
As the second stage, organizations work to identify sources of evidence to support the risk scenarios identified as being relevant to their business. With each risk scenario, work needs to be done to determine what sources of potential digital evidence exist, or could be generated, and what happens to the potential evidence in terms of authenticity and integrity.
Generally, the purpose of completing this stage is to create an inventory of data sources where digital evidence is readily available throughout the organization. Not only does this inventory support the proactive gathering of digital evidence to support digital forensics readiness, but it also allows the organization to identify systems and applications that are deficient in their data collection requirements.
The most familiar technology where potential digital evidence is located comes from traditional personal computing systems such as desktops, laptops, and servers. Typically, with these technologies digital evidence will be located directly on the internal storage medium, such as the internal hard drive(s), or indirectly on external storage medium, such as optical discs or universal serial bus (USB) devices.
However, organizations should also consider the possibility that data sources exist beyond the more traditional personal computing systems. With the widespread use of technology in business operations, every organization will have electronically stored information (ESI) that is considered potential digital evidence generated across various sources.
Careful consideration must be given when determining what potential digital evidence should be gathered from data sources. When identifying data sources, organizations should consider placing the potential digital evidence into either of the following categories.
Background evidence is data that has been gathered and stored as part of normal business operations, according to the organization’s policies and standards governance framework. The gathering of this type of evidence includes:
• Network devices such as routers/switches, firewalls, domain name system (DNS) servers, and dynamic host configuration protocol (DHCP) servers
• Authentication records such as directory services logs, physical access logs, and employee profile databases
• Electronic communication channels such as email, text, chat, and instant messaging
• Data management solutions such as backups, archives, classification engines, integrity checkers, and transaction registers
• Other sources such as internet service providers (ISP) and cloud service providers (CSP)
Foreground evidence is data that has been specifically gathered and stored to support an investigation or identify perpetrators. The action of gathering this type of evidence can also be referred to as “monitoring” because it typically involves analyzing—in real time—the activities of subjects. Depending on regulations and laws concerning privacy and rights, organizations should consult with their legal teams to ensure that the active monitoring of employees is done correctly. The gathering of this type of evidence includes:
• Network monitoring systems such as intrusion prevention systems (IPS), packet sniffers, and anti-malware
• Application software such as anti-malware and data loss prevention (DLP)
• Business process systems such as fraud monitoring
While the above sample of data sources is by no means a complete representation of potential digital evidence, every organization has different requirements and will need to determine the relevance and usefulness of each data source as it is identified. Refer to Chapter 3, “Digital Evidence Management,” for further discussion about types and sources of digital evidence.
Like how a service catalog provides organizations with a better understanding of how to hierarchically align individual security controls with the forensics readiness program, discussed further in Addendum B, “Service Catalog,” each data source must be placed into a similar hierarchical structure. The methodology for successfully creating a data source inventory includes activities that have been completed previously and well as activities that will be completed afterward, as discussed in subsequent chapters of this book.
Specific to the scope of this chapter, creating a data source inventory includes the following phases:
Phase #1: Prepare an Action Plan
An action plan is an excellent tool for making sure the strategies used by the organization when developing the data source inventory achieve the desired final vision. The action plan consists of four steps that must be completed to deliver a complete and accurate inventory:
• What tasks and/or activities need to take place for data sources to be identified
• Who will be responsible and accountable for ensuring the tasks/activities are completed
• When the tasks/activities will take place, in what order, and for how long
• What resources (e.g., funding, people) are needed to complete the tasks/activities
At this point, there are several questions that organizations need to answer so that when it comes time to identify and document data sources, they will be able to thoroughly and accurately collect the information they need to produce the inventory. In no order, these basic questions should include:
• Where is the data generated? Have the systems and/or applications that are creating this data been identified and documented in the organization’s service catalog?
• What format it is in? Is the data in a structure that can be interpreted and processed by existing tools and/or processes; or are new tools and/or processes required?
• How long is it stored for? Will the data be retained for a duration that will ensure availability for investigative needs?
• How it is controlled, secured, and managed? Is the authenticity, integrity, and custody of the data maintained throughout its lifecycle?
• Who has access to it? Are adequate authentication and authorization mechanisms in place to limit access to only those who require it?
• How much data is produced at a given interval? What volume of relevant data is created that needs to be stored?
• How, where, and for how long is the data archived? Are there sufficient resources (e.g., network bandwidth, long-term storage, systems) available to store it?
• How much data is currently being reviewed? What percentage of the data is currently being analyzed using what tools, techniques, and resources?
