
Chapter 3. Managing Dependencies
Object-oriented programming languages contend that they are efficient and effective because of the way they model reality. Objects reflect qualities of a real-world problem and the interactions between those objects provide solutions. These interactions are inescapable. A single object cannot know everything, so inevitably it will have to talk to another object.
If you could peer into a busy application and watch the messages as they pass, the traffic might seem overwhelming. There’s a lot going on. However, if you stand back and take a global view, a pattern becomes obvious. Each message is initiated by an object to invoke some bit of behavior. All of the behavior is dispersed among the objects. Therefore, for any desired behavior, an object either knows it personally, inherits it, or knows another object who knows it.
The previous chapter concerned itself with the first of these, that is, behaviors that a class should personally implement. The second, inheriting behavior, will be covered in Chapter 6, Acquiring Behavior Through Inheritance. This chapter is about the third, getting access to behavior when that behavior is implemented in other objects.
Because well designed objects have a single responsibility, their very nature requires that they collaborate to accomplish complex tasks. This collaboration is powerful and perilous. To collaborate, an object must know something know about others. Knowing creates a dependency. If not managed carefully, these dependencies will strangle your application.
Understanding Dependencies
An object depends on another object if, when one object changes, the other might be forced to change in turn.
Here’s a modified version of the Gear class, where Gear is initialized with four familiar arguments. The gear_inches method uses two of them, rim and tire, to create a new instance of Wheel. Wheel has not changed since you last you saw it in Chapter 2, Designing Classes with a Single Responsibility.
1 class Gear
2 attr_reader :chainring, :cog, :rim, :tire
3 def initialize(chainring, cog, rim, tire)
4 @chainring = chainring
5 @cog = cog
6 @rim = rim
7 @tire = tire
8 end
9
10 def gear_inches
11 ratio * Wheel.new(rim, tire).diameter
12 end
13
14 def ratio
15 chainring / cog.to_f
16 end
17 # ...
18 end
19
20 class Wheel
21 attr_reader :rim, :tire
22 def initialize(rim, tire)
23 @rim = rim
24 @tire = tire
25 end
26
27 def diameter
28 rim + (tire * 2)
29 end
30 # ...
31 end
32
33 Gear.new(52, 11, 26, 1.5).gear_inches
Examine the code above and make a list of the situations in which Gear would be forced to change because of a change to Wheel. This code seems innocent but it’s sneakily complex. Gear has at least four dependencies on Wheel, enumerated as follows. Most of the dependencies are unnecessary; they are a side effect of the coding style. Gear does not need them to do its job. Their very existence weakens Gear and makes it harder to change.
Recognizing Dependencies
An object has a dependency when it knows
• The name of another class. Gear expects a class named Wheel to exist.
• The name of a message that it intends to send to someone other than self. Gear expects a Wheel instance to respond to diameter.
• The arguments that a message requires. Gear knows that Wheel.new requires a rim and a tire.
• The order of those arguments. Gear knows the first argument to Wheel.new should be rim, the second, tire.
Each of these dependencies creates a chance that Gear will be forced to change because of a change to Wheel. Some degree of dependency between these two classes is inevitable, after all, they must collaborate, but most of the dependencies listed above are unnecessary. These unnecessary dependencies make the code less reasonable. Because they increase the chance that Gear will be forced to change, these dependencies turn minor code tweaks into major undertakings where small changes cascade through the application, forcing many changes.
Your design challenge is to manage dependencies so that each class has the fewest possible; a class should know just enough to do its job and not one thing more.
Coupling Between Objects (CBO)
These dependencies couple Gear to Wheel. Alternatively, you could say that each coupling creates a dependency. The more Gear knows about Wheel, the more tightly coupled they are. The more tightly coupled two objects are, the more they behave like a single entity.
If you make a change to Wheel you may find it necessary to make a change to Gear. If you want to reuse Gear, Wheel comes along for the ride. When you test Gear, you’ll be testing Wheel too.
Figure 3.1 illustrates the problem. In this case, Gear depends on Wheel and four other objects, coupling Gear to five different things. When the underlying code was first written everything worked fine. The problem lies dormant until you attempt to use Gear in another context or to change one of the classes upon which Gear depends. When that day comes the cold hard truth is revealed; despite appearances, Gear is not an independent entity. Each of its dependencies is a place where another object is stuck to it. The dependencies cause these objects to act like a single thing. They move in lockstep; they change together.
