
Chapter 7. Sharing Role Behavior with Modules
The previous chapter ended on a high note, with code that looked so promising you may be wondering where it’s been all your life. However, before you decide to use classical inheritance to solve every imaginable design problem, consider this: What will happen when FastFeet develops a need for recumbent mountain bikes?
If the solution to this new design problem feels elusive, that’s perfectly understandable. Creation of a recumbent mountain bike subclass requires combining the qualities of two existing subclasses, something that inheritance cannot readily accommodate. Even more distressing is the fact that this failure illustrates just one of several ways in which inheritance can go wrong.
To reap benefits from using inheritance you must understand not only how to write inheritable code but also when it makes sense to do so. Use of classical inheritance is always optional; every problem that it solves can be solved another way. Because no design technique is free, creating the most cost-effective application requires making informed tradeoffs between the relative costs and likely benefits of alternatives.
This chapter explores an alternative that uses the techniques of inheritance to share a role. It begins with an example that uses a Ruby module to define a common role and then proceeds to give practical advice about how to write all inheritable code.
Understanding Roles
Some problems require sharing behavior among otherwise unrelated objects. This common behavior is orthogonal to class; it’s a role an object plays. Many of the roles needed by an application will be obvious at design time, but it’s also common to discover unanticipated roles as you write the code.
When formerly unrelated objects begin to play a common role, they enter into a relationship with the objects for whom they play the role. These relationships are not as visible as those created by the subclass/superclass requirements of classical inheritance but they exist nonetheless. Using a role creates dependencies among the objects involved and these dependencies introduce risks that you must take into account when deciding among design options.
This section unearths a hidden role and creates code to share its behavior among all players, while at the same time minimizing the dependencies thereby incurred.
Finding Roles
The Preparer duck type from Chapter 5, Reducing Costs with Duck Typing, is a role. Objects that implement Preparer’s interface play this role. Mechanic, TripCoordinator, and Driver each implement prepare_trip; therefore, other objects can interact with them as if they are Preparers without concern for their underlying class.
The existence of a Preparer role suggests that there’s also a parallel Preparable role (these things often come in pairs). The Trip class acts as a Preparable in the Chapter 5 example; it implements the Prepareable interface. This interface includes all of the messages that any Preparer might expect to send to a Preparable, that is, the methods bicycles, customers, and vehicle. The Preparable role is not terribly obvious because Trip is its only player but it’s important to recognize that it exists. Chapter 9, Designing Cost-Effective Tests, suggests techniques for testing and documenting the Preparable role so as to distinguish it from the Trip class.
Although the Preparer role has multiple players, it is so simple that it is entirely defined by its interface. To play this role all an object need do is implement its own personal version of prepare_trip. Objects that act as Preparers have only this interface in common. They share the method signature but no other code.
Preparer and Preparable are perfectly legitimate duck types. It’s far more common, however, to discover more sophisticated roles, ones where the role requires not only specific message signatures, but also specific behavior. When a role needs shared behavior you’re faced with the problem of organizing the shared code. Ideally this code would be defined in a single place but be usable by any object that wished to act as the duck type and play the role.
Many object-oriented languages provide a way to define a named group of methods that are independent of class and can be mixed in to any object. In Ruby, these mix-ins are called modules. Methods can be defined in a module and then the module can be added to any object. Modules thus provide a perfect way to allow objects of different classes to play a common role using a single set of code.
When an object includes a module, the methods defined therein become available via automatic delegation. If this sounds like classical inheritance, it also looks like it, at least from the point of view of the including object. From that object’s point of view, messages arrive, it doesn’t understand them, they get automatically routed somewhere else, the correct method implementation is magically found, it is executed, and the response is returned.
Once you start putting code into modules and adding modules to objects, you expand the set of messages to which an object can respond and enter a new realm of design complexity. An object that directly implements few methods might still have a very large response set. The total set of messages to which an object can respond includes
• Those it implements
• Those implemented in all objects above it in the hierarchy
• Those implemented in any module that has been added to it
• Those implemented in all modules added to any object above it in the hierarchy
If this seems like a frighteningly large and potentially confusing response set, you have a clear grasp of the problem. Acquiring an understanding of the behavior of a deeply nested hierarchy is at best intimidating, at worst, impossible.
