
Integration of Big Data and Data Warehousing
It is a capital mistake to theorize before one has data.
—Sherlock Holmes, A Study in Scarlett (Arthur Conan Doyle)
Introduction
The data warehouse of today, while still building on the founding principles of an “enterprise version of truth” and a “single data repository,” must address the needs of data of new types, new volumes, new data-quality levels, new performance needs, new metadata, and new user requirements. As discussed in earlier chapters, there are several issues in the current data warehouse environments that need to be addressed and, more importantly, the current infrastructure cannot support the needs of the new data on the same platform. We have also discussed the emergence of new technologies that can definitely enhance the performance needs of the current data warehouse and provide a holistic platform for the extended requirements of the new data and associated user needs. The big question is how do we go about integrating all of this into one data warehouse? And, more importantly, how do we justify the data warehouse of the future?
The focus of this chapter is to discuss the integration of Big Data and the data warehouse, the possible techniques and pitfalls, and where to leverage a technology. How do we deal with complexity and heterogeneity of technologies? What are the performance and scalabilities of each technology, and how can we sustain performance for the new environment?
If one were to take a journey back in history and look at the architectural wonders that were built, we often wonder what kind of blueprints the architects considered, how they decided on the laws of physics, and how they combined chemical properties of materials for the structures to last for centuries while supporting visitor volumes and climate changes. In building the new data warehouse, we need to adapt a radical thinking like the architects of the yore, where we will retain the fundamental definition of the data warehouse as stated by Bill Inmon, but we will be developing a physical architecture that will not be constrained by the boundaries of a single platform like the RDBMS.
The next-generation data warehouse architecture will be complex from a physical architecture deployment, consisting of a myriad of technologies, and will be data-driven from an integration perspective, extremely flexible, and scalable from a data architecture perspective.
Components of the new data warehouse
Figure 10.1 shows the high-level components that will be the foundational building blocks of the next-generation data warehouse, which is the integration of all the data in the enterprise including Big Data. The lowest tier represents the data, the next tier represents the technologies that will be used in integrating the data across the multiple types and sources of data, and the topmost layer represents the analytical layer that will be used to drive the visualization needs of the next generation of business intelligence and analytics. Let us first look at each layer of the components in detail and then move onto the physical architecture options.
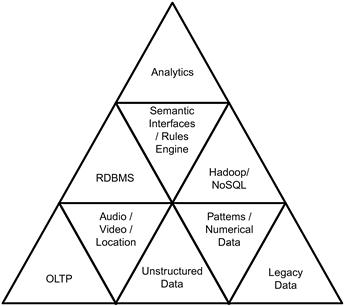
Data layer
As discussed in prior chapters, the next-generation data warehouse will have data from across the enterprise that will be integrated and presented to the users for business decision-making and analysis purposes. The data layer in the new platform includes the following.
• Legacy data. Data from all legacy systems and applications that include structured and semi-structured formats of data, stored online or offline, can be integrated into the data architecture. There are lots of use cases for this data type. Seismic data, hurricane data, census data, urban planning data, and socioeconomic data are all forms of data that have been classified as legacy over a period of time.
• Transactional (OLTP) data. Data from transactional systems traditionally is loaded to the data warehouse. Due to scalability issues, transactional data is often modeled such that not all the data from the source systems is used in analysis. The new platform can be used to load and analyze the data in its entirety as a preprocessing or second-pass processing step. Data from ERP, SCM, and CRM systems often gets left out in processing, and these segments of data can be used in creating a powerful back-end data platform that analyzes data and organizes it at every processing step.
• Unstructured data. Content management platforms are more oriented toward either producing and storing content or just storing content. Most of the content is not analyzed, and there are no standard techniques to create analytical metrics on content. Content of any nature is specific to the context in which it was created and to the organization that owns the content. The next-generation platform will provide interfaces to tap into the content by navigating it based on user-defined rules for processing. The output of content processing will be used in defining and designing analytics for exploration mining of unstructured data. The output from processing content data can be integrated using semantic technologies and used for visualization and visual data mining.
