
One feature many drivers need is to schedule execution of some tasks at a later time without resorting to interrupts. Linux offers two different interfaces for this purpose: task queues and kernel timers. Task queues provide a flexible utility for scheduling execution at a later time, with various meanings for later; they are most useful when writing interrupt handlers, and we’ll see them again in Section 9.4, in Chapter 9. Kernel timers are used to schedule a task to run at a specific time in the future and are dealt with later in this chapter, in Section 6.5.
A typical situation in which you might use task queues is for
managing hardware that cannot generate interrupts but still allows
blocking read. You need to poll the device, while taking care not to
burden the CPU with unnecessary operations. Waking the reading process
at fixed time intervals (for example, using
current->timeout) isn’t a suitable approach, because
each poll would require two context switches and often a suitable
polling mechanism can be implemented only outside of a process’s
context.
A similar problem is giving timely input to a simple hardware device. For example, you might need to feed steps to a stepper motor that is directly connected to the parallel port--the motor needs to be moved by single steps on a timely basis. In this case, the controlling process talks to your device driver to dispatch a movement, but the actual movement should be performed step by step after returning from write.
The preferred way to perform such floating operations quickly is to register a task for later execution. The kernel supports task ``queues,'' where tasks accumulate to be ``consumed'' when the queue is run. You can declare your own task queue and trigger it at will, or you can register your tasks in predefined queues, which are run (triggered) by the kernel itself.
The next section first describes task queues, then introduces predefined task queues, which provide a good start for some interesting tests (and hang the computer if something goes wrong), and finally introduces how to run your own task queues.
A task queue is a list of tasks, each task being
represented by a function pointer and an argument.
When a task is run, it receives a single void * argument and
returns void. The pointer argument can be used to pass along
a data structure to the routine, or it can be ignored. The queue
itself is a list of structures (the tasks) that are owned by the
kernel module declaring and queueing them. The module is completely
responsible for allocating and deallocating the structures;
static structures are commonly used for this purpose.
A queue element is described by the following structure,
copied directly from <linux/tqueue.h>:
struct tq_struct {
struct tq_struct *next; /* linked list of active bh's */
int sync; /* must be initialized to zero */
void (*routine)(void *); /* function to call */
void *data; /* argument to function */
};The ``bh'' in the first comment means bottom-half. A bottom-half is ``half of an interrupt handler''; we’ll discuss this topic thoroughly when we deal with interrupts in Section 9.4 in Chapter 9.
Task queues are an important resource for dealing with asynchronous events, and most interrupt handlers schedule part of their work to be executed when task queues are run. On the other hand, some task queues are bottom halves, in that their execution is triggered by the do_bottom_half function. While I intend for this chapter to make sense even if you don’t understand bottom-halves, nonetheless, I do refer to them when necessary.
The most important fields in the data structure shown above are
routine and data. To queue a task for later
execution, you need to set both these fields before queueing the
structure, while
next and sync should be cleared. The sync flag
in the structure is used to prevent queueing the same task more than
once, as this would corrupt the next pointer. Once the task has
been queued, the structure is considered ``owned'' by the kernel and
shouldn’t be modified.
The other data structure involved in task queues is
task_queue, which is currently just a pointer to struct tq_struct; the decision to typedef this pointer to another
symbol permits the extension of task_queue in the future, should
the need arise.
The following list summarizes the operations that can be performed
on struct tq_structs; all the functions are inlines.
-
void queue_task(struct tq_struct *task, task_queue *list); As its name suggests, this function queues a task. It disables interrupts to prevent race conditions and can be called from any function in your module.
-
void queue_task_irq(struct tq_struct *task,,task_queue *list); This function is similar to the previous one, but it can be called only from a non-reentrant function (such as an interrupt handler, whence the name). It is slightly faster than queue_task because it doesn’t disable interrupts while queueing. If you call this routine from a reentrant function, you risk corruption of the queue due to the unmasked race condition. However, this function does mask against queueing-while-running (queueing a task at the exact place where the queue is being consumed).
-
void queue_task_irq_off(struct tq_struct *task,,task_queue *list); This function can be called only when interrupts are disabled. It is faster than the previous two, but doesn’t prevent either concurrent-queueing or queueing-while-running race conditions.
-
void run_task_queue(task_queue *list); run_task_queue is used to consume a queue of accumulated tasks. You won’t need to call it yourself unless you declare and maintain your own queue.
