
A key rule in solving any problem, no matter how challenging, is “know your tools!” As you have learned from several of the previous chapters, one such tool is the Spread Group Communication Toolkit. Spread may very well be the Swiss army knife of the distributed systems world, but there are several aspects to consider when choosing to use such a tool. First, you need to properly understand the principles behind the features that the tool provides to pick the appropriate ones to solve a problem. Second, you must evaluate the price that you pay for having features that you don’t really need—you don’t want to be the hero of the classic tale of squashing a mosquito by using a cannon. Finally, you need to learn how to properly use the tool, to understand its quirks and caveats.
This appendix covers these aspects for Spread, providing a minimal theoretical background, installation instructions, and configuration and usage examples.
Every distributed architecture has one inherently fundamental component that is also critical to its overall effectiveness: communication between the various participants. Communication between only two nodes in the Internet may occasionally pose some problems as well, but the methods and caveats are well understood and are the object of any Introduction to Networking class. Basically, using UDP/IP for unreliable communication and TCP/IP for reliable communication covers 99% of point-to-point communication needs. What happens, though, when communication is needed between several participants—especially if they are not all part of the same LAN?
Point-to-point communication between all participants without any additional logic is obviously both expensive and chaotic. Reliable IP-multicast can be employed in certain situations, but it is more adequate in scenarios that involve a single sender and a large number of receivers, whose identities are not necessarily important to the sender. In contrast, the problems that we want to tackle usually involve a relatively small number of participants, whose identities are important to be known at all times, and who may act simultaneously both as senders and receivers. This points us toward another possible communication paradigm: group communication.
The group communication paradigm provides a framework meant to ease the process of managing the communication aspect of distributed applications. The paradigm provides an intuitive abstraction and a set of communication primitives with meaningful and well-defined properties that are not trivial to satisfy in an asynchronous, unreliable network.
First, we identify the participants (or processes) in a distributed application as members of a group. Any member of a group can send messages to the entire group and also receive all the messages sent by the other members. Groups may also be open, in which case processes that are not part of the group are allowed to send messages to the entire group.
The second important abstraction, directly related to the notion of group, is the group membership. A group communication system provides the process with primitives that identify all the members of a group that the process is part of at any given moment time. This may include notifications when new members join the group or when current members leave the group, either voluntarily or due to intermittent network communication issues or process crashes.
Finally, group communication systems provide primitives that enable and govern the communication between the participating processes. These primitives are basically group broadcast primitives whose properties are defined from two perspectives:
-
Reliability
-
Ordering
Messages sent to a group may be unreliable or reliable. Unreliable messages may be lost and are not recovered by the group communication system. Reliable messages are received by all members of a group, as long as they do not crash or become otherwise disconnected from the group.
The ordering guarantees define the order in which messages are delivered by the group communication system to each recipient. Several common ordering guarantees are identified here:
-
FIFO ordering—If process X sends messages A and B, in this order, all members of the group who receive A and B will receive them in the order in which they were sent.
-
Causal ordering—If messages A and B are sent by process X in this order, or if process X sends message B subsequent to receiving message A sent by another member, all members of the group will receive message A before receiving message B (B is potentially causally dependent on A). Causal order is an extension of FIFO ordering.
-
Total ordering—If process X receives messages A and B in this order, any process Y that receives messages A and B will receive them in the same order. Total ordering is not necessarily consistent with FIFO or causal ordering, although in practice it is particularly useful when combined with causal or at least FIFO guarantees.
Spread is a group communication toolkit developed at the Center for Networking and Distributed Systems at Johns Hopkins University and distributed as source and binary under a BSD-style license with an advertisement clause.
Spread uses a tiered architecture, which it leverages to optimize communication between a larger set of participants, spanning multiple groups. This architecture may prove confusing, however, for those not used to this paradigm. An application/process that wants to use Spread must connect, using primitives provided as library calls, to a Spread daemon. The Spread daemon may reside on the same machine as the application, but it may be on any machine that the application can access in the Internet or the local network. The ideal image of a Spread network consists of several Spread daemons “spread” across the Internet, each with many applications connected to it locally (LAN or “closer” network-wise). Most of the uses of Spread in this book revolve around strictly local area use. We’ll touch a bit on the aspects of wide area operation but stick to examples that pertain mainly to previous discussions. Figure A.1 depicts a typical local area Spread configuration.
