CHAPTER 5
ATTACKING WEB AUTHORIZATION
We just saw in Chapter 4 how authentication determines if users can log into a web application. Authorization determines what parts of the application authenticated users can access, as well as what actions they can take within the application. Since the stateless HTTP protocol lacks even the most basic concept of discrete sessions for each authenticated user, web authorization is challenging to implement and consequently profitable to attack.
NOTE
We will sometimes abbreviate authentication as “authn,” and authorization as “authz.”
Authorization is classically implemented by providing the authenticated user’s session with an access token that uniquely identifies him or her to the application. The application then makes decisions about whether to grant or deny access to an internal object based on a comparison of identifiers within the token and access control list (ACL) on the object. If the provided identifiers match the configured permission on the object, access is granted; if there is no match, access is denied. The token, effectively acting as a persistent re-authentication mechanism, is provided with each request and obviates the need for a user to continually and manually re-authenticate. Upon logout or session timeout, the token is typically deleted, expired, or otherwise invalidated.
NOTE
Often the identifier used to distinguish unique sessions, commonly called a session ID, is the same thing as the access token. It is usually stored within a cookie.
NOTE
HTTP Basic authn takes the old-fashioned approach—it submits the Base64-encoded username:password in the HTTP Authorize header for every request in the same realm.
Clearly, access tokens provide great convenience for the user, but as always, convenience comes at a price. By guessing, stealing, or otherwise replaying someone else’s token, a malicious hacker might be able to impersonate another user by viewing data or executing transactions on behalf of the targeted user (horizontal privilege escalation), or even targeted administrators (vertical privilege escalation). When server-side authorization vulnerabilities do occur, they are often the result of improperly defined ACLs or software bugs in the business logic and authorization checks that determine access to application resources and functionality.
Attackers targeting application authorization functionality will concentrate their efforts on one of two goals: hijacking valid authorization/session tokens used by the application and/or bypassing server-side ACLs. This chapter is organized primarily around these two aspects of authz and is divided into the following major sections:
• Fingerprinting authz
• Attacking ACLs
• Attacking tokens
• Authz attack case studies
• Authz best practices
In many ways, authorization is the heart and soul of any system of security controls, and as you may agree by the end of this chapter, no web application can survive having it excised by a skillful adversary.
FINGERPRINTING AUTHZ
Web application authorization can be complex and highly customized. Methodical attackers will thus seek to “fingerprint” the authz implementation first in order to get the lay of the land before launching overt attacks.
Crawling ACLs
The easiest way to check the ACLs across a site is to simply crawl it. We discussed web crawling techniques in Chapter 2, including several tools that automate the process (these are sometimes called offline browsers since they retrieve files locally for later analysis). We’ll introduce an additional web crawler here called Offline Explorer Pro (from MetaProducts Software Corp.) because it provides better visibility into web ACLs than the ones discussed in Chapter 2.
Like most web crawlers, the operation of Offline Explorer Pro (OEP) is straightforward—simply point it at a URL and it grabs all linked resources within a specified depth from the provided URL. The interesting thing about OEP is that it displays the HTTP status code that it receives in response to each request, permitting easy visibility into ACLs on files and folders. For example, in Figure 5-1, OEP’s Download Progress pane shows an Error: 401 Unauthorized response, indicating that this resource is protected by an ACL and requires authentication.
OEP also natively supports most popular web authn protocols (including Windows NTLM and HTML forms), which makes performing differential analysis on the site easy. Differential analysis involves crawling the site using unauthenticated and authenticated sessions, or sessions authenticated as different users, in order to reveal which portions are protected and from which users. The authentication configuration option in OEP may be a bit hard to find—it’s located on the Project Properties page for a given project (File | Properties), under the Advanced category, labeled “Passwords.” This is shown in Figure 5-2.
TIP
For command-line junkies, OE.exe can take parameters via the command line.
The only real drawback to web crawling is that this approach only “sees” portions of the web site that are linked from other pages. Thus, you may not get a complete picture (for example, the hidden “admin” page may not be linked from any of the site’s main pages and thus be invisible to the crawler). Of course, as we noted in Chapter 2, automated crawling provides a great head start on more rigorous manual analysis, which has a better chance of turning up such hidden content.
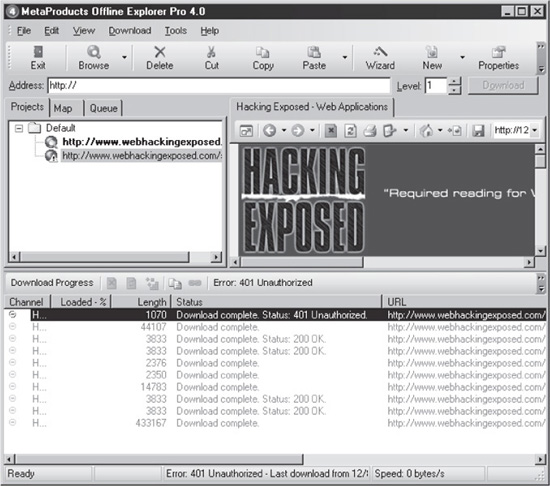
Figure 5-1 Offline Explorer Pro lists HTTP status codes in the Download Progress pane, indicating resources that might be protected by ACLs.
Identifying Access Tokens
Access tokens (or session IDs) are often easy to see within web application flows; sometimes they are not, however. Table 5-1 lists information commonly found access tokens, along with common abbreviations, to give the reader an idea of what we’ll be looking for in later sections.
COTS Session IDs
Many common off-the-shelf (COTS) web servers have the capability to generate their own pseudorandom session IDs. Table 5-2 lists some common servers and their corresponding session-tracking variables. The IDs generated by more modern servers are generally
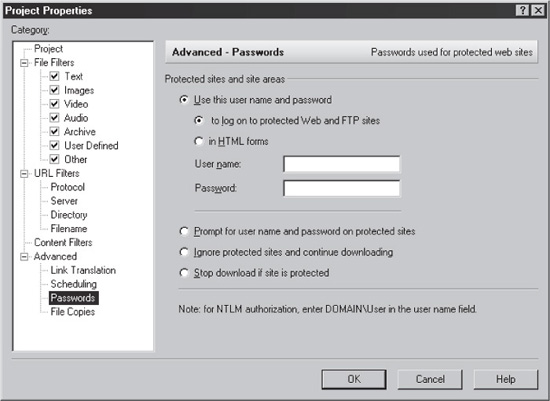
Figure 5-2 Offline Explorer Pro’s authentication configuration screen
random enough to preclude guessing attacks, although they are all vulnerable to replay (we’ll discuss each of these in the upcoming section on attacking tokens).

Table 5-1 Information Commonly Stored in a Web Application Access/Session Token

Table 5-2 Some Common Off-the-Shelf Session IDs
Analyzing Session Tokens
OK, you’re fingerprinting a web application’s authorization/session management functionality, and you’ve identified a value that is probably the session token, but it’s a visually indecipherable blob of ASCII characters or a jumbled numeric value that offers no immediate visual cues as to how it’s being used. Surrender and move on? Of course not! This section discusses some approaches to determining what you’re up against.
Even though the session data may not immediately appear to be comprehensible, a little extra analysis (backed by lots of experience!) can reveal subtle clues that, in fact, enable calculated guessing. For example, some session components tend to be quite predictable because they have a standard format or they behave in a predictable fashion. A datestamp, for example, could be identified by values in the token that continuously increment. We list several common attacks against such deterministic items in Table 5-3.
TIP
Use the GNU date +%s command to view the current epoch time. To convert back to a human-readable format, try the Perl command:
perl -e 'use Time::localtime; print ctime(<epoch number>)'
Analyzing Encoding and Encryption
Visually indecipherable blobs of ASCII characters usually mean one of two things: encoding or cryptography is at work. If the former, there is a ray of sunlight. If the latter, your best effort may only allow minimal additional insight into the function of the application.

Table 5-3 Common Session Token Contents
Defeating Encoding
Base64 is the most popular encoding algorithm used within web applications. If you run into encoding schemes that use upper- and lowercase Roman alphabet characters (A-Z, a-z), the numerals (0-9), the + and / symbols, and that end with the = symbol, then the scheme is most likely Base64.
Numerous encoder/decoder tools exist. For example, the Fiddler HTTP analysis tool discussed in Chapter 1 comes with a utility that will encode/decode Base64, URL, and hexadecimal formats. Burp and the other popular HTTP proxy applications also support encoding and decoding of data in various formats.
If you want to write your own Base64 handler, such as for automated session analysis, Perl makes it simple to encode and decode data in Base64. Here are two Perl scripts (actually, two effective lines of Perl) that encode and decode Base64:
#!/usr/bin/perl
# be64.pl
# encode to base 64
use MIME:: Base64;
print encode_base64($ARGV[0]);
Here’s the decoder:
#!/usr/bin/perl
# bd64.pl
# decode from base 64
use MIME:: Base64;
print decode_base64($ARGV[0]);
Analyzing Crypto
Web applications may employ encryption and/or hashing to protect authorization data. The most commonly used algorithms are not trivially decoded, as with Base64. However, they are still subject to replay and fixation attacks, so the attacker may find it helpful to identify hashed or encrypted values within a token.
For example, the popular hashing algorithm, MD5, is commonly used within web applications. The output of the MD5 algorithm is always 128 bits. Consequently, MD5 hashes can be represented in three different ways:
• 16-byte binary digest Each byte is a value from 0 to 255 (16 × 8 = 128).
• 32-character hexadecimal digest The 32-character string represents a 128-bit number in hexadecimal notation. Each hexadecimal character represents 4 bits in the 128-bit MD5 hash.
• 22-byte Base64 digest The Base64 representation of the 128 bits.
An encrypted session token is hard to identify. For example, data encrypted by the Data Encryption Algorithm (DES) or Triple-DES usually appear random. There’s no hard-and-fast rule for identifying the algorithm used to encrypt a string, And there are no length limitations to the encryption, although multiples of eight bytes tend to be used.
We’ll talk more about attacking crypto later in this chapter.
Analyzing Numeric Boundaries
When you identify numeric values within session IDs, identifying the range in which those numbers are valid can be beneficial. For example, if the application gives you a session ID number of 1234567, what can you determine about the pool of numbers that make a valid session ID? Table 5-4 lists several tests and what they can imply about the application.
The benefit of testing for a boundary is that you can determine how difficult it would be to launch a brute-force attack against that particular token. From an input validation or SQL injection point of view, it provides an extra bit of information about the application’s underlying structure.
Differential Analysis
When it is not clear what values are important for determining authz decisions, an approach known as differential analysis can often be of use. The technique is very simple:

Table 5-4 Numeric Boundaries
you essentially crawl the web site with two different accounts and note the differences, such as where the cookies and/or other authorization and state-tracking data differ. For example, some cookie values may reflect differences in profiles or customized settings. Other values, ID numbers for one, might be close together. Still other values might differ based on the permissions for each user.