• Video. Corporations and government agencies alike have a need to harness into video-based data. There are three components in a video—the content, the audio, and the associated metadata—and processing techniques and algorithms for this data type is nascent and complex. The new data platforms, however, provide the infrastructure necessary to process this data. The next-generation data warehouse can integrate this data type and its associated analytics into the data warehouse architecture. The data will be needed as organizations start adopting gamification strategies in customer engagement, government agencies start using the data in managing multiple areas of defense and security, weather agencies use the data for analysis and reporting, and news and media agencies use multiple public and private videos to provide education to consumers on real-time and historical news in one mashup. The possibilities of how to leverage the data in commercial and noncommercial aspects are deep and wide to cover in this section. The next-generation data warehouse will be a holistic platform for processing and integrating all these one-off data types, which will be stored as contextualized data with associated metadata.
• Audio. Data from call centers to audio extracts from videos contains a lot of intelligence about customers, competition, and many more categories. While the current data warehouse has limitations on processing and integrating this data, the new data platforms and technologies have enabled processing of this data seamlessly and integrating it into the context of the data warehouse. Audio data extracts can be processed and stored as contextual data with the associated metadata in the next-generation data warehouse.
• Images. Static images carry a lot of data that can be very useful in government agencies (geospatial integration), healthcare (X-ray and CAT scans), and other areas. Integrating this data in the data warehouse will provide benefits in a large enterprise, where sharing such data can result in big insights and generate business opportunities where none existed due to lack of data availability.
• Numerical/patterns/graphs. Seismic data, sensor data, weather data, stock market data, scientific data, RFID, cellular tower data, automotive on-board computer chips, GPS data, streaming video, and other such data are either patterns, numeric data, or graphs that occur and repeat their manifests in periodic time intervals. Processing such data and integrating the results with the data warehouse will provide analytical opportunities to perform correlation analysis, cluster analysis, or Bayesian types of analysis, which will help identify opportunities in revenue leakage, customer segment behavior, and many other opportunities where business risk can be identified and processed by decision makers for business performance optimization.
• Social media data. Typically classified as Facebook, LinkedIn, or Twitter data, the social media data transcends beyond those channels. This data can be purchased from third-party aggregators such as Datasift, Gnip, and Nielsen. The processing of this data in the data warehouse can be accomplished using the rules engine and semantic technologies. Output from the processing can be integrated with multiple dimensions of the data warehouse.
The data layer consists of data sets that are most commonly available to organizations as their asset or from third-party sources. The known data sets that can be processed today consist of 20% of the data that has been discussed in the data layer. How do we process the remaining data and how does the integration happen? To answer these questions, let us discuss the underlying algorithms that need to be integrated into the processing architecture and technology layers.
Algorithms
Big Data processing needs to happen in the order shown in Figure 10.2.

The first step after acquisition of data is to perform discovery of data. This is where the complexity of processing data lies especially in unstructured data. To accelerate the reduction of complexity, there are several algorithms that have evolved in commercial or open-source solutions. The key algorithms that are useful include:
• Text mining. These algorithms are available as commercial off-the-shelf software solutions and can be integrated into the data architecture with ease. The primary focus of the text mining algorithms are to process text based on user-defined business rules and extract data that can be used in classifying the text for further data exploration purposes. Semantic technologies play a vital role in integrating the data within the data warehouse ecosystem.
• Data mining. These algorithms are available as commercial software from companies like SAS and IBM, and open-source implementations like Mahout. The primary focus of data mining algorithms is to produce data output based on statistical data models that work on population clustering, data clustering, and segmentation based on dimensions and time called microsegmentation techniques. The data output is deep and wide, providing a cube-based environment for executing data exploration exercises.
• Pattern processing. These algorithms are developed for pattern processing, which includes patterns from credit card data; POS data; ATM data; stock market signals; sensor data from buildings, trains, trucks, automobiles, airplanes, ships, satellites, images, and audio; cryptographic data, and symbolic languages. When a pattern is detected the data is processed in a transactional manner for that single instance. The advantage of integrating this data in the data warehouse will be the ability to tap into these one-time occurrences and the entire data set to arrive at a more defined predictive model of data behaviors. The next-generation platforms offer the infrastructure to store both the raw data and the output from the processing of pattern algorithms, to provide a holistic data architecture and exploration capability.
• Statistical models. These algorithms are models used largely in financial services and healthcare to compute statistical data for managing population segments. These algorithms are customized for every organization that uses them and produces outputs that today cannot be reused in computation due to the size of data and the associated processing complexity. In the next generation of the data warehouse these models can be computed and driven based on the data available in the data warehouse whether structured, semi-structured, unstructured, or a combination of all. These models can be developed in technologies like R and other open-source models as opposed to closed architectures like SAS or IBM SPSS.
