Wanted: easy-to-update web pages. It’s time to take things into your own hands and start writing code that updates your web pages on the fly. Using the Document Object Model, your pages can take on new life, responding to users’ actions, and you can ditch unnecessary page reloads forever. By the time you’ve finished this chapter, you’ll be able to find, move, and update content virtually anywhere on your web page. So turn the page, and let’s take a stroll through the Webville Tree Farm.
So far, most of the apps we’ve built have sent requests, gotten a response, and then used that response to update part of a page’s content.
But what if you need to do more than just change the content of a <div> or replace the label on a button? What if an image needs to actually move on a page? How would you accomplish that?

Your users can’t change your XHTML.
The structure of your page is defined in your XHTML, and people viewing your pages definitely can’t mess around with that structure. Otherwise, all the work you’d put into your pages would be a total waste of time.

The browser CAN change your web page’s structure
You’ve already seen that the browser lets you interact with a server-side program, grab elements from a page, and even change properties of those elements. So what about the structure of a page?
Well, the browser can change that, too. In fact, think about it like this: in a lot of ways, the structure of your page is just a property of the page itself. And you already know how to change an object’s properties...
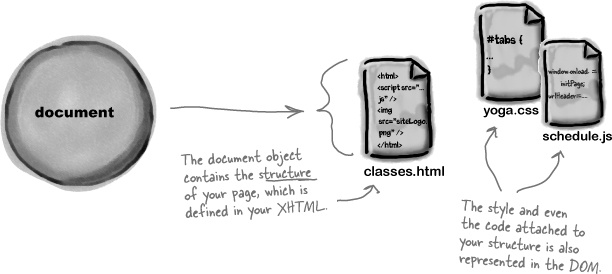
The browser doesn’t see your XHTML as a text file with a bunch of letters and angle brackets. It sees your page as a set of objects, using something called the Document Object Model, or DOM.
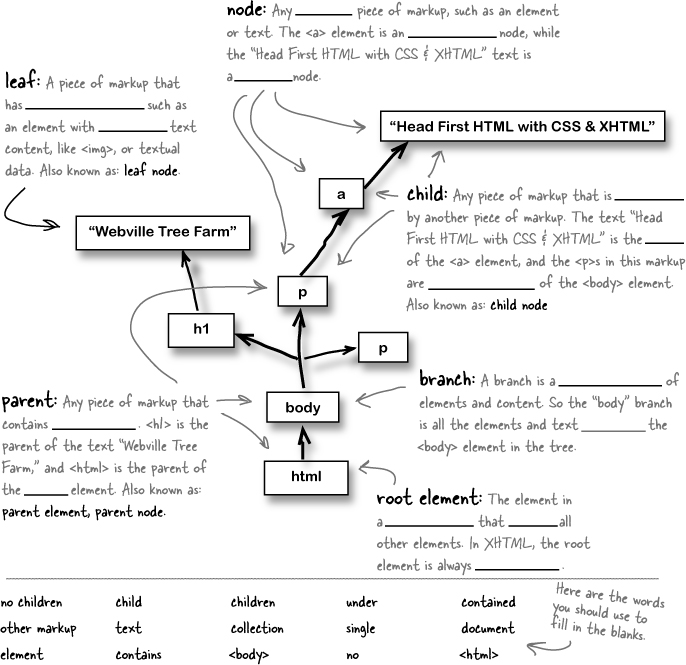
And everything in the DOM begins with the document object. That object represents the very “top level” of your page:
You’ve actually used the DOM, and in particular the document object, several times. Every time you look up an element, you use document:

In fact, every time you treat an element on a page like an object and set properties of that object, you’re working with the DOM. That’s because the browser uses the DOM to represent every part of your web page.

When you’re creating a web page, you write XHTML to represent the structure and content of your page. Then you give that XHTML to the browser, and the browser figures out how to represent the XHTML on the screen. But if you want to change your web page using JavaScript, you need to know exactly how the browser sees your XHTML.
Suppose you’ve got this simple XHTML document:

The browser has to make some sense of all that markup, and organize it in a way that allows the browser—and your JavaScript code—to work with the page. So the browser turns your XHTML page into a tree of objects:
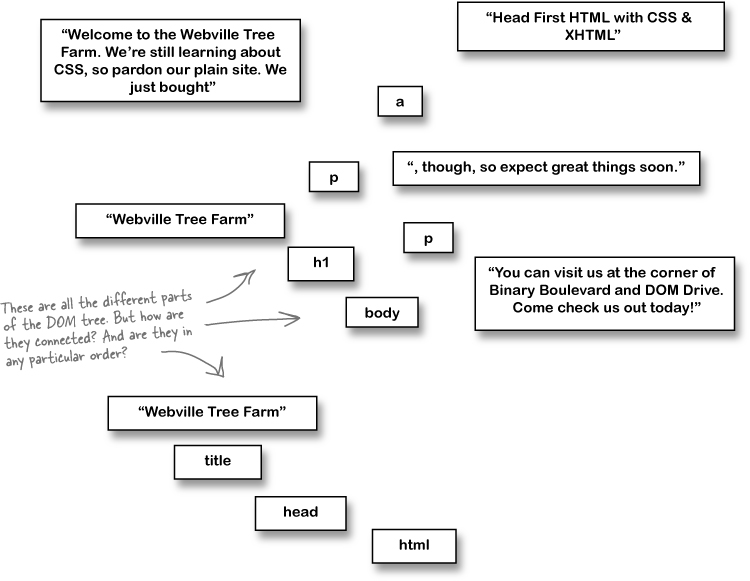