NOTE
We provide a real-world example of differential analysis in the “Authorization Attack Case Studies” section later in this chapter.
Role Matrix
A useful tool to aid the authorization audit process is a role matrix. A role matrix contains a list of all users (or user types) in an application and corresponding access privileges. The role matrix can help graphically illustrate the relationship between access tokens and ACLs within the application. The idea of the matrix is not necessarily to exhaustively catalog each permitted action, but rather to record notes about how the action is executed and what session tokens or other parameters the action requires. Table 5-5 has an example matrix.

Table 5-5 An Example Role Matrix
The role matrix is similar to a functionality map. When we include the URIs that each user accesses for a particular function, patterns might appear. Notice how the example in Table 5-5 shows that an administrator views another user’s profile by adding the EUID parameter. The matrix also helps identify where session information, and consequently authorization methods, are being handled. For the most part, web applications seem to handle session state in a consistent manner throughout the site. For example, an application might rely solely on cookie values, in which case the matrix might be populated with cookie names and values such as AppRole=manager, UID=12345, or IsAdmin=false. Other applications may place this information in the URL, in which case the same value shows up as parameters. Of course, these are examples of how insecure applications might make authz decisions based on user-supplied data. After all, when an application expects the user to tell it important authz-related information, such as whether he or she is an administrative user or not, then something is quite seriously wrong with the implementation of the authz component. Boolean flags such as IsAdmin, role name parameters like AppRole, and sequential user ID values should always be treated as highly suspect. Secure applications will typically encrypt this information in an authz cookie to prevent tampering, or not store the role-related data on the client at all. In fact, not storing the role-related data on client machines is often the safest approach as it both prevents tampering and replay attacks.
The role matrix helps even more when the application does not use straightforward variable names. For example, the application could simply assign each parameter a single letter, but that doesn’t preclude you from modifying the parameter’s value in order to bypass authorization. Eventually, you will be able to put together various attack scenarios—especially useful when the application contains many tiers of user types.
Next, we’ll move on to illustrate some example attacks against web application authorization mechanisms.
ATTACKING ACLS
Now that we know what the authorization data is and where it sits, we can ask, “How is it commonly attacked?”
We discuss ACL attacks first because they are the “lowest common denominator” of web application authz: all web applications to some degree rely on resource ACLs for protection, whereas not all web apps implement access/session tokens (many apps achieve essentially the same effect via local account impersonation). Put another way, ACL attacks are the most straightforward to attack, while successfully compromising authz and session tokens often involves more work and good fortune. Generally speaking, the easiest authz vulnerabilities to identify are those related to weak ACLs.
As noted in Chapter 1, the relatively straightforward syntax of the URI makes crafting arbitrary resource requests, some of which may illuminate hidden authorization boundaries or bypass them altogether, really easy. We’ll discuss some of the most commonly used URI manipulation techniques for achieving this next.
 Directory Traversal
Directory Traversal
Directory traversal attacks are one common method by which application ACLs can be bypassed to obtain unauthorized access to restricted directories. Directory traversal attacks are characterized by the use of the characters “../” (dot-dot-slash) used in filesystem navigation operations to traverse “up” from a subdirectory and back into the parent directory. One infamous example of this vulnerability in the real world was the well-publicized Unicode and Double Decode attack in 2001 that took advantage of a weakness in the IIS web application server’s parsing and authorization engine. The Unicode variant of this vulnerability was exploited as follows: Normally, IIS blocks attempts to escape the web document root with dot-dot-slash URLs such as “/scripts/../../../../winnt”. However, it was discovered that this authz check could be bypassed due to a canonicalization bug that failed to properly handle Unicode representations of the slash character “/” such as “%c0%af” (URL-encoded). This resulted in malicious users being able to access objects outside the document root with specially constructed URLs such as “/scripts/..%c0%af..%c0%af..%c0%afwinnt”.
“Hidden” Resources
Careful profiling of the application (see Chapter 2) can also reveal patterns in how application folders and files are named. For example, if a /user/menu directory exists, then one could posit that an /admin/menu might exist as well. Oftentimes, developers will rely on obfuscation and “hidden” resource locations rather than properly defined and enforced ACLs to protect access to sensitive resources. This makes directory and file name-guessing a profitable way to dig up “hidden” portions of a site, which can be used to seed further ACL footprinting, as we mentioned earlier.
Such “security through obscurity” usually yields to even the most trivial tampering. For example, by simply modifying the object name in the URL, a hacker can sometimes retrieve files that he would not normally be able to access. One real-world example of such a flaw occurred in March 2010 against an iPhone photo-sharing application known as Quip. Using Quip, users were able to send messages containing media, primarily photographs, to other iPhone users. Pictures and media sent with the service were assigned a randomly generated filename composed of five lowercase letters and digits (e.g., http://pic.quiptxt.com/fapy6). Due to insecure authorization controls on the media servers, it was found that anyone could directly access the uploaded media content by accessing the corresponding URL in any web browser. Furthermore, because filenames were generated using only a small handful of random characters and digits (this naming scheme only allows for 36 × 36 × 36 × 36 × 36 = 60,466,176 possibilities), attackers were able to brute-force the names of other legitimate media files by sending thousands upon thousands of requests. Several scripts to automate this attack were created, and thousands of private pictures and messages were compromised. Repositories of the compromised media are still hosted online today.
Another real-world example of bypassing authorization via URL tampering is the Cisco IOS HTTP Authorization vulnerability. The URL of the web-based administration interface contains a two-digit number between 16 and 99:
http://www.victim.com/level/NN/exec/...
By guessing the value of NN (the two-digit number), it was possible to bypass authorization and access the device administration interface at the highest privilege level.
Custom application parameter-naming conventions can also give hints about hidden directory names. For example, maybe the application profile (see Chapter 2) did not reveal any “secret” or administration directories—but you noticed that the application frequently appends “sec” to variable names (secPass) and some pages (secMenu.html). In such an application, looking for hidden folders and files that follow the same convention (i.e., “/secadmin” instead of “admin”) might be worthwhile.
TIP
Common “hidden” web application resources frequently targeted by path-guessing attacks are listed in Chapter 8.
ATTACKING TOKENS
This section describes common attacks against web application access/session tokens. There are three basic classes of access/session token attacks:
• Prediction (manual and automated)
• Capture/replay
• Fixation
Let’s discuss each one in that order.
Manual Prediction
Access/session token prediction is one of the most straightforward attacks against web application authorization. It essentially involves manipulating the token in targeted ways in order to bypass access control. First, we’ll discuss manual prediction; in the next section, we’ll describe automated analysis techniques that can accelerate prediction of seemingly indecipherable tokens.
Manual guessing is often effective in predicting the access token and session ID values when those values are constructed with a human-readable syntax or format. For example, in Chapter 1, you saw how simply changing the “account_type” value in Foundstone’s sample Hacme Bank web application from “Silver” to “Platinum” resulted in a privilege escalation attack. This section will describe manual tampering attacks against the following common mechanisms for tracking session state:
• Query string
• POST data
• HTTP headers
• Cookies
Query String Manual Prediction
As discussed in Chapter 1, the client-supplied HTTP query string may contain multiple ampersand-delimited attribute-value pairs in the URI after the question mark (?) that are passed to and processed by the application server. Access tokens and session IDs frequently appear in the query string. For example:
http://www.mail.com/mail.aspx?mailbox=joe&company=acme
The query string portion of this URI containing the user-supplied parameters to be passed to mail.aspx is mailbox=joe&company=acme. In this scenario, one obvious attack would be to change the query mailbox parameter value to that of another username (i.e., /mail.aspx?mailbox=j ane&company=acme), in an attempt to view Jane’s mailbox despite being authenticated as Joe. The query string is visible in the location bar on the browser and is easily changed without any special web tools. Keep in mind that certain characters with special meaning in the URI, such as =, &, #, etc., will require URL encoding before they can be properly passed to the remote server.
 Use POST for Sensitive Data!
Use POST for Sensitive Data!
Relaying the session ID in the query string is generally discouraged because it’s trivially alterable by anyone who pays attention to the address bar in his or her browser. Furthermore, unlike POST data, the URI and query string are often recorded in the client browser history, by intermediate devices processing the request such as proxies, and on remote web and application servers. This logging presents more opportunities for exposure to attackers. Unsophisticated users who are unaware of the sensitive nature of the data stored in the query string may also unknowingly expose their account to attack by sharing URIs through e-mail and public forums. Finally, it’s interesting to note that the query string is exposed in all of these scenarios even if SSL is used.
Because of these issues, many web application programmers prefer to use the POST method to relay sensitive session- and authorization-related data (which carries parameter values in the body of the HTTP request where it is obscured from trivial tampering), as opposed to the GET method (which carries the data in the query string, more open to attack in the browser cache, logs, etc.).
CAUTION
Don’t be fooled into thinking that manipulating POST data is difficult, just because the client can’t “see” it. As we illustrated clearly in Chapter 1, it’s actually quite easy.
Of course, in any case, sensitive authorization data should be protected by other means than simple obscurity. However, as we’ve said elsewhere in this book, security plus obscurity can’t hurt.
POST Data Manual Prediction
POST data frequently contains authorization- and session-related information, since many applications need to associate any data provided by the client with the session that provided it. The following example shows how to use the cURL tool to construct a POST to a bank account application containing some interesting fields called authmask (not sure what this might be, but the fragment auth sure looks interesting), uid, and a parameter simply called a that has a value of viewacct.
$ curl -v -d 'authmask=8195' -d 'uid=213987755' -d 'a=viewacct'
> --url https://www.victim.com/
* Connected to www.victim.com (192.168.12.93)
> POST / HTTP/1.1
User-Agent: curl/7.9.5 (i686-pc-cygwin) libcurl 7.9.5 (OpenSSL 0.9.6c)
Host: www.victim.com
Pragma: no-cache
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*
Content-Length: 38
Content-Type: application/x-www-form-urlencoded
authmask=8195&uid=213987 755&a=viewacct
The POST parameters are shown in the final line of the above text. Like the query string case, attribute-value pairs are delimited using the ampersand character and encoding of either the parameter name or value may be required if they contain special characters. One interesting thing to note in this example is how cURL automatically calculates the Content-Length HTTP header, which must match the number of characters in the POST data. This field has to be recalculated if the POST payload is tampered with.
“Hidden” Form Fields
Another classic security-through-obscurity technique is the use of so-called hidden values within HTML forms to pass sensitive data such as session ID, product pricing, or sales tax. Although these fields are hidden from the user viewing a web site through a browser, they are, of course, still visible in the web page’s HTML source code. Attackers will often examine the actual form field tags, since the field name or HTML comments may provide additional clues to the field’s function.
TIP
The WebScarab tool discussed in Chapter 1 provides a nifty “reveal hidden fields” feature that makes them just appear in the normal browser session.