• Mathematical models. These algorithms are models used for disease predictions, weather prediction, fraud analytics, and other nonstatistical computes that require mathematical models. The current-state data requirements of these algorithms cannot be met to the fullest extent by the existing infrastructure and compute technologies. In the next-generation data warehouse, the data required by these models and associated computing fabrics are both available within the data warehouse processing layers.
The next generation of data architecture and data processing activities will need to include the algorithms discussed in this section to solve the specific categories of data processing and reporting and analytics delivery from the data warehouse. Now that we have the data and the associated types of algorithms, before we discuss the integration strategies, let’s revisit the technology layer.
Technology layer
In the preceding chapters we have discussed the different types of technologies that will be used to architect the next-generation data warehouse for supporting data processing of structured, semi-structured, and unstructured or Big Data. To recap the technologies that will be mixed and integrated into the heterogeneous architecture, the list includes:
These technologies will present significant integration challenges in building the foundational architecture for the next-generation data warehouse from a solution architecture point of view. Each technology listed here has its own specific performance and scalability strengths and limitations, and one needs to understand the nuances of how to combine the strengths of the technologies to create a sustainable platform.
A key critical success factor in the design approach for the next-generation data warehouse architecture is a clearly documented and concise user requirement. With the appropriate user specification on the data and the associated processing requirements and outcomes, a program can be developed toward the implementation of the solution.
The next section’s focus and discussion is on the integration strategy and architecture. There are two primary portions of the integration architecture: data integration and architecture, and the physical implementation architecture.
Integration strategies
Data integration refers to combining data from different source systems for usage by business users to study different behaviors of the business and its customers. In the early days of data integration, the data was limited to transactional systems and their applications. The limited data set provided the basis for creating decision support platforms that were used as analytic guides for making business decisions.
The growth of the volume of data and the data types over the last three decades, along with the advent of data warehousing, coupled with the advances in infrastructure and technologies to support the analysis and storage requirements for data, have changed the landscape of data integration forever.
Traditional data integration techniques have been focused on ETL, ELT, CDC, and EAI types of architecture and associated programming models. In the world of Big Data, however, these techniques will need to either be modified to suit the size and processing complexity demands, including the formats of data that need to be processed. Big Data processing needs to be implemented as a two-step process. The first step is a data-driven architecture that includes analysis and design of data processing. The second step is the physical architecture implementation, which is discussed in the following sections.
Data-driven integration
In this technique of building the next-generation data warehouse, all the data within the enterprise are categorized according to the data type, and depending on the nature of the data and its associated processing requirements, the data processing is completed using business rules encapsulated in processing logic and integrated into a series of program flows incorporating enterprise metadata, MDM, and semantic technologies like taxonomies.
Figure 10.3 shows the inbound data processing of different categories of data. This model segments each data type based on the format and structure of the data, and then processes the appropriate layers of processing rules within the ETL, ELT, CDC, or text processing techniques. Let us analyze the data integration architecture and its benefits.
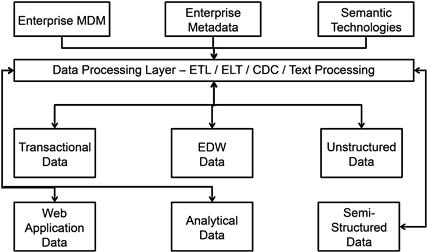
Data classification
As shown in Figure 10.3, there are broad classifications of data:
• Transactional data—the classic OLTP data belongs to this segment.
• Web application data—the data from web applications that are developed by the organization can be added to this category. This data includes clickstream data, web commerce data, and customer relationship and call center chat data.
• EDW data—this is the existing data from the data warehouse used by the organization currently. It can include all the different data warehouses and datamarts in the organization where data is processed and stored for use by business users.
• Analytical data—this is data from analytical systems that are deployed currently in the organization. The data today is primarily based on EDW or transactional data.
• Unstructured data—under this broad category, we can include:
• Text—documents, notes, memos, contracts.
• Images—photos, diagrams, graphs.
• Videos—corporate and consumer videos associated with the organization.
• Social media—Facebook, Twitter, Instagram, LinkedIn, Forums, YouTube, community websites.