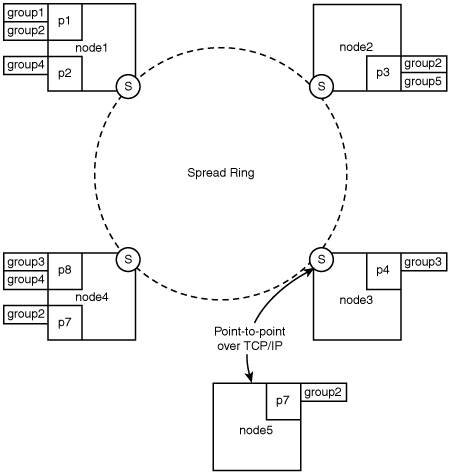
After connecting to a Spread daemon, the application may request to join one or more groups and can start sending/receiving messages to/from these groups. The Spread daemons connect to each other automatically, forming the Spread network, and act as brokers for the applications, managing multiple groups, enforcing the requested delivery and ordering guarantees within each group, and providing notifications of membership changes to the application for the groups that they belong to.
All Spread daemons in a Spread network (or configuration) know each other’s identities and maintain a strict knowledge of their ability to communicate with each other. In effect they establish and maintain a daemon membership. The daemon membership is transparent to the applications, but a change in the daemon membership, either due to a daemon crash or to temporary network partitioning, may induce changes in the application group membership. The application group membership may also change due to applications voluntarily joining/leaving the group or due to an application crashing.
Spread supports all the standard group communication delivery properties mentioned previously. When a process sends a message to a group, it can specify the level of service requested for the delivery of that message:
-
Unreliable
-
Reliable
-
FIFO (also reliable)
-
Causal (also FIFO)
-
Agreed (provides Total Order and Causal guarantees)
-
Safe (provides Total Order with additional safety delivery guarantee)
The safe delivery is the most powerful delivery guarantee offered by Spread. A safe message is delivered to a receiving application only if the Spread daemon that the application is connected to knows that all the other Spread daemons have the message and will therefore deliver it to their respective receiving applications unless they or the applications crash. It is possible that a Spread daemon detects a change in the daemon membership before it can determine whether all daemons that were part of the old membership have the message. In this case, the daemon will deliver the safe message to the applications interested in receiving it, only after signaling them that a membership change is about to occur. This is done using a transitional membership change notification.
The safe delivery mechanism is part of the Extended Virtual Synchrony (EVS) paradigm mentioned in Chapter 8, “Distributed Databases Are Easy, Just Read the Fine Print,” and can be used to build powerful and delicate distributed applications that require a high degree of synchronization between the participating processes. However, safe delivery is significantly slower than agreed or FIFO delivery, and therefore it should not be employed casually if the application does not require the additional guarantees.
Spread is licensed as Open Source. The license is similar to a BSD license with the addition of an advertisement requirement clause.
Spread can be downloaded either as a collection of binaries or as source tarball from http://www.spread.org/. Although the binaries may do the trick for some systems, we recommend compiling from source. Because Spread uses autoconf, for most users the installation is as simple as ./configure; make; make install.
At the time of publishing, in addition to the stable 3.17.3 release, RC2 of the new Spread 4.0 is also available for download. If you’re using Spread for the first time, you may consider trying this version because it presents several significant improvements, including support for dynamic configuration of sets of daemons without requiring a restart and enforcing identical configuration files at all nodes. However, because Spread 4.0 is still in release candidate status and we have not had the chance to test this release thoroughly yet, we will base the instructions and examples in the remainder of this appendix on the 3.17 release.
Each Spread daemon relies on a configuration file (spread.conf) to define some of the runtime parameters and, more importantly, to specify the list of all other potential Spread daemons in the network.
There are two common ways to configure Spread. In the first situation as seen in Listing A.1, we establish a LAN Spread configuration.
Listing A.1. spread.conf—A Simple Local Area Spread Configuration
Spread_Segment 192.168.221.255:4803 {
ifog2 192.168.221.102
ifog3 192.168.221.103
ifog4 192.168.221.104
ifog5 192.168.221.105
ifog6 192.168.221.106
ifog7 192.168.221.107
ifog8 192.168.221.108
ifog9 192.168.221.109
ifog10 192.168.221.110
ifog11 192.168.221.111
ifog13 192.168.221.113
ifog14 192.168.221.114
ifog15 192.168.221.115
ifog16 192.168.221.116
}
In the second situation, as seen in Listing A.2, the Spread daemons are distributed in several sites connected by the Internet.
