
Information Management and Life Cycle for Big Data
The only things that evolve by themselves in an organization are disorder, friction, and malperformance.
—Peter Drucker
Introduction
Managing information complexity as data volumes have exploded is one of the biggest challenges since the dawn of information management. In traditional systems the problem has always been the limitations of the RDBMS and the SAN, which over time have continued to be a bottleneck even with the commoditization of hardware and storage. Part of the problem has been about effective information management in terms of metadata and master data management, and part of the problem has been the multiple different technologies that have been deployed in the industry to facilitate data processing, each of which has its own formats. Fast forward and add Big Data to this existing scenario and the problem compounds significantly. How do we deal with this issue, especially considering the fact that Hadoop is being considered as a low-cost storage that can become the enterprise data repository? This chapter deals with how to implement information life-cycle management principles to Big Data and create a sustainable process that will ensure that business continuity is not interrupted and data is available on demand.
Information life-cycle management
Information life-cycle management is the practice of managing the life cycle of data across an enterprise from its creation or acquisition to archival. The concept of information life-cycle management has always existed as “records management” since the early days of computing, but the management of records meant archival and deletion with extremely limited capability to reuse the same data when needed later on. Today, with the advancement in technology and commoditization of infrastructure, managing data is no longer confined to periods of time and is focused as a data management exercise.
Why manage data? The answer to this question lies in the fact that data is a corporate asset and needs to be treated as such. To manage this asset, you need to understand the needs of the enterprise with regards to data life cycle, data security, compliance requirements, regulatory requirements, auditability and traceability, storage and management, metadata and master data requirements, and data stewardship and ownership, which will help you design and implement a robust data governance and management strategy.
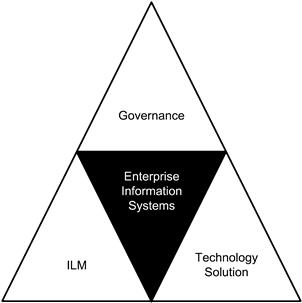
Information life-cycle management forms one of the foundational pillars in the management of data within an enterprise. It is the platform on which the three pillars of data management are designed. The first pillar represents process, the second represents the people, and the third represents the technology.
Goals
• Data management as an enterprise function.
• Improve operational efficiencies of systems and processes.
• Reduce total cost of ownership by streamlining the use of hardware and resources.
• Productivity gains by reducing errors and improving overall productivity by automating data management and life cycle.
• Implement an auditable system.
Information life-cycle management consists of the subcomponents shown in Figure 12.1.
Information management policies
The policies that define the business rules for the data life cycle from acquisition, cleansing, transformation, retention, and security are called information management policies:
• Data acquisition policies are defined:
• Applications where data entry functions are performed
• Data warehouse or datamart ETL or CDC processes
• Analytical databases ETL processes
• Data transformation policies are business rules to transform data from source to destination, and include transformation of granularity levels, keys, hierarchies, metrics, and aggregations.
• Data quality policies are defined as part of data transformation processes.
• Traditionally, data retention policies have been targeted at managing database volumes across the systems within the enterprise in an efficient way by developing business rules and processes to relocate data from online storage in the database to an offline storage in the file. The offline data can be stored at remote secure sites. The retention policy needs to consider the requirements for data that mandates support for legal case management, compliance auditing management, and electronic discovery.
• With Big Data and distributed storage on commodity hardware, the notion of offline storage is now more a label. All data is considered active and accessible all the time. The goals of data retention shift to managing the compression and storage of data across the disk architecture. The challenge in the new generation will be on the most efficient techniques of data management.
• Data security policies are oriented toward securing data from an encryption and obfuscation perspective and also data security from a user access perspective.
Governance
Information and program governance are two important aspects of managing information within an enterprise. Information governance deals with setting up governance models for data within the enterprise and program governance deals with implementing the policies and processes set forth in information governance. Both of these tasks are fairly people-specific as they involve both the business user and the technology teams.
