
1.2. Structured Exception Handling
There are two different ways in which computer programs respond to, or handle, exceptions. Many procedural languages use unstructured exception handling, in which execution jumps to a specified line in your program whenever an exception it thrown.
However, the preferred method for object-oriented languages is to use structured exception handling. Structured exception handling uses language constructs to isolate blocks of code. It allows you to implement one or more exception handlers that execute if and only if an exception is thrown, and a finally handler that always executes, regardless of whether an exception is thrown. Exception handlers can be configured to catch specific exceptions. Exception handlers can also be chained together in order of most to least specific exception type, in order to form a type-filtered exception handling mechanism.
While the throwing and handling of exceptions consumes resources, the language constructs through which structured exception handling is implemented are very efficient, in that they incur no additional resources or overhead when an error does not actually occur.
1.2.1. Handling Exceptions
In .NET languages, the construct that isolates a block of code is called a try block. Exception handlers (code that executes if and only if an exception is thrown from a try block) are contained in one or more catch blocks. A catch block may also define a variable that contains a reference to the exception object that it catches. The finally handler (code that always executes, regardless of whether an exception is thrown) is contained in a finally block.
It is a compile-time error to code a try block without an associated handler — that is, without at least one catch and/or finally block. A try-catch, a try-finally, or a try-catch-finally are all legal constructs. A try by itself is not.
1.2.1.1. Try-Catch
In .NET structured exception handling, you place code that might throw an exception in a try block. You then place code that handles the exception in a catch block.
Let's rework the method from Listing 1 a little bit by including an exception handler, as shown in Listing 2.
Example 2. LogEntry method with exception handler
protected void LogEntry(object sender, EventArgs e)
{
string path = GetPathToLog();
try
{
StreamWriter writer = File.AppendText(path);
writer.WriteLine(DateTime.Now.ToString(CultureInfo.InstalledUICulture));
writer.WriteLine("Entry: {0}", txtLogEntry.Text);
writer.WriteLine("--------------------");
writer.Dispose();
}
catch (Exception)
{
Response.Write("An error has occured.");
}
} |
The handler in Listing 2 will be executed if any runtime error occurs, because it is coded to catch any exception. As we'll explain a bit later on, this usually isn't a good idea in practice. Instead (if you need to handle exceptions at all), you should catch a specific exception type or types and act on them independently. Let's look at how to do that next.
1.2.1.2. Type Filtering
As previously mentioned, an exception handler can include a type filter to specify the exception types it should handle. Also, multiple type-filtered exception handlers can be chained together. When you do that, exceptions are caught and handled by the first handler that specifies a filter that matches the type of exception or any type the exception derives from. All remaining exception handlers are ignored, even if they specify a matching filter. Take a look at Listing 3.
Example 3. LogEntry method with exception type-filtering
protected void LogEntry(object sender, EventArgs e)
{
string path = GetPathToLog();
try
{
StreamWriter writer = File.AppendText(path);
writer.WriteLine(DateTime.Now.ToString(CultureInfo.InstalledUICulture));
writer.WriteLine("Entry: {0}", txtLogEntry.Text);
writer.WriteLine("--------------------");
writer.Dispose();
}
catch (PathTooLongException){
Response.Write(
"The path contains too many characters.");
}
catch (DirectoryNotFoundException)
{
Response.Write("The specified path is invalid.");
}
catch (IOException)
{
Response.Write("There was a problem accessing the file.");
}
} |
Here, when an exception of type T is thrown from the try block, the runtime will search each successive exception handler, then execute the first one that contains a filter of T or any base type of T. For example, if path points to an unmapped drive, a DirectoryNotFoundException will be thrown. A DirectoryNotFoundException has IOException as a base type, which means that both the second and third handlers are a match; however, only the second one actually runs.
1.2.1.3. Finally
If you need to make sure an action always fires no matter what, you can enclose it in a finally block. Code in a finally block is always executed, whether an exception is thrown or not. For example, you can use a finally block to clean up resources, or to reset the UI to a beginning state. Since the code in a finally block must run in all cases, it is a compile-time error to transfer execution flow out of a finally block using break, continue, or return.
