
Workload Management in the Data Warehouse
For the machine meant the conquest of horizontal space. It also meant a sense of that space which few people had experienced before—the succession and superimposition of views, the unfolding of landscape in flickering surfaces as one was carried swiftly past it, and an exaggerated feeling of relative motion (the poplars nearby seeming to move faster than the church spire across the field) due to parallax. The view from the train was not the view from the horse. It compressed more motifs into the same time. Conversely, it left less time in which to dwell on any one thing.
—Robert Hughes, The Shock of the New
Introduction
There are several systems that have been built for data warehouses over the last 30 years. The primary goal of a data warehouse has evolved from being a rear-view look at the business and metrics for decision making to a real-time and predictive engine. The evolution has been really fast in the last 5 years compared to the 25 years prior, and such a pace of growth mandates several changes to happen in the entire data processing ecosystem to scale up and scale out to handle the user demands and data processing requirements. One of the key aspects to consider for designing the newer architectures is to understand what we are processing and what is required from a system perspective for this processing to happen in an acceptable performance time. Apart from the initial processing, we need to design the system to sustain the performance, remain scalable, and remain financially viable for any enterprise. The answer to this lies in understanding the workloads that happen in the system today and in the future, and create architectures that will meet these requirements.
Workload-driven data warehousing is a concept that will help the architects and system administrators to create a solution based on the workload of processing data for each data type and its final integration into the data warehouse. This is key to understanding how to build Big Data platforms that will remain independent of the database and have zero or very minimal dependency on the database. This is the focus of this chapter and the design and integration will be discussed in Chapters 11 and 12.
Current state
Performance, throughput, scalability, and flexibility are all areas that have challenged a data warehouse and will continue to be an area of challenge for data warehousing until we understand the grassroots of the problem and address it. To understand the problem, we need to go beyond just managing the database-related tuning and architectural nuances, and understand the workload aspects of the entire system, thereby managing the design process of both data and systems architecture to accomplish the goal of overcoming challenges and turning those into opportunities.
Defining workloads
According to Dictionary.com, workload is defined as the amount of work that a machine produces or can produce in a specified time period. By delving deeper and applying this definition to a data processing machine (we should include the application server, network, database server, and storage as one unit for this definition), we define the query processing of the database in terms of throughput or how many rows/second we have read or written or, in system terms, inserted, updated, or deleted. There are several benchmarks that one can conduct to determine throughput (please refer to Transaction Processing Council at www.tpc.org). This throughput, however, is constrained to one unit in the entire machine—the database—and the number of users and queries it can manage at any point in time (i.e., a multi-user work processing or multi-user workload constrained to a specific pattern of queries).
While the database definitely manages the number-crunching tasks on a data warehouse or OLTP platform, it has to rely on the capabilities of the network, the operating system, and the storage infrastructure to create a sustainable and scalable performance.
Why do we need to understand workloads better when we discuss data warehousing or analytics? Because the design of the next-generation data warehouses will be largely focused on building workload-characterized architectures, and integrating them through logical layers. Gartner calls this the logical data warehouse, and my definition is workload-driven data warehousing. For example, if we are designing a near-real-time integration between a traditional decision support platform and a web application or a point-of-sale (POS) kiosk, we are discussing two different types of system architectures that work at different response rates. Without understanding the workload capabilities of these systems, designing a platform will be delivering an underperforming system or often can lead to failure of adoption.
Another perspective to look at regarding workloads is to understand the need for static versus dynamic systems. A low-end digital camera is a static system. It is designed once and mass- produced with the only requirement being how many pictures it can take in different settings provided as options. There is not much room to change the basic architecture of a camera until you start talking about high-end devices or light-field cameras. Whereas, a data warehouse can receive different data types and process requests from different types of users in the same timeframe or across different times in a day. This requires a lot of dynamic data processing as opposed to a static system.