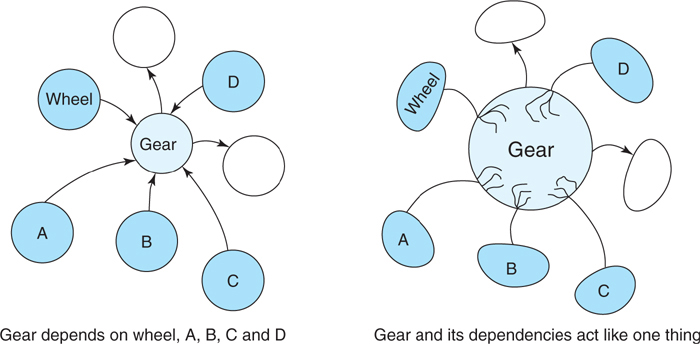
Figure 3.1. Dependencies entangle objects with one another.
When two (or three or more) objects are so tightly coupled that they behave as a unit, it’s impossible to reuse just one. Changes to one object force changes to all. Left unchecked, unmanaged dependencies cause an entire application to become an entangled mess. A day will come when it’s easier to rewrite everything than to change anything.
Other Dependencies
The remainder of this chapter examines the four kinds of dependencies listed above and suggests techniques for avoiding the problems they create. However, before going forward it’s worth mentioning a few other common dependency related issues that will be covered in other chapters.
One especially destructive kind of dependency occurs where an object knows another who knows another who knows something; that is, where many messages are chained together to reach behavior that lives in a distant object. This is the “knowing the name of a message you plan to send to someone other than self” dependency, only magnified. Message chaining creates a dependency between the original object and every object and message along the way to its ultimate target. These additional couplings greatly increase the chance that the first object will be forced to change because a change to any of the intermediate objects might affect it.
This case, a Law of Demeter violation, gets its own special treatment in Chapter 4, Creating Flexible Interfaces.
Another entire class of dependencies is that of tests on code. In the world outside of this book, tests come first. They drive design. However, they refer to code and thus depend on code. The natural tendency of “new-to-testing” programmers is to write tests that are too tightly coupled to code. This tight coupling leads to incredible frustration; the tests break every time the code is refactored, even when the fundamental behavior of the code does not change. Tests begin to seem costly relative to their value. Test-to-code over-coupling has the same consequence as code-to-code over-coupling. These couplings are dependencies that cause changes to the code to cascade into the tests, forcing them to change in turn.
The design of tests is examined in Chapter 9, Designing Cost-Effective Tests.
Despite these cautionary words, your application is not doomed to drown in unnecessary dependencies. As long as you recognize them, avoidance is quite simple. The first step to this brighter future is to understand dependencies in more detail; therefore, it’s time to look at some code.
Writing Loosely Coupled Code
Every dependency is like a little dot of glue that causes your class to stick to the things it touches. A few dots are necessary, but apply too much glue and your application will harden into a solid block. Reducing dependencies means recognizing and removing the ones you don’t need.
The following examples illustrate coding techniques that reduce dependencies by decoupling code.
Inject Dependencies
Referring to another class by its name creates a major sticky spot. In the version of Gear we’ve been discussing (repeated below), the gear_inches method contains an explicit reference to class Wheel:
1 class Gear
2 attr_reader :chainring, :cog, :rim, :tire
3 def initialize(chainring, cog, rim, tire)
4 @chainring = chainring
5 @cog = cog
6 @rim = rim
7 @tire = tire
8 end
9
10 def gear_inches
11 ratio * Wheel.new(rim, tire).diameter
12 end
13 # ...
14 end
15
16 Gear.new(52, 11, 26, 1.5).gear_inches
The immediate, obvious consequence of this reference is that if the name of the Wheel class changes, Gear’s gear_inches method must also change.
On the face of it this dependency seems innocuous. After all, if a Gear needs to talk to a Wheel, something, somewhere, must create a new instance of the Wheel class. If Gear itself knows the name of the Wheel class, the code in Gear must be altered if Wheel’s name changes.
In truth, dealing with the name change is a relatively minor issue. You likely have a tool that allows you to do a global find/replace within a project. If Wheel’s name changes to Wheely, finding and fixing all of the references isn’t that hard. However, the fact that line 11 above must change if the name of the Wheel class changes is the least of the problems with this code. A deeper problem exists that is far less visible but significantly more destructive.
When Gear hard-codes a reference to Wheel deep inside its gear_inches method, it is explicitly declaring that it is only willing to calculate gear inches for instances of Wheel. Gear refuses to collaborate with any other kind of object, even if that object has a diameter and uses gears.
