CHAPTER 10
THE ENTERPRISE WEB APPLICATION SECURITY PROGRAM
Up to this point, we’ve generally assumed the perspective of a would-be intruder with minimal initial knowledge of the web application under review. Of course, in the real world, a security assessment often begins with substantial knowledge about, and access to, the target web application. For example, the web development test team may perform regular application security reviews using a full-knowledge approach (where application information and access is made readily available) during the development process, as well as zero-knowledge assessments (when little to no application information or access is provided) after release.
This chapter describes the key aspects of an ideal enterprise web application security program. It assumes the perspective of a corporate web application development team or technical security audit department interested in improving the security of its products and practices (of course, the techniques outlined in this chapter can also be used to perform “gray-box” security reviews—a hybrid approach that leverages the best features of both black- and white-box analysis techniques). We’ll also cover the processes and technologies of interest to IT operations staff and managers seeking to automate the Hacking Exposed Web Applications assessment methodology so it is scalable, consistent, and delivers measurable return on investment (ROI). This methodology is based on the authors’ collective experience as security managers and consultants for large enterprises. The organization of the chapter reflects the major components of the full-knowledge methodology:
• Threat modeling
• Code review
• Security testing
We’ll finish the chapter with some thoughts on how to integrate security into the overall web development process using best practices that are increasingly common at security-savvy organizations.
THREAT MODELING
As the name suggests, threat modeling is the process of systematically deriving the key threats relevant to an application in order to efficiently identify and mitigate potential security weaknesses before releasing it. In its simplest form, threat modeling can be a series of meetings among development team members (including intra- or extraorganizational security expertise as needed) where such threats and mitigation plans are discussed and documented.
Threat modeling is best employed during the requirements and design phase of development, since its results almost always influence the rest of the development process (especially coding and testing). The threat model should also be revisited before release, and following any significant update. Figure 10-1 illustrates an optimal threat modeling schedule. Based on the experiences of major software companies that have implemented it, threat modeling is one of the most critical steps you can take to improve the security of your web applications.
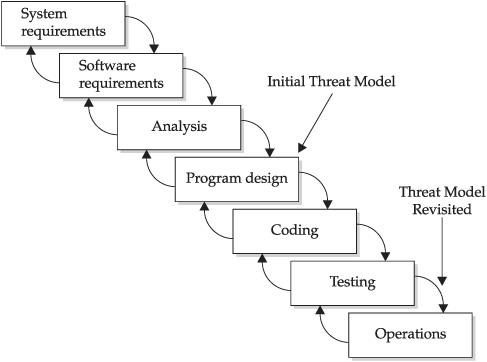
Figure 10-1 An example threat modeling schedule mapped to a hypothetical development process
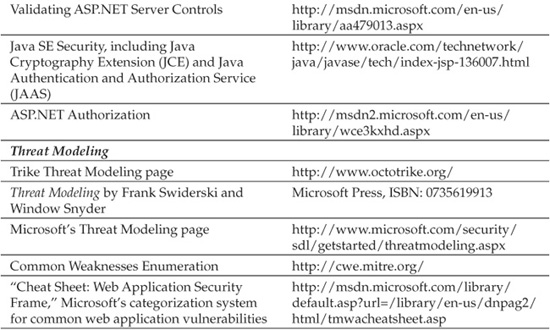
The detailed process of threat modeling software applications is best described in The Security Development Lifecycle (Chapter 9), Writing Secure Code, 2nd Edition, and Threat Modeling, the seminal works on the topic (see “References & Further Reading” at the end of this chapter for more information). The basic components of the methodology are as follows (adapted from the resources cited above and from our own experience implementing similar processes for our consulting clientele):
• Clarify security objectives to focus the threat modeling activity and determine how much effort to spend on subsequent steps.
• Identify assets protected by the application (it is also helpful to identify the confidentiality, integrity, availability, and audit-logging (CIAA) requirements for each asset).
• Create an architecture overview (this should at the very least encompass a data flow diagram, or DFD, that illustrates the flow of sensitive information throughout the application and related systems).
• Decompose the application, paying particular attention to security boundaries (for example, application interfaces, privilege use, authentication/authorization model, logging capabilities, and so on).
• Identify and document threats.
• Rank the threats using a consistent model (ideally, a quantitative model).
• Develop threat mitigation strategies and a schedule for those threats deemed serious enough.
• Implement the threat mitigations according to the agreed-upon schedule.
TIP
Microsoft publishes a threat modeling tool that can be downloaded from the link provided in “References & Further Reading” at the end of this chapter.
In this section, we will illustrate this basic threat modeling methodology as it might be applied to a sample web application—a standard online bookstore shopping cart, which has a two-tier architecture comprised of a frontend web server and a backend database server. The database server contains all the data about the customer and the items that are available for purchase online; the front end provides an interface to the customers to log in and purchase items.
Clarify Security Objectives
Although it may seem obvious, we have found that documenting security objectives can make the difference between an extremely useful threat model and a mediocre one. Determining concise objectives sets an appropriate tone for the exercise: what’s in scope and what’s out, what are priorities and what are not, what are musts vs. coulds vs. shoulds, and last but not least, the all-important “what will help you sleep better at night.” We’ve also found that this clarification lays the foundation for subsequent steps (for example, identifying assets), since newcomers to threat modeling often have unrealistic security expectations and have a difficult time articulating what they don’t want to protect. Having a solid list of security objectives really helps constrain things to a reasonable scope.
Identify Assets
Security begins with first understanding what it is you’re trying to secure. Thus, the foundational step of threat modeling is inventorying the application assets. For web applications, this exercise is usually straightforward: our sample application contains valuable items such as customer information (possibly including financial information), user and administrative passwords, and business logic. The development team should list all of the valuable assets protected by the application, ranked by sensitivity. This ranking can usually be obtained by considering the impact of loss of confidentiality, integrity, or availability of each asset. The asset inventory should be revisited in the next step to ensure that the architecture overview and related data flow diagrams properly account for the location of each asset.
One nuance often overlooked by threat modelers: assets do not necessarily always take the form of tangible, fixed items. For example, the computational resources of a web application could be considered its most important asset (think of a search application). And, of course, there is always the intangible asset of reputation or brand. Although discussion of intangibles like brand can create irresolvable conflicts among threat modeling team members due to disparate perspectives on how to value such assets, it’s worthwhile to consider the impact on intangibles during threat modeling.
Architecture Overview
A picture is worth a thousand words, and threat modeling is no exception. Data flow diagrams (DFDs) help determine security threats by modeling the application in a visually meaningful manner and are one of the primary benefits of the full-knowledge approach over the zero-knowledge approach (since it’s unlikely that zero-knowledge testers would have access to detailed DFDs). We usually find that level 0 (overview) and level 1 (component-level) DFDs are the minimal necessary for this purpose. The level 0 and level 1 DFDs for our hypothetical shopping cart application are shown in Figures 10-2 and 10-3.
The browser sends a request to log in to the site with the credentials; the credentials are passed to the backend database that verifies them and sends a response to the web server. The web server, based on the response received from the database, either displays a success page or an error page. If the request is successful, the web server also sets a new cookie value and a session ID on the client. The client can then make additional requests to the site to add to his shopping cart or update his profile and checkout.
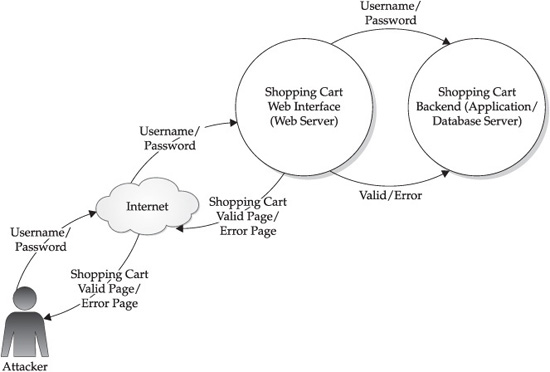
Figure 10-2 Level 0 DFD for our hypothetical shopping cart web application
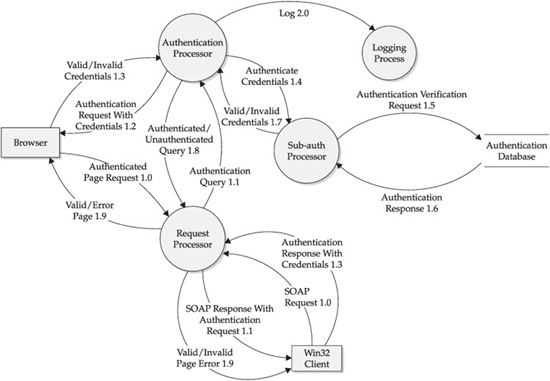
Figure 10-3 Level 1 DFD
Decompose the Application
Now that the application has been broken down into functional components, the next step is to decompose the application further to indicate important security (or trust) boundaries, including user and programmatic interfaces, privilege use, authentication/authorization model, logging capabilities, and so on. Figure 10-4 shows our level 1 DFD with the relevant security boundaries overlaid. All the dashed lines are entry points. The box represents the security/trust boundaries.