Organizing Responsibilities
Now that you have a sufficiently somber view of the possibilities, it’s time to look at a manageable example. Just as with classical inheritance, before you can choose whether to create a duck type and put shared behavior into a module, you have to know how to do it correctly. Fortunately, the classical inheritance example in Chapter 6, Acquiring Behavior Through Inheritance, is about to pay off; this example builds on those techniques and is significantly shorter.
Consider the problem of scheduling a trip. Trips occur at specific points in time and involve bicycles, mechanics, and motor vehicles. Bikes, mechanics, and vehicles are real things in the physical world that can’t be in two places at once. FastFeet needs a way to arrange all of these objects on a schedule so that it can determine, for any point in time, which objects are available and which are already committed.
Determining if an unscheduled bike, mechanic, or vehicle is available to participate in a trip is not as simple as looking to see if it’s idle throughout the interval during which the trip is scheduled. These real-world things need a bit of downtime between trips, they cannot finish a trip on one day and start another the next. Bicycles and motor vehicles must undergo maintenance, and mechanics need a rest from being nice to customers and a chance to do their laundry.
The requirements are that bicycles have a minimum of one day between trips, vehicles a minimum of three days, and mechanics, four days.
The code to schedule these objects can be written in many ways, and, as has been true throughout the book, this example will evolve. It begins with some rather alarming code and works it way to a satisfactory solution, all in the interest of exposing likely antipatterns.
Assume that a Schedule class exists. Its interface already includes these three methods:
scheduled?(target, starting, ending)
add(target, starting, ending)
remove(target, starting, ending)
Each of the above methods takes three arguments: the target object and the start and end dates for the period of interest. The Schedule is responsible for knowing if its incoming target argument is already scheduled and for adding and removing targets from the schedule. These responsibilities rightly belong here in the Schedule itself.
These methods are fine, but unfortunately there’s a gap in this code. It is true that knowing if an object is scheduled during some interval is all the information needed to prevent over-scheduling an already busy object. However, knowing that a object is not scheduled during an interval isn’t enough information to know if it can be scheduled during that same interval. To properly determine if an object can be scheduled, some object, somewhere, must take lead time into account.
Figure 7.1 shows an implementation where the Schedule itself takes responsibility for knowing the correct lead time. The schedulable? method knows all the possible values and it checks the class of its incoming target argument to decide which lead time to use.
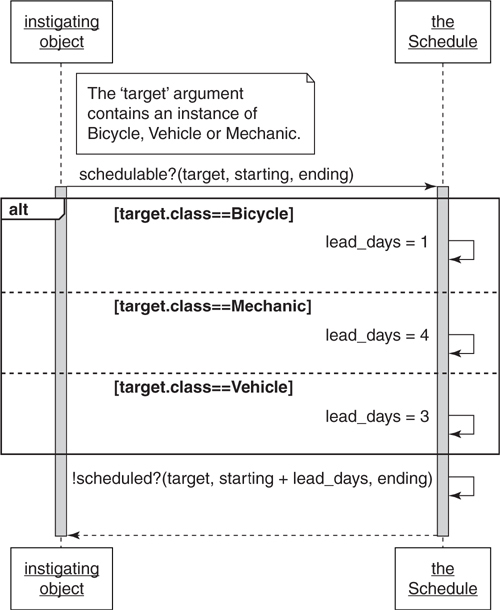
Figure 7.1. The schedule knows the lead time for other objects.
You’ve seen the pattern of checking class to know what message to send; here the Schedule checks class to know what value to use. In both cases Schedule knows too much. This knowledge doesn’t belong in Schedule, it belongs in the classes whose names Schedule is checking.
This implementation cries out for a simple and obvious improvement, one suggested by the pattern of the code. Instead of knowing details about other classes, the Schedule should send them messages.
Removing Unnecessary Dependencies
The fact that the Schedule checks many class names to determine what value to place in one variable suggests that the variable name should be turned into a message, which in turn should be sent to each incoming object.
Discovering the Schedulable Duck Type
Figure 7.2 shows a sequence diagram for new code that removes the check on class from the schedulable? method and alters the method to instead send the lead_days message to its incoming target argument. This change replaces an if statement that checks the class of an object with a message sent to that same object. It simplifies the code and pushes responsibility for knowing the correct number of lead days into the last object that could possibly know the correct answer, which is exactly where this responsibility belongs.