The browser organizes your page into a tree structure, with a root and branches.
When a browser loads an XHTML page, it starts out with the <html> element. Since this is at the “root” of the page, <html> is called the root element.
Then, the browser figures out what elements are directly nested within <html>, like <head> and <body>. These branch out from the <html> element, and they have a whole set of elements and text of their own. Of course, the elements in each branch can have branches and children of their own...until an entire page is represented.
Eventually, the browser gets to a piece of markup that has nothing beneath it, like the text in a <p> element or an <img> element. These pieces of markup with nothing under them are called leaves. So your entire page ends up being one big tree to the web browser.
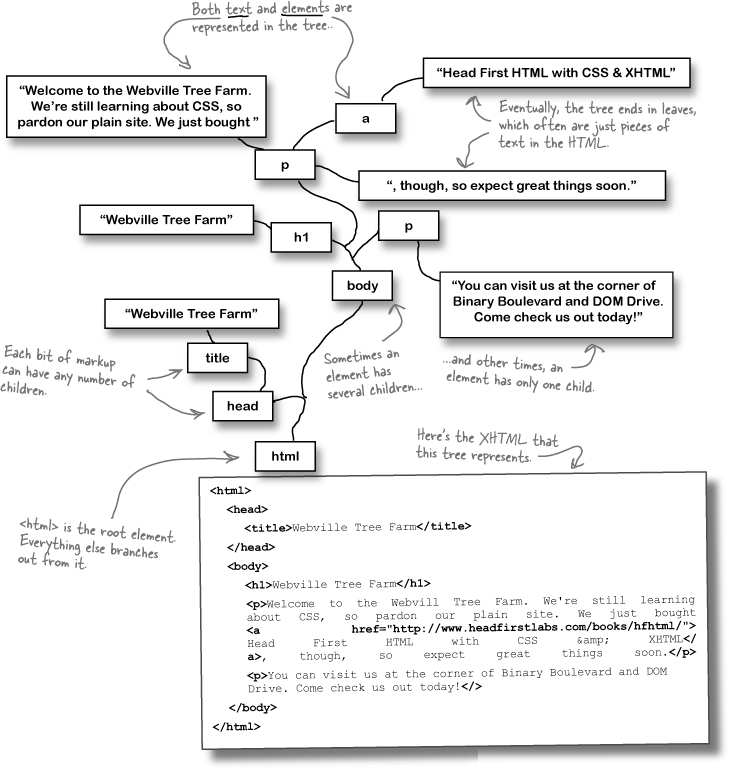
So let’s look at that tree structure again, but this time, with some lines added to make the connections between the markup a little clearer.
Exercise
Write Your Own Web Dictionary
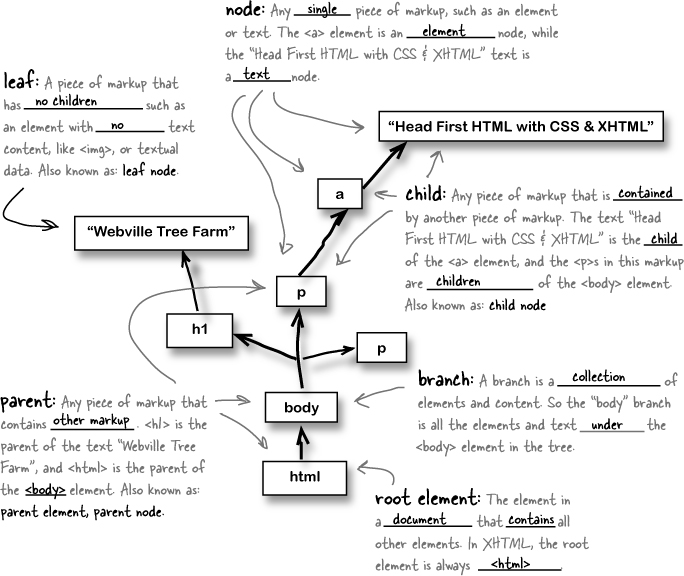
What good is looking at a bunch of definitions? This is Head First, and we want your brain working, not just your eyes. Below are several entries from a Web Dictionary, with some of the words in each definition removed. Your job is to complete each entry by filling in the blanks.
Sharpen your pencil
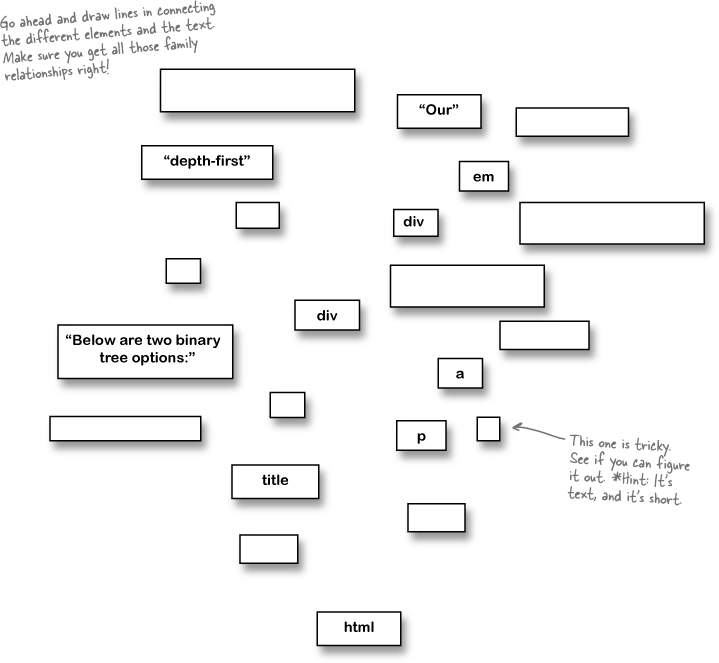
It’s time to load markup trees into your brain. Below is an XHTML document. Your job is to figure out how a web browser organizes this markup into a tree structure. On the right is the tree, ready for you to fill in its branches and the relationships between each piece. To get you started, we’ve provided spaces for each piece of markup; be sure you’ve filled each space with an element or text from the XHTML markup before showing off your DOM tree to anyone else!
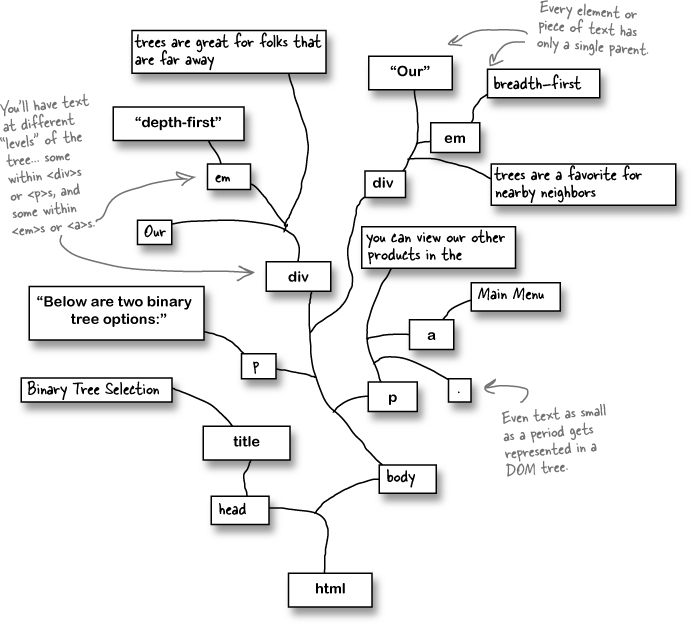
<html> <head> <title>Binary Tree Selection</title> </head> <body> <p>Below are two binary tree options:</p> <div> Our <em>depth-first</em> trees are great for folks who are far away. </div> <div> Our <em>breadth-first</em> trees are a favorite for nearby neighbors. </div> <p>You can view other products in the <a href="menu.html">Main Menu</a>. </p> </body> </html>
![]() Answers in Sharpen your pencil Solution.
Answers in Sharpen your pencil Solution.
Exercise Solution
Below are several entries from a Web Dictionary, with some of the words in each definition removed. Your job was to complete each entry by filling in the blanks.
Sharpen your pencil Solution
Your job was to build a DOM tree from the XHTML in Sharpen your pencil. You also should have drawn in the connections between the different elements and text. How did you do?
Now that we know a bit about the DOM, we can use that knowledge to make our apps do even more interesting things. Let’s take on a project for the Webville Puzzle Company. They’ve been working on a bunch of new web-based games, and they need help with their online Fifteen Puzzle.
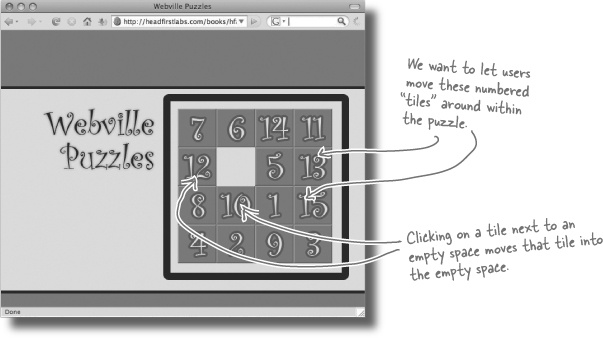
In a Fifteen Puzzle, you can move a tile into the empty space, which then creates a new empty space. Then you can move another tile into that new empty space, and so on. There’s always one empty space, and the goal is to get all the numbers lined up in sequential order, like this:


