
Chapter 9
Secure coding
After completing this chapter, you will be able to:
Understand the fundamental rules of writing secure code.
Write defensive code that can withstand attack.
Understand common insecure coding issues and how to fix them.
Implement some effective security testing techniques.
Insecure code
Too much code written today is insecure. It’s not because developers are lazy; it’s often because developers simply don’t know what constitutes secure code. But this is where it gets interesting. Most of the time, an insecure system works correctly and passes all functional tests. So why don’t testers find security issues? There is a reason, and it lies in this statement:
“A secure system is a system that does what it is supposed to do, and nothing else.”
Simply put, when the “nothing else” becomes “something else” is when security issues are found, because it’s typically when a malicious actor takes advantage of a weakness.
Here’s an example: a database system using SQL commands will probably pass all your functional tests, even if it has a SQL injection vulnerability. But an attacker can take advantage of this weakness and cause the system to do “something else,” like view another table or delete data in a table or even the table itself. It’s this “something else” that is a security concern!
Your goal as a developer is to avoid having “something else” conditions in your code. When developing systems, there are two high-level goals you need to keep in mind:
Reduce the number of vulnerabilities in your code.
Reduce the severity of the vulnerabilities you miss.
The first basically states, “Try to get everything right,” and the second boils down to, “But assume you won’t.” It’s a healthy tension to consider when writing code. Everything in this chapter revolves around these two guiding principles.
Rule #1: All input is evil
We have said this for over 20 years, and it is as valid today as it was at the turn of the century:
All input is evil.
This statement transcends programming language, operating system, development process, deployment environment, and everything in between. It applies to Windows services written in C++, Linux drivers written in C, containerized applications written in Go on AWS, C# code running in Azure Functions, and a humble web app written in PHP running on nginx.
![]() Important
Important
The idea is simple: incoming data is at the root of numerous security vulnerabilities, so it is important that all data coming into your code be validated for correctness.
About 20 years ago, in the earliest days of trustworthy computing and the Microsoft Security Development Lifecycle (SDL), Michael was charged with educating new software engineering staff about secure design and development. New employees had to attend a four-hour class entitled “Basics of Secure Software Design, Development, and Test.” The associated PowerPoint deck had about 100 slides of dense material. Slide 52, shown in Figure 9-1, was this somewhat tongue-in-cheek statement right before 50 slides of insecure code examples and remedies.

FIGURE 9-1 Slide 52 from a PowerPoint deck from the early 2000s at Microsoft.
Some of the most common and serious code-level security issues are simply the result of failing to verify that data coming from untrusted sources is correct. For example, the infamous Apache log4j (CVE-2021-44228) vulnerability of December 2021 was an invalid input issue. Examples of input trust issues include the following:
Memory corruption (such as buffer overruns)
Integer overflow and underflow
Cross-site scripting (XSS)
Directory traversal
Open redirects
Server-side request forgery (SSRF)
Cross-site request forgery (CSRF)
SQL injection
XML injection
Canonicalization
OS command injection
We cover some of these vulnerabilities in this chapter, but not all of them, because each one can be remedied simply by verifying untrusted data as it enters your code. Our main focus here is on the core concept that underlies each of these issues: untrusted data.
![]() Important
Important
The core lesson is, if your code accepts input from a potentially untrusted source, it must validate that input for correctness.
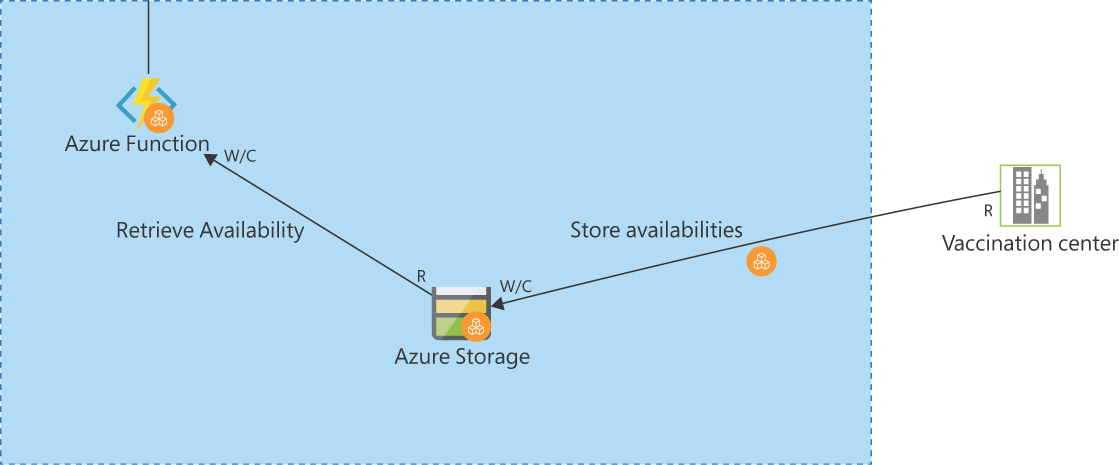
FIGURE 9-2 Data entering the environment from a vaccination center. The data crosses a trust boundary and must be validated for correctness.
Understanding who an attacker might be
Keeping in mind that “all input is evil,” it’s important to understand who an attacker might be and what an attacker can control. Let’s look at each of these now.
With regard to who an attacker might be, let’s use a simple example. Suppose you have two REST APIs:
The first API is exposed to the internet, and it has no authentication.
The second API is listening only on a small IP address range and requires modern authentication using your tenant Azure Active Directory as the identity provider.
Who is the potential attacker for the first API? Anyone on the planet! Potentially, billions of people—bored teenagers, nation-states, bots, and everything in between. In contrast, the potential attacker for the second API is anyone coming from the small IP address range who has an account in your tenant’s Azure Active Directory. This might only be 100 or so users, depending on how many accounts you have.
Clearly, the first API is more “at risk.” Data coming into that API could be from anyone—which means there is a high probability that the data will be malformed at best and malicious at worst. So, any code associated with this API must be rock-solid. The second API has a much lower probability of being a victim of malicious input because the population of potential attackers is so much smaller. This doesn’t mean you can write any junk code in the second API; it just means you have a finite amount of time to work with, so you need to spend more time making sure the code for the first API is solid. (Remember, though, that insiders can pose a threat, too, as discussed in Chapter 3, “Security patterns.”)
The level of exposure will help drive how you prioritize your time when it comes to code review and testing. We often refer to this exposure level as an application’s attack surface. You should always try to reduce an application’s attack surface. One way to do this is to reduce network exposure. In Azure, reducing network exposure means moving from public access to doing one of the following:
Allowing subnet or VNet access only—for example, by using private endpoints
Restricting access to a small set of IP addresses or CIDR range, often achieved by using PaaS firewalls and network security groups (NSGs) to restrict incoming requests to IP addresses
You can also reduce the attack surface by increasing the level of authentication and authorization. In the case of the first API, you could move from no authentication to authentication with no authorization or authentication with appropriate authorization.
When looking at data flows in a threat model that cross a trust boundary, it’s important to understand how the lower-trust side of the data flow is authenticated and how actions are authorized, as well as the network accessibility of that data flow. Figure 9-3 sums up the concept of attack surface.
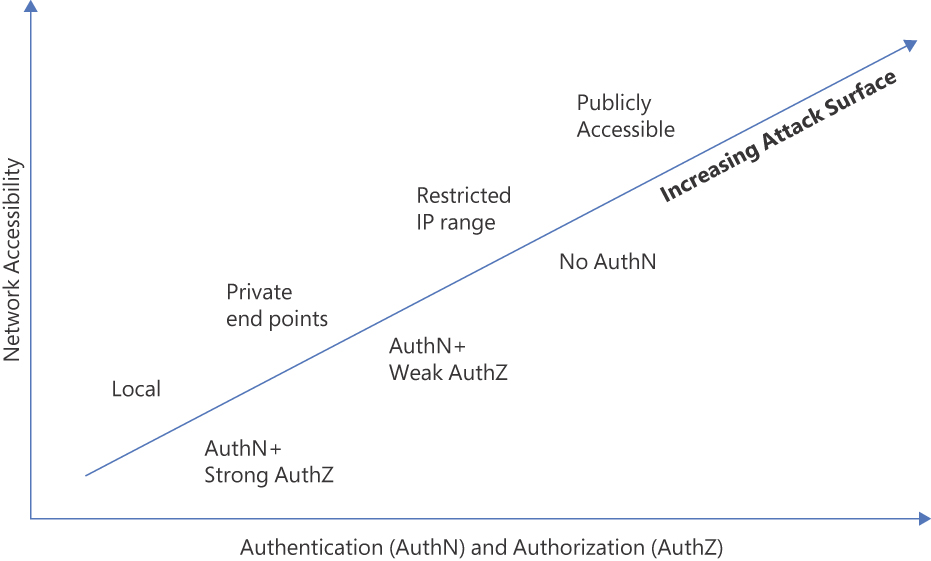
FIGURE 9-3 How network accessibility and authentication/authorization contribute to attack surface.
The effects of attack surface can be summed in one sentence: increased attack surface is bad; reducing attack surface is good. This is because an increased attack surface means more attackers and more potential vulnerabilities.
Understanding what an attacker controls
Imagine the following low-level C code:
char dst[4];This simple code allocates 4 bytes (because a char is one byte) of memory for a variable named dst (for destination).
Now look at this code:
char dst[4];
dst[4] = ‘X’;The second line seems to write 'X' at the fourth element (offset) in the array. But in fact, it writes ‘X’ to the fifth element, because arrays in C (and any self-respecting programming language) start at 0, not 1. The element numbered 4 is in fact element 5: 0, 1, 2, 3, 4.
This is a classic memory corruption or a buffer overrun issue. But is it a security vulnerability? The answer is a resounding no! Because the attacker controls nothing. It is absolutely a code quality bug that should be fixed, however.
