
Chapter 2. Asset Security
This chapter covers the following topics:
![]() Asset Security Concepts: Concepts discussed include data policy, roles and responsibilities, data quality, and data documentation and organization.
Asset Security Concepts: Concepts discussed include data policy, roles and responsibilities, data quality, and data documentation and organization.
![]() Classify Information and Assets: Classification topics discussed include sensitivity and criticality, commercial business classification, military and government classifications, the information life cycle, database maintenance, and data audit.
Classify Information and Assets: Classification topics discussed include sensitivity and criticality, commercial business classification, military and government classifications, the information life cycle, database maintenance, and data audit.
![]() Asset Ownership: Entities discussed include data owners, systems owners, business/mission owners, and asset management.
Asset Ownership: Entities discussed include data owners, systems owners, business/mission owners, and asset management.
![]() Asset Privacy: Components include data processors, data storage and archiving, data security, data remanence, and collection limitation.
Asset Privacy: Components include data processors, data storage and archiving, data security, data remanence, and collection limitation.
![]() Asset Retention: Retention concepts discussed include media, hardware, and personnel.
Asset Retention: Retention concepts discussed include media, hardware, and personnel.
![]() Data Security Controls: Topics include data at rest, data in transit, data security, data access and sharing, baselines, scoping and tailoring, standards selections, and cryptography.
Data Security Controls: Topics include data at rest, data in transit, data security, data access and sharing, baselines, scoping and tailoring, standards selections, and cryptography.
![]() Asset Handling Requirements: Topics include marking, labeling, storing, and destruction.
Asset Handling Requirements: Topics include marking, labeling, storing, and destruction.
Assets are any entities that are valuable to an organization and include tangible and intangible assets. As mentioned in Chapter 1, “Security and Risk Management,” tangible assets include computers, facilities, supplies, and personnel. Intangible assets include intellectual property, data, and organizational reputation. All assets in an organization must be protected to ensure the organization’s future success. While securing some assets is as easy as locking them in a safe, other assets require more advanced security measures.
A security professional must be concerned with all aspects of asset security. The most important factor in determining the controls used to ensure asset security is an asset’s value. While some assets in the organization may be considered more important because they have greater value, you should ensure that no assets are forgotten. This chapter covers all the aspects of asset security that you as an IT security professional must understand.
![]() Data policy
Data policy
![]() Roles and responsibilities
Roles and responsibilities
![]() Data quality
Data quality
![]() Data documentation and organization
Data documentation and organization
Data Policy
As a security professional, you should ensure that your organization implements a data policy that defines long-term goals for data management. It will most likely be necessary for each individual business unit within the organization to define its own data policy, based on the organization’s overall data policy. Within the data policy, individual roles and responsibilities should be defined to ensure that personnel understand their job tasks as related to the data policy.
Once the overall data policy is created, data management practices and procedures should be documented to ensure that the day-to-day tasks related to data are completed. In addition, the appropriate quality assurance and quality control procedures must be put into place for data quality to be ensured. Data storage and backup procedures must be defined to ensure that data can be restored.
As part of the data policy, any databases implemented within an organization should be carefully designed based on user requirements and the type of data to be stored. All databases should comply with the data policies that are implemented.
Prior to establishing a data policy, you should consider several issues that can affect it. These issues include cost, liability, legal and regulatory requirements, privacy, sensitivity, and ownership.
The cost of any data management mechanism is usually the primary consideration of any organization. Often organizations do not implement a data policy because they think it is easier to allow data to be stored in whatever way each business unit or user desires. However, if an organization does not adopt formal data policies and procedures, data security issues can arise because of the different storage methods used. For example, suppose an organization’s research department decides to implement a Microsoft SQL Server database to store all research data, but the organization does not have a data policy. If the database is implemented without a thorough understanding of the types of data that will be stored and the user needs, the research department may end up with a database that is difficult to navigate and manage.
Liability involves protecting the organization from legal issues. Liability is directly affected by legal and regulatory requirements that apply to the organization. Data issues that can cause liability issues include data misuse, data inaccuracy, data breach, and data loss.
Data privacy is determined as part of data analysis. Data classifications must be determined based on the value of the data to the organization. Once the data classifications are determined, data controls should be implemented to ensure that the appropriate security controls are implemented based on data classifications. Privacy laws and regulations must also be considered.
Sensitive data is any data that could adversely affect an organization or individual if it were released to the public or obtained by attackers. When determining sensitivity, you should understand the type of threats that can occur, the vulnerability of the data, and the data type. For example, Social Security numbers are more sensitive than physical address data.
Data ownership is the final issue that you must consider as part of data policy design. This is particularly important if multiple organizations store their data within the same database. One organization may want completely different security controls in place to protect its data. Understanding legal ownership of data is important to ensure that you design a data policy that takes into consideration the different requirements of multiple data owners. While this is most commonly a consideration when multiple organizations are involved, it can also be an issue with different business units in the same organization. For example, human resources department data has different owners and therefore different requirements than research department data.
Roles and Responsibilities
The roles that are usually tied to asset security are data owners and data custodians. Data owners are the personnel who actually own a given set of data. These data owners determine the level of access that any user is given to their data. Data custodians are the personnel who actually manage the access to a given set of data. While data owners determine the level of access given, it is the data custodians who actually configure the appropriate controls to grant or deny the user’s access, based on the data owner’s approval.
Note
Both of these roles are introduced in the “Security Roles and Responsibilities” section of Chapter 1.
Data Owner

Data owners must understand the way in which the data they are responsible for is used and when that data should be released. They must also determine the data’s value to and impact on the organization. A data owner should understand what it will take to restore or replace data and the cost that will be incurred during this process. Finally, data owners must understand when data is inaccurate or no longer needed by the organization.
In most cases, each business unit within an organization designates a data owner, who must be given the appropriate level of authority for the data for which he or she is responsible. Data owners must understand any intellectual property rights and copyright issues for the data. Data owners are responsible for ensuring that the appropriate agreements are in place if third parties are granted access to the data.
Data Custodian
Data custodians must understand the levels of data access that can be given to users. Data custodians work with data owners to determine the level of access that should be given. This is an excellent example of split controls. By having separate roles such as data owners and data custodians, an organization can ensure that no single role is responsible for data access.
Data custodians should understand data policies and guidelines. They should document the data structures in the organization and the levels of access given. They are also responsible for data storage, archiving, and backups. Finally, they should be concerned with data quality and should therefore implement the appropriate audit controls.
Centralized data custodians are common. Data owners give the data custodians the permission level that users and groups should be given. Data custodians actually implement the access control lists (ACLs) for the devices, databases, folders, and files.
Data Quality
Data quality is defined as data’s fitness for use. Data quality must be maintained throughout the data life cycle, including during data capture, data modification, data storage, data distribution, data usage, and data archiving. Security professionals must ensure that their organization adopts the appropriate quality control and quality assurance measures so that data quality does not suffer.
Security professionals should work to document data standards, processes, and procedures to monitor and control data quality. In addition, internal processes should be designed to periodically assess data quality. When data is stored in databases, quality control and assurance are easier to ensure using the internal data controls in the database. For example, you can configure a number field to only allow the input of specific currency amounts. By doing this, you would ensure that only values that use two decimal places could be input into the data fields. This is an example of input validation.
Data contamination occurs when data errors are introduced. Data errors can be reduced through implementation of the appropriate quality control and assurance mechanisms. Data verification, an important part of the process, evaluates how complete and correct the data is and whether it complies with standards. Data verification can be carried out by personnel who have the responsibility of entering the data. Data validation evaluates data after data verification has occurred and tests data to ensure that data quality standards have been met. Data validation must be carried out by personnel who have the most familiarity with the data.
Organizations should develop procedures and processes that keep two key data issues in the forefront: error prevention and correction. Error prevention is provided at data entry, while error correction usually occurs during data verification and validation.
Data Documentation and Organization
Data documentation ensures that data is understood at its most basic level and can be properly organized into data sets. Data sets ensure that data is arranged and stored in a relational way so that data can be used for multiple purposes. Data sets should be given unique, descriptive names that indicate their contents.
By documenting the data and organizing data sets, organizations can also ensure that duplicate data is not retained in multiple locations. For example, the sales department may capture all demographic information for all customers. However, the shipping department may also need access to this same demographic information to ensure that products are shipped to the correct address. In addition, the accounts receivable department will need access to the customer demographic information for billing purposes. There is no need for each business unit to have separate data sets for this information. Identifying the customer demographic data set as being needed by multiple business units prevents duplication of efforts across business units.