We need to move those tiles around... and that requires the DOM.
This is a perfect example of needing the DOM. We don’t want to just change the content of a table, or replace some text on a button or in a <p>. Instead, we need to move around the images that represent a tile.
Webville Puzzles is using a table with four rows and four columns to represent their board. So we might need to move an image in the third row, fourth column to the empty space in the third row, third column. We can’t just change the innerHTML property of a <div> or <td> to get that working.
What we need is a way to actually grab an <img>, and move it within the overall table. And that’s where the DOM comes in handy. And, as you’ll soon see, this is exactly the sort of thing that Ajax apps have to do all the time: dynamically change a page.
All Ajax apps need to respond DYNAMICALLY to users.
The DOM lets you CHANGE a page without reloading that page.
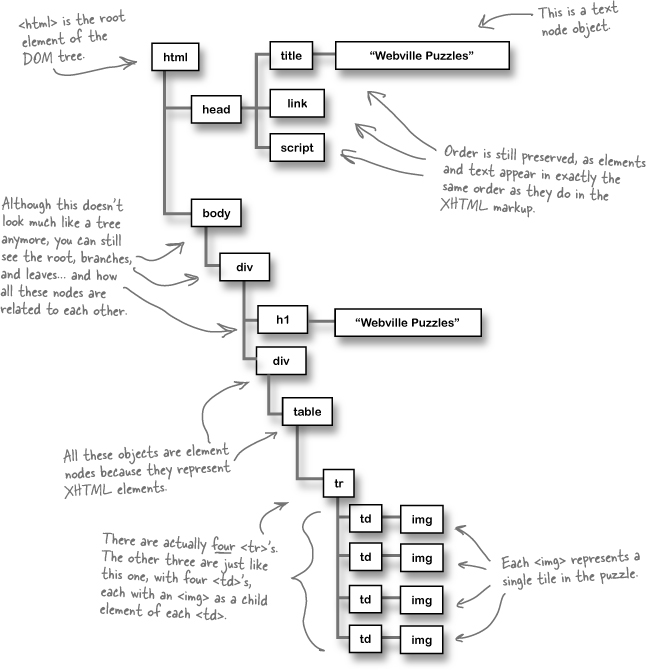
To really understand how the DOM helps out, let’s take a look at Webville Puzzles’ XHTML, and see what the browser does with that XHTML. Then we can figure out how to use the DOM to make the page do what we want.

Sharpen your pencil Solution
Your job was to draw out a DOM tree for the fifteen-puzzle.html’s XHTML structure and content. Here’s what we did... we started with the root element on the top-left, and worked our way down. Did you come up with something similar?
Sharpen your pencil
The exercises just keep coming! This time, you’ve got to swap two particular nodes in the DOM tree structure below. Your job is to write out exactly what steps you’d take. Don’t worry about method names, just write out what you’d do.
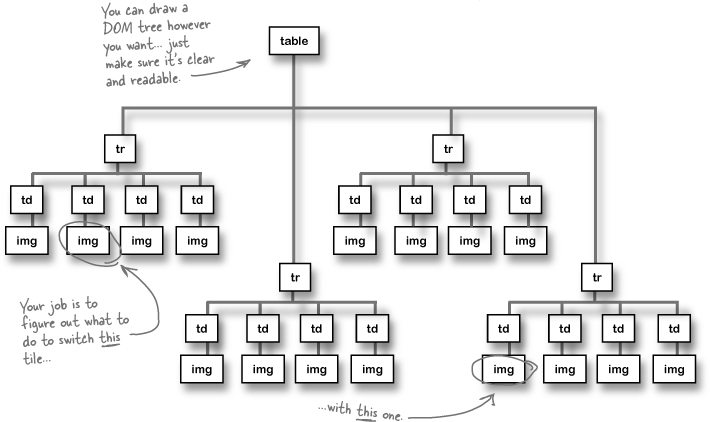
Assume you know which table cell was clicked on, and you also know the destination table cell. What would you do?

