
Chapter 2. Designing Classes with a Single Responsibility
The foundation of an object-oriented system is the message, but the most visible organizational structure is the class. Messages are at the core of design, but because classes are so obvious this chapter starts small and concentrates on how to decide what belongs in a class. The design emphasis will gradually shift from classes to messages over the next several chapters.
What are your classes? How many should you have? What behavior will they implement? How much do they know about other classes? How much of themselves should they expose?
These questions can be overwhelming. Every decision seems both permanent and fraught with peril. Fear not. At this stage your first obligation is to take a deep breath and insist that it be simple. Your goal is to model your application, using classes, such that it does what it is supposed to do right now and is also easy to change later.
These are two very different criteria. Anyone can arrange code to make it work right now. Today’s application can be beat into submission by sheer force of will. It’s a standing target at a known range. It is at your mercy.
Creating an easy-to-change application, however, is a different matter. Your application needs to work right now just once; it must be easy to change forever. This quality of easy changeability reveals the craft of programming. Achieving it takes knowledge, skill, and a bit of artistic creativity.
Fortunately, you don’t have to figure everything out from scratch. Much thought and research has gone into identifying the qualities that make an application easy to change. The techniques are simple; you only need to know what they are and how to use them.
Deciding What Belongs in a Class
You have an application in mind. You know what it should do. You may even have thought about how to implement the most interesting bits of behavior. The problem is not one of technical knowledge but of organization; you know how to write the code but not where to put it.
Grouping Methods into Classes
In a class-based OO language like Ruby, methods are defined in classes. The classes you create will affect how you think about your application forever. They define a virtual world, one that constrains the imagination of everyone downstream. You are constructing a box that may be difficult to think outside of.
Despite the importance of correctly grouping methods into classes, at this early stage of your project you cannot possibly get it right. You will never know less than you know right now. If your application succeeds many of the decisions you make today will need to be changed later. When that day comes, your ability to successfully make those changes will be determined by your application’s design.
Design is more the art of preserving changeability than it is the act of achieving perfection.
Organizing Code to Allow for Easy Changes
Asserting that code should be easy to change is akin to stating that children should be polite; the statement is impossible to disagree with yet it in no way helps a parent raise an agreeable child. The idea of easy is too broad; you need concrete definitions of easiness and specific criteria by which to judge code.
If you define easy to change as
• Changes have no unexpected side effects
• Small changes in requirements require correspondingly small changes in code
• Existing code is easy to reuse
• The easiest way to make a change is to add code that in itself is easy to change.
Then the code you write should have the following qualities. Code should be
• Transparent The consequences of change should be obvious in the code that is changing and in distant code relies upon it
• Reasonable The cost of any change should be proportional to the benefits the change achieves
• Usable Existing code should be usable in new and unexpected contexts
• Exemplary The code itself should encourage those who change it to perpetuate these qualities
Code that is Transparent, Reasonable, Usable, and Exemplary (TRUE) not only meets today’s needs but can also be changed to meet the needs of the future. The first step in creating code that is TRUE is to ensure that each class has a single, well-defined responsibility.
Creating Classes That Have a Single Responsibility
A class should do the smallest possible useful thing; that is, it should have a single responsibility.
Illustrating how to create a class that has a single responsibility and explaining why it matters requires an example, which in turn requires a small divergence into the domain of bicycles.
An Example Application: Bicycles and Gears
Bicycles are wonderfully efficient machines, in part because they use gears to provide humans with mechanical advantage. When riding a bike you can choose between a small gear (which is easy to pedal but not very fast) or a big gear (which is harder to pedal but sends you zooming along). Gears are great because you can use small ones to creep up steep hills and big ones to fly back down.
Gears work by changing how far the bicycle travels each time your feet complete one circle with the pedals. More specifically, your gear controls how many times the wheels rotate for each time the pedals rotate. In a small gear your feet spin around several times to make the wheels rotate just once; in a big gear each complete pedal rotation may cause the wheels to rotate multiple times. See Figure 2.1.
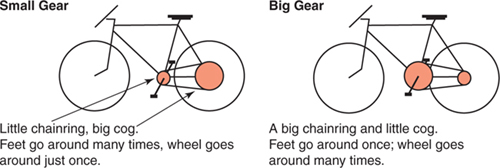
Figure 2.1. Small versus big bicycle gears.