Within each data set, documentation must be created for each type of data. In the customer demographic data set example, customer name, address, and phone number are all collected. For each of the data types, the individual parameters for each data type must be created. While an address may allow a mixture of numerals and characters, a phone number should allow only numerals. In addition, each data type may have a maximum length. Finally, it is important to document which data is required—meaning that it must be collected and entered. For example, an organization may decide that fax numbers are not required but phone numbers are required. Remember that each of these decisions are best made by the personnel working most closely with the data.
Once all the documentation has occurred, the data organization must be mapped out. This organization will include all interrelationships between the data sets. It should also include information on which business units will need access to data sets or subsets of a data set.
Note
Big data is a term for large or complex sets so large or complex that they cannot be analyzed by traditional data processing applications. Specialized applications have been designed to help organizations with their big data. The big data challenges that may be encountered include data analysis, data capture, data search, data sharing, data storage, and data privacy.
Classify Information and Assets
Data should be classified based on its value to the organization and its sensitivity to disclosure. Assigning a value to data allows an organization to determine the resources that should be used to protect the data. Resources that are used to protect data include personnel resources, monetary resources, access control resources, and so on. Classifying data allows you to apply different protective measures. Data classification is critical to all systems to protect the confidentiality, integrity, and availability (CIA) of data.
After data is classified, the data can be segmented based on its level of protection needed. The classification levels ensure that data is handled and protected in the most cost-effective manner possible. An organization should determine the classification levels it uses based on the needs of the organization. A number of commercial business and military and government information classifications are commonly used.
The information life cycle, covered in more detail later in this chapter, should also be based on the classification of the data. Organizations are required to retain certain information, particularly financial data, based on local, state, or government laws and regulations.
In this section, we discuss the sensitivity and criticality of data, commercial business classifications, military and government classifications, the information life cycle, database maintenance, and data audit.
Sensitivity and Criticality
Sensitivity is a measure of how freely data can be handled. Some data requires special care and handling, especially when inappropriate handling could result in penalties, identity theft, financial loss, invasion of privacy, or unauthorized access by an individual or many individuals. Some data is also subject to regulation by state or federal laws and requires notification in the event of a disclosure.
Data is assigned a level of sensitivity based on who should have access to it and how much harm would be done if it were disclosed. This assignment of sensitivity is called data classification.
Criticality is a measure of the importance of the data. Data that is considered sensitive may not necessarily be considered critical. Assigning a level of criticality to a particular data set requires considering the answers to a few questions:
![]() Will you be able to recover the data in case of disaster?
Will you be able to recover the data in case of disaster?
![]() How long will it take to recover the data?
How long will it take to recover the data?
![]() What is the effect of this downtime, including loss of public standing?
What is the effect of this downtime, including loss of public standing?
Data is considered essential when it is critical to the organization’s business. When essential data is not available, even for a brief period of time, or when its integrity is questionable, the organization is unable to function. Data is considered required when it is important to the organization but organizational operations would continue for a predetermined period of time even if the data were not available. Data is non-essential if the organization is able to operate without it during extended periods of time.
Once the sensitivity and criticality of data are understood and documented, the organization should then work to create a data classification system. Most organizations will either use a commercial business classification system or a military and government classification system.
Commercial Business Classifications
Commercial businesses usually classify data using four main classification levels, listed from highest sensitivity level to lowest:
1. Confidential
2. Private
4. Public
Data that is confidential includes trade secrets, intellectual data, application programming code, and other data that could seriously affect the organization if unauthorized disclosure occurred. Data at this level would only be available to personnel in the organization whose work relates to the data’s subject. Access to confidential data usually requires authorization for each access. Confidential data is exempt from disclosure under the Freedom of Information Act. In most cases, the only way for external entities to have authorized access to confidential data is as follows:
![]() After signing a confidentiality agreement
After signing a confidentiality agreement
![]() When complying with a court order
When complying with a court order
![]() As part of a government project or contract procurement agreement
As part of a government project or contract procurement agreement
Data that is private includes any information related to personnel, including human resources records, medical records, and salary information, that is only used within the organization. Data that is sensitive includes organizational financial information and requires extra measures to ensure its CIA and accuracy. Public data is data that would not cause a negative impact on the organization.
Military and Government Classifications
Military and governmental entities usually classify data using five main classification levels, listed from highest sensitivity level to lowest:
1. Top Secret
2. Secret
3. Confidential
4. Sensitive but unclassified
5. Unclassified
Data that is top secret includes weapon blueprints, technology specifications, spy satellite information, and other military information that could gravely damage national security if disclosed. Data that is secret includes deployment plans, missile placement, and other information that could seriously damage national security if disclosed. Data that is confidential includes patents, trade secrets, and other information that could seriously affect the government if unauthorized disclosure occurred. Data that is sensitive but unclassified includes medical or other personal data that might not cause serious damage to national security but could cause citizens to question the reputation of the government. Military and government information that does not fall into any of the four other categories is considered unclassified and usually has to be granted to the public based on the Freedom of Information Act.
Information Life Cycle
Organizations should ensure that any information they collect and store is managed throughout the life cycle of that information. If no information life cycle is followed, the storage required for the information will grow over time until more storage resources are needed. Security professionals must therefore ensure that data owners and custodians understand the information life cycle.
For most organizations, the five phases of the information life cycle are as follows:
1. Create/receive
2. Distribute
3. Use
4. Maintain
5. Dispose/store
During the create/receive phase, data is either created by organizational personnel or received by the organization via the data entry portal. If the data is created by organizational personnel, it is usually placed in the location from which it will be distributed, used, and maintained. However, if the data is received via some other mechanism, it may be necessary to copy or import the data to an appropriate location. In this case, the data will not be available for distribution, usage, and maintenance until after the copy or import.
After the create/receive phase, organizational personnel must ensure that the data is properly distributed. In most cases, this involves placing the data in the appropriate location and possibly configuring the access permissions as defined by the data owner. Keep in mind, however, that in many cases the storage location and appropriate user and group permissions may already be configured. In such a case, it is just a matter of ensuring that the data is in the correct distribution location. Distribution locations include databases, shared folders, network-attached storage (NAS), storage-attached networks (SANs), and data libraries.
Once data has been distributed, personnel within the organization can use the data in their day-to-day operations. While some personnel will have only read access to data, others may have write or full control permissions. Remember that the permissions allowed or denied are designated by the data owner but configured by the data custodian.
Now that data is being used in day-to-day operations, data maintenance is key to ensuring that data remains accessible and secure. Maintenance includes auditing, performing backups, monitoring performance, and managing data.
Once data has reached the end of the life cycle, you should either properly dispose of it or ensure that it is securely stored. Some organizations must maintain data records for a certain number of years per local, state, or federal laws or regulations. This type of data should be archived for the required period. In addition, any data that is part of litigation should be retained as requested by the court of law, and organizations should follow appropriate chain of custody and evidence documentation processes. Data archival and destruction procedures should be clearly defined by the organization.
All organizations need procedures in place for the retention and destruction of data. Data retention and destruction must follow all local, state, and government regulations and laws. Documenting proper procedures ensures that information is maintained for the required time to prevent financial fines and possible incarceration of high-level organizational officers. These procedures must include both retention period and destruction process.
Figure 2-1 shows the information life cycle.

Databases
Databases have become the technology of choice for storing, organizing, and analyzing large sets of data. Users generally access a database though a client interface. As the need arises to provide access to entities outside the enterprise, the opportunities for misuse increase. In this section, concepts necessary to discuss database security are covered as well as the security concerns surrounding database management and maintenance.
DBMS Architecture and Models
Databases contain data and the main difference in database models is how that information is stored and organized. The model describes the relationships among the data elements, how the data is accessed, how integrity is ensured, and acceptable operations. The five models or architectures we discuss are:
![]() Network
Network
![]() Object-oriented
Object-oriented
![]() Object-relational
Object-relational
The relational model uses attributes (columns) and tuples (rows) to organize the data in two-dimensional tables. Each cell in the table, representing the intersection of an attribute and a tuple, represents a record.
When working with relational database management systems, you should understand the following terms:
![]() Relation: A fundamental entity in a relational database in the form of a table.
Relation: A fundamental entity in a relational database in the form of a table.
![]() Tuple: A row in a table.
Tuple: A row in a table.
![]() Attribute: A column in a table.
Attribute: A column in a table.
![]() Schema: Description of a relational database.
Schema: Description of a relational database.