Now look at this variant:
if (recv(sock, (char*)data, sizeof(data), 0) >= 0) {
dst[data.index] = data.value;This code reads some data from a TCP socket and uses that data to write a value held in data.value into the array at offset data.index. If the socket has a high attack surface, it’s accessible on the internet with no authentication. I think we can agree that this data cannot be trusted. But as this code stands, the code can write any data at any point in memory. For example, the following are all possible:
dst[12234] = ‘a’;
dst[-9872] = ‘z’;In this scenario, the attacker has unfettered access to both the array offset and the data to write to that array offset. This is incredibly dangerous and is a serious security vulnerability. This must be fixed.
So, we just described two memory-corruption scenarios. One was a code-quality issue because the attacker controlled nothing, but the other was a bona-fide security vulnerability because the attacker controlled a great deal.
While our example is in C, this kind of issue applies to other languages, too. Imagine server code in Java that reads an untrusted index coming from a REST API and then uses that to index an array, like the following code snippet:
if (index < arr.length)
arr[index] = n;On the surface, the code looks fine—until you remember that Java does not have unsigned variables, so the index is signed. A value of -1 gets past the array length check and attempts to write n to a negative array offset, and the application crashes with a java.lang.ArrayIndexOutOfBounds-Exception. The same type of error would happen in C# if index were an int rather than a uint.
When you review code and you need to determine the likelihood of a code-quality bug being a security bug, be sure you understand what the attacker controls. The more they control, the higher the likelihood that the issue could be a serious security issue. Also be cognizant of idiosyncrasies like signed ints in Java.
Verify explicitly
President Ronald Reagan once said of the Soviet Union, “Trust, but verify.” But in a world of zero trust we say, “Verify explicitly”—and that’s exactly what we’re going to discuss next.
There are three basic steps to constraining incoming and outgoing data:
Determine correctness.
Reject known bad.
Encode data.
Let’s look at each in detail.
Determine correctness
Determining correctness means verifying data is well-formed. This is the opposite of determining incorrectness. Determining that data is incorrect is a good backup strategy, but it’s not a replacement for validating that data is correct, because no one can know all the potential ways to malform incoming data.
![]() Note
Note
Testing for correctness and failing if the correct data is not found is an example of the fail secure principle, discussed in Chapter 2, “Secure design.”
“Don’t look for bad things.” Doing so assumes you know all the bad things, and no one does. Instead, validate for correct and well-formed data. That way, your code always fails secure, sometimes called failing closed. Stop and think for a moment: if a user provides valid input but it’s not seen as valid by your code, at worst you have a support ticket to deal with.
![]() Important
Important
If you know the data for a particular field should be an integer, why would you allow anything else? If a string should be no longer than 16 characters, why allow anything longer?
There are many strategies to constrain data to its correct form. Most programming languages offer library functions or methods that perform basic constraint checking. You can use regular expressions, too, but they should be reserved for more complex data formats or when alternate methods don’t work correctly.
![]() Important
Important
All security-related data validation must be performed by the server. It’s fine to validate at the client to prevent a round-trip to the server, but client-side logic does not provide any security benefit whatsoever.
Let’s return to the vaccination booking application as an example. Suppose the file uploaded by the vaccination center is a simple text comma-separated value (CSV) file with the following fields:
centerId, date and time, vaccination type, open spots, commentIt’s simple. The formats for each data item are as follows:
centerID This is the vaccination center ID. It is a six-digit number. This field cannot be blank.
date and time For this, you use the ISO 8601 date and time format. This field cannot be blank.
vaccination type This is a string that represents the name of a valid vaccine manufacturer. This field cannot be blank.
open spots This is a number from 0 to 999. This field can be blank; when it is, it equates to zero.
comment This is a text field in which a representative from the vaccination center can enter a comment. This comment can be up to 200 characters long.
The CSV file will have one line for each vaccination center, date and time, and vaccine type. The file is uploaded to an Azure Storage account, and from there it is read by an Azure Function. With this in mind, you can build some code that checks that the data is correctly formed. There is more than one way of doing it, so we’ll show a few examples.
When checking validity, you want to be as performant as possible. Regular expressions (regex) are a common way to validate data, but simple data formats do not require a regex, and other options are faster and good enough.
Before you validate each item in each line of the CSV file, you need to make sure each line contains the correct number of fields. This is simple. You just split the line based on the delimiter. If the file is JSON or XML, you could also make sure it’s valid JSON or XML. You could also validate against a schema.
The following C# code checks that a line of the CSV file is five fields and only five fields. Anything other than five is incorrect data.
C#
if (line.Split(",").Length == NUM_FIELDS) {
// Correct number of fields
}JavaScript
if (line.split(",").length == NUM_FIELDS) {
// Correct number of fields
}C++ does not support a split() method. If you use the Boost C++ library (https://www.boost.org/), you could use boost::split. Failing that you must write your own method:
C++
#include <vector>
#include <string>
using namespace std;
auto split(const string &str, const string &delim) {
vector<string> vs;
size_t pos = 0;
for (size_t i = 0; (i = str.find(delim, pos)) != string::npos; pos = i + delim.size())
vs.emplace_back(str.data() + pos, str.data() + i);
vs.emplace_back(str.data() + pos, str.data() + str.size());
return vs;
}
vector<string> v = split(line, ",");
if (v.size() == NUM_FIELDS) {
// Correct # items
}Go
import (
"strings"
)
res := len(strings.Split(line, ","))
if res == NUM_FIELDS {
// Correct # items
}
Python
if len(line.split(",")) == NUM_FIELDS:
# Correct # items
PowerShell
if ($line.Split(",").Count -eq NUM_FIELDS) {
# Correct # items
}
Java
if (line.split(",").length == NUM_FIELDS) {
# Correct # items
}Validating the vaccination center ID
This is a six-digit number that cannot be blank. In C#, you could use TryParse(). For example:
if (UInt32.TryParse(id, out val) == true) {
// Is an unsigned int
if (val >= 0 && val <= 999999) {
// correct
}
}UInt32.TryParse() is fast, but imprecise, because a UInt32 can represent 0 .. 4294967295, but for detecting malicious input, this might be totally fine. You could use this code, and if it’s successful, verify that the returning integer is between 0 and 999999. You could also use a regex for more precision, as shown in the following code:
C#
var re = new Regex(@"^d{6}$");
if (re.IsMatch(id)) {
// Is exactly six digits
}This regex looks for input that is precisely six digits long; anything else is incorrect.
In JavaScript, you can’t use isNaN() (is not a number) or parseInteger() because they are not precise enough. IsNaN() will flag -3.1415926536 as a number, but it’s nothing like the data form we need. parseInteger() will return 42 if the incoming string is "42xyzzy123". The best solution is to use a regex.
JavaScript
const re = /^d{6}$/;
if (id.match(re) != null) {
// Is exactly six digits
}Java does not have unsigned integers, so extra validation is needed to make sure the result is within the defined range of 0–999999.
Java
try {
int num = Integer.parseInt(id);
if (num >= 0 && num <= 999999) {
// valid
} else {
// Invalid
}
} catch (java.lang.NumberFormatException ex) {
// Invalid
}Validating the date and time
Interestingly, this is more efficient and more correct than using a regex. The date format is in ISO 8601 format, so it has the following form:
2022-02-23T03:08:00-06:00which is this syntax:
YYYY-MM-ddThh:mm:ss[+/-]hh:mmThe last part is the time offset from UTC or Zulu time. UTC is marked as +00:00 or having the string end in a Z for Zulu. Note that ISO 8601 date and time formats can have multiple arrangements, but this is the one we’re choosing. Internet dates and times are defined in RFC 3339, which is a profile of ISO 8601, available at https://datatracker.ietf.org/doc/html/rfc3339.
The following C# performs this parsing for us correctly:
C#
if (DateTime.TryParse(dt, out dt2) == true) {
// Valid datetime
}The following regex will match an ISO 8601 date and time, but not the time zone offset:
^(-?(?:[1-9][0-9]*)?[0-9]{4})-(1[0-2]|0[1-9])-(3[01]|0[1-9]|[12][0-9])T(2[0-3]|[01][0-9]):([0-5]
[0-9]):([0-5][0-9])(.[0-9]+)?(Z|[+-](?:2[0-3]|[01][0-9]):[0-5][0-9])?$Unfortunately, regexes get complex quickly and can be error prone and difficult to debug! There are websites that let you experiment with regexes and help parse apart the syntax so you can find errors. Examples include:
Checking an ISO 8601 datetime in PowerShell is easy. If the format is incorrect, the following code will raise an exception:
PowerShell
[datetime]::Parse($date)Java has a class that can parse dates, including ISO 8601. There are many supported date formats; you just need to set the format in DateTimeFormatter.
Java
try {
DateTimeFormatter formatter = DateTimeFormatter.ISO_OFFSET_DATE_TIME;
var odt = LocalDate.parse(dt, formatter);
} catch (java.time.format.DateTimeParseException ex) {
// Not valid
}Validating the vaccination type
This is simple. It’s just a string compare against a list of vaccine types. The following C# example uses Language Integrated Query (LINQ) to search for the pharmaceutical company. It’s not the only way to search a list, but it’s short, concise, and obvious.
C#
string[] validPharam = { "PharmaA", "PharmaB", "PharmaC" };
bool valid = validPharam.Any(x => x.Contains(pharma, StringComparison.OrdinalIgnoreCase));
JavaScript
var validPharma = ["PharmaA","PharmaB","PharmaC"];
var valid = validPharma.find((str) => str === pharma);
if (valid != undefined) {
// pharma is valid
}The Contains() method in Go is specific to strings. Go 1.18 adds generics, but at the time of writing 1.18 was still in prerelease testing. Once generics are released, this code could be changed to support the most common data types.
Go
func Contains(s []string, e string) bool {
for _, v := range s {
if v == e {
return true
}
}
return false
}
arrPharma := []string{"PharmaA", "PharmaB", "PharmaC"}
if Contains(arrPharma, pharma) == true {
// pharma is valid
}In these code examples, the list of drug providers is hard-coded, which is not a great idea. Instead, the list should be stored in a configuration file somewhere for the code to read at load time. But when you do this, you need to be aware of the authorization policy (RBAC, ACLs, permissions, etc.) on the file used to store the list of providers. From a threat-modeling perspective, we care about the tampering threat.
Validating open spots
This is a number from 0–999. It is highly unlikely there will ever be 999 spots open, but it gives you plenty of headroom. You can use code like this in C#, where min is 0 and max is 999.