The terms small and big are not very precise. To compare different gears, bicyclists use the ratio of the numbers of their teeth. These ratios can be calculated with this simple Ruby script:
1 chainring = 52 # number of teeth
2 cog = 11
3 ratio = chainring / cog.to_f
4 puts ratio # -> 4.72727272727273
5
6 chainring = 30
7 cog = 27
8 ratio = chainring / cog.to_f
9 puts ratio # -> 1.11111111111111
The gear created by combining a 52-tooth chainring with an 11-tooth cog (a 52 × 11) has a ratio of about 4.73. Each time your feet push the pedals around one time your wheels will travel around almost five times. The 30 × 27 is a much easier gear; each pedal revolution causes the wheels to rotate a little more than once.
Believe it or not, there are people who care deeply about bicycle gearing. You can help them out by writing a Ruby application to calculate gear ratios.
The application will be made of Ruby classes, each representing some part of the domain. If you read through the description above looking for nouns that represent objects in the domain you’ll see words like bicycle and gear. These nouns represent the simplest candidates to be classes. Intuition says that bicycle should be a class, but nothing in the above description lists any behavior for bicycle, so, as yet, it does not qualify. Gear, however, has chainrings, cogs, and ratios, that is, it has both data and behavior. It deserves to be a class. Taking the behavior from the script above, you create this simple Gear class:
1 class Gear
2 attr_reader :chainring, :cog
3 def initialize(chainring, cog)
4 @chainring = chainring
5 @cog = cog
6 end
7
8 def ratio
9 chainring / cog.to_f
10 end
11 end
12
13 puts Gear.new(52, 11).ratio # -> 4.72727272727273
14 puts Gear.new(30, 27).ratio # -> 1.11111111111111
This Gear class is simplicity itself. You create a new Gear instance by providing the numbers of teeth for the chainring and cog. Each instance implements three methods: chainring, cog, and ratio.
Gear is a subclass of Object and thus inherits many other methods. A Gear consists of everything it directly implements plus everything it inherits, so the complete set of behavior, that is, the total set of messages to which it can respond, is fairly large. Inheritance matters to your application’s design, but this simple case where Gear inherits from object is so basic that, at least for now, you can act as if these inherited methods do not exist. More sophisticated forms of inheritance will be covered in Chapter 6, Acquiring Behavior Through Inheritance.
You show your Gear calculator to a cyclist friend and she finds it useful but immediately asks for an enhancement. She has two bicycles; the bicycles have exactly the same gearing but they have different wheel sizes. She would like you to also calculate the effect of the difference in wheels.
A bike with huge wheels travels much farther during each wheel rotation than one with tiny wheels, as shown in Figure 2.2.
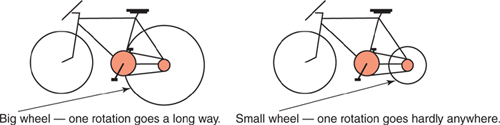
Figure 2.2. Effect of wheel size on distance traveled.
Cyclists (at least those in the United States) use something called gear inches to compare bicycles that differ in both gearing and wheel size. The formula follows:
gear inches = wheel diameter * gear ratio
where
wheel diameter = rim diameter + twice tire diameter.
You change the Gear class to add this new behavior:
1 class Gear
2 attr_reader :chainring, :cog, :rim, :tire
3 def initialize(chainring, cog, rim, tire)
4 @chainring = chainring
5 @cog = cog
6 @rim = rim
7 @tire = tire
8 end
9
10 def ratio
11 chainring / cog.to_f
12 end
13
14 def gear_inches
15 # tire goes around rim twice for diameter
16 ratio * (rim + (tire * 2))
17 end
18 end
19
20 puts Gear.new(52, 11, 26, 1.5).gear_inches
21 # -> 137.090909090909
22
23 puts Gear.new(52, 11, 24, 1.25).gear_inches
24 # -> 125.272727272727
The new gear_inches method assumes that rim and tire sizes are given in inches, which may or may not be correct. With that caveat, the Gear class meets the specifications (such as they are) and the code, with the exception of the following bug, works.
1 puts Gear.new(52, 11).ratio # didn't this used to work?