A governance process is a multistructured organization of people who play different roles in managing information. The hierarchy of the different bodies of the governance program is shown in Figure 12.2, and the roles and responsibilities are outlined in the following subsections.
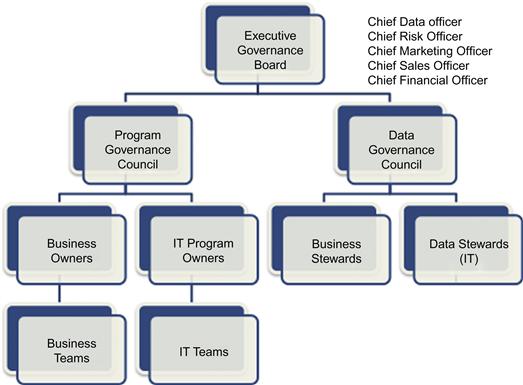
Program governance council
• Consists of program owners who are director-level members of the executive organization. There can be multiple representatives in one team for a small organization, while a large organization can have multiple smaller teams that will fold into a large charter team.
• Responsible for overall direction of the program, management of business and IT team owners, coordination of activities, management of budget, and prioritization of tasks and programs.
Business teams
• Consists of members of a particular business unit, for example, marketing or market research or sales.
• Responsible for implementing the program and data governance policies in their projects, report to the council on issues and setbacks, and work with the council on resolution strategies.
IT owners
• Consists of IT project managers assigned to lead the implementation and support for a specific business unit.
• Responsible for leading the IT teams to work on the initiative, the project delivery, issue resolution, and conflict management, and work with the council to solve any issue that can impact a wider audience.
IT teams
• Consists of members of IT teams assigned to work with a particular business team for implementing the technology layers and supporting the program.
• Responsible for implementing the program and data governance technologies and frameworks in the assigned projects, report to the council on issues and setbacks, and work with the council on resolution strategies.
Data governance council
• Consists of business and IT stakeholders from each unit in the enterprise. The members are SMEs who own the data for that business unit and are responsible for making the appropriate decisions for the integration of the data into the enterprise architecture while maintaining their specific requirements within the same framework.
• Master data management policies
Governance has been a major focus area for large and midsize enterprises for implementing a successful business transformation initiative, which includes data and information management as a subcomponent. Properly executed governance for both data and program aspects have benefitted enterprises by providing confidence to the teams executing business decisions based on the information available in the enterprise. These initiatives have increased ROI and decreased risk when implemented with the right rigor.
Technology
Implementing the program from a concept to reality within data governance falls in the technology layers. There are several different technologies that are used to implement the different aspects of governance. These include tools and technologies used in Data acquisition, Data cleansing, Data transformation and Database code such as stored procedures, programming modules coded as application programming interface (API), Semantic technologies and Metadata libraries.
Data quality
• Is implemented as a part of the data movement and transformation processes.
• Is developed as a combination of business rules developed in ETL/ELT programs and third-party data enrichment processes.
• Is measured in percentage of corrections required per execution per table. The lower the percentage of corrections, the higher the quality of data.
Data enrichment
• This is not a new subject area in the world of data. We have always enriched data to improve its accuracy and information quality.
• In the world of Big Data, data enrichment is accomplished by integrating taxonomies, ontologies, and third-party libraries as a part of the data processing architecture.
• Enriched data will provide the user capabilities:
• To define and manage hierarchies.
• To create new business rules on-the-fly for tagging and classifying the data.
• To process text and semi-structured data more efficiently.
• Explore and process multilingual and multistructured data analysis.
Data transformation
• Is implemented as part of ETL/ELT processes.
• Is defined as business requirements by the user teams.
• Uses master data and metadata program outputs for referential data processing and data standardization.
• Includes auditing and traceability framework components for recording data manipulation language (DML) outputs and rejects from data quality and integrity checks.
Data archival and retention
• Is implemented as part of the archival and purging process.
• Is developed as a part of the database systems by many vendors.
• Is often misquoted as a database feature.
• Often fails when legacy data is imported back due to lack of correct metadata and underlying structural changes. This can be avoided easily by exporting the metadata and the master data along with the data set.
