
Chapter 4
Decoupling Mechanisms Using AWS Services
This chapter covers the following topics:
This chapter covers content that’s important to the following exam domain/objective:
Domain 1: Design Resilient Architectures
Objective 1.3 Design decoupling mechanisms using AWS services
The AWS Certified Solutions Architect - Associate (SAA-C02) exam requires that you understand what AWS services assist in developing applications that are hosted in the AWS cloud. The exam does not expect that you’re a developer per se, but it does expect that you can help advise developers and educate them on what services could be useful for creating stateless applications in the cloud.
Although the cloud can certainly host legacy and monolithic applications, the exam tests whether you understand the purpose of AWS application integration services. Lifting and shifting an application from an on-premises location into the cloud does work, but in the long term, that approach does not take advantage of all the features of the public cloud. A service that is part of an application stack that stores data for processing or long-term storage has no idea that it is part of an application; it’s just doing the job it was designed to do. Data storage can be persistent over the long term or persistent for a very short period of time until it’s no longer required. The type of storage depends on the type of data being utilized.
This chapter demystifies the terms stateful and stateless as they pertain to the AWS cloud. This chapter also takes a look at two services that can be very useful in designing applications: Lambda and Amazon API Gateway.
“Do I Know This Already?” Quiz
The “Do I Know This Already?” quiz allows you to assess whether you should read this entire chapter thoroughly or jump to the “Exam Preparation Tasks” section. If you are in doubt about your answers to these questions or your own assessment of your knowledge of the topics, read the entire chapter. Table 4-1 lists the major headings in this chapter and their corresponding “Do I Know This Already?” quiz questions. You can find the answers in Appendix A, “Answers to the ‘Do I Know This Already?’ Quizzes and Q&A Sections.”
Table 4-1 “Do I Know This Already?” Section-to-Question Mapping
Foundation Topics Section |
Questions |
|---|---|
Stateless and Stateful Design |
1, 2 |
Application Integration Services |
3, 4 |
Lambda |
5, 6 |
API Gateway |
7, 8 |
Caution
The goal of self-assessment is to gauge your mastery of the topics in this chapter. If you do not know the answer to a question or are only partially sure of the answer, you should mark that question as wrong for purposes of the self-assessment. Giving yourself credit for an answer you correctly guess skews your self-assessment results and might provide you with a false sense of security.
1. Which of the following AWS services is stateful?
Security Group
SQS
Route 53
Availability Zone
2. Which of the following terms would apply to a virtual server that saves data about each current client session?
Stateless
Stateful
Primary
Secondary
3. What service could be useful for storing application state during a data processing cycle?
SNS
SQS
S3
EBS
4. Which AWS service is used to send notifications about AWS service changes to both humans and services?
SES
SNS
Chime
Kinesis
5. What AWS service can be used to host and execute custom functions?
EC2
Lambda
IAM
SQS
6. What is the commercial charging model for AWS Lambda?
Processing time
RAM/CPU and processing time
Number of functions executed per month per account
RAM and CPU allocated per function
7. What AWS service can be used to host and execute custom APIs?
SNS
API Gateway
SQS
AWS Glue
8. What AWS service is called by API Gateway to carry out custom tasks?
Certificate Manager
Lambda
CloudWatch
CloudTrail
Foundation Topics
Stateful Design
Way back in 2005, when hosted applications were not as popular as they are today, applications were run on massive single servers and shared with a number of clients. The local server stored all the information about your user account, and the entire application stack was stored locally on one server. An application server hosted at AWS could have most of its dependencies moved to a variety of management services, as illustrated in Figure 4-1. The local server also contained a local database, logging services, and any other middleware required to support and run the application. The application’s performance was limited by the size and speed of the physical hardware components (CPU, RAM, and hard drive). The design of such an application stack is referred to as stateful; all of the application components are located in one physical location, typically on an application server racked in the local data center for the organization. Over time, the database server and the application server came to be hosted separately but were still hosted in the same physical location.