C#
public bool IntegerRangeCheck(string input, out uint result, uint min, uint max) {
return uint.TryParse(input, out result) && (result >= min && result <= max);
}In Go, you’ll use a regex. Note the use of backticks for the regex strings. This is so the string is treated literally, and you can use characters safely without having to resort to escaping special characters. This makes the string easier to read.
Go
re, _ := regexp.Compile(`^d{1,3}$`)
if (len(re.FindString(dt)) > 0) {
// 000–999
}
Python
val = int(line)
if val >=0 and val <= 999:
# validFor PowerShell, you could use the earlier PowerShell code that checks for 0–999999 but restricts the result to 0–999. You could also use the same Java code as before, which checks for 0–999999 but restricts the result to 0–999.
Validating the comment field, including international characters
This can be tricky, because a comment field is an area for text, but that text might include characters other than a–zA-Z0–9. For example, a comment might say, “This will be administered by Dr. Françoise d'Aubigné.” Note the cedilla and acute accents under the c and over the e, respectively. Neither of these are in the range a–zA–Z, so you need to be mindful of this.
Because you don’t trust the data, you need to make sure the data is well-formed. First, you need to define which subset of characters can go in the comment field. As noted, a–zA–Z does not represent all possible characters in other languages—for example, French, Spanish, Greek, and obviously many more. Thankfully, many modern regex’s support international characters using a p escape. The following is a sample testbed written in Rust:
use regex::Regex;
use lazy_static::lazy_static;
fn is_valid_comment(comment: &str) -> bool {
if comment.len() > 200 {
return false;
}
lazy_static! {
static ref RE: Regex = Regex::new(r"^[p{Letter}p{Number}p{Other_Punctuation}s]+$").
unwrap();
}
RE.is_match(comment)
}
fn main() {
let comments =
vec!["باتكلا اذه نم ريثكلا تملعت.", // Arabic
"我从这本书中学到了很多东西。", // Chinese
"Jeg lærte meget af denne bog.", // Danish
"He nui aku ako mai i tēnei pukapuka.", // Māori
"私はこの本から多くのことを学びました。", // Japanese
"I learned a lot from this book.", // English
"למדתי הרבה מהספר הזה.", // Hebrew
"ከዚህ መጽሐፍ ብዙ ተምሬያለሁ ።", // Amharic
"This won't <script> work!"];
for comment in comments.iter() {
if is_valid_comment(comment) {
println!("Valid: {}", comment);
} else {
println!("Invalid: {}", comment);
}
}
}This code iterates through various languages and succeeds on each except the last because it includes characters that are not in the list of allowed characters.
![]() Note
Note
Remember, we’re looking for “goodness” as our main defense against potentially malicious input, not “badness.”
Breaking the regex down, you have the following:
^ The start of the string.
[ The start of a set of characters.
p{Letter} Any Unicode letter, uppercase or lowercase—not just a–z or A–Z. Note that
p{L}is also valid.p{Number} Any Unicode number, not just 0–9. Note that
p{N}is also valid.p{Other_Punctuation} Various punctuation, including ¿ and ¡ in Spanish. Note that
p{Op}is also valid.s A space.
] The end of a set of characters.
+ One or more.
$ The end of the string.
In this example, you cannot use p{Punctuation}, because it includes the < and > punctuation marks. These are used in HTML and can be employed in a cross-site scripting (XSS) attack. Also, the + in the regex could be replaced with other length constraints.
There’s one important caveat: some languages don’t natively include a regex library that can handle Unicode, and some languages don’t support the long names for the character classes. For example, .NET supports p{L} but not p{Letter}.
For JavaScript, including Node.js, you need to use the u qualifier as part of the regex. The following short test code shows this in action. The first regex works, but the second returns null because it does not have a u qualifier.
let str = "Έμαθα πολλά από αυτό το βιβλίο.";
console.log(str.match(/p{L}/gu) );
console.log(str.match(/p{L}/g) );![]() Tip
Tip
For a good overview of Unicode strings in regular expressions, see https://azsec.tech/5tq.
Before we move on to the next section, we have to confess something: there is a bug in the code! We left it until now, mainly to show how easy it is to make simple mistakes. The problem is that the comment field is freeform with some restrictions. So, you can add commas to the comment field, but this would make the code that checks for fieldcount==5 wrong.

FIGURE 9-4 The Greek question mark in the Windows Character Map.
To fix this, you could always strip out commas from the comment field. But this is dangerous because it can lead to the “commas save lives” problem—that is, there is a big difference between “Let’s eat, Grandma” and “Let’s eat Grandma.” Alternatively, you could escape all commas in the comment field with the HTML-escaped version, '. So, a sentence like, “Let’s eat, Grandma” becomes “Let’s eat' Grandma.” It’s ugly, but it’s safe. Honestly, all this shows the fragility of CSV files. It might be better to use a JSON representation of the data.
What to do with errors
What should you do if you detect an error (malicious or accidental) in some incoming data? First, you don’t want to tell the potential attacker too much, so keep the response short, terse, and devoid of anything they can use to change their plan of attack. For example, a simple 400 error might suffice. Also, be consistent. If you send a 400 error because an API argument is incorrect, then send a 400 error for other API errors, too.
Also, be sure to log the reason for the error so an admin can act. You could use a text file or a storage account for the data or custom logs for use in Azure Monitor. For more information about this, refer to Chapter 6, “Monitoring and auditing.” You can also read more about it here: https://azsec.tech/js8.
Reject known bad data
Restricting to only known data is always the right strategy when verifying incoming data. However, some developers go one step further and add another defensive layer that checks for known illegal data. For example, let’s say your code expects a filename in an argument, like in the following Python code:
import re
def is_filename_valid(filename):
valid = re.match("^.+.(?i)(jpg|png|gif|bmp|tiff)$",filename)
return (valid != None)This is a simple regex that also happens to be too loose and vulnerable. This will allow filenames like the following:
diving-the-uss-vandenberg.jpg
picsofdogs.bmp
CatsBehavingBadly.png
This seems fine. However, the regex will also allow the following:
....docs axreturn2022.jpg
/home/blake/docs/mysecretinvention.doc
c:secretpics icoles-taxreturn2022.jpg
Oops!
One thing you could do is add another regex that looks for bad things to reject anything you might have missed in the first regex. For example:
def is_filename_valid(filename):
valid = re.match("^.+.(?i)(jpg|png|gif|bmp|tiff)$",filename)
bad = re.match("[:\/]+",filename)
return (valid != None and bad == None)This regex looks for bad things—most notably colon, slash, and backslash characters.
The real fix, though, is to create a more restrictive regex, like this one:
import re
def is_filename_valid(filename):
valid = re.match("^(?i)[a-z0-9]{1,24}.(?i)(jpg|png|gif|bmp|tiff)$").,filename)
return (valid != None)This regex is correct. However, there’s no harm in taking a “the regex might not be right” view and adding a list of known bad characters in a filename—again, colon, slash, and backslash characters.
![]() Important
Important
Adding a check to look for bad things is fine, but not as a replacement for a check that looks for good things.
Regular expressions are a great way to validate data, but they have a dark side: adding them can make your code vulnerable! This is because some classes of regex are subject to a regex denial of service (ReDoS). For more information about ReDoS, read this write-up on the issue published by OWASP here: https://azsec.tech/z5y. Much of the earliest work on this topic was done by Bryan Sullivan at Microsoft.
Also, a regex can take up quite a bit of memory. It might look like a small string, but under the hood the regex code builds a state machine that can get complex and occupy large amounts of memory. This increased memory consumption is especially true for certain regex constructs. For example, the + (one-or-more) qualifier will create a smaller state machine than a {1,200} (between 1 and 200 characters inclusive) qualifier.
The following Rust code will fail ton run:
static ref RE: Regex = Regex::new(r"^[p{Letter}p{Number}p{Other_Punctuation}s]{1,200}}$").
unwrap();The error is
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value:
CompiledTooBig(10485760)', srcmain.rs:102:103But the regex runs correctly if you switch out {1,200} with +. Why? As noted, the state machine for {1,200} is considerably more complex than a simple + and consumes more memory. By default, Rust will allow only a maximum 1 MB state machine, but this state machine weighs in at 22 MB!
In Rust, you can change the default memory limit by using code like this:
use regex::RegexBuilder;
let re = RegexBuilder::new(r"^[p{Letter}p{Number}}p{Other_Punctuation}s]{1,200}$")
.size_limit(22 * 1024 * 1024) // 22MB
.build()
.unwrap();You can experiment with this code at the Rust Playground, located here: https://azsec.tech/y6i. Run the code, remove the .size_limit() method, and rerun.
![]() Important
Important
Different regex implementations have different memory implications, but it’s worth understanding what the memory impact might be for your operating system, programming language, and library used.
The next issue is performance. To improve performance, don’t put a regular expression definition in a loop or in a function that is heavily used. As mentioned, constructing the state machine takes time. That’s why the sample Rust code uses a lazy static, so the regex is compiled on the first call and then referenced from then on. You could also create your regexes once using a class construction.
![]() Tip
Tip
For .NET, you should read the following page for information about reusing regexes: https://azsec.tech/jfs.
One important final note about regular expressions: never use untrusted input as part of a regular expression string. In other words, the attacker should never control any part of the regex string.
![]() Note
Note
At the time of this writing, with .NET 7 RC 1 has been released, and it includes a Regex Source Generator. This dramatically improves the performance of regexes by precompiling the regex rather than building the regex at runtime. You can read more here: https://azsec.tech/leb.
Encode data
This is mostly for data that is echoed back to a user’s browser. Even after encoding all the incoming data, it is beneficial and safer to clean up the data before it is sent back to a browser. This is mostly true of any data that comes from an untrusted source. The goal of this is to render potential HTML and scripting useless, primarily to mitigate XSS issues.
If you have any data that comes from a potentially untrusted source and is then echoed back in a browser, this data must be encoded before it is echoed back. The most well-known way to achieve this is to simply HTML-encode all output. Some frameworks—for example, ASP.NET MVC and Razor—do this automatically. For others, you might need to call a function that takes the data, encodes it, and then renders it in the browser.