Let’s take a look at part of an HTML form extracted from an application’s login page to see how it might be exploited in an authorization attack:
<FORM name=login_form action=
https://login.victim.com/config/login?4rfr0naidr6d3 method=post >
<INPUT name=Tries type=hidden> <INPUT value=us name=I8N type=hidden>
<INPUT name=Bypass type=hidden> <INPUT value=64mbvjoubpd06 name=U
type=hidden> <INPUT value=pVjsXMKjKD8rlggZTYDLWwNY_Wlt name=Challenge
type=hidden>
User Name:<INPUT name=Login>
Password:<INPUT type=password maxLength=32 value="" name=Passwd>
When the user submits her username and password, she is actually submitting seven pieces of information to the server, even though only two were visible on the web page. Table 5-6 summarizes these values.
From this example, it appears that the U hidden field may be tracking session state information, but at this point, it’s not clear as to whether a vulnerability exists. Check out our discussion of automated session ID prediction later in this chapter for ideas on how to analyze unknown values.
HTTP Header Manual Prediction
HTTP headers are passed as part of the HTTP protocol itself and are sometimes used to pass authorization/session data. Cookies are perhaps the most well-known HTTP header, and they are commonly used for authorization and session state-tracking. Some applications will also make (rather insecurely) authz decisions based on the value of HTTP Referer: and other headers (and don’t worry, we’ll deal with the misspelling of Referer momentarily).
NOTE
The application might also rely on custom headers to track a particular user attribute.
User-Agent
One of the simplest authorization tests to overcome is that of a check against the client browser make and model, which is typically implemented via the User-Agent


Table 5-6 Examples of Hidden Form Field Values
HTTP header. Many tools, cURL included, enable the user to specify an arbitrary User-Agent header, so this check is really meaningless as an authorization mechanism. For example, if an application requires Internet Explorer for political reasons as opposed to technical ones (such as requiring a particular ActiveX component), you can change the User-Agent header to impersonate IE:
$ curl --user-agent "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)"
> --url www.victim.com
While not terribly common, if this vulnerability does occur in the wild, it is likely to appear in applications that do not rely on standard web browsers such as IE and Firefox, but rather on a custom implementation of an HTTP client that sends a special User-Agent value. If the remote application server processing the requests is insecurely implemented to trust any request specifying that special User-Agent value, then a malicious user may possibly be able to bypass authz and access sensitive data and resources.
Cookies
Cookie values may be the most common location for storing authorization and state information. They are set using the HTTP Set-Cookie header, as shown in the following example:
Set-Cookie: NAME=VALUE; expires=DATE; path=PATH;
domain=DOMAIN_NAME; secure
Once set, the client simply replays the cookie back to the server using the Cookie header, which looks almost exactly like the Set-Cookie header, minus the extraneous attributes domain, path, and secure.
Since cookies are so commonly used for authorization, we’ll discuss them on their own shortly in an upcoming section of this chapter.
Referer
A common mistake web application developers often make is to trust information included as part of the Referer header and utilize that as a form of authentication. Well, what does the Referer header do? Why is it a security mistake? And for that matter, why is it misspelled?
The Referer header is very simple. Basically, it tells the server the URI of the resource from which the URI in the request was obtained (i.e., “where I’m coming from”). They are automatically added by your browser when you click links, but not included if you type in the URI yourself. For example, if you were on Site A, and clicked a link to go to Site B, the Referer header would contain the URI of Site A as part of the HTTP request header, like so:
Referer: http://www.siteA.com/index.html
Why is it a mistake to rely on Referer headers for authorization? As it is commonly implemented in web applications, each time a new area is accessed by following a link, a piece of custom code on the server checks the Referer header. If the URL included in the Referer header is “expected,” then the request is granted. If it is not, then the request is denied, and the user is shunted to some other area, normally an error page or something similar.
We can see how this process works in the following code sample. It’s a simple Referer header authentication protocol included as part of an .asp page.
strReferer = Request.ServerVariables("HTTP_REFERER")
If strReferer = "http://www.victim.com/login.html" Then
' this page is called from login..htm!
' Run functionality here
End If
In this case, the code only looks for an expected URL, http://www.victim.com/login.html. If that is present, the request is granted. Otherwise, it is denied. Why would a developer use a URL included as part of a Referer header for authentication? Primarily, as a shortcut. It relies on the assumption that users who accessed a specific application page can be treated as properly authenticated. That has some obvious, negative real-world implications. Say, for instance, that a site contains an Administrative area that relies on the Referer header value for authentication and authorization. Once the user has accessed a specific page, such as the menu page, then each additional page in that area is accessible.
The important thing to recognize is that the Referer value is controlled by the client and, therefore, the server cannot rely on it to make security-related decisions. The Referer value is easily spoofed using a variety of methods. The following Perl script shows one way to spoof the Referer value:
use HTTP:: Request::Common qw(POST GET);
use LWP::UserAgent;
$ua = LWP::UserAgent->new();
$req = POST ' http://www.victim.com/doadminmenu.html ';
$req->header(Referer => ' http://www.victim.com/adminmenu.html '),
$res = $ua->request($req);
In this example, the code sets the Referer value to make it appear as if the request originated from adminmenu.html, when in it obviously did not. It should be clear from this example that setting the Referer header to an arbitrary value is a trivial operation. As the old security adage goes, it is never a good idea to base security on the name of something, as that information can easily be impersonated, replayed, or even guessed. A related security principle is also pertinent here: never trust client input.
And the misspelling? It harkens back to the early days of the Internet when there was an “anything goes” mentality, and the misspelling fell through the cracks long enough to become standardized. It’s just been carried forward until now. That should tell you everything you need to know about utilizing HTTP Referer headers for authentication!
Manually Predicting Cookies
As we noted earlier, cookies remain the most popular form of authorization/session management within web applications despite a somewhat checkered security history (because of their central role, malicious hackers have devised numerous ways to capture, hijack, steal, manipulate, or otherwise abuse cookies over the years). However, the long history of security attacks targeting cookies is not indicative of a design problem with cookies in particular, but rather evidence of just how important these little bits of data are to authentication, authorization, and state management in application servers. Readers interested in learning more about how cookies are used to manage state in web applications are encouraged to review RFC 2109 (see the “References & Further Reading” section at the end of this chapter for links to this and other references on cookies). As we noted in the earlier section in this chapter on HTTP headers, cookies are managed using the Set-Cookie and Cookie HTTP headers.
Cookies are commonly used to store almost any data, and all of the fields can be easily modified using HTTP analysis tools like those outlined in Chapter 1. When performing real-world assessments, we prefer using the Burp web proxy’s raw request editor functionality. Modifying the cookie value is possible when intercepting requests and responses, or when replaying requests in the repeater pane. Figure 5-3 shows the cookie values set by an application. Figure 5-4 shows how to use Burp to change a cookie’s value in the repeater pane.
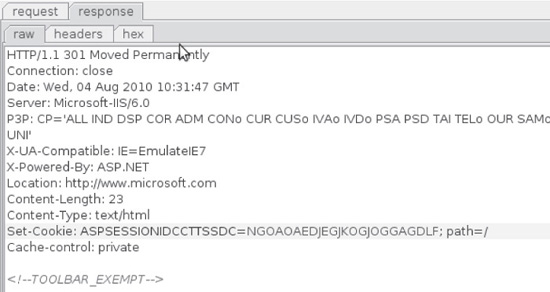
Figure 5-3 Using Burp to examine cookie values set in response
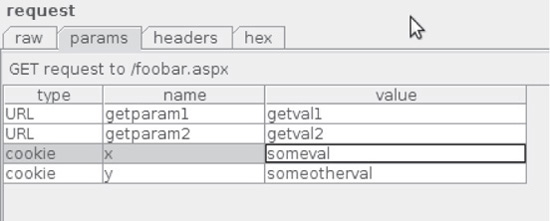
Figure 5-4 Editing a cookie value with Burp
How are cookies commonly abused to defeat authorization? Here’s an example of an application that uses a cookie to implement “remember me”-type functionality for authorization/state-tracking:
Set-Cookie: autolog=bWlrZTpteXMzY3IzdA%3D%3D; expires=Sat, 01-Jan-2037
00:00:00 GMT; path=/; domain=victim.com
Despite the somewhat cryptic content of this cookie, even an unsophisticated attacker could simply copy the cookie value and replay it to impersonate the corresponding user. Astute readers may notice the last four characters of the autolog cookie value are the URL-encoded value %3D%3D. Decoded, this value is == (two back-to-back equals characters), and this combination of characters appended to the end of gibberish values such as the one shown for the autolog cookie almost always indicates the use of Base64 encoding. Decoding the Base64 cookie reveals the ASCII string mike: mys3cr3t, which is clearly the username and password of the corresponding user. Finally, both the secure and HTTPOnly flags are not set for this cookie. When the secure flag is not set, the browser will send the cookie value over unencrypted channels (any normal HTTP connection, as opposed to HTTPS). The HTTPOnly flag is used to prevent malicious JavaScript from accessing the value of the cookie and exfiltrating it to an attacker-controlled system.
Bypassing Cookie Expire Times
When you log out of an application that uses cookies, the usual behavior is to set the cookie value to NULL (i.e., Set-Cookie: foobar=) with an expire time in the past. This effectively erases the cookie. An application might also use the expire time to force users to re-authenticate every 20 minutes. The cookie would only have a valid period of 20 minutes from when the user first authenticated, and when that 20 minutes has elapsed, the client browser will delete it. Because subsequent requests will no longer contain the deleted authorization/session cookie, the server will redirect the client to an authentication page. This can be an effective way to time-out unused sessions automatically, although, like any security sensitive functionality, it requires careful implementation.
For example, if the application sets a “has password” value that expires in 20 minutes, then an attacker might attempt to extend the expire time and see if the server still honors the cookie (note the bolded text, where we’ve changed the date one year into the future):
Set-Cookie: HasPwd=45lfhj28fmnw; expires=Tue, 17-Apr-2010
12:20:00 GMT; path=/; domain=victim.com
Set-Cookie: HasPwd=45lfhj28fmnw; expires=Tue, 17-Apr-2011
12:20:00 GMT; path=/; domain=victim.com
From this, the attacker might determine if there are any server-side controls on session times. If this new cookie, valid for 20 minutes plus one year, lasts for an hour, then the attacker knows that the 20-minute window is arbitrary—the server is enforcing a hard timeout of 60 minutes.
Automated Prediction
If an access token or session ID doesn’t yield to human intuition, automated analysis can be used to assist in identifying potential security vulnerabilities This section covers techniques for automated analysis of predictable session IDs and cryptographically protected values.
Collecting Samples
When analyzing the security and true randomness of server-issued session IDs, it is necessary to first collect a large enough sample of session IDs in order to perform a meaningful statistical analysis. You’ll want to do this with a script or other automated tool (the Burp sequencer tool is great for this purpose) since collecting 10,000 values manually quickly becomes monotonous! Here are three example Perl scripts to help you get started. You’ll need to customize each one to collect a particular variable (we’ve grep’ed for some COTS session IDs in these examples just for illustration purposes).