2 # ArgumentError: wrong number of arguments (2 for 4)
3 # from (irb):20:in 'initialize'
4 # from (irb):20:in 'new'
5 # from (irb):20
6
The bug above was introduced when the gear_inches method was added. Gear.initialize was changed to require two additional arguments, rim and tire. Altering the number of arguments that a method requires breaks all existing callers of the method. This would normally be a terrible problem that would have to be dealt with instantly, but because the application is so small that Gear.initialize currently has no other callers, the bug can be ignored for now.
Now that a rudimentary Gear class exists, it’s time to ask the question: Is this the best way to organize the code?
The answer, as always, is: it depends. If you expect the application to remain static forever, Gear in its current form may be good enough. However, you can already foresee the possibility of an entire application of calculators for bicyclists. Gear is the first of many classes of an application that will evolve. To efficiently evolve, code must be easy to change.
Why Single Responsibility Matters
Applications that are easy to change consist of classes that are easy to reuse. Reusable classes are pluggable units of well-defined behavior that have few entanglements. An application that is easy to change is like a box of building blocks; you can select just the pieces you need and assemble them in unanticipated ways.
A class that has more than one responsibility is difficult to reuse. The various responsibilities are likely thoroughly entangled within the class. If you want to reuse some (but not all) of its behavior, it is impossible to get at only the parts you need. You are faced with two options and neither is particularly appealing.
If the responsibilities are so coupled that you cannot use just the behavior you need, you could duplicate the code of interest. This is a terrible idea. Duplicated code leads to additional maintenance and increases bugs. If the class is structured such that you can access only the behavior you need, you could reuse the entire class. This just substitutes one problem for another.
Because the class you’re reusing is confused about what it does and contains several tangled up responsibilities, it has many reasons to change. It may change for a reason that is unrelated to your use of it, and each time it changes there’s a possibility of breaking every class that depends on it. You increase your application’s chance of breaking unexpectedly if you depend on classes that do too much.
Determining If a Class Has a Single Responsibility
How can you determine if the Gear class contains behavior that belongs somewhere else? One way is to pretend that it’s sentient and to interrogate it. If you rephrase every one of its methods as a question, asking the question ought to make sense. For example, “Please Mr. Gear, what is your ratio?” seems perfectly reasonable, while “Please Mr. Gear, what are your gear_inches?” is on shaky ground, and “Please Mr. Gear, what is your tire (size)?” is just downright ridiculous.
Don’t resist the idea that “what is your tire?” is a question that can legitimately be asked. From inside the Gear class, tire may feel like a different kind of thing than ratio or gear_inches, but that means nothing. From the point of view of every other object, anything that Gear can respond to is just another message. If Gear responds to it, someone will send it, and that sender may be in for a rude surprise when Gear changes.
Another way to hone in on what a class is actually doing is to attempt to describe it in one sentence. Remember that a class should do the smallest possible useful thing. That thing ought to be simple to describe. If the simplest description you can devise uses the word “and,” the class likely has more than one responsibility. If it uses the word “or,” then the class has more than one responsibility and they aren’t even very related.
OO designers use the word cohesion to describe this concept. When everything in a class is related to its central purpose, the class is said to be highly cohesive or to have a single responsibility. The Single Responsibility Principle (SRP) has its roots in Rebecca Wirfs-Brock and Brian Wilkerson’s idea of Responsibility-Driven Design (RDD). They say “A class has responsibilities that fulfill its purpose.” SRP doesn’t require that a class do only one very narrow thing or that it change for only a single nitpicky reason, instead SRP requires that a class be cohesive—that everything the class does be highly related to its purpose.
How would you describe the responsibility of the Gear class? How about “Calculate the ratio between two toothed sprockets”? If this is true, the class, as it currently exists, does too much. Perhaps “Calculate the effect that a gear has on a bicycle”? Put this way, gear_inches is back on solid ground, but tire size is still quite shaky.
The class doesn’t feel right. Gear has more than one responsibility but it’s not obvious what should be done.
Determining When to Make Design Decisions
It’s common to find yourself in a situation where you know something isn’t quite right with a class. Is this class really a Gear? It has rims and tires, for goodness sake! Perhaps Gear should be Bicycle? Or maybe there’s a Wheel in here somewhere?
If you only knew what feature requests would arrive in the future you could make perfect design decisions today. Unfortunately, you do not. Anything might happen. You can waste a lot of time being torn between equally plausible alternatives before rolling the dice and choosing the wrong one.
Do not feel compelled to make design decisions prematurely. Resist, even if you fear your code would dismay the design gurus. When faced with an imperfect and muddled class like Gear, ask yourself: “What is the future cost of doing nothing today?”
