
Mapping high-level programming languages to OpenCL 2.0
A compiler writer’s perspective
I-Jui (Ray) Sung; Wen-Heng (Jack) Chung; Yun-Wei Lee; Wen-Mei Hwu
Abstract
While OpenCL was originally designed as an application programming interface (API) for human developers, it can also serve as an implementation platform for higher-level object-oriented programming languages such as C++. Targeting OpenCL rather than vendor-specific platforms allows high-level language compiler developers to focus on language implementation issues rather than the vendor-specific intricacies across different types of devices in a heterogeneous computing system. In this chapter, we show that OpenCL 2.0 provides a strong foundation for implementing C++ Accelerated Massive Parallelism (AMP), a parallel extension to C++. We show a mapping of C++ AMP constructs to OpenCL. We also demonstrate that the OpenCL kernels generated from C++ AMP parallel_for_all and related constructs with automatically generated data transfer API calls can achieve a performance level that is comparable to that of hand-coded OpenCL kernels. We expect that compiler developers who need to target other high-level languages to heterogeneous computing systems will benefit from the techniques and experience presented in this chapter.
11.1 Introduction
High-level programming languages and domain-specific languages can often benefit from the increased power efficiency of heterogeneous computing. However, it should not require the compiler writers for these languages to deal with vendor-specific intricacies across graphics processing unit (GPU) platforms and the complexity of generating code for them. Instead, OpenCL itself can serve as a compiler target for portable code generation and runtime management. By using OpenCL as the target platform, compiler writers can focus on more important, higher-level problems in language implementation. Such improved productivity can enable a proliferation of high-level programming languages for heterogeneous computing systems.
In this chapter we use C++ Accelerated Massive Parallelism (AMP), a parallel programming extension to C++, as an example to show how efficient OpenCL code can be generated from a higher-level programming model. The C++ language provides several high-level, developer-friendly features that are missing from OpenCL. These high-level features support software engineering practices and improve developer productivity. It is the compiler writer’s job to translate these features into the OpenCL constructs without incurring an excessive level of overhead. We present some important implementation techniques in this translation process; for compiler writers interested in mapping other programming models to OpenCL these implementation techniques can be useful too.
We will start with a brief introduction of C++ AMP, and a simple vector addition “application” will serve as the running example. With the example, subsequent sections illustrates how C++ AMP features are mapped to OpenCL. The actual, working implementation consists of a compiler, a set of header files, and a runtime library, which together are publicly accessible as an open source project.1
11.2 A Brief Introduction to C++ AMP
C++ AMP is a programming model that supports expression of data-parallel algorithms in C++. Compared with other GPU programming models such as OpenCL and CUDA C, C++ AMP encapsulates many low-level details of data movement so the program looks more concise. But it still contains features to let programmers address system intricacies for performance optimization.
Developed initially by Microsoft and released in Visual Studio 2012, C++ AMP is defined as an open specification. Based on open source Clang and LLVM compiler infrastructure, MulticoreWare2 has published Clamp, a C++ AMP implementation which targets OpenCL for GPU programs. It runs on Linux and Mac OS X, and supports all major GPU cards from vendors such as AMD, Intel, and NVIDIA.
C++ AMP is an extension to the C++11 standard. Besides some C++ header files which define classes for modeling data-parallel algorithms, it adds two additional rules to the C++ programming language. The first one specifies additional language restrictions for functions to be executed on GPUs, and the second one allows cross-thread data sharing among GPU programs. This chapter does not aim to be a comprehensive introduction to C++ AMP. We will highlight the most important core concepts and show how a C++ AMP compiler can implement such features based on OpenCL. For those who are interested in a comprehensive tutorial on C++ AMP itself, Microsoft has published a book on C++ AMP [1] that serves as a good starting point.
Let us start from a simple vector addition program in C++ AMP (Figure 11.1).

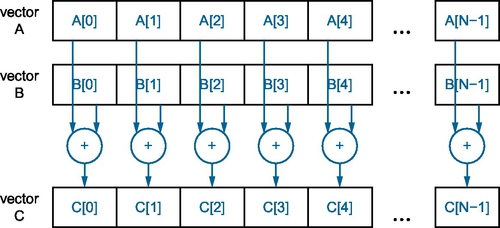
Conceptually, the C++ AMP code here computes vector addition as shown in Figure 11.2.
Line 1 in Figure 11.1 includes the C++ AMP header, amp.h, which provides the declarations of the core features. The C++ AMP classes and functions are declared within the concurrency namespace. The “using” directive on the next line makes the C++ AMP names visible in the current scope. It is optional but helps avoid the need to prefix C++ AMP names with a concurrency:: scope specifier.
This main function in line 4 is executed by a thread running on the host, and it contains a data-parallel computation that may be accelerated. The term “host” has the same meaning in the C++ AMP documentation as in OpenCL. While OpenCL uses the term “device” to refer to the execution environment used for accelerated execution, C++ AMP uses the term “accelerator” for the same purpose. One high-level feature in C++ AMP and commonly seen in other high-level languages is Lambda. Lambda enables C++ AMP host and accelerator code to be collocated in the same file and even within same function. So there is no separation of flow in the source of device code and host code in C++ AMP. Later we will talk about how a C++11-ish Lambda is compiled into OpenCL in the context of C++ AMP.