• Who is responsible for this data? What business line within the organization manages and is responsible for each aspect of the data’s lifecycle?
• Who is the data owner? Which specific individual is responsible for the data?
• How can it be made available for investigations? What processes, tools, or techniques exist that allow this data to be gathered for investigative needs?
• What business processes does this data relate to? What are the business and/or operational workflows where this data is created, used, and stored?
• Does it contain any personally identifiable information (PII)? Does the data contain any properties that can be used to reveal confidential and/or sensitive personal information?
Phase #2: Identify Data Sources
Following the direction set in the action plan, the organization will be better equipped to identify data sources—throughout their environment—where digital evidence exists. As data sources are identified, each must be catalogued and recorded in a centralized inventory matrix.
There are no pre-defined requirements indicating what specific elements must be included in the inventory matrix, leaving the decision to include or exclude elements entirely up to the subjectivity of the organization. The most common descriptive elements that organizations should use in the data source inventory matrix, as provided as a reference in the “Templates” section of this book, should include the following:
• Overall status provides a visual representation of the organization’s maturity related to the gathering of digital evidence for the overall business scenario, including the following labels:
• Green = fully implemented
• Blue = partially implemented
• Orange = in progress
• Yellow = plan in place
• Red = not implemented
• Business scenario indicates which of the business scenarios, as discussed in Chapter 5, “Digital Forensics as a Business,” the data source contributes to as digital evidence.
• Operational service aligns the data source to the operational service it is associated with as documented in the organization’s service catalog, which is discussed further in Addendum B, “Service Catalog,” such as digital investigations, litigation support.
• Data format describes the high-level grouping of how the information is arranged in this data source, such as structured or unstructured.
• Data origin identifies the system and/or application where the information is generated, such as email archive, end-user system, network share, or cloud service provider.
• Data category illustrates the exact type of information available in this data source, such as multimedia, email messages, or productivity suite documents.
• Data location determines how the information persists within the data source, such as at-rest, in-transit, or in-use.
• Data owner documents the specific individual who is responsible for the data.
• Business use case identifies the high-level grouping representing the motive for why this information exists, such as data loss prevention, data classification, or intrusion prevention.
• Technology name documents the organization that created and provides ongoing support for the solution where the data source persists.
• Technology vendor documents the organization that created and provides ongoing support for the solution where the data source persists.
• Technology owner documents the specific individual who is responsible for the solution where the data source persists.
• Status provides a visual representation of the organization’s maturity related to the gathering of digital evidence for the specific data source, including the following labels:
• Green = fully implemented
• Blue = partially implemented
• Orange = in progress
• Yellow = plan in place
• Red = not implemented
• Status details provide a justification for the status assigned to the maturity rating for the specific data source.
• Action plan describes the activities required for the organization to improve the maturity rating for the specific data source.
Phase #3: Document Deficiencies
As the inventory matrix is being developed, the organization might encounter instances where there is insufficient information currently available in a data source or gaps in the availability of information from unidentified data sources. Resolving these findings should be done separately because the activities that need to be performed are somewhat different in scope.
Insufficient Data Availability
Although a data source has been identified and included in the inventory matrix, this does not mean that it contains relevant and useful information to support forensics readiness. Generally, determining whether a data source provides an acceptable level of digital evidence requires that organizations ensure that the information contained within supports the investigation with either content or context.
Content Awareness Content is the element that exists within information that describe details about an event or incident. Information that can be used as digital evidence during an investigation must provide the organization with details sufficient to allow them to arrive at evidence-based conclusions.
Commonly categorized as foreground evidence, information gathered from data sources should contain enough content to support the “who, where, what, when, and how” aspects of an investigation. This requires that, at a minimum, all information within data sources that will be used as digital evidence include the following metadata properties:
• Timestamp of when the event/incident occurred, including full date and time fields with time zone offset
• Source of where the event/incident originated, including an identifier such as hostname or IP address
• Destination of where the event/incident was targeted, including an identifier such as hostname or IP address
• Description provides an unstructured, textual description of the event or incident
In addition to these minimum requirements, organizations must recognize that every data source is different and depending on the system (or application) that created it the information contained within will provide varying types of additional details. By assessing the content of a data source, organizations will be able to determine if it contains information that is relevant and useful as digital evidence.
Contextual Awareness Context is the circumstances whereby supplemental information can be used to further describe an event or incident. Commonly categorized as background evidence, supplemental information gathered from data sources can improve the “who, where, what, when, and how” aspects of an investigation.
Consider a layered stack model, like that of the open systems interconnection (OSI) model, where each layer serves both the layer above and below it. The model for how context is used to enhance digital evidence can also be grouped into distinct categories that each provides its own supplemental benefit to the data source information.