This is a (very) small application. It has one developer. You are intimately familiar with the Gear class. The future is uncertain and you will never know less than you know right now. The most cost-effective course of action may be to wait for more information.
The code in the Gear class is both transparent and reasonable, but this does not reflect excellent design, merely that the class has no dependencies so changes to it have no consequences. If it were to acquire dependencies it would suddenly be in violation of both of those goals and should be reorganized at that time. Conveniently, the new dependencies will supply the exact information you need to make good design decisions.
When the future cost of doing nothing is the same as the current cost, postpone the decision. Make the decision only when you must with the information you have at that time.
Even though there’s a good argument for leaving Gear as is for the time being, you could also make a defensible argument that it should be changed. The structure of every class is a message to future maintainers of the application. It reveals your design intentions. For better or for worse, the patterns you establish today will be replicated forever.
Gear lies about your intentions. It is neither usable nor exemplary. It has multiple responsibilities and so should not be reused. It is not a pattern that should be replicated.
There is a chance that someone else will reuse Gear, or create new code that follows its pattern while you are waiting for better information. Other developers believe that your intentions are reflected in the code; when the code lies you must be alert to programmers believing and then propagating that lie.
This “improve it now” versus “improve it later” tension always exists. Applications are never perfectly designed. Every choice has a price. A good designer understands this tension and minimizes costs by making informed tradeoffs between the needs of the present and the possibilities of the future.
Writing Code That Embraces Change
You can arrange the code so that Gear will be easy to change even if you don’t know what changes will come. Because change is inevitable, coding in a changeable style has big future payoffs. As an additional bonus, coding in these styles will improve your code, today, at no extra cost.
Here are a few well-known techniques that you can use to create code that embraces change.
Depend on Behavior, Not Data
Behavior is captured in methods and invoked by sending messages. When you create classes that have a single responsibility, every tiny bit of behavior lives in one and only one place. The phrase “Don’t Repeat Yourself” (DRY) is a shortcut for this idea. DRY code tolerates change because any change in behavior can be made by changing code in just one place.
In addition to behavior, objects often contain data. Data is held in an instance variable and can be anything from a simple string or a complex hash. Data can be accessed in one of two ways; you can refer directly to the instance variable or you can wrap the instance variable in an accessor method.
Hide Instance Variables
Always wrap instance variables in accessor methods instead of directly referring to variables, like the ratio method does below:
1 class Gear
2 def initialize(chainring, cog)
3 @chainring = chainring
4 @cog = cog
5 end
6
7 def ratio
8 @chainring / @cog.to_f # <-- road to ruin
9 end
10 end
Hide the variables, even from the class that defines them, by wrapping them in methods. Ruby provides attr_reader as an easy way to create the encapsulating methods:
1 class Gear
2 attr_reader :chainring, :cog # <-------
3 def initialize(chainring, cog)
4 @chainring = chainring
5 @cog = cog
6 end
7
8 def ratio
9 chainring / cog.to_f # <-------
10 end
11 end
Using attr_reader caused Ruby to create simple wrapper methods for the variables. Here’s a virtual representation of the one it created for cog:
1 # default implementation via attr_reader
2 def cog
3 @cog
4 end
This cog method is now the only place in the code that understands what cog means. Cog becomes the result of a message send. Implementing this method changes cog from data (which is referenced all over) to behavior (which is defined once).
If the @cog instance variable is referred to ten times and it suddenly needs to be adjusted, the code will need many changes. However, if @cog is wrapped in a method, you can change what cog means by implementing your own version of the method. Your new method might be as simple as the first implementation below, or more complicated, like the second:
1 # a simple reimplementation of cog
2 def cog
3 @cog * unanticipated_adjustment_factor
4 end
1 # a more complex one
2 def cog
3 @cog * (foo? ? bar_adjustment : baz_adjustment)
4 end
The first example could arguably have been done by making one change to the value of the instance variable. However, you can never be sure that you won’t eventually need something like the second example. The second adjustment is a simple behavior change when done in a method, but a code destroying mess when applied to a bunch of instance variable references.
Dealing with data as if it’s an object that understands messages introduces two new issues. The first issue involves visibility. Wrapping the @cog instance variable in a public cog method exposes this variable to the other objects in your application; any other object can now send cog to a Gear. It would have been just as easy to create a private wrapping method, one that turns the data into behavior without exposing that behavior to the entire application. Choosing between these two alternatives is covered in Chapter 4, Creating Flexible Interfaces.