The following script, gather.sh, collects ASPSESSIONID values from an HTTP server using netcat:
#!/bin/sh
# gather.sh
while [ 1 ]
do
echo -e "GET / HTTP/1.0
" |
nc -vv $1 80 |
grep ASPSESSIONID
done
The next script, gather_ssl.sh, collects JSESSIONID values from an HTTPS server using the openssl client:
#!/bin/sh
# gather_ssl.sh
while [ 1 ]
do
echo -e "GET / HTTP/1.0
" |
openssl s_client -quiet -no_tls1 -connect $1:443 2>/dev/null |
grep JSESSIONID
done
Finally, the gather_nudge.sh script collects JSESSIONID values from an HTTPS server using the openssl client, but also POSTs a specific login request that the server requires before setting a cookie:
#!/bin/sh
# gather_nudge.sh
while [ 1 ]
do
cat nudge
openssl s_client -quiet -no_tls1 -connect $1:443 2>/dev/null |
grep JSESSIONID
done
The contents of the “nudge” file referenced in this script are as follows:
POST /secure/client.asp?id=9898 HTTP/1.1
Accept: */*
Content-Type: text/xml
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0; Q312461)
Host: www.victim.com
Content-Length: 102
Connection: Keep-Alive
Cache-Control: no-cache
<LoginRequest><User><SignInName>latour</SignInName><Password>Eiffel
</Password></User></LoginRequest>
Each one of the scripts runs in an infinite loop. Make sure to redirect the output to a file so you can save the work. For example:
$ ./gather.sh www.victim.com | tee cookies.txt
$ ./gather_ssl.sh www.victim.com | tee cookies.txt
$ ./gather_nudge.sh www.victim.com | tee cookies.txt
TIP
Use the GNU cut command along with grep to parse the actual value from the cookies.txt.
Nonlinear Analysis
How can you test the actual randomness of a collection of session IDs? In April 2001, Michal Zalewski of the Bindview team applied nonlinear analysis techniques to the initial sequence numbers (ISN) of TCP connections and made some interesting observations on the “randomness” of the values. The most illustrative part of the paper was the graphical representation of the analysis. Figures 5-5 and 5-6 show the visual difference in the relative random nature of two sources.
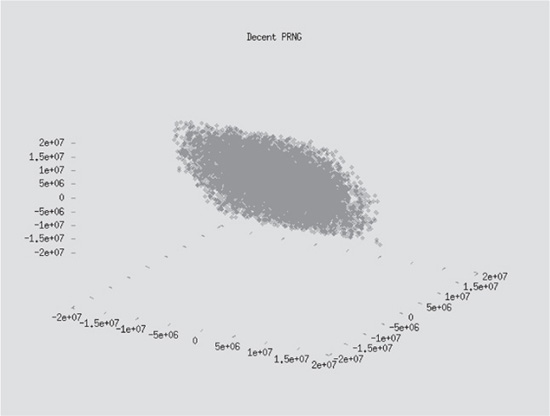
Figure 5-5 Decently randomized ISN values
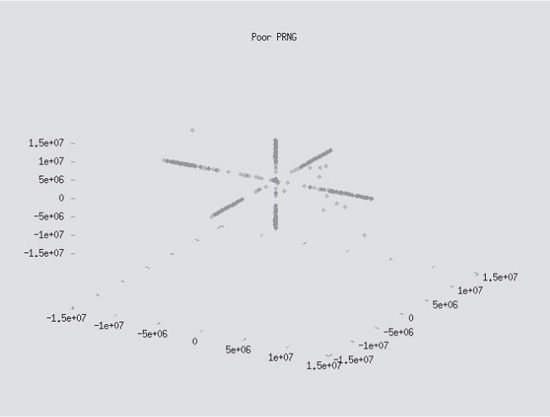
Figure 5-6 Poorly randomized ISN values
The ISN is supposed to be a random number used for every new TCP connection, much like the session ID generated by a web server. The functions used to generate the graphs do not require any complicated algorithm. Each coordinate is defined by:
x[t] = seq[t] - seq[t-1]
y[t] = seq[t-1] - seq[t-2]
z[t] = seq[t-2] - seq[t-3]
The random values selected from the dataset are the seq array; t is the index of the array. Try applying this technique to session values you collect from an application. It is actually trivial to generate the dataset. The following Perl script accepts a sequence of numbers, calculates each point, and (for our purposes) outputs x, y, and z:
#!/usr/bin/perl
# seq.pl
@seq = ();
@x = @y = @z = ();
while(<>) {
chomp($val = $_);
push(@seq, $val);
}
for ($i = 3; $i < $#seq; $i++) {
push(@x, $seq[$i] - $seq[$i - 1]);
push(@y, $seq[$i - 1] - $seq[$i - 2]);
push(@z, $seq[$i - 2] - $seq[$i - 3]);
}
for ($i = 0; $i < $#seq; $i++) {
print $x[$i] . " " . $y[$i] . " " . $z[$i] . "
";
}
NOTE
This function does not predict values; it only hints at how difficult it would be to predict a value. Poor session generators have significant trends that can be exploited.
To use this script, we would collect session numbers in a file called session.raw, and then pipe the numbers through the Perl script and output the results to a data file called 3d.dat:
$ cat session.raw | ./seq.pl > 3d.dat
The 3d.dat file contains an X, Y, and Z coordinate on each line. Gnuplot can then be used to produce a graphical representation of the results. Remember, while this procedure does not predict session ID values, it is very useful for determining how hard it would be to predict values.
Users of the Burp web proxy may be familiar with the sequencer tab and built-in randomness statistical analysis tool. The sequencer utility not only simplifies collection of tokens, but also retrieves them from anywhere in the server response, and the mathematical analysis of the randomness is performed automatically as the tokens are retrieved. Populating the sequencer tool with a request/response pair is as simple as right-clicking on any response in Burp and selecting Send To Sequencer. The next step is to define the boundaries of the token in the response using either unique textual delimiters or static byte counts. Once the token boundary has been properly defined, the collection of tokens and automated analysis can begin. Interested readers should refer to the Burp project main web site (a link is provided in the “References & Further Reading” section at the end of this chapter).
Brute-force/Dictionary Attacks
In the earlier section on fingerprinting, we noted some key characteristics of MD5 hashes. If you are sure that you’ve found an MD5 hash in an application session cookie, you could use classic brute-force guessing to determine the original cleartext value (note that while this section focuses on MD5, the information applies to any hashing algorithm). For example, the following Perl commands using the Digest::MD5 module take different combinations of the login credentials and generate the corresponding MD5 hash values:
$ perl -e 'use Digest::MD5;
> print Digest::MD5::md5_base64("userpasswd") '
ZBzxQ5hVyDnyCZPUM89n+g
$ perl -e 'use Digest::MD5;
> print Digest::MD5::md5_base64("passwduser") '
seV1fBcI3Zz2rORI1wiHkQ
$ perl -e 'use Digest::MD5;
> print Digest::MD5::md5_base64("passwdsalt") '
PGXfdI2wvL2fNopFweHnyA
If the session token matches any of these values, then you’ve figured out how it’s generated. Although this example illustrates how this process would be manually performed, a simple script to automate test value generation and comparison with a target value is trivial to develop.
Sites that use MD5 and other hashing algorithms often insert random data or other dynamically generated values in order to defeat brute-force guessing attacks like this. For example, a more secure way of generating the token, especially if it is based on a user password, involves concatenating the password with another piece of secret data (commonly referred to as a salt) and a timestamp:
MD5( epoch time + secret + password )
Placing the most dynamic data at the beginning causes MD5 to “avalanche” more quickly. The avalanche effect means that two seed values that only differ by a few bits will produce two hash values that differ greatly. The advantage is that a malicious user only has one of the three pieces of the seed value. It wouldn’t be too hard to find the right value for the epoch time (it may only be one of 100 possible values), but the server’s secret would be difficult to guess. A brute-force attack could be launched, but a successful attack would be difficult given a properly chosen secret value.
A “less” secure (“more” and “less” are ill-defined terms in cryptography) but equally viable method would be to use only the server’s secret and user password:
MD5( secret + password )
In this case, an attacker would only need to guess the server’s secret value to crack the method by which the target session/authorization token is generated. If the secret contains few characters, is a commonly used password, dictionary word, or phrase, then a successful attack is conceivable.
This same approach to analyzing and figuring out how session/authorization token values are generated can be applied to encrypted values as well.
Bit Flipping
The attacker may be able to gain a leg up by noticing trends across a collection of encrypted values. For example, you might collect a series of session tokens that only differ in certain parts:
46Vw8VtZCAvfqpSY3FOtMGbhI
4mHDFHDtyAvfqpSY3FOtMGbjV
4tqnoriSDAvfqpSY3FOtMGbgV
4zD8AEYhcAvfqpSY3FOtMGbm3
Each of these values begins with the number 4. If these are encrypted values, the leading digit 4 is probably not part of what has been encrypted. There are eight random bytes after the 4, then fourteen bytes that do not change, followed by a final two random bytes. If this is an encrypted string, then we could make some educated guesses about its content. We’ll assume it’s encrypted with Triple-DES, since DES is known to be weak:
String = digit + 3DES(nonce) + 3DES(username (+ flags)) + 3DES(counter )
4 8 bytes 14 bytes 2 bytes
Here’s why we make the assumption:
• The field of eight characters always changes. The values are encrypted, so we have no way of knowing if they increment, decrement, or are truly random. Anyway, the source must be changing so we’ll refer to it as a nonce.
• The fourteen bytes remain constant. This means the encrypted data come from a static source, perhaps the username, or first name, or a flag set for “e-mail me a reminder.”
• The final two bytes are unknown. The data is short, so we could guess that it’s only a counter or some similar value that changes but does not represent a lot of information. It could also be a checksum for the previous data, added to ensure no one tampers with the cookie.
Using this information, an attacker could perform “bit flipping” attacks: blindly change portions of the encrypted string and monitor changes in the application’s performance. Let’s take a look at an example cookie and three modifications:
Original: 4zD8AEYhcAvfqpSY3FOtMGbm3
Modification 1: 4zD8AEYhcAAAAAAAAAAAAAAm3
Modification 2: 4zD8AEYhcBvfqpSY3FOtMGbm3
Modification 3: 4zD8AEYhcAvfqpSYAvfqpSYm3
We’re focusing the attack on the static, 14-byte field. First, we try all similar characters. If the cookie is accepted on a login page, for example, then we know that the server does not inspect that portion of the data for authentication credentials. If the cookie is rejected on the page for viewing the user’s profile, then we can guess that portion contains some user information.
In the second case, we change one letter. Now we’ll have to submit the cookie to different portions of the application to see where it is accepted and where it is rejected. Maybe it represents a flag for users and superusers? You never know. (But you’d be extremely lucky!)