FIGURE 4-1 Locally Hosted Application Server Versus AWS Hosted Server
When organizations moved to the cloud, migration tools lifted and shifted the on-premises applications to the cloud. If your servers were virtual, so much the better; the local image of the server was migrated into an image supported by the cloud provider, and your app was off and running. The only difference at this point is that clients were connecting to the application across the Internet; the server was virtualized and hosted in an AWS data center. AWS knows that the application servers and database servers should be on separate subnets, hosted in different data centers in different availability zones. In the early days of the AWS cloud, administrators just didn’t do this as the assumption was that the cloud would never go down; in fact, most of the time it doesn’t, but then again, sometimes it does.
With AWS, it is common—and a best practice—for an application to be hosted in separate data centers, with separate application and database servers, and for the application to be accessed by first communicating to a load balancer. When you click on the URL pointing to your application, the heavy lifting is done in the background, and you are sent to one of the application servers. Say that, as illustrated in Figure 4-2, you have two servers for your application: Server A and Server B. You are connected to Server A, you present your logon credentials, you are verified and logged in, and your user session information is stored on Server A; as long as there are no problems in the application stack, you have access to the application. Because of the addition of the load balancer, the application can be defined as stateless. At AWS, the load balancer software is running on an EC2 instance that is part of a massive server farm of thousands of load balancers. If one load balancer fails, another one can take its place almost instantaneously. Therefore, there are choices for providing the load-balancing service, just as there are choices for the application server to which the end user will be connected.
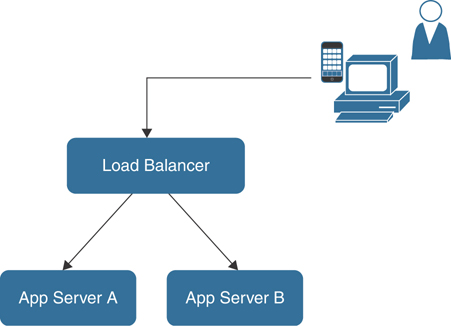
FIGURE 4-2 Adding a Load Balancer and Changing the Design to Stateless
In addition, the load balancer enables a feature called sticky sessions, also called session affinity, which ensures that whenever a user begins a session with the application, the user is sent to Server A and continues communicating with Server A. Server B doesn’t know anything about the current user session because there has been no communication with Server B. In this case, however, after the end user has successfully authenticated with Server A, when they again interface with the application to complete their order, unknown to the end user, Server A is having hardware issues and is not responding, and the load balancer sends the end user to Server B. Server B has the same application; in fact, it’s an identical image to Server A, but because the user session information for the application is stored on Server A, where the session began, Server B doesn’t know anything about the current session or the identity of the end user, and it asks the end user to logon.
Changing User State Locations
The sticky sessions concept was a predecessor of the concept of single sign-on (SSO), which requires an end user to sign on once and doesn’t require another sign-on. Of course, in case the initial server has issues and is unavailable, it is necessary to find a better location for storing the user state information. There are a number of ways to solve this problem.
One solution is to store user session information on your computer system in your browser cache rather than on the application server. When the end user communicates with the application again, that user sends a session token along with the URL for the application. The load balancer checks the session information; if it is still valid, the end user is sent to any available application server. There might be only two servers, or there might be hundreds of them, but the user session information is not stored on the servers. For this example, the server is not holding on to and maintaining the session state information for the user; it is free from managing this information, and the server is now stateless and just dealing with application requests. If the server were responsible for holding on to and managing the session information, it would be defined as stateful; the server would be responsible for storing and maintaining and updating all states—application, application data, and user session states. The session token would be stored at the client and would have to be presented to the load balancer multiple times to continue the user session in progress.
This is a very simple example of the concept of stateless processing. In this example, no user session information is being retained by the server. However, there is still stateful information being used by the application server, even though its primary purpose as part of the application stack is now defined as stateless; the server is a generic copy, as every application server is built using exactly the same image.
A properly designed application hosted in the cloud uses key AWS services to secure both the user and application states and the application data records:
The user authentication credentials must be stored in an AWS Identity and Access Management (IAM) database or similar authentication database; the user account information is stateful, which means their credentials remain the same until changed by the end user.
The application state (of orders and requests, for example) is stored in some sort of messaging queue, such as in Amazon Simple Queue Service (SQS), which is discussed later in this chapter.
The application data is stored in a database solution, most likely with a primary and standby database design.
If you look at the entire communication process from client to application—for example, ordering something from Amazon.com—you can see that the essential data that is generated is a combination of stateful and stateless data (see Table 4-2). Keep in mind that stateless data is not retained forever but for only a period of time. This period of time could be during an authenticated user session while ordering a product, listening to music online, or playing games online. The Amazon order process involves the following stateful and stateless data:
Stateful data includes changing user account information, purchases, history, refunds, games played, high scores, music listened to, or music downloaded.
Stateless data includes user session information, such as information on browsing for products, browsing for games, review account information, or searching for music.
Table 4-2 Data Choices at AWS
Type of Data |
Stateful or Stateless |
AWS Service |
|---|---|---|
User account data |
Stateful |
RDS, Active Directory Domain Services, IAM |
Session information data |
Stateless |
DynamoDB, ElastiCache |
Load balancer |
Stateless |
ELB/sticky sessions |
Database query |
Stateful |
Database instance/read replica |
Application state data |
Stateless |
SQS |
Event notification data |
Stateless |
SNS |
Where does the application stack/system need to store the data? If the data should be stored long term in a database, the data is stateful. The data needs to be stored as a permanent record, and from time to time it will be updated and changed, but it still needs to be persistently stored.
If the data is being used for a short time, or potentially even a longer time but not permanently, the data is defined as stateless; it is useful for a short or longer period of time, but it can be discarded after it has been used (for example, user session information) or processed (for example, items in a shopping cart).
Stateless data sometimes changes format and is retained forever, in which case it becomes stateful. Social media could provide an example here, as every speck of information generated is saved.
Note
For the AWS Certified Solutions Architect - Associate (SAA-C02) exam, it is important to understand the distinction between stateless and stateful data in the context of stateless and stateful components.
User Session Management
There are two common ways to manage AWS user sessions:
Sticky sessions: When you deploy an application load balancer (ALB), you can enable sticky sessions by opening the attributes of the target group of registered servers that will be served content by the load balancer. The term sticky means that once you start a user session with a particular application server, the session will continue on that application server, and the load balancer will honor that relationship for the life of the user session. The drawback is that if the application server fails, all session information is lost.
Distributed session management: Another way to address shared data storage for user sessions is to use an in-memory key/value store hosted by ElastiCache and deploy either Redis or Memcached to cache HTTP session state. In-memory data stores are fast and can be used to cache any information, including HTTP session information. For a simple solution with no redundancy, you could choose to employ ElastiCache for Memcached, but this provides no replication support. For a redundant distributed session solution, you could deploy ElastiCache for Redis, which supports replication of the stored information between multiple nodes across multiple availability zones. Figure 4-3 shows the operation of a distributed cache. When the user communicates with the application stack, the session information is stored in an ElastiCache for Redis distributed cache. When Server A fails, the user session can be continued on Server B because the user session information has been stored in ElastiCache instead of in the application server.