If your application expands to include objects such as disks or cylinders and you need to know the gear inches of gears which use them, you cannot. Despite the fact that disks and cylinders naturally have a diameter you can never calculate their gear inches because Gear is stuck to Wheel.
The code above exposes an unjustified attachment to static types. It is not the class of the object that’s important, it’s the message you plan to send to it. Gear needs access to an object that can respond to diameter; a duck type, if you will (see Chapter 5, Reducing Costs with Duck Typing). Gear does not care and should not know about the class of that object. It is not necessary for Gear to know about the existence of the Wheel class in order to calculate gear_inches. It doesn’t need to know that Wheel expects to be initialized with a rim and then a tire; it just needs an object that knows diameter.
Hanging these unnecessary dependencies on Gear simultaneously reduces Gear’s reusability and increases its susceptibility to being forced to change unnecessarily. Gear becomes less useful when it knows too much about other objects; if it knew less it could do more.
Instead of being glued to Wheel, this next version of Gear expects to be initialized with an object that can respond to diameter:
1 class Gear
2 attr_reader :chainring, :cog, :wheel
3 def initialize(chainring, cog, wheel)
4 @chainring = chainring
5 @cog = cog
6 @wheel = wheel
7 end
8
9 def gear_inches
10 ratio * wheel.diameter
11 end
12 # ...
13 end
14
15 # Gear expects a 'Duck' that knows 'diameter'
16 Gear.new(52, 11, Wheel.new(26, 1.5)).gear_inches
Gear now uses the @wheel variable to hold, and the wheel method to access, this object, but don’t be fooled, Gear doesn’t know or care that the object might be an instance of class Wheel. Gear only knows that it holds an object that responds to diameter.
This change is so small it is almost invisible, but coding in this style has huge benefits. Moving the creation of the new Wheel instance outside of Gear decouples the two classes. Gear can now collaborate with any object that implements diameter. As an extra bonus, this benefit was free. Not one additional line of code was written; the decoupling was achieved by rearranging existing code.
This technique is known as dependency injection. Despite its fearsome reputation, dependency injection truly is this simple. Gear previously had explicit dependencies on the Wheel class and on the type and order of its initialization arguments, but through injection these dependencies have been reduced to a single dependency on the diameter method. Gear is now smarter because it knows less.
Using dependency injection to shape code relies on your ability to recognize that the responsibility for knowing the name of a class and the responsibility for knowing the name of a message to send to that class may belong in different objects. Just because Gear needs to send diameter somewhere does not mean that Gear should know about Wheel.
This leaves the question of where the responsibility for knowing about the actual Wheel class lies; the example above conveniently sidesteps this issue, but it is examined in more detail later in this chapter. For now, it’s enough to understand that this knowledge does not belong in Gear.
Isolate Dependencies
It’s best to break all unnecessary dependences but, unfortunately, while this is always technically possible it may not be actually possible. When working on an existing application you may find yourself under severe constraints about how much you can actually change. If prevented from achieving perfection, your goals should switch to improving the overall situation by leaving the code better than you found it.
Therefore, if you cannot remove unnecessary dependencies, you should isolate them within your class. In Chapter 2, Designing Classes with a Single Responsibility, you isolated extraneous responsibilities so that they would be easy to recognize and remove when the right impetus came; here you should isolate unnecessary dependences so that they are easy to spot and reduce when circumstances permit.
Think of every dependency as an alien bacterium that’s trying to infect your class. Give your class a vigorous immune system; quarantine each dependency. Dependencies are foreign invaders that represent vulnerabilities, and they should be concise, explicit, and isolated.
Isolate Instance Creation
If you are so constrained that you cannot change the code to inject a Wheel into a Gear, you should isolate the creation of a new Wheel inside the Gear class. The intent is to explicitly expose the dependency while reducing its reach into your class.
The next two examples illustrate this idea.
In the first, creation of the new instance of Wheel has been moved from Gear’s gear_inches method to Gear’s initialization method. This cleans up the gear_inches method and publicly exposes the dependency in the initialize method. Notice that this technique unconditionally creates a new Wheel each time a new Gear is created.
1 class Gear
2 attr_reader :chainring, :cog, :rim, :tire
3 def initialize(chainring, cog, rim, tire)
4 @chainring = chainring
5 @cog = cog
6 @wheel = Wheel.new(rim, tire)
7 end
8
9 def gear_inches
10 ratio * wheel.diameter
11 end
12 # ...