The following C# code snippet demonstrates this:
using System.Text.Encodings.Web;
using System.Text.Unicode;
string bad = @"<script>alert(1);</script>";
var encoder = HtmlEncoder.Create(allowedRanges: new[] { UnicodeRanges.BasicLatin });
Console.WriteLine(encoder.Encode(bad));Recall the comment field example from earlier in the chapter. Processing text entered in this field involves the following steps:
A user enters a comment.
The server accepts the input and runs it through a regex to make sure the comment is well-formed. If it is not correct, the comment is rejected. If the format is correct, the comment is written to a Cosmos DB database.
When another user scrolls through comments, each comment is read from Cosmos DB.
Each comment is passed through an HTML function.
The result of HTML encoding is rendered in the user’s browser.
![]() Tip
Tip
You can read more about encoding HTML by reading the OWASP XSS Prevention Cheat Sheet at https://azsec.tech/e33.
Common vulnerabilities
There are hundreds if not thousands of distinct vulnerability types, and there is no way we can cover every single one here. Because of this, we’re going to focus on one of the industry’s most well-known “go to” lists of vulnerabilities: the OWASP Top 10. This is discussed in a little more detail in Chapter 10, “Cryptography in Azure,” and is available here: https://owasp.org/Top10. There is also an OWASP API Security Top 10 at https://azsec.tech/4tq.
If you want to learn as much as possible about each vulnerability class, we recommend taking the following steps:
Read about each of the 10 issues discussed in the following section.
For each issue on the OWASP website, read the issue and then look at the cross-reference of CWEs at the bottom of each page.
Click the link of any of the CWEs and learn about the issues in more depth.
Now let’s look at each of the 10 issues through an Azure lens.
A01: Broken access control
Further information https://azsec.tech/kgp
As we stress in Chapter 5, access control is critical. In Azure, this usually means using role-based access control (RBAC), although some services support attribute-based access control (ABAC). Some services in Azure, such as storage accounts, also support shared access signature (SAS) tokens, which are used to allow access to a process or user that has the token. A SAS token can include access requirements such as Read, Write, and Delete.
In Azure, implementing access control also means having a limited set of users with elevated roles, such as Owner and Contributor, but also extending to service-specific roles such as Storage Account Contributor. Accounts with these roles can often read and configure services but not change access policies.
![]() Important
Important
It is critical that all access policies be as restrictive as possible, allowing only principals the access they need to perform their tasks and nothing more.
A02: Cryptographic failures
Further information https://azsec.tech/q8v
In part, this covers encryption of data at rest and in motion, or “on the wire.” For data at rest, this means lack of cryptographic defenses or poor implementation, such as not encrypting a sensitive column in SQL Server. For data in motion, this usually means not using a secure protocol such as TLS 1.2.
Many of these can be enforced using Azure Policy, as discussed in Chapter 7, “Governance.” For example, the sample found at https://azsec.tech/t0x enforces HTTPS (HTTP over TLS) for Azure Storage accounts. One level lower, this can include using insecure cipher suites in TLS (such as TLS_RSA_WITH_3DES_EDE_CBC_SHA) or insecure cryptographic algorithms (such as RC4, DES, 3DES, MD5).
Other examples of cryptographic failure include the following:
Poor key generation, such as using a deterministic random number generator
Poor key derivation, such as using a password directly as a cryptographic key
Using “custom” cryptographic algorithms rather than industry-standard reviewed algorithms
Encrypting data but not providing tamper-detection, too
Reuse of initialization vectors (IVs)
![]() Tip
Tip
If you use the Microsoft Crypto SDK, described in Chapter 10, many of the aforementioned points are addressed by the library.
A03: Injection
Further information https://azsec.tech/u90
Examples of injection include SQL injection (SQLi) and cross-site scripting. One way to resolve this collection of issues is by verifying input and encoding output. Another is to use technologies that have specific defenses to mitigate injection. For example, SQL has parameterized queries to neuter variables used as part of the query. The following C# code uses the SQLParameter class to build a dynamic SQL query safely:
SqlDataAdapter myCommand = new SqlDataAdapter(
"SELECT au_lname, au_fname FROM Authors WHERE au_id = @au_id", conn);
SQLParameter parm = myCommand.SelectCommand.Parameters.Add("@au_id",
SqlDbType.VarChar, 11);
Parm.Value = idAuthor;![]() Tip
Tip
SQLi is not a vulnerability in the back-end database. It’s an issue in the way SQL statements are constructed by the client. This page has a good overview of SQLi: https://azsec.tech/30v.
Also, many application frameworks and constructs automatically create SQL statements from text. For example, in C# LINQ to SQL is designed to create secured SQL queries. You can learn more here: https://azsec.tech/5mh.
Azure Logic Apps are subject to SQLi, as explained here: https://azsec.tech/hzj. The same goes for Cosmos DB when using the SQL client, discussed here: https://azsec.tech/uwi. Microsoft Defender for SQL offers SQL Advanced Threat Protection to detect attempted SQLi attacks in near real time. You can learn more here: https://azsec.tech/p0g.
As mentioned, XSS is another example of injection. The core problem with XSS is accepting untrusted input—which could include HTML or scripts—and then using it as HTML output. The fix is simple: validate incoming data, and HTML encode outgoing data using methods like .NET’s HttpUtility.HtmlEncode(). This combination of input and output logic is often called filter input, escape output (FIEO).
A04: Insecure design
Further information https://azsec.tech/4i6
This is mitigated with threat modeling. The whole point of threat modeling is to understand a solution’s design and what defenses are used to protect that system. If security issues are found during the threat-modeling process, these issues can be resolved, which leads to a more secure design.
A05: Security misconfiguration
Further information https://azsec.tech/ng0
This is incredibly common. People deploy a secure configuration, but over time, small changes creep in, and services slowly drift away from the original secure defaults. This is why you use governance services in Azure such as Azure Policy: to restrict this drift and to prevent new services from deploying with insecure defaults.
One of the most common issues we have seen is virtual machines (VMs) with public IP addresses. VMs should be behind a load balancer or a bastion service such as Azure Bastion. But we’ve been in more than one conversation with customers whose VMs have an RDP or SSH port open directly to the internet. This is a bad idea.
![]() Tip
Tip
Azure Resource Graph allows you to analyze settings on all services in use. For example, the query at https://azsec.tech/dwo displays all VMs with public IP addresses.
Misconfiguration often extends to how you configure various services. A classic and common error is failing to add security-related headers to HTTP servers. Any HTTP server should set the following headers, whether you’re using an Apache server in a Linux VM or an App Service. These headers instruct the browser how to enforce specific security rules. The current list of common, security-related HTTP headers is as follows:
Content-Security-PolicyReferrer-PolicyStrict-Transport-SecurityX-Content-Type-OptionsX-Frame-OptionsX-XSS-ProtectionAccess-Control-Allow-Origin(cross-origin resource sharing [CORS])
This list is dynamic. Over the years, new headers have been added or updated. The Security Headers site (https://securityheaders.com/) has an excellent analysis of the various headers and what they should be set to, as does the Mozilla Developer Network (https://azsec.tech/ggb).
For Azure App services (for example, the service that runs https://azsecuritypodcast.net), you can update web.config. The following code is the web.config file used by the Azure Security Podcast:
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<system.webServer>
<httpProtocol>
<customHeaders>
<clear />
<add name="Content-Security-Policy" value="default-src 'self' *.rss.com; script-
src 'self' https://ajax.aspnetcdn.com "/>
<add name="Referrer-Policy" value="strict-origin-when-cross-origin" />
<add name="Strict-Transport-Security" value="max-age=63072000" />
<add name="X-Content-Type-Options" value="nosniff" />
<add name="X-Frame-Options" value="ALLOW-FROM https://player.rss.com" />
<add name="X-XSS-Protection" value="1; mode=block" />
<add name="Access-Control-Allow-Origin" value="https://player.rss.com https://
apollo.rss.com" />
<add name="Cache-Control" value="max-age=31536000" />
</customHeaders>
</httpProtocol>
</system.webServer>
</configuration>The Content-Security-Policy (CSP) header is complex and powerful, and having a good understanding of how it works is critical. Notice that the preceding sample contains references to *.rss.com. This is a media player implemented using HTML that allows a user to play an episode in the browser. If the various headers did not allow *.rss.com, the media player would not render, because the HTML is fetched from another site. Also, notice that script-src references ajax.aspnetcdn.com, which allows the browser to pull in jQuery from outside the core website. Again, without this, jQuery would not load when using CSP.
Finally—and this is important—these headers will often cause a site to incorrectly render, so you might need to change your site’s code or tweak the headers. One good example is using inline code or styles to help you wrangle Content-Security-Policy. You should move inline code and styles to a separate file and reference it at the start of your HTML files.
You can use a tool like the one at https://report-uri.com/home/generate to help you build a policy string. For an Azure static website, you can add a new file in the root folder named staticwebapps.config.json like so:
{
"globalHeaders": {
"content-security-policy": "default-src 'self'",
"Referrer-Policy":"no-referrer",
"Strict-Transport-Security": "max-age=63072000",
"X-Frame-Options": "SAMEORIGIN",
"X-Permitted-Cross-Domain-Policies": "none",
"X-Content-Type-Options": "nosniff"
}
}Other web servers and environments have their own header configuration files. For example, in Apache (running in a VM), you can edit httpd.conf to add this at the end of the file:
<IfModule mod_headers.c>
Header always set X-Content-Type-Options "nosniff"
Header always set Content-Security-Policy "default-src 'self'"
Header always set Referrer-Policy "no-referrer"
Header always set Strict-Transport-Security "max-age=31536000; includeSubDomains"
Header always set X-Frame-Options "DENY"
Header always set X-XSS-Protection "1; mode=block"
</IfModule>![]() Note
Note
The industry is moving away from using X-Frame-Options to using Content-Security-Policy frame-ancestors instead because CSP is more encompassing.
There is one other new header: Permissions-Policy. It replaces Feature-Policy. You can learn more about it here: https://www.permissionspolicy.com/. To check if the browsers your applications support can handle the header, you can use the Can I Use site, located here: https://caniuse.com/?search=Permissions-Policy. The Azure Security Podcast site does not set this header on purpose. When it becomes more popular, we will enable it in the site.