Listing A.2. spread.conf—A Simple Wide Area Spread Configuration
Spread_Segment x.220.221.255:4803 {
machine1 x.220.221.21
machine2 x.220.221.206
}
Spread_Segment x.44.222.255:4913 {
machine1 x.44.222.31
machine4 x.44.222.35
machine5 x.44.222.201
machine x.44.222.12
}
Spread_Segment x.22.33.255:4893 {
m1 x.22.33.31
m2 x.22.33.111
}
The key aspect about the Spread configuration files is that they need to be identical on all servers. If by chance you end up with configurations that are slightly different, you may end up with daemons that act as if nothing is wrong, yet cannot talk to each other.
Several other options can be set in the configuration file. DebugFlags specifies the level that debug information will be displayed during the daemon’s run. By default, these messages are displayed either to standard error or to the log file specified by EventLogFile in the configuration. The amount of logged information is highly configurable. You may specify which levels to include and which to exclude. For example:
DebugFlags = {PRINT EXIT}
DebugFlags = {ALL !EVENTS !MEMORY}
Let’s try to set up a Spread network with just two daemons:
# cat spread.conf
DebugFlags = { PRINT EXIT }
EventTimeStamp
DangerousMonitor = true
Spread_Segment 10.0.0.255:4913 {
www-0-1 10.0.0.132
www-0-2 10.0.0.133
}
#./spread
/===========================================================================
| The Spread Toolkit. |
| Copyright (c) 1993-2002 Spread Concepts LLC |
...
| All rights reserved. |
| Version 3.17.03 Built 15/October/2004 |
===========================================================================/
Conf_init:using file:spread.conf
[Mon 08 May 2006 07:32:19] ENABLING Dangerous Monitor Commands! Make sure Spread
network is secured
[Mon 08 May 2006 07:32:19] Conf_init:My proc id (192.168.221.22) is not in
configuration
Exit caused by Alarm(EXIT)
It looks like we were unable to start. This is the first hurdle that you may encounter when trying to start up Spread. Notice that the error we get even refers to a different IP address from any of the ones in our config file. In fact, Spread by default does something that you might not expect: It determines the name of the hostname, resolves that to an IP address, and looks for that in the configuration file. However, we can tell Spread which named entry from the configuration file it should use to start up:
$./spread -n www-0-1
| Version 3.17.03 Built 15/October/2004 |
===========================================================================/
Conf_init:using file:spread.conf
[Mon 08 May 2006 08:15:54] ENABLING Dangerous Monitor Commands! Make sure Spread
network is secured
Looks like the daemon was able to start! Well, we don’t have a message saying that, but at least it is not exiting like before. From this point on, we basically have a couple of options: Start up another daemon and see whether the two can communicate, or start the spuser application that comes with Spread and try to join a group and send a message to show that we have a functioning daemon. Let’s go the second route:
# ./spuser
Spread library version is 3.17.3
SP_error: (-2) Could not connect. Is Spread running?
Bye.
# ./spuser usage
Usage: spuser
[-u <user name>] : unique (in this machine) user name
[-s <address>] : either port or port@machine
[-n <username>] : username for authentication
[-p <password>] : users password
[-r ] : use random user name
# ./spuser -s 4913
Spread library version is 3.17.3
User: connected to 4913 with private group #user#fog1
==========
User Menu:
----------
j <group> -- join a group
l <group> -- leave a group
s <group> -- send a message
b <group> -- send a burst of messages
r -- receive a message (stuck)
p -- poll for a message
e -- enable asynchonous read (default)
d -- disable asynchronous read
q -- quit
User> j test
User> s test
enter message: weee
User> q
Bye.