FIGURE 4-3 An ElastiCache for Redis Distributed User Session Cache
For the AWS Certified Solutions Architect - Associate (SAA-C02) exam, you need to understand the concepts of stateful and stateless data storage options well enough to be able to provide advice as an AWS architect to your developers as to what AWS architectural solutions are available for the various types of data that will be stored and retrieved. This chapter looks at the AWS services shown in Figure 4-4 that store both stateless and stateful data.

FIGURE 4-4 Data Store Options at AWS
Note
The terms stateless and stateful have slightly different meanings when you’re talking about security groups or network access control lists (NACLs). A security group is a firewall that protects an EC2 instance’s incoming network traffic and tracks what traffic requests are allowed in and what traffic is allowed out. Any requests allowed in by a security group are also allowed back out. Security groups remember the incoming and outgoing network traffic flow state, and in this sense, they are stateful. In contrast, a NACL operates with a stateless mindset. A NACL is a subnet firewall that either allows or denies incoming and outgoing requests at the subnet level. The NACL decision-making process about what traffic is allowed in or out is not dependent on what traffic was previously allowed in or out. Incoming traffic decisions are determined by inbound allow and deny rules, and outgoing traffic decisions are determined by the defined outbound allow and deny rules.
Application Integration Services
The sections that follow cover the following application integration services:
Amazon SNS
Amazon SQS
AWS Step Functions
Amazon SNS
Amazon Simple Notification Service (SNS) enables you to send messages using push notifications from a publisher to a subscriber. An example of a publisher could be any AWS service. A subscriber could be an end user, AWS service, EC2 instance, or Lambda, the serverless service hosted at AWS. SNS can send both individual or bulk messages to a large number of recipients, or subscribers. (Think of push notifications as the messages you get when you install a new application on your smartphone.) SNS allows you to decouple your applications into smaller independent components that relay messages or events to distributed applications, move data between S3 objects stores, or react when changes occur to a DynamoDB table, or Cloud Watch alarms.
SNS is completely integrated with the built-in AWS monitoring service CloudWatch. Every AWS service has a number of CloudWatch metrics, and each metric can be utilized for monitoring many key components of each service. When issues or situations occur that need attention, an alarm can issue numerous SNS notifications. SNS messages are stored across multiple geographically dispersed servers, and the service is designed to be fully scalable and capable of supporting your application communication needs. SNS can send messages from applications to users or from one application to other application services at AWS. SNS can be used as an important building block in designing and deploying hosted application stacks at AWS. Every AWS service can communicate as a publisher sending messages and notifications to SNS topics.
To receive notifications from SNS you or the appropriate service must subscribe to a topic. Each SNS topic has a choice of subscribers, as shown in Figure 4-5, including serverless Lambda functions, queues, microservices, and other delivery streams, such as the following:
AWS Lambda: Custom functions that can execute any API at AWS
Amazon SQS: Queues that relay the received messages to subscribed services
Amazon Kinesis Data Firehose: A service that ingests streaming data into S3, Redshift, or Elasticsearch data stores for further analysis
HTTP/S endpoints: Endpoints that deliver notifications to a specific URL
Email: Email subscribers
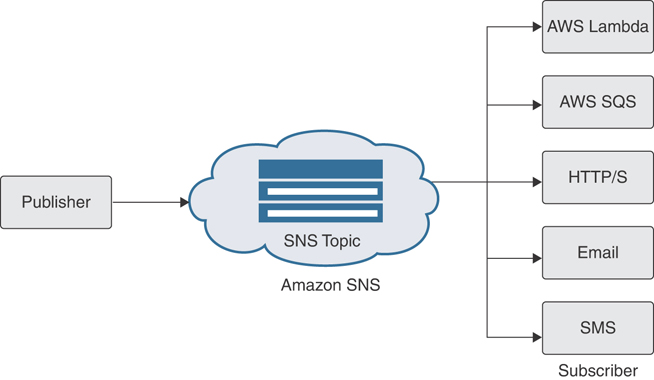
FIGURE 4-5 SNS Publisher and Subscriber Push Options
SNS is commonly used for sending event notifications when AWS service failures occur. However, for the AWS Certified Solutions Architect - Associate (SAA-C02) exam, you need to understand that SNS also allows you to send messages to other distributed services that are part of an application stack hosted at AWS. Event updates and notifications concerning approvals, changes to inventory, or shipment status can be immediately delivered to system components as well as to end users. For example, when you order a product at Amazon.com, many SNS notifications are executed in the background while completing your order. The process works as follows:
Step 1. You order a new set of dishes.
Step 2. A notification is issued to check for stock.
Step 3. After confirmation of inventory, the order is placed against your account.
Step 4. Your credit card information is checked.
Step 5. Taxes and relevant fees are added to the order.
Step 6. Shipping is calculated.
Step 7. An email is sent to your email account, thanking you for the order.
To use SNS, you start by creating a topic that is linked to a specific event type or subject. Subscribers can subscribe to selected topics and receive notifications. When you create an SNS topic, you define policies such as who can publish messages to the topic and what notification protocols are allowed for delivery of the message. Figure 4-6 illustrates the creation of a notification topic.