Notice there is nothing to remove the Server: header, which announces the web server type and version number. Removing or replacing this header is of no real security value; it is just security theater, because a somewhat-knowledgeable attacker can easily “fingerprint” the server to determine its type and version.
On a related note, the Access-Control-Allow-Origin header, which is used to support cross-origin resource sharing, does not improve security. In fact, it reduces security somewhat by allowing a controlled weakening of the browser same-origin security policy. The reason CORS exists is to have a preferred way to send HTTP requests across websites without resorting to some disastrous work-arounds used in the past. CORS allows for some more secure OAuth2 flows. Some services in Azure support CORS—for example, Azure Functions, as shown in Figure 9-5.
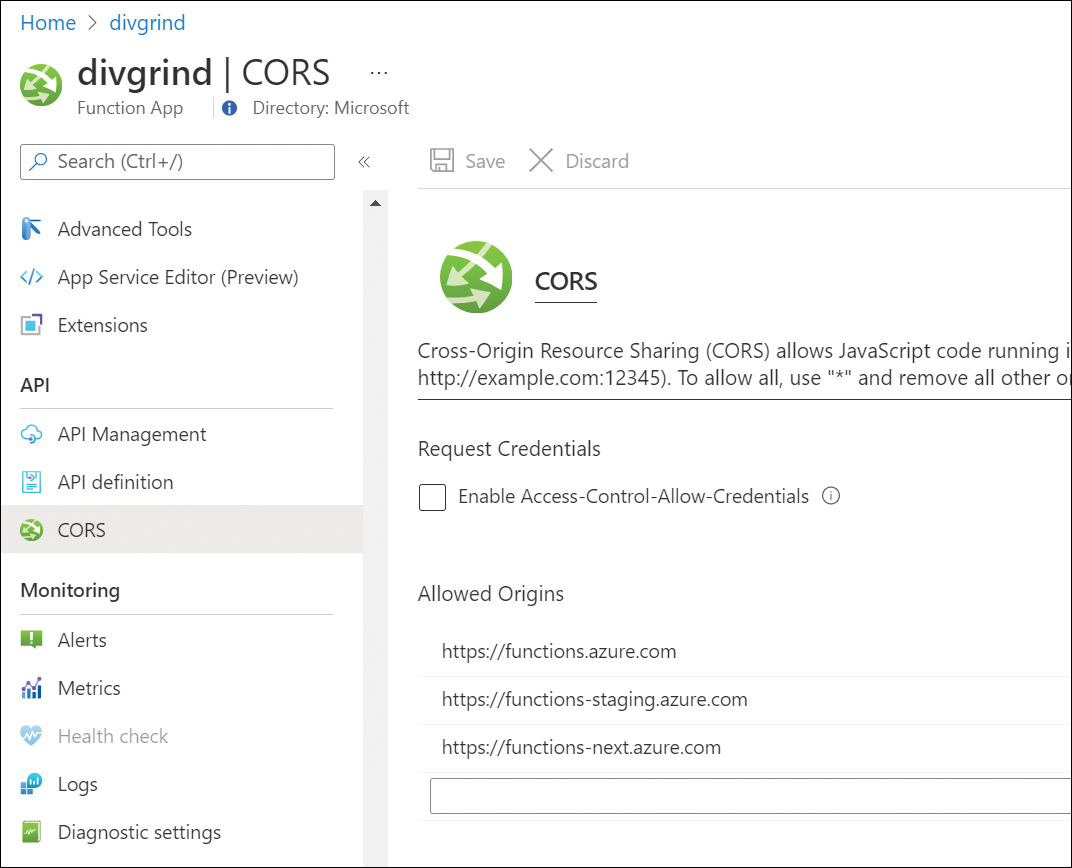
FIGURE 9-5 An example CORS in an Azure Function.
Even though the screenshot shown in Figure 9-5 mentions using * as a wildcard, you should not allow all domains to access your Function App. Allow only required domains to interact with your Function app. Also, as shown in Figure 9-6, Microsoft Defender for Cloud warns against setting CORS to *.
![]() Important
Important
Don’t set CORS to *.
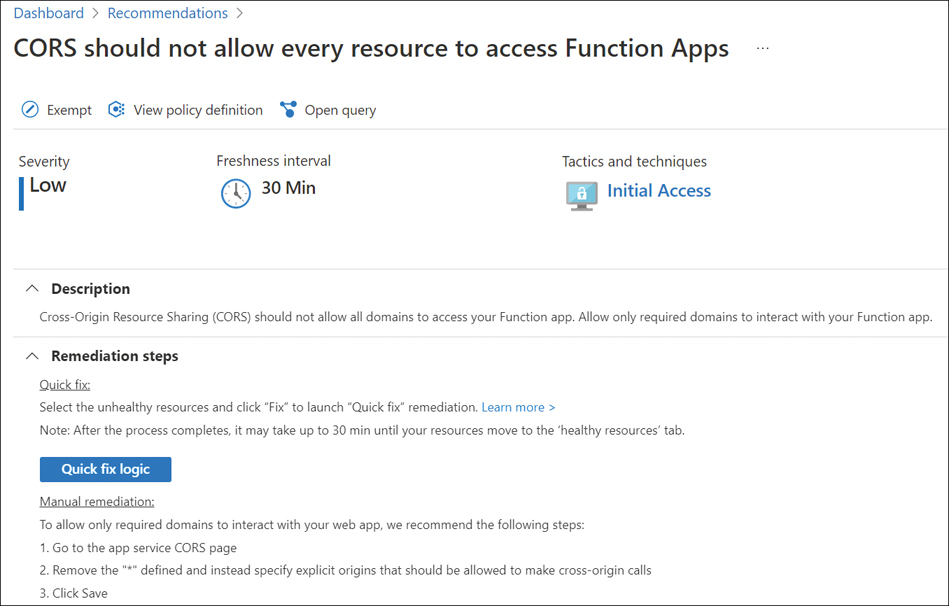
FIGURE 9-6 The CORS recommendation in Defender for Cloud; note the manual remediation suggests removing *.
Contrary to popular belief, the HTTP Strict-Transport-Security (HSTS) heading does not force all HTTP connections to HTTPS. HSTS requires one validated HTTPS connection to the server (that is, with no certificate errors) before the browser will honor the HSTS header. The reason is because an attacker can manipulate an HTTP body, including headers, making the HSTS setting untrustworthy in an HTTP response. However, HSTS also maintains a preload database of known sites that require HTTPS. To add your site to the list, go to the HSTS Preload Submission site at https://hstspreload.org/.
Another header type, cookies, should set the following flags:
HttpOnlySecureExpiresSameSite
HttpOnly helps mitigate XSS attacks from stealing cookie content. While you should certainly set cookies to use this option, be aware that it has value only if the cookie is used for authentication purposes, and it’s not a great defense against some forms of XSS. However, using cookies for session state and client configuration access is better than using HTML storage. You can read more on this here: https://azsec.tech/bpw. You should also mark cookies with the Secure flag so they are passed between the browser and server only when using HTTPS (HTTP over TLS).
Cookies should be set to expire using the Expires flag. The duration is up to you and depends on your business requirements because you need to balance security with usability. We have seen many developers set this flag to between one and six months.
SameSite provides some protection against client-side request forgery attacks by restricting when cookies are sent. If you set the SameSite=Strict flag on a cookie, then a browser sends cookies only for first-party context requests. These are requests originating from the site that set the cookie. If the request originated from a different URL than that of the current location, none of the cookies tagged with the Strict attribute is sent. You can read more about the flag at https://azsec.tech/bux to determine what cookie SameSite attribute works best for your sites. Here is an example cookie with these flags set:
Set-Cookie: sessionid=c92620e1; HttpOnly; Secure; SameSite=Strict; Expires=Fri, 1 Jul 2022
00:00:00 GMT![]() Important
Important
HTTP security headers are a useful defense against some classes of attacks, but they should be considered an extra defensive layer only.
A06: Vulnerable and outdated components
Further information https://azsec.tech/it1
Many applications are built with other components such as libraries. These components might not be controlled by you, so if they contain vulnerabilities, you will need to update your solutions with new solutions.
It is incredibly important to maintain a software bill of materials (SBOM) that tracks all the components that comprise your applications. This includes the following:
Component or package name
Version number
Vendor or source code repository
Programming language
Location of security information about that component
![]() Note
Note
A 2021 Executive Order in the United States called out the need to use an SBOM to improve cybersecurity. You can read the relevant document here: https://azsec.tech/kpi in §10.j.
GitHub has a tool called Dependabot to help you identify third-party packages you use that are out of date and have security issues. You can learn more here: https://azsec.tech/hud. This tool is just one part of GitHub’s security supply chain initiative and is discussed in further detail at https://azsec.tech/m0q.
A07: Identification and authentication failures
Further information https://azsec.tech/f3u
In the world of cloud-based solutions, identity is critical. Still, network boundaries are important—especially when it comes to the need for network segmentation in a zero-trust environment. A core part of identity is strong authentication. This is also a core element of your threat models. All processes must be authenticated, as well as devices and users.
Interestingly, the OWASP documentation calls out CWE-297, “Improper Validation of Certificate with Host Mismatch.” We see this error often, but it extends beyond host name validation. If your code initiates a connection over TLS, it’s important that the code performs all the relevant certificate checks. These include the following:
The certificate’s signature is valid. This verifies that it is not tampered with.
The name in the certificate matches the name of the system or user you want to communicate with.
The certificate chains up to a trusted root CA certificate. This is a critical step to prove the certificate is trusted.
The extended key usage is correct—for example, server authentication.
The date range is valid. That is, today is between the
NotBeforeandNotAfterfields.Whether the certificate is revoked. There are two common ways to check if a certificate is revoked. The first is to use a certificate revocation list (CRL). The location of the CRL is held in the certificate using a CRL distribution point (CDP), which is just a URL. The other way to check if a certificate is revoked is to use the Online Certificate Status Protocol (OCSP).