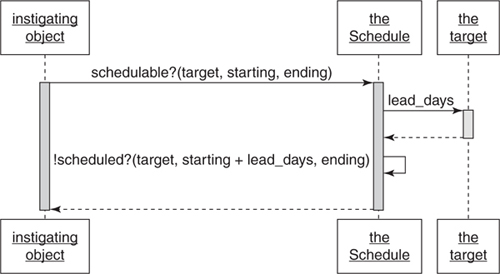
Figure 7.2. The schedule expects targets to know their own lead time.
A close look at Figure 7.2 reveals something interesting. Notice that this diagram contains a box labeled “the target.” The boxes on sequence diagrams are meant to represent objects and are commonly named after classes, as in “the Schedule” or “a Bicycle.” In Figure 7.2, the Schedule intends to send lead_days to its target, but target could be an instance of any of a number of classes. Because target’s class is unknown, it’s not obvious how to label the box for the receiver of this message.
The easiest way to draw the diagram is to sidestep this issue by labeling the box after the name of the variable and sending the lead_days message to that “target” without being precise about its class. The Schedule clearly does not care about target’s class, instead it merely expects it to respond to a specific message. This message-based expectation transcends class and exposes a role, one played by all targets and made explicitly visible by the sequence diagram.
The Schedule expects its target to behave like something that understands lead_days, that is, like something that is “schedulable.” You have discovered a duck type.
Right now this new duck type is shaped much like the Preparer duck type from Chapter 5; it consists only of this interface. Schedulables must implement lead_days but currently have no other code in common.
Letting Objects Speak for Themselves
Discovering and using this duck type improves the code by removing the Schedule’s dependency on specific class names, which makes the application more flexible and easier to maintain. However, Figure 7.2 still contains unnecessary dependencies that should be removed.
It’s easiest to illustrate these dependencies with an extreme example. Imagine a StringUtils class that implements utility methods for managing strings. You can ask StringUtils if a string is empty by sending StringUtils.empty?(some_string).
If you have written much object-oriented code you will find this idea ridiculous. Using a separate class to manage strings is patently redundant; strings are objects, they have their own behavior, they manage themselves. Requiring that other objects know about a third party, StringUtils, to get behavior from a string complicates the code by adding an unnecessary dependency.
This specific example illustrates the general idea that objects should manage themselves; they should contain their own behavior. If your interest is in object B, you should not be forced to know about object A if your only use of it is to find things out about B.
The sequence diagram in Figure 7.2 violates this rule. The instigator is trying to ascertain if the target object is schedulable. Unfortunately, it doesn’t ask this question of target itself, it instead asks a third party, Schedule. Asking Schedule if a target is schedulable is just like asking StringUtils if a string is empty. It forces the instigator to know about and thus depend upon the Schedule, even though its only real interest is in the target.
Just as strings respond to empty? and can speak for themselves, targets should respond to schedulable?. The schedulable? method should be added to the interface of the Schedulable role.
Writing the Concrete Code
As it currently stands, the Schedulable role contains only an interface. Adding the schedulable? method to this role requires writing some code and it’s not immediately obvious where this code should reside. You are faced with two decisions; you must decide what the code should do and where the code should live.
The simplest way to get started is to separate the two decisions. Pick an arbitrary concrete class (for example, Bicycle) and implement the schedulable? method directly in that class. Once you have a version that works for Bicycle you can refactor your way to a code arrangement that allows all Schedulables to share the behavior.
Figure 7.3 shows a sequence diagram where this new code is in Bicycle. Bicycle now responds to messages about its own “schedulability.”
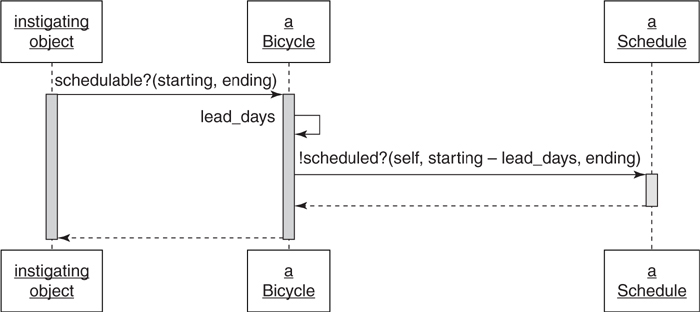
Figure 7.3. Bicycle classes know if they are schedulable.