Sharpen your pencil Solution
Your job was to write out exactly what steps you’d take. Assume you know which table cell was clicked on, and you also know the destination table cell. What would you do?
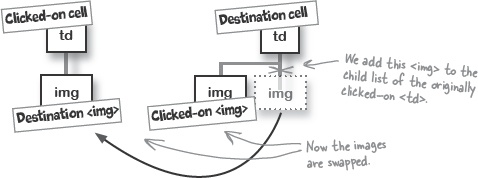
Get the child of the selected table cell
You could use
getElementsByTagName(), but we know that the<img>representing the clicked-on tile is the child of the selected cell. So we can use the DOM to get that child element.Get the child of the destination table cell
Once we start swapping things around, it’s going to be harder to keep the selected
<img>separate from the destination<img>. So before we start moving things around, let’s get a reference to the<img>in the destination<td>, too.Add the clicked on <img> as a child of the new destination table cell.
We need to move the
<img>in the selected cell to the destination cell. So we can just add the clicked-on<img>to the destination<td>’s list of children.Add the <img> in the destination cell as a child of the originally clicked-on table cell.
Now for the other part of the swap. We need to move the destination
<img>under the<td>that was originally clicked on. Here’s why we got the reference to this<img>in step 2: since there are two child<img>’s under the destination<td>, having a reference already makes this easy.
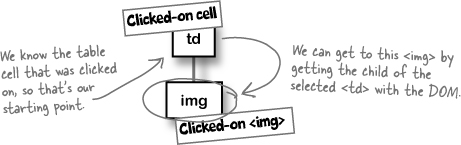
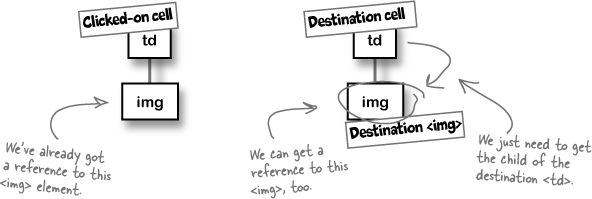
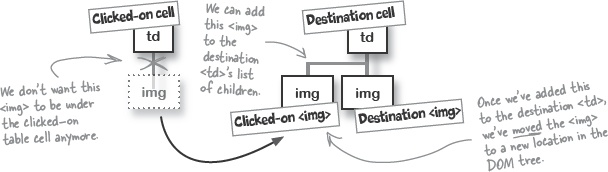


Do you want to CHANGE an element or MOVE an element? There’s a big difference.
You could definitely write code that simply swaps out the values of the two <img>’s src properties, like this:

The problem with this is that you’re actually just changing the properties of an image, and not moving those images around on the page.
So what’s the big deal with that? Well, what about the other properties of each image? Remember that each <img> had an alt attribute?

If you change the src attribute, you’re only changing a part of the <img>. The rest would stay the same... and then the alt attribute would not match the image!
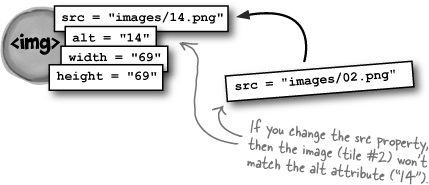
What you need to do is swap the entire <img> objects. That way, each <img> keeps its properties. The image doesn’t change, but the location of that <img> in the DOM tree (and on the visual representation of the page) does.
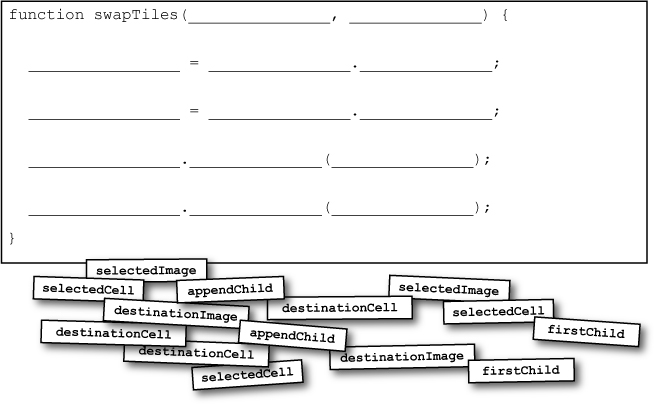
JavaScript & DOM Magnets
You’ve already figured out what needs to happen to swap two tiles. Now it’s time to turn those general steps into actual code. Below is the skeleton for a new function, swapTiles(). But all the pieces of code have fallen to the ground... can you figure out how to complete the function?
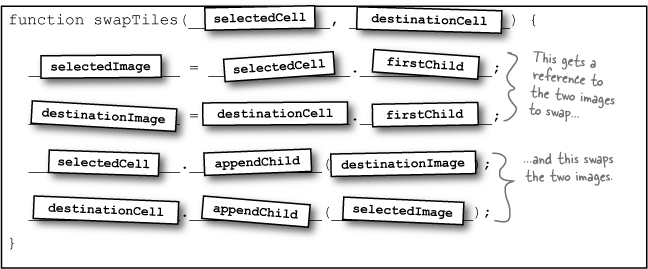
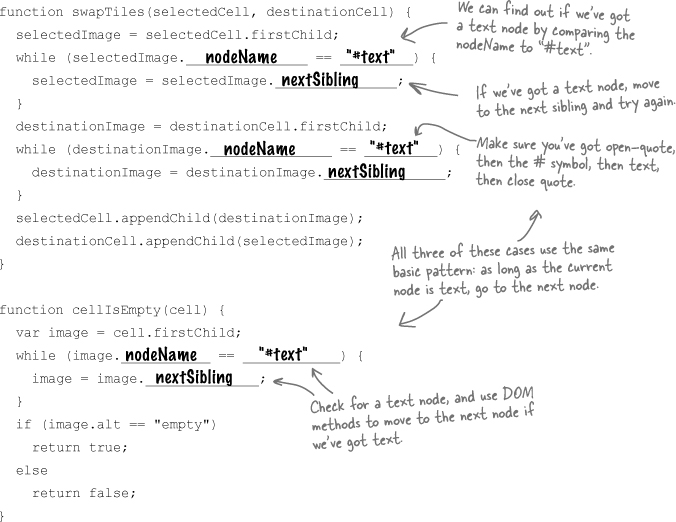
JavaScript & DOM Magnet Solution
It’s time to turn those general steps from Sharpen your pencil Solution into actual code. Below is the skeleton for a new function, swapTiles(). Your job was to put the pieces of code into a working function.