Identify and Document Threats
With our visual representation of the application, including security boundaries and entry points, we can now begin to determine any threats to the application. The biggest challenge of threat modeling is being systematic and comprehensive, especially in light of ever-changing technologies and emerging attack methodologies. There are no techniques available that can claim to identify 100 percent of the feasible threats to a complex software product, so you must rely on best practices to achieve as close to 100 percent as possible, and use good judgment to realize when you’ve reached a point of diminishing returns.
The easiest approach is to view the application DFD and create threat trees or threat lists (see “References & Further Reading” for more information on attack/threat trees). Another helpful mechanism is Microsoft’s STRIDE model: attempt to brainstorm Spoofing, Tampering, Repudiation, Information disclosure, Denial of service, and Elevation of privilege threats for each documented asset inventoried previously. If you considered confidentiality, integrity, availability, and audit-logging (CIAA) requirements when documenting your assets, you’re halfway home: you’ll note that STRIDE and CIAA work well together.
Considering any known threats against web applications is also very useful. Internal or external security personnel can assist with bringing this knowledge to the threat modeling process. Additionally, visiting and reviewing security mailing lists like Bugtraq and security web sites like www.owasp.org can also help create a list of threats. Microsoft publishes a “cheat sheet” of common web application security threats and vulnerability categories (see “References & Further Reading” at the end of this chapter for a link). Of course, the book you’re holding is also a decent reference for determining common web security threats.
TIP
Don’t waste time determining if/how these threats are/should be mitigated at this point; that comes later, and you can really derail the process by attempting to tackle mitigation at this point.
Here is a sample threat list for the shopping cart application:
• Authentication
• Brute-force credential guessing.
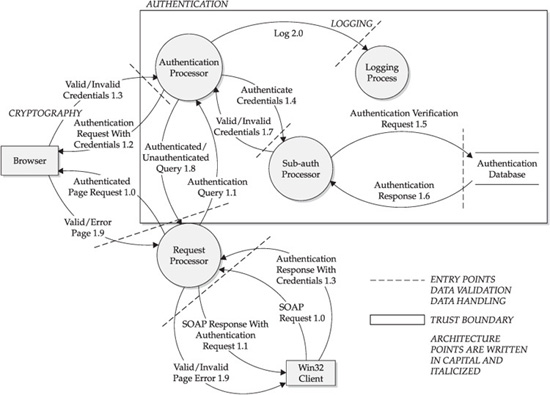
Figure 10-4 Level 1 with trust boundaries and entry points
• Session management
• Session key might be easily guessable.
• Session key doesn’t expire.
• Secure cookie is not implemented.
• Attacker able to view another user’s cart
• Authorization may not be implemented correctly.
• User may not have logged off on a shared PC.
• Improper input validation
• SQL injection to bypass authentication routine.
• Message board allows for cross-site scripting (XSS) attack to steal credentials.
• Error messaging
• Verbose error messages display SQL errors.
• Verbose error messages display invalid message for invalid username and invalid password.
• Verbose error message during authentication enables user enumeration.
• SSL not enforced across the web site
• Allows eavesdropping on sensitive information.
Rank the Threats
Although the security folks in the audience might be salivating at this point, a raw list of threats is often quite unhelpful to software development people who have limited time and budgets to create new (or disable insecure) features on schedule for the next release. Thus, it’s very important to rank, or prioritize, the list of threats at this point by employing a systematic metric, so you can efficiently align limited resources to address the most critical threats.
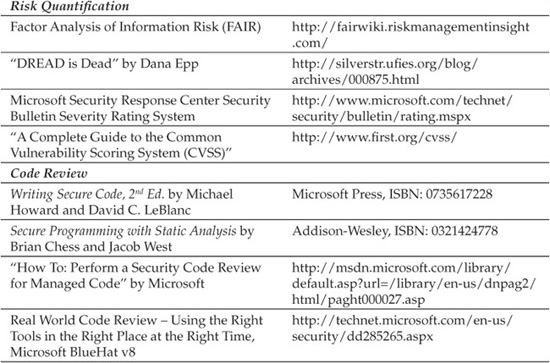
Numerous metric systems are available for ranking security risk. A classic and simple approach to risk quantification is illustrated in the following formula:
Risk = Impact × Probability
This system is really simple to understand and even enables greater collaboration between business and security interests within an organization. For example, the quantification of business Impact could be assigned to the office of the Chief Financial Officer (CFO), and the Probability estimation could be assigned to the Chief Security Officer (CSO), who oversees the Security and Business Continuity Process (BCP) teams.
In this system, Impact is usually expressed in monetary terms, and Probability as a value between 0 and 1. For example, a vulnerability with a $100,000 impact and a 30 percent probability has a Risk ranking of $30,000 ($100,000 × 0.30). Hard-currency estimates like this usually get the attention of management and drive more practicality into risk quantification. The equation can be componentized even further by breaking Impact into (Assets × Threats) and Probability into (Vulnerabilities × Mitigations).
Other popular risk quantification approaches include Factor Analysis of Information Risk (FAIR), which is similar to the above model and one of our recommended approaches to this important task. The Common Vulnerability Scoring System (CVSS) provides an innovative representation of common software vulnerability risks (we really like this componentized approach that inflects a base security risk score with temporal and environmental factors unique to the application). Microsoft’s DREAD system (Damage potential, Reproducibility, Exploitability, Affected users, and Discoverability), as well as the simplified system used by the Microsoft Security Response Center in its security bulletin severity ratings, are two other approaches. Links to more information about all of these systems can be found at the end of this chapter in the “References & Further Reading” section.
We encourage you to tinker with each of these approaches and determine which one is right for you and your organization. Perhaps you may even develop your own, based on concepts garnered from each of these approaches or built from scratch. Risk quantification is highly sensitive to perception, and you are unlikely to ever find a system that results in consensus among even a few people. Just remember the main point: apply whatever system you choose consistently over time so that relative ranking of threats is consistent. This is the goal after all—deciding the priority of which threats will be addressed.
We’ve also found that it’s very helpful to set a threshold risk level, or “bug bar,” above which a given threat must be mitigated. There should be broad agreement on where this threshold lies before the ranking process is complete. A bug bar creates consistency across releases and makes it harder to game the system by simply moving the threshold around (it also tends to smoke out people who deliberately set low scores to come in below the bug bar).
Develop Threat Mitigation Strategies
At this point in the threat modeling process, we have produced a list of threats to our shopping cart application, ranked by perceived risk to the application/business. Now it’s time to develop mitigation strategies for the highest ranking threats (i.e., those that surpass the agreed-upon risk threshold).
TIP
You can create mitigation strategies for all threats if you have time; in fact, mitigations to lower-risk threats could be implemented with very little effort. Use good judgment.
Threat/risk mitigation strategies can be unique to the application, but they tend to fall into common categories. Again, we cite Microsoft’s Web Application Security Framework “cheat sheet” for a useful organization of mitigation strategies into categories that correspond to common attack techniques. Generally, the mitigation is fairly obvious: eliminate (or limit the impact of) the vulnerability exploited by the threat, using common preventive, detective, and reactive security controls (such as authentication, cryptography, and intrusion detection).
TIP
Not every threat has to be mitigated in the next release; some threats are better addressed long-term across iterative releases, as application technology and architectures are updated.
For example, in our hypothetical shopping cart application, the threat of “brute-force credential guessing” against the authentication system could be mitigated by using CAPTCHA technology, whereby after six failed attempts, the user is required to manually input the information displayed in a CAPTCHA image provided in the login interface (see Chapter 4 for more information about CAPTCHA). (Obviously, any tracking of failed attempts should be performed server-side, since client-provided session data can’t be trusted; in this example, it might be more efficient to simply display the CAPTCHA with every authentication challenge.) Another option is to use increasing time delays between failed logon attempts to throttle the rate at which automated attacks can occur; this technique has the added benefit of mitigating load issues on servers being attacked. The use of these two mitigation techniques reflects the importance of evolving the application threat model over time and keeping abreast of new security threats.
Obviously, threat mitigation strategies should not only help your organization mitigate threats, but also prevent inadvertent creation of new threats. A common example of this is setting an account lockout threshold of six attempts, after which the account is disabled. Such a feature might be implemented to mitigate password-guessing threats. However, if attackers can guess or otherwise obtain valid usernames (think of a financial institution where the account numbers might be simply incremental in nature), they might be able to automate a password-guessing attack that could easily create a denial-of-service (DoS) condition for all the users of the application. Such an attack might also overwhelm support staff with phone calls requesting account resets.