• Audio—call center conversations, broadcasts.
• Sensor data—includes data from sensors on any or all devices that are related to the organization’s line of business. For example, smart meter data makes a business asset for an energy company, and truck and automotive sensors relate to logistics and shipping providers like UPS and FedEx.
• Weather data—is used by both B2B and B2C businesses today to analyze the impact of weather on the business; has become a vital component of predictive analytics.
• Scientific data—this data applies to medical, pharmaceutical, insurance, healthcare, and financial services segments where a lot of number-crunching type of computation is performed including simulations and model generation.
• Stock market data—used for processing financial data in many organizations to predict market trends, financial risk, and actuarial computations.
• Semi-structured data—this includes emails, presentations, mathematical models and graphs, and geospatial data.
Architecture
With the different data types clearly identified and laid out, the data characteristics, including the data type, the associated metadata, the key data elements that can be identified as master data elements, the complexities of the data, and the business users of the data from an ownership and stewardship perspective, can be defined clearly.
Workload
The biggest need for processing Big Data is workload management, as discussed in earlier chapters. The data architecture and classification allow us to assign the appropriate infrastructure that can execute the workload demands of the categories of the data.
There are four broad categories of workload based on volume of data and the associated latencies that data can be assigned to (Figure 10.4). Depending on the type of category the data can then be assigned to physical infrastructure layers for processing. This approach to workload management creates a dynamic scalability requirement for all parts of the Data Warehouse, which can be designed by efficiently harnessing the current and new infrastructure options. The key point to remember at this juncture is the processing logic needs to be flexible to be implemented across the different physical infrastructure components since the same data might be classified into different workloads depending on the urgency of processing.

The workload architecture will further identify the conditions of mixed workload management where the data from one category of workload will be added to processing along with another category of workload.
For example, processing high-volume, low-latency data with low-volume, high-latency data creates a diversified stress on the data processing environment, where you normally would have processed one kind of data and its workload. Add to this complexity the user query and data loading happening at the same time or in relatively short intervals, and now the situation can get out of hand in a quick succession and impact the overall performance. If the same infrastructure is processing Big Data and traditional data together with all of these complexities, the problem just compounds itself.
The goal of using the workload quadrant is to identify the complexities associated with the data processing and how to mitigate the associated risk in infrastructure design to create the next-generation data warehouse.
Analytics
Identifying and classifying analytical processing requirements for the entire set of data elements at play is a critical requirement in the design of the next-generation data warehouse platform. The underpinning for this requirement stems from the fact that you can create analytics at the data discovery level, which is very focused and driven by the business consumer and not aligned with the enterprise version of the truth, and you can equally create analytics after data acquisition in the data warehouse.
Figure 10.5 shows the analytics processing in the next-generation data warehouse platform. The key architecture integration layer here is the data integration layer, which is a combination of semantic, reporting, and analytical technologies, which is based on the semantic knowledge framework, which is the foundation of next-generation analytics and business intelligence. This framework is discussed later in this chapter.
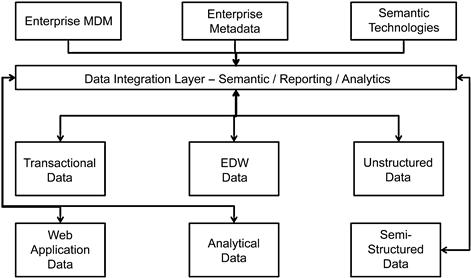
Finalizing the data architecture is the most time-consuming task, which once completed will provide a strong foundation for the physical implementation. The physical implementation will be accomplished using technologies from the earlier discussions including Big Data and RDBMS systems.
Physical component integration and architecture
The next-generation data warehouse will be deployed on a heterogeneous infrastructure and architectures that integrate both traditional structured data and Big Data into one scalable and performing environment. There are several options to deploy the physical architecture with pros and cons for each option.
The primary challenges that will confront the physical architecture of the next-generation data warehouse platform include data loading, availability, data volume, storage performance, scalability, diverse and changing query demands against the data, and operational costs of maintaining the environment. The key challenges are outlined here and will be discussed with each architecture option.
Data loading
• With no definitive format or metadata or schema, the loading process for Big Data is simply acquiring the data and storing it as files. This task can be overwhelming when you want to process real-time feeds into the system, while processing the data as large or microbatch windows of processing. An appliance can be configured and tuned to address these rigors in the setup as opposed to a pure-play implementation. The downside is a custom architecture configuration may occur, but this can be managed.