11.2.1 C++ AMP array_view
In C++ AMP, the primary vehicle for reading and writing large data collections is the class template array_view. An array_view provides a multidimensional reference to a rectangular collection of data locations. This is not a new copy of the data but rather a new way to access the existing memory locations. The template has two parameters: the type of the elements of the source data, and an integer that indicates the dimensionality of the array_view. Throughout C++ AMP, template parameters that indicate dimensionality are referred as the rank of the type or object. In this example, we have a 1-dimensional array_view (or “an array_view of rank 1”) of C++ float values.
For example, in line 14 in Figure 11.1, array_view av(a) provides a one-dimensional reference to the C++ vector a. It tells the C++ AMP compiler that accesses to a vector through av will use it only as an input (const), treat it as a one-dimensional array (1), and assume that the size of the array is given by a variable (N).
The constructor for array_view of rank 1, such as cv on line 16, takes two parameters. The first is an integer value which is the number of data elements. In the case of av, bv, and cv, the number of data elements is given by N. In general the set of per-dimension lengths is referred to as an extent. To represent and manipulate extents, C++ AMP provides a class template, extent, with a single integer template parameter which captures the rank. For objects with a small number of dimensions, various constructors are overloaded to allow specification of an extent as one or more integer values, as is done for cv. The second parameter for the cv constructor is a standard container storing the host data. In vecAdd the host data is expressed as a C-style pointer to contiguous data.
11.2.2 C++ AMP parallel_for_each, or Kernel Invocation
Line 16 in Figure 11.1 illustrates the parallel_for_each construct, which is the C++ AMP code pattern for a data-parallel computation. This corresponds to the kernel launch in OpenCL. In OpenCL terminology, the parallel_for_each creates an “NDRange of work items.” In C++ AMP, the set of elements for which a computation is performed is called the compute domain, and is defined by an extent object. Like in OpenCL, each thread will invoke the same function for every point, and threads are distinguished only by their location in the domain (NDRange).
Similarly to the standard C++ STL algorithm for_each, the parallel_for_each function template specifies a function to be applied to a collection of values. The first argument to a parallel_for_each is a C++ AMP extent object which describes the domain over which a data-parallel computation is performed. In this example, we perform an operation over every element in an array_view, and so the extent passed into the parallel_for_each is the extent of the cv array_view. In the example, this is accessed through the extent property of the array_view type (cv.get_extent()). This is a one-dimensional extent, and the domain of the computation consists of integer values 0…n − 1.
Functors as kernels
The second argument to a parallel_for_each is a C++ function object (or functor). In Figure 11.1, we use the C++11 Lambda syntax as a convenient way to build such an object. The core semantics of a parallel_for_each is to invoke the function defined by the second parameter exactly once for every element in the compute domain defined by the extent argument.
Captured variables as kernel arguments
The leading [=] indicates that variables declared inside the containing function but referenced inside the Lambda are “captured” and copied into data members of the function object built for the Lambda. In this case this will be the three array_view objects. The function invoked has a single parameter that is initialized to the location of a thread within the compute domain. This is again represented by a class template, index, which represents a short vector of integer values. The rank of an index is the length or number of elements of this vector, and is the same as the rank of the extent. The index parameter idx values can be used to select elements in an array_view, as illustrated on line 20.
The restrict(amp) modifier
A key extension to C++ is shown in this example: the restrict(amp) modifier. In C++ AMP, the existing C99 keyword “restrict” is borrowed and allowed in a new context: it may trail the formal parameter list of a function (including Lambda functions). The restrict keyword is then followed by a parenthesized list of one or more restriction specifiers. While other uses are possible, in C++ AMP only two such specifiers are defined: amp and cpu. They more or less work like markers to guide the compiler to generate either central processing unit (CPU) code or accelerator code out of a function definition and whether the compiler should enforce a subset of the C++ language. Details follow.
As shown in line 18, the function object passed to parallel_for_each must have its call operator annotated with a restrict(amp) specification. Any function called from the body of that operator must similarly be restricted. The restrict(amp) specification identifies functions that may be invoked on a hardware accelerator. Analogously, restrict(cpu) indicates functions that may be invoked on the host. When no restriction is specified, the default is restrict(cpu). A function may have both restrictions, restrict(cpu,amp), in which case it may be called from either host or accelerator contexts and must satisfy the restrictions of both contexts.
As mentioned earlier, the restrict modifier allows a subset of C++ to be defined for use in a body of code. In the first release of C++ AMP, the restrictions reflect current common limitations of GPUs when used as accelerators of data-parallel code. For example, the C++ operator new, recursions. and calls to virtual methods are prohibited. Over time we can expect these restrictions to be lifted. and the open specification for C++ AMP includes a possible road map of future versions which are less restrictive. The restrict(cpu) specifier, of course, permits all of the capabilities of C++ but, because some functions that are part of C++ AMP are accelerator specific they do not have restrict(cpu) versions and so may be used only in restrict(amp) code.