You will probably never write code to perform these steps. Instead, you should leave the validation to the libraries you use. For example, in .NET, the SslStream() class calls a delegate that can perform actions based on errors validating a certificate. Unfortunately, we see code like this quite often:
// This is invoked by the SslStream(..,..RemoteCertificateValidationDelegate, ..)
public static bool ValidateServerCertificate(
object sender,
X509Certificate certificate,
X509Chain chain,
SslPolicyErrors sslPolicyErrors) {
// Ignore all certificate errors
return true;
}This code ignores certificate errors and is a serious security vulnerability.
On the topic of certificates, be careful with self-signed certificates. If you must use self-signed certificates, check the certificate’s signature and thumbprint against a list of predetermined valid certificates. The list must have a strong access policy so it cannot be changed by untrusted entities.
Even then, be careful. Some people use self-signed certificates in test and use “real” CA-issued certificates in production. The problem with this is the test environment does not perform the same certificate tests as would be performed in production. The best way around this is to set up a certificate authority yourself—for example, using Active Directory Certificate Services (AD CS). You can install the root CA certificate from this CA on your development and test machines and test end-to-end certificate-based authentication including revocation. And because you control the certificates, you can create certificates that are invalid to see how your code reacts to, say, an expired server certificate or one where key usage is for client authentication when you expect server authentication.
![]() Tip
Tip
Microsoft has a Learning Path on the topic of certificates here: https://azsec.tech/xkq. This site does suggest using self-signed certificates for testing, which we don’t agree with, however.
A08: Software and data integrity failures
Further information https://azsec.tech/0kv
The issue here is code or data being compromised and changed. If you download code that is not digitally signed or you do not verify an out-of-band hash, there’s no way to know if the code or data is valid. In fact, looking at our vaccination booking example, the data really should be digitally signed by the vaccination center, so we know for certain it’s from the correct one.
You can create a digital signature quite easily as long as you have a certificate that has key usage for digital signatures and the associated private key. In Windows, these certificates are often referred to as Authenticode certificates.
Not only does PowerShell support signing, but it can also be configured to only allow digitally signed PowerShell files to run—for example, using cmdlets such as Set-AuthenticodeSignature to sign PowerShell files. You can see the result in the following code. The signature size is relatively constant, so it seems large compared to one line of script, but for a large script, the signature would be about the same size as for one line of script.
"Hello, World!"
# SIG # Begin signature block
# MIIFkQYJKoZIhvcNAQcCoIIFgjCCBX4CAQExCzAJBgUrDgMCGgUAMGkGCisGAQQB
-- SNIP --
# 1vbbaAkllAAg9aDVb6EXPY+AIKr5UYJli8WhCfVbWo+qV1EeWUXKlJEEDOTTaH3K
# mvZISeSM+yS+yN+hz6hNPxdy3S6QuWhjrFleL5hj1p2+OO8RAA==
# SIG # End signature blockKey Vault can perform signing operations within Key Vault, and the keys can be in hardware if you use an RSA-HSM or ECC-HSM key. The following simple C# test code demonstrates how to sign arbitrary data. This sample creates a signature by signing the SHA-512 hash using a P-521 elliptic curve.
using Azure.Identity;
using Azure.Security.KeyVault.Keys.Cryptography;
using System.Security.Cryptography;
using System.Text;
// You should pull the hash alg from a config file
string HASH_ALG = "SHA512";
SignatureAlgorithm SIG_ALG = SignatureAlgorithm.ES512; // P-521 Curve
var keyVaultUrl = "https://mykv.vault.azure.net/keys/key-name/version";
var creds = new DefaultAzureCredential(true);
var keyCryptoClient = new CryptographyClient(new Uri(keyVaultUrl), creds);
var msg = Encoding.UTF8.GetBytes("A message we want to sign");
var digest = HashAlgorithm.Create(HASH_ALG)?.ComputeHash(msg);
SignResult sig;
if (digest is not null) {
sig = keyCryptoClient.Sign(SIG_ALG, digest);
Console.WriteLine(Convert.ToBase64String(sig.Signature));
}![]() Note
Note
You need to match the signature algorithm with the hash function correctly. For example, the previous code uses a P-521 curve with an SHA-512 hash.
This code emits a Base64-encoded signature block, which could travel with the text file or separately. For example, you could do something like this:
A message we want to sign
--SIG—
AALaNsWvS9atK8xl4BqsqEdps0+IykG7bxwKXXZhyJ6zR/
rAKtYTTgpMvqqO1VyX6wEwFrwGTRb7Sl9kJeiPALmHAQ6BB6jeT/YnrRQHzBKqpoaMy9zRCWC/oDUW+ufAUnIOVsBM5WttcY
Zuj0JcEAjraGwB6eQWoc9cK23O1iM/DKNT
--ENDSIG--You could then do the reverse operation: signature verification using CryptographyClient.Verify(). There is a twist, though: you probably won’t pull the public key from Key Vault. Instead, you’ll use the public key in a certificate so you can perform all the correct certificate checks mentioned earlier. This will not only verify the certificate, but it will also check that the data came from the name in the certificate. For example, if the certificate has a field [email protected], then you know the data came from Joe. You could also use something like XMLDSig or JSON web signature to sign and verify data, so you don’t need to do the low-level work.
Remember, this section is all about integrity and authenticity. There is no encryption. It is common to do both, however. Our vaccination file could append the signature to the CSV file. The data is not encrypted, but we still have integrity and authentication due to the digital signatures, as long as your code performs all the relevant certificate checks before verifying the signature.
If a service needs to verify data, it can also use a message authentication code (MAC), which uses a symmetric key rather than public/private key pair. This would require any services to have access to the MAC key. This is why systems that use a MAC are usually one-to-one rather than one-to-many: to keep the MAC key distribution as small as possible. For example, TLS uses a unique MAC key for client-to-server communication, and a different MAC key for server-to-client communication.
What about using a hash? You can use a hash so long as:
The hash is not included with the data to be verified.
The hash is available over an authenticated and protected channel—for example, using TLS.
The hash cannot travel with the data because the data could be tampered with and the hash recalculated.
A09: Security logging and monitoring failures
Further information https://azsec.tech/4oa
This topic is covered in detail in Chapter 6.
A10: Server-side request forgery (SSRF)
Further information https://azsec.tech/3pn
Once again, this is an input trust issue. The core lesson here is to never allow an attacker to control a URL. If you must have a user control the URL, then have a list of valid URLs to validate against and only allow those URLs.
SSRF-based attacks are common against cloud-based solutions. It is believed the 2019 Capital One breach that yielded more than 100-million customer records was an SSRF attack against the company’s AWS infrastructure. You can read about the Capital One attack here: https://ejj.io/blog/capital-one.
The problem is incredibly simple:
A vulnerable server accepts a URL from an untrusted source (an attacker).
The server does not verify the URL is valid and correctly formed.
The server accesses the data at that URL.
The server returns the object at that URL back to the attacker.
The problem is if the web server has access to internal resources and the URL (that came from the attacker) points to a resource on the internal network, the attacker can start reading resources on the internal network! An example of an internal resource that is common to cloud platforms is the Instance Metadata Service (https://azsec.tech/meta), which, on Azure, is accessible on a nonroutable IP address, 169.254.169.254.
![]() Important
Important
You must always verify any IP address or DNS name that could be provided by an attacker to make sure it is a valid address or name.
Another attack, cross-site request forgery (CSRF), sounds like SSRF, but the two are not the same. In fact, CSRF was on the OWASP Top 10 back in 2017, but it’s not now, mainly because most web frameworks offer defenses, such as ASP.NET MVC. You can read more here: https://azsec.tech/0py. The remedy for CSRF is to include a random token in the session, but this is always best handled by the various web frameworks.
Comments about using C++
Some of the code samples earlier in this chapter were written in C++, and we want to explain ourselves. While we don’t see much custom-written cloud-related code written in C++, we do see code in VMs running Linux and Windows, containerized code, embedded systems, and IoT solutions using C++.
We have three items of advice when it comes to writing C++ code:
Don’t write C++ as glorified C.
Use all security-related compiler and linker defenses available to you.
Use analysis tools.
Let’s look at each.
Don’t write glorified C
C is a low-level language designed as a replacement for assembly language. The lineage of many modern programming languages originates in C.
C is small, is efficient, and has unfettered access to process memory. It is this last point that also makes C a language that requires care. The documentation for the original commercial C compiler from Whitesmiths, Ltd., in 1982 said, “C is too expressive a language to be used without discipline.” (A copy of this manual is available at https://azsec.tech/7c2; the quote is on page 22.)
C++ offers numerous quality, security, and robustness benefits over C. But you must use these features to obtain these benefits. You might have noticed that the sample C++ code we wrote, while simple, uses C++ idioms, has no direct pointer use, and passes large function arguments by reference. Honestly, it might have been easier in some examples to use low-level C, but using Modern C++ (https://azsec.tech/ko3) and the C++ Standard Library (STL; https://azsec.tech/odj) makes the code safer by far.
Use compiler and linker defenses
The two most popular C and C++ compilers are Microsoft Visual C++ and GNU gcc. Both provide extensive options to emit safer code that includes various defenses against memory corruption vulnerabilities.
For Visual C++, the following is a list of commonly used compiler and linker options and links to resources for more information. Some are enabled by default for C++ projects.
/SDL This supports enhanced security checks, including enhanced stack-corruption detection (https://azsec.tech/azk).
/DYNAMICBASE This uses address space layout randomization (ASLR) to randomly rebase the application at load time (https://azsec.tech/1s3).
/NXCOMPAT This indicates that the application supports No eXecute (NX), also known as Data Execution Prevention (DEP) (https://azsec.tech/3nt).
/SAFESEH This emits code that has a set of safe exception handlers (https://azsec.tech/18y).
/GUARD This enables Control Flow Guard (https://azsec.tech/c5y) and Exception Handler Continuation Metadata (https://azsec.tech/o1p).
/CETCOMPAT Opt in for hardware-enforced stack protection (https://azsec.tech/s1s and technical write-up at https://azsec.tech/i17).
/fsanitize=address This is a way to find security issues, mainly memory safety issues, at compile time, and to prevent security issues at runtime. It can be treated as a replacement for
/RTC(runtime checks) and/analyze(static analysis) (https://azsec.tech/vom).