Implementing an account timeout, rather than lockout, feature is the better solution. Instead of disabling the account after a threshold number of failed attempts, the account could be disabled temporarily (say, for 30 minutes). Combining this account timeout method with a CAPTCHA challenge would provide even further mitigation. Of course, each of these mechanisms has an impact on usability and should be tested in real-world scenarios so you can more fully understand the trade-offs that such security controls inevitably introduce.
Finally, don’t forget off-the-shelf components when considering threat mitigation. Here is a handful of obvious examples of such threat mitigation technologies available for web applications today:
• Many web and application servers ship with prepackaged generic error message pages that provide little information to attackers.
• Platform extensions like UrlScan and ModSecurity offer HTTP input filtering “firewalls.”
• Development frameworks like ASP.NET and Apache Struts (Java EE) offer built-in authorization and input validation routines.
CODE REVIEW
Code review is another important aspect of full-knowledge analysis and should always be performed on an application’s most critical components. The determination of what qualifies as “critical” is usually driven by the threat modeling exercise: any components with threats that rank above the threshold should probably have their source code reviewed. This, coincidentally, is a great example of how threat modeling drives much of the subsequent security development effort.
This section covers how to identify basic code-level problems that might exist in a web application. It is organized around the key approaches to code review: manual, automated, and binary analysis.
Manual Source Code Review
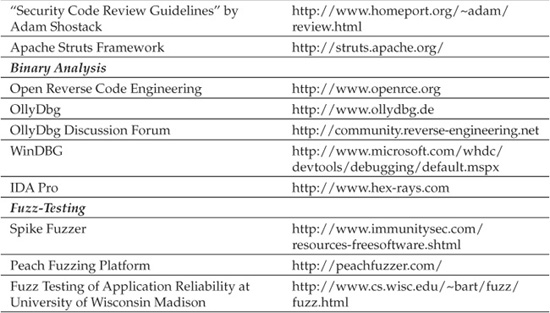
Manual code review (by competent reviewers!) is still considered the gold standard for security. However, line-by-line manual review on the entire code base of a large application is time intensive and requires highly skilled resources to be performed properly. Naturally, this approach costs more than using an automated tool to scan the application. Assuming limited resources, manual code review is best performed on only the most critical components of an application.
TIP
Relying on the development team itself (assuming the team members have been trained) to peer–code review each other’s work before checking in code can serve as a supplementary means of increasing manual code review coverage.
As we noted earlier, “critical” is best defined during the threat modeling process (and should be fairly obvious from the DFDs). Some classic considerations for manual code review include the following:
• Any modules that receive or handle user input directly, especially data sanitization routines and modules that interface with the network or datastores
• Authentication components
• Authorization/session management
• Administration/user management
• Error and exception handling
• Cryptographic components
• Code that runs with excessive privilege/crosses multiple security contexts
• Client-side code that may be subject to debugging or usurpation by rogue software
• Code that has a history of prior vulnerabilities
The process of manual code review has been documented extensively in other resources. Some of our favorites are listed in the “References & Further Reading” section at the end of this chapter. Next, we’ll discuss some examples of common web application security issues that turn up during code review.
Common Security Problems Identified Using Code Review
Numerous security-impacting issues can be identified using code review. In this section, we’ll provide examples of those most relevant to web applications, including:
• Poor input handling
• Poor SQL statement composition
• Storing secrets in code
• Poor authorization/session management
• Leaving test code in a production release
Examples of Poor Input Handling
One of our favorite mantras of secure coding is “All input received should be treated as malicious until otherwise proven innocent.” Within web applications, critical input to consider includes
• All data received from the client
• Data received by SQL statements or stored procedures
• Any data taken from untrusted sources
Failure to implement proper input validation and output encoding routines around this data can result in devastating security holes in an application, as we’ve seen throughout this book. Here are some examples of how to identify these issues at the code level.
In the shopping cart example we provided in our earlier discussion of threat modeling, if the username received from the client is not encoded and is displayed back to the client (which typically is displayed back once a user is logged in), an XSS attack could be performed in the username field. If the username is not encoded and is passed to SQL, SQL injection could result. Because a lot of web data is collected using forms, the first thing to identify in code is the <form> tag within the input pages. Then you can identify how the data is being handled. Here we’ve listed some properties of the HttpRequest ASP.NET object that is populated by the application server so request information can be programmatically accessed by the web application:
• HttpRequest.Cookies
• HttpRequest.Form
• HttpRequest.Params
• HttpRequest.QueryString
More generically, input and output should be sanitized. Sanitization routines should be closely examined during code review, as developers often assume that they are totally immunized from input attacks once they’ve implemented validation of one sort or another. Input validation is actually quite challenging, especially for applications that need to accept a broad range of input. We discussed input validation countermeasures in depth in Chapter 6, but some common examples of what to look for in input validation routines include these:
• The use of “white lists” instead of “black lists” (black lists are more prone to defeat—predicting the entire set of malicious input is practically impossible).
• For applications written in Java, the Java built-in regular expression class (java.util.regex.*) or the Validator plug-in for the Apache Struts Framework is commonly used. Unless your application is already using Struts Framework, we recommend sticking with the java.util.regex class.
• .NET provides a regular expressions class to perform input validation (System.Text.RegularExpressions). The .NET Framework also has Validator controls, which provide functionality equivalent to the Validator plug-in for the Struts Framework. The properties of the control allow you to configure input validation.
The following is an example of checking an e-mail address using the RegularExpressionValidator control from the Validator controls within the ASP.NET Framework:
E-mail: <asp:textbox id = "textbox1" runat="server"/>
<asp:RegularExpressionValidator id = "valRegEx" runat="server"
ControlToValidate = "textbox1"
ValidationExpression = ".*@.*..*"
ErrorMessage = "* Your entry is not a valid e-mail address."
display = "dynamic">*
</asp:RegularExpressionValidator>
Several good examples of input validation problems in code are illustrated in Chapter 6.
Examples of Poor SQL Statement Composition
As you saw in Chapter 7, SQL statements are key to the workings of most web applications. Improperly written dynamic SQL statements can lead to SQL injection attacks against an application. For example, in the select statement shown next, no validation (input or output) is being performed. The attacker can simply inject an ' OR '1'='1 (to make the SQL conditional statement true) into the password field to gain access to the application.
<%
strQuery = "SELECT custid, last, first, mi, addy, city, state, zip
FROM customer
WHERE username = '" & strUser & "' AND password = '" & strPass & "'"
Set rsCust = connCW.Execute(strQuery)
If Not rsCust.BOF And Not rsCust.EOF Then
Do While NOT rsCust.EOF %>
<TR> <TD> <cTypeface:Bold>Cust ID:</B> <% = rsCust("CUSTID") %></TR> </TD>
<TR> <TD> <cTypeface:Bold> First </B><% = rsCust("First") %> <% =
rsCust("MI") %>
<cTypeface:Bold> Last Name</B> <% = rsCust(”Last”) %> </TR></TD>
<% rsCust.MoveNext %>
<% Loop %>
Use of exec() inside stored procedures could also lead to SQL injection attacks, since ' OR '1'='1 can still be used to perform a SQL injection attack against the stored procedure, as shown here:
CREATE PROCEDURE GetInfo (@Username VARCHAR(100))
AS
exec('SELECT custid, last, first, mi, addy, city, state, zip FROM
customer WHERE username = ''' + @Username ''')
GO
SQL injection attacks can be prevented by performing proper input validation and also using Parameterized Queries (ASP.NET) or Prepared Statements (Java) whenever possible.
Examples of Secrets in Code
Web developers often end up storing secrets in their code. You’ll see a particularly grievous example of this in our “Binary Analysis” section later in this chapter, which will illustrate why hard-coding secrets in code is highly discouraged. Secrets should never be stored in code.
If storing secrets is absolutely necessary (such as for nonvolatile credential storage), they should be encrypted. On Windows, the Data Protection API (DPAPI) should be used for encrypting secrets and storing the keys used to encrypt these secrets (see “References & Further Reading” at the end of this chapter for a link). The keystore that comes with the Java Cryptography Extension (JCE) library can be used to store encryption keys in a Java environment.
Examples of Authorization Mistakes in Code
As we saw in Chapter 5, web developers often attempt to implement their own authorization/session management functionality, leading to possible vulnerabilities in application access control.
Here’s an example of what poor session management looks like as seen during a code review. In the following example, userID is an integer and is also used as the session ID. userID is also the primary key in the User table, thus making it relatively easy for the developer to track the user’s state. The session ID is set to be equal to the userID on a successful login.