FIGURE 4-6 Creating a Notification Topic
One of the most common deployment methods involves using Simple Notification Service and Simple Queue Service together. Most applications hosted at AWS are deployed using multiple EC2 instances. AWS best practice dictates that no data should be stored on the EC2 instances, including any application state. Instead, you should store the important information that is being worked on by the application servers in centralized SQS queues, as shown in Figure 4-7.

FIGURE 4-7 SQS and SNS Working Together
SNS Cheat Sheet
For the AWS Certified Solutions Architect - Associate (SAA-C02) exam, you need to understand the following critical aspects of SNS:
SNS provides push-based delivery from AWS.
SNS supports notifications over HTTP/HTTPS, via email, to SQS queue endpoints, as well as SMS messages.
SNS is easily integrated with AWS hosted applications.
SNS message delivery involves multiple transport protocols.
JSON is the supported data type.
SNS supports event notifications and application monitoring.
Every AWS service supports SNS.
SNS messages are stored redundantly across multiple availability zones.
Amazon SQS
Amazon Simple Queue Service (SQS) is a distributed message queuing service for storing messages in transit between systems and applications. SQS allows you to decouple your application components from their application state so that any application server failure does not result in application data loss (see Figure 4-8). There is no limit to the number of messages that can be held in each SQS queue. For example, say that you start a business that provides the service of converting photographs that are uploaded into multiple resolutions. When a photograph is uploaded, it is placed in four separate queues, named lo-res, hi-res, 4k, and 6k. Tiers of EC2 instances poll their respective queues; when pictures are uploaded, the software hosted on the EC2 instances carries out the changes to the pictures’ resolutions and delivers the finished pictures to the respective S3 buckets.
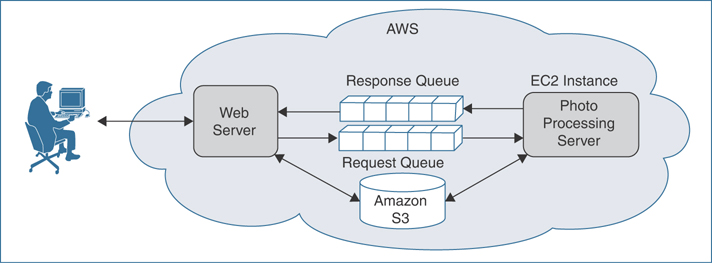
FIGURE 4-8 Response and Request Queues Decoupling Application State Information
SQS can be used with the following AWS services:
DynamoDB: You can use SQS to transfer messages to DynamoDB by using a Lambda function.
EC2 instances: You can scale an Auto Scaling group up or down when messages in the SQS queue increase.
ECS: A worker task within a container executes a script that polls for SQS messages and downloads and processes them as necessary.
RDS: A lightweight daemon connects to an SQS queue and consumes messages into a SQL database.
S3: Changes to a bucket’s contents enable event notifications to an SQS queue.
Lambda function: You can connect any custom function to an SQS queue to consume messages.
Note
If you are using third-party messaging services with on-premises applications and want to be able to quickly move your messaging service to the AWS cloud, AWS recommends that you consider using Amazon MQ. Amazon MQ supports industry-standard APIs and protocols, which means you can switch to Amazon MQ without having to rewrite the messaging code for your on-premises applications.
SQS Cheat Sheet
For the AWS Certified Solutions Architect - Associate (SAA-C02) exam, you need to understand the following critical aspects of SQS:
SQS uses pull-based, not push-based, polling.
The visibility timeout is the amount of time a message is unavailable after a message starts to be processed.
If a message cannot be processed within the visibility timeout period, the message again becomes available in the queue for processing.
If a job is processed successfully within the visibility timeout period, the message is deleted.
The maximum visibility timeout period is 12 hours.
Queues can be either standard or first in, first out (FIFO).
First-in-first-out (FIFO) preserves the exact order in which messages are sent and received.
The maximum size of SQS messages is 256 KB.
IAM can control who reads and writes messages.
Queues can be encrypted and can use Server-Side Encryption (SSE).
AWS Step Functions
AWS Step Functions is an interesting combination of SQS queues and SNS notifications integrated with application logic. Step Functions allows you to orchestrate numerous Lambda functions and multiple AWS services into a serverless GUI-driven application process. You can create multiple states by creating what a state machine. Each defined state machine workflow has checkpoints that maintain your workflow and its state throughout each of the defined stages. The output of each stage in the workflow is the starting point of the next stage, and the steps execute in the precise order defined by state machine logic. At each stage, decisions are made based on the supplied input parameters, actions are performed, and output is passed to the next stage, as shown in Figure 4-9.