In the third case, we repeated the first half of the string. Maybe the format is username:password. If we make this change, guessing that the outcome is username:username, and the login page rejects it, maybe we’re on the right track. This can quickly become long, unending guesswork.
For tools to help with encryption and decryption, try the UNIX crypt () function, Perl’s Crypt::DES module, and the mcrypt library (http://mcrypt.hellug.gr/).
Capture/Replay
As you can see, prediction attacks are usually all-or-none propositions: either the application developer has made some error, and the token easily falls prey to intuitive guessing and/or moderate automated analysis; or it remains indecipherable to the attacker and he has to move on to different attack methods.
One way for the attacker to bypass all of the complexity of analyzing tokens is to simply replay another user’s token to the application. If successful, the attacker effectively becomes that user.
Such capture/replay attacks differ from prediction in one key way: rather than guessing or reverse engineering a legitimate token, the attacker must acquire one through some other means. There are a few classic ways to do this, including eavesdropping, man-in-the-middle, and social engineering.
Eavesdropping is an omnipresent threat to any network-based application. Popular, free network monitoring tools like Wireshark (formerly known as Ethereal) and Ettercap can sniff raw network traffic to acquire web application sessions off the wire, exposing any authorization data to disclosure and replay.
The same effect can be achieved by placing a “man-in-the-middle” between the legitimate client and the application. For example, if an attacker compromises a proxy server at an ISP, the attacker would then access session IDs for all of the customers who used the proxy. Such an attack could even result in the compromise of what would normally be encrypted sessions if the proxy is responsible for HTTPS connections or an attacker successfully tricks a remote user into accepting an invalid SSL certificate.
Finally, a simple but oftentimes effective method of obtaining valid session IDs is to simply ask a prospective victim for it. As we noted in our earlier discussion of sensitive data in the query string, unsophisticated users can be deceived into sending URIs via e-mail containing such data... yet another reminder of the dangers of storing sensitive data in the query string!
Session Fixation
In December 2002, ACROS Security published a paper on session fixation, the name they gave to a class of attacks where the attacker chooses the session ID for the victim, rather than having to guess or capture it by other means (see “References & Further Reading” for a link).
Session fixation works as follows:
1. The attacker logs into a vulnerable application, establishing a valid session ID that will be used to “trap” the victim.
2. He then convinces his victim to log into the same application, using the same session ID (the ACROS paper discusses numerous ways to accomplish this, but the simplest scenario is to simply e-mail the victim a link to the application with the trap session ID in the query string).
3. Once the victim logs into the application, the attacker then replays the same session ID, effectively hijacking the victim’s session (one could say that the victim logged onto the attacker’s session).
Session fixation seems like an attacker’s dream come true, but a couple of aspects to this attack make it much less appealing than initially advertised:
• The attacker must convince the victim to launch a URI that logs them into the application using the “trap” session ID. Although, if you can trick someone into loading a URI, there are probably worse things you could do to them than fix a session ID.
• The attacker must then log into the application using the same trap session ID, before the victim logs out or the session expires (of course, if the web app doesn’t handle stale sessions appropriately, this could be an open-ended window).
Session Fixation Countermeasures
There’s also a really easy countermeasure to session fixation attacks: generate new session IDs for each successful login (i.e., after authentication), and only allow the server to choose session ID values. Finally, ensure that sessions are timed out using server-side logic and that absolute session expiry limits are set.
While session fixation vulnerabilities used to appear commonly in web applications (and even in some popular web application frameworks), this vulnerability class has largely gone the way of the Dodo due to the fact that developers have delegated most session generation and management to web application servers. However, even mature frameworks sometimes get it wrong or reintroduce vulnerabilities. Of course, during a security review, custom session generation and management functionality should be examined for this and other session-related vulnerabilities.
NOTE
Each of these countermeasures is purely application-level; the web platform is not going to protect you from session fixation.
AUTHORIZATION ATTACK CASE STUDIES
Now that you have gotten the basic techniques of attacking web application authorization and session management, let’s walk through some real-world examples from the authors’ consulting work that illustrate how to stitch the various techniques together to identify and exploit authorization vulnerabilities.
Many of the harebrained schemes we’ll recount next are becoming less and less common as overall security awareness has improved and the use of mature authorization/ session management frameworks like ASP.NET and J2EE has grown. Nevertheless, it’s astounding how many applications today still suffer from attacks similar to the ones we’ll discuss in the following sections.
NOTE
Obviously, the names and exact technical details in this chapter have been changed to protect the confidentiality of the relevant parties.
Horizontal Privilege Escalation
Horizontal privilege escalation is exploiting an authorization vulnerability to gain the privileges of a peer user with equal or fewer privileges within the application (contrast this with the more dangerous vertical escalation to higher privilege, which we’ll discuss in the next section). Let’s walk through the process of identifying such an authorization vulnerability using a fictitious web shopping application as an example.
First, we’ll set up our browser so you can view and manipulate all input and output to the web application using any one of the HTTP analysis tools discussed in Chapter 1. Then we navigate to the site and immediately set out to identify how the site creates new accounts. This is very easy since the “set up new account” feature is available right where existing users log in (these applications are usually eager to register new shoppers!), as shown in Figure 5-7.
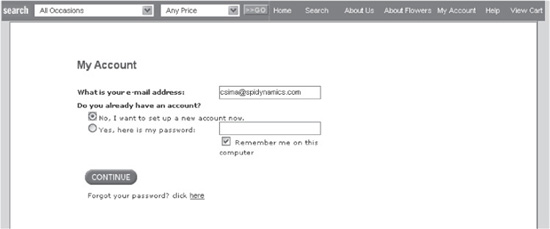
Figure 5-7 The Set Up New Account feature is usually available right at the application login screen.
Like most helpful web shopping applications, this one walks you through the account creation forms that ask for various types of personal information. We make sure to fill in all this information properly (not!). Near the very end of the process we reach a Finish or Create Account option, but we don’t click it just yet. Instead, we go to our HTTP analysis tool and clear any requests so we have a clean slate. Now it’s time to go ahead and click the button to finalize the creation of the account, which results in the screen shown in Figure 5-8.
Using our analysis tool, we look carefully at the request that was sent to the server in raw HTTP format. This is the actual POST that creates the account:
POST /secure/MyAcctBilling.asp HTTP/1.1
Host: secure2.site.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 414
Cookie: 20214200UserName=foo%40foo%2Ecom; 202142 00FirstName=Michael;
BIGipServerSecure2.TEAM.WebHosting=1852316332.20480.0000; LastURL=
http%3A%2F%2Fwww%2Esite%2Ecom; ASPSESSIONIDQAASCCQS=
GKEMINACKANKBNLFJAPKNLEM
stealth=1&RegType=1&UserID=&Salutation=Mr&FirstName=Michael&LastName=
Holmes&[email protected]&Password1=testpassword&Password2=
testpassword&DayPhone1=678&DayPhone2=555&DayPhone3=555&AltPhone1=
&AltPhone2=&AltPhone3=&Address1=294+forest+break+lane&Address2=&City=
atlanta&State=GA&Country=United+States&PostalCode=30338&CCName=0&CCNum=
&CCExpMonth=0&CCExpYear=0000&update_billing_info=on&submit.x=
43&submit.y=13
Figure 5-8 Successful account creation
And here’s the response from the server:
HTTP/1.x 302 Object moved
Set-Cookie: BIGipServerSecure2.TEAM.WebHosting=1852316332.20480.0000; path=/
Set-Cookie: UserID=2366239; path=/
Set-Cookie: ShopperID=193096346; path=/
Set-Cookie: [email protected]; path=/
Date: Wed, 12 Oct 2010 18:13:23 GMT
Server: Microsoft-IIS/6.0
X-Powered-By: ASP.NET
Location: https://secure2.site.com/secure/MyAcctBillingSuccess.asp?r=1
Content-Length: 185
Content-Type: text/html
Cache-Control: private
As we noted earlier in this chapter, cookies usually contain authorization information that is used to identify a session, so we take brief note of the Set-Cookie values in this response. They are summarized in Table 5-7.
Notice that ShopperID and UserID look very promising. The cookie names rather obviously indicate a relationship to authorization and the corresponding values are numeric, which means each value is likely subject to simple manipulation attacks (next serial iteration, etc.).
Now, our task is figuring out how these cookies are actually used, and whether the ShopperID and UserID tokens are actually what we think they are. To do this, we’ll need to replay these cookies to the application while targeting functionality that might result in privilege escalation if abused. As we noted earlier in this chapter, one of the most commonly abused aspects of web authorization is account management interfaces, especially self-help functionality. With this in mind, we make a beeline to the interface within this web application that allows users to view or edit their own account information. Using Hewlett Packard’s HTTP Editor (available to customers who’ve

Table 5-7 Cookie Information Gleaned from our Fictitious Web Shopping Application
purchased their WebInspect product), we analyze the underlying HTTP of this interface while simultaneously walking through the graphical HTML interface of the application, as shown in Figure 5-9.
Using this self-help functionality, we’ll run a few replay tests with the would-be authorization cookies we found earlier. Here’s how the cookies look when they’re replayed back from the client to the server in an HTTP header:
Cookie: 20214200UserName=foo%40foo%2Ecom; 20214200FirstName=Michael;
BIGipServerSecure2.TEAM.WebHosting=1852316332.20480.0000; LastURL=
http%3A%2F%2Fwww%2Esite%2Ecom; ShopperID=193096346;
ASPSESSIONIDQAASCCQS=GKEMINACKANKBNLFJAPKNLEM; UserID=2366239
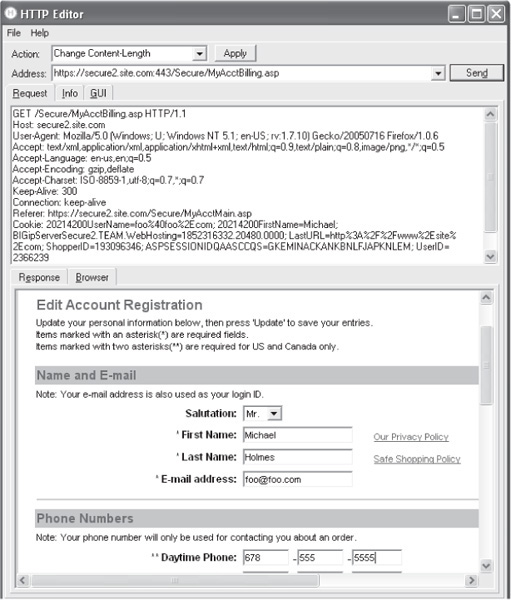
Figure 5-9 Analyzing the self-help account editing interface for our fictitious web shopping application using Hewlett Packard’s HTTP Editor
To check our guess that ShopperID and UserID are used to make authorization decisions, we now start individually removing each cookie and sending the request back. When we remove the UserID cookie, the server still responds with the account registration page shown in Figure 5-8. Therefore, this cookie is not important to our mission right now. We repeat the previous steps for each cookie until we eventually remove a cookie that will respond with an HTTP 302 redirect, which tells us that whatever token we removed was necessary for authorization. When we removed the ShopperID cookie, we ended up with the following response:
HTTP/1.1 302 Object moved
Date: Wed, 12 Oct 2010 18:36:06 GMT
Server: Microsoft-IIS/6.0
X-Powered-By: ASP.NET
Location: /secure/MyAcctLogin.asp?sid=
Content-Length: 149
Content-Type: text/html
Set-Cookie: ASPSESSIONIDQAASCCQS=OOEMINACOANKOLIIHMDAMFGF; path=/
Cache-control: private
This tells us that the ShopperID cookie is most likely the application authorization token.