Inside the body of the restrict(amp) Lambda, there are references to the array_view objects declared in the containing scope. These are “captured” into the function object that is created to implement the Lambda. Other variables from the function scope may also be captured by value. Each of these other values is made available to each invocation of the function executed on the accelerator. As for any C++11 nonmutable Lambda, variables captured by value may not be modified in the body of the Lambda. However, the elements of an array_view may be modified, and those modifications will be reflected back to the host. In this example, any changes to cv made inside the parallel_for_each will be reflected in the host data vector c.
11.3 OpenCL 2.0 as a Compiler Target
Clamp is an open source implementation of C++ AMP contributed by MulticoreWare. It consists of the following components:
• C++ AMP compiler: derived from open source Clang and LLVM projects, the compiler supports C++ AMP language extensions to C++ and emits kernel codes in OpenCL C or the Standard Portable Intermediate Representation (SPIR) format.
• C++ AMP headers: a set of C++ header files which implement classes defined in the C++ AMP specification. Some functions are simply wrappers around OpenCL built-in functions, but some require careful deliberation.
• C++ AMP runtime: a small library acts as a bridge between host programs and kernels. Linked with built executables, it would load and build kernels, set kernel arguments, and launch kernels.
SPIR is a subset of the LLVM intermediate representation (IR) that is specified to support the OpenCL C programming language. It is a portable, nonsource representation for device programs. It enables application developers to avoid shipping kernels in source form, while managing the proliferation of devices and drivers from multiple vendors. An application that uses a valid SPIR IR instance should be capable of being run on any OpenCL platform supporting the cl_khr_spir extension and the matching SPIR version (CL_DEVIce:SPIR_VERSIONS). To build program objects from kernels in SPIR format, clCreateProgramWithBinary() should be used.
There are two versions of SPIR available. SPIR 1.2 defines an encoding of an OpenCL C version 1.2 device program into LLVM (version 3.2), and SPIR 2.0 defines an encoding of OpenCL version 2.0 into LLVM. Since there is a direct correspondence between SPIR and OpenCL C, we will use code examples expressed in OpenCL C in this chapter for better readability.
Based on the vector addition example code, the rest of the chapter will show the design of the main components of the Clamp compiler. We will omit some details which are irrelevant to OpenCL and focus on how OpenCL is used to enable critical C++ AMP features. The focus is to provide insight into the use of OpenCL as an implementation platform for C++ AMP.
11.4 Mapping Key C++ AMP Constructs to OpenCL
To map a new programming model to OpenCL, one can start with a mapping of the key constructs. Table 11.1 shows a mapping of the key C++ AMP constructs to their counterparts in OpenCL. As we showed in Figure 11.1, a Lambda in a parallel_for_each construct represents a C++ functor whose instances should be executed in parallel. This maps well to OpenCL kernel functions, whose instances should be executed in parallel by the work-items. Although not shown in the vector addition example, one can also pass a functor to a parallel_for_all construct for execution in parallel. As a result, we show how C++ AMP Lambdas defined in parallel_for_each or functors passed to parallel_for_each are mapped to OpenCL kernels.
Table 11.1
Mapping Key C++ AMP Constructs to OpenCL
| OpenCL | C++AMP |
| Kernel | Lambda defined in parallel_for_each, or a functor passed toparallel_for_each |
| Kernel name | Mangled name for the C++operator() of the Lambda/functor object |
| Kernel launch | parallel_for_each |
| Kernel arguments | Captured variables in Lambda |
| cl_mem buffers | concurrency::array_view and array |
As for the names to be used for each generated OpenCL kernel, we can used the mangled names of the C++operator() of the Lambda/functor. C++ mangling rules will eliminate undesirable name conflicts and enforce correct scoping rules for the generated kernels.
The rest of the mapping has to do with the interactions between host code and device code. The C++ AMP construct parallel_for_each corresponds to the sequence of OpenCL application programming interface (API) calls for passing arguments and launching kernels. For Lambda functors such as the one shown in Figure 11.1, the arguments to be passed to the OpenCL kernels should be automatically captured according to the C++ Lambda rules. On the other hand, all array_views used in the Lambda should become explicitcl_mem buffers.
To summarize, with this conceptual mapping, we can see that the output of the C++ AMP compiler should provide the following:
1. A legitimate OpenCL kernel whose arguments present values of the captured variables from the surrounding code.
2. Host code that is able to locate, compile, prepare arguments and buffers for, and launch the kernel produced in the previous step at runtime.
Since a C++ Lambda can be viewed as an anonymous functor, we can close the gap further by conceptually rewriting the Lambda into a functor version as in Figure 11.3. The code makes the Lambda into an explicit functor; all the captured variables, va, vb, and vc, are now spelled out in the class, and the body of the Lambda becomes an operator() member function. Finally, a constructor is supplied to populate these captured variables on the host side.

However, we still see the following gaps or missing parts:
1. The operator() still needs to be mapped to an OpenCL kernel. In particular, the C++ AMP parallel_for_each construct is not accounted for in this conceptual code. Also, this functor is a class, but we need an instance to be created.