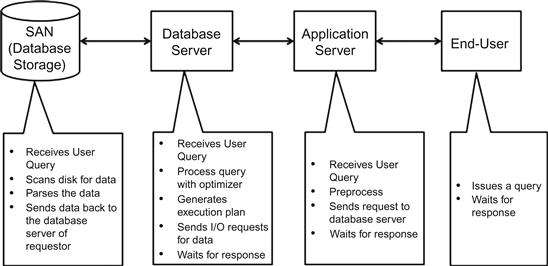
Figure 8.1 shows the classic system architecture and the associated behaviors of each portion of the system. If you closely follow the trail from the end-user application to the database storage, there are multiple steps of data movement and processing across the layers. Eventually, we also see that each layer has a wait on the subsequent layer before a final processing step can be accomplished. We often address a symptom when a problem manifests rather than take a holistic approach for the big picture. This isolated problem addressing technique needs to change for designing and addressing scalability and performance demands of today’s users.
An additional aspect to keep in perspective is the ever-changing nature of data and its associated structures. The impact of data itself is one of the most ignored areas that affect workloads of the data warehouse and datamarts. There are two categories of data that adversely affect workloads due to their volume and special needs for security in certain categories:
• Persistent data—data that is needed to be maintained for compliance and regulatory reasons and cannot be deleted or archived for a period of time; for example, customer data and sensitive data fall into this category.
• Volatile data—data that is of value for a shorter life span, but once the intelligence/analytics are drawn, the data is no longer useful to maintain; for example, a large portion of transactional data falls into this category.
Understanding workloads
In a classic systems architecture approach as shown in Figure 8.1, the workload management today is centered on the database. The primary reason for this situation is due to the fact that we can analyze what happens in the database when a query is submitted and, based on the results, interpret if the issues are within the database or outside the database. As a result of this approach, today we define workload from the database perspective alone regardless of what happens in the entire system. The results that are discussed for workload and throughput revolve around the statistics like CPU usage, elapsed time of query, the number of SQL executions, and total users on the database. Based on the results, we infer what performance impact is experienced in the current state and what can be experienced if there are spikes of increases or decreases of workloads. The resulting definitions from these exercises often fail to produce the right architectural decisions.
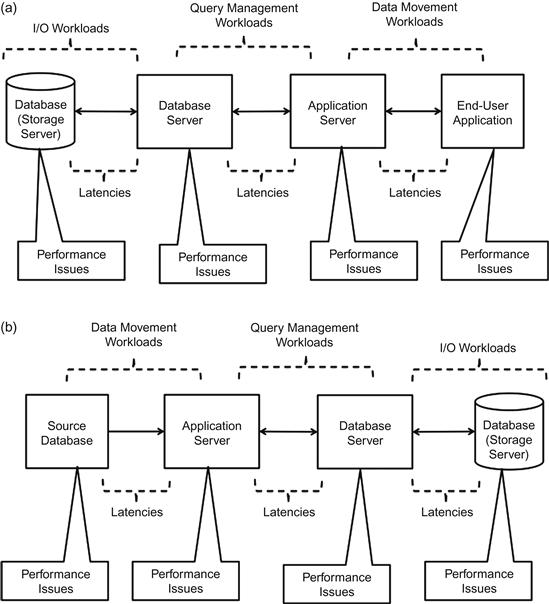
Figure 8.2 shows the problem areas that manifest in the data warehouse today. We can bucket these problems under each segment to understand the overall workload aspect of the system. The different aspects of the data warehouse affected by workloads are discussed in the following sections.
Data warehouse outbound
There are several recipients of data from the data warehouse, including end-user applications, datamarts, and analytical databases.
End-user application
This includes the reporting, analytics, web, and desktop applications that directly interact with the data warehouse. We include the web application since many reporting or analytic applications can be used on a pure-play web browser or a mobile application.
Data outbound to users
• Overheads—the end-user application layer adds security constraints to the data based on the user who is accessing the application. This constraint cannot be managed as a database-level filter in many situations, and the impact of this overhead is often data result sets that are larger than needed and will be filtered and discarded at the end-user system level.
• Dependencies—the processing capabilities of the application at the end user depend on the amount of disk, memory, cache, and processor available to the application. Large volumes of data mean multiple cycles of exchange between the application server and the end-user system, adding network traffic and waits.
• Issues—many a time, due to the volume of data and the amount of elapsed time when waiting on the data, the end user loses connection to the application server due to timeouts, the application goes into a sleep mode, or the priority of execution of the application is lowered on the end-user system.
• Note—the situation is similar or even worse when you remove the application server and directly connect to a datamart or data warehouse.