<!-- The code is run on welcome page to set the session ID = user ID -->
Response.Cookies["sessionID"].Value = userID;
On subsequent pages to maintain state, the session ID is requested from the client and appropriate content is displayed back to the client based on the session ID:
<!-- The following code is run on all pages -->
String userID = (String)Request.Cookies["sessionID"];
In this example, userID is stored in a cookie on the client and is, therefore, exposed to trivial tampering, which can lead to session hijacking.
The obvious countermeasure for custom session management is to use off-the-shelf session management routines. For example, session IDs should be created using the Session Objects provided within popular off-the-shelf development frameworks, such as the JSPSESSIONID or JSESSIONID provided by Java EE, or ASPSESSIONID provided by ASP.NET. Application servers like Tomcat and ASP.NET provide well-vetted session management functionality, including a configurable option in web.xml and web.config to expire the session after a certain period of inactivity. More advanced authorization routines are also provided by many platforms, such as Microsoft’s Authorization Manager (AzMan) or ASP.NET IsInRole offerings that enable role-based access control (RBAC). On Java platforms, many frameworks provide configuration-based RBAC such as Apache Struts.
Poor session management can have even deeper implications for an application at the data layer. Continuing with our previous example, let’s assume the userid from the cookie is passed to a SQL statement that executes a query and returns the data associated with the respective userid. Code for such an arrangement might look something like the following:
String userId = (String)cookieProps.get( "userid" );
sqlBalance = select a.acct_id, balance from acct_history a, users b " +
"where a.user_id = b.user_id and a.user_id = " + userId + " group by
a.acct_id";
This is a fairly classic concatenation of SQL statements that blindly assembles input from the user and executes a query based on it. You should always scrutinize concatenated SQL logic like this very closely.
Obviously, our previous advice about using stored procedures and parameterized queries instead of raw SQL concatenation applies here. However, we also want to emphasize the authorization implications of this example: trivial client-side tampering with the cookie userid value would allow an attacker to gain access to another user’s sensitive information—their account balance in this example. To avoid these sorts of authorization issues, session ID management should be performed by mature application frameworks or application servers, such as Microsoft’s .NET Framework or the Tomcat application server, or implemented by creating temporary tables in memory at the database level. The latter typically doesn’t scale well to large applications, so the former tends to be the most popular.
Access control can also be implemented using various frameworks like Java Authentication and Authorization Service (JAAS) and ASP.NET (see “References & Further Reading”).
Examples of Test Code in a Production Application
One of the oldest code-level security vulnerabilities in web applications is leaving testing or debugging functionality enabled in production deployments. A common example of this is providing debug parameters to view additional information about an application. These parameters are usually sent on the query string or as part of the cookie:
if( "true".equalsIgnoreCase( request.getParameter("debug") ) )
// display the variable
<%= sql %>
The entire SQL statement is displayed on the client if the debug parameter is set to “true”. Another similar example of this problem would be an isAdmin parameter. Setting this value to “true” grants administrator-equivalent access to the application, effectively creating a vertical privilege escalation attack (see Chapter 5).
Obviously, debug/admin mode switches should be removed prior to deploying an application in a production environment.
Automated Source Code Review
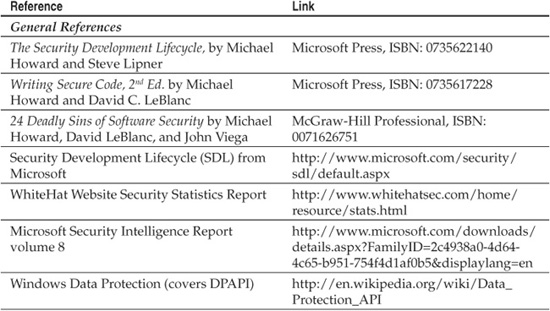
Automated code analysis can be far more efficient than manual analysis, but modern tools are far from comprehensive and never as accurate as human reviewers. Nevertheless, some good tools are available, and every simple input validation issue identified before release is worth its weight in gold versus being found in the wild. Table 10-1 lists some tools for improving code security.
CAUTION
These tools should not be considered a replacement for manual code review and secure programming practices. These tools can also have a high false-positive rate and need a lot of tuning to produce meaningful results.
Binary Analysis
Binary analysis is the art of dissecting binaries at the machine code level, typically without the benefit of access to source code (see “References & Further Reading” at the end of this chapter for more background information). Historically, binary analysis was performed by companies on competing products to understand the design philosophy or internal workings of an application. More recently, binary analysis has become a mainstay of the security assessment industry because of its ability to quickly ferret out the functionality of software viruses, worms, and other malware. This section will describe the role of binary analysis in full-knowledge web application security reviews and then demonstrate the basics of binary analysis as applied to a sample web application binary.


Table 10-1 Tools for Assessing and Improving Code Security
CAUTION
Performing binary analysis on software may violate the terms of an application’s end-user license agreement (EULA), and, in some cases, criminal penalties may result from reverse engineering of code.
The Role of Binary Analysis in Full-knowledge Reviews
Before we demonstrate the basic techniques of binary analysis, it’s important to clarify its role in full-knowledge assessment of web application security.
The primary question is “Assuming I’ve got the source code, why expend the effort to analyze the binaries?” Many security researchers have found that binary analysis strongly complements source code review, primarily because binary analysis examines the application in its native deployment environment, as it is actually executed. This process can reveal many other issues not readily apparent when viewing the source code in isolation. Such issues include modifications to the code incorporated by the compiler, code interactions and variables introduced by the runtime environment, or race conditions that only become apparent during execution.
Most importantly, binary analysis can identify vulnerabilities introduced by third-party libraries—even those for which the user does not have source code. Increasingly, in our consulting work we’ve seen a lot of external code used in developing new software. In many cases, the source code for these components is not available. So, even if you are a member of an internal security audit team, it’s not a safe assumption that you’ll have access to all the source code for your in-house web apps, which makes binary analysis an important part of the auditor’s toolkit.
Finally, it’s important to note the historic importance of compiled code within web applications. As we noted in Chapter 1, the Web grew out of a static document-serving technology, evolving increasingly sophisticated mechanisms for providing dynamic, scalable, high-performance functionality. Microsoft’s Internet Server Application Program Interface (ISAPI) and Apache loadable modules are the latest example of this evolution. They offer programmatic integration with the web server that typically provides much faster application performance than external Common Gateway Interface (CGI) executables. Using ISAPI and Apache loadable modules in high-performance web applications has become commonplace; therefore, we’ll use ISAPI to illustrate binary analysis on a real-world web app in the next section.
An Example of Binary Analysis
We’ll refer to an example ISAPI we created called “secret.dll” throughout the following section (and elsewhere in this chapter). The primary function of the ISAPI is to accept a string from the user and display a “Successful” or “Unsuccessful” page depending on the value input by the user. Secret.dll is available via a typical web interface deployed on a Microsoft IIS web server so it can be accessed via HTTP, as shown in Figure 10-5. Providing the right secret allows access to the “Successful” page; otherwise, the “Unsuccessful” page is displayed. A static secret is stored in the ISAPI DLL so it can be compared to the input provided by the user. The goal of this section is to illustrate how to obtain this secret using binary analysis on a Windows platform. We’ll assume in the following discussion that secret.dll is properly installed and running on a Windows IIS machine and that we have the ability to debug the system.
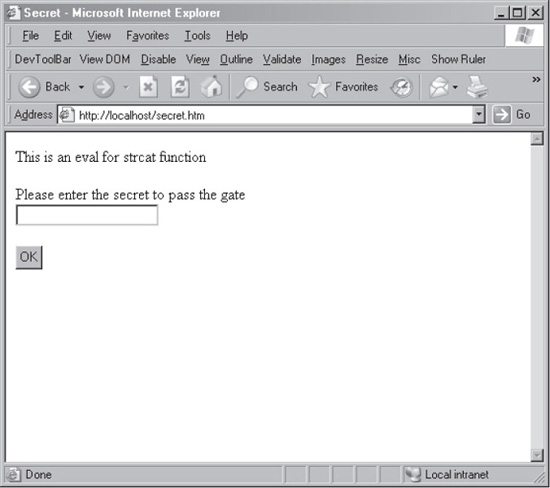
Figure 10-5 The web interface to our sample ISAPI DLL
TIP
Secret.dll is available for download on http://www.webhackingexposed.com if you want to follow along!
Debugging 101
The fist step in binary analysis is to load the target binary into your favorite debugger. In this example, we’ll use OllyDbg, a free Win32 debugger written by Oleh Yuschuk. Along with WinDBG by Microsoft, it is one of the most intuitive free debuggers available at the time of this writing. IDA Pro, a commercial tool from Hex-Rays, is another popular debugging suite.