• Continuous processing of data in the platform can create contention for resources over a period of time. This is especially true in the case of large documents or videos or images. If this requirement is a key architecture driver, an appliance can be suitable for this specificity, as the guessing game can be avoided in the configuration and setup process.
• MapReduce configuration and optimization can be daunting in large environments and the appliance architecture provides you reference architecture setups to avoid this pitfall.
Data availability
• Data availability has been a challenge for any system that relates to processing and transforming data for use by end users, and Big Data is no exception. The benefit of Hadoop or NoSQL is to mitigate this risk and make data available for analysis immediately upon acquisition. The challenge is to load the data quickly as there is no pretransformation required.
• Data availability depends on the specificity of metadata to the SerDe or Avro layers. If data can be adequately cataloged on acquisition, it can be available for analysis and discovery immediately.
• Since there is no update of data in the Big Data layers, reprocessing new data containing updates will create duplicate data and this needs to be handled to minimize the impact on availability.
Data volumes
• Big Data volumes can easily get out of control due to the intrinsic nature of the data. Care and attention needs to be paid to the growth of data upon each cycle of acquisition.
• Retention requirements for the data can vary depending on the nature of the data and the recency of the data and its relevance to the business:
• Compliance requirements: SAFE Harbor, SOX, HIPAA, GLBA, and PCI regulations can impact data security and storage. If you are planning to use these data types, plan accordingly.
• Legal mandates: There are several transactional data sets that were not stored online and were required by courts of law for discovery purposes in class-action lawsuits. The Big Data infrastructure can be used as the storage engine for this data type, but the data mandates certain compliance needs and additional security. This data volume can impact the overall performance, and if such data sets are being processed on the Big Data platform, the appliance configuration can provide the administrators with tools and tips to zone the infrastructure to mark the data in its own area, minimizing both risk and performance impact.
• Data exploration and mining is a very common activity that is a driver for Big Data acquisition across organizations, and also produces large data sets as output of processing. These data sets need to be maintained in the Big Data system by periodically sweeping and deleting intermediate data sets. This is an area that normally is ignored by organizations and can be a performance drain over a period of time.
Storage performance
• Disk performance is an important consideration when building Big Data systems and the appliance model can provide a better focus on the storage class and tiering architecture. This will provide the starting kit for longer-term planning and growth management of the storage infrastructure.
• If a combination of in-memory, SSD, and traditional storage architecture is planned for Big Data processing, the persistence and exchange of data across the different layers can be consuming both processing time and cycles. Care needs to be extended in this area, and the appliance architecture provides a reference for such complex storage requirements.
Operational costs
Calculating the operational cost for a data warehouse and its Big Data platform is a complex task that includes initial acquisition costs for infrastructure, plus labor costs for implementing the architecture, plus infrastructure and labor costs for ongoing maintenance including external help commissioned from consultants and experts.
External data integration
Figure 10.6 shows the external data integration approach to creating the next-generation data warehouse. In this approach the existing data processing and data warehouse platforms are retained, and a new platform for processing Big Data is created in new technology architecture. A data bus is developed using metadata and semantic technologies, which will create a data integration environment for data exploration and processing.
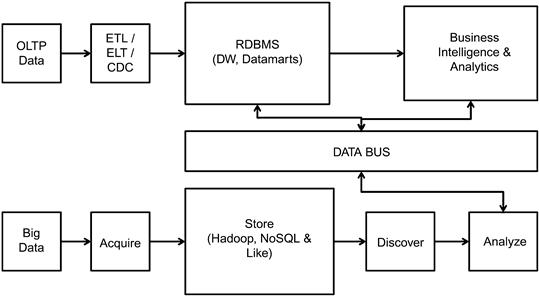
Workload processing is clearly divided in this architecture into processing Big Data in its infrastructure and the current-state data warehouse in its infrastructure. The streamlining of workload helps maintain performance and data quality, but the complexity increases in the data bus architecture, which can be a simple layer or an overwhelmingly complex layer of processing. This is a custom-built solution for each system that will be integrated into the data warehouse architecture, and needs a lot of data architecture skills and maintenance. Data processing of Big Data will be outside the RDBMS platform, and provides opportunities to create unlimited scalability at a lower price point.