• Workarounds—current workarounds include:
• Special tables and/or views (at the database layer).
• Semantic layer filters and data structures.
• Adding security filters to queries.
• Adding infrastructure to process data and move data faster.
• Complexities—the data within the data warehouse is clearly articulated for usage by the enterprise. This imposes restrictions on the amount of transformation or data granularity level for the data warehouse. From an outbound perspective this is the biggest area of complexity, as many processing iterations from a transformation requirement and different types of calculations are worked upon to complete the query’s requirement.
• Goal—the goal for creating an effective workload strategy at this layer is to minimize the amount of work to be done by this layer to manifest the dashboard, report, or metric.
Data inbound from users
End-user applications rarely send data directly to the data warehouse. The inbound data comes from ETL processes.
Datamarts
The behavior characteristics of a datamart are similar to the data warehouse but not with the same level of complexity.
Data outbound to users
• Overheads—the end-user application layer adds security constraints to the data based on the user who is accessing the application. This constraint cannot be managed as a database-level filter in many situations and the impact of this overhead is often data result sets that are larger than needed and will be filtered and discarded at the end-user system level.
• Dependencies—the processing capabilities of the application at the end user depend on the amount of disk, memory, cache, and processor available to the application. Large volumes of data mean multiple cycles of exchange between the application server and the end-user system, adding network traffic and waits.
• Issues—many times, due to the volume of data and the amount of elapsed time when waiting on the data, the end user loses connection to the application server due to timeouts, the application goes into a sleep mode, or the priority of execution of the application is lowered on the end-user system.
• Note—the situation is similar or even worse when you remove the application server and directly connect to a datamart.
• Workarounds—current workarounds include:
• Special tables and/or views (at the database layer).
• Semantic layer filters and data structures.
• Adding security filters to queries.
• Adding infrastructure to process data and move data faster.
• Complexity—the most complex operations at the datamart layer are a hierarchy-based processing of data and referential integrity management between data structures that need to integrate data across different layers of granularity and sometimes in nonrelational techniques.
• Goal—the goal for creating an effective workload strategy at this layer is to minimize the amount of work to be done by this layer to manifest the dashboard, report, or metric.
Data inbound from users
End-user applications rarely send data directly to the datamart. The inbound data comes from ETL processes.
Analytical databases
Analytical databases can be executed from within a data warehouse or outside as a separate infrastructure. The issue with a separate processing infrastructure is the tendency of extremely large data sets that need to be moved between the data warehouse and the analytical database in a bidirectional manner.
• Overheads—the end-user application adds minimal overhead from the analytical application.
• Dependencies—the processing capabilities of the application at the end user depend on the amount of disk, memory, cache, and processor available to the application. Large volumes of data mean multiple cycles of exchange between the application server and the end-user system, adding network traffic and waits.
• Issues—large volumes of data are moved back and forth between the analytical database and the data warehouse. This extremely large data extraction process adds a lot of burden to the processing database on both sides of the picture.
• Workarounds—current workarounds include:
• Special aggregate structures at the data warehouse or datamart.
• Special network connectors between the analytical database and the data warehouse to bypass the enterprise network and avoid clogging it.
• Adding infrastructure to process data and move data faster.
• Goal—the goal for creating an effective workload strategy at this layer is to minimize the amount of work to be done by this layer by shifting the data processing to the data warehouse or the underlying database in a shared-server architecture with the data warehouse, and restricting the data volume to be moved across, thereby improving the overall performance of the application.
To summarize, the outbound data processing from the data warehouse generates workloads that will require processing of data several times to the same application and processing several such applications at the same period of time. The focus areas for workload management that impact performance include the database, storage servers, and network.
Data warehouse inbound
There are several sources of data that need to be processed into the data warehouse and stored for further analysis and processing. The primary application that manages the inbound processing of data into the data warehouse is the extract, transform, and load (ETL) application. There are different variations of ETL today with extract, load and transform (ELT) and change data capture (CDC) techniques and database replication.
Data warehouse processing overheads
The processing of data into the data warehouse has several overheads associated with it, depending on the technique.