2. How does the runtime on the host side infer the name of the kernel?
3. The array_view on the host side may contain cl_mem, but on the device side it should be operating on raw pointers as OpenCL cl_mem is not allowed on the device side. It is not clear yet how these diverging needs should be fulfilled.
To close the gap further, we need to conceptually bring the functor class further as well. See the parts below the comments on lines 1, 21, 29, and 31 in Figure 11.4.

With the version shown in Figure 11.4, we can see how these three remaining gaps are closed. Line 1 defines a simplified version of concurrency::array_view to show the high-level idea, and is not meant to represent the exact semantics of a standard concurrency::array_view. The trick here is to provide two slightly different definitions of the same container type for the host and the device. Note we treat an array_view as an OpenCL buffer here, and without going too much into the C++ AMP specification, let us for now consider that an array_view is backed by an OpenCL memory object as its backing storage (hence the name backing_storage). Also we have to add two member functions and a new constructor to the functor, and these functions would have to be automatically injected by the C++ AMP compiler (eventually):
• One is compiled only in host code that provides the mangled kernel name.
• The other is an OpenCL kernel, and is compiled only in device code. It acts as a trampoline, whose mangled name can be queried and used by the host code at runtime. The trampoline function populates a clone of the functor object on the device side with the kernel arguments, and also an index object based on the global indices. Finally, the cloned version of the functor object is invoked in the trampoline.
• The new constructor defined in line 22 is also compiled only in device code, and is part of the trampoline. The purpose of that new constructor is to construct an almost identical copy of the Lambda on the GPU side on the basis of the arguments received by the trampoline. That almost identical copy of the Lambda lives in the function scope, and usually will not have its address visible outside the scope. This gives the compiler freedom for more optimization later.
However, the main point of the conceptual code in Figure 11.4 is to illustrate the way Clamp creates a mangled name of each kernel (i.e. trampoline that calls operator()), a trampoline as well as a new constructor that constructs a slightly different Lambda object on the device side, and two definitions of the same array container depending on the current mode (host or device). Ultimately in the output OpenCL code, we want the trampoline to receive these cl_mem buffers through clSetKernelArg() OpenCL API calls and take them in the same order, but appear as device memory pointers (i.e. __global float * for this case) in the device code. To satisfy this requirement, we need to implement the following capabilities in the compiler:
• Systematically pass cl_mem from the host side Lambda object to the trampoline via OpenCL clSetKernelArg() calls.
• Also, systematically recover these as pointer arguments of the trampoline, which will in turn call the new constructor and instantiate a slightly different Lambda from the device side along with other arguments (see the next point).
• The rest of the captured variables should not be affected, and their values should be passed opaquely. For example, in line 35, the values of the _sz member for array_views should be passed directly from the host to the device.
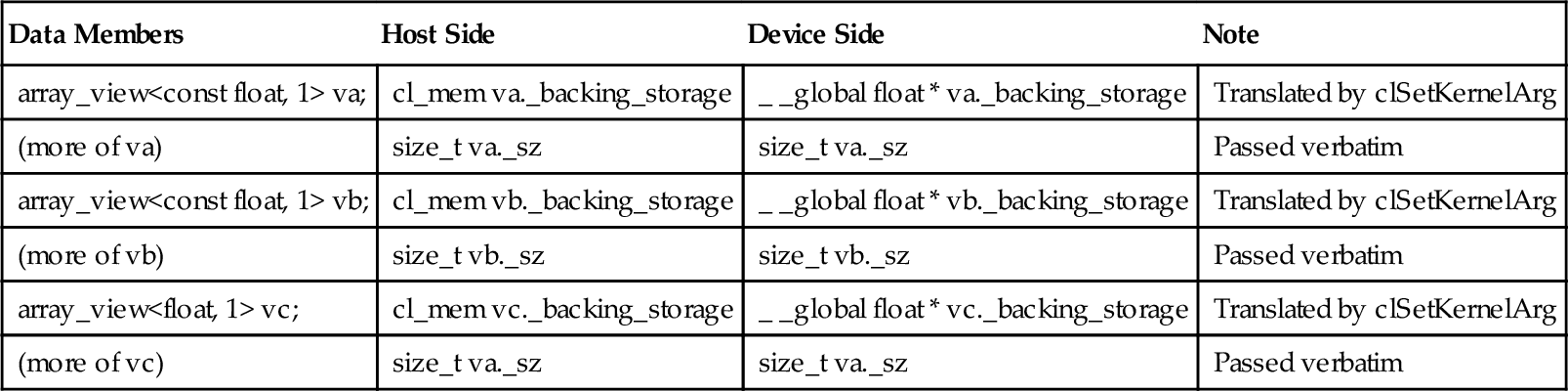
In order to systematically implement these capabilities, it is desirable to clearly specify the output code arrangements needed for each type of data member of a Lambda. Table 11.2 shows such conceptual layout arrangements of the Lambda data members in Figure 11.1 on both the device side and the host side.