For gcc, the following is a commonly used set of options that should be employed:
_FORTIFY_SOURCE This a macro (for example,
gcc -D_FORTIFY_SOURCE=2), not a compiler or linker flag, that performs checks for classes of buffer overflow (https://azsec.tech/fsp).-Wformat-overflow This detects string format overflows (https://azsec.tech/3i8).
-Wstringop-overflow This detects overflows in
memcpyandstrcpy(https://azsec.tech/3i8).-fstack-protector-strong This adds stack-based corruption detection (https://azsec.tech/qfg)
-fPIE This creates a Position Independent Executable (PIE) that uses ASLR (https://azsec.tech/opj).
/fsanitize=address This is the same technology used in VC++ (https://azsec.tech/m44).
![]() Tip
Tip
The GitHub Gist at https://azsec.tech/y1r offers an up-to-date list of security-related gcc flags and options. Also, the following article about FORTIFY_SOURCE from Red Hat is a worthwhile read: https://azsec.tech/g4o.
All these options find or detect potential memory safety issues at compile time or runtime. You should use as many of these options as possible. Many of them will fail fast in the face of an issue, enabling you to debug and fix the issue quickly.
Use analysis tools
Both gcc and VC++ include baseline code analysis functionality. While you probably don’t need to run the analysis on each build, you should perform it at least once per sprint so you can catch any issues quickly and fix them. Also, although these tools have a strong focus on security, they find other issues, too.
![]() Note
Note
As noted, both VC++ and gcc support /fsanitize=address, which includes static code analysis.
Visual C++ also has an /analyze option that performs various code quality and security checks on your code. There is an overlap between what /fsanitize=address can find and what /analyze can find. In our opinion, for native C and C++ code, you should use both until you determine that one performs better on your codebase. You can find information about /analyze here: https://azsec.tech/r7c.
In addition, Microsoft Research created the source-code annotation language (SAL) used in the Windows SDK and Microsoft Runtime headers. You should seriously consider using it in your custom C++ headers, too. You can read more about SAL here: https://azsec.tech/rxy.
Finally, the Visual C++ team wrote an excellent article about NULL-deference detection using the static analysis tools built into the compiler. You can read about it here: https://azsec.tech/bxv. For gcc, a compiler option was added to gcc v10 to provide lightweight static analysis. You can learn more here: https://azsec.tech/87z.
![]() Tip
Tip
Use these free and easy-to-use compiler tools often and early to give yourself enough time to fix any issues before you ship.
On the GitHub side, CodeQL is a tool that is free for research use and free when used with open source software. CodeQL (previously named Semmle) is a rich static analysis solution that offers advanced capabilities such as data flow and control flow analysis across various programming languages, including C, C#, C++, Go, Java, JavaScript, Python, Ruby, and TypeScript.
![]() Tip
Tip
You can experiment with CodeQL over on the https://lgtm.com/ website. The inside joke is “LGTM” means “Looks Good To Me,” but in fact, it was a cheap domain name!
CodeQL builds a database of the code. Then, a developer can use SQL-like queries to search the code for specific conditions that indicate code quality bugs, including vulnerabilities. A nice feature is that the CodeQL query language is the same regardless of the underlying programming language. Also, because anyone can create CodeQL queries, CodeQL democratizes query creation.
![]() Note
Note
In addition to CodeQL, GitHub also offers GitHub Advanced Security, which can automate many checks against your repos.
If you are reviewing commercial analysis tools, consider using tools that support Static Analysis Results Interchange Format (SARIF). You can read more about it here: https://sarifweb.azurewebsites.net/. SARIF allows the output of multiple analysis tools to feed into various reporting and all-up analysis tools. CodeQL supports SARIF, as discussed here: https://azsec.tech/7f2.
![]() Tip
Tip
There are several other tools besides these. OWASP offers a list of analysis tools at https://azsec.tech/aww.
Security code review
Chapter 1, “Software development lifecycle processes,” discusses security code review in the context of agile methods. This section covers it more generally.
Code review is critical to help secure your code. Over the years, we have devised a high-level approach to rapidly review code that leverages everything we have covered so far in this chapter. Remember, you have only a finite amount of time to review code, so we focus here on the code that is most at risk. Our code-review approach includes these steps:
Refer to the threat model to identify all the entry points into the code, especially those that cross trust boundaries. You should be able to match these entry points with some code construct such as a REST API, a WebSocket, a UDP socket, and others.
Order the entry points by attack surface, from high to low. This will be the order in which you review the code, from the top to the bottom.
From the entry point, determine the data that’s coming in. This might be a JSON payload, arguments in an HTTP query string, or a buffer from a socket. This is the data you need to evaluate carefully. In analysis parlance, it is called the source.
Trace the data from step 3 through the code. At every line of code where the data is used, determine if the construct is safe. Data use is called a sink. Essentially, you want to track data from its source to all its sinks, making sure the data is correct and used appropriately. A correct pattern is, data enters a source, is correctly validated as early as possible, and is used safely by various sinks.
Let’s take a simple example with the following parameters:
A data source is a JSON payload that is part of a POST REST API call.
One element of the JSON file is a number—let’s say it’s an unsigned 32-bit integer called
'count'—that indicates how many items to deal with.The code uses
'count' +1to dynamically allocate some objects to store items. This is the sink. The+1is added by the code as it can add another object.There is no checking to constrain the value of
'count'.
The last two points are unsafe for many reasons. For example:
What if the count is not a number, but it’s the letter Q instead?
What if the number is 1,000,000? Do you really want the attacker to force your application to allocate 1 million objects?
What if the number is 4,294,967,296? The code won’t allocate 4 billion objects. It’ll allocate zero! Why? Because 2^32 + 1 = 0. It’s an integer overflow problem. So, your code allocates space for zero objects, it attempts to copy data into the memory, and it crashes.
Having code handle incorrect data gracefully is critically important to both the security and robustness of your code. Fortunately, there’s a way to test your code against malformed data. That process is called fuzz testing, and it’s discussed next.
Keeping developers honest with fuzz testing
At the start of the chapter, we pointed out how important it is to validate input. This is probably the most important defensive security skill a developer needs to understand. We also defined what the incoming data must look like to be deemed valid by the application.
Let’s return to our vaccination booking application. To recap, the data coming from a vaccination center is a CSV file that comprises the following fields:
centerId, date and time, vaccination type, open spots, commentThe formats for each data item are as follows:
centerID This is the vaccination center ID. It is a six-digit number. This field cannot be blank.
date and time For this, you use the ISO 8601 date and time format. This field cannot be blank.
vaccination type This is a string that represents the name of a valid vaccine manufacturer. This field cannot be blank.
open spots This is a number from 0 to 999. This field can be blank; when it is, it equates to zero.
comment This is a text field in which a representative from the vaccination center can enter a comment. This comment can be up to 200 characters long.
The CSV file will have one line for each vaccination center, date/time, and vaccine type.
If we know what correct data is supposed to “look like,” we should build tests that create data that is purposefully malformed and have the application—in this case, an Azure Function—consume the malformed data to see how the function reacts. If the programmers created robust code, the function should handle all incoming data whether it is well-formed or not.
This kind of testing is just one form of nonfunctional security testing and is often called fuzz testing.
![]() Important
Important
You should add fuzzing to your application tests. Fuzz tests should be part of your normal set of regression or reliability tests. You can start small and add more coverage over time. But you should start today. Come up with a plan to add fuzz testing to your current development practices as soon as you possibly can.
Let’s assume the function returns a 200 HTTP status on success and a 401 on any kind of failure. Now you need to build a test harness that creates malformed data and sends it to the Azure Function. You have two options:
Use a preexisting fuzzing tool.
Create your own custom test cases.
There are many open source and commercial fuzzing tools. For example:
RESTler from Microsoft (https://github.com/microsoft/restler-fuzzer)
OneFuzz from Microsoft (https://github.com/microsoft/onefuzz)
Burp Suite (https://portswigger.net/burp)
OWASP ZAP (https://www.zaproxy.org/)
Google’s OSS-Fuzz (https://github.com/google/oss-fuzz)
Peach Fuzz (https://sourceforge.net/projects/peachfuzz/)
American Fuzzy Lop (https://lcamtuf.coredump.cx/afl/)
LLVM Compiler Infrastructure (https://llvm.org/docs/LibFuzzer.html)
It’s worth spending some time reviewing all of these to see if they offer some value to you and your organization. If nothing else, these tools will help you understand how fuzzing works.
In our example, vaccination centers upload their CSV file to an Azure Storage account. From there, it is read by an Azure Function using a Blob Storage Account trigger. (Find out more here: https://azsec.tech/zu8.) It is this file we will fuzz.
![]() Note
Note
If the Azure Function were called directly by the vaccination center by calling an API, we’d fuzz the API endpoint directly rather than upload a fuzzed file.
There are numerous ways to fuzz data. Here are a few:
Generate totally random data.
Mutate existing data.
Intelligently manipulate data knowing its format.
Let’s look at each of these methods through the lens of our sample CSV file. Fuzzing is an area of much research in academia and industry, but we’ll keep things simple here.
![]() Important
Important
Don’t fuzz using production data.
Generating totally random data
This is simple! Just create a random set of bytes. In our example, we’d probably create a series of lines of random data. The following PowerShell code does this:
Set-StrictMode -Version latest
function Get-RandomLine {
param (
[Parameter(Mandatory)] [int] $len
)
$charSet = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789{]+-
[*=@:)}$^%;(_!&#?>/|.'.ToCharArray()
$rng = [System.Security.Cryptography.RandomNumberGenerator]::Create()
$bytes = New-Object byte[]($len)
$rng.GetBytes($bytes)
$data = New-Object char[]($len)
for ($i = 0 ; $i -lt $len ; $i++) {
$data[$i] = $charSet[$bytes[$i] % $charSet.Length]
}
return -join $data
}
$fileName = "appointments.csv"
"" | out-file $filename
$numLines = Get-Random -Minimum 2 -Maximum 20
1..$numLines |% {
$len = Get-Random -Minimum 10 -Maximum 256
Get-RandomLine $len | out-file -Append $fileName
}You could modify the $charSet variable to include other characters, of course, but this is a reasonable start. It creates a text file of random lines. This file could be uploaded to the storage account; the Azure Function then picks it up and parses it. The function code should utterly reject this file because it is syntactically incorrect, if for no other reason than the code cannot split the lines into the five discrete fields (unless, by luck, a random line includes four commas, which can happen, but it’s unlikely).