• Scalable design for RDBMS and Big Data processing.
• Reduced overload on processing.
• Complexity of processing can be isolated across data acquisition, data cleansing, data discovery, and data integration.
• Modular data integration architecture.
• Heterogeneous physical architecture deployment, providing best-in-class integration at the data processing layer.
• Data bus architecture can become increasingly complex.
• Poor metadata architecture can creep due to multiple layers of data processing.
• Data integration can become a performance bottleneck over a period of time.
Typical use cases for this type of integration architecture can be seen in organizations where the data remains fairly stable over a period of time across the Big Data spectrum. Examples include social media channels and sensor data.
• Data loading is isolated across the layers. This provides a foundation to create a robust data management strategy.
• Data availability is controlled to each layer and security rules can be implemented to each layer as required, avoiding any associated overhead for other layers.
• Data volumes can be managed across the individual layers of data based on the data type, the life-cycle requirements for the data, and the cost of the storage.
• Storage performance is based on the data categories and the performance requirements, and the storage tiers can be configured.
• Operational costs—in this architecture the operational cost calculation has fixed and variable cost components. The variable costs are related to processing and computing infrastructure and labor costs. The fixed costs are related to maintenance and data-related costs.
• Too much data complexity at any one layer of processing.
• Incorrect data analysis within Big Data layers.
• Incorrect levels of integration (at data granularity) within the Big Data layers.
Hadoop & RDBMS
Figure 10.7 shows the integration-driven approach to creating the next-generation data warehouse. To create the next-generation data warehouse we combine the Big Data processing platform created in Hadoop or NoSQL and the existing RDBMS-based data warehouse infrastructure by deploying a connector between the two systems. This connecter will be a bridge to exchange data between the two platforms. At the time of writing, most of the RDBMS, BI, analytics, and NoSQL vendors have developed Hadoop and NoSQL connectors.
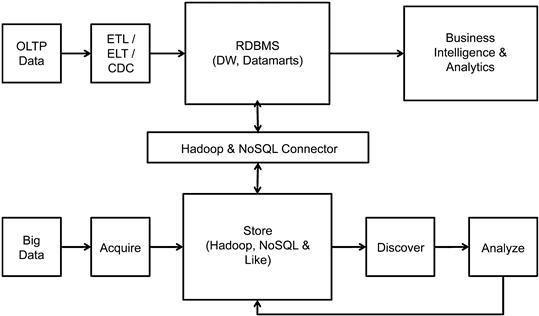
Workload processing is this architecture blends data processing across both platforms, providing scalability and reducing complexity. The streamlining of workload creates a scalable platform across both the infrastructure layers, where data discovery can be seamlessly enabled in either platform. The complexity of this architecture is the dependency on the performance of the connector. The connectors largely mimic a JDBC behavior, and the bandwidth to transport data will be a severe bottleneck, considering the query complexity in the data discovery process.
• Scalable design for RDBMS and Big Data processing.
• Modular data integration architecture.
• Heterogeneous physical architecture deployment, providing best-in-class integration at the data processing layer.
• Metadata and MDM solutions can be leveraged with relative ease across the solution.
• Performance of the Big Data connector is the biggest area of weakness.
• Data integration and query scalability can become complex.
Typical use case for this type of integration architecture can be seen in organizations where the data needs to be integrated into analytics and reporting. Examples include social media data, textual data, and semi-structured data like emails.
• Data loading is isolated across the layers. This provides a foundation to create a robust data management strategy.
• Data availability is controlled to each layer and security rules can be implemented to each layer as required, avoiding any associated overhead for other layers.
• Data volumes can be managed across the individual layers of data based on the data type, the life-cycle requirements for the data, and the cost of the storage.
• Storage performance—Hadoop is designed and deployed on commodity architecture and the storage costs are very low compared to the traditional RDBMS platform. The performance of the disks for each layer can be configured as needed by the end user.
• Operational costs—in this architecture the operational cost calculation has fixed and variable cost components. The variable costs are related to processing and computing infrastructure and labor costs. The fixed costs are related to RDBMS maintenance and its related costs.
• Too much data complexity at any one layer of processing.
• Executing large data exchanges between the different layers.
• Incorrect levels of integration (at data granularity).
• Applying too many transformation complexities using the connectors.