Table 11.2
Conceptual Mapping of Data Members on the Host Side and on the Device Side
| Data Members | Host Side | Device Side | Note |
| array_view<const float, 1> va; | cl_mem va._backing_storage | _ _global float * va._backing_storage | Translated by clSetKernelArg |
| (more of va) | size_t va._sz | size_t va._sz | Passed verbatim |
| array_view<const float, 1> vb; | cl_mem vb._backing_storage | _ _global float * vb._backing_storage | Translated by clSetKernelArg |
| (more of vb) | size_t vb._sz | size_t vb._sz | Passed verbatim |
| array_view<float, 1> vc; | cl_mem vc._backing_storage | _ _global float * vc._backing_storage | Translated by clSetKernelArg |
| (more of vc) | size_t va._sz | size_t va._sz | Passed verbatim |
With this mapping, we are ready to generate the OpenCL code sequence for a C++ AMP parallel_for_each. This can be done through the C++ template as shown in Figure 11.4. On the basis of the mapping defined so far, a conceptual implementation of parallel_for_each in Figure 11.1 is shown in Figure 11.5.

In general, in order to generate the type of OpenCL code sequence shown in Figure 11.5, we need to perform object introspection and enumerate the data members in the functor prior to kernel invocation (lines 6-11 in Figure 11.5). In particular, they need to appear in the same order as they appear in the argument list of the trampoline.
As stated earlier, functors are the way C++ AMP passes data to and from the kernels, but kernel function arguments are the way OpenCL passes data to and from kernels. Essentially an instance of the functor in CPU address space will have to be copied and converted to an instance in the GPU address space: most data members of the functor are copied (i.e. by value), and that is what our initial implementation does. Remember that we are going to pass an OpenCL buffer by value. But the tricky part is that we also need to pass opaque handles (i.e. cl_mem) and rely on the underlying OpenCL runtime to convert them to pointers in the GPU address space and perform the memory copy. This is the case for all pre-OpenCL 2.0 runtimes.
At this point, the reader may recognize that the code sequence in Figure 11.5 is quite similar to that for object serialization,3 except that this time it is not for external storage and retrieval, but is more for squeezing the object contents through a channel implemented by clSetKernelArg(), which does some translation on cl_mems into device-side pointers ready to be used in kernels. We need to make sure class instances are stored in a format that is available to the GPU side so that these objects can be properly reconstructed on the GPU side.
Note that in languages such as Java, serialization and deserialization code sequences can be generated through reflection, but reflection is not yet possible at the C++ source level without major modifications to the compiler (and the language itself). In the actual C++ AMP compiler, these serialization and deserialization code sequences are generated as more or less straightforward enumeration of member data and calls to appropriate clSetKernelArgs().
11.5 C++ AMP Compilation Flow
With the conceptual mapping of C++ AMP to OpenCL defined above, it is easier to understand how to compile and link a C++ AMP program. The Clamp compiler employs a multistep process:
1. As a first step, the input C++ AMP source code is compiled in a special “device mode” so that all C++ AMP-specific language rules will be checked and applied. The Clamp compiler will emit OpenCL kernels (based on AMP-restricted functions called from the parallel_for_each function) into an LLVM bitcode file. All functions called from a kernel will be inlined into the kernel. The host program will also be compiled and emitted into the same bitcode file in order to fulfill C++ function name mangling rules.
2. The LLVM bitcode file will then go through some transformation passes to ensure that it can be lowered into correct OpenCL programs. All host codes will be pruned first, then all pointers in the kernels and instructions which use them will be declared with the correct address space ( _ _global, _ _constant, _ _local, _ _private ) per the OpenCL specification. It is worth noting that there is a fundamental difference between OpenCL and C++ AMP on the address spaces. In OpenCL, the address space is part of the pointer type, whereas in C++ AMP it is part of the pointer value. Hence, a static compiler analysis is necessary to infer the address space of pointers from how they are assigned and used. Additional metadata will also be provided by the transformation so the resulting LLVM bitcode is compatible with the OpenCL SPIR format.
3. The transformed LLVM bitcode is now an OpenCL SPIR bitcode and can be linked and executed on platforms which support the cl_khr_spir extension. It is saved as an object file which would be linked against host programs. An additional, optional step could be applied to lower it to OpenCL C format so the resultant kernel can be used on any OpenCL platforms that may not support SPIR.
4. The input C++ AMP source code will be compiled again in “host mode” to emit host codes. C++ AMP headers are designed so that none of the kernel codes will be directly used in host mode. Instead, calls to C++ AMP runtime API functions will be used instead to launch kernels.
5. Host codes and device codes are linked to produce the final executable file.
11.6 Compiled C++ AMP Code
Let us revisit the C++ AMP Lambda in the vector addition example (line 17 in Figure 11.1), shown again in Figure 11.6 for easy reference.
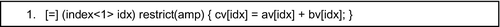
The OpenCL kernel code after it has been compiled by the Clamp compiler is shown in Figure 11.7.