FIGURE 4-9 Step Functions: Combining the SQL and SNS Services with Logic
Step functions also have built-in application-level controls, including try/catch and retry and rollback capabilities to help deal with errors and exceptions automatically. The following are examples of functions that are possible with Step Functions:
Consolidating data from multiple databases into a unified report
Fulfilling orders or tracking inventory processes
Implementing a user registration process
Implementing a custom workflow
The state machine that makes up each step function is defined by two integrated components:
Activity tasks: These tasks allow you to assign a specific step in your defined workflow to software code running externally. The external function polls the function it is associated with for any required work requests; when required, it performs its work and returns the results. The activity task can run on any application that is able to make an HTTP connection from its location, such as an EC2 instance hosted at AWS, a mobile device, or an on-premises server.
Service tasks: These tasks allow you to connect steps in your defined workflow to a supported AWS service. In contrast to an activity task, a service task pushes requests to other AWS services; the service performs its action, reports back to the workflow once the action is completed, and moves to the next step. Examples of service tasks include the following:
Running an Amazon Elastic Container Service (ECS) or Fargate task hosted in a VPC
Submitting an AWS batch job and waiting for completion
Retrieving or placing a new item into a Dynamo DB table
The building blocks of Step Functions automate the relationship between SNS (the service tasks) and SQS (the activity tasks). Step Functions integrates SNS and SQS with a logical processing framework. In addition, you can add the SNS notification service to a Step Functions workflow at the end of processing to trigger notifications. For example, when your workflow is successful, you can trigger another service or signal completion. Workflow failure could trigger additional communications back to developers indicating the problem and relevant error messages.
AWS Step Functions state machines are defined using JSON as the declarative language. You can create activity tasks by using any AWS SDK that supports code written in Node.js, Python, Go, or C#. There are two choices for creating workflows:
Express workflows: You use express workflows for workloads with high event rates of more than 100,000 per second and short durations of less than 5 minutes.
Standard workflows: Standard workflows are suitable for long-running durable and auditable workflows that may include machine learning models, generating reports, and the processing of credit cards. Standard workflows guarantee one execution of each workflow step with a maximum duration of 1 year; you can also inspect a processing workflow during and after the workflow execution has completed.
Table 4-3 compares the functions and use cases of SNS, SQS, and Step Functions.
Table 4-3 SNS, SQS, and Step Functions
Service |
Function |
Use Case |
|---|---|---|
SNS |
Sending notifications from the AWS cloud |
Alerting when services or applications have issues |
Step Functions |
Coordinating AWS service communication components |
Handling order processing |
SQS |
Messaging queueing, including store-and-forward operations |
Decoupling applications |
Amazon MQ |
Message brokering |
Migrating from existing message brokers to AWS |
Note
Amazon MQ is a hosted message broker service that provides broad compatibility with many third-party message brokers that you may be using on premises. Amazon recommends using Amazon MQ for easier application migration to the AWS cloud for compatibility with JMS APIs or protocols such as AMQP, OpenWire, or STOMP.
Lambda
Serverless computing is a fancy buzzword today, but the concept has been around for quite a while. It is important to understand that, with serverless computing, there are still servers; EC2 instances in the background are running the requested code functions. We haven’t yet reached the point where artificial intelligence can dispense with servers, but the code being run on the EC2 instance is completely managed by AWS. Serverless computing is essentially platform as a service; you don’t actually build and manage the infrastructure components, but you take advantage of the compute power by using Lambda to upload and execute functions that you’ve either written or selected from the available library of created functions. At AWS, any talk of serverless computing usually means Lambda is involved.
With Lambda, you are charged for every function that runs, based on the RAM/CPU and processing time the function requires to execute. With a serverless environment, there are no EC2 instances that you need to manage, and you’re not paying for idle processing time; you pay for just the time required to execute your function. Therefore, the coding hosted by Lambda is focused on the single function that provides the logic required in the situation, such as creating a custom function to log DynamoDB streams (see Figure 4-10). Serverless computing gives you the best bang for your buck at AWS. After all, you’re not paying for EC2 instances, EBS volumes, Auto Scaling, ELB load balancers, or CloudWatch monitoring; Amazon takes care of all those functions for you. Lambda is hosted by a massive server farm that is totally managed by AWS; it has to be able to scale upon demand using Auto Scaling and is also monitored using CloudWatch.