Look again at Listing 3. Note that if an exception is thrown at some point inside the try block, normal execution of the program is immediately diverted to the appropriate handler. The Dispose method is therefore never reached, which may leave the file locked. Listing 4 corrects this situation.
Example 4. LogEntry method with finally block
protected void LogEntry(object sender, EventArgs e)
{
string path = GetPathToLog();
StreamWriter writer = null;
try
{
writer = File.AppendText(path);
writer.WriteLine(DateTime.Now.ToString(CultureInfo.InstalledUICulture));
writer.WriteLine("Entry: {0}", txtLogEntry.Text);
writer.WriteLine("--------------------");
}
catch (PathTooLongException)
{
Response.Write(
"The path contains too many characters.");
}
catch (DirectoryNotFoundException){
Response.Write("The specified path is invalid.");
}
catch (IOException)
{
Response.Write("There was a problem accessing the file.");
}
finally
{
if (writer != null) writer.Dispose();
}
} |
Note that the declaration of the writer variable has been promoted to method-level scope, so that it's accessible to the finally handler.
For objects that implement IDisposable, as an alternative to a finally block, you can declare and instantiate them in a using statement. A using statement ensures that Dispose is always called, even if an exception occurs. The code in Listing 5 is equivalent to that in Listing 4.
Example 5. LogEntry method with using statement
protected void LogEntry(object sender, EventArgs e)
{
string path = GetPathToLog();
try
{
using (StreamWriter writer = File.AppendText(path))
{
writer.WriteLine(
DateTime.Now.ToString(CultureInfo.InstalledUICulture));
writer.WriteLine("Entry: {0}", txtLogEntry.Text);
writer.WriteLine("--------------------");
}
}
catch (PathTooLongException)
{
Response.Write(
"The path contains too many characters.");
}
catch (DirectoryNotFoundException)
{
Response.Write("The specified path is invalid.");
}
catch (IOException)
{
Response.Write("There was a problem accessing the file.");
}
} |
1.2.2. Exception Propagation: Part 1
As you've just learned, an exception is thrown whenever a runtime error occurs. You also learned that if the code that causes the exception is surrounded by a try block, the runtime executes any code contained in the finally block associated with the try block, if one exists. Then, the runtime looks for an associated exception handler that matches the type of exception (or one of its base types) and executes any code within it.
But what happens if the code is not enclosed in a try block; or if it is, but no matching exception handler can be found?
If the code that caused the exception is not contained in a try block or if there is no exception handler that matches the exception, the runtime passes the exception up the call stack. That is to say, it searches the method that called the currently executing method for a matching exception handler. If none is found, then the method that called that method is searched, and so on, all the way up the call stack, back to the original calling method. This is known as exception propagation or exception bubbling.
NOTE
Recall that an exception can sometimes be caught, wrapped in further detail, and rethrown. For example, during exception propagation, if the call stack contains a static constructor or field initializer, a TypeInitializationException is thrown, encasing the original exception in its InnerException property. This is something you need to keep in mind while debugging or if you intend to handle the exception in a higher stack frame.
If the exception reaches the top of the stack and still no matching handler is found, the exception is considered unhandled, at which point execution of the program stops and control is transferred to the runtime.
This process is illustrated in Figure 1.
Figure 1. Exception propagation.