![]() Record: A collection of related data items.
Record: A collection of related data items.
![]() Base relation: In SQL, a relation that is actually existent in the database.
Base relation: In SQL, a relation that is actually existent in the database.
![]() View: The set of data available to a given user. Security is enforced through the use of these.
View: The set of data available to a given user. Security is enforced through the use of these.
![]() Degree: The number of columns in a table.
Degree: The number of columns in a table.
![]() Cardinality: The number of rows in a relation.
Cardinality: The number of rows in a relation.
![]() Domain: The set of allowable values that an attribute can take.
Domain: The set of allowable values that an attribute can take.
![]() Primary key: Columns that make each row unique.
Primary key: Columns that make each row unique.
![]() Foreign key: An attribute in one relation that has values matching the primary key in another relation. Matches between the foreign key to the primary key are important because they represent references from one relation to another and establish the connection among these relations.
Foreign key: An attribute in one relation that has values matching the primary key in another relation. Matches between the foreign key to the primary key are important because they represent references from one relation to another and establish the connection among these relations.
![]() Candidate key: An attribute in one relation that has values matching the primary key in another relation.
Candidate key: An attribute in one relation that has values matching the primary key in another relation.
![]() Referential integrity: Requires that for any foreign key attribute, the referenced relation must have a tuple with the same value for its primary key.
Referential integrity: Requires that for any foreign key attribute, the referenced relation must have a tuple with the same value for its primary key.
An important element of database design that ensures that the attributes in a table depend only on the primary key is a process called normalization. Normalization includes:
![]() Eliminating repeating groups by putting them into separate tables
Eliminating repeating groups by putting them into separate tables
![]() Eliminating redundant data (occurring in more than one table)
Eliminating redundant data (occurring in more than one table)
![]() Eliminating attributes in a table that are not dependent on the primary key of that table
Eliminating attributes in a table that are not dependent on the primary key of that table
In the hierarchical model, data is organized into a hierarchy. An object can have one child (an object that is a subset of the parent object), multiple children, or no children. To navigate this hierarchy, you must know the branch in which the object is located. An example of the use of this system is the Windows registry and a Lightweight Directory Access Protocol (LDAP) directory.
In the network model, as in the hierarchical model, data is organized into a hierarchy but unlike the hierarchical model, objects can have multiple parents. Because of this, knowing which branch to find a data element in is not necessary because there will typically be multiple paths to it.
The object-oriented model has the ability to handle a variety of data types and is more dynamic than a relational database. Object-oriented database (OODB) systems are useful in storing and manipulating complex data, such as images and graphics. Consequently, complex applications involving multimedia, computer-aided design (CAD), video, graphics, and expert systems are more suited to it. It also has the characteristics of ease of reusing code and analysis and reduced maintenance.
Objects can be created as needed, and the data and the procedure (or methods) go with the object when it is requested. A method is the code defining the actions that the object performs in response to a message. This model uses some of the same concepts of a relational model. In the object-oriented model, a relation, column, and tuple (relational terms) are referred to as class, attribute, and instance objects.
The object-relational model is the marriage of object-oriented and relational technologies, combining the attributes of both. This is a relational database with a software interface that is written in an object-oriented programming (OOP) language. The logic and procedures are derived from the front-end software rather than the database. This means each front-end application can have its own specific procedures.
Database Interface Languages
Access to information in a database is facilitated by an application that allows you to obtain and interact with data. These interfaces can be written in several different languages. This section discusses some of the more important data programming languages:
![]() ODBC: Open Database Connectivity (ODBC) is an API that allows communication with databases either locally or remotely. An API on the client sends requests to the ODBC API. The ODBC API locates the database, and a specific driver converts the request into a database command that the specific database will understand.
ODBC: Open Database Connectivity (ODBC) is an API that allows communication with databases either locally or remotely. An API on the client sends requests to the ODBC API. The ODBC API locates the database, and a specific driver converts the request into a database command that the specific database will understand.
![]() JDBC: As one might expect from the title, Java Database Connectivity (JDBC) makes it possible for Java applications to communicate with a database. A Java API is what allows Java programs to execute SQL statements. It is database agnostic and allows communication with various types of databases. It provides the same functionality as the ODBC.
JDBC: As one might expect from the title, Java Database Connectivity (JDBC) makes it possible for Java applications to communicate with a database. A Java API is what allows Java programs to execute SQL statements. It is database agnostic and allows communication with various types of databases. It provides the same functionality as the ODBC.
![]() XML: Data can now be created in XML format, but the XML:DB API allows XML applications to interact with more traditional databases, such as relational databases. It requires that the database have a database-specific driver that encapsulates all the database access logic.
XML: Data can now be created in XML format, but the XML:DB API allows XML applications to interact with more traditional databases, such as relational databases. It requires that the database have a database-specific driver that encapsulates all the database access logic.
![]() OLE DB: Object Linking and Embedding Database (OLE DB) is a replacement for ODBC, extending its functionality to non-relational databases. Although it is COM-based and limited to Microsoft Windows-based tools, it provides applications with uniform access to a variety of data sources, including service through ActiveX objects.
OLE DB: Object Linking and Embedding Database (OLE DB) is a replacement for ODBC, extending its functionality to non-relational databases. Although it is COM-based and limited to Microsoft Windows-based tools, it provides applications with uniform access to a variety of data sources, including service through ActiveX objects.
Data Warehouses and Data Mining
Data warehousing is the process of combining data from multiple databases or data sources in a central location called a warehouse. The warehouse is used to carry out analysis. The data is not simply combined but is processed and presented in a more useful and understandable way. Data warehouses require stringent security because the data is not dispersed but located in a central location.
Data mining is the process of using special tools to organize the data into a format that makes it easier to make business decisions based on the content. It analyzes large data sets in a data warehouse to find non-obvious patterns. These tools locate associations between data and correlate these associations into metadata. It allows for more sophisticated inferences (sometimes called business intelligence [BI]) to be made about the data. Three measures should be taken when using data warehousing applications:
![]() Control metadata from being used interactively.
Control metadata from being used interactively.
![]() Monitor the data purging plan.
Monitor the data purging plan.
![]() Reconcile data moved between the operations environment and data warehouse.
Reconcile data moved between the operations environment and data warehouse.
Database Maintenance
Database administrators must regularly conduct database maintenance. Databases must be backed up regularly. All security patches and updates for the hardware and software, including the database software, must be kept up to date. Hardware and software upgrades are necessary as organizational needs increase and as technology advances.
Security professionals should work with database administrators to ensure that threat analysis for databases is performed at least annually. They should also work to develop the appropriate mitigations and controls to protect against the identified threats.
Database Threats
Security threats to databases usually revolve around unwanted access to data. Two security threats that exist in managing databases involve the processes of aggregation and inference. Aggregation is the act of combining information from various sources. The way this can become a security issue with databases is when a user does not have access to a given set of data objects, but does have access to them individually or least some of them and is able to piece together the information to which he should not have access. The process of piecing the information together is called inference. Two types of access measures can be put in place to help prevent access to inferable information:
![]() Content-dependent access control bases access on the sensitivity of the data. For example, a department manager might have access to the salaries of the employees in his/her department but not to the salaries of employees in other departments. The cost of this measure is an increased processing overhead.
Content-dependent access control bases access on the sensitivity of the data. For example, a department manager might have access to the salaries of the employees in his/her department but not to the salaries of employees in other departments. The cost of this measure is an increased processing overhead.
![]() Context-dependent access control bases the access to data on multiple factors to help prevent inference. Access control can be a function of factors such as location, time of day, and previous access history.
Context-dependent access control bases the access to data on multiple factors to help prevent inference. Access control can be a function of factors such as location, time of day, and previous access history.
Access to the information in a database is usually controlled through the use of database views. A view refers to the given set of data that a user or group of users can see when they access the database. Before a user is able to use a view, she must have permission on both the view and all dependent objects. Views enforce the concept of least privilege.
Database locks are used when one user is accessing a record that prevents another user from accessing the record at the same time to prevent edits until the first user is finished. Locking not only provides exclusivity to writes but also controls reading of unfinished modifications or uncommitted data.
Polyinstantiation is a process used to prevent data inference violations like the database threats covered earlier in this chapter. It does this by enabling a relation to contain multiple tuples with the same primary keys, with each instance distinguished by a security level. It prevents low-level database users from inferring the existence of higher-level data.