A layered context model follows the same methodology as the OSI model where each layer brings supplemental information that can be applied as an additional layer onto existing digital evidence. As illustrated in Figure 8.1, the attributes comprised within a layered context model include:
• Network: Any arrangement of interconnected hardware that supports the exchange of data
• Device: Combination of hardware components adapted specifically to execute software-based systems
• Operating system: Variations of software-based systems that manage the underlying hardware components to provide a common set of processes, services, applications, etc.
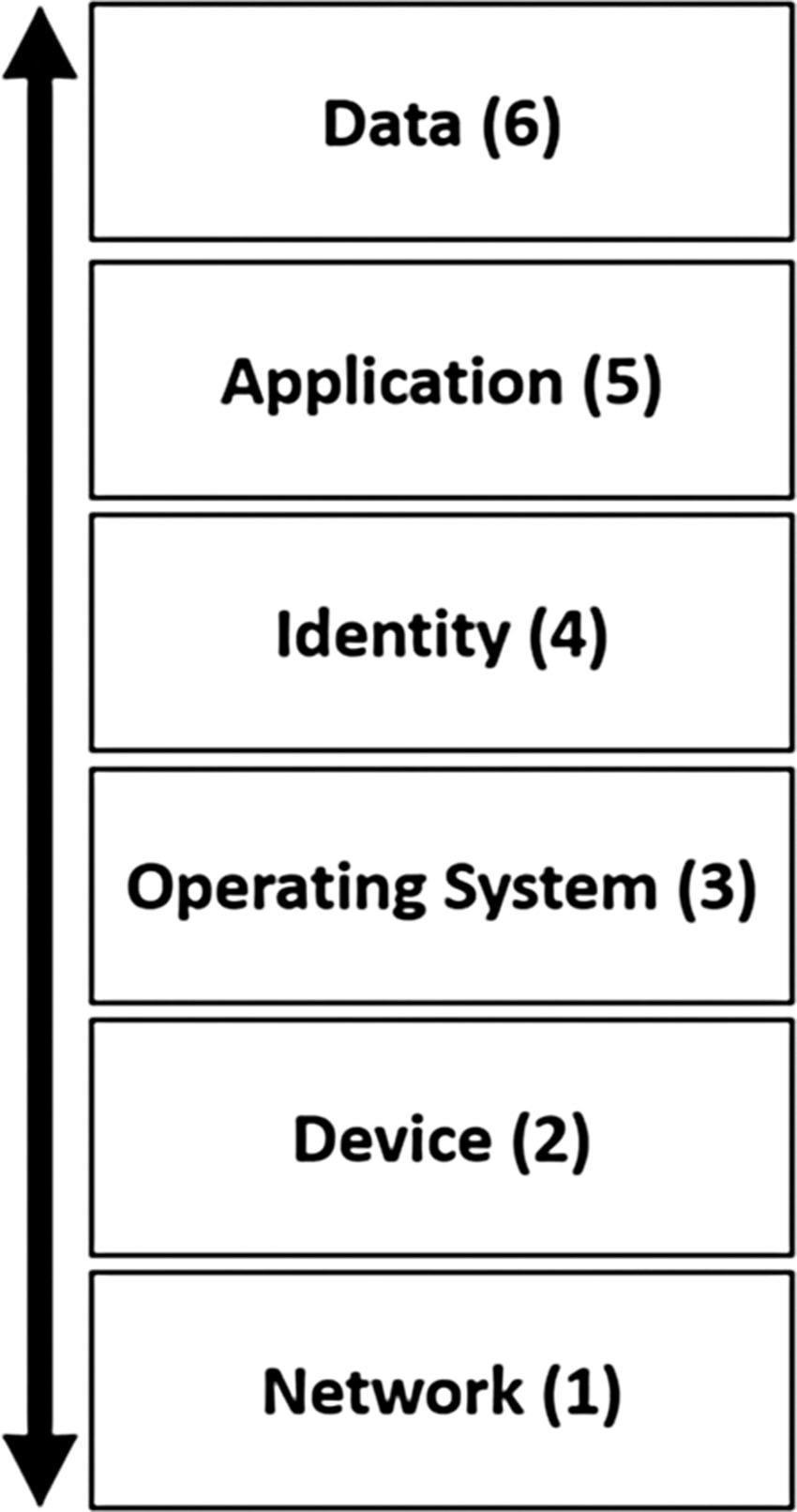
Figure 8.1 Context awareness model.
