of a typo or other inadvertent minor error. Good compilers not only tell you what you did wrong, they point you to the exact place in your code where you made the mistake. The great ones even suggest a remedy!
You can see this by intentionally putting an error into your program. If HELLO.cpp ran smoothly, edit it now and remove the closing brace on line 7 of Listing 1.1. Your program now looks like Listing 1.2.
Listing 1.2. Demonstration of Compiler Error
1: #include <iostream>
2:
3: int main()
4: {
5: std::cout << "Hello World!
";
6: return 0;
Recompile your program and you should see an error that looks similar to the following:
Hello.cpp(7) : fatal error C1004: unexpected end of file found
This error tells you the file and line number of the problem and what the problem is (although I admit it is somewhat cryptic). In this case, the compiler is telling you that it ran out of source lines and hit the end of the source file without finding the closing brace.
Sometimes, the error messages just get you to the general vicinity of the problem. If a compiler could perfectly identify every problem, it would fix the code itself.
Summary
After reading today’s lesson, you should have a good understanding of how C++ evolved and what problems it was designed to solve. You should feel confident that learning C++ is the right choice for anyone interested in programming. C++ provides the tools of object-oriented programming and the performance of a systems-level language, which makes C++ the development language of choice.
Today, you learned how to enter, compile, link, and run your first C++ program, and what the normal development cycle is. You also learned a little of what object-oriented programming is all about. You will return to these topics during the next three weeks.
Q&A
Q What is the difference between a text editor and a word processor?
A A text editor produces files with plain text in them. No formatting commands or other special symbols are used that might be required by a particular word processor. Simple text editors do not have automatic word wrap, bold print, italic, and so forth.
Q If my compiler has a built-in editor, must I use it?
A Almost all compilers will compile code produced by any text editor. The advantages of using the built-in text editor, however, might include the capability to quickly move back and forth between the edit and compile steps of the development cycle. Sophisticated compilers include a fully integrated development environment, enabling the programmer to access help files, edit, and compile the code in place, and to resolve compile and link errors without ever leaving the environment.
Q Can I ignore warning messages from my compiler?
A Compilers generally give warnings and errors. If there are errors, the program will not be completely built. If there are just warnings, the compiler will generally go ahead and still create the program.
Many books hedge on this question. The appropriate answer is: No! Get into the habit, from day one, of treating warning messages as errors. C++ uses the compiler to warn you when you are doing something you might not intend. Heed those warnings and do what is required to make them go away. Some compilers even have a setting that causes all warnings to be treated like errors, and thus stop the program from building an executable.
Q What is compile time?
A Compile time is the time when you run your compiler, in contrast to link time (when you run the linker) or runtime (when running the program). This is just programmer shorthand to identify the three times when errors usually surface.
Workshop
The Workshop provides quiz questions to help you solidify your understanding of the material covered and exercises to provide you with experience in using what you’ve learned. Try to answer the quiz and exercise questions before checking the answers in Appendix D, and be certain you understand the answers before continuing to tomorrow’s lesson.
Quiz
1. What is the difference between an interpreter and a compiler?
2. How do you compile the source code with your compiler?
3. What does the linker do?
4. What are the steps in the normal development cycle?
Exercises
1. Look at the following program and try to guess what it does without running it.
1: #include <iostream>
2: int main()
3: {
4: int x = 5;
5: int y = 7;
6: std::cout << endl;
7: std::cout << x + y << " " << x * y;
8: std::cout << end;
9: return 0;
10:}
2. Type in the program from Exercise 1, and then compile and link it. What does it do? Does it do what you guessed?
3. Type in the following program and compile it. What error do you receive?
1: include <iostream>
2: int main()
3: {
4: std::cout << "Hello World
";
5: return 0;
6: }
4. Fix the error in the program in Exercise 3 and recompile, link, and run it. What does it do?