I may be paranoid, but all’s too quiet on the western front as the saying goes. We did find out that we have to specify the port that Spread is running on for spuser to be able to connect, but after that I am a bit disappointed that the message I sent to a group that I joined does not seem to be received. At this point we need to find out more about what is going on, so let’s enable a few more DebugFlag options in the spread.conf file and start over:
# grep DebugFlags spread.conf
DebugFlags = { PRINT EXIT SESSION MEMBERSHIP GROUPS }
# ./spread -n www-0-2
[Mon 08 May 2006 07:58:57] Sess_init: ended ok
[Mon 08 May 2006 07:58:57] Scast_alive: State is 2
[Mon 08 May 2006 07:58:58] Scast_alive: State is 2
[Mon 08 May 2006 07:58:59] Send_join: State is 4
[Mon 08 May 2006 07:59:00] Send_join: State is 4
[Mon 08 May 2006 07:59:01] Send_join: State is 4
[Mon 08 May 2006 07:59:02] Send_join: State is 4
[Mon 08 May 2006 07:59:03] Send_join: State is 4
[Mon 08 May 2006 07:59:09] Memb_token_loss: I lost my token, state is 5
[Mon 08 May 2006 07:59:09] Scast_alive: State is 2
[Mon 08 May 2006 07:59:10] Scast_alive: State is 2
[Mon 08 May 2006 07:59:11] Send_join: State is 4
[Mon 08 May 2006 07:59:12] Send_join: State is 4
[Mon 08 May 2006 07:59:13] Send_join: State is 4
[Mon 08 May 2006 07:59:14] Send_join: State is 4
[Mon 08 May 2006 07:59:15] Send_join: State is 4
[Mon 08 May 2006 07:59:21] Memb_token_loss: I lost my token, state is 5
[Mon 08 May 2006 07:59:21] Scast_alive: State is 2
[Mon 08 May 2006 07:59:22] Scast_alive: State is 2
[Mon 08 May 2006 07:59:23] Send_join: State is 4
[Mon 08 May 2006 07:59:24] Send_join: State is 4
[Mon 08 May 2006 07:59:25] Send_join: State is 4
[Mon 08 May 2006 07:59:26] Send_join: State is 4
[Mon 08 May 2006 07:59:27] Send_join: State is 4
[Mon 08 May 2006 07:59:33] Memb_token_loss: I lost my token, state is 5
[Mon 08 May 2006 07:59:33] Scast_alive: State is 2
[Mon 08 May 2006 07:59:34] Scast_alive: State is 2
[Mon 08 May 2006 07:59:35] Send_join: State is 4
Aha! Although it may not be obvious what each of the preceding messages means, something seems not right about the fact that the token gets lost all the time and the states seem to be changing periodically in a loop that doesn’t seem to finish. Let’s go back to the basics. The good news is that the Spread configuration is simple, so there are not many places that we could have gone wrong. In fact, let’s check the nodes definitions again. We are telling Spread to start on the node called www-0-2, which has the IP address 10.0.0.133. Let’s make sure just in case:
# /sbin/ifconfig
fxp0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
options=8<VLAN_MTU>
inet 10.0.0.132 netmask 0xffffff00 broadcast 10.0.0.255
inet6 fe80::290:27ff:fef6:3a0e%fxp0 prefixlen 64 scopeid 0x2
ether 00:90:27:f6:3a:0e
media: Ethernet autoselect (100baseTX <full-duplex>)
status: active
Oops! It looks like we got confused about the machine we’re running on, and we’re trying to start up Spread on www-0-1, telling it that it is www-0-2 instead! That’s our mistake, although you would expect to see a more alarming message when Spread cannot bind to the network interface. Let’s see whether this is our only problem:
#./spread -n www-0-1
Conf_init: using file: spread.conf
[Mon 08 May 2006 07:48:21] ENABLING Dangerous Monitor Commands! Make sure Spread
network is secured
[Mon 08 May 2006 07:48:21] Memb_token_loss: I lost my token, state is 1
[Mon 08 May 2006 07:48:21] Sess_init: INET bind for port 4913 interface 0.0.0.0 ok
[Mon 08 May 2006 07:48:21] Sess_init: INET went ok on mailbox 6
[Mon 08 May 2006 07:48:21] Sess_init: UNIX bind for name /tmp/4913 ok
[Mon 08 May 2006 07:48:21] Sess_init: UNIX went ok on mailbox 7
[Mon 08 May 2006 07:48:21] G_init:
[Mon 08 May 2006 07:48:21] Sess_init: ended ok
[Mon 08 May 2006 07:48:21] Scast_alive: State is 2
[Mon 08 May 2006 07:48:22] Scast_alive: State is 2
[Mon 08 May 2006 07:48:23] Send_join: State is 4
[Mon 08 May 2006 07:48:24] Send_join: State is 4
[Mon 08 May 2006 07:48:25] Send_join: State is 4
[Mon 08 May 2006 07:48:26] Send_join: State is 4
[Mon 08 May 2006 07:48:27] Send_join: State is 4
[Mon 08 May 2006 07:48:28] Memb_handle_token: handling form2 token
[Mon 08 May 2006 07:48:28] Handle_form2 in FORM
[Mon 08 May 2006 07:48:28] Memb_transitional
[Mon 08 May 2006 07:48:28] G_handle_trans_memb:
[Mon 08 May 2006 07:48:28] G_handle_trans_memb in GOP
[Mon 08 May 2006 07:48:28] G_handle_trans_memb: Received trans memb id of:
{proc_id: -1062675178 time: 1147088908}
[Mon 08 May 2006 07:48:28] Memb_regular
Membership id is ( -1062675178, 1147088909)
[Mon 08 May 2006 07:48:28] --------------------