• Identity: Characteristics that define subjects interacting with software-based systems, processes, services, applications, etc.
• Application: Software-based processes, services, applications, etc. that allow subjects to interface (read, write, execute) with the data layer
• Data: Structured and/or unstructured content that is gathered as foreground digital evidence in support of an investigation
By applying meaningful contextual information to digital evidence, evidence-based conclusions can be reached at a much quicker rate because the team can answer the questions of “who, where, what, when, why, and how” with a much higher level of confidence.
In 2013, Target retailers were the victims of a sophisticated cyber-attack that lead to an eventual data breach where cyber criminals stole approximately 40 million credit/debit cards and approximately 70 million personal records of customers (i.e., name, address, email, phone).
In a statement made by Target’s spokesperson, it was indicated that:
Like any large company, each week at Target there are a vast number of technical events that take place and are logged.
Furthermore, the Target spokesperson stated that:
Through our investigation, we learned that after these criminals entered our network, a small amount of their activity was logged and surfaced to our team. That activity was evaluated and acted upon.
However, the Target spokesperson continued to say that:
Based on their interpretation and evaluation of that activity, the team determined that it did not warrant immediate follow up… With the benefit of hindsight, we are investigating whether if different judgments had been made the outcome may have been different.
From the statements made by Target’s spokesperson, it is recognized that the company was well equipped with proper information security defenses that ultimately identified and alerted their security team of the ongoing attack. However, Target indicated that the ability of their security team to make an informed decision was affected by the absence of context about the alert.
Before a decision is made to include these data sources in the inventory matrix, organization must first determine the relevance and usefulness of the data during an investigation. When assessing additional data sources, the business scenarios aligned to the forensics readiness program must be used as the foundation for the final decision to include or exclude the data.
If a decision is made to include the data source into the inventory matrix, the organization will need to start back at the first phase, Phase #1: Preparation, to ensure that the action plan is followed and all prerequisite questions have been answered.
Retrieving digital evidence from data sources owned by the organization can be relatively straightforward. However, with the continuous growth in the use of cloud service providers (CSP) there is a new level of complexity when it comes to gathering digital evidence from this type of data source.
For the most part, with these cloud environments, organizations do not have direct access to or ownership over the physical systems where their digital evidence can persist. This requires that, to guarantee digital evidence will be readily available in an acceptable state (i.e., integrity, authenticity), organizations need to ensure that a service agreement contract is established with the CSP where service level objectives (SLO) for incident response are outlined.
Where a CSP has been contracted to manage and offer computing services, organizations must ensure that the service agreement between both parties includes terms and conditions specific to incident response and investigation support. Generally, the CSP must become an extension of the organization’s incident response team and ensure that they follow forensically sound processes to preserve digital evidence in their environment(s).
Organizations must first obtain a reasonable level of assurance that the CSP will protect their data and respond to incidents and/or event within an acceptable SLO. The terms and conditions for how this assurance is achieved should be included as part of the service agreement established between both parties. Once the terms and conditions have been agreed to by both parties, the roles and responsibilities of the CSP during an incident or investigation must be defined so that the organization knows who will be involved and what roles they will play.
Having established the terms and conditions specific to incident response and investigative support, it is essential that organizations involve the CSP when practicing their computer incident response program.
Refer to Chapter 18, “Forensics Readiness in Cloud Environments,” for further discussion about applying forensics readiness capabilities within cloud computing environments.
The aggregation of data from multiple sources into a single repository ensures that digital evidence is proactively gathered and is readily available during an investigation. However, the security posture of the aggregated digital evidence from the multiple data sources is extremely critical and should be subject to stringent requirements for technical, administrative, and physical security controls.
Essentially, the collection of this digital evidence into a common repository has the potential to become a single point of vulnerability for the organization. Completion of a risk assessment on this common data repository, as discussed further in Addendum E, “Risk Assessment,” will identify the organization’s requirements for implementing necessary countermeasures to effectively secure and protect the digital evidence.
Traditionally, investigations have been performed in response to a security event or incident to determine root cause or assess business impact. Generally, the objective for performing any investigation is to establish factual evidence-based conclusions from relevant data sources (e.g., mobile devices, computer systems) across dissimilar architectures (e.g., corporate, cloud) in varying states (i.e., volatile, persistent). Ever since the formalization of the digital forensics discipline, there have been ongoing efforts to strategically integrate its foundational principles, methodologies, and techniques throughout an organization’s security capabilities so that there is a higher level of assurance that credible digital evidence will be available when required.