Both queue_task_irq and queue_task_irq_off have been removed in version 2.1.30 of the kernel, as the speed gain was not worth the effort. See Section 17.4 in Chapter 17, for details.
Before delving into the details of the queues, I’d better explain some of the subtleties that hide behind the scenes. Queued tasks execute asynchronously with respect to system calls; this asynchronous execution requires additional care and is worth explaining first.
Task queues are executed at a safe time. Safe here means that there aren’t stringent requirements about the execution times. The code doesn’t need to be extremely fast, because hardware interrupts are enabled during execution of task queues. Queued functions should be reasonably fast anyway because only hardware interrupts can be dealt with by the system as long as a queue is being consumed.
Another concept related to task queues is that of
interrupt time. In Linux, interrupt time is a software
concept, enforced by the global kernel variable
intr_count. This variable keeps a count of the number of
nested interrupt handlers being executed at any
time.[21]
During the normal computation flow, when the processor is executing
on behalf of a process, intr_count is 0. When intr_count
is not 0, on the other hand, the code is asynchronous with the rest of
the system. Asynchronous code
might be handling a hardware interrupt or a ``software
interrupt''--a task that is executed independent of any processes, which
we’ll refer to as running ``at interrupt time.'' Such code
is not allowed to perform certain
operations; in particular, it cannot put the current process to sleep
because the value of the current pointer is not related to the
software interrupt code being run.
A typical example is code executed on exit from a system call.
If for some reason there is a job scheduled for execution, the
kernel can dispatch it as soon as a process returns from a system
call. This is a ``software interrupt,'' and intr_count is
incremented before dealing with the pending job. The function being
dispatched is at ``interrupt time'' because the main instruction
stream has been interrupted.
When intr_count is non-zero, the scheduler can’t be
invoked. This also means that kmalloc(GFP_KERNEL) is not
allowed. Only atomic allocations (see Section 7.1.1 in Chapter 7) can
be performed at interrupt time, and atomic allocations are more
prone to fail than ``normal'' allocations.
If code being executed at interrupt time calls schedule, an error message like ``Aiee: scheduling in interrupt'' is printed on the console, followed by the hexadecimal address of the calling instruction. From version 2.1.37 onwards, this message is followed by an oops, to help debug the problem by analyzing the registers. Trying to allocate memory at interrupt time with non-atomic priority generates an error message that includes the caller’s address.
The easiest way to perform deferred execution is to use the queues
that are already maintained by the kernel. There are four of these
queues, described below, but your driver can use only the first three.
The queues are declared in <linux/tqueue.h>, which you should
include in your source.
-
tq_scheduler This queue is consumed whenever the scheduler runs. Since the scheduler runs in the context of the process being scheduled out, tasks that run in the scheduler queue can do almost anything; they are not executed at interrupt time.
-
tq_timer This queue is run by the timer tick. Since the tick (the function do_timer) runs at interrupt time, any task within this queue runs at interrupt time as well.
-
tq_immediate The immediate queue is run as soon as possible, either on return from a system call or when the scheduler is run, whichever comes first. The queue is consumed at interrupt time.
-
tq_disk This queue, not present in version 1.2 of the kernel, is used internally in memory management and can’t be used by modules.
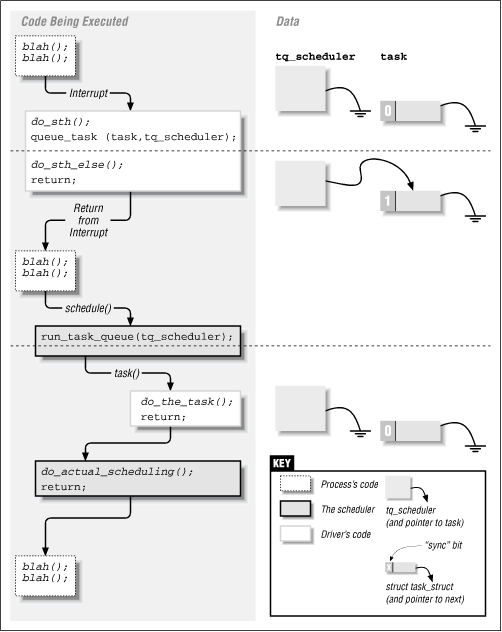
The timeline of a driver using a task queue is represented in
Figure 6.1. The figure shows a driver that queues
a function in tq_scheduler from an interrupt handler.