[Mon 08 May 2006 07:48:28] Configuration at www-0-1 is:
[Mon 08 May 2006 07:48:28] Num Segments 1
[Mon 08 May 2006 07:48:28] 1 10.0.0.255 4913
[Mon 08 May 2006 07:48:28] www-0-1 10.0.0.132
[Mon 08 May 2006 07:48:28] ====================
[Mon 08 May 2006 07:48:28] G_handle_reg_memb: with (10.0.0.132, 1147088909) id
[Mon 08 May 2006 07:48:28] G_handle_reg_memb in GTRANS
This time it looks like we were successful! In fact, if we now go back to the minimal set of DebugFlags, we will be able to tell that we started successfully:
# grep Debug spread.conf
DebugFlags = { PRINT EXIT }
# ./spread -n relay-0-1
Conf_init: using file: spread.conf
[Mon 08 May 2006 08:12:52] ENABLING Dangerous Monitor Commands! Make sure Spread
network is secured
Membership id is ( -1062675178, 1147090380)
[Mon 08 May 2006 08:12:59] --------------------
[Mon 08 May 2006 08:12:59] Configuration at www-0-1 is:
[Mon 08 May 2006 08:12:59] Num Segments 1
[Mon 08 May 2006 08:12:59] 1 10.0.0.255 4913
[Mon 08 May 2006 08:12:59] www-0-1 10.0.0.132
[Mon 08 May 2006 08:12:59] ====================
Keep in mind that the preceding output is something we want to see after we start Spread because it shows that the daemon that we just started was able to successfully establish a membership. Let’s see now whether we can get more satisfying results out of playing with the spuser application:
# ./spuser -s 4913
Spread library version is 3.17.3
User: connected to 4913 with private group #user#www-0-1
==========
User Menu:
----------
j <group> -- join a group
l <group> -- leave a group
s <group> -- send a message
b <group> -- send a burst of messages
r -- receive a message (stuck)
p -- poll for a message
e -- enable asynchonous read (default)
d -- disable asynchronous read
q -- quit
User> j test
User>
============================
Received REGULAR membership for group test with 1 members, where I am member 0:
#user#www-0-1
grp id is -1062675178 1147091682 1
Due to the JOIN of #user#www-0-1
User> s test
enter message: weee
User>
============================
received SAFE message from #user#www-0-1, of type 1, (endian 0) to 1 groups
(5 bytes): weee
Indeed, this looks much more like what we would expect to see. We joined a group that we called test and sent a message that was actually received. Let’s attempt to bring the second server up as well:
# ./spread -n www-0-2
Conf_init:using file:spread.conf
[Mon 08 May 2006 08:44:41] ENABLING Dangerous Monitor Commands! Make sure Spread
network is secured
Membership id is ( -1062675179, 1147092289)
[Mon 08 May 2006 08:44:48] --------------------
[Mon 08 May 2006 08:44:48] Configuration at www-0-2 is:
[Mon 08 May 2006 08:44:48] Num Segments 1
[Mon 08 May 2006 08:44:48] 2 10.0.0.255 4913
[Mon 08 May 2006 08:44:48] www-0-1 10.0.0.132
[Mon 08 May 2006 08:44:48] www-0-2 10.0.0.133
[Mon 08 May 2006 08:44:48] ====================
++++++++++++++++++++++
Num of groups: 1
[1] group test with 1 members:
[1] #user#www-0-1
----------------------
In the output generated by www-0-1, we can see the exact same membership—a good sign. We also notice that both daemons are aware of the existence of a group called test and an application that is a member of that group because we did not quit the spuser connection.
In this case, we probably passed most of the typical hurdles that you would encounter when starting and setting up Spread for the first time. It is possible, however, that when we start up the second Spread daemon, it will not be able to communicate with the first one. On www-0-2, you might see something like this:
Membership id is ( -1062675178, 1147092289)
[Mon 08 May 2006 08:44:48] --------------------
[Mon 08 May 2006 08:44:48] Configuration at www-0-2 is:
[Mon 08 May 2006 08:44:48] Num Segments 1
[Mon 08 May 2006 08:44:48] 2 10.0.0.255 4913
[Mon 08 May 2006 08:44:48] www-0-2 10.0.0.133
[Mon 08 May 2006 08:44:48] ====================
On www-0-1, the output might look like this:
Membership id is ( -1062675179, 1147092272)
[Mon 08 May 2006 08:44:48] --------------------
[Mon 08 May 2006 08:44:48] Configuration at www-0-1 is:
[Mon 08 May 2006 08:44:48] Num Segments 1
[Mon 08 May 2006 08:44:48] 2 10.0.0.255 4913
[Mon 08 May 2006 08:44:48] www-0-1 10.0.0.132
[Mon 08 May 2006 08:44:48] ====================
The two daemons cannot communicate with each other. Most commonly this behavior is caused by firewall restrictions. Spread needs to communicate via UDP/IP and TCP/IP on the port specified in the configuration file, as well as the port immediately above that! In the preceding example, these would be ports 4913 and 4914. By default, Spread comes configured to run on port 4803.