Within the realms of information and cyber security, the CIA triad (confidentiality, integrity, and availability) describes the fundamental components for implementing security controls to safeguard informational assets. Likewise, following this CIA methodology, security architectures contain design principles that consider relationships and dependencies between various technology architectures with the goal of protecting informational assets and systems. Naturally, this approach introduces complications for enabling digital forensics capabilities because potential evidence may be unavailable due to improper design and implementation of security architectures.
As the starting point, the design of security architectures—that proactively support digital forensics capabilities—can be accomplished through the development of reference architecture templates (or blueprints). By having these templates readily available, organizations will have a common framework with a consistent glossary of terms as reference for stakeholders (e.g., development teams) to understand digital forensics requirements. For example, organizations can outline the following as components of their digital forensics requirements for security architectures:
• Regularly performing system and application backups and maintaining them as defined in the organization’s enterprise governance framework
• Enabling audits of security information and events for corporately managed assets (i.e., end-user systems, servers, network devices) into a centralized repository
• Maintaining records of known-good and known-bad signatures for systems and applications
• Maintaining accurate and complete records of network, system, and application configurations
• Establishing an evidence management framework to address the control of evidence to guarantee authenticity and integrity throughout its lifecycle
Traditionally, accurately identifying and successfully implementing technical security requirements fell within the responsibility of network or system administrators. However, given the dynamic and mobile nature of today’s workforce, coupled with the continuously evolving threat landscape and expanded scope of potential digital evidence, it has become apparent that assurance for adequate security standards needs to be integrated as part of the organization’s overall security assurance procedures.
This doesn’t mean that organizations need to re-invent the wheel by developing new processes by which they can effectively integrate digital forensics requirements into their security architectures. Rather, as a strategy they should look to incorporating reference architectures for digital forensics into existing systems’—and applications’—lifecycle processes. It is important to note that the word “development” was not included because security is concerned with not only the development phases, but also the ongoing operations and maintenance phases after the system (or application) has been developed.
Traditionally, the system (or application) lifecycle has followed a waterfall methodology where each phase of the process is performed in a steady downward sequence (non-iterative). With this approach, the next phase is only executed once the preceding phase has been completed. While there are many iterations of the waterfall methodology, each with its own variations, the following illustrates the high-level phases of the model:
• Requirements is the initiation point where the concept is captured and requirements are documented.
• Design analyzes requirements to create models and schemas resulting in the system architecture.
• Implementation includes product coding, proving, and testing.
• Operations involves the installation with ongoing support and maintenance of the completed product.
Under the waterfall model, incorporating security requirements must be systematically achieved right from the beginning of the process. This way, when it comes time to design and implement the system (or application), due diligence has been completed to minimize the attack surface and reduce risk from security flaws. However, with the velocity of technology advancements and the rate at which technology is being consumerized, it became apparent that customer expectations were that greater functionality could come at a much faster pace. Because the waterfall model is linear in nature, which can result in an extended time until a completed product is delivered, organizations began looking to the agile methodology as an alternative.
With the agile model, work products are delivered through incremental and iterative phases, otherwise known as “sprints.” Unlike the waterfall, the agile model continually revisits development requirements throughout the lifecycle, which can result in the direction of a project changing suddenly. Considering how the agile model enables organizations to follow a continuous integration and development approach, security has a key place in this methodology because of the extreme risk related to original requirements and changing design. Generally, with each iteration of agile development, security needs to be incorporated by documenting and understanding:
1. The current state, including:
• Affected systems, applications, users, etc.
• Data flows, interchanges, and communications between systems, applications, and users
• Review of previously documented security concerns and findings to prevent reoccurrence
• Impact assessment of change against enterprise security program
2. What product will be delivered, including:
• Business operations and service involved
• Threat and risk assessment of informational assets and systems requiring protection
3. How to securely delivery the product, including:
• Apply the principle of least access privilege
• Incorporate proactive capabilities (as described in the sections above)
Ensuring security requirements are incorporated as a component of either methodology is easier said than done. Without security being interwoven throughout the systems’ (and applications’) lifecycle, the organization’s digital forensics capabilities will be hindered when it comes to the availability of potential digital evidence. Also, the absence of security within the systems’ (and applications’) lifecycle will result in digital forensics capabilities being impeded from becoming more proactive in terms of maturity, rather than continuing to operate reactively.
Digital evidence that is beneficial in supporting proactive investigations can be identified from a broad range of data sources. As this data is being gathered, not only does it need to provide details about the incident and/or event, it must provide investigators with the contextual information to make informed conclusions. Incorporating forensics requirements during the SDLC will further enhance an organization’s ability to gather digital evidence from data sources that is meaningful and relevant.