Master data management
• Is implemented as a standalone program.
• Is implemented in multiple cycles for customers and products.
• Is implemented for location, organization, and other smaller data sets as an add-on by the implementing organization.
• Measured as a percentage of changes processed every execution from source systems.
• Operationalized as business rules for key management across operational, transactional, warehouse, and analytical data
Metadata
• Is implemented as a data definition process by business users,
• Has business-oriented definitions for data for each business unit. One central definition is regarded as the enterprise metadata view of the data.
• Has IT definitions for metadata related to data structures, data management programs, and semantic layers within the database.
• Has definitions for semantic layers implemented for business intelligence and analytical applications.
All the technologies used in the processes described above have a database, a user interface for managing data, rules and definitions, and reports available on the processing of each component and its associated metrics.
There are many books and conferences on the subject of data governance and program governance. We recommend readers peruse the available material for continued reading on implementing governance for a traditional data warehouse.1–4
Benefits of information life-cycle management
• Increases process efficiencies.
• Helps enterprises optimize data quality.
• Helps reduce the total cost of ownership for data and infrastructure investments.
• Data management strategies help in managing data and holistically improve all the processes, including:
• Predictable system availability
• Optimized system performance
• Improved reusability of resources
• Improved management of metadata and master data
• Improved systems life-cycle management
• Streamlined operations management of data life cycle
• Legal and compliance requirements
With the advance of technology and commoditization of infrastructure it has become easier to implement information life-cycle management processes today than ever before.
Information life-cycle management for Big Data
The advent of Big Data is a boon and a curse to many enterprises. The reason for this sentiment is the unique set of challenges being brought by Big Data in terms of volume, velocity, and variety of data. Many enterprises today are planning to implement a Big Data project and designing an information life-cycle management program to help manage and streamline the Big Data.
Big Data acquisition and processing has been discussed in prior chapters in this book. While the technology is inexpensive to acquire the data, there are several complexities with managing and processing the data within the new technology environments and further integrating it with the RDBMS or DBMS. A governance process and methodology is required to manage all of these processes.
Data in the Big Data world is largely created and stored as files. All the processes associated with managing data and processing data are file-based, whether in Hadoop or NoSQL environments. While the new technologies are special file systems, simply deleting files will not be the right solution, and we need to create a robust and well-defined data retention and archiving strategy.
Processing data in the Big Data world uses enterprise metadata and master data. With the volume and data type to be processed, we need to implement policies to manage this environment extremely closely to prevent any unwanted alterations.
Example: information life-cycle management and social media data
Social media data is one of the most popular data assets that every organization likes to tap into for getting a clearer view of their customers and the likes and dislikes that are being expressed by their customers about their products, services, competition, and the impact of the sharing of these sentiments. The data for this exercise is extracted from social media channels and websites, Internet forums and user communities, and consumer websites and reviews.
There is a lot of hidden value within the data from social media and there are several insights that provide critical clues to the success or failure of a particular brand related to a campaign, product, service, and more. The bigger questions are: What is the value of the data once the initial discoveries have been completed? Is there any requirement to keep the data to actually monitor the trend? Or is a statistical summary enough to accomplish the same result?
In the case of social media data, the lifetime value of the data is very short—from the time of acquisition to insights the entire process may take hours to a week probably. The information life-cycle management policy for this data will be storage for two to four weeks for the raw data, six to eight weeks for processed data sets after the processing of the raw data, and then one to three years for summary data aggregated from processed data sets to be used in analytics. The reason for this type of a policy suggestion is the raw data does not have value once it has been processed with the different types of business rules and the processed data sets do not carry value beyond the additional eight weeks. Data is typically discarded from the storage layer and is not required to be stored offline or offsite for any further reuse or reloading.
Without creating a governance policy on information life-cycle management for data, we will end up collecting a lot of data that is having no business impact or value, and end up wasting processing and computing cycles. A strong information life-cycle management policy is necessary for ensuring the success of Big Data.