Big Data appliances
Data warehouse appliances emerged as a strong black-box architecture for processing workloads specific to large-scale data in the last decade. One of the extensions of this architecture is the emergence of Big Data appliances. These appliances are configured to handle the rigors of workloads and complexities of Big Data and the current RDBMS architecture.
Figure 10.8 shows the conceptual architecture of the Big Data appliance, which includes a layer of Hadoop and a layer of RDBMS. While the physical architectural implementation can differ among vendors like Teradata, Oracle, IBM, and Microsoft, the underlying conceptual architecture remains the same, where Hadoop and/or NoSQL technologies will be used to acquire, preprocess, and store Big Data, and the RDBMS layers will be used to process the output from the Hadoop and NoSQL layers. In-database MapReduce, R, and RDBMS specific translators and connectors will be used in the integrated architecture for managing data movement and transformation within the appliance.

The Big Data appliance is geared to answer some key areas that emerge as risks or challenges when dealing with extremely large data processing. The primary areas include data loading, availability, data volume, storage performance, scalability, diverse and changing query demands against the data, and operational costs of the next-generation data warehouse platform. The risks can be applied to both the structured and the unstructured data that will be coexisting in this platform.
• Data loading is isolated across the layers. This provides a foundation to create a robust data management strategy.
• Data availability is controlled to each layer and security rules can be implemented to each layer as required, avoiding any associated overhead for other layers.
• Data volumes can be managed across the individual layers of data based on the data type, the life-cycle requirements for the data, and the cost of the storage.
• Storage performance is based on the data categories and the performance requirements, and the storage tiers can be configured.
• Operational costs—the appliance architecture enables a quick way to calculate the total cost of ownership and especially operational costs, since the configuration of the appliance is focused on satisfying all the known requirements as documented.
The areas discussed here are some key considerations for looking at the appliance as a solution rather than building out your own architecture.
Workload processing in this architecture is configured to the requirements as specified by the users, including data acquisition, usage, retention, and processing. The complexity of this architecture is the configuration and initial setup, which will need significant rework if the specifications are not clear or tend to change over time, since the initial configuration is customized.
• Scalable design and modular data integration architecture.
• Heterogeneous physical architecture deployment, providing best-in-class integration at the data processing layer.
• Custom configured to suit the processing rigors as required for each organization.
• Customized configuration is the biggest weakness.
• Data integration and query scalability can become complex as the configuration changes over a period of time.
This architecture can be deployed to process all types of Big Data, and is the closest to a scalable and integrated next-generation data warehouse platform.
• Custom configuration can be maintenance-heavy.
• Executing large data exchanges between the different layers can cause performance issues.
• Too much dependency on any one transformation layer creates scalability bottlenecks.
• Data security implementation with LDAP integration should be avoided for the unstructured layers.
Data virtualization
Data virtualization technology can be used to create the next-generation data warehouse platform. As shown in Figure 10.9, the biggest benefit of this deployment is the reuse of existing infrastructure for the structured portion of the data warehouse. This approach also provides an opportunity to distribute workload effectively across the platforms thereby allowing for the best optimization to be executed in the architectures. Data Virtualization coupled with a strong semantic architecture can create a scalable solution.
• Extremely scalable and flexible architecture.
• Lower initial cost of deployment.
• Lack of governance can create too many silos and degrade performance.
• Complex query processing can become degraded over a period of time.
• Performance at the integration layer may need periodic maintenance.
• Data loading is isolated across the layers. This provides a foundation to create a robust data management strategy.
• Data availability is controlled to each layer and security rules can be implemented to each layer as required, avoiding any associated overhead for other layers.
• Data volumes can be managed across the individual layers of data based on the data type, the life-cycle requirements for the data, and the cost of the storage.
• Storage performance is based on the data categories and the performance requirements, and the storage tiers can be configured.
• Operational costs—in this architecture the operational cost calculation has fixed and variable cost components. The variable costs are related to processing and computing infrastructure and labor costs. The fixed costs are related to maintenance of the data virtualization platform and its related costs.
• Loosely coupled data integration.
• Incorrect data granularity across the different systems.
• Poor metadata across the systems.
• Complex data integration involving too many computations at the integration layer.