Figure 10-6 shows the main interface for OllyDbg, including the CPU window, where most debugging work occurs. The CPU window contains five panes: Disassembler, Information, Register, Dump, and Stack. The Disassembler pane displays code of debugged program, the Information pane decodes arguments of the first command

Figure 10-6 OllyDbg
selected in the Disassembler pane, the Register pane interprets the contents of CPU registers for the currently selected thread, the Dump pane displays the contents of memory, and the Stack pane displays the stack of the current thread.
An application can be debugged by opening it directly in OllyDbg (File | Open), or by attaching OllyDbg to the running application process (File | Attach | <Process Exe Name> | Attach). Debugging a live application while it is processing input is the best way to reverse engineer its functionality, so this is the approach we’ll take with secret.dll. Since secret.dll is an ISAPI, it runs inside the IIS web server process. Thus, we will attach the main IIS process (inetinfo) using OllyDbg (File | Attach | inetinfo.exe | Attach).
Once attached, we quickly discover that secret.dll contains a function called IsDebuggerPresent that terminates execution as we try to step through it. This technique is commonly used to discourage debugging, but it’s easily circumvented. The simplest way to do this is to load OllyDbg’s command-line plug-in (ALT-F1) and insert the following command:
set byte ptr ds:[fs:[30]+2]] = 0
This command sets the IsDebuggerPresent API to always return “false”, effectively disguising the presence of the debugger.
Alternatively, we could set a breakpoint on the IsDebuggerPresent function and manually change its value to 0. This method requires more effort, but we’ll describe it here because it illustrates some basic debugging techniques. We’ll first reload secret.dll (using OllyDbg’s CTRL-F2 shortcut key), and once the debugger has paused, we’ll load the command-line plug-in (ALT-F1) and set a breakpoint on the function call IsDebuggerPresent (type bp IsDebuggerPresent), as shown in Figure 10-7.
TIP
Plug-ins should be visible as part of the toolbar; if they are not, then the plug-in path needs to be set. To set the plug-in path, browse to Options | Plugin path and then update the location of the plug-in (typically, the home directory of OllyDbg).
We continue to load the DLL (SHIFT-F9) until we reach the breakpoint at IsDebuggerPresent (highlighted by the top arrow in Figure 10-8). We then execute the next two instructions (SHIFT-F7) and stop at the function indicated by the second
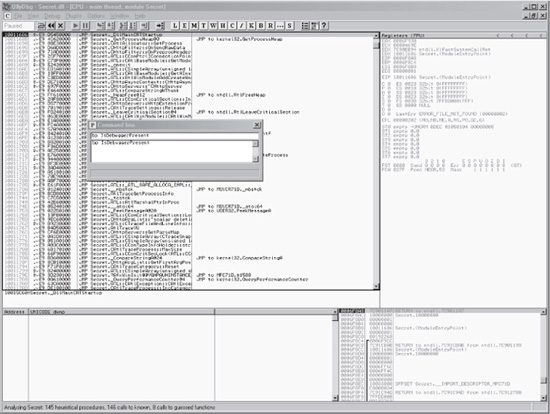
Figure 10-7 Setting a breakpoint on the IsDebuggerPresent function
arrow in Figure 10-8. By right-clicking in the Disassembler pane and selecting Follow from Dump | Memory Address, the location and value of the IsDebuggerPresent function is displayed in the Dump pane. The location is 7FFDA002 and the contents are
01 00 FF FF FF FF 00 00 40 00 A0 1E 19 00
Right-clicking the first value in this string (01) and selecting BinaryFill With 00’s should update the results of the function to 00, as illustrated by the lower two arrows in Figure 10-8.
Now we’ve manually changed the return value of the IsDebuggerPresent API to always be 0. Thus, the DLL can now be loaded without being terminated by the presence of the OllyDbg.
Binary Analysis Techniques
Now, we can start getting to the nuts and bolts of binary analysis. The primary techniques we’ll use include these:
• Enumerate functions. We’ll look for functions commonly associated with security problems, like string manipulation APIs such as strcpy and strcat.
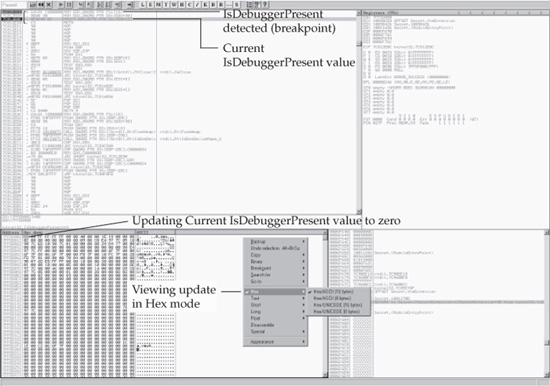
Figure 10-8 Bypassing the IsDebuggerPresent function
• Identify ASCII strings. These may include hidden secret strings or may point out common routines (which can help further analysis by “mapping” the functionality of the binary for us).
• Step-through key functionality. Once we’ve got a basic inventory of functions and strings, we can step through the execution of the binary, set breakpoints on interesting routines, and so on. This will ultimately expose any key security vulnerabilities.
First, we’ll enumerate all the functions that are used by secret.dll. Back in OllyDbg, right-click the secret.dll option from the list of executable modules loaded (View | Executable Modules) and select View Names to display a list of the functions used by secret.dll. This list contains both imported and exported function calls. Some functions that might be of interest include strcpy and strcat (since string manipulation using these older functions is often vulnerable to buffer overflow attacks), as well as memcpy (which suffers from similar issues). Problematic C/C++ functions like these are well-documented; simply searching for “insecure C/C++ functions” on the Internet will turn up several good references.
TIP
Function calls can also be dumped using the command-line dumpbin.exe utility, which is provided with Visual C++ (dumpbin /EXPORTS secret.dll).
We’ll identify ASCII strings inside secret.dll by right-clicking inside the Disassembler pane where secret.dll is loaded and selecting Search For | All Referenced Text Strings.
TIP
The “strings” utility can also be used to extract ASCII strings inside secret.dll.
Finally, we’ll analyze secret.dll’s key functionality by probing some of the more intriguing functions a little more deeply. First, we’ll try right-clicking MSVCR71.strcpy to select references on import. A new pane with a list of references pops up, and we’ll set a breakpoint on the references (OllyDbg’s f2 shortcut key is handy for setting breakpoints). We’ll repeat the task for MSVCR71.strcat and MSVCR71.memcpy.
We’ll also set breakpoints on the ASCII string by right-clicking in the Disassembler window and selecting Search For | All Referenced Text Strings. Immediately, we spy something interesting in the output: “You don’t have a valid key, The key you attempted was”. This is likely the error message that is printed back on invalid string input, potentially pointing the way toward the function that compares the input with the secret string!
TIP
In some applications, developers change the error message into a character array to avoid such attacks, thus making it a little more difficult to find the string.
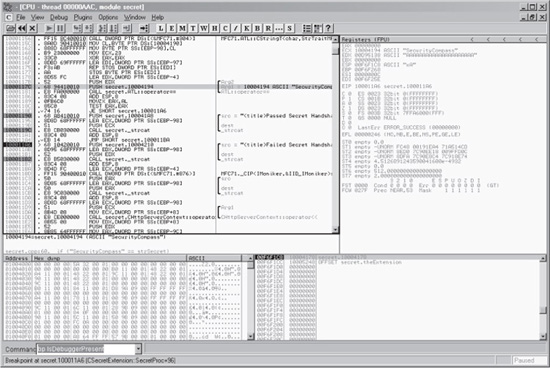
Figure 10-9 Discovering an interesting ASCII string in secet.dll
Let’s actually provide some input to secret.dll at this point and see what it shows us. We’ll browse to the web page shown previously in Figure 10-5 and input the arbitrary string AAAAAAAA. OllyDbg pauses at the “Failed Secret Test” error message. Right-click in the Disassembler pane and select Analysis | Analyze Code. Reviewing the code a few lines above the breakpoint after the analysis has completed, we note another ASCII string, “SecurityCompass”. Our discovery is shown in Figure 10-9.
Examining the code further, we note that the string “SecurityCompass” is being compared with Arg2. Arg2 is assigned the value passed via the Web and pushed onto the stack using the EDX register (Memory location 1000117D). Once both the values are loaded onto the stack, the values are compared (memory location 10001183 CALL secret.10001280) in the function call. The result is the update of the EAX register. The register is set to 1 or 0. If EAX (TEST EAX,EAX) is set to 0, then the compare jumps to the “Fail Message”; otherwise, it jumps to the “Successful Message”. Thus, if the string “SecurityCompass” is provided in the web interface, a “Successful Message” is displayed; otherwise, a “Fail Message” is displayed. Jackpot! We’ve discovered the equivalent of “opensesame” for this web application.