• ETL—the most common processing model, the ETL design includes movement of data to an intermediate staging area, often shared in the same storage as the data warehouse and applying transformation rules including lookup processing. The data is often extracted from both the staging and data warehouse areas and compared in memory for processing. Depending on the volume of data from both ends, the process may spiral into an uncontrolled timespan causing a major impact on the data warehouse. A second continuum of overhead persists in the transformation of data within the data warehouse. There are several business rules to be completed for the processing of data and these rules can add workload overheads. Similarly, constraints on the tables within the data warehouse add to processing overheads when inserting or updating data within the data warehouse.
• Dependencies—the processing capabilities of the ETL application apart from the business rules and the data processing complexities depend on the amount of disk, memory, cache, and processor available to the application server. Large volumes of data mean multiple cycles of exchange between the application server and the database, adding network traffic and waits.
• Issues—large volumes of data are moved back and forth between the ETL application server and the data warehouse. This extremely large data extraction process adds a lot of burden to the processing database on both sides.
• Workarounds—current workarounds include:
• Minimizing data movement when processing large data sets by incorporating ETL and ETL-hybrid architectures.
• Special network connectors between the ETL server and the data warehouse to bypass the enterprise network and avoid clogging it.
• Adding infrastructure to process data and move data faster.
• Implementing SOA-type architectures to data processing.
• Goal—the goal for creating an effective workload strategy at this layer is to minimize the amount of work to be done by either the ETL or the data warehouse or, in a different approach, maximize each processing or iteration cycle where the resources are effectively utilized.
Query classification
There are primarily four categories of workload that are generated today: wide/wide, wide/narrow, narrow/wide, and narrow/narrow (Figure 8.3).
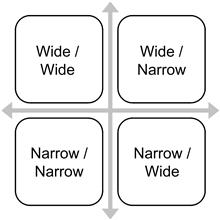
Wide/Wide
Wide/wide workloads are queries from analytics or multidimensional analysis, and can also be triggered by ad-hoc users and return long sets of columns typically joining more than two tables in the result set. The resulting complexity from these queries are impacted by the:
Typically, these queries exhibit the following traits:
Wide/Narrow
Wide/narrow workloads are queries that are generated by standard reports and dashboards and run execution on wide columns from more than two tables returning a narrow set of columns in the result set. The resulting complexity from these queries are impacted by the:
Typically, these queries exhibit the following traits:
Narrow/Wide
Narrow/wide workloads are queries generated by ad-hoc users or analytic users and run execution on a narrow set of columns from two to four tables returning a wide set of columns in the result set. The resulting complexity from these queries are impacted by the:
Typically, these queries exhibit the following traits:
Narrow/Narrow
Narrow/narrow workloads are queries generated by standard reports and run execution on a narrow set of columns, summarized tables, or aggregate structures returning a narrow set of columns in the result set. The resulting complexity from these queries are impacted by the:
Typically, these queries exhibit the following traits:
Unstructured/semi-structured data
Another big impact on query performance comes from the integration of data in the query from a non-RDBMS structure like Excel files, CSV files, and other storage structures. The impact on the workload performance is the actual loading of the data into memory from the file for each cycle of operation and managing the intermediate data sets. The queries affected here are across all the different types of classifications discussed in this section, and they exhibit the following traits:
File-based data in the traditional data management platform is a threat to increasing and skewing workloads since they are managed in a serial fashion in terms of reads and writes. In the traditional data integration architecture, there is no parallelism involved in file-based operations due to consistency management, which has been a big deterrent in the performance and negatively impacted workloads.
While queries by themselves are a problem when it comes to workload management, the associated data integration challenges that are present in this layer of the architecture make it one of the most complex areas to design, maintain, and manage on an ongoing basis.
ETL and CDC workloads
Figure 8.4 shows the categorization of ETL and CDC workloads. Depending on the data type, the associated business rule for transformation, and the underlying data model and architecture, the processing of loading, updating, or deleting data to the tables can generate a lot of workload on the application and the database server.