The next alternative isolates creation of a new Wheel in its own explicitly defined wheel method. This new method lazily creates a new instance of Wheel, using Ruby’s ||= operator. In this case, creation of a new instance of Wheel is deferred until gear_inches invokes the new wheel method.
1 class Gear
2 attr_reader :chainring, :cog, :rim, :tire
3 def initialize(chainring, cog, rim, tire)
4 @chainring = chainring
5 @cog = cog
6 @rim = rim
7 @tire = tire
8 end
9
10 def gear_inches
11 ratio * wheel.diameter
12 end
13
14 def wheel
15 @wheel ||= Wheel.new(rim, tire)
16 end
17 # ...
In both of these examples Gear still knows far too much; it still takes rim and tire as initialization arguments and it still creates its own new instance of Wheel. Gear is still stuck to Wheel; it can calculate the gear inches of no other kind of object.
However, an improvement has been made. These coding styles reduce the number of dependencies in gear_inches while publicly exposing Gear’s dependency on Wheel. They reveal dependencies instead of concealing them, lowering the barriers to reuse and making the code easier to refactor when circumstances allow. This change makes the code more agile; it can more easily adapt to the unknown future.
The way you manage dependencies on external class names has profound effects on your application. If you are mindful of dependencies and develop a habit of routinely injecting them, your classes will naturally be loosely coupled. If you ignore this issue and let the class references fall where they may, your application will be more like a big woven mat than a set of independent objects. An application whose classes are sprinkled with entangled and obscure class name references is unwieldy and inflexible, while one whose class name dependencies are concise, explicit, and isolated can easily adapt to new requirements.
Isolate Vulnerable External Messages
Now that you’ve isolated references to external class names it’s time to turn your attention to external messages, that is, messages that are “sent to someone other than self.” For example, the gear_inches method below sends ratio and wheel to self, but sends diameter to wheel:
1 def gear_inches
2 ratio * wheel.diameter
3 end
This is a simple method and it contains Gear's only reference to wheel.diameter. In this case the code is fine, but the situation could be more complex. Imagine that calculating gear_inches required far more math and that the method looked something like this:
1 def gear_inches
2 #... a few lines of scary math
3 foo = some_intermediate_result * wheel.diameter
4 #... more lines of scary math
5 end
Now wheel.diameter is embedded deeply inside a complex method. This complex method depends on Gear responding to wheel and on wheel responding to diameter. Embedding this external dependency inside the gear_inches method is unnecessary and increases its vulnerability.
Any time you change anything you stand the chance of breaking it; gear_inches is now a complex method and that makes it both more likely to need changing and more susceptible to being damaged when it does. You can reduce your chance of being forced to make a change to gear_inches by removing the external dependency and encapsulating it in a method of its own, as in this next example:
1 def gear_inches
2 #... a few lines of scary math
3 foo = some_intermediate_result * diameter
4 #... more lines of scary math
5 end
6
7 def diameter
8 wheel.diameter
9 end
The new diameter method is exactly the method that you would have written if you had many references to wheel.diameter sprinkled throughout Gear and you wanted to DRY them out. The difference here is one of timing; it would normally be defensible to defer creation of the diameter method until you had a need to DRY out code; however, in this case the method is created preemptively to remove the dependency from gear_inches.
In the original code, gear_inches knew that wheel had a diameter. This knowledge is a dangerous dependency that couples gear_inches to an external object and one of its methods. After this change, gear_inches is more abstract. Gear now isolates wheel.diameter in a separate method and gear_inches can depend on a message sent to self.
If Wheel changes the name or signature of its implementation of diameter, the side effects to Gear will be confined to this one simple wrapping method.
This technique becomes necessary when a class contains embedded references to a message that is likely to change. Isolating the reference provides some insurance against being affected by that change. Although not every external method is a candidate for this preemptive isolation, it’s worth examining your code, looking for and wrapping the most vulnerable dependencies.
An alternative way to eliminate these side effects is to avoid the problem from the very beginning by reversing the direction of the dependency. This idea will be addressed soon but first there’s one more coding technique to cover.
Remove Argument-Order Dependencies
When you send a message that requires arguments, you, as the sender, cannot avoid having knowledge of those arguments. This dependency is unavoidable. However, passing arguments often involves a second, more subtle, dependency. Many method signatures not only require arguments, but they also require that those arguments be passed in a specific, fixed order.
In the following example, Gear’s initialize method takes three arguments: chainring, cog, and wheel. It provides no defaults; each of these arguments is required. In lines 11–14, when a new instance of Gear is created, the three arguments must be passed and they must be passed in the correct order.