Examples of deferred computation are available in the jiq
(Just In Queue) module, from which the source in this section has been
extracted. This module creates /proc files that can be read
using dd or other tools; this is similar to jit.
The sample module can’t run on Linux 1.2
because it uses dynamic /proc files.
The process reading a jiq file is put to sleep until the
buffer is full.[22] The buffer is filled
by successive runs of a task queue. Each pass through the queue
appends a text string to the buffer being filled; each string
reports the current time (in jiffies), the process that is
current during
this pass, and the value of intr_count.
For best results, the file should be read in one shot, with the
command dd count=1; if you use a command like cat,
the read method is invoked several times, and the results overlap,
as explained in Section 4.2.1, in Chapter 4.
The code for filling the buffer is confined to the jiq_print function, which executes at each run through the queue being used. The printing function is not interesting and is not worth showing here; instead, let’s look at the initialization of the task to be inserted in a queue:
struct tq_struct jiq_task; /* global: initialized to zero */ /* this lines are in init_module() */ jiq_task.routine = jiq_print; jiq_task.data = (void *)&jiq_data;
There’s no need to clear the sync and
next fields of jiq_task because static variables are
initialized to 0 by the compiler.
The easiest queue to use is tq_scheduler because queued
tasks are not constrained by being executed at interrupt time.
/proc/jiqsched is a sample file that uses tq_scheduler.
The read function
for the file dispatches everything to the task queue, in the following
way:
int jiq_read_sched(char *buf, char **start, off_t offset,
int len, int unused)
{
jiq_data.len = 0; /* nothing printed, yet */
jiq_data.buf = buf; /* print in this place */
jiq_data.jiffies = jiffies; /* initial time */
/* jiq_print will queue_task() again in jiq_data.queue */
jiq_data.queue = &tq_scheduler;
queue_task(&jiq_task, &tq_scheduler); /* ready to run */
interruptible_sleep_on(&jiq_wait); /* sleep till completion */
return jiq_data.len;
}Reading /proc/jiqsched is interesting, because it shows when
the scheduler is run--the value of jiffies shown is the value
when the scheduler gets invoked.
If CPU-bound processes are active on the system,
there is a delay between successive runs of the queue; the
scheduler won’t preempt the processes before several clock ticks have
elapsed. Reading the file can thus take several seconds, since the file is
roughly 100 lines long (or twice that on the Alpha).
The simplest way to test this situation is to run a process
that executes an empty loop. The load50 program is a
load-raising program that executes 50 concurrent busy loops in the
user space; you’ll find its source in the sample programs. When
load50 is running in the system, head
extracts the following from /proc/jiqsched:
time delta intr_count pid command 1643733 0 0 701 head 1643747 14 0 658 load50 1643747 0 0 3 kswapd 1643755 8 0 655 load50 1643761 6 0 666 load50 1643764 3 0 650 load50 1643767 3 0 661 load50 1643769 2 0 659 load50 1643769 0 0 6 loadmonitor
Note that the scheduler queue is run immediately after entering
schedule, and thus the current process is the one that is
being scheduled out. That’s why the first line in
/proc/jiqsched always represents the process reading the file;
it has just gone to sleep and is being scheduled out. Note also that
both kswapd and loadmonitor (a program
I run on my system) execute for less than 1 time tick, while
load50 is preempted when its time quantum expires, several
clock ticks after it acquires the processor.