The typical traits of ETL workloads are:
• Higher I/O for longer bursts of time
• Large volumes of data moved across the network
• Large transaction cycles—leading to many flushes of log files and cache in the database, creating additional operating system–level workload
• Depending on the software and the programming model, additional file management can be necessary
CDC workloads exhibit the following traits:
• Higher I/O for shorter bursts of time
• Smaller volumes of data moved across the network
Depending on the set of operations executed in the data warehouse at any given point in time, you can have multiple workloads being processed on the entire system. This is the underlying design concept that needs to be thought about when designing a data warehouse. Database vendors like Oracle, Teradata, and IBM have created workload management algorithms and toolsets to help users manage their database performance. These tools aid the database and system administrators to create a set of optimization rules based on which the database and the associated data architecture can be utilized to create an efficient execution map for querying and loading data.
In the early days of data warehouse implementation, data was always processed in a batch execution environment, and that process was always executed when the data warehouse was not utilized and there were no users on the system. This situation provided administrators to optimize the database and the servers to either load or query data within the data warehouse. In the last decade we have seen the trend change to load more real-time data to the data warehouse, which means there is no downtime for specifically loading data. This situation is called mixed-workload architecture where the data warehouse now has to be able to handle multiple types of query workloads while loading or transforming data. The challenge that confronts the architects is not about the infrastructure capability, but rather the data structure and architecture.
Measurement
Before we move on to discussing how we think of the modern data warehouse design, we need to understand how to measure the workload. In today’s situation we focus on the database and the operations cycle time it takes to execute any unit of work, and multiply that unit of work by resource cost from the infrastructure to arrive at a query cost/minute and throughput/minute. From an OLTP perspective there are multiple types of measurement standards published by the Transaction Processing Council, and from a data warehouse perspective there is one called TPC-H (http://www.tpc.org/tpch/default.asp).
The most known technique to measure workload for a data warehouse is to calculate the sum of all parts:
• Number of records affected: insert, update, delete
• Indexes affected: build time
• Application server throughput
• Application server throughput
• Application server processing time
If we effectively measure and add all the different components, we will get a better picture that will help us to optimize the layers of architecture and better assist in the design of the newer architectures. By doing this exercise, we can determine which component has the most latencies and how to address its workload.
Current system design limitations
There are several design limitations in the current data warehouse architectures and we discussed them in Chapters 6 and 7. To recap:
• Sharding. The RDBMS cannot shard data efficiently due to the ACID compliance rules. The application of sharding concepts in data partitioning methods does not lend to scalability and workload reduction. Partitioning often tends to increase workloads.
• Disk architecture. The disk architecture for SAN underperforms and, due to the data architecture and data model issues, the data distribution is highly skewed, causing poor optimization to occur at the database layer.
• Data layout architecture. The data layout on the disk is a major performance inhibitor and contributes to higher workloads. Often there are large tables that are colocated in the same disk along with their indexes. Another issue is undersizing of disk or unit of storage, causing too many fragments of the same table and leading to excessive chaining.
• Underutilization of CPU. In many systems, the CPU is always underutilized and this needs to be corrected for efficient throughput and scalable thread management.
• Underutilization of memory. A large amount of data integration often bypasses usage of memory and relies on disk. These situations often use one or more smaller tables and two or more large tables in a join. Efficient design of the query can result in using the smaller tables in memory and the larger tables can be processed in a combination of memory and disk. This will reduce several roundtrips between the database server and storage, reducing disk workloads and network workloads.
• Poor query design. A silent contributor to the workload situation is poorly designed queries. Whether the queries are written by developers or generated based on the semantic layer integration in a reporting tool, when a query complies and has a large number of joins, the workload typically increases across the system and there are several opportunities to improve the reduction of the workload. One example is to generate star-schema types of queries on a third normal form (3NF) database model, albeit with some semantic layer in the database including aggregate table and summary views. This situation will always generate a high volume of I/O and tends to cause poor network throughput. If you add more operation to the query and you can see the workload increase greatly on disk I/O. Another example is to execute a query with a high number of aggregates on a database where you can utilize three or more tables in the query.
Though many architects and system designers try to create workarounds for the current state, since the system is already in place from a foundational perspective, the workarounds do not provide a clear workload optimization. It does not matter whether you have a world-class infrastructure or you have implemented your design on a commodity infrastructure, the current limitations add more weight to the already voluminous data warehouse from a workload perspective, causing overwhelming workloads and underperforming systems. Distributing the workload does not improve scalability and reduce workload, as anyone would anticipate since each distribution comes with a limited scalability.