An Online Transaction Processing (OLTP) system is used to monitor for problems such as processes that stop functioning. Its main goal is to prevent transactions that don’t happen properly or are not complete from taking effect. An ACID test ensures that each transaction has the following properties before it is committed:
![]() Atomicity: Either all operations are complete, or the database changes are rolled back.
Atomicity: Either all operations are complete, or the database changes are rolled back.
![]() Consistency: The transaction follows an integrity process that ensures that data is consistent in all places where it exists.
Consistency: The transaction follows an integrity process that ensures that data is consistent in all places where it exists.
![]() Isolation: A transaction does not interact with other transactions until completion.
Isolation: A transaction does not interact with other transactions until completion.
![]() Durability: After it’s verified, the transaction is committed and cannot be rolled back.
Durability: After it’s verified, the transaction is committed and cannot be rolled back.
Data Audit
While an organization may have the most up-to-date data management plan in place, data management alone is not enough to fully protect data. Organizations must also put into place a data auditing mechanism that will help administrators identify vulnerabilities before attacks occur. Auditing mechanisms can be configured to monitor almost any level of access to data. However, auditing mechanisms affect the performance of the systems being audited. Always carefully consider any performance impact that may occur as a result of the auditing mechanism. While auditing is necessary, it is important not to audit so many events that the auditing logs are littered with useless or unused information.
Confidential or sensitive data should be more carefully audited than public information. As a matter of fact, it may not even be necessary to audit access to public information. But when considering auditing for confidential data, an organization may decide to audit all access to that data or just attempts to change the data. Only the organization and its personnel are able to develop the best auditing plan.
Finally, auditing is good only if there is a regular review of the logs produced. Administrators or security professionals should obtain appropriate training on reviewing audit logs. In addition, appropriate alerts should be configured if certain critical events occur. For example, if multiple user accounts are locked out due to invalid login attempts over a short period of time, this may be an indication that systems are experiencing a dictionary or other password attack. If an alert were scheduled to notify administrators when a certain number of lockouts occur over a period of time, administrators may be able to curtail the issue before successful access is achieved by the attacker.
Asset Ownership
While assets within an organization are ultimately owned by the organization, it is usually understood that assets within the organization are owned and managed by different business units. These business units must work together to ensure that the organizational mission is achieved and that the assets are protected.
For this reason, security professionals must understand where the different assets are located and work with the various owners to ensure that the assets and data are protected. The owners that security professionals need to work with include data owners, system owners, and business/mission owners. As part of asset ownership, security professionals should ensure that appropriate asset management procedures are developed and followed.
Data Owners
As stated earlier, data owners actually own the data. Unfortunately, in most cases, data owners do not own the systems on which their data resides. Therefore, it is important that the data owner work closely with the system owner. Even if the appropriate ACLs are configured for the data, the data can still be compromised if the system on which the data resides is not properly secured.
System Owners
System owners are responsible for the systems on which data resides. While the data owner owns the data and the data custodian configures the appropriate permissions for user access to the data, the system owner must administer the system. This includes managing all the security controls on the system, applying patches, configuring the host-based firewall (if there is one), and maintaining backups.
Business/Mission Owners
Business or mission owners must ensure that all operations fit within the business goals and mission. This includes ensuring that collected data is necessary for the business to function. Collecting unnecessary data wastes time and resources. Because the business/mission owner is primarily concerned with the overall business, conflicts between data owners, data custodians, and system owners may need to be resolved by the business/mission owner, who will need to make the best decision for the organization. For example, say that a data owner requests more room on a system for the storage of data. The data owner strongly believes that the new data being collected will help the sales team be more efficient. However, storage on the system owner’s asset is at a premium. The system owner is unwilling to allow the data owner to use the amount of space he has requested. In this case, the business/mission owner would need to review both sides and decide whether collecting and storing the new data would result in enough increased revenue to justify the cost of allowing the data owner more storage space. If so, it may also be necessary to invest in more storage media for the system or to move the data to another system that has more resources available. But keep in mind that moving the data would possibly involve another system owner.
Security professionals should always be part of these decisions because they understand the security controls in place for any systems involved and the security controls needed to protect the data. Moving the data to a system that does not have the appropriate controls may cause more issues than just simply upgrading the system on which the data currently resides. Only a security professional is able to objectively assess the security needs of the data and ensure that they are met.
Asset Management
In the process of managing these assets, several issues must be addressed. Certainly access to the asset must be closely controlled to prevent its deletion, theft, or corruption (in the case of digital assets) and from physical damage (in the case of physical assets). Moreover, the asset must remain available when needed. This section covers methods of ensuring availability, authorization, and integrity.
Redundancy and Fault Tolerance
One of the ways to provide uninterrupted access to information assets is through redundancy and fault tolerance. Redundancy refers to providing multiple instances of either a physical or logical component such that a second component is available if the first fails. Fault tolerance is a broader concept that includes redundancy but refers to any process that allows a system to continue making information assets available in the case of a failure.
In some cases, redundancy is applied at the physical layer of the Open Systems Interconnection (OSI) reference model, such as network redundancy provided by a dual backbone in a local network environment or by using multiple network cards in a critical server. In other cases, redundancy is applied logically, such as when a router knows multiple paths to a destination in case one fails.
Fault tolerance countermeasures are designed to combat threats to design reliability. Although fault tolerance can include redundancy, it also refers to systems such as Redundant Array of Independent Disks (RAID) in which data is written across multiple disks in such a way that a disk can fail and the data can be quickly made available from the remaining disks in the array without resorting to a backup tape. Be familiar with a number of RAID types because not all provide fault tolerance. RAID is covered later in this chapter. Regardless of the technique employed for fault tolerance to operate, a system must be capable of detecting and correcting the fault.
Backup and Recovery Systems
Although a comprehensive coverage of backup and recovery systems is found in Chapter 7, “Security Operations,” it is important to emphasize here the role of operations in carrying out those activities. After the backup schedule has been designed, there will be daily tasks associated with carrying out the plan. One of the most important parts of this system is an ongoing testing process to ensure that all backups are usable in case a recovery is required. The time to discover that a backup did not succeed is during testing and not during a live recovery.
Identity and Access Management
Identity and access management are covered thoroughly in Chapter 5, “Identity and Access Management.” From an operations perspective, it is important to realize that managing these things is an ongoing process that might require creating accounts, deleting accounts, creating and populating groups, and managing the permissions associated with all of these concepts. Ensuring that the rights to perform these actions are tightly controlled and that a formal process is established for removing permissions when they are no longer required and disabling accounts that are no longer needed is essential.
Another area to focus on is the control of the use of privileged accounts, or accounts that have rights and permissions that exceed those of a regular user account. Although this obviously applies to built-in administrator or supervisor accounts (called root accounts in some operating systems) that have vast permissions, it also applies to accounts such as the Windows Power User account that was used prior to Windows 7, which also confers some special privileges to the user.
Moreover, maintain the same tight control over the numerous built-in groups that exist in Windows to grant special rights to the group members. When using these groups, make note of any privileges held by the default groups that are not required for your purposes. You might want to remove some of the privileges from the default groups to support the concept of least privilege.
RAID
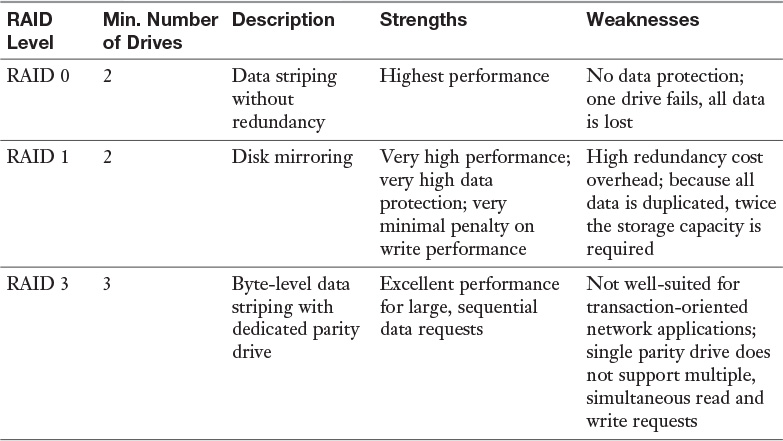
Redundant Array of Independent Disks (RAID) refers to a system whereby multiple hard drives are used to provide either a performance boost or fault tolerance for the data. When we speak of fault tolerance in RAID, we mean maintaining access to the data even in a drive failure without restoring the data from a backup media. The following are the types of RAID with which you should be familiar.