The compiled code may seem daunting at first, but it is actually not hard to understand with the following mapping:
• Line 1: name of trampoline, mangled
• Lines 2-3: serialized array_view va
• Lines 4-5: serialized array_view vb
• Lines 6-7: serialized array_view vc
• Line 11: get global work-item index, idx in C++ AMP Lambda
• Line 12: load va[idx]
• Line 13: load vb[idx]
• Line 14: calculate va[idx] +vb[idx] and store to vc[idx]
11.7 How Shared Virtual Memory in OpenCL 2.0 Fits in
One of the most important new features of OpenCL 2.0 is shared virtual memory (SVM). It is an address space exposed to both the host and the devices within the same context. It supports the use of shared pointer-based data structures between OpenCL host code and kernels. It logically extends a portion of the device global memory into the host address space, therefore giving work-items access to the host address space.
According to the OpenCL 2.0 specification, there are three types of SVM:
1. Coarse-grained buffer SVM: sharing occurs at the granularity of OpenCL buffer memory objects. Consistency happens only at synchronization points—for example, kernel launch, mapping/unmapping.
2. Fine-grained buffer SVM : sharing occurs at the granularity of OpenCL buffer memory objects. Consistency happens not only at synchronization points but also at atomic operations performed on either the host side or the device side.
3. Fine-grained system SVM : sharing occurs at the granularity of individual loads/stores into bytes occurring anywhere within the host memory.
The difference between fine-grained and coarse-grained buffer SVM is best illustrated with a small example. Suppose we have a chunk of data to be made visible to a kernel running on an OpenCL 2.0 GPU, and let us say the kernel is computing some sort of histogramming and will update the chunk of data atomically. Table 11.3 shows how this data sharing can be done on pre-2.0, 2.0 coarse-grained, and 2.0 fine-grained operations and the implications.
Table 11.3
Data Sharing Behavior and Implications of OpenCL 2.0 SVM Support
| Steps | Pre-2.0 | 2.0/Coarse-Grained Buffer SVM | 2.0/Fine-Grained Buffer SVM |
| Copy to device | clEnqueueWriteBuffer | No need | No need |
| Device atomic updates visible to host? | NA | No | Yes |
| When would changes from the device side be visible to the host | Not until copy back | After kernel has finished | After kernel has finished or after device-side atomics |
| Copy from device | clEnqueueReadBuffer | No need | No need |

NA, not applicable.
The unique aspect of OpenCL 2.0 fine-grained buffer SVM is that it enables concurrent host and device atomic operations. In an histogramming example, fine-grained buffer SVM means the histogramming can be done concurrently by the host and the devices; all of them may share the same buffer, and changes made by all entities will be visible to the others as long as they are done through atomics.
Only coarse-grained buffer SVM is mandatory in OpenCL 2.0, and the two other types are optional. In this section, we demonstrate how to adopt coarse-grained buffer SVM in C++ AMP. Note that coarse-grained buffer SVM is similar to the OpenCL 1.x type of buffers, except that there is no need for explicit copying through clEnqueueWriteBuffer() API calls. Because of that similarity, in Clamp we mainly treat coarse-grained buffer SVM as a performance improvement venue for the implementation of concurrency::array_views.
To utilize coarse-grained buffer SVM, a host program needs to use clSVMAlloc() to allocate SVM buffers that can be shared by hosts and devices. cl_mem buffers are then created by calling clCreateBuffer() with CL_MEM_USE_HOST_PTR with the pointers to the buffers that are allocated by clSVMAlloc() supplied as host_ptr.
The contents of these buffers are automatically shared between host codes and device codes. There is no need for calls to clEnqueueWriteBuffer() and clEnqueueReadBuffer() for the device to access these shared buffers.
Once an SVM buffer is no longer needed, clReleaseMemObject()is used to release it. After that, clSVMFree() is used to deallocate the SVM buffer.
11.8 Compiler Support for Tiling in C++AMP
Tiling is one of the most important techniques in optimizing GPU programs. Depending on the level of abstraction, a programming model can provide either implicit or explicit support for tiling. An implicit approach may involve automatically deducing the part of memory accesses to be tiled from a given kernel, and generate appropriate code to either transparently or semitransparently tile the memory access pattern to achieve better memory locality and usually better performance. Conversely, an explicit approach relies on the user to explicitly define memory objects in different address spaces that correspond to on-chip and off-chip memory, and also the data movement between them. C++ AMP, CUDA, and OpenCL are all examples of such explicit programming models. The rest of this section considers supporting explicit tiling in C++ AMP from a compiler writer’s perspective.
For programming models that explicitly support tiling, one can usually find the following traits:
• A way to divide the compute domain into fixed-sized chunks.
• A way to explicitly specify the address space where a data buffer resides, usually on-chip, off-chip, or thread-private. These map to OpenCL __local, __global, and __private respectively.
• A way to provide barrier synchronization within these fixed-sized chunks of computation (i.e. work-items in a work-group) to coordinate their execution timing.
We first review some background knowledge for readers who are not familiar with tiling in C++ AMP. In C++ AMP, an extent describes the size and the dimension of the compute domain. In addition, tile_extent describes how to divide the compute domain. The division is analogous to how OpenCL work-group sizes divide the OpenCL work-item dimensions.
11.8.1 Dividing the Compute Domain
In C++ AMP, a template method “tile” in the class extent is used to compute a tile_extent. Its template parameters indicate the tiling size. From here it becomes clear that unlike tiling in OpenCL, tiling in C++ AMP is parameterized statically. To notify the library and compiler about tiling, we use a Lambda kernel that has a slightly different signature (line 13 in the following listing), which in turn uses tiled_index. A tiled_index is analogous to a tuple that represents values of OpenCL get_global_id(), get_local_id(), and get_group_id().