Now let’s make the fuzzing a little smarter. Rather than creating random data, let’s create five fields of random data. This should get us past the code that checks the number of fields in each row. We can tweak the PowerShell code to this:
$fileName = "appointments.csv"
"" | out-file $filename
$numLines = Get-Random -Minimum 2 -Maximum 20
$numFields = 5
1..$numLines |% {
$line = ""
1..$numFields |% {
$len = Get-Random -Minimum 0 -Maximum 64
$field = Get-RandomLine $len
$line += ($field + ",")
}
$line.TrimEnd(",") | out-file -Append $fileName
}This produces a CSV file made up of a random number of lines, and each line comprises comma-separated random characters. This might get past the check for the number of fields, but some lines might fail because the comma is in the list of random characters, and we get more than four commas.
This will work in some cases, but not many. There’s a fine line between data that’s “corrupted a little bit” and data that’s a complete mess. Most systems will detect incoming data that is completely random. Again, the CSV data is probably syntactically incorrect. We can do better!
Mutating existing data
This is a favorite among security researchers because it’s effective. You take a corpus of valid data, tweak the data, and then send the data to the application and see how it reacts. For example, if this were a REST endpoint, you could tweak the JSON payload before it hits the wire, where it would then be consumed by the server.
For our example, we need to collect or generate a corpus of thousands of valid lines of data that go in the CSV file. But, to keep this simple, we’re going to work with one line. Remember, the format is as follows:
centerId, date and time, vaccination type, open spots, commentWe will use this:
98722, 2022-03-16T15:50-06:00, PharmaA, 4, These are the last batches of PharmaARecall that we said you want to find the fine line between tweaking the data slightly and making it totally random. Here, we need to set a threshold, so we make tiny changes. Examples of these small changes might include the following:
Inserting random characters
Deleting random characters
Setting or resetting the high bit of a character
Byte swapping
Truncating the data
Adding data at the end or start of the data
Inserting special characters (for example, file system special characters, like
,/,:, etc.) or character sequences (for example, HTML or SQL)Inserting interesting numbers, such as
2^n - 1,2^n + 1,0,MAX_INT,MAX_UINT
![]() Tip
Tip
On the topic of interesting special characters, there’s a “big-list-of-naughty-strings” at https://azsec.tech/oql worth looking at and using.
The following snippet of C# code takes a byte array (passed in the constructor, not part of this snippet) and fuzzes the array if a threshold is met. For example, we might only want to fuzz 5 percent of the incoming data. You need to find what this threshold is for your data. The code also performs multiple passes over the incoming data, so a string can have more than one mutation. Finally, you can set a random number seed to reproduce an error.
public SimpleFuzz(int threshold=5, int? seed = null) {
_rnd = seed is null ? new Random() : new Random((int)seed);
_threshold = threshold;
}
public byte[] Fuzz(byte[] input) {
if (input.Length == 0) return Array.Empty<byte>();
if (_rnd.Next(0, 100) > _threshold) return Array.Empty<byte>();
var mutationCount = _rnd.Next(1, 5);
for (int i = 0; i < mutationCount; i++) {
if (input.Length == 0) break;
var whichMutation = _rnd.Next(0, 7);
int lo = _rnd.Next(0, input.Length);
int range = _rnd.Next(1, 1+ input.Length / 10);
if (lo + range >= input.Length) range = input.Length - lo;
switch (whichMutation)
{
case 0: // set all upper bits to 1
for (int j = lo; j < lo + range; j++)
input[j] |= 0x80;
break;
case 1: // set all upper bits to 0
for (int j = lo; j < lo + range; j++)
input[j] &= 0x7F;
break;
case 2: // set one char to a random value
input[lo] = (byte)_rnd.Next(0, 256);
break;
case 3: // insert interesting numbers
byte[] interesting = new byte[] { 0, 1, 7, 16, 15, 63, 64, 127, 128, 255 };
input[lo] = interesting[_rnd.Next(0,interesting.Length)];
break;
case 4: // swap bytes
for (int j = lo; j < lo + range; j++) {
if (j + 1 < input.Length)
(input[j + 1], input[j]) = (input[j], input[j + 1]);
}
break;
case 5: // remove sections of the data
input = _rnd.Next(100) > 50 ? input[..lo] : input[(lo + range)..];
break;
case 6: // add interesting pathname/filename characters
var fname = new string[] { "\", "/", ":", ".."};
int which = _rnd.Next(fname.Length);
for (int j = 0; j < fname[which].Length; j++)
if (lo+j < input.Length)
input[lo+j] = (byte)fname[which][j];
break;
default:
break;
}
}
return input.ToArray();
}Figure 9-7 shows part of the Locals window in Visual Studio, and you can see that the incoming string, named data, has been partially corrupted in the res variable. Part of the first field is removed, part of the second field looks like the upper bit is set, and some parts of the last field have been flipped.
FIGURE 9-7 An example of a fuzzed row of the sample CSV file.
As you can see, the fuzzing is much subtler than the previous methods of using random data. The goal of more subtle fuzzing is to attempt to get greater code coverage, if possible.
![]() Tip
Tip
This fuzzing code sample is available at the book’s GitHub repository, at https://github.com/AzureDevSecurityBook.
Intelligently manipulating data knowing its format
The last type of fuzzing is when the fuzzing logic understands the data format—for example, if you have a custom-written graphic image parser that handles Portable Network Graphics (PNG) image files. Understanding the data format is important for some data types, because when the logic understands the format and structure of the file, it can make surgical changes to a file. A PNG file will have elements like X- and Y-dimensions, color depth, and more, that can be smartly fuzzed—for example, by the following:
Setting X or Y to negative numbers
Setting X or Y to alphabet characters
Setting X or Y to massive values
Setting the color depth to crazy values
Perhaps most importantly, PNG files also have checksums. If your code injects random data into the file, the file checksums will be incorrect, and the code you’re trying to fuzz will reject the file quickly, before it gets further into the code. This means that after the file is fuzzed, the checksums will need to be recalculated.
Fuzzing APIs
We want to wrap this section up with one more important topic: fuzzing APIs. Today, exposed APIs are a common target of attack. These can relate to code-level vulnerabilities as well as design issues such as a lack of authentication or authorization and more. One website, APIsecurity.io (https://apisecurity.io/), is an excellent resource to learn more about real API vulnerabilities in the real world.
![]() Note
Note
Akamai’s research shows that 25 percent of all traffic is API traffic. You can read the startling details here: https://azsec.tech/jd8.
You should perform security testing of your APIs—for example, those exposed by Azure Functions, Azure App Service, or code written in Node.js running in a container. Fuzzing is one type of test; you can take the aforementioned practices and ideas and apply them to APIs, too. For example, if an API uses the HTTP GET method to read a resource, you can corrupt parameters on the query string. Or if you use a POST to create a resource, you can corrupt the JSON or XML payload in the HTTP body.
Suppose our vaccination booking application uses an HTTP POST API call with a JSON payload rather than uploading a file to Azure. A request might look something like this:
{
"centerId" : "98722",
"date_time" : "2022-03-16T15:50-06:00",
"vaccination_type" : "PharmaA",
"open_spots" : "4",
"comment" : "These are the last batches of PharmaA"
}Of course, the payload will probably have more than one item, but we want to keep things simple. Your fuzzing logic could apply the same tactics on this payload, but by manipulating the fields of the JSON file.
Be careful when fuzzing files like JSON and XML. You probably don’t want to fuzz the structure of the file—for example, replacing the opening { with a random value—because corrupting the structure of the JSON file won’t get beyond the JSON parser, let alone get to the code you really want to test!
The following code is an update to the preceding code that can handle a JSON file:
public byte[] Fuzz(JsonDocument doc) {
byte[] fuzzResult = Array.Empty<byte>();
using var stream = new MemoryStream();
using (var writer = new Utf8JsonWriter(stream)) {
writer.WriteStartObject();
foreach (var elem in doc.RootElement.EnumerateObject()) {
writer.WritePropertyName(elem.Name);
byte[] fuzzed = Fuzz(elem.Value.ToString());
writer.WriteStringValue(fuzzed.Length > 0
? System.Text.Encoding.UTF8.GetString(fuzzed)
: elem.Value.GetRawText().Trim('"'));
}
writer.WriteEndObject();
writer.Flush();
fuzzResult = stream.GetBuffer();
}
return fuzzResult;
}Figure 9-8 shows a run of about 15 generations of the preceding code. As you can see, every line has one or more subtle changes. Each line represents the same starting text, but the mutations are different each run. Ask yourself, do you think your API code could handle all these lines of JSON without crashing?
FIGURE 9-8 The output of 15 runs of the JSON fuzzer.
One final note: you need to detect at the code level if the application fails to handle the incoming data. Historically, you would use a debugger and log the debug spew, but in Azure, you should use Application Insights to monitor the API or code as it responds to incoming nasty data.
![]() Tip
Tip
If you need general API guidance, see https://azsec.tech/l4m.
![]() Important
Important
If applicable, you must test your IoT REST APIs, too. APIs are not just a “cloud-thing!”
Summary
We can’t stress enough how important it is that your code validates all incoming data. As we say in zero trust, “verify explicitly.” Most security vulnerabilities are input trust issues.
Be sure you review the OWASP Top 10 and stay on top of application security vulnerabilities in the industry. Review and learn from the OWASP Testing Guide at https://azsec.tech/fcr. Also, use static and dynamic analysis available in your development tools where possible.
Fuzz testing is a form of dynamic analysis. It is a useful technique for testing code that consumes files and code that exposes APIs. Even “light” fuzzing is a great test to make sure your code is resilient in the face of malformed input.
As discussed in more detail in Chapter 1, someone in your organization must stay up to date on new vulnerabilities, exploits, and defenses to make sure your code is built with the latest threats in mind. This is an important role!