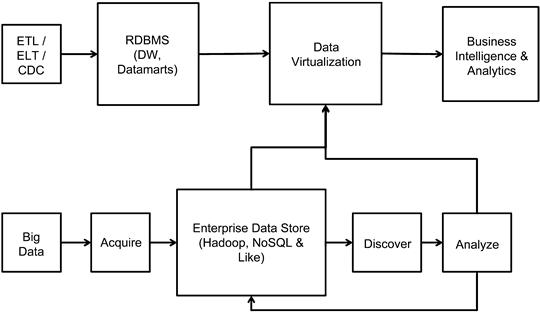
There are many more possible architectural deployments to integrate Big Data and create the next-generation data warehouse platform. This chapter’s goal is to provide you a starter kit to begin looking at what it will take for any organization to implement the next-generation data warehouse. In the next section we discuss the semantic framework approach.
Semantic framework
Building the next-generation data warehouse requires strong metadata architecture for data integration, but that does not solve the data exploration requirements. When data from multiple sources and systems is integrated together, there are multiple layers of hierarchies including jagged and skewed hierarchies, data granularity at different levels, and data quality issues especially with unstructured data, including text, image, video, and audio data. Processing data and presenting data for visualization at both ends requires a more robust architecture, which is the semantic framework.
Figure 10.10 shows the concept of the semantic framework architecture. The framework consists of multiple layers of processing and data integration techniques that will be deployed as a part of the next-generation data warehouse. The layers and their functions include the following.
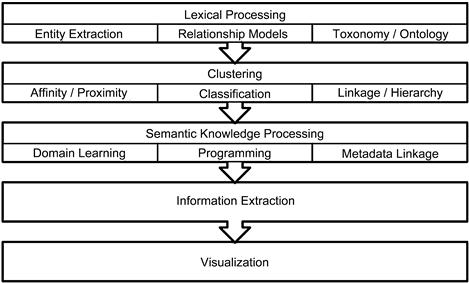
Lexical processing
This layer can be applied to both input data processing of Big Data and the processing of data exploration queries from the visualization layer. Lexical processing includes processing tokens and streams of text. The three main subcomponents of lexical processing include:
• Entity extraction—a process to identify key data tokens that can include keys and master data elements. For example, identifying “product_name” from a twitter feed.
• Taxonomy—a process to navigate across domains within the text stream to identify the contexts in the text that may be feasible, and discover relationship attributes for cross-hierarchy navigation.
• Relationship models—a process to derive the relationship between different data elements and layers resulting in an exploration roadmap. This process will use outputs from the prior components in this process.
Clustering
In this process all the data from lexical processing will be clustered to create a logical grouping of data processed in the Big Data layers and from any data exploration queries. The subcomponents in this layer include:
• Affinity/proximity—in this process there are two components:
1. Affinity—this feature will determine the affinity of data across different formats. For example, a group of videos, audio, and documents containing data about cardiac diseases.
2. Proximity—the occurrence of specific data elements within a given unstructured text.
• Classification—in this process that is more back-end oriented, the data can be classified into multiple groups of topics or be aligned to subject areas similar to the structured data in the data warehouse.
• Linkage/hierarchy—in this process the output from the classification stage is linked in a lexical map including the associated hierarchy information.
Semantic knowledge processing
This process consists of integrating the data outputs from lexical and clustering layers to provide a powerful architecture for data visualization. This process consists of the following subcomponents:
• Domain learning—in this process the data from different domains is paired and integrated with semantic technologies. The data at this stage includes structured and Big Data.
• Programming—in this process software programs are created and deployed to complete the semantic integration process. This section also includes machine learning techniques and additional lexical processing to complete the integration as needed for visualization.
• Metadata linkage—a last step in the semantic processing is the integration of data with metadata links that will be used in visual exploration and mining.
Information extraction
In this process the visualization tools extract the data from the prior layers of processing and load it for visual exploration and analytics. The data at this stage can be loaded into technology like in-memory for further analysis.
Visualization
In this process the data can be visualized using new technologies like Tableau and Spotfire, or with R, SAS, or traditional technologies like Microstrategy, Business Objects, or Cognos. These tools can directly leverage the semantic architecture from their integration layers and create a scalable interface.
Summary
In summary, as observed in this chapter, heterogeneity is permanent in the future of the data warehouse, and the concept remains the same as defined 40 years ago by Bill Inmon, but the physical implementation will be different from the prior generations of data warehousing. In the next chapter we will focus on the data-driven integration architecture, and the impact of data governance, metadata, and master data in creating the next-generation data warehouse.