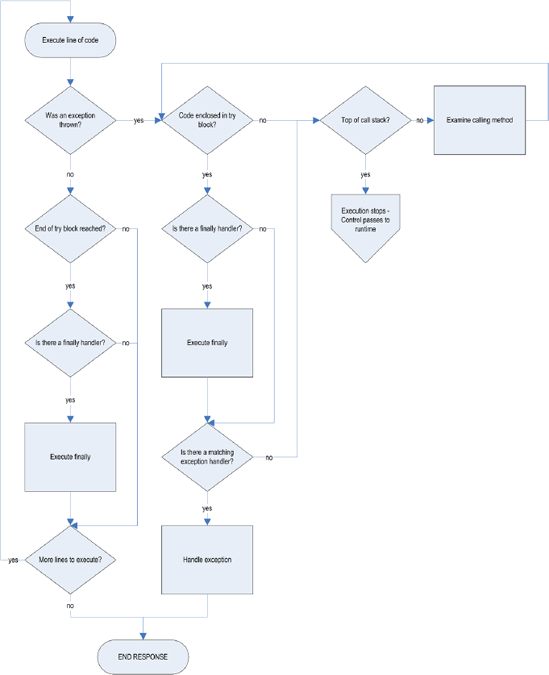
Exactly what happens next depends on the context in which the application is running — a Windows application, console application, class library, control library, Windows service, or an ASP.NET web site. I will discuss in detail how ASP.NET processes unhandled exceptions in a later section. For now, it's only important to understand how exception propagation works in general.
1.2.3. Throwing Exceptions
Remember, you aren't limited to only catching exceptions; you can throw them as well. It is common to throw exceptions from helper methods or from methods in a logical application layer in situations in which the method cannot provide its defined functionality.
Let's move our LogEntry method out to an external Log class and make it more flexible by letting those who consume this method specify the path to the log file, as in Listing 6.
Example 6. LogEntry method enhanced
public static void LogEntry(string entry, string path)
{
{
if (path == null)
{
throw new ArgumentNullException(
"path",
"The path cannot be null.");
}
if (path.Length > 248)
{
throw new ArgumentOutOfRangeException(
"path",
"You specified a path containing " +
path.Length +
" characters. The path cannot exceed 248 characters.");
}
try
{
using (StreamWriter writer = File.AppendText(path))
{
writer.WriteLine(
DateTime.Now.ToString(CultureInfo.InstalledUICulture));
writer.WriteLine("Entry: {0}", entry);
writer.WriteLine("--------------------");
}
}
catch (UnauthorizedAccessException ex)
{
throw new InvalidOperationException(
"You do not have permission to access '" + path + "'.", ex);
}
}
} |
In Listing 6, you see that the method checks if the passed-in path is null, and if so, throws an ArgumentNullException. It also checks the length of the path, and if it's too long, the method throws an ArgumentOutOfRangeException.
Also, if the caller doesn't have sufficient permission to access the log file, it catches the resulting exception and throws a new InvalidOperationException, which wraps the original exception.
NOTE
When handling an exception, avoid throwing a new exception that fails to include the original exception in its InnerException property, as all the information about the original exception is then lost. The new exception starts a new stack trace starting from the exact spot where you threw it, making it appear as though this is where the error actually originated.
Also note that in each case, a detailed custom message string that describes the error is passed to the exception constructor. When throwing an exception, you should always include a message describing the condition that caused the exception to be thrown. Make it detailed enough to help debug the error if necessary, but avoid putting sensitive information into the message string. Here, we've included information about the path that was supplied by the caller.
You may also find it useful to catch an exception, do something with it, and then rethrow it without changes. For example, Listing 7 shows a method that logs entries into a database instead of a text file. Here, if a SqlException occurs, it is caught, logged to the Windows Event Log, and rethrown, perhaps to be handled again in a higher tier. This lets you preserve information about the error for later review.
Example 7. Rethrowing an exception
public static void LogEntryToDatabase(string entry)
{
using (SqlConnection connection = new SqlConnection(connectionString))
{
const string insert =
"INSERT INTO [LogTable] ([Entry], [Date]) VALUES (@Entry, @Date)";
SqlCommand command = new SqlCommand(insert, connection);
command.CommandType = CommandType.Text;
command.Parameters.AddWithValue("@Entry", entry);
command.Parameters.AddWithValue("@Date", DateTime.Now);
try
{
connection.Open();
command.ExecuteNonQuery();
}
catch (SqlException ex){
LogErrorToEventLog(ex);
//throw ex; // DON'T DO THIS!
throw;
}
}
} |
NOTE
Note the commented-out line in Listing 7. Doing this resets the call stack from the point of the throw. When rethrowing the original exception without wrapping it, use the throw keyword by itself as shown, to preserve the original stack trace.