FIGURE 4-10 Creating a Custom Lambda Function for a Specific Task
Lambda functions run on EC2 instances in a specialized virtual machine format called Firecracker. Firecracker is a kernel-based virtual machine and utilizes a small footprint of approximately 5 MB of memory. Thousands of Firecracker VMs can be run in a single EC2 instance (see Figure 4-11). Each Firecracker microVM can be launched in 125 ms or less. In order to secure each Lambda function during operation, each Firecracker VM runs in an isolated guest mode that locks the ability of the VM to do much of anything except carry out the prescribed Lambda function, using a network device for communication, a block I/O device to store the function code, and a programmable interval timer. The libraries required for execution are included in the local executable code, and no outside libraries are required.

FIGURE 4-11 Firecracker Micro VM Architecture
AWS uses serverless computing with a variety of AWS management services that have been integrated with Lambda functions:
S3 bucket: A file is uploaded to a bucket, which triggers a Lambda function. The Lambda function, in turn, converts the file into three different resolutions and stores the file in three different S3 buckets.
DynamoDB table: An entry is made in a DynamoDB table, which triggers a Lambda function that could, for example, perform a custom calculation and deposit the result into another field in the table.
CloudWatch alerts: You can define a condition for an AWS service such as IAM. For example, you might fire off a Lambda function, which alerts you whenever the root account is used in an AWS account.
CloudWatch logs: You can specify that any content delivered to a CloudWatch log triggers an SNS notification if issues are found that you should know about and calls a Lambda function to carry out a specific task.
AWS Config: You can create rules that analyze whether resources created in an AWS account follow a company’s compliance guidelines. The rules are Lambda functions. If the result is an AWS resource that doesn’t meet the defined compliance level, a Lambda function could be executed to remove the out-of-bounds resource.
Application Load Balancer (ALB): Incoming requests can be directed to Lambda functions. ALB can be a key component of a serverless mobile application.
Step Functions: Step Functions is based on Lambda functions.
SNS notifications: An SNS notification has the option of calling a custom Lambda function.
CloudFront: Both ingress and egress traffic flow to and from an edge location can be intercepted by Lambda functions running at the edge location for a CloudFront CDN distribution.
Lambda allows you to upload and run code written in languages such as Java, Go, PowerShell, node.js, C#, and Python. Each Lambda function is packaged as a ZIP file and uploaded to an S3 bucket. Uploads must be less than 50 MB compressed. Lambda functions might, for example, be used to form the engine behind a mobile application that allows users to order concert tickets, as shown in Figure 4-12.

FIGURE 4-12 Lambda Functions Executing Actions Using AWS Managed Services
When you create a Lambda function, you specify the required security and amount of memory that needs to be allocated to your function (see Figure 4-13), as well as how long your function needs to execute. In turn, the required CPU power is allocated. Memory can be requested at 64 MB increments from 128 MB to 1.2 GB. The maximum execution CPU time is 15 minutes, and the minimal execution time is 1 second.

FIGURE 4-13 Lambda Function Execution Settings
Lambda Cheat Sheet
For the AWS Certified Solutions Architect - Associate (SAA-C02) exam, you need to understand the following critical aspects of Lambda:
Lambda allows you to run code as custom functions without provisioning servers.
AWS handles the required vCPU, RAM, and execution of Lambda functions.
Lambda functions consist of programming code and any associated dependencies.
Lambda runs in a lightweight virtual machine environment (microVMs) called Firecracker.
Uploaded AWS Lambda code is encrypted and stored in S3.
Each Lambda function receives 500 MB of temporary disk space for use during execution.
Lambda monitors executing functions using real-time CloudWatch metrics.
Lambda functions are covered by a compute savings plan.
Lambda functions support versioning.
Lambda allows you to package and deploy functions as Docker container images.
API Gateway
API Gateway allows customers to publish APIs they have crafted to a central hosted location at AWS. An application programming interface (API) is basically a defined path to a backend service or function. For a user’s app hosted on a phone running a mobile application, the API or APIs for the application could be hosted at AWS. The API is part of the source code—or it may be the entire source code for an application—but thanks to API Gateway, it is hosted at AWS. Let’s expand the definition of API a bit more:
The A, for application, could be a custom function, the entire app, or something in between.
The P is related to the type of programming language or platform that created the API.
The I stands for interface, and API Gateway interfaces with HTTP/REST APIs or WebSocket APIs. Java API types can direct HTTP requests to AWS on the private AWS network; the APIs, however, are only exposed publicly with HTTPS endpoints.
APIs are commonly made available by third-party companies for use on other mobile and web applications. One of the most popular APIs is the API for Google Maps. When you book a hotel room using a mobile application, the application is likely using the Google API to call Google Maps with a location request and receive a response back. Most websites and social media sites have several third-party APIs that are part of the overall application from the end user’s point of view. APIs can be thought of as software plug-ins that allow integration from one system to another. The Google API, for example, is the public frontend that communicates with the backend Google Maps application.
Note
For an older example, think of an EXE file, which is matched up with a library of DLLs. The library file contains any number of functions that, if called by the EXE file, would be fired to carry out a job. If the EXE were a word processor, the associated DLL could contain the code for calling the spell check routine or review.
If you’re programming applications that will be hosted at AWS, you should consider hosting your applications’ APIs by using API Gateway. Think of API Gateway as a doorway into any service of AWS that you need to integrate with your mobile or web application. You can also think of API Gateway as the front door that, with authentication, allows entry to the AWS cloud where the selected AWS service resides. There are several methods available for communicating with API Gateway, including public communications through an edge location via CloudFront, through a regional endpoint from a specific AWS region, or from a service hosted in a VPC using a private interface endpoint (see Figure 4-14).