Before this change, every instigating object had to know about and thus had a dependency on the Schedule. This change allows bicycles to speak for themselves, freeing instigating objects to interact with them without the aid of a third party.
The code to implement this sequence diagram is straightforward. Here’s a very simple Schedule. This is clearly not a production-worthy implementation but it provides a good enough stand-in for the rest of the example.
1 class Schedule
2 def scheduled?(schedulable, start_date, end_date)
3 puts "This #{schedulable.class} " +
4 "is not scheduled
" +
5 " between #{start_date} and #{end_date}"
6 false
7 end
8 end
This next example shows Bicycle’s implementation of schedulable?. Bicycle knows its own scheduling lead time (defined on line 23 and referenced on line 13 below), and delegates scheduled? to the Schedule itself.
1 class Bicycle
2 attr_reader :schedule, :size, :chain, :tire_size
3
4 # Inject the Schedule and provide a default
5 def initialize(args={})
6 @schedule = args[:schedule] || Schedule.new
7 # ...
8 end
9
10 # Return true if this bicycle is available
11 # during this (now Bicycle specific) interval.
12 def schedulable?(start_date, end_date)
13 !scheduled?(start_date - lead_days, end_date)
14 end
15
16 # Return the schedule's answer
17 def scheduled?(start_date, end_date)
18 schedule.scheduled?(self, start_date, end_date)
19 end
20
21 # Return the number of lead_days before a bicycle
22 # can be scheduled.
23 def lead_days
24 1
25 end
26
27 # ...
28 end
29
30 require 'date'
31 starting = Date.parse("2015/09/04")
32 ending = Date.parse("2015/09/10")
33
34 b = Bicycle.new
35 b.schedulable?(starting, ending)
36 # This Bicycle is not scheduled
37 # between 2015-09-03 and 2015-09-10
38 # => true
Running the code (lines 30–35) confirms that Bicycle has correctly adjusted the starting date to include the bicycle specific lead days.
This code hides knowledge of who the Schedule is and what the Schedule does inside of Bicycle. Objects holding onto a Bicycle no longer need know about the existence or behavior of the Schedule.
Extracting the Abstraction
The code above solves the first part of current problem in that it decides what the schedulable? method should do, but Bicycle is not the only kind of thing that is “schedulable.” Mechanic and Vehicle also play this role and therefore need this behavior. It’s time to rearrange the code so that it can be shared among objects of different classes.
The following example shows a new Schedulable module, which contains an abstraction extracted from the Bicycle class above. The schedulable? (line 8) and scheduled? (line 12) methods are exact copies of the ones formerly implemented in Bicycle.
1 module Schedulable
2 attr_writer :schedule
3
4 def schedule
5 @schedule ||= ::Schedule.new
6 end
7
8 def schedulable?(start_date, end_date)
9 !scheduled?(start_date - lead_days, end_date)
10 end
11
12 def scheduled?(start_date, end_date)
13 schedule.scheduled?(self, start_date, end_date)
14 end
15
16 # includers may override
17 def lead_days
18 0
19 end
20
21 end
Two things have changed from the code as it previously existed in Bicycle. First, a schedule method (line 4) has been added. This method returns an instance of the overall Schedule.
Back in Figure 7.2 the instigating object depended on the Schedule, which meant there might be many places in the application that needed knowledge of the Schedule. In the next iteration, Figure 7.3, this dependency was transferred to Bicycle, reducing its reach into the application. Now, in the code above, the dependency on Schedule has been removed from Bicycle and moved into the Schedulable module, isolating it even further.
The second change is to the lead_days method (line 17). Bicycle’s former implementation returned a bicycle specific number, the module’s implementation now returns a more generic default of zero days.
Even if there were no reasonable application default for lead days, the Schedulable module must still implement the lead_days method. The rules for modules are the same as for classical inheritance. If a module sends a message it must provide an implementation, even if that implementation merely raises an error indicating that users of the module must implement the method.
Including this new module in the original Bicycle class, as shown in the example below, adds the module’s methods to Bicycle’s response set. The lead_days method is a hook that follows the template method pattern. Bicycle overrides this hook (line 4) to provide a specialization.