Every node has a parentNode property... but the parentNode property is read-only.
Every node in a DOM tree—that’s elements, text, even attributes—has a property called parentNode. That property gives you the parent of the current node. So for example, the parent node of an <img> in a table cell is the enclosing <td>.
But in the DOM, that’s a read-only property. So you can get the parent of a node, but you can’t set the parent. Instead, you have to use a method like appendChild().
appendChild() is a method used to add a new child node to an element. So if you run destinationCell.appendChild(selectedImage), you’re adding the selectedImage node to the children that destinationCell already has:
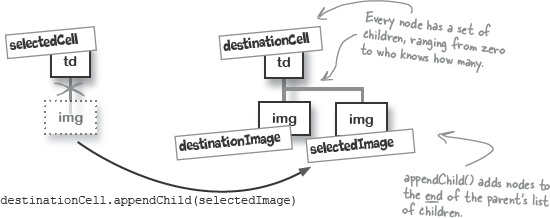
When you assign a node a new child, that new child’s parentNode property is automatically updated. So even though you can’t change the parentNode property directly, you can move a node, and let the DOM and your browser handle changing the property for you.
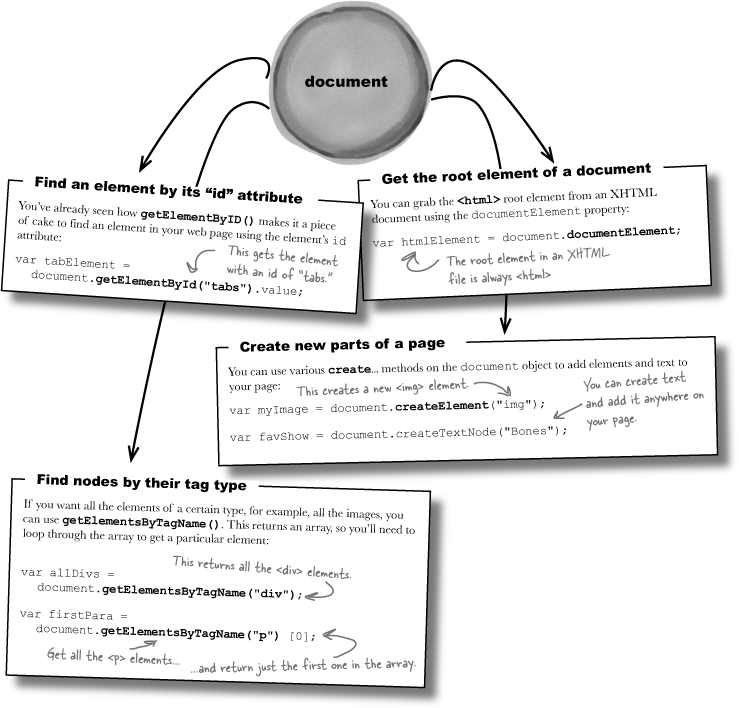
If you think about your page as a collection of nodes in a DOM tree, methods like getElementById() and getElementsByTagName() make a lot more sense.
You use getElementById() to find a specific node anywhere in the tree, using the node’s id. And getElementsByTagName() finds all elements in the tree, based on the node’s tag name.