Alternatively, Spread may be configured to run using IP multicast by specifying a multicast address in the Spread segment. If you run into trouble while attempting to use multicast with Spread, the first step should be to independently check the multicast setup of the network. Often problems with multicast setups have nothing to do with Spread and require separate troubleshooting. Another common situation is that Spread seems to work in a setup with two daemons, but it stops working when a third daemon is added. Spread tacitly falls back from using multicast or broadcast, when they don’t work, to using unicast if the configuration allows it. However, when three or more nodes are in a segment, unicast is not an option, and the network problem becomes apparent by causing Spread to stop working.
Spread comes with two other tools that are useful for troubleshooting network problems without using Spread itself at all—spsend and sprecv:
# make spsend
gcc -g -O2 -Wall -I. -I. -DHAVE_CONFIG_H -c s.c
gcc -o spsend s.o alarm.o data_link.o events.o memory.o -lnsl
fog2:~/spread-src-3.17.3 $ make sprecv
gcc -g -O2 -Wall -I. -I. -DHAVE_CONFIG_H -c r.c
gcc -o sprecv r.o alarm.o data_link.o -lnsl
$ ./spsend
Checking (127.0.0.1, 4444). Each burst has 100 packets, 1024 bytes each with
10 msec delay in between, for a total of 10000 packets
sent 1000 packets of 1024 bytes
sent 2000 packets of 1024 bytes
sent 3000 packets of 1024 bytes
sent 4000 packets of 1024 bytes
sent 5000 packets of 1024 bytes
sent 6000 packets of 1024 bytes
sent 7000 packets of 1024 bytes
sent 8000 packets of 1024 bytes
sent 9000 packets of 1024 bytes
sent 10000 packets of 1024 bytes
total time is (1,300054), with 0 problems
# ./spsend usage
Usage:
[-p <port number>] : to send on, default is 4444
[-b <burst>] : number of packets in each burst, default is 100
[-t <delay>] : time (mili-secs) to wait between bursts, default 10
[-n <num packets>] : total number of packets to send, default is 10000
[-s <num bytes>] : size of each packet, default is 1024
[-a <IP address>] : default is 127.0.0.1
# ./sprecv usage
Usage: r
[-p <port number>] : to receive on, default is 4444
[-a <multicast class D address>] : if receiving multicast is desirable,
default is 0
[-i <IP interface>] : set interface, default is 0
[-d ] : print a detailed report whenever messages are missed
The usage of the preceding programs is straightforward and orthogonal to Spread itself, so we will not go into details about them. However, Spread comes with another tool that is useful for both basic and advanced troubleshooting of problems: spmonitor. With spmonitor we can view information about the current state of the Spread daemons, and we can also cause artificial network partitions to test the robustness of our applications in the presence of network faults:
#./spmonitor -n `hostname`
=============
Monitor Menu:
-------------
0. Activate/Deactivate Status {all, none, Proc, CR}
1. Define Partition
2. Send Partition
3. Review Partition
4. Cancel Partition Effects
5. Define Flow Control
6. Send Flow Control
7. Review Flow Control
8. Terminate Spread Daemons {all, none, Proc, CR}
9. Exit
Monitor> 0
=============
Activate Status
-------------
Enter Proc Name: www-0-1
Enter Proc Name:
Monitor: send status query
Monitor>
============================
============================
Status at www-0-1 V 3.17. 3 (state 1, gstate 1) after 718730 seconds :
Membership : 9 procs in 1 segments, leader is www-0-1
rounds : 18742726 tok_hurry : 3874314 memb change: 33
sent pack: 930924 recv pack : 6136167 retrans : 1270737
u retrans: 1219986 s retrans : 50751 b retrans : 0
My_aru : 2560710 Aru : 2560710 Highest seq: 2560710
Sessions : 2 Groups : 5 Window : 60
Deliver M: 12011390 Deliver Pk: 12479141 Pers Window: 15
Delta Mes: 146 Delta Pack: 146 Delta sec : 10
==================================