But wait—there’s more! Continuing to execute the next few lines of instructions (using the OllyDbg SHIFT-F9 shortcut key), the execution should pause at the strcat breakpoint. We’ll add additional breakpoints at src and dst, the arguments to strcat. We’ll then go back and provide some arbitrary input to the application again to watch execution in the debugger. The application should now stop at src, which should contain the string “SecurityCompass” that was passed from the interface, and the dst should contain the “Successful Message” string. Thus, strcat is being used to generate the final string that is displayed back to the client.
As we noted earlier, strcat is a C/C++ string manipulation function with well-known security problems. For example, strcat doesn’t take any maximum length value (unlike the safer strncat). Thus, a long enough string might cause improper behavior when passed to the ISAPI. To determine the length that might be problematic in the ISAPI, review the code around the strcat function that would give the max length assigned to the destination value, as shown in Figure 10-10.
The destination is loaded onto the stack using the instruction LEA ECX,DWORD PTR SS:[EBP-98]. Thus, the maximum value that can be stored is 98 in hexadecimal, i.e., 152 bytes in the decimal system (space declared in the program is 140 bytes and the remaining bytes are required for alignment). Providing more than 152 characters of input might cause a buffer overflow in secret.dll. The 152 characters also include the entire page (104 characters) that is displayed back to the client. Therefore, sending a string around 152 characters long would crash the application.
NOTE
More detailed errors may be available if the C++ Error Handler compiler option is disabled.
Another simple attack that comes to mind here is cross-site scripting, since secret.dll doesn’t appear to be performing any input sanitation. We can easily test for this vulnerability by sending the following input to the web input interface:
<script>alert('ISAPI XSS')</script>)
In summary, performing binary analysis not only helps find secrets, but it helps find bugs in applications, too!

Figure 10-10 Tracing the strcat function
SECURITY TESTING OF WEB APP CODE
Wouldn’t it be great if code review was sufficient to catch all security bugs? Unfortunately, this is not the case for a variety of reasons, primarily because no single security assessment mechanism is perfect. Thus, no matter what level of code review is performed on an application, rigorous security testing of the code in a real-world environment always shakes loose more bugs, some of them quite serious. This section will detail some of the key aspects of web application security testing, including
• Fuzz-testing
• Test tools, utilities, and harnesses
• Pen-testing
Fuzzing
Fuzzing is sending arbitrary as well as maliciously structured data to an application in an attempt to make it behave unexpectedly. By analyzing the responses, the assessor can identify potential security vulnerabilities. Numerous articles and books have been published on fuzz-testing, so a lengthy discussion is out of scope, but we’ll briefly discuss off-the-shelf fuzzers as well as home-grown varieties here. For more information on fuzzing, see “References & Further Reading” at the end of this chapter.
Of course, fuzzing is also performed during black-box testing. In this section, we’ll focus on fuzzing in white-box scenarios, i.e., with a debugger hooked up to the target application so that faults can be easily identified and diagnosed.
Off-the-shelf Fuzzers
There are a number of off-the-shelf fuzzers. One of the better ones is Spike, which focuses on C and C++ applications. Spike Proxy applies the same fuzzing approach to web applications. Written in Python, it performs input validation and authorization attacks including SQL injection, form input field overflows, and cross-site scripting.
Spike Proxy is started by running a batch file (runme.bat) and then configuring the browser to use the local Spike Proxy server (localhost on port 8080). Next, you simply connect to the target web application. The Spike Proxy takes over the connection and creates a test console available at http://spike. The console lists possible attack techniques against the application, including “Delve into Dir,” “argscan,” “dirscan,” “overflow,” and “VulnXML Tests.” Select the individual links to perform these attacks against the application. Spike displays the results of the scans in the lower frame of the browser.
Spike Proxy can also be used to find the vulnerability in our secret.dll ISAPI that we created and used earlier for binary analysis. As you saw in that section, having something to “pitch” so the application under analysis can “catch” while being debugged is very useful, as it reveals key aspects of the code while in motion. Fuzzers are great “pitchers.”
For example, to find the vulnerability in the secret.dll ISAPI, load OllyDbg and attach to the web server process as before. Start Spike Proxy and browse to the application, and then browse to the local Spike interface (http://spike). Select Overflow to perform a buffer overflow attack against the ISAPI.
As you saw while using OllyDbg in the “Binary Analysis” section, the string passed from the URL is loaded into EDI. The string is written on the stack, as shown in the Stack pane. The overly long string crashes the ISAPI. The access violation is an indication that the ISAPI has crashed. EAX and ECX registers have been overwritten with the 41414141 (hex representation of AAAA). This is shown in Figure 10-11.
Building Your Own Fuzzer
Any scripting language can be used to build your own fuzzer. Utilities like cURL and netcat can also be wrapped in scripts to simplify the level of effort required to create basic HTTP request-response functionality. Of course, for faster performance, it is always better to write fuzzers in C/C++.
Next is a sample Perl script that makes a POST request to our example secret.dll ISAPI web application. Note that we’ve created a loop routine that iterates through several requests containing a random number (between 1 and 50) of As.
#!/usr/local/bin/perl -w
use HTTP::Request::Common qw(POST GET);
use LWP::UserAgent;
$ua = LWP::UserAgent->new();
$url = "http://127.0.0.1/_vti_script/secret.dll";
//Loop
for ($i=0; $i <= 10; $i++)
{
//Random A's generated
$req = $ua->post( $url, [MfcISAPICommand => SecretProc, Secret => 'A'x
int(rand(50))]);
my $content = $req->content;
print $content;
print "
";
}
This script is a very basic fuzzer.
CAUTION
Fuzzing a live application can cause it to behave unexpectedly and oftentimes create a denial-of-service condition. Be sure you properly plan ahead and obtain permission from all application and server stakeholders before attempting to conduct fuzz-testing.
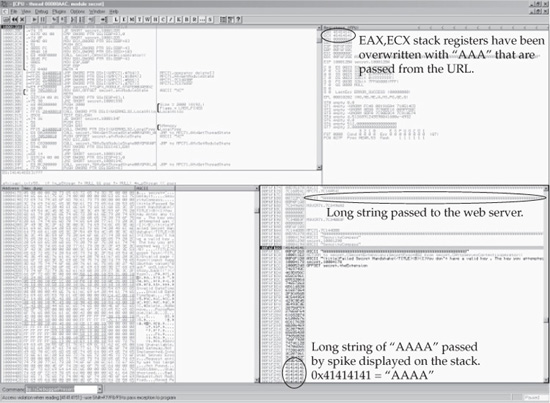
Figure 10-11 OllyDbg displays an access violation in secret.dll while being tested for buffer overflows using Spike Proxy.
Test Tools, Utilities, and Harnesses
Numerous other tools are available for generic web application testing, but at the time of this writing, the market is just starting to evolve quality assurance (QA) testing tools focused on web app security. Hewlett-Packard provides some of the more popular general web application testing tools, such as Quality Center, which include some security testing functionality. One of the few tools specific to web application security is Hewlett-Packard’s QAInspect.
We find that many development shops like to cobble together their own test suites using low-cost (or free) HTTP analysis software. See Chapter 1 for a list of HTTP analysis utilities that can be used to create test harnesses.
Pen-testing
Penetration testing (pen-testing) is most aptly described as “adversarial use by experienced attackers.” Other terms have been used to describe the same concept: tiger team testing, ethical hacking, and so on. The word “experienced” in this definition is critical: we find time and again that the quality of results derived from pen-testing is directly proportional to the skill of the personnel who perform the tests.
We believe pen-testing should be incorporated into the normal development process for every software product, at least at every major release. Since web applications are much more dynamic than traditional software applications (often receiving substantial updates on a weekly basis), we recommend at least an annual or semi-annual pen-test review for high-value web apps.
Pen-testing requires a special type of person, someone who really enjoys circumventing, subverting, and/or usurping technology built by others. At most organizations we’ve worked with, very few individuals are philosophically and practically well-situated to perform such work. It is even more challenging to sustain an internal pen-test team over the long haul, due to this “cognitive dissonance” as well as the perpetual mismatch between the market price for good pen-testing skills and the perceived value by management across successive budget cycles. Thus, we recommend critically evaluating the abilities of internal staff to perform pen-testing and strongly considering an external service provider for such work. A third party gives the added benefit of impartiality, a fact that can be leveraged during external negotiations or marketing campaigns. For example, demonstrating to potential partners that regular third-party pen-testing is conducted can make the difference in competitive outsourcing scenarios.
Given that you elect to hire third-party pen-testers to attack your product, here are some of the key issues to consider when striving for maximum return on investment:
• Schedule Ideally, pen-testing occurs after the availability of beta-quality code but early enough to permit significant changes before ship date should the pen-test team identify serious issues. Yes, this is a fine line to walk.