FIGURE 4-14 API Gateway Communication Options
API Gateway is another one of the AWS managed services hosted by a massive server farm running a custom software program that can accept hundreds of thousands of requests to the hosted API. You can build HTTP, REST, and WebSocket APIs (see Figure 4-15).

FIGURE 4-15 Choosing the API Protocol to Use
Note
API Gateway hosted API’s can also call Lambda functions hosted on EC2 instances hosted in your AWS account, as well as HTTP endpoints that access Elastic Beanstalk deployments.
API Gateway has the following features:
Security: API Gateway supports IAM and AWS Cognito for authorizing API access.
Traffic throttling: It is possible to cache API responses to incoming requests to take the load off the backend service, as cached responses to an API with the same query can be answered from the cache. You can define the number of requests an API can receive, as well as metering plans for an API’s allowed level of traffic.
Multiple-version support: Multiple API versions can be hosted at the same time by API Gateway.
Metering: Using metering allows you to throttle and control desired access levels to your hosted API.
Access: When an API is called, API Gateway checks whether an authorized process can carry out the task that the API needs done. Choices are either a Lambda authorizer or a Cognito user pool (see Figure 4-16). API Gateway then calls the selected authorizer, passing the incoming authorization token for verification. A Cognito user pool can be configured to allow a mobile application to authenticate an end user request by using a variety of methods, including single sign-on (SSO), using OAuth, or using an email address to access the backend application components.

FIGURE 4-16 Selecting an Authorizer for the API Gateway
Note
API Gateway can create client-side SSL certificates to verify that all requests made to your backend resources were sent by API Gateway, using the associated public key of the certificate. Private APIs can be created for use only with select VPCs across private VPC endpoints.
API Gateway Cheat Sheet
For the AWS Certified Solutions Architect - Associate (SAA-C02) exam, you need to understand the following critical aspects of APIs:
With AWS, developers can publish, maintain, and secure APIs at any scale.
API Gateway can process up to hundreds of thousands of concurrent API calls.
API Gateway works together with Lambda to create the application-facing serverless infrastructure.
CloudFront can be used as a public endpoint for API Gateway requests.
Edge-optimized APIs can be used for clients in different geographic locations. API requests are routed to the nearest edge location.
Regional API endpoints are designed for clients in the same AWS region.
Private API endpoints can only be accessed from a VPC using an interface VPC endpoint.
API Gateway can scale to any traffic level required.
API Gateway logs track performance metrics for the backend, including API calls, latency, and error rates.
You pay only when your hosted APIs are called. The API calls that are received are billed based on the amount of data that is transferred out.
API keys can be created and distributed to developers.
API requests can be throttled to prevent overloading your backend services.
Building a Serverless Web App
Lambda and API Gateway can be used together to create a serverless application such as an event website that allows users to register for a corporate function. To call a Lambda function from a mobile app, you would use API Gateway and RESTful functions from the mobile device. A simple web-based interface would allow users to register for the corporate function after registering as attendees. Figure 4-17 illustrates this scenario, and the following sections describe the development process in more detail.

FIGURE 4-17 A Serverless Corporate Application
Step 1: Create a Static Website
The first step in building the serverless web app just described is to create a website that can be hosted in an S3 bucket (see Figure 4-18). Because the website is going to be hosted in an S3 bucket, it can be a simple static website with no dynamic assets. After you configure the S3 bucket for website hosting, all the HTML, Cascading Style Sheets (CSS), images, and web server files are uploaded and stored.