Watch it!
Watch the “s” in your method names.
getElementById() is Element, without an “s”, because it returns one element. getElementsByTagName is Elements, with an “s”, because it can return more than one element.
Exercise
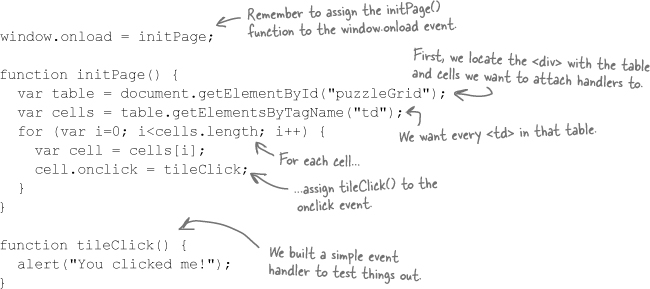
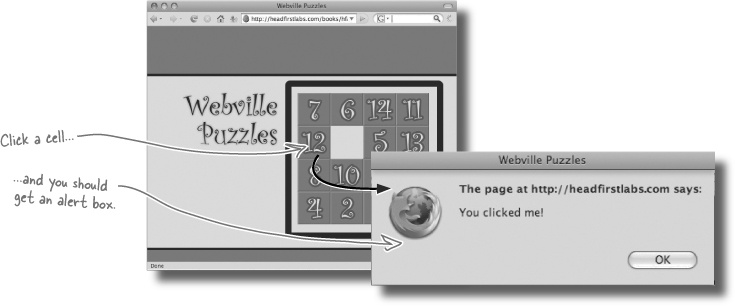
Go ahead and write the code for an initPage() function. You need to make sure that every time a table cell is clicked on, an event handler called tileClick() gets run. We’ll write the code for tileClick() later, but you may want to build a test version with an alert() statement to make sure your code works before turning the page.
Sharpen your pencil
Here are a few questions to get your left brain into gear. Answer each before turning the page... and once you’re done, you might want to double-check your code for initPage() above, too.
Should the event handler for moving a tile be on the table cell or the image within that cell?
Why did you make the choice you did?__________________________________
___________________________________________________________________________
How can we figure out if an empty tile was clicked on?________________
___________________________________________________________________________
How can we figure out the destination cell for a tile?________________
___________________________________________________________________________
![]() Answers in Sharpen your pencil Solution.
Answers in Sharpen your pencil Solution.
Your job was to write an initPage() function that set up the event handlers for the Fifteen Puzzle. What did you come up with? Here’s what we did:
Now that the basic structure is in place, it’s time to get the puzzle working. Since a tile can only be moved to the empty square, the first thing we need to figure out is, “Where’s the empty square?”
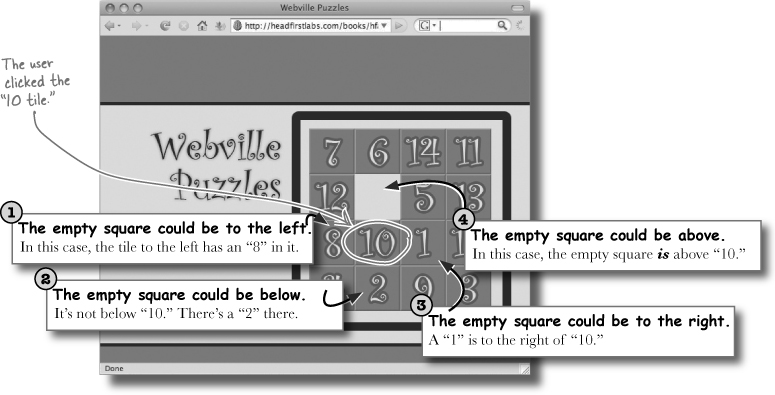
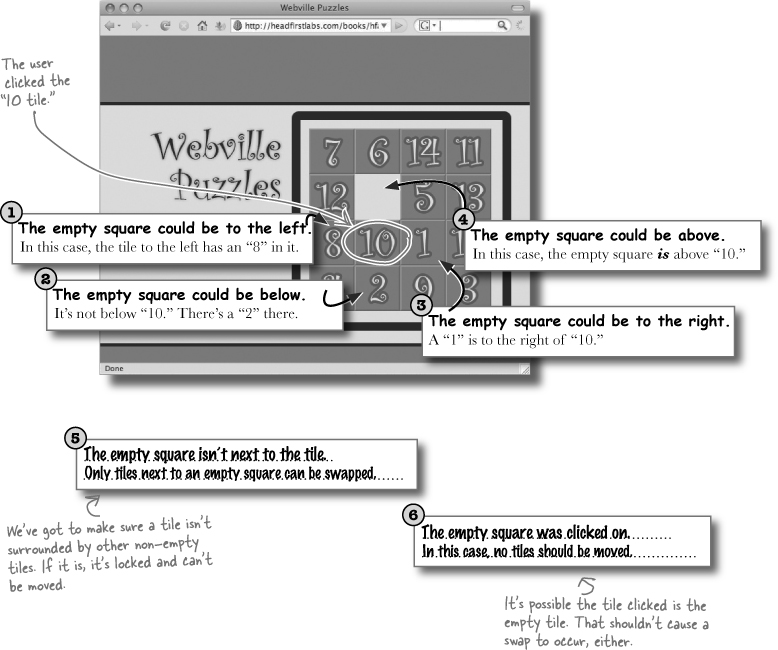
For any clicked-on tile, there are six different possibilities for where the empty tile is. Suppose the user clicked the “10” tile on the board below:
Sharpen your pencil
There are two more possible situations related to the position of the empty tile. Can you figure out what they are?

![]() Answers in Sharpen your pencil Solution.
Answers in Sharpen your pencil Solution.
Sharpen your pencil Solution
Here are a few questions to get your left brain into gear. Answer each before turning the page... and once you’re done, you might want to double-check your code for initPage() above, too.
Should the event handler for moving a tile be on the table cell or the image within that cell?
Why did you make the choice you did?
How can we figure out if an empty tile was clicked on?
How can we figure out the destination cell for a tile?

Joe: Why? The user’s clicking on “7,” not the second tile on the third row.
Frank: Well, they’re clicking on the table cell that image is in, too.
Jill: So suppose we put the handler on the image. And then when a user clicks on the image...
Joe: ...we swap that image out with the empty square...
Jill: Right. But the handler’s attached to the image, not the table cell.
Frank: Oh. I see.
Joe: What? I don’t get it.
Frank: The event handler would move with the image. So every time an image gets moved, the event handler moves with it.
Joe: So?
Frank: Well, we’re going to use the DOM to figure out where the empty square is in relation to the clicked-on image, right?
Joe: I guess so. What’s that got to do with the handler on the image?
Frank: If the handler’s on the image, we’ll constantly have to be getting the image’s parent. If the handler’s on the cell, we can avoid that extra step. We can just check the cells around the clicked-on cell.
Jill: Exactly! We don’t need to move to the image’s parent cell in our handler.
Joe: So all this is to avoid one line of code? Just asking the image for its parent?
Jill: One line of code for every click. That could be hundreds of clicks... or even thousands! Have you ever worked one of those puzzles? It takes some time, you know.
Joe: Wow. I’m not even that clear on how we’d find the empty square in the first place...
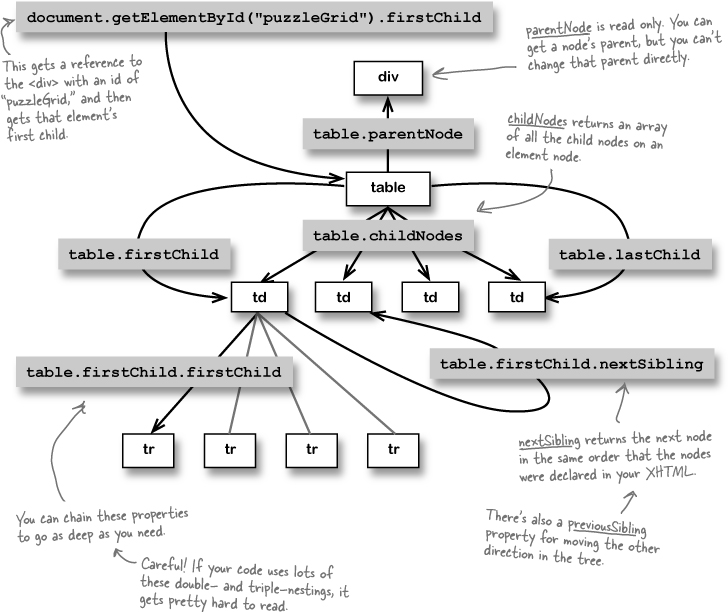
Suppose you wanted to find out the parent of an <img> or get a reference to the next <td> in a table. A DOM tree is all connected, and you can use the family-type properties of the DOM to move around in the tree.
parentNode moves up the tree, childNodes gives you an element’s children, and you can move between nodes with nextSibling and previousSibling. You can also get an element’s firstChild and lastChild. Take a look:
Sharpen your pencil
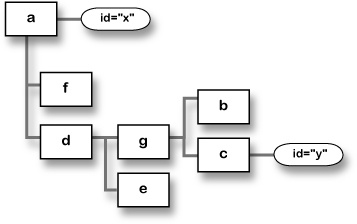
Below is a DOM tree and some JavaScript statements. In the JavaScript, each letter is a variable that represents the matching node in the DOM tree. Can you figure out which node each statement refers to?
| ______________ |
| ______________ |
| ______________ |
| ______________ |
| ______________ |
| ______________ |
| ______________ |
Sharpen your pencil Solution
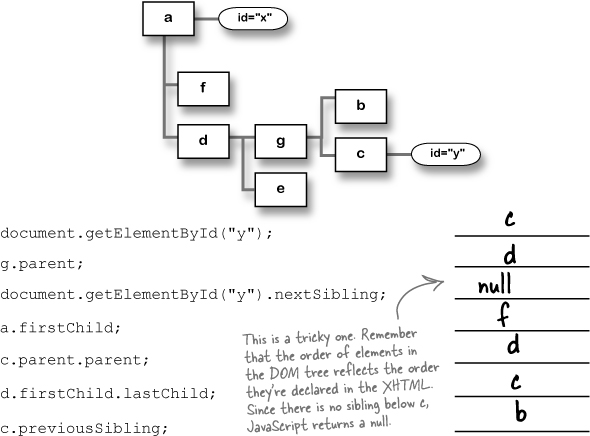
Below is a DOM tree and some JavaScript statements. In the JavaScript, each letter is a variable that represents the matching node in the DOM tree. Can you figure out which node each statement refers to?