Running the code reveals that Bicycle retains the same behavior as when it directly implemented this role.
1 class Bicycle
2 include Schedulable
3
4 def lead_days
5 1
6 end
7
8 # ...
9 end
10
11 require 'date'
12 starting = Date.parse("2015/09/04")
13 ending = Date.parse("2015/09/10")
14
15 b = Bicycle.new
16 b.schedulable?(starting, ending)
17 # This Bicycle is not scheduled
18 # between 2015-09-03 and 2015-09-10
19 # => true
20
Moving the methods to the Schedulable module, including the module and overriding lead_days, allows Bicycle to continue to behave correctly. Additionally, now that you have created this module other objects can make use of it to become Schedulable themselves. They can play this role without duplicating the code.
The pattern of messages has changed from that of sending schedulable? to a Bicycle to sending schedulable? to a Schedulable. You are now committed to the duck type and the sequence diagram shown in Figure 7.3 can be altered to look like the one in Figure 7.4.

Figure 7.4. The schedulable duck type.
Once you include this module in all of the classes that can be scheduled, the pattern of code becomes strongly reminiscent of inheritance. The following example shows Vehicle and Mechanic including the Schedulable module and responding to the schedulable? message.
1 class Vehicle
2 include Schedulable
3
4 def lead_days
5 3
6 end
7
8 # ...
9 end
10
11 class Mechanic
12 include Schedulable
13
14 def lead_days
15 4
16 end
17
18 # ...
19 end
20
21 v = Vehicle.new
22 v.schedulable?(starting, ending)
23 # This Vehicle is not scheduled
24 # between 2015-09-01 and 2015-09-10
25 # => true
26
27 m = Mechanic.new
28 m.schedulable?(starting, ending)
29 # This Mechanic is not scheduled
30 # between 2015-02-29 and 2015-09-10
31 # => true
The code in Schedulable is the abstraction and it uses the template method pattern to invite objects to provide specializations to the algorithm it supplies. Schedulables override lead_days to supply those specializations. When schedulable? arrives at any Schedulable, the message is automatically delegated to the method defined in the module.
This may not fit the strict definition of classical inheritance, but in terms of how the code should be written and how the messages are resolved, it certainly acts like it. The coding techniques are the same because method lookup follows the same path.
This chapter has been careful to maintain a distinction between classical inheritance and sharing code via modules. This is-a versus behaves-like-a difference definitely matters, each choice has distinct consequences. However, the coding techniques for these two things are very similar and this similarity exists because both techniques rely on automatic message delegation.
Looking Up Methods
Understanding the similarities between classical inheritance and module inclusion is easier if you understand how object-oriented languages, in general, and Ruby, in particular, find the method implementation that matches a message send.
A Gross Oversimplification
When an object receives a message, the OO language first looks in that object’s class for a matching method implementation. This makes perfect sense; method definitions would otherwise need to be duplicated within every instance of every class. Storing the methods known to an object inside of its class means that all instances of a class can share the same set of method definitions; definitions that need then exist in only one place.
Throughout this book there has been little concern with explicitly stating whether the object under discussion is an instance of a class or the class itself, expecting that the intent will be clear from the context and that you are comfortable with the notion that classes themselves are objects in their own right. Describing how method lookup works is going to require a bit more precision.
As stated above, the search for a method begins in the class of the receiving object. If this class does not implement the message, the search proceeds to its superclass. From here on only superclasses matter, the search proceeds up the superclass chain, looking in one superclass after another, until it reaches the top of the hierarchy.
Figure 7.5 shows how a generic object-oriented language would look up the spares method of the Bicycle hierarchy that you created in Chapter 6. For the purposes of this discussion, class Object sits at the top of the hierarchy. Please note that the specifics of method lookup in Ruby will turn out to be more involved, but this is a reasonable first model.
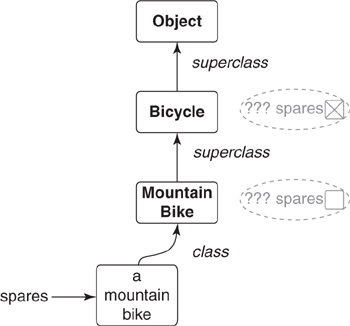
Figure 7.5. A generalization of method lookup.