NOTE
With this site, we actually found that the BIGipServer cookie also resulted in failed authorization; however, because we know that BIG-IP is a web load-balancing product from F5 Networks Inc., we disregarded it. We did have to subsequently replay the BIGip token, however, since it is necessary to communicate with the web site.
At this point, we can test the vulnerability of the ShopperID cookie by simply altering its value and replaying it to the server. Because we just created the account, let’s decrement the ShopperID number from 193096346 to 193096345 and see if we can access the information for the account that was created right before ours. Here’s what the client cookie header looks like before the change:
Cookie: BIGipServerSecure2.TEAM.WebHosting=1852316332.20480.0000;
ShopperID=193096346;
And here’s what it looks like after with the new ShopperID value:
Cookie: BIGipServerSecure2.TEAM.WebHosting=1852316332.20480.0000;
ShopperID=193096345;
We send the second, decremented value to the server and check to see whether the same account information is returned. Success! Figure 5-10 shows the account data for an “Emily Sima.” We have just identified a horizontal privilege escalation vulnerability. Furthermore, an attacker can now enumerate every account and grab personal data, or even impersonate any user with her full account privileges.
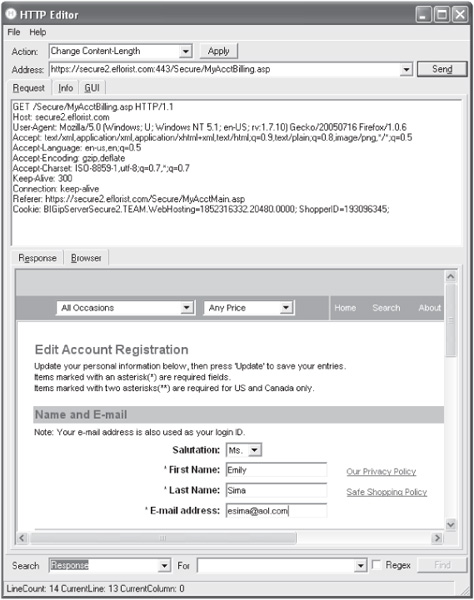
Figure 5-10 Success! The information for another account can now be changed.
Vertical Privilege Escalation
Vertical privilege escalation is the ability to upgrade or gain access to a higher account status or permission level. There are four scenarios that typically result in vertical privilege escalation.
• User-modifiable roles The application improperly permits unauthorized users to change their role information.
• Hijacked accounts Occurs when an unauthorized user can hijack another privileged user’s account or session.
• Exploiting other security flaws Ability to gain access via other security flaws to an administration area where privileges can be changed.
• Insecure admin functions Administrative functions that do not have proper authorization.
Let’s take a look at an example of each of these in a real-world scenario.
User-modifiable Roles
As we’ve seen numerous times in this chapter, many web applications store authorization data such as permission level or role level in user-modifiable locations. We just saw an example of a web shopping application that stores role information in a cookie as a plaintext value. For a similar example with a vertical escalation flavor, consider a fictitious web application with a privileged administrative interface located at http://www.site.com/siteAdmin/menu.aspx. When we try to access this page normally, the server responds with an HTTP 302 redirect back to the administrative login screen. Further analysis of the HTTP request reveals the following cookies being passed from the client to the server:
Cookie: Auth=
897ec5aef2914fd153091011a4f0f1ca8e64f98c33a303eddfbb7ea29d217b34;
Roles=End User; HomePageHits=True;ASP.NET_SessionId=
dbii2555qecqfimijxzfaf55
The Roles=End User value is almost a dead giveaway that this application is exposing authorization parameters to client manipulation. To test whether the Roles cookie could be manipulated to execute a vertical privilege escalation attack, we make repeated requests to the application server with different Roles values such as Roles= admin, Roles=root, and Roles=administrator. After several failed attempts, we take a closer look at the naming convention and try Roles=Admin User, which results in access to the administration page. Sadly, our real web application testing experiences are replete with even simpler scenarios where just appending admin= true or admin=1 to the URL has worked.
Let’s look at a more challenging example. In the following fictitious web application, we log into an application as a normal user. The cookie that is being sent in each request looks similar to the following:
Cookie: ASPSESSIONIDAACAACDA=AJBIGAJCKHPMDFLLMKNFLFME; X=
C910805903&Y=1133214680303; role=ee11cbb19052e40b07aac0ca060c23ee
We notice the cookie named role= immediately but don’t dwell too long because of the cryptic nature of the value (one of those alphanumeric blobs again!). During subsequent horizontal escalation testing, we create a second account in order to perform differential analysis (as described earlier in this chapter). When we are logged into the second account, the cookie sent with each request looks like the following:
Cookie: ASPSESSIONIDAACAACDA=KPCIGAJCGBODNLNMBIPBOAHI; C=0&T=
1133214613838&V=1133214702185; role=ee11cbb19052e40b07aac0ca060c23ee
Notice anything unusual? The value for the role cookie is the same as it was for the first account we created, indicating that the value is static and not uniquely generated for each user. In fact, when looking at it more closely, it resembles an MD5 hash. A count of the number of characters in the role value yields 32 characters As you might recall from our earlier discussion of session ID fingerprinting, a 32-byte value is one of the canonical ways to represent an MD5 hash (it is the hexadecimal representation of a standard 128-bit MD5 hash). At this point, we figure the application is using a fixed role value for users and then hashing it using the MD5 algorithm.
Lions and tigers and crypto, oh my! Slowed down only momentarily, we implement essentially the same privilege escalation attack as before, changing the cookie to role=admin, only using MD5 to first hash the string admin. After hashing the value and inserting it into our request, the cookie we send looks like the following:
Cookie: ASPSESSIONIDAACAACDA=KPCIGAJCGBODNLNMBIPBOAHI; C=0&T=
1133214613838&V=1133214702185; role=21232f297a57a5a743894a0e4a801fc3
Again, the role= value is the word admin hashed with MD5. When we request the main account screen with this cookie, the application sends back a 302 redirect back to the login page—no dice. After several additional manual attempts using strings like administrator and root (the usual suspects) hashed using MD5, we decide to go ahead and write a script to automate this process and read from a dictionary file of common user account names. Once again, if the application returns a response that is not a 302 redirect, then we will have found a correct role. It doesn’t take long; after about five minutes of running this script, we find that Supervisor was a valid role and it presents us with superuser access to the application.
Using Hijacked Accounts
Horizontal privilege escalation is usually quite easy to take vertical. For example, if the authorization token is implemented using sequential identifiers (as you saw in our previous example of the fictitious web shopping site), then finding a vertical privilege escalation opportunity can be as easy as guessing the lowest account ID that is still valid, which usually belongs to a superuser account, since those accounts are generally created first. Usually, the lower account IDs are the accounts of the developers or administrators of the application and many times those accounts will have higher privileges. We’ll discuss a systematic way to identify administrative accounts using sequential guessing like this in the upcoming section about using cURL to map permissions.
Using Other Security Flaws
This is just a given. Breaking into the system via another security flaw such as a buffer overflow in a COTS component or SQL injection will usually be enough to be able to change what you need in order to move your account up the ladder. For example, take the omnipresent web statistics page that gives away the location of an administrative interface located at http://www.site.com/cgi-bin/manager.cgi that doesn’t require any authentication (we talk about common ways to find web statistics pages in Chapter 8). Are you in disbelief? Don’t be—in our combined years of experience pen-testing web applications, this example has occurred much too often.
Insecure Admin Functions
In our travels, we’ve found many web application administrative functions that aren’t authenticated or authorized properly. For example, consider an application with a POST call to the script “http://www.site.com/admin/utils/updatepdf.asp”. Clearly, this is an administrative script based on the folder that it is stored within. Or so the application developers think, since the script is supposedly only accessible from the administrative portions of the site, which require authentication. Of course, potential intruders with a propensity to tinker and a little luck at guessing at directory naming conventions easily find the /admin/utils directory. Some simple tinkering with the updatepdf script indicates that it takes an ID number and a filename as parameters to upload a PDF file to the site. When run as even a normal user, the script will replace any PDFs currently offered to users, as you might imagine befitting of a content management role. Denial of service is written all over this. More devastating, we end up being able to use the updatepdf script to upload our own ASP pages, which then allows us almost full access to the server.
Differential Analysis
We’ve discussed the concept of differential analysis (as it relates to authorization audits) a couple of times previously in this chapter. Essentially, it involves crawling the target web site while authenticated (or not) using different accounts, noting where parameters such as cookies and/or other authorization/state-tracking data differ.
One of our recent consulting experiences highlights the use of this technique. We were contracted to perform an authenticated assessment and were provided two sets of valid credentials by the client: a “standard” application user and an administrative user. We first crawled the site while authenticated as the standard user, logging all pages and forms that were submitted. We then did the same using the administrative credentials. We then sorted both datasets and counted the totals for each type of data submitted. The results are shown in Table 5-8.

Table 5-8 Differential Analysis Results Produced While Browsing a Web Application While Authenticated as a Standard and Administrative User
Based on this data, the first obvious attack was to attempt to access the administrative forms and pages using the standard user account. No easy wins here; the pages that we hit appeared to be well protected.
We then took a closer look at how standard and admin roles were differentiated via session management. As noted in Table 5-8, both the standard and administrative user received the same number of cookies from the application. This means that the session/role authorization was possibly associated with one of the cookies. By using the process of cookie elimination shown in the Horizontal Privilege Escalation case study described earlier, we were able to identify a single cookie that appeared to perform the authorization function. Table 5-9 shows the values for both the standard and administrative user.
We next analyzed the differences between the standard and administrative cookies. Spend a couple of minutes looking at the cookies in Table 5-9 and see if what you come up with matches our observations listed here:
• The cookie value is separated into segments using periods.
• The first, third, and fourth segments are the same length and are all numeric.
• The second segment could be an MD5 hash (it’s 32-bytes long; see the earlier section entitled “Analyzing Session Tokens”).
• Each segment is the same length for each user.
• The first three numbers in the first segment for each user are the same.