When no process is actually running, the current process is always the idle task (process 0, historically called ``swapper'') and the queue is run either continuously or once every timer tick. The scheduler, and thus the queue, runs continuously if the processor can’t be put into a ``halted'' state; it runs at every timer tick only if the processor is halted by process 0. A halted processor can be awakened only by an interrupt. When this happens, the idle task runs the scheduler (and the associated queue). The following shows the results of head /proc/jitsched run on an unloaded system:
time delta intr_count pid command 1704475 0 0 730 head 1704476 1 0 0 swapper 1704477 1 0 0 swapper 1704478 1 0 0 swapper 1704478 0 0 6 loadmonitor 1704479 1 0 0 swapper 1704480 1 0 0 swapper 1704481 1 0 0 swapper 1704482 1 0 0 swapper
Using the timer queue is not too different from using the scheduler queue. The main difference is that, unlike the scheduler queue, the timer queue executes at interrupt time. Additionally, you’re guaranteed that the queue will run at the next clock tick, thus overcoming any dependency on system load. The following is what head /proc/jiqtimer returned while my system was compiling:
time delta intr_count pid command 1760712 1 1 945 cc1 1760713 1 1 945 cc1 1760714 1 1 945 cc1 1760715 1 1 946 as 1760716 1 1 946 as 1760717 1 1 946 as 1760718 1 1 946 as 1760719 1 1 946 as 1760720 1 1 946 as
One feature of the current implementation of task queues is that a
task can requeue itself in the same queue it is run from. For
instance, a task being run from the timer tick can reschedule itself
to be run on the next tick. Rescheduling is possible because the head
of the queue is replaced with a NULL pointer before consuming
queued tasks. This implementation dates back to kernel version
1.3.70. In earlier versions (such as 1.2.13),
rescheduling was not possible because the
kernel didn’t trim the queue before running it. Trying to
reschedule a task with Linux 1.2 hangs the system in
a tight loop. The ability to reschedule is the only relevant difference
in task-queue management from 1.2.13 to 2.0.x.
Although rescheduling the same task over and over might appear to be a pointless operation, it is sometimes useful. For example, my own computer moves a pair of stepper motors one step at a time by rescheduling itself on the timer queue until the target has been fulfilled. Another example is the jiq module, where the printing function reschedules itself to show each pass through the queues.
The last predefined queue that can be used by modularized
code is the immediate queue. It works like a
bottom-half interrupt handler, and thus it must be ``marked'' with
mark_bh(IMMEDIATE_BH). For efficiency, bottom-halves
are run only if they
are marked. Note that the handler must be marked after
the call to queue_task; otherwise a race condition is created.
See Section 9.4 in Chapter 9 for more detail.
The immediate queue is the fastest queue in the system--it’s
executed soonest and is consumed after incrementing
intr_count. The queue is so ``immediate'' that if you
re-register your task, it is rerun as soon as it returns. The
queue is run over and over until it is empty. If you read
/proc/jiqimmed, you’ll see that the reason it is so fast is
that it keeps control of the CPU during the entire reading process.
The queue is consumed either by the scheduler or as soon as one process returns from its system call. It’s interesting to note that the scheduler (at least with the 2.0 kernel) doesn’t keep rerunning the immediate queue until it is empty; this happens only when the queue is run on return from a system call. You can see this behavior in the next sample output--the first line of jiqimmed shows head as the current process, while the next lines don’t.
time delta intr_count pid command 1975640 0 1 1060 head 1975641 1 1 0 swapper 1975641 0 1 0 swapper 1975641 0 1 0 swapper 1975641 0 1 0 swapper 1975641 0 1 0 swapper 1975641 0 1 0 swapper 1975641 0 1 0 swapper 1975641 0 1 0 swapper
It’s clear that the queue can’t be used to delay the execution of a task--it’s an ``immediate'' queue. Instead, its purpose is to execute a task as soon as possible, but at a ``safe time.'' This feature makes it a great resource for interrupt handlers, because it offers them an entry point for executing program code outside of the actual interrupt management routine.
Although /proc/jiqimmed re-registers its task in
the queue, this technique is discouraged in real code; this uncooperative
behavior ties up the processor as long as a task is re-registering itself,
whith no advantage over completing the work in one pass.
Declaring a new task queue is not difficult. A driver is free to
declare a new task queue, or even several of them; tasks are
queued just as we’ve seen with tq_scheduler.
Unlike a predefined task queue, a custom queue is not automatically triggered by the kernel. The programmer who maintains a queue must arrange for a way of triggering it.
The following macro declares the queue and needs to be expanded where you want your task queue to be declared:
DECLARE_TASK_QUEUE(tq_custom);
After declaring the queue, you can invoke the usual functions to queue tasks. The call above pairs naturally with the following:
queue_task(&custom_task, &tq_custom);
And the following one will run tq_custom:
run_task_queue(&tq_custom);
If you want to experiment with custom queues now, you need to register a function to trigger the queue in one of the predefined queues. Although this may look like a roundabout way to do things, it isn’t. A custom queue can be useful whenever you need to accumulate jobs and execute them all at the same time, even if you use another queue to select that ``same time.''
[21] Version 2.1.34 of the kernel got rid of
intr_count. See Section 17.5 in Chapter 17 for details on this.
[22] The buffer of a /proc file
is a page of memory: 4KB or 8KB.