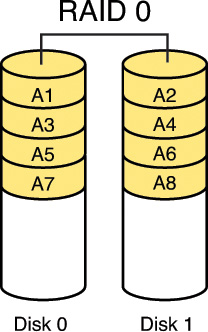
RAID 0, also called disk striping, writes the data across multiple drives. Although it improves performance, it does not provide fault tolerance. Figure 2-2 depicts RAID 0.
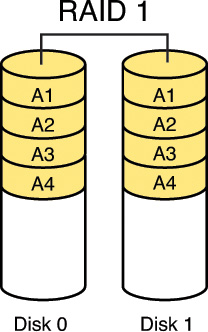
RAID 1, also called disk mirroring, uses two disks and writes a copy of the data to both disks, providing fault tolerance in the case of a single drive failure. Figure 2-3 depicts RAID 1.
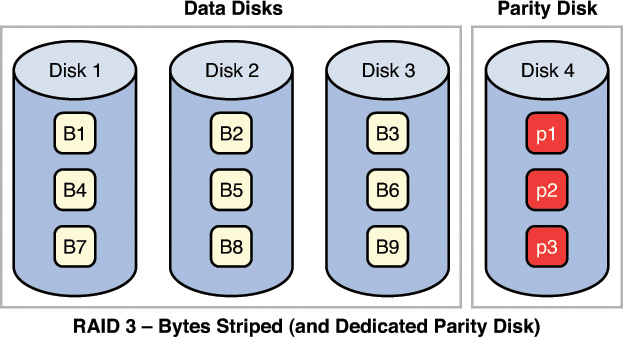
RAID 3, requiring at least three drives, also requires that the data is written across all drives like striping and then parity information is written to a single dedicated drive. The parity information is used to regenerate the data in the case of a single drive failure. The downfall is that the parity drive is a single point of failure if it goes bad. Figure 2-4 depicts RAID 3.
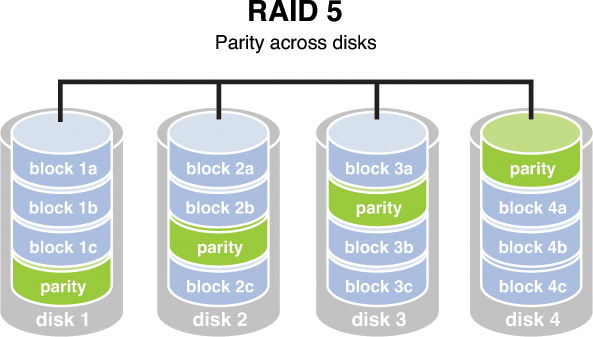
RAID 5, requiring at least three drives, also requires that the data is written across all drives like striping and then parity information is written across all drives as well. The parity information is used in the same way as in RAID 3, but it is not stored on a single drive so there is no single point of failure for the parity data. With hardware RAID Level 5, the spare drives that replace the failed drives are usually hot swappable, meaning they can be replaced on the server while it is running. Figure 2-5 depicts RAID 5.
RAID 7, which is not a standard but a proprietary implementation, incorporates the same principles as RAID 5 but enables the drive array to continue to operate if any disk or any path to any disk fails. The multiple disks in the array operate as a single virtual disk.
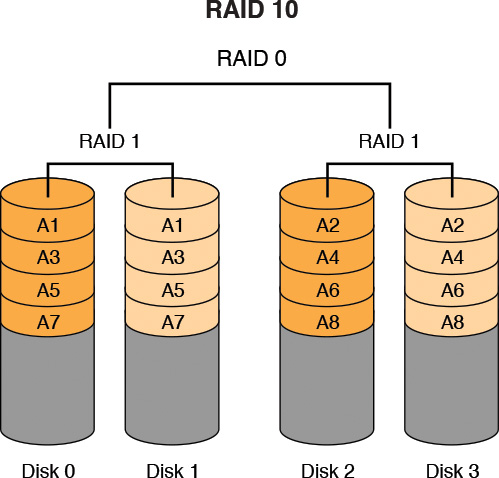
RAID 10 combines RAID 1 and RAID 0 and requires a minimum of two disks. However, most implementations of RAID 10 have four or more drives. A RAID 10 deployment contains a striped disk that is mirrored on a separate striped disk. Figure 2-6 depicts RAID 10.
Although RAID can be implemented with software or with hardware, certain types of RAID are faster when implemented with hardware. When software RAID is used, it is a function of the operating system. Both RAID 3 and 5 are examples of RAID types that are faster when implemented with hardware. Simple striping or mirroring (RAID 0 and 1), however, tend to perform well in software because they do not use the hardware-level parity drives. Table 2-1 summarizes the RAID types.

SAN
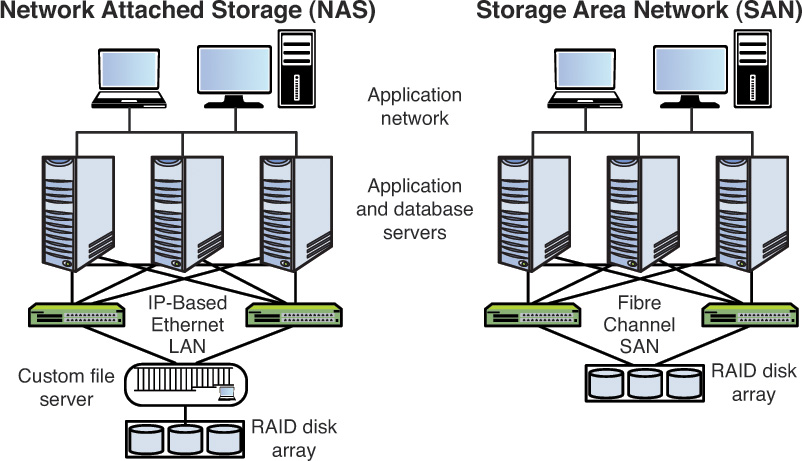
Storage-area networks (SAN) are comprised of high-capacity storage devices that are connected by a high-speed private network (separate from the LAN) using storage-specific switches. This storage information architecture addresses the collection of data, management of data, and use of data.
NAS
Network-attached storage (NAS) serves the same function as SAN, but clients access the storage in a different way. In a NAS, almost any machine that can connect to the LAN (or is interconnected to the LAN through a WAN) can use protocols such as NFS, CIFS, or HTTP to connect to a NAS and share files. In a SAN, only devices that can use the Fibre Channel, iSCSI, ATA over Ethernet, or HyperSCSI network can access the data so it is typically done though a server with this capability. Figure 2-7 shows a comparison of the two systems.
HSM
A hierarchical storage management (HSM) system is a type of backup management system that provides a continuous online backup by using optical or tape “jukeboxes.” It operates by automatically moving data between high-cost and low-cost storage media as the data ages. When continuous availability (24 hours-a-day processing) is required, HSM provides a good alternative to tape backups. It also strives to use the proper media for the scenario. For example, DVD optical discs are sometimes used for backups that require short-time storage for changeable data but require faster file access than tape.
Serial ATA (SATA) development has led to even more advances in HSM. A three-stage HSM can be implemented that writes to cheap but slower SATA arrays. Some HSM implementations even use magnetic hard drives and solid-state drives. Organizations should always research the latest technologies to see if they can save time and money.
Network and Resource Management
Although security operations focus attention on providing confidentiality and integrity of data, availability of the data is also one of its goals. This means designing and maintaining processes and systems that maintain availability to resources despite hardware or software failures in the environment. The following principles and concepts assist in maintaining access to resources:
![]() Redundant hardware: Failures of physical components, such as hard drives and network cards, can interrupt access to resources. Providing redundant instances of these components can help to ensure a faster return to access. In most cases, changing out a component might require manual intervention, even with hot-swappable devices (they can be changed with the device up and running), in which case a momentary reduction in performance might occur rather than a complete disruption of access.
Redundant hardware: Failures of physical components, such as hard drives and network cards, can interrupt access to resources. Providing redundant instances of these components can help to ensure a faster return to access. In most cases, changing out a component might require manual intervention, even with hot-swappable devices (they can be changed with the device up and running), in which case a momentary reduction in performance might occur rather than a complete disruption of access.
![]() Fault-tolerant technologies: Taking the idea of redundancy to the next level are technologies that are based on multiple computing systems working together to provide uninterrupted access even in the event of a failure of one of the systems. Clustering of servers and grid computing are both great examples of this approach.
Fault-tolerant technologies: Taking the idea of redundancy to the next level are technologies that are based on multiple computing systems working together to provide uninterrupted access even in the event of a failure of one of the systems. Clustering of servers and grid computing are both great examples of this approach.