Although we may have gleaned the algorithm used to produce the second segment, this cursory analysis hadn’t really revealed anything useful, so we probed further. We did this by systematically changing values in the cookie and resubmitting it to the application. We began by changing values in the last segment of the cookie and then worked our way to the front. Table 5-10 shows the results of some of our testing.
We interpreted the data in Table 5-10 to mean that the last segment had little to do with authorization.
We repeated this process for each segment in the cookie, and when we were done, we were surprised to find out that only the first five characters in the cookie appeared to be relevant to authorization state. Looking back at Table 5-9, the only difference between the standard and admin user accounts—within the first five characters of the cookie—was in the fifth character position: the admin user had a 0 and the standard user had a 1.

Table 5-9 Cookie Values for Both Standard and Admin User Types

Table 5-10 Input Validation Checking Results for the Last Segment of the “jonafid” Cookie
With a bit more input manipulation, we subsequently discovered that the fifth position contained serially incrementing account numbers, and that by changing these, we were able to easily hijack other users’ sessions.
When Encryption Fails
As security awareness increases, more developers are using security technologies to protect their applications, systems, and users from compromise by malicious parties. However, just because developers are using a security technology, does not mean they are using it correctly. Take encryption, for example. The primary reason to use encryption is to protect the confidentiality of the data that is being encrypted. If there is no real need to encrypt the data, then encryption should not be used because it can degrade performance and it complicates application design.
As an example of how encryption can be used improperly to provide a false sense of security, consider an application that has a user profile page accessible through a link similar to the following:
http://hackx/userprofile/userprofile.aspx?uid=ZauX%2f%2fBrHY8%3d
Notice the uid value in the above URL. Parameters called uid almost invariably represent “user IDs” and contain unique values corresponding to individual users in an application. Commonly, these values are sequential positive integers that map directly to the primary key values used in the backend database (this is not the suggested way to do this, just an extremely common and error-prone way). In the case of the above URL, the value is not an integer, but a complex string. Although it is not clear what this value might actually be, the reader should by now be clued in to the possibility that the value is base64-encoded due to the URL encoded %3d (=) at the end. Subsequent decoding of the value results in a seemingly random sequence of 8 bytes, indicating that the value is likely encrypted.
Attacking this value using some of the techniques discussed in this chapter may or may not be profitable; given its 8-byte length, random bit-flipping and brute-force cracking are likely to drain significant time, without necessarily producing results. What if there is an easier way?
The key to attacking this functionality is to realize that the same encryption scheme used for protecting other objects in the system (such as unique product and category IDs) is also used for uid values. For example, if you assume that the value underlying the encrypted uid value is an integer that corresponds to the primary key of a user row in a backend database table, then it would make sense for other encrypted object IDs to also be primary key values in their respective tables. That means that we might be able to use an encrypted product ID value as a uid value in a request to the application and gain access to the record for another user. To test whether such an attack will work, all that is required is to collect a number of encrypted product and category IDs and use those as the uid value in requests to the user profile page, userprofile.aspx. After some trial and error with this method, we hit pay dirt and succeed in accessing another user’s profile containing all his juicy personal details.
Of course, the root cause of this vulnerability is insecure authorization controls governing access to the user profile page and has nothing to do with the strength of the encryption algorithm used. Ultimately, access to the profiles of other users has to be secured by checking the identity and role of the requesting user with more than just the simple uid value in the query string. In a secure application, the uid of the current user will be tightly associated with the currently authenticated session and attempts to override that relationship by supplying a uid value in application requests will be ignored.
Using cURL to Map Permissions
cURL is a fantastic tool for automating tests. For example, suppose you are auditing an application that doles out user ID numbers sequentially. You have identified the session tokens necessary for a user to view his profile information: uid (a numeric user ID) and sessid (the session ID). The URL request is a GET command that passes these arguments: menu=4 (the number that indicates the view profile menu), userID=uid (the user ID is passed in the cookie and in the URL), profile=uid (the profile to view, assumed to be the user’s own), and r=874bace2 (a random number assigned to the session when the user first logs in). So the complete request would look like this:
GET /secure/display.php?menu=4&userID=24601&profile=24601&r=874bace2
Cookie: uid=24601; sessid=99834948209
We have determined that it is possible to change the profile and userID parameters on the URL in order to view someone else’s profile (including the ability to change the e-mail address to which password reminders are sent). Now, we know that the user ID numbers are generated sequentially, but we don’t know what user IDs belong to the application administrators. In other words, we need to determine which user IDs can view an arbitrary profile. A little bit of manual testing reveals that if we use an incorrect combination of profile and userID values, then the application returns, “You are not authorized to view this page,” and a successful request returns, “Membership profile for...”; both return a 200 HTTP code. We’ll automate this check with two cURL scripts.
The first cURL script is used to determine what other user IDs can view our profile. If another user ID can view our profile, then we assume it belongs to an administrator. The script tests the first 100,000 user ID numbers:
#!/bin/sh
USERID=1
while [ $USERID -le 100000 ] ; do
echo -e "$USERID ******
" >> results.txt
`curl -v -G
-H 'Cookie: uid=$USERID; sessid=99834948209'
-d 'menu=4'
-d 'userID=$USERID'
-d 'profile=24601'
-d 'r=874bace2'
--url https://www.victim.com/ results.txt`
echo -e "*********
" >> results.txt
UserID=`expr $USERID + 1`
done
exit
After the script executes, we still need to manually search the results.txt file for successes, but this is as simple as running a grep for “Membership profile for” against the file. In this scenario, user ID numbers 1001, 19293, and 43000 are able to view our profile—we’ve found three administrators!
Next, we’ll use the second script to enumerate all active user IDs by sequentially checking profiles. This time we leave the userID value static and increment the profile value. We’ll use the user ID of 19293 for the administrator:
#!/bin/sh
PROFILE=1
while [ $PROFILE -le 100000 ] ; do
echo -e "$PROFILE ******
" >> results.txt
`curl -v -G
-H 'Cookie: uid=19293; sessid=99834948209'
-d 'menu=4'
-d 'userID=19293'
-d 'profile=$PROFILE'
-d 'r=874bace2'
--url https://www.victim.com/ results.txt`
echo -e "*********
" >> results.txt
UserID=`expr $PROFILE + 1`
done
exit
Once this script has finished running, we will have enumerated the profile information for every active user in the application.
After taking another look at the URL’s query string parameters (menu=4 &userID= 24601&profile =24601&r=874bace2), a third attack comes to mind. So far we’ve accessed the application as a low-privilege user. That is, our user ID number, 24601, has access to a limited number of menu options. On the other hand, it is likely that the administrator who has user ID number 19293 has more menu options available. We can’t log in as the administrator because we don’t have that user’s password. We can impersonate the administrator, but we’ve only been presented with portions of the application intended for low-privilege users.
The third attack is simple. We’ll modify the cURL script and enumerate the menu values for the application. Since we don’t know what the results will be, we’ll create the script so it accepts a menu number from the command line and prints the server’s response to the screen:
#!/bin/sh
# guess menu options with curl: guess.sh
curl -v -G
-H 'Cookie: uid=19293; sessid=99834948209'
-d 'menu=$1'
-d 'userID=19293'
-d 'r=874bace2'
--url https://www.victim.com/
Here’s how we would execute the script:
$ ./guess.sh 4
$ ./guess.sh 7
$ ./guess.sh 8
$ ./guess.sh 32
Table 5-11 shows the result of the manual tests.

Table 5-11 Results of Manual Parameter Injection to the “menu” Query String Parameter
We skipped a few numbers for this example, but it looks like each power of two (4, 8, 16, 32) returns a different menu. This makes sense in a way. The application could be using an 8-bit bitmask to pull up a particular menu. For example, the profile menu appears in binary as 00000100 (4) and the delete user appears as 00100000 (32). A bitmask is merely one method of referencing data. There are two points to this example. One, examine all of an application’s parameters in order to test the full measure of their functionality. Two, look for trends within the application. A trend could be a naming convention or a numeric progression, as we’ve shown here.
There’s a final attack that we haven’t tried yet—enumerating sessid values. These cURL scripts can be easily modified to enumerate valid sessid values as well; we’ll leave this as an exercise for the reader.
Before we finish talking about cURL, let’s examine why this attack worked:
• Poor session handling The application tracked the sessid cookie value and the r value in the URL; however, the application did not correlate either value with the user ID number. In other words, once we authenticated to the application, all we needed to remain authenticated were the sessid and r values. The uid and userID values were used to check authorization, whether or not the account could access a particular profile. By not coordinating the authorization tokens (uid, userID, sessid, r), we were able to impersonate other users and gain privileged access. If the application had checked that the uid value matched the sessid value from when the session was first established, then the application would have stopped the attack because the impersonation attempt used the wrong sessid for the corresponding uid.
• No forced session timeout The application did not expire the session token (sessid) after six hours. This is a tricky point to bring up, because technically the session was active the entire time as it enumerated 100,000 users. However, applications can still enforce absolute timeouts on a session, such as one hour, and request the user to re-authenticate. Re-authenticating would not have stopped the attack, but in a situation where the session ID was hijacked or stolen it would have helped to mitigate its impact. This protects users in shared environments such as university computer labs from attackers taking their session, and also protects against session fixation attacks where the attacker attempts to fix the session expiry unrealistically far into the future.
AUTHORIZATION BEST PRACTICES
We’ve covered a lot of web app authorization attacks. Now, how do we mitigate all of those techniques?
In this chapter, we basically divided up web app authorization attacks into two camps: server-side ACL attacks and client-side token attacks. Thus, our discussion of countermeasures is divided into two parts based on those categories.
Before we begin, some general authz best practices should be enumerated. As we’ve seen throughout this chapter, authz exploits are often enabled or exaggerated by web server vulnerabilities (see Chapters 3 and 10) and input validation (Chapter 6). As such, applying countermeasures to those potential vulnerabilities has the fortunate side effect of blocking some authorization attacks as well.
Another best practice is to define clear, consistent access policies for your application. For example, design the user database to contain roles for the application’s functions. Some roles are read, create, modify, delete, and access. A user’s session information should explicitly define which roles can be used. The role table looks like a matrix, with users defined in each row and their potential roles defined in each column.
Web ACL Best Practices
As we noted, the lowest common denominator of web app authorization is provided by ACLs, particularly filesystem ACLs (although we will cover ACLs on other objects like HTTP methods in our upcoming discussion). In this section, we’ll describe best practices for web ACL configuration and then discuss how to configure ACLs on two popular web platforms, Apache and IIS.
Apache Authorization
The Apache web server uses two different directives to control user access to specific URLs. The Directory directive is used when access control is based on file paths. For example, the following set of directives limits access to the /admin URL. Only valid users who are also in the admin group can access this directory. Notice that the password and group files are not stored within the web document root.