From this example we can see that managing the information life cycle for Big Data is similar to any other data, but there are some areas that need special attention and can impact your Big Data program negatively if not implemented. Let us look at each aspect in the following section.
Governance
From a Big Data perspective you need both data and program governance to be implemented.
Data governance
• What data should be retained?
• What are the associated metadata and master data that need to be processed with the data to be retained?
• Data security: What are the user security and data security requirements?
• Metadata: What taxonomies will be needed to manage data?
• Business rules: What are the tools and associated business rules for processing?
• Data stewardship: Who owns the data type?
• Documents—legal, HR, finance, and customer service are all business units to consider
• Audit, balance, and control:
• What data needs to be audited?
• What data needs reprocessing in failure situations?
• External taxonomies can be integrated to process additional hierarchies and master data enrichment in processing Big Data. You need to understand the granularity and hierarchy of the external data.
• Third-party data from agencies can be integrated to create reference data and lookup data.
• Data extracts to the data warehouse need to be defined.
• Metadata integration with the enterprise data needs to be managed and monitored.
• The integration refresh cycles need to be defined.
• Data structures to store the Big Data need to be defined and implemented.
Program governance
A strong framework for managing the projects and the people pillars forms the crux of program governance. While there are no significant differences in program governance approaches, the following can be extended:
• What projects are currently being driven to enable information life-cycle management?
• Who are the teams that are assigned to the different programs?
• What is the cost of the implementation for each cycle for each project?
• What are the risks and identified mitigation strategies?
• What are the critical areas that need executive alerts?
• What are the critical priorities and the impact of changes to the priority to the program schedule?
• What are the budgetary constraints that impact the program?
Processing
• The data acquisition process in the world of Big Data has no predefined process. The audit process framework needs to be extended to include Big Data processing. The audit data will consist of the file name, date of process, size, and source (if available).
• Data processing in the world of Big Data contains no predefined schema to model and load the data. In this situation, extra attention needs to be given to metadata management. There will be multiple cycles of processing of the same data for different subject areas. This is where the complexity of metadata management will need to be addressed in the Big Data processing.
• There is no data-quality processing for Big Data. To enrich and improve the quality of data, you need to include metadata, master data, taxonomies, and other reference data in the processing of Big Data.
• Data storage and management of Big Data requires planning of infrastructure integration and data center planning. This is a part of the planning process for Big Data integration.
Technology
• The technologies for implementing Big Data are Hadoop, NoSQL, and text processing technologies. All these technologies treat the data as files, and create and process multiple files from the various sources as files, producing the output as files.
• In Hadoop, the availability of too many files will cause the NameNode to slow down and impact performance. To mitigate the risk associated with this situation, Hadoop introduced a process called Hadoop Archive (HAR). HAR comes with its own file system implementation and consolidates small- and medium-size files into one large file. The subfiles are available and stored in HAR.
• Since Hadoop is a file system, large data files can be exported and dropped from the primary system. This will create more space for processing. A file can always be restored from the source environment and moved for reconciliation.
Measuring the impact of information life-cycle management
To measure and monitor the impact of governance and processes for information life-cycle management, you can implement scorecards and dashboards and even extend the currently used models for the data warehouse. This is a very nascent and emerging topic, but an important topic to consider implementing when starting a Big Data program. There will be a lot of evolutions and improvements in this area in the next few years, especially in the world of Big Data and the next generation of the data warehouse.
Summary
As we conclude this chapter, you need to understand that governance and information life-cycle management are topics that are extremely important in the world of data management and will be even more important in the world of Big Data and the next generation of data warehousing. The next chapter discusses the evolution of analytics and visualization of Big Data and the emerging role of the data scientist.
1Ladley, J. (2012). How to Design, Deploy and Sustain an Effective Data Governance Program. Morgan Kaufmann.
2Soares, S. (2012). Big Data Governance: An Emerging Imperative. MC PressLLC.
3Orr, J. C. (2011). Data Governance For The Executive. Senna Publishing.
4Hill, D. G. (2009). Data Protection: Governance, Risk Management, and Compliance. Taylor & Francis Group.