1 class Gear
2 attr_reader :chainring, :cog, :wheel
3 def initialize(chainring, cog, wheel)
4 @chainring = chainring
5 @cog = cog
6 @wheel = wheel
7 end
8 ...
9 end
10
11 Gear.new(
12 52,
13 11,
14 Wheel.new(26, 1.5)).gear_inches
Senders of new depend on the order of the arguments as they are specified in Gear’s initialize method. If that order changes, all the senders will be forced to change.
Unfortunately, it’s quite common to tinker with initialization arguments. Especially early on, when the design is not quite nailed down, you may go through several cycles of adding and removing arguments and defaults. If you use fixed-order arguments each of these cycles may force changes to many dependents. Even worse, you may find yourself avoiding making changes to the arguments, even when your design calls for them because you can’t bear to change all the dependents yet again.
Use Hashes for Initialization Arguments
There’s a simple way to avoid depending on fixed-order arguments. If you have control over the Gear initialize method, change the code to take a hash of options instead of a fixed list of parameters.
The next example shows a simple version of this technique. The initialize method now takes just one argument, args, a hash that contains all of the inputs. The method has been changed to extract its arguments from this hash. The hash itself is created in lines 11–14.
1 class Gear
2 attr_reader :chainring, :cog, :wheel
3 def initialize(args)
4 @chainring = args[:chainring]
5 @cog = args[:cog]
6 @wheel = args[:wheel]
7 end
8 ...
9 end
10
11 Gear.new(
12 :chainring => 52,
13 :cog => 11,
14 :wheel => Wheel.new(26, 1.5)).gear_inches
The above technique has several advantages. The first and most obvious is that it removes every dependency on argument order. Gear is now free to add or remove initialization arguments and defaults, secure in the knowledge that no change will have side effects in other code.
This technique adds verbosity. In many situations verbosity is a detriment, but in this case it has value. The verbosity exists at the intersection between the needs of the present and the uncertainty of the future. Using fixed-order arguments requires less code today but you pay for this decrease in volume of code with an increase in the risk that changes will cascade into dependents later.
When the code in line 11 changed to use a hash, it lost its dependency on argument order but it gained a dependency on the names of the keys in the argument hash. This change is healthy. The new dependency is more stable than the old, and thus this code faces less risk of being forced to change. Additionally, and perhaps unexpectedly, the hash provides one new, secondary benefit: The key names in the hash furnish explicit documentation about the arguments. This is a byproduct of using a hash but the fact that it is unintentional makes it no less useful. Future maintainers of this code will be grateful for the information.
The benefits you achieve by using this technique vary, as always, based on your personal situation. If you are working on a method whose parameter list is lengthy and wildly unstable, in a framework that is intended to be used by others, it will likely lower overall costs if you specify arguments in a hash. However, if you are writing a method for your own use that multiplies two numbers, it’s far simpler and perhaps ultimately cheaper to merely pass the arguments and accept the dependency on order. Between these two extremes lies a common case, that of the method that requires a few very stable arguments and optionally permits a number of less stable ones. In this case, the most cost-effective strategy may be to use both techniques; that is, to take a few fixed-order arguments, followed by an options hash.
Explicitly Define Defaults
There are many techniques for adding defaults. Simple non-boolean defaults can be specified using Ruby’s || method, as in this next example:
1 # specifying defaults using ||
2 def initialize(args)
3 @chainring = args[:chainring] || 40
4 @cog = args[:cog] || 18
5 @wheel = args[:wheel]
6 end
This is a common technique but one you should use with caution; there are situations in which it might not do what you want. The || method acts as an or condition; it first evaluates the left-hand expression and then, if the expression returns false or nil, proceeds to evaluate and return the result of the right-hand expression. The use of || above therefore, relies on the fact that the [] method of Hash returns nil for missing keys.
In the case where args contains a :boolean_thing key that defaults to true, use of || in this way makes it impossible for the caller to ever explicitly set the final variable to false or nil. For example, the following expression sets @bool to true when :boolean_thing is missing and also when it is present but set to false or nil:
@bool = args[:boolean_thing] || true
This quality of || means that if you take boolean values as arguments, or take arguments where you need to distinguish between false and nil, it’s better to use the fetch method to set defaults. The fetch method expects the key you’re fetching to be in the hash and supplies several options for explicitly handling missing keys. Its advantage over || is that it does not automatically return nil when it fails to find your key.
In the example below, line 3 uses fetch to set @chainring to the default, 40, only if the :chainring key is not in the args hash. Setting the defaults in this way means that callers can actually cause @chainring to get set to false or nil, something that is not possible when using the || technique.