• Liaison Make sure managers are prepared to commit necessary product team personnel to provide information to pen-testers during testing. This will require a moderate level of engagement with the testers so the testers achieve the necessary expertise in your product to deliver good results.
• Deliverables Too often, pen-testers deliver a documented report at the end of the engagement and are never seen again. This report collects dust on someone’s desk until it unexpectedly shows up on an annual audit months later after much urgency has been lost. We recommend familiarizing the pen-testers with your in-house bug-tracking systems and having them file issues directly with the development team as the work progresses.
Finally, no matter which security testing approach you choose, we strongly recommend that all testing focus on the risks prioritized during threat modeling. This will lend coherence and consistency to your overall testing efforts that will result in regular progress toward reducing serious security vulnerabilities.
SECURITY IN THE WEB DEVELOPMENT PROCESS
We’ve talked about a number of practices that comprise the full-knowledge analysis methodology, including threat modeling, code review, security testing, and web app security technologies to automate processes. Increasingly, savvy organizations are weaving these disparate tools and processes into the application development lifecycle, so that they have simply become an inherent part of the development process itself.
Microsoft has popularized the term Security Development Lifecycle (SDL) to describe its integration of security best practices into the development process (see “References & Further Reading” for links to more information on SDL). We encourage you to read Microsoft’s full description of its implementation of SDL. In the meantime, here are some of our own reflections on important aspects of SDL that we’ve seen in our consulting travels. We’ve organized our thoughts around the industry mantra of “people, process, and technology.”
People
People are the foundation of any semi-automated process like SDL, so make sure to consider the following tips when implementing an SDL process in your organization.
Getting Cultural Buy-In
A lot of security books start out with the recommendation to “get executive buy-in” before embarking on a broad security initiative like SDL. Frankly, executive buy-in is only useful if the developers listen to executives, which isn’t always the case in our consulting experience. At any rate, some level of grass-roots buy-in is always needed, no matter how firmly executive management backs the security team; otherwise SDL just won’t get adopted to the extent required to significantly improve application security. Make sure to evangelize and pilot your SDL implementation well at all levels of the organization to ensure it gets widespread buy-in and is perceived as a reasonable and practical mechanism for improving product quality (and thus the bottom line). Emphasizing this will greatly enhance its potential for becoming part of the culture rather than some bolt-on process that everybody mocks (think TPS reports from the movie Office Space).
Appoint a Security Liaison on the Development Team
The development team needs to understand that they are ultimately accountable for the security of their product, and there is no better way to drive home this accountability than to make it a part of a team member’s job description. Additionally, it is probably unrealistic to expect members of a central enterprise security team to ever acquire the expertise (across releases) of a “local” member of the development team. Especially in large organizations with substantial, distributed software development operations, where multiple projects compete for attention, having an agent “on the ground” can be indispensable. It also creates great efficiencies to channel training and process initiatives through a single point of contact.
CAUTION
Do not make the mistake of holding the security liaison accountable for the security of the application. This must remain the sole accountability of the development team’s leadership and should reside no lower in the organization than the executive most directly responsible for the application.
Training
Most people aren’t able to do the right thing if they’ve never been taught what it is, and for developers (who have trouble even spelling “security” when they’re on a tight ship schedule) this is extremely true. Thus, training is an important part of an SDL. Training has two primary goals:
• Learning the organizational SDL process
• Imparting organizational-specific and general secure-coding best practices
Develop a curriculum, measure attendance and understanding, and, again, hold teams accountable at the executive level.
TIP
Starting a developer security training program from scratch is often difficult, especially given the potential impact on productivity. Consider using the results of a pen-test to drive an initial grass-roots training effort focused on concrete issues identified in business-relevant applications.
Hiring the Right People
Once a web SDL program is defined, fitting people into the program in a manner commensurate with their capabilities is important. Finding a good “fit” requires a delicate balancing of chemistry, skills, and well-designed roles. We can’t help you with the intangibles of chemistry, but here are some pointers to help you get the other stuff right.
Enterprises commonly underestimate the complex analytical requirements of a successful application security automation program and, therefore, frequently have trouble finding the right type of person to fill roles on that team. In our view, individuals with the right “fit” have several important qualities:
• Deep passion about and technical understanding of common software security threats and mitigations, as well as historical trends related to the same.
• Moderately deep understanding of operational security concepts (e.g., TCP/IP security, firewalls, IDS, security patch management, and so on).
• Software development experience (understanding how business requirements, use-case scenarios, functional specifications, and the code itself are developed).
• Strong project management skills, particularly the ability to multitask across several active projects at once.
• Technical knowledge across the whole stack of organizational infrastructure and applications.
• The ability to prioritize and articulate technical risk in business terms, without raising false alarms over the inevitable noise generated by automated application assessment tools.
Obviously, finding this mix of skills is challenging. Don’t expect to hire dozens of people like this overnight—be conservative in your staffing estimates and tying your overall program goals to them.
In our experience, finding this mixture is practically impossible, and most hiring managers will need to make compromises. Our advice is to look for potential hires who have both a software development and a security background, as opposed to a purely operational security background. We’ve found it easier to teach security to experienced software developers than it is to teach software development to operational security professionals. Another easy way to achieve the best of both worlds is to staff separate teams for infrastructure/operational security and another for application security. This structure also provides a viable career ladder, starting with basic trouble-ticket response and leading to more strategic interaction with application development teams.
Organizational Structure and Roles
In our experience, the most effective implementations of an application assessment program integrate tightly into existing development QA and operational support processes. The challenge here is aligning the goals of diverse teams that potentially report through different arms of the organization: IT operations, security/risk management, internal audit, and software development (which may itself be spread through various business units).
Our experience has taught us that the greater the organizational independence you can create between the fox and the chickens (metaphorically speaking), the better. Practically, this means separating security assessment from application development and operational support.
Alternatively, we’ve seen organizational structures where security accountability lives within the software QA organization, or within IT operations. We don’t recommend this in most instances because of the potential conflict of interest between delivering applications and delivering secure applications (akin to the fox guarding the chicken coop). Time and again, we’ve seen the importance of providing external checks and balances to the software development/support process (which typically operates under unrealistic deadlines that were set well before security entered the picture).
To avoid alienating the software development group by setting up an external dependency for their success, we again strongly recommend providing security subject-matter experts with software development backgrounds. This type of staffing goes a long way toward avoiding a culture of “security avoidance” in the development process.
Process
To lend coherence to the concept of SDL, you might think of each of the major sections of this chapter as a milestone in the software development process. For example, threat modeling occurs at design time, code review follows implementation, and security testing occurs during alpha and beta up through final release. Additional milestones, including developer training, or a prerelease security audit/review, may also be used where appropriate. Figure 10-12 illustrates a hypothetical software development lifecycle with SDL milestones (such as training and threat modeling) overlaid.
Beyond thinking about security as an overlay to existing development processes, more holistic process design is critical to long-term success. Next we’ll catalog some of the critical steps in designing a sound “security workflow.”
One of the first things we’ve learned to avoid in our many travels in the IT industry is the “build from scratch” syndrome. In any competent mid- to large-sized enterprise IT shop, some support infrastructure almost surely already exists. Our primary advice to those wishing to build a strong web security program is: leverage what’s already there!
This involves careful research up front. Learn about how your current organizational application-development quality assurance (QA) process works and where the most efficient integration points lie. Equally important for automated tools that will be integrated into the live production application support process, you’ll need to understand how the current operation’s support infrastructure works, from the “smart hands” contractors in the datacenter who physically touch the servers, to the Tier 1 support
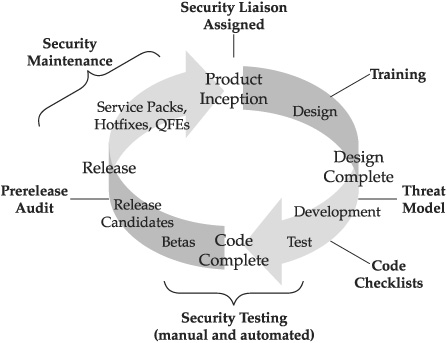
Figure 10-12 A sample SDL implementation
contractors working at a phone bank in India, through the on-staff Tier 2 and 3 system engineers, all the way to the “Tier 4” development team members (and their management!) who will ultimately receive escalations when necessary. Think hard about how your assessment methodology and toolset will integrate into this existing hierarchy, and where you might need to make some serious adjustments to the existing process.
In our experience, the important issues to consider include:
• Management awareness and support Executives should understand the relationship of the assessment process to the overall business risk management program, and be supportive of the overall direction (not necessarily intimately aware of the implementation details, however).
• Roles and accountability Management should also clearly understand organizational accountability for issues uncovered by the assessment program. It’s probably wisest to follow the accountability model just outlined, from Tier X operational staff all the way up to the senior-most executive “owner” of a given application.