11.8.2 Specifying the Address Space and Barriers
In a C++ AMP kernel function, the tile_static qualifier is used to declare a memory object that resides in on-chip memory (local memory in OpenCL terms). To force synchronization across threads in a C++ AMP tile, the barrier.wait method of a tile_static object is used. As in OpenCL, threads in the same tiling group will stop at the same program point where wait is called.
An interesting difference between OpenCL and C++ AMP lies in how the address space information is carried in pointers. In OpenCL, it is part of the pointer’s type: for a pointer that is declared with __local, it cannot point to a buffer declared using the __private qualifier. In C++ AMP, however, the address space information is part of the pointer’s value. One could have a general pointer such as
and the pointer foo can point to a buffer declared using tile_static (which is equivalent to __local in OpenCL), and with certain limitations4 the same pointer can point to a value in global memory.
One could attempt to define C++ AMP’s tile_static as a macro that expands to Clang/LLVM’s __attribute__((address_space())) qualifier, which is an extension made for Embedded C that goes to part of the pointer and memory object type. However, the approach would fail to generate the correct address space information for the pointer foo in the following code snippet:
That is, we cannot embed the address space qualifier as part of the pointer type, but we need to be able to propagate that information as part of variable definitions. The template approach does not allow proper differentiation between these values within the compiler.
An alternative approach is to specify the address space as variable attributes, which are special markers that go with a particular variable, but not part of its type. An example of such an attribute would be compiler extensions that specify in which section of the object file a variable is defined. Attributes of this kind go with the variable definition but not its type: one can have two integers of the same type but each staying in a different section, and a pointer can be pointing to either of these two without type errors. In Clamp we follow this approach—a simple mapping that allows a dataflow analysis to deduce address space information but the code would still look like largely legitimate C++ code:
• Define C++ AMP’s tile_static as a variable attribute.
• All pointers are initially without an address space.
• A static-single-assignment-based analysis is introduced to deduce the point-to variable attributes.
The analysis aims only at essentially an easy subset of the much harder pointer analysis problems, which are generally undecidable. The next section describes in detail how the address space deduction is done.
11.9 Address Space Deduction
As stated in the previous section, each OpenCL variable declaration has its own address space qualifier, indicating which memory region an object should be allocated. The address space is an important feature of OpenCL. By putting data into different memory regions, OpenCL programs can achieve high performance while maintaining data coherence. This feature, however, is typically missing from high-level languages such as C++ AMP. High-level languages put data into a single generic address space, and there is no need to indicate the address space explicitly. A declaration without an address space will be qualified as private to each work-item in OpenCL, which violates the intended behavior enforced by C++ AMP. For example, if a tile_static declaration is qualified as private, the data will no longer be shared among work-groups, and the execution result will be incorrect. To resolve this discrepancy, a special transformation is required to append a correct address space designation for each declaration and memory access.
In Clamp, after OpenCL bitcode has been generated, the generated code will go through a llvm transformation pass to decide on and promote (i.e. adding type qualifiers to) the declaration to the right address space. In theory, it is impossible to always conclusively deduce the address space for each declaration, because the analyzer lacks the global view identifying how the kernels will interact with each other. However, there are clues we can use to deduce the correct address space in practical programs.
The implementation of array and array_view provides a hint to deduce the correct address space. In C++ AMP, the only way to pass bulk data to the kernel is to wrap them by array and array_view. The C++ AMP runtime will append the underlying pointer to the argument list of the kernel. Those data will be used in the kernel by accessing the corresponding pointer on the argument of the kernel function. Those pointers, as a result, should be qualified as global, because the data pointed to by them should be visible to all the threads. The deduction process will iterate through all such arguments of the kernel function, promote pointers to global, and update all the memory operations that use the pointers.
The tile_static data declarations cannot be identified through pattern analysis, so they need to be preserved from the Clamp front end. In the current Clamp implementation, declarations with tile_static qualifiers are placed into a special section in the generated bitcode. The deduction process will propagate the tile_static attribute to any pointers that receive the address of these variables, append it to the corresponding OpenCL declarations.
Let us use a tiny C++ AMP code example to illustrate this transformation:
After the initial Clamp pass, the code will be transformed to pure LLVM IR. An address space is lacking at this stage, and this code will produce an incorrect result. Notice that the variable tmp is put to a special ELF section (“clamp_opencl_local”):
After the deduction pass in Clamp, the correct address spaces are deduced and appended to the associated declaration of mm_kernel.tmp memory operations. The generated code can now be executed correctly, as illustrated in the following refined LLVM IR:
11.10 Data Movement Optimization
As the speed of processors becomes faster and faster, computation power is no longer the major bottleneck for high-performance systems. Instead, for data-intensive computation, the bottleneck mainly lies in memory bandwidth. In many cases, the time spent moving data between the accelerator and the host system can be much greater than the time spent performing computation. To minimize the overhead, OpenCL provides various ways to create a buffer object in the accelerator. In OpenCL, CL_MEM_READ_ONLY indicates that the data will not be modified during the computation. If the object is created with CL_MEM_READ_ONLY, the data will be put into the constant memory region and need not be copied back to the host system after computation has been done. Conversely, CL_MEM_WRITE_ONLY indicates that the buffer is only used to store result data. If the object is created with CL_MEM_WRITE_ONLY, the data on the host does not need to be copied to the accelerator before computation starts. In mapping C++ AMP to OpenCL, we can utilize these features to further improve the performance.