Inspecting the state of a Spread daemon may provide good insight into the health of the Spread setup. The status message is sent at regular intervals until we turn it off; therefore, we can follow how the various figures change. On the first status line we notice the version of Spread that we are running and the uptime of the instance that we are looking at. The state and gstate variables should be “1” if the daemon membership is stable. We can see that we are looking at a membership that now has nine daemons in one segment (this is from a live configuration that has seven more nodes listed in its configuration). The number of rounds in the third line indicates the number of times the token has rotated around the Spread ring. The number of membership changes on the same line indicates how often we had daemons joining/leaving the system either due to crashes, restarts, or network issues. A large value there may indicate instability of the network setup. In the fourth and fifth lines of the status message we can see how many total packets were sent, received, and retransmitted, as well as a breakdown of the types of retransmissions (unicast, segment, broadcast). A high number of retransmissions may also indicate problems—a congested network, for example. Segment retransmissions (s_retrans) may indicate problems in the case of multisegment setups, when there are connectivity issues between two segments. The number of sessions represents the number of applications locally connected to this daemon instance; Groups refers to the number of groups that exist in the system, whereas the Window and Pers Window parameters define the flow control characteristics of the system—how many messages can be sent per token revolution and how many messages can each sender send when it holds the token. We can see the number of delivered messages and packets (a message may be split into multiple packets) from the start of this instance, as well as the number of messages/packets delivered in the Delta interval since the previous status message was sent.
We now have a Spread network running and can move on to look at the programming API used to build on our own applications.
Spread provides a unified programming API available in several programming languages: C, C++, Java, Perl, Python, PHP, Ruby, and others. Detailed documentation about the C API comes distributed with Spread as man pages and is available online for the various other languages. To keep the code short, we will use the Perl interface for our example.
The application that we will use as an example of simple yet efficient usage of Spread is a distributed file cache purging daemon. Consider a file cache that is distributed across several servers. It is a common scenario that we want to either completely remove a file from the cache or replace it with a different version. In both scenarios, we first need to remove the existing version from all caches to force the caching system to refresh its local copy next time the data is needed.
To support this feature we will deploy a cache purging daemon on every cache. The daemon just waits for messages from clients requesting the purge of files that are no longer needed. Of course, we could implement this by having a client that connects to each of the cache servers and requests the purging. However, this method is cumbersome because it requires the client to know the identity of every cache server and to connect to each one of them, one by one.
Our proposed solution has all the cache purging daemons connected through Spread and joining the same group. A client that wants to request the removal of a file needs only to connect to Spread and send a message to the group that the daemons are listening to. Spread takes care of reliably passing the request along to all daemons connected to the group.
To exemplify, we present a sample implementation of the cache purging system written in Perl. First, let’s have a look at the daemon outlined in Listing A.3, which we call sppurgecached.
Listing A.3. sppurgecached—A Spread-Based Cache Purging Daemon
01: #!/usr/bin/perl
02:
03: use strict;
04: use Spread;
05: use Getopt::Long;
06: use POSIX qw/setsid/;
07: use File::Find qw/finddepth/;
08: use IO::File;
09:
10: use vars qw /$daemon @group $cachedir $logfile/;
11:
12: GetOptions("d=s" => $daemon,
13: "g=s" => @group,
14: "l=s" => $logfile,
15: "c=s" => $cachedir);
16: $daemon ||= '[email protected]';
17: push(@group, 'cachepurge') unless(@group);
18:
19: close(STDIN);
20: if($logfile) {
21: open LOGFILE, ">>>$logfile" || die "Cannot open $logfile";
22: }
23: sub __log { syswrite(LOGFILE, shift) if($logfile); }
24:
25: die "You must be root, as I need to chroot" if($>);
26: die "Could not chroot" unless(chroot($cachedir) && chdir('/'));
27: # daemonize
28: close(STDOUT); close(STDERR);
29: fork && exit; setsid; fork && exit;
30:
31: sub removenode {
32: return if /^.{1,2}$/;
33: -d $_ ? rmdir($_) : unlink($_);
34: }
35:
36: while(1) {
37: my ($m, $g);
38: eval { # We eval so we can catch errors and reconnect.