• Security policy It should be simple, widely understood within the organization, and practically enforceable. At a minimum, it should describe computing standards, criticality criteria for identified policy violations, and an expected remediation process. It should also consider relevant regulatory standards like the Payment Card Industry Data Security Standard (PCI-DSS). If a good policy doesn’t exist, you’ll need to write it!
• Integration with existing SDL There should be a well-documented path from web security findings to the developer’s desktop for bugs of appropriate type and severity. You should also consider the applicability of assessments at different points in the SDL (e.g., preproduction versus production).
• The IT trouble-ticketing system If your choice of automation tool doesn’t integrate well here, your project is dead before it even starts. DO NOT plan on implementing your own “security” ticketing system—you will regret this when you discover that you’ll have to hire the equivalent of a duplicate Tier 1 support desk to handle the volume of alerts. Test and tune thoroughly before deploying to production.
• Incident response process If there isn’t a disciplined organizational incident escalation process already in existence, you’ll need to engage executive management pronto. Otherwise, the security team will look foolish when alerts overwhelm the existing process (or lack thereof).
• Postmortem analysis We’ve seen too many organizations fail to learn from incidents or process failures; make sure you include a robust postmortem process in your overall program.
• Process documentation In our experience, the most common external audit finding is lack of process documentation (and we’ve got the scars to prove it!). Don’t make it this easy for the bean-counters—allocate appropriate resources to create a living repository of standard operating manuals for the organization, if one does not already exist.
• Education Just as placing a “secure coding” book on a software developer’s bookshelf does not constitute a security SDL, installing the latest application security scanner on one system engineer’s desktop is also highly ineffective. Provide ongoing training on how to use the system for all levels of users, and document attendance, test understanding, and hold managers accountable.
• Meaningful metrics All of the above advice is wonderful, but assuming you implement all or some portion of it, how will you know any of it is working? Security metrics may cause eyes to glaze over, and implementing meaningful performance management in any discipline is tough (let alone software development), but there really is no other way to ensure ROI for the substantial investment demanded by effective software assurance. Don’t flinch, engage key stakeholders, be humble, practical, and make it work.
Obviously, these are really brief overviews of potentially quite complex topics. We hope this gives you a start toward further research into these areas.
Technology
Of course, technology is a key ingredient in any SDL implementation. It can bring efficiency to the SDL process itself by automating some of the more tedious components (such as source code review). SDL should also specify consistent technology standards throughout the development process, such as compile-time parameters (for example, Microsoft’s /GS flag), incorporation of standard input validation routines, and the prohibition of insecure or troublesome functions. Here are some key considerations related to these themes.
Automated Code Review Technologies
As security continues to gain prominence in business, the market will continue to evolve better security code review and testing technologies. We’ve already seen some examples in Table 10-1 earlier in this chapter. Make sure to keep your SDL toolset state-of-the-art so your applications face less risk from cutting-edge zero-day attacks.
Managed Execution Environments
We strongly recommend migrating your web applications to managed development platforms like Sun’s Java (http://www.oracle.com/technetwork/java/index.html) or Microsoft’s .NET Framework (http://www.microsoft.com/net/) if you have not already. Code developed using these environments leverages strong memory management technologies and executes within a protected security sandbox that greatly reduces the possibility of security vulnerabilities.
Input Validation/Output Encoding Libraries
Almost all software hacking rests on the assumption that input will be processed in an unexpected manner. Thus, the holy grail of software security is airtight input validation (and also output encoding). Most software development shops cobble their own input validation routines, using regular expression matching (try http://www.regexlib.com/ for great tips). For output encoding, Microsoft also publishes an Anti-XSS library that can be integrated into .NET applications. If at all possible, we recommend using such input validation libraries to deflect as much noxious input as possible from your applications.
If you choose to implement your own input validation routines, remember these cardinal rules of input validation:
• Limit the amount of expected user input to the bare minimum, especially freeform input.
• Assume all input is malicious and treat it as such, throughout the application.
• Never—ever—automatically trust client input.
• Canonicalize all input before you perform any type of checking or validation.
• Constrain the possible inputs your application will accept (for example, a ZIP code field might only accept five-digit numerals).
• Reject all input that does not meet these constraints.
• Sanitize any remaining input (for example, remove metacharacters like & ’ > < and so on, that might be interpreted as executable content).
• Encode output so even if something sneaks through, it’ll be rendered harmless to users.
TIP
See Chapter 6 for more input validation attacks and countermeasures.
Platform Improvements
Keep your eye on new technology developments like Microsoft’s Data Execution Prevention (DEP) feature. Microsoft has implemented DEP to provide broad protection against memory corruption attacks like buffer overflows (see http://support.microsoft.com/kb/875352/ for full details). DEP has both a hardware and software component. When run on compatible hardware, DEP kicks in automatically and marks certain portions of memory as nonexecutable unless it explicitly contains executable code. Ostensibly, this would prevent most stack-based buffer overflow attacks. In addition to hardware-enforced DEP, Windows XP SP2 and later also implement software-enforced DEP that attempts to block exploitation of exception-handling mechanisms in Windows.
Additional defensive mechanisms such as Address Space Layout Randomization (ASLR) and Structured Exception Handling Overwrite Protection (SEHOP) can be effective defenses against certain types of attack. For more information about these defenses and to determine whether they make sense in your application, please see “References & Further Reading” at the end of this chapter. Web application developers should be aware of these improvements coming down the pike in 64-bit platforms and start planning to migrate as soon as possible.
Automated Web Application Security Scanners
If you’re an IT admin tasked with managing security for a medium-to-large enterprise full of web apps, we don’t have to sell you on the tremendous benefits of automation. Over the years, we’ve evaluated dozens of web application security scanning tools and are frequently asked “Which one is the best?” As tempting as it is to hold a bake-off and pick our own favorites (which we did in the 2nd edition of Hacking Exposed Web Applications), we’ve come to realize that the market for such technologies evolves faster than our publishing cycle, inevitably rendering our picks somewhat obsolete by the time readers see them. Plus, the unique requirements that typical enterprise organizations bring to such comparisons are difficult to capture consistently in generic bake-offs. Finally, generic bake-offs are published regularly on the Internet, providing more up-to-date information for readers (we’ve referenced some good recent studies in “References & Further Reading” at the end of this chapter). Based on these factors and on our ongoing experiences, this chapter will provide our brief perspectives on the leading contenders in the web application scanning field, with the intent of starting readers on a path to evaluating several of these tools and picking the one that best suits their individual requirements.
NOTE
See Chapter 1 and Appendix B for noncommercial web assessment tools not covered here.
The web application security scanners we encounter most frequently (whether used by outside consultants or internal corporate security departments), in the order of most often encountered to least, include HP WebInspect, IBM AppScan, Cenzic Hailstorm, and NTObjectives NTOSpider. More recently, managed services have been appearing that perform web application security scanning and provide you with the results. Examples of such organizations include WhiteHat Security and HP SaaS Application Security Center. This would be the short list upon which we’d base an evaluation of such technologies for a large enterprise.
Some of the big players in the infrastructure security scanning market are beginning to focus on web applications. The main providers here include Qualys’ Web Module, nCircle’s WebApp360, McAfee’s Vulnerability Manager, and Tenable’s Nessus web server plug-ins. Although these tools are improving, the current state of web functionality offered by these products falls far short of the dedicated web application scanning tools mentioned previously. Nevertheless, it would be wise to consider them ongoing as the companies behind them are resourceful and clearly interested in improving capabilities at the web app layer.
Technology Evaluation and Procurement
One of the ongoing questions facing an incipient application security program is “To build or to buy?” Overall, our advice is “buy,” based on our general experience that the blood and treasure spilled in the name of developing in-house security apps isn’t worth it in the long run (we’ve even worked at some large, sophisticated software development firms where this still held true). This means you’ll have to devise a process for evaluating new technology on an ongoing basis to ensure your web app security program remains up-to-snuff.
TIP
Appendix B lists several off-the-shelf sample web applications that can be used to test security technologies.
We recommend you explicitly staff this effort, define crisp goals so it doesn’t get too “blue sky” or turn into a wonky “skunk works” project, and ensure you have allocated an appropriate budget to execute any technology selections made by the team.
SUMMARY
This chapter covered full-knowledge, or “white-box,” analysis of web application security. We described the key components of full-knowledge analysis, including threat modeling, code review, and security testing. We highlighted the importance of threat modeling and how it influences subsequent security activities like code review and security testing. Finally, we illustrated how savvy organizations are weaving the components of full-knowledge analysis into a comprehensive approach to web application security development called the Security Development Lifecycle, or SDL.
REFERENCES & FURTHER READING