In Figure 7.5, the spares message is sent to an instance of MountainBike. The OO language first looks for a matching spares method in the MountainBike class. Upon failing to find method spares in that class, the search proceeds to MountainBike’s superclass, Bicycle.
Because Bicycle implements spares, this example’s search stops here. However, in the case where no superclass implementation exists, the search proceeds from one superclass to the next until it reaches the top of the hierarchy and searches in Object. If all attempts to find a suitable method fail, you might expect the search to stop, but many languages make a second attempt to resolve the message.
Ruby gives the original receiver a second chance by sending it new message, method_missing, and passing :spares as an argument. Attempts to resolve this new message restart the search along the same path, except now the search is for method_missing rather than spares.
A More Accurate Explanation
The previous section explains only how methods are looked up for classical inheritance. This next section expands the explanation to encompass methods defined in a Ruby module. Figure 7.6 adds the Schedulable module to the method lookup path.
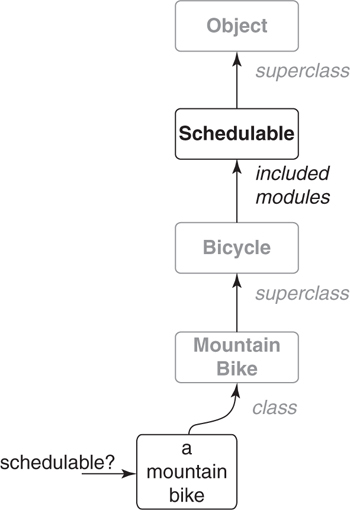
Figure 7.6. A more accurate explanation of method lookup.
The object hierarchy in Figure 7.6 looks much like the one from Figure 7.5. It differs only in that Figure 7.6 shows the Schedulable module highlighted between the Bicycle and Object classes.
When Bicycle includes Schedulable, all of the methods defined in the module become part of Bicycle’s response set. The module’s methods go into the method lookup path directly above methods defined in Bicycle. Including this module doesn’t change Bicycle’s superclass (that’s still Object), but as far as method lookup is concerned, it may as well have. Any message received by an instance of MountainBike now stands a chance of being satisfied by a method defined in the Schedulable module.
This has enormous implications. If Bicycle implements a method that is also defined in Schedulable, Bicycle’s implementation overrides Schedulable’s. If Schedulable sends methods that is does not implement, instances of MountainBike may encounter confusing failures.
Figure 7.6 shows the schedulable? message being sent to an instance of MountainBike. To resolve this message, Ruby first looks for a matching method in the MountainBike class. The search then proceeds along the method lookup path, which now contains modules as well as superclasses. An implementation of schedulable? is eventually found in Schedulable, which lies in the lookup path between Bicycle and Object.
A Very Nearly Complete Explanation
Now that you’ve seen how modules fit into the method lookup path, it’s time to complicate the picture further.
It’s entirely possible for a hierarchy to contain a long chain of superclasses, each of which includes many modules. When a single class includes several different modules, the modules are placed in the method lookup path in reverse order of module inclusion. Thus, the methods of the last included module are encountered first in the lookup path.
This discussion has, until now, been about including modules into classes via Ruby’s include keyword. As you have already seen, including a module into a class adds the module’s methods to the response set for all instances of that class. For example, in Figure 7.6 the Schedulable module was included into the Bicycle class, and, as a result, instances of MountainBike gain access to the methods defined therein.
However, it is also possible to add a module’s methods to a single object, using Ruby’s extend keyword. Because extend adds the module’s behavior directly to an object, extending a class with a module creates class methods in that class and extending an instance of a class with a module creates instance methods in that instance. These two things are exactly the same; classes are, after all, just plain old objects, and extend behaves the same for all.
Finally, any object can also have ad hoc methods added directly to its own personal “Singleton class.” These ad hoc methods are unique to this specific object.
Each of these alternatives adds to an object’s response set by placing method definitions in specific and unambiguous places along the method lookup path. Figure 7.7 illustrates the complete list of possibilities.