1 # specifying defaults using fetch
2 def initialize(args)
3 @chainring = args.fetch(:chainring, 40)
4 @cog = args.fetch(:cog, 18)
5 @wheel = args[:wheel]
6 end
You can also completely remove the defaults from initialize and isolate them inside of a separate wrapping method. The defaults method below defines a second hash that is merged into the options hash during initialization. In this case, merge has the same effect as fetch; the defaults will get merged only if their keys are not in the hash.
1 # specifying defaults by merging a defaults hash
2 def initialize(args)
3 args = defaults.merge(args)
4 @chainring = args[:chainring]
5 # ...
6 end
7
8 def defaults
9 {:chainring => 40, :cog => 18}
10 end
This isolation technique is perfectly reasonable for the case above but it’s especially useful when the defaults are more complicated. If your defaults are more than simple numbers or strings, implement a defaults method.
Isolate Multiparameter Initialization
So far all of the examples of removing argument order dependencies have been for situations where you control the signature of the method that needs to change. You will not always have this luxury; sometimes you will be forced to depend on a method that requires fixed-order arguments where you do not own and thus cannot change the method itself.
Imagine that Gear is part of a framework and that its initialization method requires fixed-order arguments. Imagine also that your code has many places where you must create a new instance of Gear. Gear’s initialize method is external to your application; it is part of an external interface over which you have no control.
As dire as this situation appears, you are not doomed to accept the dependencies. Just as you would DRY out repetitive code inside of a class, DRY out the creation of new Gear instances by creating a single method to wrap the external interface. The classes in your application should depend on code that you own; use a wrapping method to isolate external dependencies.
In this example, the SomeFramework::Gear class is not owned by your application; it is part of an external framework. Its initialization method requires fixed-order arguments. The GearWrapper module was created to avoid having multiple dependencies on the order of those arguments. GearWrapper isolates all knowledge of the external interface in one place and, equally importantly, it provides an improved interface for your application.
As you can see in line 24, GearWrapper allows your application to create a new instance of Gear using an options hash.
1 # When Gear is part of an external interface
2 module SomeFramework
3 class Gear
4 attr_reader :chainring, :cog, :wheel
5 def initialize(chainring, cog, wheel)
6 @chainring = chainring
7 @cog = cog
8 @wheel = wheel
9 end
10 # ...
11 end
12 end
13
14 # wrap the interface to protect yourself from changes
15 module GearWrapper
16 def self.gear(args)
17 SomeFramework::Gear.new(args[:chainring],
18 args[:cog],
19 args[:wheel])
20 end
21 end
22
23 # Now you can create a new Gear using an arguments hash.
24 GearWrapper.gear(
25 :chainring => 52,
26 :cog => 11,
27 :wheel => Wheel.new(26, 1.5)).gear_inches
There are two things to note about GearWrapper. First, it is a Ruby module instead of a class (line 15). GearWrapper is responsible for creating new instances of SomeFramework::Gear. Using a module here lets you define a separate and distinct object to which you can send the gear message (line 24) while simultaneously conveying the idea that you don’t expect to have instances of GearWrapper. You may already have experience with including modules into classes; in the example above GearWrapper is not meant to be included in another class, it’s meant to directly respond to the gear message.
The other interesting thing about GearWrapper is that its sole purpose is to create instances of some other class. Object-oriented designers have a word for objects like this; they call them factories. In some circles the term factory has acquired a negative connotation, but the term as used here is devoid of baggage. An object whose purpose is to create other objects is a factory; the word factory implies nothing more, and use of it is the most expedient way to communicate this idea.
The above technique for substituting an options hash for a list of fixed-order arguments is perfect for cases where you are forced to depend on external interfaces that you cannot change. Do not allow these kinds of external dependencies to permeate your code; protect yourself by wrapping each in a method that is owned by your own application.
Managing Dependency Direction
Dependencies always have a direction; earlier in this chapter it was suggested that one way to manage them is to reverse that direction. This section delves more deeply into how to decide on the direction of dependencies.
Reversing Dependencies
Every example used thus far shows Gear depending on Wheel or diameter, but the code could easily have been written with the direction of the dependencies reversed. Wheel could instead depend on Gear or ratio. The following example illustrates one possible form of the reversal. Here Wheel has been changed to depend on Gear and gear_inches. Gear is still responsible for the actual calculation but it expects a diameter argument to be passed in by the caller (line 8).