![]() Service-level agreements (SLAs): SLAs are agreements about the ability of the support system to respond to problems within a certain timeframe while providing an agreed level of service. They can be internal between departments or external to a service provider. By agreeing on the quickness with which various problems are addressed, some predictability is introduced to the response to problems, which ultimately supports the maintenance of access to resources.
Service-level agreements (SLAs): SLAs are agreements about the ability of the support system to respond to problems within a certain timeframe while providing an agreed level of service. They can be internal between departments or external to a service provider. By agreeing on the quickness with which various problems are addressed, some predictability is introduced to the response to problems, which ultimately supports the maintenance of access to resources.
![]() MTBF and MTTR: Although SLAs are appropriate for services that are provided, a slightly different approach to introducing predictability can be used with regard to physical components that are purchased. Vendors typically publish values for a product’s mean time between failure (MTBF), which describes how often a component fails on average. Another valuable metric typically provided is the mean time to repair (MTTR), which describes the average amount of time it will take to get the device fixed and back online.
MTBF and MTTR: Although SLAs are appropriate for services that are provided, a slightly different approach to introducing predictability can be used with regard to physical components that are purchased. Vendors typically publish values for a product’s mean time between failure (MTBF), which describes how often a component fails on average. Another valuable metric typically provided is the mean time to repair (MTTR), which describes the average amount of time it will take to get the device fixed and back online.
![]() Single point of failure (SPOF): Though not actually a strategy, it is worth mentioning that the ultimate goal of any of these approaches is to avoid an SPOF of failure in a system. All components and groups of components and devices should be examined to discover any single element that could interrupt access to resources if a failure occurs. Each SPOF should then be mitigated in some way.
Single point of failure (SPOF): Though not actually a strategy, it is worth mentioning that the ultimate goal of any of these approaches is to avoid an SPOF of failure in a system. All components and groups of components and devices should be examined to discover any single element that could interrupt access to resources if a failure occurs. Each SPOF should then be mitigated in some way.
Asset Privacy
Asset privacy involves ensuring that all organizational assets have the level of privacy that is needed. Privacy is discussed in detail in Chapter 1, but when it comes to asset security, you need to understand how to protect asset privacy. This section discusses data processors, data storage and archiving, data remanence, and collection limitation.
Data Processors
Data processors are any personnel within an organization who process the data that has been collected throughout the entire life cycle of the data. If any individual accesses the data in any way, that individual can be considered a data processor. However, in some organizations, data processors are only those individuals who can enter or change data.
No matter which definition an organization uses, it is important that security professionals work to provide training to all data processors on the importance of asset privacy, especially data privacy. This is usually included as part of the security awareness training. It is also important to include any privacy standards or policies that are based on laws and regulations. Once personnel have received the appropriate training, they should sign a statement saying that they will abide by the organization’s privacy policy.
Data Storage and Archiving
Data storage and archiving are related to how an organization stores data—both digital data and physical data in the form of hard copies. It is very easy for data to become outdated. Once data is outdated, it is no longer useful to the organization.
Data storage can become quite expensive as the amount of data grows. Security professionals should work with data owners and data custodians to help establish a data review policy to ensure that data is periodically reviewed to determine whether it is needed and useful for the organization. Data that is no longer needed or useful for the organization should be marked for archiving.
When considering data storage and archiving, security professionals need to ensure that the different aspects of storage are properly analyzed to ensure appropriate deployment. This includes analyzing server hardware and software, database maintenance, data backups, and network infrastructure. Each part of the digital trail that the data will travel must be understood so that the appropriate policies and procedures can be put into place to ensure asset privacy.
Data that is still needed and useful to the organization should remain in primary storage for easy access by users. Data marked for archiving must be moved to some sort of backup media or secondary storage. Organizations must determine the form of data archive storage that will best suit their needs. For some business units in the organization, it may be adequate to archive the data to magnetic tape or optical media, such as DVDs. With these forms of storage, restoring the data from the archive can be a laborious process. For business units that need an easier way to access the archived data, some sort of solid-state or hot-pluggable drive technology may be a better way to go.
No matter which media your organization chooses for archival purposes, security professionals must consider the costs of the mechanisms used and the security of the archive. Storing archived data that has been backed up to DVD in an unlocked file cabinet may be more convenient for a business unit, but it does not provide any protection of the data on the DVD. In this case, the security professional may need to work with the business unit to come up with a more secure storage mechanism for data archives. When data is managed centrally by the IT or data center staff, personnel usually better understand security issues related to data storage and may therefore not need as much guidance from security professionals.
Data Remanence
Whenever data is erased or removed from a storage media, residual data can be left behind. This can allow data to be reconstructed when the organization disposes of the media, resulting in unauthorized individuals or groups gaining access to data. Media that security professionals must consider include magnetic hard disk drives, solid-state drives, magnetic tapes, and optical media, such as CDs and DVDs. When considering data remanence, security professionals must understand three countermeasures:
![]() Clearing: This includes removing data from the media so that data cannot be reconstructed using normal file recovery techniques and tools. With this method, the data is only recoverable using special forensic techniques.
Clearing: This includes removing data from the media so that data cannot be reconstructed using normal file recovery techniques and tools. With this method, the data is only recoverable using special forensic techniques.
![]() Purging: Also referred to as sanitization, purging makes the data unreadable even with advanced forensic techniques. With this technique, data should be unrecoverable.
Purging: Also referred to as sanitization, purging makes the data unreadable even with advanced forensic techniques. With this technique, data should be unrecoverable.
![]() Destruction: Destruction involves destroying the media on which the data resides. Overwriting is a destruction technique that writes data patterns over the entire media, thereby eliminating any trace data. Degaussing, another destruction technique, exposes the media to a powerful, alternating magnetic field, removing any previously written data and leaving the media in a magnetically randomized (blank) state. Encryption scrambles the data on the media, thereby rendering it unreadable without the encryption key. Physical destruction involves physically breaking the media apart or chemically altering it. For magnetic media, physical destruction can also involve exposure to high temperatures.
Destruction: Destruction involves destroying the media on which the data resides. Overwriting is a destruction technique that writes data patterns over the entire media, thereby eliminating any trace data. Degaussing, another destruction technique, exposes the media to a powerful, alternating magnetic field, removing any previously written data and leaving the media in a magnetically randomized (blank) state. Encryption scrambles the data on the media, thereby rendering it unreadable without the encryption key. Physical destruction involves physically breaking the media apart or chemically altering it. For magnetic media, physical destruction can also involve exposure to high temperatures.
The majority of these countermeasures work for magnetic media. However, solid-state drives present unique challenges because they cannot be overwritten. Most solid-state drive vendors provide sanitization commands that can be used to erase the data on the drive. Security professionals should research these commands to ensure that they are effective. Another option for these drives is to erase the cryptographic key. Often a combination of these methods must be used to fully ensure that the data is removed.
Data remanence is also a consideration when using any cloud-based solution for an organization. Security professionals should be involved in negotiating any contract with a cloud-based provider to ensure that the contract covers data remanence issues, although it is difficult to determine that the data is properly removed. Using data encryption is a great way to ensure that data remanence is not a concern when dealing with the cloud.
Collection Limitation
For any organization, a data collection limitation exists based on the available storage space. Systems owners and data custodians should monitor the amount of free storage space so that they understand trends and can anticipate future needs before space becomes critical. Without appropriate monitoring, data can grow to the point where system performance is affected. No organization wants to have a vital data storage system shut down because there is no available free space. Disk quotas allow administrators to set disk space limits for users and then automatically monitor disk space usage. In most cases, the quotas can be configured to notify users when they are nearing space limits.
Security professionals should work with system owners and data custodians to ensure that the appropriate monitoring and alert mechanisms are configured. System owners and data custodians can then be proactive when it comes to data storage needs.
Data Retention
Data retention requirements vary based on several factors, including data type, data age, and legal and regulatory requirements. Security professionals must understand where data is stored and the type of data stored. In addition, security professionals should provide guidance on managing and archiving data. Therefore, data retention policies must be established with the help of organizational personnel.
A retention policy usually contains the purpose of the policy, the portion of the organization affected by the policy, any exclusions to the policy, the personnel responsible for overseeing the policy, the personnel responsible for data, the data types covered by the policy, and the retention schedule. Security professionals should work with data owners to develop the appropriate data retention policy for each type of data the organization owns. Examples of data types include, but are not limited to, human resources data, accounts payable/receivable data, sales data, customer data, and email.