The second issue is more abstract. Because it’s possible to wrap every instance variable in a method and to therefore treat any variable as if it’s just another object, the distinction between data and a regular object begins to disappear. While it’s sometimes expedient to think of parts of your application as behavior-less data, most things are better thought of as plain old objects.
Regardless of how far your thoughts move in this direction, you should hide data from yourself. Doing so protects the code from being affected by unexpected changes. Data very often has behavior that you don’t yet know about. Send messages to access variables, even if you think of them as data.
Hide Data Structures
If being attached to an instance variable is bad, depending on a complicated data structure is worse. Consider the following ObscuringReferences class:
1 class ObscuringReferences
2 attr_reader :data
3 def initialize(data)
4 @data = data
5 end
6
7 def diameters
8 # 0 is rim, 1 is tire
9 data.collect {|cell|
10 cell[0] + (cell[1] * 2)}
11 end
12 # ... many other methods that index into the array
13 end
This class expects to be initialized with a two-dimensional array of rims and tires:
1 # rim and tire sizes (now in milimeters!) in a 2d array
2 @data = [[622, 20], [622, 23], [559, 30], [559, 40]]
ObscuringReferences stores its initialization argument in the variable @data and obediently uses Ruby’s attr_reader to wrap the @data instance variable in a method. The diameters method sends the data message to access the contents of the variable. This class certainly does everything necessary to hide the instance variable from itself.
However, since @data contains a complicated data structure, just hiding the instance variable is not enough. The data method merely returns the array. To do anything useful, each sender of data must have complete knowledge of what piece of data is at which index in the array.
The diameters method knows not only how to calculate diameters, but also where to find rims and tires in the array. It explicitly knows that if it iterates over data that rims are at [0] and tires are at [1].
It depends upon the array’s structure. If that structure changes, then this code must change. When you have data in an array it’s not long before you have references to the array’s structure all over. The references are leaky. They escape encapsulation and insinuate themselves throughout the code. They are not DRY. The knowledge that rims are at [0] should not be duplicated; it should be known in just one place.
This simple example is bad enough; imagine the consequences if data returned an array of hashes that were referenced in many places. A change to its structure would cascade throughout your code; each change represents an opportunity to create a bug so stealthy that your attempts to find it will make you cry.
Direct references into complicated structures are confusing, because they obscure what the data really is, and they are a maintenance nightmare, because every reference will need to be changed when the structure of the array changes.
In Ruby it’s easy to separate structure from meaning. Just as you can use a method to wrap an instance variable, you can use the Ruby Struct class to wrap a structure. In the following example, RevealingReferences has the same interface as the previous class. It takes a two-dimensional array as an initialization argument and it implements the diameters method. Despite these external similarities, its internal implementation is very different.
1 class RevealingReferences
2 attr_reader :wheels
3 def initialize(data)
4 @wheels = wheelify(data)
5 end
6
7 def diameters
8 wheels.collect {|wheel|
9 wheel.rim + (wheel.tire * 2)}
10 end
11 # ... now everyone can send rim/tire to wheel
12
13 Wheel = Struct.new(:rim, :tire)
14 def wheelify(data)
15 data.collect {|cell|
16 Wheel.new(cell[0], cell[1])}
17 end
18 end
The diameters method above now has no knowledge of the internal structure of the array. All diameters knows is that the message wheels returns an enumerable and that each enumerated thing responds to rim and tire. What were once references to cell[1] have been transformed into message sends to wheel.tire.
All knowledge of the structure of the incoming array has been isolated inside the wheelify method, which converts the array of Arrays into an array of Structs. The official Ruby documentation (http://ruby-doc.org/core/classes/Struct.html) defines Struct as “a convenient way to bundle a number of attributes together, using accessor methods, without having to write an explicit class.” This is exactly what wheelify does; it creates little lightweight objects that respond to rim and tire.
The wheelify method contains the only bit of code that understands the structure of the incoming array. If the input changes, the code will change in just this one place. It takes four new lines of code to create the Wheel Struct and to define the wheelify method, but these few lines of code are a minor inconvenience compared to the permanent cost of repeatedly indexing into a complex array.