11.10.1 discard_data()
In C++ AMP, discard_data is a member function of array_view. Calling this function tells the runtime that the current data in the array will be discarded (overwritten), and therefore there is no need to copy the data to the device before computation starts. In this case, we can create a buffer object with CL_MEM_WRITE_ONLY.
11.10.2 array_view<const T, N>
If an array_view’s first template parameter is qualified as const, we can create the buffer object with CL_MEM_READ_ONLY. This way, the OpenCL runtime knows that underlying data will not be changed during the computation, and therefore there is no need to copy the data back from the device after computation has finished.
11.11 Binomial Options: A Full Example
In this section we present a nontrivial application, from an application programmer’s view, that requires all the techniques described above to compile it into a valid and well-optimized OpenCL implementation. The application chosen is binomial options. Note we will not dive into the mathematical aspects nor the financial side of this application, but will present it as a “put-it-all-together” example for compiler writers.
The code snippet above is the prototype of the binomial options function. v_s, v_x, v_vdt, v_pu_by_df, and v_pd_by_df hold the input data separately; call_value is used to store the result.
In order to use input data in the kernel function, data should be wrapped by the containers provided by C++ AMP. In this example, concurrency::array_view is used. discard_data is called for av_call_value here to tell the runtime not to copy data from the host to the device.
Notice that av_s, av_x, av_vdt, av_pi_by_df, and av_pd_by_df are wrapped by const array_views and will not be copied back after computation has finished.
After the calculation of the computation range, the C++ AMP code calls parallel_for_each to do the calculation. After the computation has finished, the synchronize member function is called to ensure the result is synchronized back to the source container. All the data in use will be handled by the runtime implicitly. Programmers do not need to explicitly pass or copy the data between the host and the device. Note that the parallel_for_each construct uses explicit tiling for locality control.
The declarations stating with tile_static declare shared arrays that will be shared among work-items in the same tiling group. To ensure memory data consistency of the shared array, the tidx.barrier.wait function call is used. Work-items in same tiling group will stop and wait at the same program point where wait is called until all work-items in the same tiling group have arrived at that point.
11.12 Preliminary Results
In order to assess the efficiency of our C++ AMP implementation, we measure the execution time of the binomial options benchmark5 in two ways. The first way is to implement the benchmark directly in OpenCL and execute it on a particular OpenCL implementation. The second way is to implement the benchmark in C++ AMP, compile it through Clamp, and execute the translated OpenCL code on the same platform In this experiment, we use the following configuration:
• Linux kernel: 3.16.4-1-ARCH
• AMD Catalyst driver: 14.301.1001
• AMD OpenCL accelerated parallel processing (APP) software development kit (SDK): v2.9-1
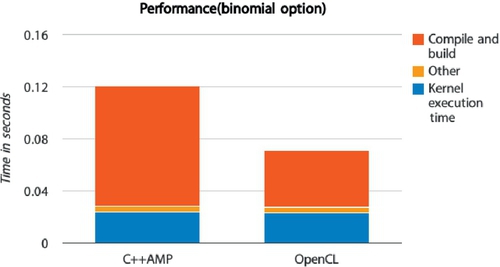
The chart shows that the C++ AMP-generated kernel execution time is almost the same as the OpenCL kernel execution time, but the time spent compiling the automatically generated OpenCL kernel code is much longer. This is because the current implementation appends mathematical built-in functions to the kernel, making the kernel source code about 10 times larger for this benchmark. “Other” includes the time to write OpenCL buffers and pass arguments. Because CL_MEM_USE_HOST_PTR is used in the benchmark, there is almost no performance overhead in these activities for the C++ AMP version.
Because the kernel compilation time is incurred only when a kernel is launched the first time in an application, the compile time is typically amortized across many launches in real applications. For these applications, users will experience comparable execution times between the two versions of the benchmark.
For the binomial options benchmark, the host off-loading code plus the kernel code is 160 lines of OpenCL code versus 80 lines of C++ AMP code. This clearly shows the higher-level programming nature of C++ AMP as compared with OpenCL.
11.13 Conclusion
In this chapter, we presented a case study of implementing C++ AMP on top of OpenCL. In C++ AMP, users can leave the data movement between the host and the device to the compiler. We showed the key transformations for compiling high-level, object-oriented C++ AMP code into OpenCL host code and device kernels. Using the binomial options benchmark, we showed that Clamp, the MulticoreWare C++ AMP implementation achieves comparable execution time between automatically generated kernels and hand-written OpenCL ones. This shows that OpenCL is an effective platform for implementing high-level programming languages such as C++ AMP for data-parallel algorithms.