Use descriptive names for your elements and your id attributes.
When you’re writing XHTML, the element names are already pretty clear. Nobody’s confused about what <div> or <img> means. But you should still use descriptive ids like “background” or “puzzleGrid.” You never know when those ids will show up in your code, and make your code easier to understand... or harder.
The clearer your element names and ids, the clearer your code will be to you and other programmers.
Sharpen your pencil Solution
There were two more possibilities for where an empty tile could be on a puzzle grid. Did you figure out what they were?
Long Exercise
It’s time to get busy building the rest of the Fifteen Puzzle Code. Here’s your assignment:
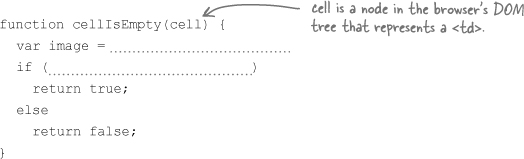
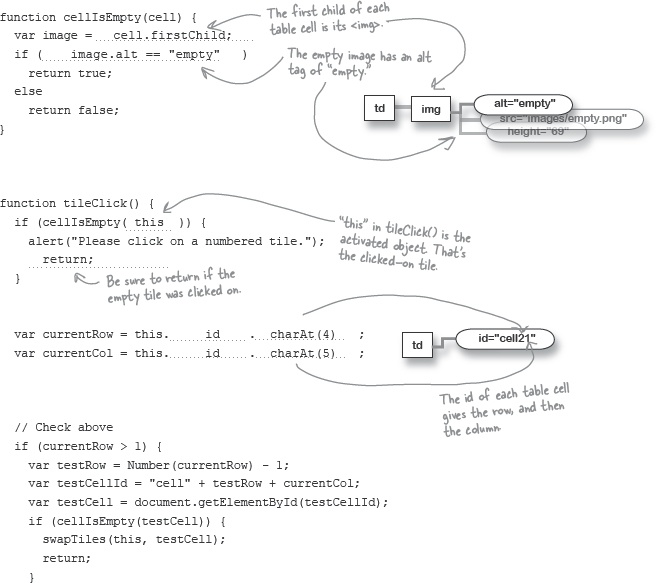
Write a cellIsEmpty() function.
Given a node representing a
<td>, figure out if the image in that cell is the empty image. To help you out, here’s the XHTML for the empty cell:<td id="cell22"> <img src="images/empty.png" alt="empty" width="69" height="69" /> </td>
Here’s part of the function to get you started:
Look for an empty cell in the tileClick() event handler.
Let’s start building
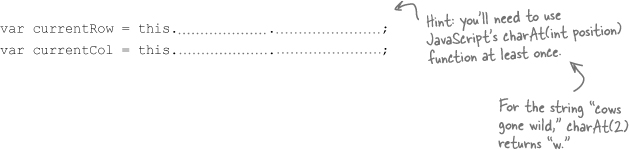
tileClick(), the event handler we attached to each table cell. First, we need to check for an empty cell. If the clicked-on cell was empty, let’s show a message indicating the user needs to click on a different tile.function tileClick() { if (cellIsEmpty( )) { alert("Please click on a numbered tile."); _________________ } }Figure out what row and column was clicked.
Here’s the XHTML for a couple of cells in the puzzle:
<td id="cell13"> <img src="images/14.png" alt="14" width="69" height="69" /> </td> <td id="cell14"> <img src="images/11.png" alt="11" width="69" height="69" /> </td> </tr> <tr> <td id="cell21"> <img src="images/12.png" alt="12" width="69" height="69" /> </td> ... etc ...Given this (and the rest of the XHTML, in You start with XHTML...), can you figure out how to get the row and column of the clicked on tile?
Finish up the tileClick() event handler.
Once we’ve made sure that the empty tile wasn’t clicked, and gotten the current row and column, you have everything you need. Your job is to handle the 5 remaining possible situations for where the empty square is, and then if possible, swap the selected tile with the empty square.
To get you started, here’s the code to check above the selected tile:
The rest of
tileClick()is up to you. Refer back to the different possibilities you have to handle from Sharpen your pencil Solution, and good luck!

Long Exercise Solution
Your job was to build the cellIsEmpty() function, and then complete the clickTile() event handler. Did you figure everything out? Here’s what we did:

The DOM is great for code that involves positioning and moving nodes around on a page.