<Directory /var/www/htdocs/admin>
AuthType Digest
AuthName "Admin Interface"
AuthUserFile /etc/apache/passwd/users
AuthGroupFile /etc/apache/passwd/groups
Require group admin
</Directory>
You can also limit access to certain HTTP commands. For example, HTTP and WebDAV support several commands: GET, POST, PUT, DELETE, CONNECT, OPTIONS, TRACE, PATCH, PROPFIND, PROPPATCH, MKCOL, COPY, MOVE, LOCK, and UNLOCK. The WebDAV commands provide a method for remote administration of a web site’s content. Even if you allow WebDAV to certain directories, use the Limit directives to control those commands. For example, only permit GET and POST requests to user pages:
<Directory /var/www/htdocs>
Options -MultiViews -Indexes -Includes
Limit GET POST
Order allow,deny
Allow from all
/Limit
</Directory>
Thus, users can only use the GET and POST commands when requesting pages in the /htdocs directory, the web root. The HEAD command is assumed with GET. Now, if you wish to enable the WebDAV options for a particular directory, you could set the following:
<Directory /var/www/htdocs/articles/preview>
AuthType Digest
AuthName "Author Site"
AuthUserFile /etc/apache/passwd/users
AuthGroupFile /etc/apache/passwd/groups
Limit GET POST PUT CONNECT PROPFIND COPY LOCK UNLOCK
Require group author
/Limit
</Directory>
We haven’t permitted every WebDAV option, but this should be enough for users in the author group who wish to access this portion of the web application.
The Location directive is used when access control is based on the URL. It does not call upon a specific file location:
<Location /member-area>
AuthType Digest
AuthName "My Application"
AuthUserFile /etc/apache/passwd/users
AuthGroupFile /etc/apache/passwd/groups
Require valid-user
</Location>
Just about any of the directives that are permitted in <Directory> tags are valid for <Location> tags.
IIS Authorization
Starting with IIS7, Microsoft has unified configuration of IIS file authorization settings under the standard Windows filesystem permission interfaces. Also, they’ve unified standard access under the IIS_IUSRS group, which is now the default identity for applications running in any application pool to access resources. To configure access control for web directories and files under IIS, open the IIS Manager tool (Start | Run | inetmgr), navigate to the site, application, or virtual directory that you want to secure, right-click and select Edit Permissions.... On IIS7, this displays the interface shown in Figure 5-11, which illustrates the default security applied to the built-in Default Web Site for the IIS_IUSRS group.
CAUTION
Avoid permitting web users to write content. If you do, it is even more important not to give execute or script permissions to user-writeable directories, in order to prevent upload and execution of malicious code.
Besides file authorization, Microsoft also supports URL authorization via web.config files, under the system.web/authorization section (in Integrated Pipeline mode, IIS7 uses the system.webServer/authorization section). This mechanism is very similar to the Apache authorization mechanisms described previously, using structured text strings to define what identities have what level of access to resources. See “References & Further Reading” at the end of this chapter for pointers to tutorials on configuring authorization using web.config in various scenarios, including some subtle differences between IIS7 and ASP.NET URL Authorization behavior.
Figure 5-11 Configuring IIS7 directory security
IP Address Authorization
Although we don’t normally recommend it, IIS also permits IP address-based access control. Configuration is accessible via the “Edit Bindings...” feature of a given site. This might be useful in scenarios where only certain addresses, subnets, or DNS names are allowed access to an administration directory, for example. It’s highly discouraged for Internet-facing applications, since sequential requests are not guaranteed to come from the same IP address, and multiple users can come from the same IP address (think corporate networks).
Web Authorization/Session Token Security
As we’ve seen in this chapter, authorization/session security can be a complex topic. Here is a synopsis of authorization/session management techniques best practices:
• Use SSL. Any traffic that contains sensitive information should be encrypted to prevent sniffing attacks.
• Mark cookies using the Secure parameter of the Set-Cookie response header, per RFC 2109.
• Don’t roll your own authz. Off-the-shelf authorization features, such as those that come with web application platforms like ASP.NET and PHP that we will discuss shortly, are likely to have received more scrutiny in real-world environments than anything developed from scratch by even the largest web app development shops. Leave the security stuff to the professionals and keep focused on your core business. You’ll suffer fewer vulnerabilities for it; trust us.
• Don’t include personally sensitive data in the token. Not only does this lead to session hijacking (since this data is often not really secret—ever tried finding someone’s home address on Google?), but if it’s disclosed, the user is out more than just some randomly generated session ID. The attacker may have stolen their government ID, secret password, or whatever other information was used to populate the token.
• Regenerate session IDs upon privilege changes. Most web applications assign a session ID upon the first request for a URL, even for anonymous users. If the user logs in, then the application should create and assign a new session ID to the user. This not only represents that the user has authenticated, but it reduces the chances of eavesdropping attacks if the initial access to the application wasn’t conducted over SSL. It also mitigates against session fixation attacks discussed earlier in the chapter, where an attacker goes to a site and gets a session ID, then e-mails it to the victim and allows them to log in using the ID that the attacker already knows.
• Enforce session time limits to close down the window for replay attacks. Invalidate state information and session IDs after a certain period of inactivity (for example, 10 minutes) or a set period of time (perhaps 30 minutes). In addition to relative per-session expiry, we recommend the application set global absolute limits on session lengths to prevent attacks that attempt to fix session IDs far into the future. And always remember: the server should invalidate the ID or token information; it should not rely on the client to do so. This protects the application from session replay attacks.
• Enforce concurrent login limits. Disallow users from having multiple, concurrent authenticated sessions to the application. This could prevent malicious users from hijacking or guessing valid session IDs.
• Perform strict input validation. Cookie names and values, just like POST, GET, and other HTTP header values, are under the complete control of the user and can be modified to contain data that the application does not expect. Therefore, strict input validation of cookie values must be performed at that application server to ensure that attackers cannot maliciously modify the cookie data to exploit security vulnerabilities.
To Be or To Impersonate
One of the most important questions when it comes to web app authorization is this: In what security (account) context will a given request execute? The answer to this question will almost always define what resources the request can access (a.k.a. authorization). Here’s some brief background to shed some light on this often misunderstood concept.
As we discussed in Chapter 1, web applications are client-server oriented. There are essentially two options for servers when it comes to honoring client requests:
• Perform the request using the server’s own identity (in the case of web applications, this is the web server/daemon).
• Perform the request by impersonating the client (or some other identity with similar privileges).
In software terms, impersonation means the server process spawns a thread and gives it the identity of the client (i.e., it attaches the client’s authorization token to the new thread). This thread can now access local server resources on the user’s behalf just as in the simple authz model presented at the beginning of this chapter.
NOTE
The impersonated thread may also be able to access resources remote to the first server; Microsoft terms this delegation and requires a special configuration and a higher level of privilege to perform this.
Web applications use both options just described, depending first upon the make and model of the web daemon and second upon whether the request is for a filesystem object or whether it’s to launch a server-side executable (such as a CGI or ISAPI application). For example, Microsoft’s IIS prior to version 6 always impersonated access to filesystem objects (whether as a fixed account like IUSR_machinename, or as the authenticated account specified by the client). For executables, it does not impersonate by default but can be configured to do so. The default configuration of ASP.NET applications on IIS6 and later don’t impersonate—all requests execute in the context of the Network Service account; impersonation for ASP.NET applications can be configured via machine.config or web.config under system.web/identity impersonate.
Apache does not impersonate requests for filesystem objects or executables, but rather executes everything within the security context of the web daemon process (although there are add-on modules that allow it to approximate impersonation of executables via setuid/setgid operations).
CAUTION
Because web app authorization is mediated almost entirely by the web server daemon, be especially wary of vulnerabilities in web daemons that bypass the standard authorization mechanism, such as the IIS Unicode and Double Decode issues discovered in 2001.
In any case, it should be evident that the user account that runs the web server, servlet engine, database, or other components of the application should have the least possible privileges. We’ve included links to several articles in the “References & Further Reading” section at the end of this chapter that describe the details of which accounts are used in default scenarios on IIS and Apache and how to configure them.
ASP.NET Authorization
As with many Microsoft products, IIS is but one layer in a stack of technology offerings that can be composed into complex applications. For development efforts that decide to adopt Microsoft’s IIS web server product, adopting their web development framework—Active Server pages (ASP), now called ASP.NET since its integration with Microsoft’s broader .NET programming ecosystem—is usually practical.
ASP.NET provides some very compelling authorization options, the details of which are too voluminous to go into here. We recommend checking out the “References & Further Reading” section at the end of this chapter to understand the authorization options provided by ASP.NET.
One thing we would like to highlight for those who do implement ASP.NET: if you choose to specify authn/authz credentials in the <identity> elements of your web .config files, you should encrypt them using either the Aspnet_regiis.exe tool (for ASP .NET version 2) or the Aspnet_setreg.exe tool (on ASP.NET version 1.1). In-depth descriptions of how to use these tools can be found in “References & Further Reading” at the end of this chapter.
Security Logs
Another access control countermeasure that often gets overlooked is security logging. The web application’s platform should already be generating logs for the operating system and web server. Unfortunately, these logs can be grossly inadequate for identifying malicious activity or re-creating a suspect event. Many additional events affect the user’s account and should be tracked, especially when dealing with financial applications:
• Profile changes Record changes to significant personal information such as phone number, address, credit card information, and e-mail address.
• Password changes Record any time the user’s password is changed.
Optionally, notify the user at their last known good e-mail address. (Yahoo! does this, for example.)
• Modify other user Record any time an administrator changes someone else’s profile or password information. This could also be triggered when other users, such as help desk employees, update other users’ information. Record the account that performed the change and the account that was changed.
• Add/delete user Record any time users are added to or removed from the system.
The application should log as much detail as possible. Of course, there must be a balance between the amount and type of information logged. At a minimum, information that identifies the user who originated the request should be logged. This information includes the source IP address, username, and other identification tokens, date, and time the event occurred.
Logging the actual values that were changed might not be a good idea. Logs should already be treated with a high degree of security in order to maintain their integrity, but if the logs contain Social Security numbers, credit card numbers, and other highly sensitive personal or corporate information, then they could be at risk of compromise from internal and external threats. In some cases, storing personally identifiable information (PII) such as addresses, financial data, and health information in logs may violate local or national laws, or be a violation of industry regulations. Whenever storing this type of data in log files, care should be taken to study and understand what can and cannot be stored, how long the data can be stored, and what level of protection is required.
SUMMARY
In this chapter, you saw that the typical web application authorization model is based heavily on server-side ACLs and authorization/session tokens (either off-the-shelf or custom-developed) that are vulnerable to several common attacks. Poorly implemented ACLs and tokens are easily defeated using common techniques to bypass, replay, spoof, fix, or otherwise manipulate authorization controls to masquerade as other users, including administrators. We also described several case studies that illustrated how such techniques can be combined to devastate web app authorization at multiple levels. Finally, we discussed the toolset available to web administrators and developers to counteract many of the basic attack techniques described in this chapter, as well as some broader “defense-in-depth” strategies that can help harden the overall security posture of a typical web application.
REFERENCES & FURTHER READING