This style of code allows you to protect against changes in externally owned data structures and to make your code more readable and intention revealing. It trades indexing into a structure for sending messages to an object. The wheelify method above isolates the messy structural information and DRYs out the code. It makes this class far more tolerant of change.
Although it might be easier to just have an array of Wheels to begin with, it is not always possible. If you can control the input, pass in a useful object, but if you are compelled to take a messy structure, hide the mess even from yourself.
Enforce Single Responsibility Everywhere
Creating classes with a single responsibility has important implications for design, but the idea of single responsibility can be usefully employed in many other parts of your code.
Extract Extra Responsibilities from Methods
Methods, like classes, should have a single responsibility. All of the same reasons apply; having just one responsibility makes them easy to change and easy to reuse. All the same design techniques work; ask them questions about what they do and try to describe their responsibilities in a single sentence.
Look at the diameters method of class RevealingReferences:
1 def diameters
2 wheels.collect {|wheel|
3 wheel.rim + (wheel.tire * 2)}
4 end
This method clearly has two responsibilities: it iterates over the wheels and it calculates the diameter of each wheel.
Simplify the code by separating it into two methods, each with one responsibility. This next refactoring moves the calculation of a single wheel’s diameter into its own method. The refactoring introduces an additional message send but at this point in your design you should act as if sending a message is free. Performance can be improved later, if need be. Right now the most important design goal is to write code that is easily changeable.
1 # first - iterate over the array
2 def diameters
3 wheels.collect {|wheel| diameter(wheel)}
4 end
5
6 # second - calculate diameter of ONE wheel
7 def diameter(wheel)
8 wheel.rim + (wheel.tire * 2))
9 end
Will you ever need to get the diameter of just one wheel? Look at the code again; you already do. This refactoring is not a case of overdesign, it merely reorganizes code that is currently in use. The fact that the singular diameter method can now be called from other places is a free and happy side effect.
Separating iteration from the action that’s being performed on each element is a common case of multiple responsibility that is easy to recognize. In other cases the problem is not so obvious.
Recall the gear_inches method of the Gear class:
1 def gear_inches
2 # tire goes around rim twice for diameter
3 ratio * (rim + (tire * 2))
4 end
Is gear_inches a responsibility of the Gear class? It is reasonable that it would be. But if it is, why does this method feel so wrong? It is muddled and uncertain and seems likely to cause trouble later. The root cause of the problem is that the method itself has more than one responsibility.
Hidden inside gear_inches is the calculation for wheel diameter. Extracting that calculation into this new diameter method will make it easier to examine the class’s responsibilities.
1 def gear_inches
2 ratio * diameter
3 end
4
5 def diameter
6 rim + (tire * 2)
7 end
The gear_inches method now sends a message to get wheel diameter. Notice that the refactoring does not alter how diameter is calculated; it merely isolates the behavior in a separate method.
Do these refactorings even when you do not know the ultimate design. They are needed, not because the design is clear, but because it isn’t. You do not have to know where you’re going to use good design practices to get there. Good practices reveal design.
This simple refactoring makes the problem obvious. Gear is definitely responsible for calculating gear_inches but Gear should not be calculating wheel diameter.
The impact of a single refactoring like this is small, but the cumulative effect of this coding style is huge. Methods that have a single responsibility confer the following benefits:
• Expose previously hidden qualities Refactoring a class so that all of its methods have a single responsibility has a clarifying effect on the class. Even if you do not intend to reorganize the methods into other classes today, having each of them serve a single purpose makes the set of things the class does more obvious.
• Avoid the need for comments How many times have you seen a comment that is out of date? Because comments are not executable, they are merely a form of decaying documentation. If a bit of code inside a method needs a comment, extract that bit into a separate method. The new method name serves the same purpose as did the old comment.
• Encourage reuse Small methods encourage coding behavior that is healthy for your application. Other programmers will reuse the methods instead of duplicating the code. They will follow the pattern you have established and create small, reusable methods in turn. This coding style propagates itself.
• Are easy to move to another class When you get more design information and decide to make changes, small methods are easy to move. You can rearrange behavior without doing a lot of method extraction and refactoring. Small methods lower the barriers to improving your design.
Isolate Extra Responsibilities in Classes
Once every method has a single responsibility, the scope of your class will be more apparent. The Gear class has some wheel-like behavior. Does this application need a Wheel class?