FIGURE 4-18 Using an S3 Bucket for Static Website Hosting
You provide a URL via email using a registered domain owned by the company to each corporate user who wants to sign up for the conference. To host a website, you need to ensure that the S3 bucket has public read access and upload the DNS records on Route 53 by adding alias records that point to the website.
Step 2: Handle User Authentication
You need to create a Cognito user pool for the users who will be registering for the conference (see Figure 4-19). The corporate users will use their corporate email addresses to register themselves as new users on the website. You need to configure Cognito to send a user who registers on the conference website a standard confirmation email that includes a verification code the user then uses to confirm his or her identity.
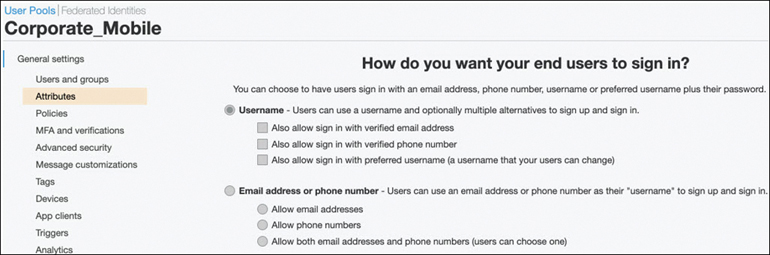
FIGURE 4-19 Creating an Authentication Pool Using Cognito
After the users have successfully signed in to the website, a JavaScript function communicates with AWS Cognito, authenticating them using the Secure Remote Password (SRP) protocol and returning a web token that will be used to identify users as they request access to the conference.
Step 3: Create the Serverless Backend Components
You create a Lambda function that, when it is called from the API hosted at API Gateway, registers users to the conference and sends them an attendance code. When each user registers for the conference, the registration request is stored in a DynamoDB table that returns a registration code to the end user (see Figure 4-20).

FIGURE 4-20 Creating a DynamoDB Table
Step 4: Set Up the API Gateway
Next, you have the registration request invoke the Lambda function, which is securely called from the browser of the user carrying out the registration as a RESTful API call to Amazon API Gateway (see Figure 4-21). This background process allows registered users to register for the conference. (Remember that the registered users have already been approved through registration and verification by being a member of the Cognito user pool.)

FIGURE 4-21 Registering the RESTful API with the API Gateway
On user devices, JavaScript works in the background with the publicly exposed API hosted by API Gateway to carry out a stateful RESTful request. Representational State Transfer (REST) is a key authentication component of the AWS cloud, and RESTful APIs are the most common AWS API format. REST uses the following HTTP verbs to describe the type of each request:
GET: Request a record
PUT: Update a record
POST: Create a record
DELETE: Delete a record
A user who types a URL into a browser is carrying out a GET request. Submitting a request for the conference is a POST request.
RESTful communication is defined as stateless, which means that all the information needed to process a RESTful request is self-contained within the actual request; the server doesn’t need additional information to be able to process the request. The beauty of this design is that you don’t need any of your own servers at the backend. You just need Lambda hosting your functions, which are called based on the logic of the application and the application request that is carried out by the user.
Step 5: Register for Conference
The user sees none of the infrastructure that has been described to this point and just wants to register for the conference. Figure 4-22 shows the user interface.
FIGURE 4-22 The Mobile Application on the User’s Phone
Exam Preparation Tasks
As mentioned in the section “How to Use This Book” in the Introduction, you have a couple of choices for exam preparation: the exercises here, Chapter 14, “Final Preparation,” and the exam simulation questions in the Pearson Test Prep Software Online.
Review All Key Topics
Review the most important topics in the chapter, noted with the key topics icon in the outer margin of the page. Table 4-4 lists these key topics and the page number on which each is found.
Table 4-4 Chapter 4 Key Topics
Key Topic Element |
Description |
Page Number |
|---|---|---|
Stateful application design |
138 |
|
Adding a load balancer to change the design to stateless |
139 |
|
Data choices and AWS |
141 |
|
ElastiCache for a Redis distributed user session cache |
143 |
|
Paragraph |
Amazon SQS |
145 |
Creating a notification topic |
146 |
|
List |
SNS cheat sheet |
147 |
Paragraph |
AWS services used with SQS |
148 |
List |
SQS cheat sheet |
149 |
SNS, SQS, and Step Functions |
152 |
|
Paragraph |
AWS serverless computing and Lambda functions |
154 |
Lambda functions executing actions using AWS managed services |
155 |
|
List |
Lambda cheat sheet |
156 |
List |
API Gateway cheat sheet |
160 |
Registering the RESTful API with API Gateway |
163 |
Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
stateless, stateful, application programming interface (API), sticky session, user state, distributed session, event notification, queue, serverless, regional endpoint
Q&A
The answers to these questions appear in Appendix A. For more practice with exam format questions, use the Pearson Test Prep Software Online.
1. What is the disadvantage of enabling sticky sessions?
2. What is the advantage of using a central location to store user state information?
3. What is the purpose of enabling notifications with Simple Notification Service?
4. How can Simple Notification Service and Simple Queue Service work together?
5. Where is the advantage in using Step Functions?
6. What is the advantage of using Lambda to respond to SNS notifications?
7. Why would you use Lambda to create serverless applications?
8. How can Lambda be used with API Gateway?