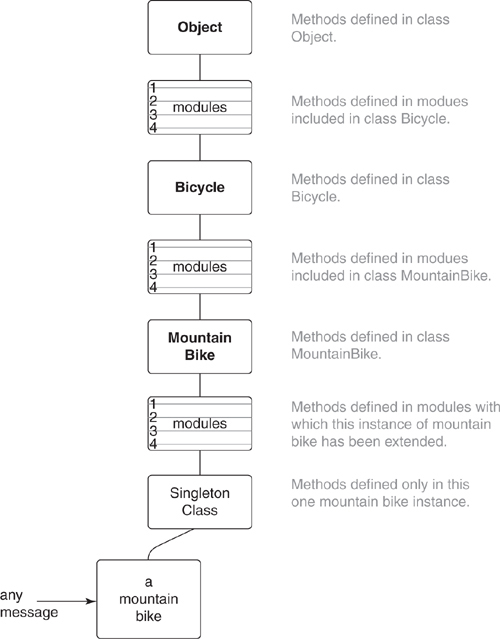
Figure 7.7. A nearly complete explanation of method lookup.
Before continuing, here’s a word of warning. Figure 7.7 is accurate enough to guide the behavior of most designers, but it is not the complete story. For most application code it is perfectly adequate to behave as if class Object is the top of the hierarchy but, depending on your version of Ruby, this may not be technically true. If you are writing code for which you think this issue might matter, make sure you understand the object hierarchy of the Ruby in question.
Inheriting Role Behavior
Now that you’ve seen how to define a role’s shared code in a module and how a module’s code gets inserted into the method lookup path, you are equipped to write some truly frightening code. Imagine the possibilities. You can write modules that include other modules. You can write modules that override the methods defined in other modules. You can create deeply nested class inheritance hierarchies and then include these various modules at different levels of the hierarchy.
You can write code that is impossible to understand, debug, or extend.
This is powerful stuff, and dangerous in untutored hands. However, because this very same power is what allows you to create simple structures of related objects that elegantly fulfill the needs of your application, your task is not to avoid these techniques but to learn to use them for the right reasons, in the right places, in the correct way.
This first step along this path is to write properly inheritable code.
Writing Inheritable Code
The usefulness and maintainability of inheritance hierarchies and modules is in direct proportion to the quality of the code. More so than with other design strategies, sharing inherited behavior requires very specific coding techniques, which are covered in the following sections.
Recognize the Antipatterns
There are two antipatterns that indicate that your code might benefit from inheritance.
First, an object that uses a variable with a name like type or category to determine what message to send to self contains two highly related but slightly different types. This is a maintenance nightmare; the code must change every time a new type is added. Code like this can be rearranged to use classical inheritance by putting the common code in an abstract superclass and creating subclasses for the different types. This rearrangement allows you to create new subtypes by adding new subclasses. These subclasses extend the hierarchy without changing the existing code.
Second, when a sending object checks the class of a receiving object to determine what message to send, you have overlooked a duck type. This is another maintenance nightmare; the code must change every time you introduce a new class of receiver. In this situation all of the possible receiving objects play a common role. This role should be codified as a duck type and receivers should implement the duck type’s interface. Once they do, the original object can send one single message to every receiver, confident than because each receiver plays the role it will understand the common message.
In addition to sharing an interface, duck types might also share behavior. When they do, place the shared code in a module and include that module in each class or object that plays the role.
Insist on the Abstraction
All of the code in an abstract superclass should apply to every class that inherits it. Superclasses should not contain code that applies to some, but not all, subclasses. This restriction also applies to modules: the code in a module must apply to all who use it.
Faulty abstractions cause inheriting objects to contain incorrect behavior; attempts to work around this erroneous behavior will cause your code to decay. When interacting with these awkward objects, programmers are forced to know their quirks and into dependencies that are better avoided.
Subclasses that override a method to raise an exception like “does not implement” are a symptom of this problem. While it is true that expediency pays for all and that it is sometimes most cost effective to arrange code in just this way, you should be reluctant to do so. When subclasses override a method to declare that they do not do that thing they come perilously close to declaring that they are not that thing. Nothing good can come of this.
If you cannot correctly identify the abstraction there may not be one, and if no common abstraction exists then inheritance is not the solution to your design problem.
Honor the Contract
Subclasses agree to a contract; they promise to be substitutable for their superclasses. Substitutability is possible only when objects behave as expected and subclasses are expected to conform to their superclass’s interface. They must respond to every message in that interface, taking the same kinds of inputs and returning the same kinds of outputs. They are not permitted to do anything that forces others to check their type in order to know how to treat them or what to expect of them.