If circumstances allow you to create a separate Wheel class, perhaps you should. For now, imagine that you choose not to create a new, permanent, publicly available class at this moment. Perhaps some design restriction has been imposed upon you, or perhaps you are so uncertain about where you’re going that you don’t want to create a new class that others might start depending on, lest you change your mind.
It may seem impossible for Gear to have a single responsibility unless you remove its wheel-like behavior; the extra behavior is either in Gear or it’s not. However, casting the design choice in either/or terms is shortsighted. There are other choices. Your goal is to preserve single responsibility in Gear while making the fewest design commitments possible. Because you are writing changeable code, you are best served by postponing decisions until you are absolutely forced to make them. Any decision you make in advance of an explicit requirement is just a guess. Don’t decide; preserve your ability to make a decision later.
Ruby allows you to remove the responsibility for calculating tire diameter from Gear without committing to a new class. The following example extends the previous Wheel Struct with a block that adds a method to calculate diameter.
1 class Gear
2 attr_reader :chainring, :cog, :wheel
3 def initialize(chainring, cog, rim, tire)
4 @chainring = chainring
5 @cog = cog
6 @wheel = Wheel.new(rim, tire)
7 end
8
9 def ratio
10 chainring / cog.to_f
11 end
12
13 def gear_inches
14 ratio * wheel.diameter
15 end
16
17 Wheel = Struct.new(:rim, :tire) do
18 def diameter
19 rim + (tire * 2)
20 end
21 end
22 end
Now you have a Wheel that can calculate its own diameter. Embedding this Wheel in Gear is obviously not the long-term design goal; it’s more an experiment in code organization. It cleans up Gear but defers the decision about Wheel.
Embedding Wheel inside of Gear suggests that you expect that a Wheel will only exist in the context of a Gear. If you lift your head from this book for a moment and look out at the real world, common sense suggests otherwise. In this case, enough information exists right now to support the creation of an independent Wheel class. However, every domain isn’t this clear-cut.
If you have a muddled class with too many responsibilities, separate those responsibilities into different classes. Concentrate on the primary class. Decide on its responsibilities and enforce your decision fiercely. If you identify extra responsibilities that you cannot yet remove, isolate them. Do not allow extraneous responsibilities to leak into your class.
Finally, the Real Wheel
While you’re pondering the design of the Gear class, the future arrives. You show your calculator to your cyclist friend again and she tells you that it’s very nice but that while you’re writing calculators she would also like to have one for “bicycle wheel circumference.” She has a computer on her bike that calculates speed; this computer has to be configured with the bicycle’s wheel circumference to do its job.
This is the information you’ve been waiting for; it’s a new feature request that supplies the exact information you need to make the next design decision.
You know that the circumference of a wheel is PI times its diameter. Your embedded Wheel already calculates diameter; it’s a simple matter to add a new method to calculate circumference. These changes are minor; the real change here is that now your application has an explicit need for a Wheel class that it can use independently of Gear. It’s time to set Wheel free to be a separate class of it’s own.
Because you have already carefully isolated the Wheel behavior inside of the Gear class, this change is painless. Simply convert the Wheel Struct to an independent Wheel class and add the new circumference method:
1 class Gear
2 attr_reader :chainring, :cog, :wheel
3 def initialize(chainring, cog, wheel=nil)
4 @chainring = chainring
5 @cog = cog
6 @wheel = wheel
7 end
8
9 def ratio
10 chainring / cog.to_f
11 end
12
13 def gear_inches
14 ratio * wheel.diameter
15 end
16 end
17
18 class Wheel
19 attr_reader :rim, :tire
20
21 def initialize(rim, tire)
22 @rim = rim
23 @tire = tire
24 end
25
26 def diameter
27 rim + (tire * 2)
28 end
29
30 def circumference
31 diameter * Math::PI
32 end
33 end
34
35 @wheel = Wheel.new(26, 1.5)
36 puts @wheel.circumference
37 # -> 91.106186954104
38
39 puts Gear.new(52, 11, @wheel).gear_inches
40 # -> 137.090909090909
41
42 puts Gear.new(52, 11).ratio
43 # -> 4.72727272727273
Both classes have a single responsibility. The code is not perfect, but in some ways it achieves a higher standard: it is good enough.
Summary
The path to changeable and maintainable object-oriented software begins with classes that have a single responsibility. Classes that do one thing isolate that thing from the rest of your application. This isolation allows change without consequence and reuse without duplication.