39: ($m, $g) = Spread::connect( { spread_name => "$daemon",
40: private_name => "scpd_$$" } );
41: die "Could not connect to Spread at $daemon" unless $m;
42: die "Could not join" unless(grep {Spread::join($m, $_)} @group);
43: __log("Connected to spread: $daemon
");
44: while(my @p = Spread::receive($m)) {
45: if(@p[0] & Spread::REGULAR_MESS()){
46: chomp(my $victim = @p[5]);
47: __log("[@p[1]] purges $victim
");
48: if(-d $victim) {
49: # For directories, we recursively delete
50: finddepth( { postprocess => &removenode,
51: wanted => &removenode,
52: no_chdir => 1 }, $victim);
53: } else {
54: unlink($victim);
55: }
56: }
57: }
58: };
59: __log($@) if($@);
60: Spread::disconnect($m) if($m);
61: sleep(1);
62: }
The cache purging daemon connects to a Spread daemon and then joins the designated group (lines 39–43). The Spread::connect call specifies the address of the daemon that the application connects to as well as a private name by which the application will be identified. The private name must be unique per the Spread daemon. By default, our application assumes that the Spread daemon runs on the standard Spread port on the local host. The group that the spcachepurged daemons listen to is cachepurge, but another group name can be specified using the -g command-line option (lines 16–17). Because our program is supposed to remove files at request, we also make sure that it can only do so within the designated cache directory (lines 25–26).
The daemon then starts listening for messages by calling the blocking Spread::receive call. The receive call reads both regular messages and membership change notifications, but for the current application we are only interested in REGULAR (data) messages (lines 44–45). After a message is received, we check its payload and attempt to remove the file whose name was sent (lines 46–55). The daemon then goes back to listening for another request.
Now let’s have a look at the sample client on Listing A.4 that connects to the daemon and requests the purge of a file from the distributed cache.
Listing A.4. spcachepurge—A Simple Local Area Spread Configuration
01: #!/usr/bin/perl
02:
03: use strict;
04: use Spread;
05: use Getopt::Long;
06: use vars qw /$daemon $group/;
07:
08: GetOptions("d=s" => $daemon,
09: "g=s" => $group);
10: $daemon ||= 4803;
11: $group ||= 'cachepurge';
12:
13: my ($m, $g) = Spread::connect( { spread_name => "$daemon",
14: private_name => "scp_$$" } );
15: die "Could not connect to Spread at $daemon
" unless($m);
16:
17: if(!@ARGV) {
18: print STDERR "$0 [-d spread] [-g group] file1 ...
";
19: exit;
20: }
21: while(my $file = shift) {
22: Spread::multicast($m, RELIABLE_MESS, $group, 0, $file);
23: }
24: Spread::disconnect($m);
The client’s sole purpose is to inform the cache daemons about the files that it needs deleted. Because we want to avoid cache inconsistencies, the request needs to be reliably delivered to all cache daemons. The client needs to be able to communicate to the spcachepurged daemons that are listening on a dedicated Spread group; therefore, we provide the clients with the option of specifying the Spread daemon that they need to connect to and the name of the group that the daemons are listening on. In a standard configuration the spcachepurge client is being run on one machine in the cluster. Therefore, by default, we set the $daemon variable to connect to the standard Spread port 4803 (line 10). The syntax used for specifying the Spread daemon is the same as the one used to start a Spread daemon. If the client is running on a machine without a Spread daemon, we can specify the proper daemon address: ./sppurgecache -d port@ip. The default communication group can also be overruled by using the -g parameter.
First The client connects to the Spread daemon (lines 13–15); then, for each file passed as an argument, it broadcasts a reliable message to the cache group. Because the message is broadcast using the RELIABLE delivery guarantee, all daemons listening to the group will remove the requested file.
This example shows the convenience and efficiency of using the right tool. However, the solution is not as perfect as it appears. Even though we send the purge request as a RELIABLE message, it is possible that one of the purge cache daemons, or its corresponding Spread daemon, was crashed at the time the purge request was made or was disconnected from the rest of the servers due to a temporary network partition. In both cases, when the cache server becomes operational, it will still have the file that was removed on the other servers. Attempting to deal with this scenario in our application is a much more difficult problem and would require both the use of the more expensive SAFE messages as well as adding additional logic into the cache purging daemons. However, this level of precaution is not necessary for an application such as the one we are describing. Instead, given the notion of a cache, we can clear the entire cache upon a restart, thereby making sure that we will serve the correct documents, paying the small price of repopulating the cache on demand.
Understanding the requirements and trade-offs of the distributed problem you are trying to solve and choosing the appropriate tool and approach for the solution is, as mentioned at the beginning of this appendix, essential for developing smart distributed applications.