To design data retention policies, the organization should answer the following questions:
![]() What are the legal/regulatory requirements and business needs for the data?
What are the legal/regulatory requirements and business needs for the data?
![]() What are the types of data?
What are the types of data?
![]() What are the retention periods and destruction needs for the data?
What are the retention periods and destruction needs for the data?
The personnel who are most familiar with each data type should work with security professionals to determine the data retention policy. For example, human resources personnel should help design the data retention policies for all human resources data. While designing data retention policies, an organization must consider the media and hardware that will be used to retain the data. Then, with this information in hand, the organization and/or business unit should draft and formally adopt the data retention policies.
Once the data retention policies have been created, personnel must be trained to comply with these policies. Auditing and monitoring should be configured to ensure data retention policy compliance. Periodically, data owners and processors should review the data retention policies to determine whether any changes need to be made. All data retention policies, implementation plans, training, and auditing should be fully documented.
Remember that within most organizations, it is not possible to find a one-size-fits-all solution because of the different types of data. Only those most familiar with each data type can determine the best retention policy for that data. While a security professional should be involved in the design of the data retention policies, the security professional is there to ensure that data security is always considered and that data retention policies satisfy organizational needs. The security professional should act only in an advisory role and should provide expertise when needed.
Data Security and Controls
Now it is time to discuss the data security and controls that organizations must consider as part of a comprehensive security plan. Security professionals must understand the following as part of data security and controls: data security, data at rest, data in transit, data access and sharing, baselines, scoping and tailoring, standards selection, and cryptography.
Data Security
Data security includes the procedures, processes, and systems that protect data from unauthorized access. Unauthorized access includes unauthorized digital and physical access. Data security also protects data against any threats that can affect data confidentiality, integrity, or availability.
To provide data security, security should be implemented using a defense-in-depth strategy, as discussed in Chapter 1. If a single layer of access is not analyzed, then data security is at risk. For example, you can implement authentication mechanisms to ensure that users must authenticate before accessing the network. But if you do not have the appropriate physical security controls in place to prevent unauthorized access to your facility, an attacker can easily gain access to your network just by connecting an unauthorized device to the network.
Security professionals should make sure their organization implements measures and safeguards for any threats that have been identified. In addition, security professionals must remain vigilant and constantly be on the lookout for new threats.
Data at Rest
Data at rest is data that is being stored and not being actively used at a certain point in time. While data is at rest, security professionals must ensure that the confidentiality, integrity, and availability of the data are ensured. Confidentiality can be provided by implementing data encryption. Integrity can be provided by implementing the appropriate authentication mechanisms and ACLs so that only authenticated, authorized users can edit data. Availability can be provided by implementing a fault-tolerant storage solution, such as RAID.
Data in Transit
Data in transit is data that is being transmitted over a network. While data is being transmitted, security professionals must ensure that the confidentiality, integrity, and availability of the data are ensured. Confidentiality can be provided by implementing link encryption or end-to-end encryption. As with data at rest, authentication and ACLs can help with data integrity of data in transit. Availability can be provided by implementing server farms and dual backbones.
Data Access and Sharing
Personnel must be able to access and share data in their day-to-day duties. This access starts when the data owner approves access for a user. The data custodian then gives the user the appropriate permissions for the data. But these two steps are an over-simplification of the process. Security professionals must ensure that the organization understands issues such as the following:
![]() Are the appropriate data policies in place to control the access and use of data?
Are the appropriate data policies in place to control the access and use of data?
![]() Do the data owners understand the access needs of the users?
Do the data owners understand the access needs of the users?
![]() What are the different levels of access needed by the users?
What are the different levels of access needed by the users?
![]() Which data formats do the users need?
Which data formats do the users need?
![]() Are there subsets of data that should have only restricted access for users?
Are there subsets of data that should have only restricted access for users?
![]() Of the data being collected, is there clearly identified private versus public data?
Of the data being collected, is there clearly identified private versus public data?
![]() Is data being protected both when it is at rest and when it is in transit?
Is data being protected both when it is at rest and when it is in transit?
![]() Are there any legal or jurisdictional issues related to data storage location, data transmission, or data processing?
Are there any legal or jurisdictional issues related to data storage location, data transmission, or data processing?
While the data owners and data custodians work together to answer many of these questions, security professionals should be involved in guiding them through this process. If a decision is made to withhold data, the decision must be made based on privacy, confidentiality, security, or legal/regulatory restrictions. The criteria by which these decisions are made must be recorded as part of an official policy.
Baselines
One practice that can make maintaining security simpler is to create and deploy standard images that have been secured with security baselines. A baseline is a set of configuration settings that provide a floor of minimum security in the image being deployed. Organizations should capture baselines for all devices, including network devices, computers, host computers, and virtual machines.
Baselines can be controlled through the use of Group Policy in Windows. These policy settings can be made in the image and applied to both users and computers. These settings are refreshed periodically through a connection to a domain controller and cannot be altered by the user. It is also quite common for the deployment image to include all of the most current operating system updates and patches as well.
When a network makes use of these types of technologies, the administrators have created a standard operating environment. The advantages of such an environment are more consistent behavior of the network and simpler support issues. System scans should be performed weekly to detect changes from the baseline.
Security professionals should help guide their organization through the process of establishing baselines. If an organization implements very strict baselines, it will provide a higher level of security that may actually be too restrictive. If an organization implements a very lax baseline, it will provide a lower level of security that will likely result in security breaches. Security professionals should understand the balance between protecting organizational assets and allowing users access, and they should work to ensure that both ends of this spectrum are understood.
Scoping and Tailoring
Scoping and tailoring are closely tied to the baselines. Scoping and tailoring allow an organization to narrow its focus to identify and address the appropriate risks.
Scoping instructs an organization on how to apply and implement security controls. Baseline security controls are the minimums that are acceptable to the organization. When security controls are selected based on scoping, documentation should be created that includes the security controls that were considered, whether the security controls were adopted, and how the considerations were made.
Tailoring allows an organization to more closely match security controls to the needs of the organization. When security controls are selected based on tailoring, documentation should be created that includes the security controls that were considered, whether the security controls were adopted, and how the considerations were made.
National Institute of Standards and Technology (NIST) Special Publication (SP) 800-53, which is covered briefly in Chapter 1, provides some guidance on tailoring. The tailoring process comprises several steps, including:
1. Identify and designate common controls. If an information system inherits a common control, such as environmental controls within a data center, that system does not need to explicitly implement that control. Organizational decisions on which security controls are designated as common controls may greatly affect the responsibilities of individual system owners with regard to the implementation of controls in a particular baseline.
2. Apply scoping considerations. When applied in conjunction with risk management guidance, scoping considerations can eliminate unnecessary security controls from the initial security control baselines and help ensure that organizations select only those controls needed to provide the appropriate level of protection for information systems. When scoping considerations are applied, compensating controls may need to be selected to provide alternative means to achieve security requirements.
3. Supplement baselines. Additional security controls and control enhancements are selected if needed to address specific threats and vulnerabilities.
Standards Selection
Because organizations need guidance on protecting their assets, security professionals must be familiar with the standards that have been established. Many standards organizations have been formed, including NIST, the U.S. Department of Defense (DoD), and the International Organization for Standardization (ISO).
The NIST standards include Federal Information Processing Standards (FIPS) and Special Publications (SP). FIPS 199 defines standards for security categorization of federal information systems. The FIPS 199 nomenclature may be referred to as the aggregate CIA score. This U.S. government standard establishes security categories of information systems used by the federal government.
FIPS 199 requires federal agencies to assess their information systems in each of the categories of confidentiality, integrity, and availability and rate each system as low, moderate, or high impact in each category. An information system’s overall security category is the highest rating from any category.
A potential impact is low if the loss of any tenet of CIA could be expected to have a limited adverse effect on organizational operations, organizational assets, or individuals. This occurs if the organization is able to perform its primary function but not as effectively as normal. This category involves only minor damage, financial loss, or harm.
A potential impact is moderate if the loss of any tenet of CIA could be expected to have a serious adverse effect on organizational operations, organizational assets, or individuals. This occurs if the effectiveness with which the organization is able to perform its primary function is significantly reduced. This category involves significant damage, financial loss, or harm.
A potential impact is high if the loss of any tenet of CIA could be expected to have a severe or catastrophic adverse effect on organizational operations, organizational assets, or individuals. This occurs if an organization is not able to perform one or more of its primary functions. This category involves major damage, financial loss, or severe harm.