Where superclasses place restrictions on input arguments and return values, subclasses can indulge in a slight bit of freedom without violating their contract. Subclasses may accept input parameters that have broader restrictions and may return results that have narrower restrictions, all while remaining perfectly substitutable for their superclasses.
Subclasses that fail to honor their contract are difficult to use. They’re “special” and cannot be freely substituted for their superclasses. These subclasses are declaring that they are not really a kind-of their superclass and cast doubt on the correctness of the entire hierarchy.
Use the Template Method Pattern
The fundamental coding technique for creating inheritable code is the template method pattern. This pattern is what allows you to separate the abstract from the concrete. The abstract code defines the algorithms and the concrete inheritors of that abstraction contribute specializations by overriding these template methods.
The template methods represent the parts of the algorithm that vary and creating them forces you to make explicit decisions about what varies and what does not.
Preemptively Decouple Classes
Avoid writing code that requires its inheritors to send super; instead use hook messages to allow subclasses to participate while absolving them of responsibility for knowing the abstract algorithm. Inheritance, by its very nature, adds powerful dependencies on the structure and arrangement of code. Writing code that requires subclasses to send super adds an additional dependency; avoid this if you can.
Hook methods solve the problem of sending super, but, unfortunately, only for adjacent levels of the hierarchy. For example, in Chapter 6, Bicycle sent hook method local_spares that MountainBike overrode to provide specializations. This hook method serves its purpose admirably, but the original problem reoccurs if you add another level to the hierarchy by creating subclass MonsterMountainBike under MountainBike. In order to combine its own spare parts with those of its parent, MonsterMountainBike would be forced to override local_spares, and within it, send super.
Create Shallow Hierarchies
The limitations of hook methods are just one of the many reasons to create shallow hierarchies.
Every hierarchy can be thought of a pyramid that has both depth and breadth. An object’s depth is the number of superclasses between it and the top. Its breadth is the number of its direct subclasses. A hierarchy’s shape is defined by its overall breadth and depth and it is this shape that determines ease of use, maintenance, and extension. Figure 7.8 illustrates a few of the possible variations of shape.
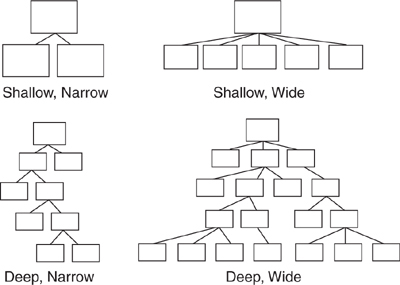
Figure 7.8. Hierarchies come in different shapes.
Shallow, narrow hierarchies are easy to understand. Shallow, wide hierarchies are slightly more complicated. Deep, narrow hierarchies are a bit more challenging and unfortunately have a natural tendency to get wider, strictly as a side effect of their depth. Deep, wide hierarchies are difficult to understand, costly to maintain, and should be avoided.
The problem with deep hierarchies is that they define a very long search path for message resolution and provide numerous opportunities for objects in that path to add behavior as the message passes by. Because objects depend on everything above them, a deep hierarchy has a large set of built-in dependencies, each of which might someday change.
Another problem with deep hierarchies is that programmers tend to be familiar with just the classes at their tops and bottoms; that is, they tend to understand only the behavior implemented at the boundaries of the search path. The classes in the middle get short shrift. Changes to these vaguely understood middle classes stand a greater chance of introducing errors.
Summary
When objects that play a common role need to share behavior, they do so via a Ruby module. The code defined in a module can be added to any object, be it an instance of a class, a class itself, or another module.
When a class includes a module, the methods in that module get put into the same lookup path as methods acquired via inheritance. Because module methods and inherited methods interleave in the lookup path, the coding techniques for modules mirror those of inheritance. Modules, therefore, should use the template method pattern to invite those that include them to supply specializations, and should implement hook methods to avoid forcing includers to send super (and thus know the algorithm).
When an object acquires behavior that was defined elsewhere, regardless of whether this elsewhere is a superclass or an included module, the acquiring object makes a commitment to honoring an implied contract. This contract is defined by the Liskov Substitution Principle, which in mathematical terms says that a subtype should be substitutable for its supertype, and in Ruby terms this means that an object should act like what it claims to be.