New workloads and Big Data
Big Data brings about a new definition to the world of workloads. Apart from traditional challenges that exist in the world of data, the volume, velocity, variety, complexity, and ambiguous nature of Big Data creates a new class of challenges and issues. The key set of challenges and issues that we need to understand regarding data in the Big Data world include:
• Data does not have a finite architecture and can have multiple formats.
• Data is self-contained and needs several external business rules to be created to interpret and process the data.
• Data has a minimal or zero concept of referential integrity.
• Data needs more analytical processing.
• Data depends on metadata for creating context.
• Data has no specificity with volume or complexity.
• Data is semi-structured or unstructured.
• Data needs multiple cycles of processing, but each cycle needs to be processed in one pass due to the size of the data.
• Data needs business rules for processing like we handle structured data today, but these rules need to be created in a rules engine architecture rather than the database or the ETL tool.
Big Data workloads
Workload management as it pertains to Big Data is completely different from traditional data and its management. The major areas where workload definitions are important to understand for design and processing efficiency include:
• Data is file based for acquisition and storage—whether you choose Hadoop, NoSQL, or any other technique, most of the Big Data is file based. The underlying reason for choosing file-based management is the ease of management of files, replication, and ability to store any format of data for processing.
• Data processing will happen in three steps:
1. Discovery—in this step the data is analyzed and categorized.
2. Analysis—in this step the data is associated with master data and metadata.
3. Analytics—in this step the data is converted to metrics and structured.
• Each of these steps bring a workload characteristic:
• Discovery will mandate interrogation of data by users. The data will need to be processed where it is and not moved across the network. The reason for this is due to the size and complexity of the data itself, and this requirement is a design goal for Big Data architecture. Compute and process data at the storage layer.
• Analysis will mandate parsing of data with data visualization tools. This will require minimal transformation and movement of data across the network.
• Analytics will require converting the data to a structured format and extracting for processing to the data warehouse or analytical engines.
• Big Data workloads are drastically different from the traditional workloads due to the fact that no database is involved in the processing of Big Data. This removes a large scalability constraint but adds more complexity to maintain file system–driven consistency. Another key factor to remember is there is no transaction processing but rather data processing involved with processing Big Data. These factors are the design considerations when building a Big Data system, which we will discuss in Chapters 10 and 11.
• Big Data workloads from an analytical perspective will be very similar to adding new data to the data warehouse. The key difference here is the tables that will be added are of the narrow/narrow type, but the impact on the analytical model can be that of a wide/narrow table that will become wide/wide.
• Big Data query workloads are more program execution of MapReduce code, which is completely opposite of executing SQL and optimizing for SQL performance.
The major difference in Big Data workload management is the impact of tuning the data processing bottlenecks results in linear scalability and instant outcomes, as opposed to the traditional RDBMS world of data management. This is due to the file-based processing of data, the self-contained nature of the data, and the maturity of the algorithms on the infrastructure itself.
Technology choices
As we look back and think about how to design the next generation of data warehouses with the concept of a workload-driven architecture, there are several technologies that have come into being in the last decade, and these technologies are critical to consider for the new architecture. A key aspect to remember is the concept of data warehousing is not changing but the deployment and the architecture of the data warehouse will evolve from being tightly coupled into the database and its infrastructure to being distributed across different layers of infrastructure and data architecture. The goal of building the workload-driven architecture is to leverage all the technology improvements into the flexibility and scalability of the data warehouse and Big Data processing, thereby creating a coexistence platform leveraging all current-state and future-state investments to better ROI. Another viewpoint to think about is that by design Big Data processing is built around procedural processing (more akin to programming language–driven processing), which can take advantage of multicore CPU and SSD or DRAM technologies to the fullest extent, as opposed to the RDBMS architecture where large cycles of processing and memory are left underutilized.
Summary
The next chapter will focus on these technologies that we are discussing including Big Data appliances, cloud computing, data virtualization, and much more. As we look back at what we have learned from this chapter, remember that without understanding the workload of the system, if you create architectures, you are bound to have limited success. In conclusion, the goal is for us to start thinking like designers of space exploration vehicles, which mandate several calculations and optimization techniques to achieve superior performance and reusable systems. This radical change of thinking will help architects and designers of new solutions to create robust ecosystems of technologies.