1 class Gear
2 attr_reader :chainring, :cog
3 def initialize(chainring, cog)
4 @chainring = chainring
5 @cog = cog
6 end
7
8 def gear_inches(diameter)
9 ratio * diameter
10 end
11
12 def ratio
13 chainring / cog.to_f
14 end
15 # ...
16 end
17
18 class Wheel
19 attr_reader :rim, :tire, :gear
20 def initialize(rim, tire, chainring, cog)
21 @rim = rim
22 @tire = tire
23 @gear = Gear.new(chainring, cog)
24 end
25
26 def diameter
27 rim + (tire * 2)
28 end
29
30 def gear_inches
31 gear.gear_inches(diameter)
32 end
33 # ...
34 end
35
36 Wheel.new(26, 1.5, 52, 11).gear_inches
This reversal of dependencies does no apparent harm. Calculating gear_inches still requires collaboration between Gear and Wheel and the result of the calculation is unaffected by the reversal. One could infer that the direction of the dependency does not matter, that it makes no difference whether Gear depends on Wheel or vice versa.
Indeed, in an application that never changed, your choice would not matter. However, your application will change and it’s in that dynamic future where this present decision has repercussions. The choices you make about the direction of dependencies have far reaching consequences that manifest themselves for the life of your application. If you get this right, your application will be pleasant to work on and easy to maintain. If you get it wrong then the dependencies will gradually take over and the application will become harder and harder to change.
Choosing Dependency Direction
Pretend for a moment that your classes are people. If you were to give them advice about how to behave you would tell them to depend on things that change less often than you do.
This short statement belies the sophistication of the idea, which is based on three simple truths about code:
• Some classes are more likely than others to have changes in requirements.
• Concrete classes are more likely to change than abstract classes.
• Changing a class that has many dependents will result in widespread consequences.
There are ways in which these truths intersect but each is a separate and distinct notion.
Understanding Likelihood of Change
The idea that some classes are more likely to change than others applies not only to the code that you write for your own application but also to the code that you use but did not write. The Ruby base classes and the other framework code that you rely on both have their own inherent likelihood of change.
You are fortunate in that Ruby base classes change a great deal less often than your own code. This makes it perfectly reasonable to depend on the * method, as gear_inches quietly does, or to expect that Ruby classes String and Array will continue to work as they always have. Ruby base classes always change less often than your own classes and you can continue to depend on them without another thought.
Framework classes are another story; only you can assess how mature your frameworks are. In general, any framework you use will be more stable than the code you write, but it’s certainly possible to choose a framework that is undergoing such rapid development that its code changes more often than yours.
Regardless of its origin, every class used in your application can be ranked along a scale of how likely it is to undergo a change relative to all other classes. This ranking is one key piece of information to consider when choosing the direction of dependencies.
Recognizing Concretions and Abstractions
The second idea concerns itself with the concreteness and abstractness of code. The term abstract is used here just as Merriam-Webster defines it, as “disassociated from any specific instance,” and, as so many things in Ruby, represents an idea about code as opposed to a specific technical restriction.
This concept was illustrated earlier in the chapter during the section on injecting dependencies. There, when Gear depended on Wheel and on Wheel.new and on Wheel.new(rim, tire), it depended on extremely concrete code. After the code was altered to inject a Wheel into Gear, Gear suddenly begin to depend on something far more abstract, that is, the fact that it had access to an object that could respond to the diameter message.
Your familiarity with Ruby may lead you to take this transition for granted, but consider for a moment what would have been required to accomplish this same trick in a statically typed language. Because statically typed languages have compilers that act like unit tests for types, you would not be able to inject just any random object into Gear. Instead you would have to declare an interface, define diameter as part of that interface, include the interface in the Wheel class, and tell Gear that the class you are injecting is a kind of that interface.
Rubists are justifiably grateful to avoid these gyrations, but languages that force you to be explicit about this transition do offer a benefit. They make it painfully, inescapably, and explicitly clear that you are defining an abstract interface. It is impossible to create an abstraction unknowingly or by accident; in statically typed languages defining an interface is always intentional.
In Ruby, when you inject Wheel into Gear such that Gear then depends on a Duck who responds to diameter, you are, however casually, defining an interface. This interface is an abstraction of the idea that a certain category of things will have a diameter. The abstraction was harvested from a concrete class; the idea is now “disassociated from any specific instance.”