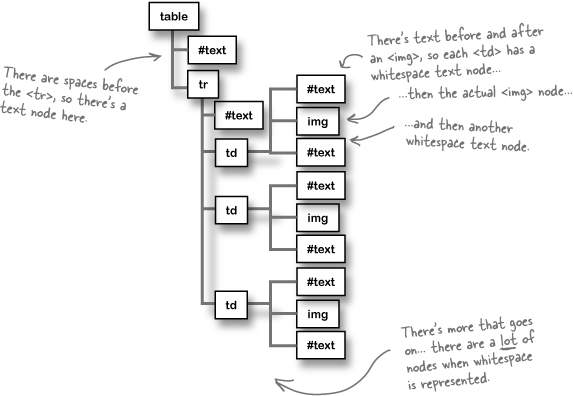
Most XHTML pages don’t have every element, from the opening <html> to the closing </html> crammed onto one line. That would be a real pain to read. Instead, your page is full of spaces, tabs, and returns (sometimes called “end-of-lines”):

Even though those spaces are invisible to you, the browser tries to figure out what to do with them. Usually they get represented by text nodes in your DOM tree. So a <table> node might have lots of text nodes full of spaces in addition to all the <tr> children you’d expect.
The bad news is that not all browsers do things the same way. So sometimes you get empty text nodes, and sometimes you don’t. It’s up to you to account for these text nodes, but you can’t assume they’ll always be there. Sounds a bit confusing, doesn’t it?
There are some inconsistencies in how browsers treat whitespace. Never assume a browser will always ignore, or always represent, whitespace.
One browser might create a DOM tree for your page that looks like this:
Another browser might create a different DOM tree for the same XHTML:
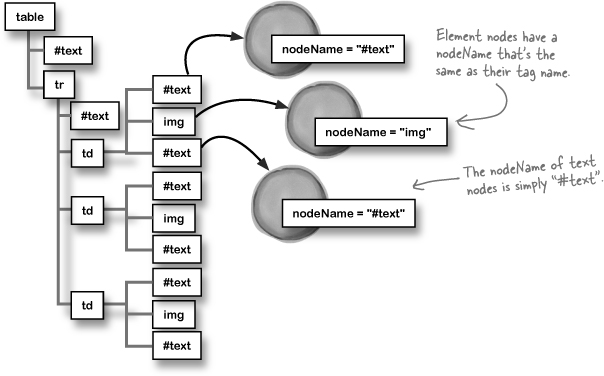
A text node always has a nodeName property with a value of “#text.” So you can find out if a node is a text node by checking its nodeName:

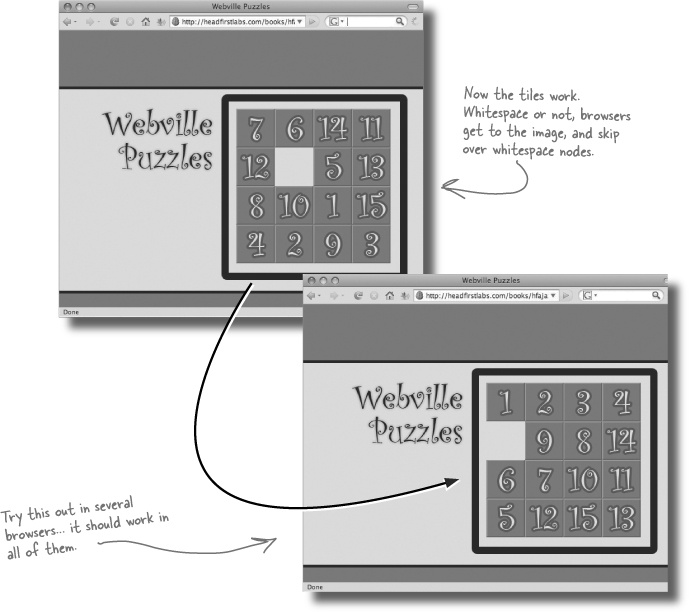
All that’s left is to figure out when a player’s won. Then, every time two tiles are swapped, we can check this function to see if the board is in order. If it is, the player’s solved the puzzle.
Here’s a puzzleIsComplete() function that uses the names of each image to see if all the tiles are in order:

There’s even a special class that Webville Puzzles put in their CSS for showing a winning animation. The class is called “win,” and when the puzzle is solved, you can set the <div> with an id of “puzzleGrid” to use this class and display the animation.
That means we just need to check if the puzzle is solved every time we swap tiles.


The DOM is just a tool, and you won’t use it all the time... or sometimes, all that much.
You’ll rarely write an application that is mostly DOM-related code. But when you’re writing your JavaScript, and you really need that next table cell, or the containing element of an image, then the DOM is the perfect tool.
And, even more importantly, without the DOM, there’s really no way to get around a page, especially if every element on your page doesn’t have an id attribute. The DOM is just one more tool you can use to take control of your web pages.
In the next chapter, you’re going to see how the DOM lets you do more than just move things around... it lets you create elements and text on the fly, and put them anywhere on the page you want.
The DOM is a great tool for getting around within a web page.
It also makes it easy to find elements that DON’T have an id attribute.
DOMAcrostic
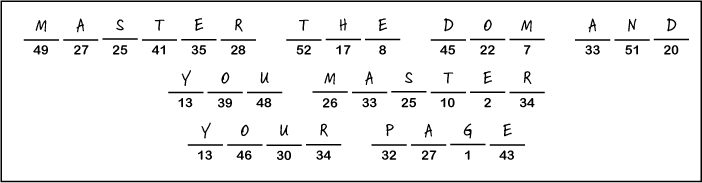
Take some time to sit back and give your right brain something to do. Answer the questions up top, and then use the answer letters to fill in the secret message.
This method returns a specific element based on its ID
This property returns all the children of an element
The browser translates this into an element tree
This element property represents the element’s container
This is what the browser creates for you
This element gives you access to the whole tree
DOMAcrostic
Your job was to answer the questions up top, and then use the answer letters to fill in the secret message.
This method returns a specific element based on its ID
This property returns all the children of an element
The browser translates this into an element tree
This element property represents the element’s container
This is what the browser creates for you
This element gives you access to the whole tree