FIPS 199 provides a helpful chart that ranks the levels of CIA for information assets, as shown in Table 2-2.

It is also important that security professionals and organizations understand the information classification and life cycle. Classification varies depending on whether the organization is a commercial business or a military/government entity.
According to Table 2-2, FIPS 199 defines three impacts (low, moderate, and high) for the three security tenets. But the levels that are assigned to organizational entities must be defined by the organization because only the organization can determine whether a particular loss is limited, serious, or severe.
According to FIPS 199, the security category (SC) of an identified entity expresses the three tenets with their values for an organizational entity. The values are then used to determine which security controls should be implemented. If a particular asset is made up of multiple entities, then you must calculate the SC for that asset based on the entities that make it up. FIPS 199 provides a nomenclature for expressing these values, as shown here:
SCinformation type = {(confidentiality, impact), (integrity, impact), (availability, impact)}
Let’s look at an example of this nomenclature in a real-world example:
SCpublic site = {(confidentiality, low), (integrity, moderate), (availability, high)}
SCpartner site = {(confidentiality, moderate), (integrity, high), (availability, moderate)}
SCinternal site = {(confidentiality, high), (integrity, medium), (availability, moderate)}
Now let’s assume that all of the sites reside on the same web server. To determine the nomenclature for the web server, you need to use the highest values of each of the categories:
SCweb server = {(confidentiality, high), (integrity, high), (availability, high)}
Some organizations may decide to place the public site on a web server and isolate the partner site and internal site on another web server. In this case, the public web server would not need all of the same security controls and would be cheaper to implement than the partner/internal web server.
The United States DoD Instruction 8510.01 establishes a certification and accreditation process for DoD information systems. It can be found at http://www.dtic.mil/whs/directives/corres/pdf/851001_2014.pdf.
The ISO organization works with the International Electrotechnical Commission (IEC) to establish many standards regarding information security. The ISO/IEC standards that security professionals need to understand are covered in Chapter 1.
Security professionals may also need to research other standards, including standards from the European Network and Information Security Agency (ENISA), European Union (EU), and United States National Security Agency (NSA). It is important that the organization researches the many standards available and apply the most beneficial guidelines based on the organization’s needs.
Crytography
Cryptography, also referred to as encryption, can provide different protection based on which level of communication is being used. The two types of encryption communication levels are link encryption and end-to-end encryption.
Link Encryption
Link encryption encrypts all the data that is transmitted over a link. In this type of communication, the only portion of the packet that is not encrypted is the data-link control information, which is needed to ensure that devices transmit the data properly. All the information is encrypted, with each router or other device decrypting its header information so that routing can occur and then re-encrypting before sending the information to the next device.
If the sending party needs to ensure that data security and privacy is maintained over a public communication link, then link encryption should be used. This is often the method used to protect email communication or when banks or other institutions that have confidential data must send that data over the Internet.
Link encryption protects against packet sniffers and other forms of eavesdropping and occurs at the data link and physical layers of the OSI model. Advantages of link encryption include: All the data is encrypted, and no user interaction is needed for it to be used. Disadvantages of link encryption include: Each device that the data must be transmitted through must receive the key, key changes must be transmitted to each device on the route, and packets are decrypted at each device.
End-to-End Encryption
End-to-end encryption encrypts less of the packet information than link encryption. In end-to-end encryption, packet routing information, as well as packet headers and addresses, are not encrypted. This allows potential hackers to obtain more information if a packet is acquired through packet sniffing or eavesdropping.
End-to-end encryption has several advantages. A user usually initiates end-to-end encryption, which allows the user to select exactly what gets encrypted and how. It affects the performance of each device along the route less than link encryption because every device does not have to perform encryption/decryption to determine how to route the packet.
Asset Handling Requirements
Organizations should establish the appropriate asset handling requirements to protect their assets. As part of these handling requirements, personnel should be instructed on how to mark, label, store, and destroy or dispose of media.
Marking, Labeling, and Storing
Plainly label all forms of storage media (tapes, optical, and so on) and store them safely. Some guidelines in the area of media control are to
![]() Accurately and promptly mark all data storage media.
Accurately and promptly mark all data storage media.
![]() Ensure proper environmental storage of the media.
Ensure proper environmental storage of the media.
![]() Ensure the safe and clean handling of the media.
Ensure the safe and clean handling of the media.
![]() Log data media to provide a physical inventory control.
Log data media to provide a physical inventory control.
The environment where the media will be stored is also important. For example, damage starts occurring to magnetic media above 100 degrees. The Forest Green Book is a Rainbow Series book that defines the secure handling of sensitive or classified automated information system memory and secondary storage media, such as degaussers, magnetic tapes, hard disks, floppy disks, and cards. The Rainbow Series is discussed in more detail in Chapter 3.
Destruction
During media disposal, you must ensure no data remains on the media. The most reliable, secure means of removing data from magnetic storage media, such as a magnetic tape cassette, is through degaussing, which exposes the media to a powerful, alternating magnetic field. It removes any previously written data, leaving the media in a magnetically randomized (blank) state. More information on the destruction of media is given earlier in this chapter, in the “Data Remanence” section.
Exam Preparation Tasks
Review All Key Topics
Review the most important topics in this chapter, noted with the Key Topics icon in the outer margin of the page. Table 2-3 lists a reference of these key topics and the page numbers on which each is found.
Table 2-3 Key Topics for Chapter 2
Complete the Tables and Lists from Memory
Print a copy of CD Appendix A, “Memory Tables,” or at least the sections for this chapter, and complete the tables and lists from memory. Appendix B, “Memory Tables Answer Key,” includes completed tables and lists to check your work.
Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
hierarchical storage management (HSM) system
International Organization for Standardization (ISO)
International Electrotechnical Commission (IEC)
ISO/IEC 27000
Java Database Connectivity (JDBC)
mean time between failure (MTBF)
network-attached storage (NAS)
object linking and embedding (OLE)
object linking and embedding database (OLE DB)
object-oriented programming (OOP)
object-oriented database (OODB)
Online Transaction Processing system
open database connectivity (ODBC)
personally identifiable information (PII)
Answer Review Questions
1. What is the highest military security level?
a. Confidential
b. Top Secret
c. Private
d. Sensitive
2. Which of the following is also called disk striping?
a. RAID 0
b. RAID 1
c. RAID 10
d. RAID 5
3. Which of the following is also called disk mirroring?
a. RAID 0
b. RAID 1
c. RAID 10
d. RAID 5
4. Which of the following is composed of high-capacity storage devices that are connected by a high-speed private (separate from the LAN) network using storage-specific switches?
a. HSM
b. SAN
c. NAS
d. RAID
5. Who is responsible for deciding which users have access to data?
a. business owner
b. system owner
c. data owner
d. data custodian
6. Which term is used for the fitness of data for use?
c. data quality
d. data classification
7. What is the highest level of classification for commercial systems?
a. public
b. sensitive
c. private
d. confidential
8. What is the first phase of the information life cycle?
a. maintain
b. use
c. distribute
d. create/receive
9. Which organizational role owns a system and must work with other users to ensure that data is secure?
a. business owner
b. data custodian
c. data owner
d. system owner
10. What is the last phase of the information life cycle?
a. distribute
b. maintain
c. dispose/store
d. use
Answers and Explanations
1. b. Military and governmental entities classify data using five main classification levels, listed from highest sensitivity level to lowest:
1. Top Secret
2. Secret
3. Confidential
4. Sensitive but unclassified
5. Unclassified
2. a. RAID 0, also called disk striping, writes the data across multiple drives, but although it improves performance, it does not provide fault tolerance.
3. b. RAID 1, also called disk mirroring, uses two disks and writes a copy of the data to both disks, providing fault tolerance in the case of a single drive failure.
4. b. Storage-area networks (SANs) are composed of high-capacity storage devices that are connected by a high-speed private (separate from the LAN) network using storage specific switches.
5. c. The data owner is responsible for deciding which users have access to data.
6. c. Data quality is the fitness of data for use.
7. d. Commercial systems usually use the following classifications, from highest to lowest:
1. Confidential
2. Private
3. Sensitive
4. Public
8. d. The phases of the information life cycle are as follows:
1. Create/receive
2. Distribute
3. Use
4. Maintain
5. Dispose/store
9. d. The system owner owns a system and must work with other users to ensure that data is secure.
10. c. The phases of the information life cycle are as follows:
1. Create/receive
2. Distribute
3. Use
4. Maintain
5. Dispose/store