The wonderful thing about abstractions is that they represent common, stable qualities. They are less likely to change than are the concrete classes from which they were extracted. Depending on an abstraction is always safer than depending on a concretion because by its very nature, the abstraction is more stable. Ruby does not make you explicitly declare the abstraction in order to define the interface, but for design purposes you can behave as if your virtual interface is as real as a class. Indeed, in the rest of this discussion, the term “class” stands for both class and this kind of interface. These interfaces can have dependents and so must be taken into account during design.
Avoiding Dependent-Laden Classes
The final idea, the notion that having dependent-laden objects has many consequences, also bears deeper examination. The consequences of changing a dependent-laden class are quite obvious—not so apparent are the consequences of even having a dependent-laden class. A class that, if changed, will cause changes to ripple through the application, will be under enormous pressure to never change. Ever. Under any circumstances whatsoever. Your application may be permanently handicapped by your reluctance to pay the price required to make a change to this class.
Finding the Dependencies That Matter
Imagine each of these truths as a continuum along which all application code falls. Classes vary in their likelihood of change, their level of abstraction, and their number of dependents. Each quality matters, but the interesting design decisions occur at the place where likelihood of change intersects with number of dependents. Some of the possible combinations are healthy for your application; others are deadly.
Figure 3.2 summarizes the possibilities.
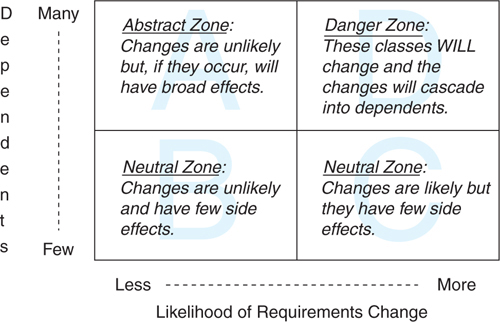
Figure 3.2. Likelihood of change versus number of dependents
The likelihood of requirements change is represented on the horizontal axis. The number of dependents is on the vertical. The grid is divided into four zones, labeled A through D. If you evaluate all of the classes in a well-designed application and place them on this grid, they will cluster in Zones A, B, and C.
Classes that have little likelihood of change but contain many dependents fall into Zone A. This Zone usually contains abstract classes or interfaces. In a thoughtfully designed application this arrangement is inevitable; dependencies cluster around abstractions because abstractions are less likely to change.
Notice that classes do not become abstract because they are in Zone A; instead they wind up here precisely because they are already abstract. Their abstract nature makes them more stable and allows them to safely acquire many dependents. While residence in Zone A does not guarantee that a class is abstract, it certainly suggests that it ought to be.
Skipping Zone B for a moment, Zone C is the opposite of Zone A. Zone C contains code that is quite likely to change but has few dependents. These classes tend to be more concrete, which makes them more likely to change, but this doesn’t matter because few other classes depend on them.
Zone B classes are of the least concern during design because they are almost neutral in their potential future effects. They rarely change and have few dependents.
Zones A, B, and C are legitimate places for code; Zone D, however, is aptly named the Danger Zone. A class ends up in Zone D when it is guaranteed to change and has many dependents. Changes to Zone D classes are costly; simple requests become coding nightmares as the effects of every change cascade through each dependent. If you have a very specific concrete class that has many dependents and you believe it resides in Zone A, that is, you believe it is unlikely to change, think again. When a concrete class has many dependents your alarm bells should be ringing. That class might actually be an occupant of Zone D.
Zone D classes represent a danger to the future health of the application. These are the classes that make an application painful to change. When a simple change has cascading effects that force many other changes, a Zone D class is at the root of the problem. When a change breaks some far away and seemingly unrelated bit of code, the design flaw originated here.
As depressing as this is, there is actually a way to make things worse. You can guarantee that any application will gradually become unmaintainable by making its Zone D classes more likely to change than their dependents. This maximizes the consequences of every change.
Fortunately, understanding this fundamental issue allows you to take preemptive action to avoid the problem.
Depend on things that change less often than you do is a heuristic that stands in for all the ideas in this section. The zones are a useful way to organize your thoughts but in the fog of development it may not be obvious which classes go where. Very often you are exploring your way to a design and at any given moment the future is unclear. Following this simple rule of thumb at every opportunity will cause your application to evolve a healthy design.
Summary
Dependency management is core to creating future-proof applications. Injecting dependencies creates loosely coupled objects that can be reused in novel ways. Isolating dependencies allows objects to quickly adapt to unexpected changes. Depending on abstractions decreases the likelihood of facing these changes.
The key to managing dependencies is to control their direction. The road to maintenance nirvana is paved with classes that depend on things that change less often than they do.